
A Faster and More Effective Cross-View Matching Method of UAV and Satellite Images for UAV Geolocalization


Abstract
:
1. Introduction
2. Materials and Methods
2.1. Datasets and Evaluation Indicators
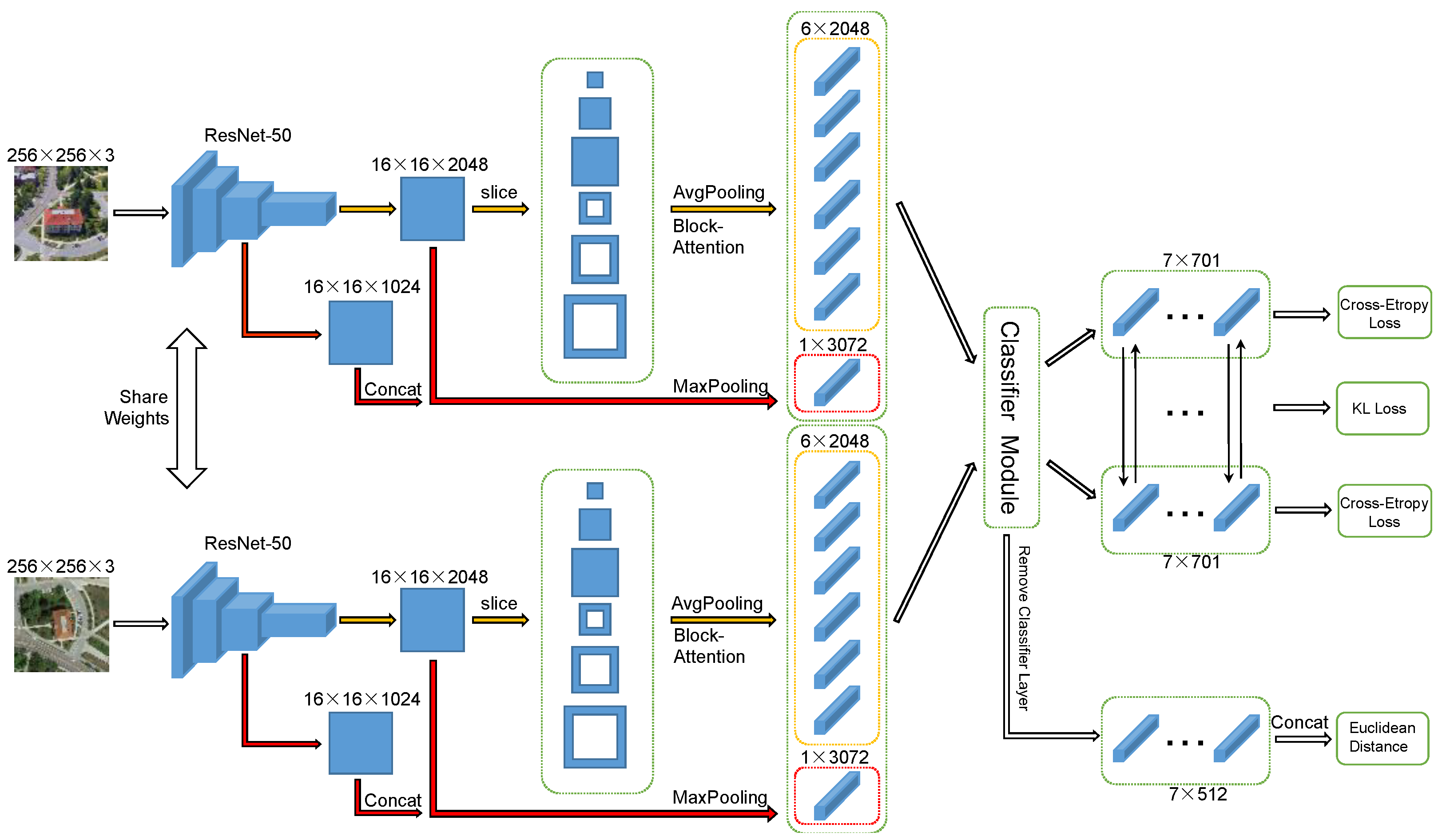
2.2. Backbone Structure
2.3. Multiscale Block
2.4. Global Branch
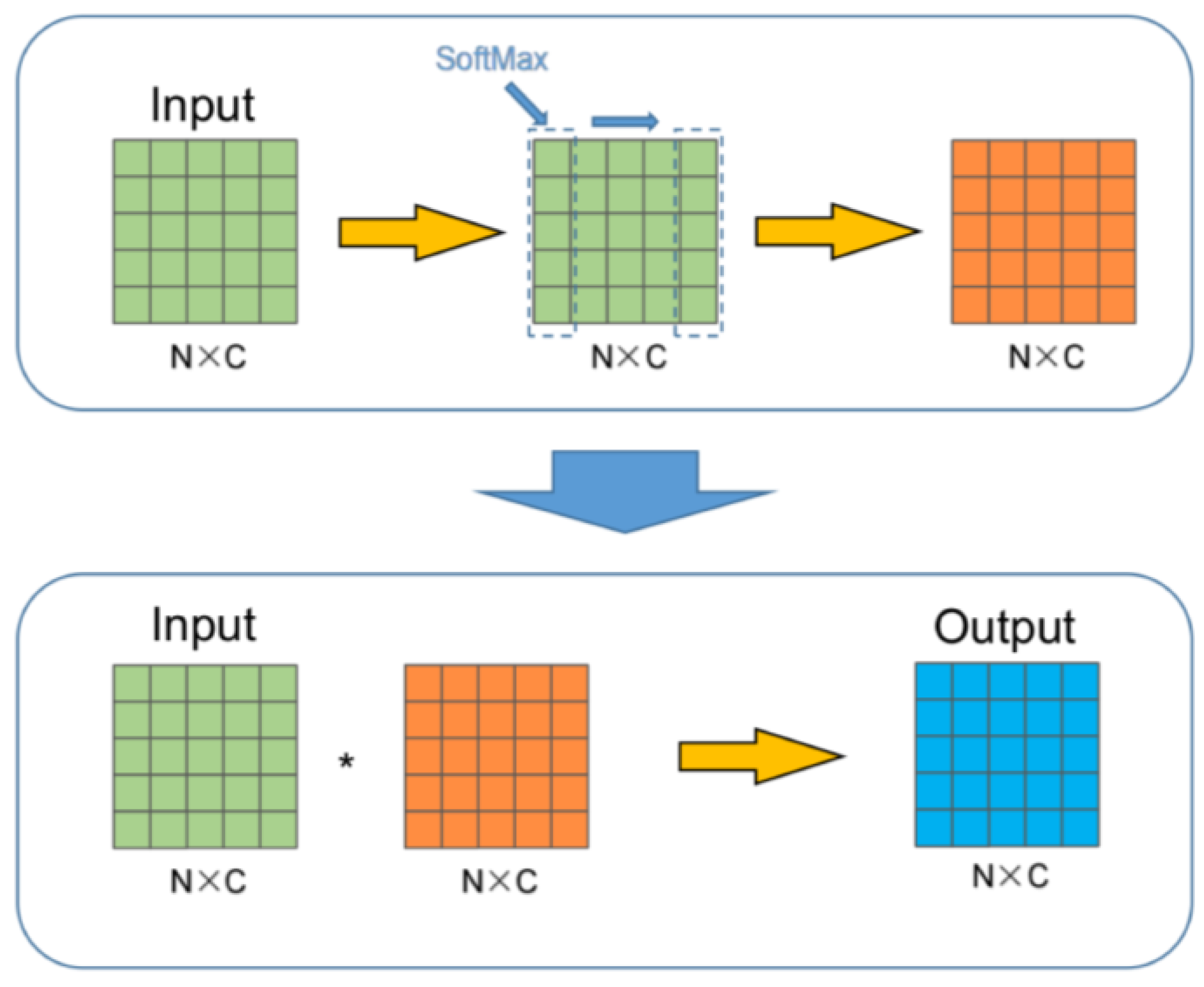
2.5. Block Attention (BA)
2.6. Loss Function and Improvement in Inference
2.7. Implementation
3. Experiments Results
3.1. Comparison with the State of the Art
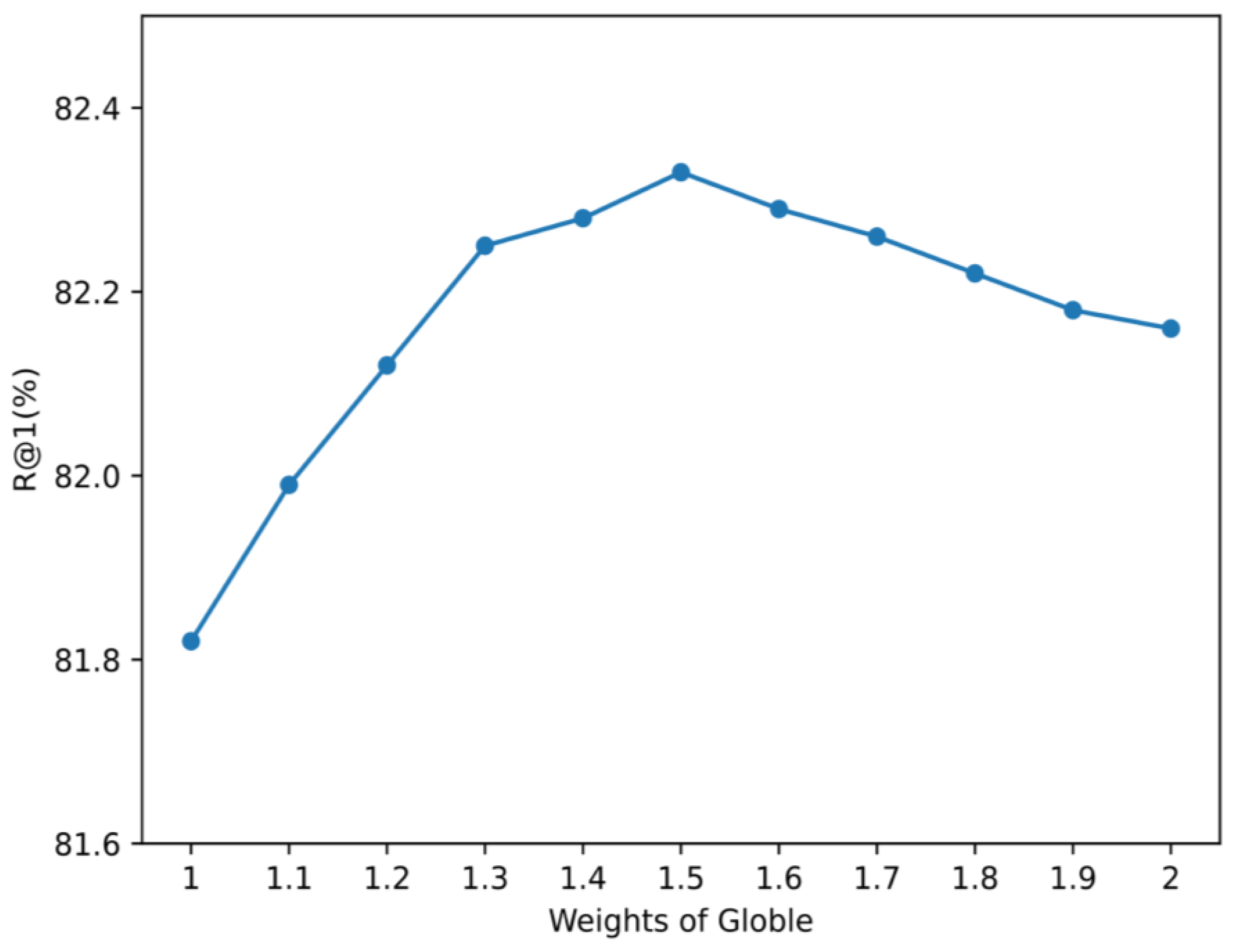
3.2. Ablation Study of Methods
3.3. Offset and Scale Ablation
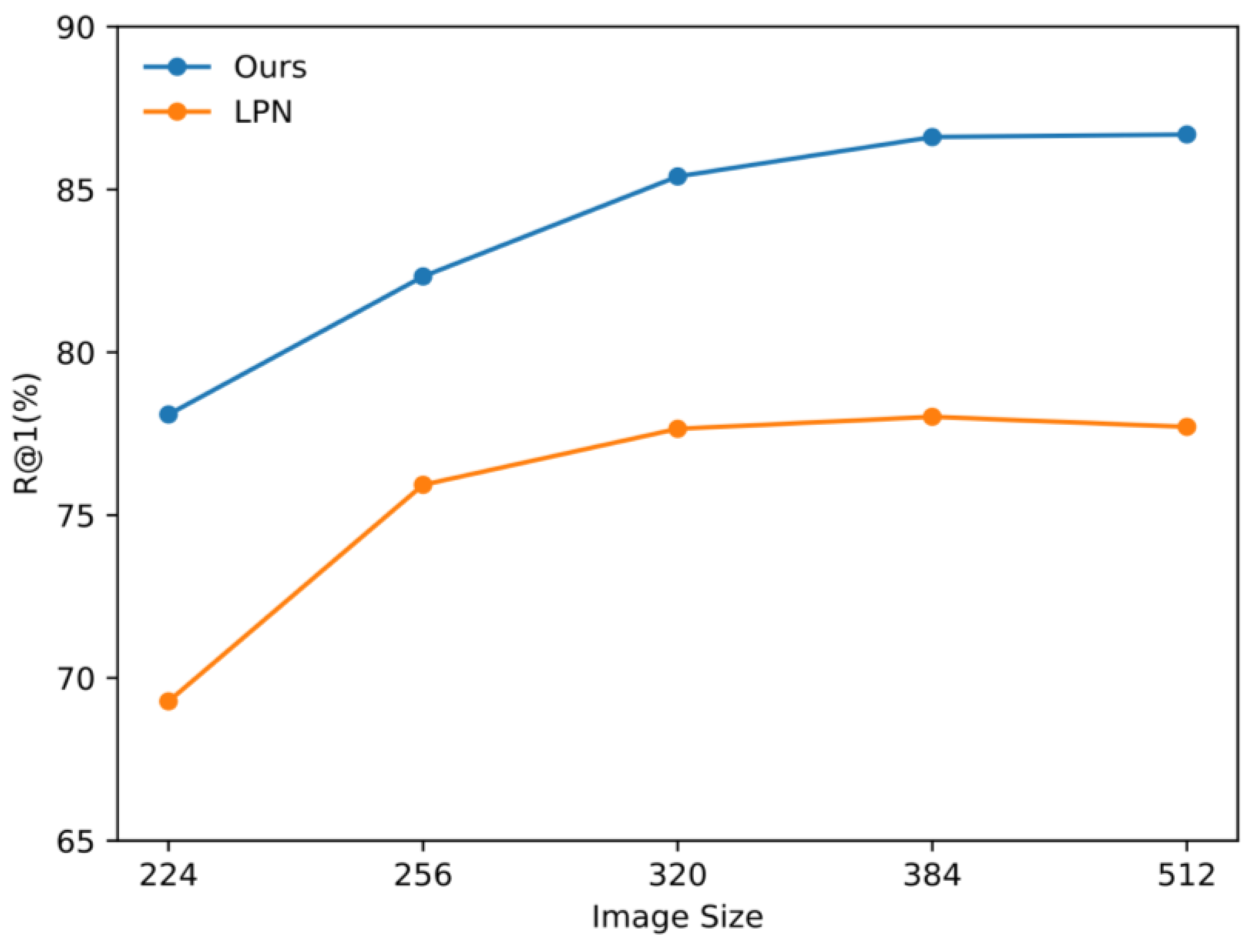
3.4. Input Size Ablation
3.5. Inference with Different Branches
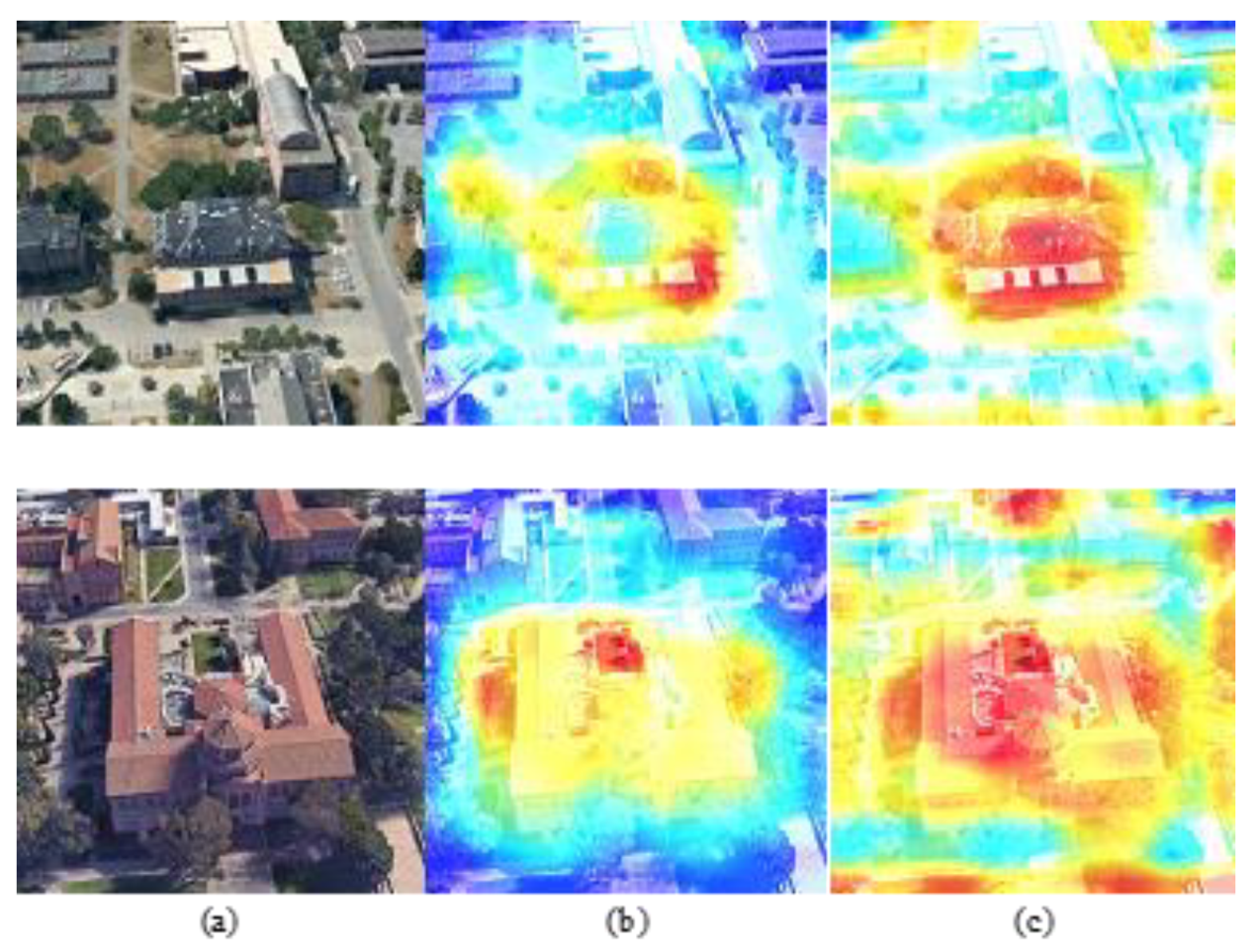
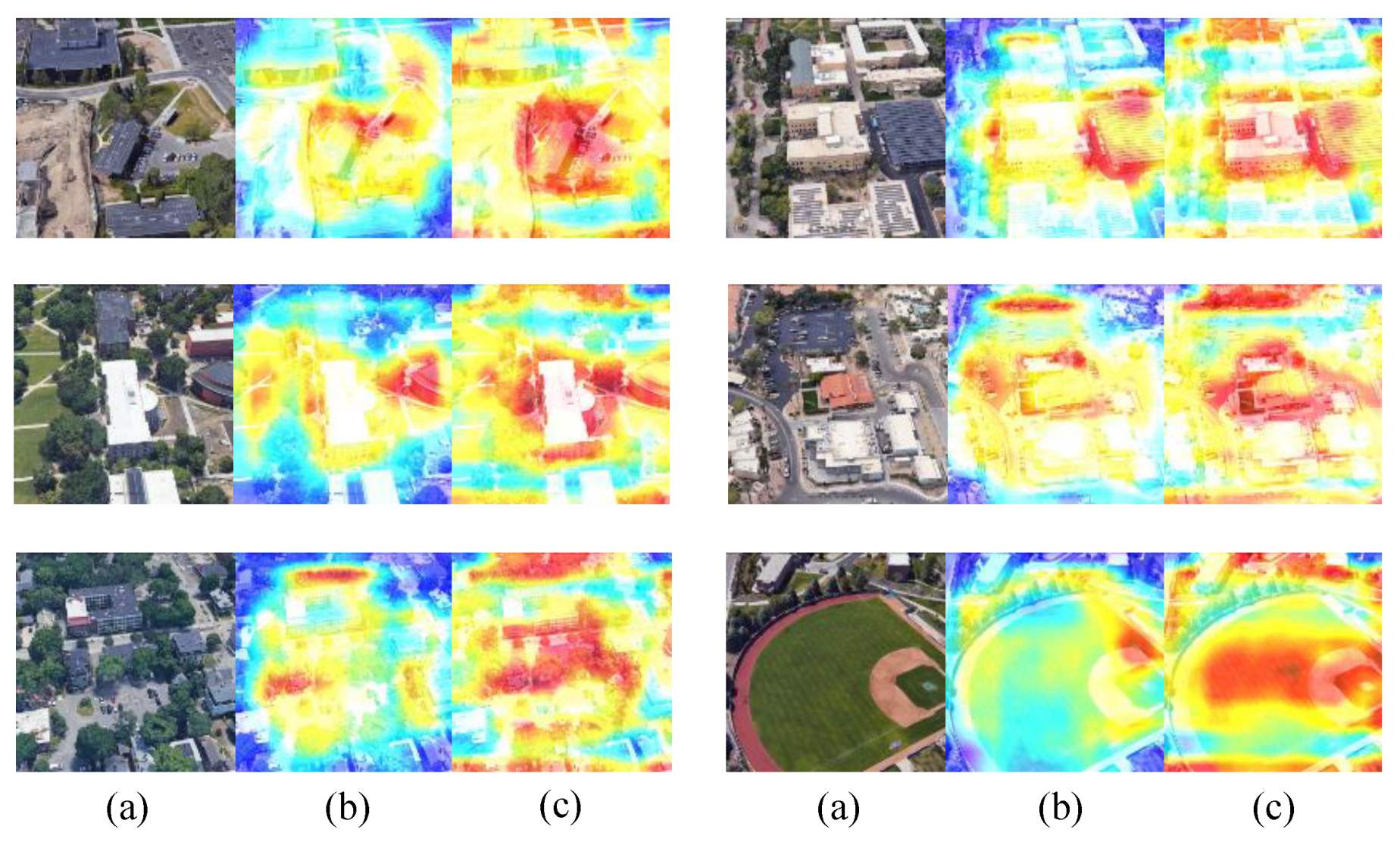
3.6. Result Visualization
4. Discussions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alexander, C.; Korstjens, A.H.; Hankinson, E.; Usher, G.; Harrison, N.; Nowak, M.G.; Abdullah, A.; Wich, S.A.; Hill, R.A. locating emergent trees in a tropical rainforest using data from an Unmanned Aerial Vehicle (UAV). Int. J. Appl. Earth Obs. Geoinf. 2018, 72, 86–90. [Google Scholar] [CrossRef]
- Ammour, N.; Alhichri, H.; Bazi, Y.; Benjdira, B.; Alajlan, N.; Zuair, M. Deep learning approach for car detection in UAV imagery. Remote Sens. 2017, 9, 312. [Google Scholar] [CrossRef] [Green Version]
- Deng, L.; Mao, Z.; Li, X.; Hu, Z.; Duan, F.; Yan, Y. UAV-based multispectral remote sensing for precision agriculture: A comparison between different cameras. ISPRS J. Photogramm. Remote Sens. 2018, 146, 124–136. [Google Scholar] [CrossRef]
- Lin, Y.-C.; Cheng, Y.-T.; Zhou, T.; Ravi, R.; Hasheminasab, S.M.; Flatt, J.E.; Troy, C.; Habib, A. Evaluation of UAV LiDAR for mapping coastal environments. Remote Sens. 2019, 11, 2893. [Google Scholar] [CrossRef] [Green Version]
- Yan, Y.; Deng, L.; Liu, X.; Zhu, L. Application of UAV-based multi-angle hyperspectral remote sensing in fine vegetation classification. Remote Sens. 2019, 11, 2753. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Yang, M.; Xie, M.; Guo, Z.; Li, E.; Zhang, L.; Pei, T.; Wang, D. Accurate building extraction from fused DSM and UAV images using a chain fully convolutional neural network. Remote Sens. 2019, 11, 2912. [Google Scholar] [CrossRef] [Green Version]
- Ferrer-González, E.; Agüera-Vega, F.; Carvajal-Ramírez, F.; Martínez-Carricondo, P. UAV Photogrammetry accuracy assessment for corridor mapping based on the number and distribution of ground control points. Remote Sens. 2020, 12, 2447. [Google Scholar] [CrossRef]
- Castaldo, F.; Zamir, A.; Angst, R.; Palmieri, F.; Savarese, S. Semantic cross-view matching. In Proceedings of the Workshops of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1044–1052. [Google Scholar]
- Lin, T.; Belongie, S.; Hays, J. Cross-view image geolocalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 891–898. [Google Scholar]
- Senlet, T.; Elgammal, A. A framework for global vehicle localization using stereo images and satellite and road maps. In Proceedings of the Workshops of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2034–2041. [Google Scholar]
- Bansal, M.; Sawhney, H.; Cheng, H.; Daniilidis, K. Geo-localization of street views with aerial image databases. In Proceedings of the ACM International Conference on Multimedia, New York, NY, USA, 28 November 2011; pp. 1125–1128. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 539–546. [Google Scholar]
- Liu, L.; Li, H. Lending orientation to neural networks for cross-view geo-localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5624–5633. [Google Scholar]
- Hu, S.; Feng, M.; Nguyen, R.M.; Hee Lee, G. Cvm-net: Cross-view matching network for image-based ground-to-aerial geo-localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7258–7267. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. Netvlad: Cnn architecture for weakly supervised place recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5297–5307. [Google Scholar]
- Liu, L.; Li, H.; Dai, Y. Stochastic attraction-repulsion embedding for large scale image localization. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 2570–2579. [Google Scholar]
- Vo, N.N.; Hays, J. Localizing and orienting street views using overhead imagery. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 494–509. [Google Scholar]
- Shi, Y.; Liu, L.; Yu, X.; Li, H. Spatial-aware feature aggregation for image based cross-view geo-localization. In Proceedings of the Neural Information Processing Systems, Vancouver, VBC, Canada, 8–14 December 2019. [Google Scholar]
- Shi, Y.; Yu, X.; Campbell, D.; Li, H. Where am I looking at? Joint location and orientation estimation by cross-view matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4063–4071. [Google Scholar]
- Zhai, M.; Bessinger, Z.; Workman, S.; Jacobs, N. Predicting ground-level scene layout from aerial imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 867–875. [Google Scholar]
- Zheng, Z.; Wei, Y.; Yang, Y. University-1652: A multi-view multi-source benchmark for drone-based geo-localization. In Proceedings of the ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1395–1403. [Google Scholar]
- Zheng, Z.; Zheng, L.; Garrett, M.; Yang, Y.; Xu, M.; Shen, Y.-D. Dual-path convolutional image-text embeddings with instance loss. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 1–23. [Google Scholar] [CrossRef]
- Zheng, Z.; Zheng, L.; Yang, Y. A Discriminatively Learned CNN Embedding for Person Reidentification. ACM Trans. Multimedia Comput. Commun. Appl. 2017, 14, 1–20. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 501–518. [Google Scholar]
- Zheng, L.; Huang, Y.; Lu, H.; Yang, Y. Pose-invariant embedding for deep person re-identification. IEEE Trans. Image Process. 2019, 28, 4500–4509. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wei, L.; Zhang, S.; Yao, H.; Gao, W.; Tian, Q. Glad: Global– local-alignment descriptor for scalable person re-identification. IEEE Trans. Multimed. 2018, 21, 986–999. [Google Scholar] [CrossRef]
- Zheng, Z.; Zheng, L.; Yang, Y. Pedestrian alignment network for large-scale person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3037–3045. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Zheng, Z.; Yan, C.; Zhang, J.; Sun, Y.; Zheng, B.; Yang, Y. Each part matters: Local patterns facilitate cross-view geo-localization. IEEE Trans. Circuits Syst. Video Technol. 2021. [Google Scholar] [CrossRef]
- Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; Chen, Z. Relation-aware global attention for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3183–3192. [Google Scholar]
- Zhao, L.; Li, X.; Zhuang, Y.; Wang, J. Deeply-learned part-aligned representations for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3239–3248. [Google Scholar]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Mask-guided contrastive attention model for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1179–1188. [Google Scholar]
- Suh, Y.; Wang, J.; Tang, S.; Mei, T.; Lee, K.M. Part-aligned bilinear representations for person re-identification. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 418–437. [Google Scholar]
- Xu, J.; Zhao, R.; Zhu, F.; Wang, H.; Ouyang, W. Attention-aware compositional network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2119–2128. [Google Scholar]
- Zhao, H.; Tian, M.; Sun, S.; Shao, J.; Yan, J.; Yi, S.; Wang, X.; Tang, X. Spindle net: Person re-identification with human body region guided feature decomposition and fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 907–915. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, C.; Zhang, Q.; Huang, C.; Liu, W.; Wang, X. Mancs: A multi-task attentional network with curriculum sampling for person re-identification. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 384–400. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Harmonious attention network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2285–2294. [Google Scholar]
- Chen, B.; Deng, W.; Hu, J. Mixed high-order attention network for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 371–381. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6450–6458. [Google Scholar]
- Yang, F.; Yan, K.; Lu, S.; Jia, H.; Xie, X.; Gao, W. Attention driven person re-identification. Pattern Recognit. 2019, 86, 143–155. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Li, K.; Li, K.; Zhong, B.; Fu, Y. Residual non-local attention networks for image restoration. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7130–7138. [Google Scholar]
- Wang, G.; Gong, S.; Cheng, J.; Hou, Z. Faster person re-identification. In Proceedings of the European Conference on Computer Vision, Online Platform, 23–28 August 2020. [Google Scholar]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep mutual learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4320–4328. [Google Scholar]
- Ding, L.; Zhou, J.; Meng, L.; Long, Z. A practical cross-view image matching method between UAV and Satellite for UAV-based geo-localization. Remote Sens. 2020, 13, 47. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Radenovic, F.; Tolias, G.; Chum, O. Fine-tuning CNN image retrieval with no human annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1655–1668. [Google Scholar] [CrossRef] [PubMed] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Dataset | ||
|---|---|---|
| Views | Numbers of Buildings | Numbers of Images |
| Drone | 701 | 37,854 |
| Satellite | 701 | 701 |
| Testing Dataset | ||
| Views | Numbers of Buildings | Numbers of Images |
| Dronequery | 701 | 37,854 |
| Satellitequery | 701 | 701 |
| Dronegallery | 951 | 51,355 |
| Satellitegallery | 951 | 951 |
| Method | Publication | Backbone | Drone → Satellite R@1 AP | Satellite → Drone R@1 AP |
|---|---|---|---|---|
| Soft margin triplet loss [13] | CVPR’19 | VGG16 | 53.21 58.03 | 65.62 54.47 |
| Instance loss [22] | TOMM’20 | ResNet-50 | 58.23 62.91 | 74.47 59.45 |
| Instance loss + verification loss [23,16] | TOMM’17 | ResNet-50 | 61.30 65.68 | 75.04 62.87 |
| Instance loss + gem pooling [52] | TPAMI’18 | ResNet-50 | 65.32 69.61 | 79.03 65.35 |
| LCM [48] | Remote Sens’20 | ResNet-50 | 66.65 70.82 | 79.89 65.38 |
| LPN [28] | TCSVT’21 | ResNet-50 | 74.16 77.39 | 85.16 73.68 |
| Ours | - | ResNet-50 | 82.33 84.78 | 90.58 81.61 |
| Ours(s384) | - | ResNet-50 | 86.61 88.55 | 92.15 84.45 |
| Method | Drone → Satellite R@1 AP | Satellite → Drone R@1 AP |
|---|---|---|
| LPN | 74.16 77.39 | 85.16 73.68 |
| Baseline(ours) | 76.17 79.20 | 86.02 74.37 |
| +Multiscale | 77.18 79.94 | 85.93 75.12 |
| +Global branch | 78.47 81.42 | 86.16 77.17 |
| +Block attention | 79.55 82.30 | 87.87 79.94 |
| +KL loss | 81.29 83.85 | 89.73 80.64 |
| +Reweights | 82.33 84.78 | 90.58 81.61 |
| Padding Pixel | Drone → Satellite R@1 AP | Satellite → Drone R@1 AP |
|---|---|---|
| 0 | 86.61 88.55 | 92.15 84.45 |
| 10 | 86.22 88.23 | 92.01 84.24 |
| 20 | 85.02 87.21 | 90.87 83.43 |
| 30 | 83.95 85.46 | 89.44 81.95 |
| 40 | 81.48 83.52 | 88.30 79.64 |
| 50 | 77.53 80.64 | 85.59 75.84 |
| Distance | Drone → Satellite R@1 AP |
|---|---|
| All | 82.33 84.78 |
| Short | 86.02 87.93 |
| Middle | 86.02 88.09 |
| Long | 74.94 78.27 |
| Input Image Size | Drone → Satellite R@1 AP | Satellite → Drone R@1 AP |
|---|---|---|
| 224 | 78.09 80.95 | 87.30 77.37 |
| 256 | 82.33 84.78 | 90.58 81.61 |
| 320 | 85.40 87.47 | 92.01 84.23 |
| 384 | 86.61 88.55 | 92.15 84.45 |
| 512 | 86.69 88.66 | 92.01 84.45 |
| Part Combination | Drone → Satellite R@1 AP | Satellite → Drone R@1 AP | Inference Time |
|---|---|---|---|
| P1 | 51.73 56.64 | 70.76 51.31 | — |
| P2 | 59.66 63.77 | 77.75 58.85 | — |
| P3 | 52.89 57.18 | 78.32 53.17 | — |
| P4 | 63.49 67.70 | 79.32 62.95 | — |
| P5 | 63.30 67.37 | 78.17 62.53 | — |
| P6 | 55.09 55.09 | 78.03 55.28 | — — — |
| Global | 73.59 76.93 | 84.74 73.12 | 0.72× |
| All | 81.29 83.85 | 89.73 80.64 | 1.05× |
| All(RW) | 82.33 84.78 | 90.58 81.61 | 1.05× |
| LPN | 74.16 77.39 | 85.16 73.68 | 1.00× |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhuang, J.; Dai, M.; Chen, X.; Zheng, E. A Faster and More Effective Cross-View Matching Method of UAV and Satellite Images for UAV Geolocalization. Remote Sens. 2021, 13, 3979. https://doi.org/10.3390/rs13193979
Zhuang J, Dai M, Chen X, Zheng E. A Faster and More Effective Cross-View Matching Method of UAV and Satellite Images for UAV Geolocalization. Remote Sensing. 2021; 13(19):3979. https://doi.org/10.3390/rs13193979
Chicago/Turabian StyleZhuang, Jiedong, Ming Dai, Xuruoyan Chen, and Enhui Zheng. 2021. "A Faster and More Effective Cross-View Matching Method of UAV and Satellite Images for UAV Geolocalization" Remote Sensing 13, no. 19: 3979. https://doi.org/10.3390/rs13193979
APA StyleZhuang, J., Dai, M., Chen, X., & Zheng, E. (2021). A Faster and More Effective Cross-View Matching Method of UAV and Satellite Images for UAV Geolocalization. Remote Sensing, 13(19), 3979. https://doi.org/10.3390/rs13193979