
Compound Multiscale Weak Dense Network with Hybrid Attention for Hyperspectral Image Classification



Abstract
:
1. Introduction
- (1)
- A compound multiscale weak dense network model combining a hybrid attention mechanism (CMWD-HA) is proposed for HSI classification. This model shows good classification performance and high efficiency;
- (2)
- A hybrid spectral–spatial attention mechanism is proposed in preprocessing. This attention mechanism aims to weight HSI data simultaneously at both spectral and spatial levels. In addition, the mechanism is learnable and consumes fewer computing resources;
- (3)
- Spectral and spatial multiscale feature extraction modules and weak dense spectral and spatial feature extraction modules are designed, and spectral feature extraction branches and spatial feature extraction branches are constructed based on the above modules. The extracted high-level semantic features can distinguish different categories of pixels well, with good generalization ability;
- (4)
- Dropout and dynamic learning rates are used to ensure the rapid convergence of the model.
2. Related Work
ResNet and DenseNet
3. Methodology
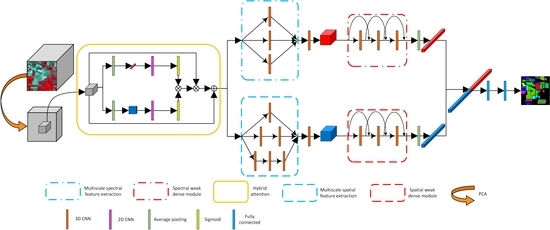
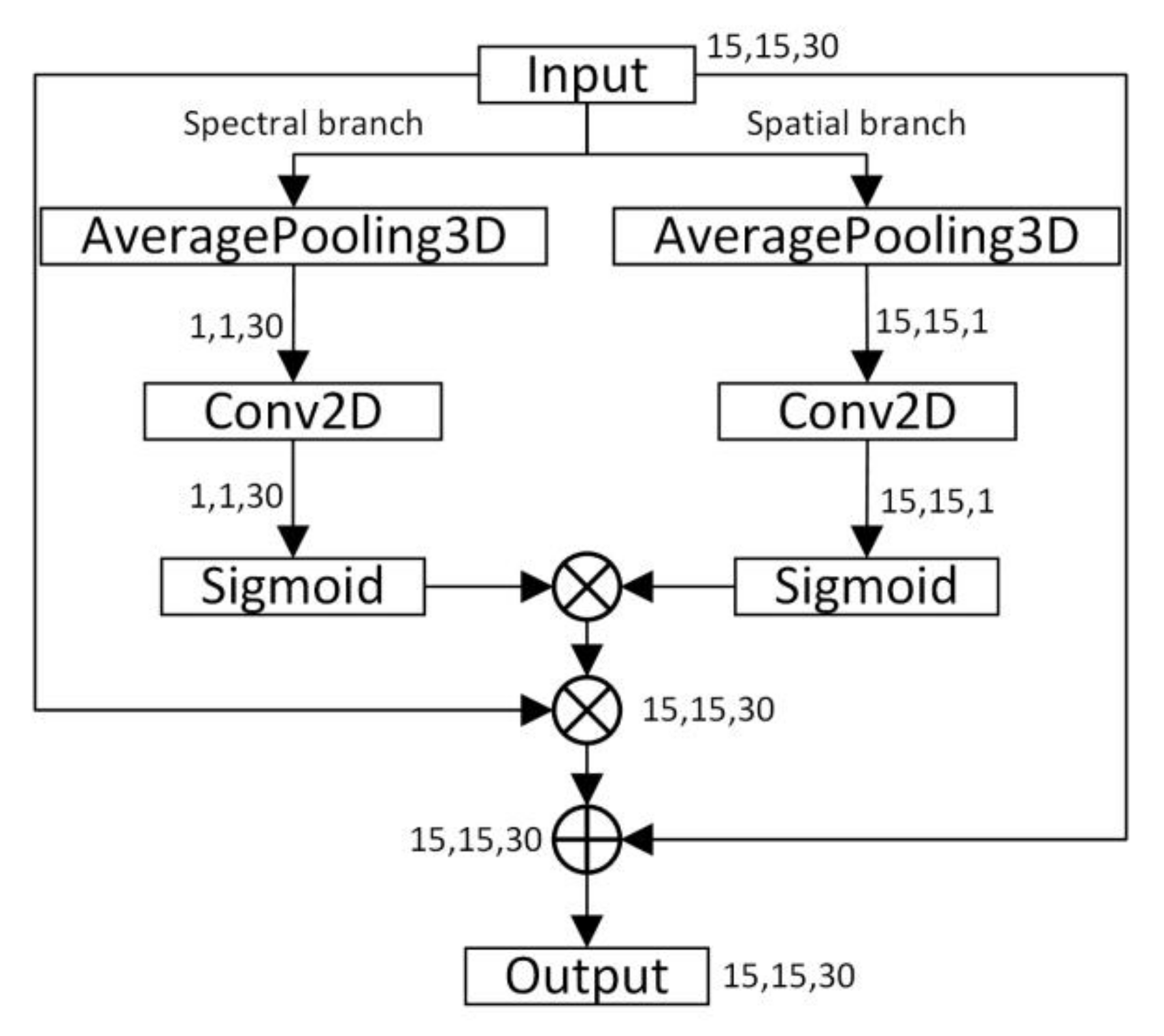
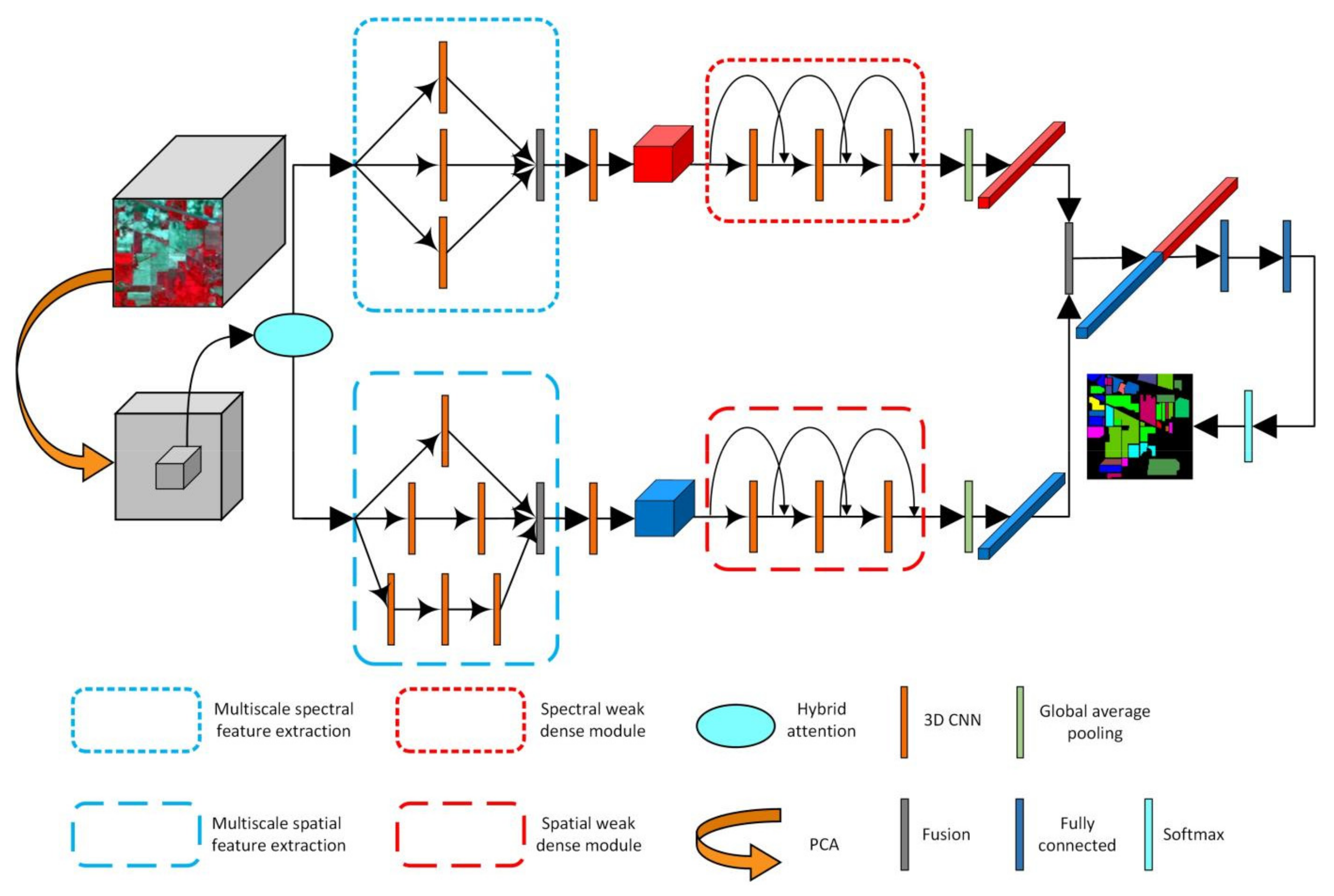
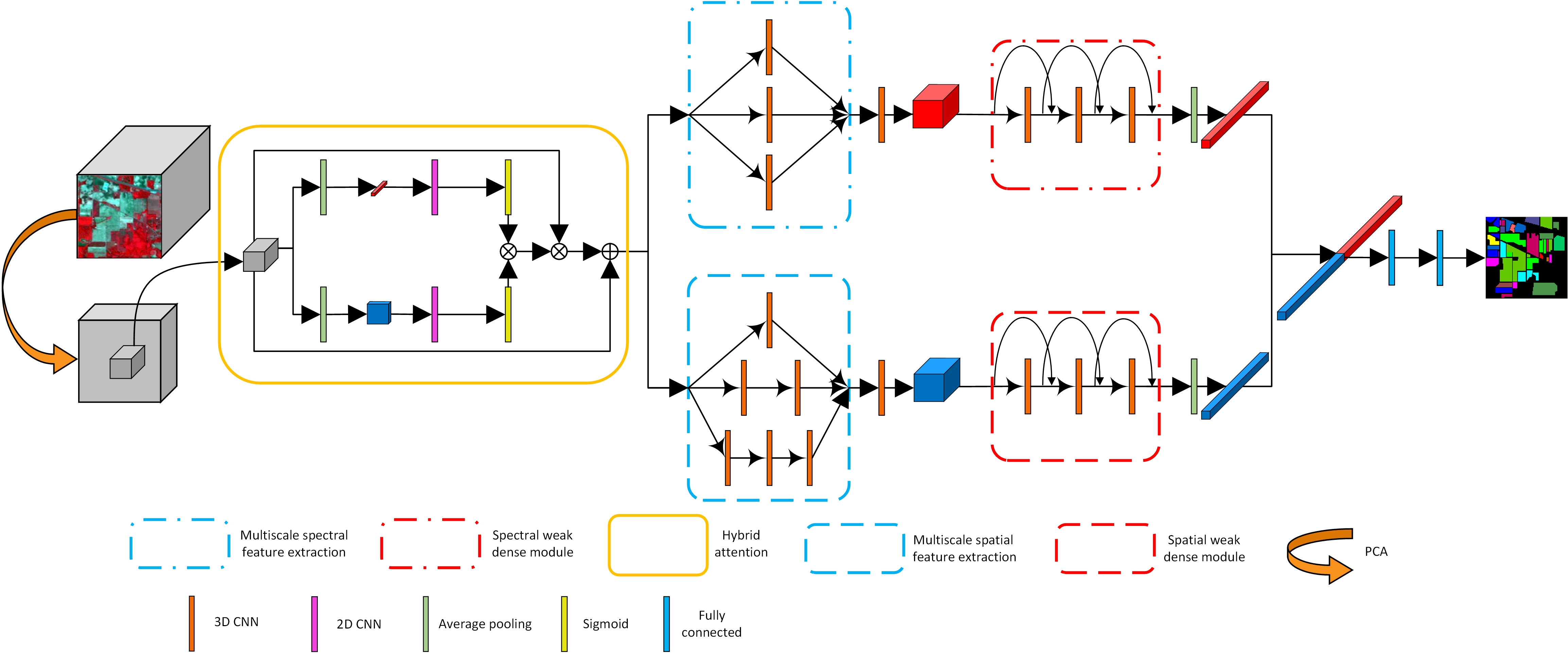
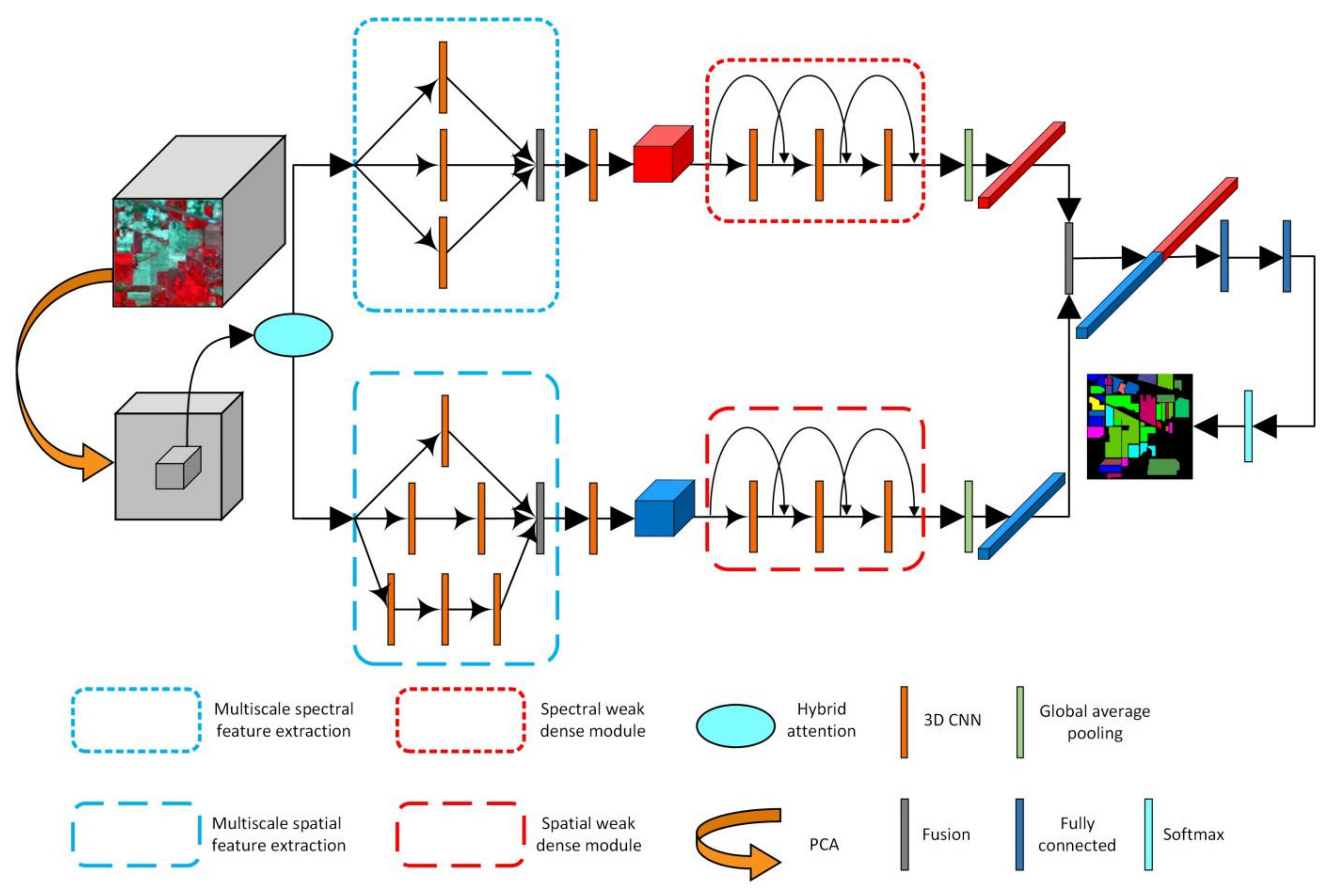
3.1. Hybrid Attention Mechanism
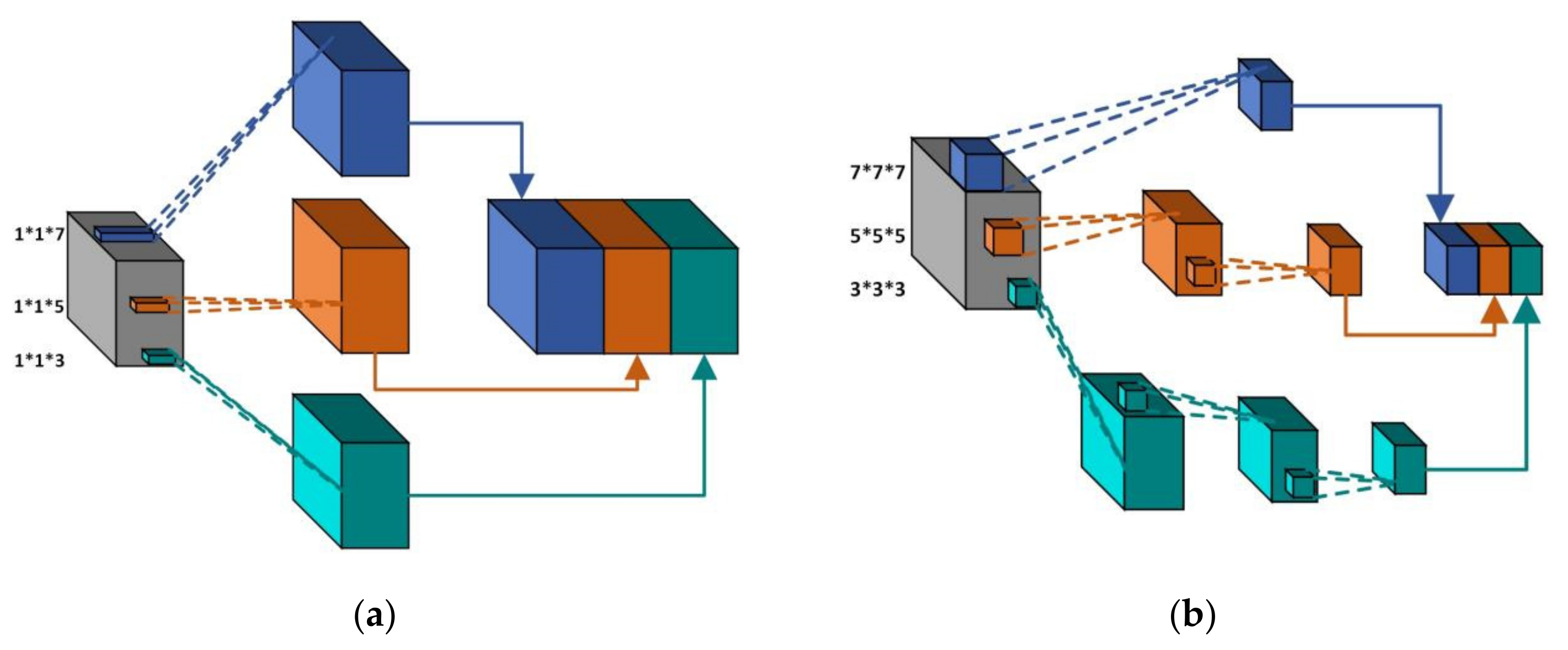
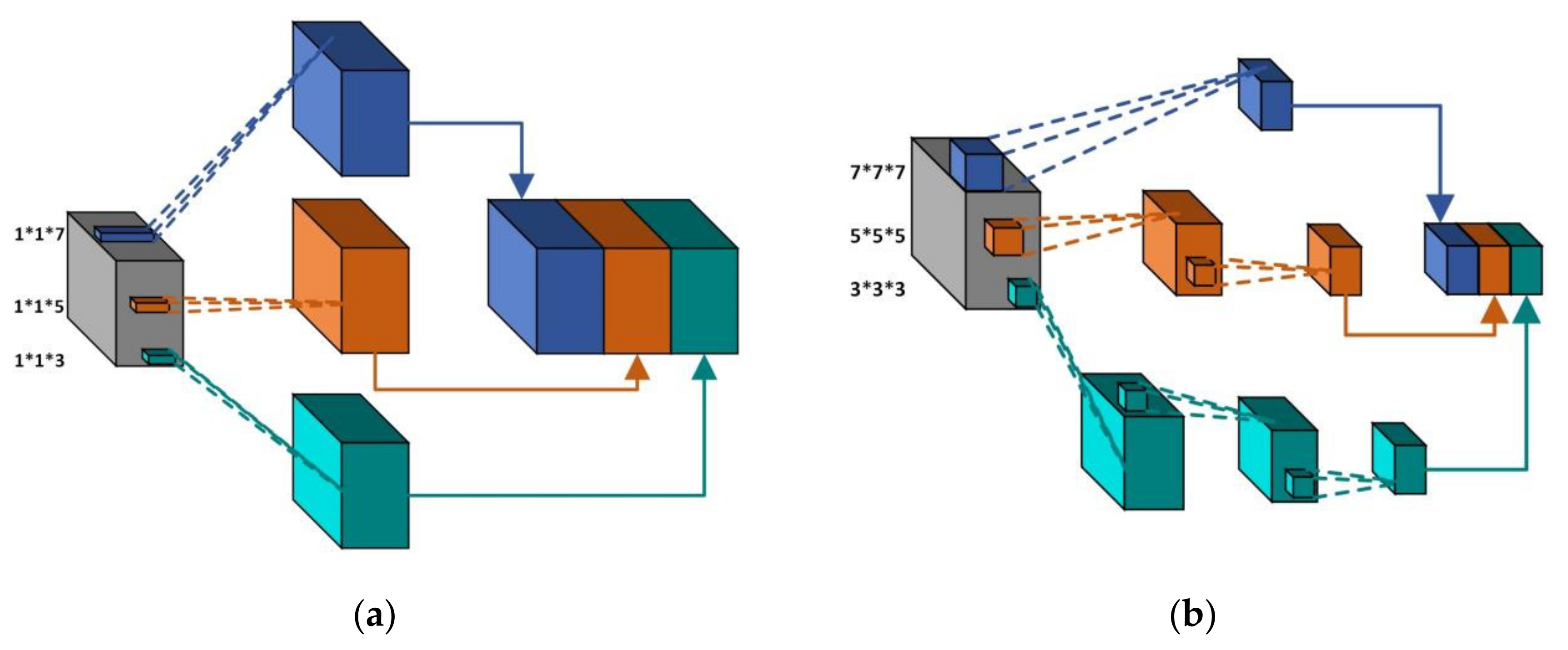
3.2. Multiscale Spectral and Spatial Feature Extraction
3.3. Weak Dense Spectral and Spatial Feature Extraction
3.4. Compound Multiscale Weak Dense Network with Hybrid Attention for HSI Classification
3.5. Measures Taken to Prevent Overfitting
4. Experiments and Results
4.1. Data Description
4.2. Experimental Setup
- (1)
- SVM: This method takes the spectral information of pixels as features and classifies them by means of an SVM.
- (2)
- CDCNN: This method selects a 5 × 5 × L spatial size of the image cubes as the input and combines a 2D CNN and ResNet to construct a network architecture. L indicates the number of the spectral bands of the image cubes. The details of the method are provided in [19].
- (3)
- SSRN: This method selects a 7 × 7 × L spatial size of the image cubes as the input, and combines a 3D CNN and ResNet to construct a network architecture. The details of the method are provided in [20].
- (4)
- FDSSC: This method selects a 9 × 9 × L spatial size of the image cubes as the input, and combines a 3D CNN and DenseNet to construct a network architecture. The details of the method are provided in [21].
- (5)
- HybridSN: This method selects a 25 × 25 × L spatial size of the image cubes as the input, and builds a network model based on a 2D CNN and 3D CNN. The details of the method are provided in [22].
- (6)
- DBMA: This method selects a 7 × 7 × L spatial size of the image cubes as the input, and builds a network model based on a 3D CNN, DenseNet, and an attention mechanism. The details of the method are provided in [39].
- (7)
- DBDA: This method selects a 9 × 9 × L spatial size of the image cubes as the input, and builds a network model based on a 3D CNN, DenseNet, and an attention mechanism. The details of the method are provided in [40].
4.3. Quantitative Evaluation of Classification Results
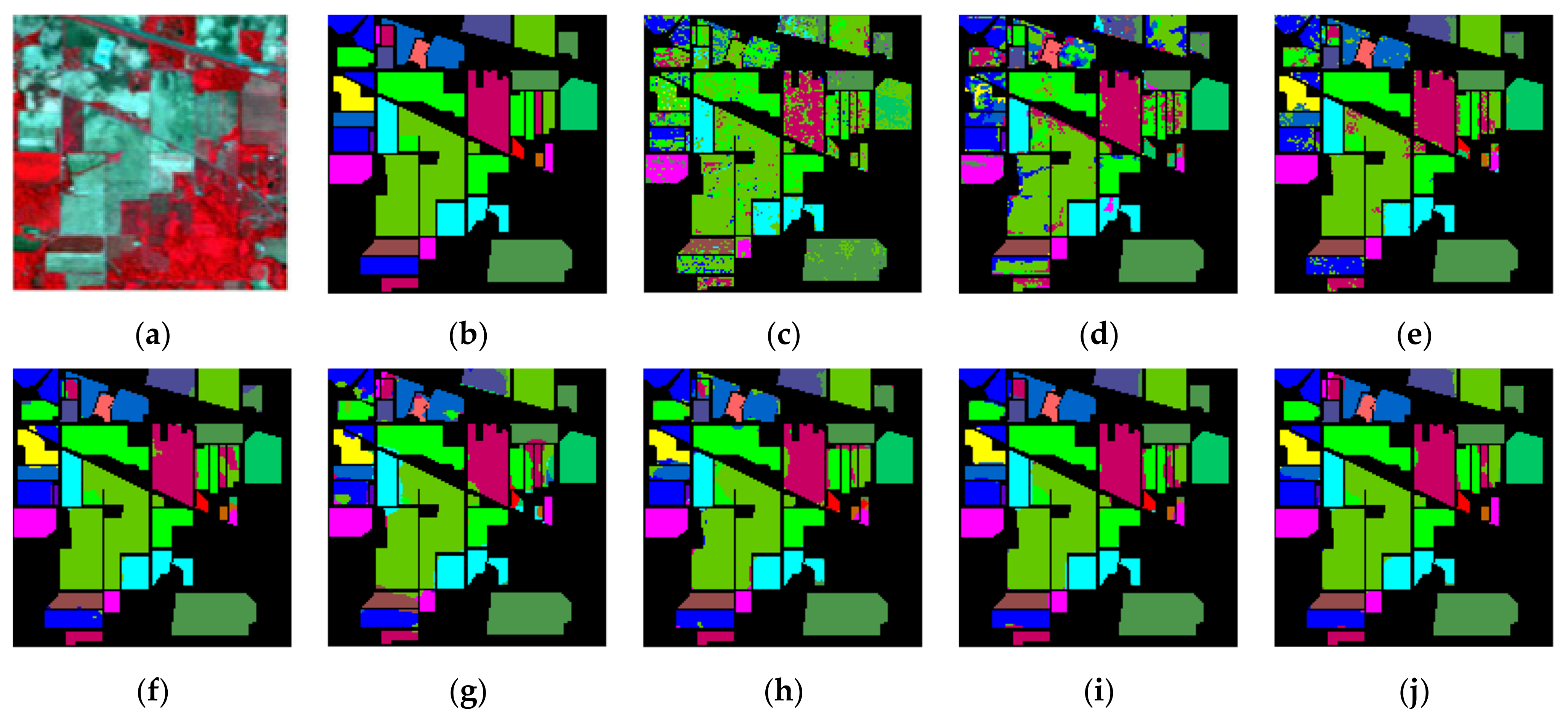
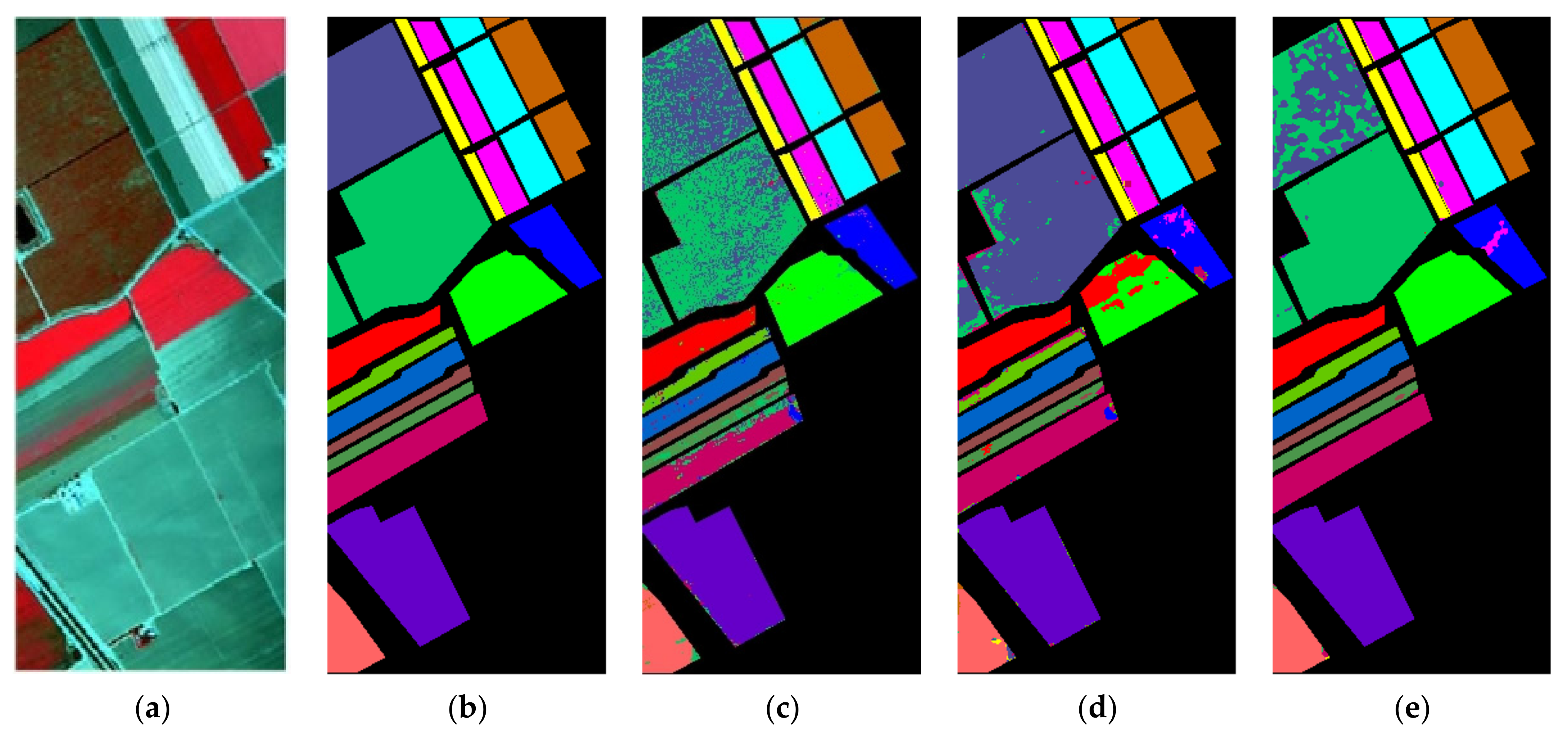
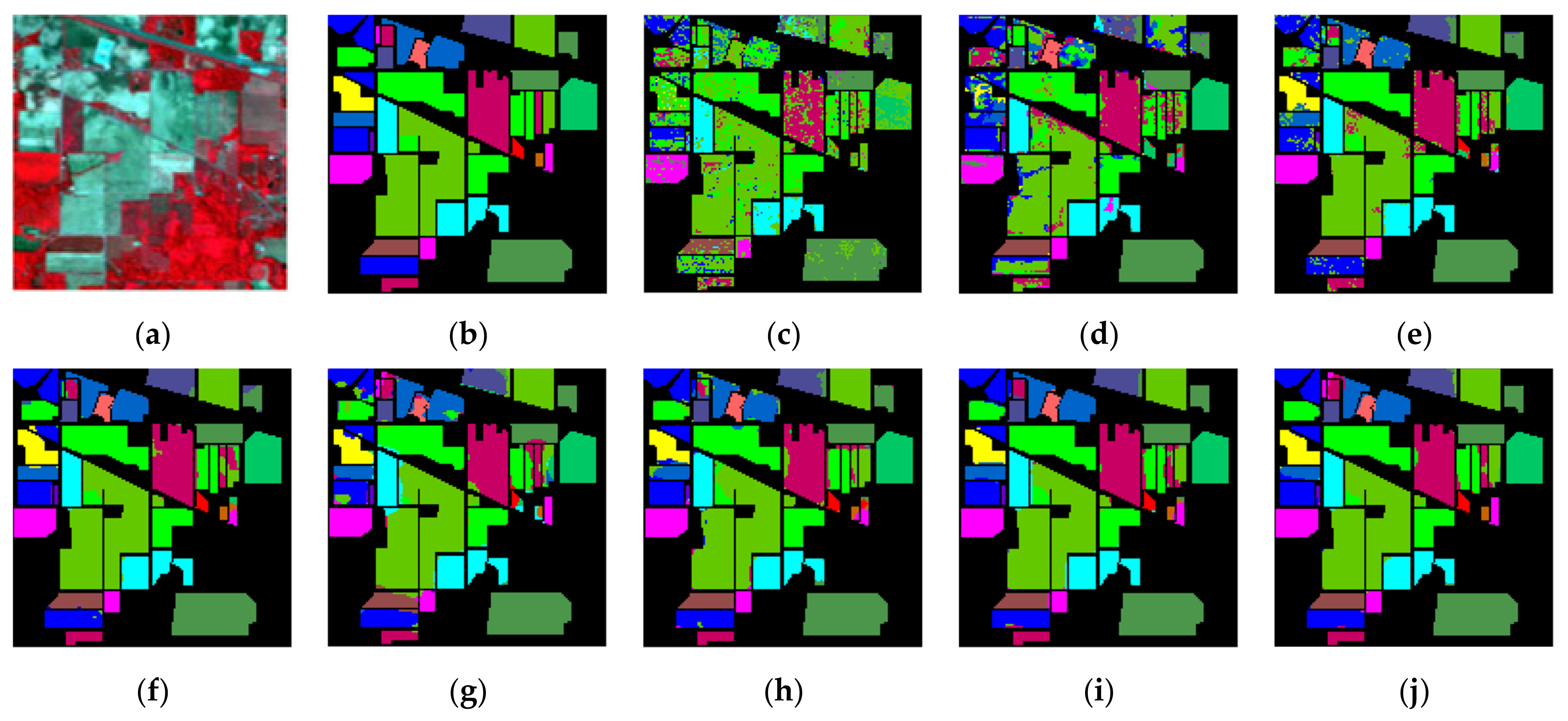
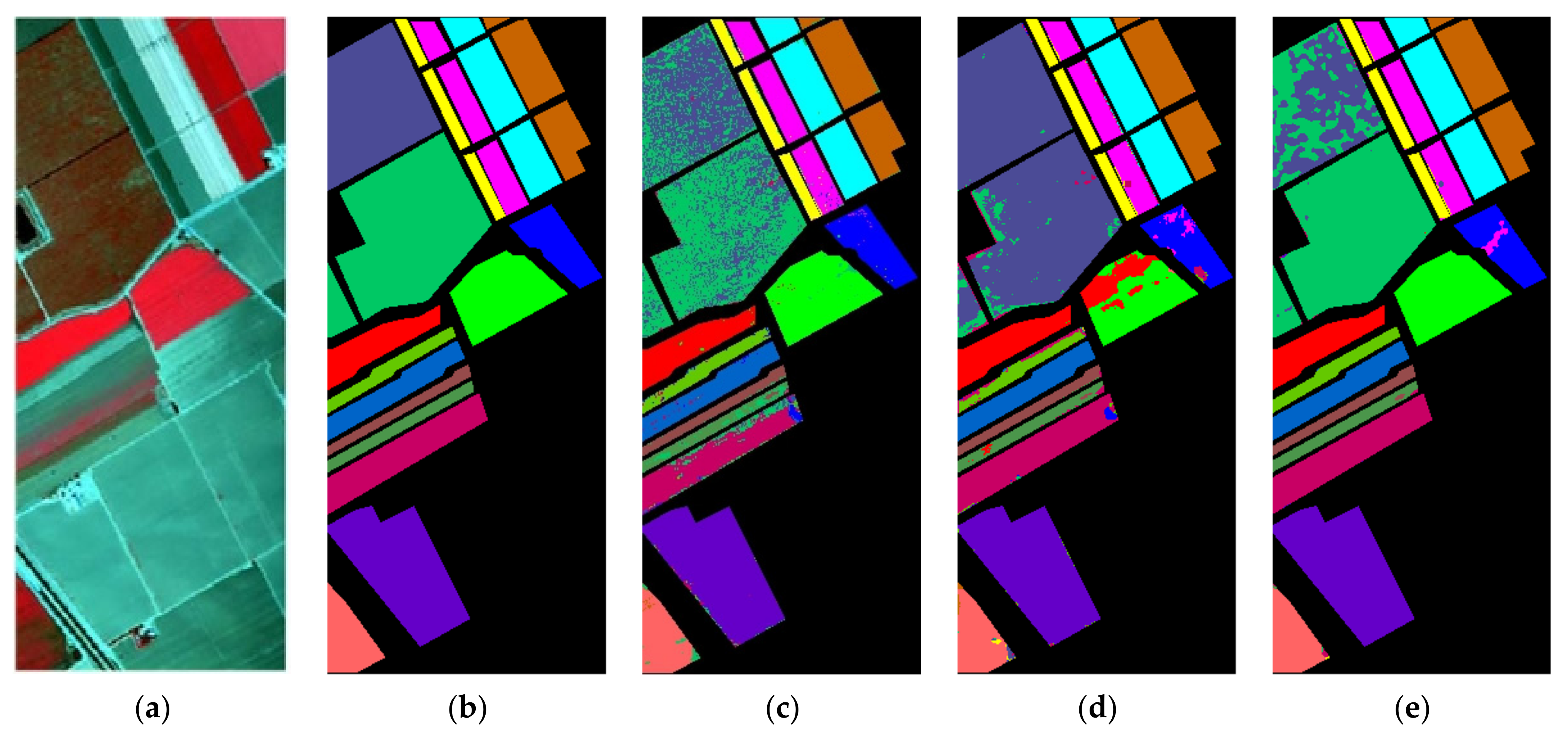
4.4. Qualitative Evaluation of Classification Results
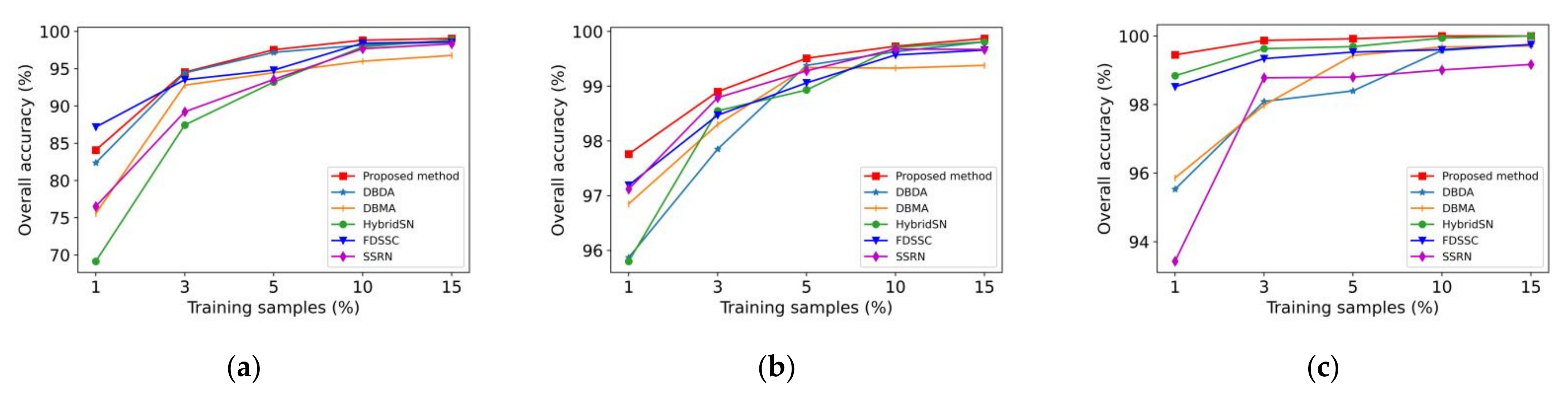
4.5. Comparison of Different Methods When Different Training Samples Are Considered
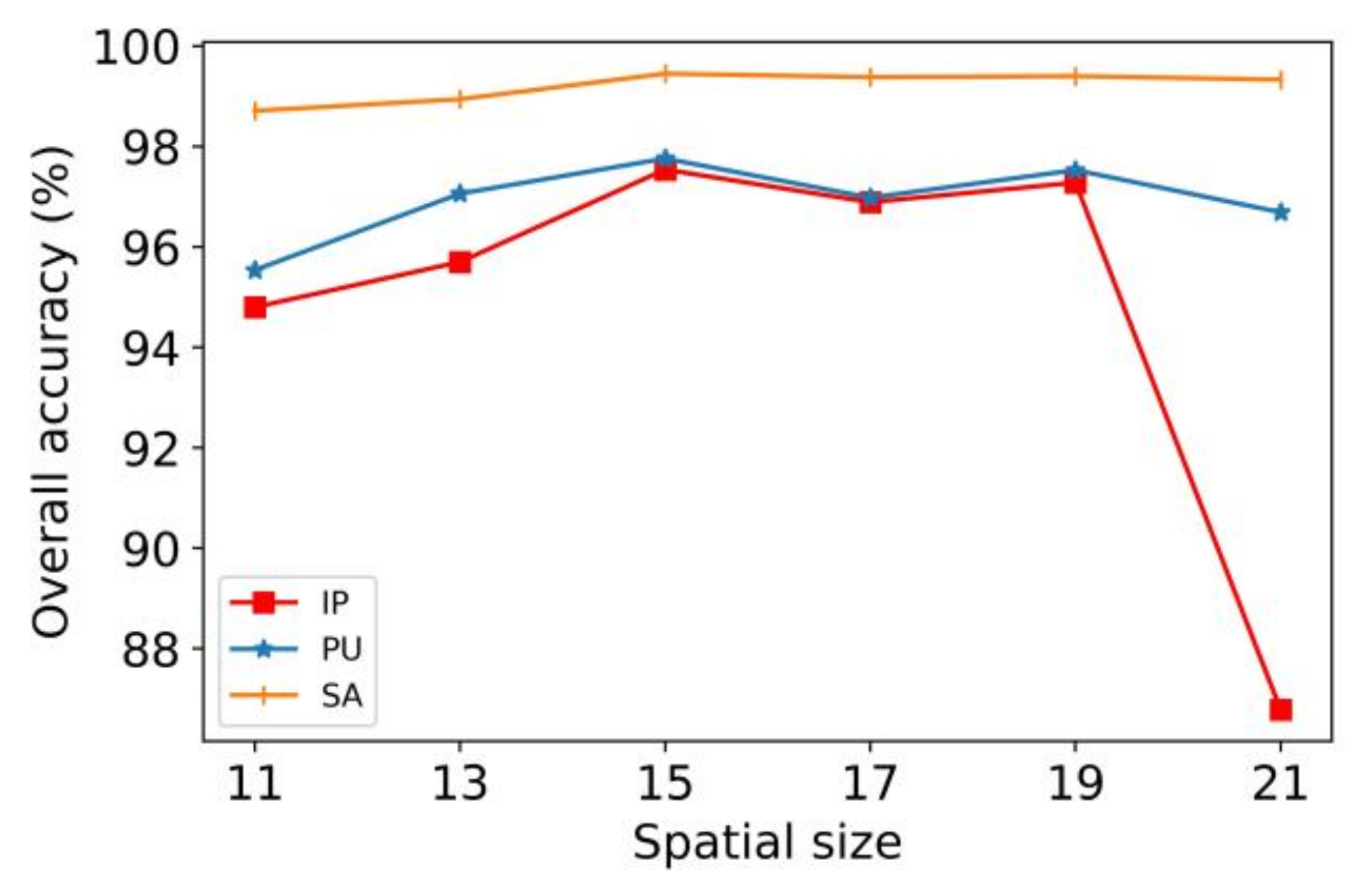
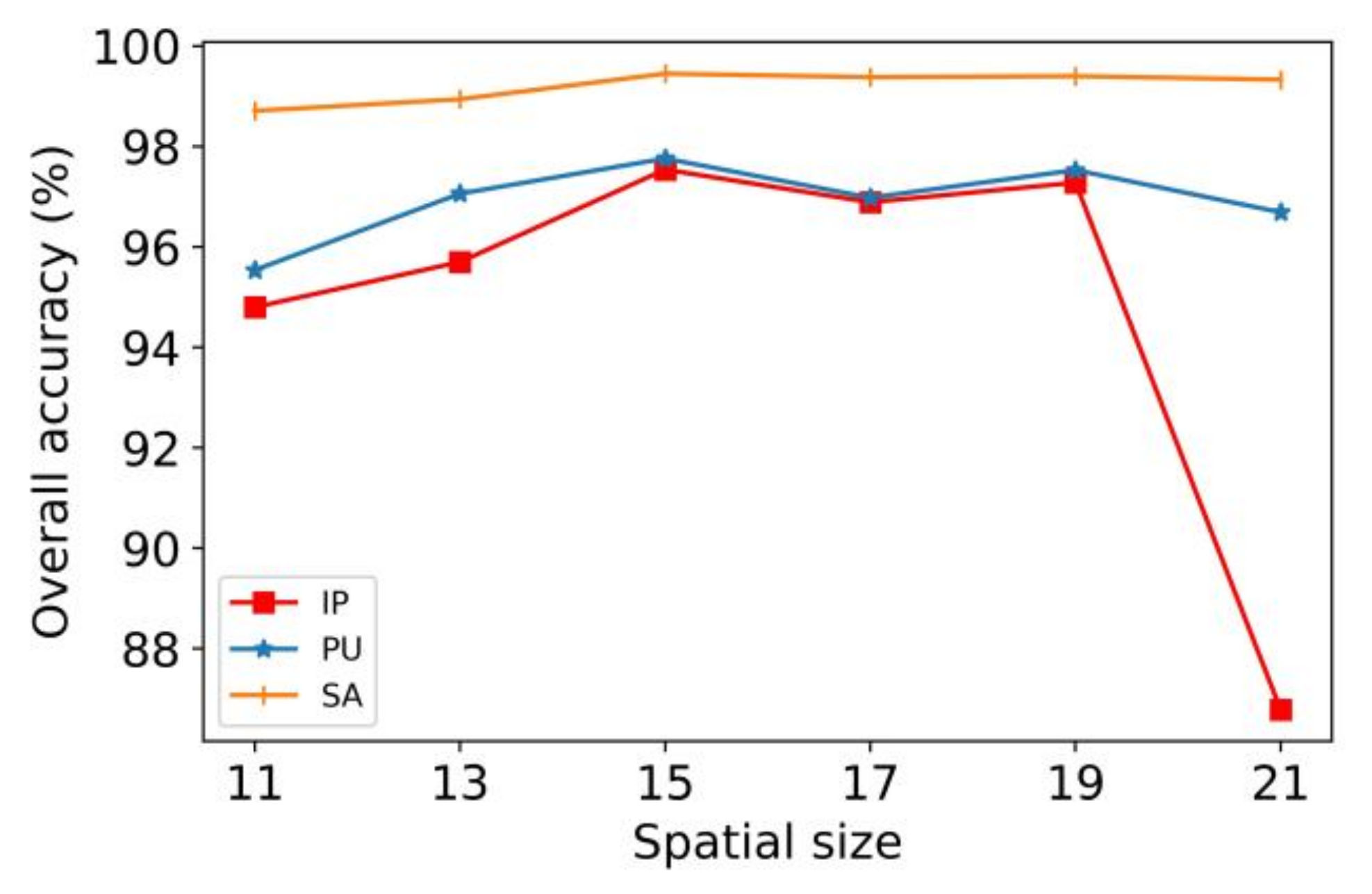
4.6. Comparison of OA for Different Spatial Sizes
4.7. Comparison of OA for Different Learning Rates
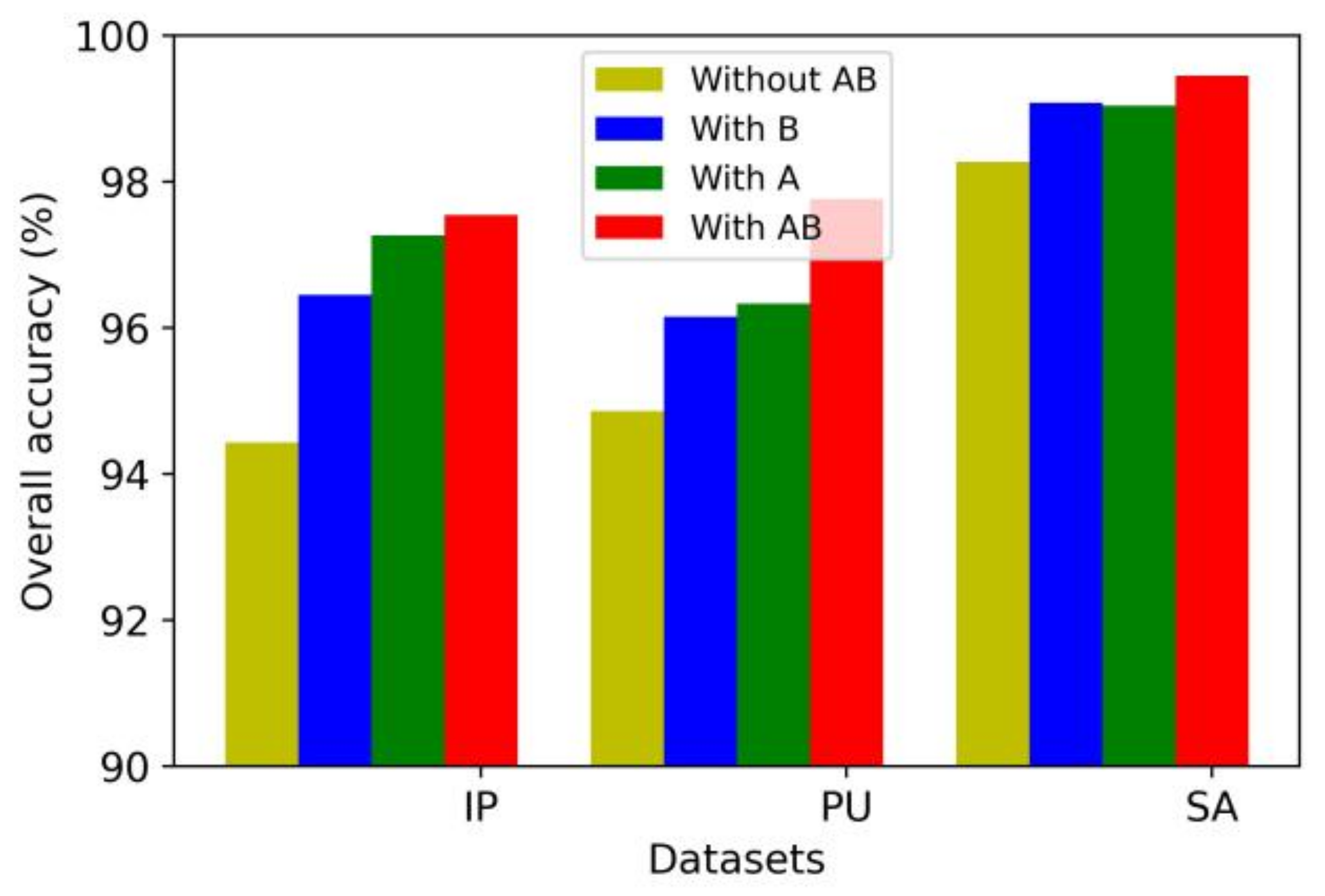
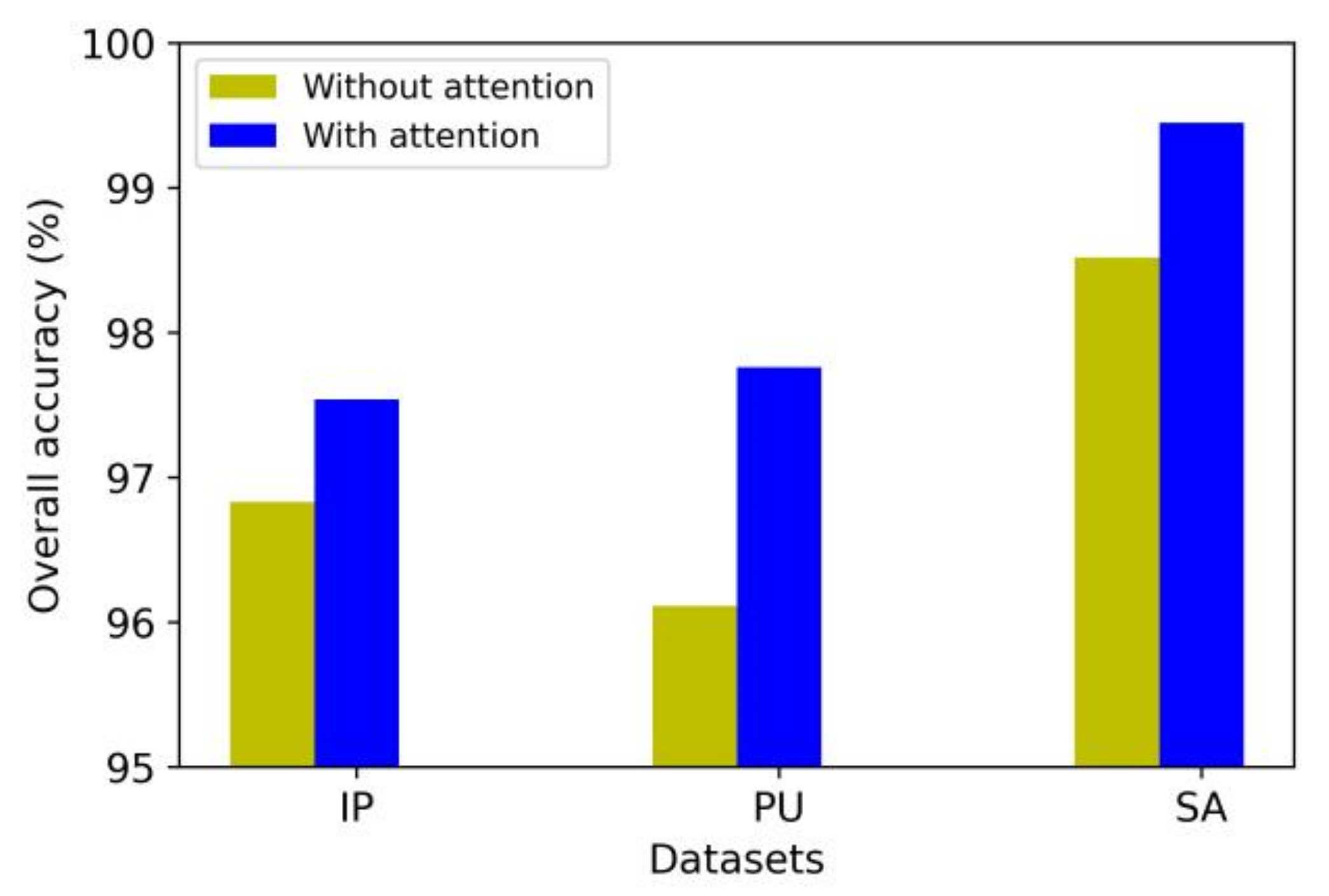
4.8. Analysis of the Attention Mechanism’s Effectiveness
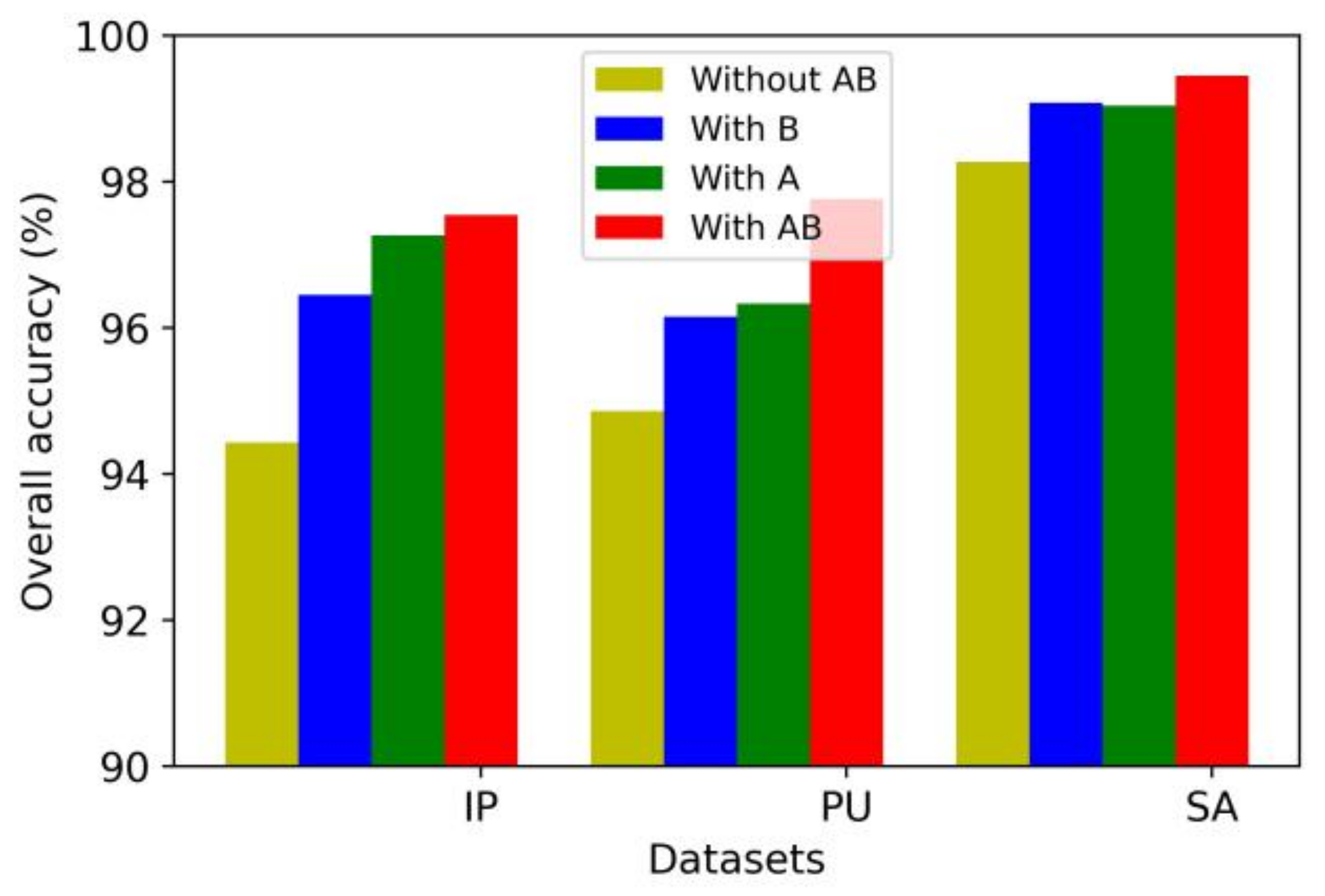
4.9. The Effectiveness of the Multiscale Method
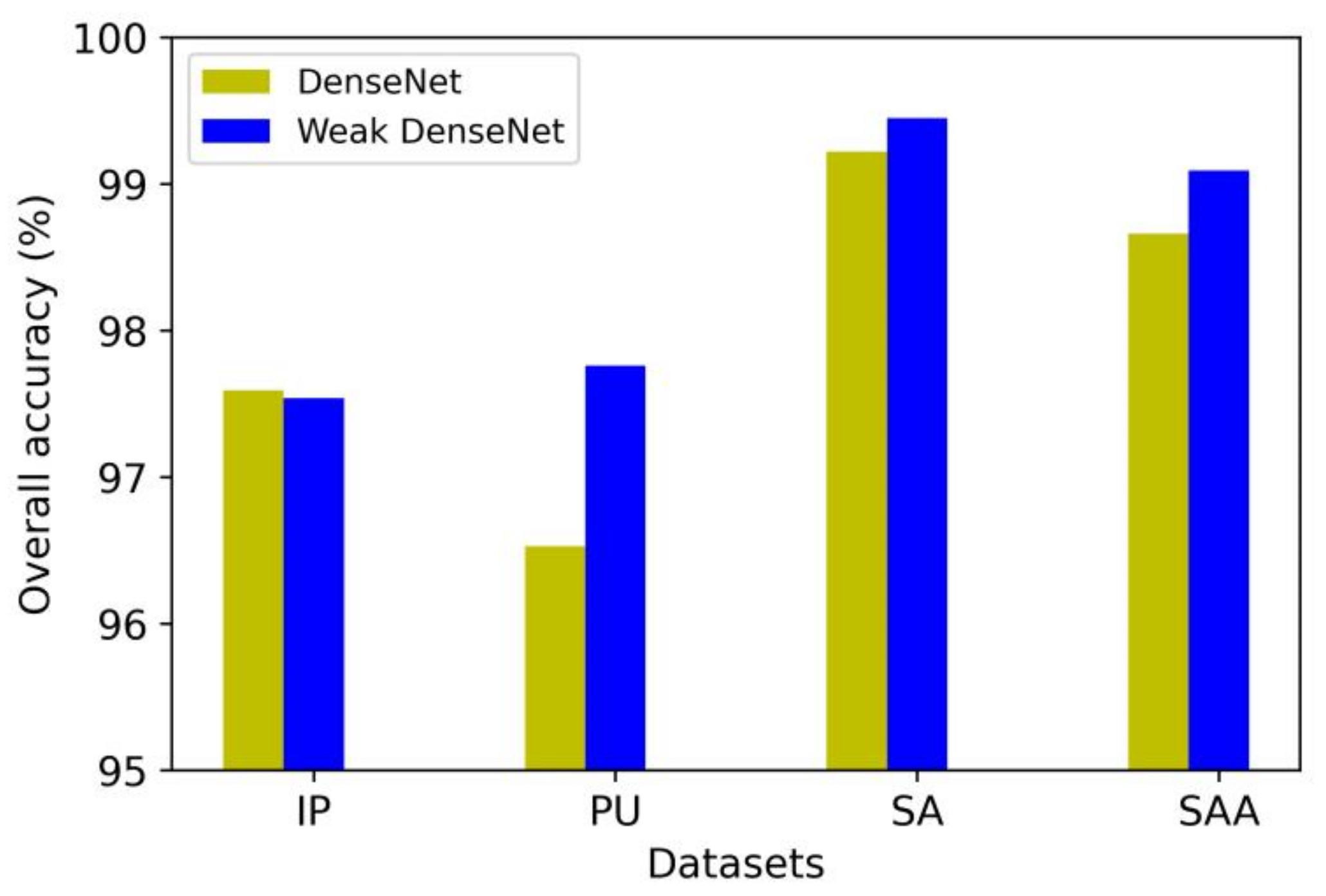
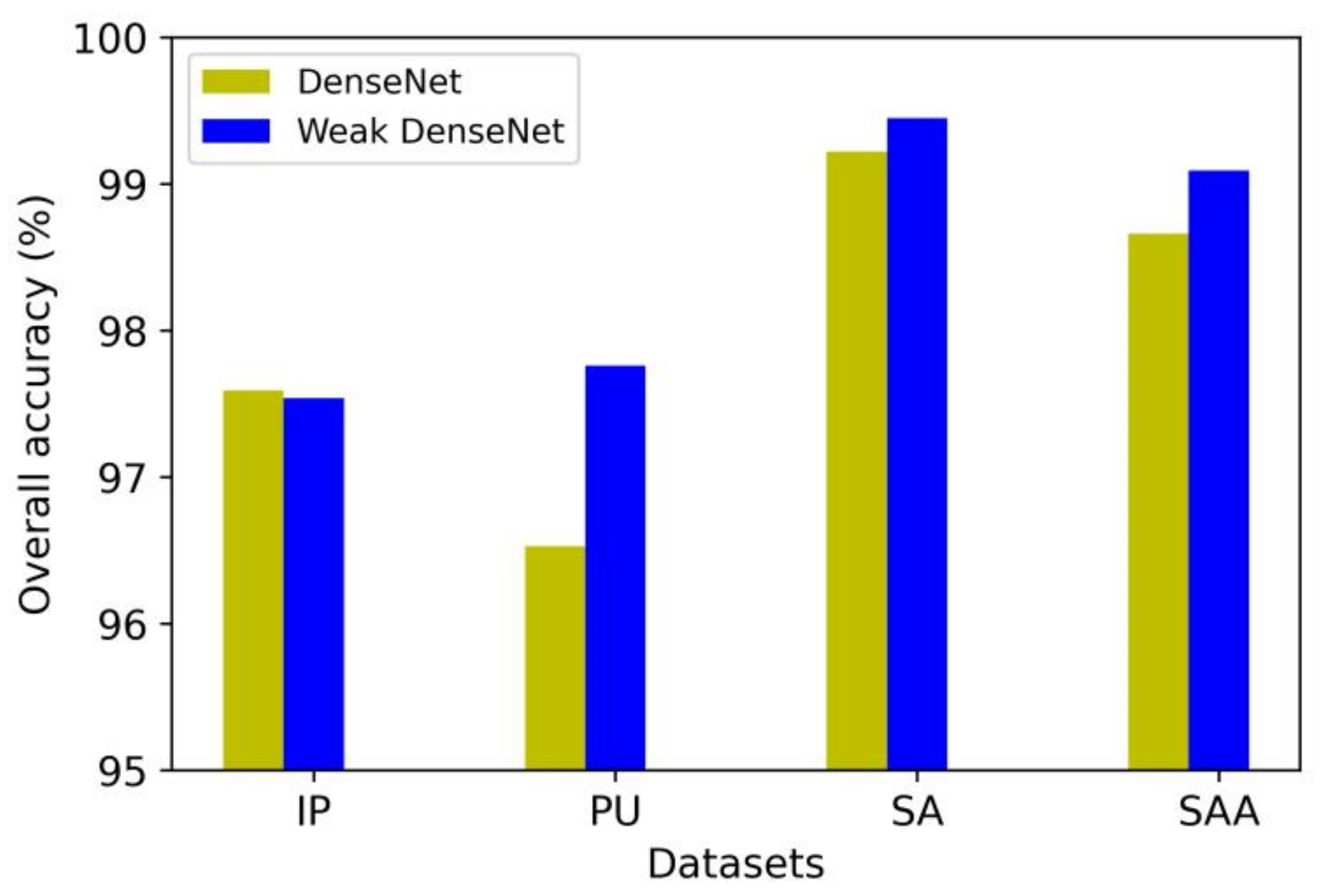
4.10. The Comparison of DenseNet and Weak DenseNet
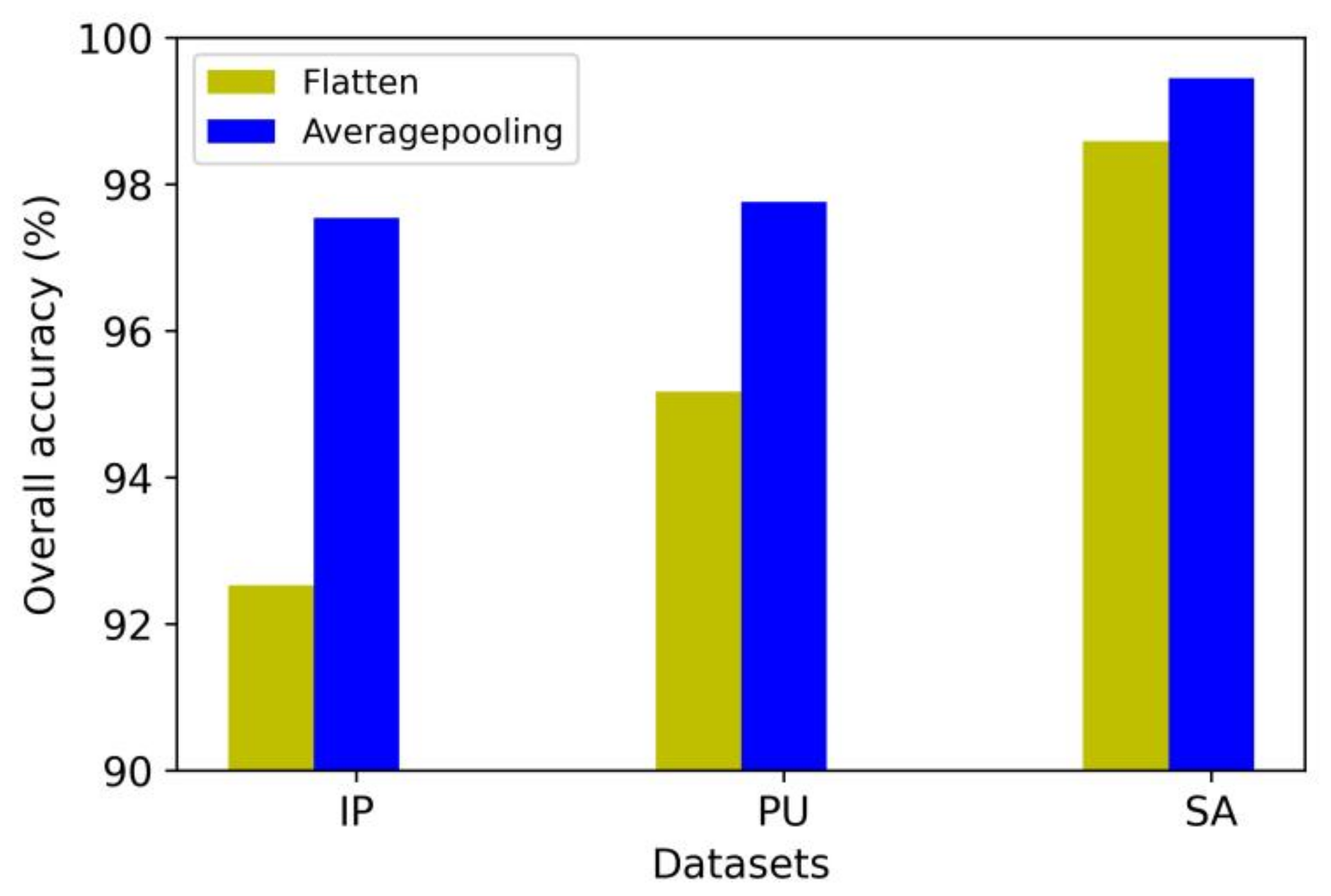
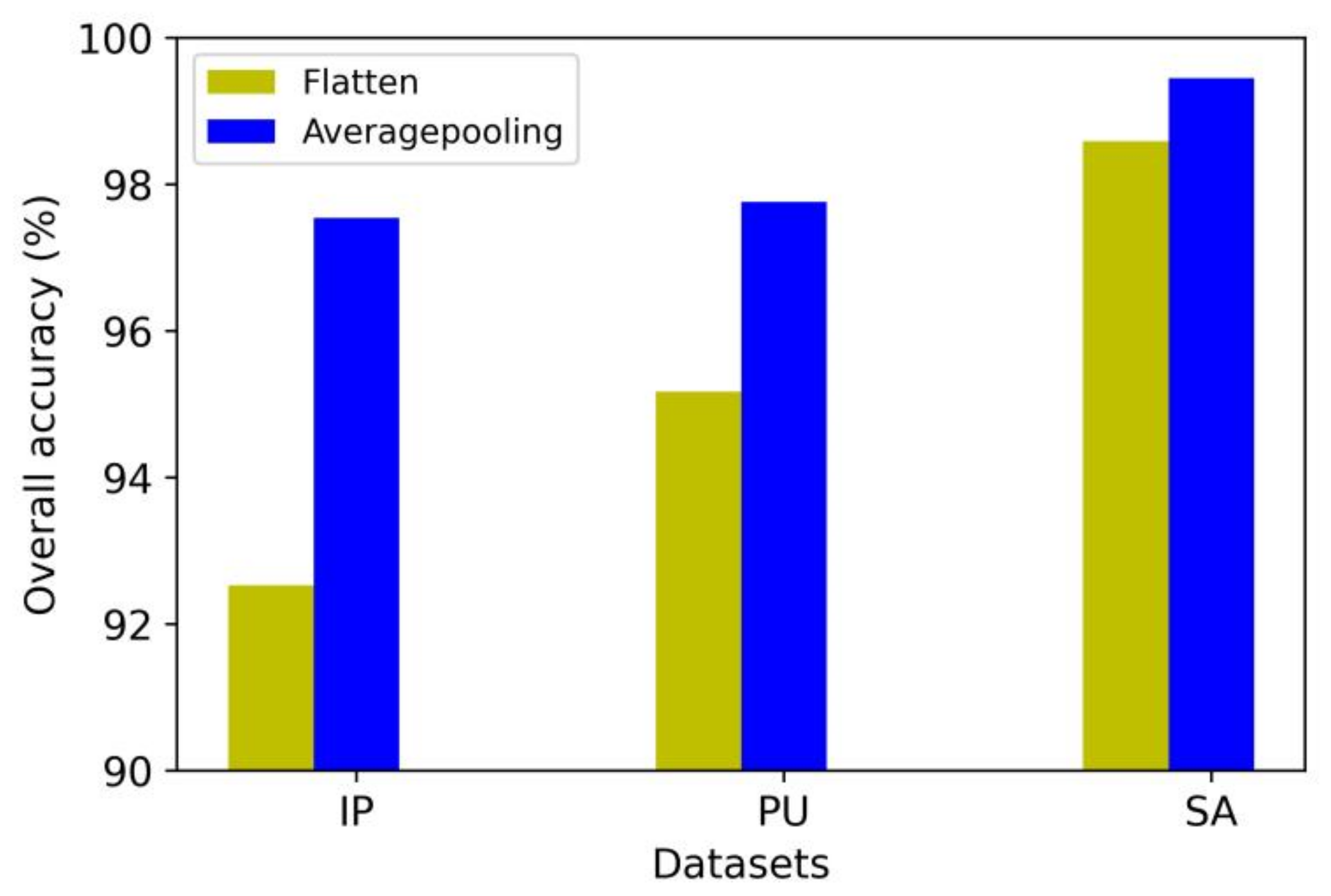
4.11. The Comparison of Averagepooling and Flatten at the End of the Model
4.12. Investigation on Running Time
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, S.; Li, J.; Khodadadzadeh, M.; Marinoni, A.; Gamba, P.; Li, B. Abundance-indicated subspace for hyperspectral classifification with limited training samples. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1265–1278. [Google Scholar] [CrossRef]
- Zhang, M.; Li, W.; Du, Q. Diverse region-based CNN for hyperspectral image classifification. IEEE Trans. Image Process. 2018, 27, 2623–2634. [Google Scholar] [CrossRef] [PubMed]
- Garaba, S.P.; Aitken, J.; Slat, B.; Dierssen, H.M.; Lebreton, L.; Zielinski, O.; Reisser, J. Sensing ocean plastics with an airborne hyperspectral shortwave infrared imager. Environ. Sci. Technol. 2018, 52, 11699–11707. [Google Scholar] [CrossRef] [PubMed]
- Ibrahim, A.; Franz, B.; Ahmad, Z.; Healy, R.; Knobelspiesse, K.; Gao, B.; Proctor, C.; Zhai, P. Atmospheric correction for hyperspectral ocean color retrieval with application to the Hyperspectral Imager for the Coastal Ocean (HICO). Remote Sens. Environ. 2018, 204, 60–75. [Google Scholar] [CrossRef] [Green Version]
- Carrino, T.A.; Crósta, A.P.; Toledo, C.L.; Silva, A.M. Hyperspectral remote sensing applied to mineral exploration in southern peru: A multiple data integration approach in the Chapi Chiara gold prospect. Int. J. Appl. Earth Obs. Geoinf. 2018, 64, 287–300. [Google Scholar] [CrossRef]
- Lorenz, S.; Salehi, S.; Kirsch, M.; Zimmermann, R.; Unger, G.; Sørensen, E.V.; Gloaguen, R. Radiometric correction and 3D integration of longrange ground-based hyperspectral imagery for mineral exploration of vertical outcrops. Remote Sens. 2018, 10, 176. [Google Scholar] [CrossRef] [Green Version]
- Shi, Q.; Liu, X.; Li, X. Road detection from remote sensing images by generative adversarial networks. IEEE Access 2017, 6, 25486–25494. [Google Scholar] [CrossRef]
- Wang, F.; Gao, J.; Zha, Y. Hyperspectral sensing of heavy metals in soil and vegetation: Feasibility and challenges. ISPRS J. Photogramm. Remote Sens. 2018, 136, 73–84. [Google Scholar] [CrossRef]
- Lassalle, G.; Credoz, A.; Hédacq, R.; Fabre, S.; Dubucq, D.; Elger, A. Assessing soil contamination due to oil and gas production using vegetation hyperspectral reflectance. Environ. Sci. Technol. 2018, 52, 1756–1764. [Google Scholar] [CrossRef]
- Ke, C. Military Object Detection Using Multiple Information Extracted from Hyperspectral Imagery. In Proceedings of the 2017 International Conference on Progress in Informatics and Computing (PIC), Nanjing, China, 15–17 May 2017; pp. 124–128. [Google Scholar] [CrossRef]
- Shimoni, M.; Haelterman, R.; Perneel, C. Hypersectral imaging for military and security applications: Combining myriad processing and sensing techniques. IEEE Geosci. Remote Sens. Mag. 2019, 7, 101–117. [Google Scholar] [CrossRef]
- Jia, S.; Jiang, S.; Lin, Z.; Xu, M.; Yu, S. A survey: Deep learning for hyperspectral image classification with few labeled samples. Neurocomputing 2021, 448, 179–204. [Google Scholar] [CrossRef]
- Yuan, Y.; Wang, C.; Jiang, Z. Proxy-Based Deep Learning Framework for Spectral-Spatial Hyperspectral Image Classification: Efficient and Robust. IEEE Trans. Geosci. Remote Sens. 2021, 1–15. [Google Scholar] [CrossRef]
- Shen, Y.; Zhu, S.; Chen, C.; Du, Q.; Xiao, L.; Chen, J.; Pan, D. Efficient deep learning of nonlocal features for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6029–6043. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Hoi, C. Deep Learning for Image Super-resolution: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [Green Version]
- Minaee, M.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Haeb-Umbach, R.; Watanabe, S.; Nakatani, T.; Bacchiani, M.; Hoffmeister, B.; Seltzer, M.; Zen, H.; Souden, M. Speech Processing for Digital Home Assistants: Combining Signal Processing With Deep-Learning Techniques. IEEE Signal Process. Mag. 2019, 36, 111–124. [Google Scholar] [CrossRef]
- Alshemali, B.; Kalita, J. Improving the reliability of deep neural networks in NLP: A review. Knowl.-Based Syst. 2020, 191, 105210. [Google Scholar] [CrossRef]
- Lee, H.; Kwon, H. Going deeper with contextual CNN for hyperspectral image classifification. IEEE Trans. Image Process. 2017, 26, 4843–4855. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M.; Weinberger, Q. Spectral-spatial residual network for hyperspectral image classifification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Wang, W.; Dou, S.; Jiang, Z.; Sun, L. A Fast Dense Spectral-Spatial Convolution Network Framework for Hyperspectral Images Classifification. Remote Sens. 2018, 10, 1068. [Google Scholar] [CrossRef] [Green Version]
- Roy, S.K.; Krishna, K.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN feature hierarchy for hyperspectral image classifification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef] [Green Version]
- Ge, Z.; Cao, G.; Li, X.; Fu, P. Hyperspectral image classifification method based on 2D–3D CNN and multibranch feature fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5776–5788. [Google Scholar] [CrossRef]
- Huang, L.; Chen, Y. Dual-path siamese CNN for hyperspectral image classification with limited training samples. IEEE Geosci. Remote Sens. Lett. 2020, 18, 518–522. [Google Scholar] [CrossRef]
- Safari, K.; Prasad, S.; Labate, D. A multiscale deep learning approach for high-resolution hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2020, 18, 167–171. [Google Scholar] [CrossRef]
- Praveen, B.; Menon, V. Study of Spatial-Spectral Feature Extraction frameworks with 3D Convolutional Neural Network for Robust Hyperspectral Imagery Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1717–1727. [Google Scholar] [CrossRef]
- Meng, Z.; Jiao, L.; Liang, M.; Zhao, F. A Lightweight Spectral-Spatial Convolution Module for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2021, 1–5. [Google Scholar] [CrossRef]
- Gao, H.; Chen, Z.; Li, C. Sandwich Convolutional Neural Network for Hyperspectral Image Classification Using Spectral Feature Enhancement. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3006–3015. [Google Scholar] [CrossRef]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the 32nd International Conference on Machine Learning (PMLR), Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Fukui, H.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Attention Branch Network: Learning of Attention Mechanism for Visual Explanation. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10705–10714. [Google Scholar] [CrossRef] [Green Version]
- Song, J.; Zeng, P.; Gao, L.; Shen, H. From Pixels to Objects: Cubic Visual Attention for Visual Question Answering. In Proceedings of the 27 International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; pp. 906–912. [Google Scholar]
- Mou, L.; Zhu, X. Learning to pay attention on spectral domain: A spectral attention module-based convolutional network for hyperspectral image classifification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 110–122. [Google Scholar] [CrossRef]
- Mei, X.; Pan, E.; Ma, Y.; Dai, X.; Huang, J.; Fan, F.; Du, Q.; Zheng, H.; Ma, J. Spectral–spatial attention networks for hyperspectral image classifification. Remote Sens. 2019, 11, 963. [Google Scholar] [CrossRef] [Green Version]
- Ge, Z.; Cao, G.; Zhang, Y.; Li, X.; Shi, H.; Fu, P. Adaptive Hash Attention and Lower Triangular Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 1–19. [Google Scholar] [CrossRef]
- Yu, C.; Han, R.; Song, M.; Liu, C.; Chang, C. Feedback Attention-Based Dense CNN for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 1–16. [Google Scholar] [CrossRef]
- Zhu, M.; Jiao, L.; Liu, F.; Yang, S.; Wang, J. Residual Spectral-Spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 449–462. [Google Scholar] [CrossRef]
- Lin, J.; Mou, L.; Zhu, X.; Ji, X.; Wang, Z.J. Attention-Aware Pseudo-3-D Convolutional Neural Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 1–13. [Google Scholar] [CrossRef]
- Guo, W.; Ye, H.; Cao, F. Feature-Grouped Network With Spectral-Spatial Connected Attention for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 1–13. [Google Scholar] [CrossRef]
- Ma, W.; Yang, Q.; Wu, Y.; Zhao, W.; Zhang, X. Double-branch multi-attention mechanism network for hyperspectral image classifification. Remote Sens. 2019, 11, 1307. [Google Scholar] [CrossRef] [Green Version]
- Li, R.; Zheng, S.; Duan, C.; Yang, Y.; Wang, X. Classifification of hyperspectral image based on double-branch dual-attention mechanism network. Remote Sens. 2020, 12, 582. [Google Scholar] [CrossRef] [Green Version]
- Tang, X.; Meng, F.; Zhang, X.; Cheung, Y.; Liu, F.; Jiao, L. Hyperspectral Image Classification Based on 3-D Octave Convolution With Spatial-Spectral Attention Network. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2430–2447. [Google Scholar] [CrossRef]
- Xue, Z.; Zhang, M.; Liu, Y.; Du, P. Attention-Based Second-Order Pooling Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 1–16. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, D.; Gao, D.; Shi, G. S3Net: Spectral-Spatial-Semantic Network for Hyperspectral Image Classification With the Multiway Attention Mechanism. IEEE Trans. Geosci. Remote Sens. 2021, 1–17. [Google Scholar] [CrossRef]
- Pu, C.; Huang, H.; Luo, L. Classfication of Hyperspectral Image with Attention Mechanism-Based Dual-Path Convolutional Network. IEEE Geosci. Remote Sens. Lett. 2021, 1–5. [Google Scholar] [CrossRef]
- Cui, Y.; Yu, Z.; Han, J.; Gao, S.; Wang, L. Dual-Triple Attention Network for Hyperspectral Image Classification Using Limited Training Samples. IEEE Geosci. Remote Sens. Lett. 2021, 1–5. [Google Scholar] [CrossRef]
- Zhao, Z.; Hu, D.; Wang, H.; Yu, X. Center Attention Network for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3415–3425. [Google Scholar] [CrossRef]
- Xue, Z.; Yu, X.; Liu, B.; Tan, X.; Wei, X. HResNetAM: Hierarchical Residual Network with Attention Mechanism for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3566–3580. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar] [CrossRef] [Green Version]
- Galassi, A.; Lippi, M.; Torroni, P. Attention in natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Dong, Z.; Wu, T.; Song, S.; Zhang, M. Interactive Attention Model Explorer for Natural Language Processing Tasks with Unbalanced Data Sizes. In Proceedings of the 2020 IEEE Pacific Visualization Symposium (PacificVis), Tianjin, China, 3–5 June 2020; pp. 46–50. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, L.; Phonevilay, V.; Gu, K.; Xia, R.; Xie, J.; Zhang, Q.; Yang, K. Image super-resolution reconstruction based on feature map attention mechanism. Appl. Intell. 2021, 51, 4367–4380. [Google Scholar] [CrossRef]
- Xu, R.; Tao, Y.; Lu, Z.; Zhong, Y. Attention-mechanism-containing neural networks for high-resolution remote sensing image classification. Remote Sens. 2018, 10, 1602. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving Neural Networks by Preventing Coadaptation of Feature Detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Layer | Input Shape | Output Shape | Kernel Size | Filters | Connected to |
|---|---|---|---|---|---|---|
| Multiscale spectral feature extraction | Input | - | (15,15,30,1) | - | - | - |
| Conv3d_111 | (15,15,30,1) | (15,15,28,16) | (1,1,3) | 16 | Input | |
| Conv3d_112 | (15,15,30,1) | (15,15,26,16) | (1,1,5) | 16 | Input | |
| Conv3d_113 | (15,15,30,1) | (15,15,24,16) | (1,1,7) | 16 | Input | |
| Fusion11 | (15,15,28,16) (15,15,26,16) (15,15,24,16) | (15,15,78,16) | - | - | Conv3d_111 Conv3d_112 Conv3d_113 | |
| Conv3d_114 | (15,15,78,16) | (9,9,72,16) | (7,7,7) | 16 | Fusion11 |
| Module | Layer | Input Shape | Output Shape | Kernel Size | Filters | Connected to |
|---|---|---|---|---|---|---|
| Multiscale spatial feature extraction | Input | - | (15,15,30,1) | - | - | - |
| Conv3d_121 | (15,15,30,1) | (9,9,24,16) | (7,7,7) | 16 | Input | |
| Conv3d_1221 | (15,15,30,1) | (11,11,26,8) | (5,5,5) | 8 | Input | |
| Conv3d_1222 | (11,11,26,8) | (9,9,24,16) | (3,3,3) | 16 | Conv3d_1221 | |
| Conv3d_1231 | (15,15,30,1) | (13,13,28,4) | (3,3,3) | 4 | Input | |
| Conv3d_1232 | (13,13,28,4) | (11,11,26,8) | (3,3,3) | 8 | Conv3d_1231 | |
| Conv3d_1233 | (11,11,26,8) | (9,9,24,16) | (3,3,3) | 16 | Conv3d_1232 | |
| Fusion21 | (9,9,24,16) (9,9,24,16) (9,9,24,16) | (9,9,72,16) | - | - | Conv3d_121 Conv3d_1222 Conv3d_1233 | |
| Conv3d_214 | (9,9,72,16) | (9,9,72,16) | (1,1,1) | 16 | Fusion21 |
| Module | Layer | Input Shape | Output Shape | Kernel Size | Filters | Connected to |
|---|---|---|---|---|---|---|
| Spectral weak dense module | Conv3d_121 | (9,9,72,16) | (9,9,72,16) | (1,1,3) | 16 | Fusion_11 |
| Fusion121 | (9,9,72,16) (9,9,72,16) | (9,9,144,16) | - | - | Conv3d_114 Conv3d_121 | |
| Conv3d_122 | (9,9,144,16) | (9,9,72,16) | (1,1,3) | 16 | Fusion121 | |
| Fusion122 | (9,9,72,16) (9,9,72,16) | (9,9,144,16) | - | - | Conv3d_121 Conv3d_122 | |
| Conv3d_123 | (9,9,144,16) | (9,9,72,16) | (1,1,3) | 16 | Fusion122 | |
| Fusion123 | (9,9,72,16) (9,9,72,16) | (9,9,144,16) | - | - | Conv3d_122 Conv3d_123 |
| Module | Layer | Input Shape | Output Shape | Kernel Size | Filters | Connected to |
|---|---|---|---|---|---|---|
| Spatial weak dense module | Conv3d_221 | (9,9,72,16) | (9,9,72,16) | (3,3,3) | 16 | Fusion_21 |
| Fusion221 | (9,9,72,16) (9,9,72,16) | (9,9,144,16) | - | - | Conv3d_124 Conv3d_221 | |
| Conv3d_222 | (9,9,144,16) | (9,9,72,16) | (3,3,3) | 16 | Fusion221 | |
| Fusion222 | (9,9,72,16) (9,9,72,16) | (9,9,144,16) | - | - | Conv3d_221 Conv3d_222 | |
| Conv223 | (9,9,144,16) | (9,9,72,16) | (3,3,3) | 16 | Fusion222 | |
| Fusion223 | (9,9,72,16) (9,9,72,16) | (9,9,144,16) | - | - | Conv3d_222 Conv3d_223 |
| No. | Class | Train | Val | Test | Total |
|---|---|---|---|---|---|
| 1 | Alfalfa | 2 | 2 | 42 | 46 |
| 2 | Corn-notill | 71 | 71 | 1286 | 1428 |
| 3 | Corn-mintill | 42 | 42 | 746 | 830 |
| 4 | Corn | 12 | 12 | 213 | 237 |
| 5 | Grass-pasture | 24 | 24 | 435 | 483 |
| 6 | Grass-trees | 36 | 36 | 658 | 730 |
| 7 | Grass-pasture-mowed | 1 | 1 | 26 | 28 |
| 8 | Hay-windrowed | 24 | 24 | 430 | 478 |
| 9 | Oats | 1 | 1 | 18 | 20 |
| 10 | Soybean-notill | 49 | 49 | 874 | 972 |
| 11 | Soybean-mintil | 123 | 123 | 2209 | 2455 |
| 12 | Soybean-clean | 30 | 30 | 533 | 593 |
| 13 | Wheat | 10 | 10 | 185 | 205 |
| 14 | Woods | 63 | 63 | 1139 | 1265 |
| 15 | Buildings-Grass-Trees-Drives | 19 | 19 | 348 | 386 |
| 16 | Stone-Steel-Towers | 5 | 5 | 83 | 93 |
| Total | 512 | 512 | 9225 | 10,249 |
| No. | Class | Train | Val | Test | Total |
|---|---|---|---|---|---|
| 1 | Asphalt | 66 | 66 | 6499 | 6631 |
| 2 | Meadows | 186 | 186 | 18,277 | 18,649 |
| 3 | Gravel | 21 | 21 | 2057 | 2099 |
| 4 | Trees | 31 | 31 | 3002 | 3064 |
| 5 | Painted metal sheets | 13 | 13 | 1319 | 1345 |
| 6 | Bare Soil | 50 | 50 | 4929 | 5029 |
| 7 | Bitumen | 13 | 13 | 1304 | 1330 |
| 8 | Self-Blocking Bricks | 37 | 37 | 3608 | 3682 |
| 9 | Shadows | 9 | 9 | 929 | 947 |
| Total | 426 | 426 | 41,924 | 42,776 |
| No. | Class | Train | Val | Test | Total |
|---|---|---|---|---|---|
| 1 | Brocoli-green-weeds-1 | 20 | 20 | 1969 | 2009 |
| 2 | Brocoli-green-weeds-2 | 37 | 37 | 3652 | 3726 |
| 3 | Fallow | 20 | 20 | 1936 | 1976 |
| 4 | Fallow-rough-plow | 14 | 14 | 1366 | 1394 |
| 5 | Fallow-smooth | 27 | 27 | 2624 | 2678 |
| 6 | Stubble | 40 | 40 | 3879 | 3959 |
| 7 | Celery | 36 | 36 | 3507 | 3579 |
| 8 | Grapes-untrained | 113 | 113 | 11,045 | 11,271 |
| 9 | Soil-vinyard-develop | 62 | 62 | 6079 | 6203 |
| 10 | Corn-senesced-green-weeds | 33 | 33 | 3212 | 3278 |
| 11 | Lettuce-romaine-4wk | 11 | 11 | 1046 | 1068 |
| 12 | Lettuce-romaine-5wk | 19 | 19 | 1889 | 1927 |
| 13 | Lettuce-romaine-6wk | 9 | 9 | 898 | 916 |
| 14 | Lettuce-romaine-7wk | 11 | 11 | 1048 | 1070 |
| 15 | Vinyard-untrained | 73 | 73 | 7122 | 7268 |
| 16 | Vinyard-vertical-trellis | 18 | 18 | 1771 | 1807 |
| Total | 543 | 543 | 53,043 | 54,129 |
| Class | SVM | CDCNN | SSRN | FDSSC | HybridSN | DBMA | DBDA | Proposed |
|---|---|---|---|---|---|---|---|---|
| 1 | 10.87 | 0 | 86.67 | 96.51 | 85.29 | 75.93 | 100 | 97.78 |
| 2 | 66.74 | 71.98 | 96.99 | 87.84 | 96.69 | 95.89 | 98.46 | 98.26 |
| 3 | 45.90 | 53.34 | 99.11 | 95.96 | 83.45 | 93.22 | 95.89 | 95.72 |
| 4 | 8.02 | 73.21 | 97.00 | 96.26 | 94.48 | 100 | 99.51 | 99.55 |
| 5 | 69.15 | 87.56 | 99.01 | 99.28 | 81.02 | 95.48 | 96.73 | 97.02 |
| 6 | 90.68 | 94.52 | 98.33 | 98.65 | 89.18 | 99.22 | 94.36 | 99.41 |
| 7 | 17.86 | 25.00 | 86.96 | 84.29 | 100 | 69.57 | 80.00 | 100 |
| 8 | 50.63 | 84.36 | 96.01 | 98.33 | 100 | 100 | 100 | 98.48 |
| 9 | 30.00 | 93.33 | 66.67 | 80.77 | 85.00 | 76.92 | 100 | 100 |
| 10 | 62.35 | 62.67 | 82.55 | 89.94 | 92.61 | 93.64 | 93.68 | 95.69 |
| 11 | 83.30 | 78.13 | 90.89 | 97.79 | 94.44 | 91.56 | 99.03 | 96.73 |
| 12 | 23.78 | 50.36 | 92.02 | 97.49 | 92.93 | 92.84 | 97.03 | 97.51 |
| 13 | 79.51 | 84.33 | 100 | 100 | 95.45 | 100 | 100 | 98.99 |
| 14 | 90.28 | 91.83 | 94.87 | 96.39 | 99.83 | 95.05 | 96.60 | 98.85 |
| 15 | 12.18 | 91.46 | 95.24 | 93.98 | 91.82 | 95.45 | 95.89 | 99.13 |
| 16 | 7.53 | 92.31 | 98.82 | 97.08 | 89.19 | 97.67 | 98.81 | 93.75 |
| OA | 68.94 | 76.36 | 93.56 | 94.81 | 93.20 | 94.46 | 97.19 | 97.54 |
| AA | 46.80 | 70.90 | 92.57 | 94.41 | 91.96 | 92.03 | 96.62 | 97.93 |
| Kappa | 59.63 | 72.97 | 92.65 | 94.10 | 92.24 | 93.67 | 96.80 | 97.19 |
| Class | SVM | CDCNN | SSRN | FDSSC | HybridSN | DBMA | DBDA | Proposed |
|---|---|---|---|---|---|---|---|---|
| 1 | 84.65 | 90.21 | 98.90 | 99.44 | 95.76 | 96.50 | 96.07 | 98.29 |
| 2 | 92.57 | 94.66 | 98.23 | 99.45 | 98.73 | 98.72 | 98.86 | 99.34 |
| 3 | 74.94 | 64.95 | 98.93 | 99.52 | 85.03 | 100 | 100 | 96.34 |
| 4 | 70.53 | 97.24 | 99.64 | 97.61 | 97.83 | 97.85 | 98.74 | 96.70 |
| 5 | 90.19 | 98.36 | 99.70 | 99.70 | 99.70 | 99.25 | 100 | 98.66 |
| 6 | 66.41 | 93.11 | 98.62 | 98.50 | 99.82 | 99.15 | 99.88 | 99.98 |
| 7 | 78.87 | 96.88 | 94.25 | 100 | 89.09 | 96.97 | 99.25 | 98.87 |
| 8 | 83.84 | 88.98 | 84.91 | 80.08 | 88.47 | 83.23 | 74.81 | 87.68 |
| 9 | 98.94 | 99.17 | 99.78 | 99.89 | 98.62 | 100 | 99.67 | 97.45 |
| OA | 84.71 | 91.88 | 97.12 | 97.19 | 96.38 | 96.85 | 95.87 | 97.76 |
| AA | 82.33 | 91.51 | 96.99 | 97.13 | 94.78 | 96.85 | 96.36 | 97.03 |
| Kappa | 79.45 | 89.15 | 96.17 | 96.27 | 95.19 | 95.81 | 94.51 | 97.03 |
| Class | SVM | CDCNN | SSRN | FDSSC | HybridSN | DBMA | DBDA | Proposed |
|---|---|---|---|---|---|---|---|---|
| 1 | 99.10 | 64.11 | 99.95 | 100 | 98.42 | 100 | 100 | 100 |
| 2 | 97.61 | 99.92 | 99.97 | 100 | 99.97 | 99.92 | 100 | 100 |
| 3 | 98.18 | 95.48 | 99.83 | 98.38 | 100 | 100 | 99.34 | 100 |
| 4 | 97.20 | 94.00 | 96.37 | 94.45 | 95.50 | 97.47 | 93.70 | 99.64 |
| 5 | 96.64 | 93.40 | 93.48 | 99.92 | 88.23 | 81.79 | 99.71 | 97.93 |
| 6 | 98.41 | 99.01 | 100 | 99.97 | 100 | 100 | 100 | 100 |
| 7 | 99.16 | 99.07 | 100 | 99.91 | 99.69 | 100 | 99.91 | 100 |
| 8 | 73.29 | 96.75 | 78.06 | 98.40 | 98.77 | 89.38 | 99.06 | 98.69 |
| 9 | 98.21 | 99.84 | 99.77 | 100 | 99.84 | 99.61 | 99.06 | 99.98 |
| 10 | 79.77 | 82.52 | 97.96 | 92.41 | 99.63 | 96.43 | 99.37 | 99.88 |
| 11 | 92.79 | 92.64 | 100 | 100 | 100 | 99.24 | 99.90 | 100 |
| 12 | 97.30 | 99.63 | 99.89 | 100 | 100 | 99.95 | 100 | 100 |
| 13 | 97.27 | 97.56 | 96.87 | 100 | 99.55 | 100 | 99.89 | 100 |
| 14 | 69.81 | 98.85 | 99.41 | 98.48 | 98.78 | 95.74 | 98.86 | 94.28 |
| 15 | 67.47 | 41.64 | 98.82 | 97.31 | 96.38 | 98.06 | 77.38 | 99.74 |
| 16 | 94.19 | 98.87 | 100 | 99.09 | 100 | 99.88 | 100 | 100 |
| OA | 86.89 | 76.84 | 93.43 | 98.52 | 98.33 | 95.86 | 95.53 | 99.45 |
| AA | 91.03 | 90.83 | 97.52 | 98.65 | 98.42 | 97.34 | 97.89 | 99.38 |
| Kappa | 85.37 | 74.63 | 92.65 | 98.36 | 98.15 | 95.38 | 95.04 | 99.38 |
| CDCNN | SSRN | FDSSC | HybridSN | DBMA | DBDA | Proposed | |
|---|---|---|---|---|---|---|---|
| Train (s) | 55.62 | 198.03 | 347.15 | 144.42 | 277.34 | 195.92 | 84.95 |
| Test (s) | 3.29 | 5.65 | 5.42 | 2.86 | 9.59 | 5.98 | 4.01 |
| CDCNN | SSRN | FDSSC | HybridSN | DBMA | DBDA | Proposed | |
|---|---|---|---|---|---|---|---|
| Train (s) | 39.29 | 102.26 | 209.81 | 33.39 | 104.93 | 122.71 | 85.12 |
| Test (s) | 14.44 | 18.84 | 28.63 | 3.41 | 36.99 | 33.13 | 19.01 |
| CDCNN | SSRN | FDSSC | HybridSN | DBMA | DBDA | Proposed | |
|---|---|---|---|---|---|---|---|
| Train (s) | 29.38 | 233.84 | 565.45 | 51.18 | 260.34 | 297.41 | 87.69 |
| Test (s) | 18.26 | 33.16 | 61.56 | 4.77 | 55.85 | 69.81 | 24.88 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, Z.; Cao, G.; Shi, H.; Zhang, Y.; Li, X.; Fu, P. Compound Multiscale Weak Dense Network with Hybrid Attention for Hyperspectral Image Classification. Remote Sens. 2021, 13, 3305. https://doi.org/10.3390/rs13163305
Ge Z, Cao G, Shi H, Zhang Y, Li X, Fu P. Compound Multiscale Weak Dense Network with Hybrid Attention for Hyperspectral Image Classification. Remote Sensing. 2021; 13(16):3305. https://doi.org/10.3390/rs13163305
Chicago/Turabian StyleGe, Zixian, Guo Cao, Hao Shi, Youqiang Zhang, Xuesong Li, and Peng Fu. 2021. "Compound Multiscale Weak Dense Network with Hybrid Attention for Hyperspectral Image Classification" Remote Sensing 13, no. 16: 3305. https://doi.org/10.3390/rs13163305
APA StyleGe, Z., Cao, G., Shi, H., Zhang, Y., Li, X., & Fu, P. (2021). Compound Multiscale Weak Dense Network with Hybrid Attention for Hyperspectral Image Classification. Remote Sensing, 13(16), 3305. https://doi.org/10.3390/rs13163305