
Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images



Abstract
:1. Introduction
- (1)
- A novel bilateral structure composed of convolution layers and transformer blocks is proposed for understanding and labelling very fine resolution urban scene images. It provides a new perspective for capturing textural information and long-range dependencies simultaneously in a single network.
- (2)
- A feature aggregation module is developed to fuse the textural feature and long-range dependent feature extracted by the bilateral structure. It employs linear attention to reduce the fitting residual and greatly improves the generalization of fused features.
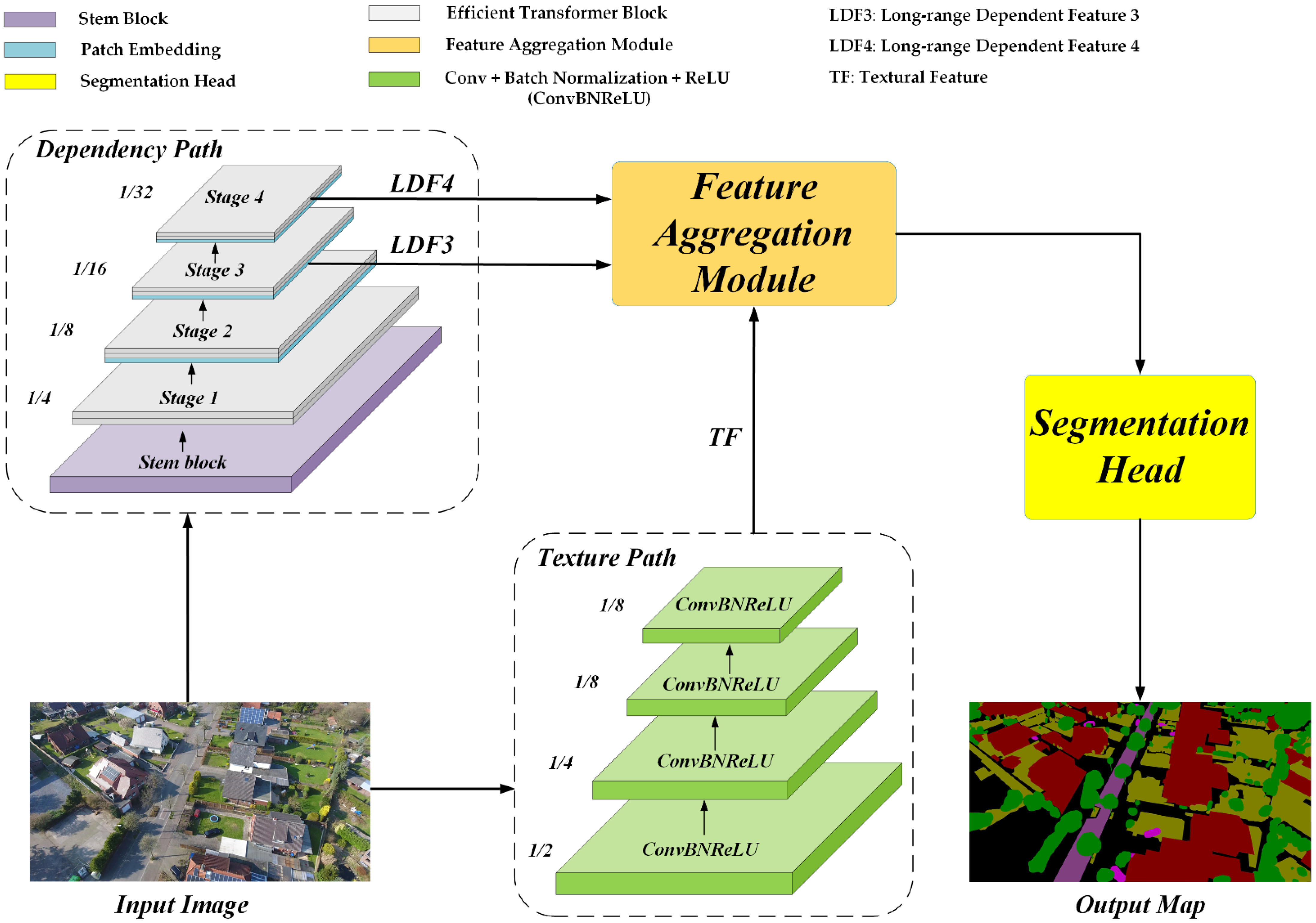
2. Bilateral Awareness Network
2.1. Overview
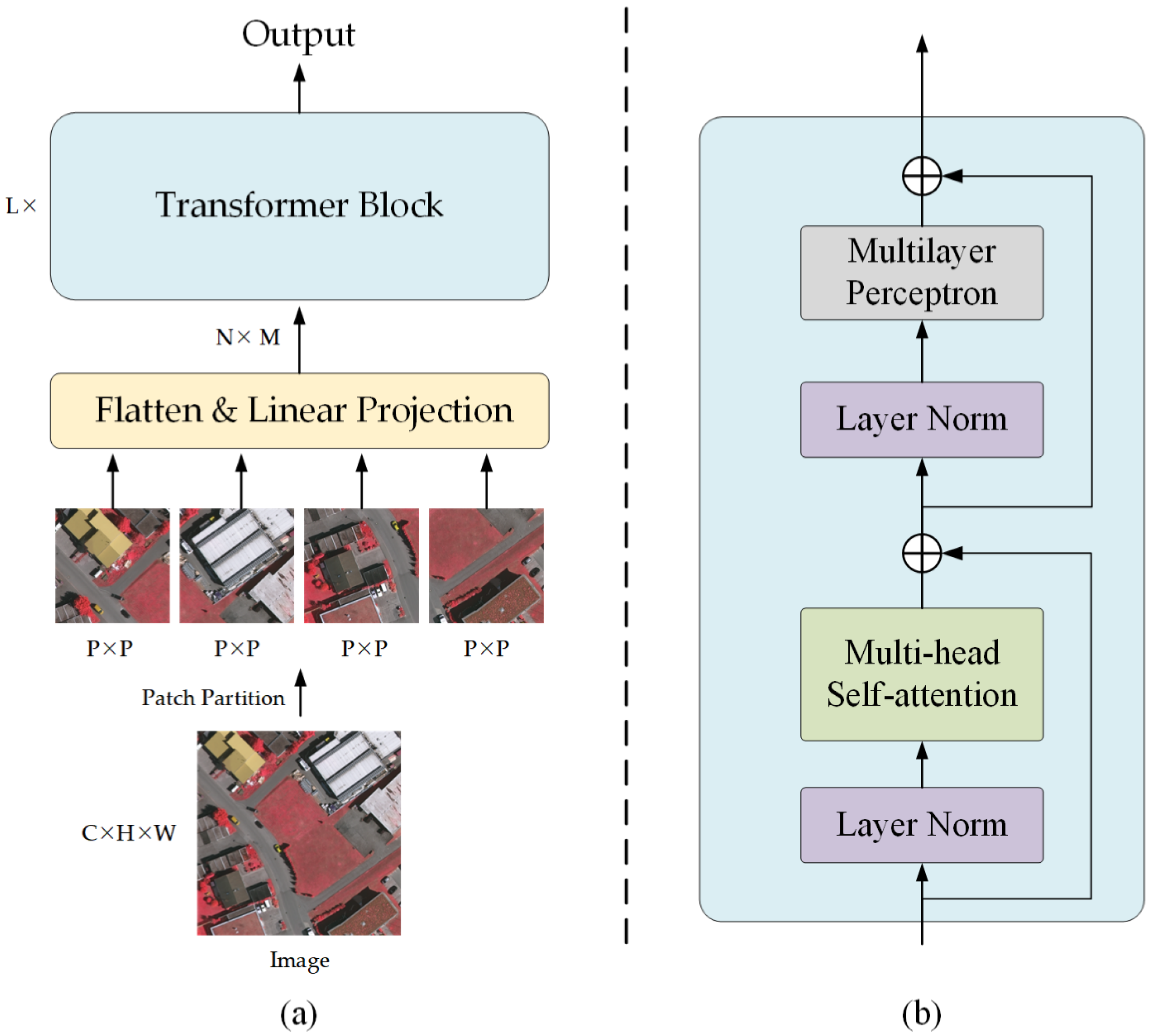
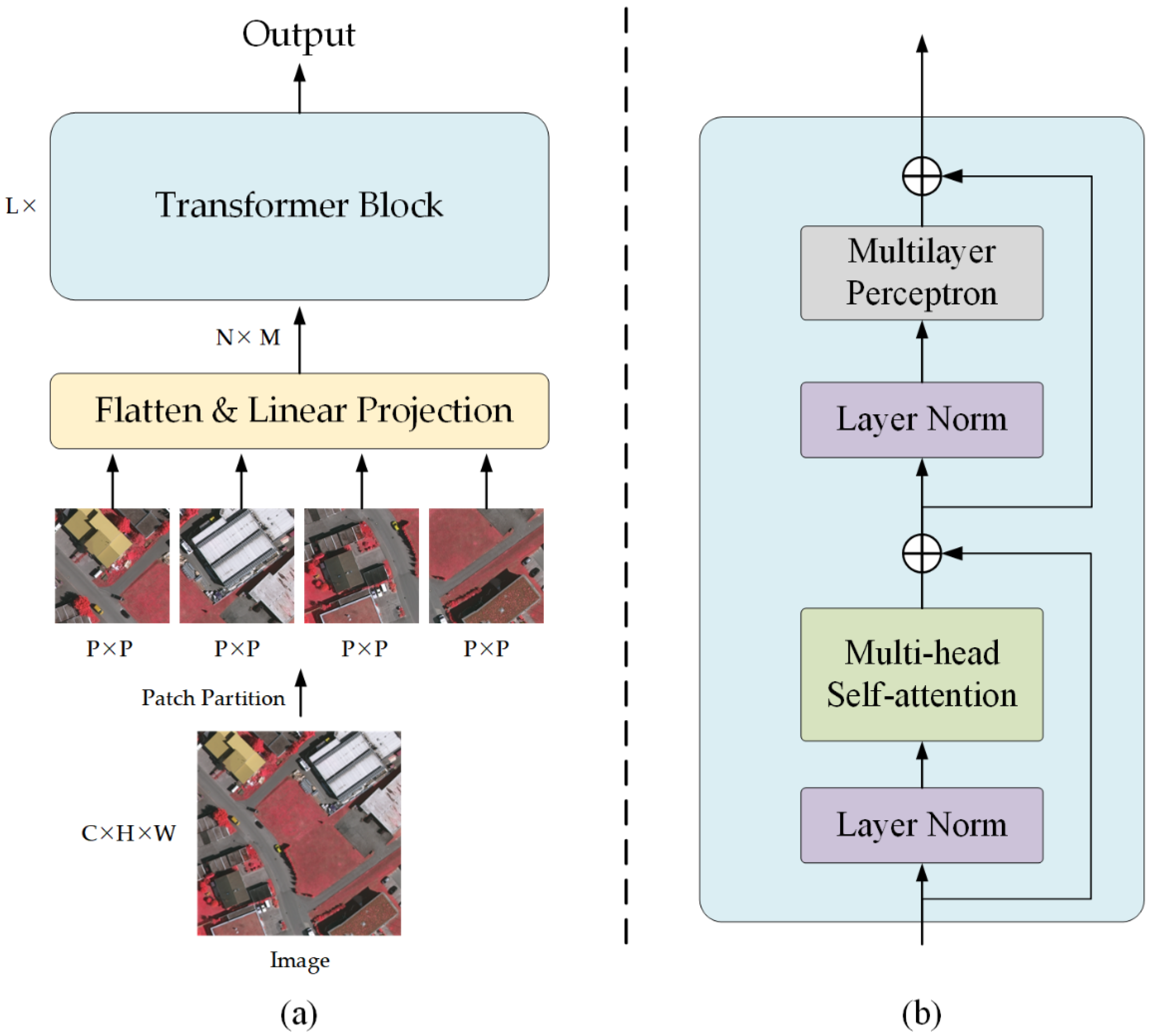
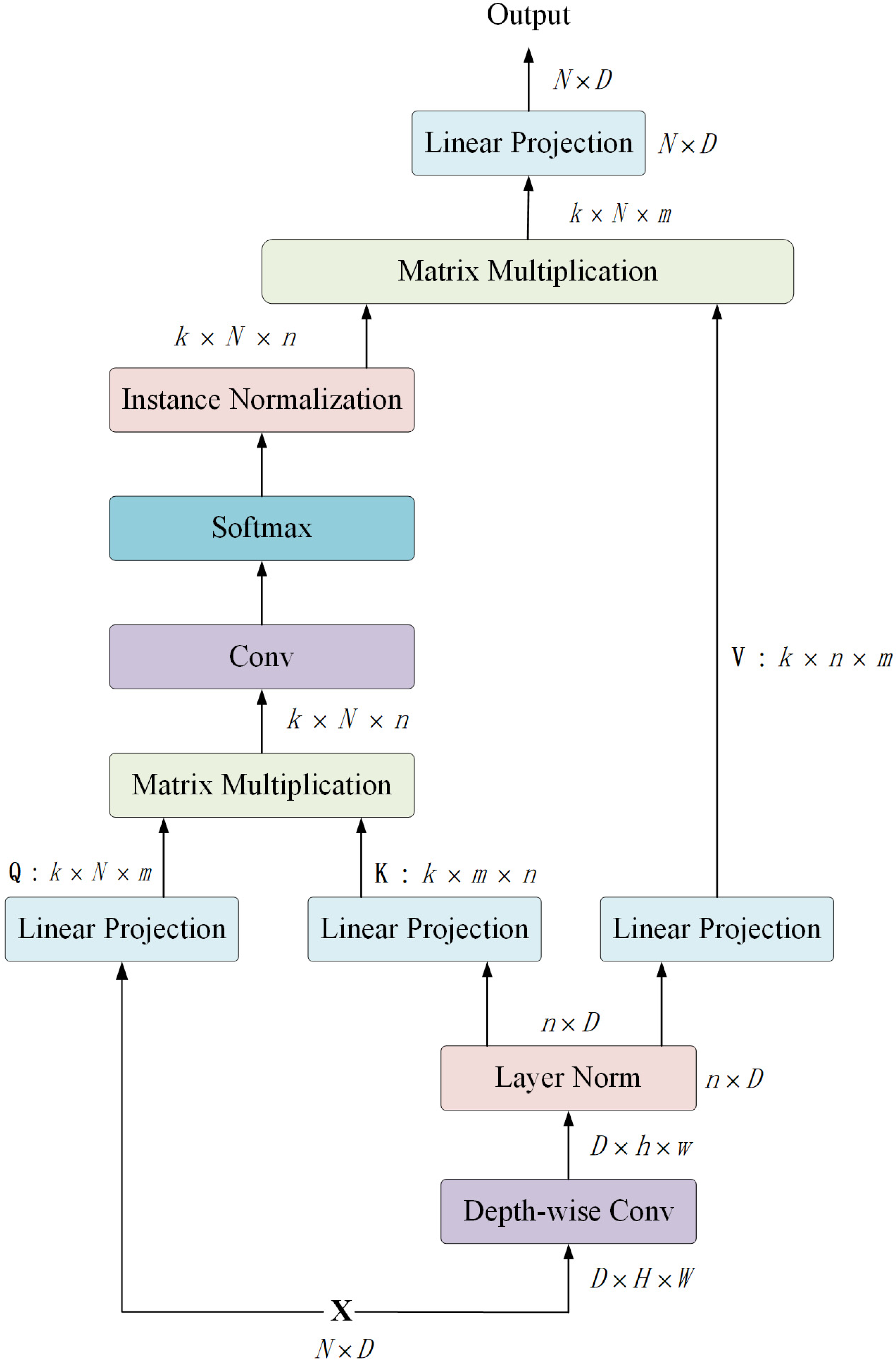
2.2. Dependency Path
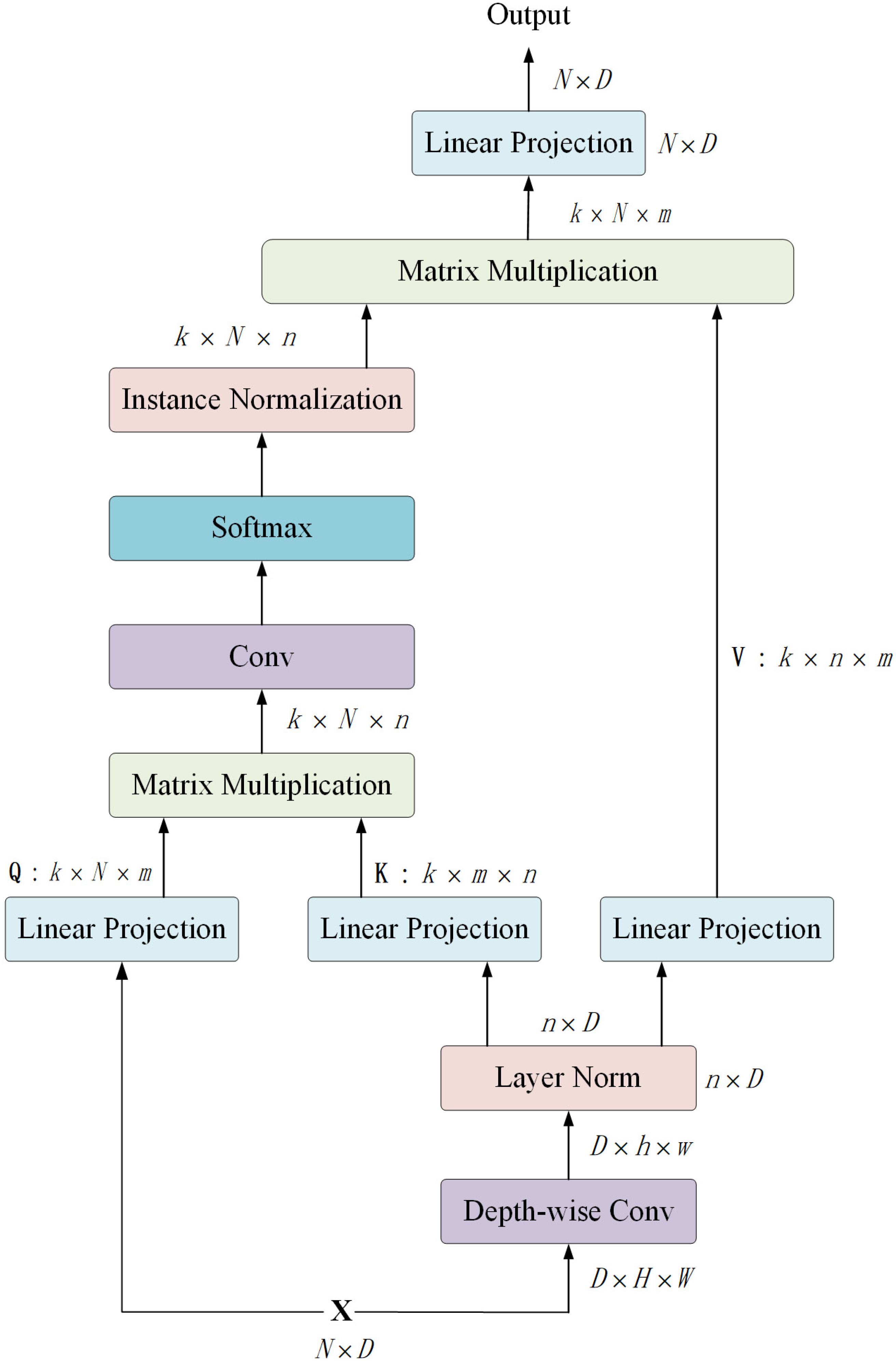
- (1)
- EMSA obtains three vectors from the input vector . Different from the standard multi-head self-attention, EMSA first deploys a depth-wise convolution with a kernel size of r+1 and stride of r to decrease the resolution of and , thereby compressing the computation and memory. For the four transformer stages, r is set as 8, 4, 2, 1, respectively.
- (2)
- To be specific, the input vector is reshaped to a new vector with a shape of , where . Proceed by the depth-wise convolution, the new vector is reshaped to . Here, and . Then, the new vector is recovered to as the input of LN, where . Thus, the initial shape of and is . The initial shape of is .
- (3)
- The three vectors are fed into three linear projections and reshaped to , and , respectively. Here, denotes the number of heads, m denotes the head dimension, .
- (4)
- A matrix multiplication operation is applied on and to generate an attention map with the shape of .
- (5)
- The attention map is further proceeded by a convolution layer, a Softmax activation function and an Instance Normalization [55] operation.
- (6)
- A matrix multiplication operation is applied on the proceeded attention map and . Finally, a linear projection is utilized to generate the output vector. The formalization of EMSA can be referred to the Equation (5).
2.3. Texture Path
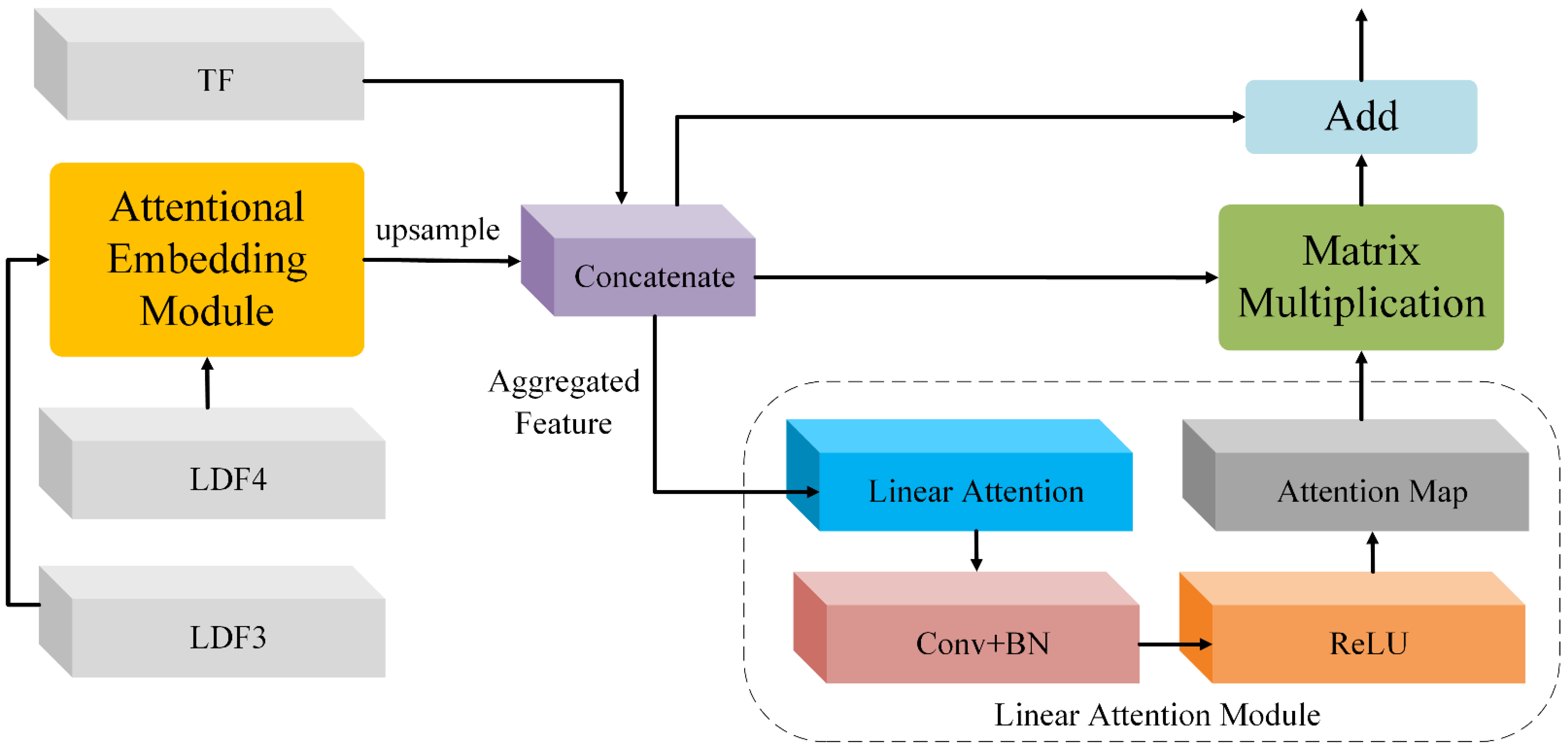
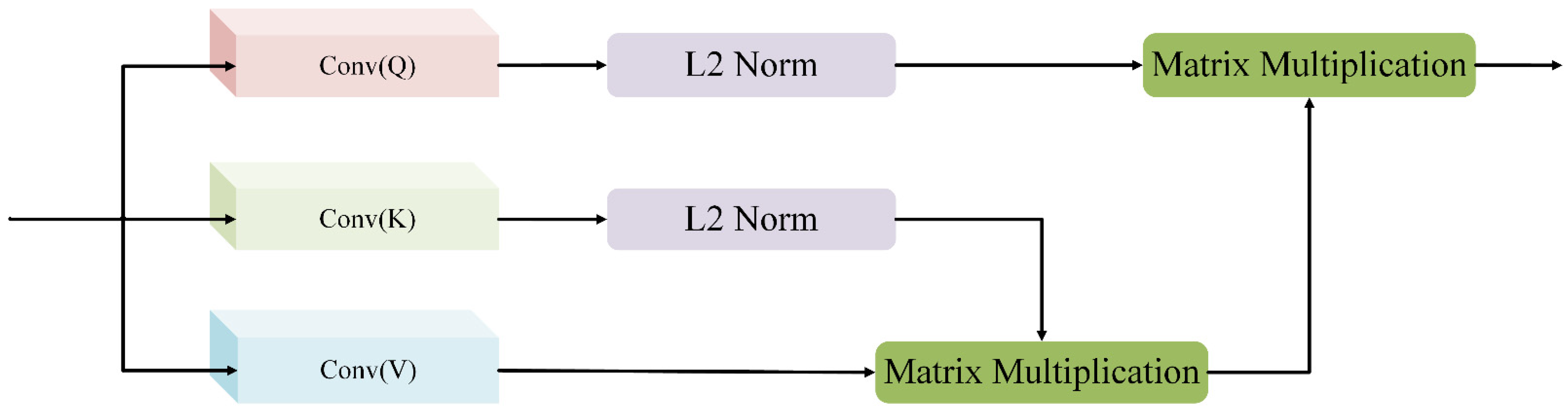
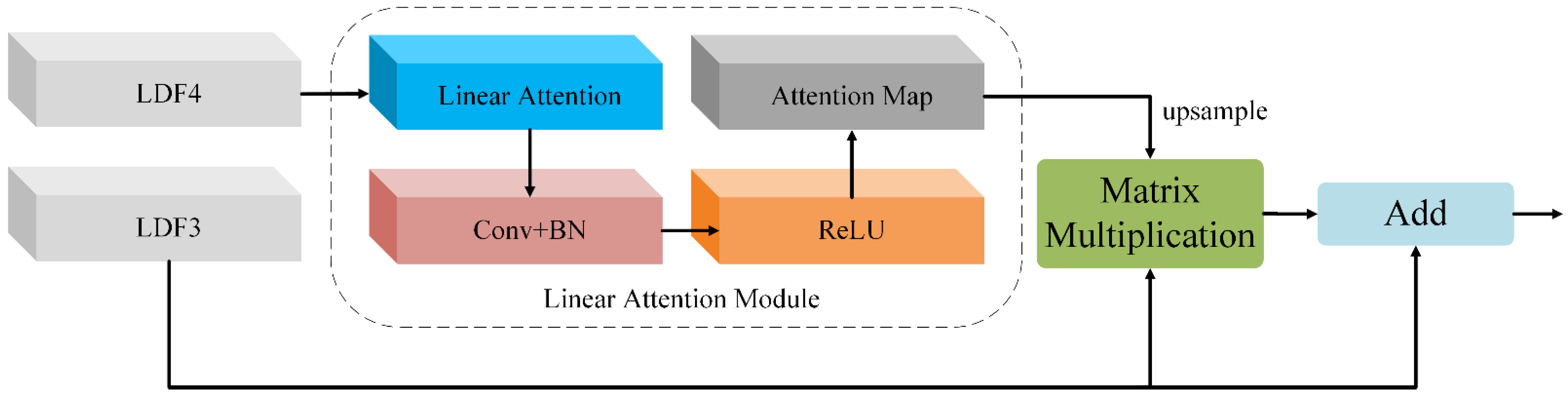
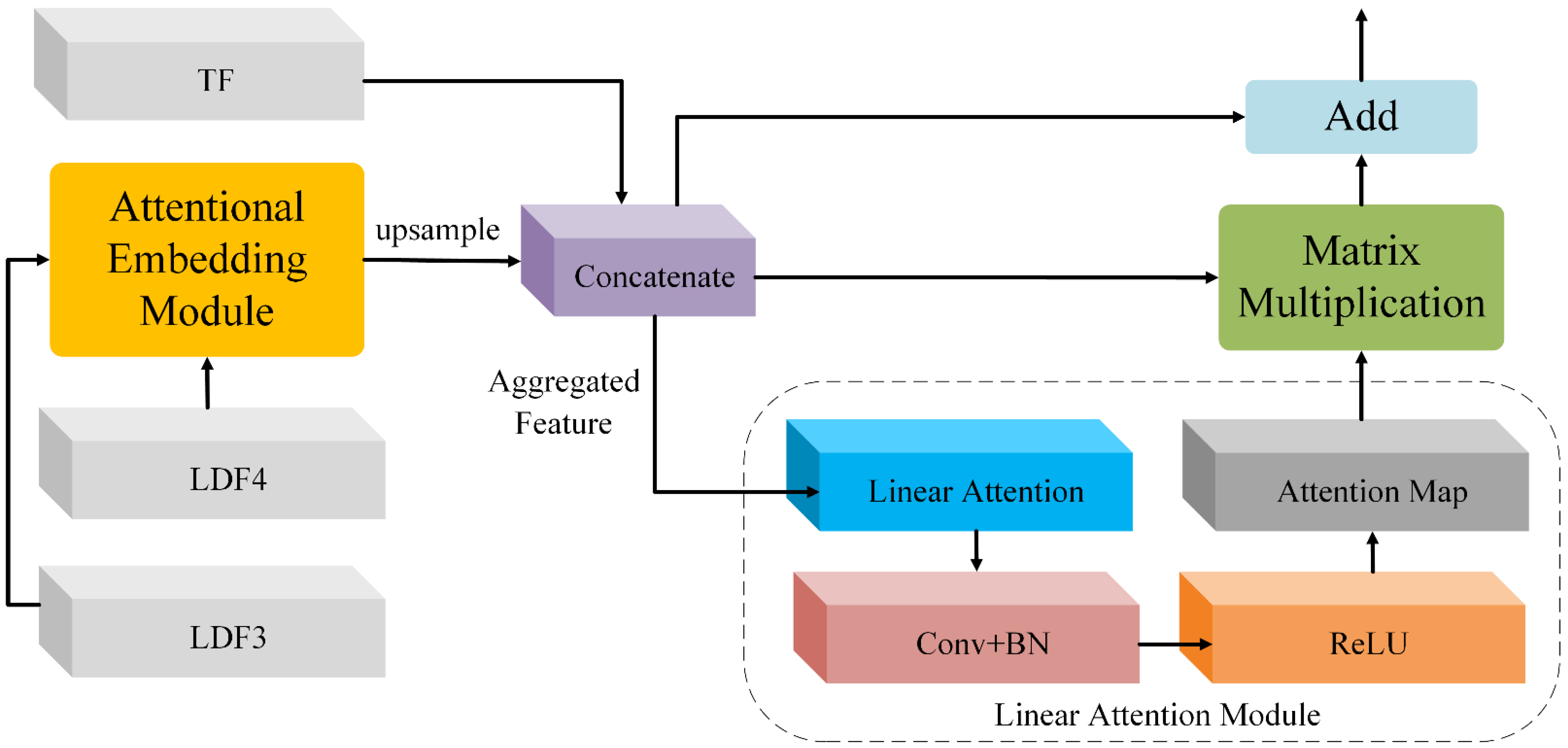
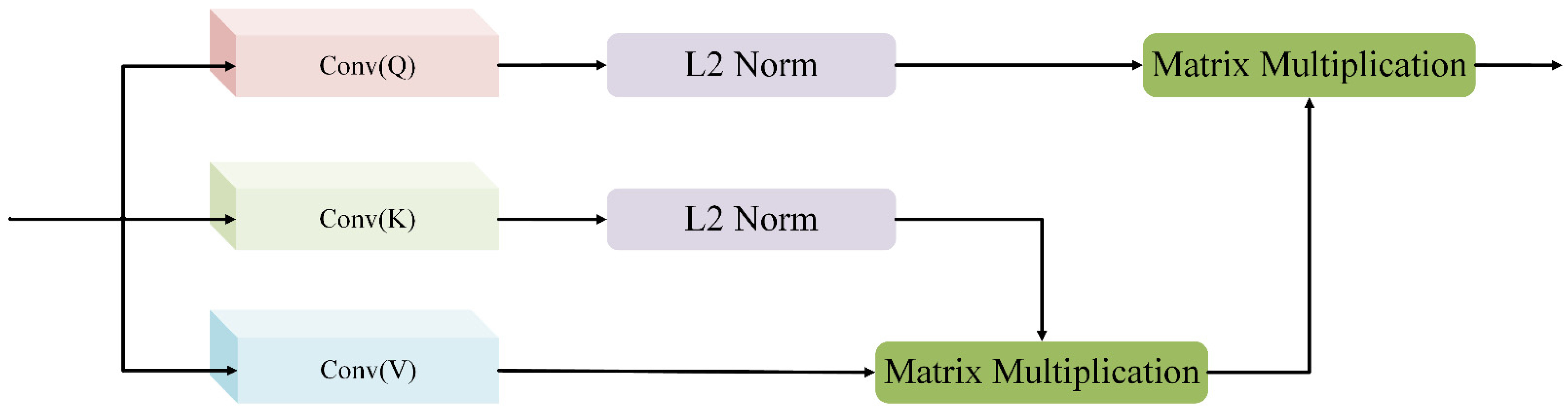
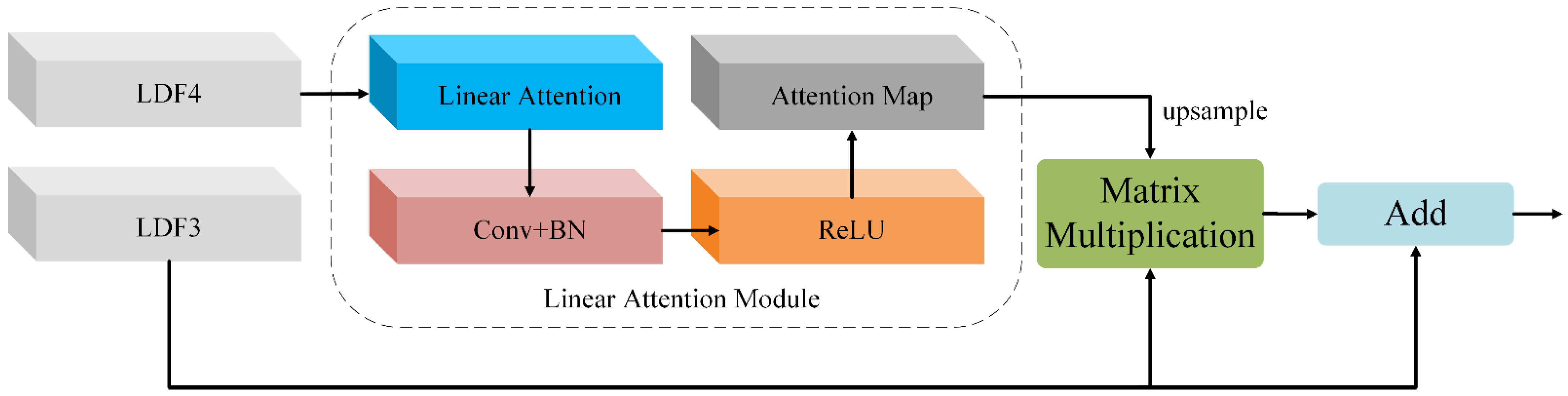
2.4. Feature Aggregation Module
3. Experiments
3.1. Experiments on the ISPRS Vaihingen and Potsdam Datasets
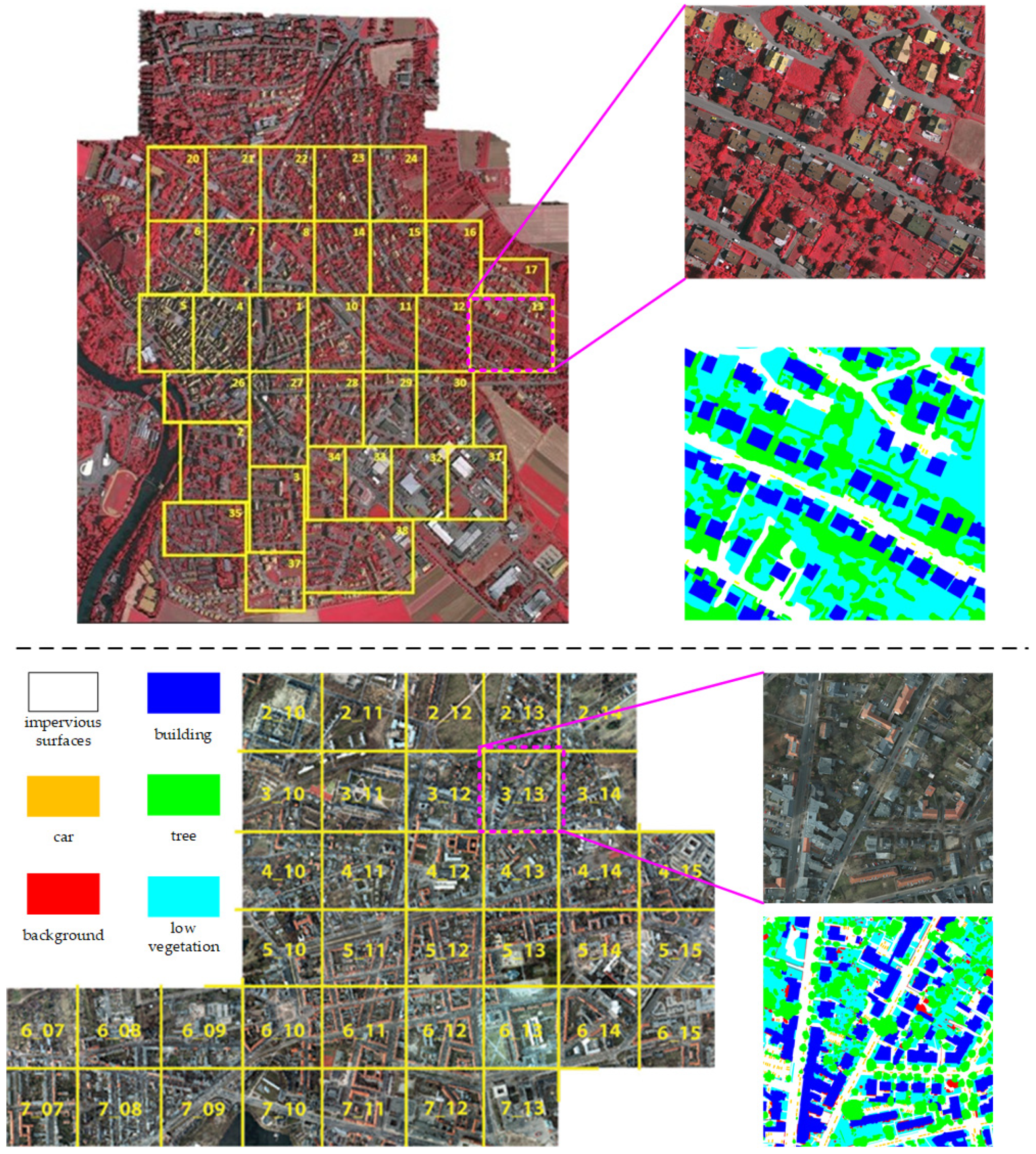
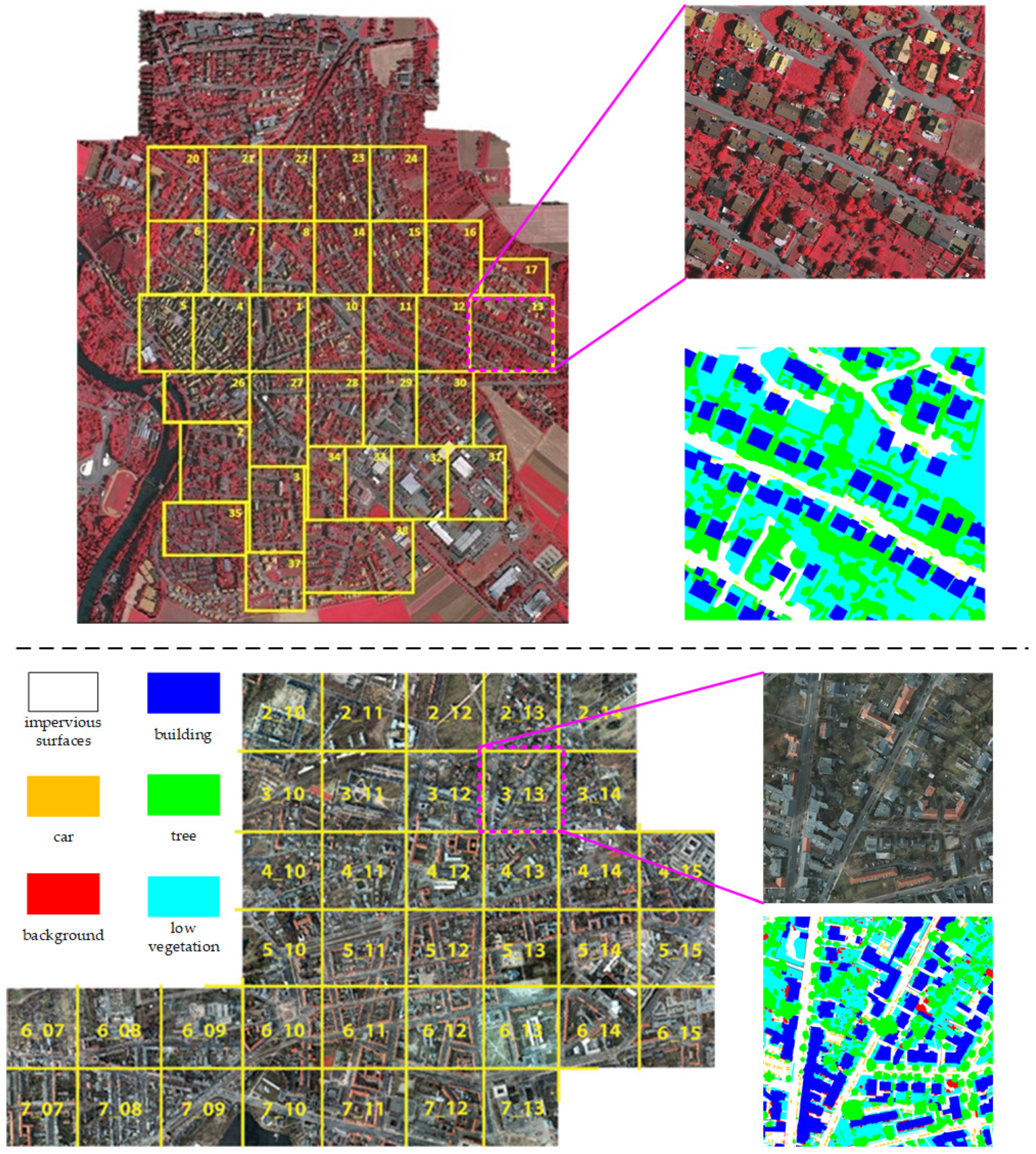
3.1.1. Datasets
3.1.2. Training Setting
3.1.3. Evaluation Metrics
3.1.4. Experimental Results
3.2. Experiments on the UAVid Dataset
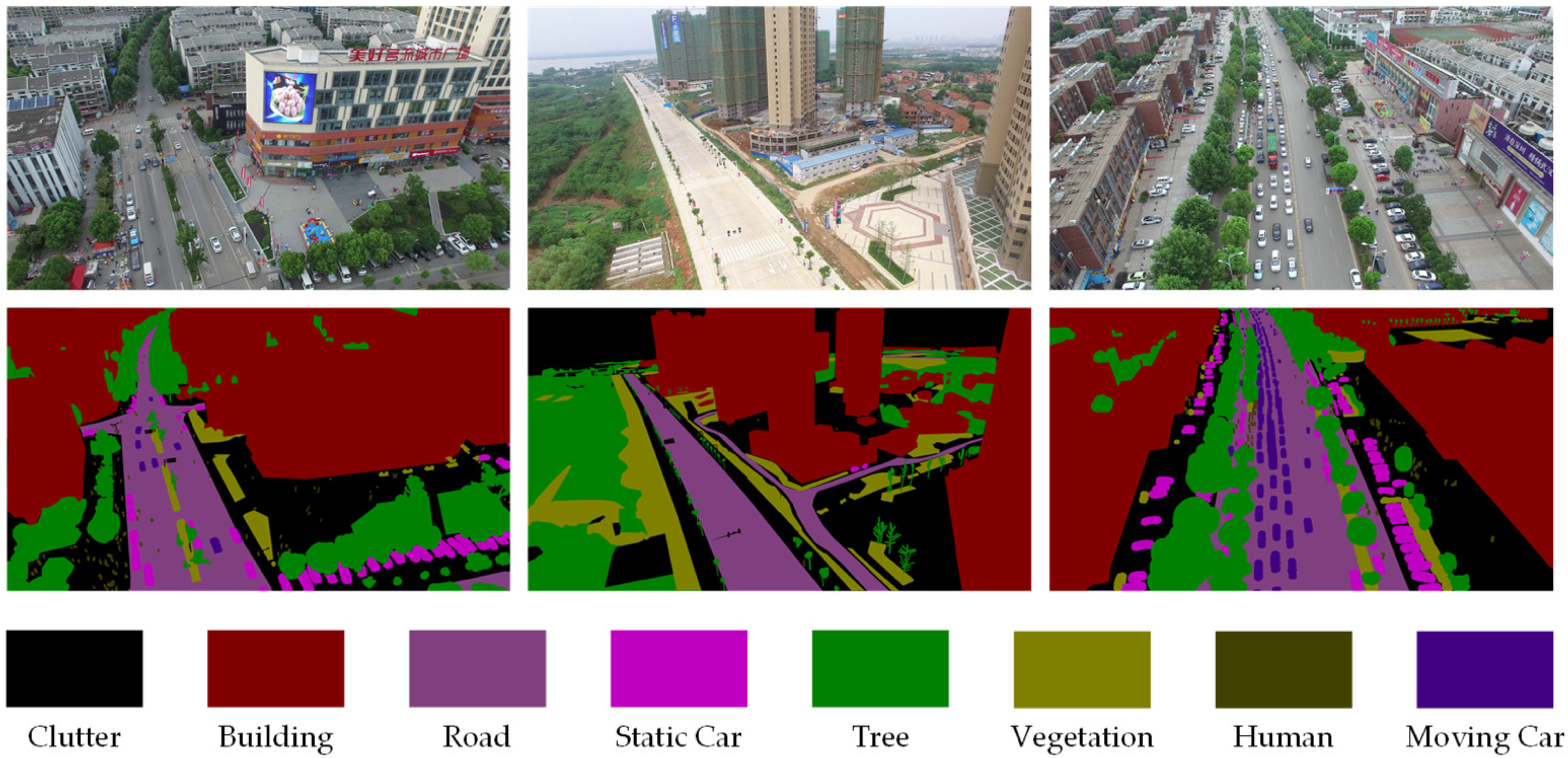
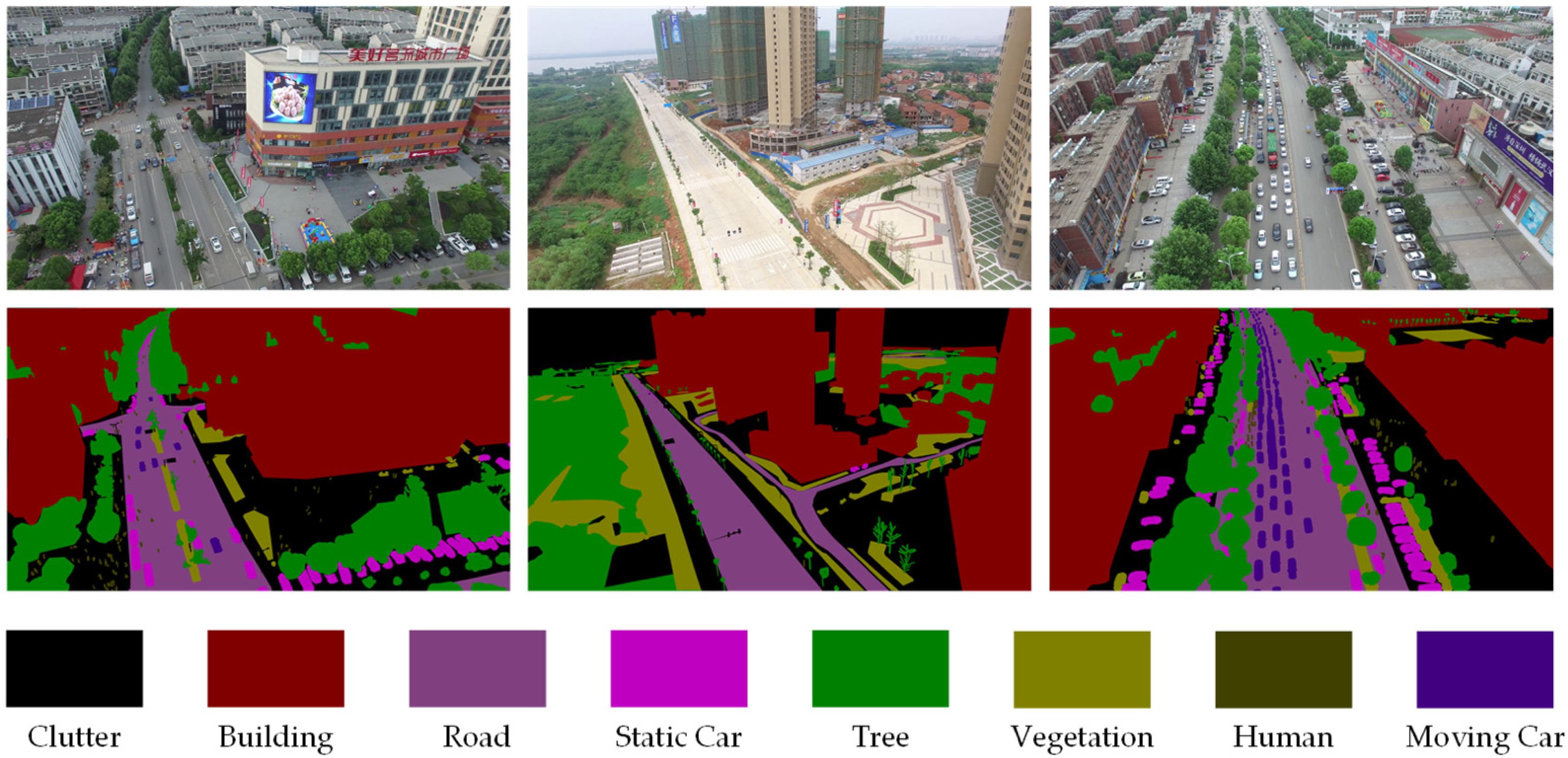
3.2.1. Dataset
3.2.2. Evaluation Metrics
3.2.3. Experimental Results
4. Discussion
4.1. Ablation Study
4.2. Application Scenarios
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| VFR | Very Fine Resolution |
| DCNNs | Deep Convolutional Neural Networks |
| FCN | Fully Convolutional Neural Network |
| SVM | Support Vector Machine |
| RF | Random Forest |
| CRF | Conditional Random Field |
| MHSA | Multi-Head Self-Attention |
| MLP | Multilayer Perceptron |
| FAM | Feature Aggregation Module |
| BANet | Bilateral Awareness Network |
| TF | Textural Features |
| AF | Aggregated Feature |
| LDF | Long-range Dependent Features |
| BN | Batch Normalization |
| GSD | Ground Sampling Distance |
| UAV | Unmanned Aerial Vehicle |
| LA | Linear Attention |
| AEM | Attentional Embedding Module |
| EMSA | Efficient Multi-head Self-attention |
References
- Zhang, C.; Atkinson, P.M.; George, C.; Wen, Z.; Diazgranados, M.; Gerard, F. Identifying and mapping individual plants in a highly diverse high-elevation ecosystem using UAV imagery and deep learning. ISPRS J. Photogramm. Remote Sens. 2020, 169, 280–291. [Google Scholar] [CrossRef]
- Zhang, C.; Harrison, P.A.; Pan, X.; Li, H.; Sargent, I.; Atkinson, P.M. Scale sequence joint deep learning (SS-JDL) for land use and land cover classification. Remote Sens. Environ. 2020, 237, 111593. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Su, J.; Zhang, C. Multistage attention ResU-Net for Semantic segmentation of fine-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2021. [Google Scholar] [CrossRef]
- Li, R.; Duan, C.; Zheng, S.; Zhang, C.; Atkinson, P.M. MACU-Net for semantic segmentation of fine-resolution remotely sensed images. IEEE Geosci. Remote Sens. Lett. 2021. [Google Scholar] [CrossRef]
- Wang, L.; Fang, S.; Zhang, C.; Li, R.; Duan, C.; Meng, X.; Atkinson, P.M. SaNet: Scale-aware neural network for semantic labelling of multiple spatial resolution aerial images. arXiv 2021, arXiv:2103.07935. [Google Scholar]
- Huang, Z.; Wei, Y.; Wang, X.; Shi, H.; Liu, W.; Huang, T.S. AlignSeg: Feature-Aligned segmentation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Yao, H.; Qin, R.; Chen, X. Unmanned aerial vehicle for remote sensing applications—A review. Remote Sens. 2019, 11, 1443. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Segment-before-Detect: Vehicle detection and classification through semantic segmentation of aerial images. Remote Sens. 2017, 9, 368. [Google Scholar] [CrossRef] [Green Version]
- Matikainen, L.; Karila, K. Segment-based land cover mapping of a suburban area—Comparison of high-resolution remotely sensed datasets using classification trees and test field points. Remote Sens. 2011, 3, 1777–1804. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Seto, K.C. Mapping urbanization dynamics at regional and global scales using multi-temporal DMSP/OLS nighttime light data. Remote Sens. Environ. 2011, 115, 2320–2329. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Z.; Xu, M. Road structure refined CNN for road extraction in aerial image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Li, E.; Femiani, J.; Xu, S.; Zhang, X.; Wonka, P. Robust rooftop extraction from visible band images using higher order CRF. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4483–4495. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Ji, Y.; Chen, J.; Deng, Y.; Chen, J.; Jie, Y. Combining segmentation network and nonsubsampled contourlet transform for automatic marine raft aquaculture area extraction from sentinel-1 images. Remote Sens. 2020, 12, 4182. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Bester, M.S.; Guillen, L.A.; Ramezan, C.A.; Carpinello, D.J.; Fan, Y.; Hartley, F.M.; Maynard, S.M.; Pyron, J.L. Semantic segmentation deep learning for extracting surface mine extents from historic topographic maps. Remote Sens. 2020, 12, 4145. [Google Scholar] [CrossRef]
- Kalajdjieski, J.; Zdravevski, E.; Corizzo, R.; Lameski, P.; Kalajdziski, S.; Pires, I.M.; Garcia, N.M.; Trajkovik, V. Air pollution prediction with multi-modal data and deep neural networks. Remote Sens. 2020, 12, 4142. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Li, R.; Duan, C. ABCNet: Attentive bilateral contextual network for efficient semantic segmentation of fine-resolution remote sensing images. arXiv 2021, arXiv:2102.02531. [Google Scholar]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. Joint deep learning for land cover and land use classification. Remote Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. An object-based convolutional neural network (OCNN) for urban land use classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Sherrah, J. Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery. arXiv 2016, arXiv:1606.02585. [Google Scholar]
- Guo, Y.; Jia, X.; Paull, D. Effective sequential classifier training for SVM-based multitemporal remote sensing image classification. IEEE Trans. Image Process. 2018, 27, 3036–3048. [Google Scholar] [CrossRef] [Green Version]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. Adv. Neural Inf. Process. Syst. 2011, 24, 109–117. [Google Scholar]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Marcos, D.; Volpi, M.; Kellenberger, B.; Tuia, D. Land cover mapping at very high resolution with rotation equivariant CNNs: Towards small yet accurate models. ISPRS J. Photogramm. Remote Sens. 2018, 145, 96–107. [Google Scholar] [CrossRef] [Green Version]
- Yue, K.; Yang, L.; Li, R.; Hu, W.; Zhang, F.; Li, W. TreeUNet: Adaptive Tree convolutional neural networks for subdecimeter aerial image segmentation. ISPRS J. Photogramm. Remote Sens. 2019, 156, 1–13. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95. [Google Scholar] [CrossRef] [Green Version]
- Yang, M.Y.; Kumaar, S.; Lyu, Y.; Nex, F. Real-time semantic segmentation with context aggregation network. ISPRS J. Photogramm. Remote Sens. 2021, 178, 124–134. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention network for semantic segmentation of fine-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 405–420. [Google Scholar]
- Kampffmeyer, M.; Salberg, A.-B.; Jenssen, R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. High-resolution aerial image labeling with convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7092–7103. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Duan, C.; Pan, J.; Li, R. Thick cloud removal of remote sensing images using temporal smoothness and sparsity regularized tensor optimization. Remote Sens. 2020, 12, 3446. [Google Scholar] [CrossRef]
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Urban land cover classification with missing data modalities using deep convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1758–1768. [Google Scholar] [CrossRef] [Green Version]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Huan, L.; Xia, G.-S.; Gong, J. Parsing very high resolution urban scene images by learning deep ConvNets with edge-aware loss. ISPRS J. Photogramm. Remote Sens. 2020, 170, 15–28. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Liu, Q.; Kampffmeyer, M.; Jenssen, R.; Salberg, A.B. Dense Dilated Convolutions’ Merging Network for Land Cover Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6309–6320. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Wang, X.; Wei, Y.; Huang, L.; Shi, H.; Liu, W.; Huang, T.S. CCNet: Criss-cross attention for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Wang, L.; Li, R.; Duan, C.; Fang, S. Transformer meets DCFAM: A novel semantic segmentation scheme for fine-resolution remote sensing images. arXiv 2021, arXiv:2104.12137. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve Restricted Boltzmann machines. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Zhang, Q.; Yang, Y. ResT: An efficient transformer for visual recognition. arXiv 2021, arXiv:2105.13677. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022v3. [Google Scholar]
- Lyu, Y.; Vosselman, G.; Xia, G.-S.; Yilmaz, A.; Yang, M.Y. UAVid: A semantic segmentation dataset for UAV imagery. ISPRS J. Photogramm. Remote Sens. 2020, 165, 108–119. [Google Scholar] [CrossRef]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Hu, P.; Perazzi, F.; Heilbron, F.C.; Wang, O.; Lin, Z.; Saenko, K.; Sclaroff, S. Real-time semantic segmentation with fast attention. IEEE Robot. Autom. Lett. 2021, 6, 263–270. [Google Scholar] [CrossRef]
- Oršić, M.; Šegvić, S. Efficient semantic segmentation with pyramidal fusion. Pattern Recognit. 2021, 110, 107611. [Google Scholar] [CrossRef]
- Zhuang, J.; Yang, J.; Gu, L.; Dvornek, N. Shelfnet for fast semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019; pp. 847–856. [Google Scholar]
- Poudel, R.P.K.; Liwicki, S.; Cipolla, R. Fast-scnn: Fast semantic segmentation network. arXiv 2019, arXiv:1902.04502. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Imp. Surf. | Building | Low Veg. | Tree | Car | Mean F1 | OA | mIoU |
|---|---|---|---|---|---|---|---|---|---|
| BiSeNet | ResNet-18 | 89.12 | 91.30 | 80.87 | 86.91 | 73.12 | 84.26 | 87.08 | 75.82 |
| FANet | ResNet-18 | 90.65 | 93.78 | 82.60 | 88.56 | 71.60 | 85.44 | 88.87 | 75.61 |
| MAResU-Net | ResNet-18 | 91.97 | 95.04 | 83.74 | 89.35 | 78.28 | 87.68 | 90.07 | 78.58 |
| EaNet | ResNet-18 | 91.68 | 94.52 | 83.10 | 89.24 | 79.98 | 87.70 | 89.69 | 78.68 |
| SwiftNet | ResNet-18 | 92.22 | 94.84 | 84.14 | 89.31 | 81.23 | 88.35 | 90.20 | 79.58 |
| ShelfNet | ResNet-18 | 91.83 | 94.56 | 83.78 | 89.27 | 77.91 | 87.47 | 89.81 | 78.94 |
| BANet | ResT-Lite | 92.23 | 95.23 | 83.75 | 89.92 | 86.76 | 89.58 | 90.48 | 81.35 |
| Method | Backbone | Imp. Surf. | Building | Low Veg. | Tree | Car | Mean F1 | OA | mIoU |
|---|---|---|---|---|---|---|---|---|---|
| BiSeNet | ResNet-18 | 90.24 | 94.55 | 85.53 | 86.20 | 92.68 | 89.84 | 88.16 | 81.72 |
| FANet | ResNet-18 | 91.99 | 96.10 | 86.05 | 87.83 | 94.53 | 91.30 | 89.82 | 84.16 |
| MAResU-Net | ResNet-18 | 91.41 | 95.57 | 85.82 | 86.61 | 93.31 | 90.54 | 89.04 | 83.87 |
| EaNet | ResNet-18 | 92.01 | 95.69 | 84.31 | 85.72 | 95.11 | 90.57 | 88.70 | 83.38 |
| SwiftNet | ResNet-18 | 91.83 | 95.94 | 85.72 | 86.84 | 94.46 | 90.96 | 89.33 | 83.84 |
| ShelfNet | ResNet-18 | 92.53 | 95.75 | 86.60 | 87.07 | 94.59 | 91.31 | 89.92 | 84.38 |
| BANet | ResT-Lite | 93.34 | 96.66 | 87.37 | 89.12 | 95.99 | 92.50 | 91.06 | 86.25 |
| Method | Building | Tree | Clutter | Road | Vegetation | Static Car | Moving Car | Human | mIoU |
|---|---|---|---|---|---|---|---|---|---|
| MSD | 79.8 | 74.5 | 57.0 | 74.0 | 55.9 | 32.1 | 62.9 | 19.7 | 57.0 |
| Fast-SCNN | 75.7 | 71.5 | 44.2 | 61.6 | 43.4 | 19.5 | 51.6 | 0.0 | 45.9 |
| BiSeNet | 85.7 | 78.3 | 64.7 | 61.1 | 77.3 | 63.4 | 48.6 | 17.5 | 61.5 |
| SwiftNet | 85.3 | 78.2 | 64.1 | 61.5 | 76.4 | 62.1 | 51.1 | 15.7 | 61.1 |
| ShelfNet | 76.9 | 73.2 | 44.1 | 61.4 | 43.4 | 21.0 | 52.6 | 3.6 | 47.0 |
| BANet | 85.4 | 78.9 | 66.6 | 80.7 | 62.1 | 52.8 | 69.3 | 21.0 | 64.6 |
| Method | Imp. Surf. | Building | Low Veg. | Tree | Car | Mean F1 | OA | mIoU |
|---|---|---|---|---|---|---|---|---|
| ResNet | 90.91 ± 0.45 | 95.18 ± 0.35 | 84.86 ± 0.92 | 86.44 ± 0.37 | 94.03 ± 0.63 | 90.28 ± 0.28 | 88.48 ± 0.50 | 82.34 ± 0.55 |
| ResT | 92.01 ± 0.58 | 95.73 ± 0.70 | 85.87 ± 0.58 | 87.24 ± 0.80 | 94.13 ± 0.49 | 91.00 ± 0.60 | 89.63 ± 0.49 | 83.80 ± 0.74 |
| Dp+Tp(Sum) | 92.11 ± 0.48 | 95.63 ± 0.43 | 86.5 ± 0.59 | 87.09 ± 0.97 | 94.44 ± 0.30 | 91.15 ± 0.53 | 89.87 ± 0.63 | 84.15 ± 0.72 |
| Dp+Tp(Cat) | 92.30 ± 0.55 | 95.99 ± 0.53 | 86.18 ± 0.64 | 87.57 ± 1.04 | 94.58 ± 0.77 | 91.32 ± 0.68 | 90.35 ± 0.23 | 85.31 ± 0.75 |
| BAResNet | 92.46 ± 0.21 | 95.37 ± 0.43 | 85.92 ± 0.84 | 87.24 ± 0.70 | 94.79 ± 0.28 | 91.16 ± 0.48 | 89.60 ± 0.54 | 84.07 ± 0.64 |
| BANet | 93.27 ± 0.11 | 96.53 ± 0.15 | 87.19 ± 0.23 | 88.63 ± 0.45 | 95.58 ± 0.44 | 92.24 ± 0.23 | 90.86 ± 0.18 | 85.78 ± 0.46 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images. Remote Sens. 2021, 13, 3065. https://doi.org/10.3390/rs13163065
Wang L, Li R, Wang D, Duan C, Wang T, Meng X. Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images. Remote Sensing. 2021; 13(16):3065. https://doi.org/10.3390/rs13163065
Chicago/Turabian StyleWang, Libo, Rui Li, Dongzhi Wang, Chenxi Duan, Teng Wang, and Xiaoliang Meng. 2021. "Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images" Remote Sensing 13, no. 16: 3065. https://doi.org/10.3390/rs13163065
APA StyleWang, L., Li, R., Wang, D., Duan, C., Wang, T., & Meng, X. (2021). Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images. Remote Sensing, 13(16), 3065. https://doi.org/10.3390/rs13163065