
Comparison of Gridded DEMs by Buffering



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methods and Data
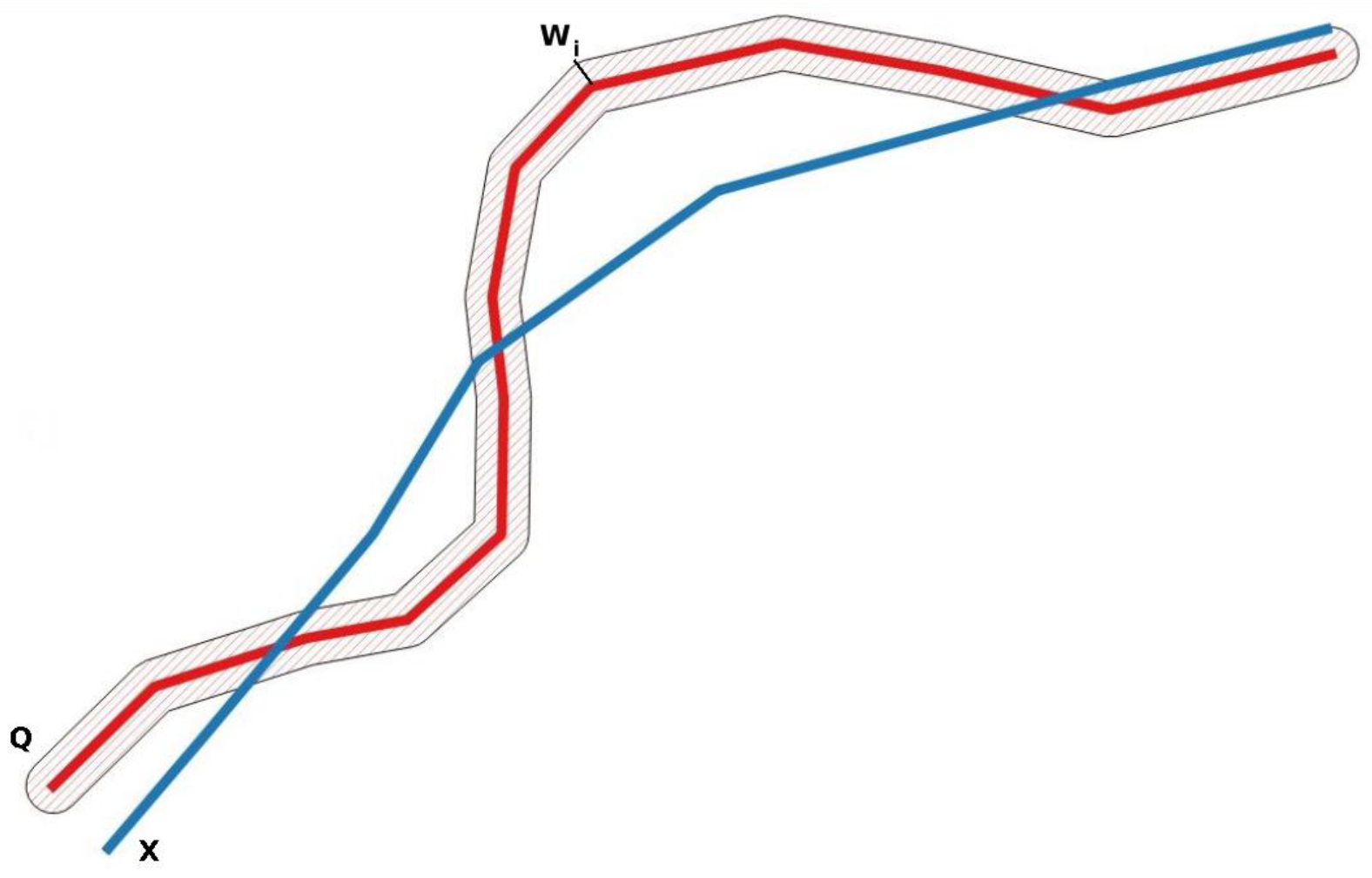
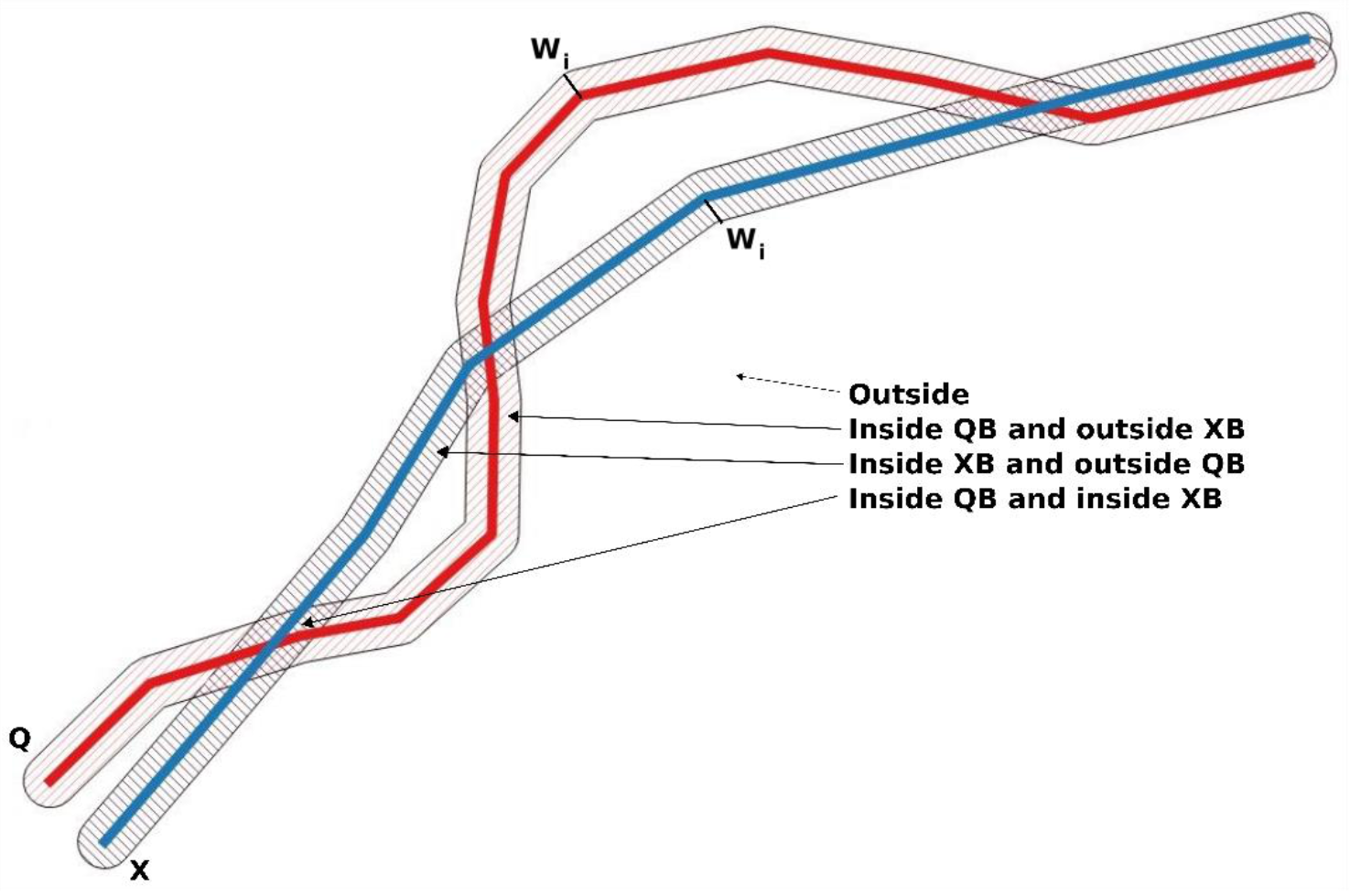
2.1. The Single-Buffer Method
- (a)
- one for the evolution of negatives discrepancies (S2 below S1, i.e., ),
- (b)
- also the same for positive discrepancies (S2 above S1, i.e., )
- (c)
- and in absolute value (i.e., ).
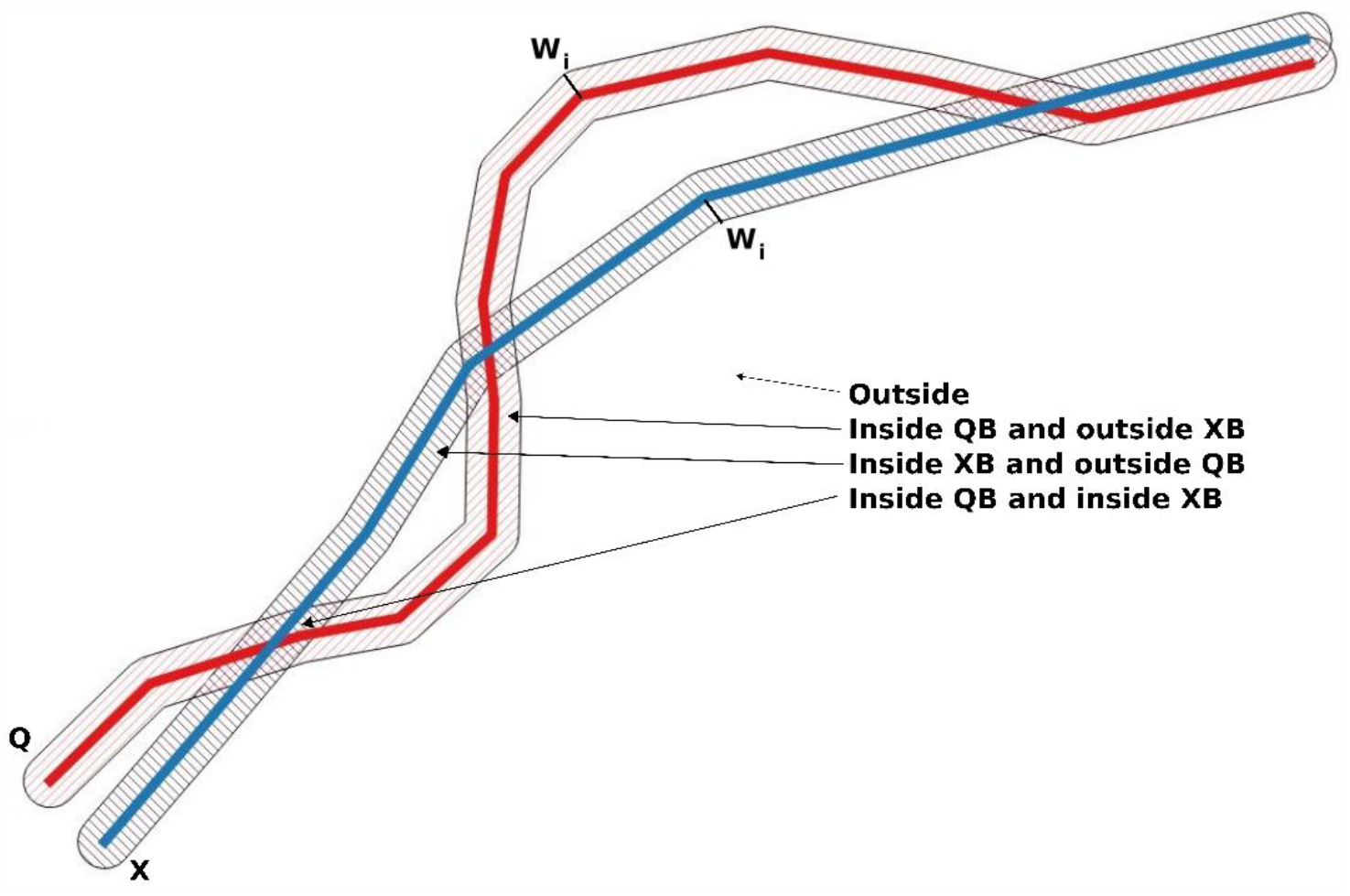
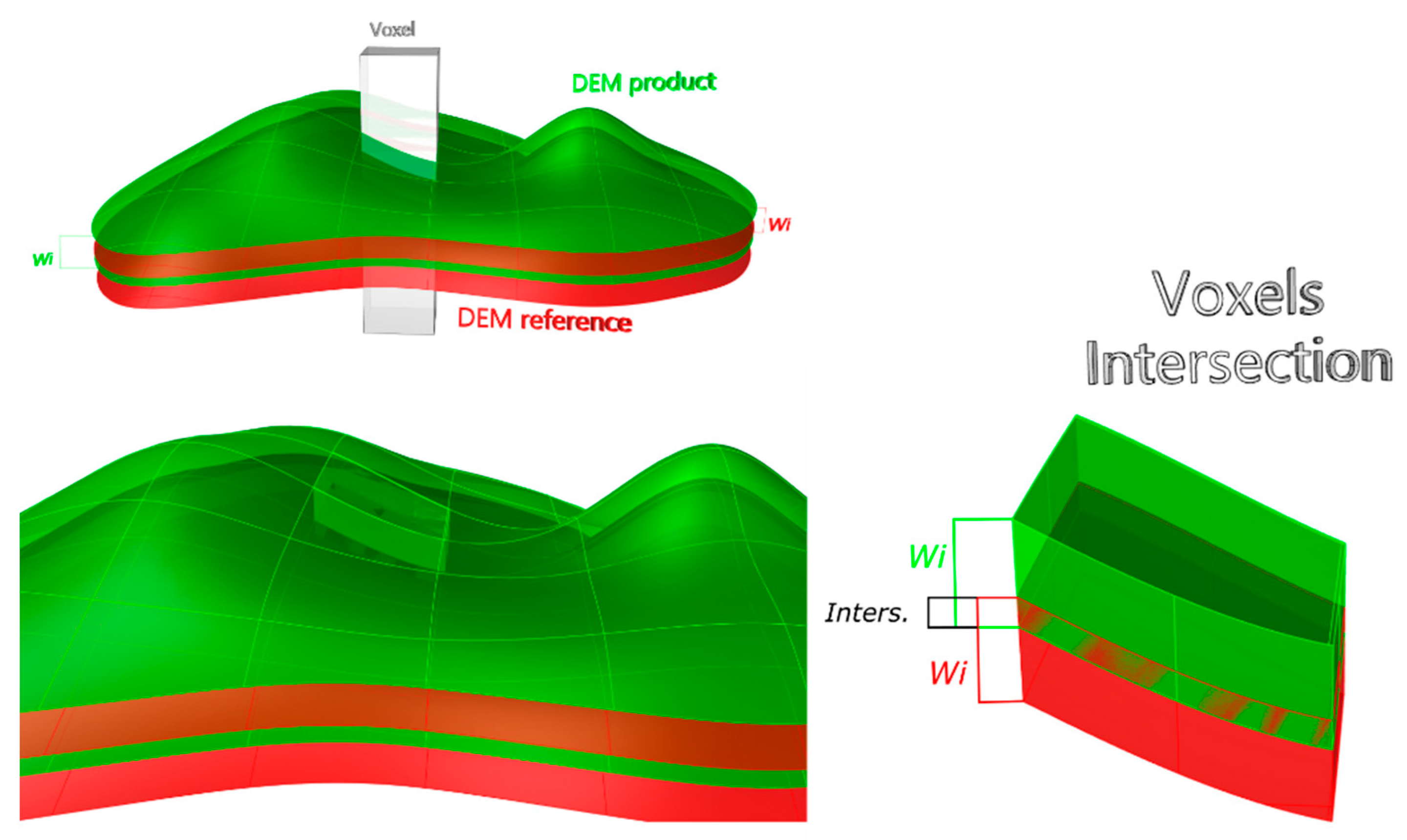
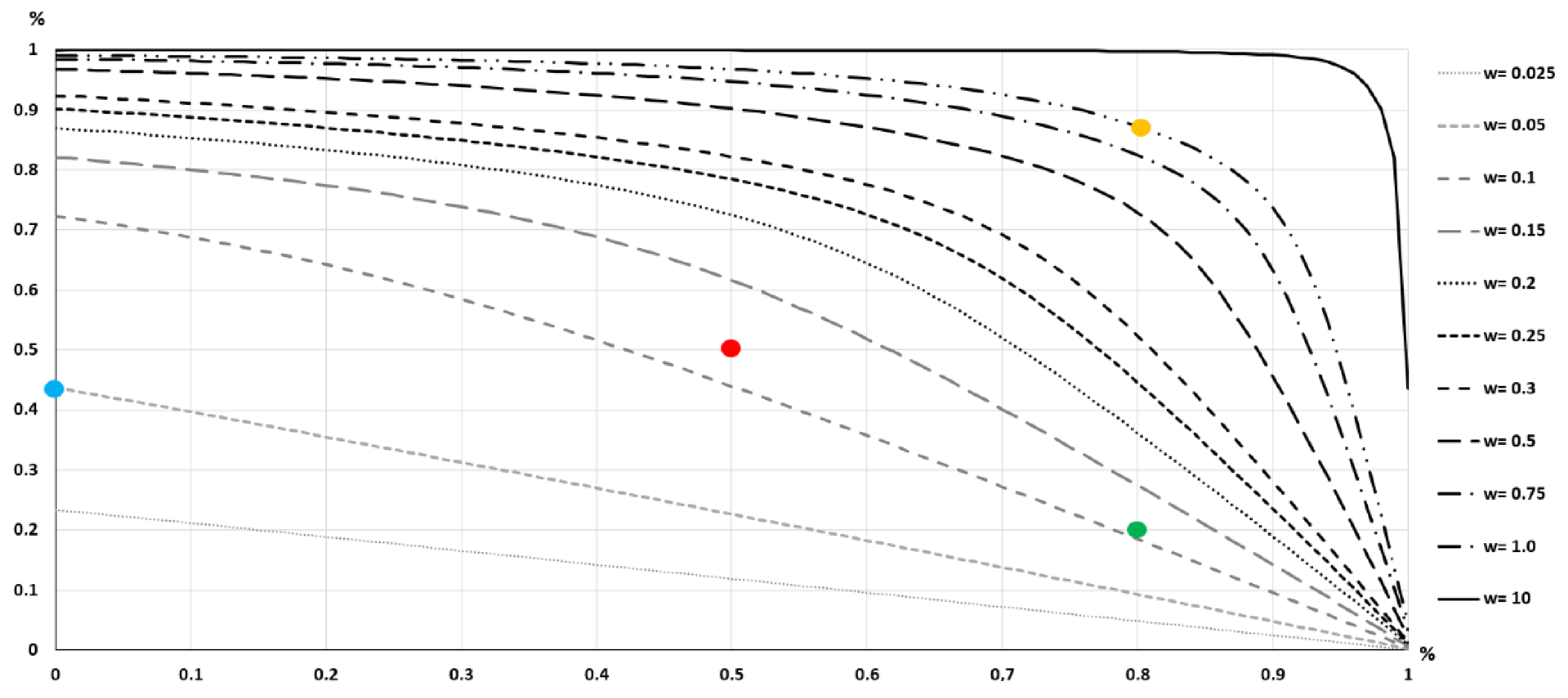
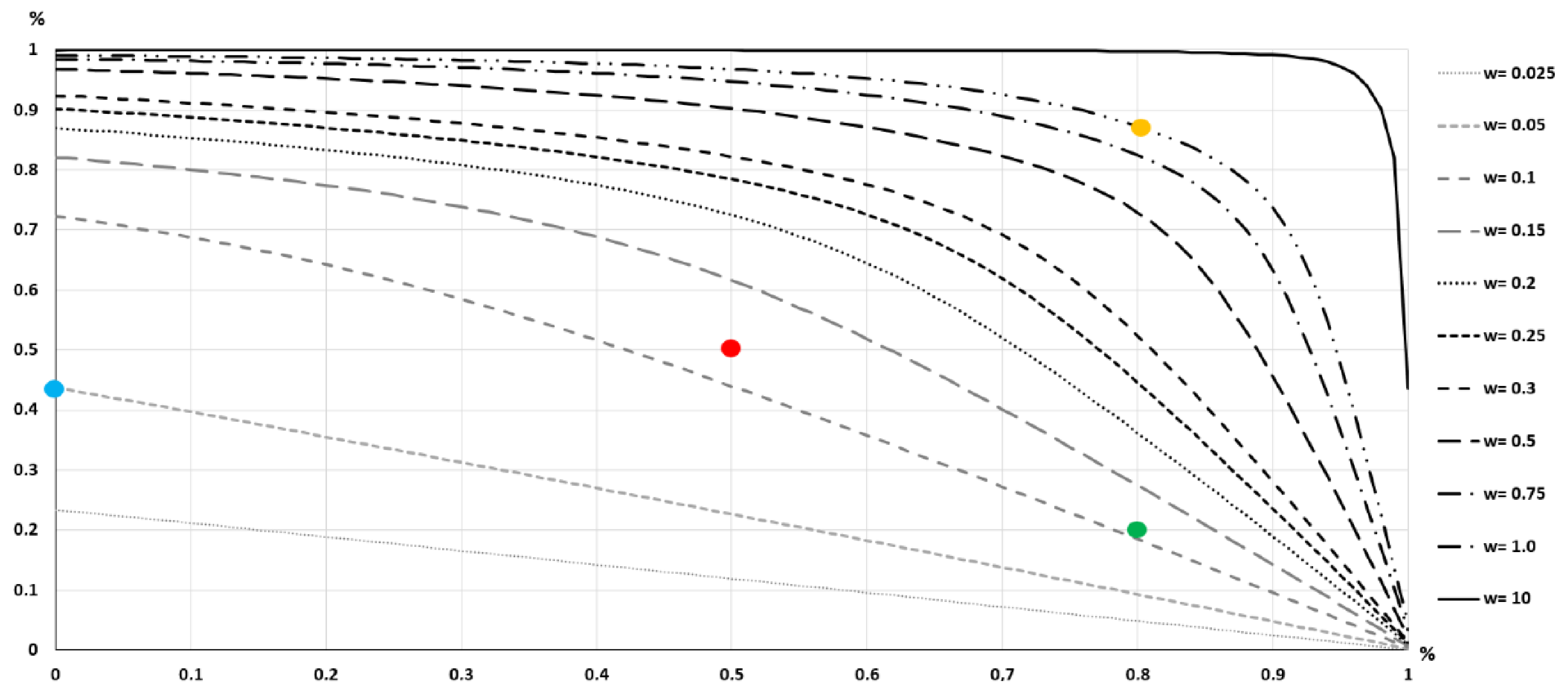
2.2. The Double-Buffer Method
- There is no intersection. There is no intersection between the voxels of the two buffered surfaces. This means that the vertical distance between S1 and S2 exceeds 2 × wi.
- There is an intersection. There is an intersection between the voxels of the two buffered surfaces. This means that the vertical distance between S1 and S2 is less than 2 × wi. If the distance between S1 and S2 is zero, there will be a complete match of the voxels (100% intersection). In this case, for a given wi and a specific position in the DEM, the degree of intersection between the voxels of S1 and S2 can be considered as a fuzzy or probabilistic approximation.
2.3. Data
- DEM02. This is a gridded DEM (2 × 2 meter resolution), it was generated in 2017 and its primary data source is an aerial LiDAR survey (RMSEz ≤ 20 cm) (second coverage of the PNOA-LiDAR project https://pnoa.ign.es/estado-del-proyecto-lidar/segunda-cobertura, accessed on 28 July 2021). The informed positional accuracies for the DEM are RMSEXY ≤ 50 cm and RMSEZ-02 ≤ 25 cm. It is considered as the reference in our work: S1.
- DEM05. This is a gridded DEM (5 × 5 meter resolution), it was generated in 2012 and its primary data source is an aerial LiDAR survey (RMSEz ≤ 40 cm) (first coverage of the PNOA-LiDAR project https://pnoa.ign.es/estado-del-proyecto-lidar/primera-cobertura, accessed on 28 July 2021). The informed positional accuracies for the DEM are RMSEXY ≤ 50 cm and RMSEZ-05 ≤ 50 cm. It is considered as the product under analysis in our work: S2.
3. Results
3.1. The Single-Buffer Method
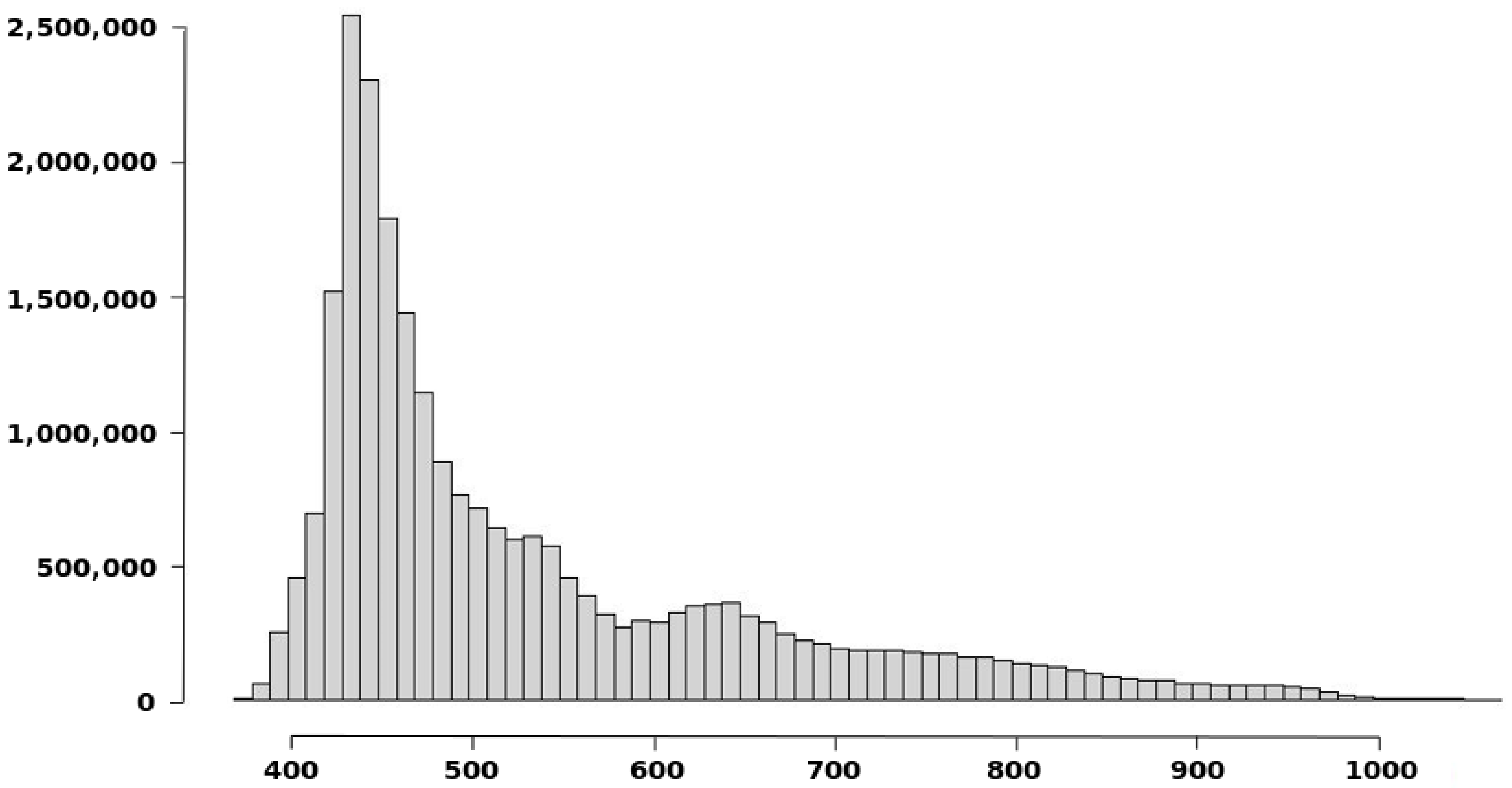
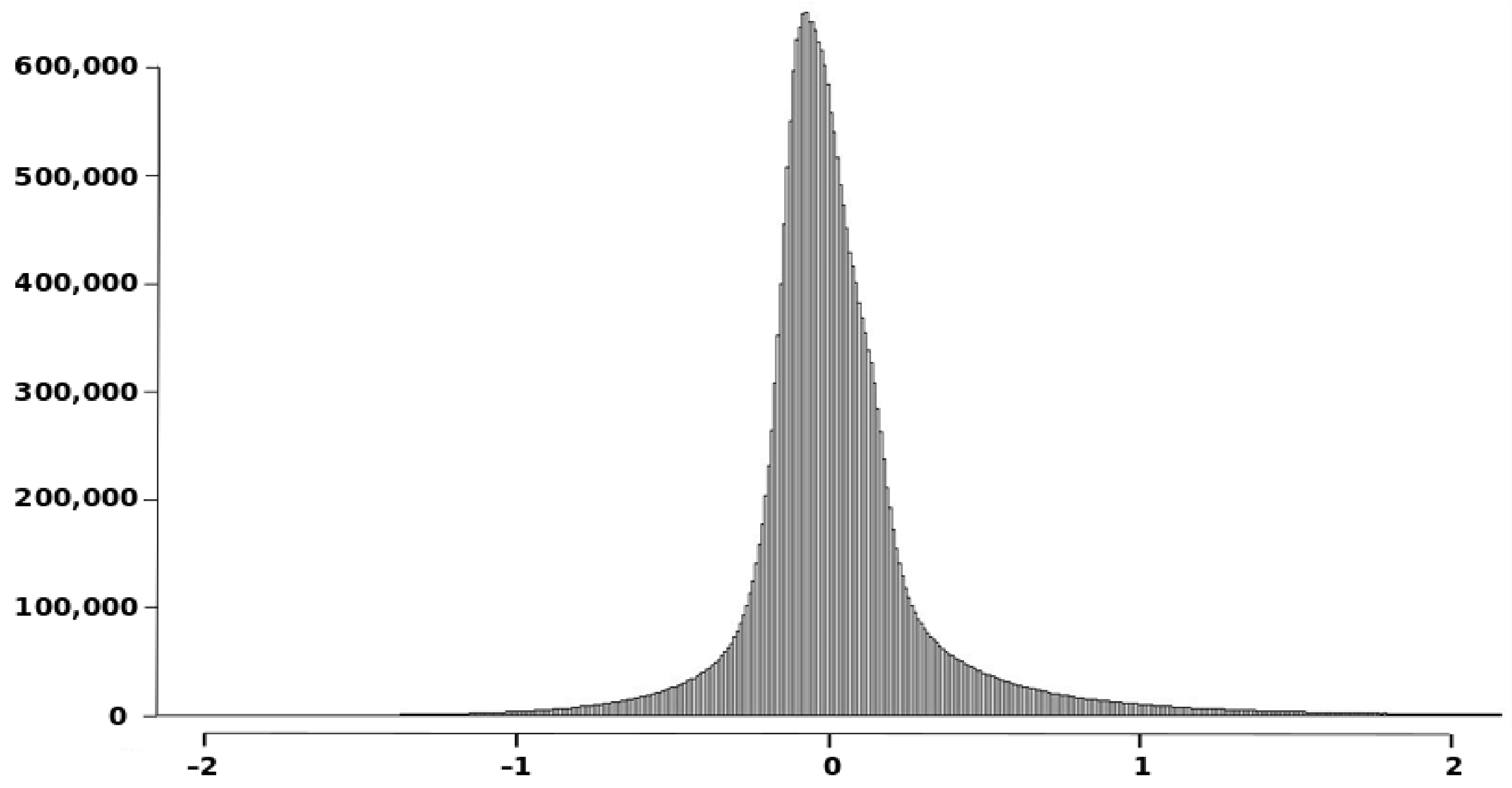
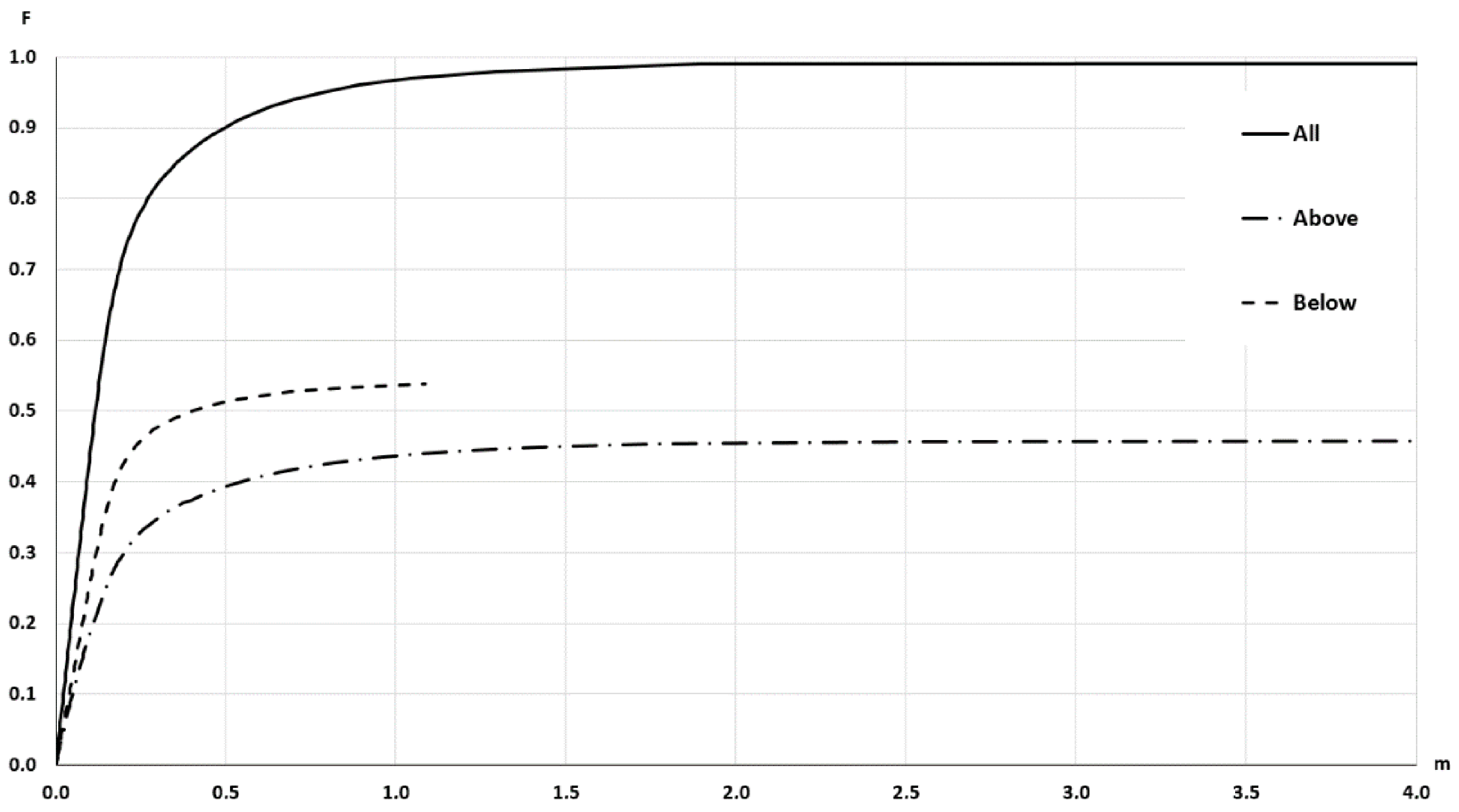
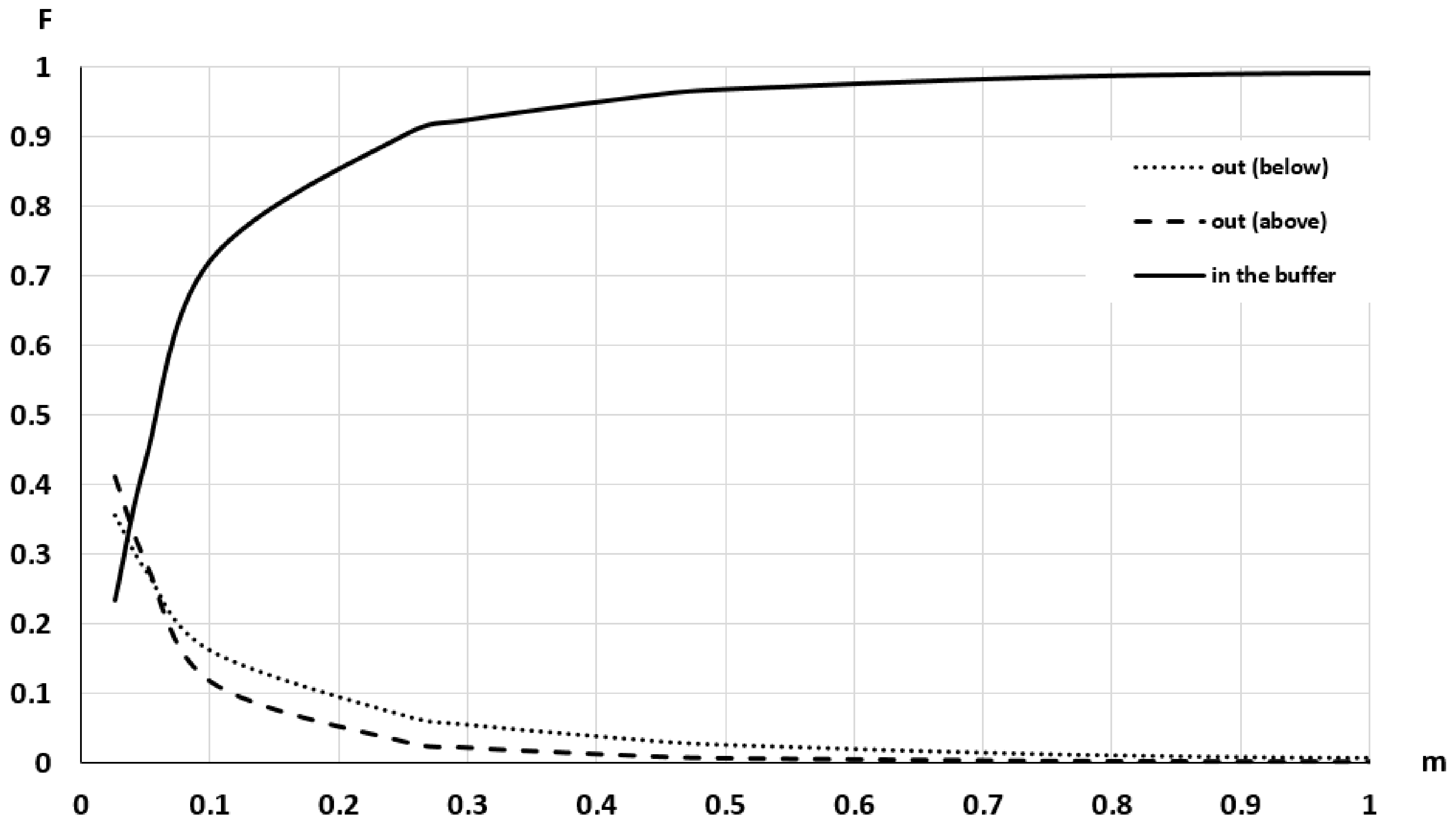
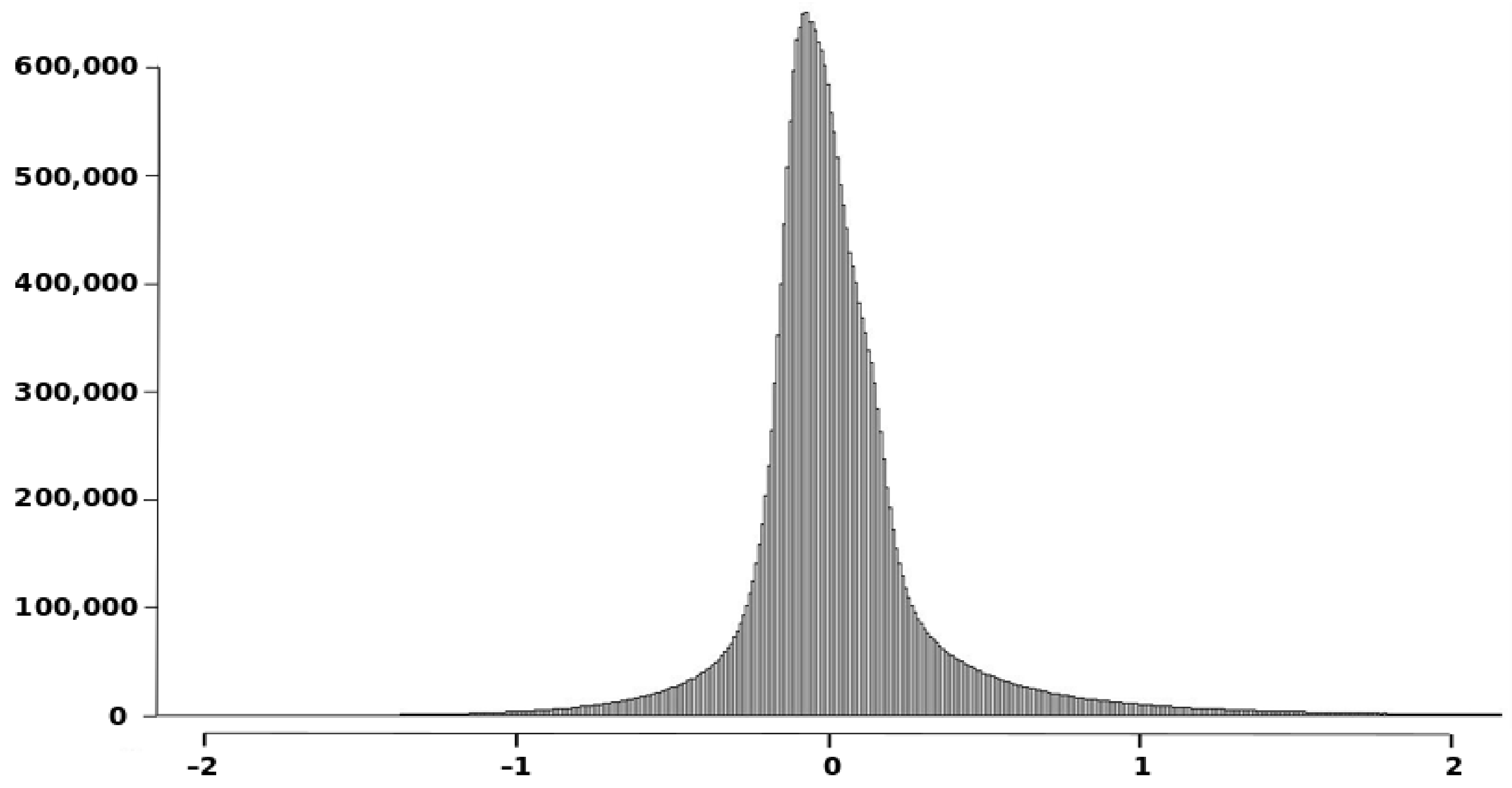
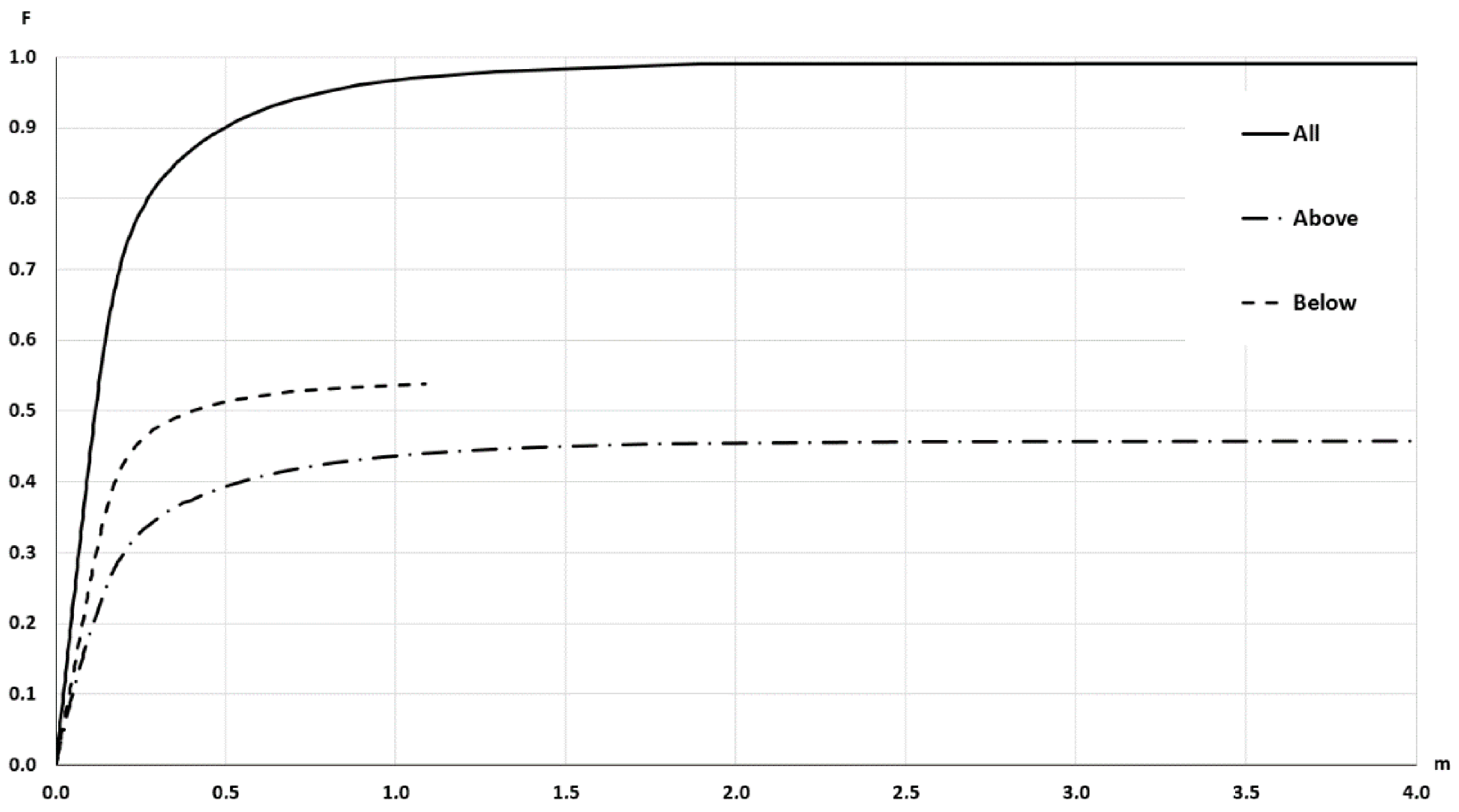
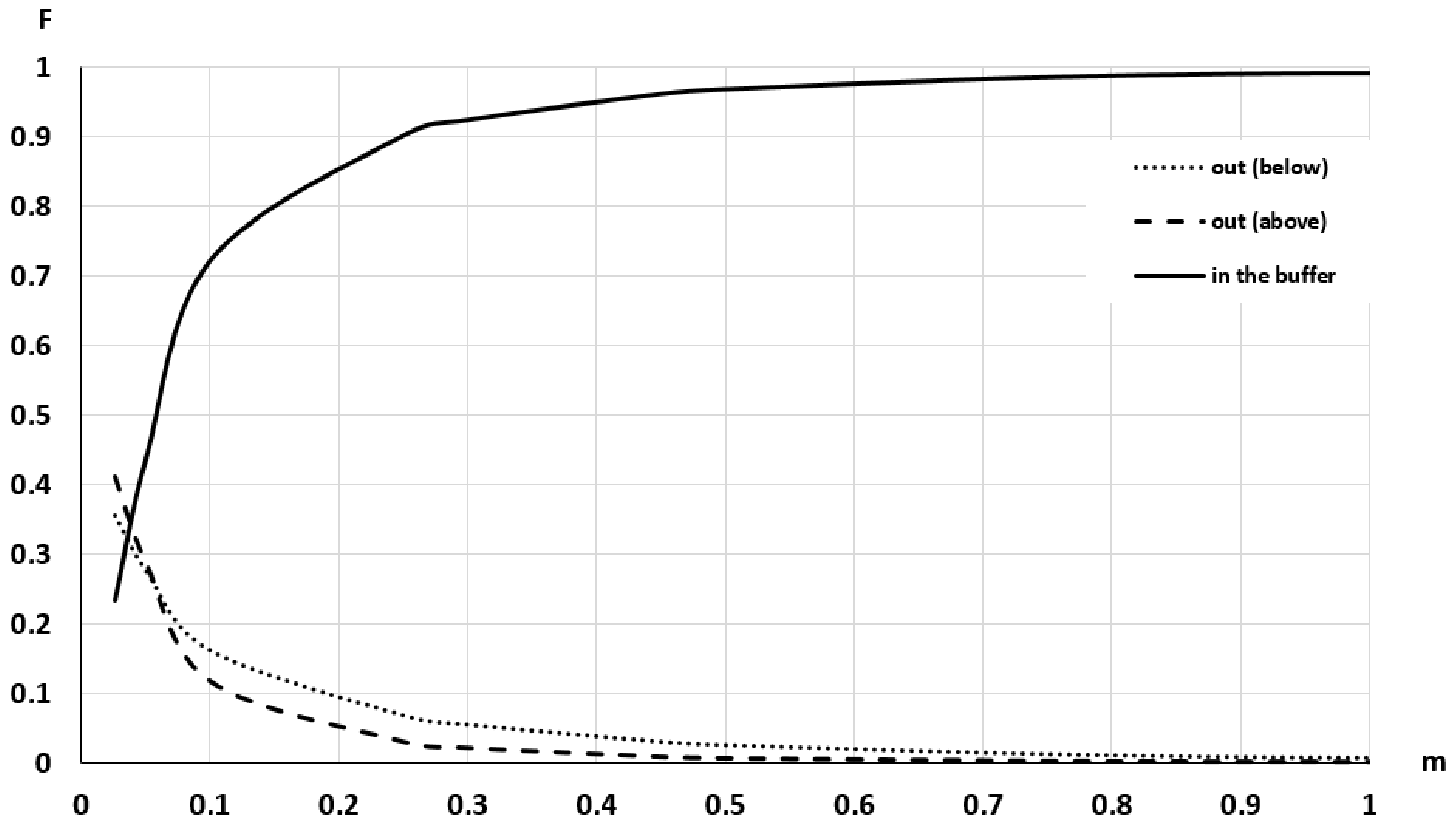
- To recognize the presence of outliers. Outliers are excessively large discrepancies between the S1 and S2 with low presence probabilities and, in general, would correspond to the presence of peaks or wells. This presence would generate the need for a very large value of wi to achieve their inclusion and an asymptotic flattening of the curve close to the value of unity on the vertical axis (100% inclusion). As can be seen in Figure 8, this is the case 99% inclusion is reached approximately for 1.89 m, while there is a long tail, which will extend up to 55.39 m to achieve 100% inclusion. Thus, in the data under analysis, there is the presence of outliers.
- To recognize the presence of vertical bias. The vertical bias, in this case, means that one DEM has an altimetric predominance over the other. In this case, we compare the curves for the cases Above and Below and observe that the below curve is over the above curve. This implies that, in general, S1 is over S2, which means a vertical bias. Here we can remember that the mean value of the discrepancies is μ = –0.0347, the bias is small but in terms of frequencies the difference is in the order of 7.57%, which means an imbalance between the Above and Below cases.To determine the uncertainty, either by establishing a percentile of interest (e.g., 90%) and determining the corresponding distance (≈0.5 m), or by establishing a distance (e.g., d = 1 m) and determining its corresponding percentile (96.5%). The use of a single percentile is fully equivalent to what is proposed in some DEM evaluation methods for non-normal data (e.g., [2,6]). However, the use of a curve such as the one presented in Figure 8 offers much more information and the possibility of using several percentiles for better control of the distribution of discrepancies. In this line, the method proposed by [26] allows the use of several tolerances for the case of non-normal data.
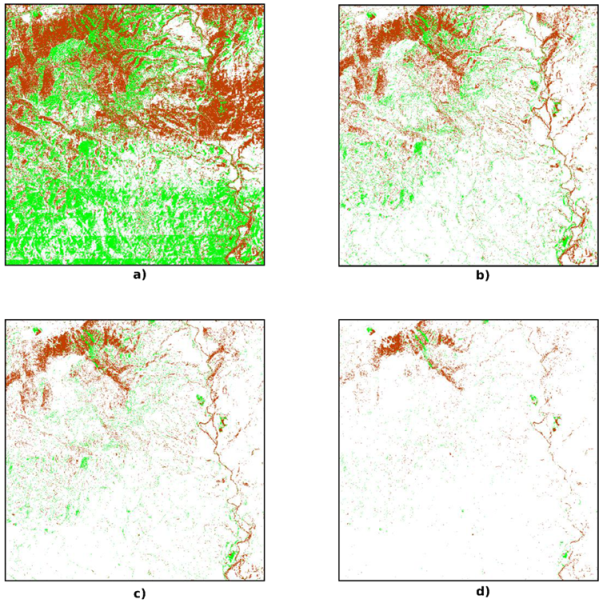
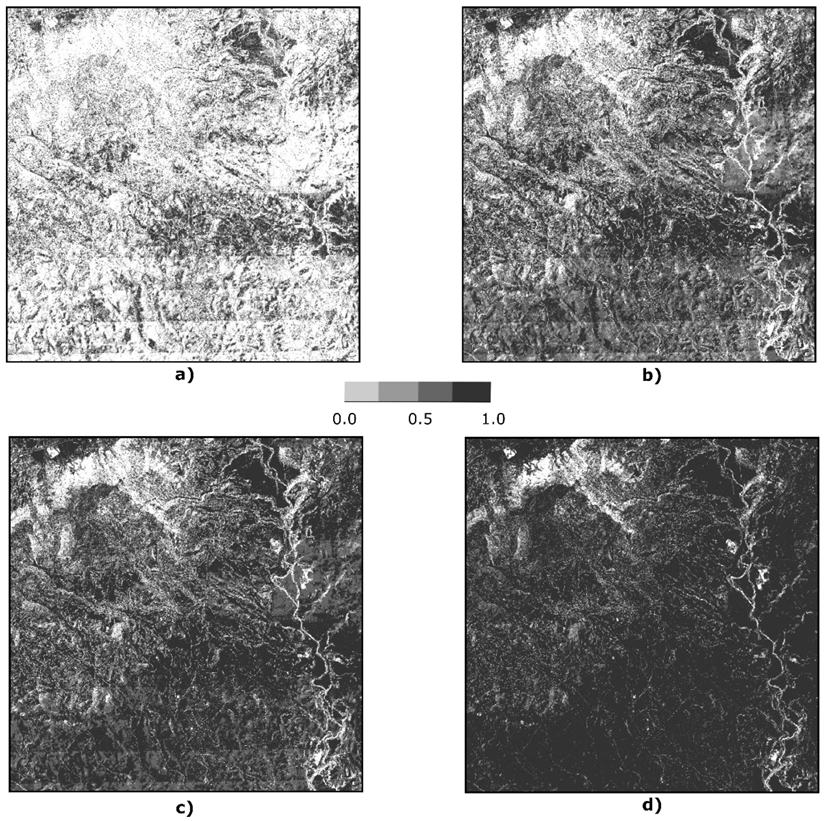
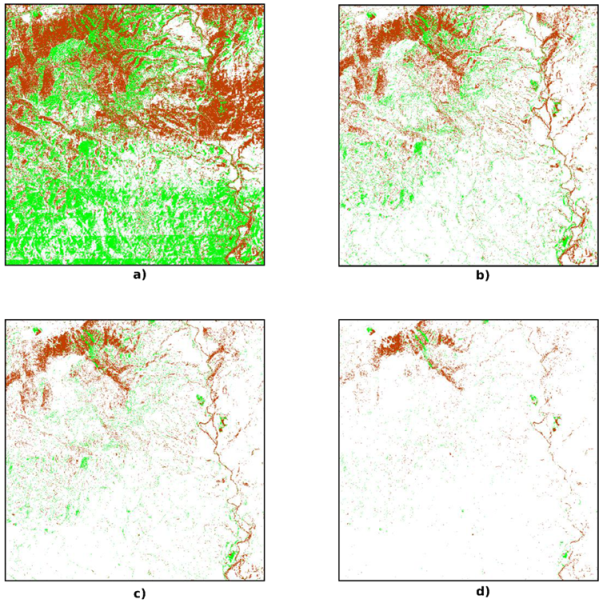
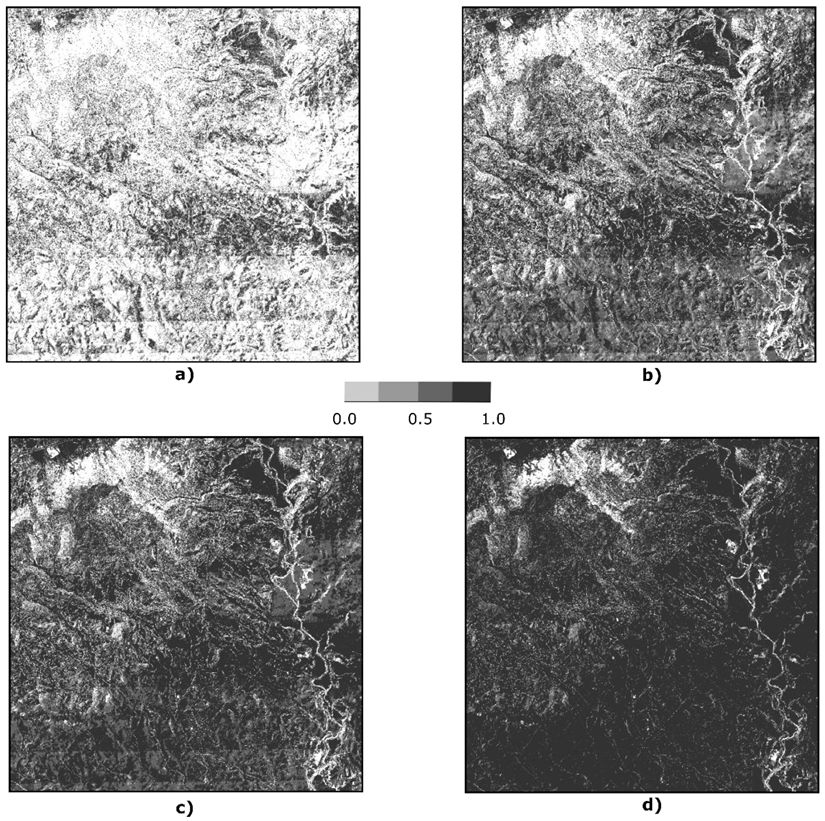
3.2. Double-Buffer Method
4. Discussion
- Concept. The leap from the application of buffering methods from lines to DEM is quite straightforward and the concepts handled are very similar. The application of the buffer methods to lines entails a certain dimensional change, from 1D to 2D, which in our proposal should have led to a step from 2D to 3D. For simplicity, and because it is more usual to deal with area units than with volume units, the first perspective was developed. The presence of the 3D perspective is included in the application of the DBM when dealing with voxel-overlapping. Of course, the volume could also have been analyzed for the case of the SBM, but in this case, a curve like the one in Figure 8 would be obtained but scaled in units of volume. The use of areas allows the application of these methods also quite directly to the case of other variables such as slope and elevation.
- Algorithms. The application to the case of grid-type DEMs is straightforward, the use of simple map algebra operations allows executing these processes without problem, with agility and for large amounts of data. Working with other DEM data would require coding more complex algorithms.
- Analysis element. In this sense, there is a radical change with respect to the assessment usually applied to DEM, which is based on points (e.g., altimetric error assessments). The analysis based on surfaces seems to us more natural and closer to the reality that we want to analyze. As in the case of application to linear elements, the proposed methods allow them to be applied to a single surface, or to a set of surfaces, regardless of their extension.
- Discrepancies. Since distributional curves are obtained (e.g., those of Figure 8, Figure 11 and Figure 12), more information is available on the behavior of the discrepancies between two DEM data sets. Since the discrepancies do not usually fit a normal distribution, having curves relative to observed distributions allows working with percentiles in a direct way. In the case of wanting to carry out quality control (hypothesis testing), these curves can be used as a basis for control methods based on tolerances (one or more tolerances) (see [26]).
- Analysis capabilities. In relation to the results and possibilities of analysis, the SBM and the DBM are different, as happened in the case of application to linear data and their complementary results, since they present two different perspectives of the same reality. In general, the results of the SBM are easier to interpret than those of the DBM when a partial voxel intersection perspective is adopted on it. In any case, both methods generate curves very similar to observed distribution functions (global or partial). This offers a powerful analysis tool since it visualizes what happens in the entire population or sub-population of interest. Furthermore, the use of these observed distribution functions eliminates the need for the normality hypothesis on discrepancies and allows the application of quality control techniques by means of tolerance(s).
- Applicability of SBM and DBM. We consider that the SBM is more suitable for the case in which the accuracy of S1 is much greater than that of S2, in such a way that it can be considered negligible. In the case of analysis of positional accuracy by points, this circumstance is considered valid when its accuracy is at least three times better. In this case, discrepancies can be considered as errors of S2 in relation to the reference (S1). We consider the DBM to be more suitable for the case where the accuracy of S1 and S2 are approximately equal.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- GISGeography. GIS Dictionary—Geospatial Definition Glossary. 2021. Available online: https://gisgeography.com/gis-dictionary-definition-glossary/#D (accessed on 28 July 2021).
- Maune, D.F. (Ed.) Digital Elevation Model Technologies and Applications: The Dem User’s Manual; American Society for Photogrammetry and Remote Sensing: Bethesda, MD, USA, 2007; ISBN 978-1-57083-082-2. [Google Scholar]
- Felicísimo, M.A. Modelos Digitales Del Terreno: Introducción y Aplicaciones En Las Ciencias Ambientales Pentalfa; Pentalfa Ediciones: Oviedo, Spain, 1994; ISBN 84-7848-475-2. [Google Scholar]
- ISO. ISO 19157: 2013 Geographic Information—Data Quality; ISO: Geneva, Switzerland, 2013. [Google Scholar]
- Mesa-Mingorance, J.L.; Ariza-López, F.J. Accuracy Assessment of Digital Elevation Models (DEMs): A Critical Review of Prac-414 tices of the Past Three Decades. Remote Sens. 2020, 12, 2630. [Google Scholar] [CrossRef]
- Bhatta, B.; Shrestha, S.; Shrestha, P.K.; Talchabhadel, R. Evaluation and application of a SWAT model to assess the climate impact on the hydrology of the Himalayan River Basin. Catena 2019, 181, 104082. [Google Scholar] [CrossRef]
- Gao, J. Impact of sampling intervals on the reliability of topographic variables mapped from grid DEMs at a micro-scale. Int. J. Geogr. Inf. Sci. 1998, 12, 875–890. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, W.; Chen, L. Constructing DEM based on InSAR and the Relationship between InSAR DEM’s Precision and Terrain Factors. Energy Procedia 2012, 16, 184–189. [Google Scholar] [CrossRef] [Green Version]
- Mukherjee, S.; Joshi, P.K.; Mukherjee, S.; Ghosh, A.; Garg, R.D.; Mukhopadhyay, A. IU accuracy of open source Digital Elevation Model (DEM). Int. J. Appl. Earth Obs. Geoinf. 2013, 21, 205–217. [Google Scholar] [CrossRef]
- Kinsey-Henderson, A.E.; Wilkinson, S.N. Evaluating Shuttle Radar and interpolated DEMs for slope gradient and soil erosion estimation in low relief terrain. Environ. Model. Softw. 2013, 40, 128–139. [Google Scholar] [CrossRef]
- Avtar, R.; Yunus, A.P.; Kraines, S.; Yamamuro, M. Evaluating of DEM generation based on Interferometric SAR using TanDEM-X data in Tokyo. Phys. Chem. Earth 2015, 83, 166–177. [Google Scholar] [CrossRef]
- Wang, B.; Shi, W.; Liu, E. Robust methods for assessing the accuracy of linear interpolated DEM. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 198–206. [Google Scholar] [CrossRef]
- Mcneill, S.J.; Belliss, S.E. Assessment of Digital Elevation Model Accuracy using ALOS-PRISM Stereo Imagery. In Proceedings of the 24th International Conference Image and Vision Computing (IVCNZ), Wellington, New Zealand, 23–25 November 2009. [Google Scholar]
- Liu, X. Accuracy assessment of LiDAR elevation data using survey marks. Surv. Rev. 2011, 43, 80–93. [Google Scholar] [CrossRef] [Green Version]
- Carabajar, C.C.; Harding, D.J.; Suchdeo, V.P. IceSat LiDAR and Global Digial Elevation Models: Applications to DESDYNI. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Honolulu, HI, USA, 25–30 July 2010. [Google Scholar]
- Gesch, D.B.; Larson, K.S. Techniques for development of Global 1-Kilometer Digital Elevation Models. In Proceedings of the Pecora Thirteen: Human Interactions with the Environment: Perspective from Space, Sioux Falls, SD, USA, 20–22 August 1997. [Google Scholar]
- Becek, K. Assessing Global Digital Elevation Models using the Runway Method: The Advanced Spaceborne Thermal Emission and Reflection Radiometer versus the Shuttle Radar Topography Mission case. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4823–4831. [Google Scholar] [CrossRef]
- Oksanen, J.; Sarjakoski, T. Error propagation of DEM-based Surface derivates. Comput. Geosci. 2005, 31, 1015–1027. [Google Scholar] [CrossRef]
- Zhang, F.; Zhao, P.; Thiyagalingam, J.; Kirubarajan, T. Terrain-influenced incremental watchtower expansion for wildfire detection. Sci. Total Environ. 2019, 654, 164–176. [Google Scholar] [CrossRef]
- Li, L.; Nearing, M.A.; Nichols, M.H.; Polyakov, V.O.; Guertin, D.P.; Cavanaugh, M.L. The effects of DEM interpolation on quantifying soil surface roughness using terrestrial LiDAR. Soil Tillage Res. 2020, 198, 104520. [Google Scholar] [CrossRef]
- Heo, J.; Jung, J.; Kim, B.; Han, S. Digital Elevation Model-Based convolutional neural network modelling for searching of high solar energy regions. Appl. Energy 2020, 262, 114588. [Google Scholar] [CrossRef]
- United Nations. The Global Fundamental Geospatial Data Themes; Committee of Experts on Global Geospatial Information Management: New York, NY, USA, 2019; Available online: http://ggim.un.org/meetings/GGIMcommittee /9th-Session/documents/Fundamental_Data_Publication.pdf (accessed on 6 July 2020).
- Shen, Z.Y.; Chen, L.; Liao, R.M.; Huang, Q. A comprehensive study of the effect of GIS data on hydrology and non-point source pollution modelling. Agric. Water Manag. 2013, 118, 93–102. [Google Scholar] [CrossRef]
- Rodríguez-Gonzálvez, P.; Garcia-Gago, J.; Gomez-Lahoz, J.; González-Aguilera, D. Confronting passive and active sensors with non-gaussian statistics. Sensors 2014, 14, 13759–13777. [Google Scholar] [CrossRef] [Green Version]
- Rodríguez-Gonzálvez, P.; González-Aguilera, D.; Hernández-López, D.; González-Jorge, H. Accuracyassessment of airborne laser scanner dataset by means of parametric and non-parametric statistical methods. IET Sci. Meas. Technol. 2015, 9, 505–513. [Google Scholar] [CrossRef]
- Ariza-López, F.; Rodríguez-Avi, J.; González-Aguilera, D.; Rodríguez-Gonzálvez, P. A New Method for Positional Accuracy Control for Non-Normal Errors Applied to Airborne Laser Scanner Data. Appl. Sci. 2019, 9, 3887. [Google Scholar] [CrossRef] [Green Version]
- ASCE. Map Uses, Scales and Accuracies for Engineering and Associated Purposes; American Society of Civil Engineers, Committee on Cartographic Surveying, Surveying and Mapping Division: New York, NY, USA, 1983. [Google Scholar]
- FGDC. FGDC-STD-007: Geospatial Positioning Accuracy Standards, Part 3; National Standard for Spatial Data Accuracy; Federal Geographic Data Committee: Reston, VA, USA, April 1998. Available online: https://www.fgdc.gov/standards/projects/accuracy/part3/chapter3 (accessed on 28 July 2021).
- ASPRS. ASPRS Positional accuracy standards for digital geospatial data. Photogramm. Eng. Remote Sens. 2015, 81, A1–A26. Available online: http://www.asprs.org/a/society/divisions/pad/Accuracy/Draft_ASPRS_Accuracy_Standards_for_Digital_Geospatial_Data_PE&RS.pdf (accessed on 28 July 2021). [CrossRef]
- UNE. UNE 148002: 2016 Metodología de Evaluación de la Exactitud Posicional de la Información Geográfica; UNE: Madrid, Spain, 2016. [Google Scholar]
- NATO. STANAG 2215 Evaluation of Land Maps, Aeronautical Charts and Digital Topographic Data; NATO: Brussels, Belgium, 2010. [Google Scholar]
- Circulaire du 16 Septembre 2003 relative à la miseen ceuvre de l’arrèté du 16 Septembre 4 2003 portant sur les classesde precisions applicables aux categories de travaux topographiques réalisés par l’Etat, les collectivités locales, ou pour leur compte. J. Off. République Fr. 2003, 252, 18459–18556. Available online: https://www.legifrance.gouv.fr/jorf/id/JORFTEXT000000429763 (accessed on 28 July 2021).
- Polidori, L.; Hage, M.E. Digital Elevation Model Quality Assessment Methods: A Critical Review. Remote Sens. 2020, 12, 3522. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Hunter, G. A simple positional accuracy measure for linear features. Int. J. Geogr. Inf. Sci. 1997, 11, 206–299. [Google Scholar] [CrossRef]
- Tveite, H. An accuracy assessment method for geographical line data sets based on buffering. Int. J. Geogr. Inf. Sci. 1999, 13, 27–47. [Google Scholar] [CrossRef]
- Mozas-Calvache, A.T.; Ariza-López, F.J. New method for positional quality control in cartography based on lines. A comparative study of methodologies. Int. J. Geogr. Inf. Sci. 2011, 25, 1681–1695. [Google Scholar] [CrossRef]
- Ariza-López, F.J.; Mozas-Calvache, A.T. Comparison of four line-based positional assessment methods by means of synthetic data. Geoinformatica 2012, 16, 221–243. [Google Scholar] [CrossRef]
- Heo, J.; Jeong, S.; Han, S.; Kim, C.; Hong, S.; Sohn, H. Discrete displacement analysis for geographic linear features and the application to glacier termini. Int. J. Geogr. Inf. Sci. 2013, 27, 1631–1650. [Google Scholar] [CrossRef]
- Howard, V. Quantifying positional error induced by line simplification. Int. J. Geogr. Inf. Sci. 2000, 14, 113–130. [Google Scholar] [CrossRef]
- Ruiz-Lendínez, J.J.; Ariza-López, F.J.; Ureña-Cámara, M.A. Automatic positional accuracy assessment of geospatial databases using line-based methods. Surv. Rev. 2013, 45, 332–342. [Google Scholar] [CrossRef]
- Wernette, P.; Shortridge, A.; Lusch, D.P.; Arbogast, A.F. Accounting for positional uncertainty in historical shoreline change analysis without ground reference information. Int. J. Remote Sens. 2017, 38, 3906–3922. [Google Scholar] [CrossRef]
- Wu, H.; Lin, A.; Clarke, K.C.; Cardenas-Tristan, A.; Tu, Z. A comprehensive quality assessment framework for linear features from Volunteered Geographic Information. Int. J. Geogr. Inf. Sci. 2020, 0, 1–22. [Google Scholar] [CrossRef]
- Kyriakidis, P.C.; Goodchild, M.F. On the prediction error variance of three common spatial interpolation schemes. Int. J. Geogr. Inf. Sci. 2006, 20, 823–855. [Google Scholar] [CrossRef]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ariza-López, F.J.; Reinoso-Gordo, J.F. Comparison of Gridded DEMs by Buffering. Remote Sens. 2021, 13, 3002. https://doi.org/10.3390/rs13153002
Ariza-López FJ, Reinoso-Gordo JF. Comparison of Gridded DEMs by Buffering. Remote Sensing. 2021; 13(15):3002. https://doi.org/10.3390/rs13153002
Chicago/Turabian StyleAriza-López, Francisco Javier, and Juan Francisco Reinoso-Gordo. 2021. "Comparison of Gridded DEMs by Buffering" Remote Sensing 13, no. 15: 3002. https://doi.org/10.3390/rs13153002
APA StyleAriza-López, F. J., & Reinoso-Gordo, J. F. (2021). Comparison of Gridded DEMs by Buffering. Remote Sensing, 13(15), 3002. https://doi.org/10.3390/rs13153002