
Collision Avoidance on Unmanned Aerial Vehicles Using Neural Network Pipelines and Flow Clustering Techniques





Abstract
:1. Introduction
- the development of an efficient and simple but robust software architecture for reacting and avoiding collisions with static or dynamic obstacles that are not known beforehand;
- proposal of a dataset of different individuals throwing balls at a UAV;
- and collision Avoidance Algorithm that uses an NNP for predicting collisions, and an Object Trajectory Estimation (OTE) algorithm using Optical Flow.
2. Materials and Methods
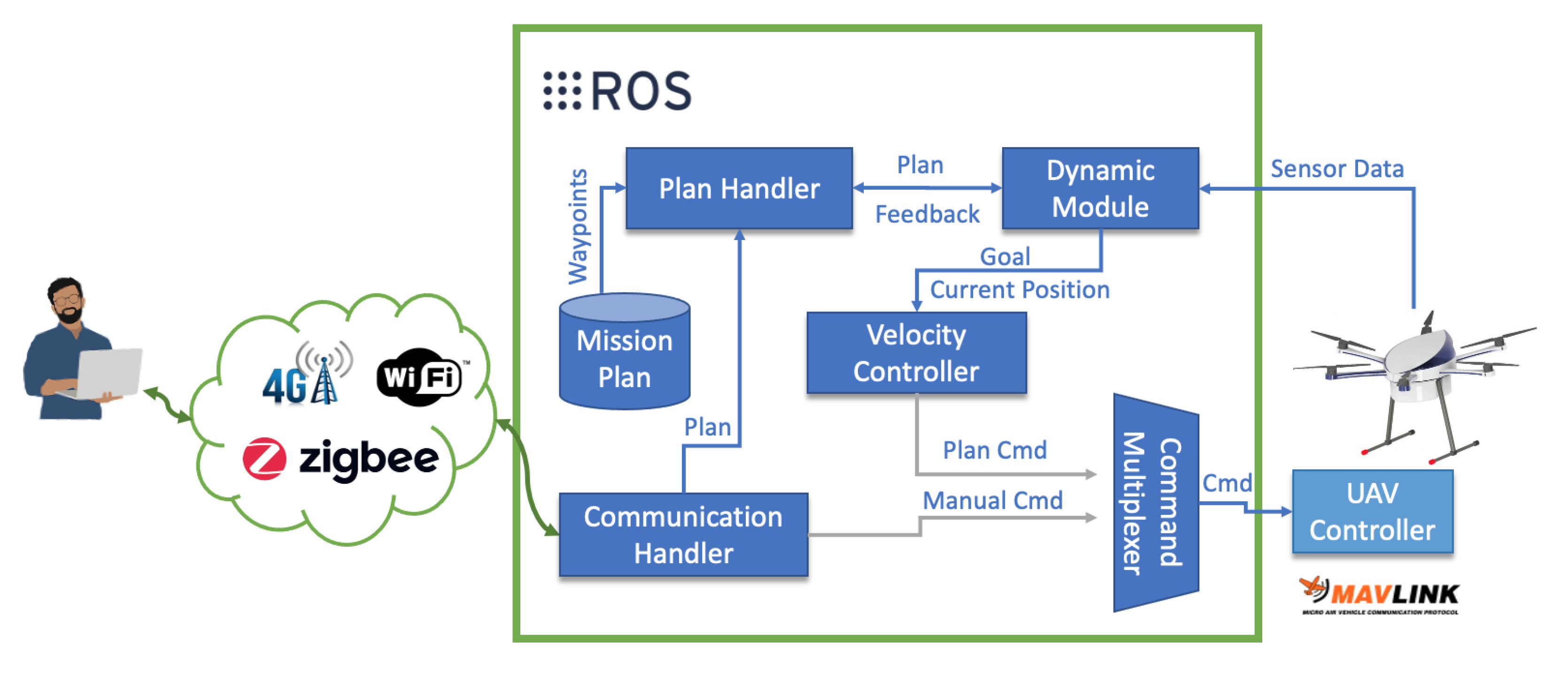
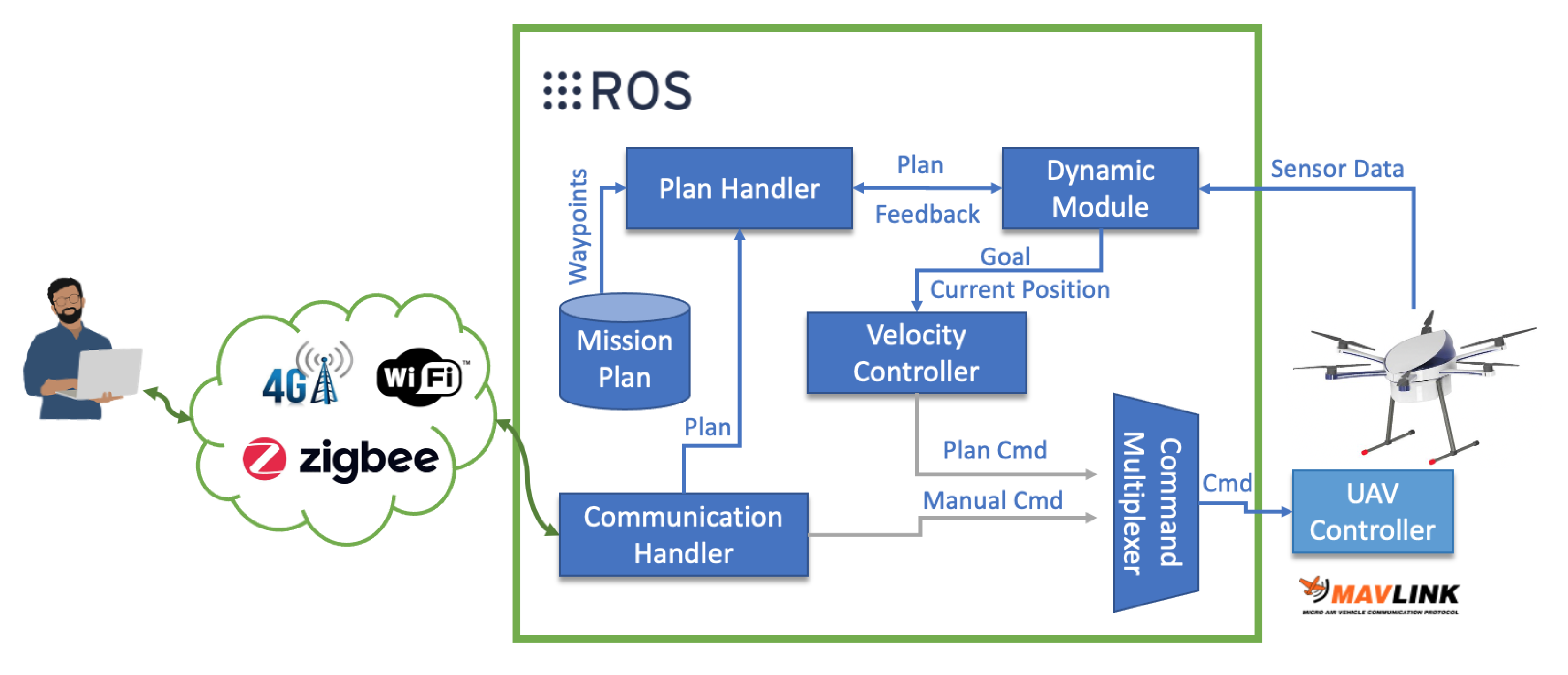
2.1. Collision Avoidance Framework for Autonomous Uavs
- Communication Handler: The Communication Handler block is responsible for maintaining interoperability between the user and the UAV. It is also responsible for triggering the pre-saved UAV mission through an activation topic.
- Plan Handler: This block is responsible for sending each waypoint of the complete mission to the Positioning Module block through a custom service in order to increase the security of communication and the entire system pipeline [35]. In this custom service, the Positioning block asks the Plan Handler block for the next point of the mission to be reached. In turn, the Plan Handler block returns the next point, where they contain the local coordinates of the intended destination.
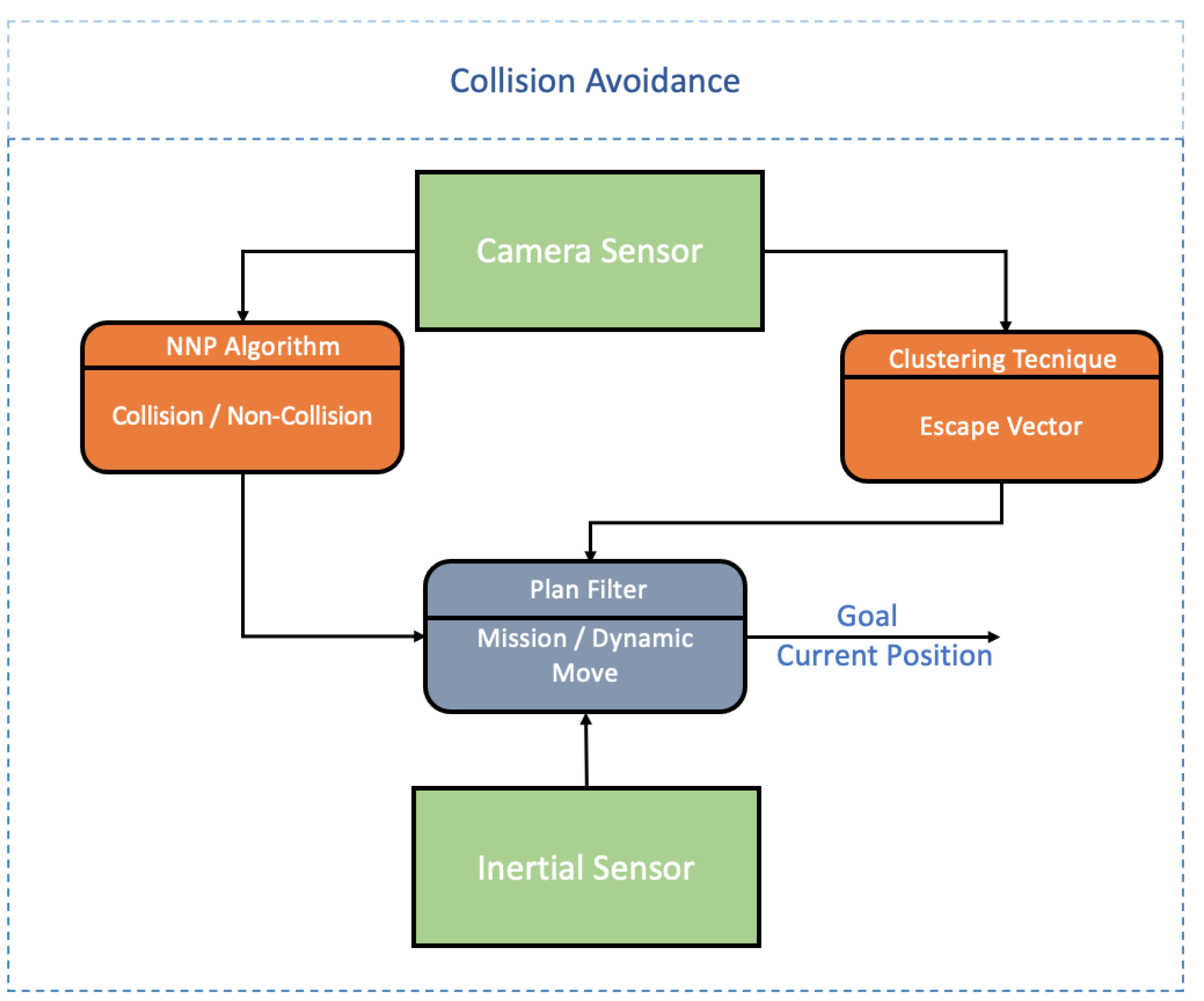
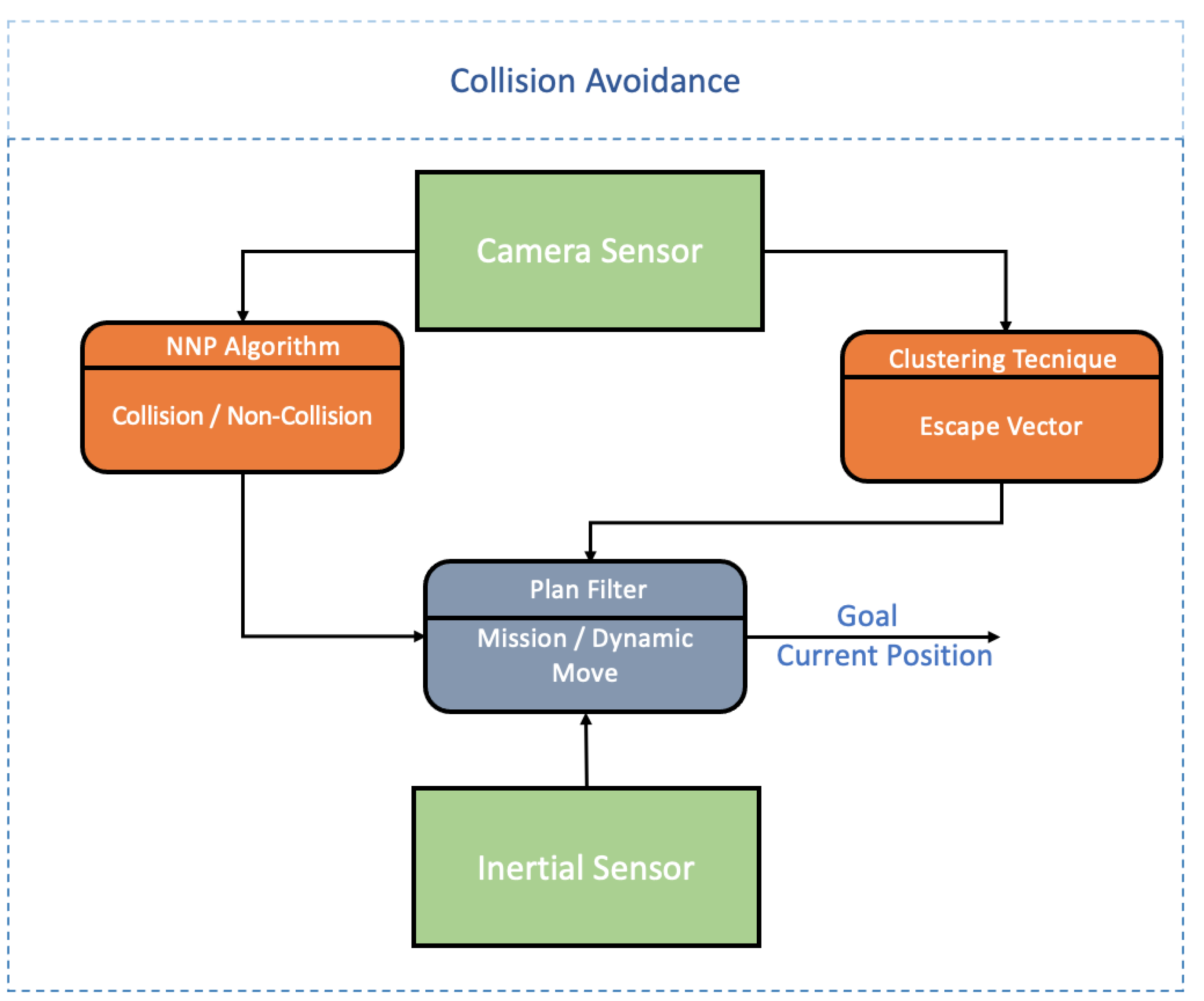
- Dynamic Module: This module computes possible dynamic object collisions. Through the camera, the inertial sensors, and the algorithm proposed in Section 2.2, it is possible to detect and avoid dynamic objects. Figure 2 presents the connections required for this module works.It is possible to observe in Figure 2 that there are 2 distinct processes: NNP for the static and dynamic obstacles prediction and detection; Clustering technique for grouping different objects in the same image and its, respectively, 2D movement direction to know the UAV escape trajectory.Through the inertial sensor, it is possible to know the UAV position and how to avoid when the obstacle avoidance algorithm is activated. In case the algorithm is not activated, the pre-defined mission by the user is carried out, through the Plan Handler module. The UAV position and the desired destination are then sent to the Velocity Controller block that navigates the UAV to the desired destination.
- Velocity Controller: The Velocity Controller block calculates the velocity required to reach the desired destination (with the mavros package [36]) using the inputs from the Positioning Module block and the Dynamic Module. This controller extends a proportional–integral–derivative (PID) controllers, where the variables change depending on the type of UAV, and the UAV’s velocity calculation on the three axes were based on Reference [37], where:andwhere represents the error position, the goal position, the current position at time instant t, and is the distance error position .With Equations (1) and (2), it is possible to normalize the error, as shown in Equation (3).where is the error normalized.If the distance is lower than a certain threshold, (in this work, the threshold value value is set to m), Equation (4) is activated.where is the velocity vector, and is the Smooth Factor (the was set to 2 [37]).If the distance is higher than 4 m (threshold), Equation (5) is then used.In Equation (5), is the Param Max Velocity and is equal to 2.In this way, it is allowed to dynamically vary the UAV speed depending on the UAV distance in relation to the desired destination without any sudden changes regarding the UAV’s acceleration;
- Command Multiplexer: The Command Multiplexer (CM) block subscribes to a list of topics, which are publishing commands and multiplexes them according to a priority criteria. The input with the highest priority controls the UAV by mavros package [36] with the mavlink protocol [38], becoming the active controller.
2.2. The Proposed Collision Avoidance Algorithm
| Algorithm 1: Proposed Algorithm for collision avoidance with moving objects. |
| # message publisher |
| reactiveCmdPub = ros.Publisher () |
| # last known escape vector |
| escapeVector = {x: 0.0 , y: 0.0 , z: 0.0} |
| # OAF algorithm will constantly update the escapeVector var |
| opticalFlowThread = threading.Thread (target = OAF) |
| # Callback for Hybrid Collision Avoidance function |
| # it should be called whenever a new frame is obtained |
| def hca(videoFrame): |
| # Use the DCA algorithm to detect collisions |
| if(dcaProcessFrame (videoFrame)): |
| reactiveCmdPub.pub (escapeVector) |
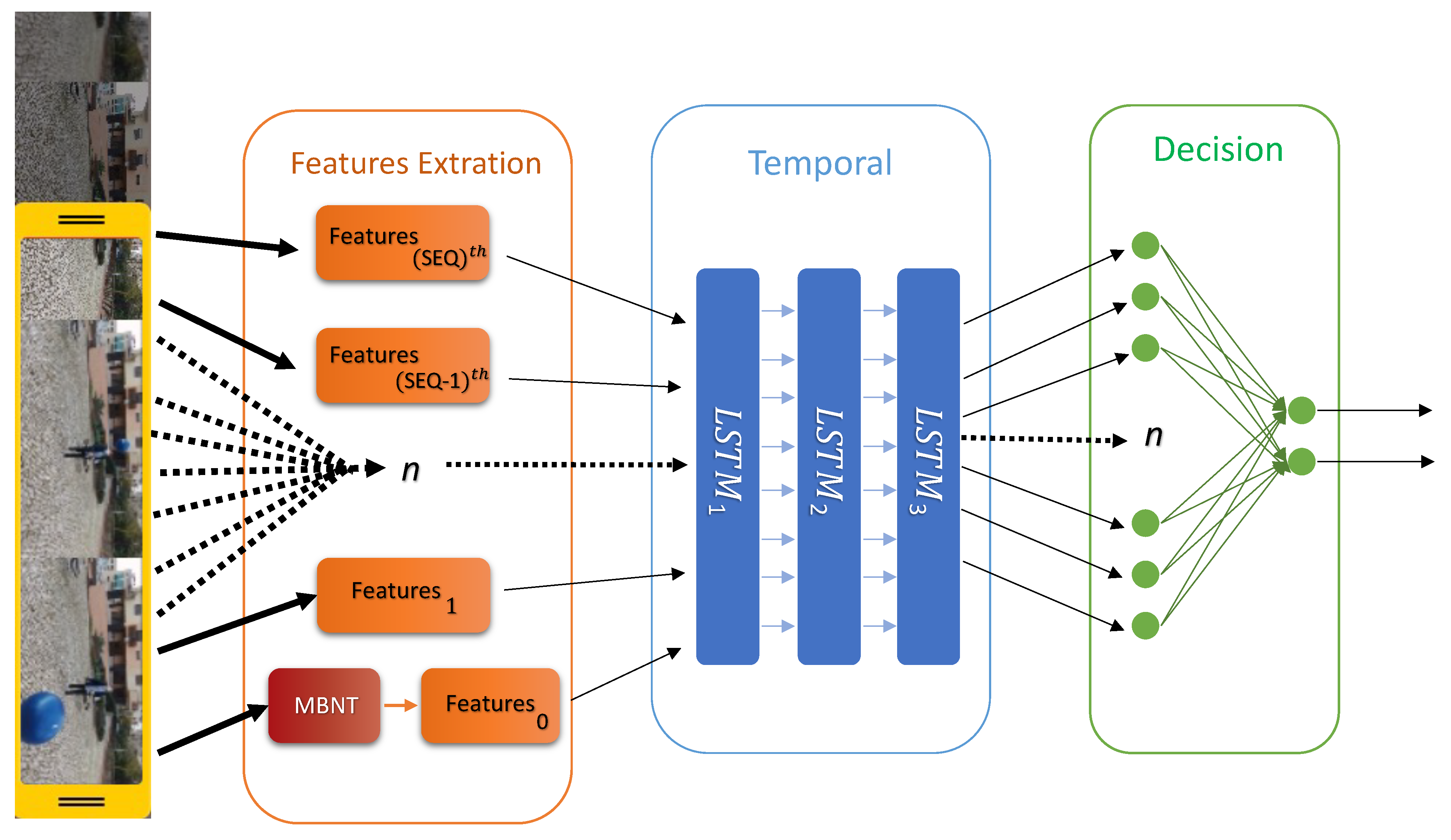
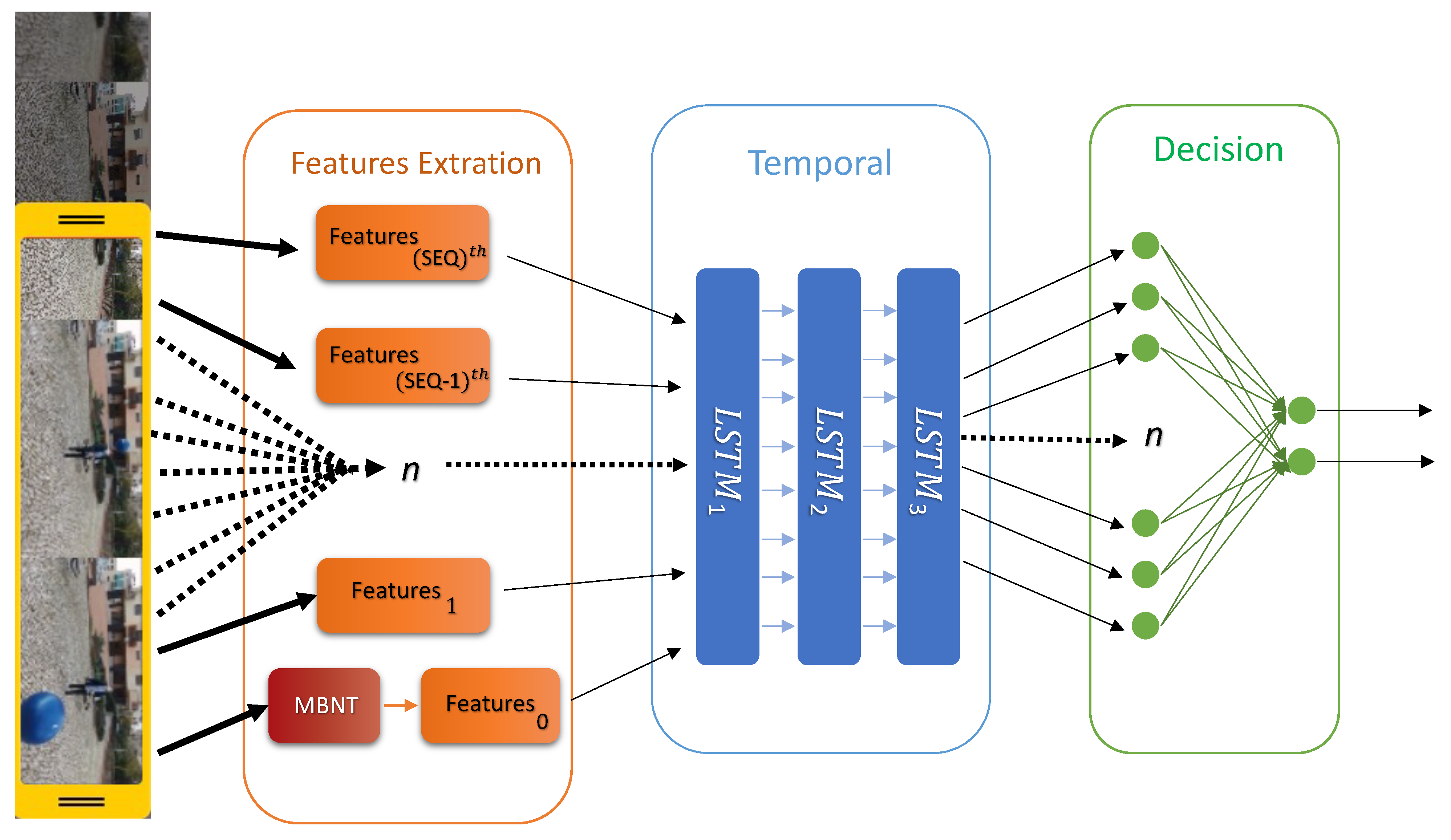
2.2.1. Neural Network Pipeline
Feature Extraction
Temporal Correlation and Decision
| Algorithm 2: Neural Network Pipeline—processing the latest video frame. |
| SEQ_LEN = 25 |
| features_queue = deque (maxlen=SEQ_LEN) # Double-ended queue |
| def dcaProcessFrame(videoFrame): |
| # Resize image to cnn input size |
| img = video_frame.resize (224,224,3) |
| # ML libs predict functions outputs arrays |
| cnn_pred = cnn_model.predict(img) [0] |
| # Shift add the image features to the features queue |
| features_queue.append cnn_pred) |
| # Check if enough images have been seen |
| if(len(features_queue) >= SEQ_LEN): |
| rnn_pred = rnn_model.predict(features_queue)[0] |
| return decision_model.predict(rnn_pred)[0] # return result |
| else: |
| return 0 # return no collision |
2.2.2. Object Trajectory Estimation
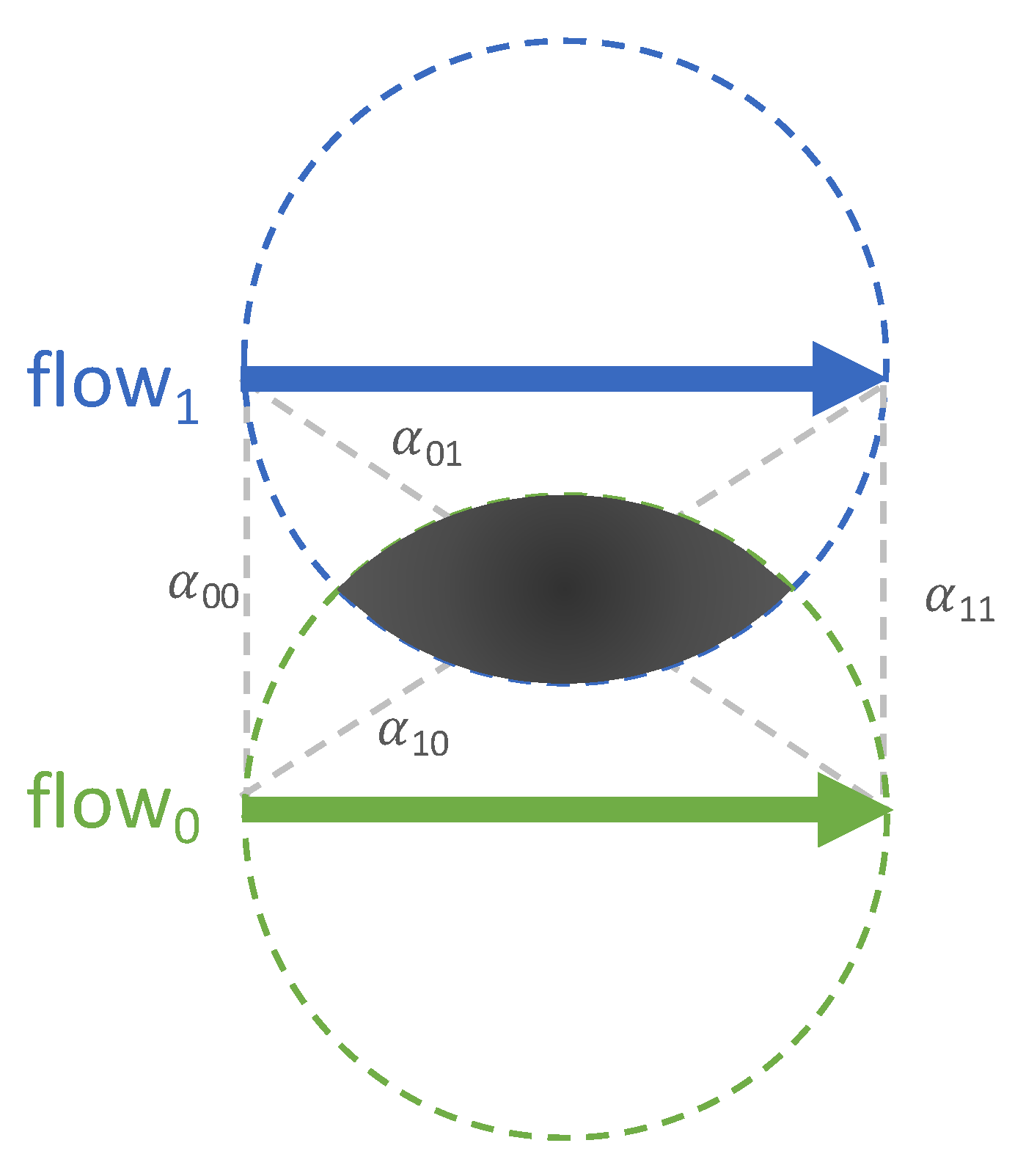
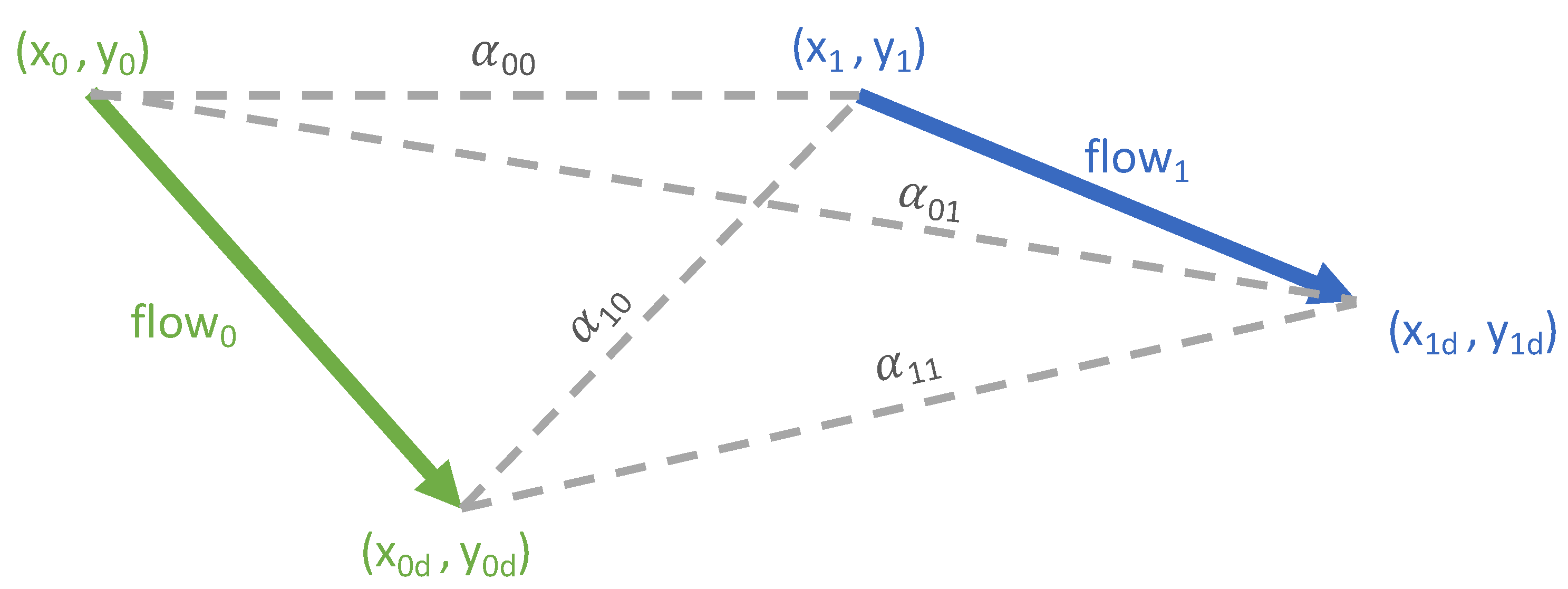
Flow Vectors
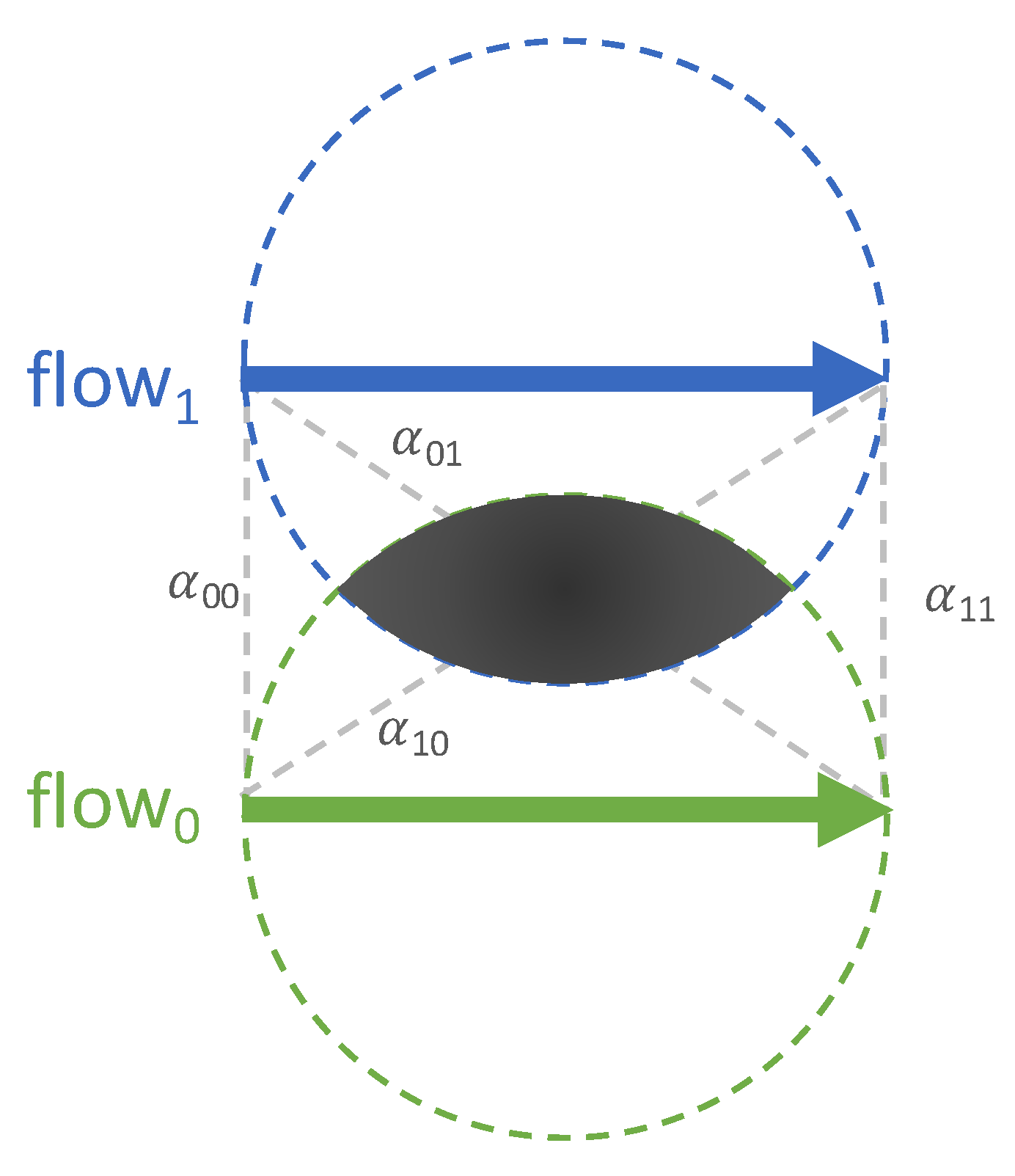
Flow Distances and Dimension Reduction
- Euclidian: ;
- Manhattan: ; and
- Mahanalobis: , where is the covariance matrix between the components of the feature vectors.
- Isomap [47] is a low-dimensional embedding approach that is commonly used to compute a quasi-isometric, low-dimensional embedding of a series of high-dimensional data points. Centered on a rough approximation of each data point’s neighbors on the manifold, the algorithm provides a straightforward procedure for estimating the intrinsic geometry of a data manifold. Isomap is highly efficient and can be applied to a wide variety of data sources and dimensionalities.
- Multidimensional Scaling (MDS) [48,49,50] is a technique for displaying the degree of resemblance between particular cases in a dataset. MDS is a method for converting the information about the pairwise ’distances’ among a collection of vectors into a structure of points mapped into an abstract Cartesian space.
- T-distributed Stochastic Neighbor Embedding (t-SNE) [51,52] is a mathematical method for visualizing high-dimensional data by assigning a position to each datapoint on a two or three-dimensional map. Its foundation is Stochastic Neighbor Embedding. It is a nonlinear dimensionality reduction technique that is well-suited for embedding high-dimensional data for visualization in a two- or three-dimensional low-dimensional space. It models each high-dimensional object by a two- or three-dimensional point in such a way that identical objects are modeled by neighboring points and dissimilar objects are modeled by distant points with a high probability.
Flow Clustering
- Kmeans [53] is a vector quantization clustering technique that attempts to divide n observations into c clusters, with each observation belonging to the cluster with the closest mean (cluster centers or cluster centroid), which serves as the cluster’s prototype. As a consequence, the data space is partitioned into Voronoi cells [54].
- Agglomerative Ward (AW) [55] is a Agglomerative Clustering technique that recursively merges the pair of clusters that minimally increase the wards distance criterion. Ward suggested a general agglomerative hierarchical clustering procedure in which the optimal value of an objective function is used to pick the pair of clusters to merge at each node.
- Agglomerative Average (AA) [56] is a clustering technique that recursively merges pairs of clusters, ordered by by the minimum average distance criterion, which is the average of the distances between each observation.
| Algorithm 3: Optical Flow Clustering algorithm. |
| # threshold to filter the flows |
| flowThreshold = 1 |
| # N value for normalize the flows with image width and image height |
| N = math.sqrt(pow(w,2) + pow(h,2)) |
| # threshold to filter the alpha distances |
| distanceThreshold = 15 |
| # Callback for Hybrid Collision Avoidance function |
| # it should be called whenever a new frame is obtained |
| def OAF(frame1,frame2): |
| # obtain the optical flow from the 2 frames |
| flows = cv2.cuda_OpticalFlow.calc(frame1,frame2) |
| # filter meaningful flows |
| flows = filterFlows(flows,flowThreshold) |
| aggregating = True # control variable |
| regions = [] # object regions |
| while aggregating: # stop when there is no flows to merge |
| aggregating = False |
| for i in len(flows)-1: |
| for j in len(flows)-1: |
| if (i != j): # do not compare with self |
| # calculate the flows |
| alphas = calculateAlphas (flows[i],flows[j]) |
| # radius and centers |
| rac = calculateRaC (flows[i],flows[j]) |
| if (validAggregate(alphas,rac,distanceThreshold)): |
| # force a full scan |
| aggregating = True |
| # merge flows into flow [j] |
| mergeFlows (flows[j],flows[i]) |
| if flows[j] not in regions: |
| # new region found - append it |
| regions.append (flows[j]) |
| del flows[i] # remove the merged flow |
| break # go back to the first for cycle |
3. Results
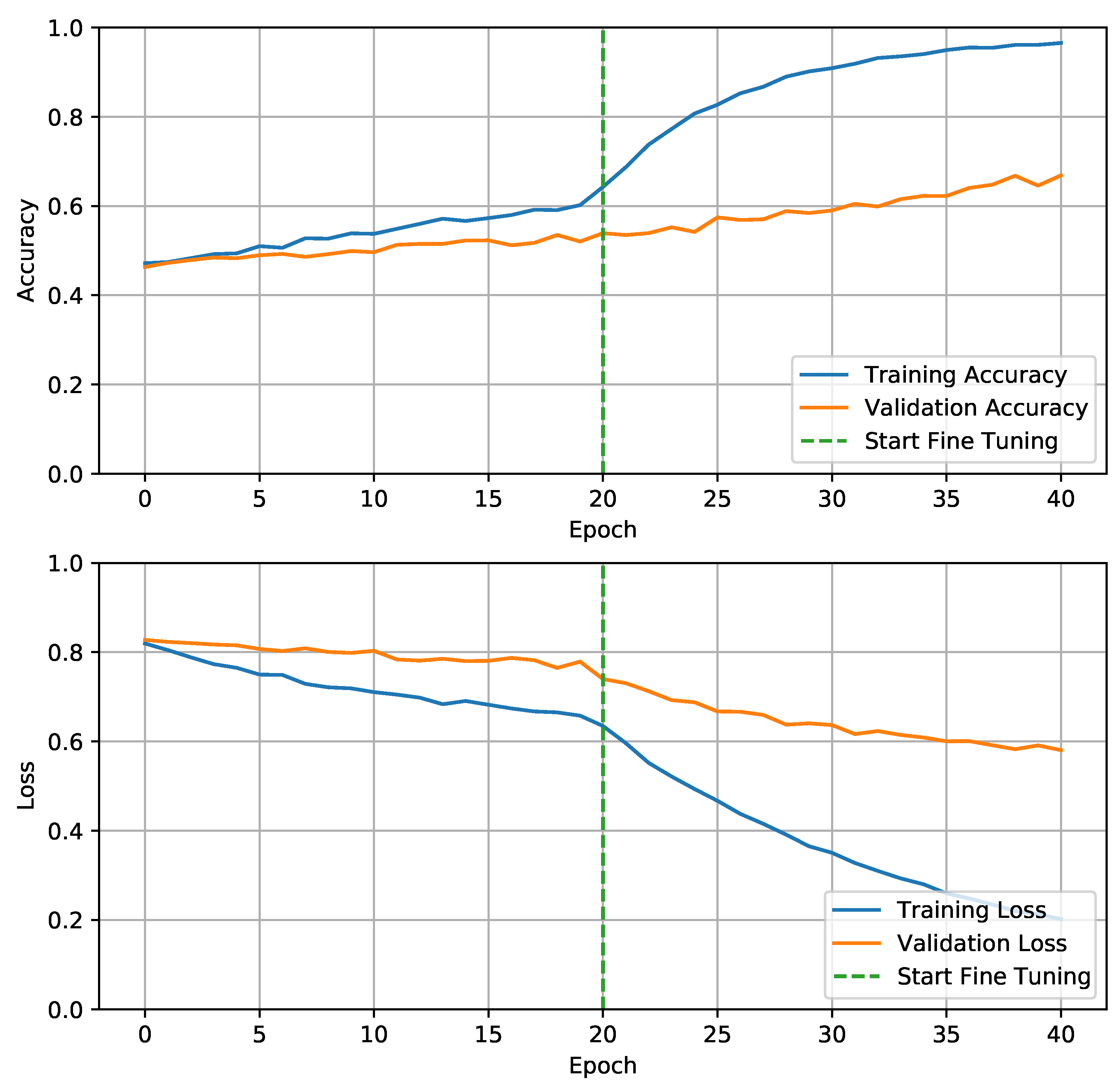
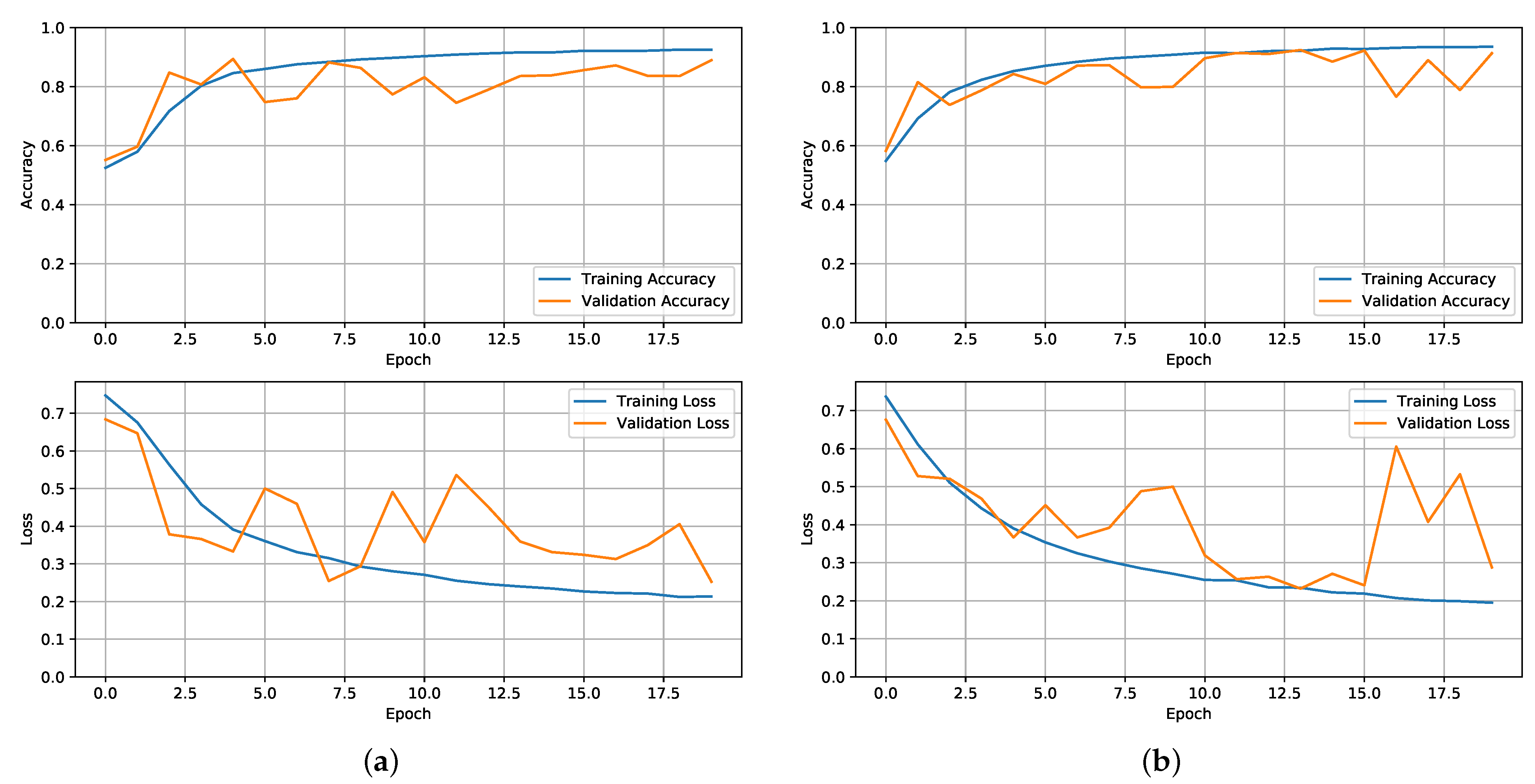
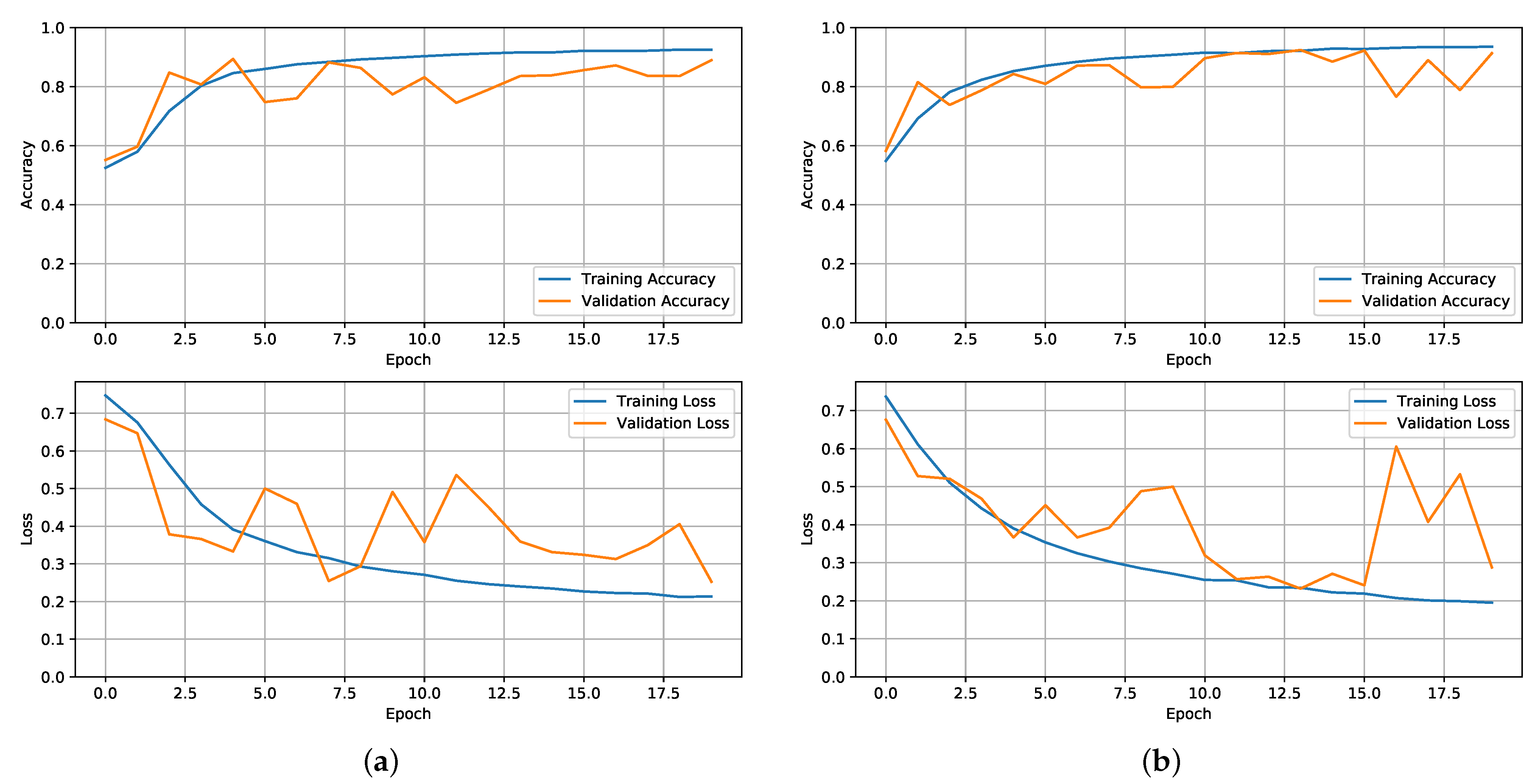
3.1. NNP Training and Results
- The input data must be a SEQ-length sequence. In this article, a value of 25 was used, but any value between 20 and 50 produced comparable results.
- The sequences produced must only contain frames from a single video. Working with video data on GPUs is not an easy process, and creating video sequences adds another layer of complexity. The model perceives the dataset as a continuous stream of data, and this constraint must be applied to prevent the model from learning jumps between videos (false knowledge).
- The goal for the whole series is the last frame target label.
3.2. Real Environment
4. Discussion
5. Conclusions and Future Work
- NNP improvement to estimate an escape vector, as postulated in the ColANet dataset;
- Optical Flow with depth estimation (using an depth camera), allowing the estimation of the distance to the object, therefore adjusting the escape speed, and facilitating the selection of the nearest object.
- CUDA implementation of the OFC algorithm to speed up computation time.
- Live tests on HEIFU hexacopters with the algorithms taking advantage of the on board GPU.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Patias, P. Introduction to Unmanned Aircraft Systems. Photogramm. Eng. Remote Sens. 2016. [Google Scholar] [CrossRef]
- Alvarez-Vanhard, E.; Houet, T.; Mony, C.; Lecoq, L.; Corpetti, T. Can UAVs fill the gap between in situ surveys and satellites for habitat mapping? Remote Sens. Environ. 2020. [Google Scholar] [CrossRef]
- Navarro, A.; Young, M.; Allan, B.; Carnell, P.; Macreadie, P.; Ierodiaconou, D. The application of Unmanned Aerial Vehicles (UAVs) to estimate above-ground biomass of mangrove ecosystems. Remote Sens. Environ. 2020. [Google Scholar] [CrossRef]
- Rödel, C.; Stadler, S.; Meschtscherjakov, A.; Tscheligi, M. Towards autonomous cars: The effect of autonomy levels on Acceptance and User Experience. In Proceedings of the AutomotiveUI 2014—6th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Seattle, WA, USA, 17–19 September 2014. [Google Scholar] [CrossRef]
- Yasin, J.N.; Mohamed, S.A.S.; Haghbayan, M.H.; Heikkonen, J.; Tenhunen, H.; Plosila, J. Unmanned Aerial Vehicles (UAVs): Collision Avoidance Systems and Approaches. IEEE Access 2020, 8, 105139–105155. [Google Scholar] [CrossRef]
- Caron, C. After Drone Hits Plane in Canada, New Fears About Air Safety. 2017. Available online: https://www.nytimes.com/2017/10/17/world/canada/canada-drone-plane.html (accessed on 19 May 2019).
- BBC. Drone’ Hits British Airways Plane Approaching Heathrow Airport. 2016. Available online: https://www.bbc.com/news/uk-36067591 (accessed on 19 May 2019).
- Canada, C. Drone that Struck Plane Near Quebec City Airport was Breaking the Rules. 2017. Available online: http://www.cbc.ca/news/canada/montreal/garneau-airport-drone-quebec-1.4355792 (accessed on 19 May 2019).
- BBC. Drone Collides with Commercial Aeroplane in Canada. 2017. Available online: https://www.bbc.com/news/technology-41635518 (accessed on 19 May 2019).
- Goglia, J. NTSB Finds Drone Pilot At Fault For Midair Collision with Army Helicopter. 2017. Available online: https://www.forbes.com/sites/johngoglia/2017/12/14/ntsb-finds-drone-pilot-at-fault-for-midair-collision-with-army-helicopter/ (accessed on 19 May 2019).
- Lin, C.E.; Shao, P.C. Failure analysis for an unmanned aerial vehicle using safe path planning. J. Aerosp. Inf. Syst. 2020. [Google Scholar] [CrossRef]
- Tellman, J.; News, T.V. First-Ever Recorded Drone-Hot Air Balloon Collision Prompts Safety Conversation. 2018. Available online: https://www.postregister.com/news/local/first-ever-recorded-drone-hot-air-balloon-collision-prompts-safety/article_7cc41c24-6025-5aa6-b6dd-6d1ea5e85961.html (accessed on 19 May 2019).
- Shakhatreh, H.; Sawalmeh, A.H.; Al-Fuqaha, A.; Dou, Z.; Almaita, E.; Khalil, I.; Othman, N.S.; Khreishah, A.; Guizani, M. Unmanned Aerial Vehicles (UAVs): A Survey on Civil Applications and Key Research Challenges. IEEE Access 2019. [Google Scholar] [CrossRef]
- Weibel, R.E.; Hansman, R.J. Safety Considerations for Operation of Unmanned Aerial Vehicles in the National Airspace System; MIT Libraries: Cambridge, MA, USA, 2005. [Google Scholar]
- Zhong, Y.; Hu, X.; Luo, C.; Wang, X.; Zhao, J.; Zhang, L. WHU-Hi: UAV-borne hyperspdectral with high spatial resolution (H2) benchmark datasets and classifier for precise crop identification based on deep convolutional neural network with CRF. Remote Sens. Environ. 2020. [Google Scholar] [CrossRef]
- Meinen, B.U.; Robinson, D.T. Mapping erosion and deposition in an agricultural landscape: Optimization of UAV image acquisition schemes for SfM-MVS. Remote Sens. Environ. 2020. [Google Scholar] [CrossRef]
- Bhardwaj, A.; Sam, L.; Akanksha; Martín-Torres, F.J.; Kumar, R. UAVs as remote sensing platform in glaciology: Present applications and future prospects. Remote Sens. Environ. 2016, 175, 196–204. [Google Scholar] [CrossRef]
- Yao, H.; Qin, R.; Chen, X. Unmanned Aerial Vehicle for Remote Sensing Applications—A Review. Remote Sens. 2019, 11, 1443. [Google Scholar] [CrossRef] [Green Version]
- Gerhards, M.; Schlerf, M.; Mallick, K.; Udelhoven, T. Challenges and Future Perspectives of Multi-/Hyperspectral Thermal Infrared Remote Sensing for Crop Water-Stress Detection: A Review. Remote Sens. 2019, 11, 1240. [Google Scholar] [CrossRef] [Green Version]
- Messina, G.; Modica, G. Applications of UAV thermal imagery in precision agriculture: State of the art and future research outlook. Remote Sens. 2020, 12, 1491. [Google Scholar] [CrossRef]
- Gaffey, C.; Bhardwaj, A. Applications of unmanned aerial vehicles in cryosphere: Latest advances and prospects. Remote Sens. 2020, 12, 948. [Google Scholar] [CrossRef] [Green Version]
- Pedro, D.; Matos-Carvalho, J.P.; Azevedo, F.; Sacoto-Martins, R.; Bernardo, L.; Campos, L.; Fonseca, J.M.; Mora, A. FFAU—Framework for Fully Autonomous UAVs. Remote Sens. 2020, 12, 3533. [Google Scholar] [CrossRef]
- Gallup, D.; Frahm, J.M.; Mordohai, P.; Pollefeys, M. Variable baseline/resolution stereo. In Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008. [Google Scholar] [CrossRef] [Green Version]
- Mueggler, E.; Forster, C.; Baumli, N.; Gallego, G.; Scaramuzza, D. Lifetime estimation of events from Dynamic Vision Sensors. In Proceedings of the IEEE International Conference on Robotics and Automation, Seattle, WA, USA, 26–30 May 2015. [Google Scholar] [CrossRef] [Green Version]
- Andrew, A.M. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar] [CrossRef]
- Marchidan, A.; Bakolas, E. Collision avoidance for an unmanned aerial vehicle in the presence of static and moving obstacles. J. Guid. Control. Dyn. 2020. [Google Scholar] [CrossRef]
- Fan, T.; Long, P.; Liu, W.; Pan, J. Distributed multi-robot collision avoidance via deep reinforcement learning for navigation in complex scenarios. Int. J. Robot. Res. 2020. [Google Scholar] [CrossRef]
- van Dam, G.J.; van Kampen, E. Obstacle avoidance for quadrotors using reinforcement learning and obstacle-airflow interactions. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020. [Google Scholar] [CrossRef]
- Sampedro, C.; Rodriguez-Ramos, A.; Gil, I.; Mejias, L.; Campoy, P. Image-Based Visual Servoing Controller for Multirotor Aerial Robots Using Deep Reinforcement Learning. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018. [Google Scholar] [CrossRef] [Green Version]
- Zhuge, C.; Cai, Y.; Tang, Z. A novel dynamic obstacle avoidance algorithm based on Collision time histogram. Chin. J. Electron. 2017. [Google Scholar] [CrossRef]
- Poiesi, F.; Cavallaro, A. Detection of fast incoming objects with a moving camera. In Proceedings of the British Machine Vision Conference, London, UK, 4–7 September 2017. [Google Scholar] [CrossRef] [Green Version]
- Falanga, D.; Kim, S.; Scaramuzza, D. How Fast Is Too Fast? The Role of Perception Latency in High-Speed Sense and Avoid. IEEE Robot. Autom. Lett. 2019. [Google Scholar] [CrossRef]
- Romero, A.M. ROS/Concepts. 2014. Available online: http://wiki.ros.org/ROS/Concepts (accessed on 20 May 2019).
- Kehoe, B.; Patil, S.; Abbeel, P.; Goldberg, K. A Survey of Research on Cloud Robotics and Automation. IEEE Trans. Autom. Sci. Eng. 2015, 12, 398–409. [Google Scholar] [CrossRef]
- Koubaa, A. Services. 2010. Available online: http://wiki.ros.org/Services (accessed on 20 May 2019).
- Vooon. Mavros. 2018. Available online: http://wiki.ros.org/mavros (accessed on 20 May 2019).
- Falanga, D.; Kleber, K.; Scaramuzza, D. Dynamic obstacle avoidance for quadrotors with event cameras. Sci. Robot. 2020, 5. [Google Scholar] [CrossRef]
- Project, D. MAVLink Developer Guide. 2010. Available online: https://mavlink.io/en/ (accessed on 20 May 2019).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.0486. [Google Scholar]
- Boureau, Y.L.; Ponce, J.; Lecun, Y. A theoretical analysis of feature pooling in visual recognition. In Proceedings of the ICML 2010 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef] [Green Version]
- Schlögl, S.; Postulka, C.; Bernsteiner, R.; Ploder, C. Artificial intelligence tool penetration in business: Adoption, challenges and fears. In Proceedings of the Communications in Computer and Information Science, Vienna, Austria, 20–21 September 2019. [Google Scholar] [CrossRef]
- Zach, C.; Pock, T.; Bischof, H. A Duality Based Approach for Realtime TV-L1 Optical Flow. In Proceedings of the Pattern Recognition, 29th DAGM Symposium, Heidelberg, Germany, 12–14 September 2007. [Google Scholar]
- Tenenbaum, J.B.; De Silva, V.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000. [Google Scholar] [CrossRef]
- Kruskal, J.B. Nonmetric multidimensional scaling: A numerical method. Psychometrika 1964. [Google Scholar] [CrossRef]
- Kruskal, J.B. Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis. Psychometrika 1964. [Google Scholar] [CrossRef]
- O’Connell, A.A.; Borg, I.; Groenen, P. Modern Multidimensional Scaling: Theory and Applications. J. Am. Stat. Assoc. 1999. [Google Scholar] [CrossRef]
- Van Der Maaten, L.J.P.; Hinton, G.E. Visualizing high-dimensional data using t-sne. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- van der Maaten, L. Accelerating t-SNE using tree-based algorithms. J. Mach. Learn. Res. 2014, 15, 3221–3245. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 21 June–18 July 1965. [Google Scholar]
- Wu, L.; Garcia, M.A.; Puig, D.; Sole, A. Voronoi-based space partitioning for coordinated multi-robot exploration. J. Phys. Agents 2007. [Google Scholar] [CrossRef] [Green Version]
- Müllner, D. Modern hierarchical, agglomerative clustering algorithms. arXiv 2011, arXiv:1109.2378. [Google Scholar]
- Murtagh, F.; Legendre, P. Ward’s Hierarchical Agglomerative Clustering Method: Which Algorithms Implement Ward’s Criterion? J. Classif. 2014, 31, 274–295. [Google Scholar] [CrossRef] [Green Version]
- Pedro, D.; Mora, A.; Carvalho, J.; Azevedo, F.; Fonseca, J. ColANet: A UAV Collision Avoidance Dataset. Technol. Innov. Life Improv. 2020. [Google Scholar] [CrossRef]
- Shanmugamani, R. Deep Learning for Computer Vision: Expert Techniques to Train Advanced Neural Networks Using Tensorflow and Keras; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Metz, R. Daredevil Drones: Startup Skydio has Developed a More Sophisticated Autopilot for Drones. Beyond Obstacle Avoidance, It Lets an Aircraft Orient Itself and Navigate through Busy Areas; Farlex, Inc.: Huntingdon Valley, PA, USA, 2016. [Google Scholar]
- Pedro, D.; Lousa, P.; Ramos, A.; Matos-Carvalho, J.; Azevedo, F.; Campos, L. HEIFU—Hexa Exterior Intelligent Flying Unit. In Proceedings of the DECSoS Workshop at SFECOMP 2021. Unpublished work. 2016. [Google Scholar]
- Huang, H.; Dabiri, D.; Gharib, M. On errors of digital particle image velocimetry. Meas. Sci. Technol. 1997. [Google Scholar] [CrossRef] [Green Version]
- Kazemi, M.; Ghanbari, M.; Shirmohammadi, S. A review of temporal video error concealment techniques and their suitability for HEVC and VVC. Multimed. Tools Appl. 2021. [Google Scholar] [CrossRef]
- Wang, Y.; Lin, S. Error-resilient video coding using multiple description motion compensation. IEEE Trans. Circ. Syst. Video Technol. 2002. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | MNV2 | Fine-Tuned MNV2 | NNP w/ MNV2 | NNP w/ Fine-Tuned MNV2 |
|---|---|---|---|---|
| Training Accuracy | 64.6% | 97.4% | 92.6% | 93.4% |
| Validation Accuracy | 54.4% | 66.8% | 89.4% | 91.4% |
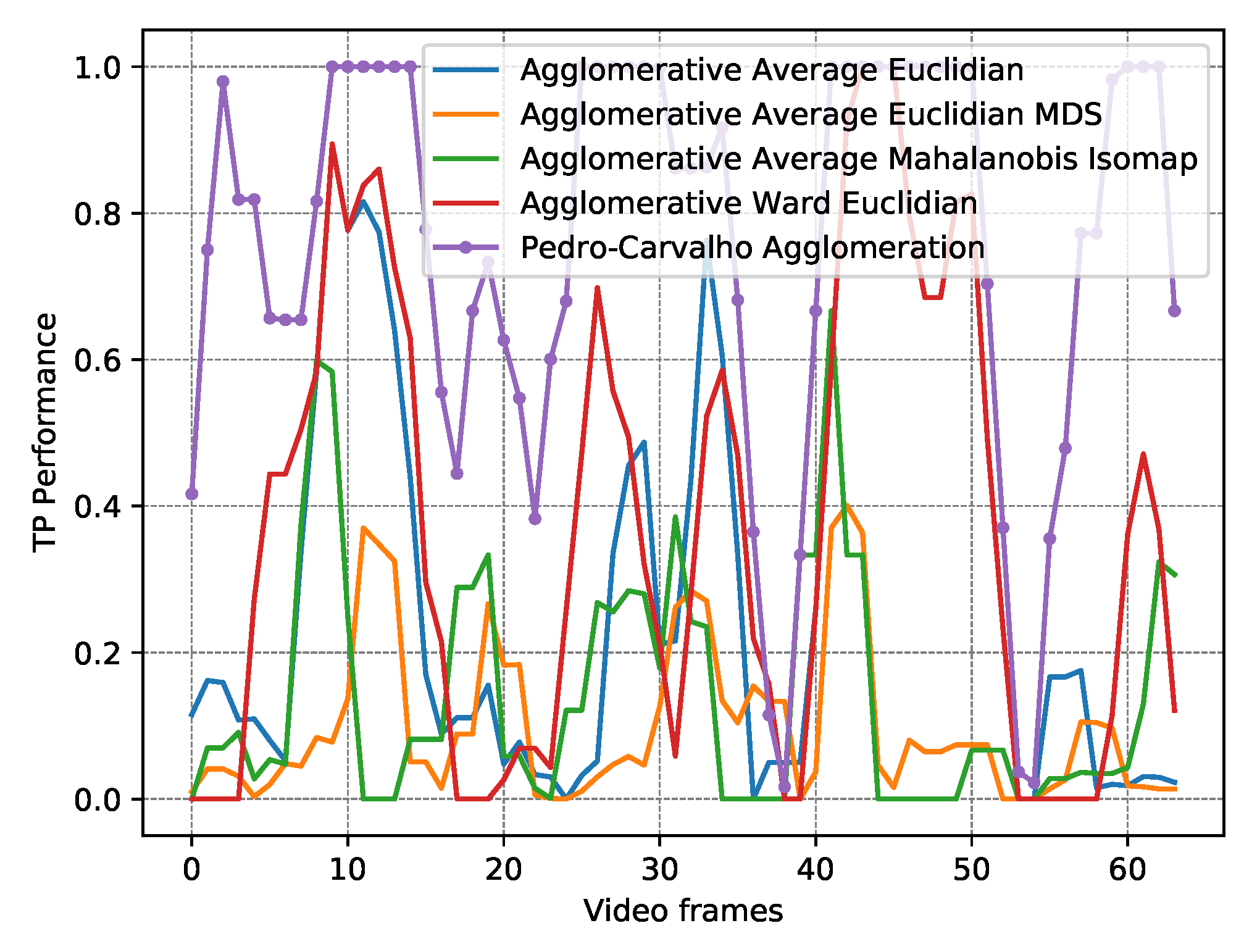
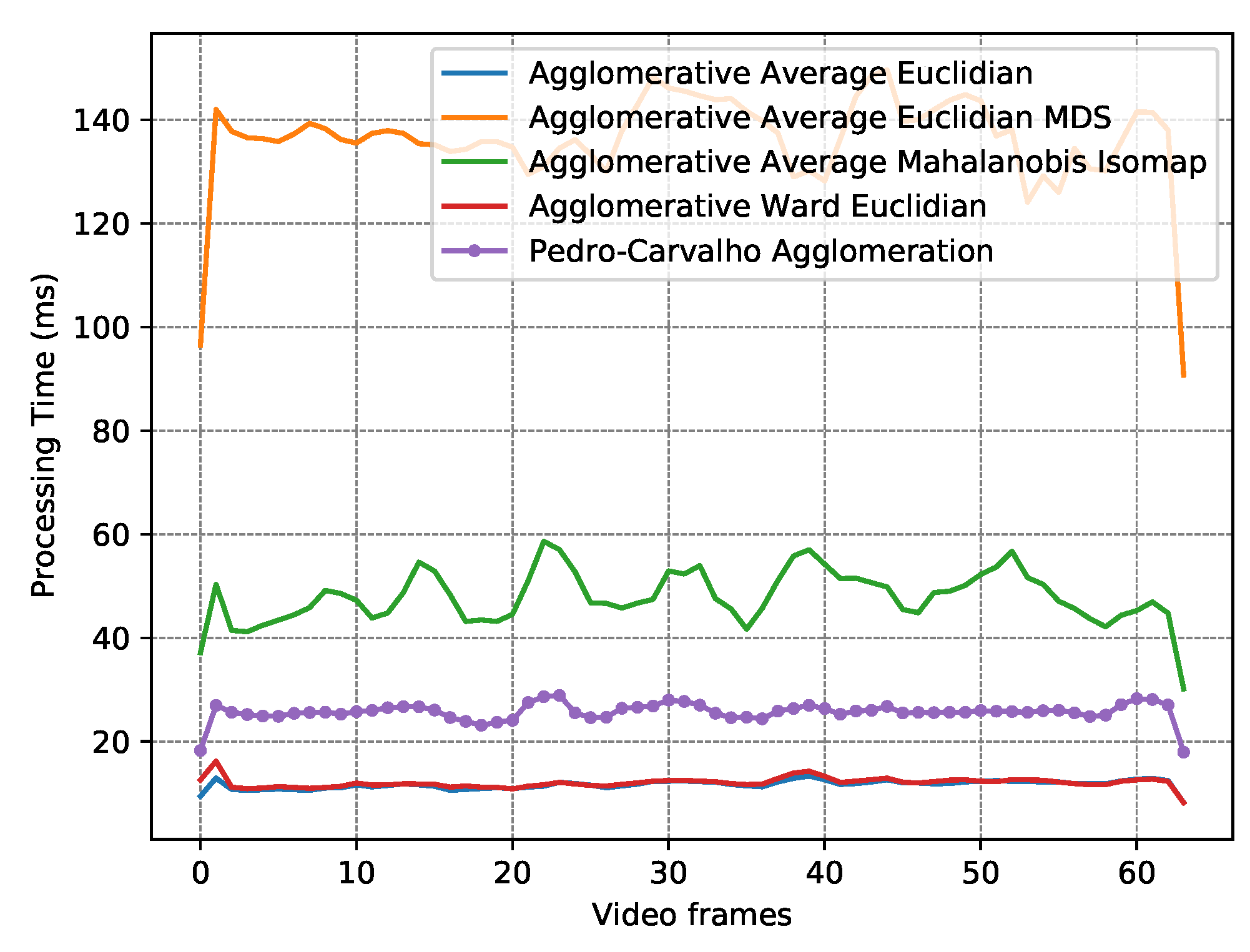
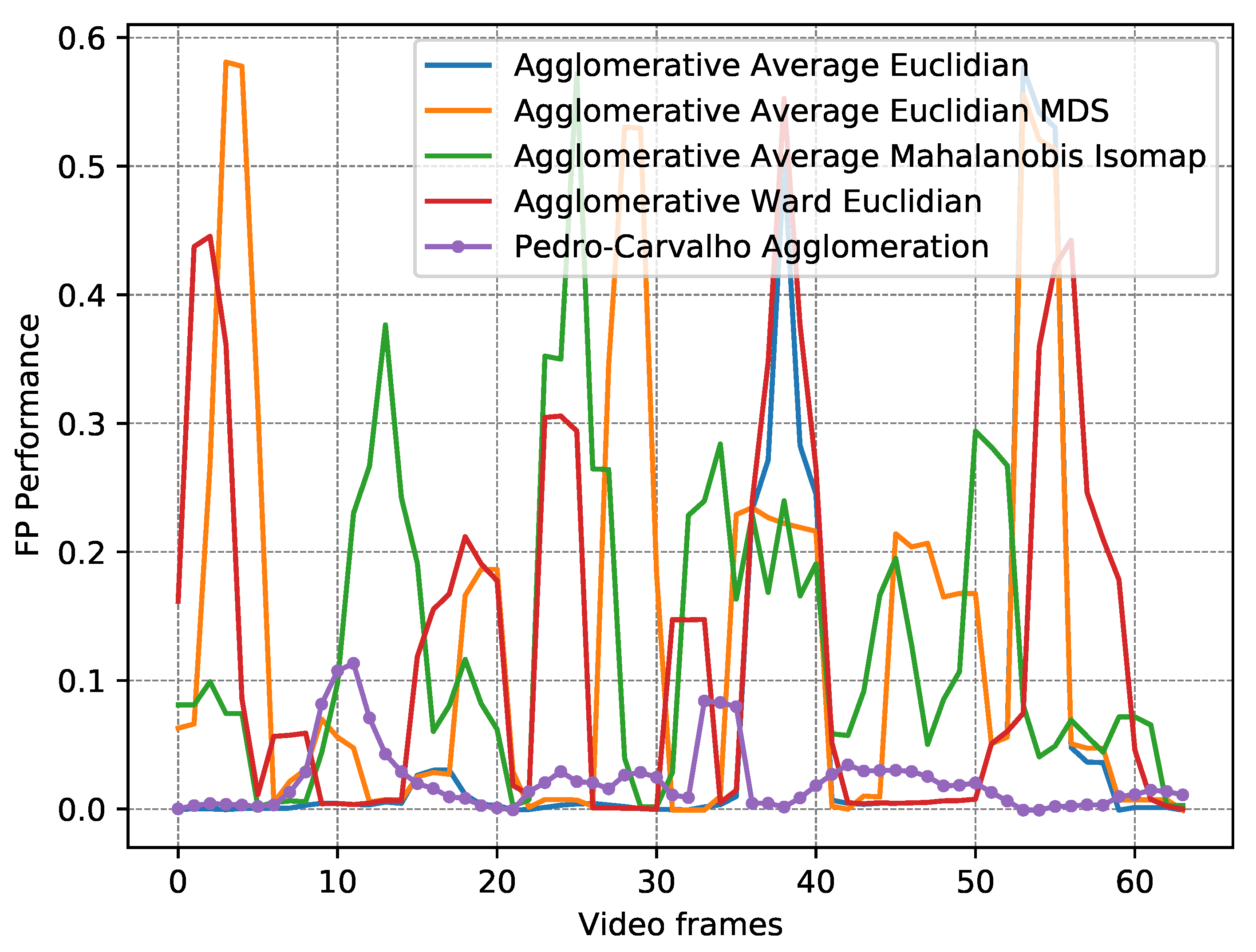
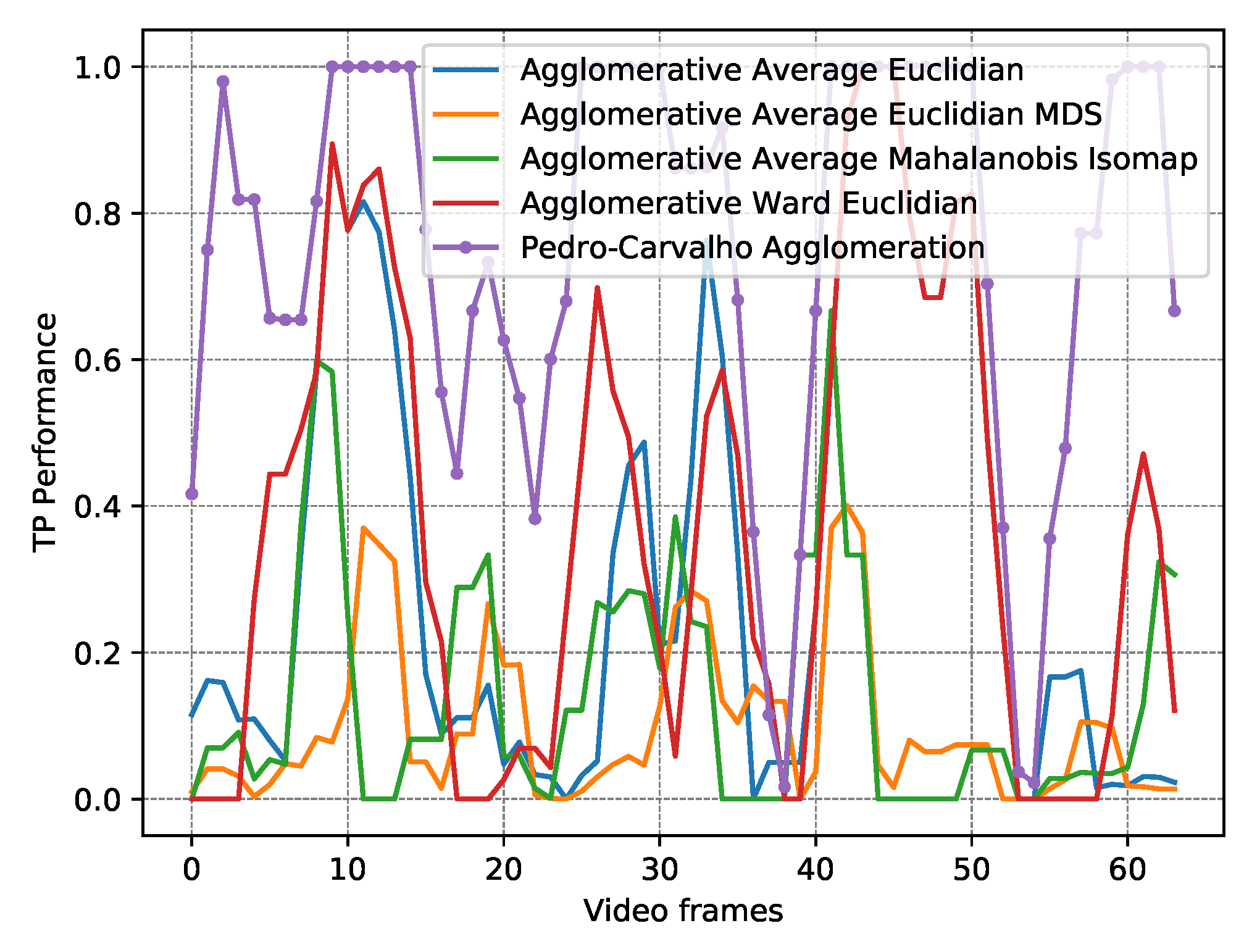
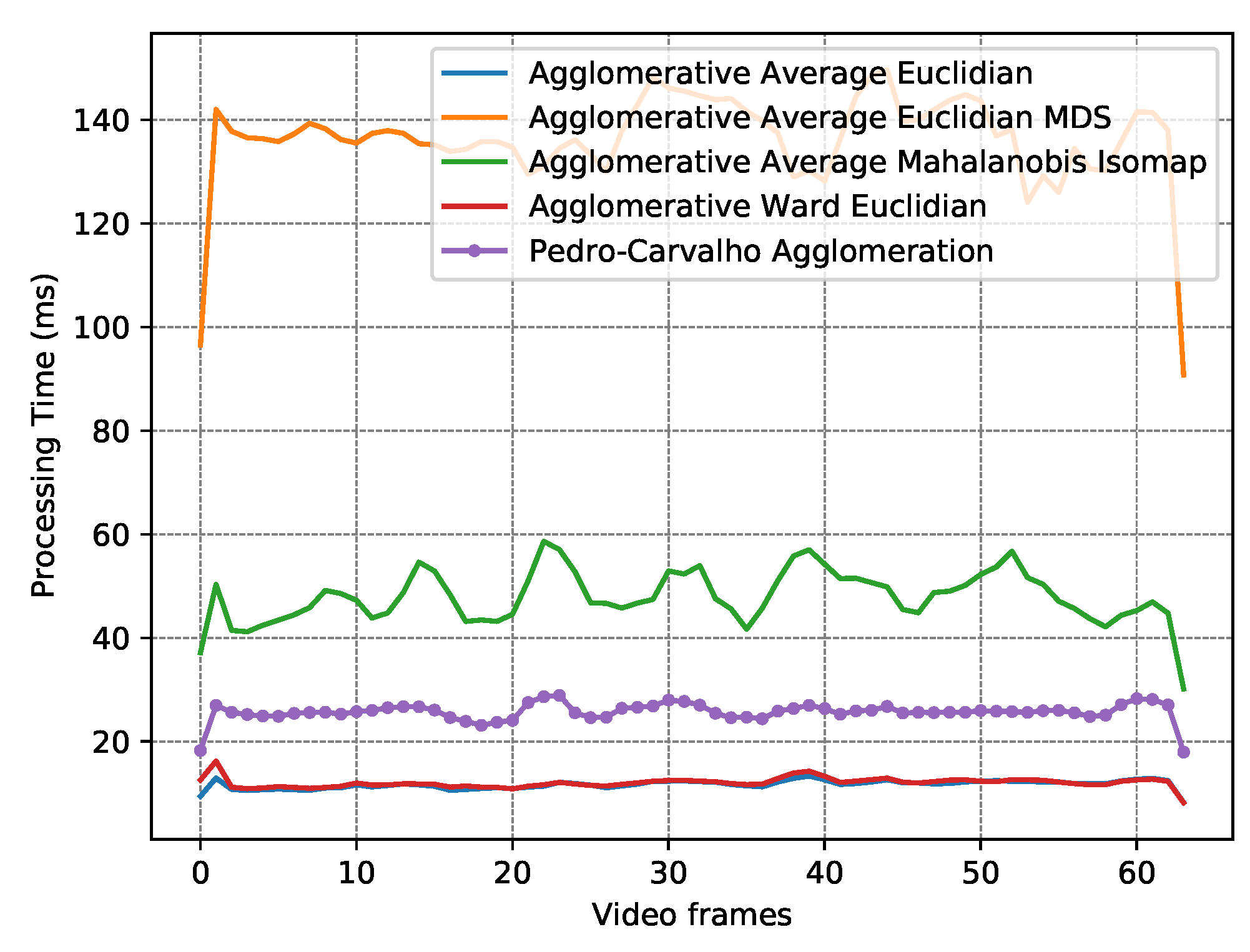
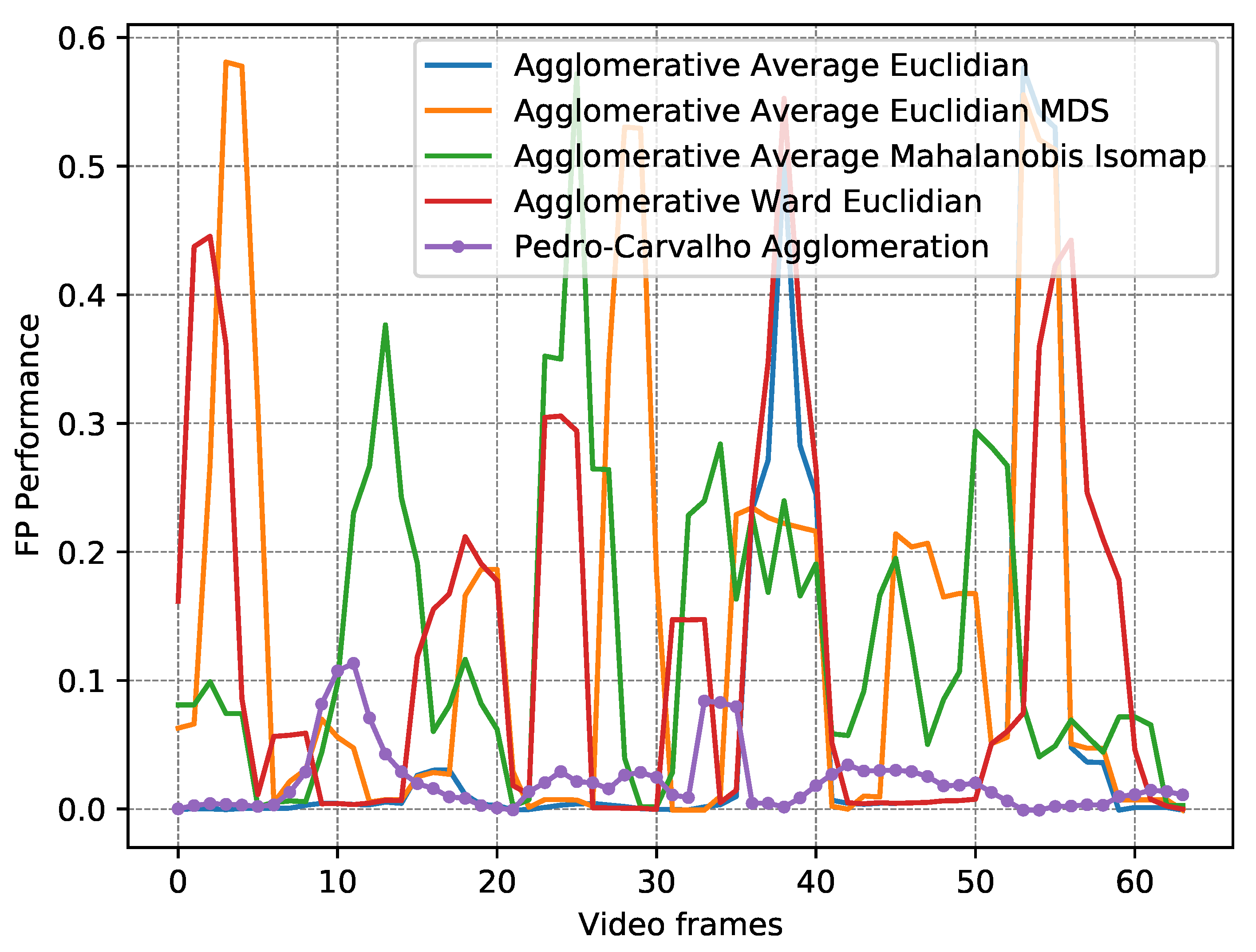
| Algorithm | Distance Metric | Dimension Reduction | Mean TP | Mean FP | RMSE | FP Perf. (Min / Mean / Max) | Mean Time (ms) |
|---|---|---|---|---|---|---|---|
| OFC Agg. | - - | - - | 0.76 | 3.40 | 0.50 | 0.00/0.02/0.06 | 25.99 |
| AA [56] | Euclidian | - - | 0.33 | 0.96 | 0.43 | 0.00/0.06/0.22 | 11.84 |
| AA [56] | Manhattan | - - | 0.33 | 0.96 | 0.43 | 0.00/0.06/0.22 | 8.69 |
| AA [56] | Mahalanobis | - - | 0.33 | 1.29 | 0.46 | 0.00/0.10/0.37 | 33.67 |
| AW [55] | Euclidian | - - | 0.37 | 1.82 | 0.47 | 0.00/0.13/0.27 | 12.23 |
| AW [55] | Manhattan | - - | 0.37 | 1.82 | 0.47 | 0.00/0.13/0.27 | 9.11 |
| AA [56] | Mahalanobis | Isomap [47] | 0.14 | 2.03 | 0.41 | 0.05/0.13/0.24 | 48.51 |
| AA [56] | Euclidian | MDS [48] | 0.10 | 1.43 | 0.37 | 0.02/0.14/0.28 | 137.63 |
| AA [56] | Manhattan | MDS [48] | 0.13 | 1.36 | 0.39 | 0.01/0.14/0.37 | 138.84 |
| Kmeans [53] | Manhattan | - - | 0.43 | 2.43 | 0.48 | 0.01/0.15/0.35 | 25.01 |
| AA [56] | Euclidian | Isomap [47] | 0.09 | 2.18 | 0.48 | 0.06/0.16/0.24 | 26.11 |
| AA [56] | Manhattan | Isomap [47] | 0.09 | 2.18 | 0.48 | 0.06/0.16/0.24 | 21.95 |
| Kmeans [53] | Euclidian | - - | 0.41 | 2.58 | 0.48 | 0.01/0.16/0.45 | 29.10 |
| AA [56] | Mahalanobis | MDS [48] | 0.13 | 1.81 | 0.39 | 0.02/0.17/0.48 | 159.93 |
| AW [55] | Mahalanobis | - - | 0.33 | 2.49 | 0.46 | 0.00/0.18/0.48 | 34.07 |
| Kmeans [53] | Mahalanobis | - - | 0.38 | 3.08 | 0.47 | 0.01/0.19/0.50 | 49.76 |
| Kmeans [53] | Mahalanobis | Isomap [47] | 0.18 | 4.67 | 0.44 | 0.07/0.23/0.41 | 64.07 |
| AW [55] | Mahalanobis | Isomap [47] | 0.18 | 3.91 | 0.46 | 0.07/0.24/0.40 | 48.91 |
| AA [56] | Mahalanobis | t-SNE [51] | 0.16 | 2.92 | 0.42 | 0.06/0.24/0.37 | 1057.79 |
| AW [55] | Mahalanobis | t-SNE [51] | 0.17 | 3.15 | 0.43 | 0.06/0.25/0.39 | 1058.15 |
| Kmeans [53] | Mahalanobis | t-SNE [51] | 0.19 | 3.51 | 0.43 | 0.06/0.26/0.36 | 1075.77 |
| AA [56] | Euclidian | t-SNE [51] | 0.13 | 2.97 | 0.45 | 0.12/0.29/0.43 | 1017.39 |
| AA [56] | Manhattan | t-SNE [51] | 0.13 | 2.97 | 0.45 | 0.12/0.29/0.43 | 1039.02 |
| Kmeans [53] | Euclidian | Isomap [47] | 0.10 | 4.37 | 0.49 | 0.07/0.29/0.44 | 41.11 |
| Kmeans [53] | Euclidian | t-SNE [51] | 0.13 | 3.43 | 0.45 | 0.10/0.30/0.47 | 1034.63 |
| Kmeans [53] | Manhattan | Isomap [47] | 0.08 | 4.70 | 0.47 | 0.07/0.31/0.49 | 36.56 |
| Kmeans [53] | Manhattan | t-SNE [51] | 0.13 | 3.43 | 0.46 | 0.10/0.31/0.47 | 1056.44 |
| AW [55] | Euclidian | t-SNE [51] | 0.11 | 3.31 | 0.47 | 0.09/0.32/0.50 | 1017.83 |
| AW [55] | Manhattan | t-SNE [51] | 0.11 | 3.31 | 0.47 | 0.09/0.32/0.50 | 1039.30 |
| AW [55] | Euclidian | Isomap [47] | 0.11 | 4.97 | 0.49 | 0.08/0.33/0.52 | 26.52 |
| AW [55] | Manhattan | Isomap [47] | 0.11 | 4.97 | 0.49 | 0.08/0.33/0.52 | 22.40 |
| AW [55] | Manhattan | MDS [48] | 0.06 | 4.15 | 0.44 | 0.20/0.42/0.63 | 139.31 |
| AW [55] | Euclidian | MDS [48] | 0.07 | 4.77 | 0.45 | 0.21/0.45/0.90 | 138.09 |
| AW [55] | Mahalanobis | MDS [48] | 0.08 | 4.92 | 0.50 | 0.17/0.52/0.99 | 160.31 |
| Kmeans [53] | Manhattan | MDS [48] | 0.03 | 6.08 | 0.42 | 0.36/0.54/0.78 | 158.46 |
| Kmeans [53] | Mahalanobis | MDS [48] | 0.04 | 5.84 | 0.44 | 0.24/0.54/0.82 | 179.07 |
| Kmeans [53] | Euclidian | MDS [48] | 0.03 | 6.33 | 0.42 | 0.30/0.58/1.00 | 158.76 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pedro, D.; Matos-Carvalho, J.P.; Fonseca, J.M.; Mora, A. Collision Avoidance on Unmanned Aerial Vehicles Using Neural Network Pipelines and Flow Clustering Techniques. Remote Sens. 2021, 13, 2643. https://doi.org/10.3390/rs13132643
Pedro D, Matos-Carvalho JP, Fonseca JM, Mora A. Collision Avoidance on Unmanned Aerial Vehicles Using Neural Network Pipelines and Flow Clustering Techniques. Remote Sensing. 2021; 13(13):2643. https://doi.org/10.3390/rs13132643
Chicago/Turabian StylePedro, Dário, João P. Matos-Carvalho, José M. Fonseca, and André Mora. 2021. "Collision Avoidance on Unmanned Aerial Vehicles Using Neural Network Pipelines and Flow Clustering Techniques" Remote Sensing 13, no. 13: 2643. https://doi.org/10.3390/rs13132643
APA StylePedro, D., Matos-Carvalho, J. P., Fonseca, J. M., & Mora, A. (2021). Collision Avoidance on Unmanned Aerial Vehicles Using Neural Network Pipelines and Flow Clustering Techniques. Remote Sensing, 13(13), 2643. https://doi.org/10.3390/rs13132643