
Domain-Adversarial Training of Self-Attention-Based Networks for Land Cover Classification Using Multi-Temporal Sentinel-2 Satellite Imagery





Abstract
:1. Introduction
2. Related Work
2.1. Land Cover and Crop Classification
2.2. Domain Adaptation
3. Study Area and Data
4. Methodology
4.1. Domain-Adversarial Neural Networks
4.2. Classification of Multi-Spectral Time Series Data with Self-Attention
4.3. DANN for Land Cover and Crop Classification
5. Experiments and Discussion
5.1. Experimental Settings
5.2. Maximum Mean Discrepancy
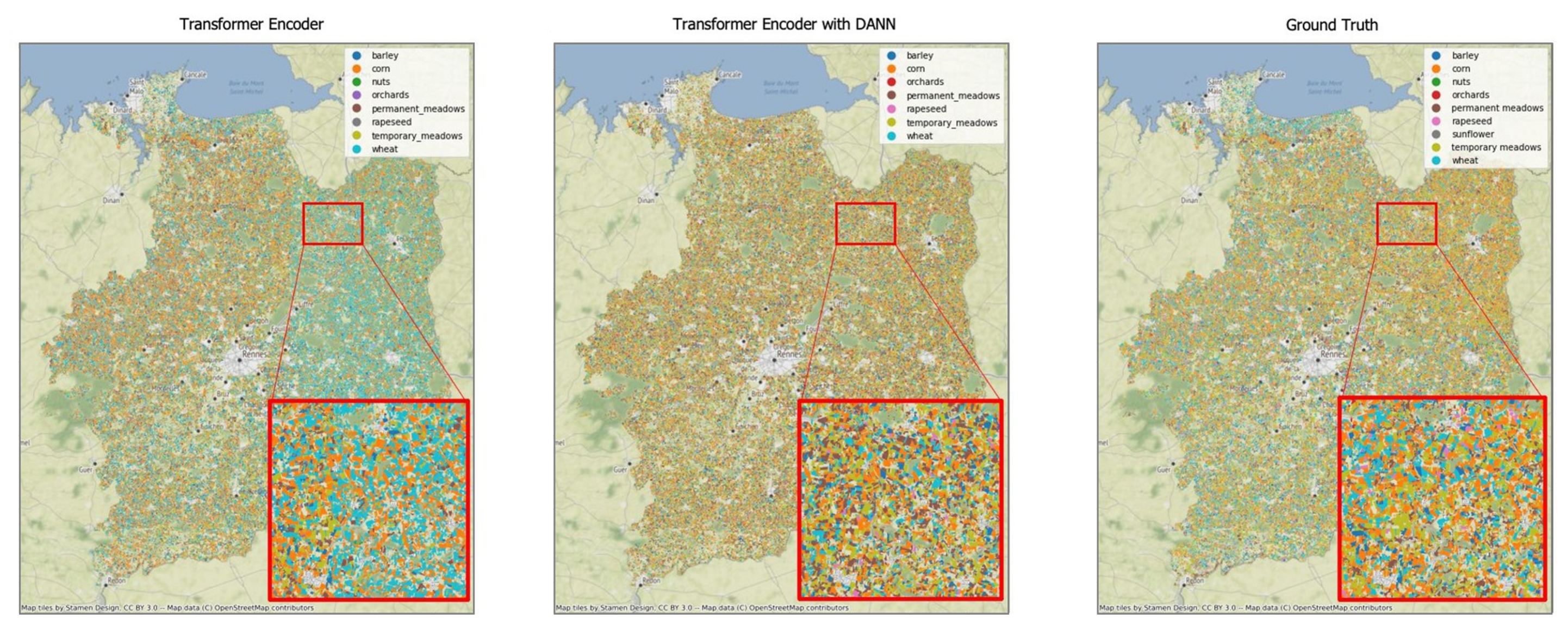
5.3. Results Discussion and Applicability Study
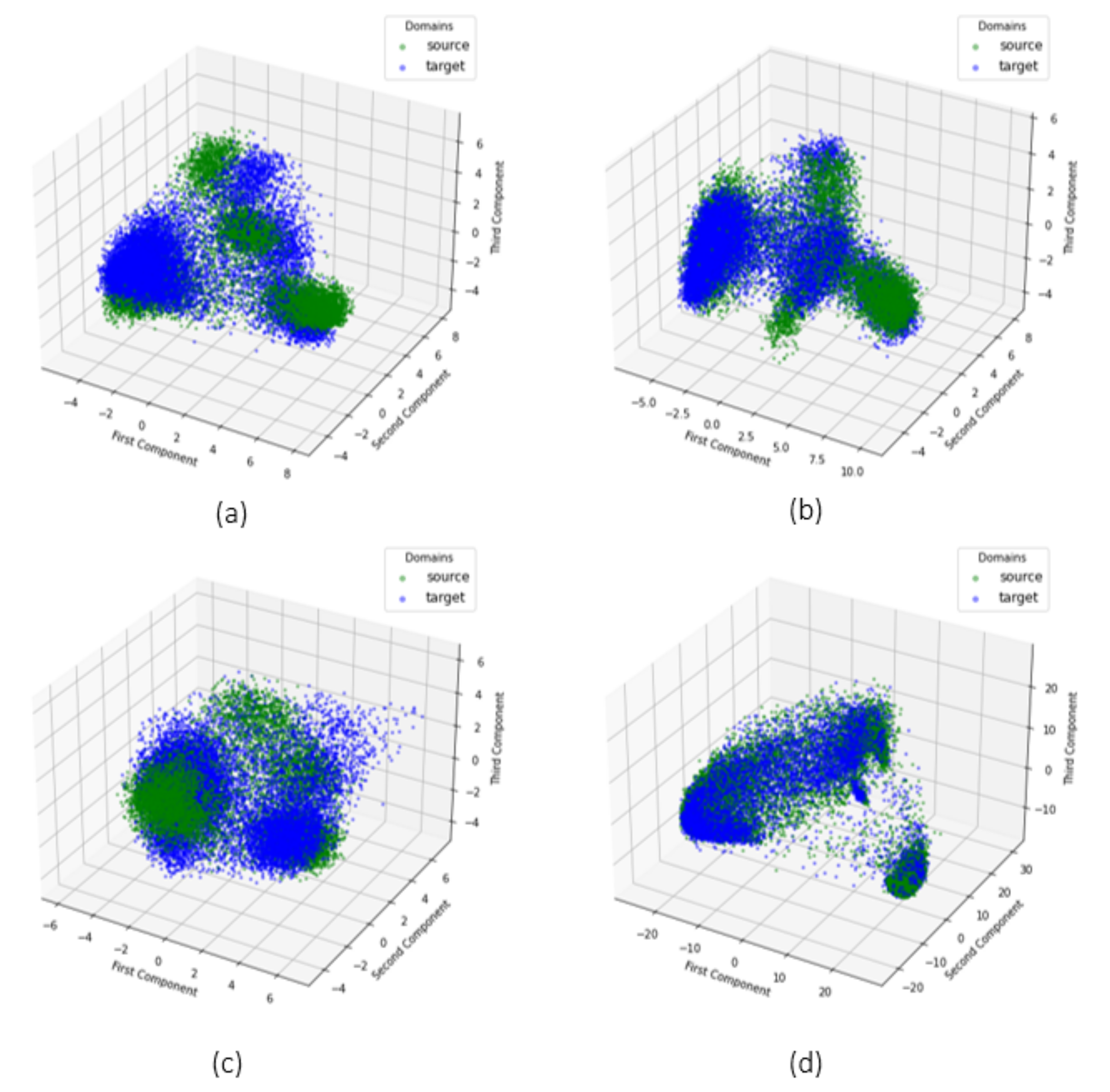
- case 1: zone 2 (source), zone 3 (target). In this case DANN shows the greatest improvements with an initial high value of MMD. Features are visually reported in Figure 7: in (a,b) when extracted by standard Transformer encoder trained on the source domain, in (c,d) when extracted by DANN. The difference is visually clear. Features distributions are matched by DANN, with a resulting overlapping shape between source and target domain.
- case 2: zone 1 (source), zone 2 (target). In this case DANN shows the worst improvements with an initial low value of MMD. Features are visually reported in (a,b) of Figure 8 when extracted by standard Transformer encoder, in (c,d) of the same Figure 8 when extracted by DANN. They appear already similar also without DANN.
- case 3: zone 4 (source), zone 3 (target). In this case DANN shows noticeable improvements, regardless an initial low value of MMD. Features are visually reported in (a,b) of Figure 9 when extracted by standard Transformer encoder, in (c,d) of Figure 9 when extracted by DANN. As with case 1, the difference is visually clear, and the effect of DANN can be easily appreciated.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rudd, J.D.; Roberson, G.T.; Classen, J.J. Application of satellite, unmanned aircraft system, and ground-based sensor data for precision agriculture: A review. In Proceedings of the 2017 ASABE Annual International Meeting. American Society of Agricultural and Biological Engineers, Spokane, WA, USA, 16–19 July 2017. [Google Scholar]
- Novelli, A.; Aguilar, M.A.; Nemmaoui, A.; Aguilar, F.J.; Tarantino, E. Performance evaluation of object based greenhouse detection from Sentinel-2 MSI and Landsat 8 OLI data: A case study from Almería (Spain). Int. J. Appl. Earth Obs. Geoinf. 2016, 52, 403–411. [Google Scholar] [CrossRef] [Green Version]
- De Jong, R.; de Bruin, S.; de Wit, A.; Schaepman, M.E.; Dent, D.L. Analysis of monotonic greening and browning trends from global NDVI time-series. Remote. Sens. Environ. 2011, 115, 692–702. [Google Scholar] [CrossRef] [Green Version]
- Pacifici, F.; Longbotham, N.; Emery, W.J. The importance of physical quantities for the analysis of multitemporal and multiangular optical very high spatial resolution images. IEEE Trans. Geosci. Remote. Sens. 2014, 52, 6241–6256. [Google Scholar] [CrossRef]
- Amorós-López, J.; Gómez-Chova, L.; Alonso, L.; Guanter, L.; Zurita-Milla, R.; Moreno, J.; Camps-Valls, G. Multitemporal fusion of Landsat/TM and ENVISAT/MERIS for crop monitoring. Int. J. Appl. Earth Obs. Geoinf. 2013, 23, 132–141. [Google Scholar] [CrossRef]
- Li, W.; Niu, Z.; Huang, N.; Wang, C.; Gao, S.; Wu, C. Airborne LiDAR technique for estimating biomass components of maize: A case study in Zhangye City, Northwest China. Ecol. Indic. 2015, 57, 486–496. [Google Scholar] [CrossRef]
- Rembold, F.; Atzberger, C.; Savin, I.; Rojas, O. Using low resolution satellite imagery for yield prediction and yield anomaly detection. Remote. Sens. 2013, 5, 1704–1733. [Google Scholar] [CrossRef] [Green Version]
- Khaliq, A.; Mazzia, V.; Chiaberge, M. Refining satellite imagery by using UAV imagery for vineyard environment: A CNN Based approach. In Proceedings of the 2019 IEEE International Workshop on Metrology for Agriculture and Forestry (MetroAgriFor), Naples, Italy, 24–26 October 2019; pp. 25–29. [Google Scholar]
- Gomez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote. Sens. 2016, 116, 55–72. [Google Scholar] [CrossRef] [Green Version]
- Khaliq, A.; Musci, M.A.; Chiaberge, M. Analyzing relationship between maize height and spectral indices derived from remotely sensed multispectral imagery. In Proceedings of the 2018 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 9–11 October 2018; pp. 1–5. [Google Scholar]
- Büttner, G.; Feranec, J.; Jaffrain, G.; Mari, L.; Maucha, G.; Soukup, T. The CORINE land cover 2000 project. EARSeL eProceedings 2004, 3, 331–346. [Google Scholar]
- Tuia, D.; Persello, C.; Bruzzone, L. Domain adaptation for the classification of remote sensing data: An overview of recent advances. IEEE Geosci. Remote. Sens. Mag. 2016, 4, 41–57. [Google Scholar] [CrossRef]
- Verrelst, J.; Alonso, L.; Caicedo, J.P.R.; Moreno, J.; Camps-Valls, G. Gaussian process retrieval of chlorophyll content from imaging spectroscopy data. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2012, 6, 867–874. [Google Scholar] [CrossRef]
- Ballanti, L.; Blesius, L.; Hines, E.; Kruse, B. Tree species classification using hyperspectral imagery: A comparison of two classifiers. Remote. Sens. 2016, 8, 445. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Ali, S.; Purushotham, S.; Wang, J.; Wang, C.; Zhang, Z. Deep multi-sensor domain adaptation on active and passive satellite remote sensing data. In 1st KDD Workshop on Deep Learning for Spatiotemporal Data, Applications, and Systems (DeepSpatial 2020); American Geophysical Union: Washington DC, USA, 2020. [Google Scholar]
- Penatti, O.A.; Nogueira, K.; Dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Mazzia, V.; Khaliq, A.; Chiaberge, M. Improvement in land cover and crop classification based on temporal features learning from Sentinel-2 data using recurrent-convolutional neural network (R-CNN). Appl. Sci. 2020, 10, 238. [Google Scholar] [CrossRef] [Green Version]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 172–181. [Google Scholar]
- Tian, C.; Li, C.; Shi, J. Dense fusion classmate network for land cover classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 192–196. [Google Scholar]
- Kuo, T.S.; Tseng, K.S.; Yan, J.W.; Liu, Y.C.; Frank Wang, Y.C. Deep aggregation net for land cover classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 252–256. [Google Scholar]
- Conjeti, S.; Katouzian, A.; Roy, A.G.; Peter, L.; Sheet, D.; Carlier, S.; Laine, A.; Navab, N. Supervised domain adaptation of decision forests: Transfer of models trained in vitro for in vivo intravascular ultrasound tissue characterization. Med Image Anal. 2016, 32, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Deng, Z.; Sun, H.; Zhou, S.; Ji, K. Semi-supervised cross-view scene model adaptation for remote sensing image classification. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 11–15 July 2016; pp. 2376–2379. [Google Scholar] [CrossRef]
- Matasci, G.; Volpi, M.; Kanevski, M.; Bruzzone, L.; Tuia, D. Semisupervised Transfer Component Analysis for Domain Adaptation in Remote Sensing Image Classification. IEEE Trans. Geosci. Remote. Sens. 2015, 53, 3550–3564. [Google Scholar] [CrossRef]
- Liu, W.; Su, F. A novel unsupervised adversarial domain adaptation network for remotely sensed scene classification. Int. J. Remote. Sens. 2020, 41, 6099–6116. [Google Scholar] [CrossRef]
- Benjdira, B.; Bazi, Y.; Koubaa, A.; Ouni, K. Unsupervised domain adaptation using generative adversarial networks for semantic segmentation of aerial images. Remote. Sens. 2019, 11, 1369. [Google Scholar] [CrossRef] [Green Version]
- Karimpour, M.; Saray, S.N.; Tahmoresnezhad, J.; Aghababa, M.P. Multi-source domain adaptation for image classification. Mach. Vis. Appl. 2020, 31, 1–19. [Google Scholar] [CrossRef]
- Bahirat, K.; Bovolo, F.; Bruzzone, L.; Chaudhuri, S. A novel domain adaptation Bayesian classifier for updating land-cover maps with class differences in source and target domains. IEEE Trans. Geosci. Remote. Sens. 2011, 50, 2810–2826. [Google Scholar] [CrossRef]
- Rußwurm, M.; Lefèvre, S.; Körner, M. Breizhcrops: A satellite time series dataset for crop type identification. In Proceedings of the International Conference on Machine Learning Time Series Workshop, Anchorage, AK, USA, 5 August 2019. [Google Scholar]
- Walker, J.; De Beurs, K.; Wynne, R. Dryland vegetation phenology across an elevation gradient in Arizona, USA, investigated with fused MODIS and Landsat data. Remote. Sens. Environ. 2014, 144, 85–97. [Google Scholar] [CrossRef]
- Arvor, D.; Jonathan, M.; Meirelles, M.S.P.; Dubreuil, V.; Durieux, L. Classification of MODIS EVI time series for crop mapping in the state of Mato Grosso, Brazil. Int. J. Remote. Sens. 2011, 32, 7847–7871. [Google Scholar] [CrossRef]
- Moranduzzo, T.; Melgani, F. Automatic car counting method for unmanned aerial vehicle images. IEEE Trans. Geosci. Remote. Sens. 2013, 52, 1635–1647. [Google Scholar] [CrossRef]
- Hao, P.; Zhan, Y.; Wang, L.; Niu, Z.; Shakir, M. Feature selection of time series MODIS data for early crop classification using random forest: A case study in Kansas, USA. Remote. Sens. 2015, 7, 5347–5369. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hubel, D.H.; Wiesel, T.N. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. J. Physiol. 1962, 160, 106–154. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote. Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote. Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Zhang, H.; Li, Y.; Zhang, Y.; Shen, Q. Spectral-spatial classification of hyperspectral imagery using a dual-channel convolutional neural network. Remote. Sens. Lett. 2017, 8, 438–447. [Google Scholar] [CrossRef] [Green Version]
- He, Z.; Liu, H.; Wang, Y.; Hu, J. Generative adversarial networks-based semi-supervised learning for hyperspectral image classification. Remote. Sens. 2017, 9, 1042. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Zhan, Y.; Hu, D.; Wang, Y.; Yu, X. Semisupervised hyperspectral image classification based on generative adversarial networks. IEEE Geosci. Remote. Sens. Lett. 2017, 15, 212–216. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. arXiv 2016, arXiv:1606.03657. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Springenberg, J.T. Unsupervised and semi-supervised learning with categorical generative adversarial networks. arXiv 2015, arXiv:1511.06390. [Google Scholar]
- Zhao, W.; Chen, X.; Chen, J.; Qu, Y. Sample generation with self-attention generative adversarial Adaptation Network (SaGAAN) for Hyperspectral Image Classification. Remote. Sens. 2020, 12, 843. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef] [Green Version]
- Ma, W.; Pan, Z.; Yuan, F.; Lei, B. Super-resolution of remote sensing images via a dense residual generative adversarial network. Remote. Sens. 2019, 11, 2578. [Google Scholar] [CrossRef] [Green Version]
- Bengana, N.M.; Heikkila, J. Improving land cover segmentation across satellites using domain adaptation. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 14, 1399–1410. [Google Scholar] [CrossRef]
- Nielsen, A.A. The regularized iteratively reweighted MAD method for change detection in multi-and hyperspectral data. IEEE Trans. Image Process. 2007, 16, 463–478. [Google Scholar] [CrossRef] [Green Version]
- Volpi, M.; Camps-Valls, G.; Tuia, D. Spectral alignment of multi-temporal cross-sensor images with automated kernel canonical correlation analysis. ISPRS J. Photogramm. Remote. Sens. 2015, 107, 50–63. [Google Scholar] [CrossRef]
- Tuia, D.; Volpi, M.; Trolliet, M.; Camps-Valls, G. Semisupervised manifold alignment of multimodal remote sensing images. IEEE Trans. Geosci. Remote. Sens. 2014, 52, 7708–7720. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial discriminative domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7167–7176. [Google Scholar]
- Hosseini-Asl, E.; Zhou, Y.; Xiong, C.; Socher, R. Augmented cyclic adversarial learning for low resource domain adaptation. arXiv 2018, arXiv:1807.00374. [Google Scholar]
- Volpi, R.; Morerio, P.; Savarese, S.; Murino, V. Adversarial feature augmentation for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5495–5504. [Google Scholar]
- Taigman, Y.; Polyak, A.; Wolf, L. Unsupervised cross-domain image generation. arXiv 2016, arXiv:1611.02200. [Google Scholar]
- Bejiga, M.B.; Melgani, F. Gan-based domain adaptation for object classification. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2018; pp. 1264–1267. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Zhang, Y.; David, P.; Gong, B. Curriculum domain adaptation for semantic segmentation of urban scenes. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2020–2030. [Google Scholar]
- Hoffman, J.; Wang, D.; Yu, F.; Darrell, T. Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv 2016, arXiv:1612.02649. [Google Scholar]
- Chang, W.L.; Wang, H.P.; Peng, W.H.; Chiu, W.C. All about structure: Adapting structural information across domains for boosting semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1900–1909. [Google Scholar]
- Li, Y.; Yuan, L.; Vasconcelos, N. Bidirectional learning for domain adaptation of semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6936–6945. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote. Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Hagolle, O.; Huc, M.; Villa Pascual, D.; Dedieu, G. A multi-temporal and multi-spectral method to estimate aerosol optical thickness over land, for the atmospheric correction of FormoSat-2, LandSat, VENμS and Sentinel-2 images. Remote. Sens. 2015, 7, 2668–2691. [Google Scholar] [CrossRef] [Green Version]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2030–2096. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Rußwurm, M.; Körner, M. Self-attention for raw optical satellite time series classification. ISPRS J. Photogramm. Remote. Sens. 2020, 169, 421–435. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A. A kernel two-sample test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Dziugaite, G.K.; Roy, D.M.; Ghahramani, Z. Training generative neural networks via maximum mean discrepancy optimization. arXiv 2015, arXiv:1505.03906. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep transfer learning with joint adaptation networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2208–2217. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Barley | Wheat | Rapeseed | Corn | Sunflower | Orchards | Nuts | Permanent Meadows | Temporary Meadows | |
|---|---|---|---|---|---|---|---|---|---|
| Zone 1 | 13,051 | 30,380 | 5596 | 44,003 | 1 | 937 | 10 | 32,641 | 52,013 |
| Zone 2 | 10,736 | 15,026 | 2349 | 36,620 | 6 | 348 | 18 | 36,536 | 39,143 |
| Zone 3 | 7154 | 27,202 | 3557 | 42,011 | 10 | 1217 | 10 | 32,524 | 52,682 |
| Zone 4 | 5981 | 17,009 | 3244 | 31,361 | 2 | 552 | 11 | 26,134 | 38,141 |
| Zone | Transformer Encoder | DANN | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Source Domain | Target Domain | Train Accuracy | Test Accuracy | F1-Accuracy | K-Score | MMD | Test Accuracy | F1-Accuracy | K-Score | MMD |
| 1 | 2 | 0.8577 | 0.7877 | 0.5675 | 0.7229 | 0.1109 | 0.7628 | 0.5540 | 0.6950 | 0.0077 |
| 1 | 3 | 0.8577 | 0.7436 | 0.5266 | 0.6606 | 0.1620 | 0.7449 | 0.5080 | 0.6714 | 0.0183 |
| 1 | 4 | 0.8577 | 0.7941 | 0.5675 | 0.7294 | 0.0516 | 0.7960 | 0.5734 | 0.7343 | 0.0086 |
| 2 | 1 | 0.8951 | 0.7433 | 0.5309 | 0.6773 | 0.1577 | 0.7403 | 0.5161 | 0.6687 | 0.0208 |
| 2 | 3 | 0.8951 | 0.4967 | 0.3592 | 0.3642 | 0.6700 | 0.6505 | 0.4544 | 0.5483 | 0.0104 |
| 2 | 4 | 0.8951 | 0.6006 | 0.4395 | 0.4912 | 0.2536 | 0.7482 | 0.4832 | 0.6735 | 0.0416 |
| 3 | 1 | 0.8750 | 0.7767 | 0.5339 | 0.7122 | 0.1819 | 0.8045 | 0.5778 | 0.7488 | 0.0121 |
| 3 | 2 | 0.8750 | 0.6638 | 0.4594 | 0.5615 | 0.6254 | 0.7589 | 0.5334 | 0.6865 | 0.0277 |
| 3 | 4 | 0.8750 | 0.7348 | 0.5074 | 0.6504 | 0.1184 | 0.7968 | 0.5778 | 0.7338 | 0.0115 |
| 4 | 1 | 0.8870 | 0.7927 | 0.5551 | 0.7354 | 0.0339 | 0.8233 | 0.5822 | 0.7753 | 0.0039 |
| 4 | 2 | 0.8870 | 0.7600 | 0.5443 | 0.6870 | 0.0953 | 0.8003 | 0.5788 | 0.7399 | 0.0084 |
| 4 | 3 | 0.8870 | 0.7111 | 0.4961 | 0.6230 | 0.0960 | 0.7673 | 0.5443 | 0.6965 | 0.0062 |
| Zone | Improvement [%] | |||
|---|---|---|---|---|
| Source Domain | Target Domain | Test Accuracy | F1-Accuracy | K-Score |
| 1 | 2 | −3.1576 | −2.3859 | −3.8508 |
| 1 | 3 | 0.1762 | −3.5378 | 1.6395 |
| 1 | 4 | 0.2296 | 1.0467 | 0.6773 |
| 2 | 1 | −0.3996 | −2.7935 | −1.2698 |
| 2 | 3 | 30.9721 | 26.4916 | 50.5414 |
| 2 | 4 | 24.5690 | 9.9474 | 37.1046 |
| 3 | 1 | 3.5803 | 8.2152 | 5.1446 |
| 3 | 2 | 14.3204 | 16.1075 | 22.2539 |
| 3 | 4 | 8.4475 | 13.8791 | 12.8283 |
| 4 | 1 | 3.8705 | 4.8817 | 5.4228 |
| 4 | 2 | 5.3053 | 6.3384 | 7.6922 |
| 4 | 3 | 7.9018 | 9.7154 | 11.8067 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martini, M.; Mazzia, V.; Khaliq, A.; Chiaberge, M. Domain-Adversarial Training of Self-Attention-Based Networks for Land Cover Classification Using Multi-Temporal Sentinel-2 Satellite Imagery. Remote Sens. 2021, 13, 2564. https://doi.org/10.3390/rs13132564
Martini M, Mazzia V, Khaliq A, Chiaberge M. Domain-Adversarial Training of Self-Attention-Based Networks for Land Cover Classification Using Multi-Temporal Sentinel-2 Satellite Imagery. Remote Sensing. 2021; 13(13):2564. https://doi.org/10.3390/rs13132564
Chicago/Turabian StyleMartini, Mauro, Vittorio Mazzia, Aleem Khaliq, and Marcello Chiaberge. 2021. "Domain-Adversarial Training of Self-Attention-Based Networks for Land Cover Classification Using Multi-Temporal Sentinel-2 Satellite Imagery" Remote Sensing 13, no. 13: 2564. https://doi.org/10.3390/rs13132564
APA StyleMartini, M., Mazzia, V., Khaliq, A., & Chiaberge, M. (2021). Domain-Adversarial Training of Self-Attention-Based Networks for Land Cover Classification Using Multi-Temporal Sentinel-2 Satellite Imagery. Remote Sensing, 13(13), 2564. https://doi.org/10.3390/rs13132564