
Infrared and Visible Image Object Detection via Focused Feature Enhancement and Cascaded Semantic Extension

 ,
,
Abstract
:
1. Introduction
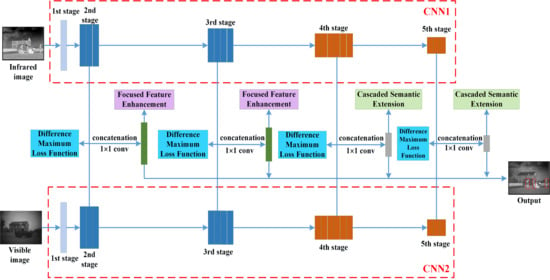
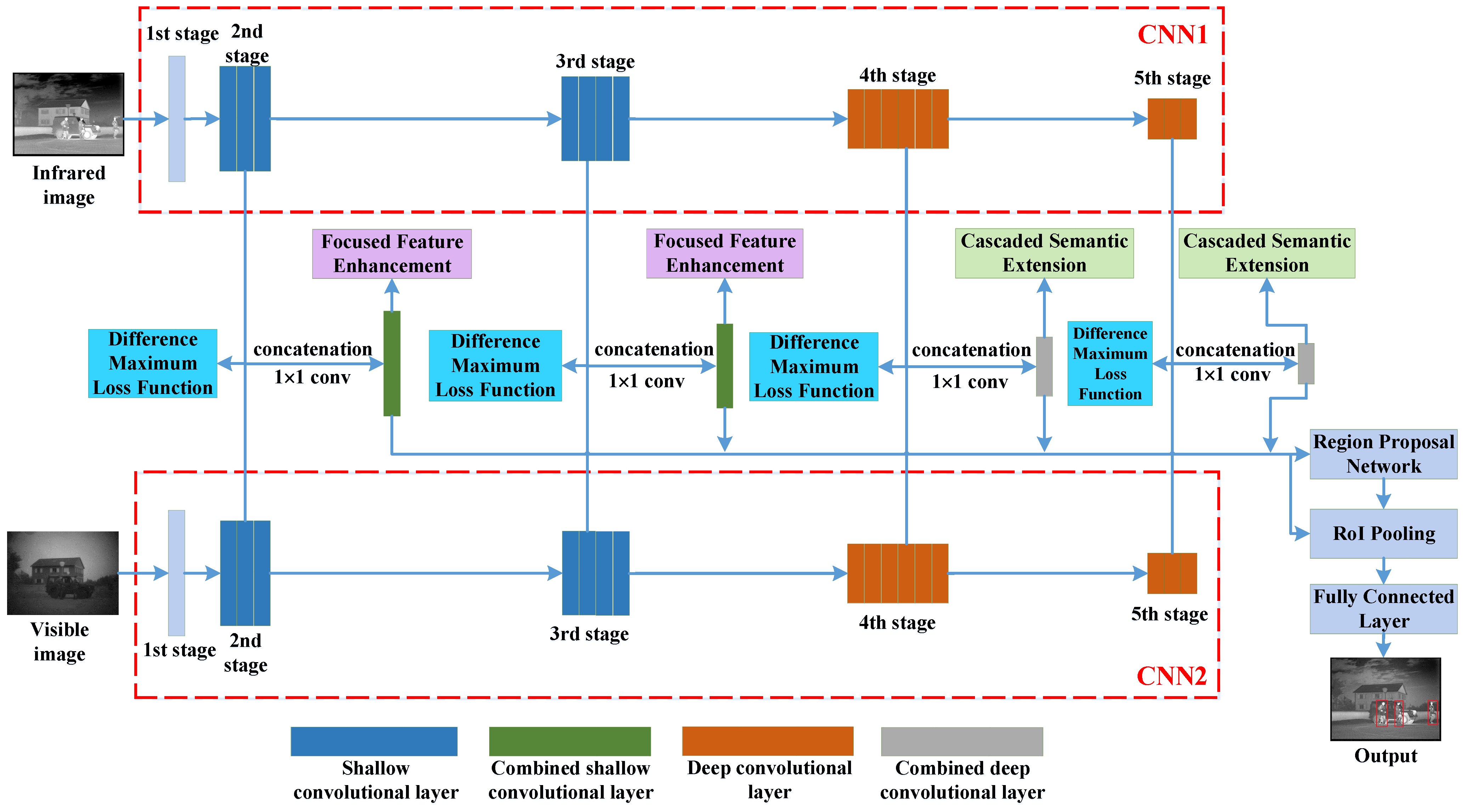
2. The Proposed Detection Network
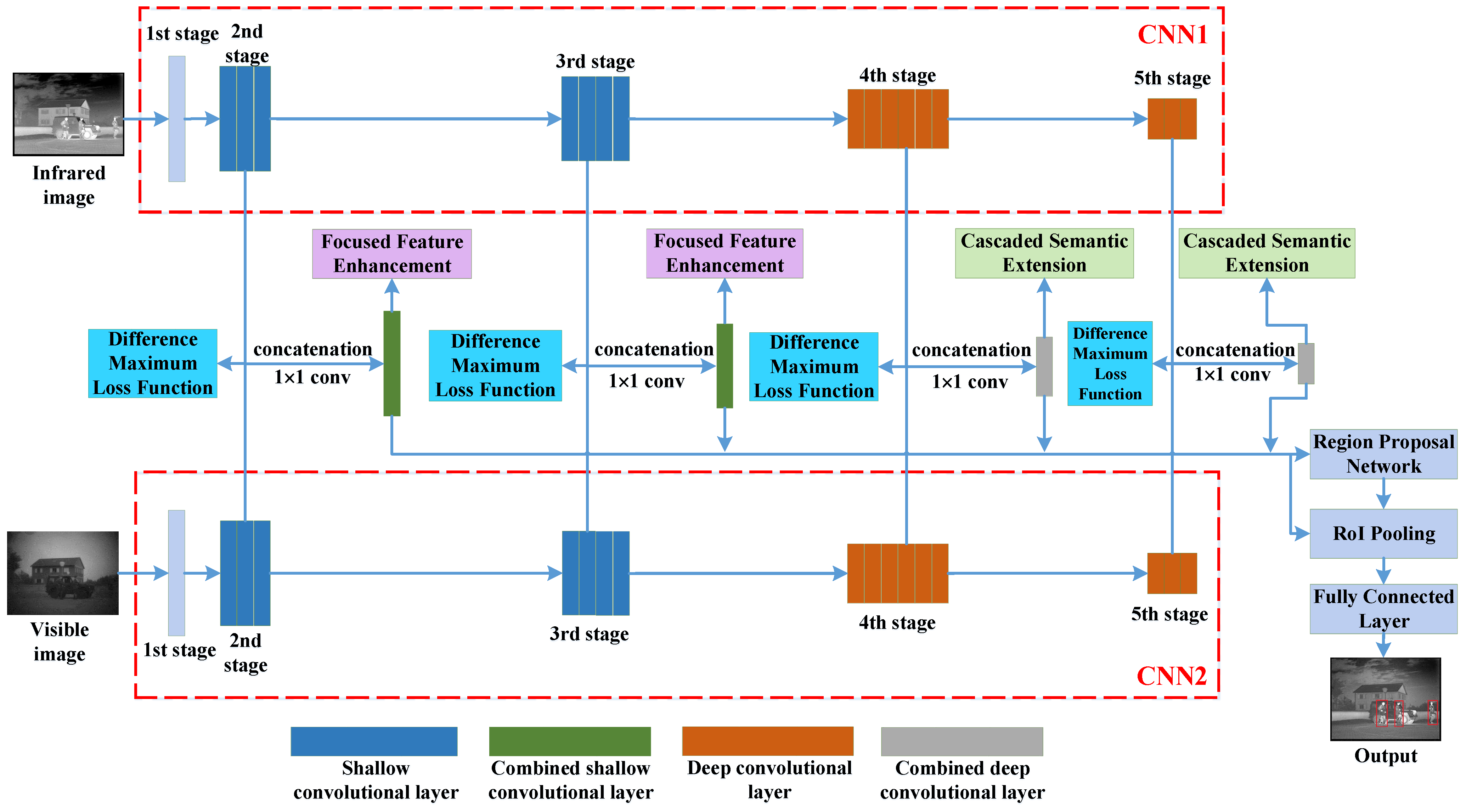
2.1. Difference Maximum Loss
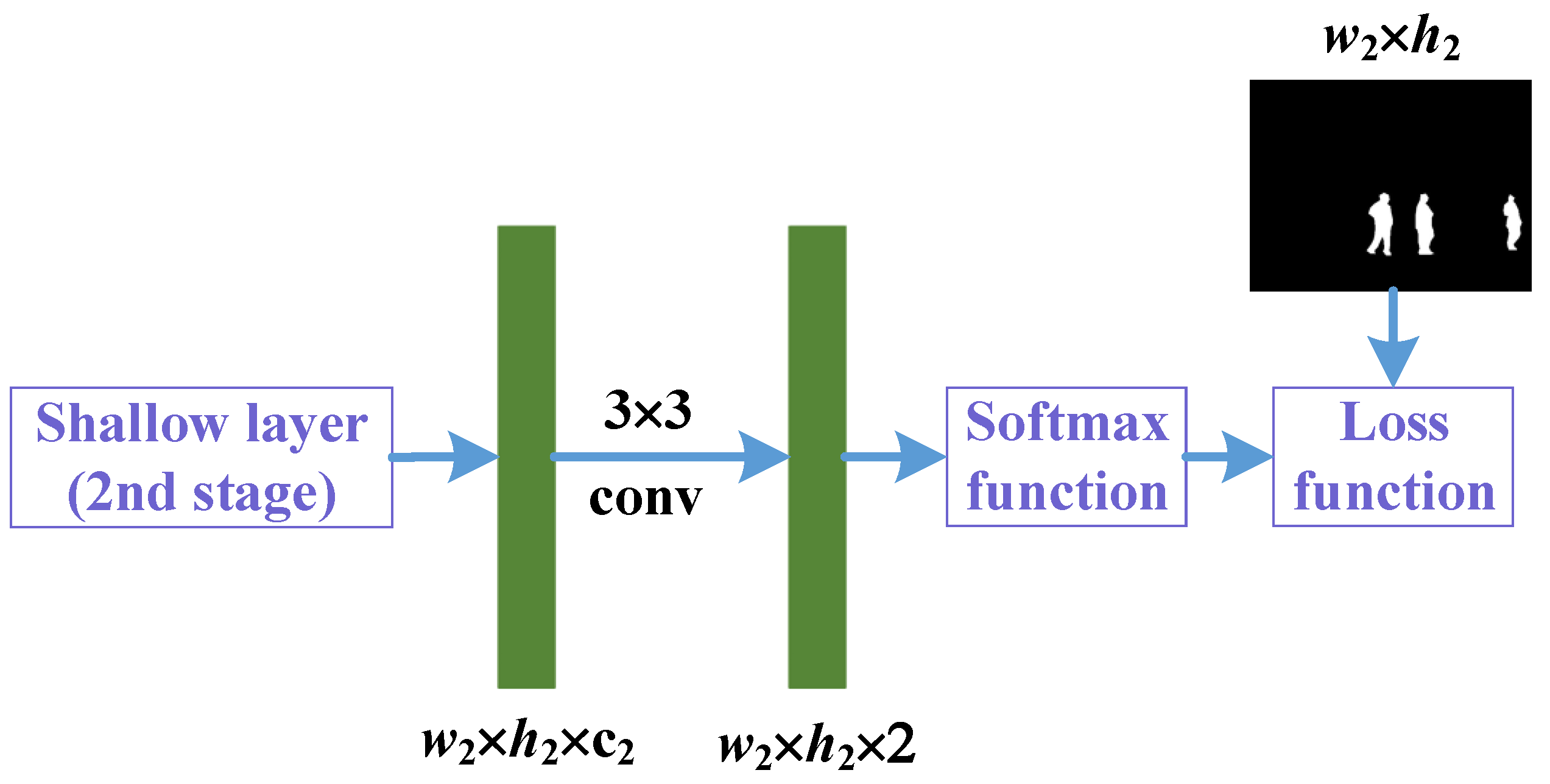
2.2. Focused Feature Enhancement
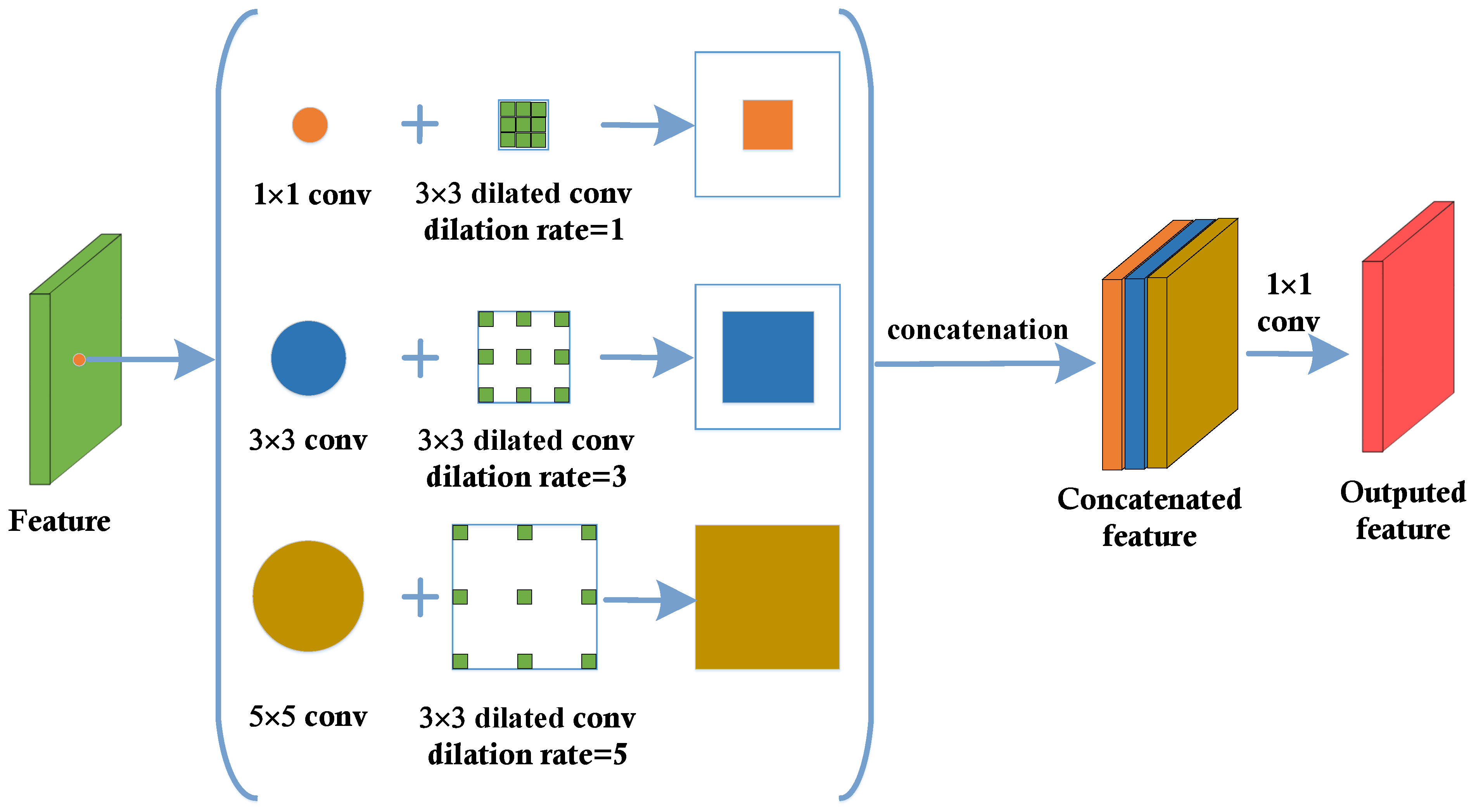
2.3. Cascaded Semantic Extension
2.4. End-to-End Training
3. Experiments
3.1. Infrared and Visible Image Dataset
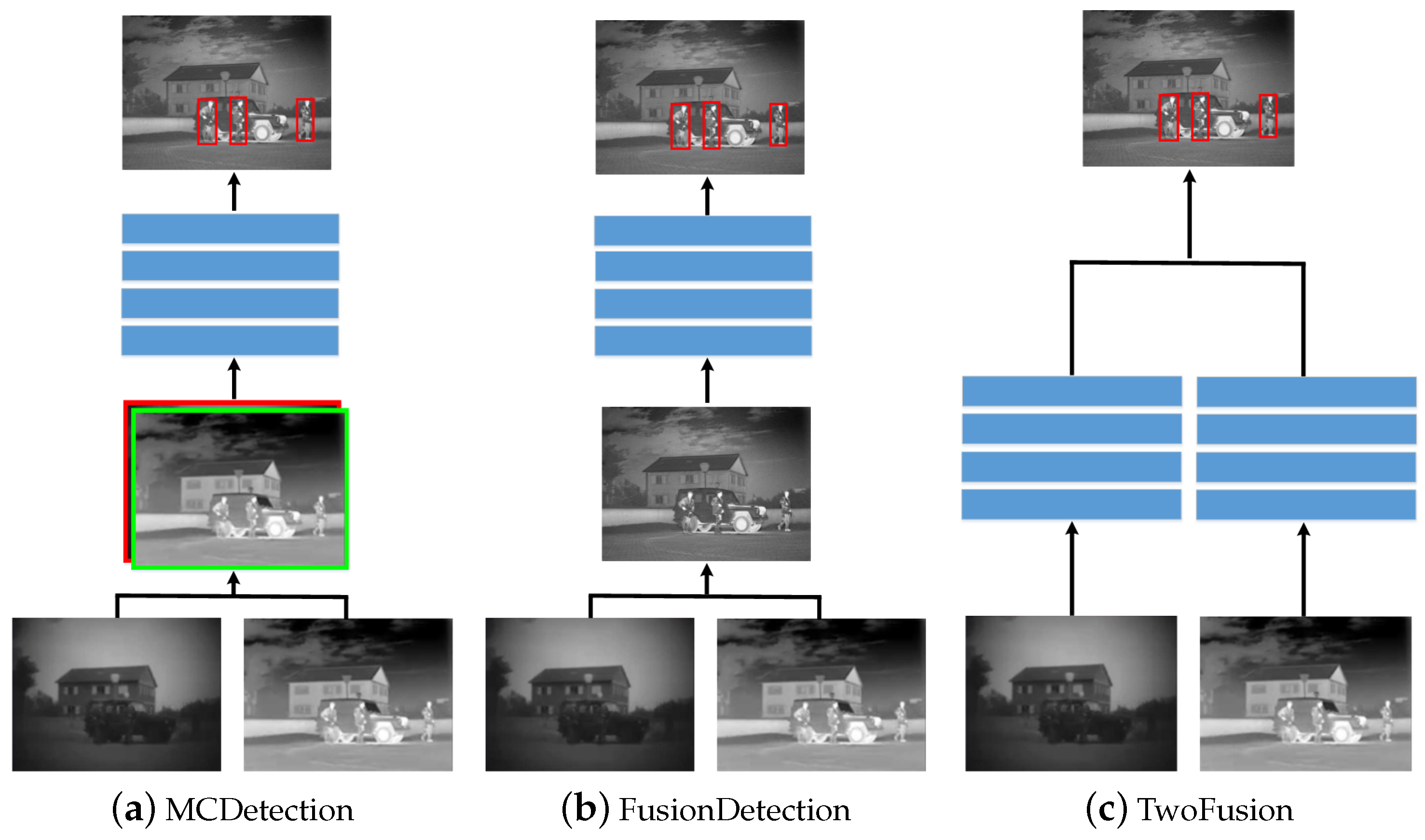
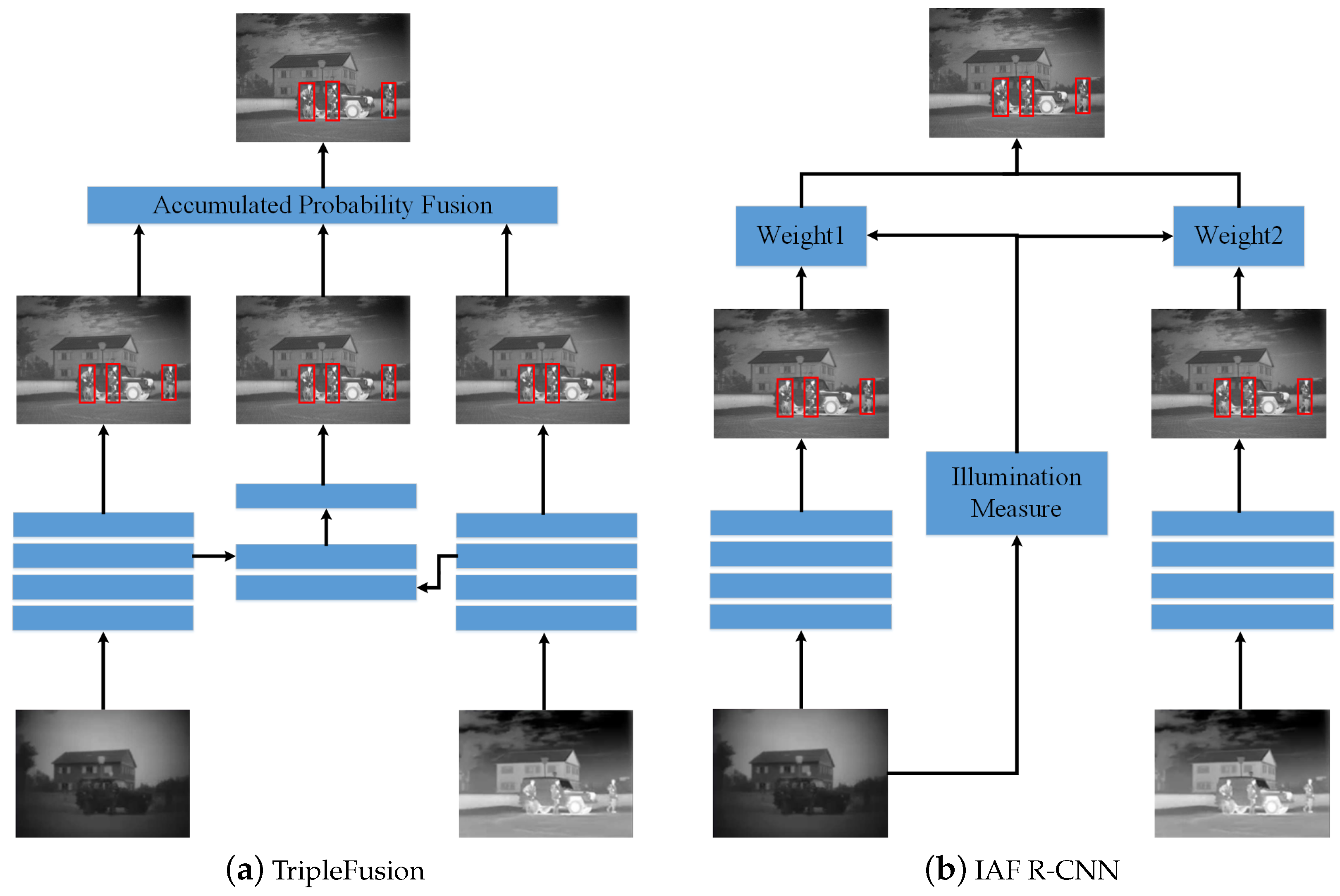
3.2. Method Comparison
3.3. Comparison
4. Individual Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, J.; Chen, K.; Yang, S.; Loy, C.C.; Lin, D. Region Proposal by Guided Anchoring. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Alejandro, G.; Fang, Z.; Yainuvis, S.; Joan, S.; David, V.; Xu, J.; Antonio, L. Pedestrian Detection at Day/Night Time with Visible and FIR Cameras: A Comparison. Sensors 2016, 16, 820. [Google Scholar]
- Konig, D.; Adam, M.; Jarvers, C.; Layher, G.; Teutsch, M. Fully Convolutional Region Proposal Networks for Multispectral Person Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Park, K.; Kim, S.; Sohn, K. Unified multi-spectral pedestrian detection based on probabilistic fusion networks. Pattern Recognit. J. Pattern Recognit. Soc. 2018, 80, 143–155. [Google Scholar] [CrossRef]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-aware Faster R-CNN for Robust Multispectral Pedestrian Detection. Pattern Recognit. 2019, 85, 161–171. [Google Scholar] [CrossRef] [Green Version]
- Shopovska, I.; Jovanov, L.; Philips, W. Deep Visible and Thermal Image Fusion for Enhanced Pedestrian Visibility. Sensors 2019, 19, 3727. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Jian, S. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Laurens, V.D.M.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Hou, Y.L.; Song, Y.; Hao, X.; Shen, Y.; Qian, M. Multispectral pedestrian detection based on deep convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Macau, China, 21–24 August 2018. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Receptive Field Block Net for Accurate and Fast Object Detection. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Kaiming, H.; Georgia, G.; Piotr, D.; Ross, G. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cao, J.; Cholakkal, H.; Anwer, R.M.; Khan, F.S.; Shao, L. D2Det: Towards High Quality Object Detection and Instance Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Dong, Z.; Li, G.; Liao, Y.; Wang, F.; Ren, P.; Qian, C. CentripetalNet: Pursuing High-quality Keypoint Pairs for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Rubner, Y.; Puzicha, J.; Tomasi, C.; Buhmann, J.M. Empirical Evaluation of Dissimilarity Measures for Color and Texture. Comput. Vis. Image Underst. 2001, 84, 25–43. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Viola, P. Rapid Object Detection using a Boosted Cascade of Simple Features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Dalal, N. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005. [Google Scholar]
- Felzenszwalb, P.F.; Mcallester, D.A.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; Mcallester, D.A. Cascade object detection with deformable part models. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R.B.; Felzenszwalb, P.F.; Mcallester, D. Object detection with grammar models. Adv. Neural Inf. Process. Syst. 2011, 24, 442–450. [Google Scholar]
- Girshick, R.B. From Rigid Templates to Grammars: Object Detection with Structured Models; University of Chicago: Chicago, IL, USA, 2012. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhou, P.; Geng, C. Transmission. Scale-Transferrable Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Singh, B.; Davis, L.S. An Analysis of Scale Invariance in Object Detection—SNIP. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Singh, B.; Najibi, M.; Davis, L.S. SNIPER: Efficient Multi-Scale Training. arXiv 2018, arXiv:1805.09300. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature Selective Anchor-Free Module for Single-Shot Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Hong, S.; Roh, B.; Kim, K.H.; Cheon, Y.; Park, M. Pvanet: Lightweight deep neural networks for real-time object detection. arXiv 2016, arXiv:1611.08588. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. J. Mach. Learn. Res. 2010, 9, 249–256. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the Effective Receptive Field in Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Zhang, X.; Zou, Y.; Wei, S. Dilated convolution neural network with LeakyReLU for environmental sound classification. In Proceedings of the 2017 22nd International Conference on Digital Signal Processing (DSP), London, UK, 23–25 August 2017. [Google Scholar]
- Qiao, Z.; Cui, Z.; Niu, X.; Geng, S.; Yu, Q. Image Segmentation with Pyramid Dilated Convolution Based on ResNet and U-Net. In International Conference on Neural Information Processing; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Chen, J.; Wang, C.; Tong, Y. AtICNet: Semantic segmentation with atrous spatial pyramid pooling in image cascade network. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 1–7. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. 2017. Available online: https://openreview.net/forum?id=BJJsrmfCZ (accessed on 14 March 2019).
- Toet, A.; Hogervorst, M.A.; Pinkus, A.R. The TRICLOBS Dynamic Multi-Band Image Data Set for the Development and Evaluation of Image Fusion Methods. PLoS ONE 2016, 11, e0165016. [Google Scholar] [CrossRef]
- CVC14 Dataset. Available online: http://adas.cvc.uab.es/elektra/enigma-portfolio/cvc-14-visible-fir-day-night-pedestrian-sequence-dataset (accessed on 25 July 2019).
- Liu, S.; Liu, Z. Multi-Channel CNN-based Object Detection for Enhanced Situation Awareness. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhou, Z.; Wang, B.; Li, S.; Dong, M. Perceptual fusion of infrared and visible images through a hybrid multi-scale decomposition with Gaussian and bilateral filters. Inf. Fusion 2016, 30, 15–26. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral Deep Neural Networks for Pedestrian Detection. arXiv 2016, arXiv:1611.02644. [Google Scholar]
- Li, S.; Kang, X.; Hu, J. Image Fusion With Guided Filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar]
- Adu, J.; Gan, J.; Wang, Y.; Huang, J. Image fusion based on nonsubsampled contourlet transform for infrared and visible light image. Infrared Phys. Technol. 2013, 61, 94–100. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, S.; Wang, Z. A general framework for image fusion based on multi-scale transform and sparse representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Zhang, Q.; Maldague, X. An adaptive fusion approach for infrared and visible images based on NSCT and compressed sensing. Infrared Phys. Technol. 2016, 74, 11–20. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Aslam, A. Object Detection for Unseen Domains while Reducing Response Time using Knowledge Transfer in Multimedia Event Processing. In Proceedings of the ICMR 20 International Conference on Multimedia Retrieval, Dublin, Ireland, 8–11 June 2020. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Images | Testing Images | Sum | |
|---|---|---|---|
| Daytime | 1289 | 352 | 1641 |
| Night | 1361 | 316 | 1677 |
| Sum | 2650 | 668 | 3318 |
| Method | Daytime | Night | ALL |
|---|---|---|---|
| MCDetection | 74.8% | 73.9% | 74.3% |
| FusionDetection | 74.4% | 75.5% | 75.1% |
| TwoFusion | 78.8% | 77.5% | 78.2% |
| TripleFusion | 81.1% | 80.1% | 80.5% |
| IAF R-CNN | 80.9% | 81.8% | 81.3% |
| Ours | 84.3% | 83.2% | 83.7% |
| Difference Maximum Loss | Focused Feature Enhancement | Cascaded Semantic Extension | mAP |
|---|---|---|---|
| × | × | × | 78.9% |
| √ | × | × | 80.7% |
| × | √ | × | 80.1% |
| × | × | √ | 81.6% |
| × | √ | √ | 82.5% |
| √ | × | √ | 82.8% |
| √ | √ | × | 82.1% |
| √ | √ | √ | 83.7% |
| With/Without | mAP |
|---|---|
| With the first stage | 83.5% |
| Without the first stage | 83.7% |
| Segmentation Labels | mAP |
|---|---|
| Ground-truth | 83.8% |
| Automatically generated | 83.7% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, X.; Wang, B.; Miao, L.; Li, L.; Zhou, Z.; Ma, J.; Dong, D. Infrared and Visible Image Object Detection via Focused Feature Enhancement and Cascaded Semantic Extension. Remote Sens. 2021, 13, 2538. https://doi.org/10.3390/rs13132538
Xiao X, Wang B, Miao L, Li L, Zhou Z, Ma J, Dong D. Infrared and Visible Image Object Detection via Focused Feature Enhancement and Cascaded Semantic Extension. Remote Sensing. 2021; 13(13):2538. https://doi.org/10.3390/rs13132538
Chicago/Turabian StyleXiao, Xiaowu, Bo Wang, Lingjuan Miao, Linhao Li, Zhiqiang Zhou, Jinlei Ma, and Dandan Dong. 2021. "Infrared and Visible Image Object Detection via Focused Feature Enhancement and Cascaded Semantic Extension" Remote Sensing 13, no. 13: 2538. https://doi.org/10.3390/rs13132538
APA StyleXiao, X., Wang, B., Miao, L., Li, L., Zhou, Z., Ma, J., & Dong, D. (2021). Infrared and Visible Image Object Detection via Focused Feature Enhancement and Cascaded Semantic Extension. Remote Sensing, 13(13), 2538. https://doi.org/10.3390/rs13132538