1. Introduction
With the rapid development of observation and sensor technology, there has been a gradual improvement in the spatial resolution of remote sensing images, which provide substantial data sources for road extraction research [
1,
2]. Road networks extracted from remote sensing images have been applied in several fields, such as geological surveys [
3,
4,
5], disease monitoring [
6,
7,
8], and analysis research [
9,
10,
11]. As remote sensing images are timely updated, the extracted road networks can be beneficial for road planning [
12,
13], construction, graphic similarity measure [
14], and maintenance [
15,
16], and they can help update road network information. As the satellites are overhead and view sensors and the remote sensing images are large, road extracting methods must overcome some problems, such as the efficiency problem, shelter occlusion problem by trees (or other objects), and the data preparation problem during the training process.
(1) Efficiency problem. As in other remote sensing image object extraction research, efficiency is very significant to the large quantity of remote sensing image resources. Initially, the experts used computer vision methods to extract specific road features, such as straight segments and bends. Those studies [
17,
18] used spectral information and topological relations, such as the line feature detection algorithm based on random transformation [
19] and aperiodic directional structure measurement (ADSM) to extract road networks [
20] and distinguish between road networks and other ground objects. These methods can accurately obtain the single road features, such as a straight road segment and a bending road segment, when their parameters are manually set to distinguish every ground object feature. These methods can accurately extract road networks only in some special remote sensing scenes. Almost all remote sensing images have various complex scenes; the single-feature extract structure cannot completely and effectively express the characteristics of the road network. Moreover, manually setting the parameter is time-consuming and subjective.
(2) Shelter occlusion problem. As outlined above, the single-feature extraction method is not enough for remote sensing images for road extraction; therefore, this study needs an appropriate multi-feature extraction technique. Some researchers have used machine learning road extraction methods, which use classification or segmentation methods to extract road networks and distinguish them from other objects [
21,
22,
23]. In traditional machine learning methods, the support vector machine (SVM), K-means, and other methods are used to capture road network features. For example, Song et al. [
24] proposed an SVM trained using the spectral information in a remote sensing image to extract roads. The K-means [
25] iteration was designed for the segmentation of images, where the class of a road can be recognised, and the recognition result is filtered using a mathematical morphology method. A new conditional random fields (CRF) method [
26] was designed to detect road marks, in which prior information is presented by high-order pixel patches, which are connected by straight line super-pixels. In deep learning methods, the powerful feature extraction neural network method uses a large number of parameters to enhance the ability of the multi-feature extraction. Xu et al. [
27] designed a semantic segmentation method based on an end-to-end neural network, which is an improved U-net [
28] framework. It employs an attention patch for semantic segmentation modules to learn global and local features. Zheng et al. [
29] used a CRF-RNN neural network to extract road networks from remote sensing images, which transfers a loss to optimise the model via the deep learning method’s widely used error transform method, backpropagation (BP) algorithm, and obtained satisfactory results. Compared with computer vision road extraction methods, traditional machine learning road extraction methods have more powerful feature-extraction abilities. However, those methods are still not enough for the remote sensing image to extract road network from complex ground object scene. The traditional machine learning road extraction methods need structural features (straight, circumplex and so on) by artificial methods, such as the adjustment loss function; it is not suitable for the remote sensing image, which shelters by trees and buildings. Machine learning methods cannot predict road networks from occluded remote sensing images [
30]. Accordingly, a novel image feature prediction method should be considered for remote sensing image extraction.
(3) Data preparation problem. As discussed above, the machine learning methods need more powerful feature prediction capabilities to recover occluded sections of road networks. Fortunately, the generative adversarial network (GAN) [
31], which uses a new training strategy that can avoid artificial errors from the loss function, was proposed. This framework is adequate for learning deep features from training data and has a certain predictive ability. For instance, the paper [
32] considers the problem of cloud cover during road extract and designs an improved GAN network that combines an edge prediction framework with a colour filling part. There are also studies that used conditional generative adversarial network (CGAN) to construct semantic segmentation framework for high-resolution remote sensing images [
33]. This method proposed a segmentation method that combined long short-term memory (LSTM). This method is named CGAN-LSTM and it uses ground truth as the constraint condition to enhance high-level spatial information for remote sensing images. The results show that GAN has a powerful ability with shape prediction for ground objects. Benefiting from the adversarial training strategy of GAN, these segmentation methods have outstanding performance in terms of precision and further reduce the influence of occlusion from buildings and trees. However, these methods almost used supervised training data to fit the parameters, which needs labeled segmentation images to constrain the training process [
34]. The road segmentation labels need artificial marking, and remote sensing images are complex. Therefore, these methods take a lot of time and resources. A novel data preparation method should be considered for remote sensing images for road extraction. Due to the adversarial strategy of GAN, it is difficult to balance the training process between the generator and the discriminator. The standard GAN loss is not enough for the GAN training process.
Accordingly, to achieve road extraction more precisely, two issues should be solved: (1): the problem of road extraction labels needing artificial marking for building the training dataset. (2): balance the influences in loss optimisation during the training process. Thus, following the research line of relating works, this study introduces some outstanding methods to promote the performance of the road network extraction algorithm. The main contributions of this study are the following:
- (1)
This study proposes a weakly supervised method based on GAN to extract road networks from remote sensing images. The weakly supervised method significantly improves the dataset preparation process compared with the current supervised method [
35], which uses remote sensing and mapping images to train the model, rather than pairs of remote sensing and binary images.
- (2)
Owing to the outstanding prediction ability of GAN, the proposed method can further overcome masking problems due to buildings and trees, allowing the detection of a clear and straight road network. Furthermore, Wasserstein GAN with gradient penalty loss (WGAN-GP) [
36] is used to strengthen the efficiency of GAN, which avoids model collapse.
- (3)
Residual network (Res-net) block [
37] is used to enhance the feature extraction ability from the complex remote sensing scene, which combines shallow information with high-frequently information and does not miss the texture information.
The remainder of this paper is organised as follows.
Section 2 presents the methodology used for this study, including the GAN mapping framework, the loss in the GAN framework, and the post-processing operations.
Section 3 presents the experimental results.
Section 4 analyses the results of the experimental and focuses on group discussions.
Section 5 provides our conclusions.
2. Road Extraction from Remote Sensing Imagery
Weakly supervised road extraction has a large focus, where relatively few studies have been devoted to remote sensing image processing. Due to limitations in training datasets, which need pairs of segmentation images to be obtained, supervised road network extraction methods still have some problems. Weakly supervised methods can alleviate onerous demands of preparing the training data and reduce the requirements for the generation of road networks for which generating very accurate segmentation results is required. Thus, this study proposes a weakly supervised method based on GAN. This extraction method is completed in three steps. In a mapping network, the remote sensing image can be converted into a mapping image. In the complex remote sensing scene, to restore the road network of shelter by the tree, the information in no tree’s road is very important. Thus, to extract more features from the global information (other place’s information in original feature map), the mapping introduces numerous Res-net blocks. Second, in the model optimisation process, the instability loss function is replaced by WGAN-GP. Finally, in the post-processing process, the mapping image is converted into a binary image by a threshold value. To obtain more precise results, this study used a morphological method, known as the dilation and erosion method (DE) [
38], to remove salt-and-pepper noise [
39]. The structure of the road extraction network is shown in
Figure 1. Especially, to clearly display the structure of mapping image generator, discriminator, and Res-net, multiple colours are used in
Figure 2, and Figure 4, which can clearly distinguish each feature map in feature map block. In
Figure 3, the different colour means a different feature map block that is calculated by the convolution process.
2.1. WSGAN Model Structure
This study designed a road network extraction method, referred to as WSGAN, which is based on GAN and transforms the remote sensing image into a mapping image using a weakly supervised method, followed by the extraction of the road networks from the generated mapping image. The advantage of the mapping network can be summarised as follows: the GAN framework can learn a loss function that self-adapts to the training dataset and avoids errors related to unsuitable loss functions. This strategy alleviates the problem of artificial design loss function error present in most deep neural networks; it is powerful enough in the image shadow area. Encouraged by the performance of the GAN for semantic segmentation, the WSGAN was designed in two parts. The first part is the generator, G. In the WSGAN framework, G is used to generate the mapping image and mislead the discriminator, D, which is the second part designed to discriminate the original mapping image from the synthesis image. Both parts are trained by a confrontation strategy. In structure G, the outstanding data normalisation strategy, BN, is used in each convolution processing. Moreover, the ReLU and Tanh are used in G and D during the BN process.
In many studies, the generator framework is composed of traditional convolution neural networks, such as end-to-end networks. However, these end-to-end networks are not sufficient for the extraction of features from road networks, which cannot restore the global information for the deep layer. Thus, the skip connections in the Res-net block can greatly restore the information in the shallow network. Res-net is efficient at extracting features from images, such that, in the generator, G, this study used numerous Res-net blocks to extract the road network features.
Figure 2 shows the details of the mapping image generation network.
The Res-net blocks employ a learning strategy termed residual learning. In previous studies, the deep learning neural network uses a non-linear method to transform input information, while Res-net proposes a new connection method termed skip connections. Compared with traditional convolution neural networks, Res-net blocks allow original information to be connected with the previous layer. Moreover, traditional convolution and fully connected frameworks easily lose information during transmission. Vanishing and exploding gradients in convolution networks hamper the training of the deep network. The parameters can be reduced in this network, and the learning target can be more easily achieved. For remote sensing images, the residual learning method further restores high-frequency feature information for road networks and ensures that the
G network can recognise more prominent road objects. Moreover, the skip-connected strategy can restore the global information (position information and other shallow features) to a great extent. The structure of Res-net accelerates the training process and improves the accuracy of the model.
Figure 3 shows the details of the Res-net.
Despite their efficacy extract results, traditional neural networks that use a self-design optimisation loss function to fit models suffer from a major drawback, i.e., the large error used by the artificial loss function, which needs the road network extract experience and through that subjective information to complect the research. To solve this problem, this study used GAN to learn the loss function using a discriminant network for each training dataset. The discriminator of GAN is a classification network that distinguishes the original mapping images from the synthesis images. Thus, through optimising the loss function, the discriminator can accurately find the difference between the original and the synthesis mapping image. Compared with the artificial design optimisation function, the discriminator can automatically learn the optimised method through this training data. Thus, the GAN can avoid artificial errors due to the loss function, which does not need to design feature loss function by subjective experience and cause the inaccuracy model optimisation.
To improve the ability of the discriminator, this study used a training strategy known as Patch GAN [
40], which used average value to replace the original sigmoid results. PatchGAN removes the sigmoid strategy and mapping the feature map as an N×N matrix. The matrix will serve as the score to evaluate the authenticity of generated mapping image. This strategy is considered the receptive field as a convolution network, and each value of the matrix represents the score of each part in generated mapping image. Compared with the original discriminator, PatchGAN greatly focuses on more field in generated mapping image. This strategy considers the effects of different parts against the image rather than discriminating the image as a whole. A recent study, employing Pixel2Pixel [
41], showed the effectiveness of this strategy by comparing the results of patches of different sizes. For an input image of 256 × 256 pixels, when the patch size was 70 × 70 pixels, the results were similar to the input image. The Patch GAN can reduce the parameter size to improve the operational efficiency, discriminate the details in every patch, and enhance the ability of the generator. Owing to the independence of each patch,
D will generate different results, where the final result is the averaged value of several intermediate results.
Figure 4 shows the structure of the discriminator.
2.2. Mapping Model WGAN-GP Optimisation Processing
The loss function was used to control the training process of the generator and discriminator. The GAN training strategy is a promising approach for the learning of image process models. This method first uses a combat strategy for training a neural network, which aims to reduce the distance between the synthesis and target images. Despite its enduring success, the structure of GAN has several problems. First, due to training by an adversarial strategy, using the GAN loss function to balance the level of training of the generator,
G, and discriminator,
D, is difficult. In previous studies, which were based on the standard GAN method, the training step was carefully designed through the experience gained until the convergence of the model. Second, during training, the generator always suffers from the model collapse phenomenon, where similar results are produced by the generator. From this, during the training process, the experiments based on standard GAN loss function would cause disordered results and broken outputs. Finally, confirming whether the training process converged is challenging. Thus, the standard GAN loss function cannot optimise the parameters for road extraction. In the original GAN framework, the adversarial loss function converges by minimising the KL distance (Kullback–Leibler divergence) [
42] and maximising the JS distance (Jensen–Shannon divergence) [
43], which causes the generator to produce sample images with high diversity, but low quality.
There are a lot of studies that have designed workarounds to solve this problem, such as WGAN-GP and WGAN [
44]. For WGAN, the Wasserstein distance has been used to calculate a new loss function, known as WGAN loss. However, the weight of the generator is required to clip results in extreme parameter values. This problem causes poor results and gradual data overload during training. Besides, gradient punishment is combined with weight clipping in WGAN-GP. This loss function further stabilises the performance of WGAN. Therefore, the WGAN-GP loss function is a weight control method in WGAN that restrains the weight of the discriminator via a gradient loss function. WGAN-GP is an effective strategy for controlling the training progress through the weight control loss in the discriminator function. For this, WGAN-GP loss replaced the original standard GAN loss and was used to optimise the discriminator. The optimisation algorithm of the mapping model is as follows:
where
,
is the distribution of the real mapping image,
is the distribution of the generated mapping image, and
is a random value between 0 and 1.
In the training process of
D, the parameter of
G is fixed, and the parameters of
D will be optimised by
D loss. The purpose of
D is distinguished generated mapping image with GT mapping image; thus the
D loss would make the bigger value in the score of
D(y) and the smaller in the score of D(G(x)). Especially, to complect the strategy of WGAN-GP, the gradient penalty is also added in
D loss. The
D loss function is as follows:
In the training process of
G, the is fixed, and the parameters of
G will be optimised by
G loss. The purpose of
G is made
D cannot distinguish generated mapping image with GT mapping image; thus the G loss would make the bigger value in the score of
D(
G(x)) and the smaller in the score of
D(
y). Especially, because the fixe of the parameter of
D,
is fixed. Thus, the
G loss is as follows:
Moreover, to improve the similarity of the generated mapping images to the original mapping images in the pixel feature, this study used the
L1 loss to optimise the generator. The complete mapping network loss function is as follows:
where
λ is the weight of the
L1 loss,
y is the original mapping image, and
y~ is the generated mapping image.
2.3. Binary Image DE Method Post-Processing
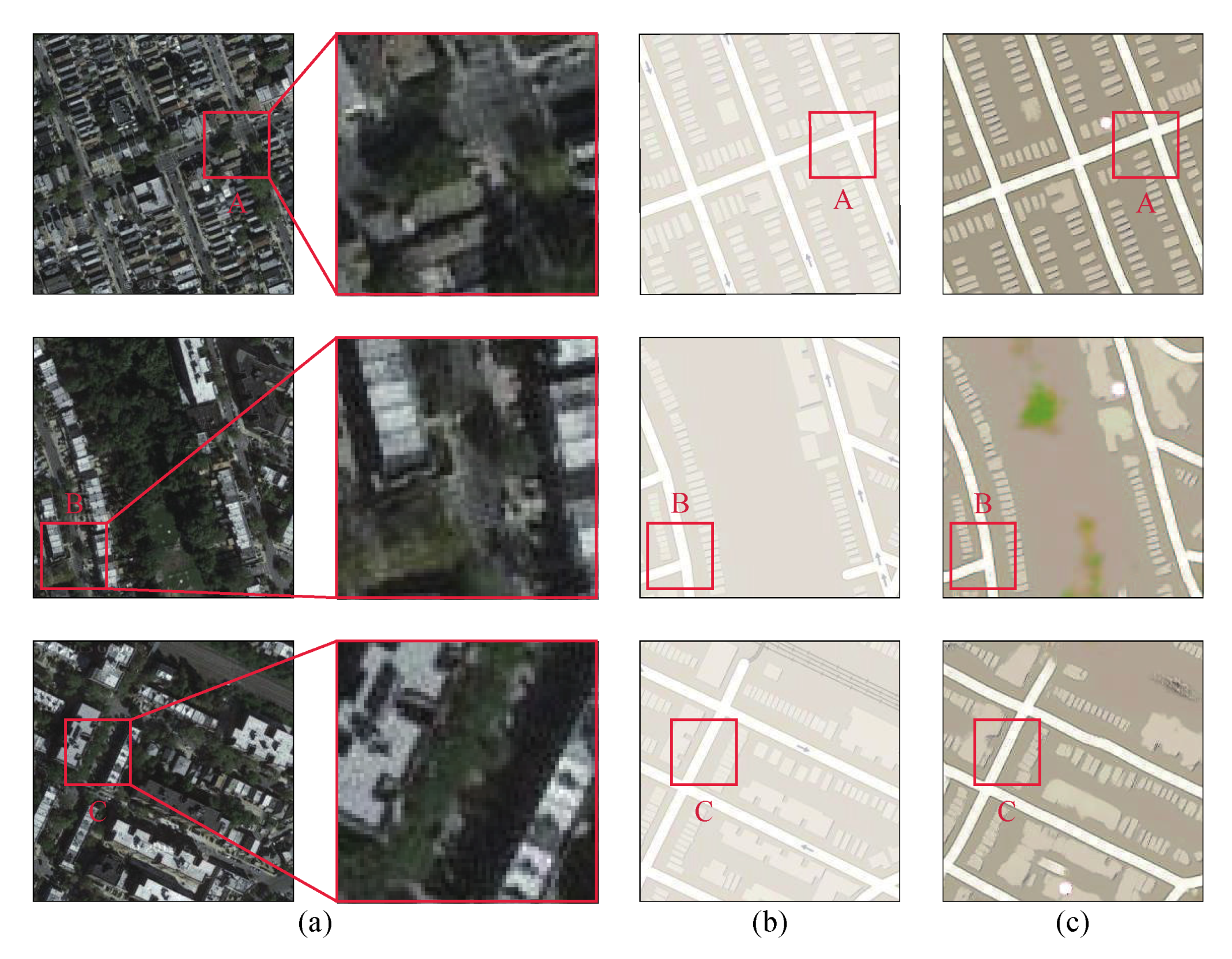
Spectra are the specific attributes of the ground object in a remote sensing image, where each type of ground object corresponds to a spectral curve. The difference in the reflected or emitted battery radiation energy in different wavebands of ground objects is due to the formation of a colour difference in the RGB image. Thus, according to the spectral characteristics of remote sensing images, road networks can be effectively extracted. In this study, remote sensing images were transformed into mapping images, which had a uniform distribution of pixel values, where the road network area had a value of 255 and other objects had a value of 0. For the mapping image, binarisation processing was used to extract the road network. A dynamic adjustment of the threshold value, selected through the binary results, was used to segment the mapping image.
Image binarisation transforms the mapping image into a binary image, whose pixel values are 0 or 255. All pixels whose values are equal to or above the threshold value were judged as belonging to the road network, with a grayscale value of 255; otherwise, pixels with values below the threshold were excluded from the road network, with their values set to 0. These areas represented the background or other objects. Thus, the mapping image can be presented as a binary image, where the road network is notable. In other words, the values of the mapping images were transformed to extreme values by an appropriate threshold value while the binary image retained the road network features in the mapping image. Binary images play a critical role in the field of digital image processing, significantly reducing the amount of data for the mapping image and highlighting the outline of the road network. At the same time, the image must be binarised to perform binary image processing or analysis.
Despite their safety and efficacy, binary images produced by a threshold value always suffer from salt-and-pepper noise, also known as impulse noise, which is a random occurrence of white or black dots in otherwise white or dark areas, as well as a light and dark point noise, which is checkered with black and white. In most instances, the image sensor, transmission channel, or decoding process produces salt-and-pepper noise. Black noise spots are known figuratively as pepper noise, while white noise spots are known as salt noise. In general, these two types of noise always appear simultaneously. Salt noise may be caused by a sudden and strong interference in the image signal during conversion from analogue to digital or during bit transmission, where a failed sensor results in a minimum pixel value (black) and a saturated sensor results in a maximum pixel value (white).
At present, morphology methods are used to remove salt-and-pepper noise. To obtain better experimental results, this study compared several morphological removal methods that can process noise under complex circumstances. The DE morphology method is efficient at removing the noise from a binary image and uses structural units to measure and extract corresponding patches to achieve image analysis and recognition. This method can effectively remove noise and retain the original features of remote sensing images.
The DE method is known as a morphological operation, which is typically used to remove noise from binary images and is similar to the contour detection method. The dilation process adds pixels to the boundaries of perceptual objects and expands the bright white areas in the enlarged image. This process allows the boundary point to shrink into the object’s interior and removes small noise points, such as salt noise. In contrast, erosion removes the noise and reduces the object size along object boundaries. This process combines the background point, which is in contact with the object, to fill the mask. The input for the noise removal method is the binary remote sensing image, while the output is the binary road network image, which is clear and straight.
Figure 5 shows the results of this method.
4. Discussion
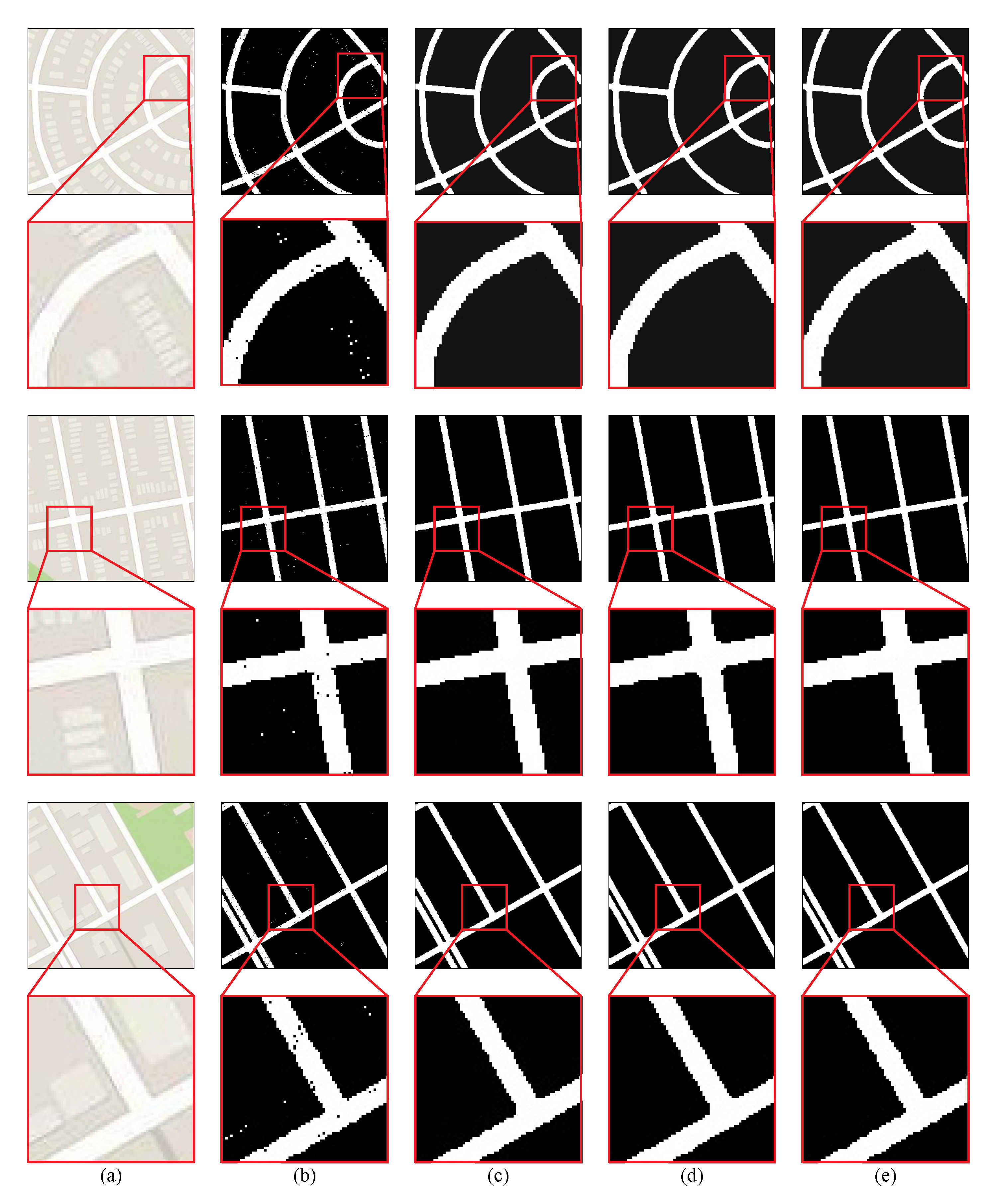
Due to the limitation in the recent road network extraction method, this study used a weakly supervised method, which had three steps: mapping, binarisation, and removal. Furthermore, to obtain more robust results, in the basic GAN model, this study made the following improvements to the mapping network. First, to obtain a complete road network and enhance the predictive ability of the generator, Res-net was used for the generator to improve the feature extraction ability. Second, during the training process, the structure of the GAN has problems converging, and the generated results become uncontrollable, a phenomenon termed model collapse. The WGAN-GP was effective at avoiding model collapse as opposed to the GAN loss during the training process. In contrast to the standard GAN, the WGAN-GP produced a weight control strategy and used the gradient control method to clip the value of the weight. For the contributions of this road network extraction method, the salt-and-pepper noise removal methods have been discussed, and the efficiency of the innovation factor was compared. Moreover, the threshold advantage of this method is fully analysed.
In
Figure 10, to accurately extract the outline of the road network, this study compared the DE method to previous studies on noise removal. Additionally, the details about the denoise results are magnified at the bottom of the results. The results of the DE were the most accurate and most similar to the ground truth. The results of the other methods showed excessively smooth edges, such that the boundary of the road network appears unrealistic, which reduces the utility of the road network extraction model and reduces the efficiency of the binary image. As shown in
Figure 10, the salt-and-pepper noise removal method showed strong robustness, which performed well on the testing dataset. The edge of the road network binary image is evident. The pepper noise in the road network and the salt noise in other objects were removed. The class of the road network with other ground objects became more notable. Therefore, our model can remove the salt-and-pepper noise from binary remote sensing images.
Moreover, to prove the effectiveness of our method, the innovation factor was compared with the binary result. The mapping images were binarised by the DE method, and the mapping methods were trained by the same training dataset, whose results are shown in
Figure 11.
As shown in
Figure 11, WGAN-GP had an outstanding performance and avoided the model collapse phenomenon. Moreover, Res-net was efficient at feature extraction, such that there was improved detection of the road network. Compared with the other methods, the WGAN-GP loss had a powerful ability with respect to image generation. The weight clip method produced an appropriate network weight rather than clipping the weights by extreme values. Moreover, in masked areas, our method recovered a sharper mapping image. The road network had straight edges in the WGAN-GP results, where the colour of the road network was distinguishable from those of other objects.
In most instances, the road network had similar spectral information with other ground objects. Therefore, although this study generated the mapping image from a remote sensing image, the road networks pose challenges when extracting them from mapping images. Thus, to extract a precise road network, the mapping image generated model must have a sensitive spectral information perception ability. To evaluate the spectral information perception ability,
Figure 12 compares our results with the improved method’s results (WGAN loss and Res-net) for each threshold, which had identical scores before the pixel value was set to 100.
As shown in
Figure 12, this study compares the scores of evaluating indicators between the proposed method and the improved method at each threshold. Among the results, F1 values higher than 0.8 are marked in pink, which indicates that the entire mapping image achieved satisfactory results at the corresponding threshold. Based on
Figure 11, the pink area corresponding to our method is larger than the improved method. Therefore, this shows that our road network extraction method has a stronger ability to capture the colour features between the road network and other features than other road network extraction methods, as well as stronger robustness due to the weakly supervised road extraction method. Moreover, this method has outstanding pixel adaptability during the processing of mapping image binarisation, with more than a 50-pixel scale (183–241). Compare with the WSGAN, the method of (b) contains a 13-pixel scale (234–247). Thus, our method provides a better solution to the difficulties associated with obtaining accurate pixel values during practical applications.
To evaluate the binary results through the image visual perception method,
Table 1 lists the IoU, ACC, P, R, and F1 scores for the WSGAN method and standard GAN with the Res-net framework to quantitatively evaluate the effectiveness. By comparing the results of the two methods (
Table 1), this study can observe that the improved GAN (this study) obtained better results, which is bold the bigger score in the
Table 1.
The standard GAN with the Res-net framework is an outstanding image transfer method, which used numerous Res-net blocks in the generation network to promote the ability of high-frequency information extraction. However, this method still does not solve the problem associated with the standard GAN training process. Benefiting from the WGAN-GP loss, the WSGAN model achieved relatively satisfactory performance with respect to the IoU, P, R, ACC, and F1 scores; therefore, the WSGAN model generally yields excellent performance.
Benefiting from the Res-net block and GAN structure, the proposed WSGAN model achieved outstanding performance in complex remote sensing scenes. At the same time, to clearly display the road network results, this study used several colours to represent the FP (False Positive), FN (False Negative), road network, and background, where the green colour is FP, red is FN, white is the road network, and black is background. The results of the analysis are shown in
Figure 13.
From
Figure 13, we can see that the road network has great performance in the shelter region and the false-positive area, and false-negative areas are very few. Especially, the shape of the road is also restored, which is total occlusion by the tree. However, there still exists some error in those results; the region in no prior information (such as the first row) has too thick trees, and has building boundary information (such as the third row) that is very difficult to restore.
5. Conclusions
In this study, a weakly supervised method was designed for road network extraction from remote sensing images, termed the WSGAN. The proposed method can be trained by an unpaired dataset with three steps. (1): The mapping network transforms the style of the remote sensing image to obtain the mapping image, which removes textural details and gives several colours for the ground object. The mapping network uses the GAN structure, which can greatly avoid artificial errors and automatically fits the generator from remote sensing images and mapping images. Through the auto discriminate in D, this study avoided design loss function by subjective experience, and the generated mapping image enhanced the road network’s feature. The generator used the Res-net block to extract more high-frequency ground object information, and in the optimisation loss function, the WGAN-GP loss solves the collapse problem. (2): To extract the road networks, the mapping image was binarised by a threshold value. To obtain the optimal binary threshold, the evaluation indices were estimated at each threshold, where 213 was the optimal value. (3): As the mapping network is not a semantic segmentation model, the binary image was unavoidably covered with salt-and-pepper noise. To solve this problem, this study selected the DE method, which effectively removed salt-and-pepper noise and retained the original information.
General learning methods for extracting roads from remote sensing images require a significant number of paired samples, where every pixel must be labelled as a road or not. In this study, a weakly supervised framework based on the GAN, which can be trained by easily obtained images (remote sensing images and corresponding mapping images), was designed. This method yielded outstanding mapped road network results, even though some roads were covered by the shadows of buildings or trees. In binarised processing, the experimental results show outstanding performance in obtaining a binary road network image, with the extraction of clear edges and a straight road network. In the future, this study will focus on cartography and use the proposed method to extract other terrain features. To obtain more accurate results, we will further optimise the mapping model. Due to unique training, the weakly supervised method cannot be evaluated similarly to other supervised methods. In future research, we will focus on establishing evaluation indices for the weakly supervised method. Especially, time complexity is also an important study point in after-years, and we will try to optimise network structure and reduce the number of parameters.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}