
Crop Yield Prediction Based on Agrometeorological Indexes and Remote Sensing Data


Abstract
1. Introduction
2. Study Area and Data
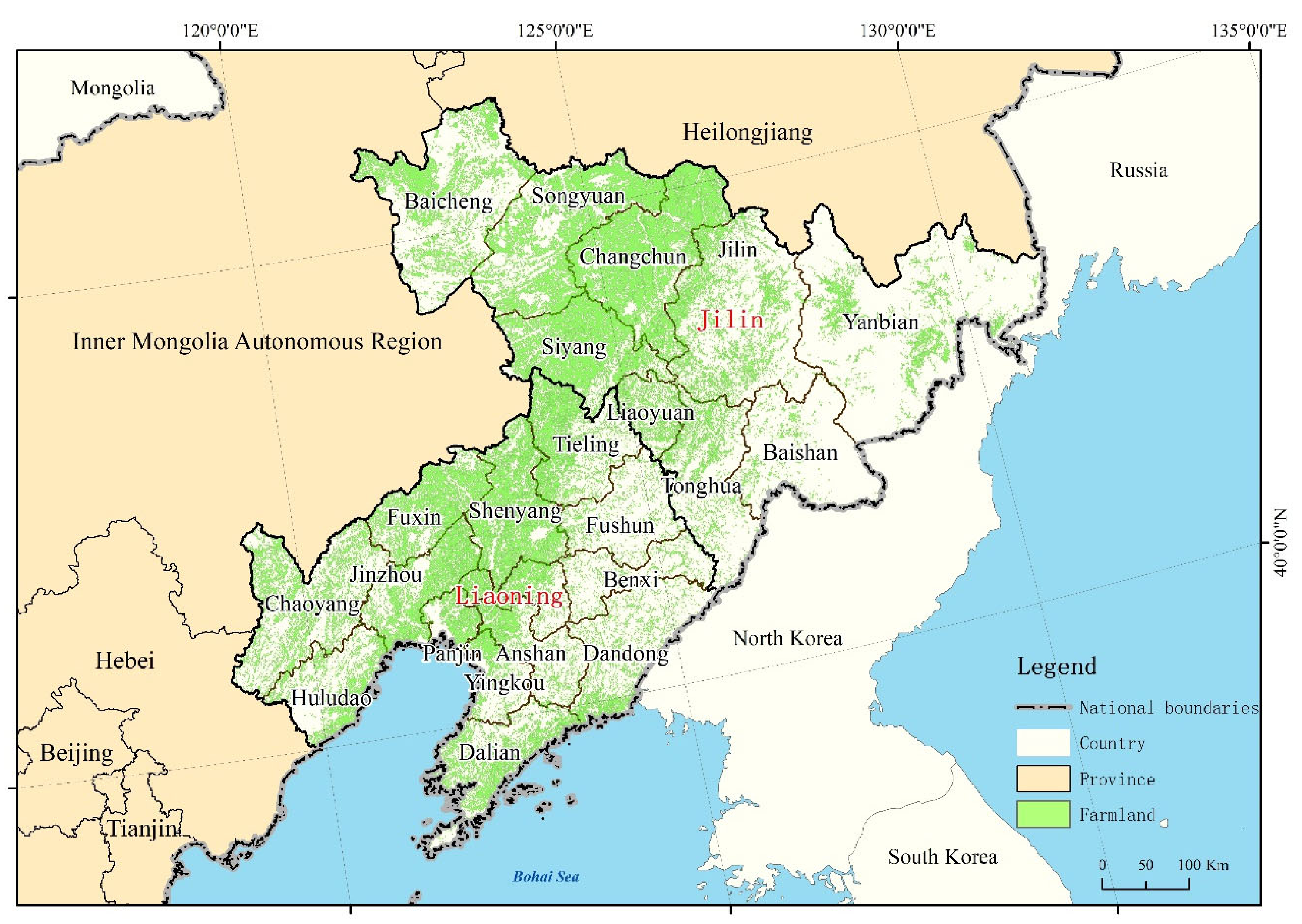
2.1. Study Area
2.2. Data
3. Methodology
3.1. Input Variable Calculation
3.1.1. Calculation of Technical Yield
3.1.2. Calculation of Agrometeorological Index
3.1.3. Calculation of NDVI and GPP Anomalies
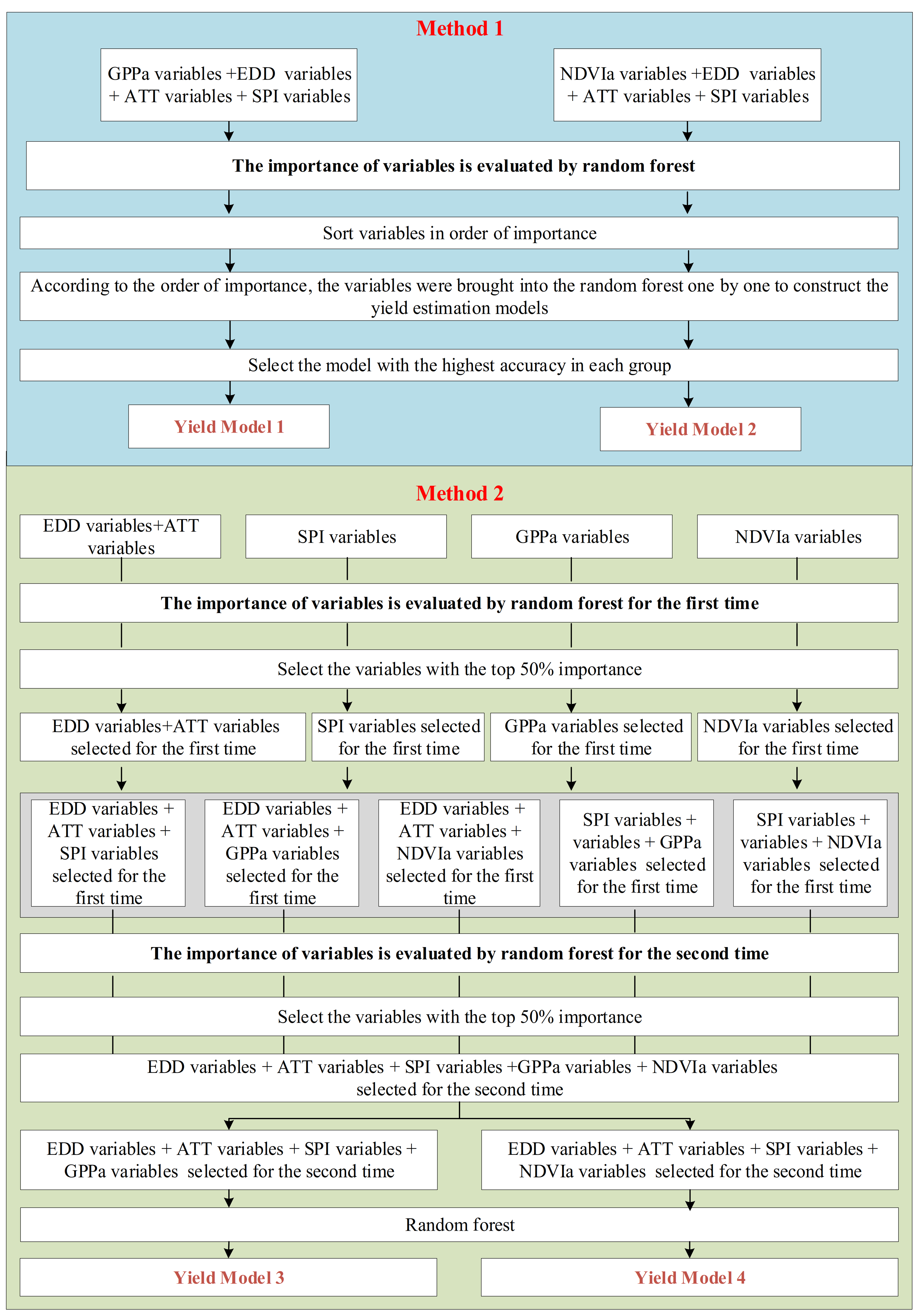
3.2. Model Building Process
3.3. Model Validation
4. Results
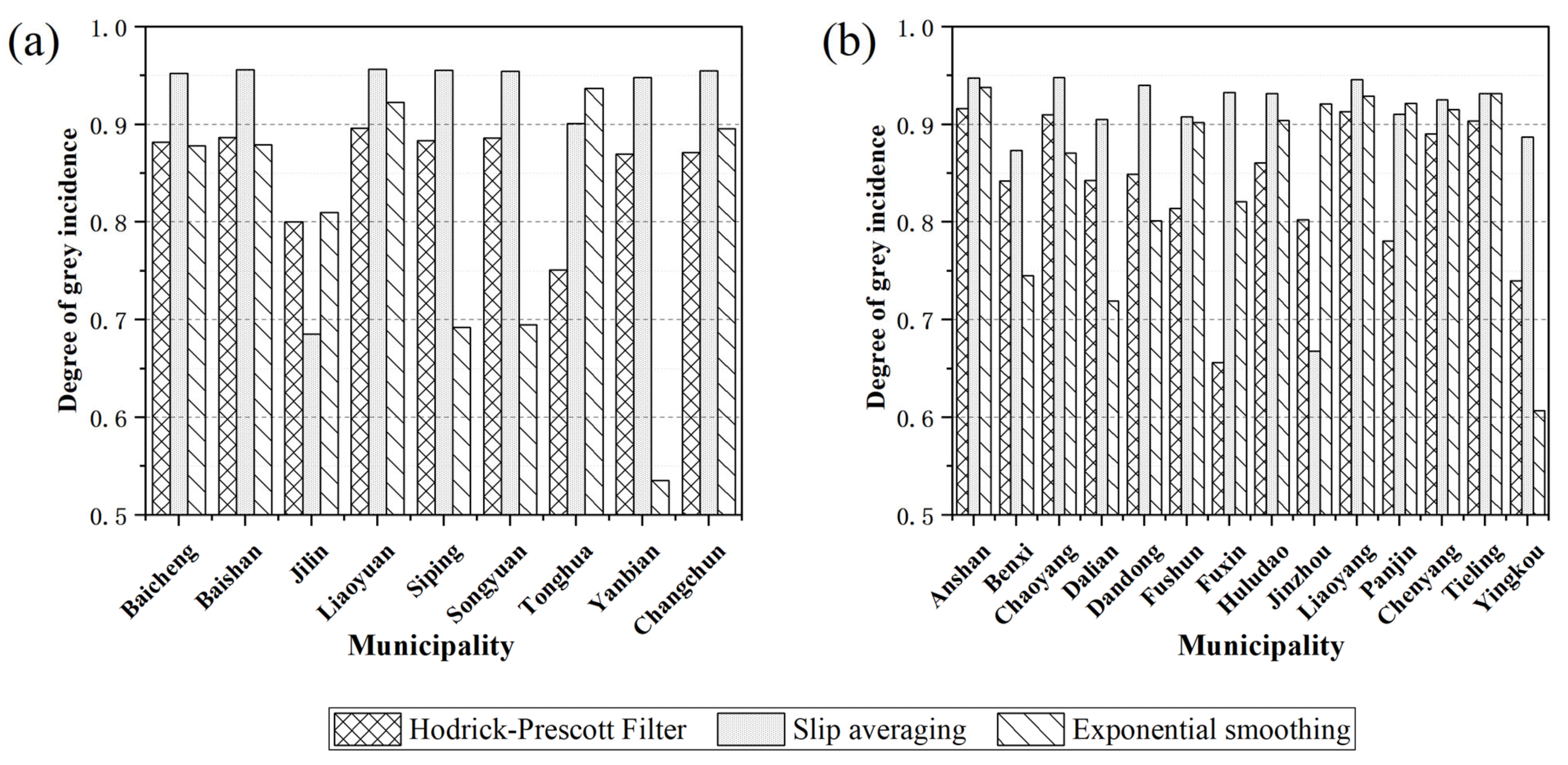
4.1. Trend Yield
4.2. Yield Estimations Models Built in Jilin and Liaoning Provinces
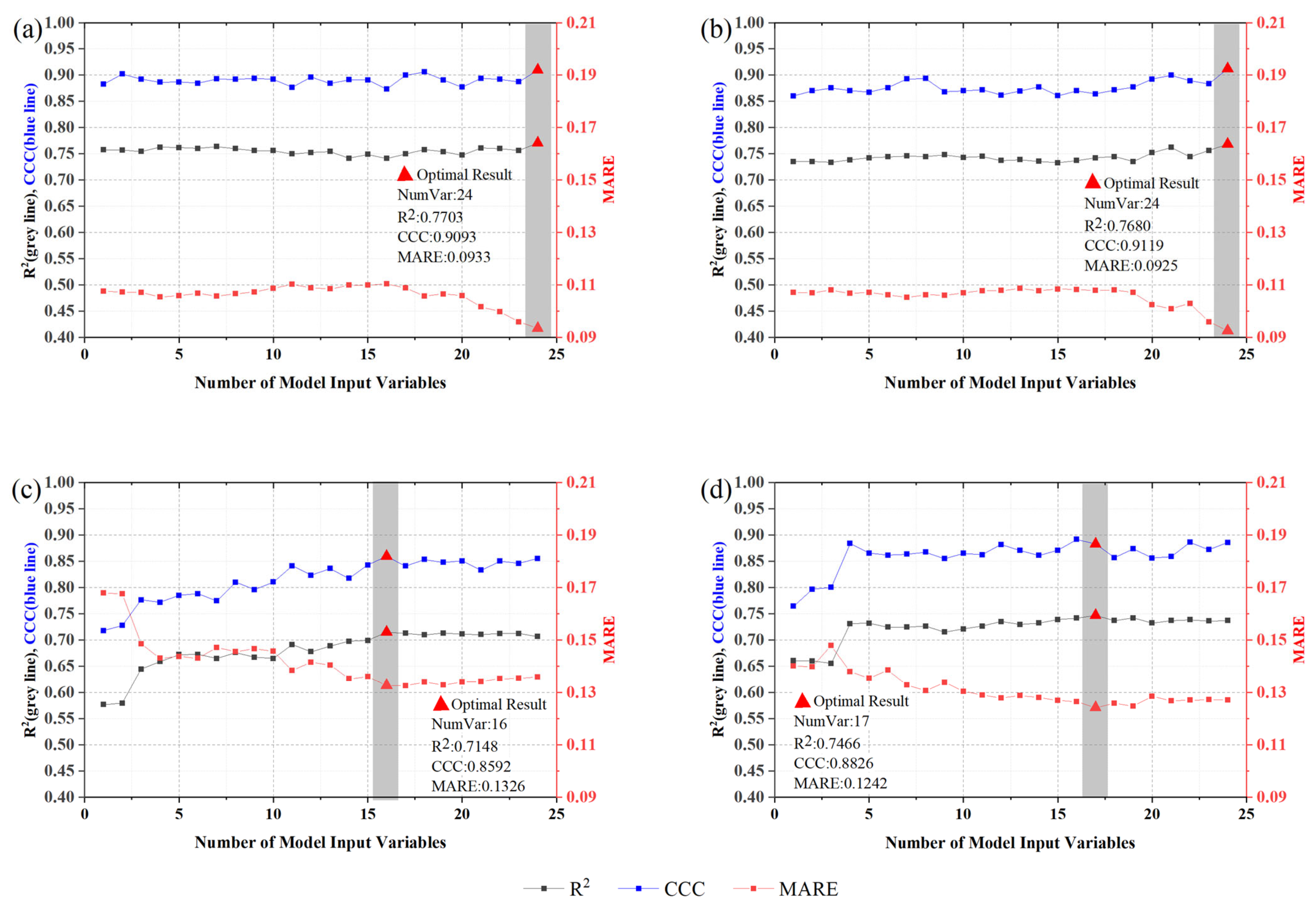
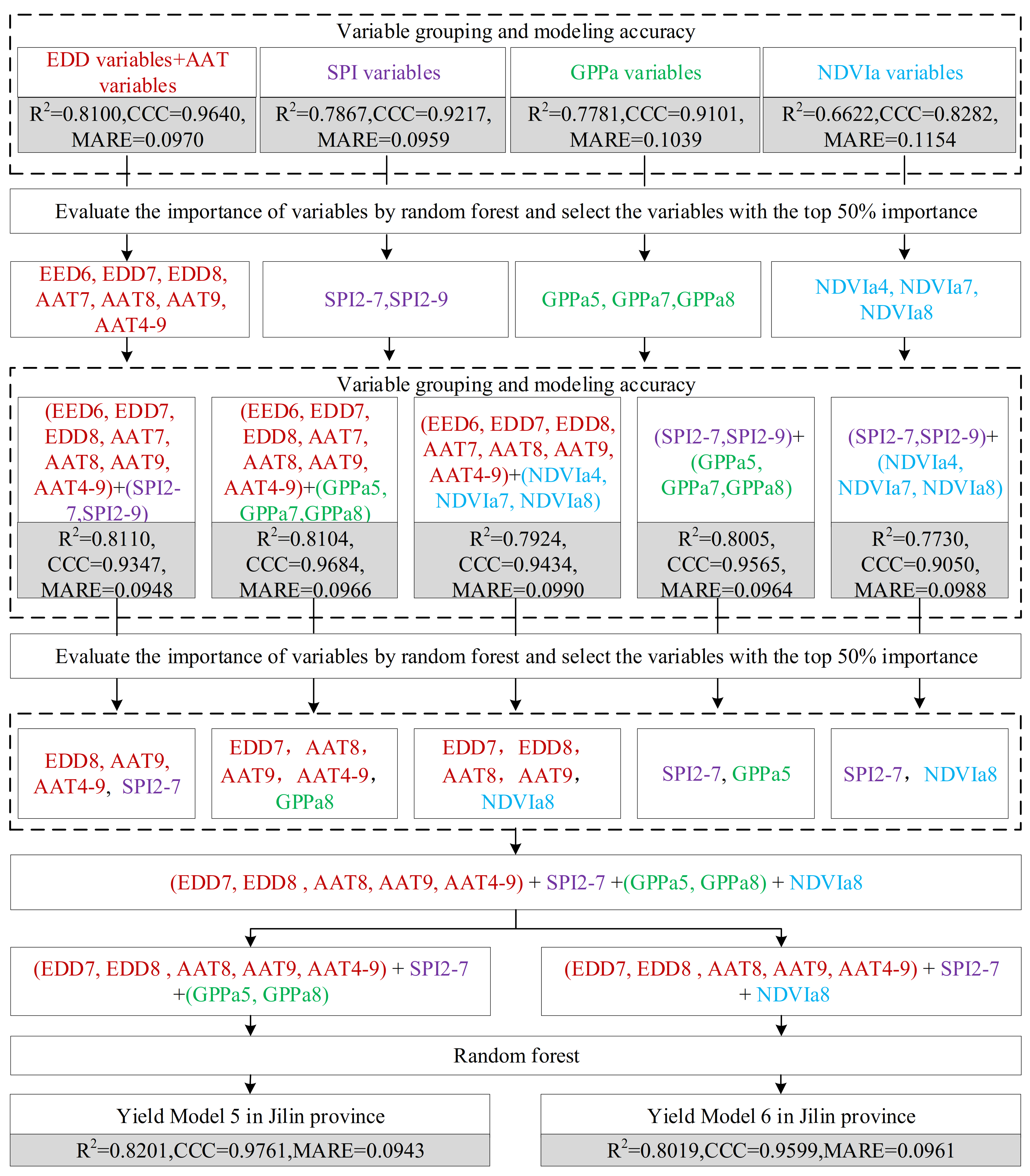
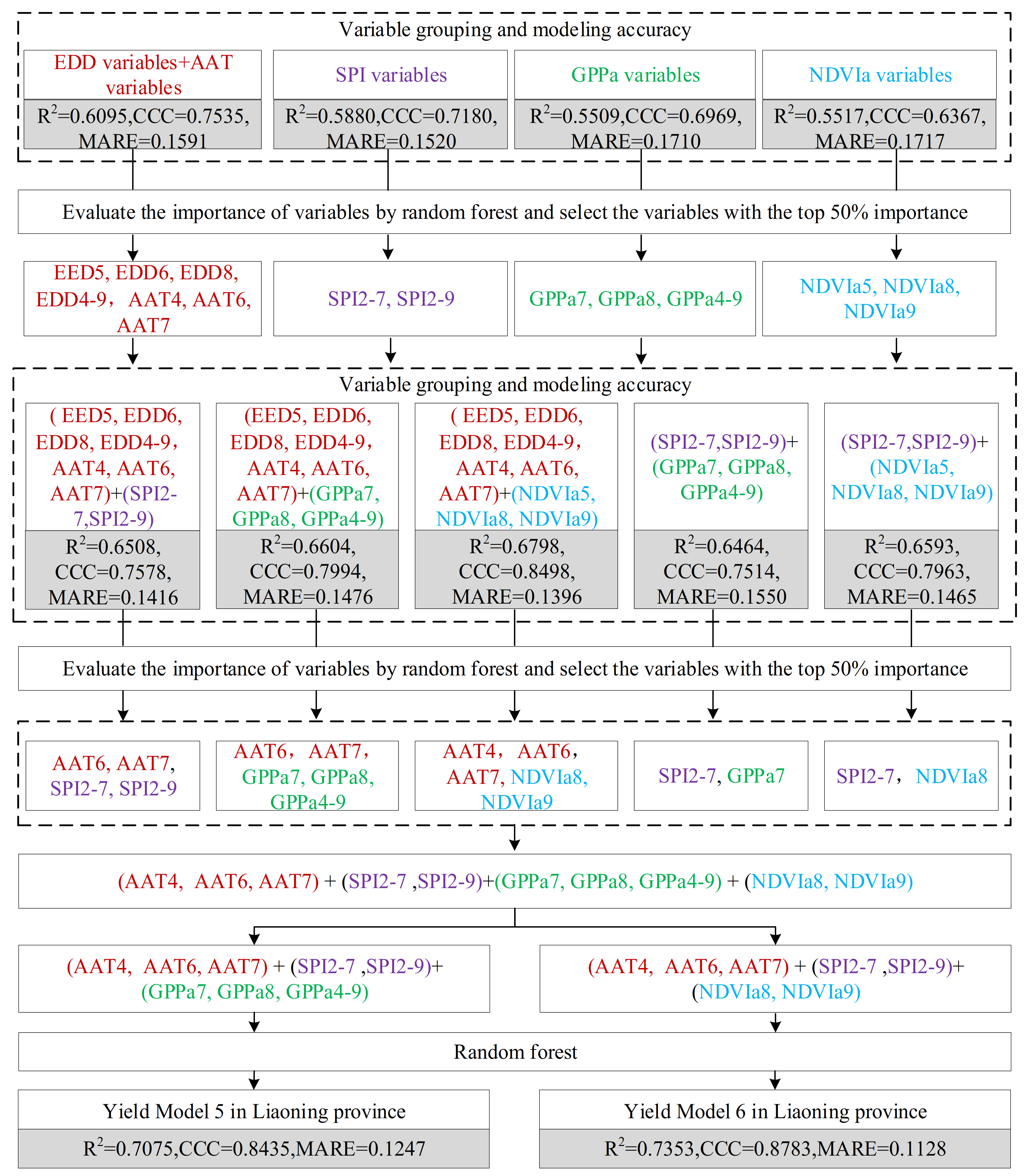
4.2.1. Models Built Using Variables Selected by Random Forest
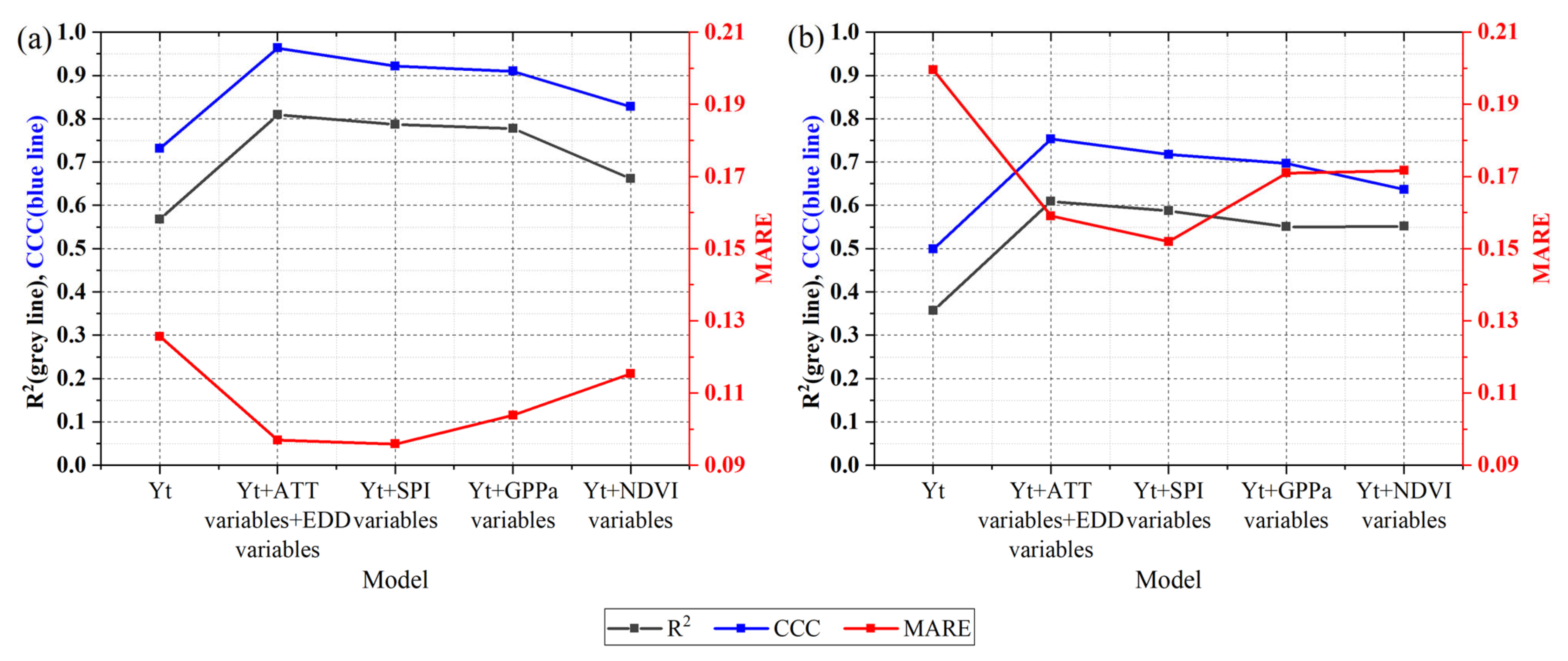
4.2.2. Model Built Using Variables Selected by a Two-Stage Importance Evaluation Method
4.2.3. Determination and Verification of the Final Yield Estimation Model
4.3. Comparision of Two Variable Selection Methods
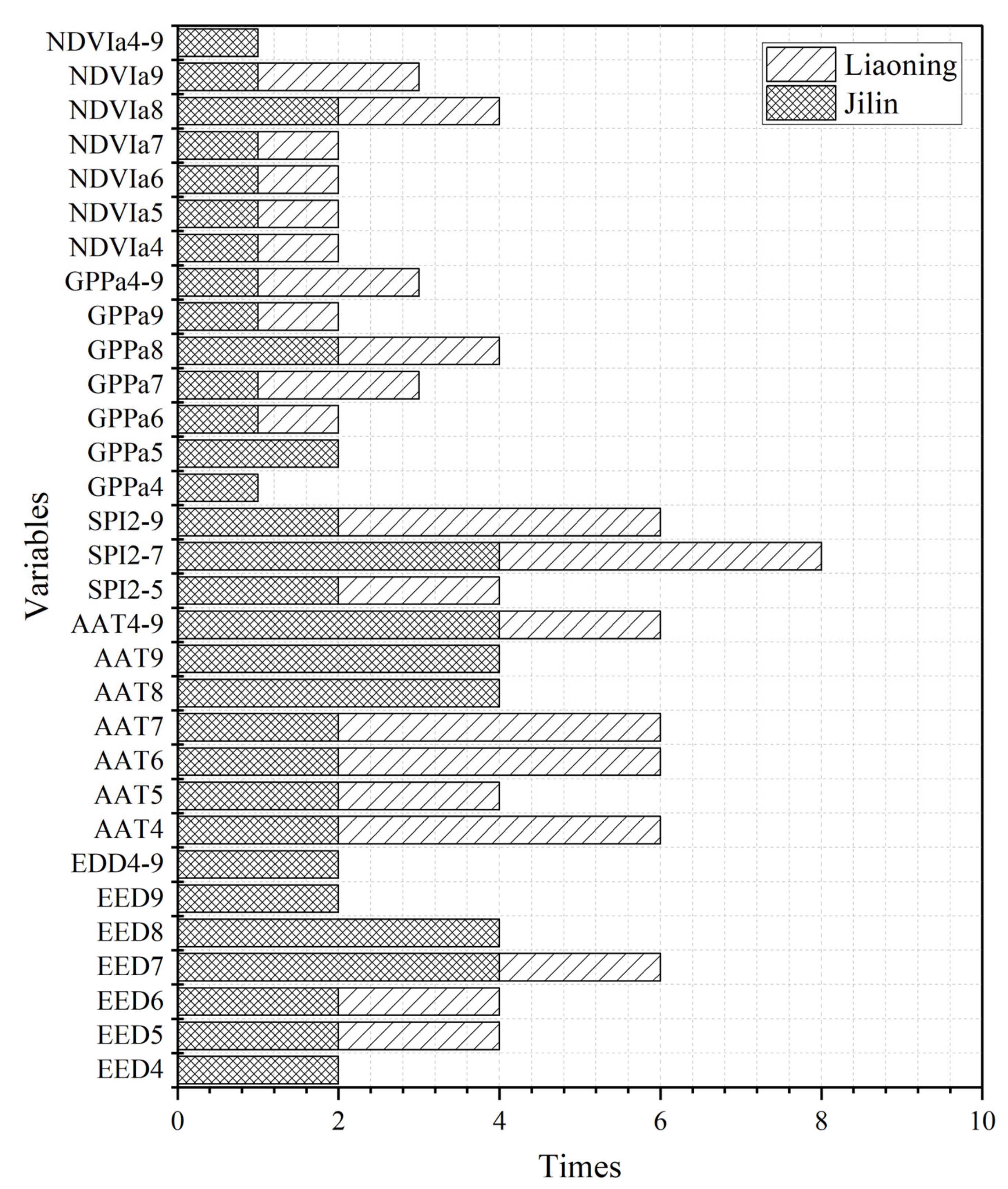
4.4. Comparison of the Importance of Different Variables
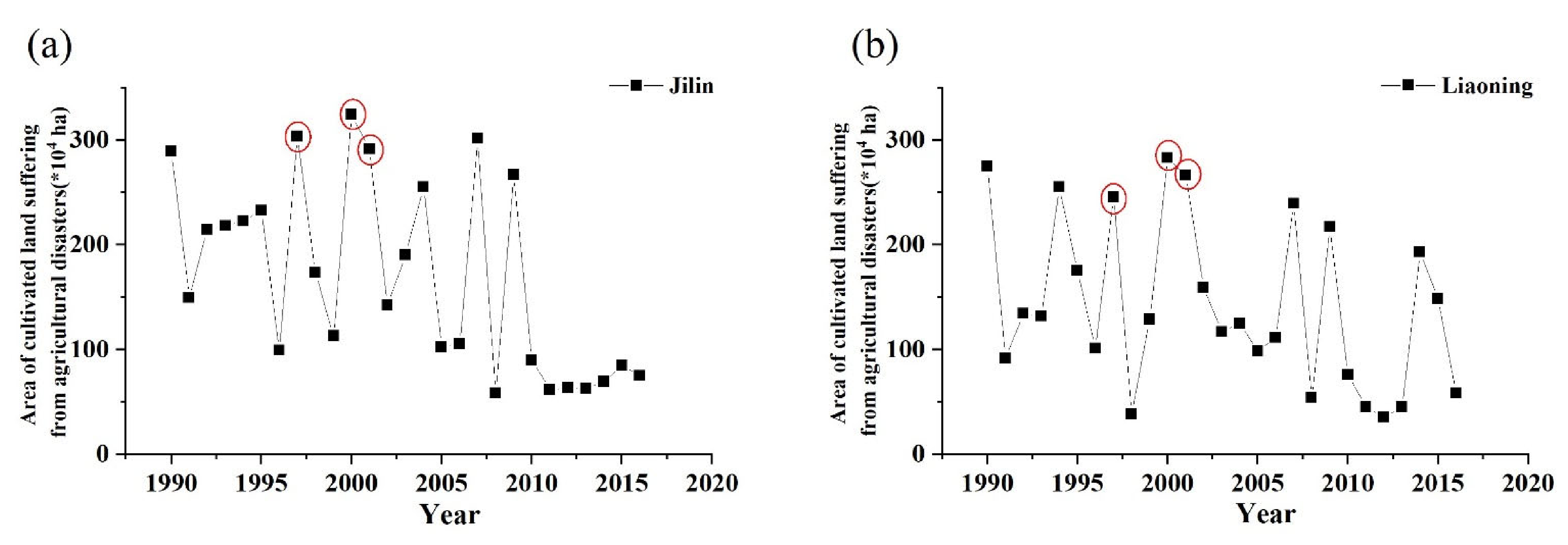
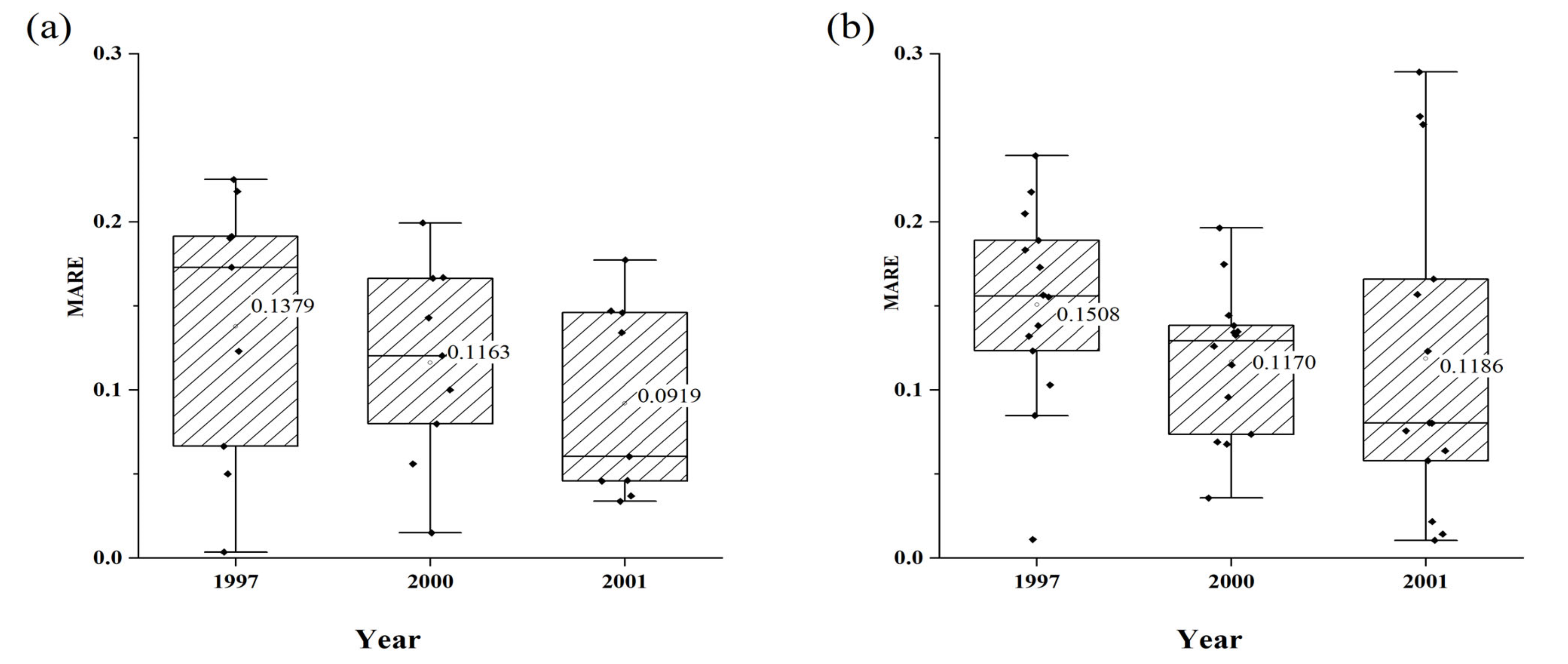
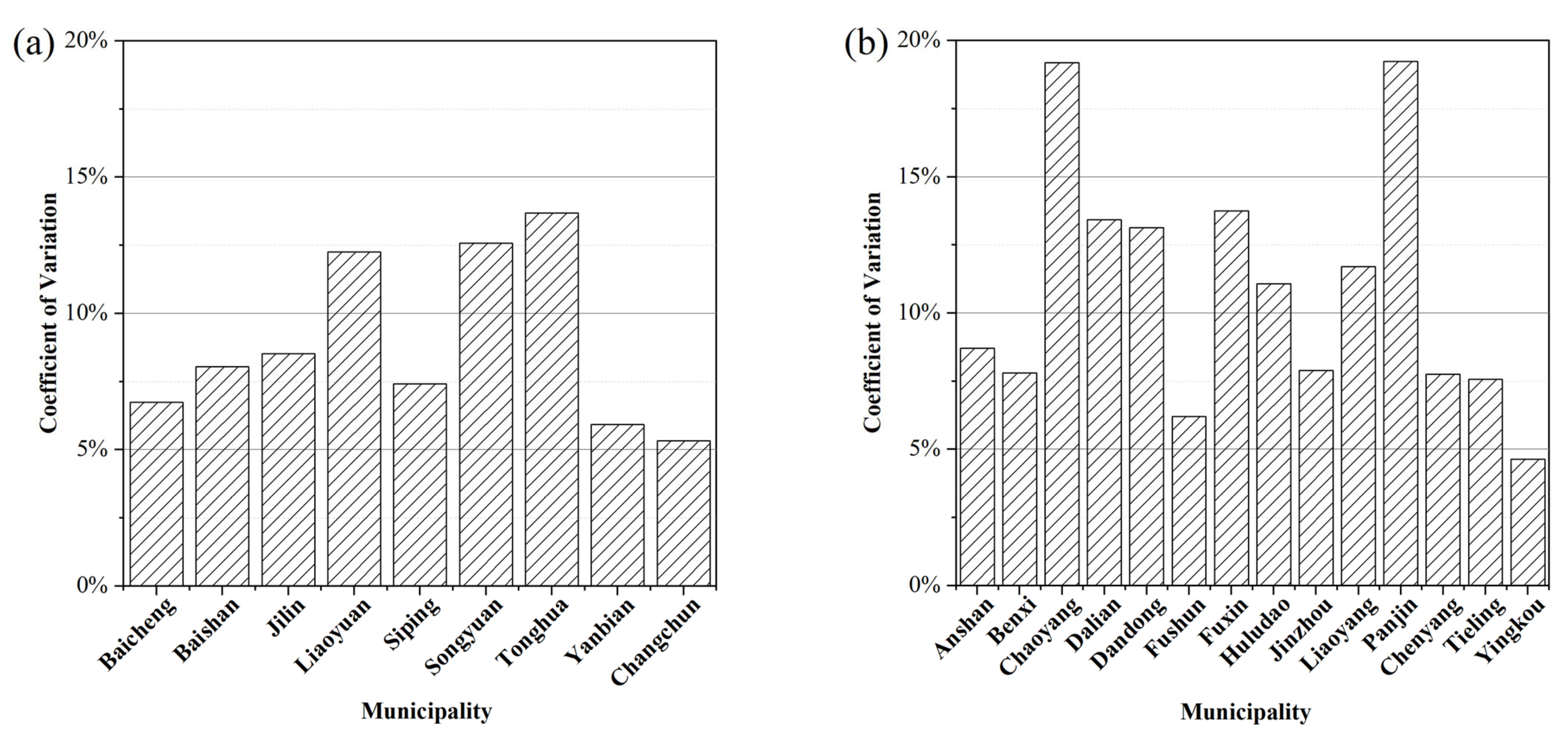
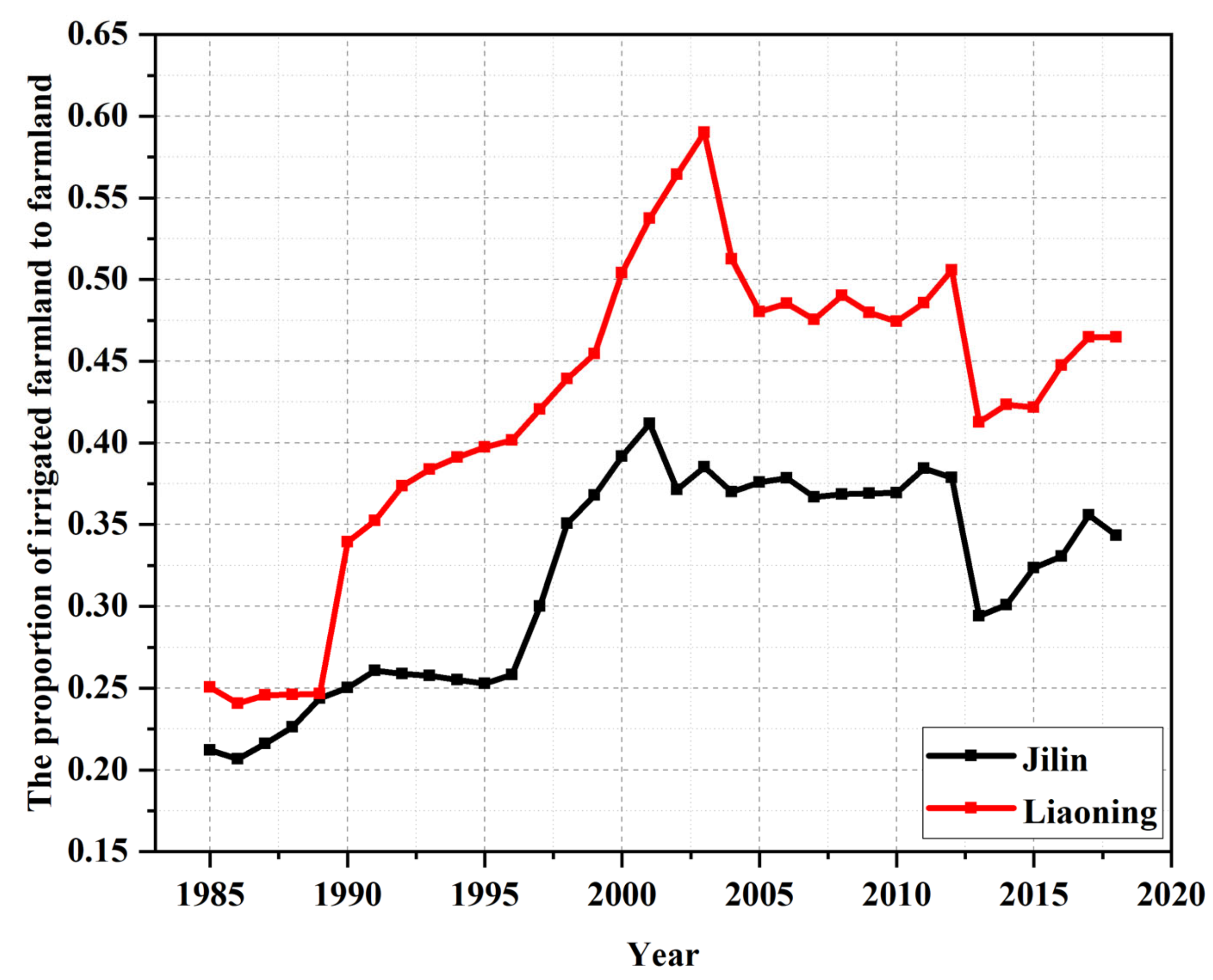
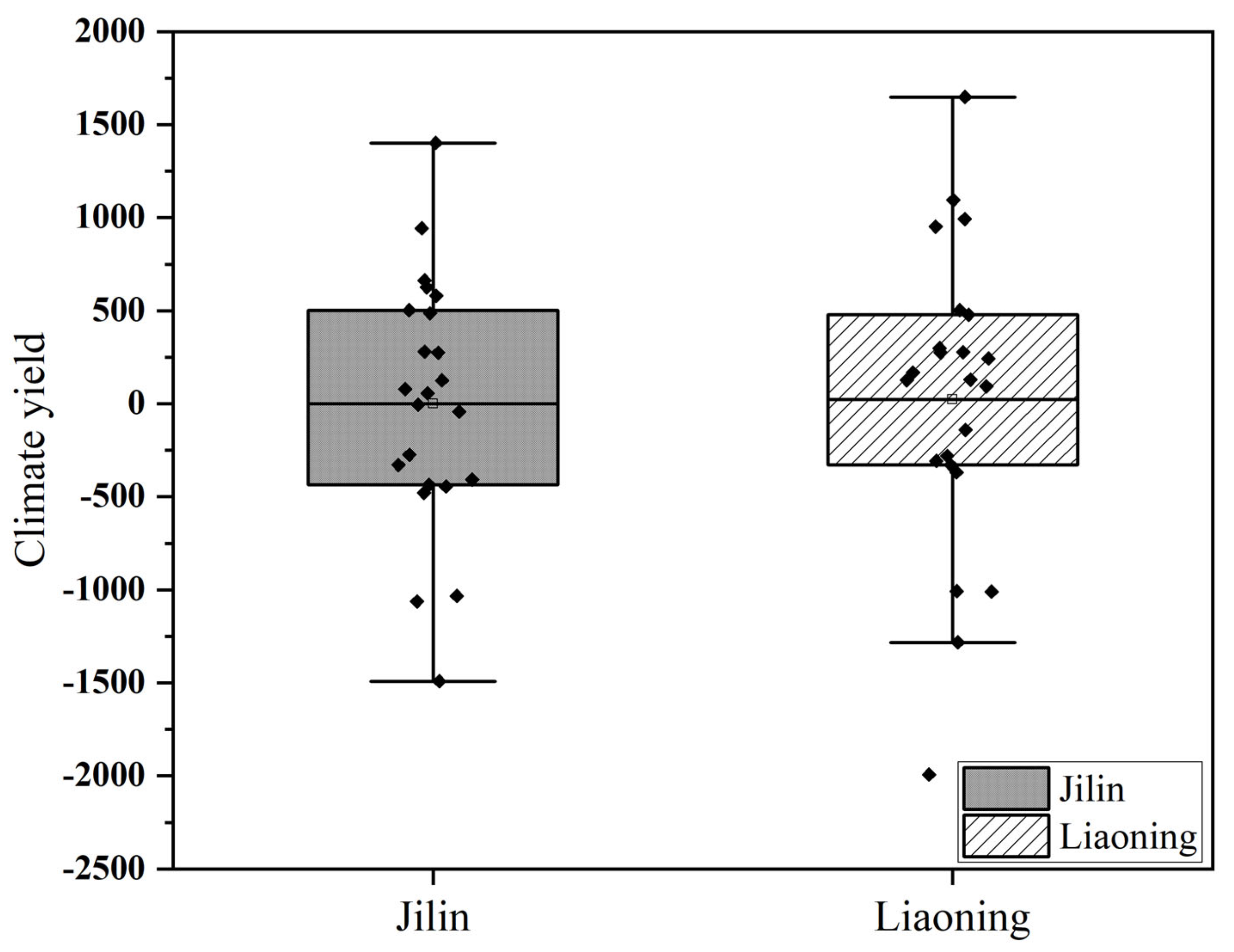
4.5. Comparision of Two Studied Provinces
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Van Ittersum, M.K.; Cassman, K.G.; Grassini, P.; Wolf, J.; Tittonell, P.; Hochman, Z. Yield gap analysis with local to global relevance–A review. Field Crops Res. 2013, 143, 4–17. [Google Scholar] [CrossRef]
- Lobell, D.B.; Cassman, K.G.; Field, C.B. Crop yield gaps: Their importance, magnitudes, and causes. Annu. Rev. Environ. Resour. 2009, 34, 179–204. [Google Scholar] [CrossRef]
- Murthy, C.S.; Thiruvengadachari, S.; Raji, P.V.; Jonna, S. Improved ground sampling and crop yield estimation using satellite data. Int. J. Remote Sens. 1996, 17, 945–956. [Google Scholar] [CrossRef]
- Kasampalis, D.A.; Alexandridis, T.K.; Deva, C.; Challinor, A.; Moshou, D.; Zalidis, G. Contribution of remote sensing on crop models: A review. J. Imaging 2018, 4, 52. [Google Scholar] [CrossRef]
- Moulin, S.; Bondeau, A.; Delecolle, R. Combining agricultural crop models and satellite observations: From field to regional scales. Int. J. Remote Sens. 1998, 19, 1021–1036. [Google Scholar] [CrossRef]
- Yao, F.; Tang, Y.; Wang, P.; Zhang, J. Estimation of maize yield by using a process-based model and remote sensing data in the Northeast China Plain. Phys. Chem. Earth 2015, 87–88, 142–152. [Google Scholar] [CrossRef]
- Huang, J.; Sedano, F.; Huang, Y.; Ma, H.; Li, X.; Liang, S.; Tian, L.; Zhang, X.; Fan, J.; Wu, W. Assimilating a synthetic Kalman filter leaf area index series into the WOFOST model to improve regional winter wheat yield estimation. Agric. For. Meteorol. 2016, 216, 188–202. [Google Scholar] [CrossRef]
- Shanahan, J.F.; Schepers, J.S.; Francis, D.D.; Varvel, G.E.; Wilhelm, W.W.; Tringe, J.M.; Schlemmer, M.R.; Major, D.J. Use of remote-sensing imagery to estimate corn grain yield. Agron. J. 2001, 93, 583–589. [Google Scholar] [CrossRef]
- Panda, S.S.; Ames, D.P.; Panigrahi, S. Application of vegetation indices for agricultural crop yield prediction using neural network techniques. Remote Sens. 2010, 2, 673–696. [Google Scholar] [CrossRef]
- Becker-Reshef, I.; Vermote, E.; Lindeman, M.; Justice, C. A generalized regression-based model for forecasting winter wheat yields in Kansas and Ukraine using MODIS data. Remote Sens. Environ. 2010, 114, 1312–1323. [Google Scholar] [CrossRef]
- Palosuo, T.; Kersebaum, K.C.; Angulo, C.; Hlavinka, P.; Moriondo, M.; Olesen, J.E.; Patil, R.H.; Ruget, F.; Rumbaur, C.; Takac, J.; et al. Simulation of winter wheat yield and its variability in different climates of Europe: A comparison of eight crop growth models. Eur. J. Agron. 2011, 35, 103–114. [Google Scholar] [CrossRef]
- Eitzinger, J.; Thaler, S.; Schmid, E.; Strauss, F.; Ferrise, R.; Moriondo, M.; Bindi, M.; Palosuo, T.; Rotter, R.; Kersebaum, K.C.; et al. Sensitivities of crop models to extreme weather conditions during flowering period demonstrated for maize and winter wheat in Austria. J. Agric. Sci. 2013, 151, 813–835. [Google Scholar] [CrossRef]
- Asseng, S.; Ewert, F.; Martre, P.; Roetter, R.P.; Lobell, D.B.; Cammarano, D.; Kimball, B.A.; Ottman, M.J.; Wall, G.W.; White, J.W.; et al. Rising temperatures reduce global wheat production. Nat. Clim. Chang. 2015, 5, 143–147. [Google Scholar] [CrossRef]
- Barlow, K.M.; Christy, B.P.; O’Leary, G.J.; Riffkin, P.A.; Nuttall, J.G. Simulating the impact of extreme heat and frost events on wheat crop production: A review. Field Crops Res. 2015, 171, 109–119. [Google Scholar] [CrossRef]
- Glotter, M.J.; Moyer, E.J.; Ruane, A.C.; Elliott, J.W. Evaluating the sensitivity of agricultural model performance to different climate inputs. J. Appl. Meteorol. Climatol. 2016, 55, 579–594. [Google Scholar] [CrossRef]
- Rotter, R.P.; Palosuo, T.; Kersebaum, K.C.; Angulo, C.; Bindi, M.; Ewert, F.; Ferrise, R.; Hlavinka, P.; Moriondo, M.; Nendel, C.; et al. Simulation of spring barley yield in different climatic zones of Northern and Central Europe: A comparison of nine crop models. Field Crops Res. 2012, 133, 23–36. [Google Scholar] [CrossRef]
- van der Velde, M.; Tubiello, F.N.; Vrieling, A.; Bouraoui, F. Impacts of extreme weather on wheat and maize in France: Evaluating regional crop simulations against observed data. Clim. Chang. 2012, 113, 751–765. [Google Scholar] [CrossRef]
- Mladenova, I.E.; Bolten, J.D.; Crow, W.T.; Anderson, M.C.; Hain, C.R.; Johnson, D.M.; Mueller, R. Intercomparison of soil moisture, evaporative stress, and vegetation indices for estimating corn and soybean yields over the US. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1328–1343. [Google Scholar] [CrossRef]
- Sepaskhah, A.R.; Fahandezh-Saadi, S.; Zand-Parsa, S. Logistic model application for prediction of maize yield under water and nitrogen management. Agric. Water Manag. 2011, 99, 51–57. [Google Scholar] [CrossRef]
- Geetha, M.C.S.; Shanthi, I.E. Predicting the soil profile through modified regression by discretisation algorithm for the crop yield in Trichy district, India. Int. J. Grid Util. Comput. 2018, 9, 235–242. [Google Scholar] [CrossRef]
- Tittonell, P.; Shepherd, K.D.; Vanlauwe, B.; Giller, K.E. Unravelling the effects of soil and crop management on maize productivity in smallholder agricultural systems of western Kenya—An application of classification and regression tree analysis. Agric. Ecosyst. Environ. 2008, 123, 137–150. [Google Scholar] [CrossRef]
- Bognar, P.; Kern, A.; Pasztor, S.; Lichtenberger, J.; Koronczay, D.; Ferencz, C. Yield estimation and forecasting for winter wheat in Hungary using time series of MODIS data. Int. J. Remote Sens. 2017, 38, 3394–3414. [Google Scholar] [CrossRef]
- Huang, J.; Wang, H.; Dai, Q.; Han, D. Analysis of NDVI Data for Crop Identification and Yield Estimation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4374–4384. [Google Scholar] [CrossRef]
- Ren, J.; Chen, Z.; Zhou, Q.; Tang, H. Regional yield estimation for winter wheat with MODIS-NDVI data in Shandong, China. Int. J. Appl. Earth Obs. Geoinf. 2008, 10, 403–413. [Google Scholar] [CrossRef]
- Zhang, P.; Anderson, B.; Tan, B.; Huang, D.; Myneni, R. Potential monitoring of crop production using a satellite-based Climate-Variability Impact Index. Agric. For. Meteorol. 2005, 132, 344–358. [Google Scholar] [CrossRef]
- Son, N.T.; Chen, C.F.; Chen, C.R.; Chang, L.Y.; Duc, H.N.; Nguyen, L.D. Prediction of rice crop yield using MODIS EVI-LAI data in the Mekong Delta, Vietnam. Int. J. Remote Sens. 2013, 34, 7275–7292. [Google Scholar] [CrossRef]
- Kouadio, L.; Duveiller, G.; Djaby, B.; El Jarroudi, M.; Defourny, P.; Tychon, B. Estimating regional wheat yield from the shape of decreasing curves of green area index temporal profiles retrieved from MODIS data. Int. J. Appl. Earth Obs. Geoinf. 2012, 18, 111–118. [Google Scholar] [CrossRef]
- Domenikiotis, C.; Spiliotopoulos, M.; Tsiros, E.; Dalezios, N.R. Early cotton yield assessment by the use of the NOAA/AVHRR derived Vegetation Condition Index (VCI) in Greece. Int. J. Remote Sens. 2004, 25, 2807–2819. [Google Scholar] [CrossRef]
- Salazar, L.; Kogan, F.; Roytman, L. Use of remote sensing data for estimation of winter wheat yield in the United States. Int. J. Remote Sens. 2007, 28, 3795–3811. [Google Scholar] [CrossRef]
- Meroni, M.; Marinho, E.; Sghaier, N.; Verstrate, M.M.; Leo, O. Remote sensing based yield estimation in a stochastic framework—Case study of durum wheat in tunisia. Remote Sens. 2013, 5, 539–557. [Google Scholar] [CrossRef]
- Sakamoto, T.; Gitelson, A.A.; Arkebauer, T.J. MODIS-based corn grain yield estimation model incorporating crop phenology information. Remote Sens. Environ. 2013, 131, 215–231. [Google Scholar] [CrossRef]
- Sakamoto, T.; Gitelson, A.A.; Arkebauer, T.J. Near real-time prediction of US corn yields based on time-series MODIS data. Remote Sens. Environ. 2014, 147, 219–231. [Google Scholar] [CrossRef]
- Bala, S.K.; Islam, A.S. Correlation between potato yield and MODIS-derived vegetation indices. Int. J. Remote Sens. 2009, 30, 2491–2507. [Google Scholar] [CrossRef]
- Seffrin, R.; de Araujo, E.C.; Bazzi, C.L. Regression models for prediction of corn yield in the state of Parana (Brazil) from 2012 to 2014. Acta Sci. Agron. 2018, 40, e36494. [Google Scholar] [CrossRef]
- Mathieu, J.A.; Aires, F. Assessment of the agro-climatic indices to improve crop yield forecasting. Agric. For. Meteorol. 2018, 253, 15–30. [Google Scholar] [CrossRef]
- Holzman, M.E.; Carmona, F.; Rivas, R.; Niclos, R. Early assessment of crop yield from remotely sensed water stress and solar radiation data. ISPRS J. Photogramm. Remote Sens. 2018, 145, 297–308. [Google Scholar] [CrossRef]
- Zhang, J.Q. Risk assessment of drought disaster in the maize-growing region of Songliao Plain, China. Agric. Ecosyst. Environ. 2004, 102, 133–153. [Google Scholar] [CrossRef]
- Ming, B.; Guo, Y.; Tao, H.; Liu, G.; Li, S.; Wang, P. SPEIPM-based research on drought impact on maize yield in North China Plain. J. Integr. Agric. 2015, 14, 660–669. [Google Scholar] [CrossRef]
- Xu, X.; Gao, P.; Zhu, X.; Guo, W.; Ding, J.; Li, C. Estimating the responses of winter wheat yields to moisture variations in the past 35 years in Jiangsu Province of China. PLoS ONE 2018, 13, e0191217. [Google Scholar] [CrossRef]
- Wang, S.; Mo, X.; Hu, S.; Liu, S.; Liu, Z. Assessment of droughts and wheat yield loss on the North China Plain with an aggregate drought index (ADI) approach. Ecol. Indic. 2018, 87, 107–116. [Google Scholar] [CrossRef]
- Chen, F.; Jia, H.; Pan, D. Risk assessment of maize drought in china based on physical vulnerability. J. Food Qual. 2019, 2019, 9392769. [Google Scholar] [CrossRef]
- Lalic, B.; Eitzinger, J.; Thaler, S.; Vucetic, V.; Nejedlik, P.; Eckersten, H.; Jacimovic, G.; Nikolic-Djoric, E. can agrometeorological indices of adverse weather conditions help to improve yield prediction by crop models? Atmosphere 2014, 5, 1020–1041. [Google Scholar] [CrossRef]
- Shumin, L. Comprehensive evaluation on the drought risk of rain-fed agriculture in China based on GIS. J. Arid Land Resour. Environ. 2011, 25, 39–44. [Google Scholar] [CrossRef]
- Chavas, D.R.; Izaurralde, R.C.; Thomson, A.M.; Gao, X. Long-term climate change impacts on agricultural productivity in eastern China. Agric. For. Meteorol. 2009, 149, 1118–1128. [Google Scholar] [CrossRef]
- Zhou, B.; Xu, Y.; Wu, J.; Dong, S.; Shi, Y. Changes in temperature and precipitation extreme indices over China: Analysis of a high-resolution grid dataset. Int. J. Climatol. 2016, 36, 1051–1066. [Google Scholar] [CrossRef]
- Wu, H.; Hou, W.; Qian, Z.-H.; Hu, J.-G. The research on the sensitivity of climate change in China in recent 50 years based on composite index. Acta Phys. Sin. 2012, 61, 149205. [Google Scholar] [CrossRef]
- Gao, G.; Huang, C.Y. Climate change and its impact on water resources in North China. Adv. Atmos. Sci. 2001, 18, 718–732. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 global reanalysis. Q. J. R. Meteorol. Soc. 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- National Earth System Science Data Center. National Science & Technology Infrastructure of China. Available online: http://www.geodata.cn/ (accessed on 7 June 2020).
- Yuan, W.; Liu, S.; Yu, G.; Bonnefond, J.M.; Chen, J.; Davis, K.; Desai, A.R.; Goldstein, A.H.; Gianelle, D.; Rossi, F. Global estimates of evapotranspiration and gross primary production based on MODIS and global meteorology data. Remote Sens. Environ. 2010, 114, 1416–1431. [Google Scholar] [CrossRef]
- Land Long Term Data Record. Available online: https://ltdr.modaps.eosdis.nasa.gov/cgi-bin/ltdr/ltdrPage.cgi (accessed on 8 June 2020).
- Gooijer, J.G.D.; Hyndman, R.J. 25 years of time series forecasting. Int. J. Forecast. 2005, 22, 443–473. [Google Scholar] [CrossRef]
- Ravn, M.O.; Uhlig, H. On Adjusting the Hodrick-Prescott filter for the frequency of observations. Rev. Econ. Stats 2002, 84, 371–375. [Google Scholar] [CrossRef]
- Gardner, E.S. Forecasting the failure of component parts in computer systems: A case study. Int. J. Forecast. 1993, 9, 245–253. [Google Scholar] [CrossRef]
- Dong, W.; Liu, S.; Fang, Z. On modeling mechanisms and applicable ranges of grey incidence analysis models. Grey Syst. Theory Appl. 2018, 8, 448–461. [Google Scholar] [CrossRef]
- Junfu, X.; Zhandong, L.I.U.; Yumin, C. Study on the water requirement and water requirement regulation of maize in china. Maize Sci. 2008, 16, 21–25. [Google Scholar]
- Cao, X.; Wang, Y.; Wu, P.; Zhao, X.; Wang, J. An evaluation of the water utilization and grain production of irrigated and rain-fed croplands in China. Sci. Total Environ. 2015, 529, 10–20. [Google Scholar] [CrossRef]
- Sun, F.; Yang, X.; Lin, E.; Ju, H.; Xiong, W. Study on the sensitivity and vulnerability of wheat to climate change in china. Sci. Agric. Sin. 2005, 38, 692–696. [Google Scholar]
- Wang, J.; Yang, X.; Lu, S.; Liu, Z.; Li, K.; Xun, X.; Liu, Y.; Wang, E. Spatial-temporal characteristics of potential yields and yield gaps of spring maize in Heilongjiang province. Sci. Agric. Sin. 2012, 45, 1914–1925. [Google Scholar] [CrossRef]
- Leng, G.Y.; Hall, J. Crop yield sensitivity of global major agricultural countries to droughts and the projected changes in the future. Sci. Total Environ. 2019, 654, 811–821. [Google Scholar] [CrossRef]
- Yu, X.; He, X.; Zheng, H.; Guo, R.; Ren, Z.; Zhang, D.; Lin, J. Spatial and temporal analysis of drought risk during the crop-growing season over northeast China. Nat. Hazards 2014, 71, 275–289. [Google Scholar] [CrossRef]
- Zhang, Z.; Chen, Y.; Wang, P.; Zhang, S.; Tao, F.; Liu, X. Spatial and temporal changes of agro-meteorological disasters affecting maize production in China since 1990. Nat. Hazards 2014, 71, 2087–2100. [Google Scholar] [CrossRef]
- McKee, T.B.; Doesken, N.J.; Kleist, J. The relationship of drought frequency and duration of time scales. In Proceedings of the Eight Conference on Apllied Climatology, American Meteorological Society, Anaheim, CA, USA, 17–23 January 1993; pp. 179–186. [Google Scholar]
- Sanchez, B.; Rasmussen, A.; Porter, J.R. Temperatures and the growth and development of maize and rice: A review. Glob. Chang. Biol. 2014, 20, 408–417. [Google Scholar] [CrossRef] [PubMed]
- Hawkins, E.; Fricker, T.E.; Challinor, A.J.; Ferro, C.A.T.; Ho, C.K.; Osborne, T.M. Increasing influence of heat stress on French maize yields from the 1960s to the 2030s. Glob. Chang. Biol. 2013, 19, 937–947. [Google Scholar] [CrossRef] [PubMed]
- Lobell, D.B.; Hammer, G.L.; McLean, G.; Messina, C.; Roberts, M.J.; Schlenker, W. The critical role of extreme heat for maize production in the United States. Nat. Clim. Chang. 2013, 3, 497–501. [Google Scholar] [CrossRef]
- Lobell, D.B.; Sibley, A.; Ivan Ortiz-Monasterio, J. Extreme heat effects on wheat senescence in India. Nat. Clim. Chang. 2012, 2, 186–189. [Google Scholar] [CrossRef]
- Schlenker, W.; Roberts, M.J. Nonlinear temperature effects indicate severe damages to US crop yields under climate change. Proc. Natl. Acad. Sci. USA 2009, 106, 15594–15598. [Google Scholar] [CrossRef]
- Chen, J.; Jonsson, P.; Tamura, M.; Gu, Z.H.; Matsushita, B.; Eklundh, L. A simple method for reconstructing a high-quality NDVI time-series data set based on the Savitzky-Golay filter. Remote Sens. Environ. 2004, 91, 332–344. [Google Scholar] [CrossRef]
- Papagiannopoulou, C.; Miralles, D.G.; Decubber, S.; Demuzere, M.; Verhoest, N.E.C.; Dorigo, W.A.; Waegeman, W. A non-linear Granger-causality framework to investigate climate-vegetation dynamics. Geosci. Model. Dev. 2017, 10, 1945–1960. [Google Scholar] [CrossRef]
- Schaefer, K.; Schwalm, C.R.; Williams, C.; Arain, M.A.; Barr, A.; Chen, J.M.; Davis, K.J.; Dimitrov, D.; Hilton, T.W.; Hollinger, D.Y.; et al. A model-data comparison of gross primary productivity: Results from the North American Carbon Program site synthesis. J. Geophys. Res. Biogeosci. 2012, 117, 15. [Google Scholar] [CrossRef]
- Wang, Y.; Tang, P.; Li, S.; Tian, Y.; Li, J. The water demand and optimal irrigation schedule of maize in drought years at eastern area of Inner Mongolia. Agric. Res. Arid Areas 2018, 36, 108–114. [Google Scholar]
- Gao, X.; Wang, C.; Zhang, J.; Xue, X. Crop water requirement and temporal-spatial variation of drought and flood disaster during growth stages for maize in Northeast during past 50 years. Trans. Chin. Soc. Agric. Eng. 2012, 28, 101–109. [Google Scholar]
- Cao, Y.; Yu, Z.; Zhao, T. Study of water demand and consumption rules in summer maize. Acta Agric. Boreali-Sin. 2003, 18, 47–50. [Google Scholar]
- Song, L.; Jin, J.; He, J. Effects of Severe Water Stress on Maize Growth Processes in the Field. Sustainability 2019, 11, 5086. [Google Scholar] [CrossRef]
- Aktas, A.F.; Ustundag, B.B. Phenology Based NDVI Time-series Compensation for Yield Estimation Analysis. In Proceedings of the 6th International Conference on Agro-Geoinformatics, Fairfax, VA, USA, 7–10 August 2017; pp. 1–5. [Google Scholar]
- Govedarica, M.; Jovanovic, D.; Sabo, F.; Borisov, M.; Vrtunski, M.; Alargic, I. Comparison of MODIS 250 m products for early corn yield predictions: A case study in Vojvodina, Serbia. Open Geosci. 2016, 8, 747–759. [Google Scholar] [CrossRef]
- Moriondo, M.; Maselli, F.; Bindi, M. A simple model of regional wheat yield based on NDVI data. Eur. J. Agron. 2007, 26, 266–274. [Google Scholar] [CrossRef]
- Mkhabela, M.S.; Mkhabela, M.S.; Mashinini, N.N. Early maize yield forecasting in the four agro-ecological regions of Swaziland using NDVI data derived from NOAAs-AVHRR. Agric. For. Meteorol. 2005, 129, 1–9. [Google Scholar] [CrossRef]
- Liu, J.; He, X.; Wang, P.; Huang, J. Early prediction of winter wheat yield with long time series meteorological data and random forest method. Trans. Chin. Soc. Agric. Eng. 2019, 35, 158–166. [Google Scholar] [CrossRef]
- Mutanga, O.; Adam, E.; Cho, M.A. High density biomass estimation for wetland vegetation using WorldView-2 imagery and random forest regression algorithm. Int. J. Appl. Earth Obs. Geoinf. 2012, 18, 399–406. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Lobell, D.; Potgieter, A.B.; Wang, S.; Peng, J.; Xu, T.; Asseng, S.; Zhang, Y.; You, L.; et al. Integrating satellite and climate data to predict wheat yield in Australia using machine learning approaches. Agric. For. Meteorol. 2019, 274, 144–159. [Google Scholar] [CrossRef]
- Huang, J.; Ma, H.; Liu, J.; Zhu, D.; Zhang, X. Regional winter wheat yield estimation by assimilating MODIS ET and LAI products into SWAP model. In Proceedings of the Second International Conference on Agro-Geoinformatics, Fairfax, VA, USA, 12–16 August 2013; pp. 452–457. [Google Scholar]
- Feng, P.; Wang, B.; Liu, D.L.; Waters, C.; Yu, Q. Incorporating machine learning with biophysical model can improve the evaluation of climate extremes impacts on wheat yield in south-eastern Australia. Agric. For. Meteorol. 2019, 275, 100–113. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Data Source | Spatial Resolution | Temporal Resolution | |
|---|---|---|---|---|
| Meteorological reanalysis data | Total precipitation | ERA5 dataset of the European Center for Medium-Term Weather Forecast (ECMWF 2017) | 0.25° | Monthly |
| 2 m temperature | ECMWF 2017 | 0.25° | Hourly | |
| Remote sensing data | Gross primary production | National Science and Technology Basic Conditions Platform-National Earth System Science Data Sharing Service Platform | 0.05° | 8 d |
| NDVI | AVH13C1 dataset of the LTDR project | 0.05° | 1 d | |
| Land use and land cover data | Resource and Environmental Science Data Center of the Chinese Academy of Sciences | 1 km | - | |
| Statistical data | Maize yield | China Bureau of Statistics | Municipality | Yearly |
| Agricultural disaster statistics | China Bureau of Statistics | Province | Yearly | |
| Province | Model | The Number of Input Variables | Input Variables | R2 | CCC | MARE |
|---|---|---|---|---|---|---|
| Jilin | Yield Model 1 | 24 | SPI2-7, AAT9, GPPa8, AAT8, EDD8, GPPa7, AAT4-9, SPI2-5, AAT5, GPPa4-9, GPPa6, EDD6, EDD4-9, GPPa5, AAT7, SPI2-9, EDD7, AAT4, GPPa4, AAT6, EDD5, GPPa9, EDD9, EDD4 | 0.7703 | 0.9093 | 0.0933 |
| Yield Model 2 | 24 | SPI2-7, AAT9, NDVIa4, NDVIa8, AAT8, EDD8, AAT4-9, SPI2-5, NDVIa7, AAT5, EDD6, EDD4-9, NDVIa5, AAT7, SPI2-9, EDD7, AAT4, NDVIa6, AAT6, EDD5, NDVIa4-9, NDVIa9, EDD9, EDD4 | 0.7680 | 0.9119 | 0.0925 | |
| Yield Model 3 | 8 | SPI2-7, AAT9, GPP8, EDD8, AAT4-9, GPPa5, AAT8, EDD7 | 0.8201 | 0.9761 | 0.0943 | |
| Yield Model 4 | 7 | SPI2-7, AAT9, EDD8, AAT4-9, NDVIa8, AAT8, EDD7 | 0.8019 | 0.9599 | 0.0961 | |
| Liaoning | Yield Model 1 | 16 | GPPa7, SPI2-5, SPI2-7, GPP4-9, GPPa8, AAT7, SPI2-9, GPPa9, EDD5, AAT6, AAT4, GPPa6, EDD6, AAT5, EDD7, AAT4-9 | 0.7148 | 0.8592 | 0.1326 |
| Yield Model 2 | 17 | NDVIa8, SPI2-5, SPI2-7, AAT7, SPI2-9, NDVIa9, NDVIa5, EDD5, AAT6, AAT4, EDD6, NDVIa6, AAT5, EDD7, NDVIa4, NDVIa7, AAT4-9 | 0.7466 | 0.8918 | 0.1241 | |
| Yield Model 3 | 8 | GPPa7, AAT6, SPI2-7, AAT7, GPPa4-9, GPPa8, SPI2-9, AAT4 | 0.7075 | 0.8435 | 0.1247 | |
| Yield Model 4 | 7 | NDVIa8, SPI2-7, AAT7, AAT4, SPI2-9, NDVIa9, AAT6 | 0.7353 | 0.8783 | 0.1128 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, X.; Guo, R.; Liu, T.; Xu, K. Crop Yield Prediction Based on Agrometeorological Indexes and Remote Sensing Data. Remote Sens. 2021, 13, 2016. https://doi.org/10.3390/rs13102016
Zhu X, Guo R, Liu T, Xu K. Crop Yield Prediction Based on Agrometeorological Indexes and Remote Sensing Data. Remote Sensing. 2021; 13(10):2016. https://doi.org/10.3390/rs13102016
Chicago/Turabian StyleZhu, Xiufang, Rui Guo, Tingting Liu, and Kun Xu. 2021. "Crop Yield Prediction Based on Agrometeorological Indexes and Remote Sensing Data" Remote Sensing 13, no. 10: 2016. https://doi.org/10.3390/rs13102016
APA StyleZhu, X., Guo, R., Liu, T., & Xu, K. (2021). Crop Yield Prediction Based on Agrometeorological Indexes and Remote Sensing Data. Remote Sensing, 13(10), 2016. https://doi.org/10.3390/rs13102016