
A Strategy of Parallel Seed-Based Image Segmentation Algorithms for Handling Massive Image Tiles over the Spark Platform




Abstract
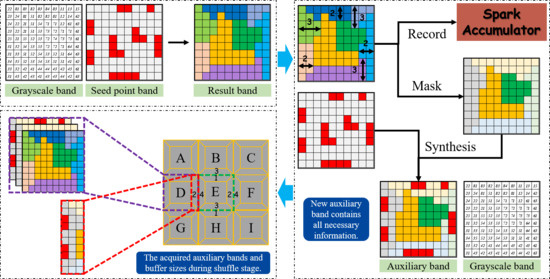
1. Introduction
- Detect the buffer size automatically to reduce the communication volume;
- Synthesize the auxiliary bands to reduce the communication volume;
- Construct the distributed strategy for seed-based segmentation algorithms and evaluate its universality with respect to 10 images in terms of accuracy and execution efficiency.
2. Materials and Methods
2.1. Image Data and Preprocessing
2.2. Methods
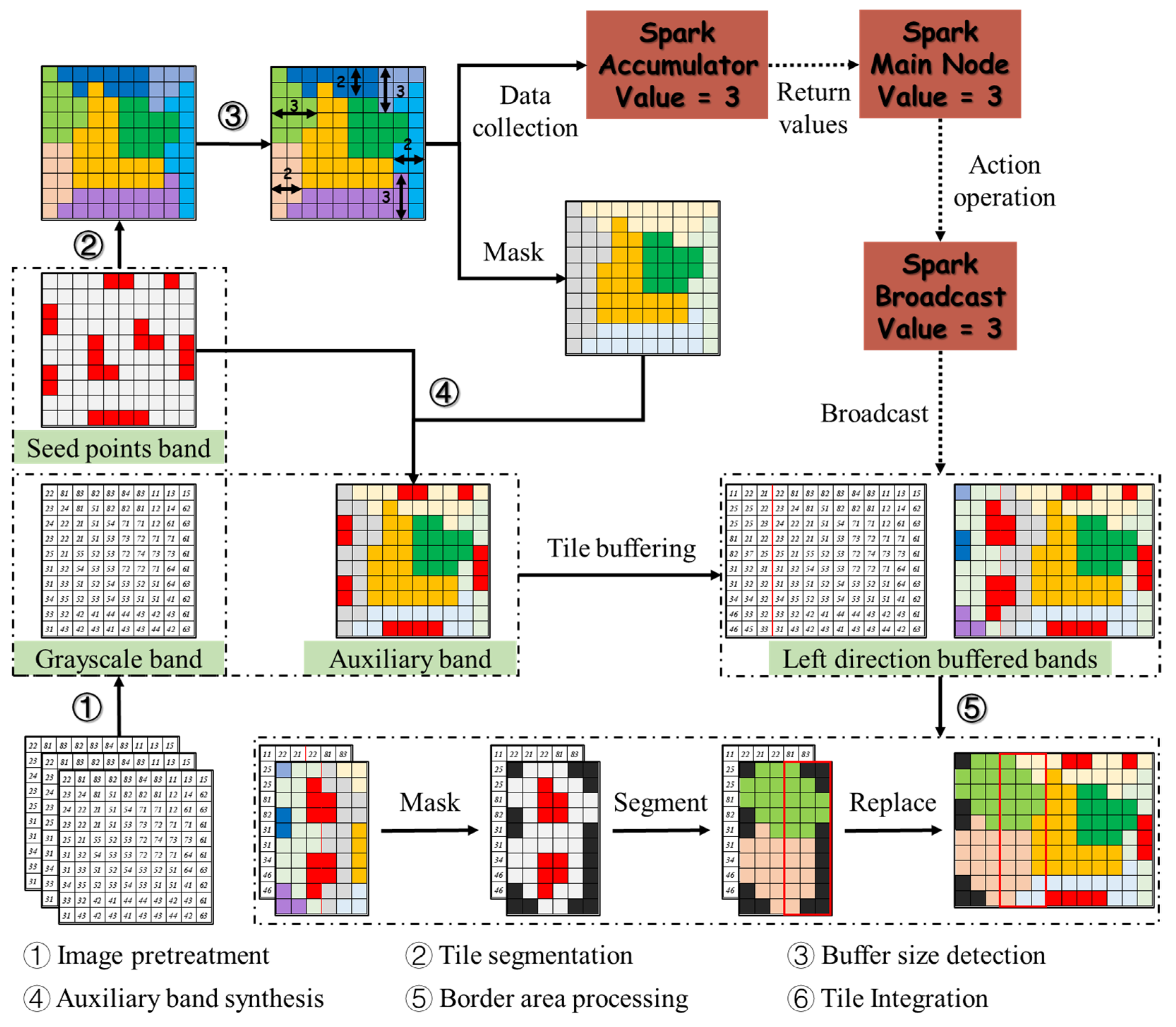
2.2.1. Overview
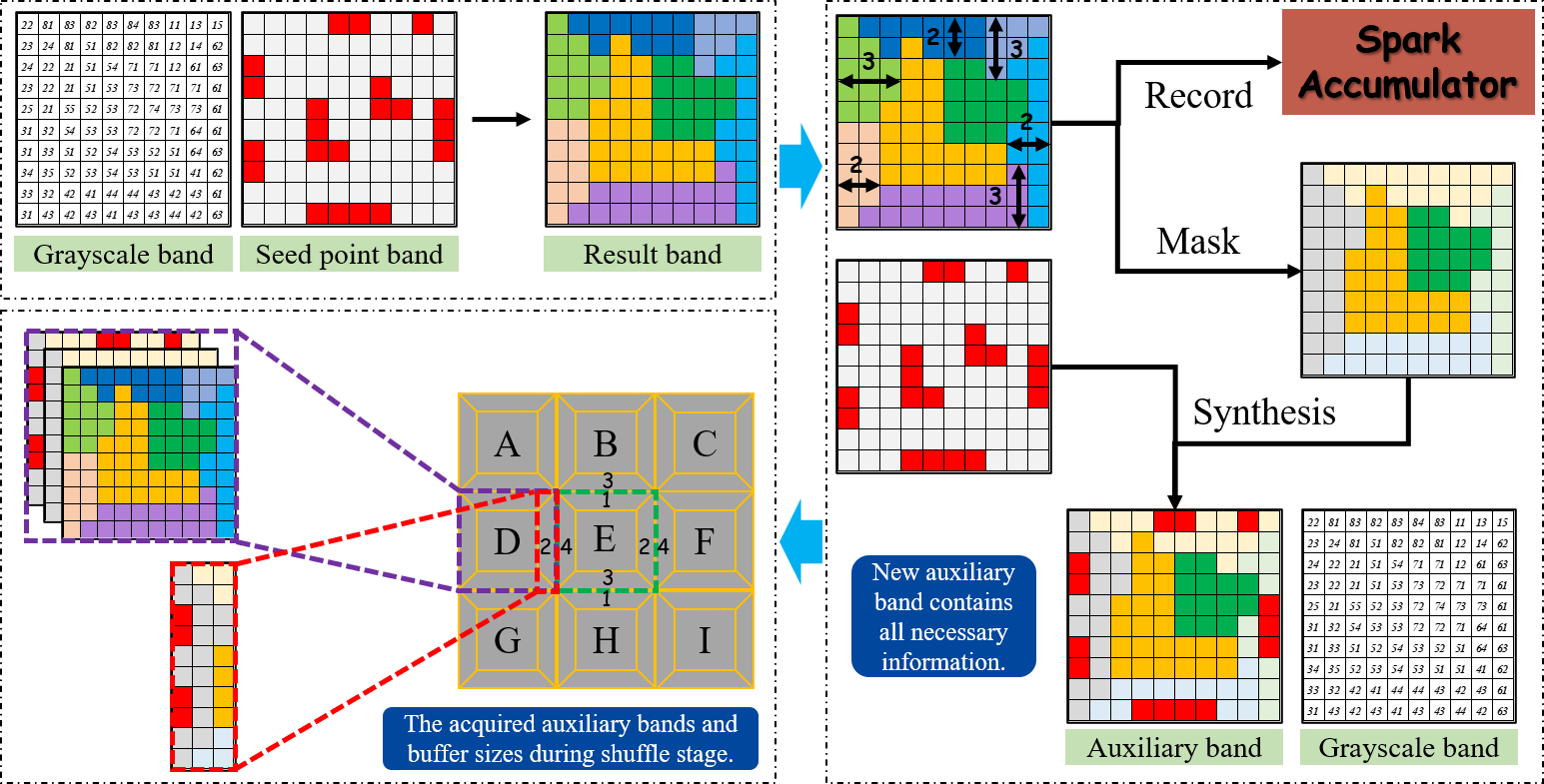
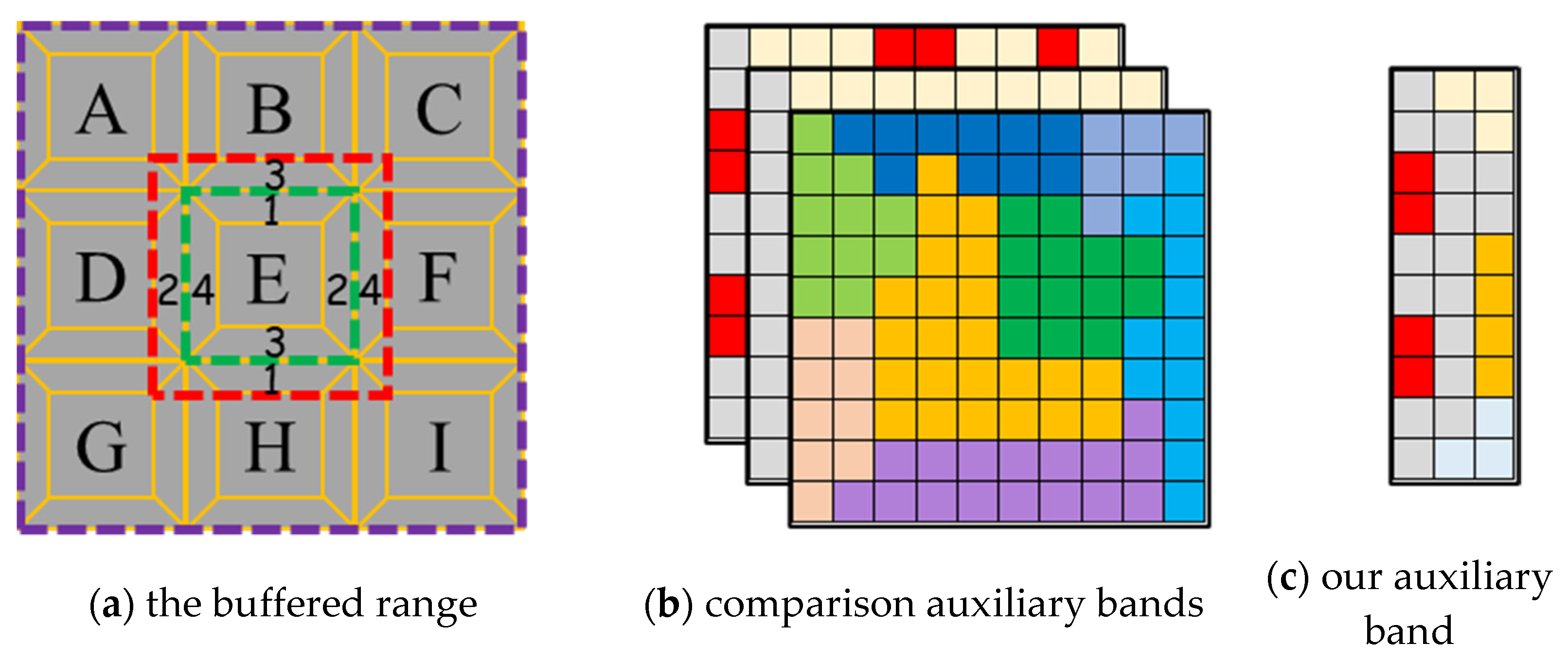
2.2.2. Automatic Buffer Size Detection
2.2.3. Auxiliary Band Synthesis
2.2.4. Performance Evaluation
3. Results
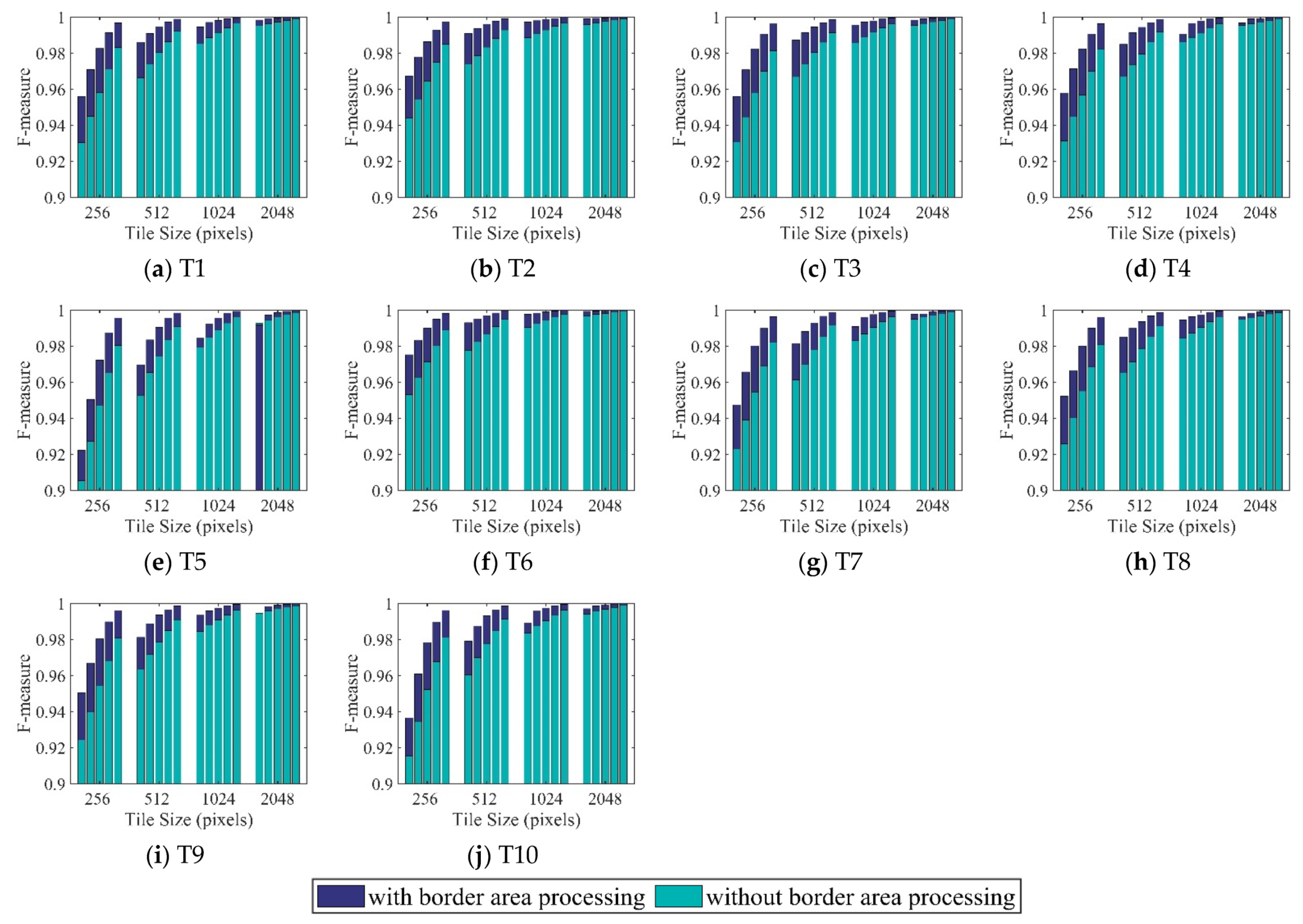
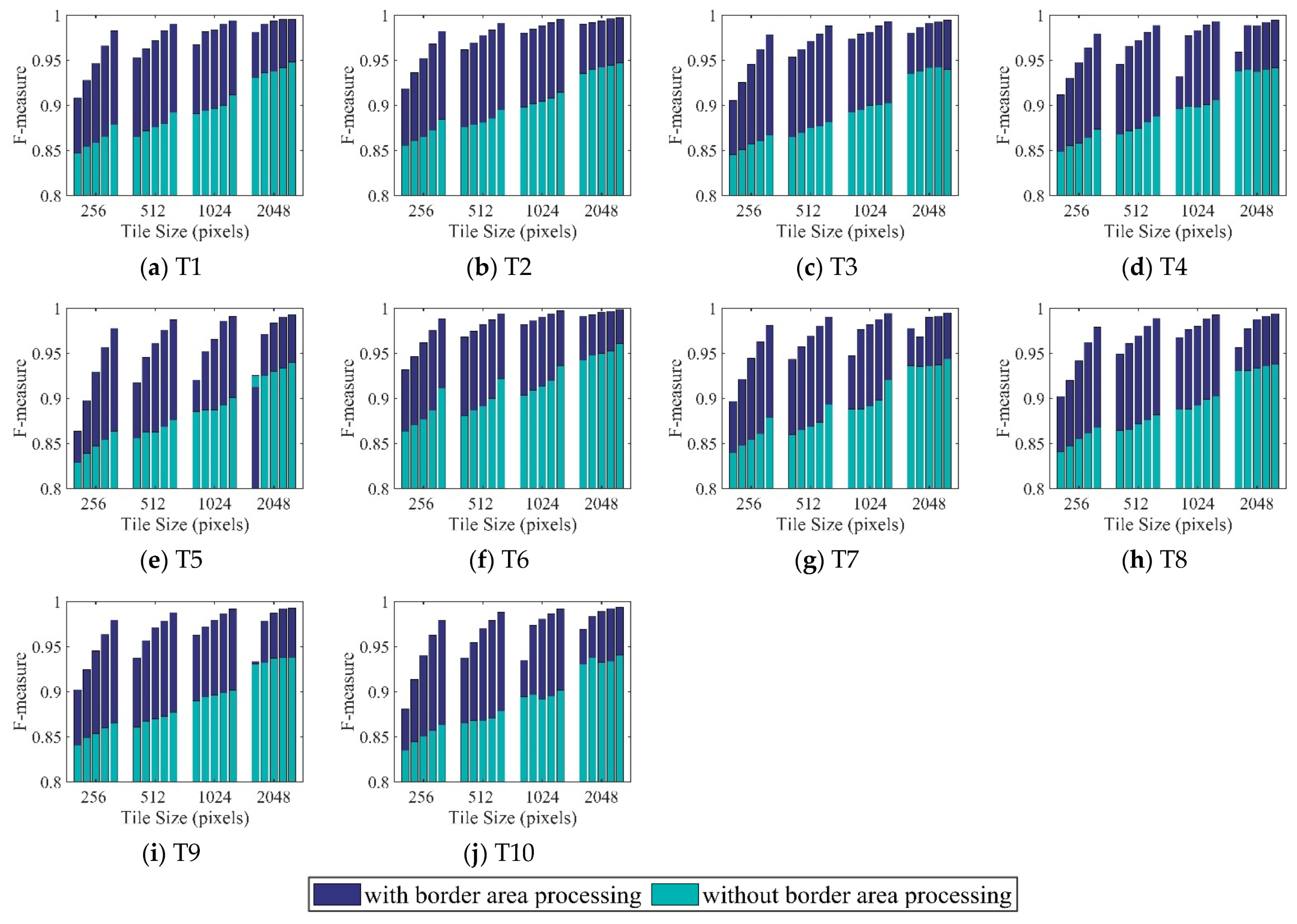
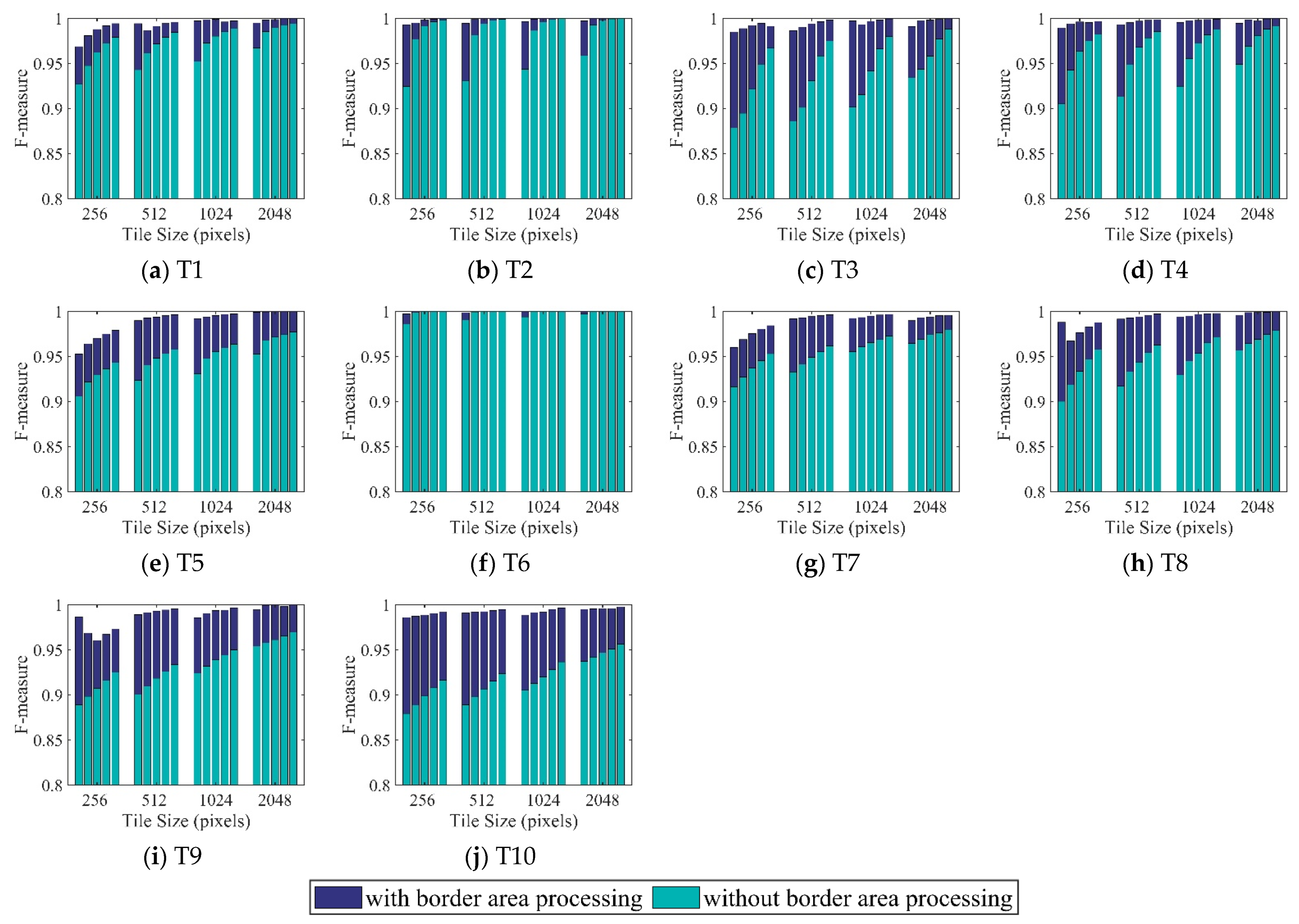
3.1. Results for Accuracy Assessment
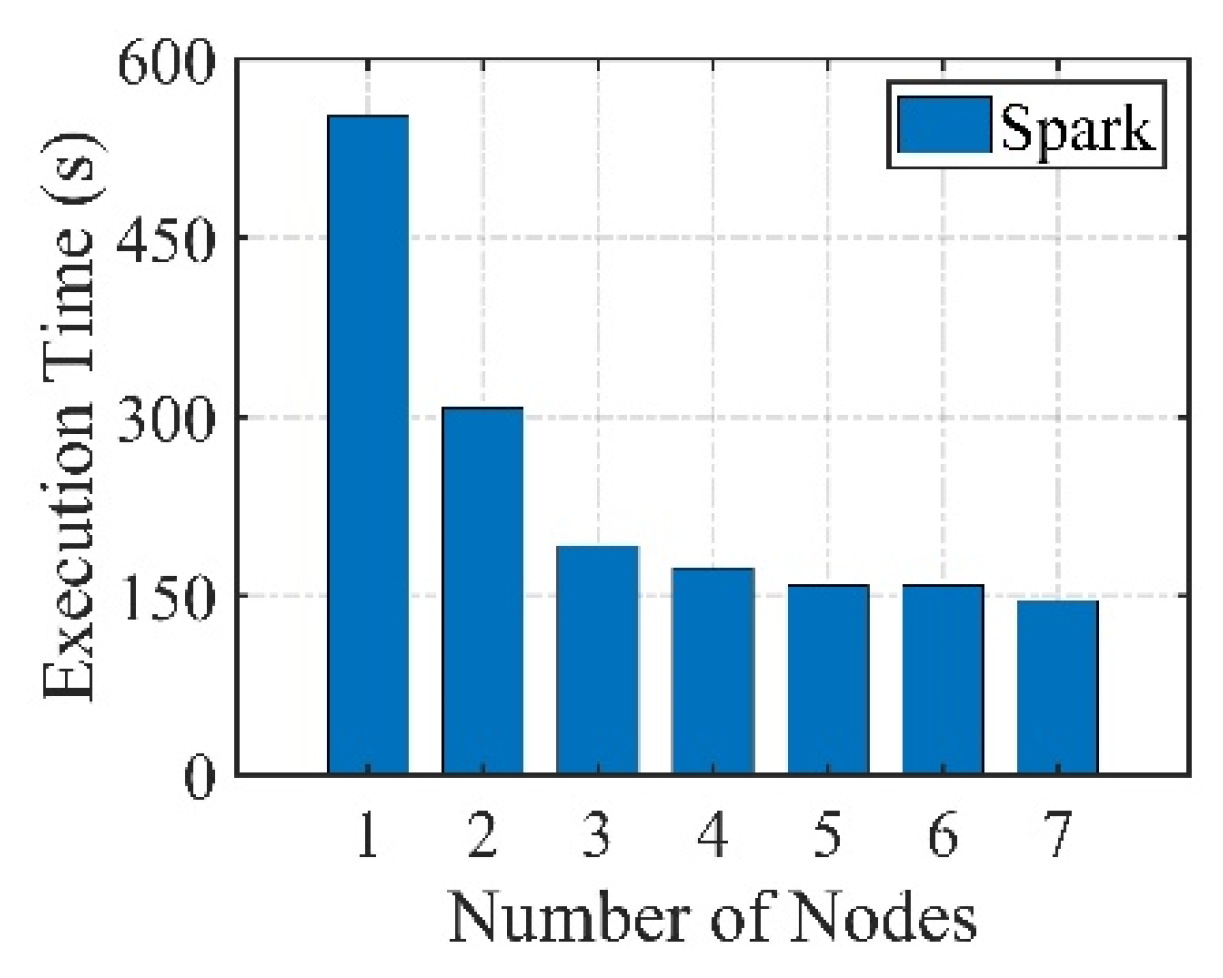
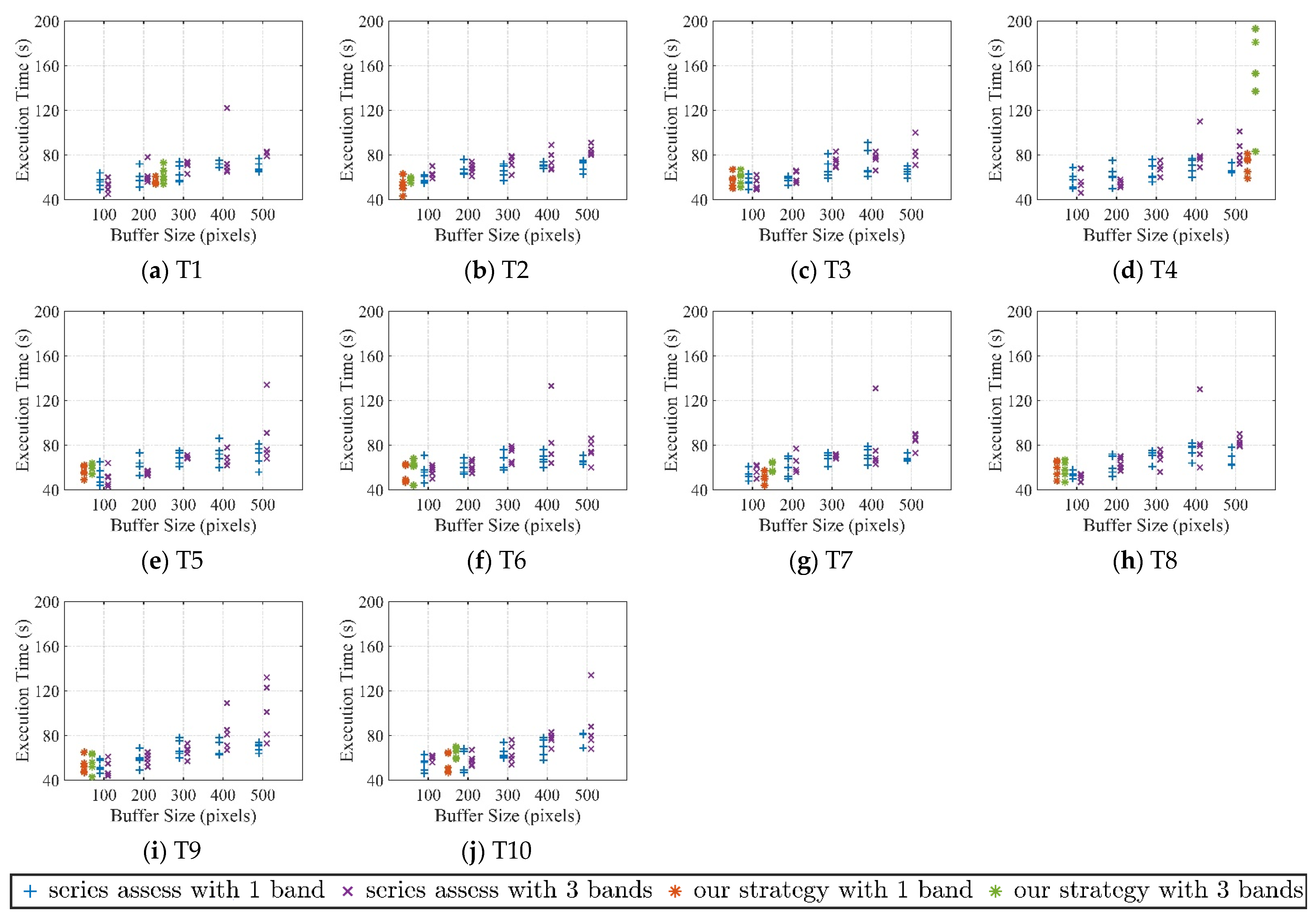
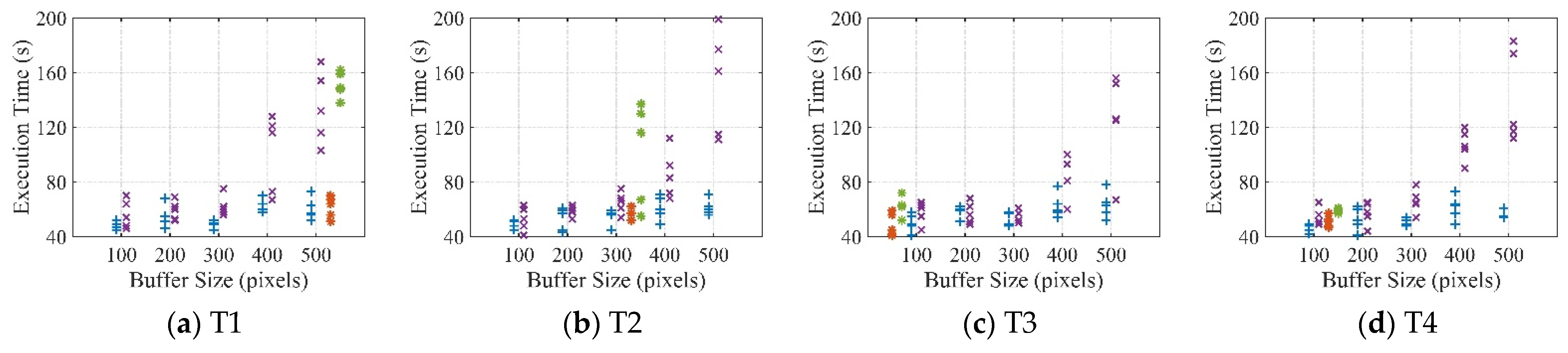
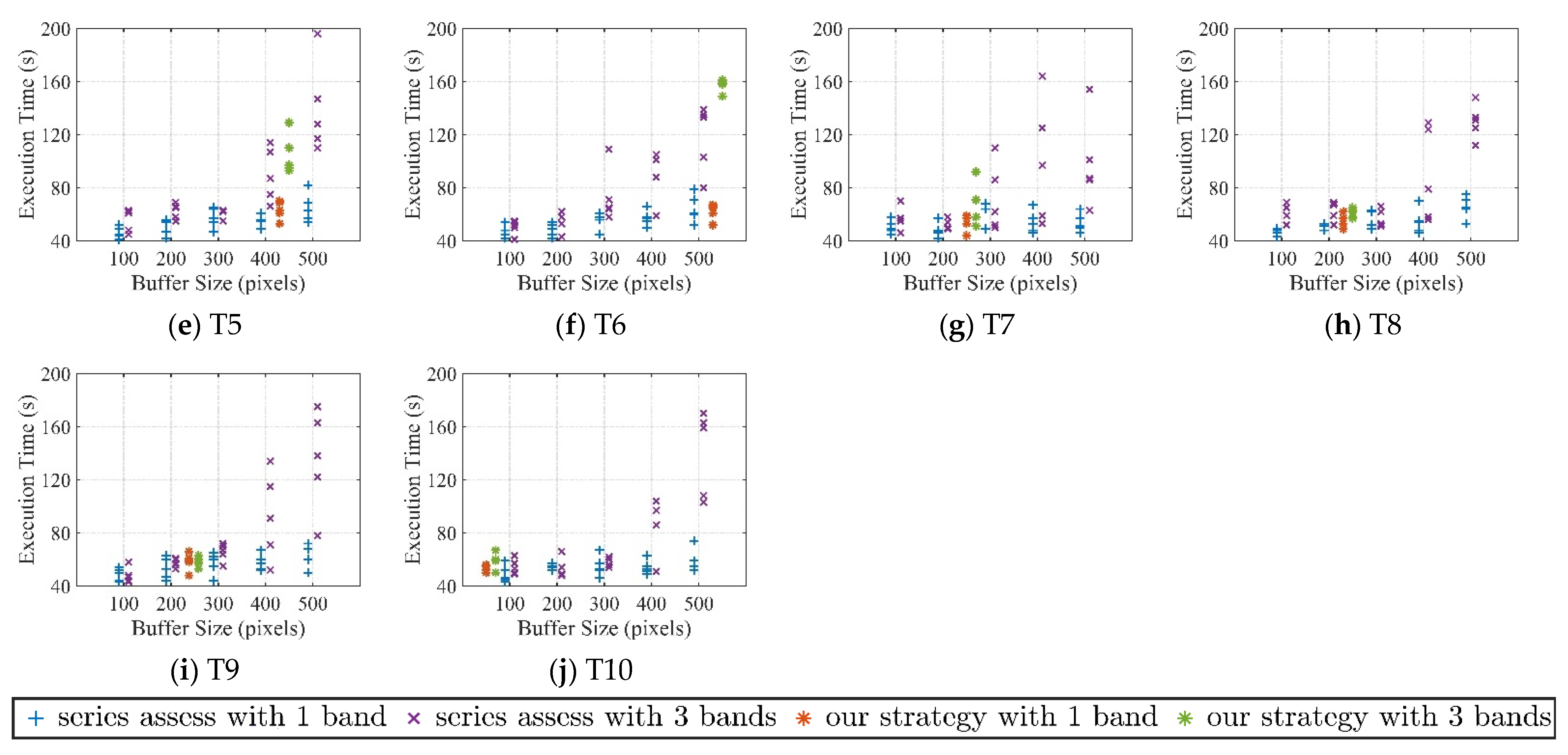
3.2. Results for Execution Efficiency
3.3. Results of Visual Comparison
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, F.P.; Feng, R.; Han, W.; Wang, L. High-Resolution Remote Sensing Image Scene Classification via Key Filter Bank Based on Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8077–8092. [Google Scholar] [CrossRef]
- Toth, C.; Jozkow, G. Remote Sensing Platforms and Sensors: A Survey. ISPRS J. Photogramm. Remote Sens. 2016, 115, 22–36. [Google Scholar] [CrossRef]
- Zhou, D.C.; Xiao, J.; Bonafoni, S.; Berger, C.; Deilami, K.; Zhou, Y.; Frolking, S.; Yao, R.; Qiao, Z.; Sobrino, J.A. Satellite Remote Sensing of Surface Urban Heat Islands: Progress, Challenges, and Perspectives. Remote Sens. 2019, 11, 48. [Google Scholar] [CrossRef]
- Happ, P.N.; da Costa, G.A.O.P.; Bentes, C.; Feitosa, R.Q.; da Silva Ferreira, R.; Farias, R. A Cloud Computing Strategy for Region-Growing Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 5294–5303. [Google Scholar] [CrossRef]
- Chen, F.; Zhang, M.M.; Tian, B.S.; Li, Z. Extraction of Glacial Lake Outlines in Tibet Plateau Using Landsat 8 Imagery and Google Earth Engine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4002–4009. [Google Scholar] [CrossRef]
- Michel, J.; Youssefi, D.; Grizonnet, M. Stable Mean-Shift Algorithm and Its Application to the Segmentation of Arbitrarily Large Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 952–964. [Google Scholar] [CrossRef]
- Yan, L.; Roy, D.P. Improving Landsat Multispectral Scanner (MSS) Geolocation by Least-Squares-Adjustment Based Time-Series Co-Registration. Remote Sens. Environ. 2021, 252, 112181. [Google Scholar] [CrossRef]
- Chen, F.; Zhang, M.M.; Guo, H.D.; Allen, S.; Kargel, J.S.; Haritashya, U.K.; Watson, C.S. Annual 30 m dataset for glacial lakes in High Mountain Asia from 2008 to 2017. Earth Syst. Sci. Data 2021, 13, 741–766. [Google Scholar] [CrossRef]
- Yu, B.; Chen, F.; Xu, C. Landslide detection based on contour-based deep learning framework in case of national scale of Nepal in 2015. Comput. Geosci. 2020, 135, 104388. [Google Scholar] [CrossRef]
- Chen, F.; Yu, B.; Li, B. A practical trial of landslide detection from single-temporal Landsat8 images using contour-based proposals and random forest: A case study of national Nepal. Landslides 2018, 15, 453–464. [Google Scholar] [CrossRef]
- Apache Hadoop. Available online: http://hadoop.apache.org/ (accessed on 20 April 2021).
- Apache Spark. Available online: http://spark.apache.org/ (accessed on 20 April 2021).
- Guo, H. Big data drives the development of Earth science. Big Earth Data 2017, 1, 1–3. [Google Scholar] [CrossRef]
- Mou, L.C.; Lu, X.Q.; Li, X.L.; Zhu, X.X. Nonlocal Graph Convolutional Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8246–8257. [Google Scholar] [CrossRef]
- Hong, D.F.; Yokoya, N.; Chanussot, J.; Zhu, X.X. An Augmented Linear Mixing Model to Address Spectral Variability for Hyperspectral Unmixing. IEEE Trans. Image Process. 2019, 28, 1923–1938. [Google Scholar] [CrossRef]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache Spark: A Unified Engine for Big Data Processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Kertesz, G.; Szenasi, S.; Vamossy, Z. Performance Measurement of a General Multi-Scale Template Matching Method. In Proceedings of the 2015-IEEE 19th International Conference on Intelligent Engineering Systems, Bratislava, Slovakia, 3–5 September 2015; pp. 153–157. [Google Scholar]
- Wang, N.; Chen, F.; Yu, B.; Qin, Y. Segmentation of large-scale remotely sensed images on a Spark platform: A strategy for handling massive image tiles with the MapReduce model. ISPRS J. Photogramm. Remote Sens. 2020, 162, 137–147. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Feitosa, R.Q.; Van der Meer, F.; Van der Werff, H.; Van Coillie, F.; et al. Geographic Object-Based Image Analysis—Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches. ISPRS J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Ventura, D.; Bonifazi, A.; Gravina, M.F.; Belluscio, A.; Ardizzone, G. Mapping and Classification of Ecologically Sensitive Marine Habitats Using Unmanned Aerial Vehicle (UAV) Imagery and Object-Based Image Analysis (OBIA). Remote Sens. 2018, 10, 1331. [Google Scholar] [CrossRef]
- Pena, J.M.; Torres-Sánchez, J.; de Castro, A.I.; Kelly, M.; López-Granados, F. Weed Mapping in Early-Season Maize Fields Using Object-Based Analysis of Unmanned Aerial Vehicle (UAV) Images. PLoS ONE 2013, 8, e77151. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Hossain, M.D.; Chen, D. Segmentation for Object-Based Image Analysis (OBIA): A review of algorithms and challenges from remote sensing perspective. ISPRS J. Photogramm. Remote Sens. 2019, 150, 115–134. [Google Scholar] [CrossRef]
- Yu, B.; Yang, L.; Chen, F. Semantic Segmentation for High Spatial Resolution Remote Sensing Images Based on Convolution Neural Network and Pyramid Pooling Module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3252–3261. [Google Scholar] [CrossRef]
- Koerting, T.S.; Castejon, E.F.; Fonseca, L.M.G. The Divide and Segment Method for Parallel Image Segmentation. Adv. Concepts Intell. Vis. Syst. Acivs. 2013, 8192, 504–515. [Google Scholar]
- Afshar, Y.; Sbalzarini, I.F. A Parallel Distributed-Memory Particle Method Enables Acquisition-Rate Segmentation of Large Fluorescence Microscopy Images. PLoS ONE 2016, 11, e0152528. [Google Scholar] [CrossRef]
- Hossam, M.A.; Ebied, H.M.; Abdel-Aziz, M.H.; Tolba, M.F. Accelerated hyperspectral image recursive hierarchical segmentation using GPUs, multicore CPUs, and hybrid CPU/GPU cluster. J. Real-Time Image Process. 2014, 14, 413–432. [Google Scholar] [CrossRef]
- Lassalle, P.; Inglada, J.; Michel, J.; Grizonnet, M.; Malik, J. A Scalable Tile-Based Framework for Region-Merging Segmentation. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5473–5485. [Google Scholar] [CrossRef]
- Ye, S.J.; Liu, D.; Yao, X.; Tang, H.; Xiong, Q.; Zhuo, W.; Du, Z.; Huang, J.; Su, W.; Shen, S.; et al. RDCRMG: A Raster Dataset Clean & Reconstitution Multi-Grid Architecture for Remote Sensing Monitoring of Vegetation Dryness. Remote Sens. 2018, 10, 1376. [Google Scholar]
- Gotz, M.; Cavallaro, G.; Géraud, T.; Book, M.; Riedel, M. Parallel Computation of Component Trees on Distributed Memory Machines. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 2582–2598. [Google Scholar] [CrossRef]
- Gu, H.; Han, Y.; Yang, Y.; Li, H.; Liu, Z.; Soergel, U.; Blaschke, T.; Cui, S. An Efficient Parallel Multi-Scale Segmentation Method for Remote Sensing Imagery. Remote Sens. 2018, 10, 590. [Google Scholar] [CrossRef]
- Huang, F.; Chen, Y.; Li, L.; Zhou, J.; Tao, J.; Tan, X.; Fan, G. Implementation of the parallel mean shift-based image segmentation algorithm on a GPU cluster. Int. J. Digit. Earth 2018, 12, 328–353. [Google Scholar] [CrossRef]
- Gazagnes, S.; Wilkinson, M.H.F. Distributed Connected Component Filtering and Analysis in 2D and 3D Tera-Scale Data Sets. IEEE Trans. Image Process. 2021, 30, 3664–3675. [Google Scholar] [CrossRef]
- Derksen, D.; Inglada, J.; Michel, J. Scaling Up SLIC Superpixels Using a Tile-Based Approach. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3073–3085. [Google Scholar] [CrossRef]
- Lin, W.; Li, Y. Parallel Regional Segmentation Method of High-Resolution Remote Sensing Image Based on Minimum Spanning Tree. Remote Sens. 2020, 12, 783. [Google Scholar] [CrossRef]
- Zhang, Z.; Barbary, K.; Nothaft, F.A.; Sparks, E.; Zahn, O.; Franklin, M.J.; Patterson, D.A.; Perlmutter, S. Scientific Computing Meets Big Data Technology: An Astronomy Use Case. In Proceedings of the 2015 IEEE International Conference on Big Data, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 918–927. [Google Scholar]
- Tang, S.; He, B.; Yu, C.; Li, Y.; Li, K. A Survey on Spark Ecosystem: Big Data Processing Infrastructure, Machine Learning, and Applications. IEEE Trans. Knowl. Data Eng. 2020, 1. [Google Scholar] [CrossRef]
- Adams, R.; Bischof, L. Seeded Region Growing. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 641–647. [Google Scholar] [CrossRef]
- Vincent, L.; Soille, P. Watersheds in Digital Spaces—An Efficient Algorithm Based on Immersion Simulations. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 583–598. [Google Scholar] [CrossRef]
- Copernicus Open Access Hub. Available online: https://scihub.copernicus.eu/ (accessed on 20 April 2021).
- Feng, Q.Z.; Gao, B.; Lu, P.; Woo, W.; Yang, Y.; Fan, Y.; Qiu, X.; Gu, L. Automatic seeded region growing for thermography debonding detection of CFRP. NDT E Int. 2018, 99, 36–49. [Google Scholar] [CrossRef]
- Huang, Z.L.; Wang, X.; Wang, J.; Liu, W.; Wang, J. Weakly-Supervised Semantic Segmentation Network with Deep Seeded Region Growing. In Proceedings of the 2018 IEEE/Cvf Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7014–7023. [Google Scholar]
- Li, J.B.; Luo, W.; Wang, Z.; Fan, S. Early detection of decay on apples using hyperspectral reflectance imaging combining both principal component analysis and improved watershed segmentation method. Postharvest Biol. Technol. 2019, 149, 235–246. [Google Scholar] [CrossRef]
- Li, J.B.; Chen, L.P.; Huang, W.Q. Detection of early bruises on peaches (Amygdalus persica L.) using hyperspectral imaging coupled with improved watershed segmentation algorithm. Postharvest Biol. Technol. 2018, 135, 104–113. [Google Scholar] [CrossRef]
- Kornilov, A.; Safonov, I. An Overview of Watershed Algorithm Implementations in Open Source Libraries. J. Imaging 2018, 4, 123. [Google Scholar] [CrossRef]
- MathWorks/rgb2gray. Available online: https://ww2.mathworks.cn/help/matlab/ref/rgb2gray.html (accessed on 20 April 2021).
- Scikit-Image: Image Processing in Python. Available online: https://scikit-image.org/ (accessed on 20 April 2021).
- Sehrish, S.; Kowalkowski, J.; Paterno, M. Spark and HPC for High Energy Physics Data Analyses. In Proceedings of the 2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Orlando, FL, USA, 29 May–2 June 2017; pp. 1048–1057. [Google Scholar]
- Karim, M.R.; Cochez, M.; Beyan, O.D.; Ahmed, C.F.; Decker, S. Mining maximal frequent patterns in transactional databases and dynamic data streams: A spark-based approach. Inf. Sci. 2018, 432, 278–300. [Google Scholar] [CrossRef]
- Yu, J.; Zhang, Z.S.; Sarwat, M. Spatial data management in apache spark: The GeoSpark perspective and beyond. Geoinformatica 2019, 23, 37–78. [Google Scholar] [CrossRef]
- Gounaris, A.; Torres, J. A Methodology for Spark Parameter Tuning. Big Data Res. 2018, 11, 22–32. [Google Scholar] [CrossRef]
- Mezzoudj, S. A parallel content-based image retrieval system using spark and tachyon frameworks. J. King Saud Univ. Comput. Inf. Sci. 2020, 32, 1218. [Google Scholar] [CrossRef]
- Zhang, X.L.; Feng, X.; Xiao, P.; He, G.; Zhu, L. Segmentation quality evaluation using region-based precision and recall measures for remote sensing images. ISPRS J. Photogramm. Remote Sens. 2015, 102, 73–84. [Google Scholar] [CrossRef]
- Yi, L.; Zhang, G.F.; Wu, Z.C. A Scale-Synthesis Method for High Spatial Resolution Remote Sensing Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4062–4070. [Google Scholar] [CrossRef]
- Crevier, D. Image segmentation algorithm development using ground truth image data sets. Comput. Vis. Image Underst. 2008, 112, 143–159. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Bands | Median Radius | Spectral | Seed Points | Tile Size Range |
|---|---|---|---|---|---|
| Region growing | 2 | 2 pixels | Grayscale | Local peaks | 4 |
| Watershed | 2 | 2 pixels | Gradients | Gradient threshold | 4 |
| Algorithm | Level 1 | Level 2 | Level 3 | Level 4 | Level 5 |
|---|---|---|---|---|---|
| Region growing | 33 × 33 | 27 × 27 | 21 × 21 | 15 × 15 | 9 × 9 |
| Watershed | Gradient < 2 | Gradient < 3 | Gradient < 4 | Gradient < 5 | Gradient < 6 |
| Algorithm | T1 | T2 | T3 | T4 | T5 | T6 | T7 | T8 | T9 | T10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Region growing | 204 | 46 | 97 | 512 | 96 | 53 | 123 | 89 | 86 | 182 |
| Watershed | 512 | 341 | 73 | 108 | 440 | 512 | 298 | 228 | 248 | 85 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, F.; Wang, N.; Yu, B.; Qin, Y.; Wang, L. A Strategy of Parallel Seed-Based Image Segmentation Algorithms for Handling Massive Image Tiles over the Spark Platform. Remote Sens. 2021, 13, 1969. https://doi.org/10.3390/rs13101969
Chen F, Wang N, Yu B, Qin Y, Wang L. A Strategy of Parallel Seed-Based Image Segmentation Algorithms for Handling Massive Image Tiles over the Spark Platform. Remote Sensing. 2021; 13(10):1969. https://doi.org/10.3390/rs13101969
Chicago/Turabian StyleChen, Fang, Ning Wang, Bo Yu, Yuchu Qin, and Lei Wang. 2021. "A Strategy of Parallel Seed-Based Image Segmentation Algorithms for Handling Massive Image Tiles over the Spark Platform" Remote Sensing 13, no. 10: 1969. https://doi.org/10.3390/rs13101969
APA StyleChen, F., Wang, N., Yu, B., Qin, Y., & Wang, L. (2021). A Strategy of Parallel Seed-Based Image Segmentation Algorithms for Handling Massive Image Tiles over the Spark Platform. Remote Sensing, 13(10), 1969. https://doi.org/10.3390/rs13101969