U2-ONet: A Two-Level Nested Octave U-Structure Network with a Multi-Scale Attention Mechanism for Moving Object Segmentation


Abstract
1. Introduction
- We propose the -ONe, which is a two-level nested U-structure network with a multi-scale attention mechanism to efficiently segment all the moving object instances in a dynamic scene, regardless of whether they are associated with a particular semantic class.
- We propose the novel octave residual U-block (ORSU block) with octave convolution to fill each stage of the -ONe. The ORSU blocks extract intra-stage multi-scale features while adopting more efficient inter-frequency information exchange, as well as reducing the spatial redundancy and memory cost in the convolutional neural network (CNN).
- We propose a hierarchical training supervision strategy that calculates both the standard binary cross-entropy loss (BCEloss) and KLloss at each level, and uses the KLloss implicit constraint gradient to enhance the opportunity of knowledge sharing in order to improve the training effect of this deep network.
- In the task of moving object segmentation, the results have proved that the -ONe is efficient, and the hierarchical training supervision strategy improves the accuracy of the deep network. The experimental results show that the proposed -ONe achieves a state-of-the-art performance in some challenging datasets, which include camouflaged objects, tiny objects, and fast camera motion.
2. Related Work
2.1. Video Foreground Segmentation
2.2. Instance Segmentation
2.3. Motion Segmentation
3. Method
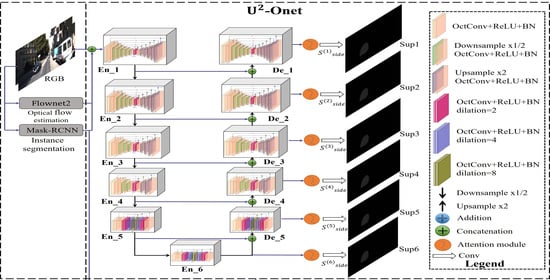
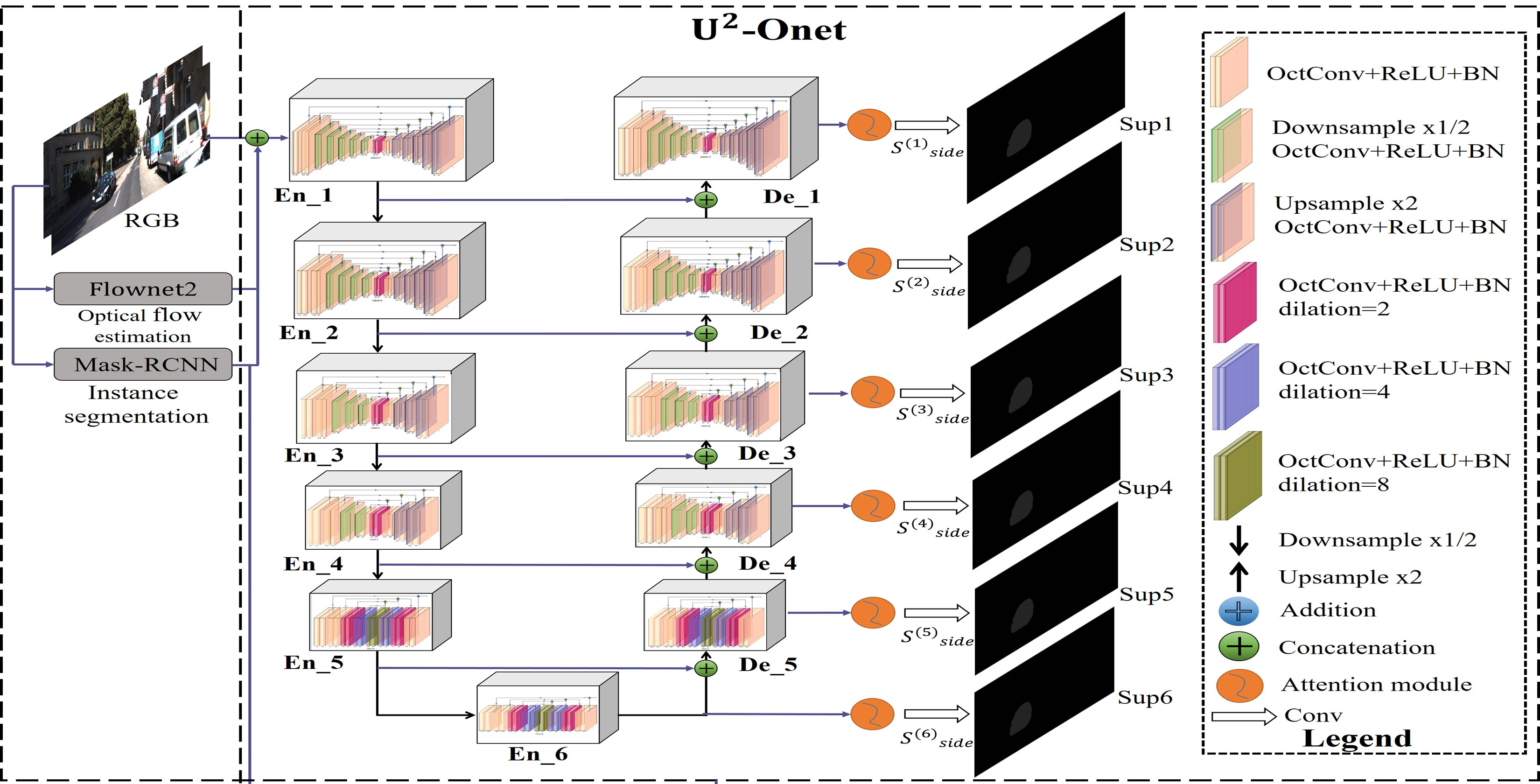
3.1. Overall Structure
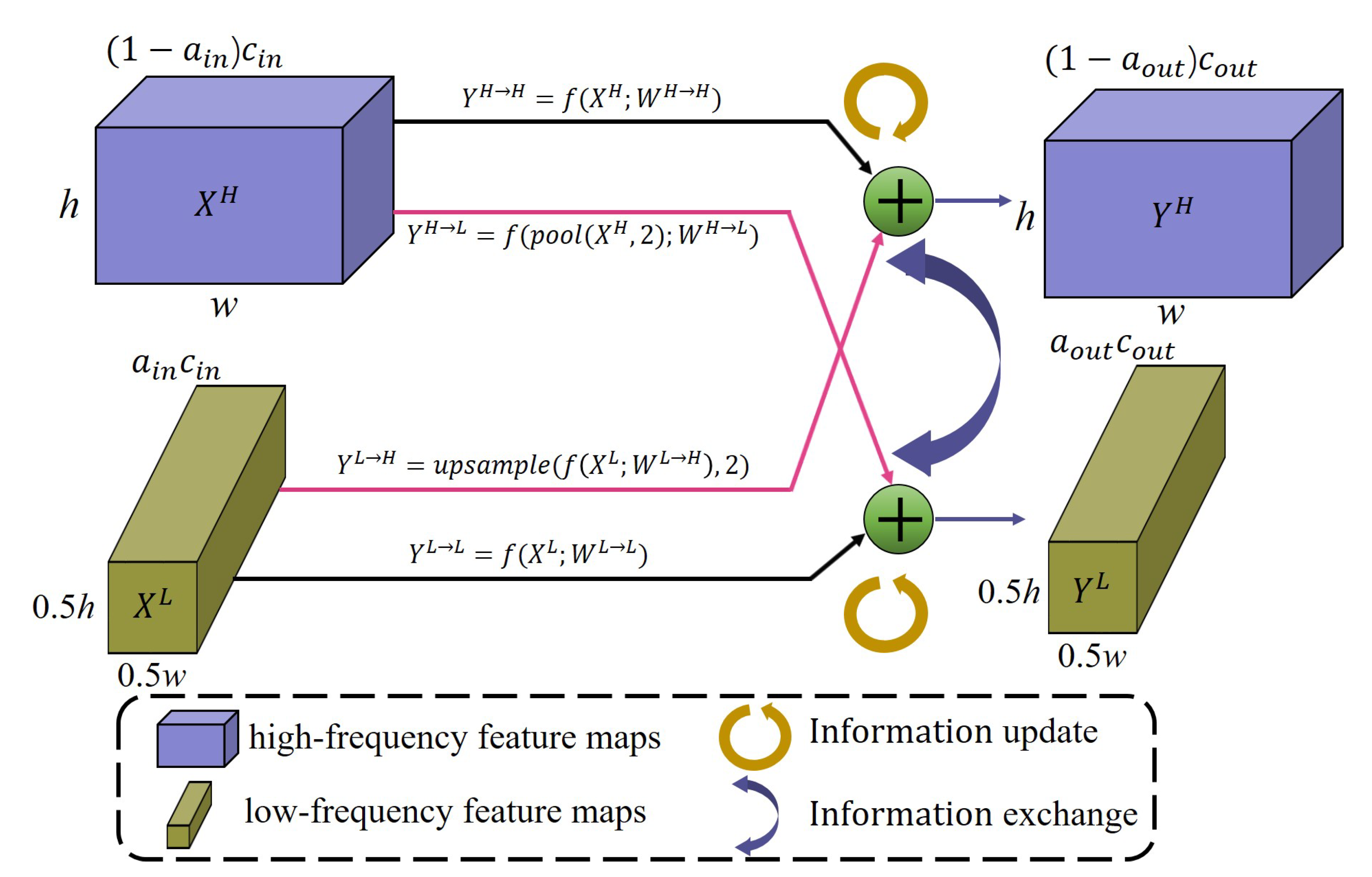
3.2. ORSU Blocks
- An input convolutional layer, which uses octave convolution (OctConv) for the local feature extraction instead of vanilla convolution. Compared with RSU blocks, ORSU blocks using OctConv further reduce the computation and memory consumption while boosting the accuracy of the segmentation. This layer transforms the input feature map into an intermediate map with the output channel of .
- A U-Net-like symmetric encoder–decoder structure with a height of L, which is deeper with a larger value of L. It takes from the input convolutional layer as input and learns to extract and encode the multi-scale contextual information , where denotes the U-Net-like structure, as shown in Figure 2.
- A residual connection for fusing local features and the multi-scale features through the summation of: .
3.3. U-ONet
- The six-stage encoder. Detailed configurations are presented in Table 2. The number “L” behind the “ORSU-” denotes the height of the blocks. , M, and represent the input channels, middle channels, and output channels of each block, respectively. A larger value of L is used to capture more large-scale information of the feature map, with larger height and width. In both the and stages, ORSU-4F blocks are used, which are the dilated version of the ORSU blocks using dilated convolution (see Figure 1), because the resolution of the feature maps in these two stages is relatively low.
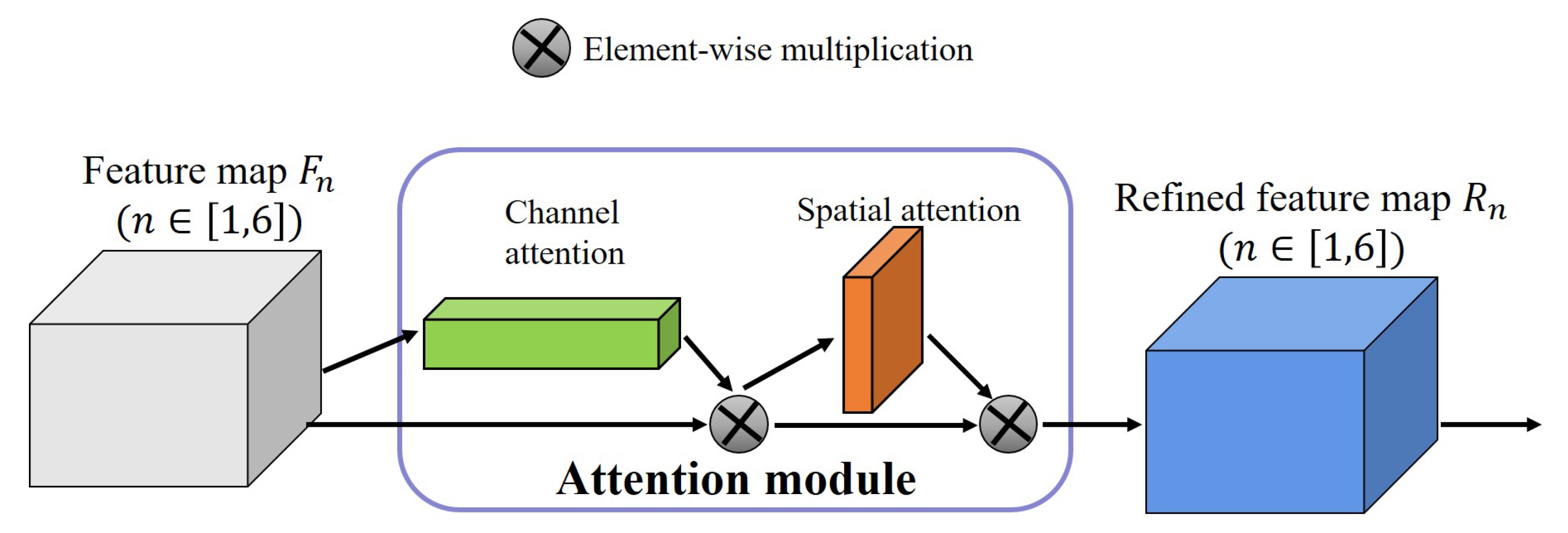
- The last part is a multi-scale attention mechanism attached to the decoder stages and the last encoder stage. At each level of the network, we add an attention module including channel and spatial attention mechanisms to eliminate the aliasing effect that should be eliminated by 3 × 3 convolution, inspired by [24] (see Figure 4) and [52]. At the same time, the channel attention mechanism is used to assign different significances to the channels of the feature map, and the spatial attention mechanism is used to discover which parts of the feature map are more important, so that the saliency of the spatial dimension of the moving objects is enhanced. Compared to -Ne for salient object detection, we maintain a deep architecture with high resolution for moving object segmentation while further enhancing the effect, reducing the computational and memory costs (see Table 1 and Table 3).
3.4. Training Supervision Strategy
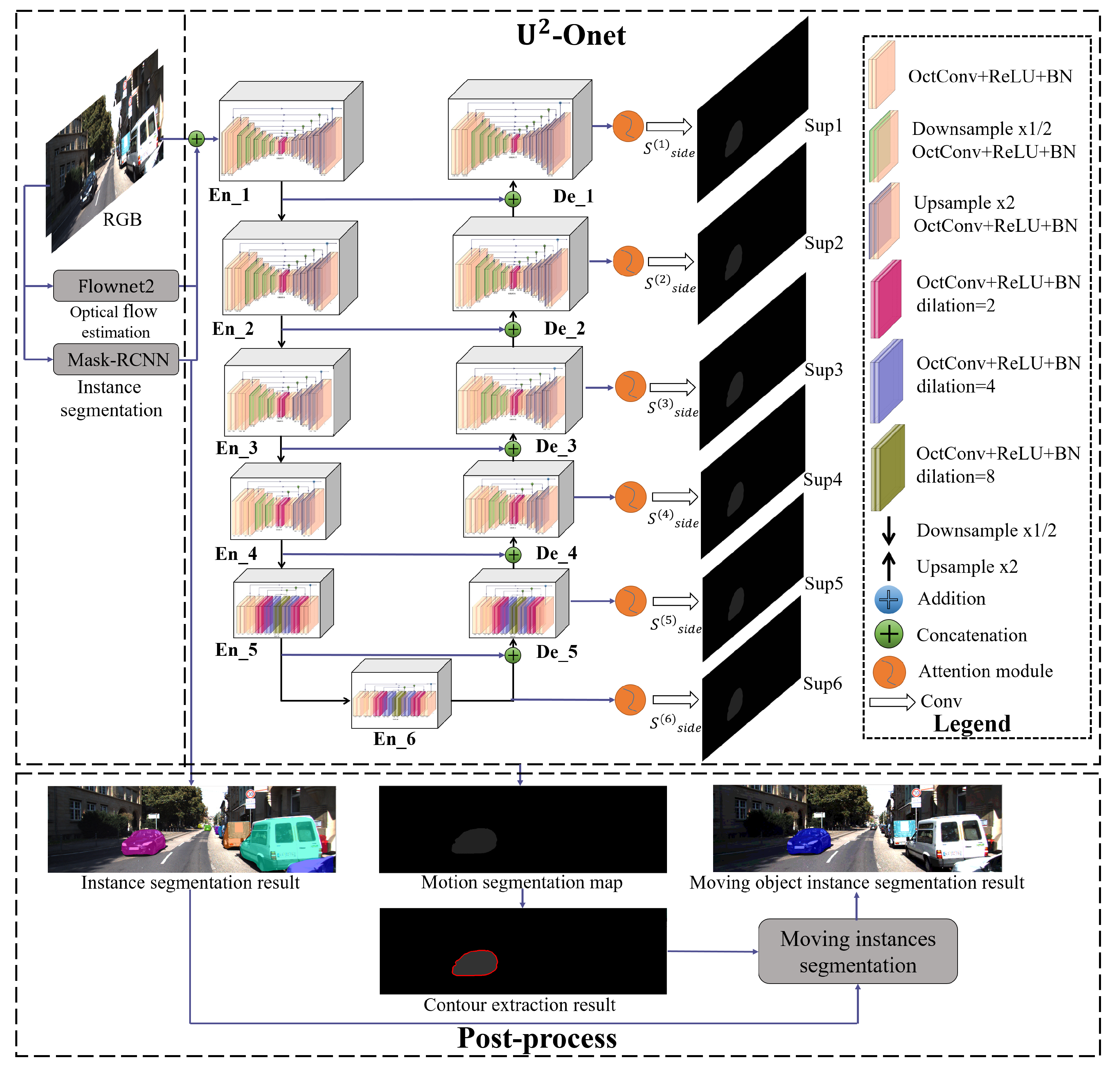
3.5. Post-Processing
| Algorithm 1 Instance-level moving object segmentation |
|
4. Experiments
4.1. Ablation Studies
4.1.1. ORSU Block Structure
4.1.2. Attention Mechanism
4.1.3. Training Supervision
4.2. Comparison with Prior Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Saputra, M.R.U.; Markham, A.; Trigoni, N. Visual SLAM and structure from motion in dynamic environments: A survey. ACM Comput. Surv. (CSUR) 2018, 51, 37. [Google Scholar] [CrossRef]
- Runz, M.; Buffier, M.; Agapito, L. Maskfusion: Real-time recognition, tracking and reconstruction of multiple moving objects. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, 16–20 October 2018; pp. 10–20. [Google Scholar]
- Wang, R.; Wan, W.; Wang, Y.; Di, K. A New RGB-D SLAM Method with Moving Object Detection for Dynamic Indoor Scenes. Remote. Sens. 2019, 11, 1143. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, Q.; Li, J.; Zhang, S.; Liu, J. A Computationally Efficient Semantic SLAM Solution for Dynamic Scenes. Remote Sens. 2019, 11, 1363. [Google Scholar] [CrossRef]
- Zha, Y.; Wu, M.; Qiu, Z.; Dong, S.; Yang, F.; Zhang, P. Distractor-Aware Visual Tracking by Online Siamese Network. IEEE Access 2019, 7, 89777–89788. [Google Scholar] [CrossRef]
- Amiranashvili, A.; Dosovitskiy, A.; Koltun, V.; Brox, T. Motion Perception in Reinforcement Learning with Dynamic Objects. Conf. Robot. Learn. (CoRL) 2018, 87, 156–168. [Google Scholar]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. In Field and Service Robotics; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Baradel, F.; Wolf, C.; Mille, J.; Taylor, G.W. Glimpse Clouds: Human Activity Recognition From Unstructured Feature Points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Chen, B.; Huang, S. An Advanced Moving Object Detection Algorithm for Automatic Traffic Monitoring in Real-World Limited Bandwidth Networks. IEEE Trans. Multimed. 2014, 16, 837–847. [Google Scholar] [CrossRef]
- Bouwmans, T.; Zahzah, E.H. Robust PCA via Principal Component Pursuit: A review for a comparative evaluation in video surveillance. Comput. Vis. Image Underst. 2014, 122, 22–34. [Google Scholar] [CrossRef]
- Wang, C.; Luo, B.; Zhang, Y.; Zhao, Q.; Yin, L.; Wang, W.; Su, X.; Wang, Y.; Li, C. DymSLAM:4D Dynamic Scene Reconstruction Based on Geometrical Motion Segmentation. arXiv 2020, arXiv:cs.CV/2003.04569. [Google Scholar]
- Zhao, X.; Qin, Q.; Luo, B. Motion Segmentation Based on Model Selection in Permutation Space for RGB Sensors. Sensors 2019, 19, 2936. [Google Scholar] [CrossRef]
- Zhang, Y.; Luo, B.; Zhang, L. Permutation preference based alternate sampling and clustering for motion segmentation. IEEE Signal Process. Lett. 2017, 25, 432–436. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bideau, P.; RoyChowdhury, A.; Menon, R.R.; Learned-Miller, E. The best of both worlds: Combining cnns and geometric constraints for hierarchical motion segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 508–517. [Google Scholar]
- Xie, C.; Xiang, Y.; Harchaoui, Z.; Fox, D. Object discovery in videos as foreground motion clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9994–10003. [Google Scholar]
- Dave, A.; Tokmakov, P.; Ramanan, D. Towards segmenting anything that moves. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019; pp. 1493–1502. [Google Scholar]
- Muthu, S.; Tennakoon, R.; Rathnayake, T.; Hoseinnezhad, R.; Suter, D.; Bab-Hadiashar, A. Motion Segmentation of RGB-D Sequences: Combining Semantic and Motion Information Using Statistical Inference. IEEE Trans. Image Process. 2020, 29, 5557–5570. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Fan, H.; Xu, B.; Yan, Z.; Kalantidis, Y.; Rohrbach, M.; Yan, S.; Feng, J. Drop an octave: Reducing spatial redundancy in convolutional neural networks with octave convolution. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3435–3444. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; So Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Papazoglou, A.; Ferrari, V. Fast Object Segmentation in Unconstrained Video. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Darling Harbour, Sydney, Australia, 2–8 December 2013; pp. 1777–1784. [Google Scholar] [CrossRef]
- Faktor, A.; Irani, M. Video Segmentation by Non-Local Consensus voting. BMVC 2014, 2, 8. [Google Scholar]
- Wang, W.; Shen, J.; Porikli, F. Saliency-aware geodesic video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3395–3402. [Google Scholar]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Van Gool, L.; Gross, M.; Sorkine-Hornung, A. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 724–732. [Google Scholar]
- Wang, W.; Song, H.; Zhao, S.; Shen, J.; Zhao, S.; Hoi, S.C.; Ling, H. Learning unsupervised video object segmentation through visual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3064–3074. [Google Scholar]
- Wang, W.; Lu, X.; Shen, J.; Crandall, D.J.; Shao, L. Zero-shot video object segmentation via attentive graph neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9236–9245. [Google Scholar]
- Lu, X.; Wang, W.; Ma, C.; Shen, J.; Shao, L.; Porikli, F. See more, know more: Unsupervised video object segmentation with co-attention siamese networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3623–3632. [Google Scholar]
- Peng, Q.; Cheung, Y. Automatic Video Object Segmentation Based on Visual and Motion Saliency. IEEE Trans. Multimed. 2019, 21, 3083–3094. [Google Scholar] [CrossRef]
- Chen, Y.; Hao, C.; Liu, A.X.; Wu, E. Multilevel Model for Video Object Segmentation Based on Supervision Optimization. IEEE Trans. Multimed. 2019, 21, 1934–1945. [Google Scholar] [CrossRef]
- Zhuo, T.; Cheng, Z.; Zhang, P.; Wong, Y.; Kankanhalli, M. Unsupervised online video object segmentation with motion property understanding. IEEE Trans. Image Process. 2019, 29, 237–249. [Google Scholar] [CrossRef]
- Yang, Z.; Wei, Y.; Yang, Y. Collaborative video object segmentation by foreground-background integration. arXiv 2020, arXiv:2003.08333. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Kang, B.R.; Lee, H.; Park, K.; Ryu, H.; Kim, H.Y. BshapeNet: Object detection and instance segmentation with bounding shape masks. Pattern Recognit. Lett. 2020, 131, 449–455. [Google Scholar] [CrossRef]
- Peng, S.; Jiang, W.; Pi, H.; Li, X.; Bao, H.; Zhou, X. Deep Snake for Real-Time Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8533–8542. [Google Scholar]
- Hurtik, P.; Molek, V.; Hula, J.; Vajgl, M.; Vlasanek, P.; Nejezchleba, T. Poly-YOLO: Higher speed, more precise detection and instance segmentation for YOLOv3. arXiv 2020, arXiv:2005.13243. [Google Scholar]
- Kong, S.; Fowlkes, C.C. Recurrent pixel embedding for instance grouping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9018–9028. [Google Scholar]
- Neven, D.; Brabandere, B.D.; Proesmans, M.; Gool, L.V. Instance segmentation by jointly optimizing spatial embeddings and clustering bandwidth. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8837–8845. [Google Scholar]
- Ying, H.; Huang, Z.; Liu, S.; Shao, T.; Zhou, K. Embedmask: Embedding coupling for one-stage instance segmentation. arXiv 2019, arXiv:1912.01954. [Google Scholar]
- Chen, L.; Strauch, M.; Merhof, D. Instance Segmentation of Biomedical Images with an Object-Aware Embedding Learned with Local Constraints. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2019; pp. 451–459. [Google Scholar]
- Xu, X.; Cheong, L.F.; Li, Z. 3D Rigid Motion Segmentation with Mixed and Unknown Number of Models. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Thakoor, N.; Gao, J.; Devarajan, V. Multibody structure-and-motion segmentation by branch-and-bound model selection. IEEE Trans. Image Process. 2010, 19, 1393–1402. [Google Scholar] [CrossRef]
- Zhao, Q.; Zhang, Y.; Qin, Q.; Luo, B. Quantized Residual Preference Based Linkage Clustering for Model Selection and Inlier Segmentation in Geometric Multi-Model Fitting. Sensors 2020, 20, 3806. [Google Scholar] [CrossRef]
- Sultana, M.; Mahmood, A.; Jung, S.K. Unsupervised Moving Object Detection in Complex Scenes Using Adversarial Regularizations. IEEE Trans. Multimed. 2020, 1. [Google Scholar] [CrossRef]
- Shen, J.; Peng, J.; Shao, L. Submodular trajectories for better motion segmentation in videos. IEEE Trans. Image Process. 2018, 27, 2688–2700. [Google Scholar] [CrossRef]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 2462–2470. [Google Scholar]
- Li, C.; Luo, B.; Hong, H.; Su, X.; Wang, Y.; Liu, J.; Wang, C.; Zhang, J.; Wei, L. Object Detection Based on Global-Local Saliency Constraint in Aerial Images. Remote Sens. 2020, 12, 1435. [Google Scholar] [CrossRef]
- Lee, C.Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-supervised nets. In Artificial Intelligence and Statistics; 2015; pp. 562–570. [Google Scholar]
- Li, D.; Chen, Q. Dynamic Hierarchical Mimicking Towards Consistent Optimization Objectives. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7642–7651. [Google Scholar]
- Suzuki, S.; Abe, K. Topological structural analysis of digitized binary images by border following. Comput. Vis. Graph. Image Process. 1985, 30, 32–46. [Google Scholar] [CrossRef]
- Ochs, P.; Malik, J.; Brox, T. Segmentation of moving objects by long term video analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1187–1200. [Google Scholar] [CrossRef] [PubMed]
- Pont-Tuset, J.; Perazzi, F.; Caelles, S.; Arbeláez, P.; Sorkine-Hornung, A.; Van Gool, L. The 2017 davis challenge on video object segmentation. arXiv 2017, arXiv:1704.00675. [Google Scholar]
- Xu, N.; Yang, L.; Fan, Y.; Yue, D.; Liang, Y.; Yang, J.; Huang, T. Youtube-vos: A large-scale video object segmentation benchmark. arXiv 2018, arXiv:1809.03327. [Google Scholar]
- Siam, M.; Mahgoub, H.; Zahran, M.; Yogamani, S.; Jagersand, M.; El-Sallab, A. Modnet: Motion and appearance based moving object detection network for autonomous driving. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2859–2864. [Google Scholar]
- Rashed, H.; Ramzy, M.; Vaquero, V.; El Sallab, A.; Sistu, G.; Yogamani, S. Fusemodnet: Real-time camera and lidar based moving object detection for robust low-light autonomous driving. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Bideau, P.; Learned-Miller, E. A detailed rubric for motion segmentation. arXiv 2016, arXiv:1610.10033. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 2881–2890. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Blocks | FLOPS | Memory | MAdd |
|---|---|---|---|
| RSU-7 | 4.39 GFLOPS | 138.67MB | 8.74 MAdd |
| ORSU-7 | |||
| Networks | FLOPS | Memory | MAdd |
| -Ne | 37.67 GFLOPS | 444.25MB | 75.20 MAdd |
| -ONe |
| Stages | ||||||
|---|---|---|---|---|---|---|
| Block | ORSU-7 | ORSU-6 | ORSU-5 | ORSU-4 | ORSU-4F | ORSU-4F |
| 15 | 64 | 128 | 256 | 512 | 512 | |
| M | 32 | 32 | 64 | 128 | 256 | 256 |
| 64 | 128 | 256 | 512 | 512 | 512 | |
| Block | ORSU-4F | ORSU-4 | ORSU-5 | ORSU-6 | ORSU-7 | |
| 1024 | 1024 | 512 | 256 | 128 | ||
| M | 256 | 128 | 64 | 32 | 16 | |
| 512 | 256 | 128 | 64 | 64 | ||
| Video Foreground Segmentation | Multi-Object Motion Segmentation | |||||||
|---|---|---|---|---|---|---|---|---|
| P (Precision) | R (Recall) | F (F-Measure) | IoU | P (Precision) | R (Recall) | F (F-Measure) | IoU | |
| -Ne(−a) | 84.6748 | 78.7881 | 80.2232 | 70.9541 | 79.8170 | 74.4494 | 75.7438 | 70.3260 |
| -ONe(−a) | 87.0821 | 79.7173 | 81.6738 | 72.4611 | 82.3621 | 75.5477 | 77.3492 | 72.1066 |
| -ONe | 88.3126 | 82.5591 | 83.7723 | 74.1656 | 83.1169 | 77.9250 | 78.9910 | 72.9785 |
| Video Foreground Segmentation | Multi-object Motion Segmentation | |||||||
|---|---|---|---|---|---|---|---|---|
| P (Precision) | R (Recall) | F (F-Measure) | IoU | P (Precision) | R (Recall) | F (F-Measure) | IoU | |
| -ONe | 87.1959 | 82.9170 | 83.3599 | 73.7483 | 82.0288 | 78.2415 | 78.5725 | 72.7251 |
| -ONe | 87.6808 | 82.4263 | 83.2078 | 73.4435 | 82.4819 | 77.7830 | 78.4259 | 72.9288 |
| -ONe | 86.5249 | 83.6013 | 83.2855 | 73.5262 | 81.3052 | 78.8389 | 78.4271 | 73.2597 |
| -ONe | 87.5558 | 83.3884 | 83.7176 | 74.0066 | 82.2579 | 78.6416 | 78.8341 | 73.2570 |
| -ONe | 88.0516 | 82.7291 | 83.6525 | 74.0434 | 82.9008 | 78.0600 | 78.9054 | 73.2325 |
| -ONe | 88.2510 | 82.3962 | 83.5610 | 73.9233 | 83.0433 | 77.7766 | 78.7818 | 73.2416 |
| -ONe | 88.1412 | 83.1088 | 83.9566 | 74.4435 | 82.9590 | 78.4306 | 79.1666 | 73.2620 |
| -ONe | 88.2951 | 82.4503 | 83.7305 | 74.1254 | 83.1775 | 77.8654 | 79.0048 | 73.1279 |
| -ONe | 88.2397 | 82.2916 | 83.4473 | 73.7114 | 83.0693 | 77.6426 | 78.6916 | 72.8023 |
| -ONe | 88.8535 | 82.2117 | 83.7729 | 74.2275 | 83.6419 | 77.6087 | 79.0023 | 72.7234 |
| -ONe | 88.3126 | 82.5591 | 83.7723 | 74.1656 | 83.1169 | 77.9250 | 78.9910 | 72.9785 |
| -ONe | 88.1056 | 82.9051 | 83.8449 | 74.1089 | 82.9020 | 78.2278 | 79.0357 | 73.3622 |
| Multi-Object Motion Segmentation | |||||
|---|---|---|---|---|---|
| P | R | F | IoU | ΔObj | |
| CCG [18] | 74.23 | 63.07 | 64.97 | – | 4 |
| OBV [19] | 75.90 | 66.60 | 67.30 | – | 4.9 |
| STB [50] | 87.11 | 66.53 | 75.44 | – | – |
| TSA [20] | 88.60 | 80.40 | 84.30 | – | – |
| Ours | 84.80 | 83.10 | 81.84 | 79.70 | 4.9 |
| Multi-Object Motion Segmentation | |||||
|---|---|---|---|---|---|
| Dataset | P | R | F | IoU | |
| DAVIS-Moving | TSA [20] | 78.30 | 78.10 | – | |
| Ours | 77.93 | 72.98 | |||
| YTVOS-Moving | TSA [20] | 74.50 | 66.40 | 68.30 | – |
| Ours | 65.67 | ||||
| Video Foreground Segmentation | ||||
|---|---|---|---|---|
| P | R | F | IoU | |
| FuseMODNet (RGB + rgbFlow) [60] | – | – | – | 49.36 |
| Ours | 74.57 | 67.62 | 68.88 | |
| Video Foreground Segmentation | ||||
|---|---|---|---|---|
| P | R | F | IoU | |
| MODNet [59] | 56.18 | 70.32 | 62.46 | 45.41 |
| Ours | ||||
| Multi-Object Motion Segmentation | ||||
|---|---|---|---|---|
| P | R | F | IoU | |
| TSA [20] | – | – | – | – |
| Ours | 63.79 | 50.62 | 56.28 | 46.79 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Li, C.; Liu, J.; Luo, B.; Su, X.; Wang, Y.; Gao, Y. U2-ONet: A Two-Level Nested Octave U-Structure Network with a Multi-Scale Attention Mechanism for Moving Object Segmentation. Remote Sens. 2021, 13, 60. https://doi.org/10.3390/rs13010060
Wang C, Li C, Liu J, Luo B, Su X, Wang Y, Gao Y. U2-ONet: A Two-Level Nested Octave U-Structure Network with a Multi-Scale Attention Mechanism for Moving Object Segmentation. Remote Sensing. 2021; 13(1):60. https://doi.org/10.3390/rs13010060
Chicago/Turabian StyleWang, Chenjie, Chengyuan Li, Jun Liu, Bin Luo, Xin Su, Yajun Wang, and Yan Gao. 2021. "U2-ONet: A Two-Level Nested Octave U-Structure Network with a Multi-Scale Attention Mechanism for Moving Object Segmentation" Remote Sensing 13, no. 1: 60. https://doi.org/10.3390/rs13010060
APA StyleWang, C., Li, C., Liu, J., Luo, B., Su, X., Wang, Y., & Gao, Y. (2021). U2-ONet: A Two-Level Nested Octave U-Structure Network with a Multi-Scale Attention Mechanism for Moving Object Segmentation. Remote Sensing, 13(1), 60. https://doi.org/10.3390/rs13010060