1.1. Background
Remote sensing images may include a variety of geomorphological information, such as roads, arable land, and buildings. To classify this different geomorphological information is of great significance for topographic surveys and military analysis. To finish the classification task, each pixel in a remote sensing image should be assigned to a label associated with a terrain category, which is consistent with image semantic segmentation.
Image semantic segmentation plays a critical role in computer vision, the task of which is to assign a semantic label to each pixel in an image. Traditional algorithms for image semantic segmentation generally consist of a feature extractor and a classifier, such as the work in [
1]. Although the traditional algorithm is efficient enough, it cannot meet the needs of high accuracy. With the successful application of Convolution Neural Network (CNN) [
2] in the field of computer vision, researchers have begun to consider using CNN in semantic segmentation [
3]. A lot of creative algorithms such as FCN [
4], Deeplabs [
5,
6,
7], CRF as RNN [
8] etc., have made surprising results. Fully Convolution Network (FCN) is the first end-to-end network for semantic segmentation, which creatively introduces deconvolution. Deeplabs mainly relies on Dilated Convolution and post-processing Conditional Random Forest (CRF) [
9] to refine the segmentation results. CRF as RNN [
8] makes the CRF integrate into the segmentation network to form an end-to-end network.
Since CNN has made an impressive achievement on image semantic segmentation, let us quickly review the excellent algorithms proposed recently. Generally, these networks can be divided into the following five aspects.
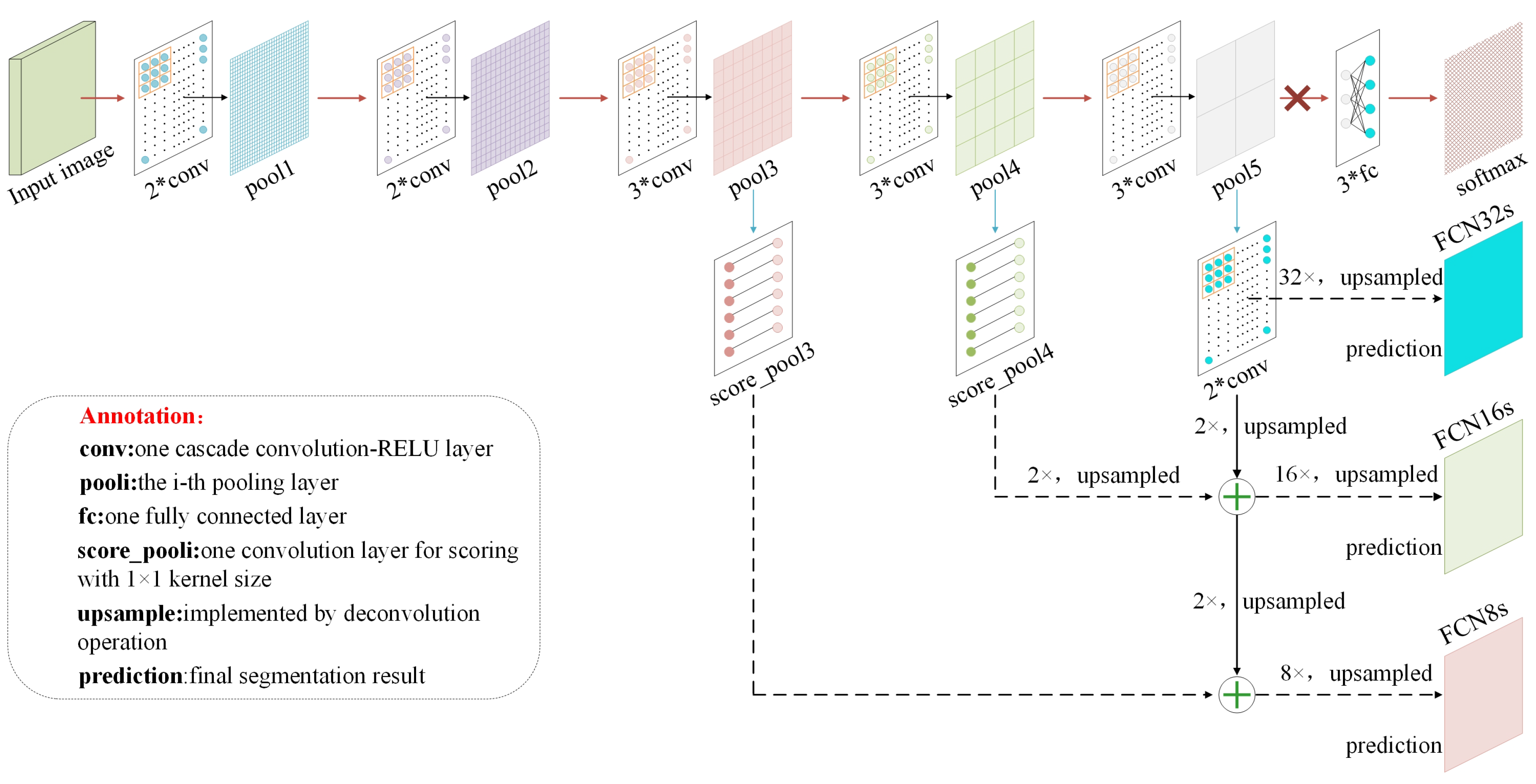
Encoder–Decoder: FCN [
4] is the first network for semantic segmentation with an encoder–decoder structure. The idea of SegNet [
10,
11] is very similar to FCN, whereas it encodes and decodes each size of feature map and uses max-pooling indices for upsampling. U-net [
12] introduces very low-level information that is effective for recovering details. Consequently, it is usually used for medical image segmentation. Fine Segmentation Network (FSN) proposed in [
13] also follows the encoder–decoder paradigm in semantic labeling of high-resolution aerial imagery and LiDAR data.
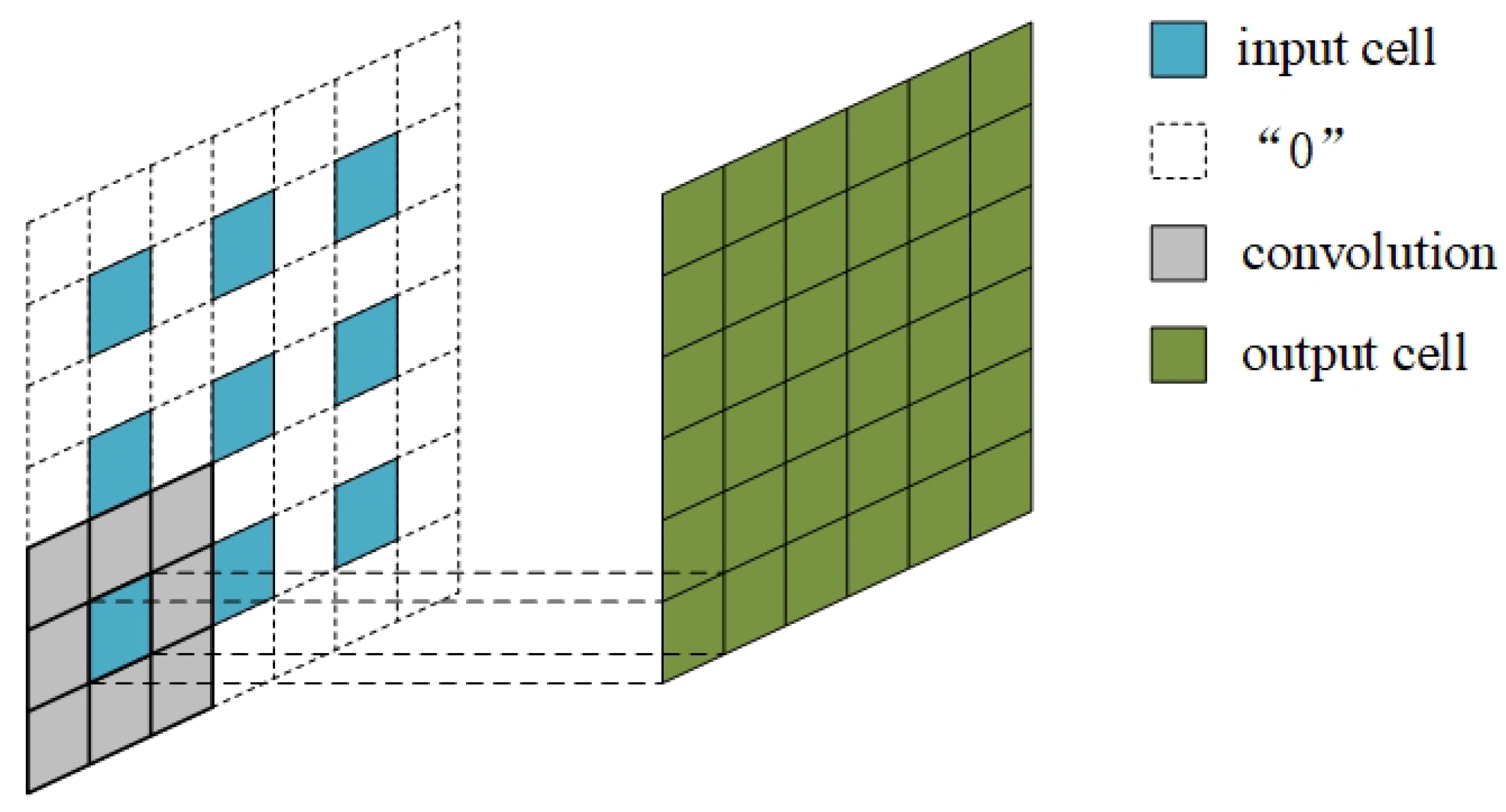
Atrous Convolution Base: Atrous convolution is proposed for enlarging the reception field by inserting “0” in filters without increasing the computation. It is widely used in Deeplab-V1 [
5], Deeplab-V2 [
6], and Deeplab-V3 [
7]. To improve the density of output class maps, ref. [
14] introduces atrous convolution in high-resolution remote sensing image classification. Moreover, Atrous Spatial Pyramid Pooling (ASPP) implemented in Deeplab-V2 [
6] is also used in remote sensing image classification [
15].
Multi-Level Fusion: It is well known that there is more spatial information in low-level feature maps while the high-level feature maps are richer in semantic information. Semantic segmentation is a joint task of localization and classification requiring both spatial information and semantic information. As a result, multi-level fusion is widely used in recent networks, such as RefineNet [
16], PSPNet [
17], and GCN [
18]. Algorithms in [
19] employ CNN to generate five-level features and then a linear model is used to fuse the features of different levels. A hierarchical multi-scale CNN with auxiliary classifiers is proposed in [
20] to learn hierarchical multi-scale spectral–spatial features for HSI classification.
CNN Integrate Traditional Algorithm: It is also popular in combining CNN and traditional algorithms in remote sensing image segmentation. Some researchers integrate a graph embedding model and FCN [
21] to extract both the shallow-linear and deep-nonlinear features to segment the remote sensing image more accurately. Methods in [
14,
22] both further refine the output class maps generated from CNN using Conditional Random Field (CRF) post-processing. Texture analysis [
23] is also widely used in semantic segmentation of remote sensing images [
24], such as classification of land cover of a Mediterranean region [
25] and road traffic condition classification [
26].
Boundary Refinement: Boundary detection is also a fundamental challenge regarding image understanding. Lots of specific methods for detecting boundaries have been proposed recently in [
27,
28,
29]. What they have in common is that they straightly concatenate the different level of features to extract the boundary. Discriminative Feature Network (DFN) [
30] is proposed for tacking the intra-class inconsistency problem and inter-class indistinction problem. In contrast to DFN, our model constrains better segmentation by finding changes in the image signal and the nature of the region signal.
Some approaches have been proposed recently on introducing edges into the semantic segmentation network. A method for correcting segmentation results using edges is proposed in [
31]. It draws on the Domain Transform method of one-dimensional signal, and uses the edge intensity as the weight of the filter to correct the original segmentation result. The diffusion method is improved in [
32], and the edge distance map is proposed to guide the direction of diffusion. Both methods in [
31,
32] belong to the method of adding edge information to correct the segmentation after the segmentation is completed. What we have done in this paper is to use an end-to-end network to combine semantic segmentation with edge detection so that the associated parameters can be updated by training.
1.2. Problem and Motivation
FCN is considered to be the landmark network since it uses the end-to-end network for the first time in semantic segmentation and has achieved satisfying results. However, many problems still exist in FCN: First, the result obtained by upsampling is still rough so some detailed information in the image may not be acquired. Secondly, the relevance between pixels is not fully used and thus the spatial consistency is lost. Thirdly, it lacks a priori knowledge constraints. To segment the remote sensing image more accurately, some researchers focus on integrating a graph embedding model and FCN to extract both the shallow-linear and deep-nonlinear features [
21]. Although these methods can significantly improve the segmentation results, the priori information is still not considered. Motivated by the successful application of prior knowledge in remote sensing image scene classification [
33], we naturally consider adding prior knowledge to remote sensing image semantic segmentation.
Edge detection is used to find out the obvious changes in brightness in the image. Therefore, it can eliminate irrelevant information in the image and preserve important structural properties. Traditional edge detection operators are similarly based on the gradient of the image signal to extract the edge information, such as Sobel operator, Roberts operator, and Canny operator [
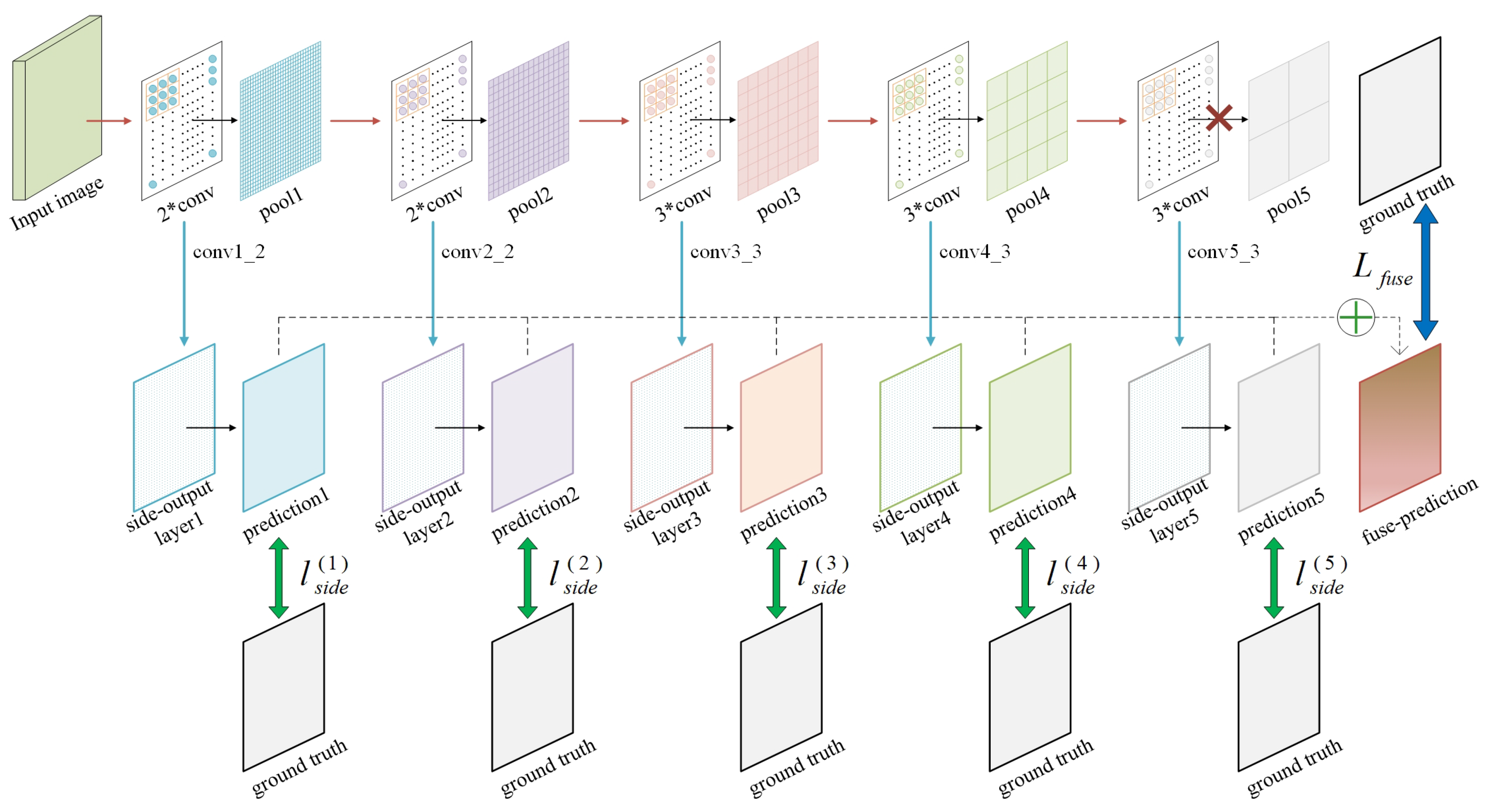
34], etc. Although using traditional operators can extract edge information fast, it may fail to get the edge information between different categories, which is needed for semantic segmentation. Holistically Nested Edge Detection (HED) network [
35] is a deep network designed for edge detection. It produces multi-scale feature maps and multiple loss functions to perform backpropagation, which can provide the edge information we want.
1.3. Structure and Contribution
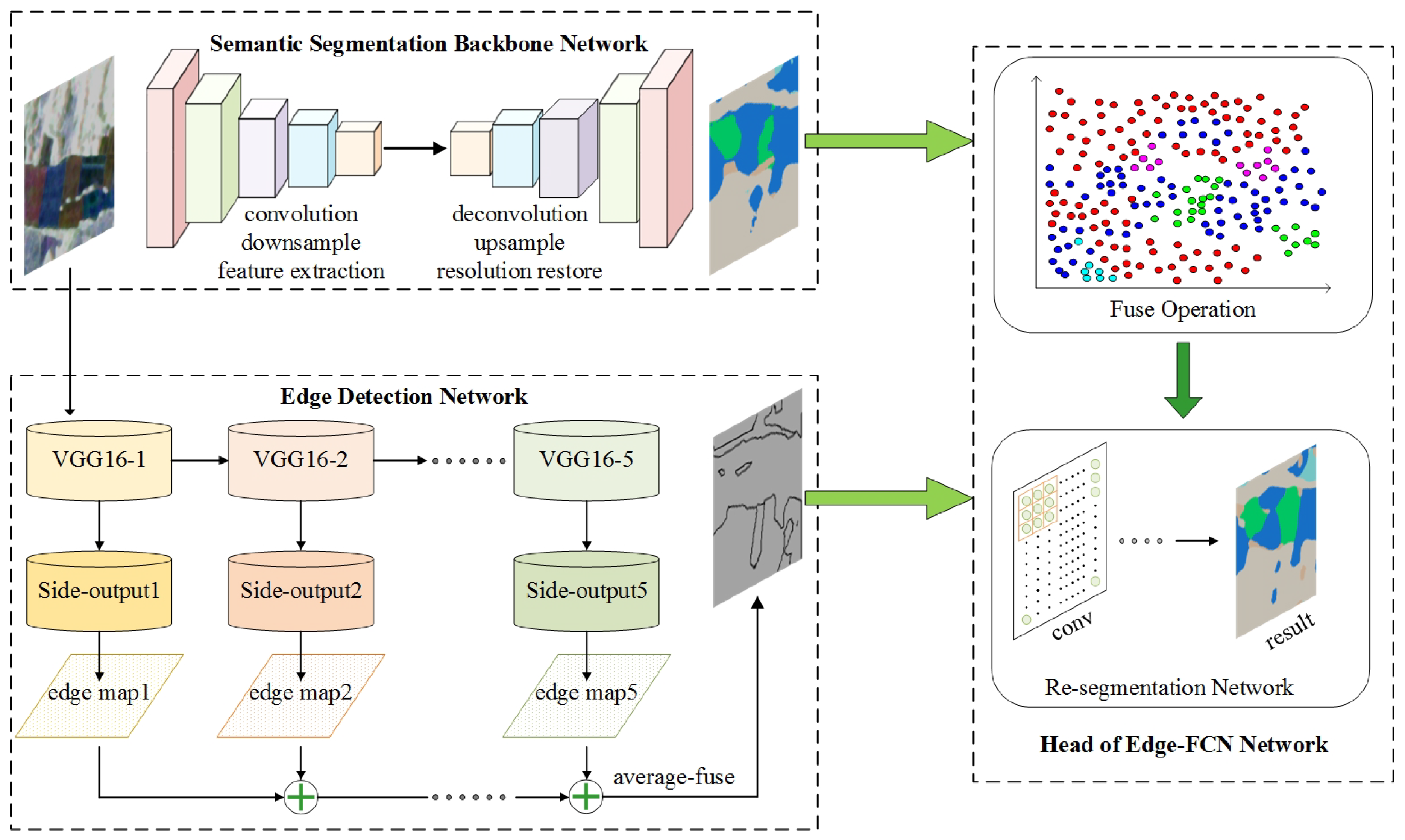
To tackle the problems in FCN, one way is to combine the FCN and HED to correct the FCN segmentation result by the possibility of each pixel as an edge point detected by HED. Accordingly, a new segmentation result can be acquired.
From the perspective of signal processing, the segmentation network is like a low-pass filter, which can smooth the image signal and assign the pixels in the similar region with the same semantic label. On the contrary, the edge detection network is like a high-pass filter, which can amplify the distinction of features and extract the semantic boundaries. By combining FCN and HED, the edge scores produced by HED can constrain the segmentation results and thus renew them.
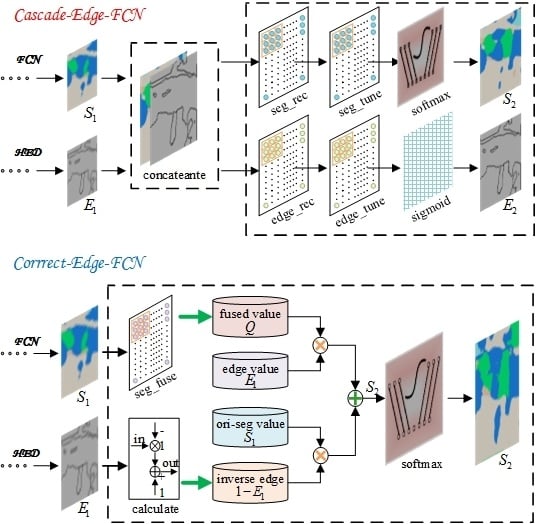
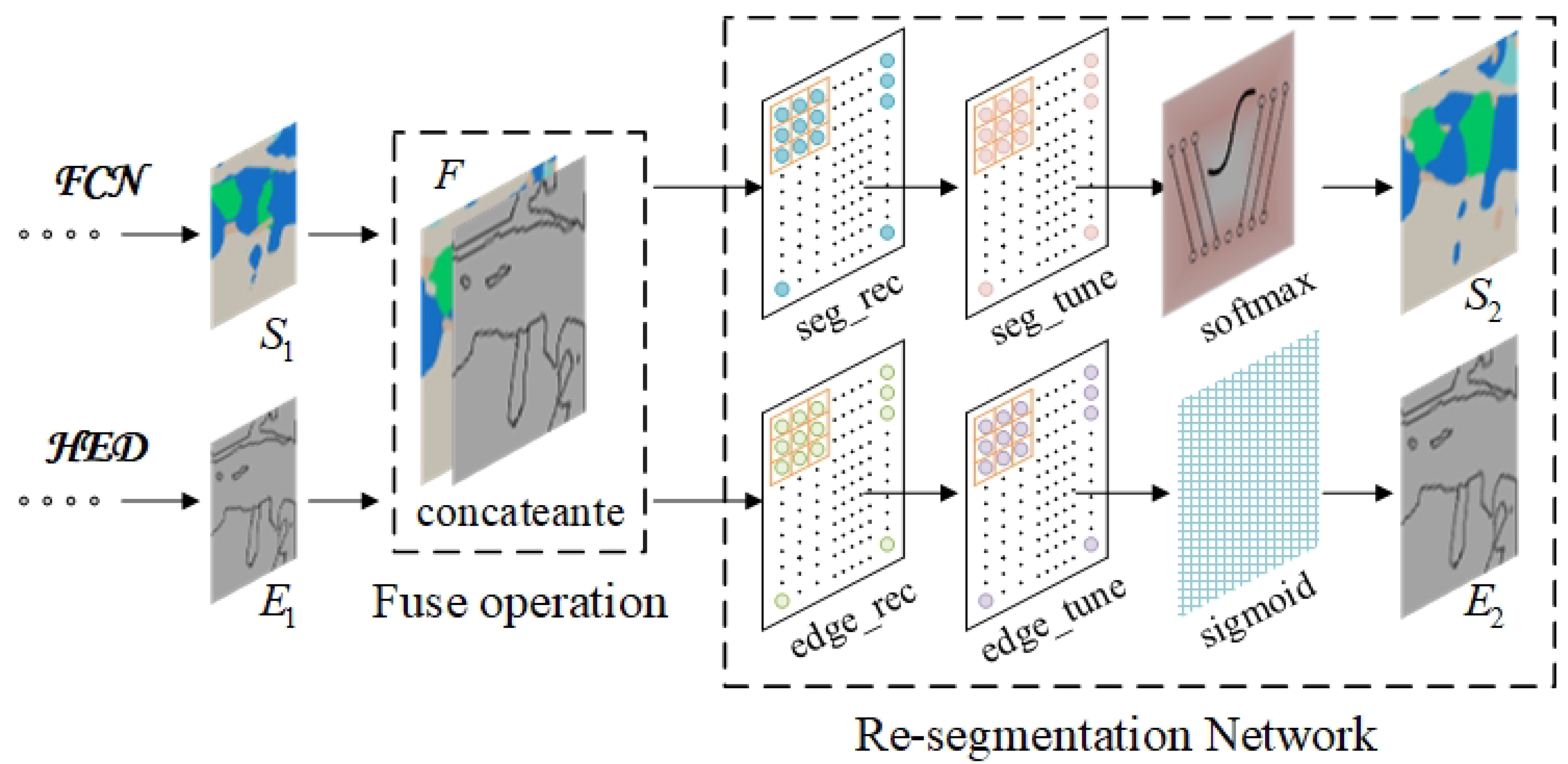
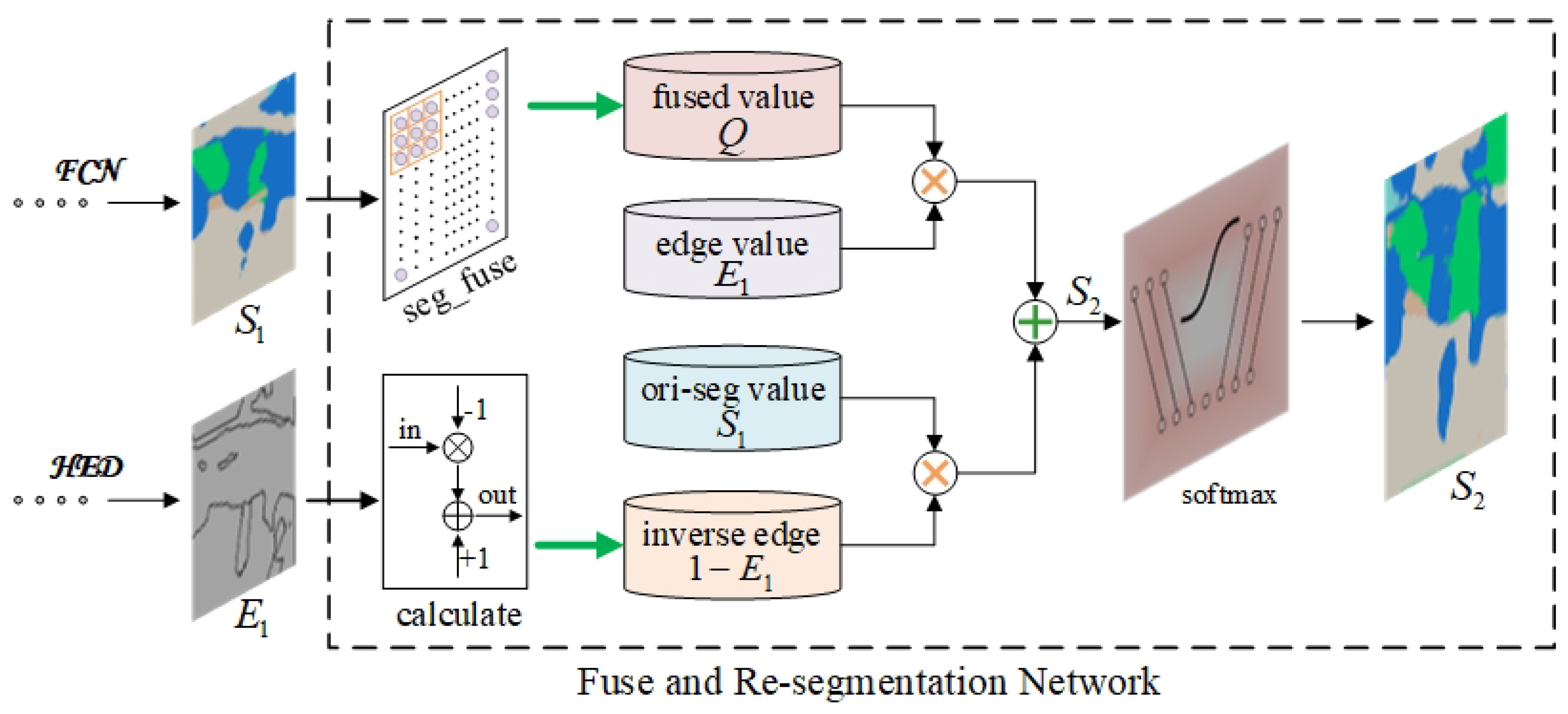
The newly proposed network is named Edge-FCN, seen in
Figure 1. According to different ways of combination, they are respectively called Cascade-Edge-FCN and Correct-Edge-FCN.
Cascade-Edge-FCN It directly concatenates the segmentation score map produced by FCN and the edge score map produced by HED and then recovers the new edge score map and new segmentation score map by using convolution layers.
Correct-Edge-FCN Based on the idea that the larger the edge score, the larger the correction should be, Correct-Edge-FCN uses edge score map to correct segmentation result, which can be realized by a convolution layer.
In summary, the main contributions of this paper are as follows:
- (1)
Edge information is used as the a priori knowledge to guide remote sensing image segmentation.
- (2)
Two conceptually simple end-to-end networks are proposed in this paper by combining FCN and HED, which can be trained and inferenced easily without complicated procedures.
- (3)
Learning from the point in HED, multiple loss fusion is applied to Edge-FCN. Therefore, deep supervision can be realized for each layer when training.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}