Comparison of Cloud Cover Detection Algorithms on Sentinel–2 Images of the Amazon Tropical Forest

 ,
,  ,
,  , ,
, ,  , , , ,
, , , ,  , and
, and
Abstract
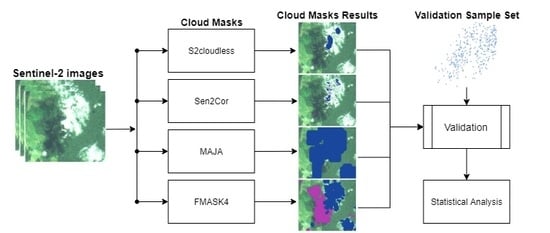
1. Introduction
2. Materials and Methods
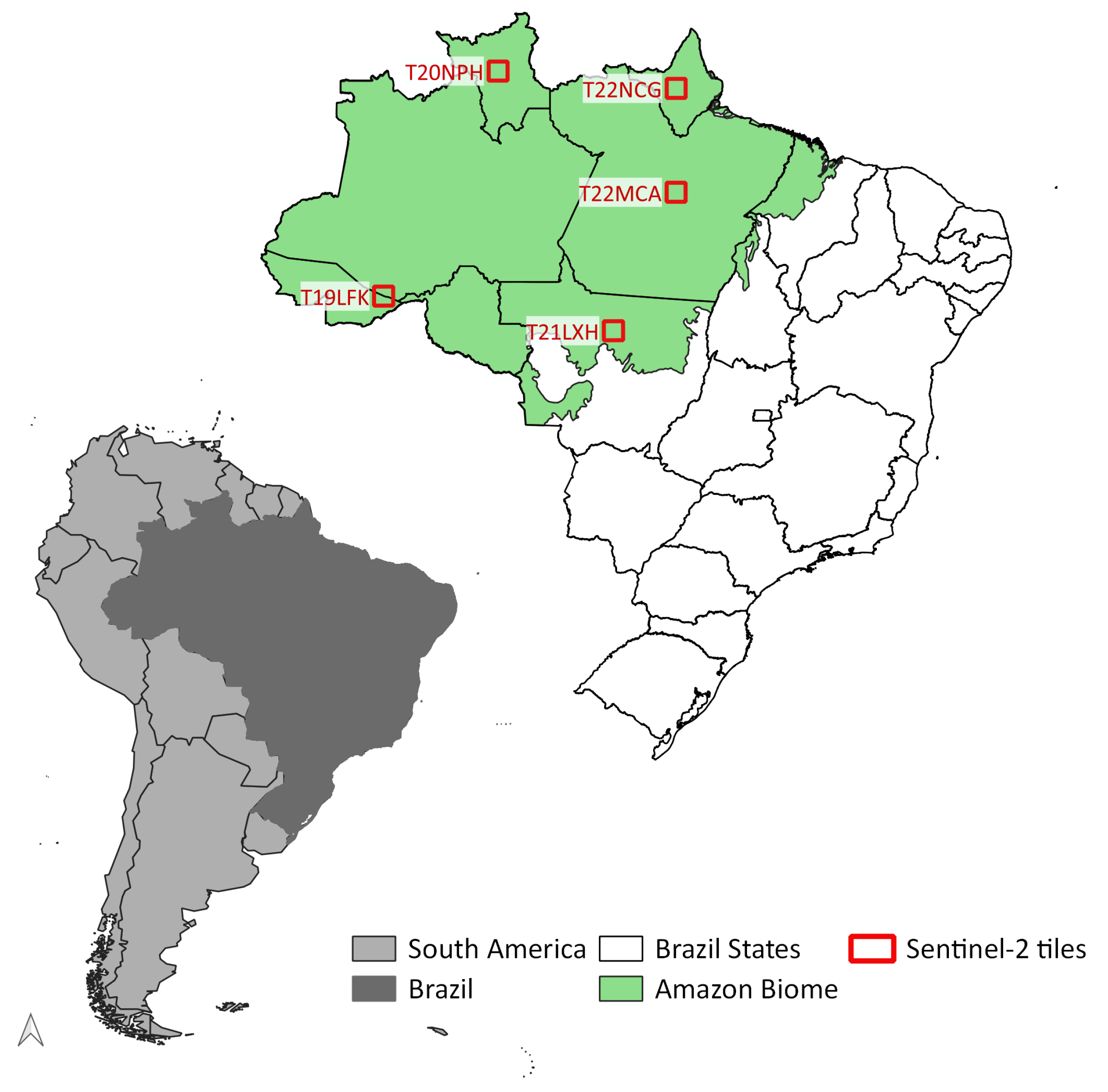
2.1. Study Area
2.2. Data Selection
- T19LFK:
- Covers part of the states of Acre and Amazonas, including an indigenous land (Terra Indígena Apurianã) and a protected area (Reserva Extrativista Chico Mendes). The region is associated with significant recent deforestation.
- T20NPH:
- This area is in the state of Roraima and it partially covers a national forest (Floresta Nacional de Roraima) and an indigenous land (Terra Indígena Yanomami).
- T21LXH:
- This area covers part of the state of Mato Grosso; it includes fragmented forest areas, soybean crops, pasture, and water reservoirs.
- T22MCA:
- In the state of Para, this area overlaps various indigenous reserves (Arara, Araweté, Kararaô, Koatinemo, and Trincheira) and part of a conservation unit; most of the area is covered by native forest with some deforested areas to the North.
- T22NCG:
- This area is in the state of Amapá, including part of a National Forest (Amapá), a national park (Montanhas do Tumucumaque), and an indigenous land (Waiãpi).
2.3. Cloud Detection Algorithms
2.4. Algorithm Configuration
- Fmask 4:
- Dilation parameters for cloud, cloud shadows, and snow were set to 3, 3, and 0 pixels, respectively. The cloud probability threshold was 20%, following Qiu et al. [47].
- S2cloudless:
- Cloud probability threshold was set to 70%, using a four-pixel convolution for averaging cloud probabilities and dilation of two pixels, following the parameters set by Zupanc et al. [27].
- Sen2Cor 2.8:
- The tests used the same configuration as that of the Land Cover maps of ESA’s Climate Change Initiative (http://maps.elie.ucl.ac.be/CCI/viewer/download.php).
- MAJA:
- The evaluation used the same configuration as that of the Sen2Agri application (http://www.esa-sen2agri.org).
2.5. Validation Sample Set
2.6. Label Compatibility
2.7. Validation Metrics
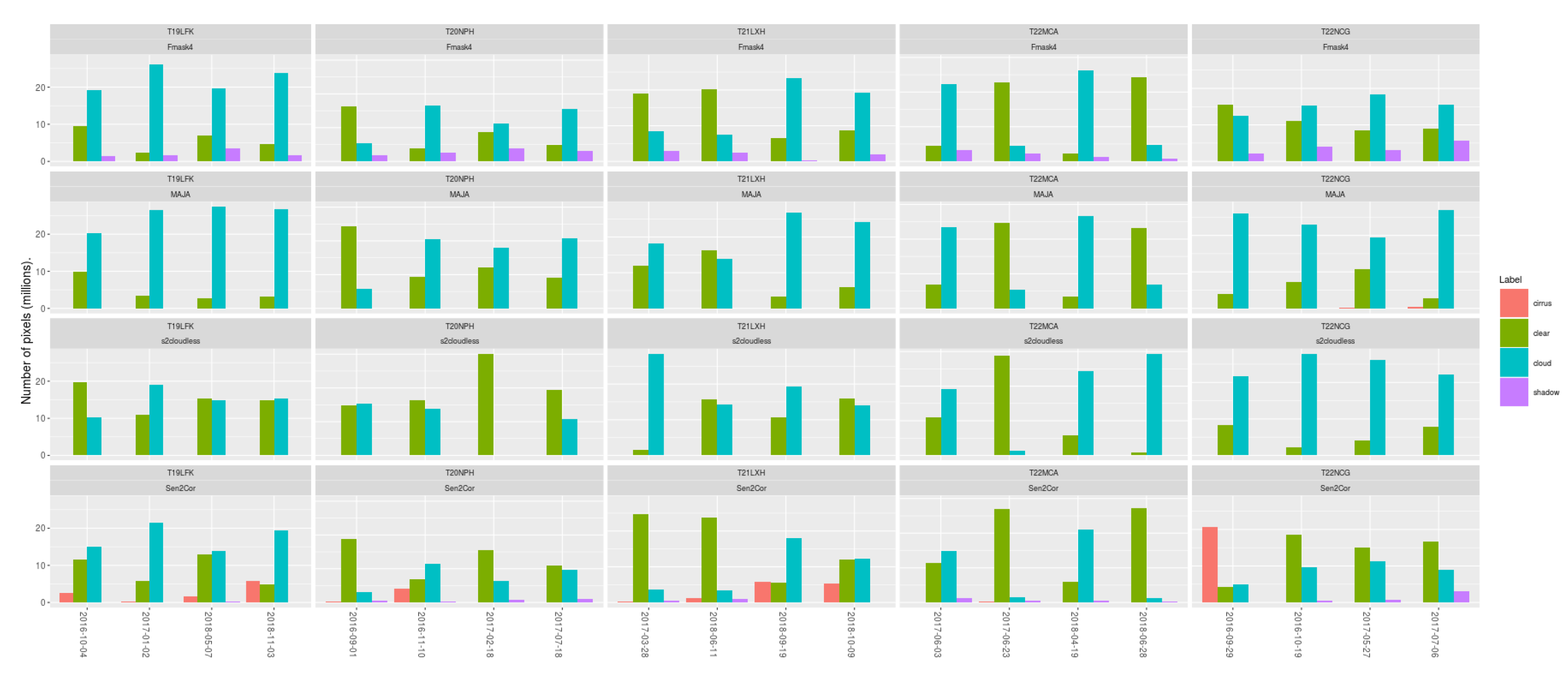
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Antonelli, A.; Zizka, A.; Carvalho, F.A.; Scharn, R.; Bacon, C.D.; Silvestro, D.; Condamine, F.L. Amazonia Is the Primary Source of Neotropical Biodiversity. Proc. Natl. Acad. Sci. USA 2018, 115, 6034–6039. [Google Scholar] [CrossRef] [PubMed]
- Ometto, J.; Aguiar, A.; Assis, T.; Soler, L.; Valle, P.; Tejada, G.; Lapola, D.; Meir, P. Amazon Forest Biomass Density Maps: Tackling the Uncertainty in Carbon Emission Estimates. Clim. Chang. 2014, 124, 545–560. [Google Scholar] [CrossRef]
- Gibbs, H.K.; Ruesch, A.S.; Achard, F.; Clayton, M.K.; Holmgren, P.; Ramankutty, N.; Foley, J.A. Tropical Forests Were the Primary Sources of New Agricultural Land in the 1980s and 1990s. Proc. Natl. Acad. Sci. USA 2010, 107, 16732–16737. [Google Scholar] [CrossRef] [PubMed]
- INPE. Amazon Deforestation Monitoring Project (PRODES); Technical Report; National Institute for Space Research: São José dos Campos, Brazil, 2019. [Google Scholar]
- Nepstad, D.; McGrath, D.; Stickler, C.; Alencar, A.; Azevedo, A.; Swette, B.; Bezerra, T.; DiGiano, M.; Shimada, J.; Seroa da Motta, R.; et al. Slowing Amazon Deforestation through Public Policy and Interventions in Beef and Soy Supply Chains. Science 2014, 344, 1118–1123. [Google Scholar] [CrossRef] [PubMed]
- Soterroni, A.C.; Mosnier, A.; Carvalho, A.X.Y.; Camara, G.; Obersteiner, M.; Andrade, P.R.; Souza, R.C.; Brock, R.; Pirker, J.; Kraxner, F.; et al. Future Environmental and Agricultural Impacts of Brazil’s Forest Code. Environ. Res. Lett. 2018, 13, 074021. [Google Scholar] [CrossRef]
- Shimabukuro, Y.E.; Santos, J.R.; Formaggio, A.R.; Duarte, V.; Rudorff, B.F.T. The Brazilian Amazon Monitoring Program: PRODES and DETER Projects. In Global Forest Monitoring From Earth Observation; Taylor and Francis: New York, NY, USA, 2012; 354p. [Google Scholar]
- Assuncao, J.; Gandour, C.; Rocha, R. Deforestation Slowdown in the Brazilian Amazon: Prices or Policies? Environ. Dev. Econ. 2015, 20, 697–722. [Google Scholar] [CrossRef]
- Gibbs, H.K.; Rausch, L.; Munger, J.; Schelly, I.; Morton, D.C.; Noojipady, P.; Soares-Filho, B.; Barreto, P.; Micol, L.; Walker, N.F. Brazil’s Soy Moratorium. Science 2015, 347, 377–378. [Google Scholar] [CrossRef]
- Almeida, C.; Coutinho, A.; Esquerdo, J.; Adami, M.; Venturieri, A.; Diniz, C.; Dessay, N.; Durieux, L.; Gomes, A. High Spatial Resolution Land Use and Land Cover Mapping of the Brazilian Legal Amazon in 2008 Using Landsat-5/TM and MODIS Data. Acta Amaz. 2016, 46, 291–302. [Google Scholar] [CrossRef]
- Souza, C., Jr.; Siqueira, J.; Sales, M.; Fonseca, A.; Ribeiro, J.; Numata, I.; Cochrane, M.; Barber, C.; Roberts, D.; Barlow, J. Ten-Year Landsat Classification of Deforestation and Forest Degradation in the Brazilian Amazon. Remote Sens. 2013, 5, 5493–5513. [Google Scholar] [CrossRef]
- Tyukavina, A.; Hansen, M.C.; Potapov, P.V.; Stehman, S.V.; Smith-Rodriguez, K.; Okpa, C.; Aguilar, R. Types and Rates of Forest Disturbance in Brazilian Legal Amazon, 2000–2013. Sci. Adv. 2017, 3, e1601047. [Google Scholar] [CrossRef] [PubMed]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [PubMed]
- Picoli, M.; Camara, G.; Sanches, I.; Simoes, R.; Carvalho, A.; Maciel, A.; Coutinho, A.; Esquerdo, J.; Antunes, J.; Begotti, R.A.; et al. Big Earth Observation Time Series Analysis for Monitoring Brazilian Agriculture. ISPRS J. Photogramm. Remote Sens. 2018, 145, 328–339. [Google Scholar] [CrossRef]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Griffiths, P.; Linden, S.; Kuemmerle, T.; Hostert, P. A Pixel-Based Landsat Compositing Algorithm for Large Area Land Cover Mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2088–2101. [Google Scholar] [CrossRef]
- Brown, J.C.; Kastens, J.H.; Coutinho, A.C.; Victoria, D.d.C.; Bishop, C.R. Classifying Multiyear Agricultural Land Use Data from Mato Grosso Using Time-Series MODIS Vegetation Index Data. Remote Sens. Environ. 2013, 130, 39–50. [Google Scholar] [CrossRef]
- Rufin, P.; Mueller, H.; Pflugmacher, D.; Hostert, P. Land Use Intensity Trajectories on Amazonian Pastures Derived from Landsat Time Series. Int. J. Appl. Earth Obs. Geoinf. 2015, 41, 1–10. [Google Scholar] [CrossRef]
- Jakimow, B.; Griffiths, P.; Linden, S.; Hostert, P. Mapping Pasture Management in the Brazilian Amazon from Dense Landsat Time Series. Remote Sens. Environ. 2018, 205, 453–468. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-Based Cloud and Cloud Shadow Detection in Landsat Imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Claverie, M.; Ju, J.; Masek, J.G.; Dungan, J.L.; Vermote, E.F.; Roger, J.C.; Skakun, S.V.; Justice, C. The Harmonized Landsat and Sentinel-2 Surface Reflectance Data Set. Remote Sens. Environ. 2018, 219, 145–161. [Google Scholar] [CrossRef]
- Louis, J.; Debaecker, V.; Pflug, B.; Main-Knorn, M.; Bieniarz, J.; Mueller-Wilm, U.; Cadau, E.; Gascon, F. SENTINEL-2 Sen2Cor: L2A Processor for Users. In Proceedings Living Planet Symposium; ESA: Paris, France, 2016; p. 8. [Google Scholar]
- Hagolle, O.; Huc, M.; Auer, S.; Richter, R.; Richter, R. MAJA Algorithm Theoretical Basis Document. 2017. Available online: https://zenodo.org/record/1209633#.XpdnZvnQ-Cg (accessed on 29 November 2019). [CrossRef]
- Frantz, D.; Haß, E.; Uhl, A.; Stoffels, J.; Hill, J. Improvement of the Fmask Algorithm for Sentinel-2 Images: Separating Clouds from Bright Surfaces Based on Parallax Effects. Remote Sens. Environ. 2018, 215, 471–481. [Google Scholar] [CrossRef]
- Qiu, S.; Zhu, Z.; He, B. Fmask 4.0: Improved Cloud and Cloud Shadow Detection in Landsats 4–8 and Sentinel-2 Imagery. Remote Sens. Environ. 2019, 231, 111205. [Google Scholar] [CrossRef]
- Baetens, L.; Desjardins, C.; Hagolle, O. Validation of Copernicus Sentinel-2 Cloud Masks Obtained from MAJA, Sen2Cor, and FMask Processors Using Reference Cloud Masks Generated with a Supervised Active Learning Procedure. Remote Sens. 2019, 11, 433. [Google Scholar] [CrossRef]
- Zupanc, A. Improving Cloud Detection with Machine Learning. 2019. Available online: https://medium.com/sentinel-hub/improving-cloud-detection-with-machine-learning-c09dc5d7cf13 (accessed on 29 November 2019).
- Roberts, G.C.; Andreae, M.O.; Zhou, J.; Artaxo, P. Cloud Condensation Nuclei in the Amazon Basin: “Marine” Conditions over a Continent? Geophys. Res. Lett. 2001, 28, 2807–2810. [Google Scholar] [CrossRef]
- Poschl, U.; Martin, S.T.; Sinha, B.; Chen, Q.; Gunthe, S.S.; Huffman, J.A.; Borrmann, S.; Farmer, D.K.; Garland, R.M.; Helas, G.; et al. Rainforest Aerosols as Biogenic Nuclei of Clouds and Precipitation in the Amazon. Science 2010, 329, 1513–1516. [Google Scholar] [CrossRef]
- Artaxo, P.; Rizzo, L.V.; Paixão, M.; De Lucca, S.; Oliveira, P.H.; Lara, L.L.; Wiedemann, K.T.; Andreae, M.O.; Holben, B.; Schafer, J.; et al. Aerosol Particles in Amazonia: Their Composition, Role in the Radiation Balance, Cloud Formation, and Nutrient Cycles. In Amazonia and Global Change; American Geophysical Union (AGU): Washington, DC, USA, 2009; pp. 233–250. [Google Scholar] [CrossRef]
- Asner, G.P. Cloud Cover in Landsat Observations of the Brazilian Amazon. Int. J. Remote Sens. 2001, 22, 3855–3862. [Google Scholar] [CrossRef]
- Cecchini, M.A.; Machado, L.A.T.; Andreae, M.O.; Martin, S.T.; Albrecht, R.I.; Artaxo, P.; Barbosa, H.M.J.; Borrmann, S.; Fütterer, D.; Jurkat, T.; et al. Sensitivities of Amazonian Clouds to Aerosols and Updraft Speed. Atmos. Chem. Phys. 2017, 17, 10037–10050. [Google Scholar] [CrossRef]
- Durieux, L. The Impact of Deforestation on Cloud Cover over the Amazon Arc of Deforestation. Remote Sens. Environ. 2003, 86, 132–140. [Google Scholar] [CrossRef]
- Wang, J.; Chagnon, F.J.F.; Williams, E.R.; Betts, A.K.; Renno, N.O.; Machado, L.A.T.; Bisht, G.; Knox, R.; Bras, R.L. Impact of Deforestation in the Amazon Basin on Cloud Climatology. Proc. Natl. Acad. Sci. USA 2009, 106, 3670–3674. [Google Scholar] [CrossRef]
- Sun, L.; Yang, X.; Jia, S.; Jia, C.; Wang, Q.; Liu, X.; Wei, J.; Zhou, X. Satellite Data Cloud Detection Using Deep Learning Supported by Hyperspectral Data. Int. J. Remote Sens. 2020, 41, 1349–1371. [Google Scholar] [CrossRef]
- Zhu, X.; Helmer, E.H. An Automatic Method for Screening Clouds and Cloud Shadows in Optical Satellite Image Time Series in Cloudy Regions. Remote Sens. Environ. 2018, 214, 135–153. [Google Scholar] [CrossRef]
- Davidson, E.A.; Araujo, A.C.; Artaxo, P.; Balch, J.K.; Brown, I.F.; Bustamante, M.M.C.; Coe, M.T.; DeFries, R.S.; Keller, M.; Longo, M.; et al. The Amazon Basin in Transition. Nature 2012, 481, 321–328. [Google Scholar] [CrossRef] [PubMed]
- Wolanin, A.; Camps-Valls, G.; Gomez-Chova, L.; Mateo-Garcia, G.; Tol, C.; Zhang, Y.; Guanter, L. Estimating Crop Primary Productivity with Sentinel-2 and Landsat 8 Using Machine Learning Methods Trained with Radiative Transfer Simulations. Remote. Sens. Environ. 2019. [Google Scholar] [CrossRef]
- Gascon, F.; Bouzinac, C.; Thepaut, O.; Jung, M.; Francesconi, B.; Louis, J.; Lonjou, V.; Lafrance, B.; Massera, S.; Gaudel-Vacaresse, A.; et al. Copernicus Sentinel-2A Calibration and Products Validation Status. Remote Sens. 2017, 9, 584. [Google Scholar] [CrossRef]
- Foga, S.; Scaramuzza, P.L.; Guo, S.; Zhu, Z.; Dilley, R.D.; Beckmann, T.; Schmidt, G.L.; Dwyer, J.L.; Joseph Hughes, M.; Laue, B. Cloud Detection Algorithm Comparison and Validation for Operational Landsat Data Products. Remote Sens. Environ. 2017, 194, 379–390. [Google Scholar] [CrossRef]
- Defourny, P.; Bontemps, S.; Bellemans, N.; Cara, C.; Dedieu, G.; Guzzonato, E.; Hagolle, O.; Inglada, J.; Nicola, L.; Rabaute, T.; et al. Near Real-Time Agriculture Monitoring at National Scale at Parcel Resolution: Performance Assessment of the Sen2-Agri Automated System in Various Cropping Systems around the World. Remote Sens. Environ. 2019, 221, 551–568. [Google Scholar] [CrossRef]
- Pekel, J.F.; Cottam, A.; Gorelick, N.; Belward, A.S. High-Resolution Mapping of Global Surface Water and Its Long-Term Changes. Nature 2016, 540, 418–422. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and Expansion of the Fmask Algorithm: Cloud, Cloud Shadow, and Snow Detection for Landsat 4-7, 8, and Sentinel 2 Images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Mueller-Wilm, U. Sen2Cor 2.8 Software Release Note; Technical Report; ESA (European Space Agency) Report: Frascati, Italy, 2019. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A Highly Efficient Gradient Boosting Decision Tree. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Lane Red Hook, NY, USA, 2017; pp. 3146–3154. [Google Scholar]
- Hagolle, O.; Huc, M.; Villa Pascual, D.; Dedieu, G. A Multi-Temporal and Multi-Spectral Method to Estimate Aerosol Optical Thickness over Land, for the Atmospheric Correction of FormoSat-2, LandSat, VENμS and Sentinel-2 Images. Remote Sens. 2015, 7, 2668–2691. [Google Scholar] [CrossRef]
- Qiu, S.; Zhu, Z.; He, B. Fmask 4.0 Handbook. 2018. Available online: https://drive.google.com/drive/folders/1oVefP9G-TD2vhoCaaKCxQjvAnUlrwB19 (accessed on 1 December 2019).
- Israel, G.D. Determining Sample Size; Technical Report; University of Florida: Gainesville, FL, USA, 1992. [Google Scholar]
- Chinchor, N. MUC-4 Evaluation Metrics. In Fourth Message Uunderstanding Conference (MUC-4); Association for Computational Linguistics: Stroudsburg, PA, USA, 1992. [Google Scholar]
- Story, M.; Congalton, R. Accuracy Assessment: A User’s Perspective. Photogramm. Eng. Remote Sens. 1986, 52, 397–399. [Google Scholar]
- Segal-Rozenhaimer, M.; Li, A.; Das, K.; Chirayath, V. Cloud Detection Algorithm for Multi-Modal Satellite Imagery Using Convolutional Neural-Networks (CNN). Remote Sens. Environ. 2020, 237, 111446. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning. Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band | Resolution (m) | Wavelength (nm) | Revisit Period (Days) |
|---|---|---|---|
| B01 Coastal aerosol | 60 | 443 | 10 |
| B02 Blue | 10 | 490 | 10 |
| B03 Green | 10 | 560 | 10 |
| B04 Red | 10 | 665 | 10 |
| B05 Vegetation red edge | 20 | 705 | 10 |
| B06 Vegetation red edge | 20 | 740 | 10 |
| B07 Vegetation red edge | 20 | 783 | 10 |
| B08 NIR | 10 | 842 | 10 |
| B8A Vegetation red edge | 20 | 865 | 10 |
| B09 Water vapour | 60 | 945 | 10 |
| B10 SWIR - Cirrus | 60 | 1375 | 10 |
| B11 SWIR | 20 | 1610 | 10 |
| B12 SWIR | 20 | 2190 | 10 |
| Tile | Date | Samples |
|---|---|---|
| T19LFK | 4 October 2016 | 382 |
| T19LFK | 2 January 2017 | 437 |
| T19LFK | 7 May 2018 | 392 |
| T19LFK | 3 November 2018 | 452 |
| T20NPH | 1 September 2016 | 326 |
| T20NPH | 10 November 2016 | 246 |
| T20NPH | 18 February 2017 | 353 |
| T20NPH | 18 July 2017 | 311 |
| T21LXH | 28 March 2017 | 496 |
| T21LXH | 11 June 2018 | 474 |
| T21LXH | 19 September 2018 | 436 |
| T21LXH | 9 October 2018 | 457 |
| T22MCA | 3 June 2017 | 368 |
| T22MCA | 23 June 2017 | 404 |
| T22MCA | 19 April 2018 | 445 |
| T22MCA | 28 June 2018 | 447 |
| T22NCG | 29 September 2016 | 464 |
| T22NCG | 19 October 2016 | 426 |
| T22NCG | 27 May 2017 | 346 |
| T22NCG | 6 July 2017 | 433 |
| Expert label | Fmask4 | MAJA | s2cloudless | Sen2Cor |
|---|---|---|---|---|
| Clear | 0 Clear land | 0–1 Clear | 0 Clear | 4 Vegetation |
| 1 Clear water | 5 Non vegetated | |||
| 3 Snow | 6 Water | |||
| 11 Snow | ||||
| Cloud | 4 Cloud | 2–3 Cloud | 1 Cloud | 8 Cloud medium probability |
| 6–7 Cloud | 9 Cloud high probability | |||
| 10–11 Cloud | 10 Thins cirrus | |||
| 14–63 Cloud | ||||
| 64–127 Cirrus | ||||
| 128–191 Cloud | ||||
| 192–255 Cirrus | ||||
| Cloud shadow | 2 Cloud shadow | 4–5 Cloud shadow | 2 Dark area pixels | |
| 8–9 Cloud shadow | 3 Cloud shadows | |||
| 12–13 Cloud shadow | ||||
| Other | 0 No data | |||
| 1 Saturated or defective | ||||
| 7 Unclassified |
| Fmask 4 | MAJA | s2cloudless | Sen2Cor | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Label | F1 | User | Prod | F1 | User | Prod | F1 | User | Prod | F1 | User | Prod |
| Clear | 0.90 | 0.90 | 0.89 | 0.73 | 0.82 | 0.66 | 0.44 | 0.42 | 0.46 | 0.77 | 0.67 | 0.89 |
| Cloud | 0.94 | 0.91 | 0.96 | 0.77 | 0.64 | 0.97 | 0.66 | 0.59 | 0.75 | 0.89 | 0.90 | 0.88 |
| C. Shadow | 0.79 | 0.84 | 0.75 | 0.00 | 0.00 | 0.50 | 0.95 | 0.34 | ||||
| Overall | 0.90 | 0.69 | 0.52 | 0.79 | ||||||||
| Fmask 4 | MAJA | s2cloudless | Sen2Cor | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tile | Label | F1 | User | Prod | F1 | User | Prod | F1 | User | Prod | F1 | User | Prod |
| T19LFK | Clear | 0.83 | 0.81 | 0.86 | 0.66 | 0.69 | 0.63 | 0.47 | 0.31 | 0.94 | 0.66 | 0.52 | 0.92 |
| Cloud | 0.96 | 0.96 | 0.96 | 0.90 | 0.85 | 0.97 | 0.77 | 0.94 | 0.66 | 0.94 | 0.96 | 0.92 | |
| C. Shadow | 0.68 | 0.71 | 0.66 | 0.00 | 0.00 | 0.00 | |||||||
| Overall | 0.92 | 0.82 | 0.64 | 0.84 | |||||||||
| T20NPH | Clear | 0.91 | 0.95 | 0.88 | 0.78 | 0.89 | 0.70 | 0.53 | 0.47 | 0.62 | 0.84 | 0.73 | 1.00 |
| Cloud | 0.95 | 0.90 | 1.00 | 0.71 | 0.56 | 0.98 | 0.57 | 0.54 | 0.60 | 0.93 | 0.99 | 0.88 | |
| C. Shadow | 0.80 | 0.82 | 0.78 | 0.00 | 0.00 | 0.59 | 1.00 | 0.42 | |||||
| Overall | 0.91 | 0.67 | 0.50 | 0.84 | |||||||||
| T21LXH | Clear | 0.88 | 0.82 | 0.95 | 0.80 | 0.89 | 0.72 | 0.35 | 0.33 | 0.36 | 0.78 | 0.64 | 0.99 |
| Cloud | 0.94 | 0.96 | 0.92 | 0.77 | 0.64 | 0.98 | 0.60 | 0.52 | 0.70 | 0.91 | 0.99 | 0.83 | |
| C. Shadow | 0.81 | 0.89 | 0.75 | 0.00 | 0.00 | 0.58 | 0.98 | 0.41 | |||||
| Overall | 0.90 | 0.71 | 0.45 | 0.81 | |||||||||
| T22MCA | Clear | 0.94 | 0.94 | 0.94 | 0.88 | 0.83 | 0.93 | 0.58 | 0.62 | 0.54 | 0.85 | 0.74 | 0.98 |
| Cloud | 0.94 | 0.90 | 0.98 | 0.82 | 0.71 | 0.97 | 0.70 | 0.56 | 0.93 | 0.95 | 1.00 | 0.90 | |
| C. Shadow | 0.81 | 0.89 | 0.74 | 0.00 | 0.00 | 0.49 | 0.87 | 0.34 | |||||
| Overall | 0.92 | 0.77 | 0.58 | 0.83 | |||||||||
| T22NCG | Clear | 0.87 | 0.95 | 0.80 | 0.42 | 0.70 | 0.30 | 0.23 | 0.34 | 0.18 | 0.63 | 0.64 | 0.63 |
| Cloud | 0.87 | 0.79 | 0.96 | 0.58 | 0.43 | 0.92 | 0.61 | 0.46 | 0.94 | 0.71 | 0.62 | 0.83 | |
| C. Shadow | 0.80 | 0.82 | 0.77 | 0.00 | 0.00 | 0.53 | 0.97 | 0.36 | |||||
| Overall | 0.86 | 0.48 | 0.43 | 0.65 | |||||||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sanchez, A.H.; Picoli, M.C.A.; Camara, G.; Andrade, P.R.; Chaves, M.E.D.; Lechler, S.; Soares, A.R.; Marujo, R.F.B.; Simões, R.E.O.; Ferreira, K.R.; et al. Comparison of Cloud Cover Detection Algorithms on Sentinel–2 Images of the Amazon Tropical Forest. Remote Sens. 2020, 12, 1284. https://doi.org/10.3390/rs12081284
Sanchez AH, Picoli MCA, Camara G, Andrade PR, Chaves MED, Lechler S, Soares AR, Marujo RFB, Simões REO, Ferreira KR, et al. Comparison of Cloud Cover Detection Algorithms on Sentinel–2 Images of the Amazon Tropical Forest. Remote Sensing. 2020; 12(8):1284. https://doi.org/10.3390/rs12081284
Chicago/Turabian StyleSanchez, Alber Hamersson, Michelle Cristina A. Picoli, Gilberto Camara, Pedro R. Andrade, Michel Eustaquio D. Chaves, Sarah Lechler, Anderson R. Soares, Rennan F. B. Marujo, Rolf Ezequiel O. Simões, Karine R. Ferreira, and et al. 2020. "Comparison of Cloud Cover Detection Algorithms on Sentinel–2 Images of the Amazon Tropical Forest" Remote Sensing 12, no. 8: 1284. https://doi.org/10.3390/rs12081284
APA StyleSanchez, A. H., Picoli, M. C. A., Camara, G., Andrade, P. R., Chaves, M. E. D., Lechler, S., Soares, A. R., Marujo, R. F. B., Simões, R. E. O., Ferreira, K. R., & Queiroz, G. R. (2020). Comparison of Cloud Cover Detection Algorithms on Sentinel–2 Images of the Amazon Tropical Forest. Remote Sensing, 12(8), 1284. https://doi.org/10.3390/rs12081284