PolSAR Image Classification Based on Statistical Distribution and MRF




Abstract
1. Introduction
2. MRF-Based Classification Models
2.1. Statistical Models
2.2. Mixture Strategies
2.2.1. Mixture Wishart for a Whole Image
2.2.2. Mixture Wishart for a Class
2.2.3. Comparison of the Two Mixture Strategies
- Initialize parameter by randomly selecting one covariance matrix from each class of the image. is initialized as 1/K.
- Compute posterior probabilities using and , then update the class labels based on the maximum a posteriori decision rule.
- Update and using (4) and (5).
- Check if the classification result has converged. If not, go back to Step 2. Otherwise, the iteration ends.
- Randomly select m covariance matrices from the training samples of each class as the initialization of . is initialized as 1/M.
- Update the parameters using (4) and (5). Note that in MWC, the parameter N denotes the number of training samples of each class.
- Construct the mixture model for each class.
- Classify the image based on the ML criterion.
2.3. MRF-Based Classification Model
2.3.1. MRF
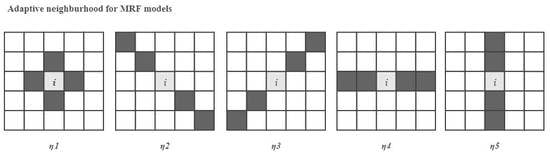
2.3.2. Adaptive Neighborhood System
2.3.3. Edge Penalty
3. Classification Schemes
3.1. Pixel-Based Classification
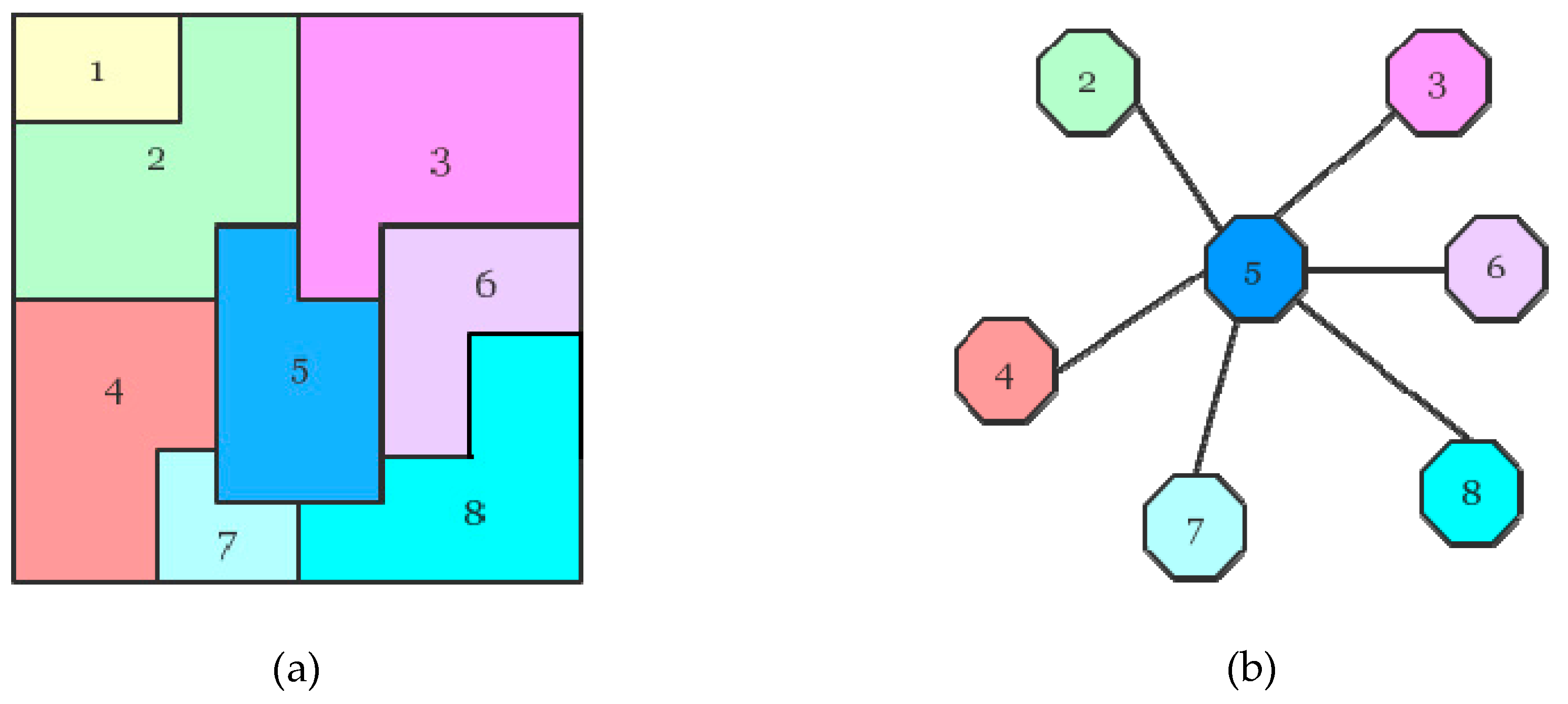
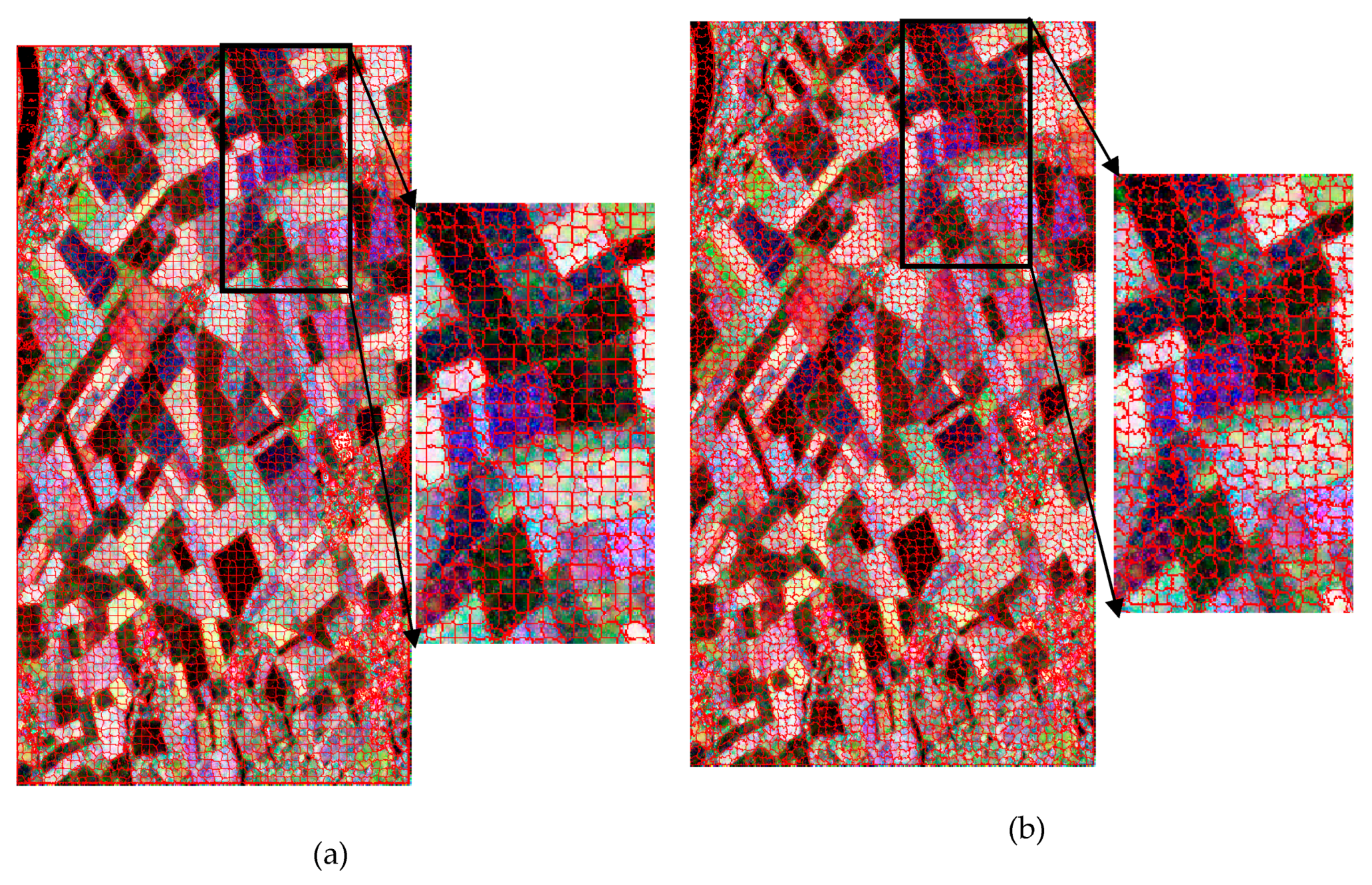
3.2. Region-Based Classification
- Divide the m × n image into regions, which are not overlapping with each other. Let denote the region labels.
- Calculate the mean covariance matrix for each region.
- Use (22) to update the region boundaries.
- Check the segmentation result. If the region area is smaller than a threshold p, reassign it to the adjacent region. The parameter p decides the smallest area of a region.
- Check if the segmentation result is converged. If not, go back to Step 2. Otherwise, end the iteration, and the superpixels are obtained.
- Calculate the mean covariance matrix of each region. Apply the ML classifier to get the final classification result.
4. Experiments and Discussions
4.1. Test Data
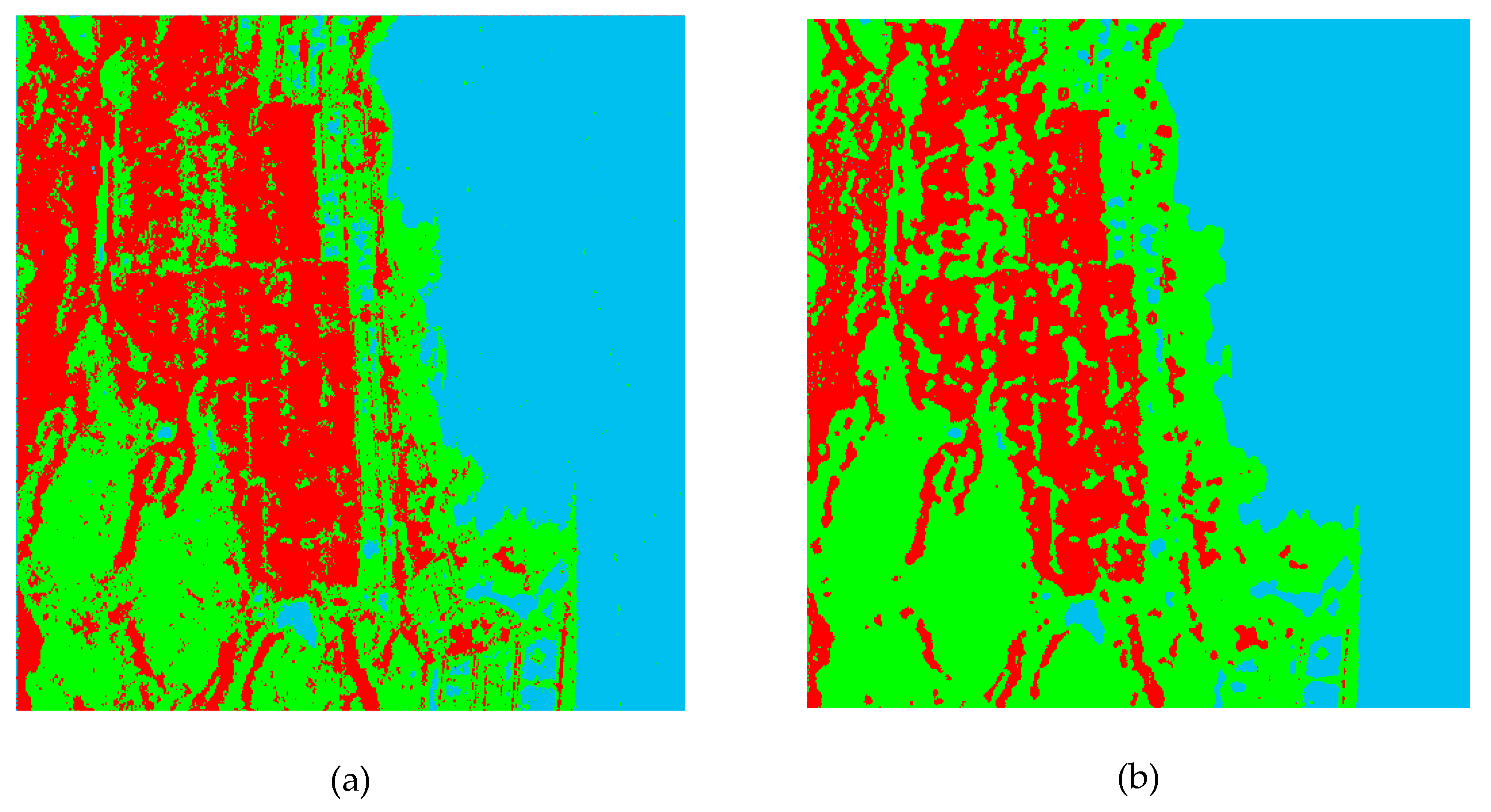
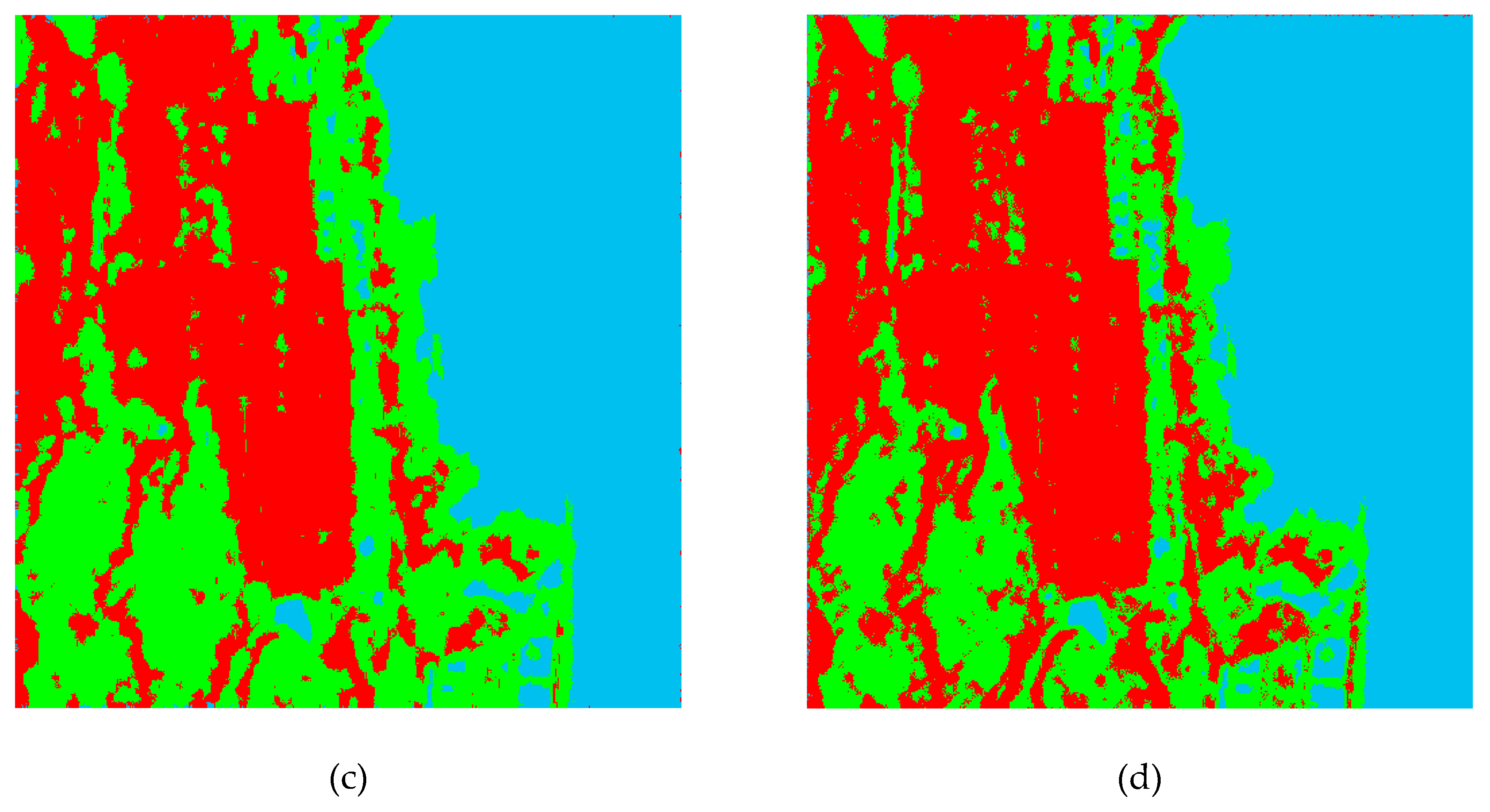
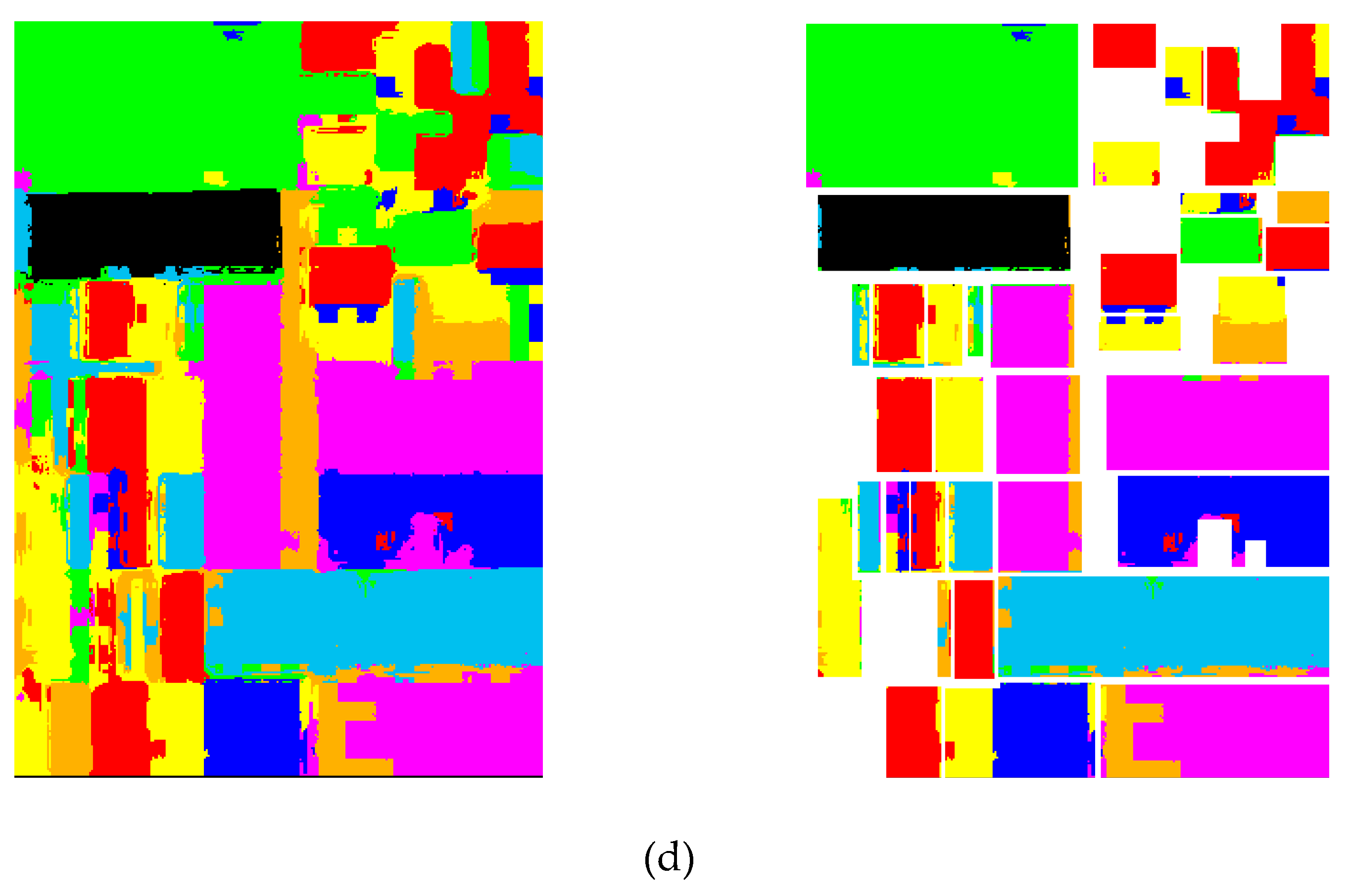
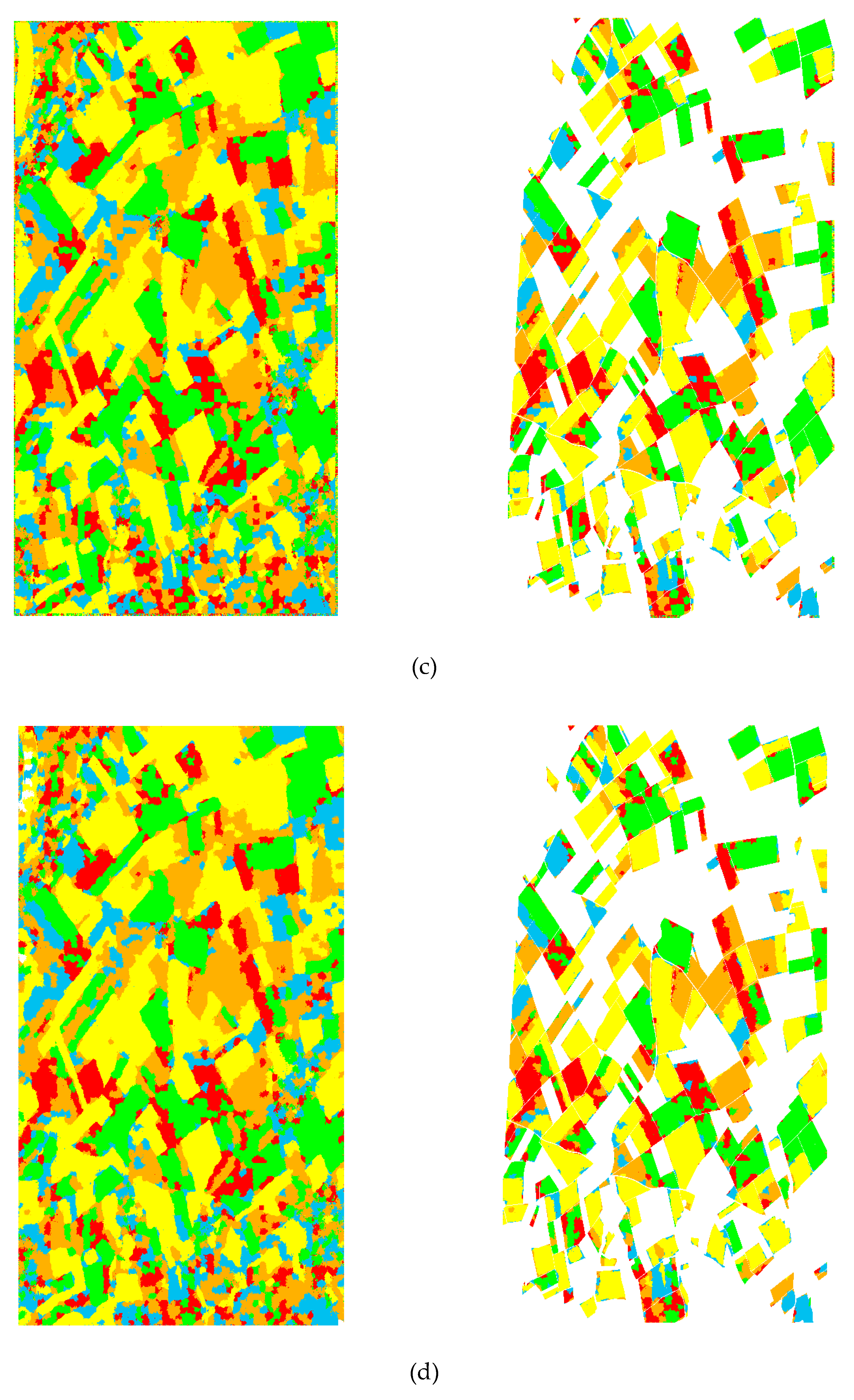
4.2. Pixel-Based Classification
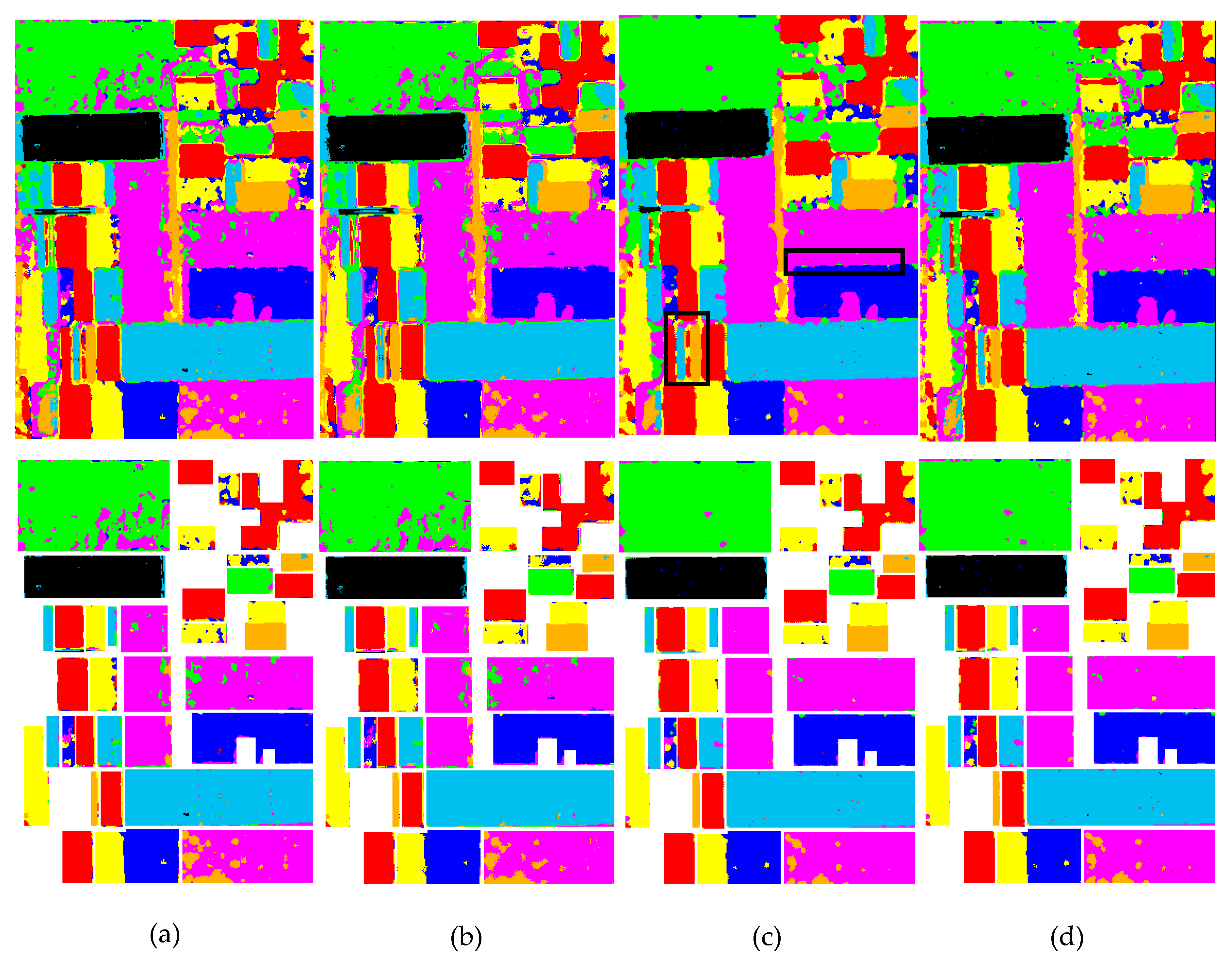
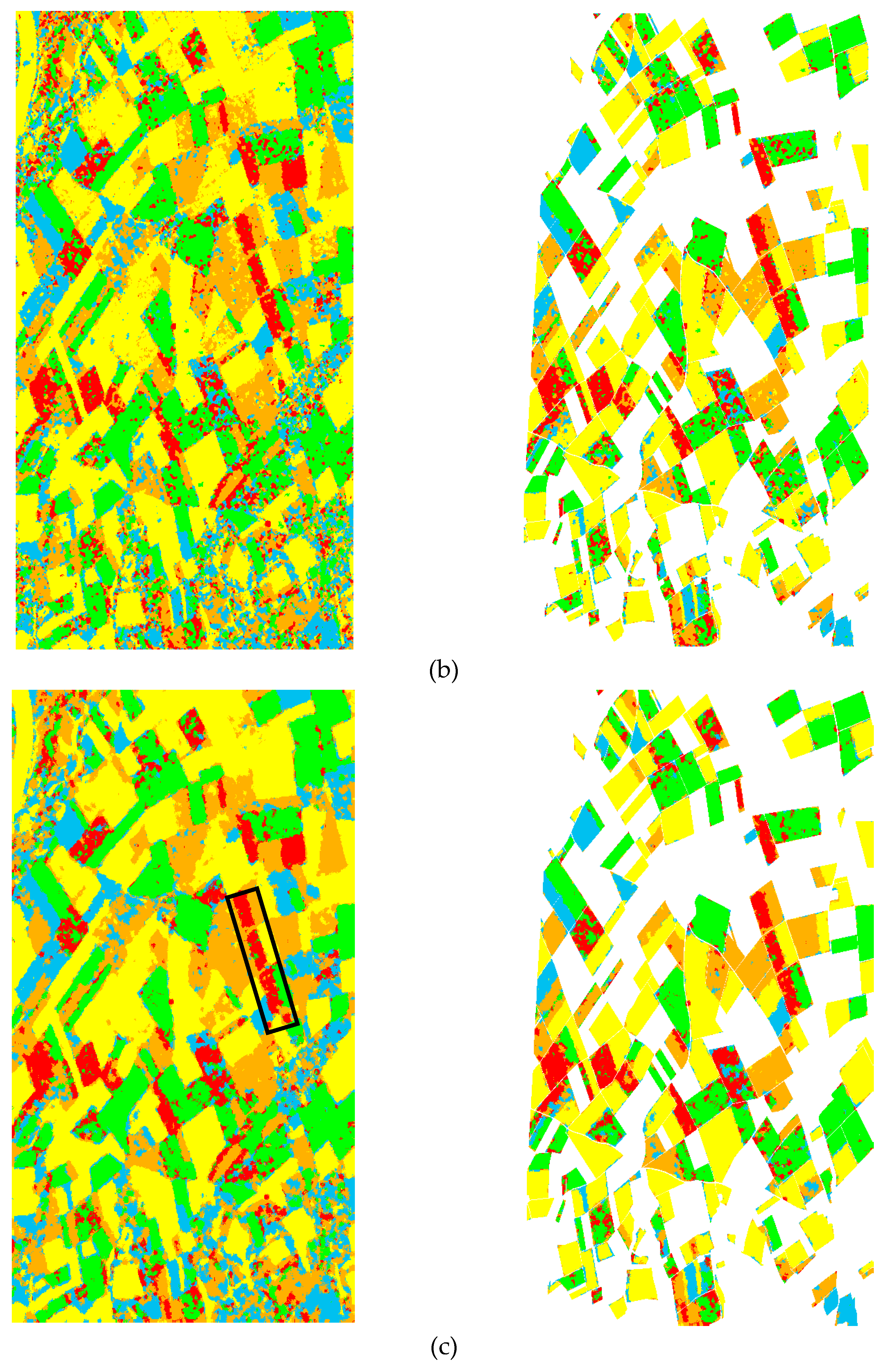
4.3. Region-Based Classification
4.4. Discussions
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Moreira, A.; Prats-Iraola, P.; Younis, M. A tutorial on synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–43. [Google Scholar] [CrossRef]
- Cloude, S.R. Polarisation: Applications in Remote Sensing, 1st ed.; Oxford University Press: New York, NY, USA, 2010. [Google Scholar]
- Lee, J.S.; Grunes, M.R.; Pottier, E. Quantitative comparison of classification capability: Fully polarimetric versus dual and single-polarization SAR. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2343–2351. [Google Scholar]
- Lee, J.S.; Grunes, M.R.; Ainsworth, T.L. Quantitative comparison of classification capability:fully-polarimetric versus partially polarimetric SAR. In Proceedings of the IEEE International Geoscience & Remote Sensing Symposium, Toronto, ON, Canada, 24–28 June 2002. [Google Scholar]
- Kong, J.A.; Swartz, A.A.; Yueh, H.A. Identification of terrain cover using the optimum polarimetric classifier. J. Electromagn. Waves Appl. 1988, 2, 171–194. [Google Scholar]
- Yin, J.; Moon, W.M.; Yang, J. Novel model-based method for identification of scattering mechanisms in polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 2016, 54, 520–532. [Google Scholar] [CrossRef]
- Lee, J.S.; Hoppel, K.; Mango, S.A. Intensity and phase statistics of multi-look polarimetric SAR imagery. IEEE Trans. Geosci. Remote Sens. 1994, 32, 1017–1028. [Google Scholar]
- Lee, J.S.; Mitchell, R.G.; Kwok, R. Classification of multi-look polarimetric SAR imagery based on complex Wishart distribution. Int. J. Remote Sens. 1994, 15, 2299–2311. [Google Scholar] [CrossRef]
- Jao, J. Amplitude distribution of composite terrain radar clutter and the κ-Distribution. IEEE Trans. Antennas Propag. 1984, 32, 1049–1062. [Google Scholar]
- Lee, J.S.; Schuler, D.L.; Lang, R.H.; Ranson., K.J. K-Distribution for Multi-Look Processed Polarimetric SAR Imagery. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Pasadena, PA, USA, 8–12 August 1994; pp. 2179–2181. [Google Scholar]
- Freitas, C.C.; Frery, A.C.; Correia, A.H. The polarimetric G distribution for SAR data analysis. Environmetrics 2005, 16, 13–31. [Google Scholar] [CrossRef]
- McLachlan, G.J.; Peel, D. Finite Mixture Models; Wiley: New York, NY, USA, 2000. [Google Scholar]
- Doulgeris, A.P.; Anfinsen, S.N.; Eltoft, T. Classification with a non-Gaussian model for PolSAR data. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2999–3009. [Google Scholar] [CrossRef]
- Gao, W.; Yang, J.; Ma, W. Land Cover Classification for Polarimetric SAR Images Based on Mixture Models. Remote Sens. 2014, 6, 3770–3790. [Google Scholar] [CrossRef]
- Doulgeris, A.P.; Anfinsen, S.N.; Eltoft, T. Automated non-Gaussian clustering of polarimetric synthetic aperture radar images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3665–3676. [Google Scholar] [CrossRef]
- Li, S.Z. Markov Random Field Modeling in Image Analysis; Springer: London, UK, 2009. [Google Scholar]
- Yamazaki, T.; Gingras, D. Image Classification Using Spectral and Spatial Information Based on MRF Models. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 1995, 4, 1333–1339. [Google Scholar] [CrossRef] [PubMed]
- Deng, H.; Clausi, D.A. Gaussian MRF rotation-invariant features for image classification. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 951–955. [Google Scholar] [CrossRef] [PubMed]
- Dong, Y.; Milne, A.K.; Forster, B.C. Segmentation and classification of vegetated areas using polarimetric SAR image data. IEEE Trans. Geosci. Remote Sens. 2001, 39, 321–329. [Google Scholar] [CrossRef]
- Wu, Y.; Ji, K.; Yu, W. Region-Based Classification of Polarimetric SAR Images Using Wishart MRF. IEEE Geosci. Remote Sens. Lett. 2008, 5, 668–672. [Google Scholar] [CrossRef]
- Liu, G.; Li, M.; Wu, Y. PolSAR image classification based on Wishart TMF with specific auxiliary field. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1230–1234. [Google Scholar]
- Shi, J.; Li, L.; Liu, F. Unsupervised polarimetric synthetic aperture radar image classification based on sketch map and adaptive Markov random field. J. Appl. Remote Sens. 2016, 10, 025008. [Google Scholar] [CrossRef]
- Masjedi, A.; Zoej, M.J.V.; Maghsoudi, Y. Classification of polarimetric SAR images based on modeling contextual information and using texture features. IEEE Trans. Geosci. Remote Sens. 2015, 54, 932–943. [Google Scholar] [CrossRef]
- Li, W.; Prasad, S.; Fowler, J.E. Hyperspectral image classification using Gaussian mixture models and Markov random fields. IEEE Geosci. Remote Sens. Lett. 2014, 11, 153–157. [Google Scholar] [CrossRef]
- Song, W.; Li, M.; Zhang, P. Mixture WGΓ-MRF Model for PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 56, 905–920. [Google Scholar] [CrossRef]
- Lee, J.S.; Pottier, E. Polarimetric Radar Imaging: From Basic to Application; CRC Press: New York, NY, USA, 2011. [Google Scholar]
- Yang, W.; Yang, X.; Yan, T. Region-Based Change Detection for Polarimetric SAR Images Using Wishart Mixture Models. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6746–6756. [Google Scholar] [CrossRef]
- Sherman, S. Markov random fields and gibbs random fields. Isr. J. Math. 1973, 14, 92–103. [Google Scholar] [CrossRef]
- Rignot, E.; Chellappa, R. Segmentation of polarimetric synthetic aperture radar data. IEEE Trans. Image Process. 1992, 1, 281–300. [Google Scholar] [CrossRef] [PubMed]
- Smits, P.C.; Dellepiane, S.G. Synthetic aperture radar image segmentation by a detail preserving Markov random field approach. IEEE Trans. Geosci. Remote Sens. 1997, 35, 844–857. [Google Scholar] [CrossRef]
- Niu, X.; Ban, Y. A novel contextual classification algorithm for multitemporal polarimetric SAR data. IEEE Geosci. Remote Sens. Lett. 2014, 11, 681–685. [Google Scholar]
- Fjortoft, R.; Lopes, A.; Marthon, P.; Cubero-Castan, E. An optimal multiedge detector for SAR image segmentation. IEEE Trans. Geosci. Remote Sens. 1998, 36, 793–802. [Google Scholar] [CrossRef]
- Schou, J.; Skriver, H.; Nielsen, A.A. CFAR edge detector for polarimetric SAR images. IEEE Trans. Geosci. Remote Sens. 2003, 41, 20–32. [Google Scholar] [CrossRef]
- Geman, S.; Geman, D. Gibbs Distributions, and the Bayesian Restoration of Images. Read. Comput. Vis. 1984, 20, 25–62. [Google Scholar]
- Kottke, D.P.; Fiore, P.D.; Brown, K.L.; Fwu, J.K. A design for HMM-based SAR ATR. In Proceedings of the SPIE—Conference Algorithms Synthetic Aperture Radar Imagery V, Orlando, FL, USA, 13 April 1998; Volume 3370, pp. 541–551. [Google Scholar]
- Besag, J. On the statistical analysis of dirty pictures. J. R. Stat. Soc. 1986, 48, 259–302. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Class 1 Bare Soil | Class 2 Barely | Class 3 Lucerne | Class 4 Pea | Class 5 Potatoes | Class 6 Rape Seed | Class 7 Beet | Class 8 Wheat | OA | Kappa |
|---|---|---|---|---|---|---|---|---|---|---|
| WMRF | 97.56% | 95.49% | 93.83% | 94.37% | 92.51%% | 87.88% | 86.75% | 90.30% | 91.56% | 0.9005 |
| KMRF | 97.58% | 95.41% | 94.10% | 94.51% | 92.39% | 89.29% | 88.35% | 90.94% | 92.12% | 0.9071 |
| MWMRF | 97.59% | 97.74% | 95.64% | 95.71% | 95.49% | 98.03% | 93.25% | 96.74% | 96.44% | 0.9580 |
| MWMRF/e | 97.37% | 97.62% | 95.00% | 95.47% | 94.97% | 97.33% | 92.65% | 96.35% | 96.02% | 0.9530 |
| Method | Class1 Barley | Class 2 Corn | Class 3 Potatoes | Class 4 Sugar Beet | Class 5 Wheat | OA | Kappa |
|---|---|---|---|---|---|---|---|
| WMRF | 88.31% | 73.44% | 58.81% | 79.95% | 92.38% | 82.25% | 0.7563 |
| KMRF | 88.24% | 74.27% | 61.59% | 79.76% | 92.19% | 82.47% | 0.7609 |
| MWMRF | 90.47% | 79.15% | 63.30% | 83.79% | 92.72% | 84.40% | 0.7854 |
| MWMRF/e | 86.13% | 79.12% | 48.98% | 84.24% | 95.13% | 84.04% | 0.7783 |
| Method | Class 1 Bare Soil | Class 2 Barely | Class 3 Lucerne | Class 4 Pea | Class 5 Potatoes | Class 6 Rape Seed | Class 7 Beet | Class 8 Wheat | OA | Kappa |
|---|---|---|---|---|---|---|---|---|---|---|
| WMRF | 99.64% | 95.35% | 91.87% | 90.77% | 99.95% | 93.00% | 93.00% | 88.59% | 93.46% | 0.9231 |
| KMRF | 97.01% | 87.37% | 84.69% | 89.58% | 89.41% | 98.24% | 87.63% | 87.93% | 90.45% | 0.8879 |
| Method | Class1 Barley | Class 2 Corn | Class 3 Potatoes | Class 4 Sugar Beet | Class 5 Wheat | OA | Kappa |
|---|---|---|---|---|---|---|---|
| WMRF | 86.41% | 75.40% | 70.91% | 84.20% | 89.29% | 83.62% | 0.7763 |
| KMRF | 86.03% | 75.07% | 70.10% | 82.10% | 89.57% | 83.20% | 0.7706 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, J.; Liu, X.; Yang, J.; Chu, C.-Y.; Chang, Y.-L. PolSAR Image Classification Based on Statistical Distribution and MRF. Remote Sens. 2020, 12, 1027. https://doi.org/10.3390/rs12061027
Yin J, Liu X, Yang J, Chu C-Y, Chang Y-L. PolSAR Image Classification Based on Statistical Distribution and MRF. Remote Sensing. 2020; 12(6):1027. https://doi.org/10.3390/rs12061027
Chicago/Turabian StyleYin, Junjun, Xiyun Liu, Jian Yang, Chih-Yuan Chu, and Yang-Lang Chang. 2020. "PolSAR Image Classification Based on Statistical Distribution and MRF" Remote Sensing 12, no. 6: 1027. https://doi.org/10.3390/rs12061027
APA StyleYin, J., Liu, X., Yang, J., Chu, C.-Y., & Chang, Y.-L. (2020). PolSAR Image Classification Based on Statistical Distribution and MRF. Remote Sensing, 12(6), 1027. https://doi.org/10.3390/rs12061027