Sketch-Based Subspace Clustering of Hyperspectral Images




Abstract
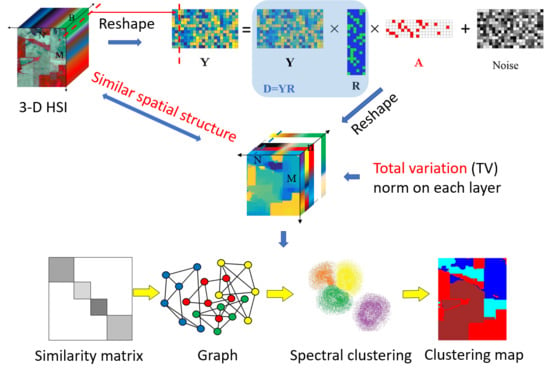
1. Introduction
- The most important contribution of this paper is a new SSC-based framework, which can be applied on large-scale HSIs while achieving excellent clustering accuracy. To the best of our knowledge, this is the first time to address the large-scale clustering problem of HSIs based on the SSC model.
- Different from the traditional SSC-based methods which use all the input data as a dictionary, we adopt a compressed dictionary by using random projection technique to reduce the dictionary size, which effectively enables a scalable subspace clustering approach.
- To account for the spatial dependencies among the neighbouring pixels, we incorporate a powerful TV regularization in our model, leading to a more discriminative coefficient matrix. The resulting model proves to be more robust to spectral noise and spectral variability.
- We develop an efficient algorithm to solve the resulting optimization problem and prove its convergence property theoretically.
2. HSI Clustering with the SSC Model
3. Sketch-SSC-TV Model for HSIs
3.1. The SSC-TV Model
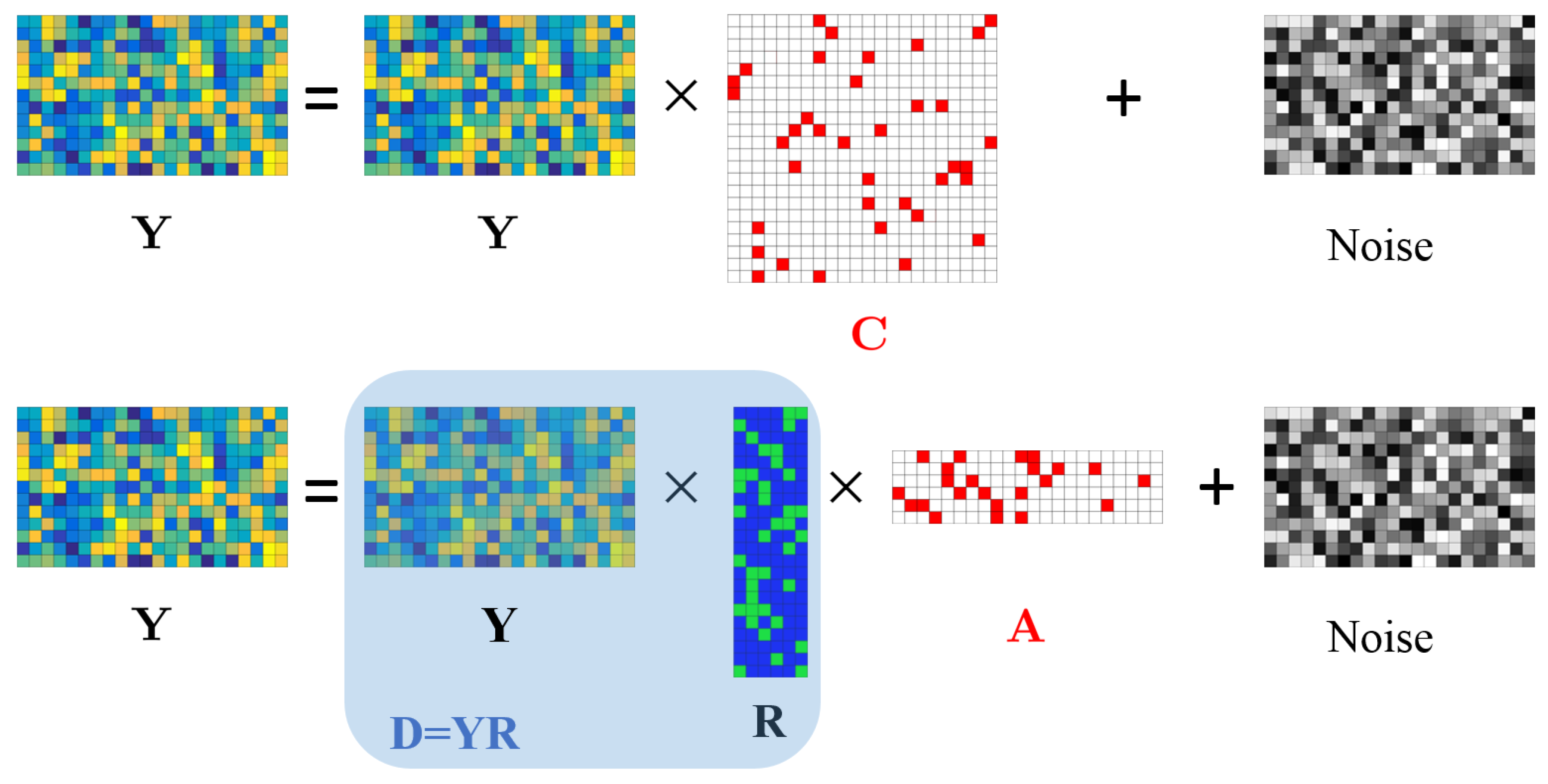
3.2. The Sketch-SSC-TV Model for Large-Scale HSIs
3.2.1. The Sketch-SSC Model
3.2.2. The Sketch-SSC-TV Model
| Algorithm 1 The complete procedure of the proposed Sketch-SSC-TV method |
| 1: Input: An input matrix , , , , k, and c. |
| 2: Calculate by solving (8). |
| 3: Construct using (9). |
| 4: Plug into spectral clustering. |
| 5: Output: A clustering map. |
3.3. Optimization
3.3.1. Update B
3.3.2. Update A
3.3.3. Update Z
3.3.4. Update
3.3.5. Update Other Parameters
| Algorithm 2 ADMM for solving the Sketch-SSC-TV model |
| 1: Input: , , and . |
| 2: Initialize: , , , , , |
| 3: Do |
| 4: Update by (14). |
| 5: Update by (17). |
| 6: Update by (18). |
| 7: Update by (22). |
| 8: Update other parameters by (23). |
| 9: While ( or or and ) |
| 10: Output: Sparse matrix . |
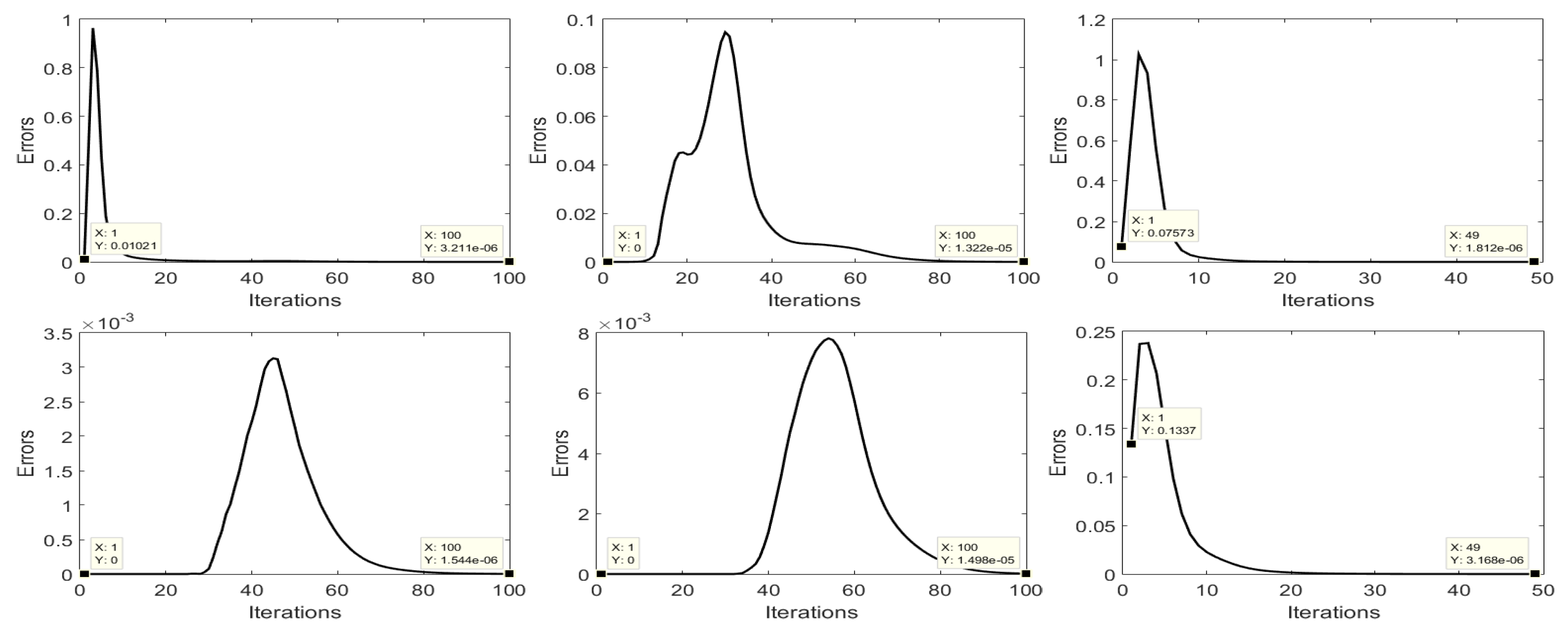
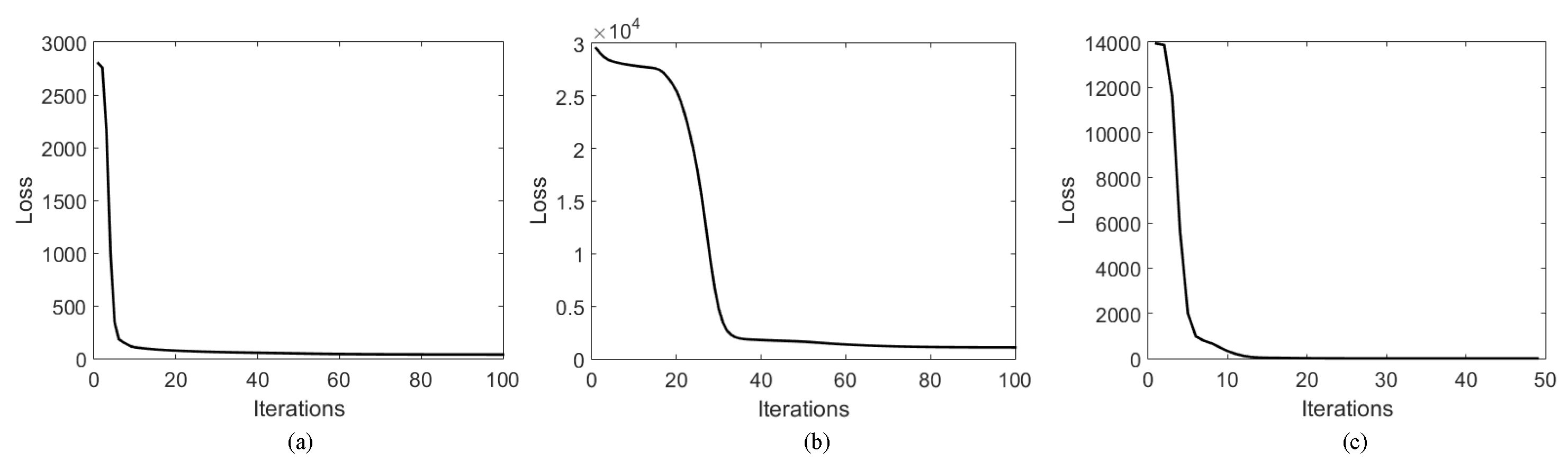
3.4. Convergence Analysis
4. Experiments
4.1. Experimental Settings
4.2. Data Description
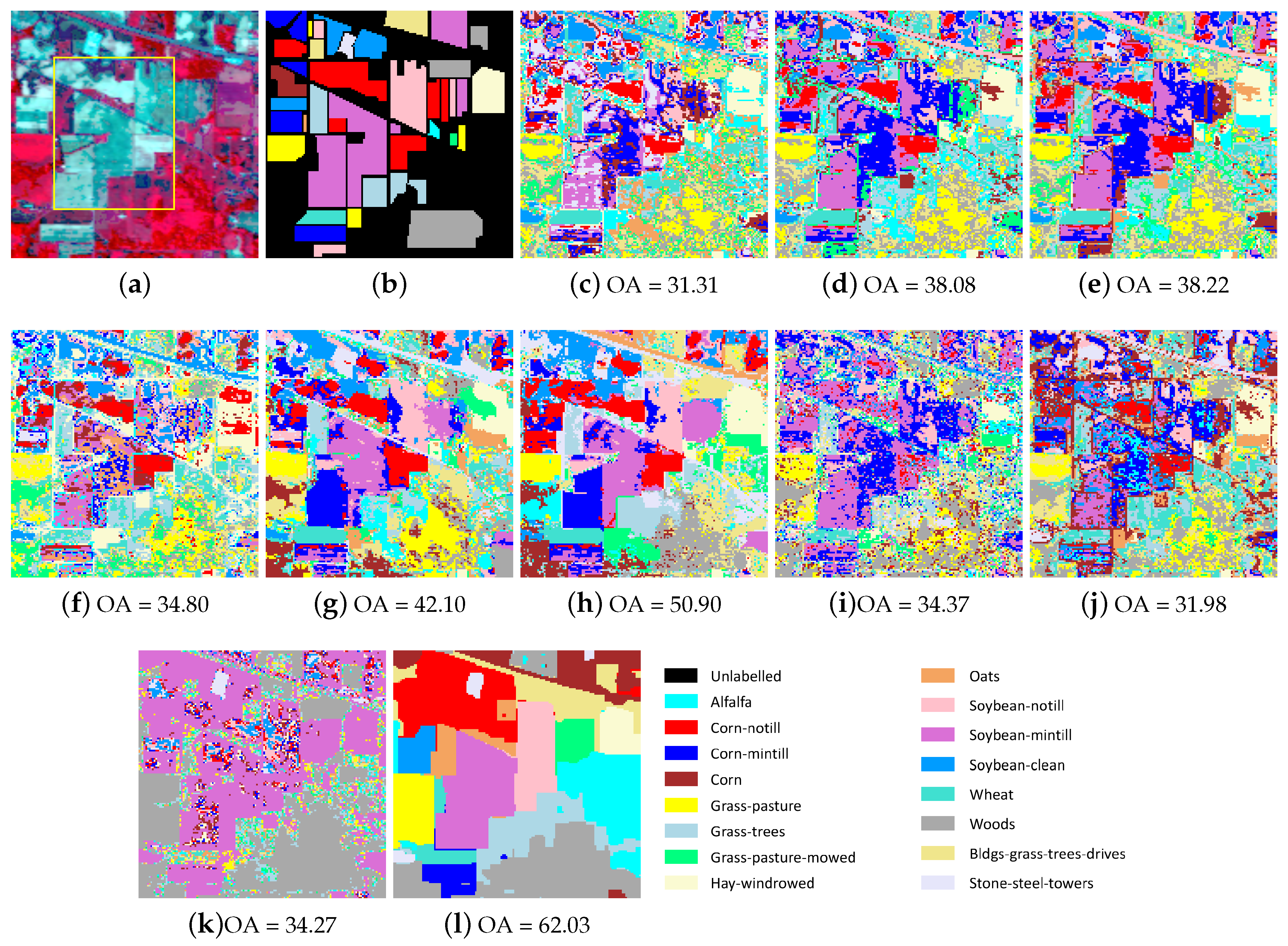
4.2.1. Indian Pines
4.2.2. Pavia University
4.2.3. Salinas
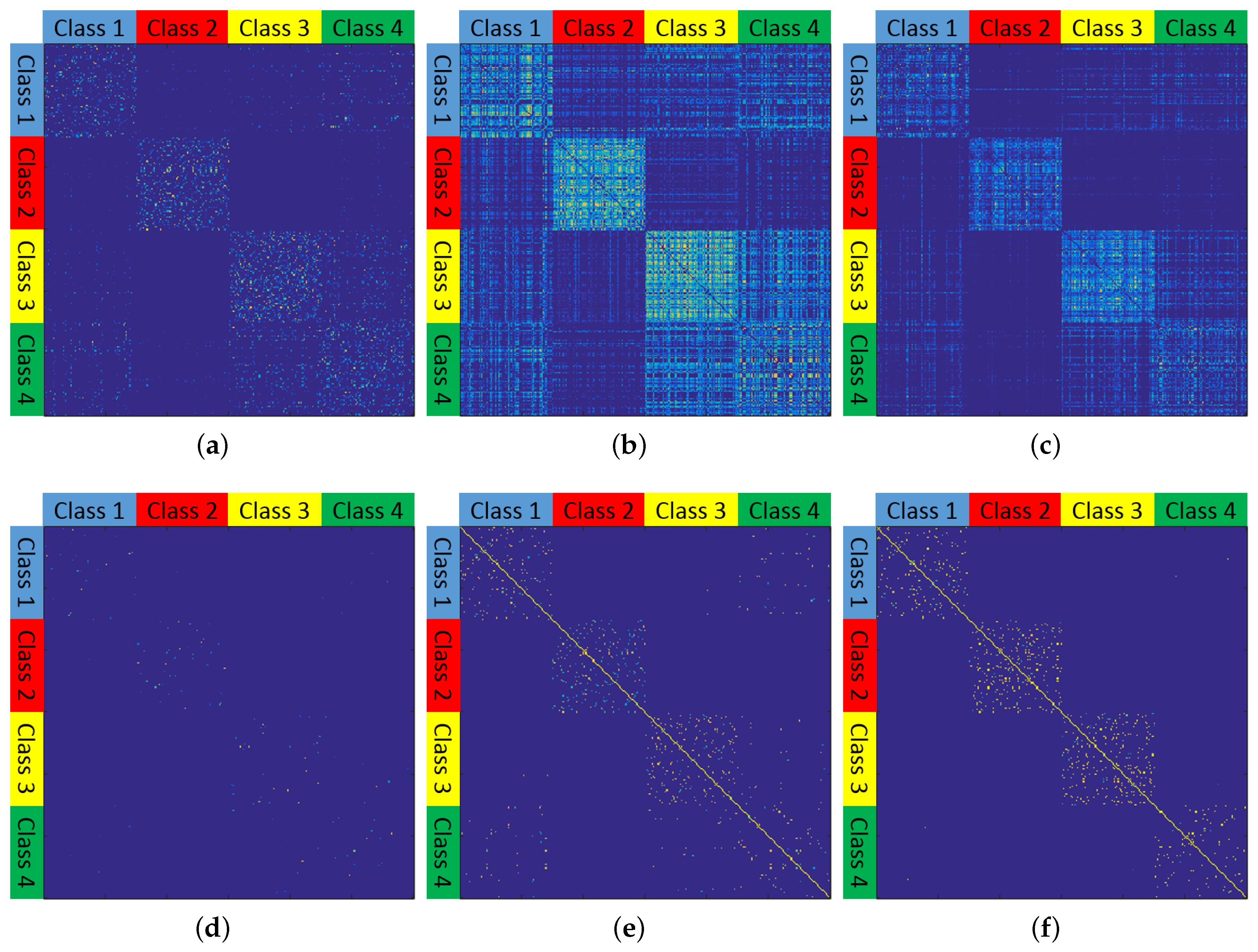
4.3. Experiments on the Small HSI
4.4. Experiments on the Large-Scale HSIs
4.5. Analysis of Parameters
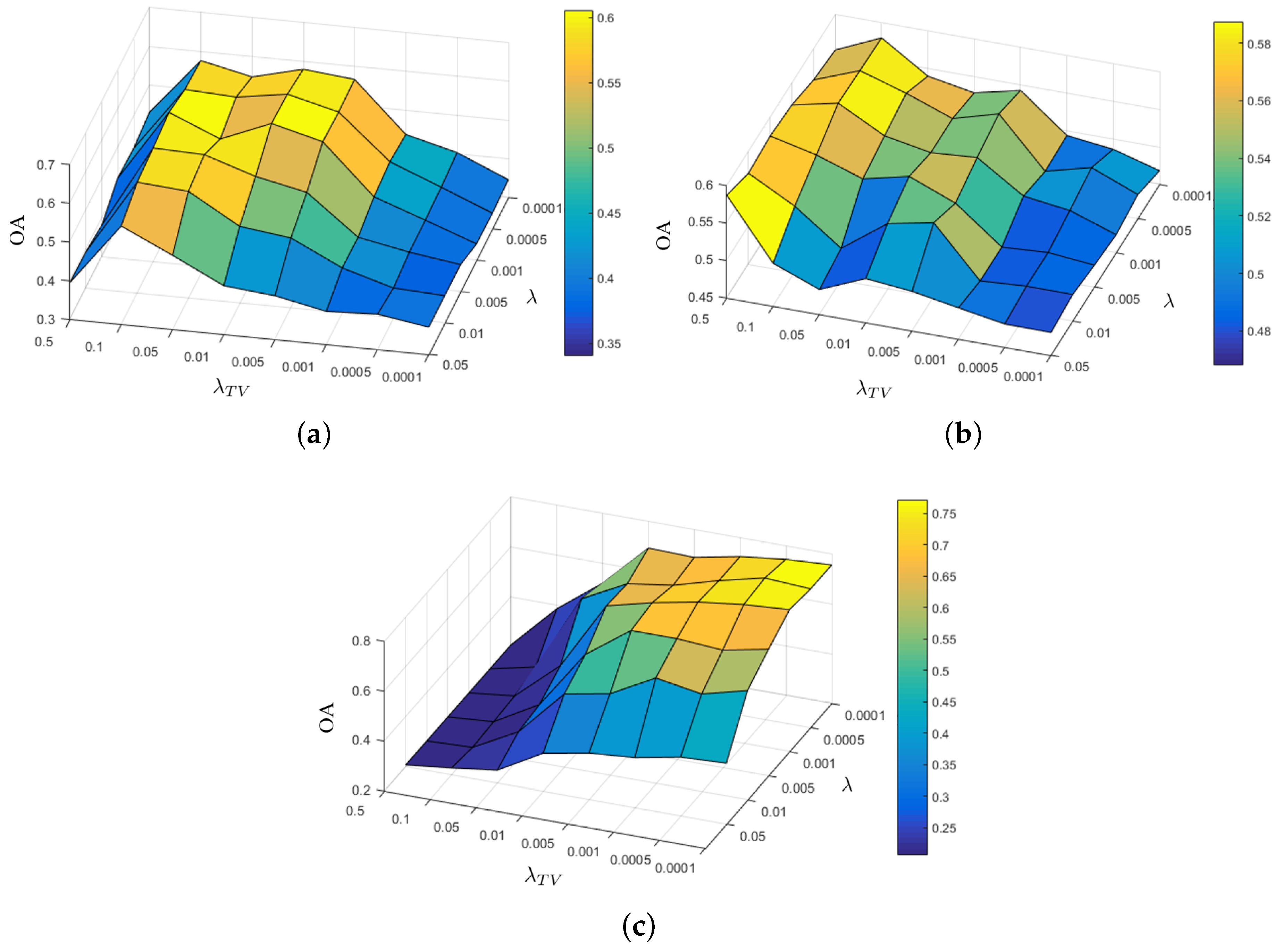
4.5.1. Effect of and
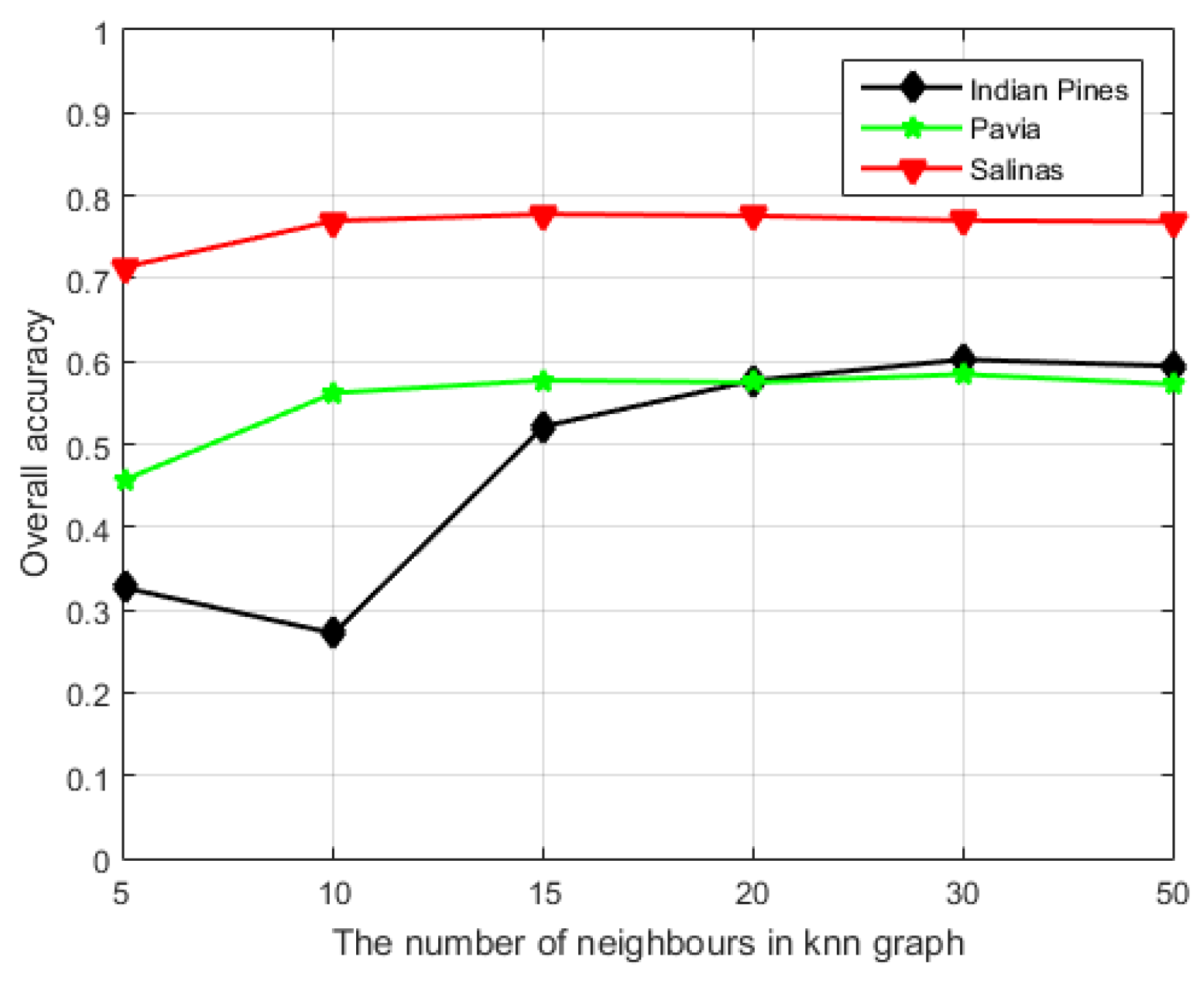
4.5.2. Effect of the Parameter n
4.5.3. Effect of the Parameter k
4.6. Experimental Convergence Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, Y.; Du, B.; Zhang, Y.; Zhang, L. Spatially Adaptive Sparse Representation for Target Detection in Hyperspectral Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1923–1927. [Google Scholar] [CrossRef]
- Wu, K.; Xu, G.; Zhang, Y.; Du, B. Hyperspectral image target detection via integrated background suppression with adaptive weight selection. Neurocomputing 2018, 315, 59–67. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Tuia, D.; Bruzzone, L.; Benediktsson, J.A. Advances in hyperspectral image classification: Earth monitoring with statistical learning methods. IEEE Signal Process. Mag. 2014, 31, 45–54. [Google Scholar] [CrossRef]
- Eismann, M.T.; Stocker, A.D.; Nasrabadi, N.M. Automated hyperspectral cueing for civilian search and rescue. Proc. IEEE 2009, 97, 1031–1055. [Google Scholar] [CrossRef]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Springer: Berlin, Germany, 2013. [Google Scholar]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Chen, G.; Lerman, G. Spectral curvature clustering (SCC). Int. J. Comput. Vis. 2009, 81, 317–330. [Google Scholar] [CrossRef]
- Dyer, E.L.; Sankaranarayanan, A.C.; Baraniuk, R.G. Greedy feature selection for subspace clustering. J. Mach. Learn Res. (JMLR) 2013, 14, 2487–2517. [Google Scholar]
- Elhamifar, E.; Vidal, R. Sparse subspace clustering. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2790–2797. [Google Scholar]
- Elhamifar, E.; Vidal, R. Sparse subspace clustering: Algorithm, theory, and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2765–2781. [Google Scholar] [CrossRef]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 171–184. [Google Scholar] [CrossRef]
- Park, D.; Caramanis, C.; Sanghavi, S. Greedy subspace clustering. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; pp. 2753–2761. [Google Scholar]
- Vidal, R. Subspace clustering. IEEE Signal Process. Mag. 2011, 28, 52–68. [Google Scholar] [CrossRef]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by latent semantic analysis. J. Am. Soc. Inform. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Zhang, T.; Szlam, A.; Wang, Y.; Lerman, G. Hybrid linear modeling via local best-fit flats. Int. J. Comput. Vis. 2012, 100, 217–240. [Google Scholar] [CrossRef]
- Goh, A.; Vidal, R. Segmenting motions of different types by unsupervised manifold clustering. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–6. [Google Scholar]
- Guo, Y.; Gao, J.; Li, F. Spatial subspace clustering for drill hole spectral data. J. Appl. Remote Sens. 2014, 8, 083644. [Google Scholar] [CrossRef]
- Guo, Y.; Gao, J.; Li, F. Random spatial subspace clustering. Knowl.-Based Syst. 2015, 74, 106–118. [Google Scholar] [CrossRef]
- Zhang, H.; Zhai, H.; Zhang, L.; Li, P. Spectral–spatial sparse subspace clustering for hyperspectral remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3672–3684. [Google Scholar] [CrossRef]
- Zhai, H.; Zhang, H.; Xu, X.; Zhang, L.; Li, P. Kernel Sparse Subspace Clustering with a Spatial Max Pooling Operation for Hyperspectral Remote Sensing Data Interpretation. Remote Sens. 2017, 9, 335. [Google Scholar] [CrossRef]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P.; Plaza, A. A new sparse subspace clustering algorithm for hyperspectral remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 43–47. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, H.; Pižurica, A. Joint Sparsity Based Sparse Subspace Clustering for Hyperspectral Images. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3878–3882. [Google Scholar]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P. Total Variation Regularized Collaborative Representation Clustering with a Locally Adaptive Dictionary for Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 57, 166–180. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, H.; Pižurica, A. Semisupervised Sparse Subspace Clustering Method with a Joint Sparsity Constraint for Hyperspectral Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 12, 989–999. [Google Scholar] [CrossRef]
- Wang, R.; Nie, F.; Wang, Z.; He, F.; Li, X. Scalable Graph-Based Clustering with Nonnegative Relaxation for Large Hyperspectral Image. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7352–7364. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, H.; Pižurica, A. Landmark-Based Large-Scale Sparse Subspace Clustering Method for Hyperspectral Images. In Proceedings of the IGARSS 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 799–802. [Google Scholar]
- Peng, X.; Zhang, L.; Yi, Z. Scalable sparse subspace clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, United States, 25–27 June 2013; pp. 430–437. [Google Scholar]
- You, C.; Robinson, D.; Vidal, R. Scalable sparse subspace clustering by orthogonal matching pursuit. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, United States, 26 June–1 July 2016; pp. 3918–3927. [Google Scholar]
- Traganitis, P.A.; Giannakis, G.B. Sketched subspace clustering. IEEE Trans. Signal Process. 2018, 66, 1663–1675. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On spectral clustering: Analysis and an algorithm. In Proc of the 14th International Conference on Neural Information Processing Systems: Natural and Synthetic; MIT Press: Cambridge, MA, USA, 2001; pp. 849–856. [Google Scholar]
- Zhang, H.; Li, J.; Huang, Y.; Zhang, L. A nonlocal weighted joint sparse representation classification method for hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2014, 7, 2056–2065. [Google Scholar] [CrossRef]
- Li, W.; Du, Q. Joint within-class collaborative representation for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2014, 7, 2200–2208. [Google Scholar] [CrossRef]
- Xue, J.; Zhao, Y.; Liao, W.; Chan, J.C. Nonlocal Low-Rank Regularized Tensor Decomposition for Hyperspectral Image Denoising. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5174–5189. [Google Scholar] [CrossRef]
- Luo, F.; Du, B.; Zhang, L.; Zhang, L.; Tao, D. Feature learning using spatial-spectral hypergraph discriminant analysis for hyperspectral image. IEEE Trans. Cybern. 2018, 49, 2406–2419. [Google Scholar] [CrossRef]
- Xu, J.; Huang, N.; Xiao, L. Spectral-spatial subspace clustering for hyperspectral images via modulated low-rank representation. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3202–3205. [Google Scholar]
- Huang, S.; Zhang, H.; Pižurica, A. A Robust Sparse Representation Model for Hyperspectral Image Classification. Sensors 2017, 17, 2087. [Google Scholar] [CrossRef]
- Mei, S.; Hou, J.; Chen, J.; Chau, L.P.; Du, Q. Simultaneous Spatial and Spectral Low-Rank Representation of Hyperspectral Images for Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2872–2886. [Google Scholar] [CrossRef]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P. Reweighted mass center based object-oriented sparse subspace clustering for hyperspectral images. J. Appl. Remote Sens. 2016, 10, 046014. [Google Scholar] [CrossRef]
- Yan, Q.; Ding, Y.; Xia, Y.; Chong, Y.; Zheng, C. Class-Probability Propagation of Supervised Information Based on Sparse Subspace Clustering for Hyperspectral Images. Remote Sens. 2017, 9, 1017. [Google Scholar] [CrossRef]
- Iordache, M.D.; Bioucas-Dias, J.M.; Plaza, A. Total variation spatial regularization for sparse hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4484–4502. [Google Scholar] [CrossRef]
- Chen, J.; Richard, C.; Honeine, P. Nonlinear Estimation of Material Abundances in Hyperspectral Images with ℓ1-Norm Spatial Regularization. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2654–2665. [Google Scholar] [CrossRef]
- Simões, M.; Bioucas-Dias, J.; Almeida, L.B.; Chanussot, J. A convex formulation for hyperspectral image superresolution via subspace-based regularization. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3373–3388. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.; Zhang, L.; Shen, H. Total-variation-regularized low-rank matrix factorization for hyperspectral image restoration. IEEE Trans. Geosci. Remote Sens. 2016, 54, 178–188. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.; Shen, H.; Zhang, L. Hyperspectral Image Denoising Using Local Low-Rank Matrix Recovery and Global Spatial–Spectral Total Variation. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2018, 11, 713–729. [Google Scholar] [CrossRef]
- Liu, H.; Sun, P.; Du, Q.; Wu, Z.; Wei, Z. Hyperspectral Image Restoration Based on Low-Rank Recovery with a Local Neighborhood Weighted Spectral-Spatial Total Variation Model. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1409–1422. [Google Scholar] [CrossRef]
- Boutsidis, C.; Zouzias, A.; Mahoney, M.W.; Drineas, P. Randomized dimensionality reduction for k-means clustering. IEEE Trans. Inf. Theory 2015, 61, 1045–1062. [Google Scholar] [CrossRef]
- Indyk, P.; Motwani, R. Approximate nearest neighbors: Towards removing the curse of dimensionality. In Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, Dallas, TX, USA, 23–26 May 1998; pp. 604–613. [Google Scholar]
- Gong, Y.; Lazebnik, S.; Gordo, A.; Perronnin, F. Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2916–2929. [Google Scholar] [CrossRef]
- Park, Y.; Park, S.; Lee, S.g.; Jung, W. Greedy filtering: A scalable algorithm for k-nearest neighbor graph construction. In International Conference on Database Systems for Advanced Applications; Springer: Cham, Switzerland, 2014; pp. 327–341. [Google Scholar]
- Glowinski, R.; Le Tallec, P. Augmented Lagrangian and Operator-splitting Methods in Nonlinear Mechanics; SIAM: Philadelphia, PA, USA, 1989; Volume 9. [Google Scholar]
- Esser, E. Applications of Lagrangian-based alternating direction methods and connections to split Bregman. CAM Rep. 2009, 9, 31. [Google Scholar]
- Chen, C.; He, B.; Ye, Y.; Yuan, X. The direct extension of ADMM for multi-block convex minimization problems is not necessarily convergent. Math. Program. 2016, 155, 57–79. [Google Scholar] [CrossRef]
- Lin, Z.; Chen, M.; Ma, Y. The augmented lagrange multiplier method for exact recovery of corrupted low-rank matrices. arXiv 2010, arXiv:1009.5055. [Google Scholar]
- Bartle, R.G.; Sherbert, D.R. Introduction to Real Analysis; Wiley: New York, NY, USA, 2000; Volume 2. [Google Scholar]
- Bertsekas, D.P. Nonlinear programming. J. Oper. Res. Soc. 1997, 48, 334. [Google Scholar] [CrossRef]
- Fang, X.; Teng, S.; Lai, Z.; He, Z.; Xie, S.; Wong, W.K. Robust latent subspace learning for image classification. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 2502–2515. [Google Scholar] [CrossRef] [PubMed]
- Xue, J.; Zhao, Y.; Liao, W.; Chan, J.C.; Kong, S.G. Enhanced Sparsity Prior Model for Low-Rank Tensor Completion. IEEE Trans. Neural Netw. Learn. Syst. 2019. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Wen, Z.; Zhang, Y. Augmented Lagrangian alternating direction method for matrix separation based on low-rank factorization. Optim. Methods Softw. 2014, 29, 239–263. [Google Scholar] [CrossRef]
- Fränti, P. Efficiency of random swap clustering. J. Big Data 2018, 5, 13. [Google Scholar] [CrossRef]
- Lovász, L.; Plummer, M.D. Matching Theory; American Mathematical Soc.: Amsterdam, The Netherlands, 1986. [Google Scholar]
- Rezaei, M.; Fränti, P. Set matching measures for external cluster validity. IEEE Trans. Knowl. Data Eng. 2016, 28, 2173–2186. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. J. Mach. Learn. Tech. 2011. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Class Name | FCM | k-Means | RSC | SSC | L2-SSC | JSSC | SSSC | SSC-OMP | Sketch-SSC | Sketch-SSC-TV |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Corn-notill | 62.39 | 69.85 | 69.65 | 60.00 | 61.09 | 74.03 | 53.31 | 69.35 | 62.19 | 61.41 |
| 2 | Grass-trees | 94.66 | 53.84 | 51.10 | 98.36 | 99.32 | 100 | 89.73 | 99.86 | 100 | 100 |
| 3 | Soybean-notill | 44.13 | 0 | 1.23 | 76.91 | 79.37 | 86.20 | 49.13 | 44.40 | 68.80 | 100 |
| 4 | Soybean-mintill | 63.83 | 57.59 | 58.63 | 50.68 | 54.89 | 87.79 | 63.85 | 41.68 | 58.87 | 93.81 |
| OA(%) | 65.34 | 50.17 | 50.33 | 65.11 | 67.78 | 86.40 | 63.28 | 58.14 | 68.12 | 88.46 | |
| 0.5118 | 0.2833 | 0.2851 | 0.5296 | 0.5629 | 0.8069 | 0.4772 | 0.4419 | 0.5628 | 0.8342 | ||
| t (seconds) | 5.6 | 2.5 | 81 | 543 | 624 | 270 | 2.2 | 22 | 2.8 | 5.8 | |
| Indian Pines | Pavia University | Salinas | |
|---|---|---|---|
| Spatial image size | |||
| Matrix size of | 21,025 × 21,025 | 207,400 × 207,400 | 111,104 × 111,104 |
| Required memory (GB) | 3.5 | 320.5 | 92 |
| No. | Class Name | FCM | k-Means | RSC | SSC | L2-SSC | JSSC | SSSC | SSC-OMP | Sketch-SSC | Sketch-SSC-TV |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Alfalfa | 23.91 | 0 | 17.39 | 36.96 | 0 | 0 | 14.78 | 0 | 7.39 | 57.83 |
| 2 | Corn-notill | 25.70 | 28.71 | 29.06 | 23.39 | 43 | 48.25 | 25.48 | 19.33 | 2.28 | 33.70 |
| 3 | Corn-mintill | 24.82 | 44.34 | 43.49 | 34.34 | 20.48 | 18.19 | 24.24 | 35.90 | 0.53 | 32.53 |
| 4 | Corn | 6.33 | 14.35 | 20.25 | 9.28 | 0 | 0.42 | 5.91 | 53.16 | 2.62 | 42.53 |
| 5 | Grass-pasture | 43.89 | 49.69 | 49.69 | 65.01 | 55.49 | 65.22 | 46.54 | 36.02 | 1.90 | 65.84 |
| 6 | Grass-trees | 25.75 | 40.82 | 44.52 | 37.95 | 56.71 | 75.21 | 48.49 | 49.04 | 12.41 | 45.18 |
| 7 | Grass-pasture-mowed | 0 | 71.43 | 0 | 0 | 85.71 | 75.00 | 7.14 | 0 | 12.86 | 0 |
| 8 | Hay-windrowed | 89.33 | 85.15 | 81.80 | 55.02 | 71.13 | 98.74 | 56.32 | 77.41 | 15.10 | 100 |
| 9 | Oats | 0 | 0 | 30.00 | 65.00 | 45 | 0 | 6.00 | 65.00 | 3.00 | 20.00 |
| 10 | Soybean-notill | 23.46 | 18.83 | 18.42 | 30.04 | 58.54 | 62.04 | 24.96 | 27.16 | 3.48 | 75.23 |
| 11 | Soybean-mintill | 28.35 | 38.98 | 39.55 | 33.93 | 37.64 | 43.34 | 38.07 | 23.87 | 89.42 | 76.85 |
| 12 | Soybean-clean | 23.61 | 18.21 | 17.20 | 22.26 | 24.28 | 44.69 | 16.42 | 19.06 | 3.27 | 64.99 |
| 13 | Wheat | 99.51 | 97.07 | 96.59 | 96.10 | 98.54 | 100 | 55.71 | 58.54 | 5.66 | 79.61 |
| 14 | Woods | 30.99 | 41.82 | 41.50 | 38.50 | 38.42 | 53.12 | 39.43 | 41.11 | 99.81 | 71.46 |
| 15 | Bldgs-grass-trees-drives | 17.62 | 18.13 | 17.36 | 21.50 | 16.06 | 38.08 | 15.18 | 11.14 | 1.40 | 11.92 |
| 16 | Stone-steel-towers | 59.14 | 86.02 | 87.10 | 19.35 | 95.70 | 67.74 | 25.59 | 18.28 | 19.78 | 79.14 |
| OA | 31.31 | 38.08 | 38.22 | 34.80 | 42.10 | 50.90 | 33.24 | 31.98 | 36.78 | 60.48 | |
| 0.2556 | 0.3099 | 0.3118 | 0.2864 | 0.3593 | 0.4525 | 0.2563 | 0.2659 | 0.2234 | 0.5575 | ||
| t (seconds) | 74 | 10 | 503 | 16906 | 20769 | 18326 | 9 | 462 | 7 | 26 | |
| No. | Class Name | FCM | k-Means | RSC | SSC * | L2-SSC * | JSSC * | SSSC | SSC-OMP | Sketch-SSC | Sketch-SSC-TV |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Asphalt | 84.54 | 90.51 | 90.63 | - | - | - | 35.60 | 59.64 | 64.88 | 99.78 |
| 2 | Meadows | 38.61 | 43.83 | 44.09 | - | - | - | 28.47 | 27.55 | 42.55 | 57.25 |
| 3 | Gravel | 7.58 | 0.10 | 0.10 | - | - | - | 11.92 | 1.05 | 20.14 | 19.43 |
| 4 | Trees | 70.33 | 63.67 | 64.07 | - | - | - | 61.29 | 82.38 | 91.17 | 75.05 |
| 5 | Painted Metal Sheets | 74.80 | 48.25 | 48.77 | - | - | - | 62.05 | 97.10 | 99.79 | 100 |
| 6 | Bare Soil | 37.78 | 32.89 | 32.49 | - | - | - | 18.56 | 31.64 | 27.94 | 60.93 |
| 7 | Bitumen | 0 | 0 | 0 | - | - | - | 5.86 | 0 | 0.38 | 0 |
| 8 | Self-Blocking Bricks | 87.48 | 94.24 | 93.75 | - | - | - | 31.48 | 77.49 | 65.11 | 0.15 |
| 9 | Shadows | 99.89 | 100 | 100 | - | - | - | 8.91 | 0 | 75.73 | 73.75 |
| OA | 51.88 | 53.41 | 53.50 | - | - | - | 30.13 | 40.65 | 49.84 | 58.71 | |
| 0.4238 | 0.4337 | 0.4343 | - | - | - | 0.1794 | 0.3093 | 0.3957 | 0.4858 | ||
| t (seconds) | 209 | 17 | 1640 | - | - | - | 30 | 72397 | 838 | 974 | |
| No. | Class Name | FCM | k-Means | RSC | SSC * | L2-SSC * | JSSC * | SSSC | SSC-OMP | Sketch-SSC | Sketch-SSC-TV |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Brocoli-green-weeds-1 | 99.75 | 98.36 | 99.90 | - | - | - | 66.99 | 0 | 99.43 | 99.94 |
| 2 | Brocoli-green-weeds-2 | 39.59 | 66.56 | 30.30 | - | - | - | 88.60 | 0.05 | 98.91 | 99.53 |
| 3 | Fallow | 19.13 | 0 | 0.00 | - | - | - | 28.64 | 0 | 11.92 | 8.21 |
| 4 | Fallow-rough-plow | 99.21 | 90.32 | 99.21 | - | - | - | 50.63 | 0 | 19.90 | 59.83 |
| 5 | Fallow-smooth | 91.67 | 76.14 | 92.87 | - | - | - | 44.20 | 0 | 99.45 | 98.92 |
| 6 | Stubble | 94.44 | 87.95 | 94.49 | - | - | - | 99.50 | 0.05 | 99.54 | 99.55 |
| 7 | Celery | 98.63 | 97.99 | 98.21 | - | - | - | 90.98 | 0 | 55.25 | 82.16 |
| 8 | Grapes-untrained | 34.08 | 93.60 | 70.95 | - | - | - | 58.62 | 98.82 | 98.67 | 98.95 |
| 9 | Soil-vinyard-develop | 57.97 | 74.13 | 75.58 | - | - | - | 77.94 | 99.92 | 99.72 | 99.94 |
| 10 | Corn-senesced-green-weeds | 7.29 | 30.96 | 33.10 | - | - | - | 44.23 | 0.06 | 88.04 | 94.26 |
| 11 | Lettuce-romaine-4wk | 4.12 | 0 | 0.00 | - | - | - | 34.01 | 0 | 54.21 | 56.95 |
| 12 | Lettuce-romaine-5wk | 89.52 | 91.65 | 96.11 | - | - | - | 12.36 | 0 | 70.97 | 90.75 |
| 13 | Lettuce-romaine-6wk | 99.02 | 98.58 | 98.80 | - | - | - | 8.84 | 0 | 0 | 0 |
| 14 | Lettuce-romaine-7wk | 87.38 | 89.25 | 88.41 | - | - | - | 54.04 | 0 | 97.78 | 78.77 |
| 15 | Vinyard-untrained | 30.02 | 0.01 | 48.56 | - | - | - | 28.46 | 0 | 0.28 | 0.30 |
| 16 | Vinyard-vertical-trellis | 12.06 | 0 | 0.00 | - | - | - | 47.58 | 0 | 97.61 | 98.17 |
| OA | 52.93 | 63.79 | 65.15 | - | - | - | 57.97 | 32.04 | 73.43 | 77.00 | |
| 0.4900 | 0.5926 | 0.6116 | - | - | - | 0.5340 | 0.1743 | 0.7007 | 0.7411 | ||
| t (seconds) | 394 | 31 | 1946 | - | - | - | 37 | 21831 | 269 | 335 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, S.; Zhang, H.; Du, Q.; Pižurica, A. Sketch-Based Subspace Clustering of Hyperspectral Images. Remote Sens. 2020, 12, 775. https://doi.org/10.3390/rs12050775
Huang S, Zhang H, Du Q, Pižurica A. Sketch-Based Subspace Clustering of Hyperspectral Images. Remote Sensing. 2020; 12(5):775. https://doi.org/10.3390/rs12050775
Chicago/Turabian StyleHuang, Shaoguang, Hongyan Zhang, Qian Du, and Aleksandra Pižurica. 2020. "Sketch-Based Subspace Clustering of Hyperspectral Images" Remote Sensing 12, no. 5: 775. https://doi.org/10.3390/rs12050775
APA StyleHuang, S., Zhang, H., Du, Q., & Pižurica, A. (2020). Sketch-Based Subspace Clustering of Hyperspectral Images. Remote Sensing, 12(5), 775. https://doi.org/10.3390/rs12050775