Automatic Detection System of Olive Trees Using Improved K-Means Algorithm


Abstract
1. Introduction
- utilizing the heuristic based, improved K-Means clustering algorithm for better segmentation results;
- developing a computationally efficient and robust multi-step based classification model for accurate detection and identification of olive trees; and
- training and testing the proposed system over a large set of diverse images with varying ground information.
2. Related Literature
2.1. Early 1990s and 2000s
2.2. Late 2000s
2.3. 2010 to Present
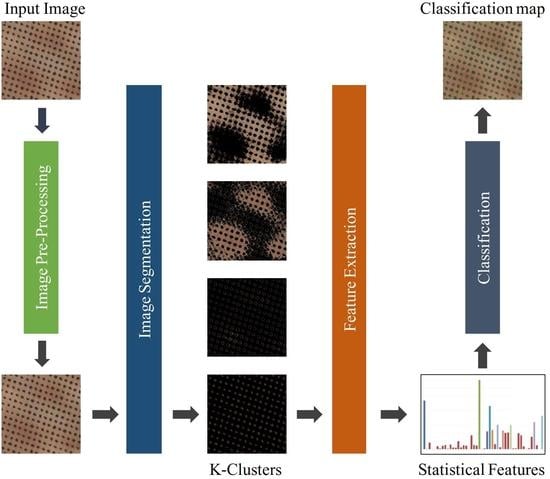
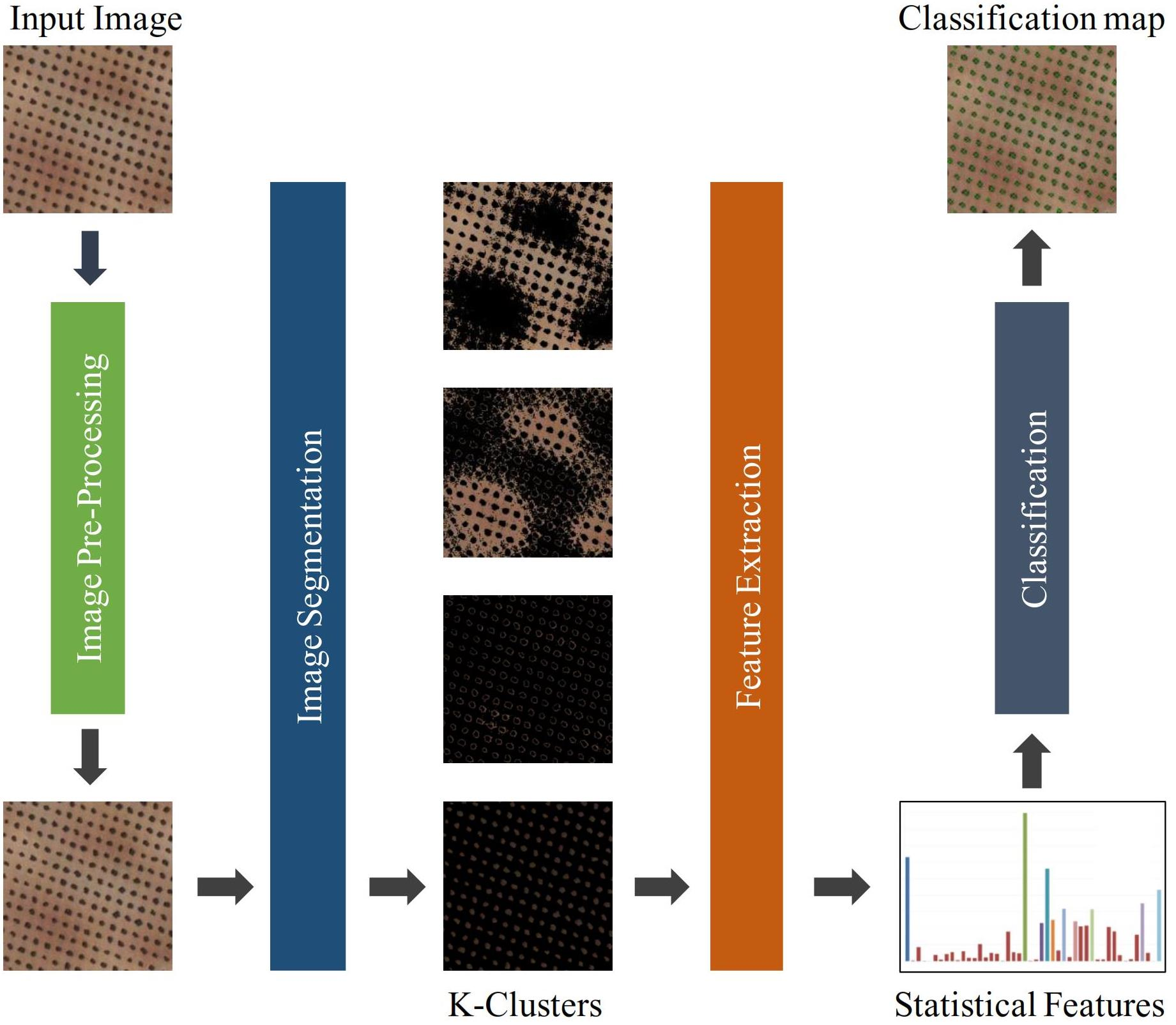
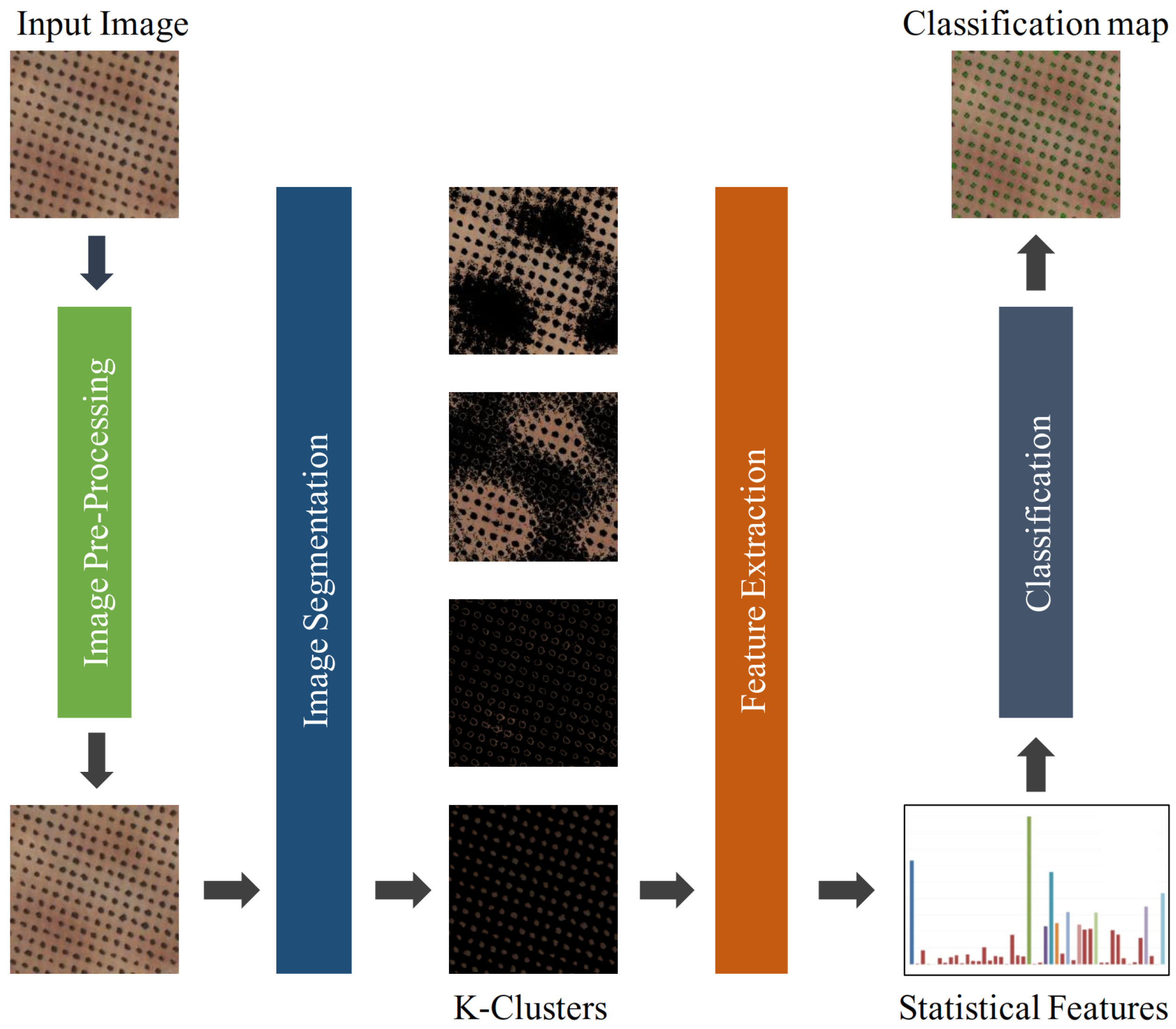
3. Proposed Scheme of Automatic Detection of Olive Trees
3.1. Image Pre-Processing
3.2. Image Enhancement Using Laplacian of Gaussian (LoG) Filtering
3.3. Image Segmentation Using K-Means Clustering
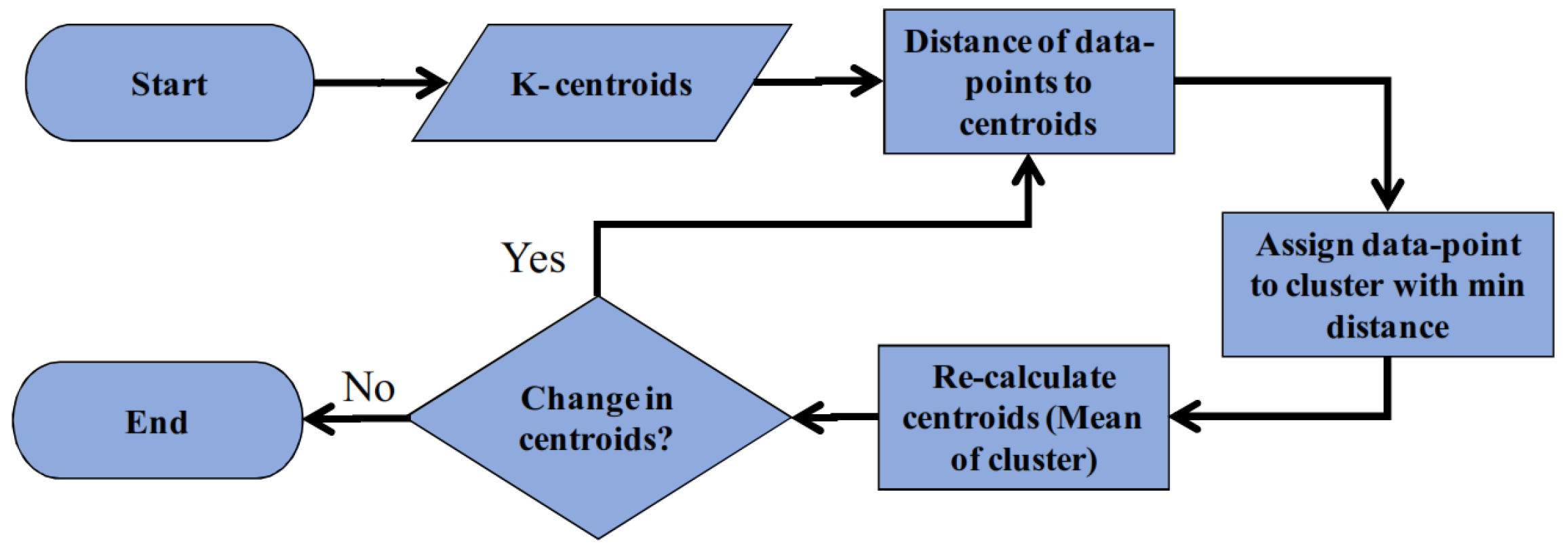
3.3.1. K-Means Clustering
3.3.2. Centroid Selection
3.4. Feature Extraction
3.5. Classification
3.5.1. Naive Bayes Classifier
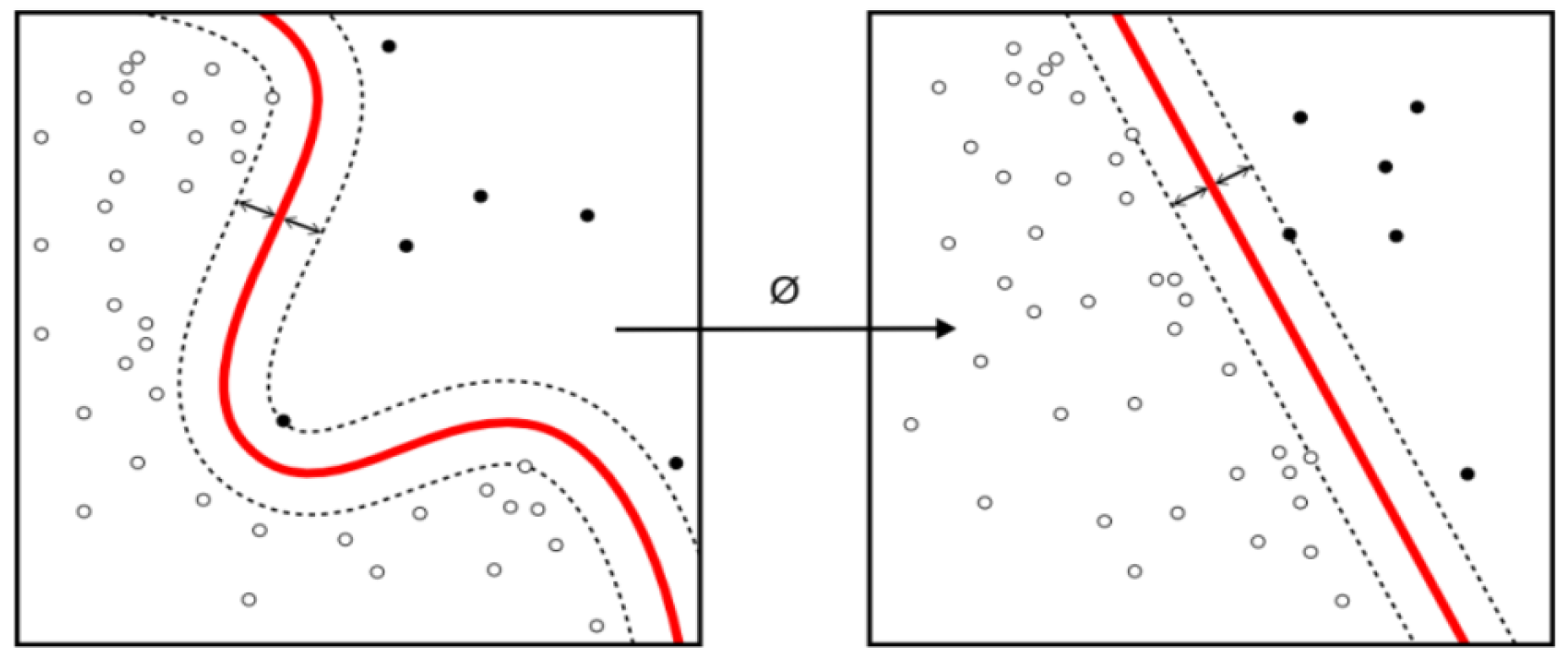
3.5.2. Support Vector Machines
3.5.3. Random Forest
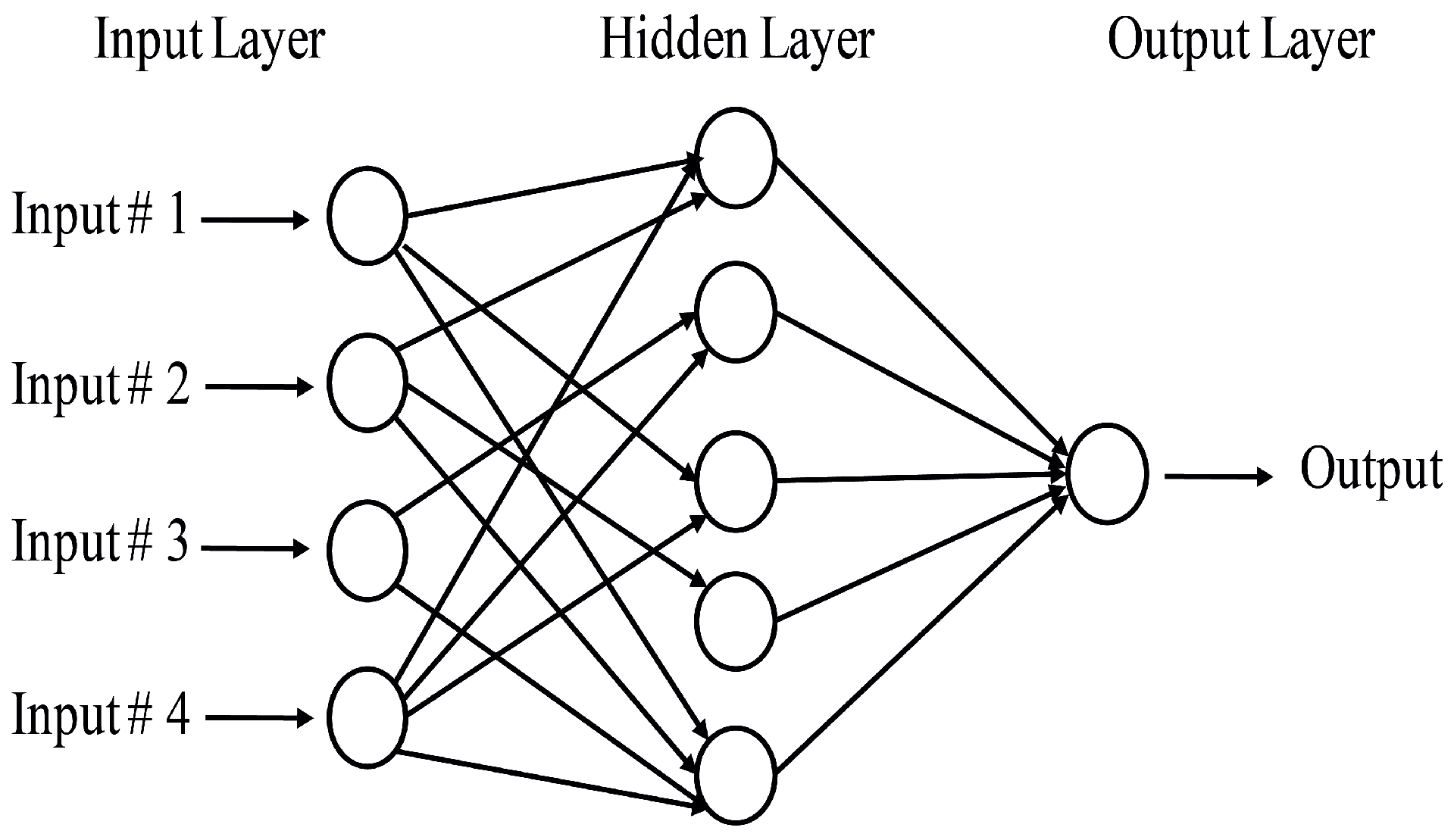
3.5.4. Multi-Layer Perceptron (MLP)
4. Materials and Methods
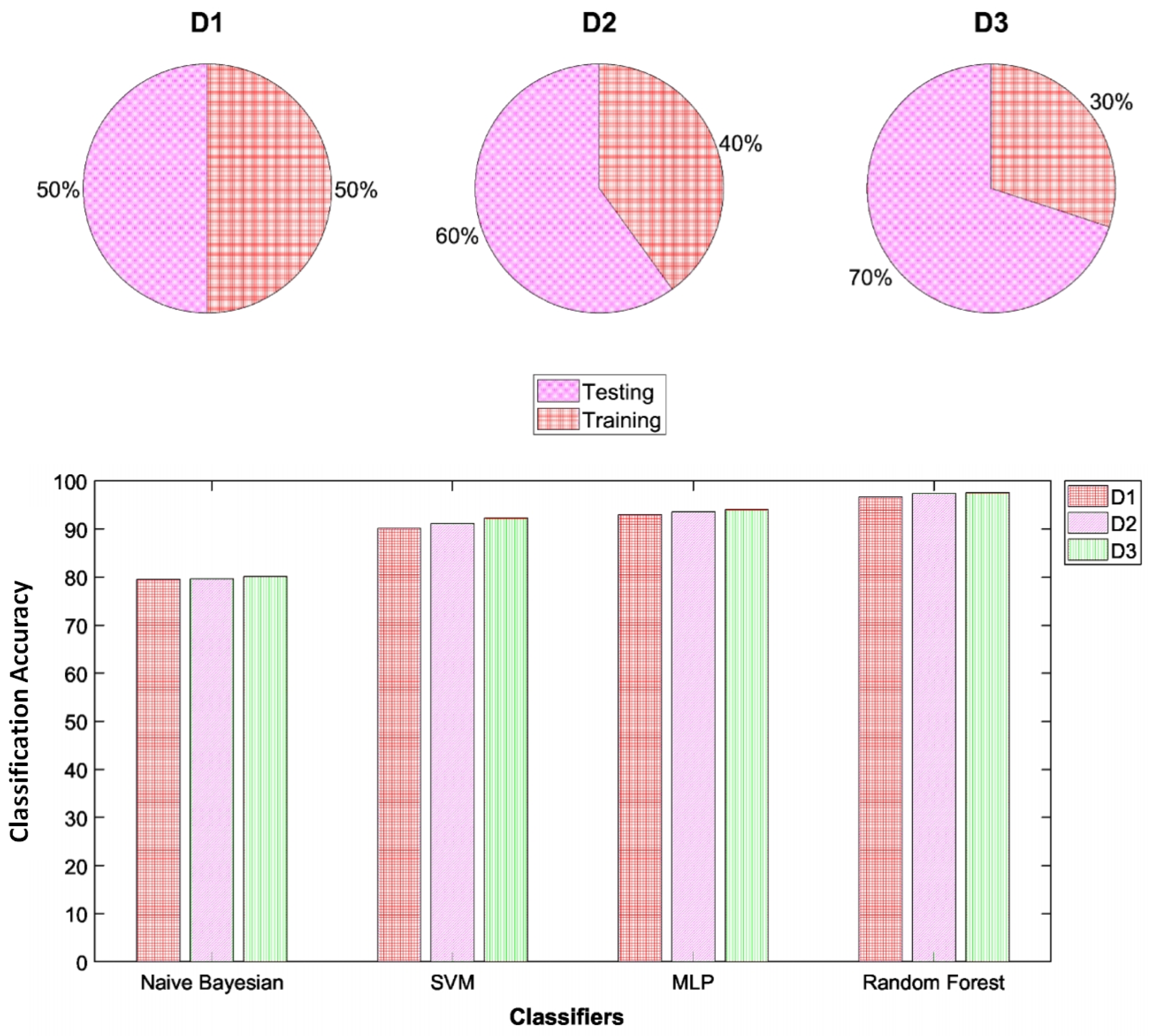
4.1. Dataset
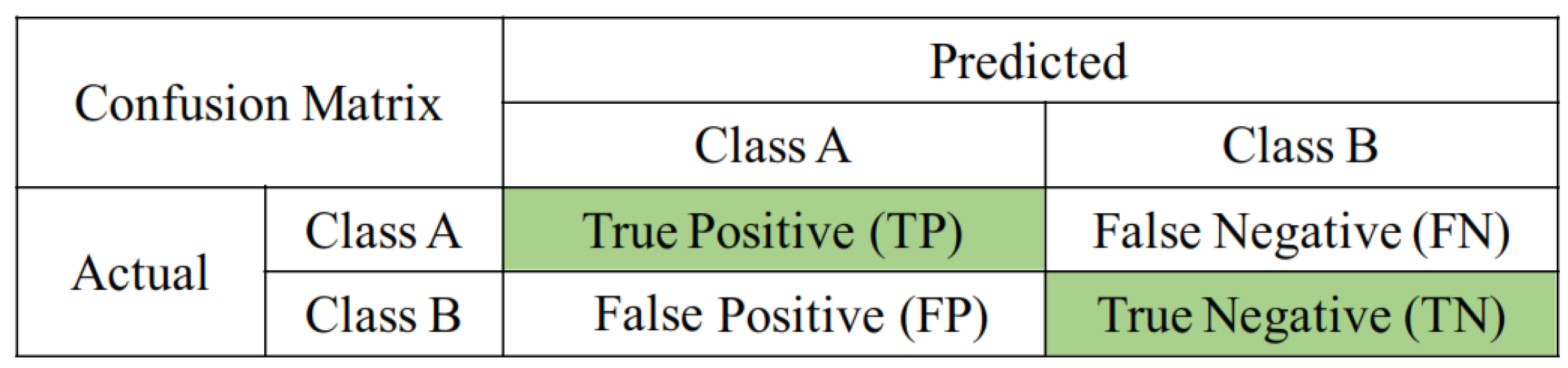
4.2. Performance Evaluation Metrics
4.2.1. Overall Accuracy (OA)
4.2.2. Commission Error (CE)
4.2.3. Omission Error (OE)
4.2.4. Estimation Error (EE)
4.2.5. Finding the Optimal Value of K
5. Experimental Results
5.1. Image Pre-Processing Results
5.2. Image Segmentation Results
5.3. Classification Results
6. Discussion
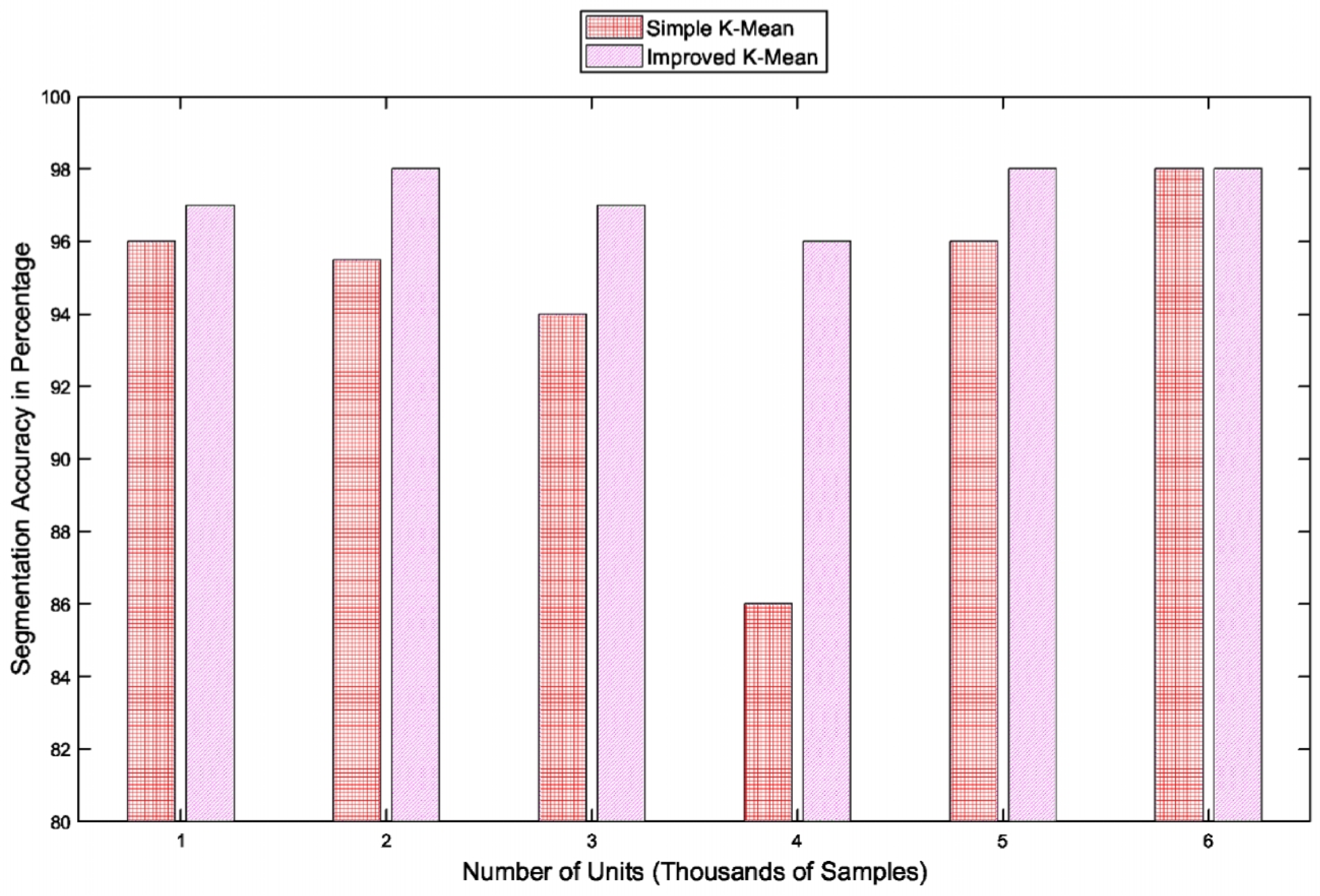
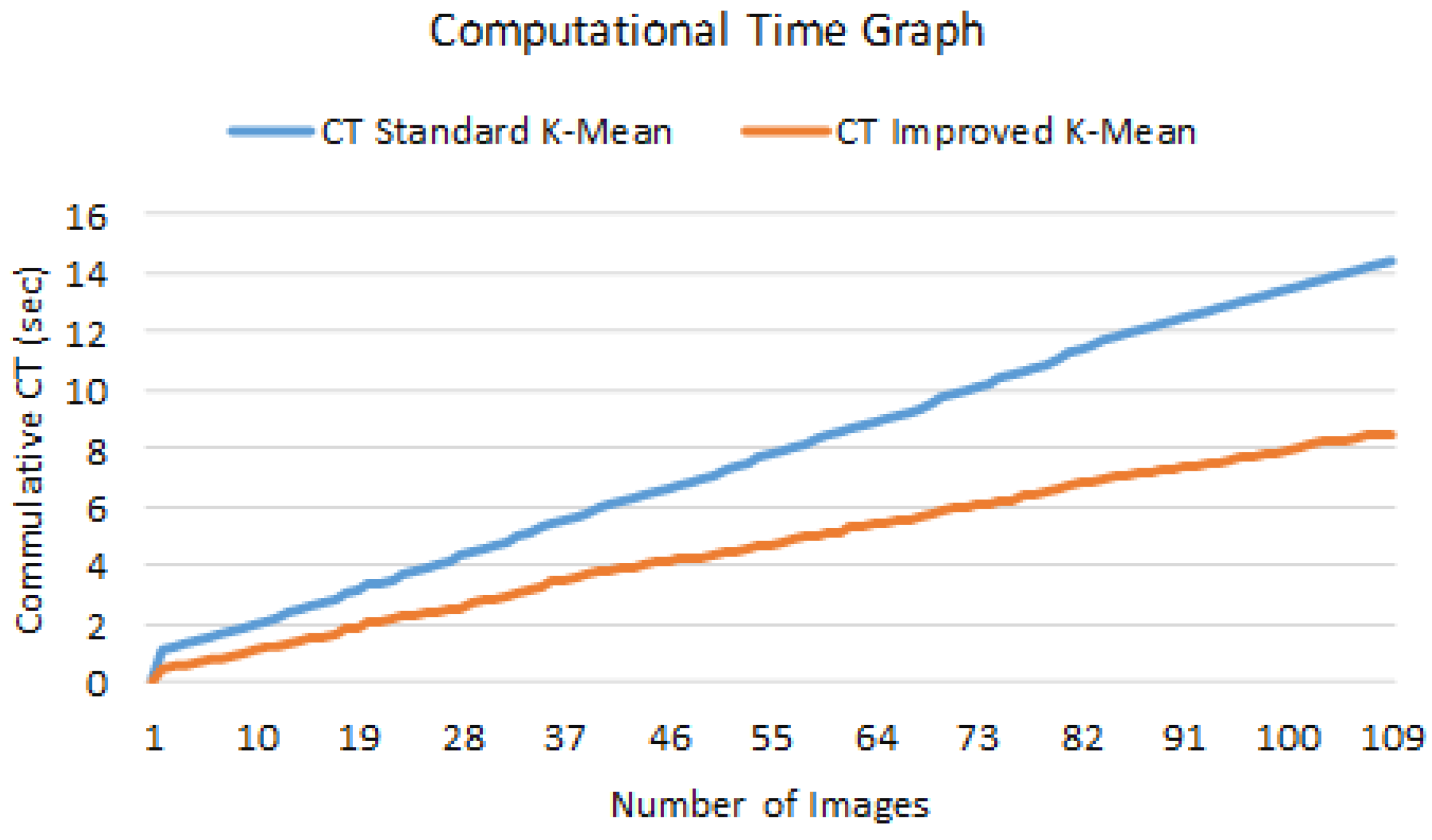
6.1. Comparative Analysis with Simple K-Mean
6.2. Comparative Analysis with Benchmark Schemes
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Radinovsky, L. 2017/18 Worldwide Olive Oil Production Estimates Compared. Available online: http://www.greekliquidgold.com/index.php/en/news/292-2017-18-worldwide-olive-oil-production-estimates-compared (accessed on 6 December 2019).
- Srestasathiern, P.; Rakwatin, P. Oil palm tree detection with high resolution multi-spectral satellite imagery. Remote Sens. 2014, 6, 9749–9774. [Google Scholar] [CrossRef]
- Moreno-Garcia, J.; Linares, L.J.; Rodriguez-Benitez, L.; Solana-Cipres, C. Olive trees detection in very high resolution images. In Information Processing and Management of Uncertainty in Knowledge-Based Systems. Applications. IPMU 2010; Communications in Computer and Information Science; Hüllermeier, E., Kruse, R., Hoffmann, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 81, pp. 21–29. [Google Scholar]
- Chemin, Y.H.; Beck, P.S. A Method to Count Olive Trees in Heterogenous Plantations from Aerial Photographs. Geoinformatics 2017. [Google Scholar] [CrossRef]
- Karantzalos, K.; Argialas, D. Towards Automatic Olive Tree Extraction from Satellite Imagery. 2014. Available online: https://pdfs.semanticscholar.org/4ba8/1e085c2bde7b925b36906697b1a49794290b.pdf (accessed on 7 December 2019).
- Daliakopoulos, I.N.; Grillakis, E.G.; Koutroulis, A.G.; Tsanis, I.K. Tree crown detection on multispectral vhr satellite imagery. Photogramm. Eng. Remote Sens. 2009, 75, 1201–1211. [Google Scholar] [CrossRef]
- González, J.; Galindo, C.; Arevalo, V.; Ambrosio, G. Applying Image Analysis and Probabilistic Techniques for Counting Olive Trees in High-Resolution Satellite Images. In Advanced Concepts for Intelligent Vision Systems. ACIVS 2007; Lecture Notes in Computer Science; Blanc-Talon, J., Philips, W., Popescu, D., Scheunders, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4678, pp. 920–931. [Google Scholar]
- Moreno-Garcia, J.; Jimenez, L.; Rodriguez-Benitez, L.; Solana-Cipres, C.J. Fuzzy logic applied to detect olive trees in high resolution images. In Proceedings of the IEEE International Conference on Fuzzy Systems, Barcelona, Spain, 18–23 July 2010. [Google Scholar] [CrossRef]
- Bazi, Y.; Al-Sharari, H.; Melgani, F. An automatic method for counting olive trees in very high spatial remote sensing images. In Proceedings of the 2009 IEEE International Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009; pp. II-125–II-128. [Google Scholar] [CrossRef]
- Peters, J.; van Coillie, F.; Westra, T.; de Wulf, R. Synergy of very high resolution optical and radar data for object-based olive grove mapping. Int. J. Geogr. Inf. Sci. 2011, 25, 971–989. [Google Scholar] [CrossRef]
- Commission, E. Joint Research Centre. Available online: https://ec.europa.eu/info/departments/joint-\research-centre-en (accessed on 12 December 2019).
- Bagli, S. Olicount v2. Technical Documentation, Joint Reseach Centre IPSC/G03/P/SKA/ska D (5217). 2005. Available online: https://www.scribd.com/document/324886236/Olicount-v2 (accessed on 14 December 2019).
- Soubeyrand, S.; de Jerphanion, P.; Martin, O.; Saussac, M.; Manceau, C.; Hendrikx, P.; Lannou, C. Inferring pathogen dynamics from temporal count data: The emergence of xylella fastidiosa in france is probably not recent. New Phytol. 2018. [Google Scholar] [CrossRef]
- Niblack, W. An Introduction to Digital Image Processing; Strandberg Publishing Company: Birkeroed, Denmark, 1985. [Google Scholar]
- Khan, A.; Khan, U.; Waleed, M.; Khan, A.; Kamal, T.; Marwat, S.N.K.; Maqsood, M.; Aadil, F. Remote sensing: An automated methodology for olive tree detection and counting in satellite images. IEEE Access 2018, 6, 77816–77828. [Google Scholar] [CrossRef]
- Bhosale, N.P.; Manza, R.R. A Review on Noise Removal Techniques From Remote Sensing Images. In Proceedings of the Radhai National Conference [CMS], Aurangabad, India, 25–26 April 2013. [Google Scholar] [CrossRef]
- Noh, Z.M.; Ramli, A.R.; Hanafi, M.; Saripan, M.I.; Ramlee, R.A. Palm vein pattern visual interpretation using laplacian and frangi-based filter. Indones. J. Electr. Eng. Comput. Sci. 2018, 10, 578–586. [Google Scholar] [CrossRef]
- Piao, W.; Yuan, Y.; Lin, H. A digital image denoising algorithm based on gaussian filtering and bilateral filtering. In Proceedings of the 4th Annual International Conference on Wireless Communication and Sensor Network (WCSN 2017), 2018; Available online: https://www.itm-conferences.org/articles/itmconf/pdf/2018/02/itmconf_wcsn2018_01006.pdf (accessed on 15 December 2019). [CrossRef]
- Kong, H.; Akakin, H.C.; Sarma, S.E. A generalized laplacian of gaussian filter for blob detection and its applications. IEEE Trans. Cybern. 2013, 43, 1719–1733. [Google Scholar] [CrossRef] [PubMed]
- Kalra, M.; Lal, N.; Qamar, S. K-Mean Clustering Algorithm Approach for Data Mining of Heterogeneous Data; Springer: Berlin, Germany, 2018; pp. 61–70. [Google Scholar]
- Hussain, R.G.; Ghazanfar, M.A.; Azam, M.A.; Naeem, U.; Rehman, S.U. A performance comparison of machine learning classification approaches for robust activity of daily living recognition. Artif. Intell. Rev. 2018, 1–23. [Google Scholar] [CrossRef]
- Chen, X.; Zeng, G.; Zhang, Q.; Chen, L.; Wang, Z. Classification of Medical Consultation Text Using Mobile Agent System Based on Naïve Bayes Classifier. In 5G for Future Wireless Networks. 5GWN 2017; Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Long, K., Leung, V., Zhang, H., Feng, Z., Li, Y., Zhang, Z., Eds.; Springer: Cham, Switzerland, 2017; Volume 211. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Mahesh, P. Random Forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Narang, A.; Batra, B.; Ahuja, A.; Yadav, J.; Pachauri, N. Classification of eeg signals for epileptic seizures using levenberg-marquardt algorithm based Multi-Layer Perceptron neural network. J. Intell. Fuzzy Syst. 2018, 34, 1669–1677. [Google Scholar] [CrossRef]
- Mohamed, H.; Zahran, M.; Saavedra, O. Assessment of Artificial Neural Network for Bathymetry Estimation using High Resolution Satellite Imagery in Shallow Lakes: Case Study el Burullus Lake. In Proceedings of the Eighteenth International Water Technology Conference, IWTC18, Sharm ElSheikh, Egypt, 12–14 March 2015. [Google Scholar]
- Duan, K.B.; Keerthi, S.S. Which Is the Best Multiclass SVM Method? An Empirical Study; Lect Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3541. [Google Scholar]
- Camarsa, G.; Gardner, S.; Jones, W.; Eldridge, J.; Hudson, T.; Thorpe, E.; O’Hara, E. Life among the Olives: Good Practice in Improving Environmental Performance in the Olive Oil Sector; Official Publications of the European Union: Luxembourg, 2010; Available online: https://op.europa.eu/en/publication-detail/-/publication/53cd8cd1-272f-4cb8-b7b5-5c100c267f8f (accessed on 15 December 2019).
- Sai Krishna, T.V.; Yesu Babu, A.; Kiran Kumar, R. Determination of Optimal Clusters for a Non-hierarchical Clustering Paradigm K-Means Algorithm. In Proceedings of International Conference on Computational Intelligence and Data Engineering; Lecture Notes on Data Engineering and Communications Technologies; Chaki, N., Cortesi, A., Devarakonda, N., Eds.; Springer: Singapore, 2018; Volume 9. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| * Sr No. | Feature | Size of Feature Vector | Description |
|---|---|---|---|
| 1 | Mean of Red band | 1×1 | Average value of pixels in red band |
| 2 | Mean of Blue band | 1×1 | Average value of pixels in blue band |
| 3 | Mean of Green band | 1×1 | Average value of pixels in green band |
| 4 | Area | 1×1 | Number of pixels in a segment |
| 5 | Combined Features | 1×4 | Mean values of the color of the segment and its size |
| * SVM | Tree | Non-Tree | Naive Bayesian | Tree | Non-Tree |
|---|---|---|---|---|---|
| Tree | 2971 | 10 | Tree | 2653 | 328 |
| Non-tree | 360 | 1474 | Non-tree | 630 | 1204 |
| ** MLP | Tree | Non-Tree | Random Forest | Tree | Non-Tree |
| Tree | 2891 | 90 | Tree | 2936 | 45 |
| Non-tree | 197 | 1637 | Non-tree | 74 | 1760 |
| Classification Algorithm | * OA | ** CE | *** OE | **** EE |
|---|---|---|---|---|
| Random Forest | 97.5 | 0.04 | 0.015 | 0.97 |
| MLP | 94.0 | 0.10 | 0.03 | 3.5 |
| SVM | 92.3 | 0.19 | 0.003 | 10.1 |
| Naive Bayesian | 80.1 | 0.34 | 0.11 | 11.7 |
| Technique | Dataset | No of Images | Spectrum | OA | CE | OE | EE |
|---|---|---|---|---|---|---|---|
| Proposed Methodology | SIGPAC Viewer | 110 | RGB | 97.5 | 4 in 100 | 1 in 100 | 0.97 |
| Reticular matching [9] | Quickbird | N/A | Grey-scale | 98 | 5 in 100 | 7 in 100 | 1.24 |
| Laplacian Maxima [7] | Quickbird / IKONOS | N/A | Grey-scale | N/A | N/A | N/A | N/A |
| GPC [11] | IKONOS-2 | 1 | RGB | 96 | N/A | N/A | 3.68 |
| K-mean Clustering [5] | SIGPAC viewer | N/A | RGB | N/A | 0 in 6 | 1 in 6 | N/A |
| Fuzzy logic [10] | SIGPAC viewer | 1 | RGB | N/A | 0 in 6 | 1 in 6 | N/A |
| Red band Thresholding + NDVI [8] | Quickbird | N/A | 4-bands | N/A | N/A | N/A | 1.3 |
| Counting Olive Trees in Heterogeneous Plantations [6] | Acquired Aerial Images | N/A | 4-bands | N/A | N/A | N/A | 13 |
| Object-based olive grove mapping [12] | Multi-sensor imagery | 4 | 4-bands | 84.3 | N/A | N/A | N/A |
| Multi-level thresholding [15] | SIGPAC viewer | 95 | Gray-scale | 96 | 3 in 100 | 3 in 100 | 1.2 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Waleed, M.; Um, T.-W.; Khan, A.; Khan, U. Automatic Detection System of Olive Trees Using Improved K-Means Algorithm. Remote Sens. 2020, 12, 760. https://doi.org/10.3390/rs12050760
Waleed M, Um T-W, Khan A, Khan U. Automatic Detection System of Olive Trees Using Improved K-Means Algorithm. Remote Sensing. 2020; 12(5):760. https://doi.org/10.3390/rs12050760
Chicago/Turabian StyleWaleed, Muhammad, Tai-Won Um, Aftab Khan, and Umair Khan. 2020. "Automatic Detection System of Olive Trees Using Improved K-Means Algorithm" Remote Sensing 12, no. 5: 760. https://doi.org/10.3390/rs12050760
APA StyleWaleed, M., Um, T.-W., Khan, A., & Khan, U. (2020). Automatic Detection System of Olive Trees Using Improved K-Means Algorithm. Remote Sensing, 12(5), 760. https://doi.org/10.3390/rs12050760