A Deep Learning Method to Accelerate the Disaster Response Process



Abstract
1. Introduction
2. Literature Review
2.1. Helicopter Landing Site Analysis
2.2. Volunteered Geographic Information
2.3. Machine Learning/Deep Learning
2.4. Training Strategies
2.5. ML/DL Challenges
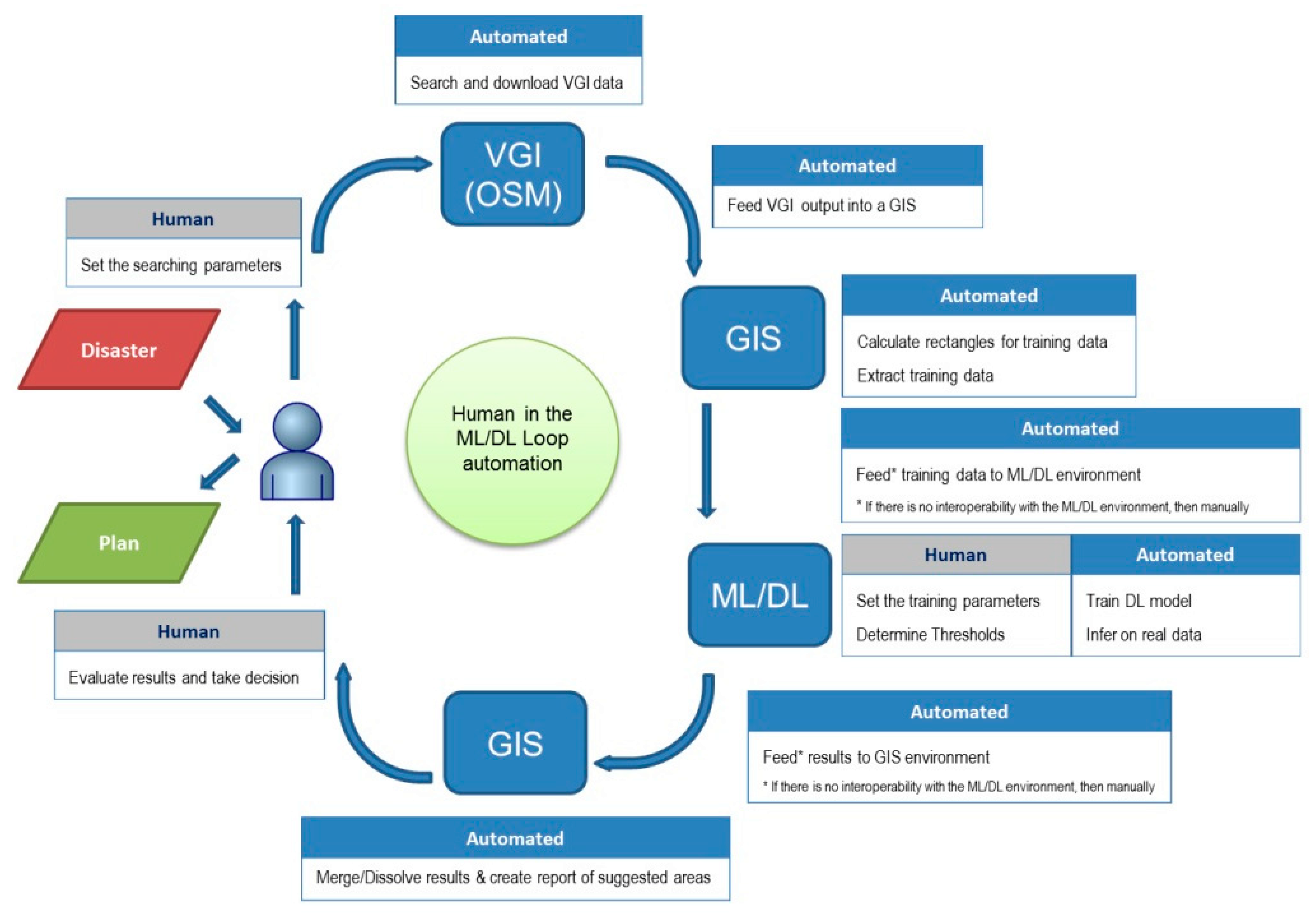
3. Methodology
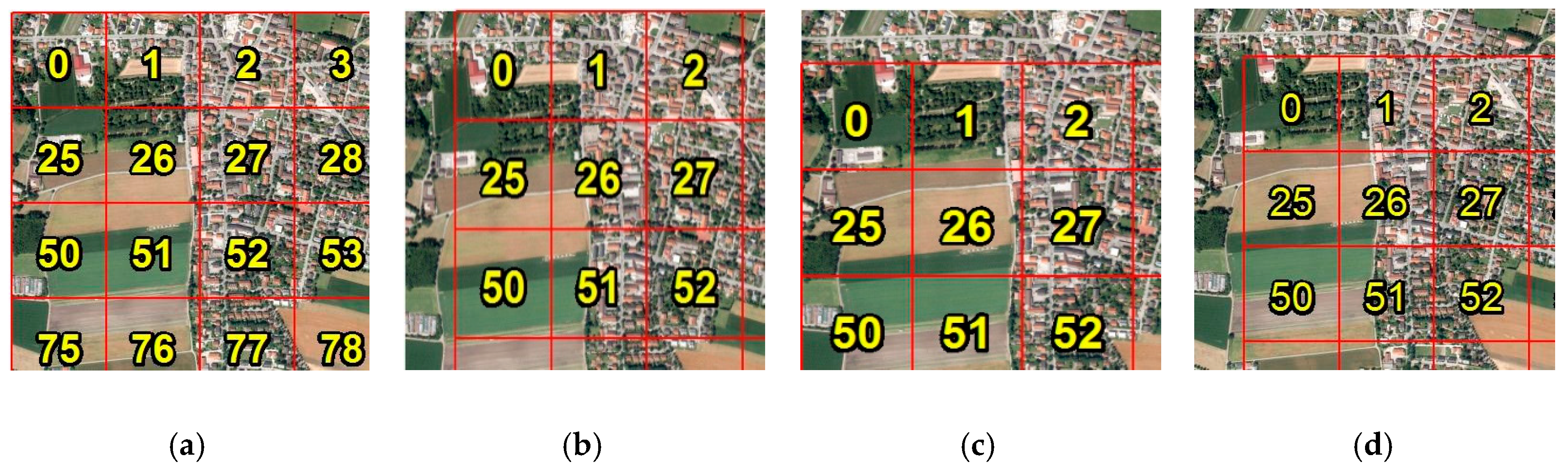
3.1. Data Acquisition
3.2. DLA and Training
3.3. DLA Evaluation
3.4. Infer Areas and Ground Truth Selection
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Euroconsult. Euroconsult Research Projects Smallsat Market to Nearly Quadruple over Next Decade|Euroconsult. Available online: http://www.euroconsult-ec.com/5_August_2019 (accessed on 14 December 2019).
- Quinn, J.A.; Nyhan, M.M.; Navarro, C.; Coluccia, D.; Bromley, L.; Luengo-Oroz, M. Humanitarian applications of machine learning with remote-sensing data: review and case study in refugee settlement mapping. Philos. Trans. R. Soc. Math. Phys. Eng. Sci. 2018, 376, 20170363. [Google Scholar] [CrossRef] [PubMed]
- Santilli, G.; Vendittozzi, C.; Cappelletti, C.; Battistini, S.; Gessini, P. CubeSat constellations for disaster management in remote areas. Acta Astronaut. 2018, 145, 11–17. [Google Scholar] [CrossRef]
- United Nations; Australian Bureau of Statistics; Queensland University of Technology; Queensland Government; Commonwealth Scientific and Industrial Research Organisation; European Commission; National Institute of Statistics and Geography; Statistics Canada. Earth Observations for Official Statistics. 2019. Available online: https://unstats.un.org/bigdata/taskteams/satellite/UNGWG_Satellite_Task_Team_Report_WhiteCover.pdf (accessed on 11 February 2020).
- Yang, C.; Yu, M.; Li, Y.; Hu, F.; Jiang, Y.; Liu, Q.; Sha, D.; Xu, M.; Gu, J. Big Earth data analytics: A survey. Big Earth Data 2019, 3, 83–107. [Google Scholar] [CrossRef]
- Chi, M.; Plaza, A.; Benediktsson, J.A.; Sun, Z.; Shen, J.; Zhu, Y. Big Data for Remote Sensing: Challenges and Opportunities. Proc. IEEE 2016, 104, 2207–2219. [Google Scholar] [CrossRef]
- Ma, Y.; Wu, H.; Wang, L.; Huang, B.; Ranjan, R.; Zomaya, A.; Jief, W. Remote sensing big data computing: Challenges and opportunities. Future Gener. Comput. Syst. 2015, 51, 47–60. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Voigt, S.; Kemper, T.; Riedlinger, T.; Kiefl, R.; Scholte, K.; Mehl, H. Satellite Image Analysis for Disaster and Crisis-Management Support. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1520–1528. [Google Scholar] [CrossRef]
- Kopp, S.; Becker, P.; Doshi, A.; Wright, D.J.; Zhang, K.; Xu, H. Achieving the Full Vision of Earth Observation Data Cubes. Data 2019, 4, 94. [Google Scholar] [CrossRef]
- Lewis, A.; Oliver, S.; Lymburner, L.; Evans, B.; Wyborn, L.; Mueller, N.; Gregory, R.; Hooke, J.; Woodcock, R.; Sixsmith, J.; et al. The Australian Geoscience Data Cube—Foundations and lessons learned. Remote Sens. Environ. 2017, 202, 276–292. [Google Scholar] [CrossRef]
- Giuliani, G.; Chatenoux, B.; Bono, A.D.; Rodila, D.; Richard, J.-P.; Allenbach, K.; Dao, H.; Peduzzi, P. Building an Earth Observations Data Cube: lessons learned from the Swiss Data Cube (SDC) on generating Analysis Ready Data (ARD). Big Earth Data 2017, 1, 100–117. [Google Scholar] [CrossRef]
- Gore, A. The digital earth: Understanding our planet in the 21st century. Photogramm. Eng. Remote Sens. 1999, 65, 528. [Google Scholar] [CrossRef]
- Craglia, M.; Bie, K.; de Jackson, D.; Pesaresi, M.; Remetey-Fülöpp, G.; Wang, C.; Annoni, A.; Bian, L.; Campbell, F.; Ehlers, M.; et al. Digital Earth 2020: Towards the vision for the next decade. Int. J. Digit. Earth 2012, 5, 4–21. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Yu, L.; Liang, L.; Wang, J.; Zhao, Y.; Cheng, Q.; Hu, L.; Liu, S.; Yu, L.; Wang, X.; Zhu, P.; et al. Meta-discoveries from a synthesis of satellite-based land-cover mapping research. Int. J. Remote Sens. 2014, 35, 4573–4588. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: an applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- He, K.; Sun, J. Convolutional Neural Networks at Constrained Time Cost. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5353–5360. [Google Scholar]
- Harris, F.D.; Kasper, E.F.; Iseler, L.E. US Civil Rotorcraft Accidents, 1963 Through 1997; National Aeronautics and Space Administration Moffett Field: Fort Belvoir, VA, USA, 2000.
- Kovařík, V. Possibilities of geospatial data analysis using spatial modeling in ERDAS IMAGINE. In Proceedings of the International Conference on Military Technologies 2011-ICMT’11, At Brno, Czech Republic, 30–31 May 2011; pp. 1307–1313. [Google Scholar]
- Fitzgerald, D.; Walker, R.; Campbell, D. A Vision Based Forced Landing Site Selection System for an Autonomous UAV. In Proceedings of the 2005 International Conference on Intelligent Sensors, Sensor Networks and Information Processing, Melbourne, Australia, 5–8 December 2005; pp. 397–402. [Google Scholar]
- Scherer, S.; Chamberlain, L.; Singh, S. First results in autonomous landing and obstacle avoidance by a full-scale helicopter. In Proceedings of the IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 951–956. [Google Scholar]
- Maturana, D.; Scherer, S. 3D Convolutional Neural Networks for landing zone detection from LiDAR. In Proceedings of the IEEE International Conference on Robotics and Automation, Seattle, WA, USA, 26–30 May 2015. [Google Scholar]
- Haklay, M.; Antoniou, V.; Basiouka, S.; Soden, R.; Mooney, P. Crowdsourced Geographic Information Use in Government; World Bank Publications: Washington, DC, USA, 2014; pp. 1–73. [Google Scholar]
- Haklay, M.; Antoniou, V.; Basiouka, S.; Soden, R.J.; Deparday, V.; Sheely, R.M.; Mooney, P. Identifying Success Factors in Crowdsourced Geographic Information Use in Government; The World Bank: Washington, DC, USA, 2018; pp. 1–157. [Google Scholar]
- Ofli, F.; Meier, P.; Imran, M.; Castillo, C.; Tuia, D.; Rey, N.; Briant, J.; Millet, P.; Reinhard, F.; Parkan, M.; et al. Combining Human Computing and Machine Learning to Make Sense of Big (Aerial) Data for Disaster Response. Big Data 2016, 4, 47–59. [Google Scholar] [CrossRef]
- Chen, J.; Zhou, Y.; Zipf, A.; Fan, H. Deep Learning From Multiple Crowds: A Case Study of Humanitarian Mapping. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1713–1722. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Ball, J.E.; Anderson, D.T.; Chan, C.S. Feature and Deep Learning in Remote Sensing Applications. J. Appl. Remote Sens. 2017, 11, 42609. [Google Scholar]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Chollet, F. Building Autoencoders in Keras. Available online: https://blog.keras.io/building-autoencoders-in-keras.html (accessed on 14 December 2019).
- Chalapathy, R.; Menon, A.K.; Chawla, S. Anomaly Detection using One-Class Neural Networks. arXiv 2018, arXiv:1802.06360. [Google Scholar]
- Kwon, D.; Kim, H.; Kim, J.; Suh, S.C.; Kim, I.; Kim, K.J. A survey of deep learning-based network anomaly detection. Clust. Comput. 2019, 22, 949–961. [Google Scholar] [CrossRef]
- Cadena, C.; Dick, A.R.; Reid, I.D. Multi-modal Auto-Encoders as Joint Estimators for Robotics Scene Understanding. Robot. Sci. Syst. 2016, 12, 1–9. [Google Scholar]
- Feng, J.; Wang, Y. 3D shape retrieval using a single depth image from low-cost sensors. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–9 March 2016. [Google Scholar]
- Huang, W.; Xiao, L.; Wei, Z.; Liu, H. Songze Tang A New Pan-Sharpening Method with Deep Neural Networks. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1037–1041. [Google Scholar] [CrossRef]
- Pan-sharpening via deep metric learning. ISPRS J. Photogramm. Remote Sens. 2018, 145, 165–183. [CrossRef]
- Lin, Z.; Chen, Y.; Zhao, X.; Wang, G. Spectral-spatial classification of hyperspectral image using autoencoders. In Proceedings of the 2013 9th International Conference on Information, Communications & Signal Processing, Kuala Lumpur, Malaysia, 10–13 December 2013. [Google Scholar]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Karalas, K.; Tsagkatakis, G.; Zervakis, M.; Tsakalides, P. Deep learning for multi-label land cover classification. In Image and Signal Processing for Remote Sensing XXI; International Society for Optics and Photonics: Toulouse, France, 2015; Volume 9643, p. 96430Q. [Google Scholar]
- Xing, C.; Ma, L.; Yang, X. Stacked Denoise Autoencoder Based Feature Extraction and Classification for Hyperspectral Images. J. Sens. 2016, 2016, 10. [Google Scholar] [CrossRef]
- Zabalzaa, J.; Rena, J.; Zhengb, J.; Zhaoc, H.; Qingd, C.; Yange, Z.; Duf, P.; Marshalla, S. Novel segmented stacked autoencoder for effective dimensionality reduction and feature extraction in hyperspectral imaging. Neurocomputing 2016, 185, 1–10. [Google Scholar] [CrossRef]
- Ma, X.; Wang, H.; Geng, J. Spectral–Spatial Classification of Hyperspectral Data Based on Deep Belief Network—IEEE Journals & Magazine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4073–4085. [Google Scholar]
- Tang, J.; Deng, C.; Huang, G.-B.; Zhao, B. Compressed-Domain Ship Detection on Spaceborne Optical Image Using Deep Neural Network and Extreme Learning Machine. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1174–1185. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep Learning Based Feature Selection for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Luus, F.P.S.; Salmon, B.P.; Bergh, F.; van den Maharaj, B.T.J. Multiview Deep Learning for Land-Use Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2448–2452. [Google Scholar] [CrossRef]
- Volpi, M.; Tuia, D. Dense Semantic Labeling of Subdecimeter Resolution Images with Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 55, 881–893. [Google Scholar] [CrossRef]
- Gilmer, J.; Adams, R.P.; Goodfellow, I.; Andersen, D.; Dahl, G.E. Motivating the Rules of the Game for Adversarial Example Research. arXiv 2018, arXiv:1807.06732. [Google Scholar]
- Hendrycks, D.; Zhao, K.; Basart, S.; Steinhardt, J.; Song, D. Natural Adversarial Examples. arXiv 2019, arXiv:1907.07174. [Google Scholar]
- Heaven, D. Why Deep-Learning AIs Are so Easy to Fool. Available online: https://www.nature.com/articles/d41586-019-03013-5 (accessed on 14 December 2019).
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Engstrom, L.; Tran, B.; Tsipras, D.; Schmidt, L.; Madry, A. Exploring the Landscape of Spatial Robustness. arXiv 2017, arXiv:1712.02779. [Google Scholar]
- Alcorn, M.A.; Li, Q.; Gong, Z.; Wang, C.; Mai, L.; Ku, W.-S.; Nguyen, A. Strike (with) a Pose: Neural Networks Are Easily Fooled by Strange Poses of Familiar Objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4845–4854. [Google Scholar]
- Geirhos, R.; Rubisch, P.; Michaelis, C.; Bethge, M.; Wichmann, F.A.; Brendel, W. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. arXiv 2018, arXiv:1811.12231. [Google Scholar]
- Brendel, W.; Bethge, M. Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet. arXiv 2019, arXiv:1904.00760. [Google Scholar]
- Brown, T.B.; Carlini, N.; Zhang, C.; Olsson, C.; Christiano, P.; Goodfellow, I. Unrestricted Adversarial Examples. arXiv 2018, arXiv:1809.08352. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Chollet, F. Deep Learning with Python; Manning Publications: Shelter Island, NY, USA, 2017; ISBN 978-1-61729-443-3. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Ienco, D.; Gaetano, R.; Dupaquier, C.; Maurel, P. Land Cover Classification via Multi-temporal Spatial Data by Recurrent Neural Networks. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1685–1689. [Google Scholar] [CrossRef]
- Ho Tong Minh, D.; Ienco, D.; Gaetano, R.; Lalande, N.; Ndikumana, E.; Osman, F.; Maurel, P. Deep Recurrent Neural Networks for Winter Vegetation Quality Mapping via Multitemporal SAR Sentinel-1. IEEE Geosci. Remote Sens. Lett. 2018, 15, 464–468. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 5, 3639–3655. [Google Scholar] [CrossRef]
- Lyu, H.; Lu, H.; Mou, L. Learning a Transferable Change Rule from a Recurrent Neural Network for Land Cover Change Detection. Remote Sens. 2016, 8, 506. [Google Scholar] [CrossRef]
- Maskey, M.; Ramachandran, R.; Miller, J. Deep learning for phenomena-based classification of Earth science images. J. Appl. Remote Sens. 2017, 11, 42608. [Google Scholar] [CrossRef]
- Xing, J.; Sieber, R.E. Propagation of Uncertainty for Volunteered Geographic Information in Machine Learning (Short Paper). In 10th International Conference on Geographic Information Science (GIScience 2018); Winter, S., Griffin, A., Sester, M., Eds.; Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik: Dagstuhl, Germany, 2018; Volume 114, pp. 66:1–66:6. [Google Scholar]
- Campos-Taberner, M.; Romero-Soriano, A.; Gatta, C.; Camps-Valls, G.; Lagrange, A.; Saux, B.L.; Beaupère, A.; Boulch, A.; Chan-Hon-Tong, A.; Herbin, S.; et al. Processing of Extremely High-Resolution LiDAR and RGB Data: Outcome of the 2015 IEEE GRSS Data Fusion Contest–Part A: 2-D Contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 5547–5559. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Cui, Y.; Belongie, S.; Hays, J. Learning deep representations for ground-to-aerial geolocalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Vo, N.N.; Hays, J. Localizing and Orienting Street Views Using Overhead Imagery. In Computer Vision—ECCV; Springer: Cham, Germany, 2016; pp. 494–509. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
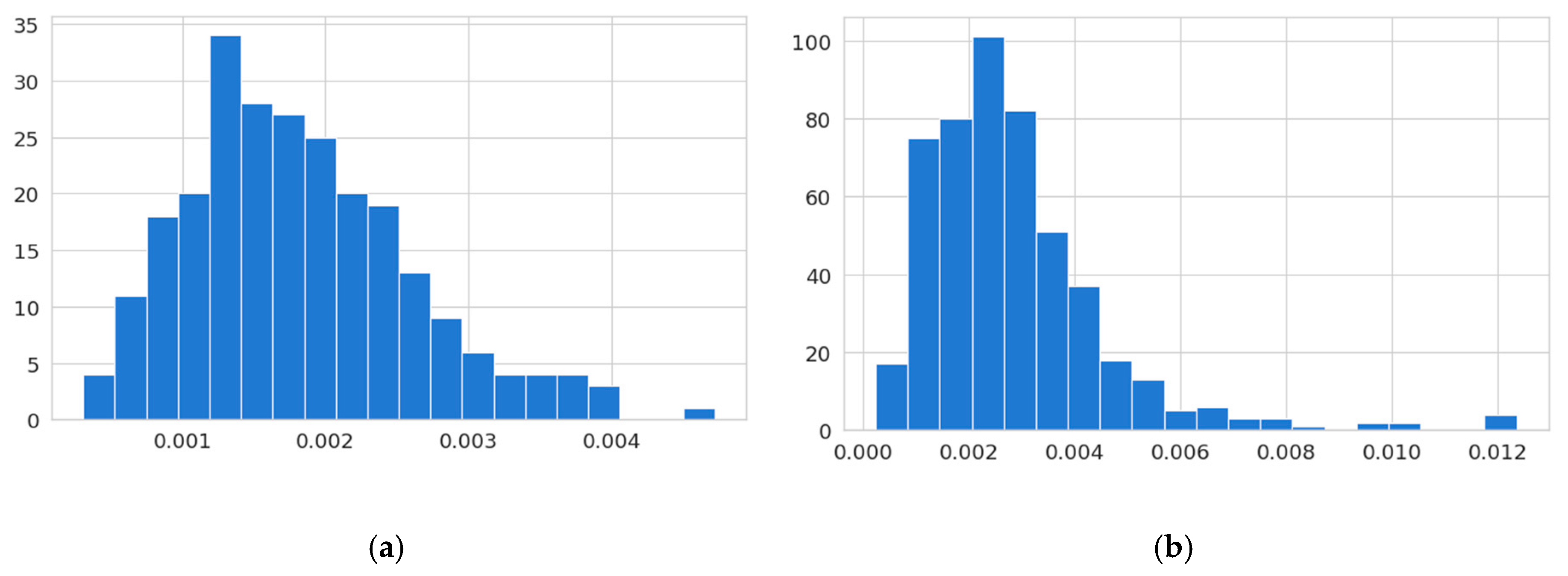
| Descriptive Statistics | Positives | Negatives |
|---|---|---|
| count | 250 | 500 |
| mean | 0.001817 | 0.002829 |
| std | 0.000785 | 0.001737 |
| min | 0.000308 | 0.000242 |
| 25% | 0.001258 | 0.001711 |
| 50% | 0.001687 | 0.002507 |
| 75% | 0.002294 | 0.003468 |
| max | 0.004719 | 0.01236 |
| Inference Area | Initial CL (km2) | CL of DLA (km2) | Reduction of CL (km2) | % of CL Reduction | Ground Truth (km2) | % of Initial Overhead | % of DLA Overhead |
|---|---|---|---|---|---|---|---|
| Berlin | 104.04 | 26.04 | 78.00 | 74.7 | 9.84 | 957 | 165 |
| Munich | 104.04 | 20.25 | 83.79 | 80.5 | 12.45 | 736 | 63 |
| Mannheim | 104.04 | 47.56 | 56.48 | 54.3 | 11.08 | 839 | 329 |
| Cologne | 104.04 | 32.23 | 71.81 | 69.0 | 10.77 | 866 | 199 |
| Total | 416.16 | 126.08 | 290.08 | 70 | 44.14 | 166 | 85.6 |
| % of Total | - | 30.3 | - | - | 10.6 | - | - |
| Inference Area | Ground Truth (Num. of Soccer Fields) | Num. of Soccer Fields Detected | % |
|---|---|---|---|
| Berlin | 37 | 32 | 86.5 |
| Munich | 59 | 46 | 78.0 |
| Mannheim | 51 | 45 | 88.2 |
| Cologne | 47 | 43 | 91.5 |
| Total | 194 | 166 | 85.6 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Antoniou, V.; Potsiou, C. A Deep Learning Method to Accelerate the Disaster Response Process. Remote Sens. 2020, 12, 544. https://doi.org/10.3390/rs12030544
Antoniou V, Potsiou C. A Deep Learning Method to Accelerate the Disaster Response Process. Remote Sensing. 2020; 12(3):544. https://doi.org/10.3390/rs12030544
Chicago/Turabian StyleAntoniou, Vyron, and Chryssy Potsiou. 2020. "A Deep Learning Method to Accelerate the Disaster Response Process" Remote Sensing 12, no. 3: 544. https://doi.org/10.3390/rs12030544
APA StyleAntoniou, V., & Potsiou, C. (2020). A Deep Learning Method to Accelerate the Disaster Response Process. Remote Sensing, 12(3), 544. https://doi.org/10.3390/rs12030544