Geometry Aware Evaluation of Handcrafted Superpixel-Based Features and Convolutional Neural Networks for Land Cover Mapping Using Satellite Imagery


Abstract
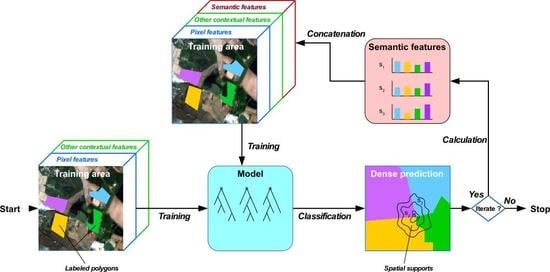
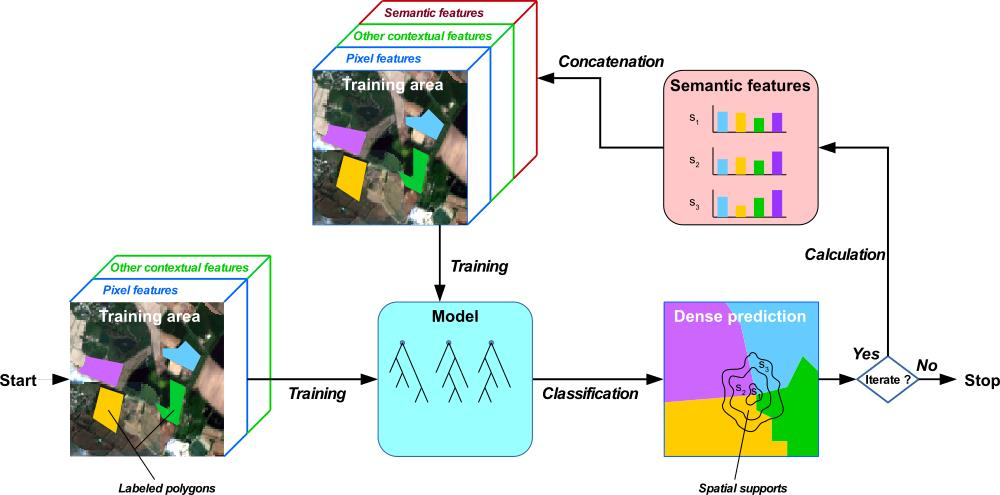
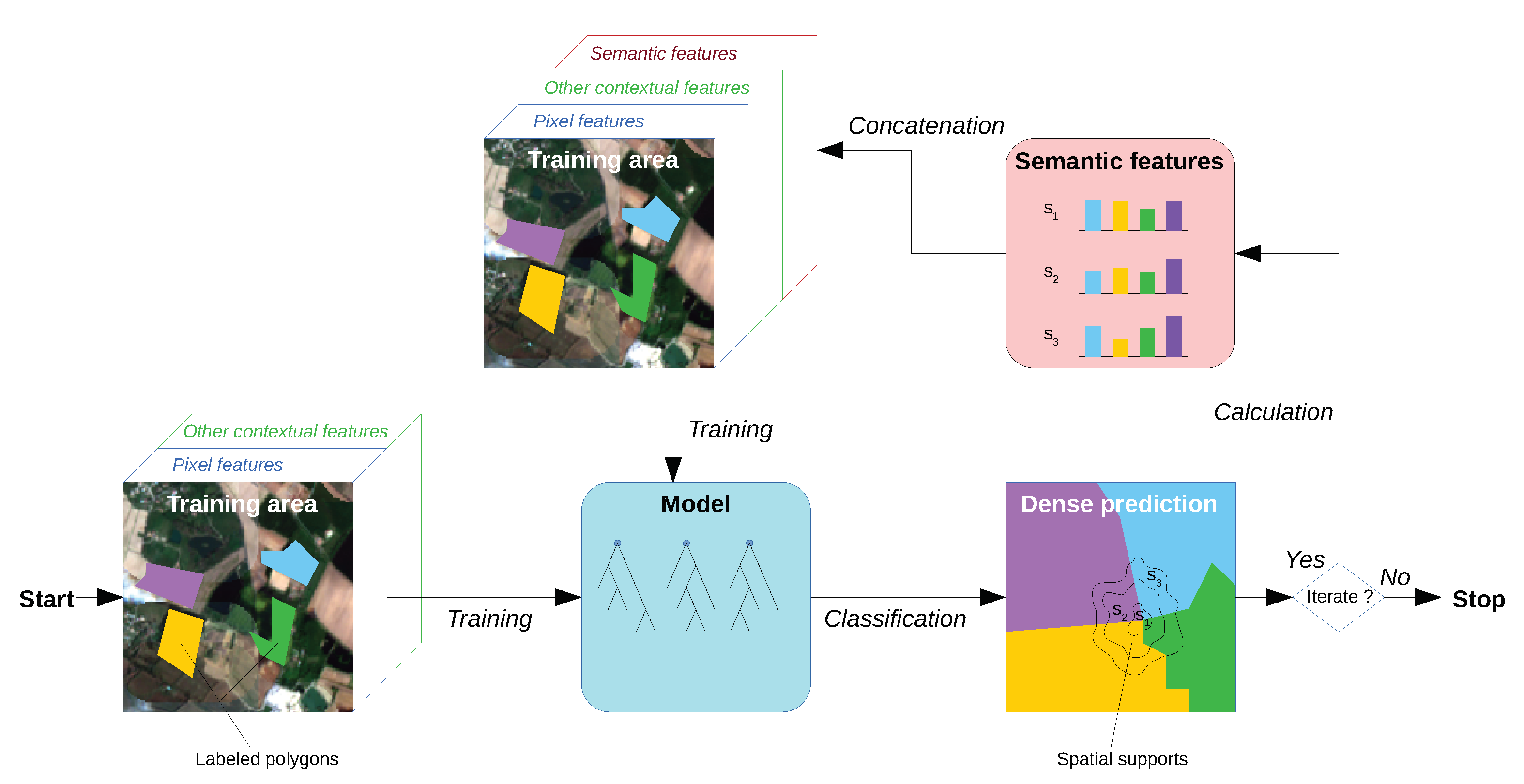
1. Introduction
2. The Histogram of Auto-Context Classes in Superpixels process
2.1. Image-Based Contextual Features
2.2. Local Class Histograms as a Contextual Feature
- The density of the initial prediction: certain methods predict the class or cluster of keypoints, whereas others use every single pixel in the image.
- Supervised or unsupervised prediction: some methods prefer the use of clustering rather than supervised classification for the initial prediction.
- The contextual features, or lack thereof, used for the initial prediction: the first prediction can be pixel-based, or can already be based on the use of pre-selected contextual descriptors.
- The number of iterations: certain methods stop at the second prediction, while others use successive predictions to improve the classification in an iterative way.
- Adaptive spatial support. The definition of the context can be a sliding window, or an adaptive spatial support.
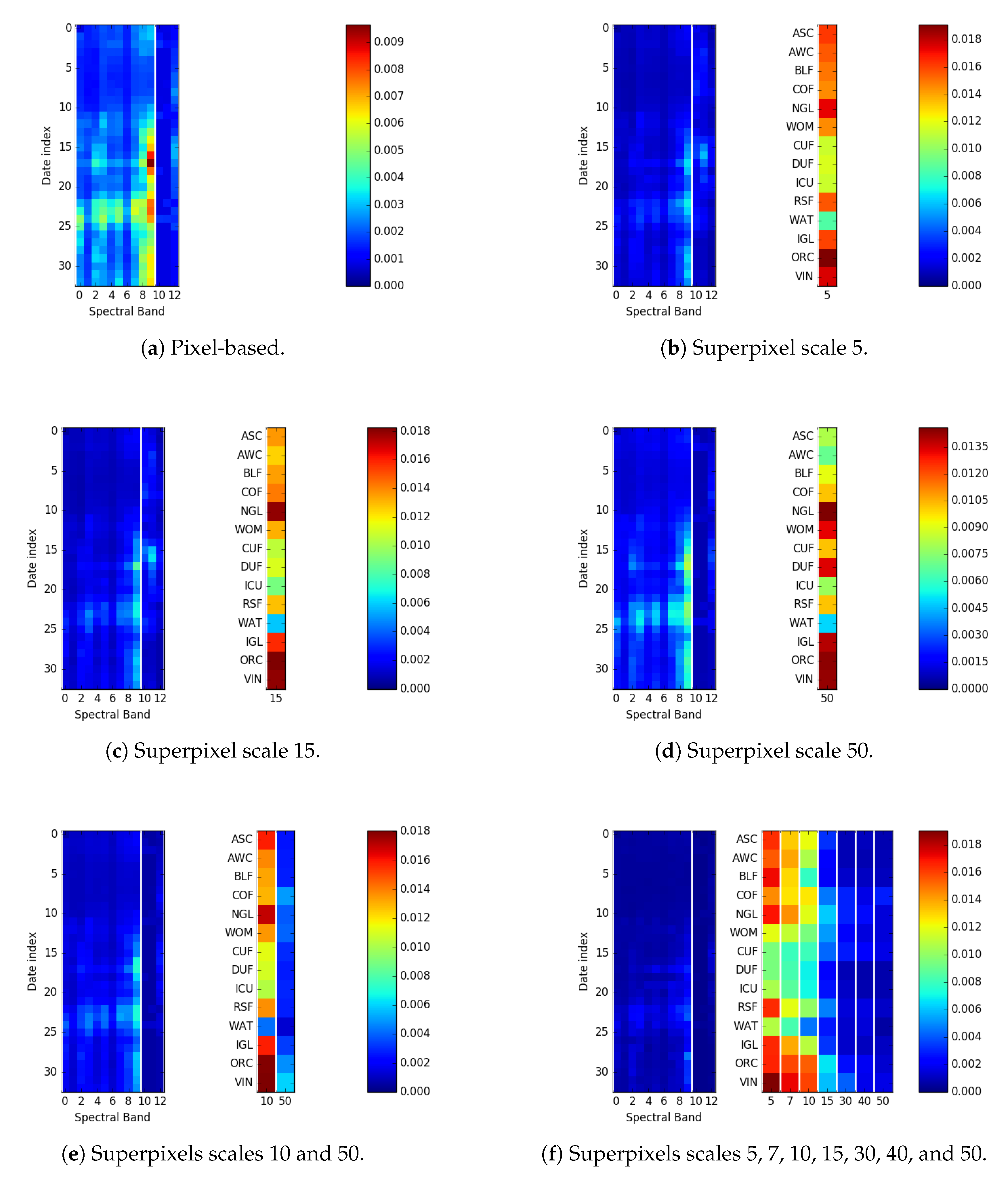
2.3. Multi-Scale Superpixels as Spatial Supports
3. Deep Convolutional Neural Networks
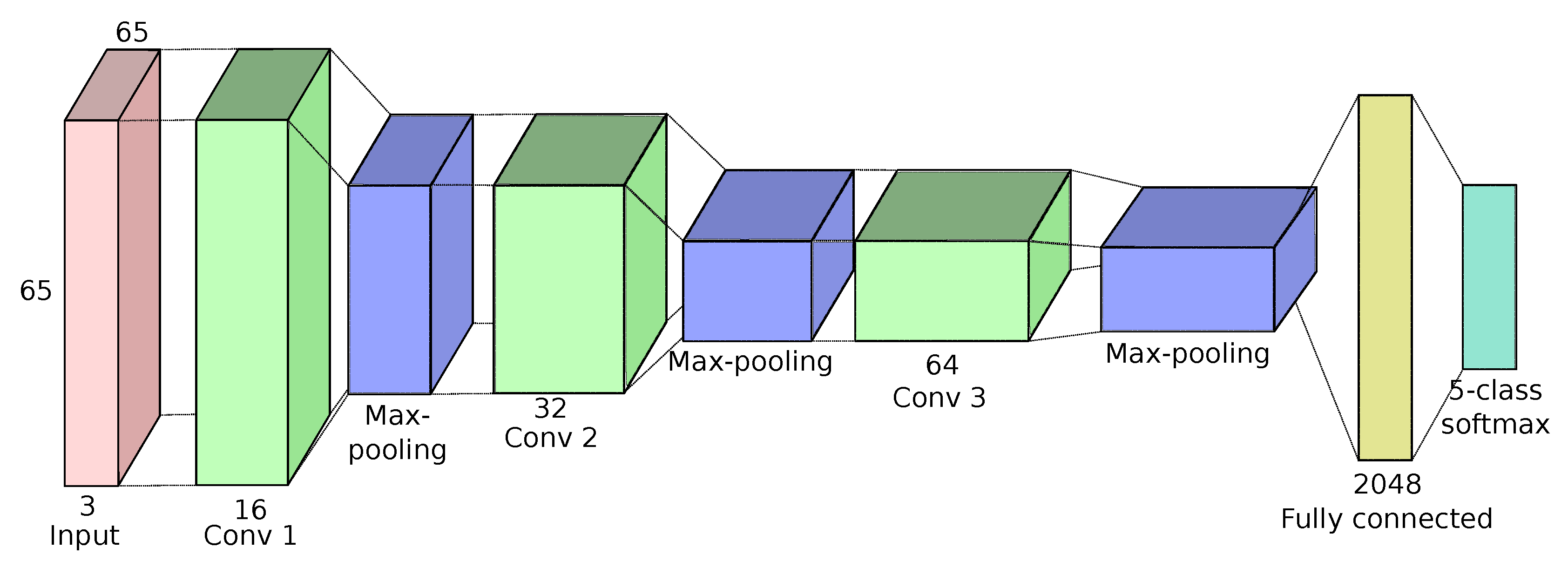
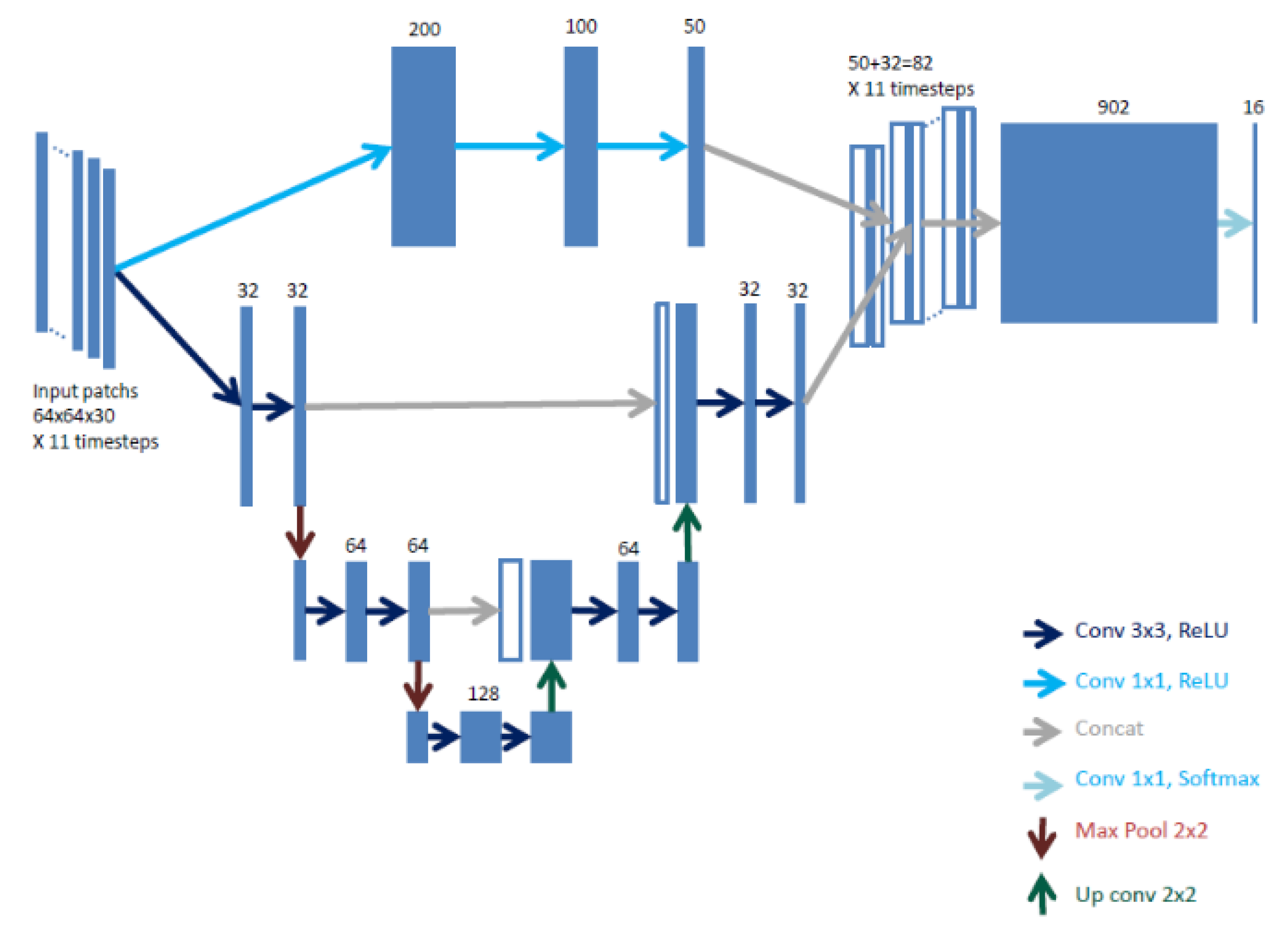
3.1. Patch-Based Network
3.2. Fully Convolutional Networks
3.3. Issues with Sparse Data
4. Experimental Results
4.1. Evaluation Metrics
4.2. Sentinel-2 Time Series Classification Problem
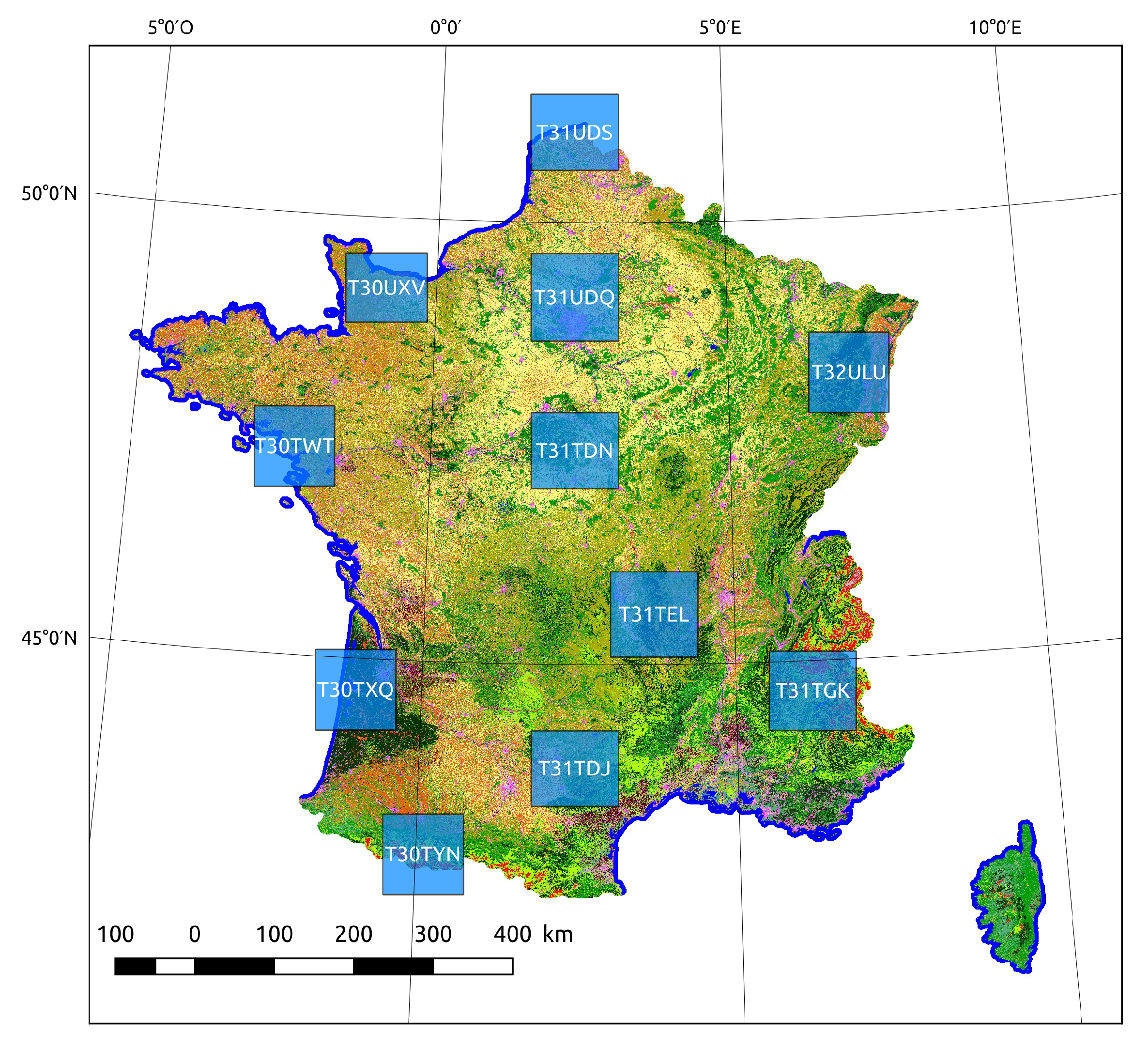
4.2.1. Description of the Sentinel-2 Data Set
- Corine Land Cover (CLC) [62] is based on manual photo-interpretation, and is updated every six years. It contains a rich description of the many land cover elements, with a nomenclature of 44 classes. This data base is used for the perennial classes: water, beaches, and bare rocks.
- Urban Atlas (UA) [63] covers all cities with over 100,000 inhabitants, and is updated every six years, like CLC. It contains 17 classes describing different levels of urban density, as well as other urban features like construction sites, sports and leisure sites. Urban Atlas is used as a reference for the four urban classes: continuous urban fabric, discontinuous urban fabric, industrial and commercial units, and road surfaces.
- National Topo Data Base (BD Topo) [64] is a regularly updated data base made by the French National Geographical Institute (IGN). The forest database describes the main woody cover classes (woody moorlands, broad-leaved and coniferous forests). The urban data base gives the outline of buildings, but does not provide an indication of the urban density.
- Graphical Parcel Registry (RPG) [65] is another product of the IGN which describes arable lands based on a graphical declaration system from the farmers. It contains an up-to-date description of the main agricultural classes.
- Randolph Glacier Inventory (RGI) [66] contains a worldwide description of the glaciers, and is updated every one or two years.The number of training samples taken for each tile is shown in Table 2. Each tile contains quite different class proportions, which implies the evaluation is performed on a variety of different situations, in order to address the particularities of some of the minority classes that are only present in certain regions.
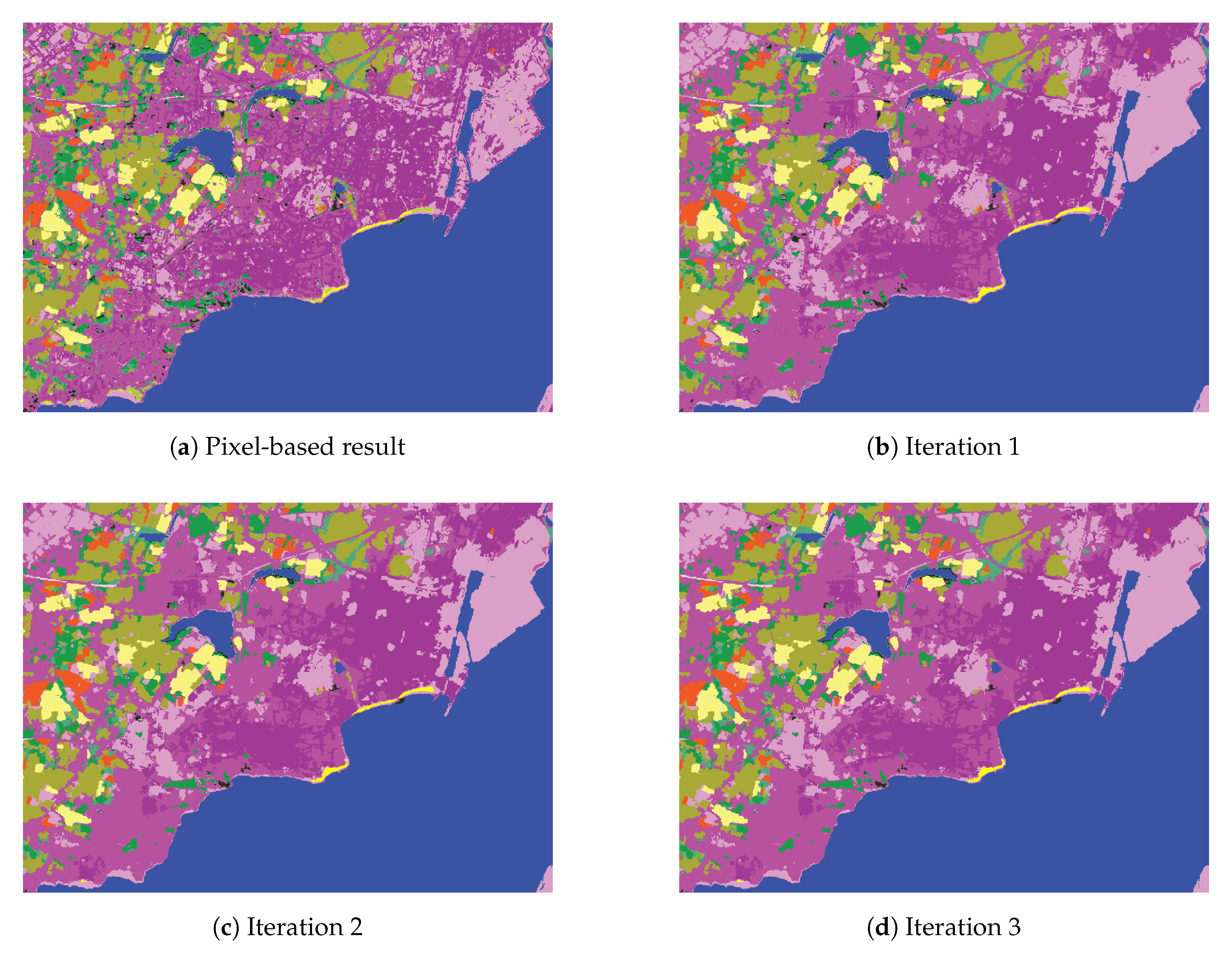
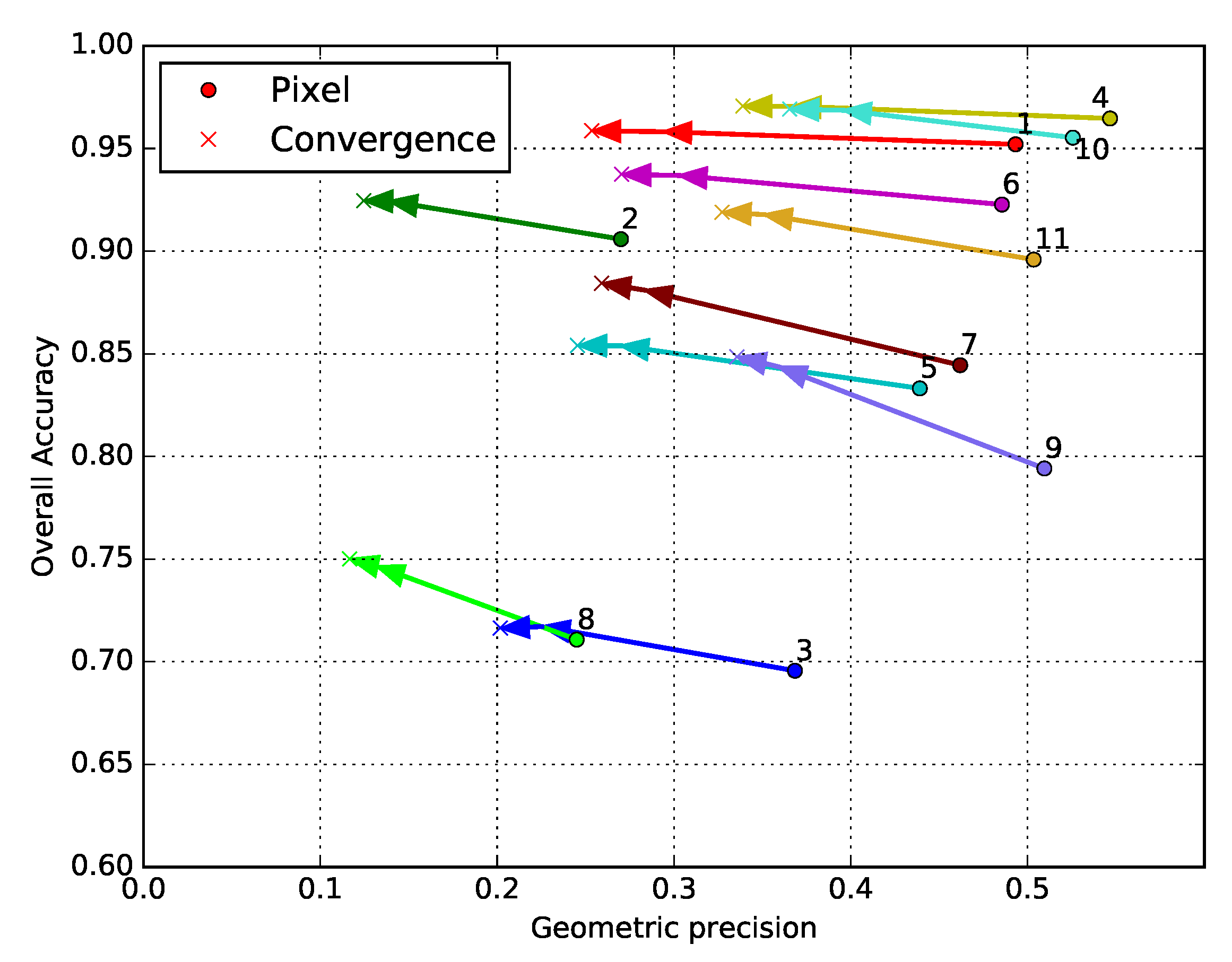
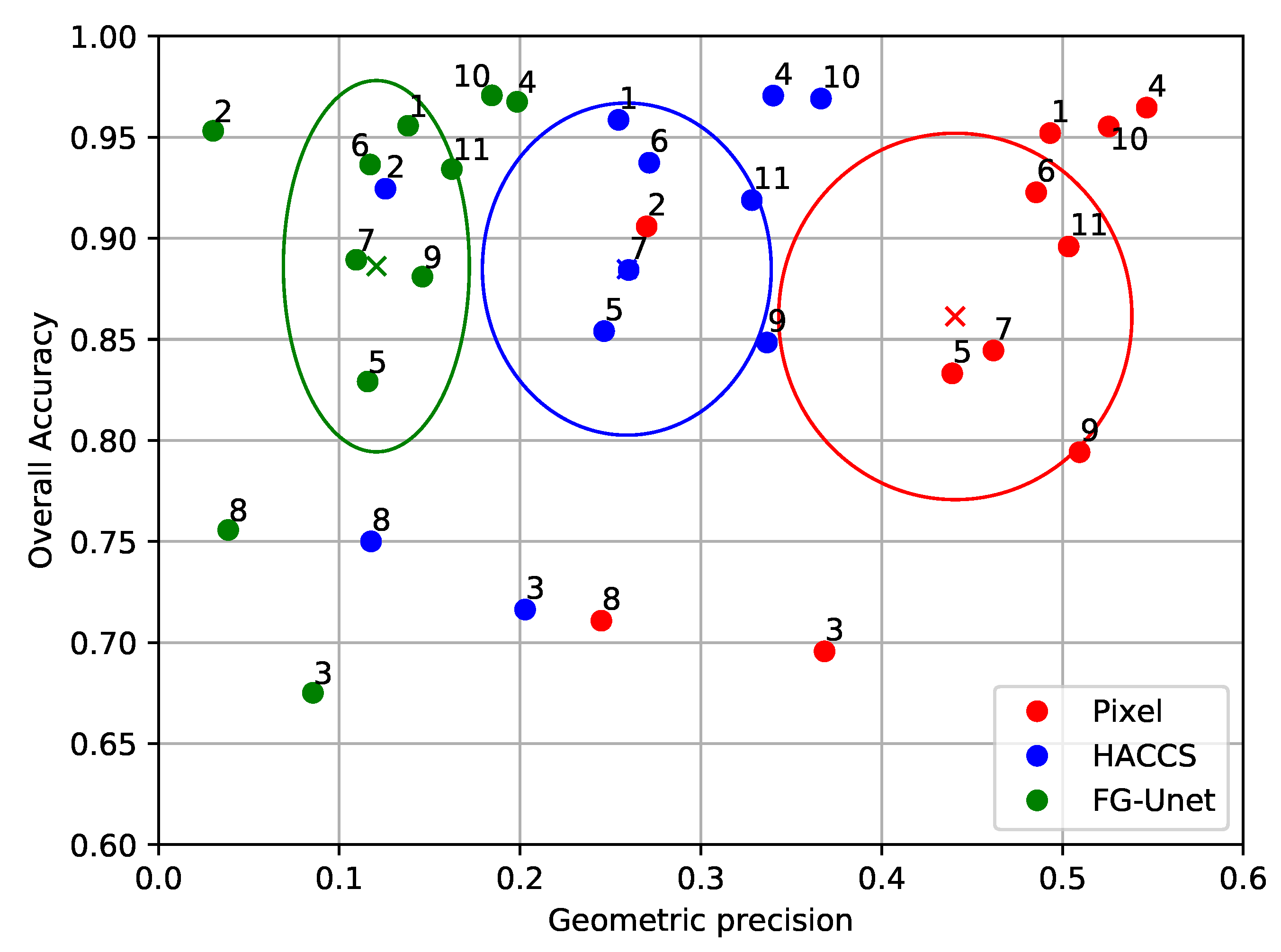
4.2.2. Results on the Sentinel-2 Problem
4.3. SPOT-7 Classification Problem
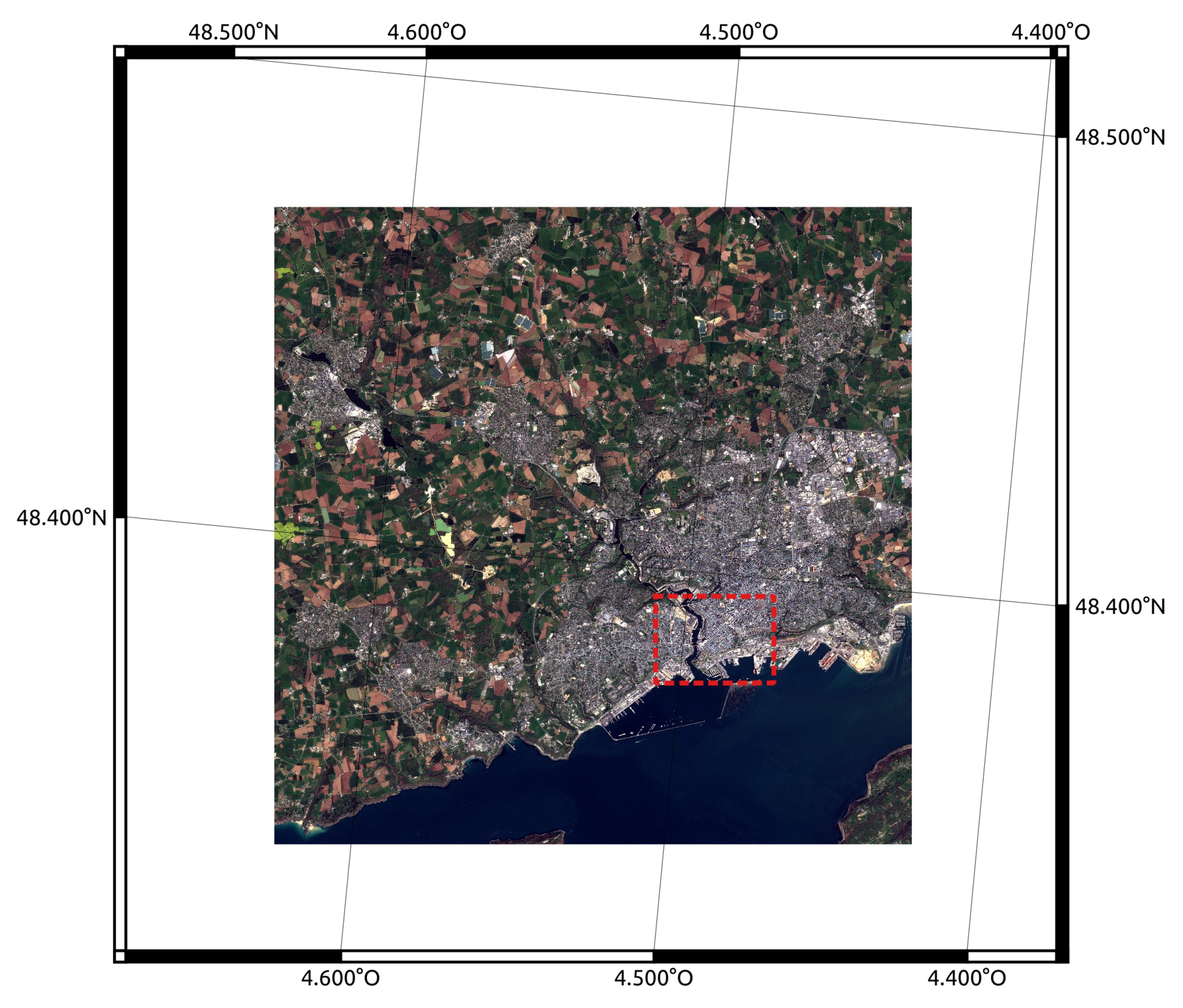
4.3.1. Description of the SPOT-7 Data Set
- The pixel-based classification. Applying HACCS here is the most basic scenario, and is essentially identical to what is done on the Sentinel-2 data set.
- The local statistic features, which in this scenario included the sample mean, variance, and edge density, defined in Section 2.1.
- The Extended Morphological Attribute Profiles (E-MAP), also defined in Section 2.1. These described context using several morphological operations on the image, with a structuring element of increasingly large size. Here, five structuring element sizes, ranging from 7 pixels to 15 pixels weare used to calculate E-MAP features using the brightness and Normalized Differential Vegetation Index (NDVI) over the area.
- The patch-based D-CNN designed by [50].
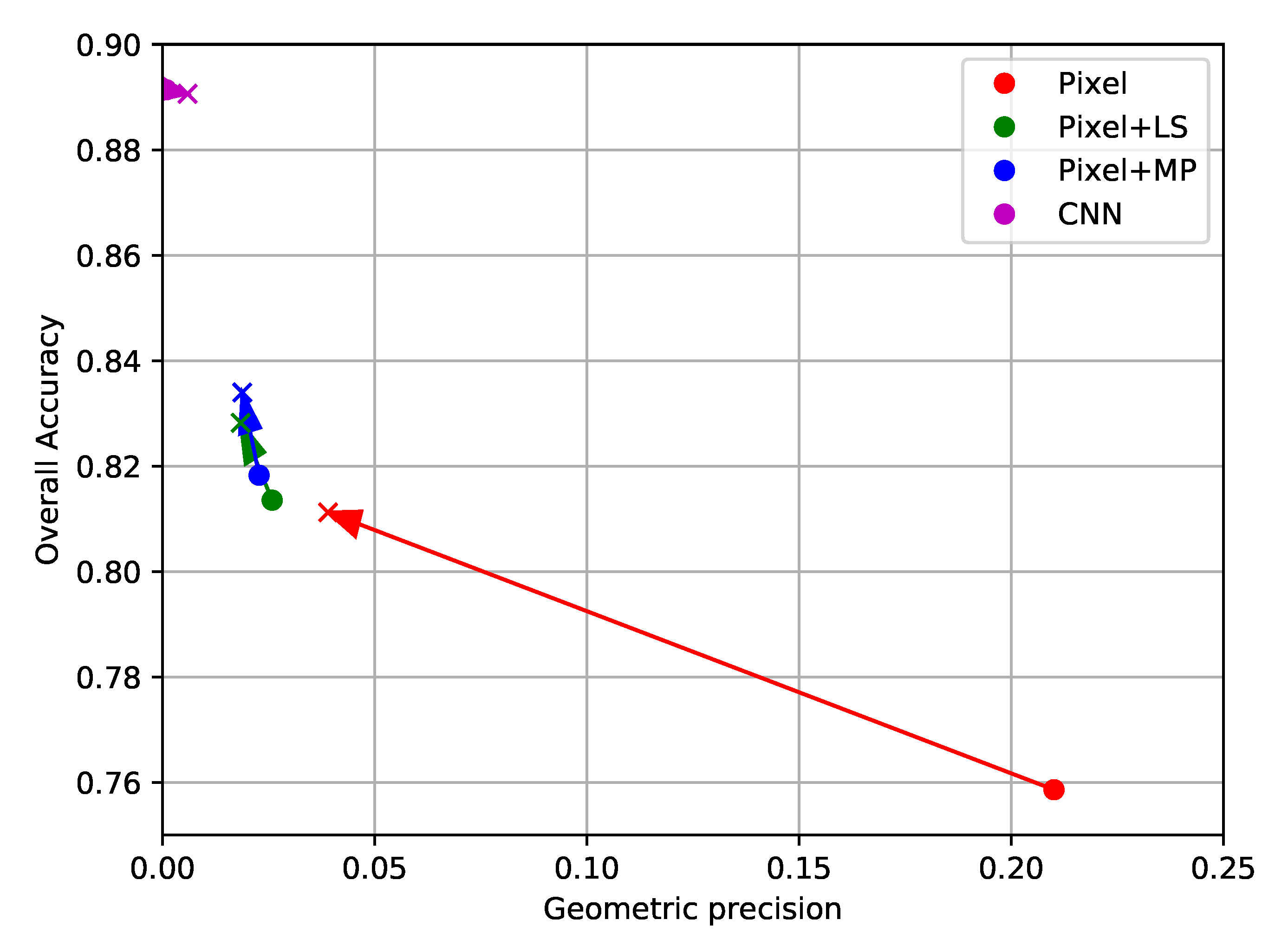
4.3.2. Results of the SPOT-7 Experiments
5. Discussion
6. Conclusions and Perspectives
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Petitjean, F.; Inglada, J.; Gançarski, P. Satellite image time series analysis under time warping. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3081–3095. [Google Scholar] [CrossRef]
- Gómez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote Sens. 2016, 116, 55–72. [Google Scholar] [CrossRef]
- Thanh Noi, P.; Kappas, M. Comparison of random forest, k-nearest neighbor, and support vector machine classifiers for land cover classification using Sentinel-2 imagery. Sensors 2018, 18, 18. [Google Scholar] [CrossRef] [PubMed]
- Griffiths, P.; Nendel, C.; Hostert, P. Intra-annual reflectance composites from Sentinel-2 and Landsat for national-scale crop and land cover mapping. Remote Sens. Environ. 2019, 220, 135–151. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Arias, M.; Tardy, B.; Morin, D.; Rodes, I. Operational high resolution land cover map production at the country scale using satellite image time series. Remote Sens. 2017, 9, 95. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Simard, P.Y.; Steinkraus, D.; Platt, J.C. Best practices for convolutional neural networks applied to visual document analysis. Icdar IEEE 2003, 3, 958. [Google Scholar]
- Chellapilla, K.; Shilman, M.; Simard, P. Optimally combining a cascade of classifiers. In Proceedings of the Recognition and Retrieval XIII International Society for Optics and Photonics, San Jose, CA, USA, 16 January 2006; Volume 6067, p. 60670Q. [Google Scholar]
- Chellapilla, K.; Puri, S.; Simard, P. High performance convolutional neural networks for document processing. In Proceedings of the Tenth International Workshop on Frontiers in Handwriting Recognition, Suvisoft, La Baule, France, 23–26 October 2006. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.J.; Vapnik, V. Support vector regression machines. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1997; pp. 155–161. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Haralick, R.M. Statistical and structural approaches to texture. Proc. IEEE 1979, 67, 786–804. [Google Scholar] [CrossRef]
- Coburn, C.; Roberts, A.C. A multiscale texture analysis procedure for improved forest stand classification. Int. J. Remote Sens. 2004, 25, 4287–4308. [Google Scholar] [CrossRef]
- Yu, Q.; Gong, P.; Clinton, N.; Biging, G.; Kelly, M.; Schirokauer, D. Object-based detailed vegetation classification with airborne high spatial resolution remote sensing imagery. Photogramm. Eng. Remote Sens. 2006, 72, 799–811. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Walker, J.; Blaschke, T. Object-based land-cover classification for the Phoenix metropolitan area: Optimization vs. transportability. Int. J. Remote Sens. 2008, 29, 2021–2040. [Google Scholar] [CrossRef]
- D’Oleire Oltmanns, S.; Marzolff, I.; Tiede, D.; Blaschke, T. Detection of gully-affected areas by applying object-based image analysis (OBIA) in the region of Taroudannt, Morocco. Remote Sens. 2014, 6, 8287–8309. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on IEEE, Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin, Germany, 2006; pp. 404–417. [Google Scholar]
- Pham, M.T.; Mercier, G.; Michel, J. PW-COG: An effective texture descriptor for VHR satellite imagery using a pointwise approach on covariance matrix of oriented gradients. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3345–3359. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- Fauvel, M.; Benediktsson, J.A.; Chanussot, J.; Sveinsson, J.R. Spectral and spatial classification of hyperspectral data using SVMs and morphological profiles. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3804–3814. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Villa, A.; Benediktsson, J.A.; Chanussot, J.; Bruzzone, L. Classification of hyperspectral images by using extended morphological attribute profiles and independent component analysis. IEEE Geosci. Remote Sens. Lett. 2010, 8, 542–546. [Google Scholar] [CrossRef]
- Song, B.; Li, J.; Dalla Mura, M.; Li, P.; Plaza, A.; Bioucas-Dias, J.M.; Benediktsson, J.A.; Chanussot, J. Remotely sensed image classification using sparse representations of morphological attribute profiles. IEEE Trans. Geosci. Remote Sens. 2014, 52, 5122–5136. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Russell, B.C.; Freeman, W.T.; Efros, A.A.; Sivic, J.; Zisserman, A. Using multiple segmentations to discover objects and their extent in image collections. In Proceedings of the 2006 Conference on IEEE Computer Society Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1605–1614. [Google Scholar]
- Larios, N.; Lin, J.; Zhang, M.; Lytle, D.; Moldenke, A.; Shapiro, L.; Dietterich, T. Stacked spatial-pyramid kernel: An object-class recognition method to combine scores from random trees. In Proceedings of the 2011 IEEE Workshop on Applications of Computer Vision (WACV), Kona, HI, USA, 5–7 January 2011; pp. 329–335. [Google Scholar]
- Moser, G.; Serpico, S.B. Combining support vector machines and Markov random fields in an integrated framework for contextual image classification. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2734–2752. [Google Scholar] [CrossRef]
- Zhao, J.; Zhong, Y.; Shu, H.; Zhang, L. High-Resolution Image Classification Integrating Spectral-Spatial- Location Cues by Conditional Random Fields. IEEE Trans. Image Process. 2016, 25, 4033–4045. [Google Scholar] [CrossRef] [PubMed]
- Shotton, J.; Johnson, M.; Cipolla, R. Semantic texton forests for image categorization and segmentation. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Fröhlich, B.; Rodner, E.; Denzler, J. Semantic segmentation with millions of features: Integrating multiple cues in a combined random forest approach. In Asian Conference on Computer Vision; Springer: Berlin, Germany, 2012; pp. 218–231. [Google Scholar]
- Tu, Z. Auto-context and its application to high-level vision tasks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2008, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Tu, Z.; Bai, X. Auto-context and its application to high-level vision tasks and 3d brain image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1744–1757. [Google Scholar] [PubMed]
- Jiang, J.; Tu, Z. Efficient scale space auto-context for image segmentation and labeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2009, Miami, FL, USA, 20–25 June 2009; pp. 1810–1817. [Google Scholar]
- Fröhlich, B.; Bach, E.; Walde, I.; Hese, S.; Schmullius, C.; Denzler, J. Land cover classification of satellite images using contextual information. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 3, W1. [Google Scholar] [CrossRef]
- Jampani, V.; Gadde, R.; Gehler, P.V. Efficient facade segmentation using auto-context. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2015; pp. 1038–1045. [Google Scholar]
- Huynh, T.; Gao, Y.; Kang, J.; Wang, L.; Zhang, P.; Lian, J.; Shen, D. Estimating CT image from MRI data using structured random forest and auto-context model. IEEE Trans. Med. Imaging 2016, 35, 174. [Google Scholar] [CrossRef] [PubMed]
- Munoz, D.; Bagnell, J.A.; Hebert, M. Stacked hierarchical labeling. In European Conference on Computer Vision; Springer: Berlin, Germany, 2010; pp. 57–70. [Google Scholar]
- Derksen, D.; Inglada, J.; Michel, J. A Metric for Evaluating the Geometric Quality of Land Cover Maps Generated with Contextual Features from High-Dimensional Satellite Image Time Series without Dense Reference Data. Remote Sens. 2019, 11, 1929. [Google Scholar] [CrossRef]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Baatz, M. Multiresolution segmentation: An optimization approach for high quality multi-scale image segmentation. In Proceedings of the Angewandte Geographische Informationsverarbeitung, Salzburg, Germany, 5–7 June 2000; pp. 12–23. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef]
- Derksen, D.; Inglada, J.; Michel, J. Scaling Up SLIC Superpixels Using a Tile-Based Approach. IEEE Trans. Geosci. Remote Sens. 2019, 1–13. [Google Scholar] [CrossRef]
- Penatti, O.A.; Nogueira, K.; dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep learning earth observation classification using ImageNet pretrained networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 105–109. [Google Scholar] [CrossRef]
- Postadjian, T.; Le Bris, A.; Sahbi, H.; Mallet, C. Investigating the Potential of Deep Neural Networks for Large-Scale Classification of Very High Resolution Satellite Images. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 183–190. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv 2015, arXiv:1511.00561. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin, Germany, 2015; pp. 234–241. [Google Scholar]
- Stoian, A.; Poulain, V.; Inglada, J.; Poughon, V.; Derksen, D. Land Cover Maps Production with High Resolution Satellite Image Time Series and Convolutional Neural Networks: Adaptations and Limits for Operational Systems. Remote Sens. 2019, 11, 1986. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Semantic segmentation of earth observation data using multimodal and multi-scale deep networks. In Asian Conference on Computer Vision; Springer: Berlin, Germany, 2016; pp. 180–196. [Google Scholar]
- Hoover, A.; Jean-Baptiste, G.; Jiang, X.; Flynn, P.J.; Bunke, H.; Goldgof, D.B.; Bowyer, K.; Eggert, D.W.; Fitzgibbon, A.; Fisher, R.B. An experimental comparison of range image segmentation algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 673–689. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Bruzzone, L.; Carlin, L. A multilevel context-based system for classification of very high spatial resolution images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2587–2600. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L.; Li, P. A multiscale feature fusion approach for classification of very high resolution satellite imagery based on wavelet transform. Int. J. Remote Sens. 2008, 29, 5923–5941. [Google Scholar] [CrossRef]
- Bossard, M.; Feranec, J.; Otahel, J. CORINE Land Cover Technical Guide: Addendum 2000; European Environment Agency: Copenhagen, Denmark, 2000. [Google Scholar]
- Montero, E.; Van Wolvelaer, J.; Garzón, A. The European urban atlas. In Land Use and Land Cover Mapping in Europe; Springer: Berlin, Germany, 2014; pp. 115–124. [Google Scholar]
- Maugeais, E.; Lecordix, F.; Halbecq, X.; Braun, A. Dérivation cartographique multi échelles de la BDTopo de l’IGN France: Mise en œuvre du processus de production de la Nouvelle Carte de Base. In Proceedings of the 25th International Cartographic Conference, Paris, France, 3–8 July 2011; pp. 3–8. [Google Scholar]
- Cantelaube, P.; Carles, M. Le registre parcellaire graphique: Des données géographiques pour décrire la couverture du sol agricole. In Le Cahier des Techniques de l’INRA; 2014; pp. 58–64. Available online: https://www6.inrae.fr/cahier_des_techniques/content/download/3813/34098/version/2/file/12_CH2_CANTELAUBE_registre_parcellaire.pdf (accessed on 2 February 2020).
- Pfeffer, W.T.; Arendt, A.A.; Bliss, A.; Bolch, T.; Cogley, J.G.; Gardner, A.S.; Hagen, J.O.; Hock, R.; Kaser, G.; Kienholz, C.; et al. The Randolph Glacier Inventory: A globally complete inventory of glaciers. J. Glaciol. 2014, 60, 537–552. [Google Scholar] [CrossRef]
- Trias Sanz, R. Semi-Automatic Rural Land Cover Classification. Ph.D. Thesis, Université Paris 5, Paris, France, 2006. [Google Scholar]
- Derksen, D. Source Code of Histogram of Auto-Context Classes. 2019. Available online: https://github.com/derksend/histogram-auto-context (accessed on 9 August 2019).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Dense | Supervised | Initial Context | Iterative | Adaptive |
|---|---|---|---|---|---|
| CRF [32] | X | X | X | ||
| BoVW [29] | X | ||||
| Stacked [42] | X | X | X | X (object) | |
| Stacked [31] | X | X | X | ||
| STF [35] | X | X | X | X (object) | |
| STF [34] | X | X | X | ||
| Auto-Context [36] | X | X | X | X | |
| HACCS | X | X | optional | X | X (superpixel) |
| Name | T30TWT | T30TXQ | T30TYN | T30UXV | T31TDJ | T31TDN | T31TEL | T31TGK | T31UDQ | T31UDS | T32ULU |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Index | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| ASC | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 2576 | 15,000 | 15,000 | 15,000 |
| AWC | 15,000 | 2484 | 9271 | 15,000 | 15,000 | 15,000 | 15,000 | 14,149 | 15,000 | 15,000 | 15,000 |
| BLF | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 |
| COF | 15,000 | 15,000 | 15,000 | 14,575 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 1541 | 15,000 |
| NGL | 6496 | 0 | 15,000 | 0 | 15,000 | 732 | 15,000 | 15,000 | 1220 | 1377 | 15,000 |
| WML | 15,000 | 15,000 | 15,000 | 7975 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 8468 | 8641 |
| CUF | 12,262 | 15,000 | 3271 | 14,154 | 1841 | 2247 | 15,000 | 373 | 15,000 | 15,000 | 15,000 |
| DUF | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 13,739 | 15,000 | 15,000 | 15,000 |
| ICU | 15,000 | 15,000 | 14,706 | 15,000 | 15,000 | 15,000 | 15,000 | 5679 | 15,000 | 15,000 | 15,000 |
| RSF | 3761 | 15,000 | 1674 | 2307 | 1029 | 2803 | 15,000 | 1214 | 15,000 | 12,900 | 9203 |
| BRO | 0 | 0 | 15,000 | 406 | 0 | 0 | 80 | 15,000 | 0 | 0 | 0 |
| BDS | 3729 | 15,000 | 0 | 3811 | 0 | 1687 | 0 | 14,315 | 0 | 3778 | 0 |
| WAT | 15,000 | 15,000 | 12,511 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 |
| GPS | 0 | 0 | 1978 | 0 | 0 | 0 | 0 | 15,000 | 0 | 0 | 0 |
| IGL | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 | 15,000 |
| ORC | 1499 | 345 | 37 | 2205 | 2171 | 809 | 202 | 6122 | 4935 | 578 | 695 |
| VIN | 4406 | 15,000 | 89 | 0 | 15,000 | 2784 | 917 | 78 | 0 | 0 | 3433 |
| Name | T30TWT | T30TXQ | T30TYN | T30UXV | T31TDJ | T31TDN | T31TEL | T31TGK | T31UDQ | T31UDS | T32ULU |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Index | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| ASC | 186,084 | 112,870 | 39,577 | 111,140 | 61,063 | 66,908 | 127,364 | 2576 | 109,349 | 32,778 | 114,279 |
| AWC | 170,839 | 2484 | 9271 | 169,424 | 132,590 | 368,659 | 186,646 | 14,149 | 1,079,411 | 151,941 | 74,096 |
| BLF | 65,003 | 92,320 | 137,546 | 47,169 | 143,008 | 438,458 | 352,358 | 143,659 | 429,562 | 56,820 | 296,402 |
| COF | 86,055 | 3,406,794 | 123,960 | 14,575 | 209,091 | 99,486 | 1,571,267 | 864,432 | 102,111 | 1541 | 985,948 |
| NGL | 6496 | 0 | 335,427 | 0 | 58,593 | 732 | 31,962 | 825,736 | 1220 | 1377 | 24,063 |
| WML | 112,019 | 102,667 | 184,257 | 7975 | 64,156 | 20,671 | 111,814 | 307,237 | 27488 | 8468 | 8641 |
| CUF | 12,262 | 34,133 | 3271 | 14,154 | 1841 | 2247 | 39,067 | 373 | 287,388 | 15,081 | 15,947 |
| DUF | 197,925 | 368,733 | 25,559 | 50,932 | 25,543 | 31,550 | 233,471 | 13,739 | 1,035,603 | 82,494 | 107,867 |
| ICU | 178,134 | 281,722 | 14,706 | 50,771 | 20,237 | 39,447 | 148,008 | 5679 | 841,308 | 108,103 | 79574 |
| RSF | 3761 | 22,572 | 1674 | 2307 | 1029 | 2803 | 19,327 | 1214 | 67,095 | 12,900 | 9203 |
| BRO | 0 | 0 | 231,491 | 406 | 0 | 0 | 80 | 77,756 | 0 | 0 | 0 |
| BDS | 3729 | 112,848 | 0 | 3811 | 0 | 1687 | 0 | 14,315 | 0 | 3778 | 0 |
| WAT | 4,650,221 | 6,458,981 | 12,511 | 1,959,898 | 58,971 | 80,282 | 46,231 | 34,065 | 84,697 | 1,894,379 | 44,049 |
| GPS | 0 | 0 | 1978 | 0 | 0 | 0 | 0 | 54,664 | 0 | 0 | 0 |
| IGL | 249,625 | 22,112 | 109,417 | 301,560 | 87,286 | 89,923 | 761,126 | 117,134 | 150,013 | 40,845 | 156,124 |
| ORC | 1499 | 345 | 37 | 2205 | 2171 | 809 | 202 | 6122 | 4935 | 578 | 695 |
| VIN | 4406 | 52,594 | 89 | 0 | 17,135 | 2784 | 917 | 78 | 0 | 0 | 3433 |
| Method | Pixel | HACCS | FG-Unet (CNN) |
|---|---|---|---|
| Average OA | 86.1% ± 0.12 | 88.5% ± 0.17 | 88.6% |
| Average Kappa | 80.6% ± 0.17 | 83.9% ± 0.23 | 84.2% |
| Average PBCM | 44.2% ± 0.24 | 26.1% ± 0.31 | 11.8% |
| Summer crop (ASC) | 0.929 | 0.940 | 0.926 |
| Winter crop (AWC) | 0.903 | 0.899 | 0.893 |
| Broad-leaved Forest (BLF) | 0.843 | 0.879 | 0.882 |
| Coniferous Forest (COF) | 0.868 | 0.899 | 0.843 |
| Nat. Grasslands (NGL) | 0.321 | 0.332 | 0.244 |
| Woody Moorlands (WML) | 0.423 | 0.469 | 0.461 |
| Cont. Urban (CUF) | 0.330 | 0.463 | 0.499 |
| Disc. Urban (DUF) | 0.713 | 0.798 | 0.835 |
| I.C. Units (ICU) | 0.556 | 0.671 | 0.660 |
| Road surfaces (RSF) | 0.509 | 0.648 | 0.666 |
| Bare Rock (BRO) | 0.430 | 0.448 | 0.423 |
| Beaches, dunes (BDS) | 0.469 | 0.551 | 0.606 |
| Water bodies (WAT) | 0.959 | 0.954 | 0.946 |
| Glaciers, snow (GPS) | 0.517 | 0.516 | 0.718 |
| Intensive Grassland (IGL) | 0.768 | 0.794 | 0.761 |
| Orchards (ORC) | 0.189 | 0.249 | 0.214 |
| Vineyards (VIN) | 0.464 | 0.579 | 0.494 |
| Method | Training Time/CPU |
|---|---|
| RF | ≈25 h |
| HACCS (three iterations) | ≈80 h |
| FG-Unet | ≈3300 h |
| Method Name | OA (%) | Kappa (%) | PBCM (%) | Urban | Crop | Water | Road | Veg. |
|---|---|---|---|---|---|---|---|---|
| Pixel | 75.86 ± 0.15 | 69.82 ± 0.19 | 21.01 ± 1.49 | 66.62 | 83.55 | 86.51 | 67.50 | 75.81 |
| Pixel + HACCS | 81.12 ± 0.16 | 76.40 ± 0.21 | 3.90 ± 0.55 | 74.96 | 88.00 | 91.48 | 69.35 | 81.86 |
| Pixel + LS | 81.35 ± 0.10 | 76.69 ± 0.12 | 2.58 ± 0.47 | 76.15 | 88.92 | 89.79 | 69.89 | 82.61 |
| Pixel + LS + HACCS | 82.82 ± 0.10 | 78.52 ± 0.12 | 1.84 ± 0.22 | 76.96 | 90.12 | 91.80 | 70.70 | 84.57 |
| Pixel + E-MAP | 81.82 ± 0.14 | 77.28 ± 0.18 | 2.28 ± 0.52 | 77.05 | 88.68 | 90.35 | 70.87 | 82.84 |
| Pixel + E-MAP + HACCS | 83.39 ± 0.10 | 79.24 ± 0.13 | 1.88 ± 0.18 | 78.21 | 90.01 | 91.75 | 72.22 | 84.98 |
| CNN | 89.13 ± 0.06 | 86.42 ± 0.07 | 0.09 ± 0.04 | 86.22 | 93.20 | 96.13 | 81.32 | 88.59 |
| CNN + HACCS | 89.06 ± 0.09 | 86.32 ± 0.11 | 0.59 ± 0.08 | 85.74 | 93.62 | 95.89 | 80.80 | 89.07 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Derksen, D.; Inglada, J.; Michel, J. Geometry Aware Evaluation of Handcrafted Superpixel-Based Features and Convolutional Neural Networks for Land Cover Mapping Using Satellite Imagery. Remote Sens. 2020, 12, 513. https://doi.org/10.3390/rs12030513
Derksen D, Inglada J, Michel J. Geometry Aware Evaluation of Handcrafted Superpixel-Based Features and Convolutional Neural Networks for Land Cover Mapping Using Satellite Imagery. Remote Sensing. 2020; 12(3):513. https://doi.org/10.3390/rs12030513
Chicago/Turabian StyleDerksen, Dawa, Jordi Inglada, and Julien Michel. 2020. "Geometry Aware Evaluation of Handcrafted Superpixel-Based Features and Convolutional Neural Networks for Land Cover Mapping Using Satellite Imagery" Remote Sensing 12, no. 3: 513. https://doi.org/10.3390/rs12030513
APA StyleDerksen, D., Inglada, J., & Michel, J. (2020). Geometry Aware Evaluation of Handcrafted Superpixel-Based Features and Convolutional Neural Networks for Land Cover Mapping Using Satellite Imagery. Remote Sensing, 12(3), 513. https://doi.org/10.3390/rs12030513