Characterizing Uncertainty in Forest Remote Sensing Studies



Abstract
1. Introduction
2. Methods
2.1. Conventionally Used Performance Metrics
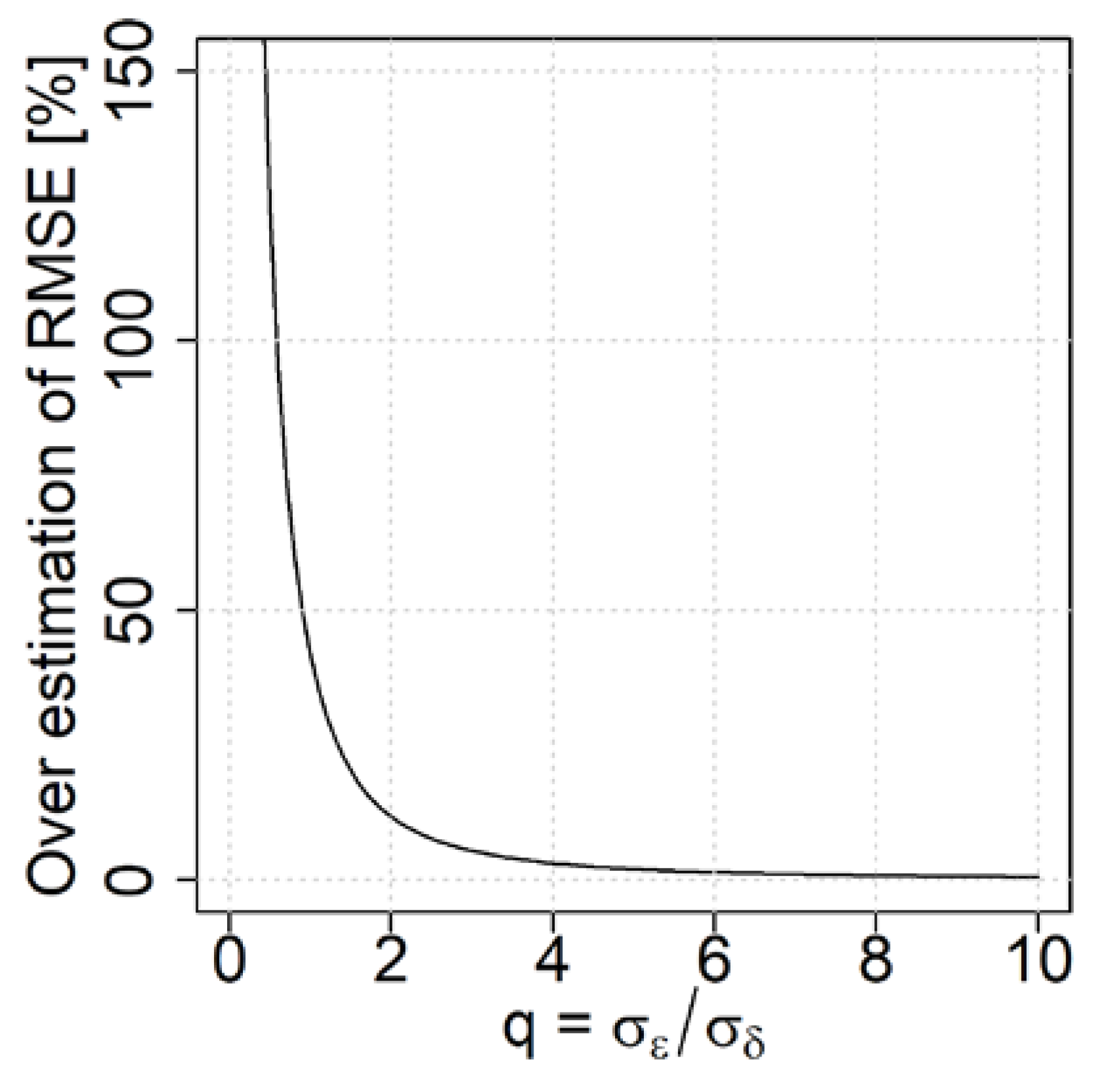
2.2. Parametric Error Model
2.3. Modeling Field Reference Data
2.3.1. Special Case:
2.3.2. General Case:
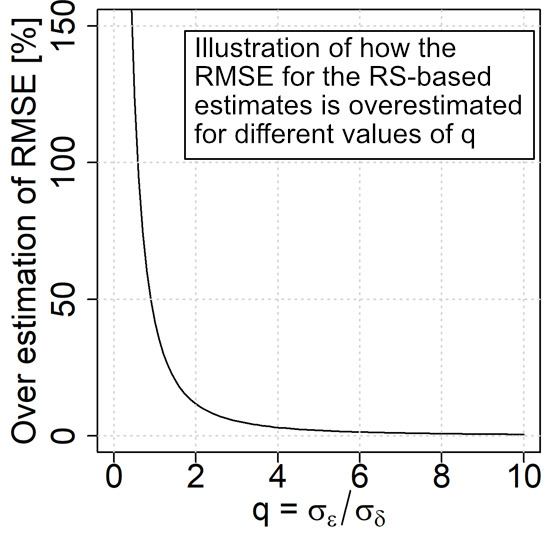
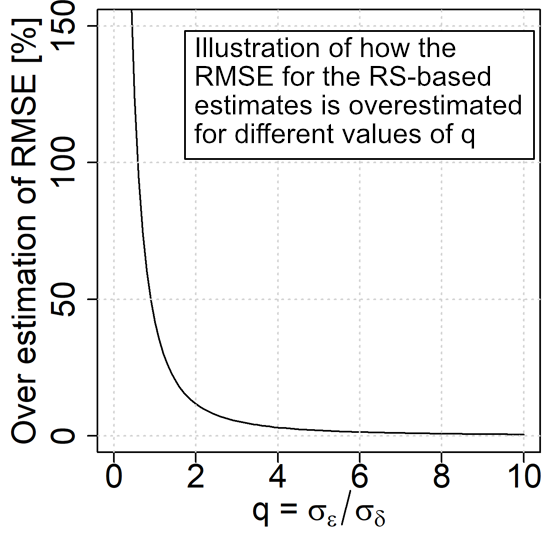
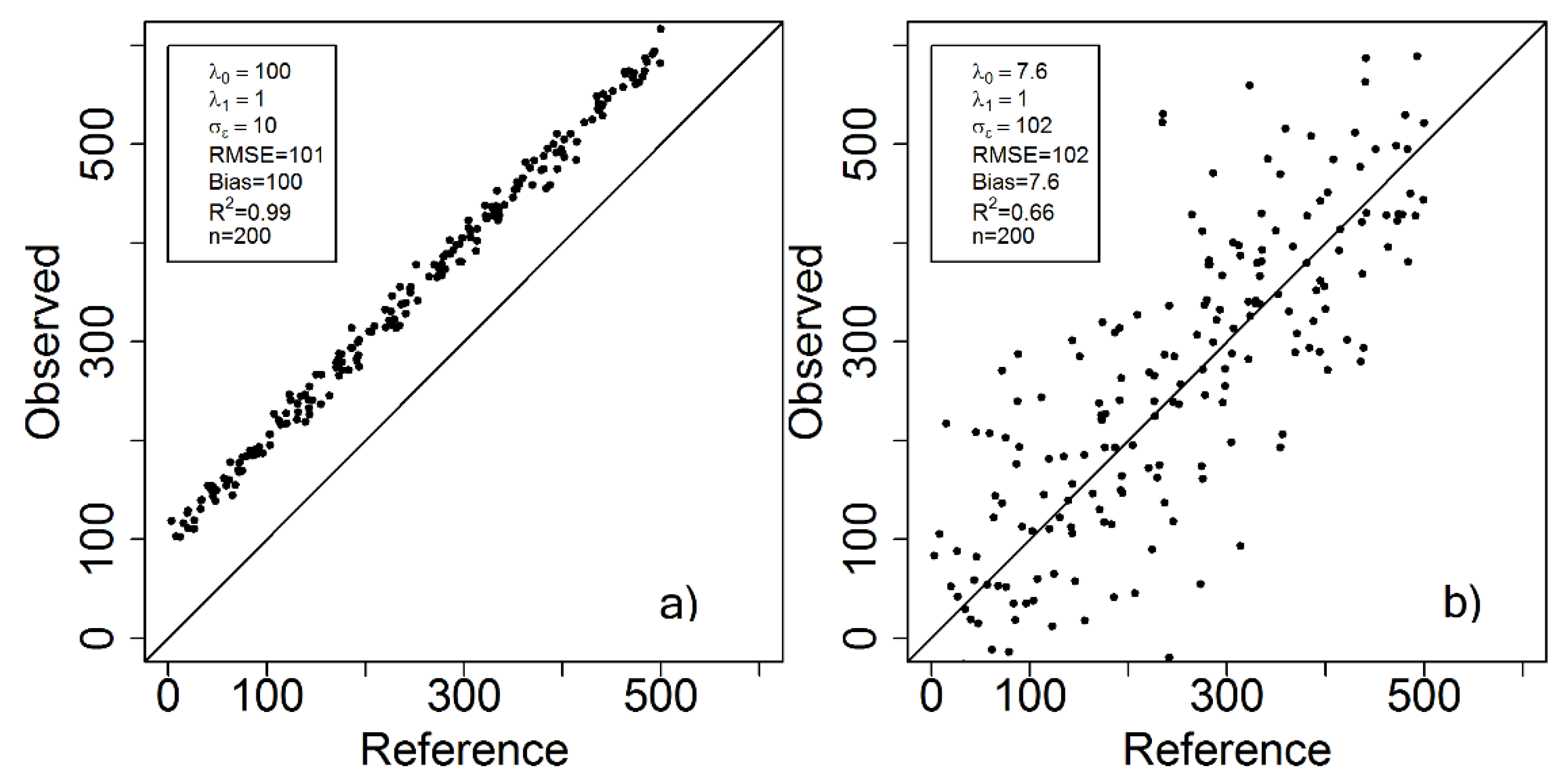
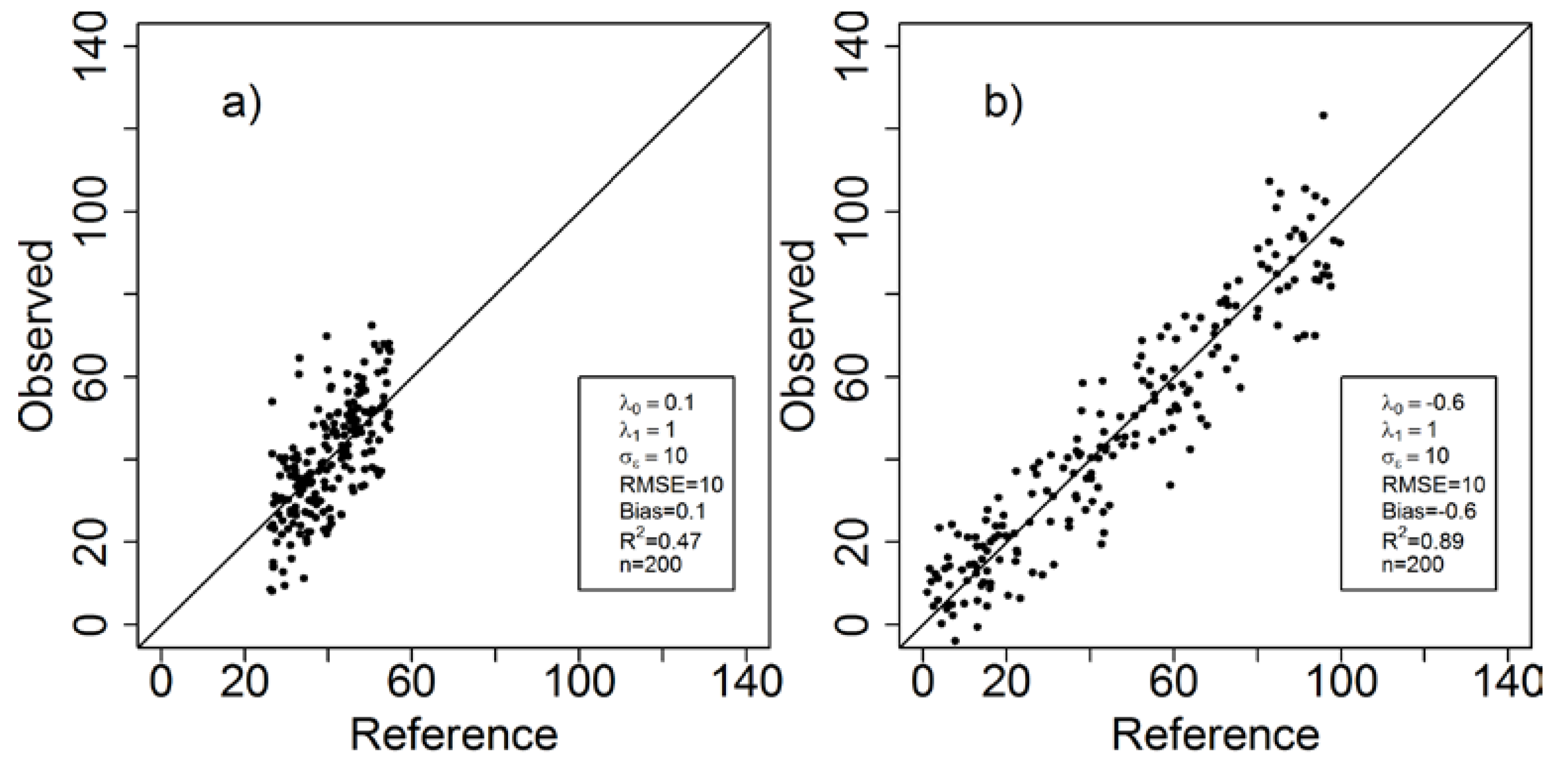
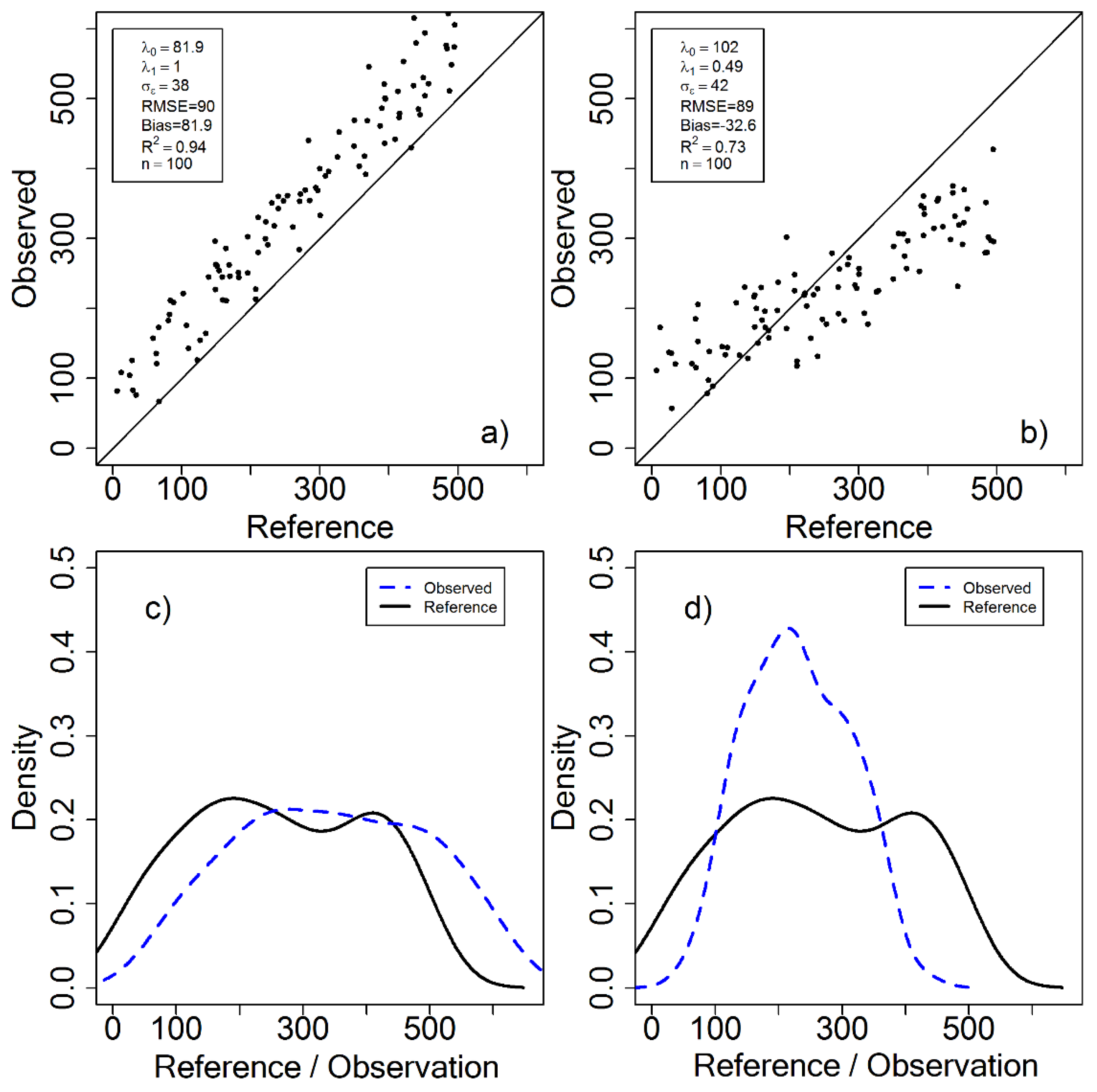
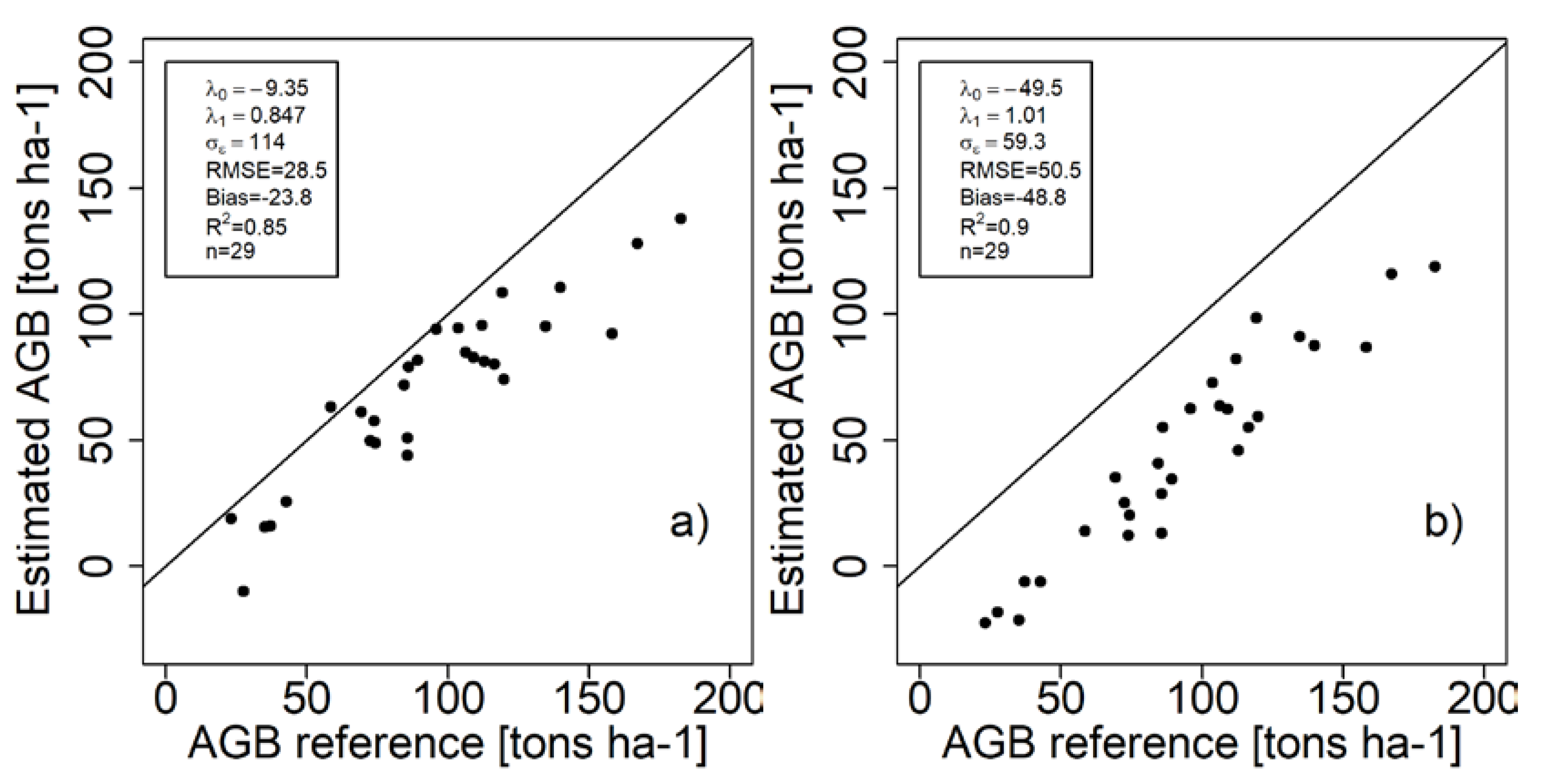
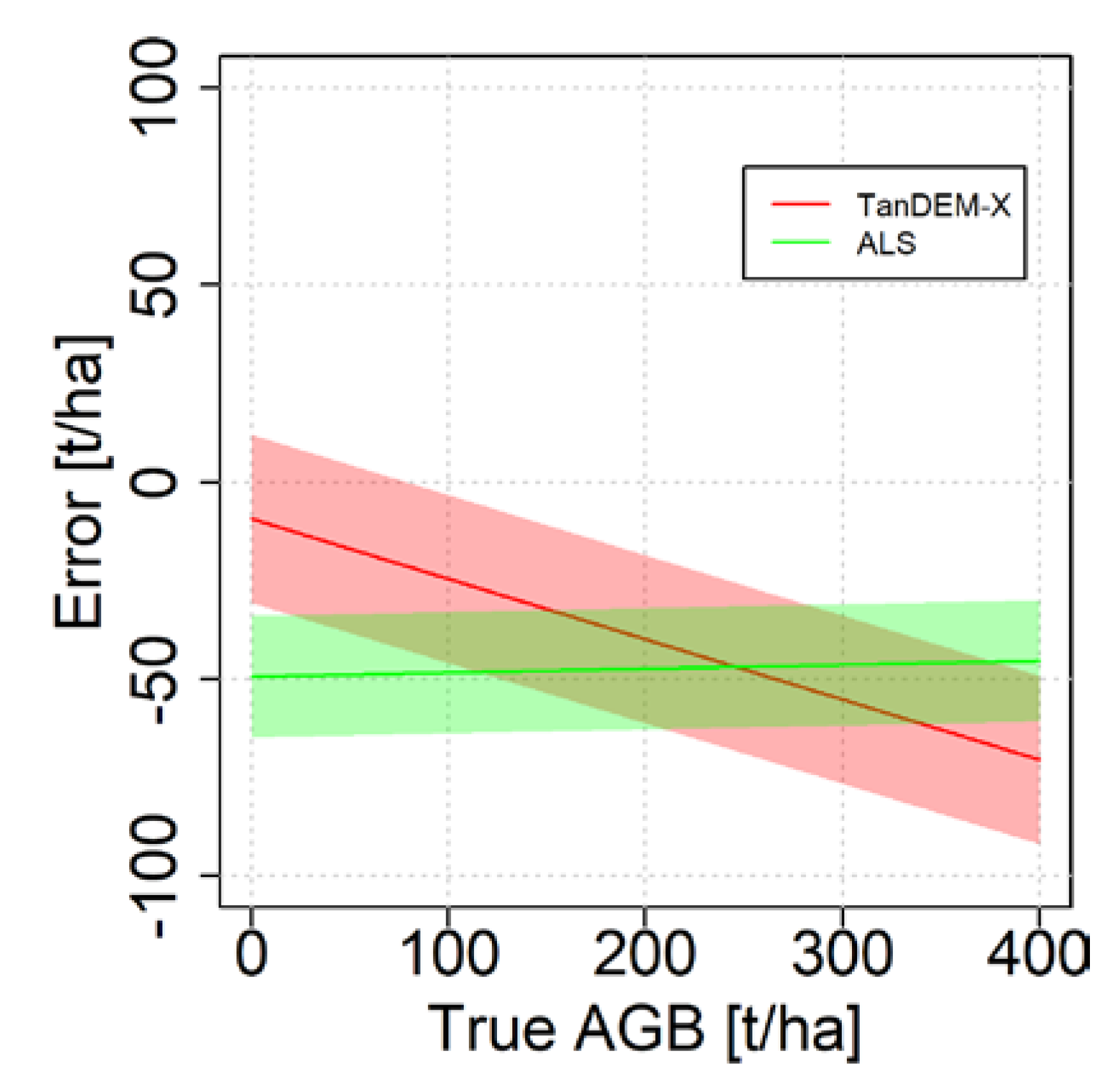
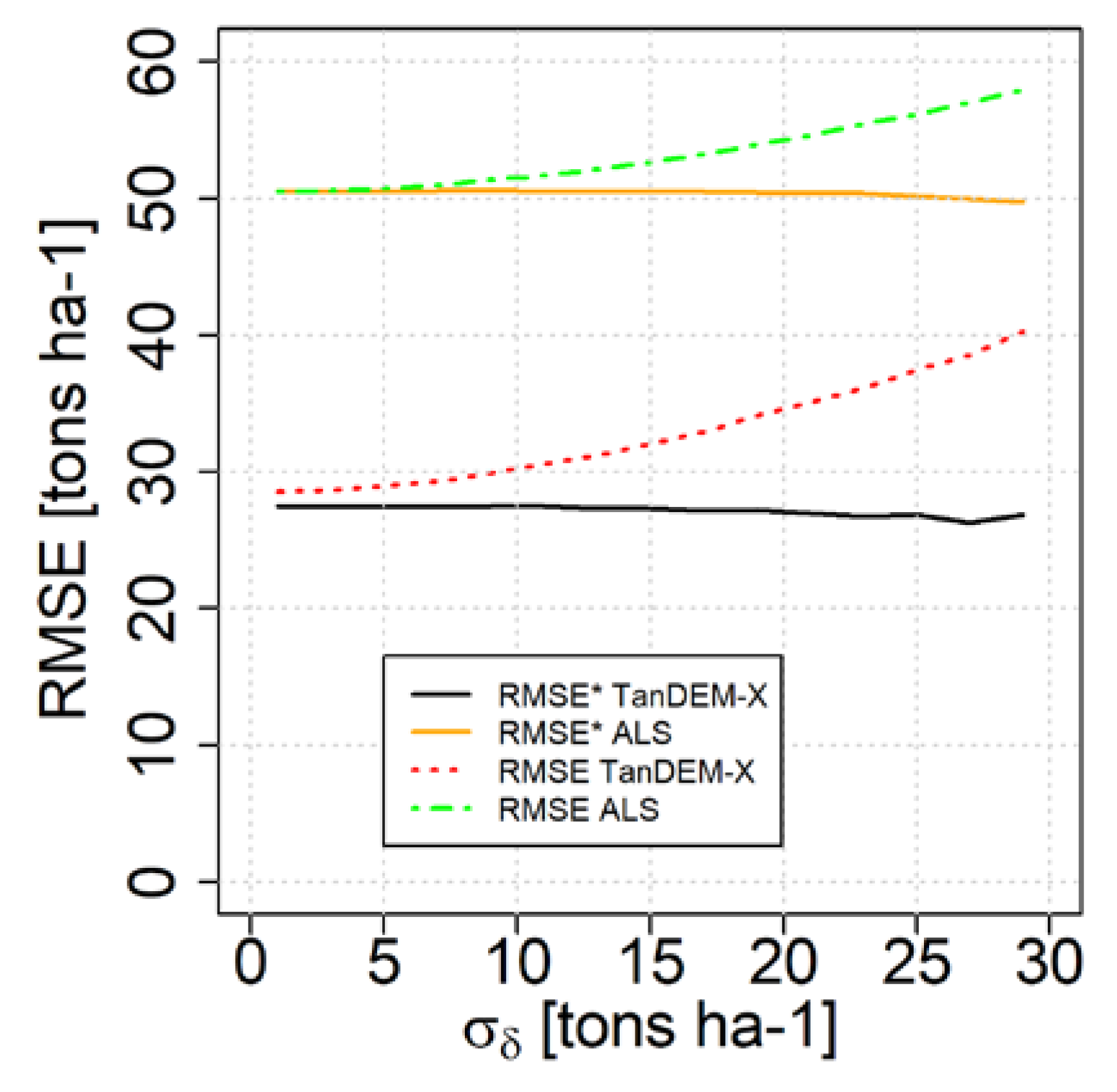
3. Case Study Demonstrations
4. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Residual Variance Estimations
Appendix B. Computational Example for TanDEM-X Case Study Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Term | Value | Description |
|---|---|---|
| 269 tons2 ha−2 | is computed as the variance of the residuals for estimated values, regressed on the reference values (evaluation). When the same dataset is used for both training and evaluation, this number is directly obtained as the variance of the estimated residuals. | |
| 1650 tons2 ha−2 | is computed as the variance of all stand means in the reference dataset. | |
| 111 tons2 ha−2 | is the mean of all stand variances, where each stand variance is computed as the variance of the stand sample plots divided by the amount of sample plots for the stand. | |
| 0.848 | is computed as the squared correlation coefficient between estimated stand values and the reference stand values | |
| 93.9 tons ha−1 | is computed as the mean stand reference. | |
| 70.1 tons ha−1 | is the mean value of the stand estimates in Krycklan, based on RS data. | |
| 260 tons2 ha−2 | is computed as the mean squared deviation from the mean of the differences between references and RS estimates. |
| Index | Field Reference AGB t/ha | sd(AGB) t/ha | RS Estimate t/ha |
|---|---|---|---|
| 1 | 85.7 | 10.1 | 50.9 |
| 2 | 72.4 | 9.69 | 49.7 |
| 3 | 69.2 | 4.96 | 61.1 |
| 4 | 58.6 | 3.84 | 63.2 |
| 5 | 104 | 16.3 | 94.5 |
| 6 | 135 | 15.0 | 95.0 |
| 7 | 183 | 13.2 | 138 |
| 8 | 119 | 11.0 | 109 |
| 9 | 106 | 8.50 | 84.8 |
| 10 | 140 | 9.97 | 111 |
| 11 | 167 | 15.4 | 128 |
| 12 | 116 | 6.15 | 80.2 |
| 13 | 23.1 | 4.47 | 18.9 |
| 14 | 74.3 | 2.92 | 48.9 |
| 15 | 86.0 | 7.74 | 78.9 |
| 16 | 158 | 24.8 | 92.3 |
| 17 | 35.1 | 5.92 | 15.4 |
| 18 | 85.6 | 8.46 | 44.0 |
| 19 | 89.3 | 6.29 | 81.7 |
| 20 | 109 | 10.9 | 82.7 |
| 21 | 120 | 11.1 | 74.0 |
| 22 | 84.5 | 6.81 | 71.9 |
| 23 | 42.7 | 7.42 | 25.6 |
| 24 | 95.8 | 8.58 | 94.0 |
| 25 | 112 | 13.1 | 95.6 |
| 26 | 73.8 | 13.6 | 57.5 |
| 27 | 27.5 | 5.75 | −10.1 |
| 28 | 113 | 9.04 | 81.3 |
| 29 | 37.1 | 5.28 | 16.0 |
References
- Tomppo, E.; Olsson, H.; Ståhl, G.; Nilsson, M.; Hagner, O.; Katila, M. Combining national forest inventory field plots and remote sensing data for forest databases. Remote Sens. Environ. 2008, 112, 1982–1999. [Google Scholar] [CrossRef]
- Næsset, E.; Gobakken, T. Estimation of above- and below-ground biomass across regions of the boreal forest zone using airborne laser. Remote Sens. Environ. 2008, 112, 3079–3090. [Google Scholar] [CrossRef]
- Mauya, E.W.; Hansen, E.H.; Gobakken, T.; Bollandsås, O.M.; Malimbwi, R.E.; Næsset, E. Effects of field plot size on prediction accuracy of aboveground biomass in airborne laser scanning-assisted inventories in tropical rain forests of Tanzania. Carbon Balance Manag. 2015, 10, 10. [Google Scholar] [CrossRef] [PubMed]
- Næsset, E. Accuracy of forest inventory using airborne laser scanning: Evaluating the first nordic full-scale operational project. Scand. J. For. Res. 2004, 19, 554–557. [Google Scholar] [CrossRef]
- Persson, H.; Fransson, J.E.S. Forest Variable Estimation Using Radargrammetric Processing of TerraSAR-X Images in Boreal Forests. Remote Sens. 2014, 6, 2084–2107. [Google Scholar] [CrossRef]
- Persson, H.J.; Fransson, J.E.S. Comparison between TanDEM-X and ALS based estimation of above ground biomass and tree height in boreal forests. Scand. J. For. Res. 2017, 32, 306–319. [Google Scholar] [CrossRef]
- Varvia, P. Uncertainty Quantification in Remote Sensing of Forests; University of Eastern Finland: Joensuu, Finland, 2018. [Google Scholar]
- Tian, Y.; Nearing, G.S.; Peters-Lidard, C.D.; Harrison, K.W.; Tang, L. Performance Metrics, Error Modeling, and Uncertainty Quantification. Mon. Weather Rev. 2016, 144, 607–613. [Google Scholar] [CrossRef]
- Pearson, K. On the Mathematical Theory of Errors of Judgment, with Special Reference to the Personal Equation. Philos. Trans. R. Soc. Lond. 1901, A198, 235–299. [Google Scholar]
- Wald, A. The Fitting of Straight Lines if Both Variables are Subject to Error. Ann. Math. Stat. 1940, 11, 284–300. [Google Scholar] [CrossRef]
- Gustafsson, P. Measurement Error and Misclassification in Statistics and Epidemiology: Impacts and Bayesian Adjustments, 1st ed.; Chapman & Hall/CRC: London, UK, 2004. [Google Scholar]
- Carroll, R.J.; Ruppert, D.; Stefanski, L.A.; Crainiceanu, C. Measurement Error in Nonlinear Models: A Modern Perspective, 2nd ed.; Chapman and Hall: Boca Raton, FL, USA, 2006. [Google Scholar]
- Buonaccorsi, J.P. Measurement Error Models, Methods and Applications; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Yi, G.Y. Statistical Analysis with Measurement Error or Misclassification: Strategy, Method and Application, 1st ed.; Springer Science+Business Media: New York, NY, USA, 2017. [Google Scholar]
- Marklund, L.G. Biomassafunktioner för Tall, Gran Och Björk i Sverige; Swedish University of Agricultural Sciences: Umeå, Sweden, 1988. [Google Scholar]
- Marklund, L.G. Biomass Functions for Norway Spruce (Picea Abies (L.) Karst.) in Sweden; Swedish University of Agricultural Sciences: Umeå, Sweden, 1987. [Google Scholar]
- Brandel, G. Volymfunktioner för Enskilda Träd: Tall, Gran Och Björk = Volume Functions for Individual Trees: Scots Pine (Pinus Sylvestris), Norway Spruce (Picea Abies) and Birch (Betula Pendula & Betula Pubescens); Swedish University of Agricultural Sciences: Garpenberg, Sweden, 1990; ISBN 9157640300 9789157640307. [Google Scholar]
- Nickless, A.; Scholes, R.J.; Archibald, S. A method for calculating the variance and confidence intervals for tree biomass estimates obtained from allometric equations. S. Afr. J. Sci. 2011, 107, 1–10. [Google Scholar] [CrossRef]
- Wulder, M.; Franklin, S.E. Remote Sensing of Forest Environments: Concepts and Case Studies; Springer: New York, NY, USA, 2003. [Google Scholar]
- Saatchi, S.S.; Quegan, S.; Ho Tong Minh, D.; Le Toan, T.; Scipal, K.; Carreiras, J.M.B.; Carvalhais, N.; Reichstein, M. Coverage of high biomass forests by the ESA BIOMASS mission under defense restrictions. Remote Sens. Environ. 2017, 196, 154–162. [Google Scholar]
- Tansey, K.; Louis, V.; Wheeler, J.; Balzter, H.; Rodríguez-Veiga, P. Quantifying Forest Biomass Carbon Stocks From Space. Curr. For. Rep. 2017, 3, 1–18. [Google Scholar]
- Næsset, E. Airborne laser scanning as a method in operational forest inventory: Status of accuracy assessments accomplished in Scandinavia. Scand. J. For. Res. 2007, 22, 433–442. [Google Scholar] [CrossRef]
- Datla, R.V.; Kessel, R.; Smith, A.W.; Kacker, R.N.; Pollock, D.B. Uncertainty analysis of remote sensing optical sensor data: Guiding principles to achieve metrological consistency. Int. J. Remote Sens. 2010, 31, 867–880. [Google Scholar] [CrossRef]
- Varvia, P.; Lahivaara, T.; Maltamo, M.; Packalen, P.; Tokola, T.; Seppänen, A. Uncertainty Quantification in ALS-Based Species-Specific Growing Stock Volume Estimation. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1671–1681. [Google Scholar] [CrossRef]
- Næsset, E. Predicting forest stand characteristics with airborne scanning laser using a practical two-stage procedure and field data. Remote Sens. Environ. 2002, 80, 88–99. [Google Scholar] [CrossRef]
- Hyyppä, J.; Kelle, O.; Lehikoinen, M.; Inkinen, M. A segmentation-based method to retrieve stem volume estimates from 3-D tree height models produced by laser scanners. IEEE Trans. Geosci. Remote Sens. 2001, 39, 969–975. [Google Scholar] [CrossRef]
- Pitkänen, J.; Maltamo, M. Adaptive Methods for Individual Tree Detection on Airborne Laser Based Canopy Height Model. Int. Arch. 2004, 36, 187–191. [Google Scholar]
- Dalponte, M.; Bruzzone, L.; Gianelle, D. A system for the estimation of single-tree stem diameter and volume using multireturn LIDAR data. IEEE Trans. Geosci. Remote Sens. 2011, 49, 2479–2490. [Google Scholar] [CrossRef]
- Dalponte, M.; Ørka, H.O.; Ene, L.T.; Gobakken, T.; Næsset, E. Tree crown delineation and tree species classification in boreal forests using hyperspectral and ALS data. Remote Sens. Environ. 2014, 140, 306–317. [Google Scholar] [CrossRef]
- Fridman, J.; Holm, S.; Nilsson, M.; Nilsson, P. Adapting National Forest Inventories to changing requirements–the case of the Swedish National Forest Inventory at the turn of the 20th century. Silva Fenn. 2014, 48, 1–29. [Google Scholar] [CrossRef]
- Eid, T.; Næsset, E. Determination of stand volume in practical forest inventories based on field measurements and photo-interpretation: The Norwegian experience. Scand. J. For. Res. 1998, 13, 246–254. [Google Scholar] [CrossRef]
- Strand, L. Determination of Volume by Means of the Relascope. For. Sci. 1964, 10, 1964. [Google Scholar]
- Henttonen, H.M.; Kangas, A. Optimal plot design in a multipurpose forest inventory. For. Ecosyst. 2015, 2, 31. [Google Scholar] [CrossRef]
- Ståhl, G. A Study on the Quality of Compartmentwise Forest Data Acquired by Subjective Inventory Methods; Swedish University of Agricultural Sciences: Umeå, Sweden, 1992; Volume 24. [Google Scholar]
- Gregoire, T.G.; Valentine, H.T. Sampling Strategies for Natural Resources and the Environment; Chapman and Hall: Boca Raton, FL, USA, 2008; Volume 64. [Google Scholar]
- Saarela, S.; Schnell, S.; Tuominen, S.; Balázs, A.; Hyyppä, J.; Grafström, A.; Ståhl, G. Effects of positional errors in model-assisted and model-based estimation of growing stock volume. Remote Sens. Environ. 2016, 172, 101–108. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Chen, Q.; Walters, B.F.; Kaisershot, D.J. The effects of global positioning system receiver accuracy on airborne laser scanning-assisted estimates of aboveground biomass. Remote Sens. Environ. 2018, 207, 42–49. [Google Scholar] [CrossRef]
- Gobakken, T.; Næsset, E. Assessing effects of positioning errors and sample plot size on biophysical stand properties derived from airborne laser scanner data. Can. J. For. Res. 2009, 39, 1036–1052. [Google Scholar] [CrossRef]
- Mauro, F.; Valbuena, R.; Manzanera, J.A. Influence of Global Navigation Satellite System errors in positioning inventory plots for tree- height distribution studies 1. Can. J. For. Res. 2011, 23, 11–23. [Google Scholar] [CrossRef]
- Frazer, G.W.; Magnussen, S.; Wulder, M.A.; Niemann, K.O. Simulated impact of sample plot size and co-registration error on the accuracy and uncertainty of LiDAR-derived estimates of forest stand biomass. Remote Sens. Environ. 2011, 115, 636–649. [Google Scholar] [CrossRef]
- Saarela, S.; Holm, S.; Healey, S.P.; Andersen, H.-E.; Petersson, H.; Prentius, W.; Patterson, P.L.; Naesset, E.; Gregoire, T.G.; Ståhl, G. Generalized Hierarchical Model-Based Estimation for Aboveground Biomass Assessment Using GEDI and Landsat Data. Remote Sens. 2018, 10, 1832. [Google Scholar] [CrossRef]
- Campbell, J.B. Introduction to Remote Sensing, 4th ed.; The Builford Press: New York, NY, USA, 2007. [Google Scholar]
- Barnston, A.G. Correspondence among the Correlation, RMSE, and Heidke Forecast Verification Measures; Refinement of the Heidke Score. Weather Forecast. 1992, 7, 699–709. [Google Scholar] [CrossRef]
- Barnston, A.G.; Thomas, J.L. Rainfall Measurement Accuracy in FACE: A Comparison of Gage and Radar Rainfalls. J. Clim. Appl. Meterol. 1983, 22, 2038–2052. [Google Scholar] [CrossRef]
- Yin, P.; Fan, X. Estimating r2 shrinkage in multiple regression: A comparison of different analytical methods. J. Exp. Educ. 2001, 69, 203–224. [Google Scholar] [CrossRef]
- Cramer, J.S. Mean and variance of R2 in small and moderate samples. J. Econ. 1987, 35, 253–266. [Google Scholar] [CrossRef]
- Mukaka, M.M. Statistics corner: A guide to appropriate use of correlation coefficient in medical research. Malawi Med. J. 2012, 24, 69–71. [Google Scholar] [PubMed]
- Hendry, D.F.; Marshall, R.C. On High and Low R2 Contributions. Oxf. Bull. Econ. Stat. 1983, 45, 313–316. [Google Scholar] [CrossRef]
- Moraes, D. Letters The Coefficient of Determination: What. Investig. Ophtalmol. Vis. Sci. 2012, 53, 6830–6832. [Google Scholar]
- Marcot, B.G. Metrics for evaluating performance and uncertainty of Bayesian network models. Ecol. Modell. 2012, 230, 50–62. [Google Scholar] [CrossRef]
- Valbuena, R.; Hernando, A.; Manzanera, J.A.; Görgens, E.B.; Almeida, D.R.A.; Mauro, F.; García-Abril, A.; Coomes, D.A. Enhancing of accuracy assessment for forest above-ground biomass estimates obtained from remote sensing via hypothesis testing and overfitting evaluation. Ecol. Modell. 2017, 366, 15–26. [Google Scholar] [CrossRef]
- Papoulis, A. Probability, Random Variables and Stochastic Processes, 2nd ed.; McGraw-Hill Education: New York, USA, 1984. [Google Scholar]
- Wilks, D. Statistical Methods in the Atmospheric Sciences, 3rd ed.; Academic Press: Cambridge, MA, USA, 2011; ISBN 9780123850225. [Google Scholar]
- Fonseca, J.R.; Friswell, M.I.; Mottershead, J.E.; Lees, A.W. Uncertainty identification by the maximum likelihood method. J. Sound Vib. 2005, 288, 587–599. [Google Scholar] [CrossRef]
- Livezey, R.E.; Hoopingarner, J.D. Verification of Official Monthly Mean 700-hPa Height Forecasts: An Update. Weather Forecast. 1995, 10, 512–527. [Google Scholar] [CrossRef][Green Version]
- Murphy, A.H. The Coefficients of Correlation and Determination as Measures of performance in Forecast Verification. Weather Forecast. 1995, 10, 681–688. [Google Scholar] [CrossRef]
- Reese, H.; Nilsson, M.; Pahlén, T.; Pahén, T.; Hagner, O.; Joyce, S.; Tingelöf, U.; Egberth, M.; Olsson, H.; Pahlén, T. Countrywide estimates of forest variables using satellite data and field data from the National Forest Inventory. AMBIO A J. Hum. Environ. 2003, 32, 542–548. [Google Scholar] [CrossRef] [PubMed]
- Lu, D. Aboveground biomass estimation using Landsat TM data in the Brazilian Amazon. Int. J. Remote Sens. 2005, 26, 2509–2525. [Google Scholar] [CrossRef]
- Labrecque, S.; Fournier, R.A.; Luther, J.E.; Piercey, D. A comparison of four methods to map biomass from Landsat-TM and inventory data in western Newfoundland. For. Ecol. Manag. 2006, 226, 129–144. [Google Scholar] [CrossRef]
- Askne, J.I.H.; Fransson, J.E.S.; Santoro, M.; Soja, M.J.; Ulander, L.M.H. Model-based biomass estimation of a hemi-boreal forest from multitemporal TanDEM-X acquisitions. Remote Sens. 2013, 5, 5574–5597. [Google Scholar] [CrossRef]
- Mitchard, E.T.A.; Saatchi, S.S.; Woodhouse, I.H.; Nangendo, G.; Ribeiro, N.S.; Williams, M.; Ryan, C.M.; Lewis, S.L.; Feldpausch, T.R.; Meir, P. Using satellite radar backscatter to predict above-ground woody biomass: A consistent relationship across four different African landscapes. Geophys. Res. Lett. 2009, 36, L23401. [Google Scholar] [CrossRef]
- Persson, H.J.; Olsson, H.; Soja, M.J.; Ulander, L.M.H.; Fransson, J.E.S. Experiences from large-scale forest mapping of Sweden using TanDEM-X data. Remote Sens. 2017, 9, 1253. [Google Scholar] [CrossRef]
- Fransson, J.E.S.; Israelsson, H. Estimation of stem volume in boreal forests using ERS-1 C- and JERS-1 L-band SAR data. Int. J. Remote Sens. 1999, 20, 123–137. [Google Scholar] [CrossRef]
- Nilsson, M.; Nordkvist, K.; Jonzén, J.; Lindgren, N.; Axensten, P.; Wallerman, J.; Egberth, M.; Larsson, S.; Nilsson, L.; Eriksson, J.; et al. A nationwide forest attribute map of Sweden derived using airborne laser scanning data and field data from the national forest inventory. Remote Sens. Environ. 2017, 194, 447–454. [Google Scholar] [CrossRef]
- Yu, X.; Hyyppä, J.; Karjalainen, M.; Nurminen, K.; Karila, K.; Kukko, A.; Jaakkola, A.; Liang, X.; Wang, Y.; Hyyppä, H.; et al. Comparison of laser and stereo optical, SAR and InSAR point clouds from air- and space-borne sources in the retrieval of forest inventory attributes. Remote Sens. 2015, 7, 15933–15954. [Google Scholar] [CrossRef]
- Fuller, W.A. Measurement Error Models, 1st ed.; John Wiley & Sons: New York, NY, USA, 1987. [Google Scholar]
- Frost, C.; Thompson, S.G. Correcting for Regression Dilution Bias: Comparison of Methods for a Single Predictor Variable. J. R. Stat. Soc. Ser. A 2000, 163, 173–189. [Google Scholar] [CrossRef]
- Li, C. Mathematical Models in Forest Resource Management Planning. An Integrated Study of Calibration, Prediction and Optimal Decision Models; Report 18; Swedish University of Agricultural Sciences: Umeå, Sweden, 1988. [Google Scholar]
- Hutcheon, J.A.; Chiolero, A.; Hanley, J.A. Random measurement error and regression dilution bias. BMJ 2010, 340, c2289. [Google Scholar] [CrossRef]
- Mcinerny, G.J.; Purves, D.W. Fine-scale environmental variation in species distribution modelling: Regression dilution, latent variables and neighbourly advice. Methods Ecol. Evol. 2011, 2, 248–257. [Google Scholar] [CrossRef]
- Tian, Y.; Huffman, G.J.; Adler, R.F.; Tang, L.; Sapiano, M.; Maggioni, V.; Wu, H. Modeling errors in daily precipitation measurements: Additive or multiplicative? Geophys. Res. Lett. 2013, 40, 2060–2065. [Google Scholar] [CrossRef]
- Vasquez, V.R.; Whiting, W.B. Accounting for both random errors and systematic errors in uncertainty propagation analysis of computer models involving experimental measurements with Monte Carlo methods. Risk Anal. 2006, 25, 1669–1681. [Google Scholar] [CrossRef]
- Solberg, S.; Astrup, R.; Gobakken, T.; Næsset, E.; Weydahl, D.J. Estimating spruce and pine biomass with interferometric X-band SAR. Remote Sens. Environ. 2010, 114, 2353–2360. [Google Scholar] [CrossRef]
- Nilsson, M. Estimation of tree heights and stand volume using an airborne lidar system. Remote Sens. Environ. 1996, 56, 1–7. [Google Scholar] [CrossRef]
- Næsset, E.; Gobakken, T.; Holmgren, J.; Hyyppä, H.; Hyyppä, J.; Maltamo, M.; Nilsson, M.; Olsson, H.; Persson, Å.; Söderman, U.; et al. Laser scanning of forest resources: The nordic experience. Scand. J. For. Res. 2004, 19, 482–499. [Google Scholar] [CrossRef]
- Nilsson, M. Estimation of Forest Variables Using Satellite Image Data and Airborne Lidar. Ph.D. Thesis, Swedish University of Agricultural Sciences, Umeå, Sweden, 1997. [Google Scholar]
- Höhle, J.; Höhle, M. Accuracy assessment of digital elevation models by means of robust statistical methods. ISPRS J. Photogramm. Remote Sens. 2009, 64, 398–406. [Google Scholar] [CrossRef]
- Maune, D.F. Digital Elevation Model Technologies and Applications: The DEM User Manual, 2nd ed.; American Society for Photogrammetry and Remote Sensing (ASPRS): Bethesda, MD, USA, 2007; ISBN 1-57083-082-7. [Google Scholar]
- Gertner, G.Z.; Köhl, M. An Assessment of Some Nonsampling Errors in a National Survey Using an Error Budget. For. Sci. 1992, 38, 525–538. [Google Scholar]







| Sensor | Model | ||
|---|---|---|---|
| TanDEM-X | Equation (19) | −208 | 10.9 |
| ALS | Equation (20) | −51.7 | 0.128 |
| Sensor | Dataset | q | RMSE tons/ha | RMSE* tons/ha | ||||
|---|---|---|---|---|---|---|---|---|
| TanDEM-X | Krycklan | −9.35 | 0.847 | 114 | −2.90 | 1.31 | 28.5 | 26.1 |
| ALS | Krycklan | −49.5 | 1.01 | 59.3 | −1.01 | 1.23 | 50.5 | 49.5 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Persson, H.J.; Ståhl, G. Characterizing Uncertainty in Forest Remote Sensing Studies. Remote Sens. 2020, 12, 505. https://doi.org/10.3390/rs12030505
Persson HJ, Ståhl G. Characterizing Uncertainty in Forest Remote Sensing Studies. Remote Sensing. 2020; 12(3):505. https://doi.org/10.3390/rs12030505
Chicago/Turabian StylePersson, Henrik Jan, and Göran Ståhl. 2020. "Characterizing Uncertainty in Forest Remote Sensing Studies" Remote Sensing 12, no. 3: 505. https://doi.org/10.3390/rs12030505
APA StylePersson, H. J., & Ståhl, G. (2020). Characterizing Uncertainty in Forest Remote Sensing Studies. Remote Sensing, 12(3), 505. https://doi.org/10.3390/rs12030505