A Two-Stream Symmetric Network with Bidirectional Ensemble for Aerial Image Matching


Abstract
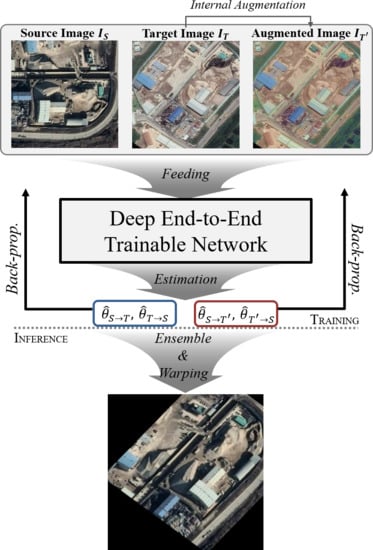
1. Introduction
1.1. Motivation
1.2. Contibutions
- For aerial image matching, we propose a deep end-to-end trainable network with a two-stream architecture. The three inputs are constructed by internal augmentation of the target image, which regularizes the training process and overcomes the shortcomings of the aerial images due to various capturing environments.
- We introduce a bidirectional training architecture and an ensemble method, inspired by the isomorphism of the geometric transformation. It alleviates the asymmetric result of image matching. The proposed ensemble method assists the deep network to become robust for the variance between estimated transformation parameters from both directions and shows improved performance in evaluation without any additional network or parameters.
- Our method shows more stable and precise matching results from the qualitative and quantitative assessment. In the aerial image matching domain, we first apply probability of correct keypoints (PCK) metrics [44] to objectively assess quantitative performance with a large volume of aerial images. Our dataset, model and source code are available at https://github.com/jaehyunnn/DeepAerialMatching.
1.3. Related Works
2. Materials and Methods
2.1. Internal Augmentation for Regularization
2.2. Feature Extraction with Backbone Network
2.3. Correspondence Matching
2.4. Regression of Transformation Parameters
2.5. Ensemble Based on Bidirectional Network
2.5.1. Bidirectional Network
2.5.2. Ensemble
2.6. Loss Function
3. Results
3.1. Implementation Details
3.2. Experimental Settings
3.2.1. Training
| Algorithm 1: Training procedure. |
| Input: Training aerial image dataset D Randomly initialized model Output: Trained model for epochs do  end |
3.2.2. Evaluation
| Algorithm 2: Inference procedure. |
| Input: Source and target images Trained model Output: Transformed image # Feed-forward ; # Ensemble ; # Transform source image to target image |
3.3. Results
3.3.1. Quantitative results
Aerial Image Dataset
Ablation Study
3.3.2. Qualitative Results
Global Matching Performance
Localization Performance
4. Discussion
4.1. Robustness for the Variance of Aerial Image
4.2. Limitations and Analysis of Failure Cases
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| DNNs | Deep Neural Networks |
| CNNs | Convolutional Neural Networks |
| ReLU | Rectified Linear Unit |
| TPS | Thin-Plate Spline |
| PCK | Probability of Correct Keypoints |
| ADAM | ADAptive Moment estimation |
| Bi-En. | Bidirectional Ensemble |
| Int. Aug. | Internal Augmentation |
| ISPRS | International Society for Photogrammetry and Remote Sensing |
References
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. (IJCV) 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L.V. SURF: Speeded Up Robust Features. In Proceedings of the European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005. [Google Scholar]
- Morel, J.-M.; Yu, G. ASIFT: A New Framework for Fully Affine Invariant Image Comparison. SIAM J. Img. Sci. 2009, 2, 438–469. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Leibe, B.; Leonardis, A.; Schiele, B. Robust Object Detection with Interleaved Categorization and Segmentation. Int. J. Comput. Vis. (IJCV) 2008, 77, 259–289. [Google Scholar] [CrossRef]
- Lamdan, Y.; Schwartz, J.T.; Wolfson, H.J. Object Recognition by Affine Invariant Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Ann Arbor, MI, USA, 5–9 June 1988. [Google Scholar]
- Xi, D.; Podolak, I.T.; Lee, S.-W. Facial Component Extraction and Face Recognition with Support Vector Machines. In Proceedings of the Fifth IEEE International Conference on Automatic Face Gesture Recognition, Washington, DC, USA, 21–21 May 2002. [Google Scholar]
- Park, U.; Choi, H.; Jain, A.K.; Lee, S.-W. Face Tracking and Recognition at a Distance: A Coaxial and Concentric PTZ Camera System. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1665–1677. [Google Scholar] [CrossRef]
- Roh, M.-C.; Shin, H.-K.; Lee, S.-W. View-independent Human Action Recognition with Volume Motion Template on Single Stereo Camera. Pattern Recog. Lett. 2010, 31, 639–647. [Google Scholar] [CrossRef]
- Roh, M.-C.; Kim, T.-Y.; Park, J.; Lee, S.-W. Accurate object contour tracking based on boundary edge selection. Pattern Recog. 2007, 40, 931–943. [Google Scholar] [CrossRef]
- Maeng, H.; Liao, S.; Kang, D.; Lee, S.-W.; Jain, A.K. Nighttime Face Recognition at Long Distance: Cross-Distance and Cross-Spectral Matching. In Proceedings of the 11th Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012. [Google Scholar]
- Kang, D.; Han, H.; Jain, A.K.; Lee, S.-W. Nighttime face recognition at large standoff: Cross-distance and cross-spectral matching. Pattern Recog. 2014, 47, 3750–3766. [Google Scholar] [CrossRef]
- Suk, H.-I.; Sin, B.-K.; Lee, S.-W. Hand Gesture Recognition based on Dynamic Bayesian Network Framework. Pattern Recog. 2010, 43, 3059–3072. [Google Scholar] [CrossRef]
- Jung, H.-C.; Hwang, B.-W.; Lee, S.-W. Authenticating Corrupted Face Image based on Noise Model. In Proceedings of the Sixth IEEE International Conference on Automatic Face and Gesture Recognition, Seoul, Korea, 19 May 2004. [Google Scholar]
- Hwang, B.-W.; Blanz, V.; Vetter, T.; Lee, S.-W. Face Reconstruction from a Small Number of Feature Points. In Proceedings of the 15th International Conference on Pattern Recognition, Barcelona, Spain, 3–7 September 2000. [Google Scholar]
- Park, J.; Kim, H.-W.; Park, Y.; Lee, S.-W. A Synthesis Procedure for Associative Memories based on Space-Varying Cellular Neural Networks. Neural Netw. 2001, 14, 107–113. [Google Scholar] [CrossRef]
- Maeng, H.; Choi, H.-C.; Park, U.; Lee, S.-W.; Jain, A.K. NFRAD: Near-Infrared Face Recognition at a Distance. In Proceedings of the International Joint Conference on Biometrics (IJCB), Washington, DC, USA, 11–13 October 2011. [Google Scholar]
- Park, S.-C.; Lim, S.-H.; Sin, B.-K.; Lee, S.-W. Tracking Non-Rigid Objects using Probabilistic Hausdorff Distance Matching. Pattern Recog. 2005, 38, 2373–2384. [Google Scholar] [CrossRef]
- Park, S.-C.; Lee, H.-S.; Lee, S.-W. Qualitative Estimation of Camera Motion Parameters from the Linear Composition of Optical Flow. Pattern Recog. 2004, 37, 767–779. [Google Scholar] [CrossRef]
- Suk, H.; Jain, A.K.; Lee, S.-W. A Network of Dynamic Probabilistic Models for Human Interaction Analysis. IEEE Trans. Circ. Syst. Vid. 2011, 21, 932–945. [Google Scholar]
- Song, H.-H.; Lee, S.-W. LVQ Combined with Simulated Annealing for Optimal Design of Large-set Reference Models. Neural Netw. 1996, 9, 329–336. [Google Scholar] [CrossRef]
- Roh, H.-K.; Lee, S.-W. Multiple People Tracking Using an Appearance Model Based on Temporal Color. In Proceedings of the Biologically Motivated Computer Vision, Seoul, Korea, 15–17 May 2000. [Google Scholar]
- Bulthoff, H.H.; Lee, S.-W.; Poggio, T.A.; Wallraven, C. Biologically Motivated Computer Vision; Springer: Berlin, Germany, 2003. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese Neural Networks for One-shot Image Recognition. In Proceedings of the International Conference on Machine Learning (ICML) Workshops, Lille, France, 10–11 July 2015. [Google Scholar]
- Chopra, S.; Hadsell, R.; Lecun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005. [Google Scholar]
- Altwaijry, H.; Trulls, E.; Hays, J.; Fua, P.; Belongie, S. Learning to Match Aerial Images With Deep Attentive Architectures. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Melekhov, I.; Kannala, J.; Rahtu, E. Siamese Network Features for Image Matching. In Proceedings of the International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Simo-Serra, E.; Trulls, E.; Ferraz, L.; Kokkinos, I.; Fua, P.; Moreno-Noguer, F. Discriminative Learning of Deep Convolutional Feature Point Descriptors. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Learning to Compare Image Patches via Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015. [Google Scholar]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015. [Google Scholar]
- Rocco, I.; Arandjelovic, R.; Sivic, J. Convolutional Neural Network Architecture for Geometric Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Rocco, I.; Arandjelovic, R.; Sivic, J. End-to-End Weakly-Supervised Semantic Alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Seo, P.H.; Lee, J.; Jung, D.; Han, B.; Cho, M. Attentive Semantic Alignment with Offset-Aware Correlation Kernels. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Brown, L.G. A Survey of Image Registration Techniques. ACM Comput. Surv. 1992, 24, 325–376. [Google Scholar] [CrossRef]
- Zitova, B.; Flusser, J. image registration methods: A survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Singh, B.; Najibi, M.; Davis, L.S. SNIPER: Efficient Multi-Scale Training. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Kim, P.-S.; Lee, D.-G.; Lee, S.-W. Discriminative Context Learning with Gated Recurrent Unit for Group Activity Recognition. Pattern Recog. 2018, 76, 149–161. [Google Scholar] [CrossRef]
- Yang, H.-D.; Lee, S.-W. Reconstruction of 3D Human Body Pose from Stereo Image Sequences based on Top-down Learning. Pattern Recog. 2007, 40, 3120–3131. [Google Scholar] [CrossRef]
- Yi, K.-M.; Trulls, E.; Lepetit, V.; Fua, P. LIFT: Learned Invariant Feature Transform. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Altwaijry, H.; Veit, A.; Belongie, S. Learning to Detect and Match Keypoints with Deep Architectures. In Proceedings of the British Machine Vision Conference (BMVC), York, UK, 19–22 September 2016. [Google Scholar]
- Wu, C.; Agarwal, S.; Curless, B.; Seitz, S. Multicore Bundle Adjustment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 29 June–1 July 2013. [Google Scholar]
- Wu, C. Towards Linear-time Incremental Structure from Motion. In Proceedings of the IEEE International Conference on 3D Vision (3DV), Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Bookstein, F. Principal Warps: Thin-Plate Splines and the Decomposition of Deformations. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 1989, 11, 567–585. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the Advances in Neural Information Processing Systems (NIPS) Workshops, Long Beach, CA, USA, 8–9 December 2017. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Yang, Y.; Ramanan, D. Articulated Human Detection with Flexible Mixtures of Parts. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2013, 35, 2878–2890. [Google Scholar] [CrossRef] [PubMed]
- Ham, B.; Cho, M.; Schmid, C.; Ponce, J. Proposal Flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–July 2016. [Google Scholar]
- Han, K.; Rezende, R.S.; Ham, B.; Wong, K.-Y.K.; Cho, M.; Schmid, C.; Ponce, J. SCNet: Learning Semantic Correspondence. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; 2017. [Google Scholar]
- Kim, S.; Min, D.; Lin, S.; Sohn, K. DCTM: Discrete-Continuous Transformation Matching for Semantic Flow. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kim, S.; Min, D.; Ham, B.; Jeon, S.; Lin, S.; Sohn, K. FCSS: Fully Convolutional Self-Similarity for Dense Semantic Correspondence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Song, W.-H.; Jung, H.-G.; Gwak, I.-Y.; Lee, S.-W. Oblique Aerial Image Matching based on Iterative Simulation and Homography Evaluation. Pattern Recog. 2019, 87, 317–331. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Nex, F.; Gerke, M.; Remondino, F.; Przybilla, H.J.; Bäumker, M.; Zurhorst, A. ISPRS Benchmark for Multi-Platform Photogrammetry. SPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2015, II-3/W4, 135–142. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | PCK (%) | ||
|---|---|---|---|
| SURF [2] | 26.7 | 23.1 | 15.3 |
| SIFT [1] | 51.2 | 45.9 | 33.7 |
| ASIFT [4] | 64.8 | 57.9 | 37.9 |
| OA-Match [61] | 64.9 | 57.8 | 38.2 |
| CNNGeo [36] (pretrained) | 17.8 | 10.7 | 2.5 |
| CNNGeo (fine-tuned) | 90.6 | 76.2 | 27.6 |
| Ours; ResNet101 [62] | 93.8 | 82.5 | 35.1 |
| Ours; ResNeXt101 [51] | 94.6 | 85.9 | 43.2 |
| Ours; Densenet169 [63] | 95.6 | 88.4 | 44.0 |
| Ours; SE-ResNeXt101 [43] | 97.1 | 91.1 | 48.0 |
| Methods | PCK (%) | ||
|---|---|---|---|
| CNNGeo [36] | 90.6 | 76.2 | 27.6 |
| CNNGeo + Int. Aug. | 90.9 | 76.6 | 28.4 |
| CNNGeo + Bi-En. | 92.1 | 79.5 | 31.8 |
| CNNGeo + Int. Aug. + Bi-En. (Ours) | 93.8 | 82.5 | 35.1 |
| Methods | PCK (%) | ||
|---|---|---|---|
| Single-stream (with Int. Aug. and Bi-En.) | 92.4 | 79.7 | 33.5 |
| Two-stream (Ours) | 93.8 | 82.5 | 35.1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.-H.; Nam, W.-J.; Lee, S.-W. A Two-Stream Symmetric Network with Bidirectional Ensemble for Aerial Image Matching. Remote Sens. 2020, 12, 465. https://doi.org/10.3390/rs12030465
Park J-H, Nam W-J, Lee S-W. A Two-Stream Symmetric Network with Bidirectional Ensemble for Aerial Image Matching. Remote Sensing. 2020; 12(3):465. https://doi.org/10.3390/rs12030465
Chicago/Turabian StylePark, Jae-Hyun, Woo-Jeoung Nam, and Seong-Whan Lee. 2020. "A Two-Stream Symmetric Network with Bidirectional Ensemble for Aerial Image Matching" Remote Sensing 12, no. 3: 465. https://doi.org/10.3390/rs12030465
APA StylePark, J.-H., Nam, W.-J., & Lee, S.-W. (2020). A Two-Stream Symmetric Network with Bidirectional Ensemble for Aerial Image Matching. Remote Sensing, 12(3), 465. https://doi.org/10.3390/rs12030465