1. Introduction
Polarimetric synthetic aperture radar (PolSAR), as one of the most advanced detectors in the field of remote sensing, can provide rich target information in all-weather and all-time. In recent years, more and more attention has been paid to the development of PolSAR information extractions due to the good properties of PolSAR systems. Especially, PolSAR image classification has been extensively studied as the basis of PolSAR image interpretation.
Deep learning [
1] has made remarkable progress in natural language processing and computer vision, and it has the potential to be applied in many other fields. Convolutional neural networks (CNNs), as one of the representative methods of deep learning, have shown strong abilities in the task of image processing [
2]. It has been proved that CNNs can obtain more abstract feature representations than traditional hand-engineered filters. The generalization performance of machine learning-based image classification algorithms has been greatly improved with the rise of CNNs. Big data, advanced algorithms, and improvements in computing power are the key factors for the success of CNNs. These factors also exist in PolSAR image classification. Therefore, it is promising to use CNNs to improve PolSAR image classification.
Before the popularity of deep learning, machine learning algorithms have been applied in PolSAR image classification for a long time. Statistical machine learning methods represented by support vector machines have been utilized to implement PolSAR image feature classification [
3]. Considering the significant achievements made by CNNs, many studies have applied CNNs to the task of SAR or PolSAR image classification and achieved remarkable results [
4]. Ding et al. introduced a four-layers CNN architecture [
5] to do SAR image target recognition for the first time. A more carefully-designed network architecture was proposed to further explore deep features [
6]. The impact of target angles was taken into consideration, and a multi-view metric based CNN was proposed to achieve high precision classification on MSTAR dataset [
7]. Ren et al. introduced a patch-sorted based architecture for high-resolution SAR image classification [
8]. Some complex tasks were implemented on the basis of deep features extracted by CNNs, such as change detection [
9] and road segmentation [
10]. In contrast, the application level of CNNs in PolSAR image classification is lower, but it is in the stage of rapid development. After some attempts on stacking shallow models [
11], Zhou et al. applied CNN to PolSAR image classification for the first time [
12]. In their work, a three-layers architecture was introduced to classify PolSAR images and obtained promising classification results. After that, many CNN architectures were introduced such as graph-based architecture [
13], fully convolutional networks [
14] and some advanced network backbones [
15,
16]. However, due to different imaging mechanisms, directly following the architectures of optical image classification may not fully utilize the capabilities of CNNs in PolSAR image classification. In other words, CNNs still have the potential to be explored in the task of PolSAR image classification.
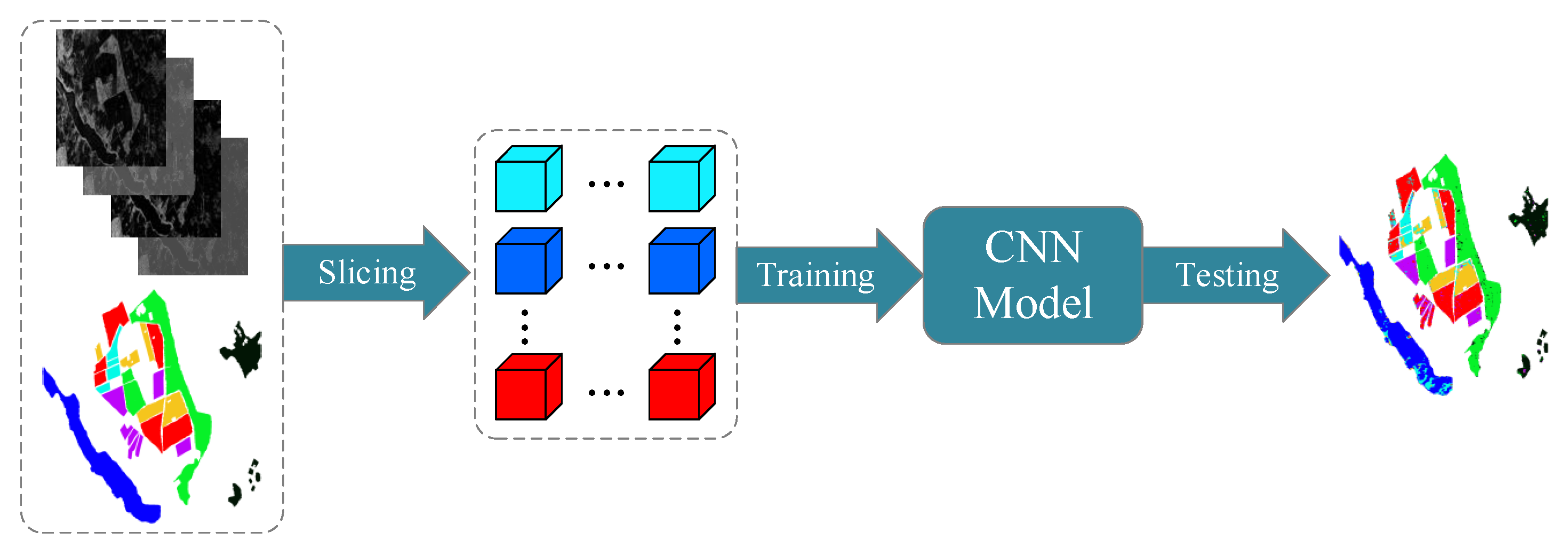
As mentioned above, designing suitable CNN architectures for PolSAR image classification is necessary to pursue more powerful performances. Related studies are being carried out and they can be roughly divided into two parts according to their focus, i.e., task characteristics and data form. Lack of supervision information is a representative task characteristic of PolSAR image classification. Although the acquisition of PolSAR images is not difficult, they do not have labels. In other words, most of the acquired PolSAR images cannot be directly used by the existing mainstream CNNs. Moreover, it is more difficult to label them manually compared with optical images. To handle this problem, weakly supervised methods, such as automatic pseudo-labels, transfer learning, and regularization techniques, were introduced to achieve PolSAR image small sample classification. A super-pixel restrained network was designed to do semi-supervised PolSAR classification with the aid of a pseudo-labels strategy [
17]. Similarly, active learning was used to do pseudo labels and deep learning-based semi-supervised PolSAR classification was achieved in [
18]. Wu et al. implemented transfer learning on a modified U-Net [
19] to realize PolSAR small sample pixel-wise classification. Bi et al. added a graph-based regularization term to the ordinary CNN and achieved semi-supervised PolSAR classification [
13]. In addition to improving the CNN architectures according to the characteristics of PolSAR classification tasks, making the architectures adapt to the complex-valued PolSAR data has also been extensively considered. Different from optical sensors, PolSAR can obtain the phase information between target and radar because of its unique scattering imaging mechanism. Therefore, the architectures which can make full use of the information contained in PolSAR data are of great significance to the development of CNNs in PolSAR image classification. This is also the objective of this work. Chen et al. tried to use the hand-engineered features as the input of CNNs to make better use of PolSAR data without changing the network architecture [
20]. Different from changing the inputs, An intuitive improvement to better utilize complex-valued PolSAR data was extending the real-valued architectures to the complex domain [
21,
22]. Zhang et al. elaborated on the previous studies in detail and designed a three-layers complex-valued CNN to adapt to the characteristics of PolSAR data and implement PolSAR image classification [
23]. At present, complex-valued architectures have been followed by many studies. Shang et al. introduced a complex-valued convolutional autoencoder network for PolSAR classification [
24]. Complex-valued fully convolutional networks were proposed in [
25] to do PolSAR semantic segmentation. Sun et al. proposed a complex-valued generative adversarial network for semi-supervised PolSAR classification [
26]. However, the development of complex-valued architectures is still in its infancy. To avoid complex operations, Liu et al. attempted to learn the feature of phase independently [
27]. A two-stream architecture was proposed to extract features from amplitude and phase respectively with the aid of a multi-task feature fusion mechanism [
28]. It is worth noting that PolSAR covariance matrix has been used as the input of CNNs in most studies [
12,
15,
16,
23,
28], and the phase information is hidden between the input channels when each element of the upper triangle of PolSAR covariance matrix is regarded as a channel of the input. Recent works have revealed that, with the aid of 3D operations, channel-wise correlations can be plugged in as an additional dimension of convolution kernels to solve the problem of feature mining on special data (e.g., videos) [
29,
30]. Such improvements induce considerable advantages when processing PolSAR data by CNNs. Zhang et al. introduced 3D operations for the first time to implement PolSAR classification [
31], which effectively improved the performance of ordinary 2D-CNNs. Tan et al. integrated complex-valued and 3D operations, and proposed a complex-valued 3D-CNN for PolSAR classification [
32]. However, the performance improvement brought by 3D convolutions is based on greatly increased model parameters [
30]. A large number of model parameters limit the speed of classification, which hinders the practical implementations of 3D-CNNs and the development of real-time interpretation systems [
33]. Lightweight alternatives of 3D convolutions, e.g., pseudo-3D convolution [
34] and depthwise separable convolution [
35,
36] are good means to solve this dilemma.
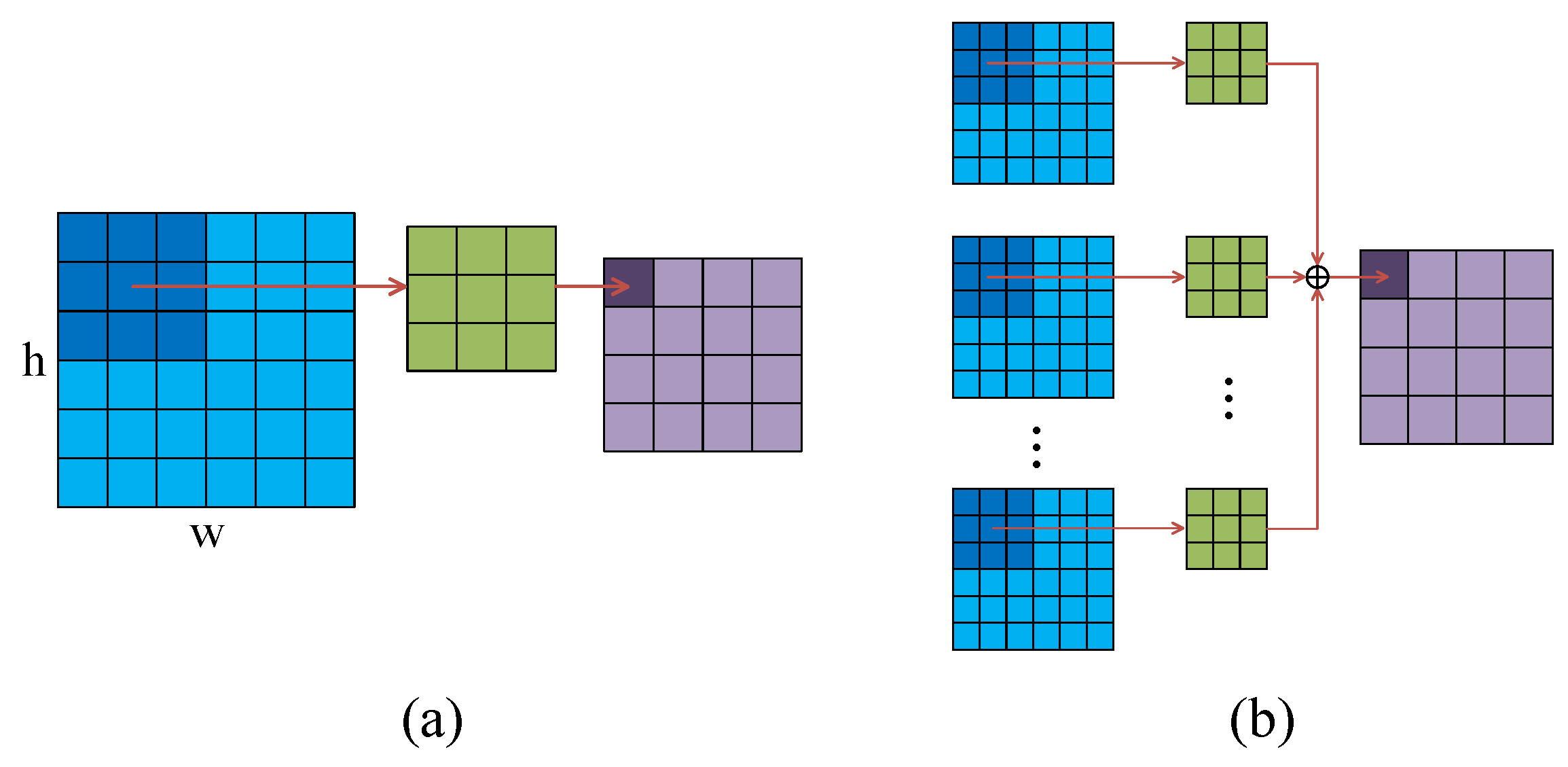
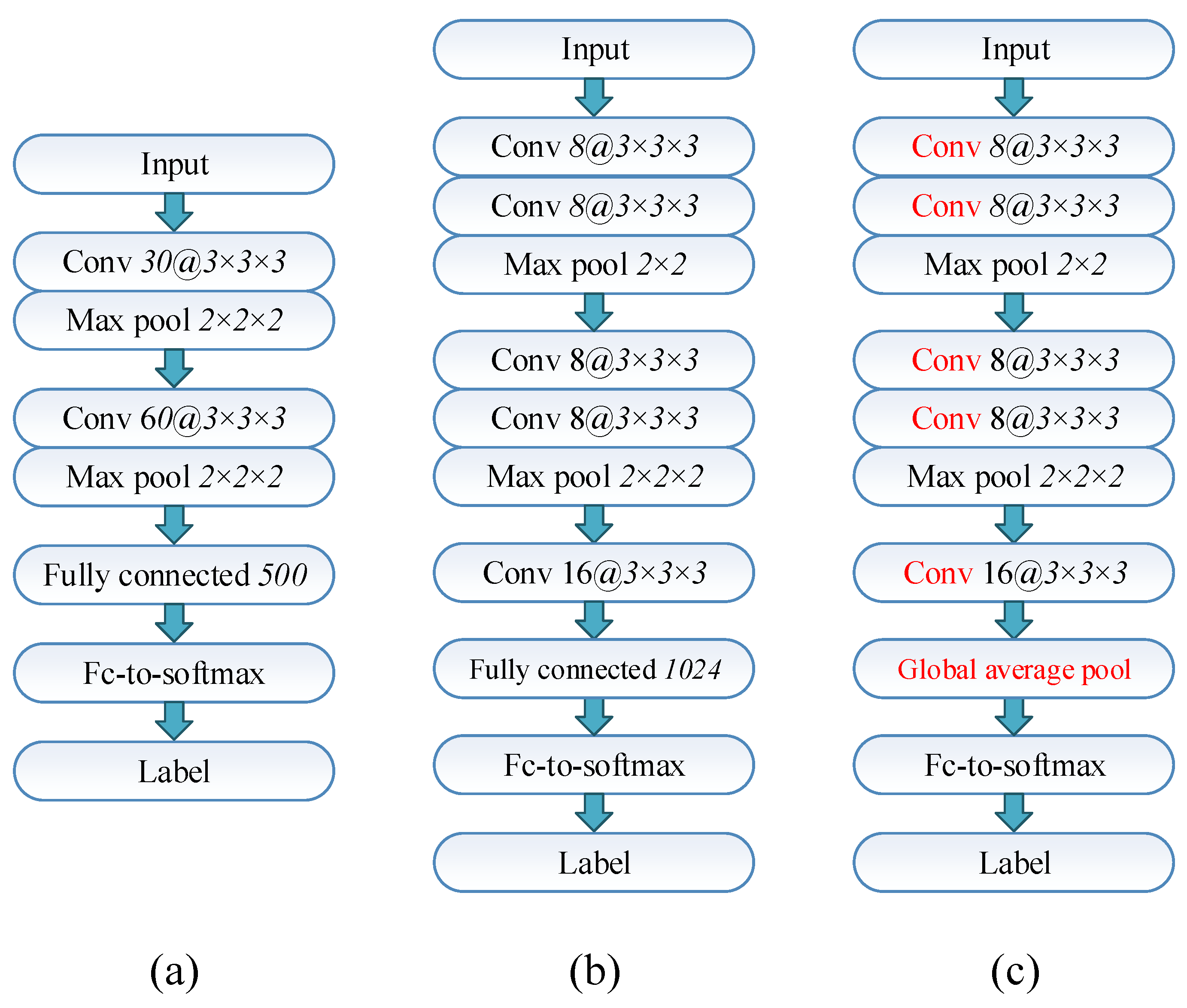
Based on the above analysis, the objective of this work is to find 3D-CNNs architectures with low computational cost as well as competitive performance for PolSAR image classification. It can be observed that almost all model parameters of a CNN exist in the convolution and fully connected layers. For these two key components, lightweight strategies are developed in this paper to compress the network architecture so as to reduce the model complexity of 3D-CNNs. Firstly, pseudo-3D convolution-based CNN (P3D-CNN) is introduced which replaces the convolution operations of 3D-CNNs by pseudo-3D convolutions. P3D-CNN uses two successive 2D operations to approximate the features extracted by 3D-CNNs. In addition, 3D-depthwise separable convolution-based CNN (3DDW-CNN) is proposed in parallel. Different from P3D-CNN, 3DDW-CNN decouples the spatial-wise and channel-wise operations that were previously mixed together to find more effective features than 3D-CNNs. The number of model parameters contained in convolution layers can be greatly reduced in the proposed two lightweight architectures. Moreover, fully connected layers of the above two architectures are eliminated and replaced by global average pooling layers [
37]. This measure reduces more than
of the model parameters in 3D-CNNs and greatly improves the computational efficiency. The dropout mechanism [
38] is configured in the proposed architectures to further prevent over-fitting. The proposed architectures can be summarized as a lightweight 3D-CNN framework, which has more efficient convolution and fully connected operations. The proposal has inspirations for the development of many other lightweight architectures. The number of trainable parameters and the computational complexity of the involved models are compared and analyzed, which illustrates the superiority of the lightweight architectures. The classification performance of the proposed methods is tested on three PolSAR benchmark datasets. Experimental results show that considerable accuracy can be maintained by the proposed methods. The main contribution of this paper can be summarized as follows:
Two lightweight 3D-CNN architectures are introduced for the fast PolSAR interpretation speed during testing.
Two lightweight 3D convolution operations, i.e., pseudo-3D and 3D-depthwise separable convolutions, and global average pooling are applied to reduce the redundancy of 3D-CNNs.
A lightweight 3D-CNN framework can be summarized. Compared with ordinary 3D-CNNs, the architectures under the framework have fewer model parameters and lower computational complexity.
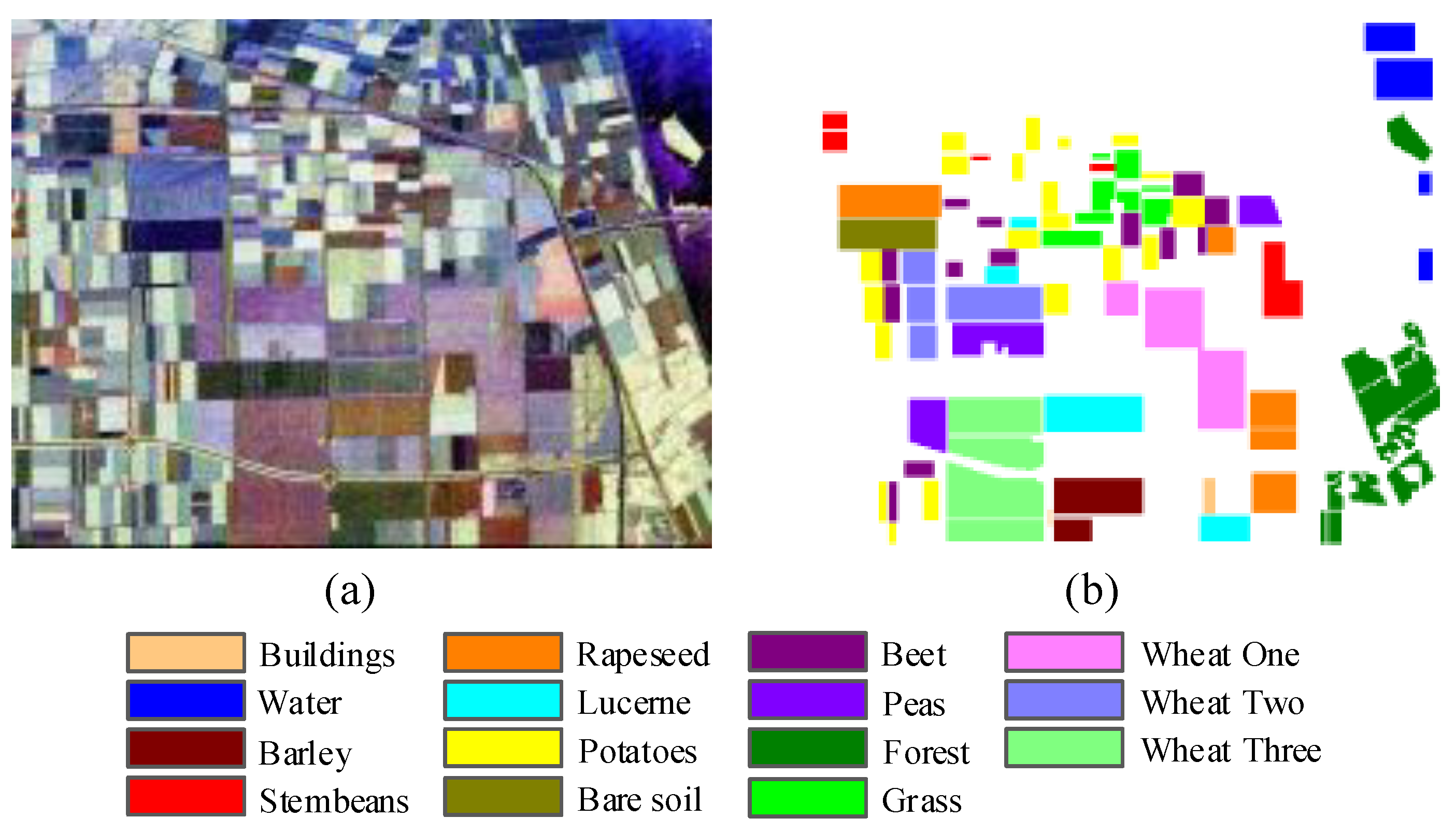
The performance of the lightweight architectures is verified on three PolSAR benchmark datasets.
The rest of this paper is organized as follows. In
Section 2, the background of vanilla convolutions and their variants are introduced. The proposed methods are introduced in
Section 3. The experimental results and analysis are presented in
Section 4. The conclusion is discussed in
Section 5.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
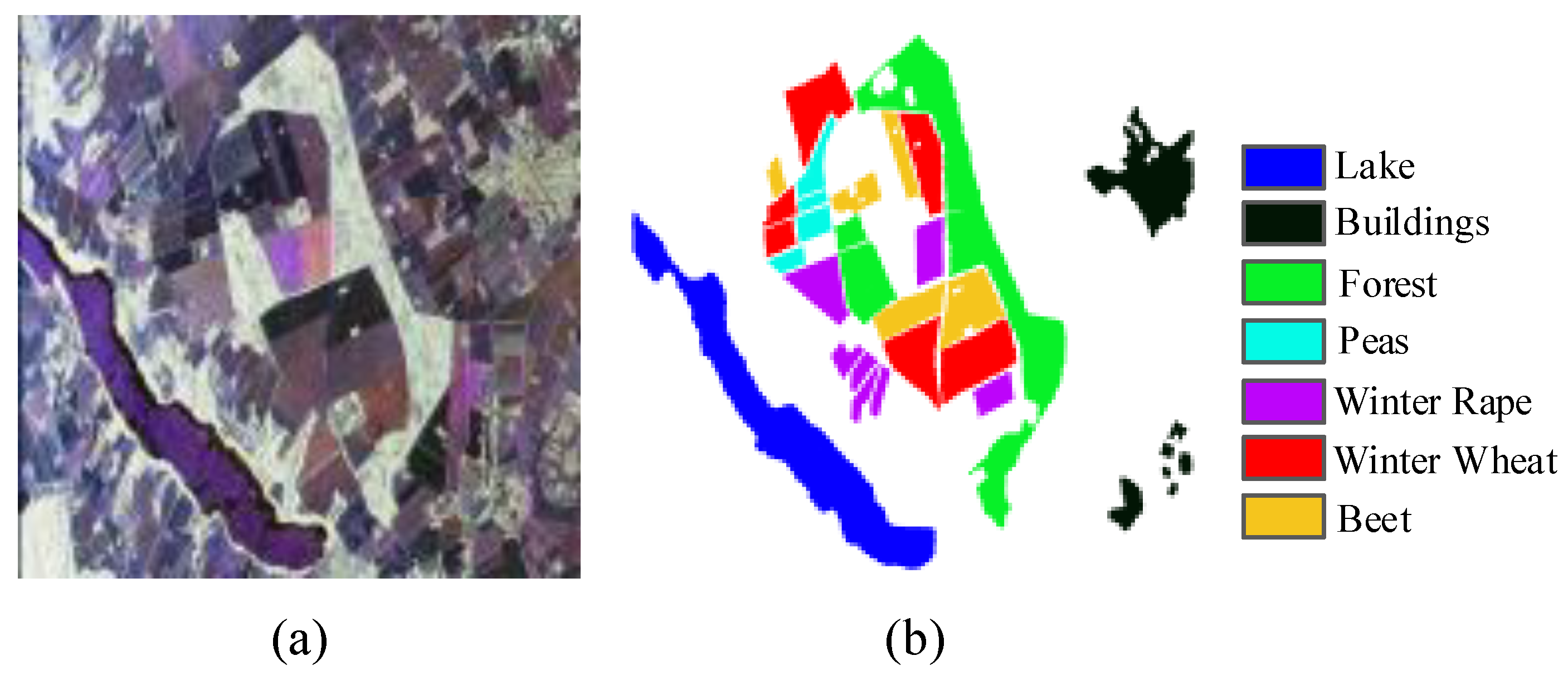{kind=link}
{kind=link}
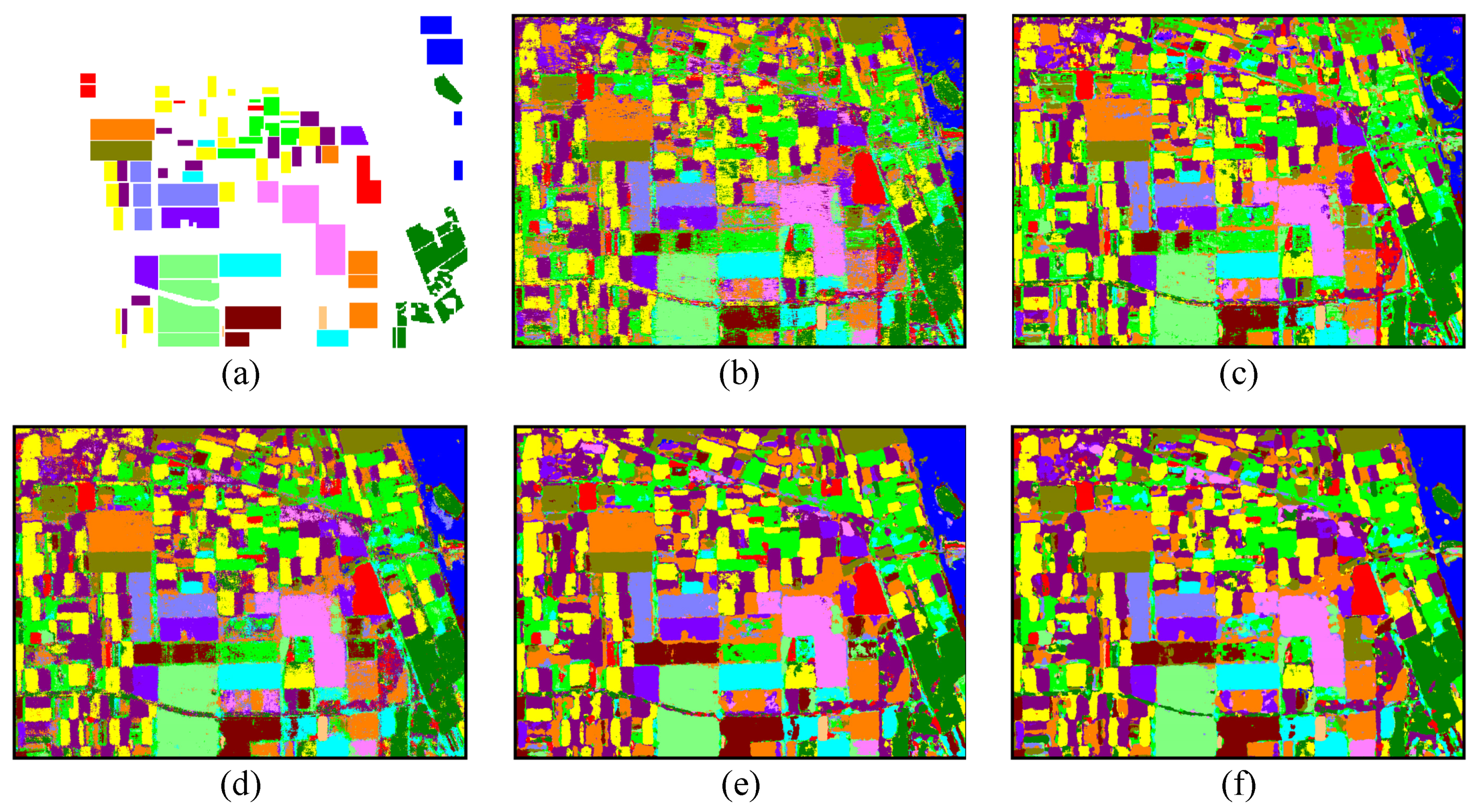{kind=link}
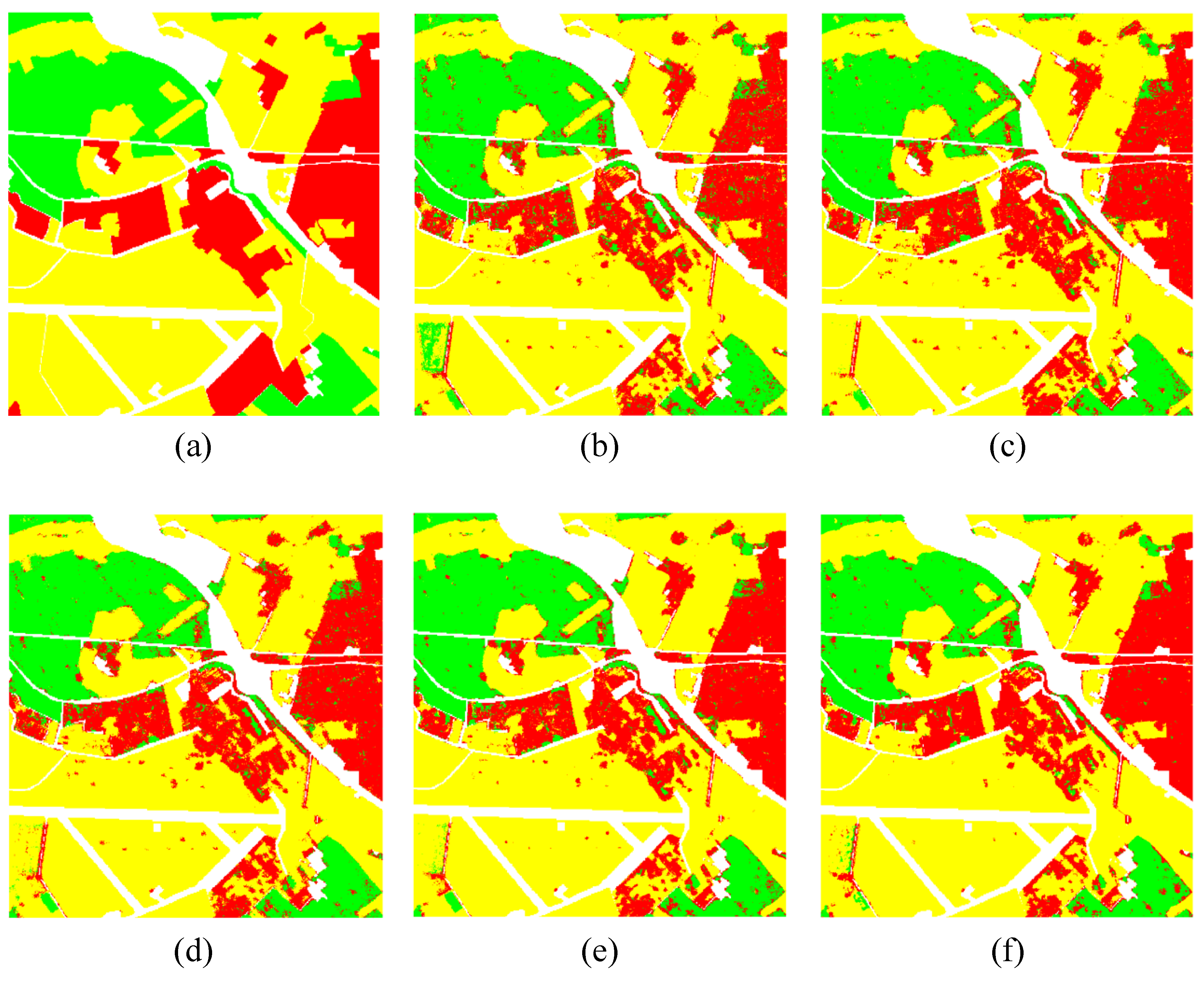{kind=link}
{kind=link}
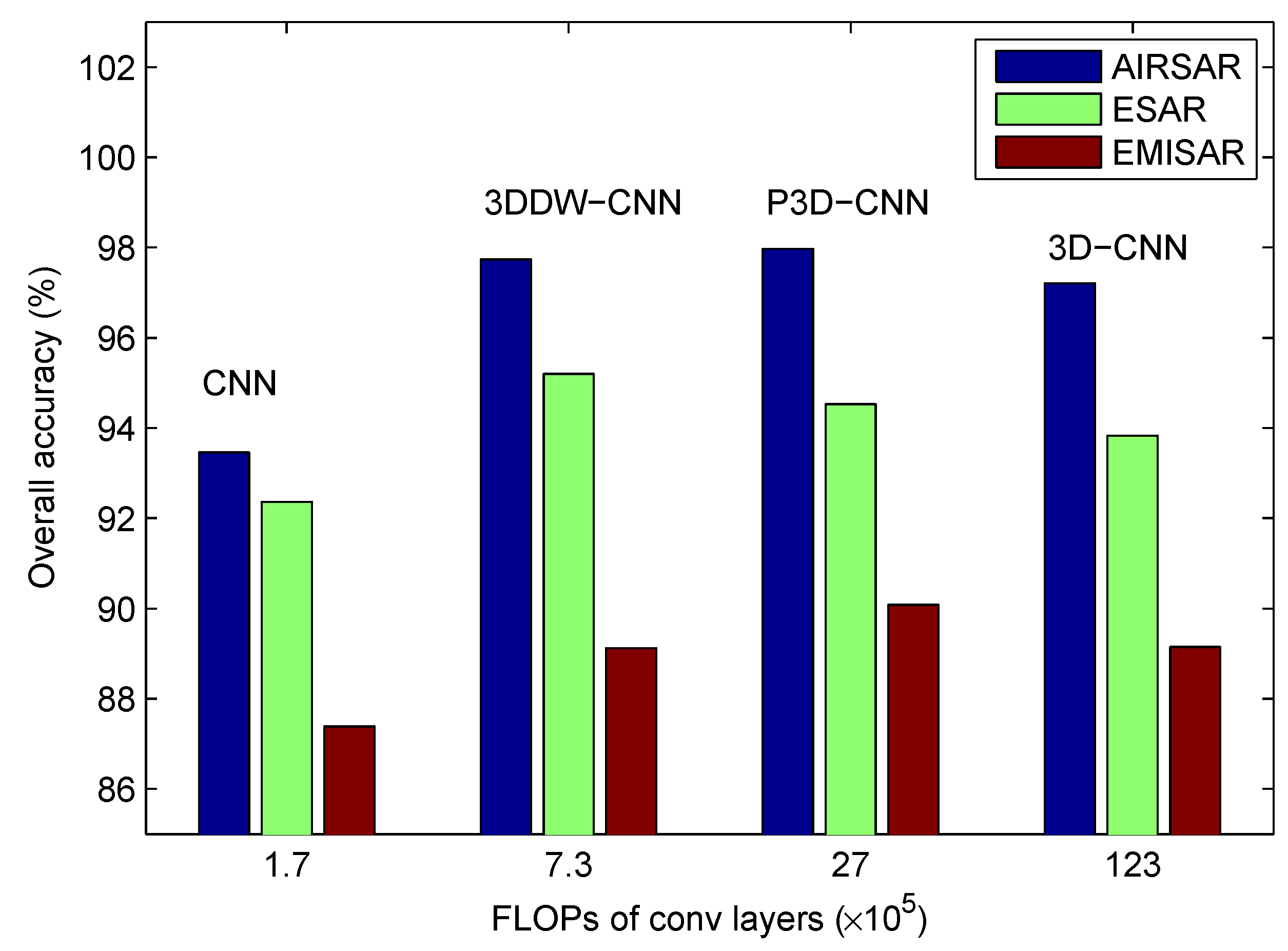{kind=link}