1. Introduction
In recent years, land-use and land-cover (LULC) classification using remote-sensing imagery plays an important role in many applications like land use planning (growth trends, suburban sprawl, policy regulations and incentives), agricultural practice (conservation easements, riparian zone buffers, cropping patterns and nutrient management), forest management (harvesting, health, resource-inventory, reforestation and stand-quality) and biological resource (fragmentation, habitat quality and wetlands) [
1,
2,
3]. Land use refers to the purpose the land serves and land cover refers to the surface cover on the ground, whether vegetation, urban infrastructure, water, bare soil or other; it does not describe the use of land, and the use of land may be different for lands with the same cover type [
4,
5]. LULC assessment is very necessary in sustaining, monitoring and planning the usage of natural resources [
6,
7]. In fact, LULC classification has a direct impact on atmospheric, soil erosion and water, while it is indirectly connected to global environmental problems [
8,
9]. At this end, the remote sensing imagery and its processing has helped in delivering up-to date and large-scale information on surface conditions.
For years, techniques mainly based on pixel or object analysis have been used for LULC classification. An object-based technique usually outperforms a pixel-based one, as demonstrated in [
10,
11,
12]. In fact, unlike the pixel-based technique, which classifies the pixels according to their spectral information, the object-based algorithms enclose semantic information not in the individual pixel but in groups of pixels with similar characteristics, such as color, texture, brightness and shape. Both the spatial and spectral resolution are used in this latter case to segment and then classify image features into meaningful objects [
13]. From the resulting segments, homogeneous image objects are extracted based on the local contrast. These homogeneous objects are then classified using traditional classification approaches such as the nearest neighbor, or using knowledge-based approaches and fuzzy classification logic [
14].
Recently, studies in literature have moved towards data integration in order to improve the accuracy of urban LULC classification [
15,
16]. Data integration refers to the integration of information from various sources or sensors, such as the integration of LiDAR and optical data, for instance [
17,
18,
19]. Nevertheless, even these techniques used in LULC classification present some issues since they are extremely affected by the environmental changes, like destruction of essential wetlands, uncontrolled urban development, haphazard, loss of prime agricultural lands, deteriorating environmental quality, and also by other factors, like cloud cover and regional fog errors. Moreover, traditional remote-sensing imagery processing offers some other concerns: the noise associated with the image, the orientation of features in the images and the maintenance of a large volume of data [
19,
20]. Several methodologies have been developed by the researchers to address those issues faced in LULC classification. Examples of these methodologies are adaptive reflectance fusion models, maximum likelihood classifiers, decision trees, convolutional neural networks (CNNs), deep neural networks (DNNs), etc. [
21,
22,
23,
24,
25]. In some cases, DNNs are also used for pre-trained the data, in other cases the image classification for LULC is accomplished via more complex machine learning (ML) algorithms. It is worth to highlight that ML algorithms have gained ground in recent years also because they resulted to be more suitable to realize unsupervised, or semi-automatic classification systems, with huge amounts of data.
With respect to recent works presented in the literature [
26,
27,
28], the study presented in this article has proposed a new algorithm, a human group-based particle swarm optimization (PSO) algorithm, with a long short-term memory (LSTM) classifier, to address the aforementioned issues and improve LULC classification, in agriculture and urban environments. Remote-sensing images are retrieved from Sat 4, Sat 6 and Eurosat datasets, also used in [
26,
27,
28], but better results are reached with the new algorithm, as shown ahead in this manuscript. In particular, a maximum improvement of 6.03% on Sat 4 and 7.17% on Sat 6 in LULC classification is reached when the proposed human group-based PSO with LSTM is compared to individual LSTM, PSO with LSTM, and Human Group Optimization (HGO) with LSTM. Moreover, an improvement of 2.56% in accuracy is achieved compared to the existing models GoogleNet, Visual Geometric Group (VGG), AlexNet, ConvNet, when the proposed method is applied.
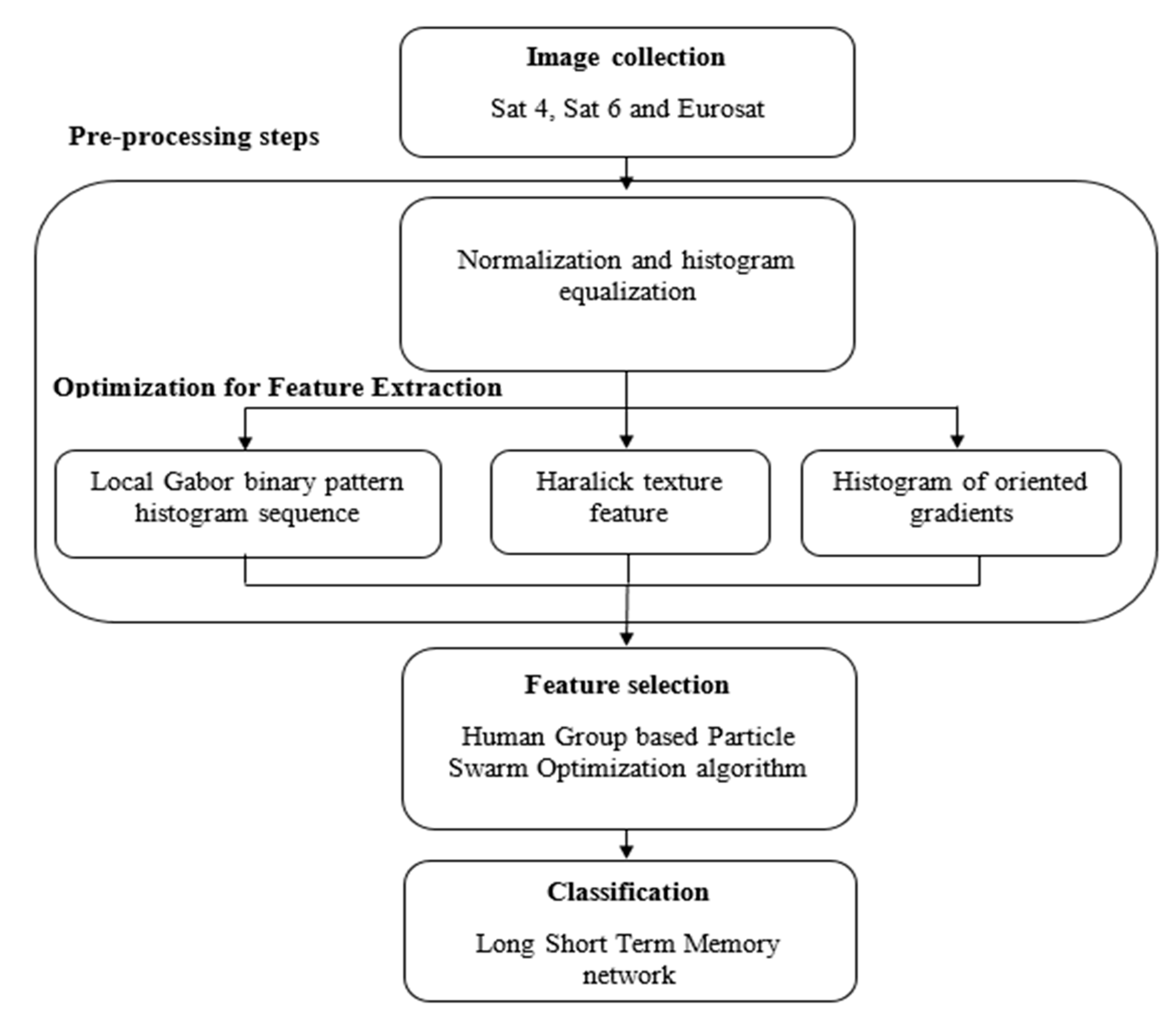
The general architecture of the proposed algorithm and the several detailed processing steps are presented and explained in detail in the
Section 3, but here the summary of the main operations is given. In particular, after the selection of the remote-sensing images, normalization and histogram equalization methods are applied to improve the visual quality of the objects. The pre-processing techniques undertaken effectively improve the contrast of the images and enhance the edges in each region of the image. After normalization, feature extraction is carried out by using the local Gabor binary pattern histogram sequence (LGBPHS), the histogram of oriented gradient (HOG) and the Haralick texture features [
29,
30,
31,
32]. The LGBPHS is utilized as a two-dimensional spatial image gradient measurement to emphasize the high spatial frequency regions based on the image edges. In addition, it is utilized to identify the absolute gradient scales at each point in a remote sensing image. Next, HOG and Haralick texture features are applied to extract the texture and color feature vectors from the image pixels. As the HOG feature descriptor operates on local cells, it is invariant to photometric and geometric transformations, which helps in attaining a better classification. The textural properties are calculated by Haralick texture features in order to understand the edge details about the image content. Then, the human group-based PSO algorithm is used to select the optimal feature vectors that significantly reduces the “curse of dimensionality” issue. The optimal feature vectors obtained are given as the input to the LSTM classifier to establish the LULC classes. In the result section, the performance of the proposed human group-based PSO with LSTM is evaluated in terms of recall, precision and classification accuracy and compared with other existing models such as GoogleNet, VGG, AlexNet and ConvNet.
This research paper is organized as follows.
Section 2 presents several existing research papers on the LULC topic, when advanced methodologies, such as HOG, LGBPHS, ML, ML in combination with object-based image analysis (OBIA), bag-of-visual words (BOVW) and scale-invariant feature transform (SIFT) methodologies are used. In
Section 3, the proposed model is explained in detail with mathematical expressions. Experimental analysis of the proposed model is then presented and discussed in the
Section 4. Conclusions of this study are drawn in
Section 5 2. Literature Survey
As already highlighted, advanced methodologies have gained ground in recent years to overcome unsolved issues of traditional methods, and because more suitable to realize unsupervised, or semi-automatic classification systems, which require a huge amount of data. This section aims to present an extensive survey of related papers.
A new rotationally invariant feature descriptor has been developed by Xiao et al. [
33] to identify cars and aircraft in the remote-sensing images. The rotationally invariant HOG descriptor used elliptic Fourier transform, orientation normalization and feature space mapping to achieve better performance in object detection from remote-sensing images. In [
34] Rahmani and Behrad developed a new automatic model for ship detection in the remote-sensing images. Initially, the collected images were divided into overlapping blocks and then the LGBPHS feature descriptor was used to extract the features from the images. Support vector machine (SVM) and artificial neural network (ANN) were used for classification after feature extraction. However, SVM supports only binary classification, which is not adaptable for multiclass classification.
Kadavi and Lee [
35] used SVM and ANN classifiers to evaluate the multi-spectral data from mount Fourpeaked, mount Kanaga, mount Augustine and mount Pavlof in the United States of America. In this study, a Landsat-8 imagery dataset was used to evaluate the efficiency and effectiveness of the developed model. The Landsat-8 imagery allowed to derive four land cover classes: vegetation, snow, water bodies and outcrops (sand, volcanic rock, etc.). Simulation results showed that the SVM classifier attained better performance in LULC classification compared to ANN classifier. For mount Kanaga, the SVM classifier achieved maximum classification accuracy, which was 9.1% superior to ANN classifier. However, the developed model was only suitable for minimum class classification, not for maximum class classification, and the developed model showed poor performance in some conditions like cloud cover and regional fog error. Pencue-Fierro et al. [
36] presented a new hybrid framework for multi-region, multi-sensor and multi-temporal satellite image classification. In this study, land-cover classification was assessed for the Cauca river region, located in the south-west part of Colombia. After image collection, a Coordination of Information on the Environment (CORINE) land-cover approach was used for extracting the feature vectors from the input image. Next, the extracted features were given as the input to a supervised classifier SVM to decide the land cover classes, like urban-area, paramo, snow, clouds, bare soil, grass-land, planted forest, permanent-crops, natural forest, water-bodies and transitory crops. However, the computational complexity was higher in the developed hybrid framework compared to the other methods.
Phiri et al. [
37] evaluated moderate-resolution atmospheric transmission, atmospheric correction, cosine topographic correction and dark object subtraction on a heterogeneous landscape in Zambia. In this study, Landsat OLI-8 with 30 and 15 m spatial resolution images were tested using a combination of random forest classifier [
38] and an OBIA [
39]. The developed method significantly improved land cover classification along with topographic corrections and pan-sharpening atmosphere. The developed framework (random forest and OBIA) effectively classified eight land-cover classes: water bodies, grassland, secondary-forests, dry-agriculture, primary forests, irrigated crops, settlements and plantation-forests. Yet, this study did not concentrate on the feature extraction that may degrade the performance of land-cover classification.
Zhao et al. [
40] implemented a new framework for land-use classification using UCMerced land-use dataset and simulated dataset. After collecting the satellite data, BOVW and SIFT [
41] methodologies were used for extracting the feature vectors from the collected data. In addition, concentric-circle based spatial rotation-invariant representation was used to describe the spatial information of data. A concentric-circle structured multi-scale BOVW was used for land use classification. The performance of the developed method was analyzed in terms of average classification accuracy. However, the developed method fails to achieve better land use classification in the large datasets due to the “curse of dimensionality” issue.
Nogueira et al. [
42] used convolutional neural networks (CNNs) in different scenarios like feature extraction, fine tuning and full training for land cover classification. The developed model’s performance was investigated on three remote sensing datasets: Brazilian coffee scene, UCMerced land-use and remote-sensing “19”. The results indicated that the developed model attained better performance in land cover classification compared to other existing algorithms.
Helber et al. [
26] developed a new patch-based LULC classification technique using Eurosat dataset. The undertaken dataset had 13 spectral bands and 10 classes with a total of 27,000 geo-referenced and labeled images. They explained how CNN was used to detect the LULC changes that helped in improving the geographical maps. However, using middle and lower level descriptors, the CNN model leads to poor classification performance because it supports only higher-level descriptors. Unnikrishnan et al. [
27] developed a new deep learning model for three different networks VGG, AlexNet and ConvNet where Sat-4 and Sat-6 datasets were used to analyze the performance of the developed model. This model included information on red and near infrared bands, with reduced number of filters, which were tested and trained to classify the images into different classes. The developed model was compared with other networks in terms of trainable parameters, recall and classification accuracy. Papadomanolaki et al. [
28] developed a deep learning model based on CNN for precise land-cover classification. The performance of the developed model was compared with the existing networks AlexNet-small, AlexNet and VGG in terms of accuracy and precision on Sat-4 and Sat-6 datasets. However, the CNN had two major concerns: computationally high cost and more data required to achieve precise classification.
Jayanth et al. [
43] developed an elephant-herding algorithm to classify LULC regions from high spatial resolution multi-spectral images. The developed elephant herding algorithm achieved high classification accuracy compared to the SVM classifier. Experimental results showed that the elephant-herding algorithm attained better performance in LULC classification on both Arsikere taluk and national institute of technology karnataka (NITK) campus datasets. Extensive experiments showed that the elephant herding algorithm misclassified the dense coconut tree class, which is considered as a major concern in the literature study. Bhosle and Musande [
44] developed a CNN model for LULC classification, in particular crop classification, in the hyperspectral remote-sensing images. In this study, the CNN model worked well on unstructured data, where it automatically extracted features for detection and classification of crops. Moreover, the extensive experiment showed that the CNN model achieved effective performance on an Indian pines dataset. However, the CNN model did not encode the orientation and position of objects (crop types) and suffered lack of ability to be spatially invariant to the input data.
Srivastava et al. [
45] compared three classification techniques in LULC analysis such as ANN, SVM, and maximum likelihood classification (MLC) to select the best technique among them. In the case of SVM, the classifier was well optimized for the degree of polynomial, penalty, and gamma, where root mean square and minimum output activation threshold were taken into account for ANN. The experimental investigation showed that the ANN classifier was superior to MLC and SVM classifiers. As discussed earlier, ANN classifier is inappropriate for maximum class classification, also showed limited performance in the conditions like regional fog error and cloud cover.
Kindu et al. [
46] analyzed LULC changes in the landscape of the Munessa-Shashemene area of the Ethiopian highlands during the period of 1973–2012. The satellite images of Landsat TM (1986), MSS (1973), rapid-eye (2012), and ETM+ (2000) were used to analyze LULC changes. The collected images were classified by using object-based image classifiers. Chatziantoniou et al. [
47] combined Sentinel-1 and Sentinel-2 data with the SVM classifier to map LULC on wetlands. In this literature study, the spectral information were derived from minimum noise fraction, grey level co-occurrence matrix, and principal component analysis in order to evaluate the classification accuracy. As stated earlier, the SVM classifier supports only binary classification, which is inappropriate for multiclass classification.
As already highlighted, a human group-based PSO with an LSTM classifier is proposed in this manuscript to address the above-discussed issues and improve the LULC classification, as it will be shown and discussed in the experimental section. It is worth underlining that the proposed model outperforms the methods presented in [
26], [
27] and [
28] as discussed above, which have made use of the same datasets. Hence, a human group-based PSO with a LSTM classifier achieved a minimum of 0.01% and a maximum of 2.56% improvement in classification accuracy on Sat 4, Sat 6 and Eurosat datasets compared to the existing methods presented in [
26,
27,
28].
3. Method
This Section presents the full architecture and all the detailed steps of the proposed algorithm, to allow interested researchers to replicate the image processing. The main workflow of human group-based PSO with an LSTM classifier is shown in
Figure 1.
3.1. Image Collection
In this study, Sat 4, Sat 6 and Eurosat datasets are utilized for experimental analysis to differentiate the things that are not related to human habitats in both urban and agricultural environments. The Sat 4 dataset comprises 500,000 image patches with four broad land-cover classes like tree, barren land, grassland and a class with all the other land covers [
48,
49]. The size of each remote-sensing image in the Sat 4 dataset is
m. The Sat 6 dataset comprises 40,500 image patches with the size of
m and it contains six land cover classes grassland like water bodies, buildings, barren land, roads, trees and other classes [
27,
28]. A sample image of Sat 4 and Sat 6 dataset is presented in
Figure 2, and the description of the land-cover classes is given in
Table 1.
In Eurosat dataset, the satellite images have been captured from European cities, and they are distributed over 34 countries. A dataset is generated with 27,000 labeled and georeferenced image patches, where the size of each image patch is
m. The Eurosat dataset includes 10 different classes, where each class contains 2000–3000 images. The LULC classes in this dataset are permanent crop, annual crop, pastures, river, sea & lake, forest, herbaceous vegetation, industrial building, highway and residential building [
26]. In addition, Eurosat images include 13 bands like aerosols, blue, green, red, red edge 1, red edge 2, red edge 3, near infrared, red edge 4, water vapor, cirrus, shortwave infrared 1 and shortwave infrared 1. A sample image of the Eurosat dataset is presented in
Figure 3, and the description of land use and land cover classes in Eurosat dataset is given in
Table 2. In addition, we have indicated the websites in the reference section, where the datasets can be downloaded [
50,
51]. Interested researchers can follow the described steps to replicate the algorithm.
The Sat 4, Sat 6, and Eurosat datasets are used in this manuscript, as highlighted at the beginning of this section, for experimental analysis to differentiate the things that are not related to human habitats, in both urban and agricultural environments. Future work will extend the proposed analysis to other applications, including human habitats.
3.2. Image Pre-Processing
After collecting the satellite images, normalization and histogram equalization methods are undertaken to improve the quality of the images. Image normalization, also called contrast stretching, changes the range of the pixel values helping in improving the visual quality of the collected satellite images. The common case of a min-max normalization to a new image ranging from 0 to 1, results in the well-known simplified formula expressed by the Equation (1).
where, original satellite image is indicated as
, minimum and maximum intensity values are represented as
respectively, which ranges from 0 to 255, the image after the min-max normalization is indicated with
, and the new minimum and maximum values are indicated with
. Then, the histogram equalization technique is used to improve the image quality without losing the image information like edges, image patches and points [
52,
53]. The histogram equalization technique changes the mean brightness of the normalized images to the mid-level of the permitted range, where the preservation of the original brightness avoids annoying artifacts in the images.
3.3. Feature Extraction
After normalization and histogram equalization of the collected satellite images, feature extraction is carried out by using a hybrid optimization procedure, based on the joint use of HOG, LGBPHS and Haralick texture features, namely correlation, contrast, energy, homogeneity, inverse diverse moment, entropy and angular second moment, to extract the feature vectors from the images.
3.3.1. HOG
In the satellite image, the HOG feature descriptor significantly captures the gradient and edge structure of the objects, though, it operates in the localized cells, and this upholds invariance to photometric and geometric transformations (except object orientation) [
54,
55]. This action helps in finding the changes appears in the large spatial regions. Here, a simple gradient operator
is applied to determine the gradient value. The gradient of the image is given by Equation (2), where
represents a generic point in the image and the image frames are denoted as
.
The magnitude of the gradients and edge orientation of the point
is calculated by following the respective conditions (Equations (3) and (4)),
For improving the invariance in illumination and noise, a normalization process is performed after the calculation of histogram values. The normalization is helpful for contrast and measurement of local histogram. In HOG, four different normalizations are used such as L2-norm, L2-Hys, L1-Sqrt and L1-norm. Among these normalizations, L2-norm gives a better performance in object detection. The blocks of normalization in HOG is given by Equation (5),
where,
is assigned as the small positive value, only when an empty cell is taken into account,
is a feature-extracted value,
is the non-normalized vector in histogram blocks, and
represents the 2-norm of HOG normalization.
3.3.2. LGBPHS
Initially, the pre-processed satellite images are transformed to obtain multiple Gabor magnitude pictures (GMP) using multi-orientation and multi-scale Gabor filters. Then, each GMP is converted into local GMP (LGMP), which is further categorized into non-overlapping rectangular regions with specific histogram and size [
56]. The LGMP histogram of all the LGMO maps is combined to form final histogram sequences. Features extracted by LGBPH are robust to illumination variations, because the LGBPH features are invariant to monotonic gray-scale changes.
3.3.3. Haralick Texture Features
The Haralick features are
order statistics that reflect the overall average degree of correlation between the pixels in different aspects like contrast, energy, inverse difference moment, entropy, homogeneity, correlation and angular second moment. Haralick texture features effectively deliver information regarding the relative position of the neighborhood image pixels in the satellite images that helps in improving LULC classification performance. The texture features are calculated from the texture information that are present in the grey-level co-occurrence matrix (GLCM) [
57]. In order to develop a number of spatial indices, Haralick uses the GLCM, because it contains the two neighboring pixels’ relative frequencies in the image. Haralick develops the vast number of textural features by starting with 14 original features that are described in [
58], but only seven features are widely used due to their importance for remote-sensing images. For instance, in [
59] they showed a better performance with respect to the others, and, therefore, in this study, those seven commonly used features are considered for the processing.
A set of seven different GLCM indicators is described by the following Equations (6)–(12):
where, the matrix cell index is depicted as
, the frequency value of the pair of index is represented as
, mean and standard deviation of the row sums are illustrated as
, and
lastly illustrates the total number of distinct gray levels in the images.
The variable importance analysis is carried out via the GLCM classification results, where the high importance of the variable is represented by high values of GLCM. From the experimental analysis, it has been proven that the Haralick’s seven selected features have the highest significance among the 14 original features, as demonstrated in [
59] and, therefore, the classification results proved that the Haralick features have higher resolutions, and this demonstrates that they are the best features, rather than others, for satellite image classification.
3.4. Feature Selection
Feature selection is carried out by using the human group-based PSO algorithm after extracting the feature vectors. Generally, PSO is a population-based searching algorithm that mimics the behavior of birds [
60]. In order to generate new positions of every particle, Equation (13) is used to update the velocity
and position
of the particles.
where,
is represented as the iteration,
are denoted as random real numbers between [0, 1],
is denoted as inertia weight,
is indicated as the best position,
is stated as local best position and
is indicated as the global best position of the particle. In PSO, the HGO algorithm is utilized initially to influence the particles and then the adaptive uniform mutation is utilized to improve the convergence rate and to make the implementation simpler.
3.4.1. Fitness Function and Encoding of Particle
Initially, HGO is used to transform a discrete multi-label into a continuous label. The undertaken algorithm finds the extracted feature vectors based on decision , where the vectors of the particle’s position are presented as .
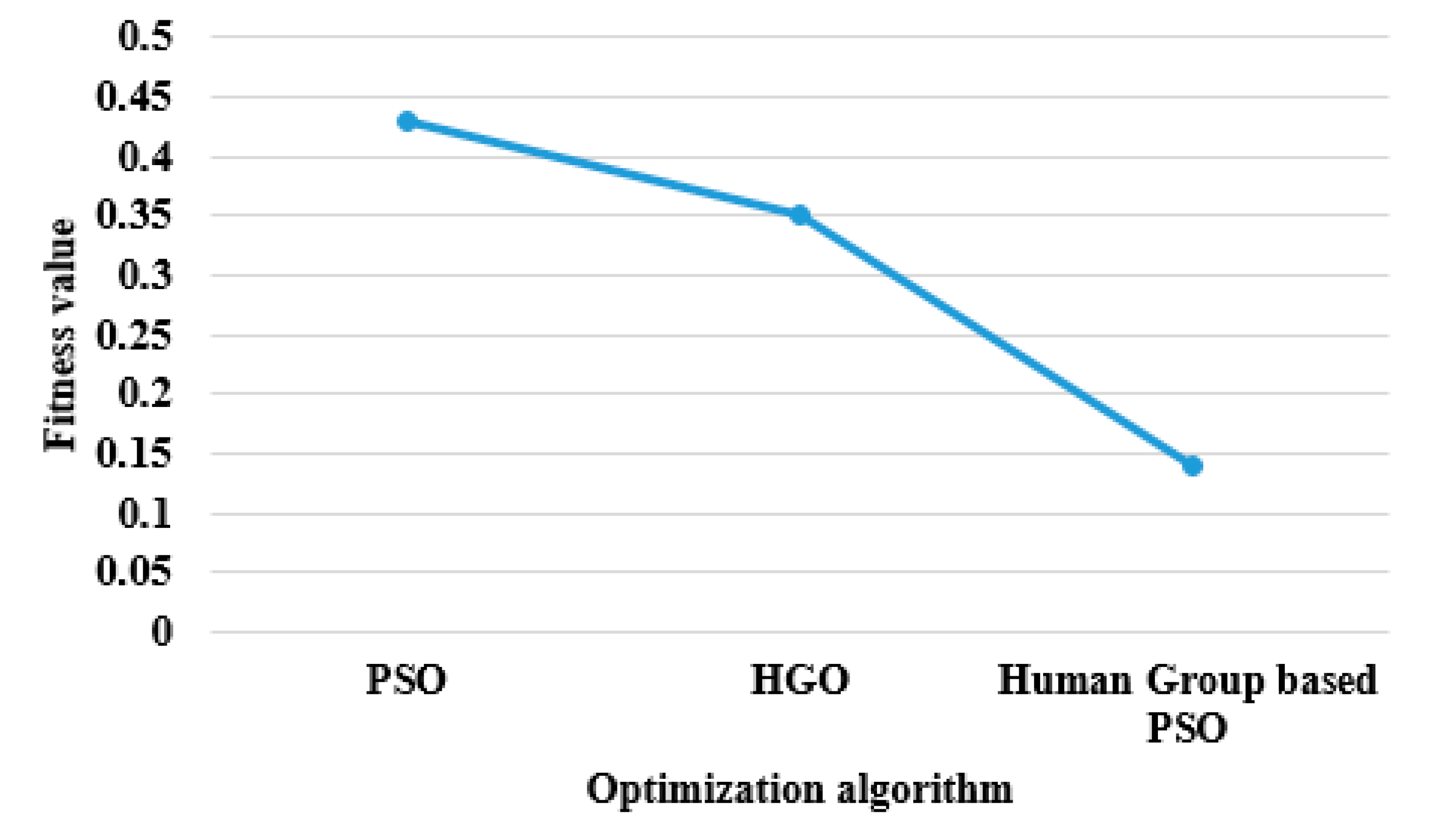
Compared to individual HGO and PSO algorithms, the proposed human group-based PSO algorithm has a minimum fitness value to select optimal feature vectors. The best fitness values of HGO, PSO and human group-based PSO algorithms is graphically represented in
Figure 4.
3.4.2. Adaptive Uniform Mutation
The adaptive uniform mutation is utilized to increase the ability of the feature selection algorithm in exploration. In this operator, a non-linear function
is used to control the range and decision of the mutation on each particle
. At every iteration,
is updated using the Equation (14).
where,
is indicated as maximum iteration,
denotes the number of iterations and the
value tends to decrease when the number of iterations increases. The mutation randomly picks the
elements from the particle, if the
value is higher than the random number between [0, 1]. Then, the mutation value of the elements within the search space is reinitialized, where
is an integer value, used for controlling the mutation range [
61,
62]. Mathematically,
value is represented in Equation (15), as:
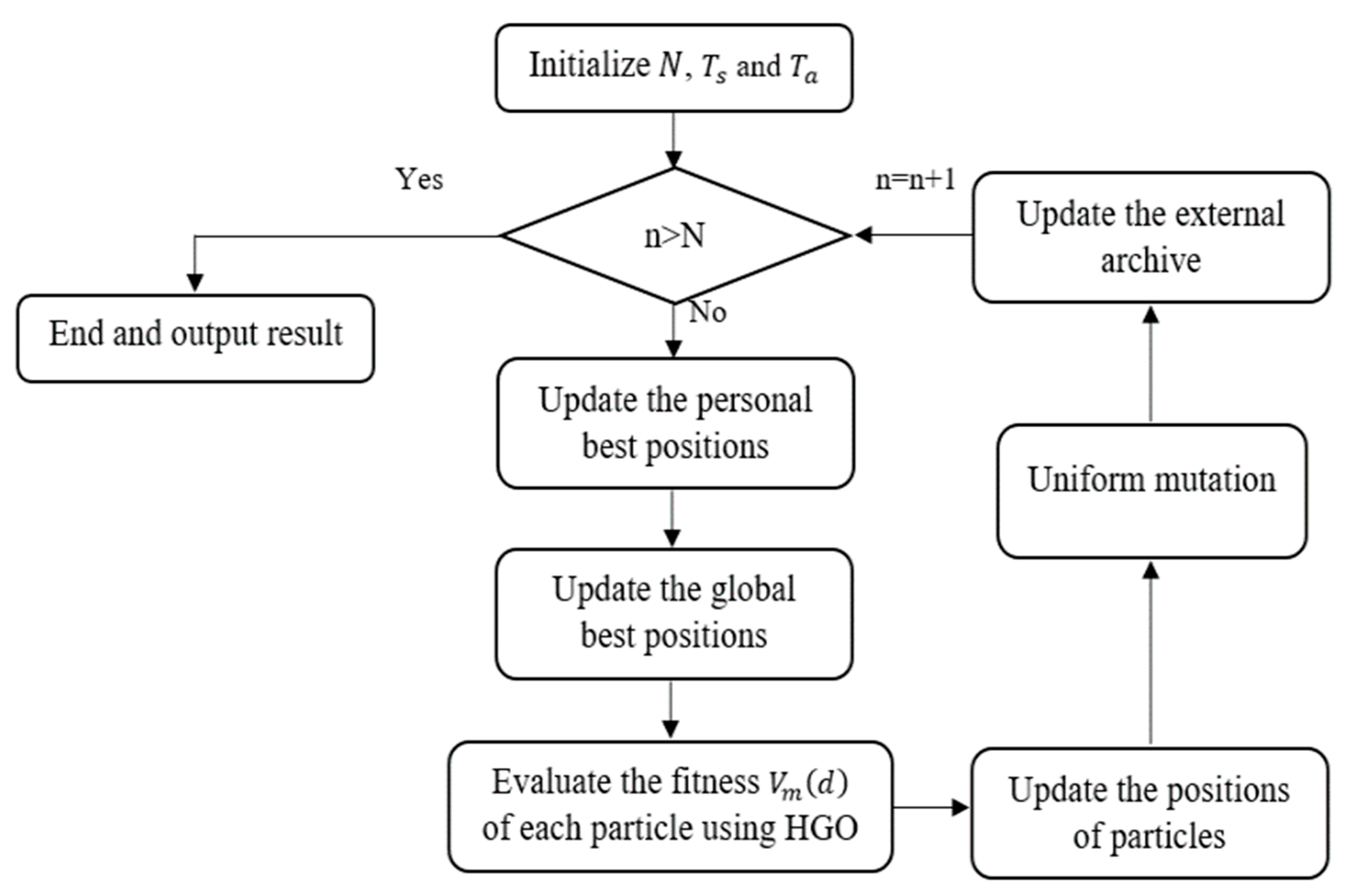
The flow chart related to the human group-based PSO algorithm is given in
Figure 5, with the further description of the steps below.
The step by step process of human group-based PSO algorithm is given below.
Step 1: Initialize the particles swarm, (a) set the number of iterations , swarm size and archive size (b) initialize the particles location, (c) estimate the objective of every particles, (d) save non-dominated solution into the archive.
Step 2: Pareto domination relationship is used to update the personal best position of the particles. If new position is better than old personal best position , or else unchanged the personal best position of the particles, where is represented as best position and is presented as local best position.
Step 3: Based on the diversity of solution, select the global best position from the archive. At first, crowding distance value is calculated and then binary tournament is used to select the global best position of the particle .
Step 4: Then, initialize the decision value based on . Every decision of the feature vector is a binary value , every feature vector is related to the fitness value that is considered as the weighted sum of stochastic contributions . However, these contributions depend on the value of decision and other decisions .
The fitness function is mathematically presented in Equation (16):
where the integer index
corresponds to the number of interacting decision values. The knowledge level of the
member is determined by the parameter
, which is the probability of each member that knows the contribution of the decision. Based on the knowledge level, every member
computes own perceived fitness using Equation (17):
where,
is denoted as the matrix, whose generic element
considers the value one with probability
with probability (
).
Step 5: Based on the decision value
, Equation (18) is used to update the velocity
and position
of the particles.
Step 6: Perform uniform mutation using the Equations (14) and (15).
Step 7: Update the external archive using crowding distance methodology.
Step 8: Analyze the termination condition: if the proposed algorithm attains the maximum iteration, then stop the algorithm, or else return to step 2. Hence, the worst particles (feature vectors) are eliminated based on the fitness function of the HGO algorithm.
In all three datasets, approximately 70−80% of the feature vectors are selected from the total extracted features with this procedure. After selecting the optimal features, classification is then carried out using the LSTM classifier.
Table 3 states the extracted and the selected features after applying the human group-based PSO algorithm.
3.5. Classification
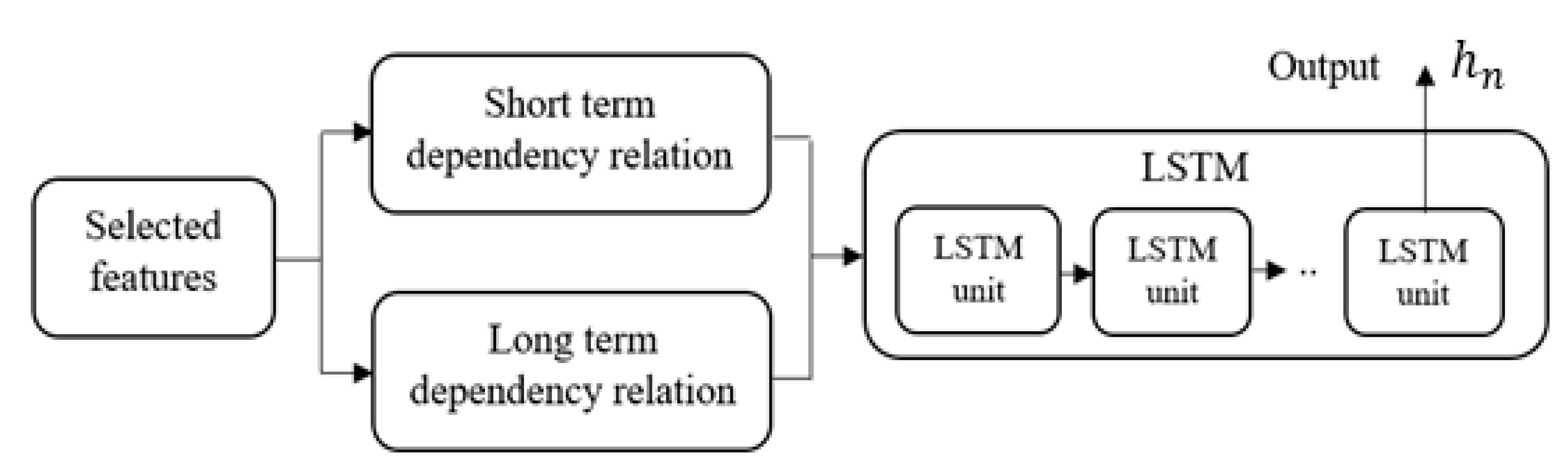
The LSTM classifier has the default behavior of remembering data information for a long period [
63,
64]. In a LULC classification, a huge number of remote sensing images are needed when neural networks are employed for attaining better results. Among different neural networks, the LSTM classifier has already proven to be the best choice in this case [
65,
66]. Generally, the LSTM classifier is composed of a series of LSTM units, where the temporal quasi-periodic features for extracting the long-term and short-term dependencies are stored. The structure of the LSTM classifier is denoted in
Figure 6, and in our case, it includes 98 LSTM units, whose details are graphically stated in
Figure 7.
Each single LSTM unit contains an
input gate , a
forget gate , a
cell and an
output gate which are mathematically expressed through the Equations (19)–(22):
where, represents the
quasi-periodic feature in different frequency bands at the
n time step. The output of the prior LSTM unit is stated as
.
Work coefficients are denoted as
, while
indicate the
hyperbolic tangent and
sigmoid activation functions, respectively. The output of the LSTM unit is mathematically denoted in the following Equation (23):
The output of the LSM unit at the n time step, contains the information of the prior time steps through , and collects the extracted features. Based on dependency relation, the cell state learns the memory information of the temporal quasi-periodic features for a long and short period during the training process.
It is worth commenting, before moving to the next section, on one main issue of neural networks, which is represented by the overfitting that is the ability of fitting the training data, but not the testing data, because the network has not learned to generalize to new situations. The neural network is unable to exert its potential when in an overfitting state, and this may apply to the LSTM case. Early stopping operation with dropout and a weight constraint is one of the solutions utilized to train the neural networks and prevent gradient explosion and disappearance. Dropout randomly selects some LSTM units to set their output to zero during every iteration. The output value of a few LSTM units is used when calculating the error value; instead, some of the other LSTM units are discarded, and used only when error back propagation calculations must be performed. A LSTM network is trained by combining dropout with the constraining of the network parameters in order to suppress the overfitting [
67], and a reasonable value for the hyper-parameters in the case of the LSTM employment are the following: 100 maximum epochs, 27 as minimum batch size, gradient threshold equals to 1, learning rate: 0.001, and layer wise hidden units respectively: layer 1: 200 units, layer 2: 225 units, layer 3: 200 units, and layer 4: 225 units. Further details can be found in [
68].
4. Result and Discussion
The proposed model is simulated using the MATLAB 2019 version on a PC with 128 GB RAM, i9 Intel core processor, Windows 10 operating system (64-bit) and 3 TB hard disk. The performance of the proposed model is compared with a few benchmark models: GoogleNet [
26], 2 band VGG [
27], hyper parameter tuned VGG [
27], 2 band AlexNet [
27], hyper parameter tuned AlexNet [
27], 2 band ConvNet [
27], hyper parameter tuned ConvNet [
27], AlexNet [
28], ConvNet [
28] and VGG [
28], in order to find out its effectiveness. Specifically, the performance of the proposed model is evaluated on the selected datasets in terms of precision, recall and accuracy parameters. The mathematical expressions of accuracy, recall and precision are represented in the following Equations (24)–(26).
where, true negative is denoted as
, false negative is represented as
, true positive as
and false positive as
.
In the following subsections, the quantitative evaluation of the proposed model is carried out when Sat 4, Sat 6 and Eurosat data are used. As a benchmark, the results presented in [
26,
27,
28] works are considered.
4.1. Quantitative Investigation on Sat 4 Dataset
The Sat 4 dataset is used to evaluate the performance of the proposed model to classify four land-cover classes: tree, barren land, grassland and a class with all the other land covers. In this case, the performance evaluation is validated by using 500,000 image patches with 70% of the data used for training and 30% for testing.
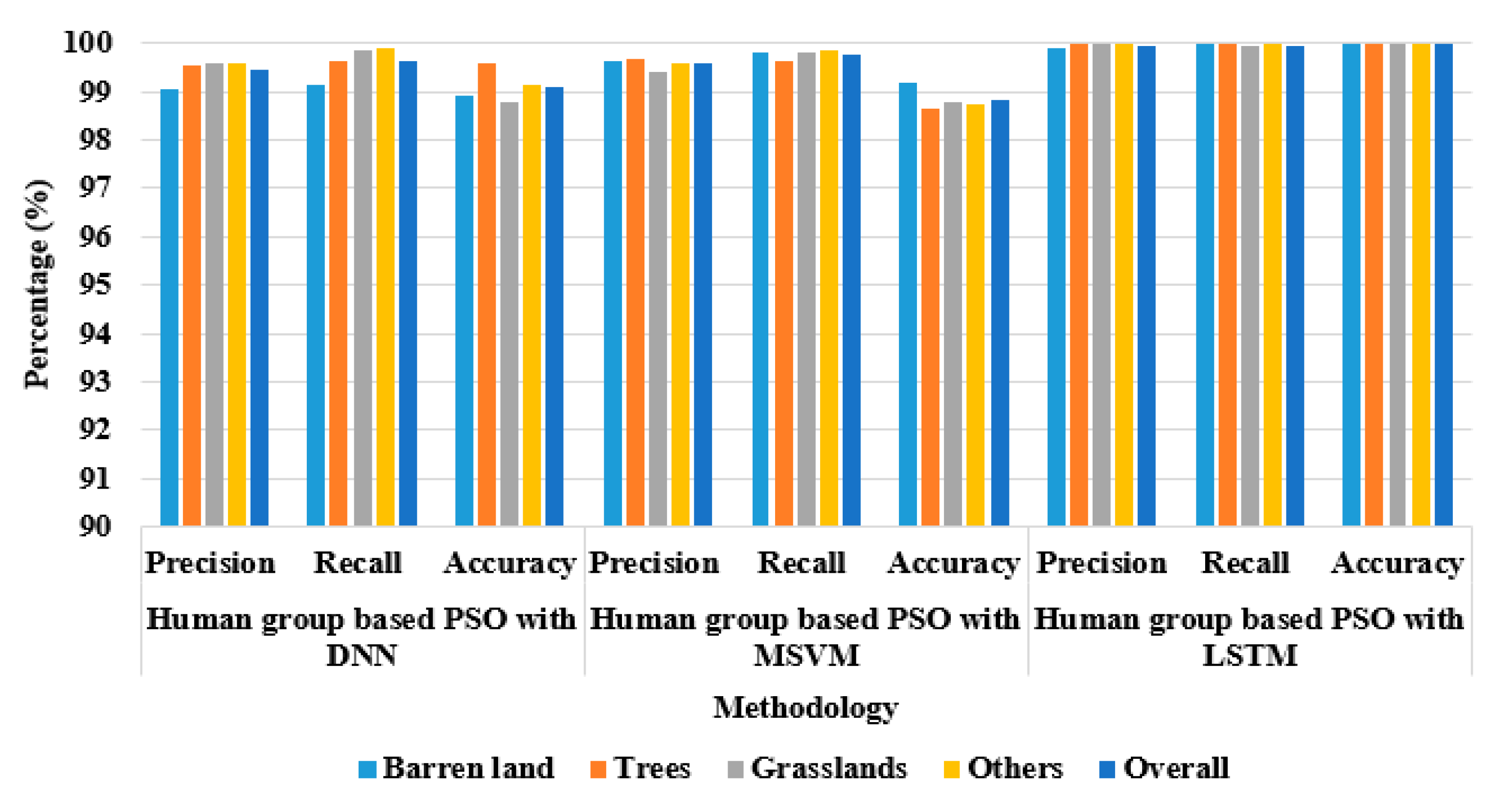
Table 4 and
Table 5 represent the performance evaluation of the proposed model, implementing an LSTM classifier, when the human group-based PSO is used with two other different classifiers, the Deep Neural Network (DNN) and the Multi Support Vector Machine (MSVM), in terms of recall and precision (
Table 4), and in terms of accuracy (
Table 5). The two tables point out that the LSTM classifier achieves better classification performance in LULC classification.
The same performance analysis of the proposed model with different classifiers on Sat 4 dataset is graphically represented in
Figure 8.
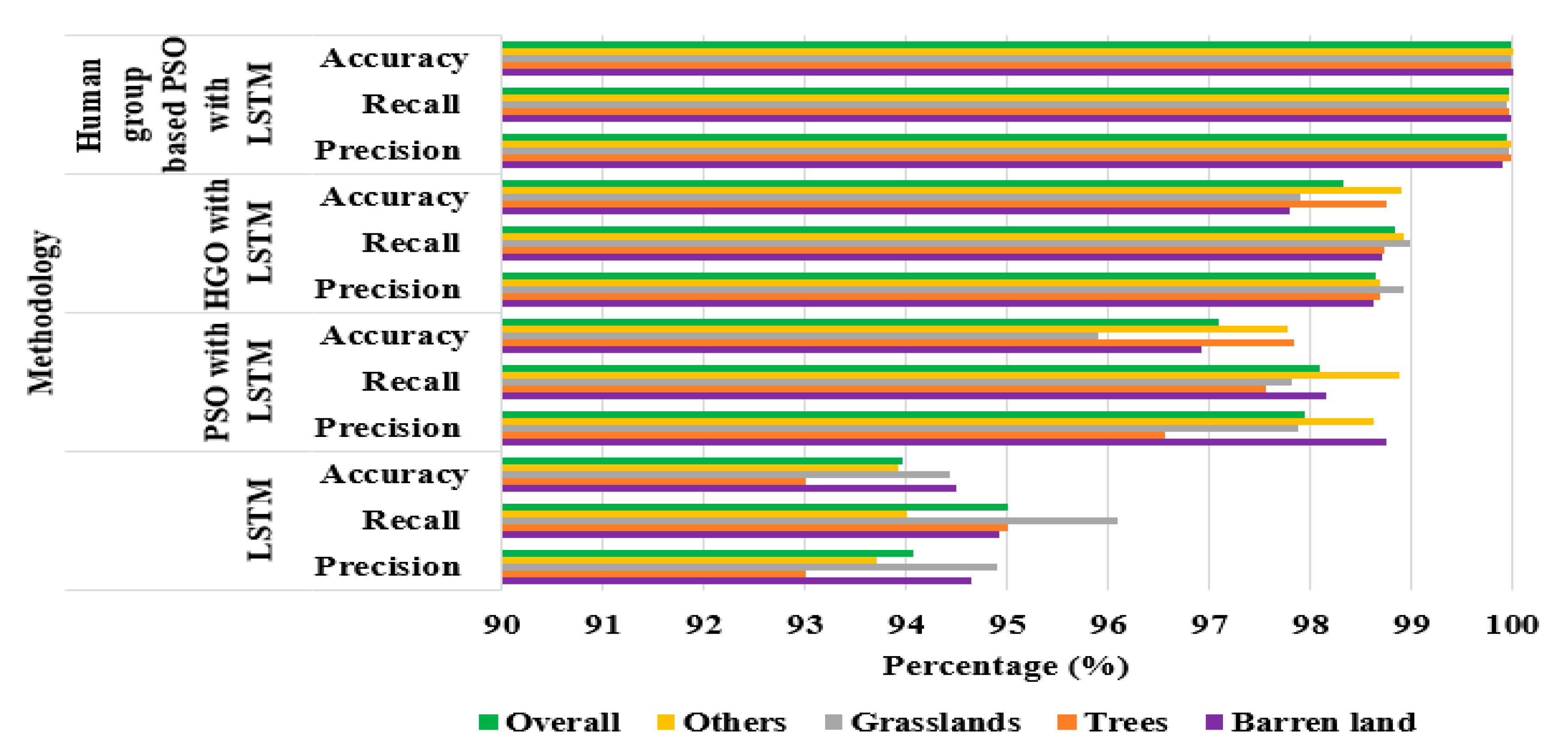
Table 6 and
Table 7 represent the performance evaluation of the proposed model when compared with other optimization techniques, like the LSTM only, the PSO with LSTM, the HGO with LSTM, and the human group-based PSO with LSTM, by means of recall and precision (
Table 6) and by means of accuracy (
Table 7). These tables are pointing out that the LSTM classifier with human group-based PSO achieves better performance in LULC classification in terms of recall, precision, and accuracy on the Sat 4 classes, as previously specified. The proposed model, the human group-based PSO with LSTM, shows a maximum of 6.03% improvement in LULC classification, if compared to LSTM, PSO with LSTM and Human Group Optimization (HGO) with LSTM.
Figure 9 shows graphically the same performance analysis.
Comparison of Proposed Method with Existing Techniques on Sat 4 Dataset
In this subsection, AlexNet, ConvNet, and VGG [
27] are selected for implementing the PSO and HGO techniques. The reason for choosing these techniques is that they are the most widely used neural network architectures for the classification of LULC on satellite images. The selected existing techniques are implemented with HGO and PSO after the max pooling layer of each existing technique. For instance, ConvNet has the output of 4.096 features in the max pooling layer and implemented the PSO and HGO as filtering technique that provides only 1000 features as output of fully ConvNet.
Table 8 shows the performance evaluation of the proposed model when compared with these various neural networks on Sat 4 dataset, in terms of classification accuracy. From the analysis, the results confirm that the proposed LSTM with PSO and HGO achieved better performance on LULC classification in terms of accuracy on Sat 4 dataset.
Sample image patches of Sat 4 dataset for the selected classes are given in
Figure 10.
It is worth to underline that the size of each image patch in Sat 4 dataset is m, quite small, and this limits the possibility to enlarge the image since it appears very unfocused.
4.2. Quantitative Investigation on Sat 6 Dataset
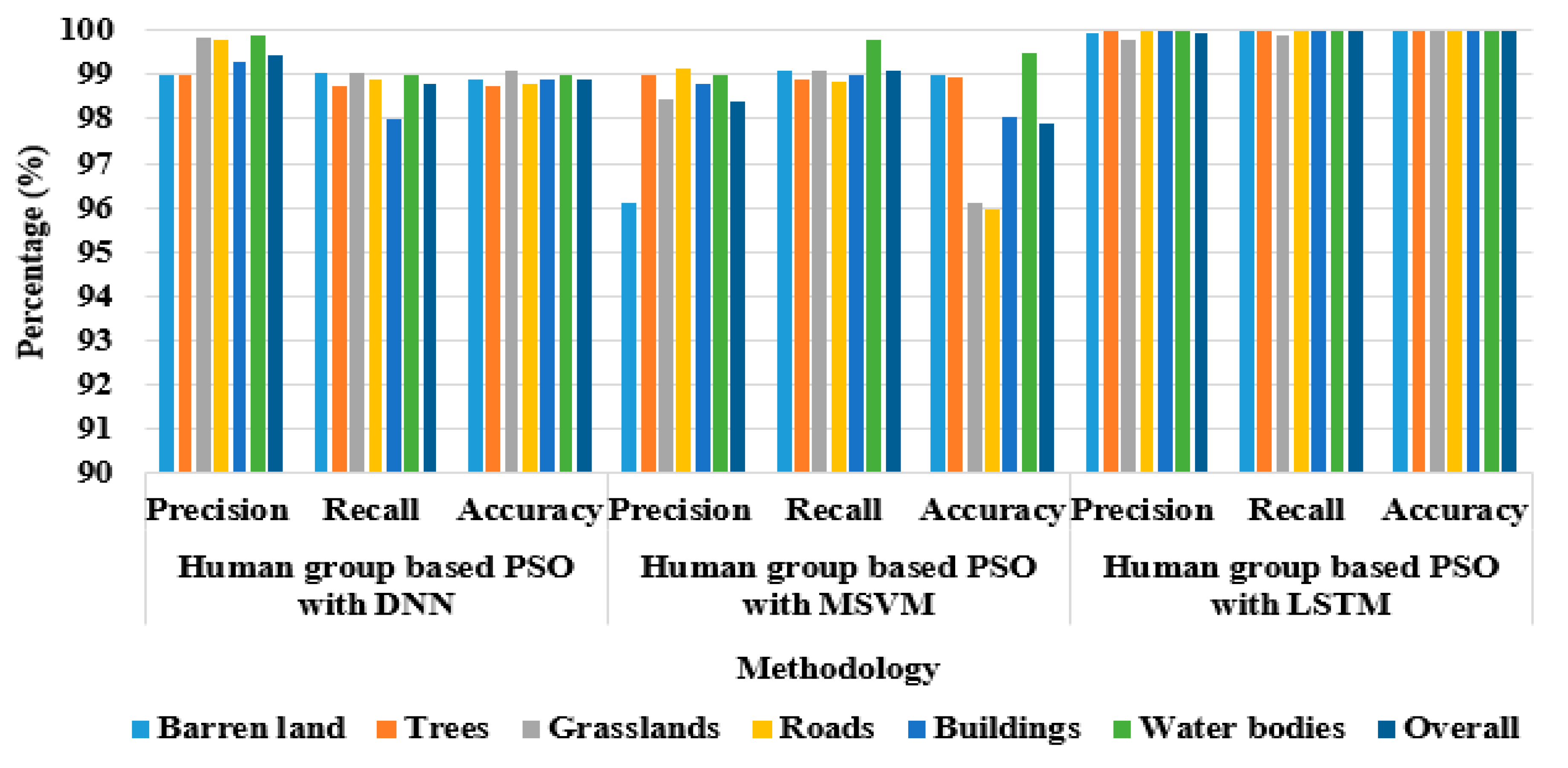
The same analysis carried out in the previous
Section 4.1 on Sat 4 is now assessed on Sat 6 dataset. In this case, the dataset is used to evaluate the performance of the proposed model to classify six land cover classes: grassland, water bodies, buildings, barren land, roads and trees. The performance analysis is carried out by using 40.500 image patches with 70% of them for training and 30% for testing. The performance of the proposed model is analyzed with different classification techniques, DNN, MSVM, LSTM (
Table 9 and
Table 10), and with different optimization techniques, LSTM only, the PSO with LSTM, the HGO with LSTM, and the human group-based PSO with LSTM (
Table 11 and
Table 12), by means of recall and precision (
Table 9 and
Table 11) and by means of accuracy (
Table 10 and
Table 12). The results summarized in the following
Table 9 and
Table 10, respectively, point out how the LSTM classifier achieves better performance in LULC classification, if compared to other classification techniques, also in this case, when Sat 6 dataset is used. Performance analysis of the proposed model with different classifiers on Sat 6 dataset is also graphically presented in
Figure 11.
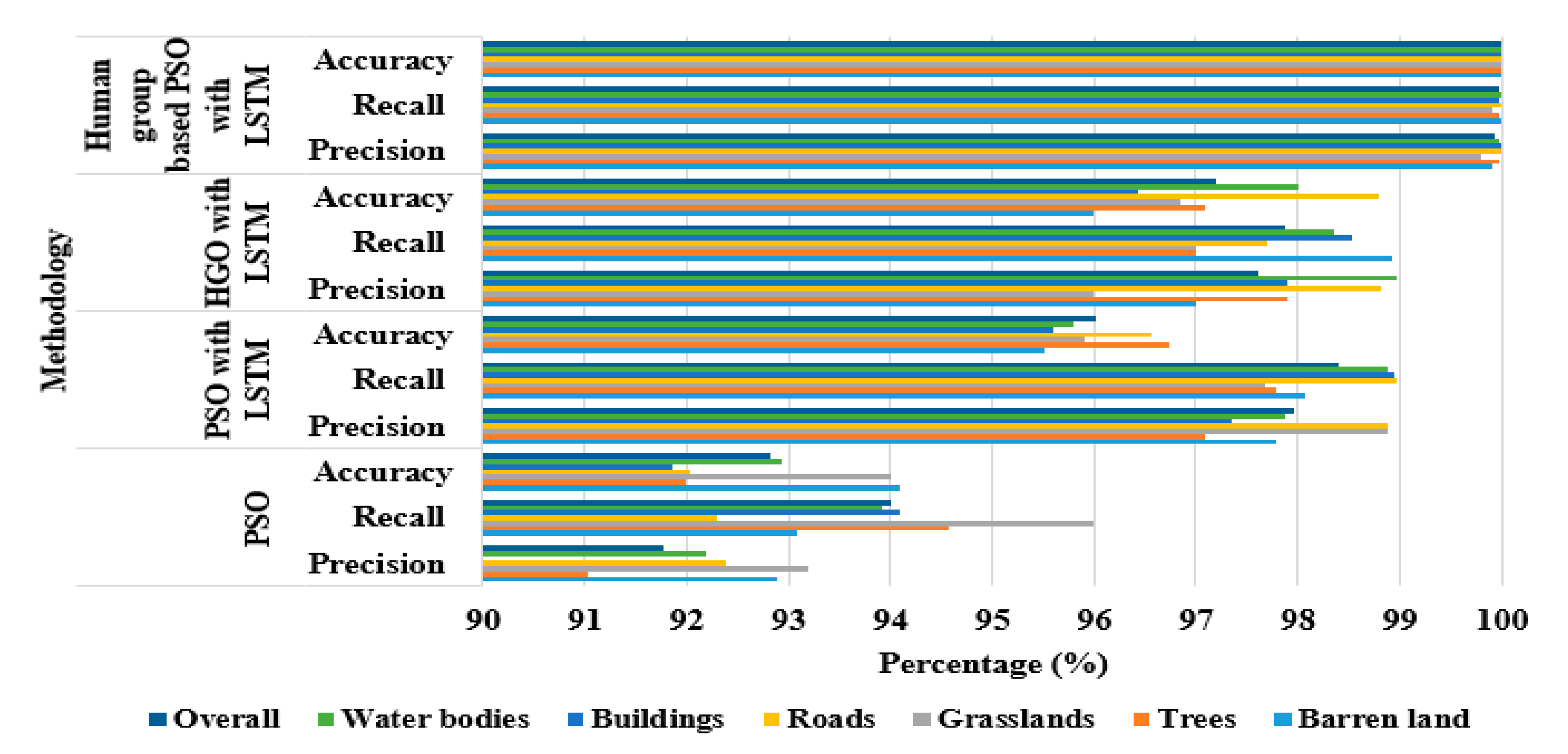
The results summarized in the following
Table 11 and
Table 12, respectively, point out how the proposed model achieves better performance in LULC classification, if compared to other different optimization techniques on Sat 6 dataset. The Tables show how the proposed model, the human group-based PSO with LSTM, reaches a maximum of 7.17% and minimum of 2.8% improvement in LULC classification compared to the only LSTM, to the PSO with LSTM and to the HGO with LSTM.
Performance analysis of the proposed model with different optimization techniques on Sat 6 dataset is also graphically presented in
Figure 12.
Comparison for the Proposed LSTM Method with Existing Techniques on Sat 6 Dataset
In this subsection, LSTM, AlexNet, VGG and ConvNet are implemented with PSO and HGO on the Sat 6 dataset. Eight layers are presented in the AlexNet, where the first five layers are convolution layers followed by max-pooling layers and the remaining three are fully connected layers. The second fully connected layer produces as output 4096 features. Here, the PSO and HGO are implemented to minimize the features. Therefore, the final output of AlexNet is 1.000 features. Likewise, the other neural networks are implemented with PSO and HGO after the max-pooling layers.
Table 13 describes the comparison of the proposed model with the different neural networks, AlexNet, VGGNet and ConvNet with PSO and HGO, on the whole Sat 6 dataset in terms of overall classification accuracy. In this case, LSTM + PSO + HGO attain 99.94% of precision, 99.97% of recall and 99.99% of accuracy. Sample image patches of the Sat 6 dataset for the selected classes are given in
Figure 13. The size of each patch is
m also in the case of the Sat 6 dataset, and the same issue already discussed is faced when images of the patches are shown.
4.3. Quantitative Investigation on Eurosat Dataset
In this section, Eurosat dataset is used to evaluate the performance of the proposed model to classify 12 LULC classes. Those are permanent crop, annual crop, pastures, river, sea and lake, forest, herbaceous vegetation, industrial building, highway and residential building. In this scenario, the performance analysis is accomplished for 27,000 image patches with 70% of the data used for training and 30% for testing with two case studies.
In this case,
Table 14 summarizes the performance values of the proposed model for different classes of LULC classification in terms of accuracy, recall and precision, with different classifiers, DNN, MSVM, LSTM, and different optimization techniques, PSO, HGO and human group-based PSO. The accuracy, recall and precision of the LSTM classifier with human group-based PSO is 97.40%, 98.70% and 97.80%, respectively. The LSTM classifier with human group-based PSO shows an improvement in LULC classification also in this case, when tested on the Eurosat dataset. Performance analysis of the proposed model on Eurosat dataset is graphically presented in
Figure 14.
Comparison of Implementing PSO and Human Group Optimization (HGO) on the Proposed Method
In this subsection, GoogleNet [
26] is implemented with optimization techniques, namely PSO and HGO, and only 1.000 features are selected. The other techniques like AlexNet, VGG, and ConvNet, as presented in [
27], worked only on the Sat 4 and Sat 6 dataset, hence, they were not considered in the case study of the Eurosat dataset. The GoogleNet uses 1 × 1 convolutions in the middle of the architecture, and global average pooling. In addition, the inception module is also different from other architectures. The 1 × 1, 3 × 3, 5 × 5 convolutions are presented in the inception module and 3 × 3 max pooling is operated in a parallel way and the input and output are stacked together for generating the final output.
Table 15 shows the comparative analysis of LSTM and GoogleNet [
26] with PSO and HGO on the whole Eurosat dataset. Sample image patches of the Eurosat dataset are given in
Figure 15. In this case, the image could be realized with a better focus, since the size of each patch is
m.
4.4. Comparative Analysis
The comparative analysis between the proposed and existing models is represented in
Table 16. Analyzing recent works from the literature, based on similar data, it was found that Helber et al. [
26] developed a new patch-based LULC classification technique using Eurosat dataset. As already discussed, this work explained how CNN was used to detect the LULC changes, by helping to improve the geographical maps. Unnikrishnan et al. [
27] implemented a novel deep learning method for three different networks VGG, AlexNet and ConvNet, and Sat 4 and Sat 6 datasets were used to analyze the performance of the developed model. Papadomanolaki et al. [
28] designed a deep learning model based on a CNN for accurate land-cover classification, by including 2 band information (red and near infrared) with a reduced number of filters, which were tested and trained to classify the images into different classes. In our manuscript, the proposed architecture was directly compared with these models in terms of precision, recall and accuracy.
Table 16 illustrates that the proposed model achieves a minimum of 0.01% and a maximum of 2.56% improvement in accuracy on Sat 4, Sat 6 and Eurosat datasets, when compared with the models presented in [
26,
27,
28]. The improvement is there, although modest, but it is worth adding also that the human group-based PSO algorithm, presented in this work, when combined with a LSTM classifier gains a better performance in LULC classification also by means of computational cost and processing time. Compared to DNN and MSVM, LSTM has less training time for all three datasets. Moreover, the proposed human group-based PSO algorithm significantly reduces the “curse of dimensionality” problem and the LSTM classifier achieves better performance in LULC classification, as demonstrated before, when compared with other classifiers. This better LULC classification may assist the researchers in many real time applications such as wildlife habitat protection, urban expansion/encroachment, natural resource management, legal boundaries for tax and property evaluation, target detection (identification of land/water interface, clearings, roads, bridges, and landing strips), damage delineation (flooding, seismic, tornadoes, volcanic, and fire), and routing/logistics planning for resource extraction activities, exploration and seismic.
4.5. Final Discussion
As highlighted in the methodology section, feature selection is an integral part of LULC classification in this research paper. Several feature vectors are extracted from the images using LGBPHS, HOG and Haralick approaches, and feature selection is used to choose optimal feature vectors for better classification. The effects of feature selection are shown in
Table 6,
Table 7,
Table 11, and
Table 12, where the experimental analysis is verified by determining the performance measures. Related to individual LSTM, PSO with LSTM, and HGO with LSTM, the proposed human group-based PSO with LSTM showed a maximum of 6.03% and a minimum of 1.66% improvement in LULC classification on Sat 4 dataset. Similarly, the proposed human group-based PSO with LSTM showed a maximum of 7.17% and minimum of 2.80% improvement in LULC classification on the Sat 6 dataset. In addition to this, the proposed human group-based PSO with LSTM achieved a minimum of 0.01% and a maximum of 2.56% improvement in classification accuracy on Sat 4, Sat 6 and Eurosat datasets compared to the existing methodologies like GoogleNet [
26], 2 band AlexNet [
27], Hyper parameter tuned AlexNet [
27], 2 band ConvNet [
27], Hyper parameter tuned ConvNet [
27], 2 band VGG [
27], Hyper parameter tuned VGG [
27], AlexNet [
28], AlexNet-small [
28], and VGG [
28]. It has been also highlighted how the proposed model presents a better performance in LULC classification even by means of computational cost and processing time.
In this work, experimental analysis was focused on differentiating the things that are not related to human habitats, in both urban and agricultural environments. Future work will extend the proposed analysis to other applications, including human habitats.
5. Conclusions
The objective of this study was to propose an effective feature selection model to classify the LULC classes of the urban and agricultural environment. The proposed model helped to analyze the changes in land productivity, soil quality, and biodiversity, for instance, which provided a clear idea about environmental quality, wildlife habitat, loss of prime agricultural lands, uncontrolled development, etc. In this study, an optimization procedure based on the combination of LGBPHS, HOG and Haralick texture features was first utilized to extract the feature vectors of the objects from the normalized remote-sensing images. The human group-based PSO algorithm was then applied to select the optimal feature vectors that helped in further improving the performance of classification. The optimal selected features were given as the input to an LSTM classifier. The proposed model achieved a better performance when compared to the existing models in LULC classification in terms of recall, accuracy and precision. The simulation results showed that the proposed model achieved enhancements in classification accuracy on the Sat 4, Sat 6 and Eurosat datasets. In addition, the computational time of the proposed model is only 1.24 s. The main findings of the human group-based PSO algorithm delivered up to date dynamics of LULC in the Sat 4, Sat 6 and Eurosat datasets. These datasets are used to monitor the future changes, LULC planning process and other similar studies in the European countries. In future work, an optimization based clustering approach will be included in the proposed model to verify if the LULC classification method can be further improved.

 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}