Figure 1 describes the algorithm structure of space target pose estimation, which is composed of two modules: the pretreatment process and the main process. The pretreatment process has two parts: first, select some images and their corresponding keypoint coordinates of the space target from the training set, and then reconstruct the three-dimensional structure of the space target through a multiview triangulation algorithm [
41]. SUbsequently, in order to reduce the influence of background interference, we use an object detection network to predict the bounding box of the space target. Through this process, we can obtain the location information of the space target in images and the coordinates of keypoints. In main process, the cropped target image is sent into the keypoint detection network, and 11 keypoint coordinates containing satellite position and attitude features are output. Finally, the two-dimensional coordinates and three-dimensional space target models are fed into the PnP solver in order to obtain the estimated values of the space target position and attitude.
In particular, for the space target detection model, target images are small due to the long shooting distance, so the high-resolution feature is particularly important for the space target detection algorithm. ResNet [
36] has the characteristics of residual connection and identity mapping. However, the downsampling of each stage of the network makes the feature map resolution increasingly lower. In order to solve this problem, we use a high-resolution network instead of the general deep residual network and use a multiscale prediction algorithm for space target detection.
For the keypoint detection model, some state-of-the-art algorithms do not consider the problem that some keypoints are blocked due to continuous adjustment of the space target’s pose [
42,
43]. Therefore, an online hard mining algorithm is introduced in order to make the network focus on obscured keypoints. The feature map’s high-resolution characteristic is important for keypoint detection, so the backbone network still uses a high-resolution network to maintain high resolution. In addition to using a high-resolution backbone deep network, the model introduces dilated convolution at each feature fusion stage to increase the receptive field of the feature to infer the keypoint information from the global information. We describe the operation process of space target pose estimation, as shown in Algorithm 1.
3.1. Problem Formulation
Formally, the problem statement for this work is the estimation of the position and attitude of the camera frame
C, with respect to the body frame of the space target
B.
is the relative position between the origin of the target’s body reference frame and the origin of the camera’s reference frame, as shown in
Figure 2. Similarly,
labels the quaternion containing the rotation relationship between the target’s body reference frame and the camera’s reference frame.
The translation vector and rotation matrix are usually used to represent the relative position and attitude of the space target. However, the orthogonality of the rotation matrix makes it inconvenient to calculate the actual pose. In the aerospace field, Euler angles [
44] (yaw, roll, and pitch) are sometimes used to represent the space target attitude, but Euler angles have the problem of universal lock. Therefore, Euler angles are not suitable for the attitude determination of space targets under omnidirectional changing angles. Quaternions can effectively avoid the problem of universal lock and are used to represent the pose of a space target. The quaternion definition formula is as follows:
The unit constraint relation in the formula is
, where
represent three imaginary units. The basic mathematical equation of quaternions is shown, as follows:
In the above formula,
represents the rotation axis, and
represents the rotation angle around the rotation axis. The corresponding relation between matrix
R and quaternion is shown, as follows:
where
,
,
.
The accuracy of pose estimation is evaluated by calculating the magnitude of the target rotation angle
and translation error
in the predicted space. Where
represents the real label of the quaternions of the target image,
q represents the prediction label of the quaternions,
represents the translation vector label of the target image,
t represents the predicted value of the translation vector,
represents absolute value,
represents dot product,
represents the 2-norm, and
i represents the i-th space target image. The rotation angle error
of the estimated rotation angle of the i-th space target image is shown, as follows:
The translation vector error formula of the
i-th space target estimation is illustrated as:
For the pose estimation of a space target image, the total error
is the sum of the rotation angle error and the translation vector error:
Finally, the average pose error of all space targets in the test set is defined as
, the number of images in the test set is
N, and the error is demostrated, as follows:
3.2. Space Target Detection Algorithm
The space target detection network is mainly used to detect target areas, which is convenient for extracting targets from deep space backgrounds and feeding them into subsequent keypoint detection networks, so that keypoint detection networks focus on keypoint detection and eliminate interference from irrelevant backgrounds. In addition, in actual project research, it is found that the obtained image is generally large, such as , , and the size of the image sent into the deep network is generally , . Therefore, it is necessary to carry out space target detection before keypoint detection; otherwise, the space target image sent into the keypoint detection network will lose detailed information and easily blur the image.
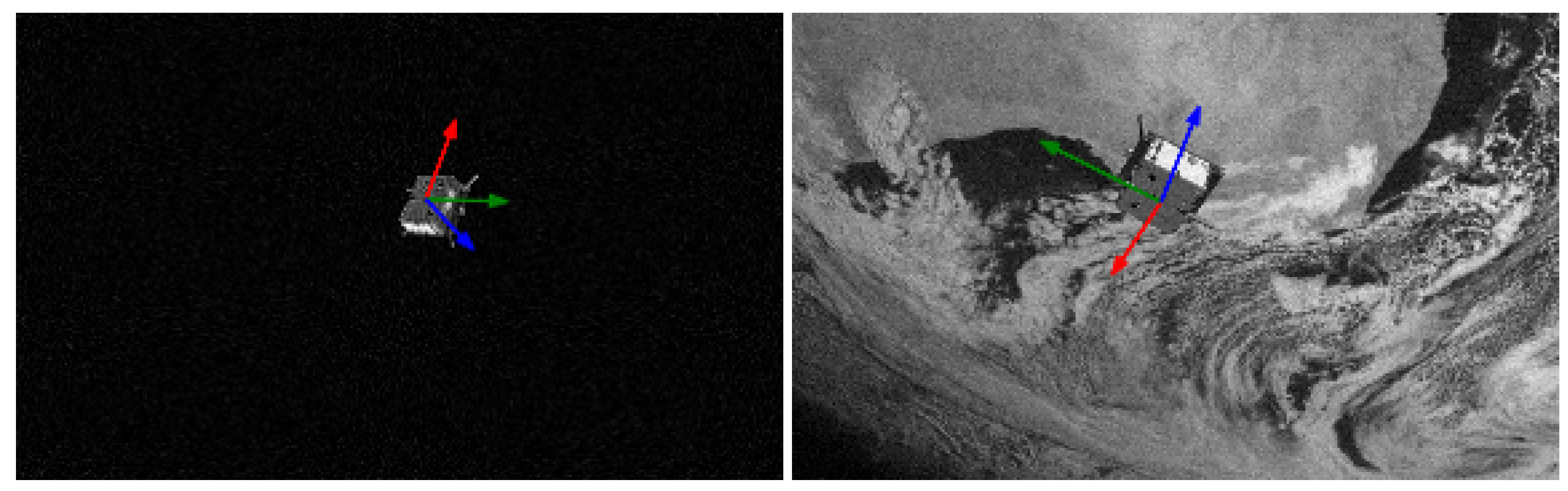
Figure 3 is an example of a space target image in a simple background and a complex background. The space target only accounts for a small part of the whole image in the image taken, as shown in
Figure 3a. If the whole image is sent into the keypoint detection network, the network cannot focus on the useful target information. The earth and clouds make the background of the space target more complex, causing accuracy interference from the background, as shown in
Figure 3b. Therefore, it is necessary to implement space target detection before keypoint detection.
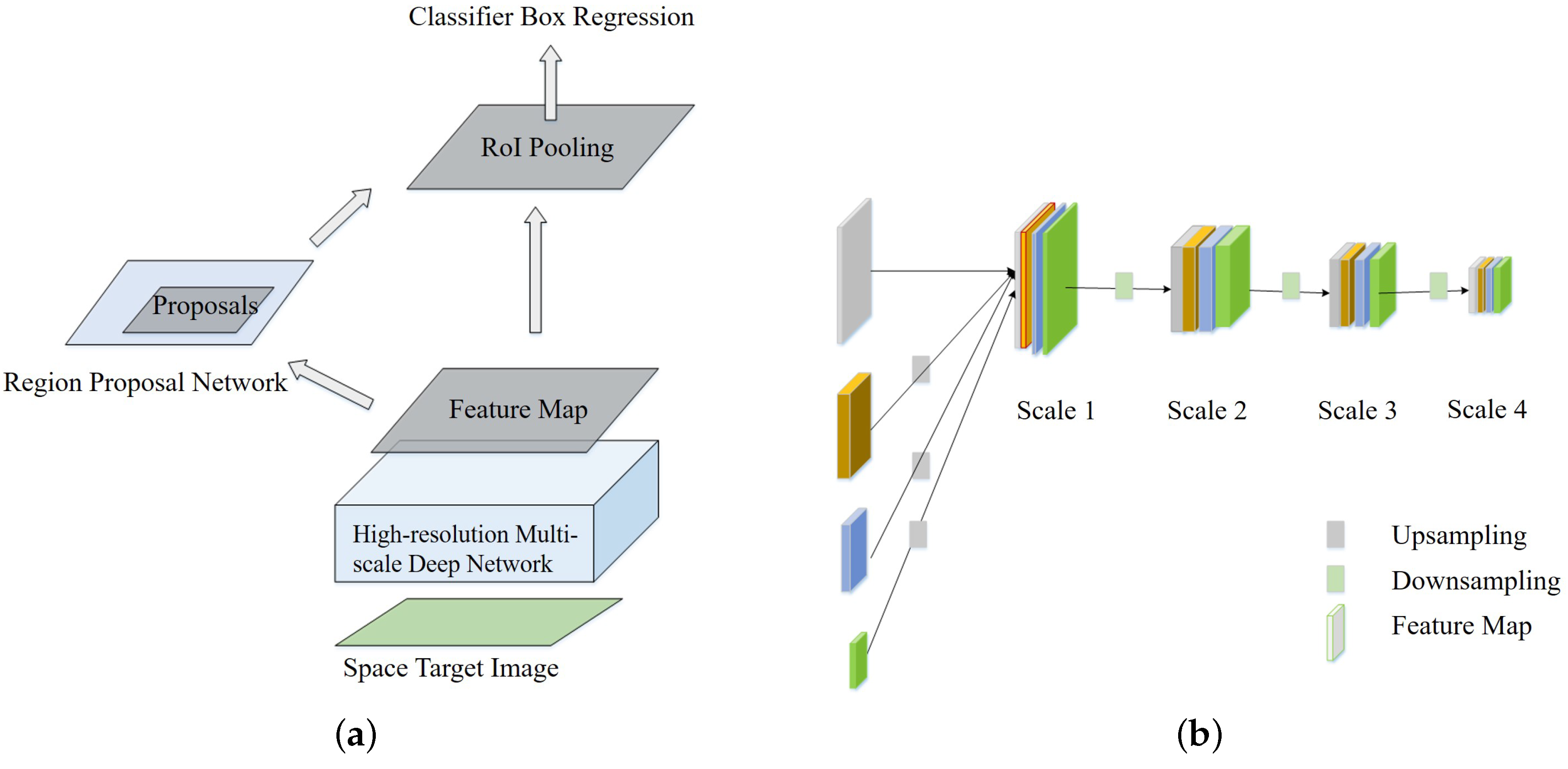
Figure 4a shows the space target detection algorithm framework, which aims to solve the multiscale problem of space targets that are caused by changes in shooting distance. Multiscale prediction networks for feature extraction improves the detection performance of small targets. Because of the higher accuracy of the two-stage target detection algorithm, the space target detection algorithm uses the Faster R-CNN model [
38,
45], and network optimization is performed on the basis of the algorithm.
The proposed space target detection network adopts a High-Resolution Network (HRNet) [
39] instead of the classic target detection backbone network ResNet. Compared with ResNet, HRNet adopts a feature fusion strategy, so that features extracted during the entire process of network learning always maintain high resolution. HRNet gradually adds high-resolution to low-resolution subnetworks, forming multiple network stages and connecting multiple subnetworks in parallel. During the entire feature extraction process in a high-resolution network, multiscale fusion is completed by repeatedly exchanging feature information through parallel multiresolution subnetworks, so that high-resolution features can be obtained from low-resolution characterization in other parallel representations. When compared with feature pyramid networks [
46] (FPN), HRNet always maintains high-resolution features, unlike FPN networks, which recover from low resolution to high resolution to obtain high-resolution features.
The HRNet low-resolution feature is obtained by one or several convolution kernels with a continuous step size of 2, and then the different resolution features are fused by adding element by element. The HRNet high-resolution feature is obtained by the nearest neighbor interpolation upsampling method, while using a or upsampling rate method to increase the resolution of the feature map to the same size as the high-resolution feature map, and finally using convolution to change the number of channels, so that it can be added and fused with the original high-resolution feature map.
The space target detection network adopts Faster R-CNN, and the original backbone network ResNet is replaced with HRNet, which makes the detection effect of small targets better. The network has a parallel subnetwork structure and a multiscale fusion strategy.
Figure 4b shows the multiscale characteristics of the space target image. There is a scale difference in the space target images due to the change in its shooting distance. If the network finally outputs only high-resolution feature maps, it will cause the large target detection accuracy rate to be low. Therefore, the detection network finally adopts a strategy similar to the feature pyramid. While the network continues to maintain high resolution, the high-resolution feature map is downsampled by average pooling in the final feature output stage, thus enabling multiscale detection. It is the network structure of the last stage of the high-resolution network, as shown in
Figure 4b. Because of the multiscale characteristics of the obtained space target images, if only the scale 1 feature map is included, then the recognition rate of the spatial target image with a short shooting distance is low, similar to FPN. After adding feature scales 2, 3, and 4, the network model is no longer limited by the shooting distance, and then space targets at all scales are well detected.
The proposed high-resolution detection algorithm that is based on Faster R-CNN aims to improve the detection accuracy of small space targets. The high-resolution feature extraction network is used to reduce the downsampling loss of feature maps. In addition, the network finally adopts multiscale prediction to achieve significant performance for the detection of large and small targets.
3.3. High-Resolution Space Target Keypoint Detection Network
Selecting the keypoints of the target surface is more meaningful than selecting the vertices of the 3D box when processing keypoint prediction on the space target dataset, speed. The keypoints of the target surface are closer to the target features than the vertices of the 3D box [
47]. Eleven space target 2D keypoints were selected, including four vertices at the bottom of the target, four vertices at the solar panel, and vertices at the ends of the three antennas of the target, as shown in
Figure 5.
Figure 6 illustrates the whole process of our improved keypoint detection network. The input image generates features through the network, and these multi-scale features are fused by dilated convolution. Then the network calculates the loss combined with the online hard keypoint mining method, and finally outputs the keypoints through the Gaussian kernel. In the space target detection section, the high-resolution network was introduced. The parallel structure of the subnetwork is adopted, so that the network always maintains high-resolution features without the need to sample and recover high-resolution features from the low-resolution features, and the exchange unit is used to perform different subnetworks. The communication between the networks can obtain the feature information of other subnetworks, and finally, HRNet can learn rich high-resolution features. However, unlike the high-resolution detection network for space targets, each keypoint belongs to detailed information, and the network model ultimately does not require multiplescale feature maps. In order to reduce the number of network parameters, only high-resolution feature maps are kept. The researches [
39,
48] have shown the importance of maintaining high-resolution representation during the whole process in object detection and pose estimation tasks. Specifically, the HRNet maintains the high-resolution representation while exchanging information across the parallel multi resolution subnetworks throughout the whole process; thus, it can generate heatmaps for keypoints with superior spatial precision [
22]. It should be emphasized that keypoint detection has higher requirements for feature resolution, while FPN networks [
46], Hourglass [
42], U-Net [
49], and other networks all obtain high-resolution features by upsampling low-resolution features. These methods of obtaining high-resolution features inevitably lose detailed information, which reduces the accuracy of keypoint detection.
In addition to the high resolution of the feature maps, increasing the perceptive field of space targets can also increase the accuracy of keypoint detection. For a space target, some keypoints are blocked due to its pose change. If the perceptive field of feature maps can be improved, the keypoint model can infer the position of the blocked keypoint according to the semantic information of feature maps. For this, we improve the high-resolution network. During feature fusion [
50], an ordinary convolution is replaced with a dilated convolution, so that the perceptive field can be expanded and the corresponding position information of the keypoints that are occluded can be inferred from the global information.
Moreover, in the process of keypoint network training, the model tends to focus on the “simple keypoints”. However, the actual space target keypoint recognition faces invisible keypoints that are caused by pose changes and complex backgrounds, which makes it difficult to detect corresponding keypoints. To solve this problem, an “online hard keypoint mining” algorithm is introduced in the high-resolution network, so that the proposed model focuses on “hard keypoints”.
The keypoint detection network mainly predicts each keypoint’s coordinate values, and the coordinates of each keypoint are represented by a corresponding probability map. The value of the pixel where the keypoint is located is 1, and the value of other pixels is 0. The predicted pixels are difficult to match with the ground truth coordinates, so the Gaussian kernel with
generates 11 heat maps on these keypoints in order to better match the predicted keypoints with the ground truth keypoints.
Figure 7 shows an example of Gaussian kernel generating heatmaps on keypoints [
51].
3.3.1. High-Resolution Network Based on Dilated Convolution
When compared with ordinary convolution, dilated convolution increases the expansion rate parameter, which is mainly used to expand the perceptive field of the convolution kernel. Additionally, the number of convolution kernel parameters remains unchanged; the difference is that the dilated convolution [
52] has a larger perceptive field. Dilated convolution supports exponential expansion of the receptive field without loss of resolution or coverage and aggregates multi-scale features and global information without losing resolution. The research shows that the model that is based on dilated convolution can improve the accuracy of segmentation and detection [
53], which is also suitable for keypoint detection. We found that the keypoints are not disorderly, they are distributed in various locations according to the structure of the space targets. Therefore, we want to use dilated convolution to improve the receptive field of the convolution kernel and make it pay more attention to the global information, so that the network can learn the internal relationship between each keypoint locations.
For the high-resolution keypoint detection network, convolutions of different resolutions are connected in parallel, and a variety of different resolution features are continuously exchanged. Each output resolution feature merges the features of two to four resolution inputs. The specific implementation method uses a convolution kernel with a step size of 2 in order to turn the high-resolution feature map into a low-resolution feature map, thereby achieving their fusion with low-resolution feature maps. Aiming at downsampling high-resolution features into low-resolution features, we introduce a dilated convolution with an expansion rate of 2. The specific improvement uses dilated convolution instead of ordinary convolution to increase the receptive field of extracted features. The whole network undergoes seven multiscale feature fusion. After each feature fusion, the connection between keypoints will be enhanced, and the overall structure of the space target will be clearer.
Figure 8 shows the features of the network fusion. Each column of images represents the features before and after feature fusion. The outline and keypoints information of the space target in the feature map fused by dilated convolution will be clearer. Each row of images represents convolution features from shallow to deep. The deeper the feature map, the more abstract it will be.
3.3.2. Robust Algorithm Design Based on Online Hard Keypoint Mining
Keypoint detection of space targets often faces the challenges that keypoints are occluded due to pose changes, and the keypoints are not easily detected in complex backgrounds. These keypoints can be regarded as “hard keypoints”, which are demostrated in
Figure 9. During the training of high-resolution networks, more attention should be payed to these hard keypoints. In order to solve this problem, we introduced an “online hard keypoint mining” algorithm in the high-resolution network by focusing on these “hard keypoints” to optimize the prediction of keypoints.
The keypoint model has a relatively large prediction error for “hard keypoints” of the space target, and these keypoints need to be specifically corrected. In the high-resolution network training phase, an online hard keypoint mining (OHKM) strategy can be introduced. The method is similar to OHEM [
54] and the research shows that the training efficiency and performance can be improved by automatically selecting hard examples for training. The obscured keypoints can be regarded as the hard examples, and the OHKM algorithm improves the detection performance of hard keypoints in a similar way. During the training, the model divides some samples with higher confidence into positive samples and lower samples into negative samples, which can be shown by loss during training. However, there are some occluded space target keypoints in the image, which are divided into negative samples because of the high loss. The OHKM algorithm will focus on training with these negative samples, mining these difficult samples, so as to improve the accuracy. In the speed space target data, 11 keypoints are selected; usually, the network calculates the overall loss of 11 keypoints. All of the keypoints are given the same attention. However, some keypoints are easy to predict, while others are difficult. We want to make the network pay more attention to the hard keypoints. In the improved algorithm, only a partial loss of the eight keypoints with the largest error contributes to the overall loss. The specific method is to first generate the 11 most likely keypoints according to the original MSE loss method. Subsequently, the OHKM algorithm is applied to the 11 keypoints. The conventional method is to take the whole 11 keypoints into the loss function. However, we only select eight of the 11 keypoints with the largest loss value, the remaining three most likely keypoints are removed from the loss function. Therefore, only the eight keypoints with the largest loss value are taken into the loss function, so that the network model pays more attention to hard keypoints, which makes it more refined. The loss function of the detection network of keypoints of the space target is as follows:
where
is the real coordinate value of the space target’s keypoint, the
coordinate value of the keypoint predicted by the proposed model,
k is the serial number of hard keypoints, and
is the total number of selected “hard keypoints” in which we select
as 8. The pseudocode of the high-resolution keypoint detection algorithm that are based on dilated convolution and hard keypoint mining is provided in Algorithm 2.
| Algorithm 2 High-resolution keypoint detection algorithm based on dilated convolution and hard keypoint mining |
| Require: space target image ; 11 groups of keypoint labels , where ; |
| Ensure: Trained keypoint detection network weight model; |
| 1: Preprocessing of input image data – Input image size is , random rotation is degrees; |
| 2: Input the image data into the high-resolution network, the feature fusion method is as follows: |
| 3: If feature map size → large: |
| 4: convolution (padding=0, stride=1)nearest neighbor upsampling; |
| 5: Else if feature map size → small: |
| 6: 3∗3 2-dilated convolution (padding=2, stride=2), BN, ReLU; |
| 7: Else: |
| 8: Identity mapping; |
| 9: Use the Gaussian kernel heat map to predict keypoint coordinates , where ; |
| 10: Use the OHKM algorithm to add the topk largest and in 11 groups; |
| 11: Backpropagate the residual computed in the previous step, adjust network weight; |
| 12: Repeat steps(1-11) until the loss converges, the keypoint detection model is trained. |


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}