Slice-Based Instance and Semantic Segmentation for Low-Channel Roadside LiDAR Data





Abstract
1. Introduction
- A novel slice-based segmentation method is proposed. The slice is used as the basic unit to segment the point cloud, which can achieve instance and semantic segmentation of low-channel LiDAR point cloud data.
- For instance segmentation, we proposed a novel regional growth method. Furthermore, to improve the extraction effect in traffic scene instance segmentation, the extraction method of the major part of the object is optimized to solve the occlusion of the traffic objects within the scene.
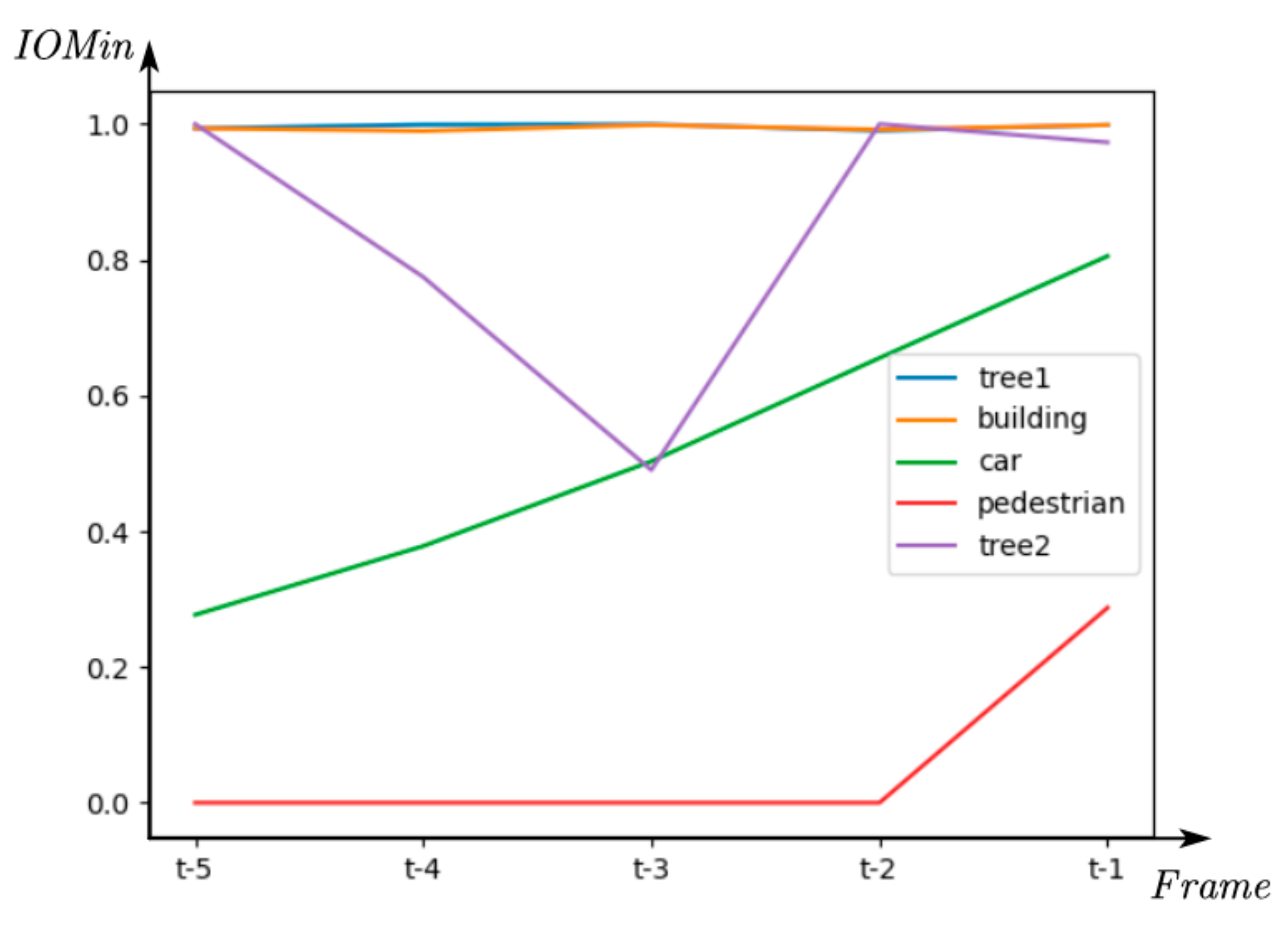
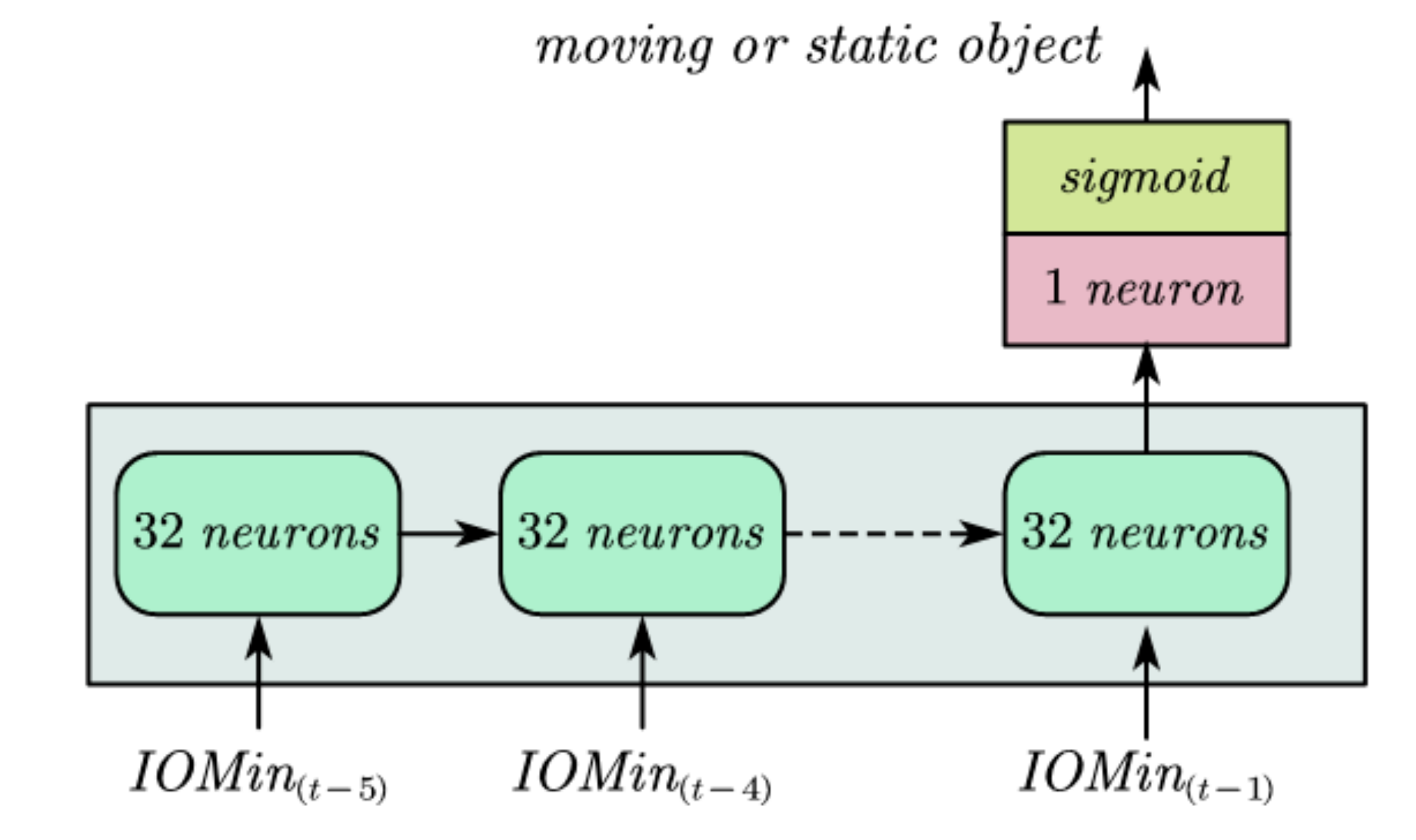
- A model based on the Intersection-Over-Union (IoU) method using the intersection over minimum volume (IOMin) of the object to distinguish the moving and stationary objects, and a machine learning model-based recurrent neural network (RNN) was used to learn and classify the moving and static objects, which can extract road users from all objects after instance segmentation.
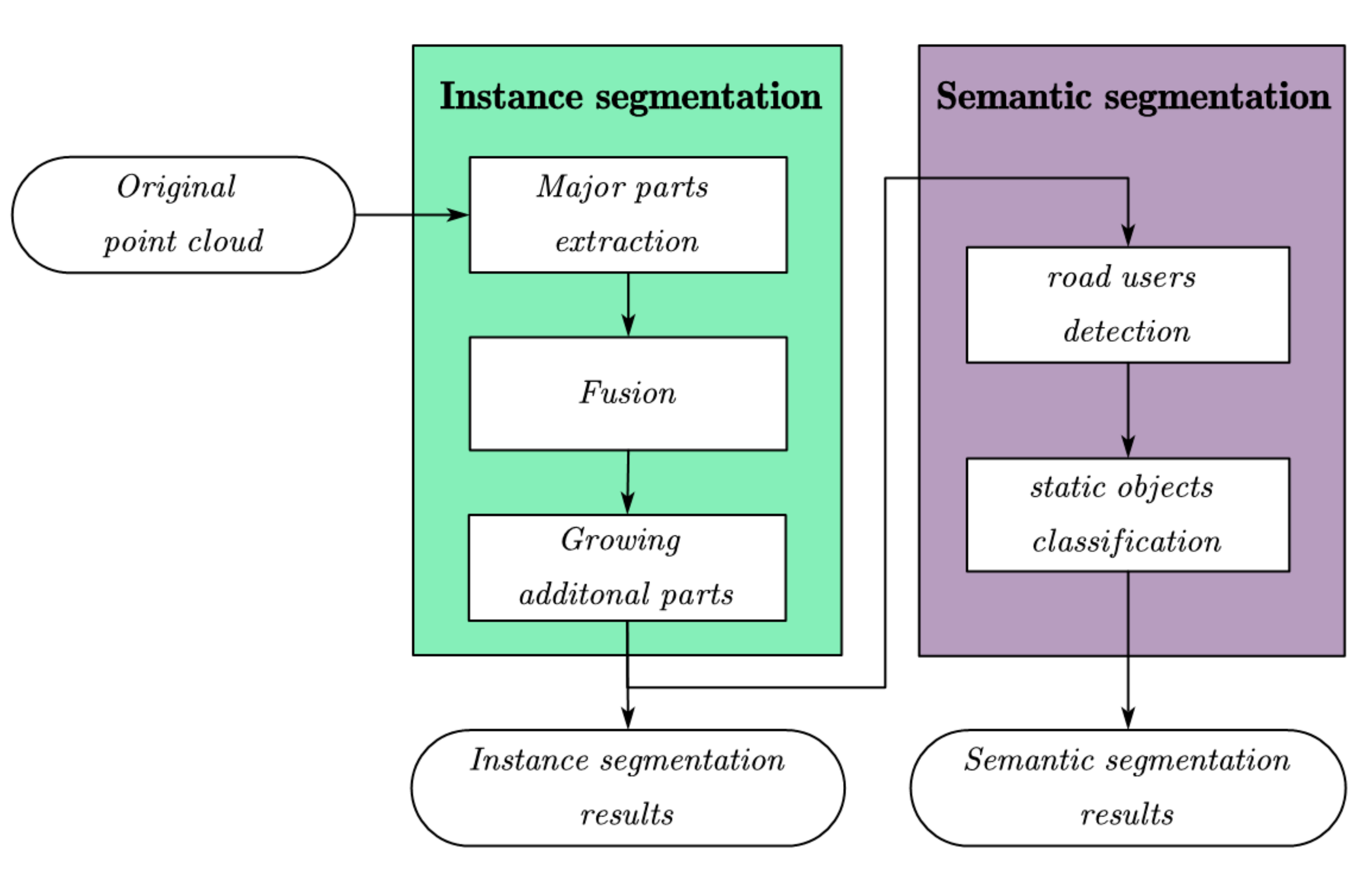
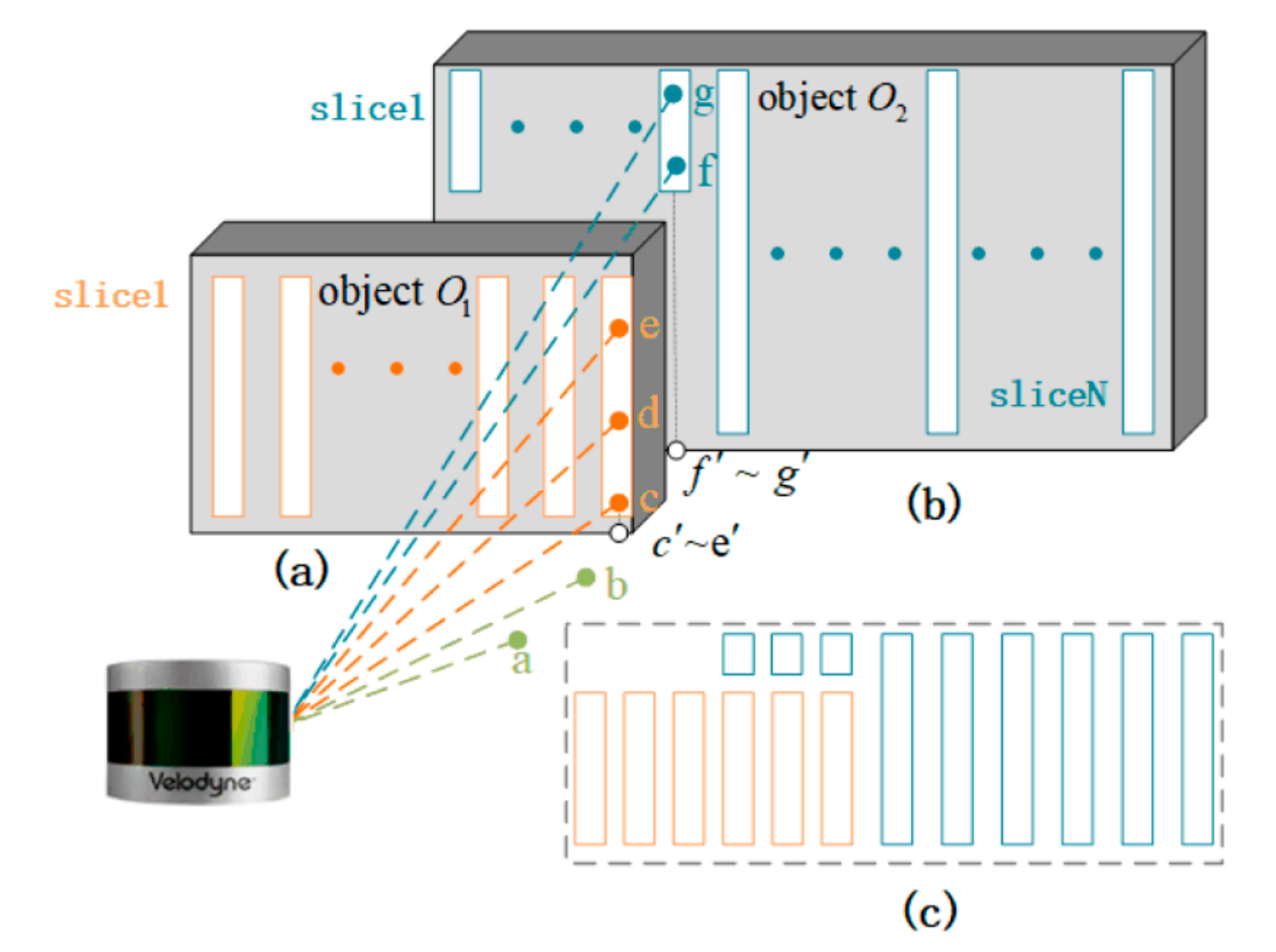
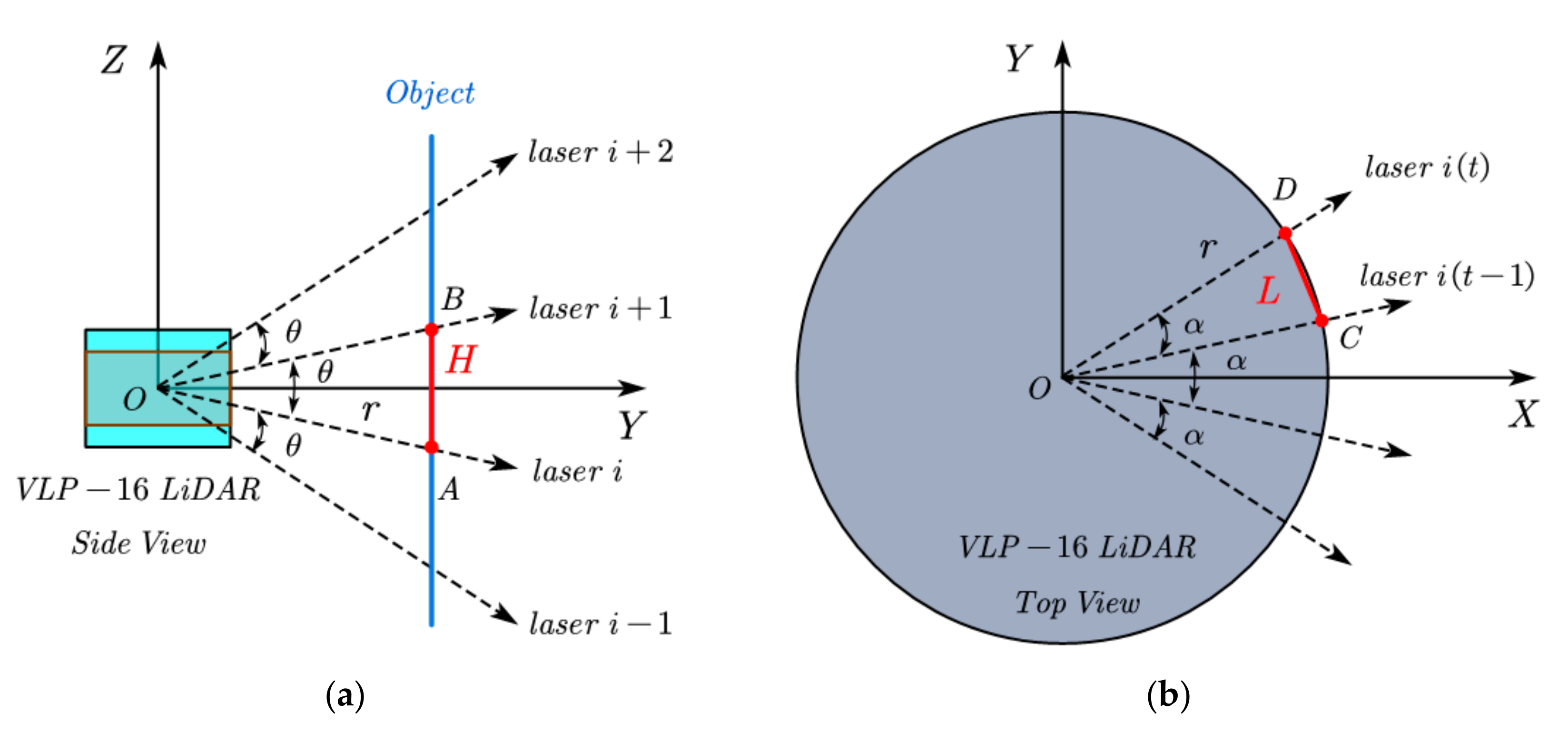
2. Slice of LiDAR Point Cloud
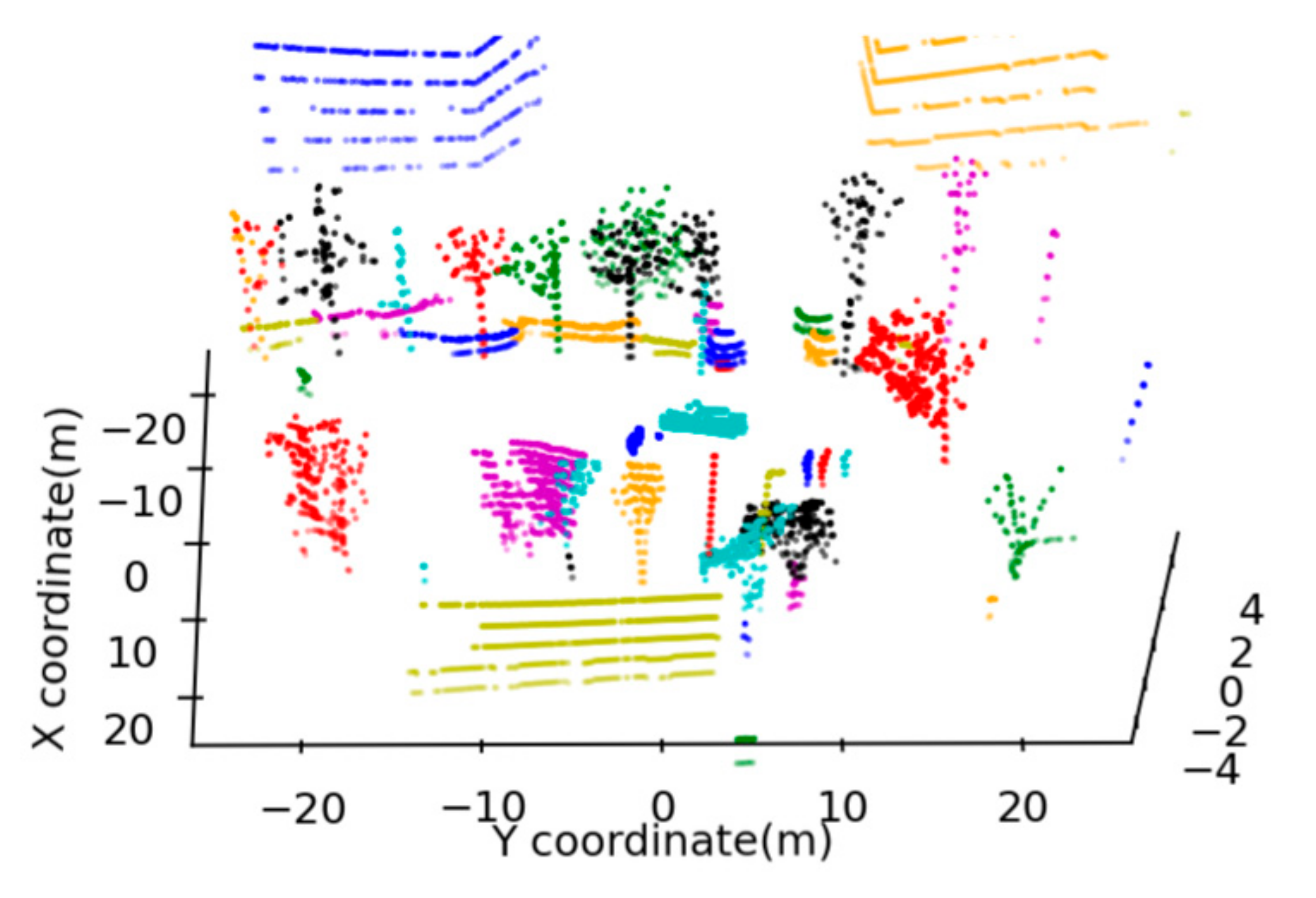
3. Instance Segmentation
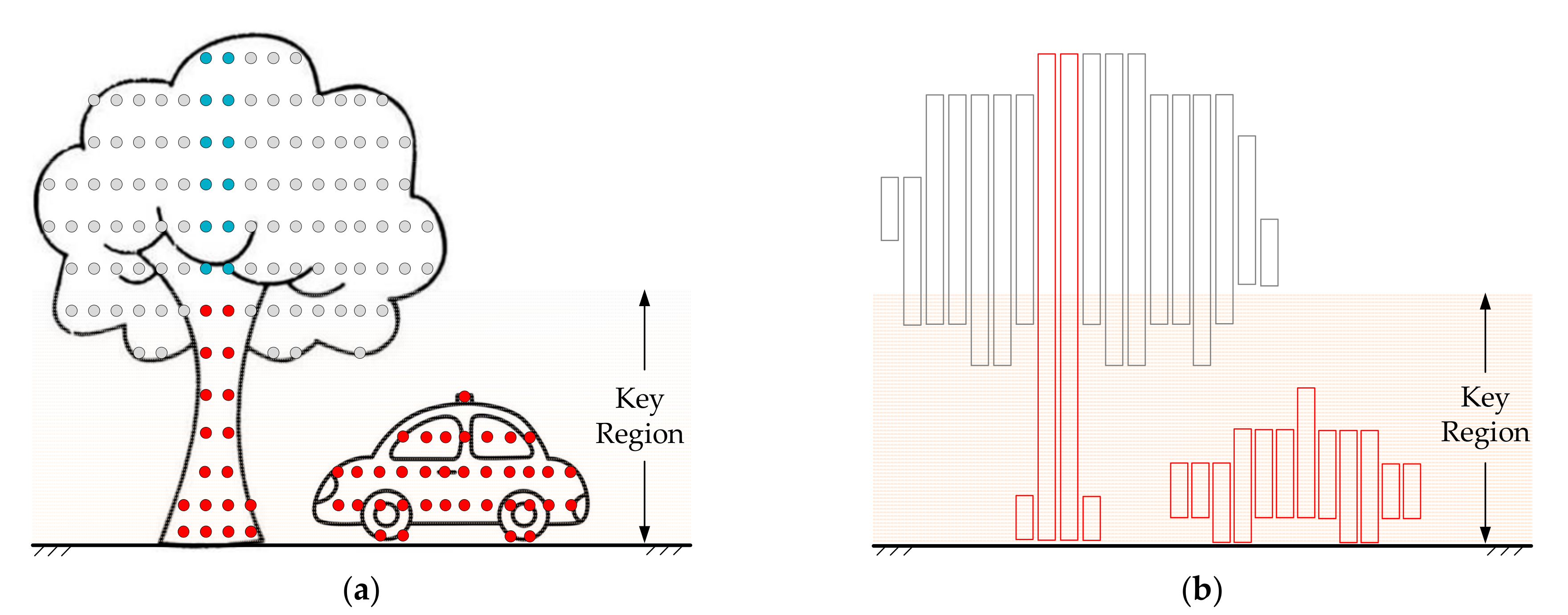
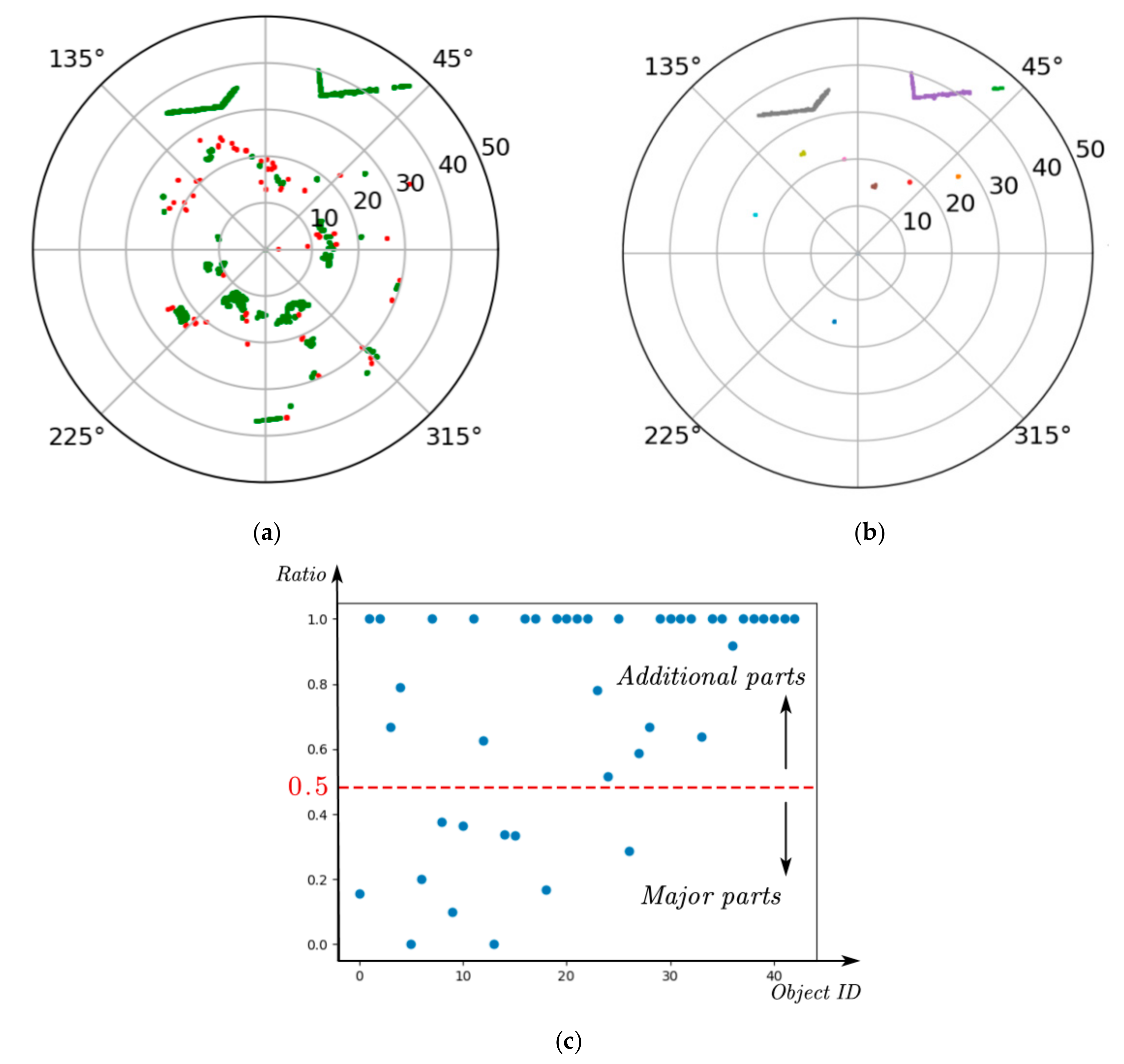
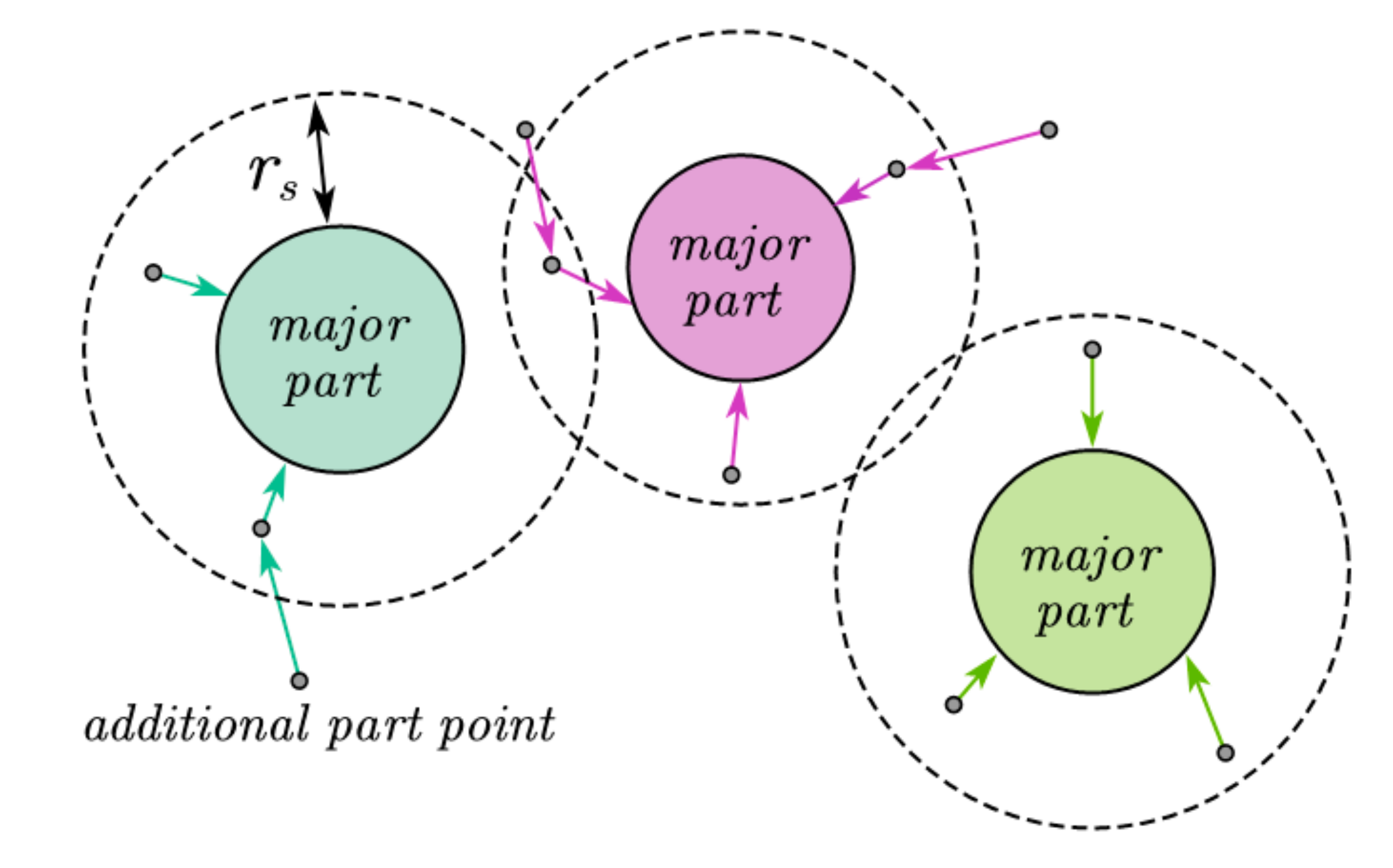
3.1. Extracting Major Parts of Objects
3.1.1. Basic Principles of Extraction
3.1.2. Implementation and Limitations
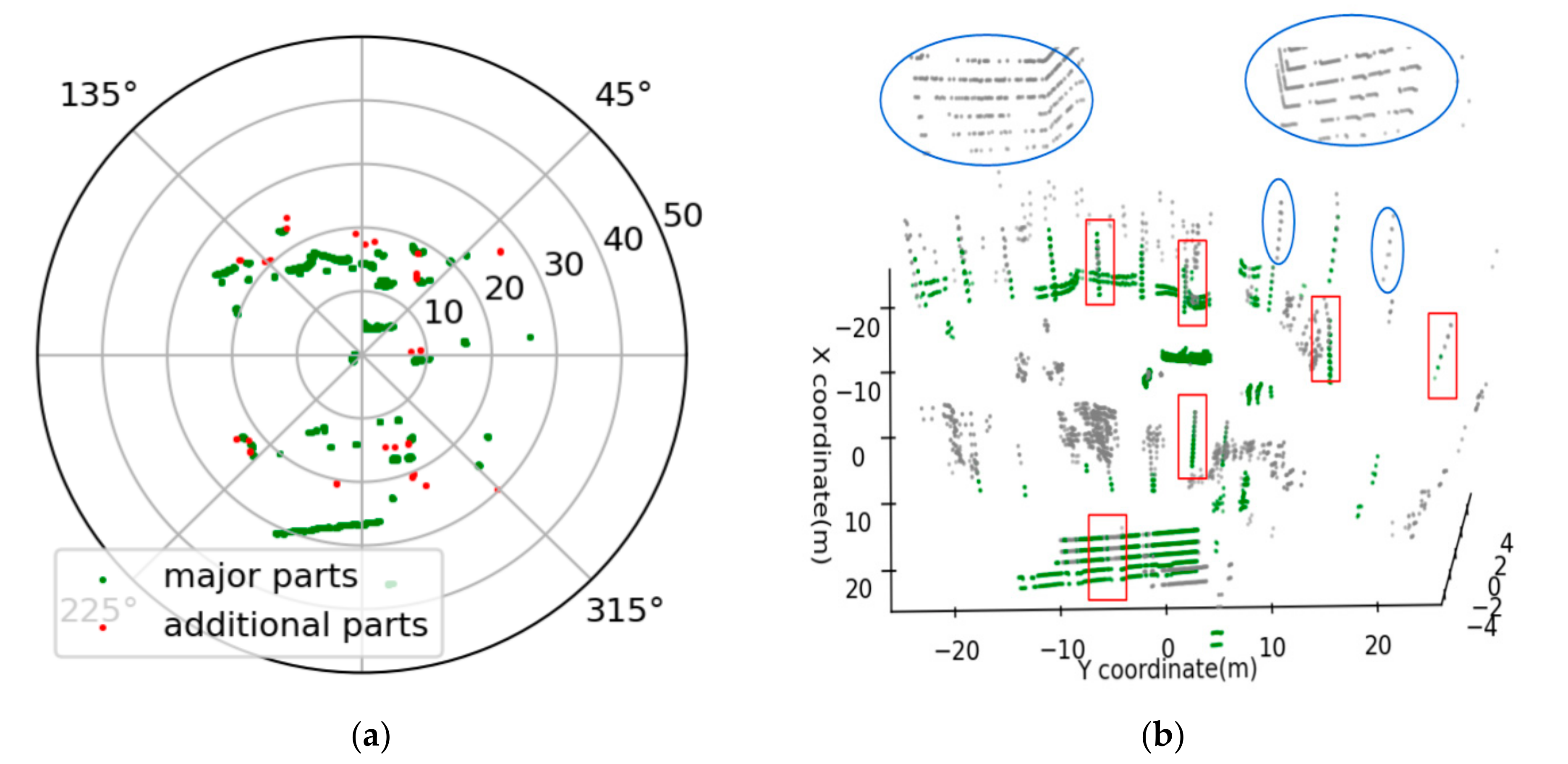
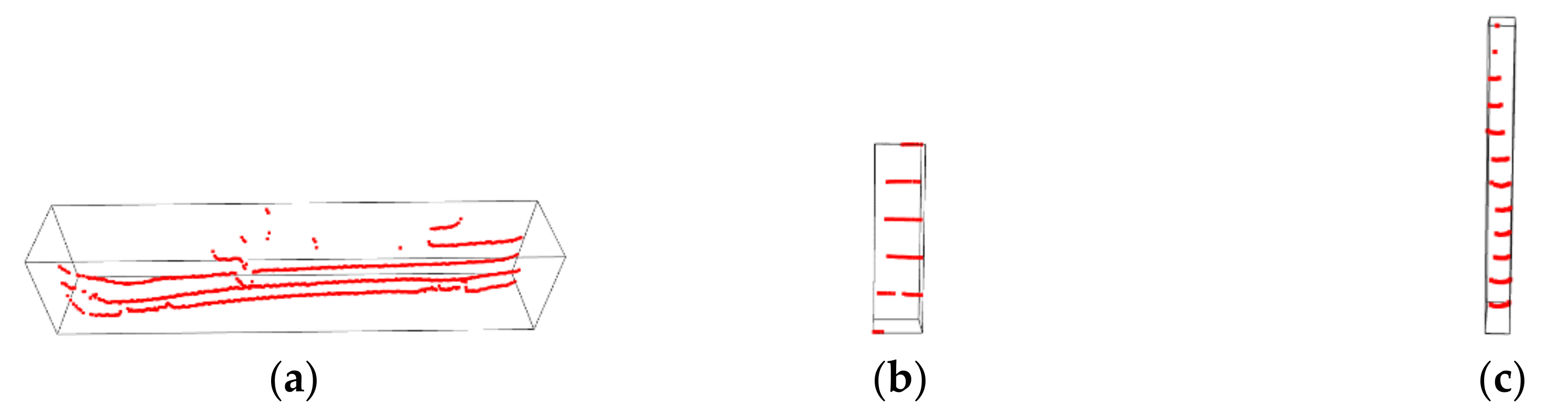
- The major part is incomplete (Error 1). The reason for this kind of error is that the major part of the objects in the real world is not always regular or vertical to the ground, which will lead to the major part points of the object in the non-key region and the major part points of the object in the key region not belonging to the same slice. This phenomenon will result in not being able to detect the incomplete major part in the non-key region. The red rectangles in Figure 5a are typical examples.
- The major part is missing (Error 2). The reason for this problem is the occlusion. Due to the characteristics of the LiDAR sensor scanning, the scanning objects far away from the LiDAR sensor are easily obscured by the near objects within the scanning range. The absence of the major parts occurs when the major part of the object in the key region is occluded by another object. The blue ellipses in Figure 5b are typical examples.
3.1.3. Improvement
- Difference 1: the leaves belong to additional parts, and the points in leaves are sparser;
- Difference 2: the average number of points per slice of the leaf is lower than that of the major part. That is because the leaves are relatively sparse and that there are a large number of slices formed by two points.
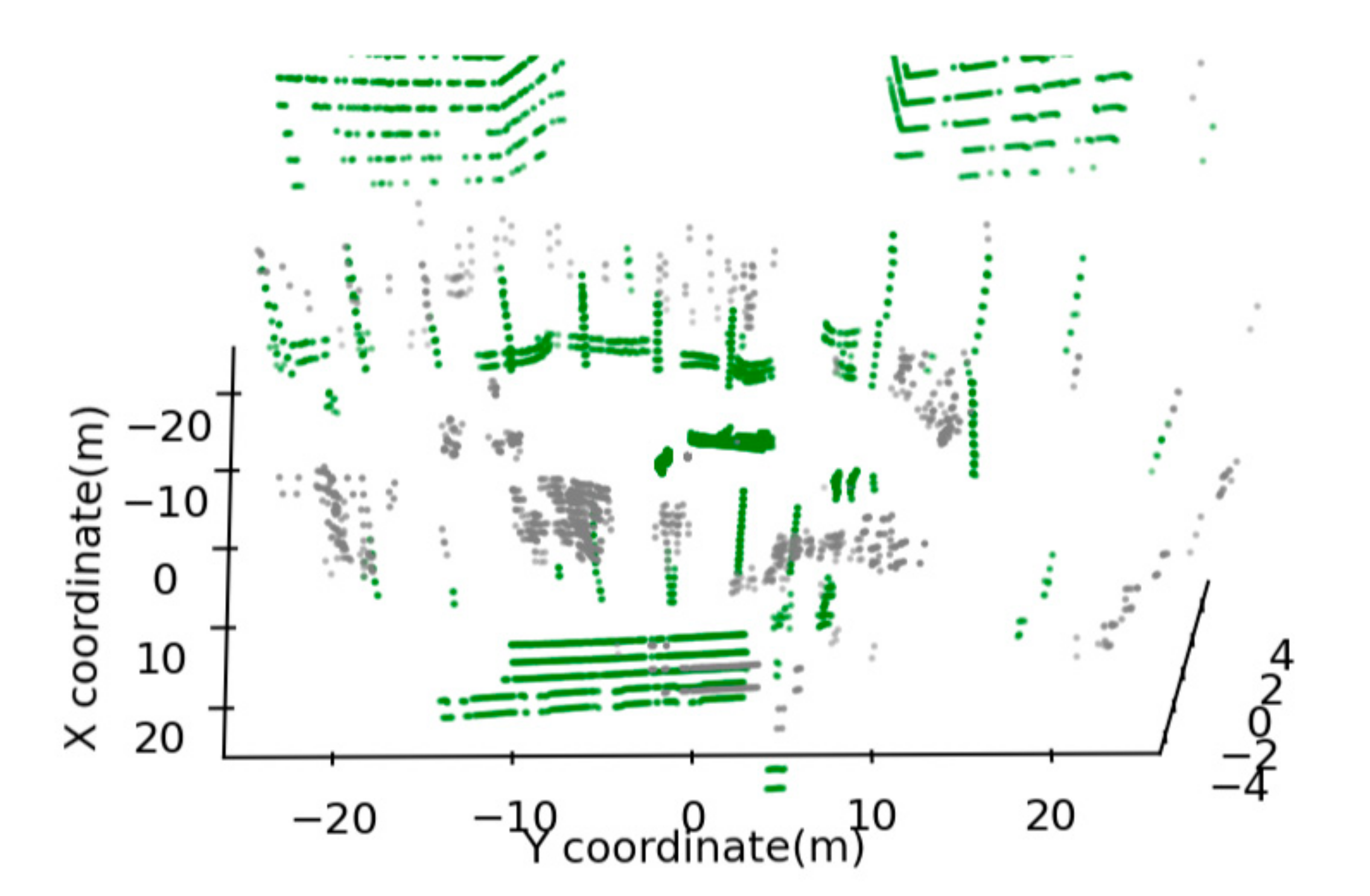
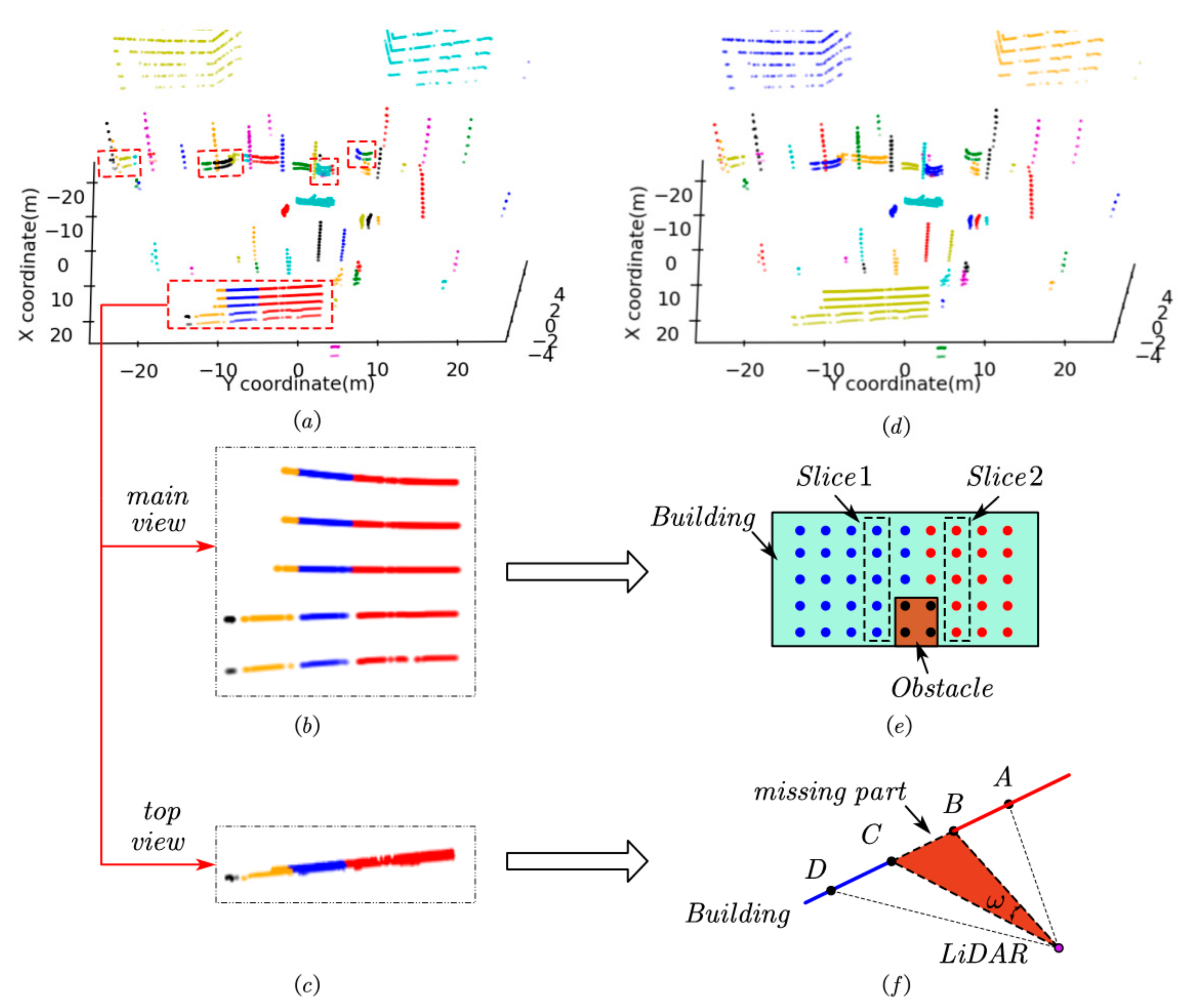
3.2. Fusing Major Parts
3.3. Growing
4. Semantic Segmentation
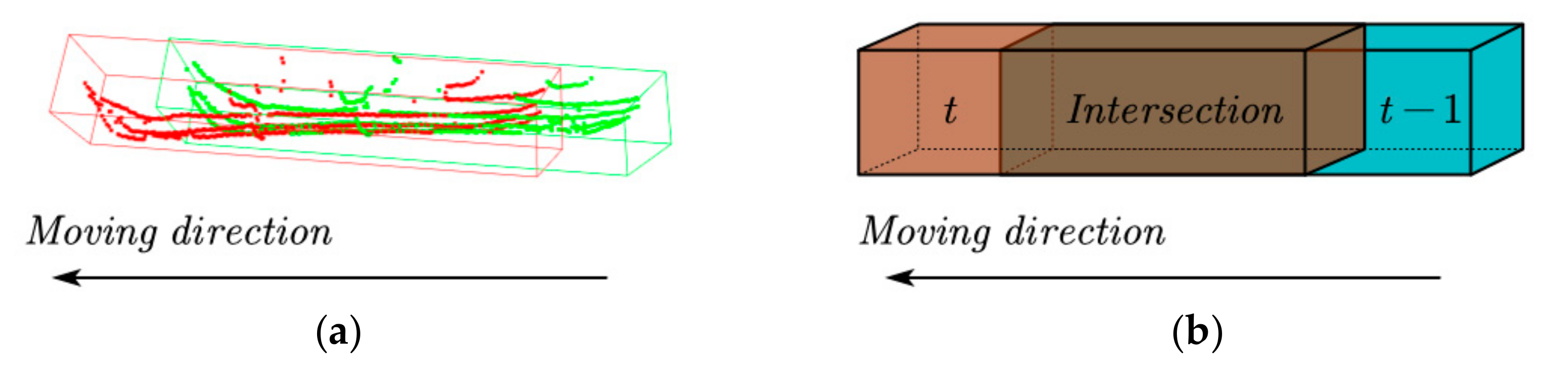
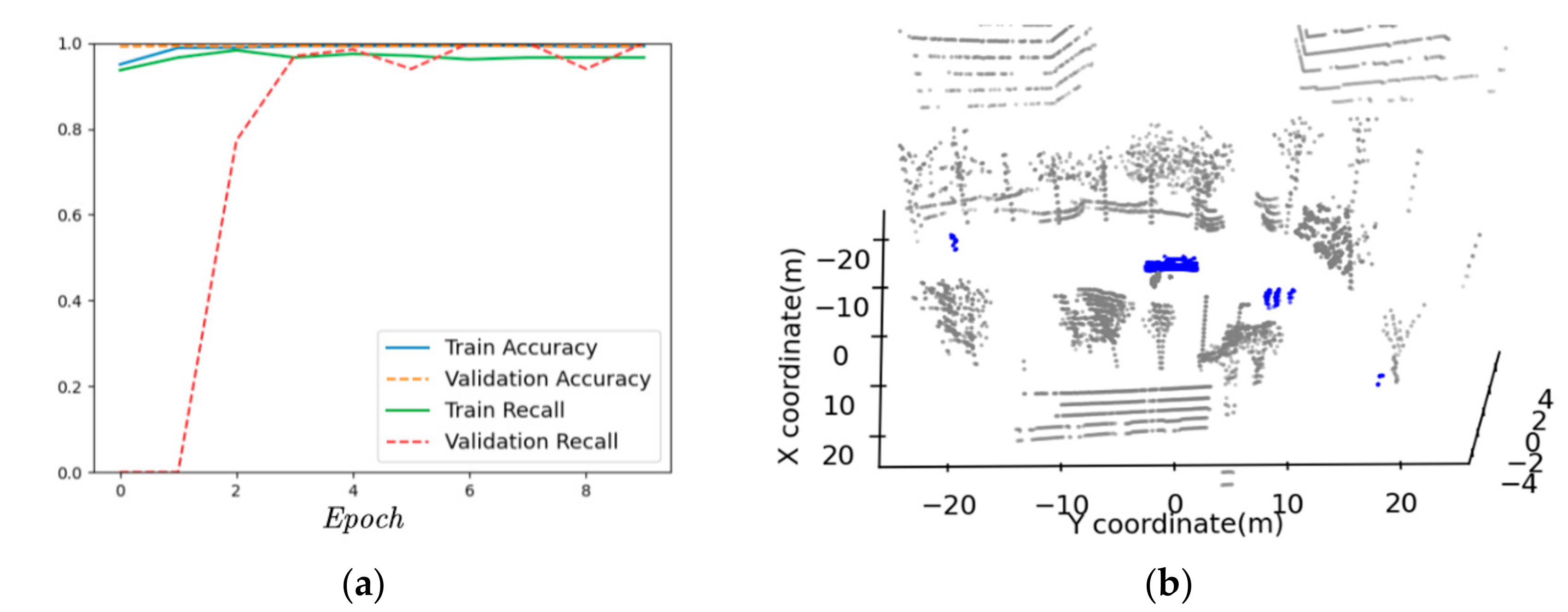
4.1. Labeling Moving Objects
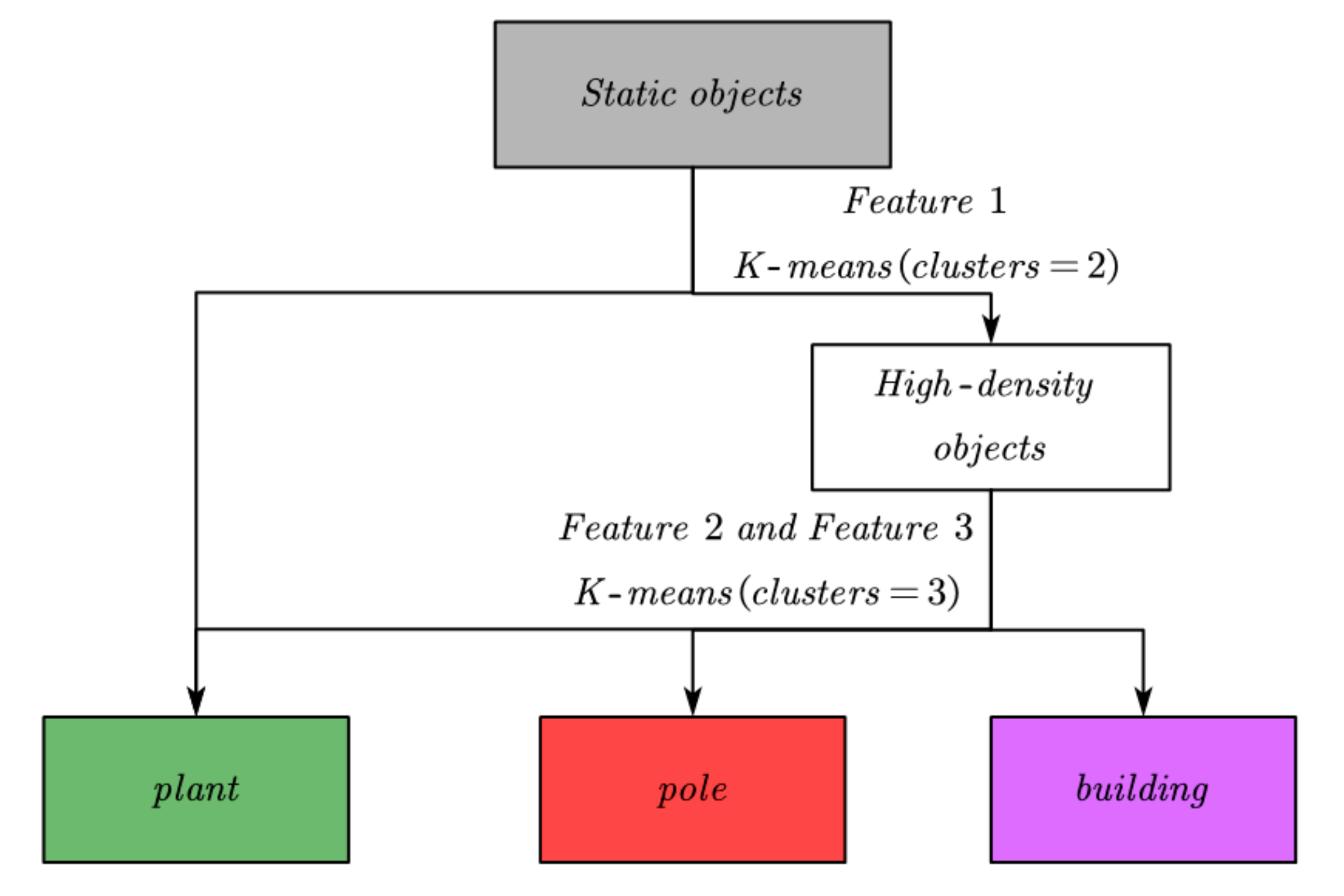
4.2. Labeling Static Objects
- Feature 1: the ratio of major part points to all points. The calculation equation is shown as Equation (11):where M is the point number contained in the major part of an object; N is the point number contained in this object.
- Feature 2: volume of the major part. The calculation equation is shown as Equation (12):where H is the height of the AABB of an object; W is the width of the AABB of the object; L is the length of the object.
- Feature 3: the height of the major part divided by the width. The calculation equation is shown as Equation (13):where H is the height of the AABB of the major part of an object; W is the width of the AABB of the major part of the object.
5. Experiment
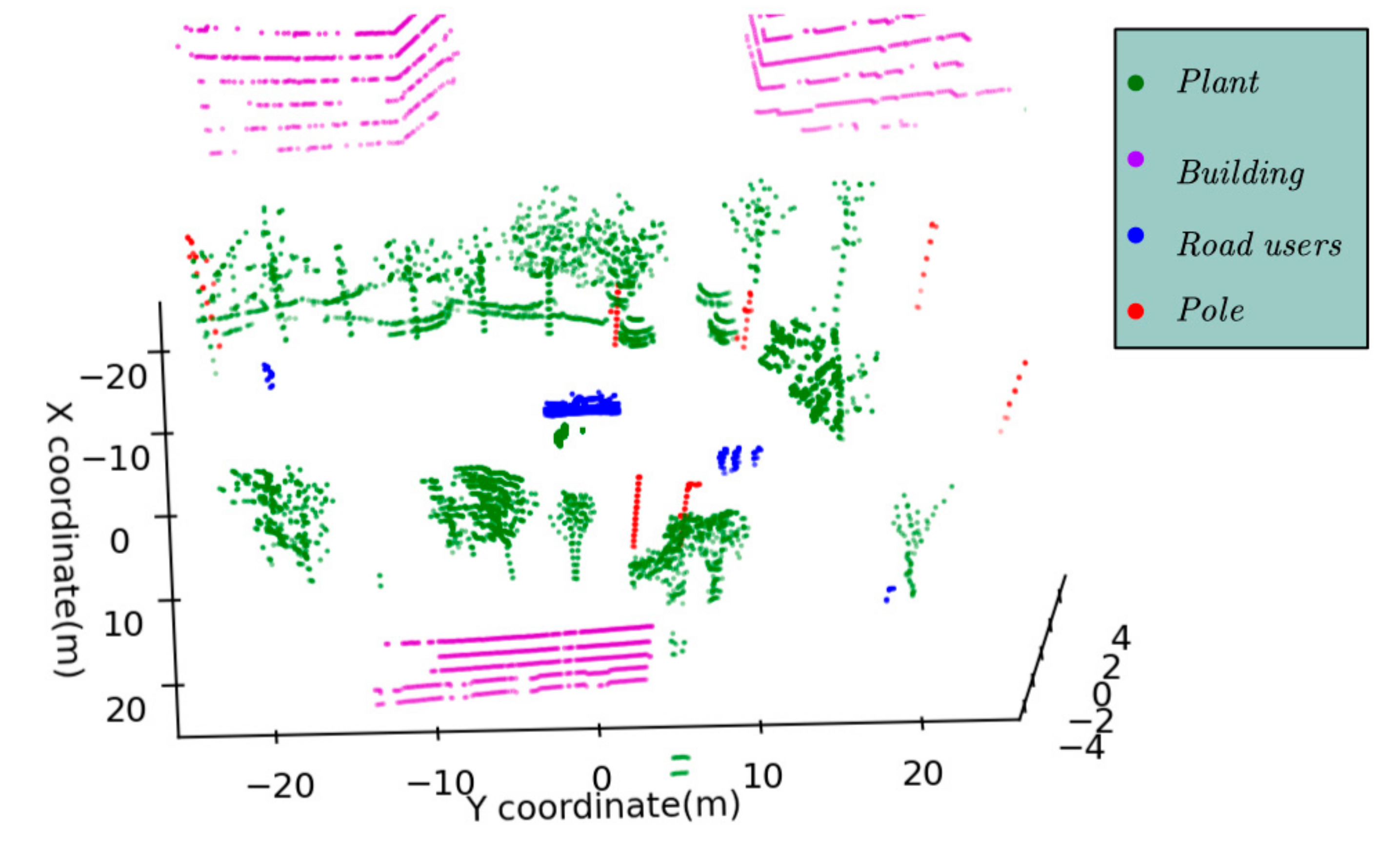
5.1. Instance Segmentation Evaluation
5.2. Semantic Segmentation Evaluation
5.2.1. Moving Objects
5.2.2. Static Objects
5.3. Robustness
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Griggs, T.; Wakabayashi, D. How a self-driving Uber killed a pedestrian in Arizona. In The New York Times; The New York Times Company: New York, NY, USA, 2018; Volume 3. [Google Scholar]
- Vlasic, B.; Boudette, N.E. ‘Self-Driving Tesla Was Involved in Fatal Crash,’US Says. In New York Times; The New York Times Company: New York, NY, USA, 2016; Volume 302016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 21–24 June 2020; pp. 7263–7271. [Google Scholar]
- You, X.; Zheng, Y. An accurate and practical calibration method for roadside camera using two vanishing points. Neurocomputing 2016, 204, 222–230. [Google Scholar] [CrossRef]
- Zhang, Z.; Zheng, J.; Xu, H.; Wang, X.; Fan, X.; Chen, R. Automatic Background Construction and Object Detection Based on Roadside LiDAR. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4086–4097. [Google Scholar] [CrossRef]
- Lin, C.; Liu, H.; Wu, D.; Gong, B. Background Point Filtering of Low-Channel Infrastructure-Based LiDAR Data Using a Slice-Based Projection Filtering Algorithm. Sensors 2020, 20, 3054. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Xu, H.; Sun, Y.; Zheng, J.; Yue, R. Automatic background filtering method for roadside LiDAR data. Trans. Res. Record 2018, 2672, 106–114. [Google Scholar] [CrossRef]
- Zhao, J. Exploring the Fundamentals of Using Infrastructure-Based LiDAR Sensors to Develop Connected Intersections. Ph.D. Thesis, Texas Tech University, Lubbock, TX, USA, 2019. [Google Scholar]
- Zhao, J.; Xu, H.; Liu, H.; Wu, J.; Zheng, Y.; Wu, D. Detection and tracking of pedestrians and vehicles using roadside LiDAR sensors. Trans. Res. Part C Emerg. Technol. 2019, 100, 68–87. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Kamnitsas, K.; Ledig, C.; Newcombe, V.F.; Simpson, J.P.; Kane, A.D.; Menon, D.K.; Rueckert, D.; Glocker, B. Efficient multi-scale 3D CNN with fully connected CRF for accurate brain lesion segmentation. Med. Image Anal. 2017, 36, 61–78. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Lee, J.-S.; Jo, J.-H.; Park, T.-H. Segmentation of Vehicles and Roads by a Low-Channel Lidar. IEEE Trans. Intell. Transp. Syst. 2019, 20, 4251–4256. [Google Scholar] [CrossRef]
- Jiang, X.Y.; Meier, U.; Bunke, H. Fast range image segmentation using high-level segmentation primitives. In Proceedings of the IEEE Workshop on Applications of Computer Vision, Wacv, Sarasota, FL, USA, 2–4 December 1996. [Google Scholar]
- Sappa, A.D.; Devy, M. Fast range image segmentation by an edge detection strategy. In Proceedings of the Third International Conference on 3-D Digital Imaging and Modeling, Quebec City, QC, Canada, 28 May–1 June 2001; pp. 292–299. [Google Scholar]
- Nguyen, A.; Le, B. 3D Point Cloud Segmentation: A Survey. In Proceedings of the 6th IEEE Conference on Robotics, Automation and Mechatronics (RAM), Manila, Philippines, 12–15 November 2013. [Google Scholar]
- Besl, P.J.; Jain, R.C. Segmentation through variable-order surface fitting. IEEE Trans. Pattern Anal. Mach. Intell. 1988, 10, 167–192. [Google Scholar] [CrossRef]
- Koster, K.; Spann, M. MIR: An approach to robust clustering-application to range image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 430–444. [Google Scholar] [CrossRef]
- Rusu, R.B.; Marton, Z.C.; Blodow, N.; Dolha, M.; Beetz, M. Towards 3D point cloud based object maps for household environments. Robot. Autonom. Syst. 2008, 56, 927–941. [Google Scholar] [CrossRef]
- Tóvári, D.; Pfeifer, N. Segmentation based robust interpolation-a new approach to laser data filtering. Int. Archives Photogram. Remote Sens. Spat. Inform. Sci. 2005, 36, 79–84. [Google Scholar]
- Fan, Y.; Wang, M.; Geng, N.; He, D.; Chang, J.; Zhang, J.J. A self-adaptive segmentation method for a point cloud. Visual Comput. 2018, 34, 659–673. [Google Scholar] [CrossRef]
- Golovinskiy, A.; Funkhouser, T. Min-cut based segmentation of point clouds. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 39–46. [Google Scholar]
- Rusu, R.B.; Holzbach, A.; Blodow, N.; Beetz, M. Fast geometric point labeling using conditional random fields. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 11–15 October 2009; pp. 7–12. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Chen, Y.; Liu, S.; Shen, X.; Jia, J. Fast point r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9775–9784. [Google Scholar]
- Shi, S.; Wang, Z.; Shi, J.; Wang, X.; Li, H. From Points to Parts: 3D Object Detection from Point Cloud with Part-aware and Part-aggregation Network. arXiv 2019, arXiv:1907.03670. [Google Scholar] [CrossRef] [PubMed]
- Song, S.; Xiao, J. Deep sliding shapes for amodal 3d object detection in rgb-d images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 808–816. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Dewan, A.; Caselitz, T.; Tipaldi, G.D.; Burgard, W. Motion-based detection and tracking in 3d lidar scans. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–20 May 2016; pp. 4508–4513. [Google Scholar]
- National Constitution Monitoring Bulletin. Available online: http://www.sport.gov.cn/index.html (accessed on 20 March 2020).
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Kdd, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Proc. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Ramiya, A.M.; Nidamanuri, R.R.; Krishnan, R. Segmentation based building detection approach from LiDAR point cloud. Egypt. J. Remote Sens. Space Sci. 2017, 20, 71–77. [Google Scholar] [CrossRef]
- Rusu, R.B.; Cousins, S. 3d is here: Point cloud library (pcl). In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Fulkerson, B. Machine Learning, Neural and Statistical Classification. Technometrics 1994, 37, 459. [Google Scholar] [CrossRef]
- Buckland, M.; Gey, F. The relationship between recall and precision. J. Am. Soc. Inform. Sci. 1994, 45, 12–19. [Google Scholar] [CrossRef]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Huang, J.; Ling, C.X. Using AUC and accuracy in evaluating learning algorithms. IEEE Trans. Knowl. Data Eng. 2005, 17, 299–310. [Google Scholar] [CrossRef]
- Krishna, K.; Murty, M.N. Genetic K-means algorithm. IEEE Trans. Syst. Man Cyber. Part B (Cybern.) 1999, 29, 433–439. [Google Scholar] [CrossRef]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On spectral clustering: Analysis and an algorithm. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 9–14 December 2002; pp. 849–856. [Google Scholar]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Proc. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.-H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Hassoun, M.H. Fundamentals of Artificial Neural Networks; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Truth Number of Objects in the Original Point Cloud | Number of Objects after Segmentation |
|---|---|---|
| Euclidean-based | 59 | 12 |
| Regional growth in PCL | 29 | |
| Our work | 51 |
| IOMin Sequence Length | Accuracy | Precision | Recall | AUC |
|---|---|---|---|---|
| 1 | 0.7382 | 0.3391 | 0.8939 | 0.8445 |
| 2 | 0.8155 | 0.4306 | 0.9394 | 0.943 |
| 3 | 0.8991 | 0.5872 | 0.9697 | 0.9769 |
| 4 | 0.9464 | 0.7253 | 0.99 | 0.9889 |
| 5 (selected) | 0.9871 | 0.9167 | 0.9903 | 0.9952 |
| 6 | 0.9883 | 0.9228 | 0.9921 | 0.9934 |
| Algorithm | Accuracy | Precision | Recall | AUC |
|---|---|---|---|---|
| K-means | 0.9112 | 0.6077 | 0.8874 | 0.901 |
| Spectral Clustering | 0.9373 | 0.7294 | 0.8212 | 0.8879 |
| Support Vector Machine (SVM) | 0.8283 | 0.2888 | 0.2219 | 0.5702 |
| Isolation Forest | 0.7974 | 0.3893 | 0.99 | 0.8794 |
| Artificial Neural Network (ANN) | 0.9678 | 0.8148 | 0.99 | 0.993 |
| Our work | 0.9871 | 0.9167 | 0.9903 | 0.9952 |
| Algorithm | Plant | Pole | Building |
|---|---|---|---|
| Spectral Clustering | 0.9573 | 0.8394 | 0.8012 |
| K-means (selected) | 0.9638 | 0.8646 | 0.826 |
| Object | Before | After |
|---|---|---|
| Road users | 7 | 7 |
| Plant | 3 | 2 |
| Pole | 5 | 3 |
| Building | 4 | 4 |
| Object | Average Precision |
|---|---|
| Road users | 0.9902 |
| Plant | 0.821 |
| Pole | 0.8507 |
| Building | 0.7562 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Lin, C.; Wu, D.; Gong, B. Slice-Based Instance and Semantic Segmentation for Low-Channel Roadside LiDAR Data. Remote Sens. 2020, 12, 3830. https://doi.org/10.3390/rs12223830
Liu H, Lin C, Wu D, Gong B. Slice-Based Instance and Semantic Segmentation for Low-Channel Roadside LiDAR Data. Remote Sensing. 2020; 12(22):3830. https://doi.org/10.3390/rs12223830
Chicago/Turabian StyleLiu, Hui, Ciyun Lin, Dayong Wu, and Bowen Gong. 2020. "Slice-Based Instance and Semantic Segmentation for Low-Channel Roadside LiDAR Data" Remote Sensing 12, no. 22: 3830. https://doi.org/10.3390/rs12223830
APA StyleLiu, H., Lin, C., Wu, D., & Gong, B. (2020). Slice-Based Instance and Semantic Segmentation for Low-Channel Roadside LiDAR Data. Remote Sensing, 12(22), 3830. https://doi.org/10.3390/rs12223830