Intercomparison of Remote Sensing Retrievals: An Examination of Prior-Induced Biases in Averaging Kernel Corrections

Abstract

1. Introduction
“The smoothing of the averaging kernel introduces an error, which will be important in any comparison between measurements made at different resolutions... However, it is possible to eliminate this smoothing error by using the averaging kernel. In comparing a high-resolution measurement (or a model calculation) with a low-resolution measurement, one computes , where is the high-resolution measurement, and compares the result to .” ([22] Section 2.5).
2. Derivation of Prior-Induced Biases
2.1. Background and Requirements
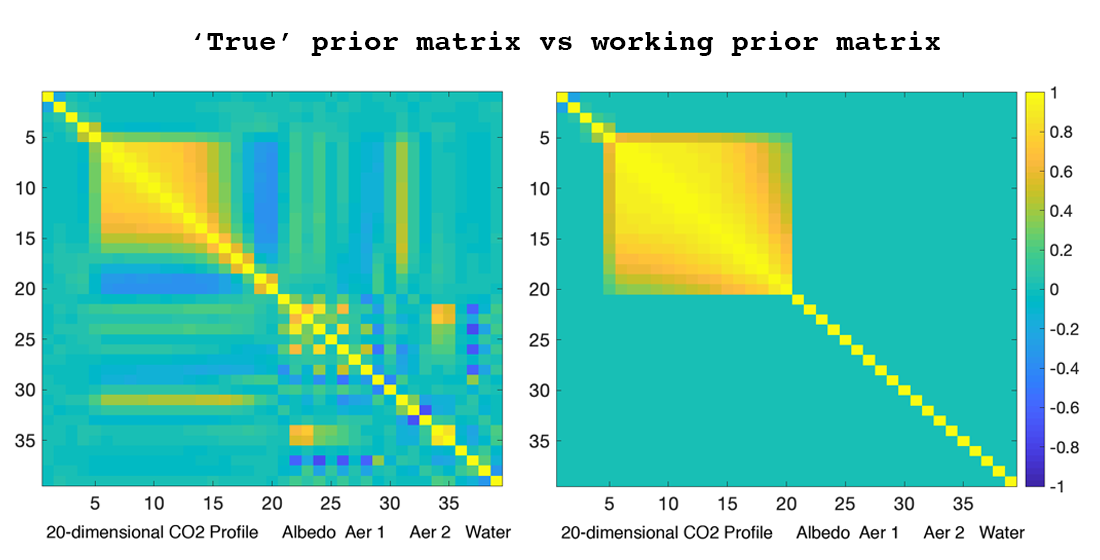
2.2. Working Prior vs. True Prior
2.3. Relative Bias from Different OE Retrievals of the Same State
2.4. Averaging Kernel Correction
2.5. Examining the Biases
2.6. Abbreviated Variant of Averaging Kernel Correction
2.7. Observation-Model Intercomparisons
3. Simulation Study
- Experiment 1
- Here, we wish to examine the impact of the misspecification of the prior mean on the relative bias. We assume that Instruments 1 and 2 are using the same prior covariance matrix and that and .
- Experiment 2
- Here, we wish to examine the impact of the prior covariance matrix on the relative bias. We assume that Instruments 1 and 2 are using the same misspecified prior mean and that and .
- Experiment 3
- Here, we wish to examine the impact of further inflating the prior covariance matrix. We assume that Instruments 1 and 2 are using the same prior mean and that and .
- Select working priors for the two retrievals (i.e., and ) from one of the three experiments in Table 3.
- Sample a state from the true prior distribution .
- Compute two radiance vectors, and , using the model given by Equation (2).
- Compute the retrieved state vectors (specifically, and ) using Equation (3) and the corresponding working priors from Step 1.
- Using as the comparison ensemble, perform averaging kernel correction on , and then, compute the difference in XCO2 (i.e.,
- Using as the comparison ensemble, perform averaging kernel correction on , and then, compute the difference in XCO2 (i.e.,
- Repeat Steps 2–6 for 3000 iterations.
4. Discussion
- If , then the averaging kernel-corrected value will be biased (i.e., ), and the intercomparison of the two instruments will also be biased (i.e., ).
- Even if retrievals and use the same prior mean and prior covariance , if the instrument noise processes are different (i.e., ), then there would be a relative bias. Similarly, if , then .
- The biases and are proportional to the vector difference . This explains the source of the common misconception that the average kernel correction can remove any relative bias. It is likely that these claims are based on the implicit assumption that , but this is highly unlikely to be, if ever, true in actual practice.
- A simple consequence of these results is that in validation studies where retrievals of a geophysical process (e.g., carbon dioxide, methane, etc.) are compared with data from a different instrument, a bias can result simply from the choice of the comparison ensemble . Therefore, validation studies should keep the choice of priors in mind as a potential source of bias. We note that if , no amount of tinkering with calibration, spectroscopy, radiative transfer models, geolocation, non-linear optimizer, or other potential causes will remove this bias.
- In the intercomparison of multiple retrievals, it is common practice to choose the comparison prior from one of the priors that produced the retrievals. Since the bias is proportional to , in general, it is recommended to choose a comparison prior with the most “accurate” prior mean.
- We showed that using a comparison prior with a less informative prior covariance matrix will result in smaller bias. Therefore, if it is not possible to assess which prior has a more accurate prior mean, all other things being equal, it is recommended to choose a prior with a larger prior covariance matrix (we note that this bullet point will only apply to the full averaging kernel correction procedure as described in [20] and not on the abbreviated procedure as described by [22]). We note that while this choice would reduce the bias, the drawback is that it may increase the variability of the difference (i.e., may be “larger”).
- If a researcher wishes to absolutely remove the choice of prior as a potential source of bias, he or she can choose a comparison ensemble where (although in practice, multiplying one of the prior covariance matrices by a sufficiently large constant is acceptable; see Experiment 3 of Section 3). This would force the prior-induced bias to approach , and the researcher can then be reasonably sure that any bias that remains is due to other causes such as calibration, geolocation, spectroscopy, etc.
- One useful exercise in validation intercomparisons is to assess the potential magnitude of the prior-induced bias, and we could do this using Equation (10), which only has one unknown . Here, the researcher can make some reasonable guesses such as being misspecified by 1% or 2% (i.e., or ), which would then produce an estimate of the prior-induced bias for comparison to other sources of errors.
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Boesch, H.; Brown, L.; Castano, R.; Christi, M.; Connor, B.; Crisp, D.; Eldering, A.; Fisher, B.; Frankenberg, C.; Gunson, M.; et al. Orbiting Carbon Observatory (OCO-2) Level 2 Full Physics Algorithm Theoretical Basis Document. Available online: https://docserver.gesdisc.eosdis.nasa.gov/public/project/OCO/OCO2_L2_ATBD.V8.pdf (accessed on 1 June 2020).
- Yoshida, Y.; Ota, Y.; Eguchi, N.; Kikuchi, N.; Nobuta, K.; Tran, H.; Morino, I.; Yokota, T. Retrieval algorithm for CO2 and CH4 column abundances from short-wavelength infrared spectral observations by the Greenhuse gases Observing SATellite. Atmos. Meas. Tech. 2011, 4, 717. [Google Scholar] [CrossRef]
- Rodgers, C.D. Inverse Methods for Atmospheric Sounding: Theory and Practice; World Scientific Press: Singapore, 2000. [Google Scholar]
- O’Dell, C.; Eldering, A.; Wennberg, P.O.; Crisp, D.; Gunson, M.; Fisher, B.; Frankenberg, C.; Kiel, M.; Lindqvist, H.; Mandrake, L.; et al. Improved retrievals of carbon dioxide from Orbiting Carbon Observatory-2 with the version 8 ACOS algorithm. Atmos. Meas. Tech. 2018, 11, 6539–6576. [Google Scholar] [CrossRef]
- Merchant, C.; Le Borgne, P.; Roquet, H.; Legendre, G. Extended optimal estimation techniques for sea surface temperature from the Spinning Enhanced Visible and Infra-Red Imager (SEVIRI). Remote Sens. Environ. 2013, 131, 287–297. [Google Scholar] [CrossRef]
- Yoshida, Y.; Kikuchi, N.; Morino, I.; Uchino, O.; Oshchepkov, S.; Bril, A.; Saeki, T.; Schutgens, N.; Toon, G.C.; Wunch, D.; et al. Improvement of the retrieval algorithm for GOSAT SWIR XCO2 and XCH4 and their validation using TCCON data. Atmos. Meas. Tech. 2013, 6, 1533–1547. [Google Scholar] [CrossRef]
- Toon, G.; Blavier, J.F.; Washenfelder, R.; Wunch, D.; Keppel-Aleks, G.; Wennberg, P.; Connor, B.; Sherlock, V.; Griffith, D.; Deutscher, N.; et al. Total column carbon observing network (TCCON). In Fourier Transform Spectroscopy; Optical Society of America: Vancouver, BC, Canada, 2009. [Google Scholar]
- Bowman, K.W.; Rodgers, C.D.; Kulawik, S.S.; Worden, J.; Sarkissian, E.; Osterman, G.; Steck, T.; Lou, M.; Eldering, A.; Shephard, M.; et al. Tropospheric Emission Spectrometer: Retrieval method and error analysis. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1297–1307. [Google Scholar] [CrossRef]
- Govaerts, Y.; Wagner, S.; Lattanzio, A.; Watts, P. Joint retrieval of surface reflectance and aerosol optical depth from MSG/SEVIRI observations with an optimal estimation approach: 1. Theory. J. Geophys. Res. Atmos. 2010, 115, D02203. [Google Scholar] [CrossRef]
- Hobbs, J.; Braverman, A.; Cressie, N.; Granat, R.; Gunson, M. Simulation-based uncertainty quantification for estimating atmospheric CO2 from satellite data. SIAM/ASA J. Uncertain. Quantif. 2017, 5, 956–985. [Google Scholar] [CrossRef]
- Connor, B.J.; Boesch, H.; Toon, G.; Sen, B.; Miller, C.; Crisp, D. Orbiting Carbon Observatory: Inverse method and prospective error analysis. J. Geophys. Res. Atmos. 2008, 113, D05305. [Google Scholar] [CrossRef]
- Su, Z.; Yung, Y.L.; Shia, R.L.; Miller, C.E. Assessing accuracy and precision for space-based measurements of carbon dioxide: An associated statistical methodology revisited. Earth Space Sci. 2017, 4, 147–161. [Google Scholar] [CrossRef]
- Nguyen, H.; Cressie, N.; Hobbs, J. Sensitivity of Optimal Estimation Satellite Retrievals to Misspecification of the Prior Mean and Covariance, with Application to OCO-2 Retrievals. Remote Sens. 2019, 11, 2770. [Google Scholar] [CrossRef]
- Wunch, D.; Wennberg, P.O.; Toon, G.C.; Connor, B.J.; Fisher, B.; Osterman, G.B.; Frankenberg, C.; Mandrake, L.; O’Dell, C.; Ahonen, P.; et al. A method for evaluating bias in global measurements of CO2 total columns from space. Atmos. Chem. Phys. 2011, 11, 12317–12337. [Google Scholar] [CrossRef]
- Parker, R.; Boesch, H.; Cogan, A.; Fraser, A.; Feng, L.; Palmer, P.I.; Messerschmidt, J.; Deutscher, N.; Griffith, D.W.; Notholt, J.; et al. Methane observations from the Greenhouse Gases Observing SATellite: Comparison to ground-based TCCON data and model calculations. Geophys. Res. Lett. 2011, 38, L15807. [Google Scholar] [CrossRef]
- Emmons, L.; Deeter, M.; Gille, J.; Edwards, D.; Attié, J.L.; Warner, J.; Ziskin, D.; Francis, G.; Khattatov, B.; Yudin, V.; et al. Validation of Measurements of Pollution in the Troposphere (MOPITT) CO retrievals with aircraft in situ profiles. J. Geophys. Res. Atmos. 2004, 109, D03309. [Google Scholar] [CrossRef]
- Inoue, M.; Morino, I.; Uchino, O.; Miyamoto, Y.; Yoshida, Y.; Yokota, T.; Machida, T.; Sawa, Y.; Matsueda, H.; Sweeney, C.; et al. Validation of XCO2 derived from SWIR spectra of GOSAT TANSO-FTS with aircraft measurement data. Atmos. Chem. Phys. 2013, 13, 9771–9788. [Google Scholar] [CrossRef]
- Miyazaki, K.; Eskes, H.; Sudo, K.; Takigawa, M.; Van Weele, M.; Boersma, K. Simultaneous assimilation of satellite NO2, O3, CO, and HNO3 data for the analysis of tropospheric chemical composition and emissions. Atmos. Chem. Phys. 2012, 12, 9545–9579. [Google Scholar] [CrossRef]
- Alexe, M.; Bergamaschi, P.; Segers, A.; Detmers, R.; Butz, A.; Hasekamp, O.; Guerlet, S.; Parker, R.; Boesch, H.; Frankenberg, C.; et al. Inverse modeling of CH4 emissions for 2010-2011 using different satellite retrieval products from GOSAT and SCIAMACHY. Atmos. Chem. Phys. 2015, 15, 113–133. [Google Scholar] [CrossRef]
- Rodgers, C.D.; Connor, B.J. Intercomparison of remote sounding instruments. J. Geophys. Res. Atmos. 2003, 108, D3. [Google Scholar] [CrossRef]
- Chevallier, F. On the statistical optimality of CO2 atmospheric inversions assimilating CO2 column retrievals. Atmos. Chem. Phys. 2015, 15, 11133–11145. [Google Scholar] [CrossRef]
- Connor, B.J.; Parrish, A.; Tsou, J.J.; McCormick, M.P. Error analysis for the ground-based microwave ozone measurements during STOIC. J. Geophys. Res. Atmos. 1995, 100, 9283–9291. [Google Scholar] [CrossRef]
- Cressie, N. Mission CO2ntrol: A Statistical Scientist’s Role in Remote Sensing of Atmospheric Carbon Dioxide (with discussion). J. Am. Stat. Assoc. 2018, 113, 152–168. [Google Scholar] [CrossRef]
- Kulawik, S.S.; Bowman, K.W.; Luo, M.; Rodgers, C.D.; Jourdain, L. Impact of nonlinearity on changing the a priori of trace gas profile estimates from the Tropospheric Emission Spectrometer (TES). Atmos. Chem. Phys. 2008, 8, 3081–3092. [Google Scholar]
- O’Dell, C.W.; Connor, B.; Bösch, H.; O’Brien, D.; Frankenberg, C.; Castano, R.; Christi, M.; Eldering, D.; Fisher, B.; Gunson, M.; et al. The ACOS CO2 retrieval algorithm Part 1: Description and validation against synthetic observations. Atmos. Meas. Tech. 2012, 5, 99–121. [Google Scholar] [CrossRef]
- Zhu, L.; Jacob, D.J.; Kim, P.S.; Fisher, J.A.; Yu, K.; Travis, K.R.; Mickley, L.J.; Yantosca, R.M.; Sulprizio, M.P.; De Smedt, I.; et al. Observing atmospheric formaldehyde (HCHO) from space: Validation and intercomparison of six retrievals from four satellites (OMI, GOME2A, GOME2B, OMPS) with SEAC4RS aircraft observations over the southeast US. Atmos. Chem. Phys. 2016, 16, 13477. [Google Scholar] [PubMed]
- Connor, B.J.; Siskind, D.E.; Tsou, J.; Parrish, A.; Remsberg, E.E. Ground-based microwave observations of ozone in the upper stratosphere and mesosphere. J. Geophys. Res. Atmos. 1994, 99, 16757–16770. [Google Scholar]


{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| Observed -dimensional vector of radiances from the i-th instrument | |
| True (hidden) r-dimensional vector of state elements | |
| -dimensional vector of radiance error for the i-th instrument | |
| Jacobian of the i-th forward model | |
| True prior mean vector of the state vector | |
| Working prior mean vector of for the i-th retrieval | |
| Comparison ensemble mean within averaging kernel correction | |
| Covariance matrix for the radiance measurement error of the i-th instrument | |
| True prior covariance matrix of the state vector | |
| Working prior covariance matrix of for the i-th retrieval | |
| Comparison ensemble covariance matrix within averaging kernel correction | |
| Gain matrix computed with the prior | |
| Averaging kernel computed with the prior | |
| Retrieved state from using the working prior | |
| Averaging kernel adjusted under the comparison ensemble |
| Name | |||
|---|---|---|---|
| CO2 Volume Mixing Ratio (means in ppm) | |||
| Vertical Level 1 (top of atmosphere) | 389.7404 | 385.8430 | 381.9456 |
| Vertical Level 2 | 395.3024 | 391.3493 | 387.3963 |
| Vertical Level 3 | 398.1116 | 394.1305 | 390.1493 |
| Vertical Level 4 | 399.1278 | 395.1365 | 391.1453 |
| Vertical Level 5 (tropopause) | 394.0883 | 397.1398 | 390.1076 |
| Vertical Level 6 | 396.4378 | 392.4734 | 388.5090 |
| Vertical Level 7 | 396.0817 | 392.1209 | 388.1601 |
| Vertical Level 8 | 395.7496 | 391.7922 | 387.8347 |
| Vertical Level 9 | 395.2420 | 391.2896 | 387.3372 |
| Vertical Level 10 | 394.7879 | 390.8400 | 386.8921 |
| Vertical Level 11 | 393.5765 | 389.6408 | 385.7050 |
| Vertical Level 12 | 392.4954 | 388.5704 | 384.6455 |
| Vertical Level 13 | 391.1232 | 387.2119 | 383.3007 |
| Vertical Level 14 | 390.0250 | 386.1247 | 382.2245 |
| Vertical Level 15 | 389.1317 | 385.2403 | 381.3490 |
| Vertical Level 16 | 388.8229 | 384.9347 | 381.0465 |
| Vertical Level 17 | 389.8204 | 385.9222 | 382.0240 |
| Vertical Level 18 | 391.4878 | 387.5729 | 383.6581 |
| Vertical Level 19 | 397.4609 | 393.4863 | 389.5117 |
| Vertical Level 20 (surface) | 401.3001 | 397.2871 | 393.2741 |
| Surface Pressure (hPa) | 998.7413 | 988.7538 | 978.7664 |
| Lambertian Albedo (the units of means are in the Supplementary Materials) | |||
| Strong CO2 Band Mean Albedo | 0.6496 | 0.6431 | 0.6366 |
| Strong CO2 Band Albedo Spectral Slope | 0 | 0 | 0 |
| Weak CO2 Band Mean Albedo | 0.6755 | 0.6687 | 0.6620 |
| Weak CO2 Band Albedo Spectral Slope | 0 | 0 | 0 |
| O2 A-Band Mean Albedo | 0.5183 | 0.5131 | 0.5079 |
| O2 A-Band Mean Albedo Spectral Slope | 0 | 0 | 0 |
| Aerosols (the units of means are in the Supplementary Materials) | |||
| Dust Log Aerosol Optical Depth | −2.4760 | −2.4512 | −2.4264 |
| Dust Profile Height | 0.8982 | 0.8892 | 0.8803 |
| Dust Log Profile Thickness | −3.6365 | −3.6001 | −3.5638 |
| Sea Salt Log Aerosol Optical Depth | −3.8290 | −3.7907 | −3.7524 |
| Sea Salt Profile Height | 0.7478 | 0.7404 | 0.7329 |
| Sea Salt Log Profile Thickness | −2.0716 | −2.0509 | −2.0302 |
| Cloud Ice Log Aerosol Depth | −2.8718 | −2.8431 | −2.8144 |
| Cloud Ice Profile Height | 0.2208 | 0.2186 | 0.2164 |
| Cloud Ice Log Profile Thickness | −3.2129 | −3.1807 | −3.1486 |
| Cloud Water Log Aerosol Depth | −4.0925 | −4.0516 | −4.0107 |
| Cloud Water Profile Height | 0.5531 | 0.5475 | 0.5420 |
| Cloud Water Log Profile Thickness | −2.3013 | −2.2783 | −2.2553 |
| Experiment 1 | ||||
| Experiment 2 | ||||
| Experiment 3 |
| Simulated | Simulated | Simulated | Theoretical | Simulated | Theoretical | |
|---|---|---|---|---|---|---|
| Experiment 1 | −1.5040 | −3.0085 | −0.6824 | −0.6851 | −1.3732 | −1.3701 |
| Experiment 2 | −0.3167 | −1.5042 | −0.1437 | −0.1514 | −0.6856 | −0.6851 |
| Experiment 3 | −0.0129 | −1.5032 | 0.0119 | −0.0060 | −0.6804 | −0.6851 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, H.; Hobbs, J. Intercomparison of Remote Sensing Retrievals: An Examination of Prior-Induced Biases in Averaging Kernel Corrections. Remote Sens. 2020, 12, 3239. https://doi.org/10.3390/rs12193239
Nguyen H, Hobbs J. Intercomparison of Remote Sensing Retrievals: An Examination of Prior-Induced Biases in Averaging Kernel Corrections. Remote Sensing. 2020; 12(19):3239. https://doi.org/10.3390/rs12193239
Chicago/Turabian StyleNguyen, Hai, and Jonathan Hobbs. 2020. "Intercomparison of Remote Sensing Retrievals: An Examination of Prior-Induced Biases in Averaging Kernel Corrections" Remote Sensing 12, no. 19: 3239. https://doi.org/10.3390/rs12193239
APA StyleNguyen, H., & Hobbs, J. (2020). Intercomparison of Remote Sensing Retrievals: An Examination of Prior-Induced Biases in Averaging Kernel Corrections. Remote Sensing, 12(19), 3239. https://doi.org/10.3390/rs12193239