Stereo Dense Image Matching by Adaptive Fusion of Multiple-Window Matching Results


Abstract

1. Introduction
- (1)
- Our proposed method utilizes intensity and disparity information to predict the appropriate weights of large and small windows in the fusion.
- (2)
- Our proposed method leverages the advantages of small and large matching windows and achieves the most accurate matching results when compared with small, large, and median matching window sizes as well as some state-of-the-art window selection methods.
- (3)
- Our proposed method provides good transferability across different datasets. The network is trained by a street view dataset, while the testing datasets are indoor images, aerial images, and satellite images.
2. Related Work
3. Methodology
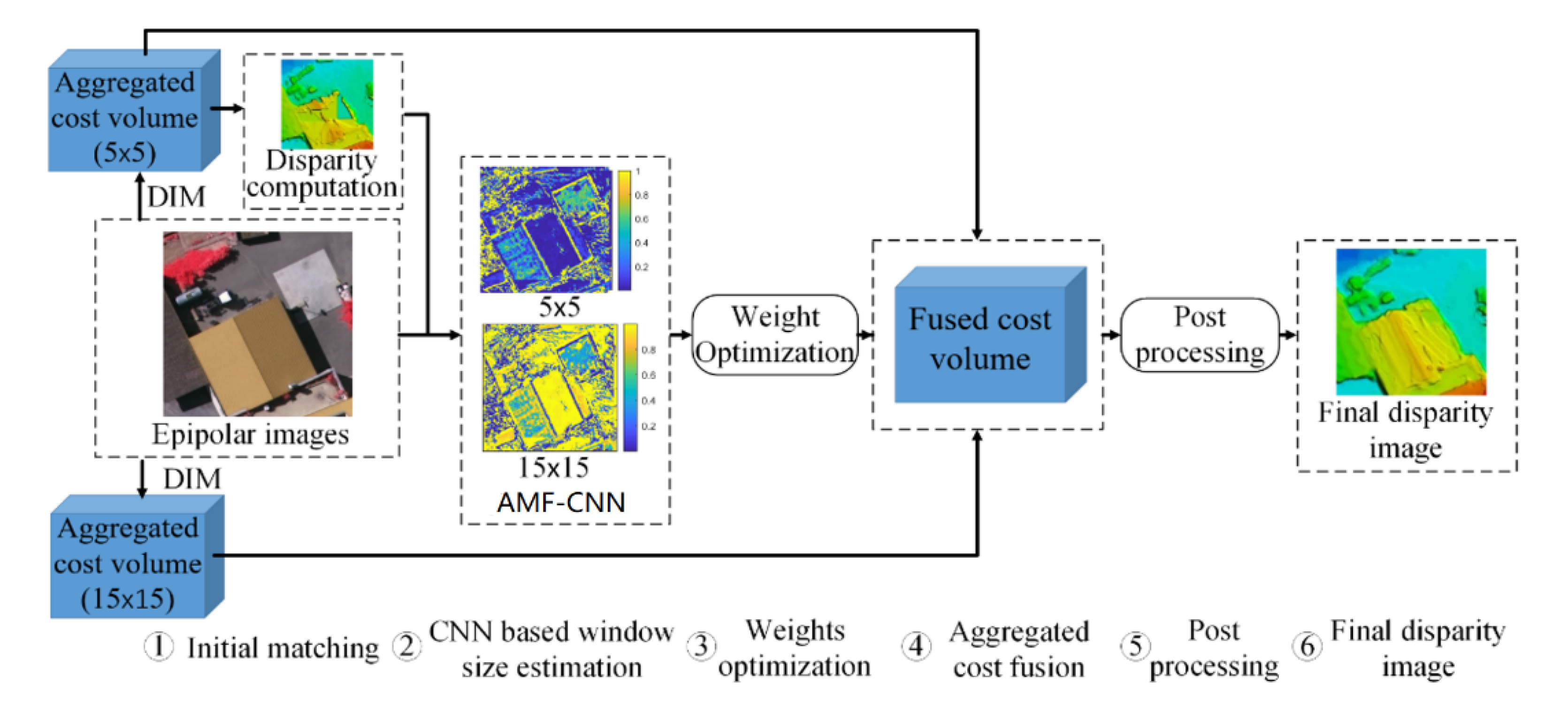
3.1. Overall Scheme
- ①
- Initial matching: we presume the availability of epipolar stereo images and use semi-global matching (SGM) [23] with different matching window sizes (15 × 15 pixels and 5 × 5 pixels) to compute aggregated matching cost volumes of left or right images. The initial disparity images can be derived from any one of the aggregated cost volumes (e.g., 5 × 5 pixels cost volumes in this paper).
- ②
- Window weights estimation from the convolutional network: we respectively estimate probabilities of large or small windows by training a convolutional neural network. Since we will use the probabilities as weights in the fusion of the finial matching results, we also term the window probabilities as windows weights in the remaining paper.
- ③
- Weights optimization: we formulate the window weight estimation problem as a global energy function and develop a comprised solution to compute more robust window weights.
- ④
- Aggregated cost fusion: considering uncertainties in matching, aggregated cost volumes of large and small windows are weighted fused for more accurate matching.
- ⑤
- Disparity computation and post-processing: after computing fused matching cost volumes for left and right images, disparities of left and right images can be derived by winner-takes-all (WTA) strategy, then mismatches are detected and eliminated by left-right consistency check (LRC), leaving holes in disparity images, which are finally interpolated by discontinuity preserving interpolation [23].
3.2. Proposed Method
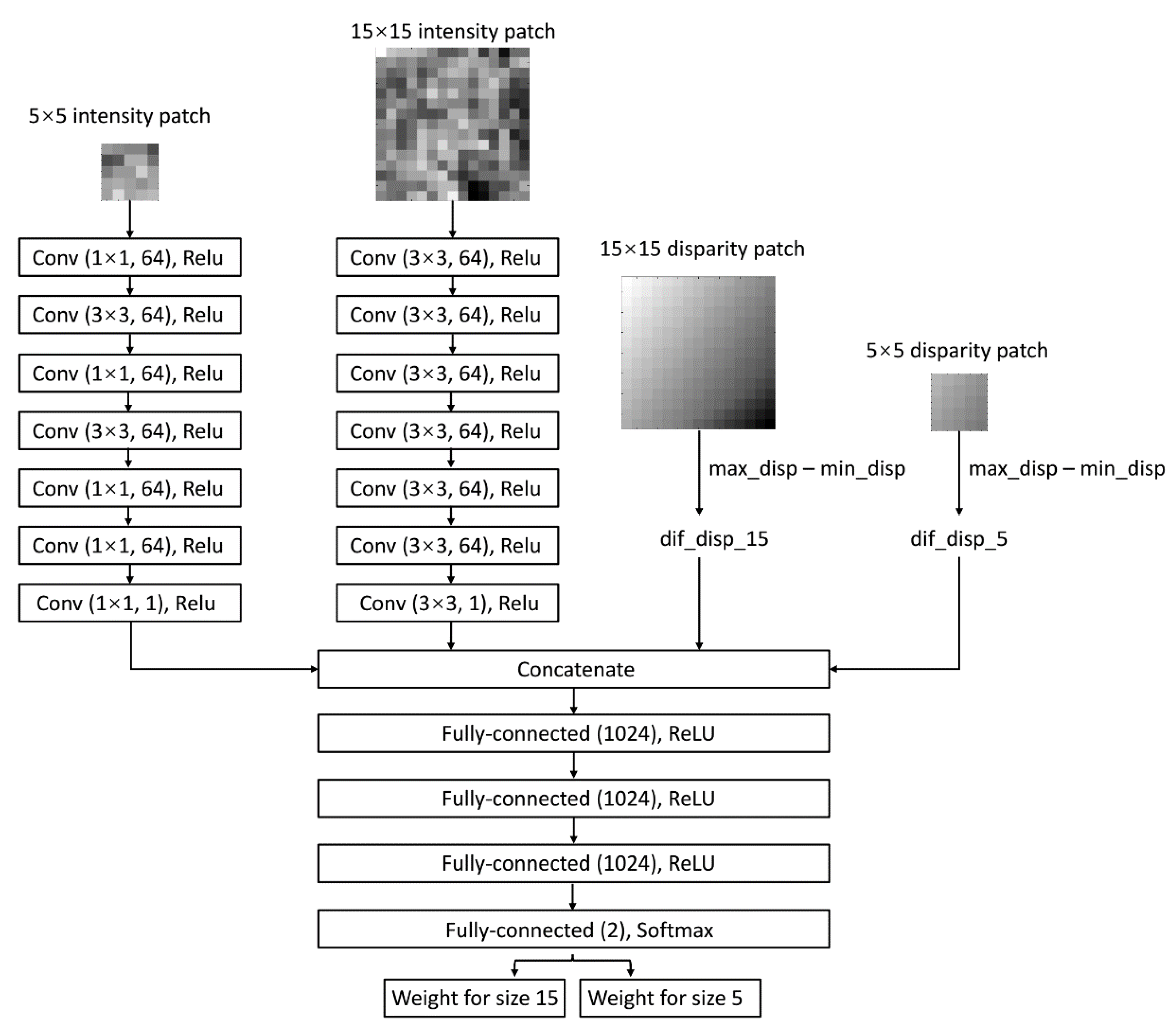
3.2.1. Adaptive Matching Fusion based on Convolutional Neural Network (AMF-CNN)
3.2.2. Solution for the Regularization Term
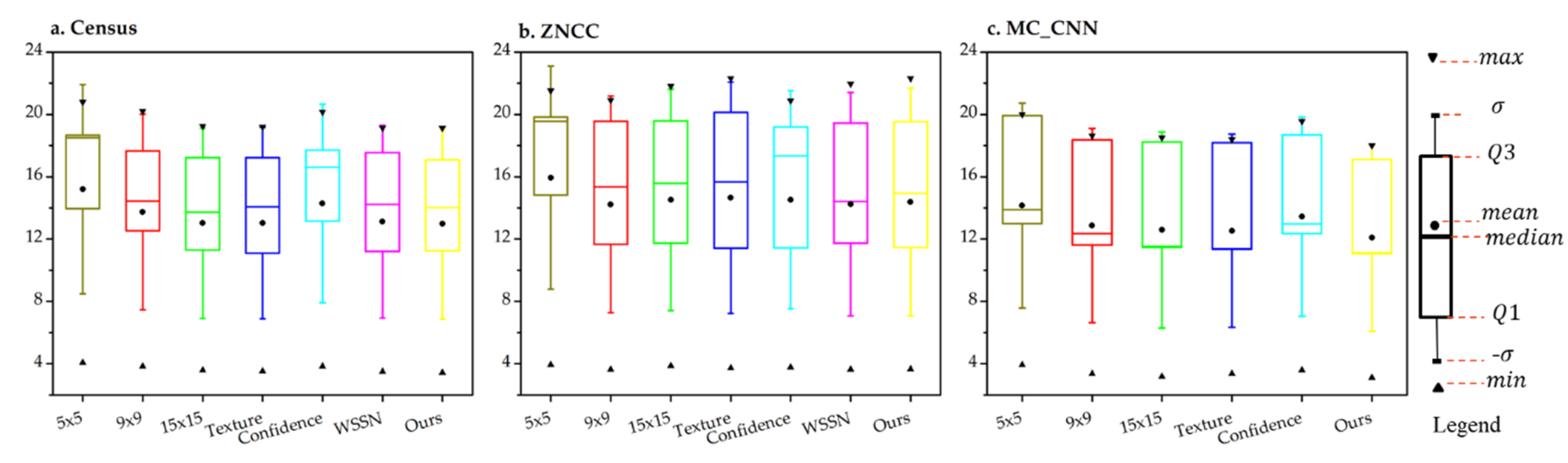
4. Experimental Results
4.1. Experimental Setup
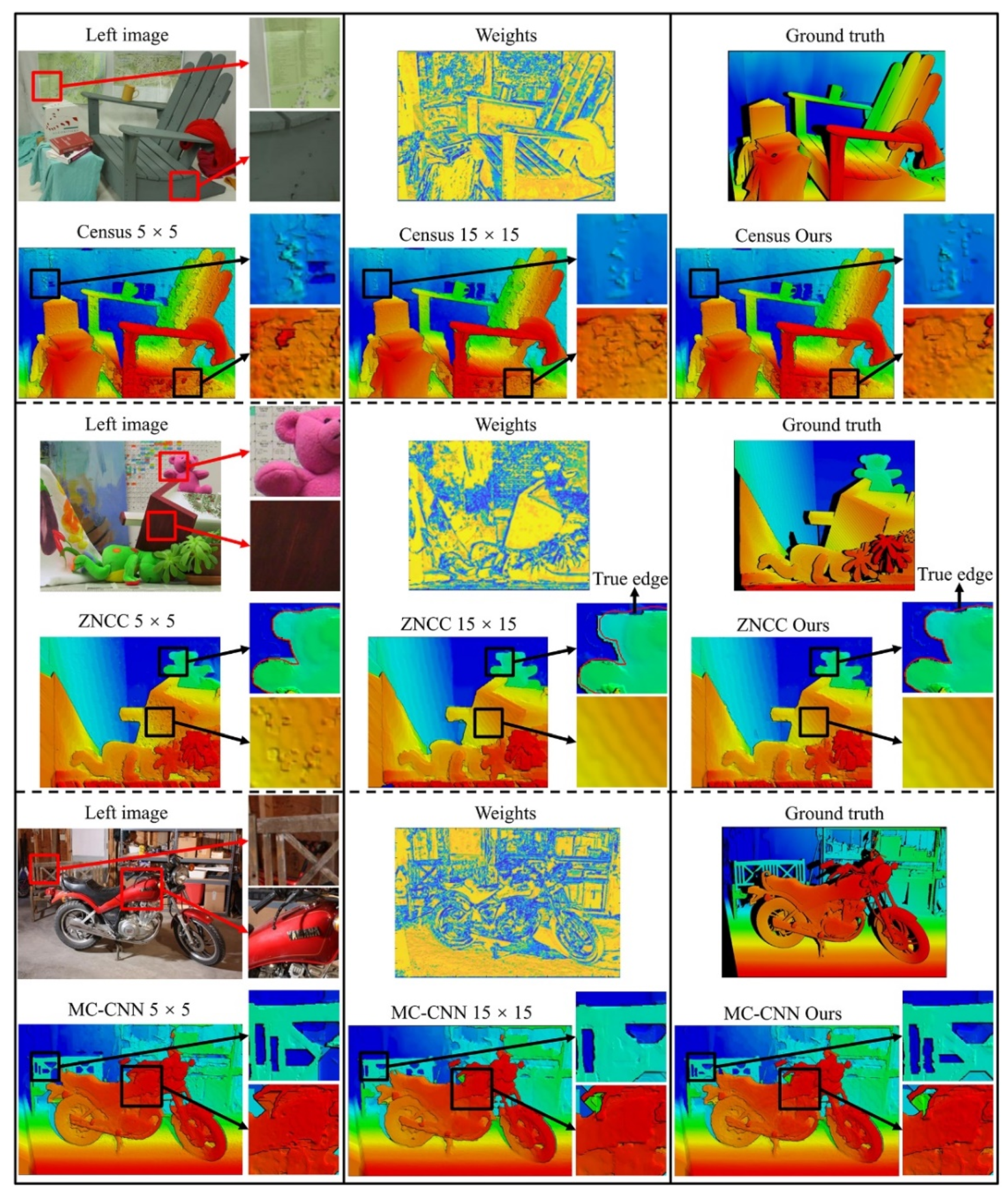
4.2. Experiment with the Middlebury Benchmark Dataset
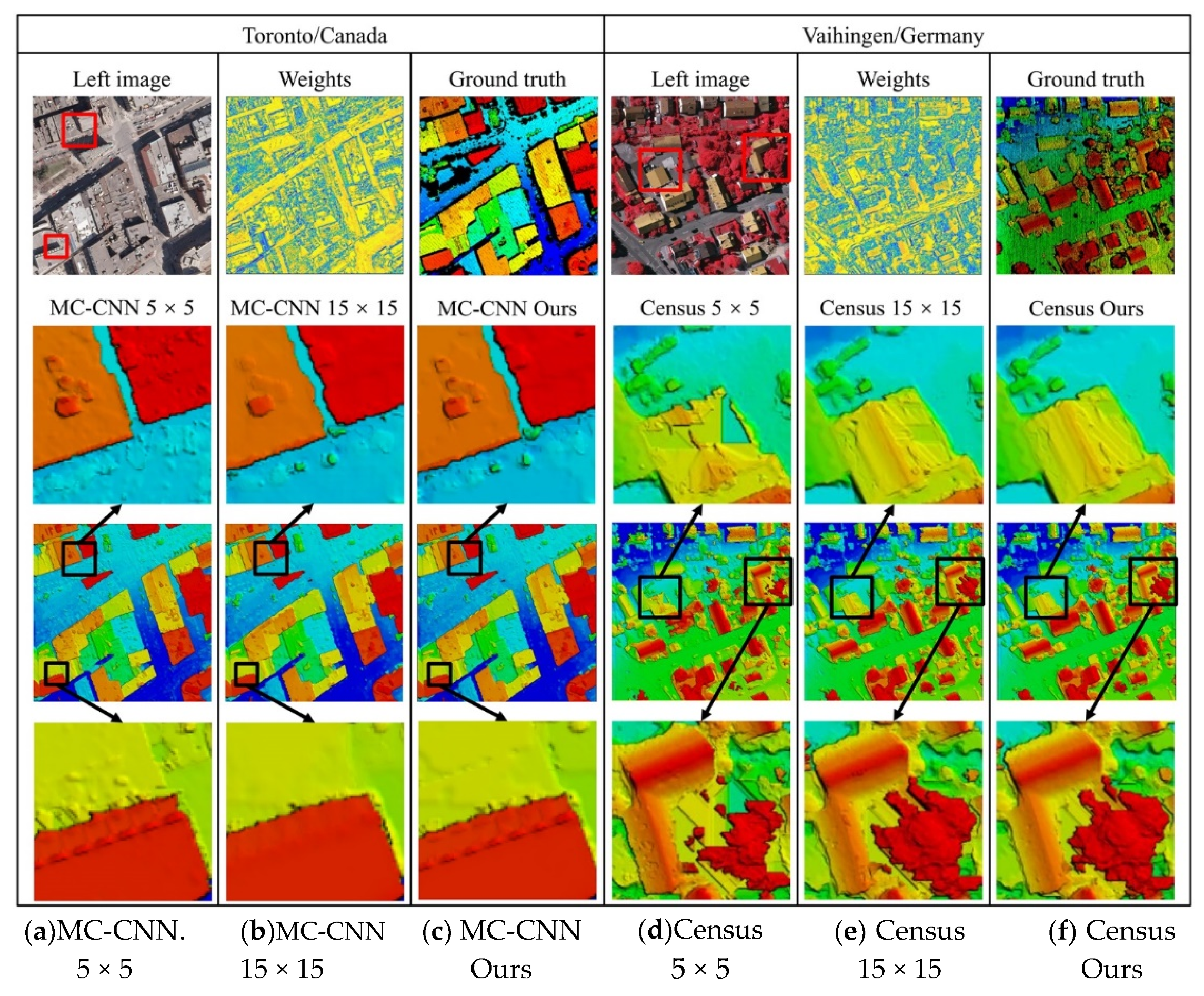
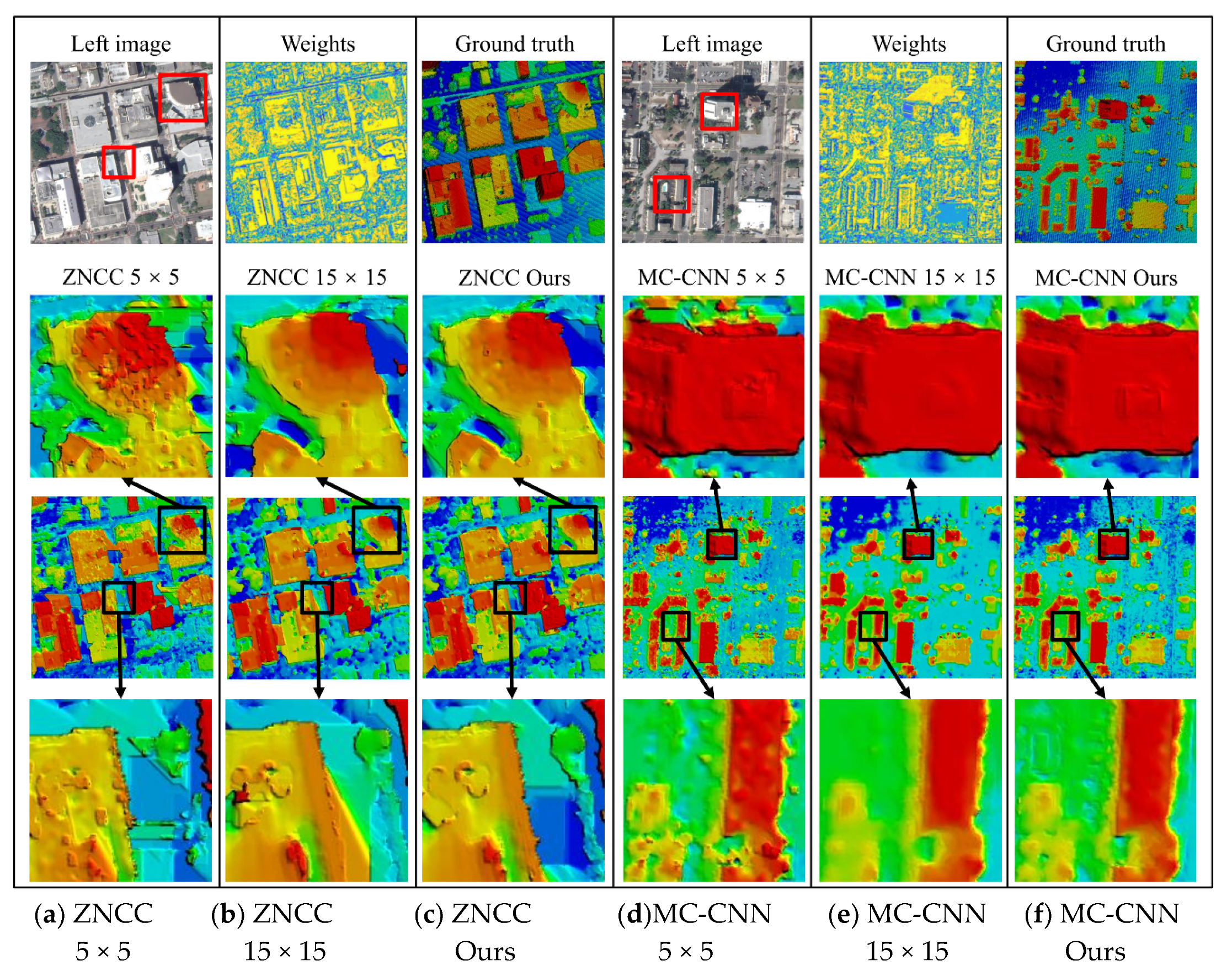
4.3. Experiment with the Aerial Dataset
4.4. Experiment with the Satellite Dataset
5. Conclusions
- (1)
- We have designed a neural network to predict window weights of matching results fusion of each pixel;
- (2)
- We have formulated the window selection problem as a global energy function so that some misestimation from the neural network could be refined;
- (3)
- A comprehensive quantitative assessment on the Middlebury dataset, the Toronto and Vaihingen aerial remote sensing dataset, and the Jacksonville satellite remote sensing dataset has been performed, with the comparative investigation with six other state-of-the-art matching window selection methods. The experimental results have shown that our proposed method achieved good transferability among different datasets.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hirschmüller, H.; Scharstein, D. Evaluation of stereo matching costs on images with radiometric differences. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1582–1599. [Google Scholar] [CrossRef]
- Yuan, W.; Yuan, X.; Xu, S.; Gong, J.; Shibasaki, R. Dense image-matching via optical flow field estimation and fast-guided filter refinement. Remote Sens. 2019, 11, 2410. [Google Scholar] [CrossRef]
- Ye, Z.; Xu, Y.; Chen, H.; Zhu, J.; Tong, X.; Stilla, U. Area-Based dense image matching with subpixel accuracy for remote sensing applications: Practical analysis and comparative study. Remote Sens. 2020, 12, 696. [Google Scholar] [CrossRef]
- Nebiker, S.; Lack, N.; Deuber, M. Building change detection from historical aerial photographs using dense image matching and object-based image analysis. Remote Sens. 2014, 6, 8310–8336. [Google Scholar] [CrossRef]
- Bergamasco, F.; Torsello, A.; Sclavo, M.; Barbariol, F.; Benetazzo, A. WASS: An open-source pipeline for 3D stereo reconstruction of ocean waves. Comput. Geosci. 2017, 107, 28–36. [Google Scholar] [CrossRef]
- Han, Y.; Qin, R.; Huang, X. Assessment of dense image matchers for digital surface model generation using airborne and spaceborne images–an update. Photogramm. Rec. 2020, 35, 58–80. [Google Scholar] [CrossRef]
- Remondino, F.; Spera, M.G.; Nocerino, E.; Menna, F.; Nex, F. State of the art in high density image matching. Photogramm. Rec. 2014, 29, 144–166. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, X.; Chen, Y.; Yan, K.; Yan, G.; Liu, Q.; Zhou, G. Generation of pixel-level resolution lunar DEM based on Chang’E-1 three-line imagery and laser altimeter data. Comput. Geosci. 2013, 59, 53–59. [Google Scholar] [CrossRef]
- Han, Y.; Wang, S.; Gong, D.; Wang, Y.; Wang, Y.; Ma, X. State of the art in digital surface modelling from multi-view high-resolution satellite images. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 2, 351–356. [Google Scholar] [CrossRef]
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Birchfield, S.; Tomasi, C. A pixel dissimilarity measure that is insensitive to image sampling. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 401–406. [Google Scholar] [CrossRef]
- Mei, X.; Sun, X.; Zhou, M.; Jiao, S.; Wang, H.; Zhang, X. On building an accurate stereo matching system on graphics hardware. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 467–474. [Google Scholar] [CrossRef]
- Hermann, S.; Vaudrey, T. The gradient-a powerful and robust cost function for stereo matching. In Proceedings of the 2010 25th International Conference of Image and Vision Computing New Zealand, Queenstown, New Zealand, 8–9 November 2010; pp. 1–8. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, Y.; Yue, Z. Image-guided non-local dense matching with three-steps optimization. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, III-3, 67–74. [Google Scholar] [CrossRef]
- Zhou, X.; Boulanger, P. Radiometric invariant stereo matching based on relative gradients. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 2989–2992. [Google Scholar] [CrossRef]
- Mozerov, M.G.; van de Weijer, J. Accurate stereo matching by two-step energy minimization. IEEE Trans. Image Process. 2015, 24, 1153–1163. [Google Scholar] [CrossRef] [PubMed]
- Zabih, R.; Woodfill, J. Non-parametric local transforms for computing visual correspondence. In Proceedings of the European Conference on Computer Vision, Stockholm, Sweden, 2–6 May 1994; pp. 151–158. [Google Scholar] [CrossRef]
- Jung, I.-L.; Chung, T.-Y.; Sim, J.-Y.; Kim, C.-S. Consistent stereo matching under varying radiometric conditions. IEEE Trans. MultiMedia 2012, 15, 56–69. [Google Scholar] [CrossRef]
- Jiao, J.; Wang, R.; Wang, W.; Dong, S.; Wang, Z.; Gao, W. Local stereo matching with improved matching cost and disparity refinement. IEEE MultiMedia 2014, 21, 16–27. [Google Scholar] [CrossRef]
- Kordelas, G.A.; Alexiadis, D.S.; Daras, P.; Izquierdo, E. Enhanced disparity estimation in stereo images. Image Vis. Comput. 2015, 35, 31–49. [Google Scholar] [CrossRef]
- Li, Y.; Zheng, S.; Wang, X.; Ma, H. An efficient photogrammetric stereo matching method for high-resolution images. Comput. Geosci. 2016, 97, 58–66. [Google Scholar] [CrossRef]
- Zbontar, J.; LeCun, Y. Stereo Matching by Training a Convolutional Neural Network to Compare Image Patches. J. Mach. Learn. Res. 2016, 17, 2. [Google Scholar]
- Hirschmüller, H. Stereo Processing by Semiglobal Matching and Mutual Information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef]
- Erway, C.C.; Ransford, B. Variable Window Methods for Stereo Disparity Determination. Machine Vision 2017. [Google Scholar] [CrossRef]
- Lin, P.-H.; Yeh, J.-S.; Wu, F.-C.; Chuang, Y.-Y. Depth estimation for lytro images by adaptive window matching on EPI. J. Imaging 2017, 3, 17. [Google Scholar] [CrossRef]
- Emlek, A.; Peker, M.; Dilaver, K.F. Variable window size for stereo image matching based on edge information. In Proceedings of the 2017 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 16–17 September 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Koo, H.-S.; Jeong, C.-S. An area-based stereo matching using adaptive search range and window size. In Proceedings of the International Conference on Computational Science, San Francisco, USA, 28–30 May 2001; pp. 44–53. [Google Scholar] [CrossRef]
- Debella-Gilo, M.; Kääb, A. Locally adaptive template sizes for matching repeat images of Earth surface mass movements. ISPRS J. Photogramm. Remote Sens. 2012, 69, 10–28. [Google Scholar] [CrossRef]
- He, Y.; Wang, P.; Fu, J. An Adaptive Window Stereo Matching Based on Gradient. In Proceedings of the 3rd International Conference on Electric and Electronics, Hong Kong, China, 24–25 December 2013. [Google Scholar] [CrossRef]
- Kanade, T.; Okutomi, M. A stereo matching algorithm with an adaptive window: Theory and experiment. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 920–932. [Google Scholar] [CrossRef]
- Adhyapak, S.; Kehtarnavaz, N.; Nadin, M. Stereo matching via selective multiple windows. J. Electron. Imaging 2007, 16, 013012. [Google Scholar] [CrossRef]
- Huang, X.; Liu, W.; Qin, R. A window size selection network for stereo dense image matching. Int. J. Remote Sens. 2020, 41, 4838–4848. [Google Scholar] [CrossRef]
- Hirschmüller, H. Accurate and efficient stereo processing by semi-global matching and mutual information. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 807–814. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Di Stefano, L.; Mattoccia, S.; Tombari, F. ZNCC-based template matching using bounded partial correlation. Pattern Recognit. Lett. 2005, 26, 2129–2134. [Google Scholar] [CrossRef]
- Cheng, F.; Zhang, H.; Sun, M.; Yuan, D. Cross-trees, edge and superpixel priors-based cost aggregation for stereo matching. Pattern Recognit. 2015, 48, 2269–2278. [Google Scholar] [CrossRef]
- Taniai, T.; Matsushita, Y.; Naemura, T. Graph cut based continuous stereo matching using locally shared labels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1613–1620. [Google Scholar] [CrossRef]
- Scharstein, D.; Hirschmüller, H.; Kitajima, Y.; Krathwohl, G.; Nešić, N.; Wang, X.; Westling, P. High-resolution stereo datasets with subpixel-accurate ground truth. In Proceedings of the German conference on pattern recognition, Münster, Germany, 2–5 September 2014; pp. 31–42. [Google Scholar] [CrossRef]
- Rottensteiner, F.; Sohn, G.; Jung, J.; Gerke, M.; Baillard, C.; Benitez, S.; Breitkopf, U. The ISPRS benchmark on urban object classification and 3D building reconstruction. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci 2012, 1, 293–298. [Google Scholar] [CrossRef]
- Bosch, M.; Foster, K.; Christie, G.; Wang, S.; Hager, G.D.; Brown, M. Semantic stereo for incidental satellite images. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 1524–1532. [Google Scholar] [CrossRef]
- Saux, B.L.; Yokoya, N.; Hänsch, R.; Brown, M. Data Fusion Contest 2019 (DFC2019). Available online: https://ieee-dataport.org/open-access/data-fusion-contest-2019-dfc2019 (accessed on 7 June 2020).
- Olsson, C.; Ulén, J.; Boykov, Y. In defense of 3d-label stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1730–1737. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Census | ZNCC | MC-CNN-fst |
|---|---|---|---|
| 5 × 5 pixels | 0.1520 | 0.1672 | 0.1183 |
| 9 × 9 pixels | 0.1372 | 0.1525 | 0.1092 |
| 15 × 15 pixels | 0.1331 | 0.1611 | 0.1136 |
| Texture-based window selection [25] | 0.1247 | 0.1729 | 0.1403 |
| Confidence-based window selection [31] | 0.1286 | 0.1562 | 0.1146 |
| Window size selection network (WSSN) [32] | 0.1243 | 0.1497 | \ |
| Ours | 0.1230 | 0.1491 | 0.1038 |
| Method | Census | ZNCC | MC-CNN-fst |
|---|---|---|---|
| 5 × 5 pixels | 0.1493 | 0.1523 | 0.1127 |
| 9 × 9 pixels | 0.1281 | 0.1328 | 0.1103 |
| 15 × 15 pixels | 0.1215 | 0.1408 | 0.1134 |
| Texture-based window selection [25] | 0.1218 | 0.1334 | 0.1147 |
| Confidence-based window selection [31] | 0.1200 | 0.1392 | 0.1137 |
| Window size selection network (WSSN) [32] | 0.1144 | 0.1345 | \ |
| Ours | 0.1119 | 0.1232 | 0.0969 |
| Method | Census | ZNCC | MC-CNN-fst | |
|---|---|---|---|---|
| 5 × 5 pixels | mean | 0.1520 | 0.1594 | 0.1415 |
| 0.0671 | 0.0716 | 0.0658 | ||
| range | 0.1674 | 0.1762 | 0.1607 | |
| Confidence interval | (0.0932,0.2108) | (0.0966,0.2222) | (0.0838,0.1992) | |
| 9 × 9 pixels | mean | 0.1373 | 0.1423 | 0.1287 |
| 0.0627 | 0.0695 | 0.0624 | ||
| range | 0.1638 | 0.1729 | 0.1527 | |
| Confidence interval | (0.0824,0.1923) | (0.0813,0.2032) | (0.0740,0.1834) | |
| 15 × 15 pixels | mean | 0.1302 | 0.1452 | 0.1258 |
| 0.0610 | 0.0710 | 0.0629 | ||
| range | 0.1566 | 0.1797 | 0.1535 | |
| Confidence interval | (0.0767,0.1837) | (0.0830,0.2075) | (0.0707,0.1809) | |
| Texture-based window selection [25] | mean | 0.1302 | 0.1464 | 0.1253 |
| 0.0615 | 0.0741 | 0.0619 | ||
| range | 0.1570 | 0.1860 | 0.1504 | |
| Confidence interval | (0.0764,0.1841) | (0.0815,0.2115) | (0.0711,0.1796) | |
| Confidence-based window selection [31] | mean | 0.1429 | 0.1452 | 0.1344 |
| 0.0637 | 0.0699 | 0.0640 | ||
| range | 0.1633 | 0.1713 | 0.1599 | |
| Confidence interval | (0.0871,0.1987) | (0.0840,0.2065) | (0.0783,0.1905) | |
| Window size selection network (WSSN) [32] | mean | 0.1312 | 0.1420 | \ |
| 0.0619 | 0.0717 | |||
| range | 0.1565 | 0.1833 | ||
| Confidence interval | (0.0769,0.1855) | (0.0795,0.2052) | ||
| Ours | mean | 0.1298 | 0.1438 | 0.1208 |
| 0.0612 | 0.0731 | 0.0599 | ||
| range | 0.1570 | 0.1867 | 0.1492 | |
| Confidence interval | (0.0762,0.1835) | (0.0797,0.2078) | (0.0684,0.1733) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, Y.; Liu, W.; Huang, X.; Wang, S.; Qin, R. Stereo Dense Image Matching by Adaptive Fusion of Multiple-Window Matching Results. Remote Sens. 2020, 12, 3138. https://doi.org/10.3390/rs12193138
Han Y, Liu W, Huang X, Wang S, Qin R. Stereo Dense Image Matching by Adaptive Fusion of Multiple-Window Matching Results. Remote Sensing. 2020; 12(19):3138. https://doi.org/10.3390/rs12193138
Chicago/Turabian StyleHan, Yilong, Wei Liu, Xu Huang, Shugen Wang, and Rongjun Qin. 2020. "Stereo Dense Image Matching by Adaptive Fusion of Multiple-Window Matching Results" Remote Sensing 12, no. 19: 3138. https://doi.org/10.3390/rs12193138
APA StyleHan, Y., Liu, W., Huang, X., Wang, S., & Qin, R. (2020). Stereo Dense Image Matching by Adaptive Fusion of Multiple-Window Matching Results. Remote Sensing, 12(19), 3138. https://doi.org/10.3390/rs12193138