Urban Building Type Mapping Using Geospatial Data: A Case Study of Beijing, China






Abstract
1. Introduction
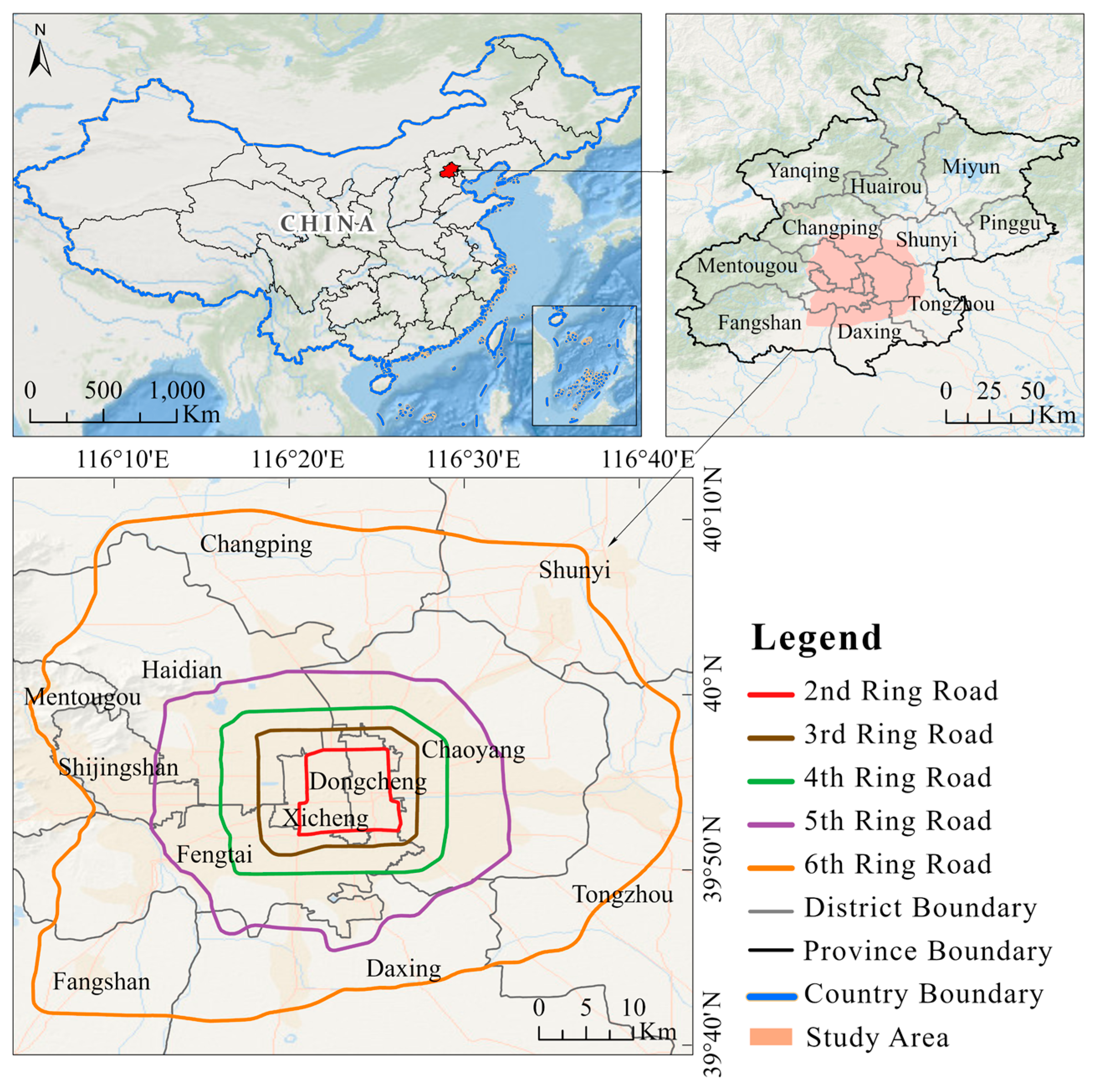
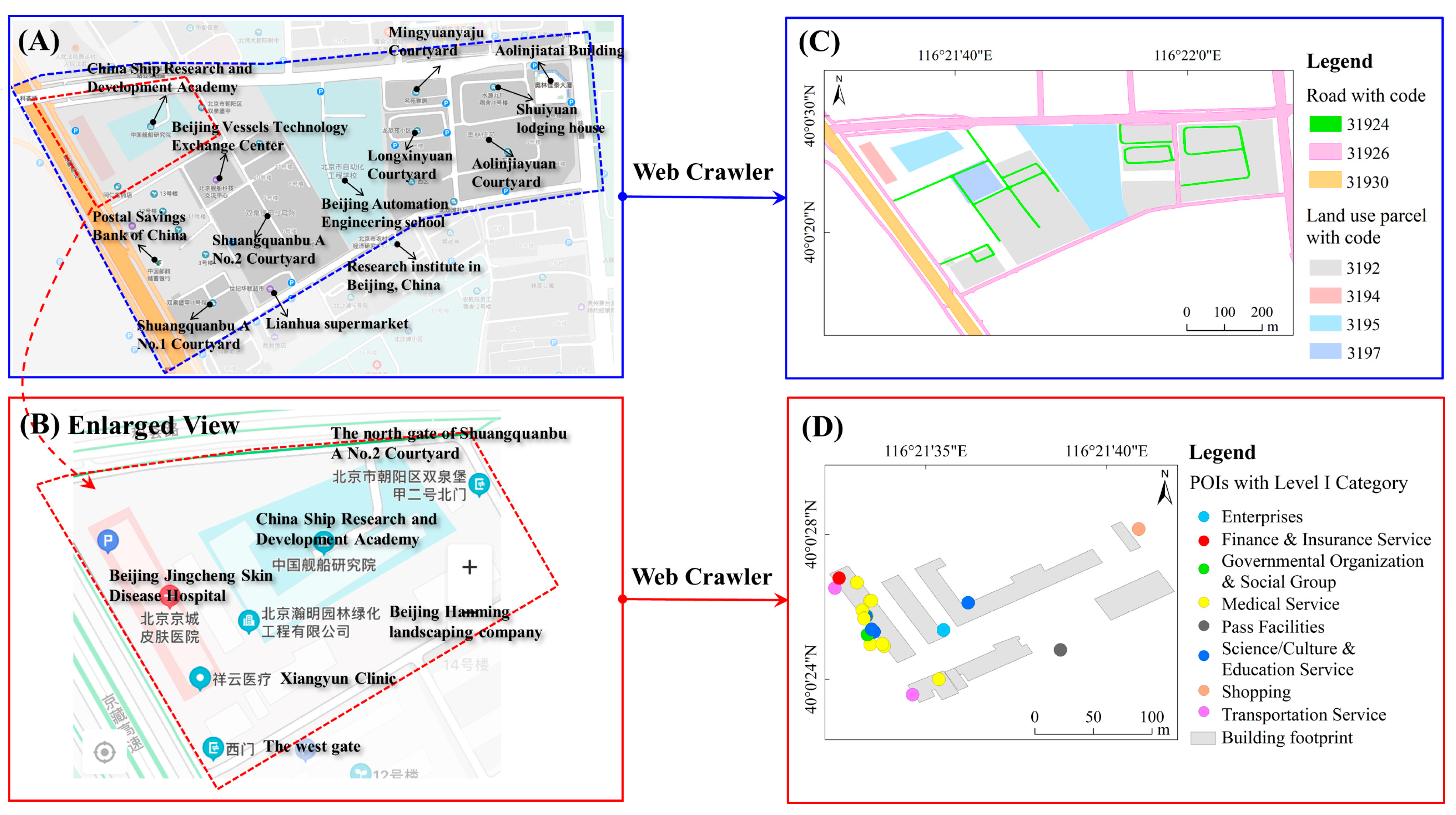
2. Study Area and Data
3. Methodology
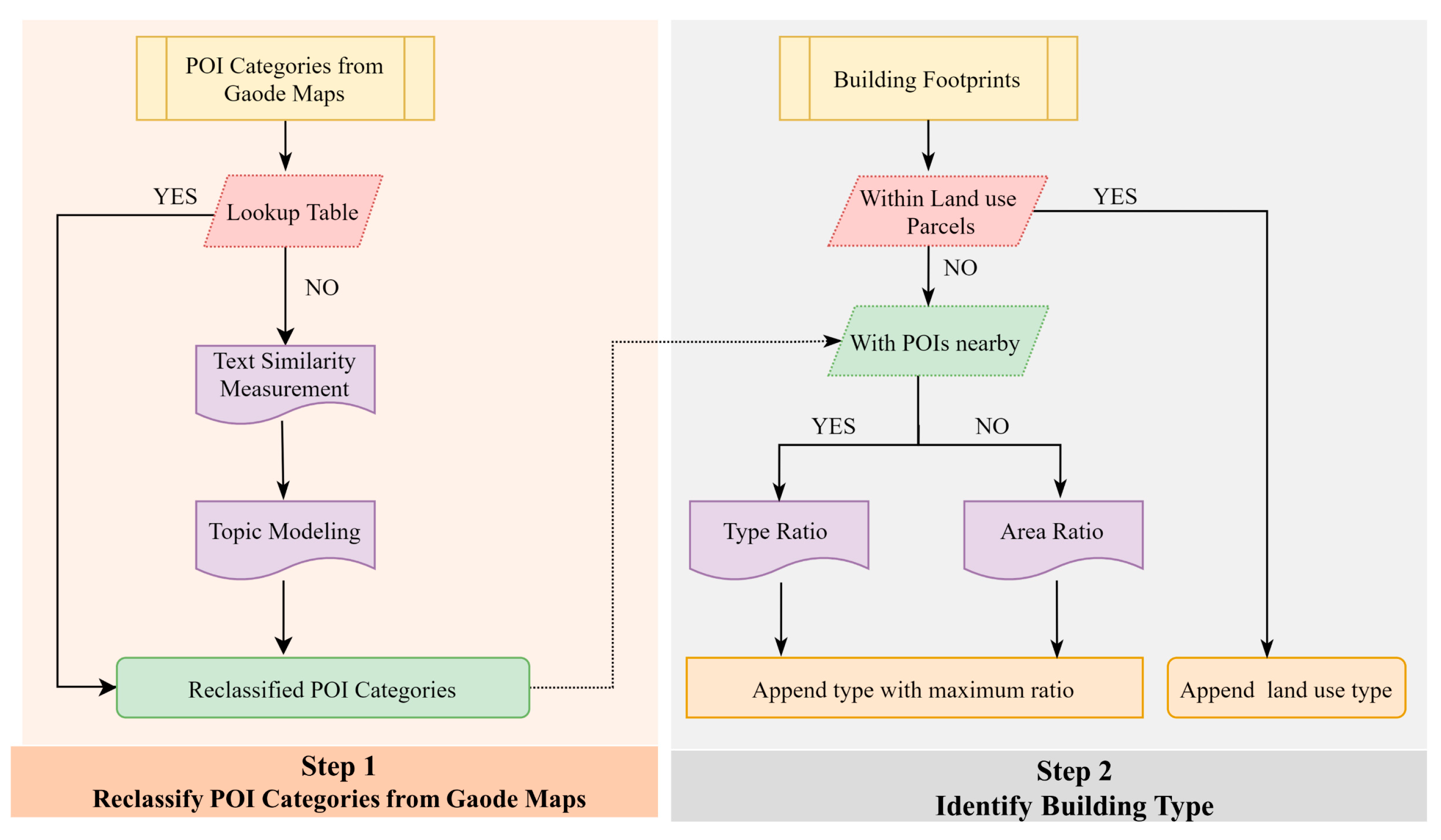
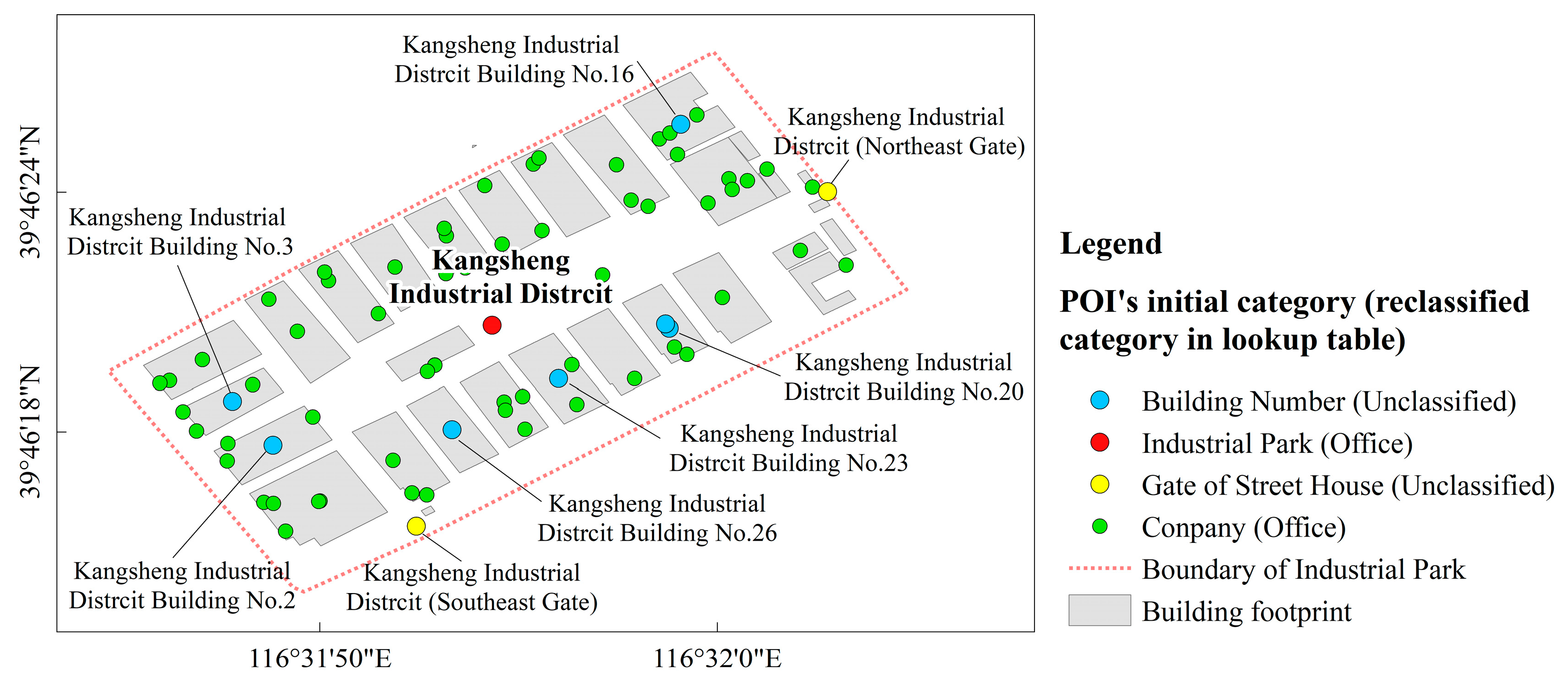
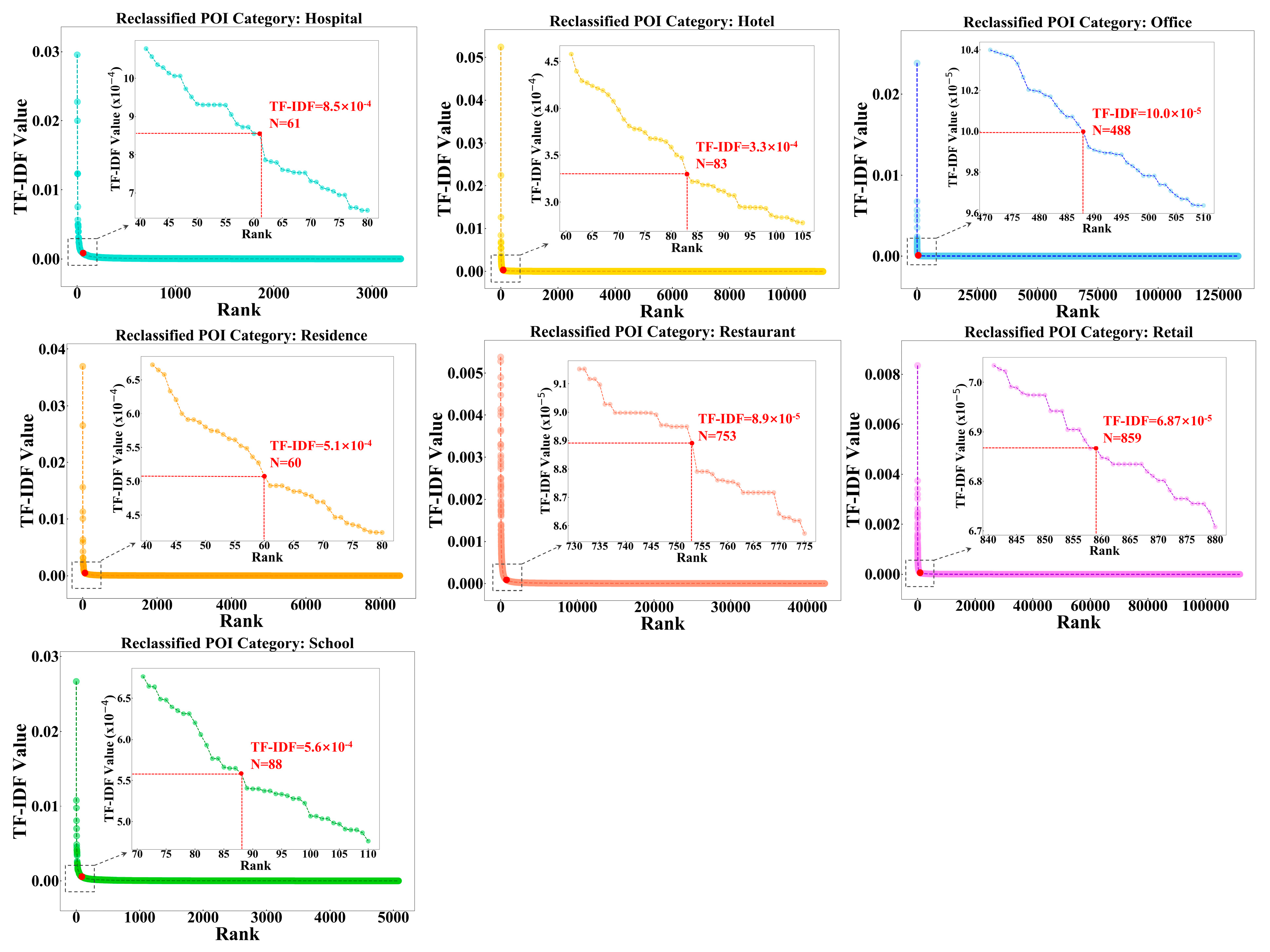
3.1. Reclassification of POI Categories
3.1.1. Text Similarity Measurement
3.1.2. Topic Modeling
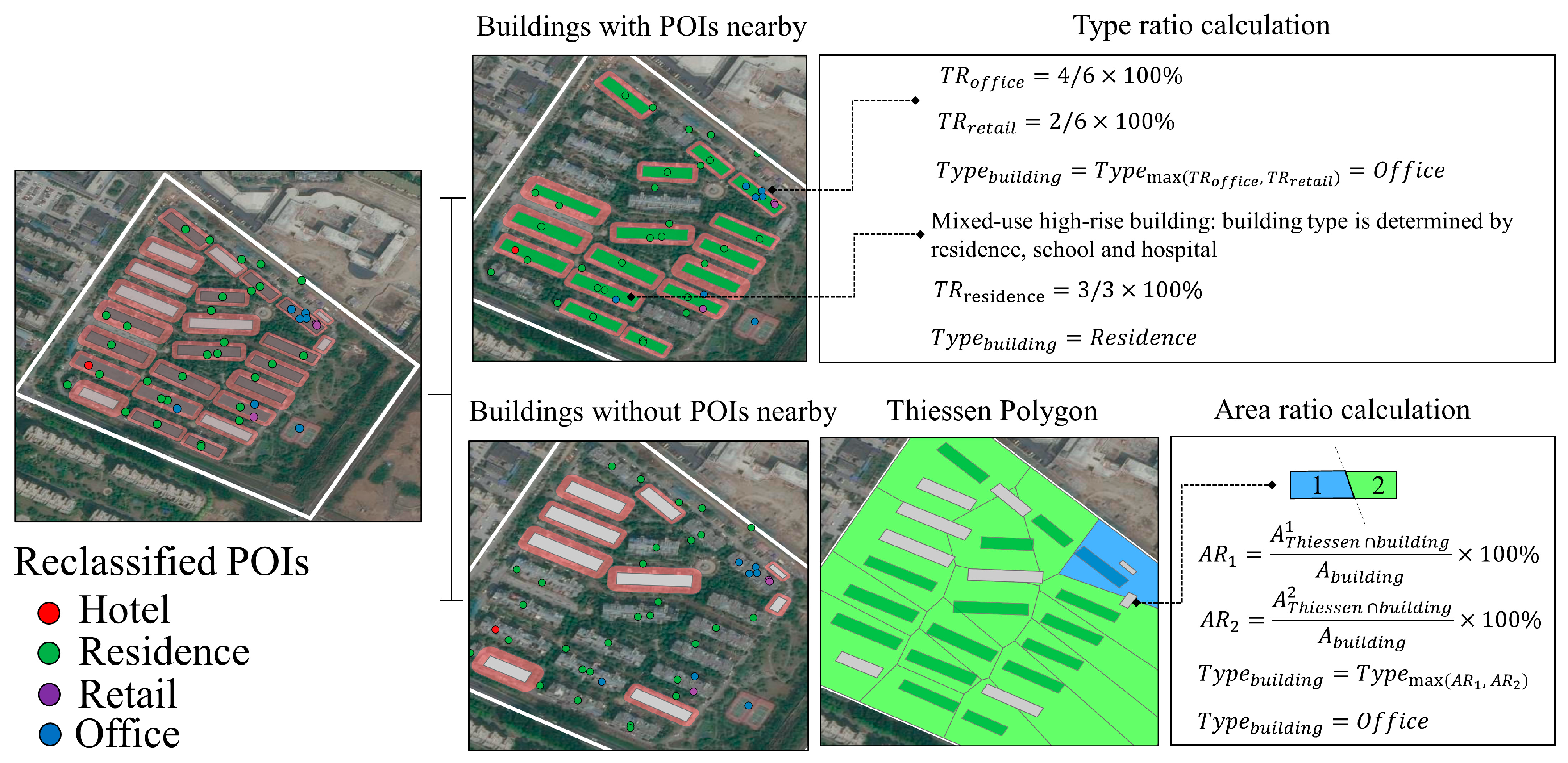
3.2. Identification of Building Types
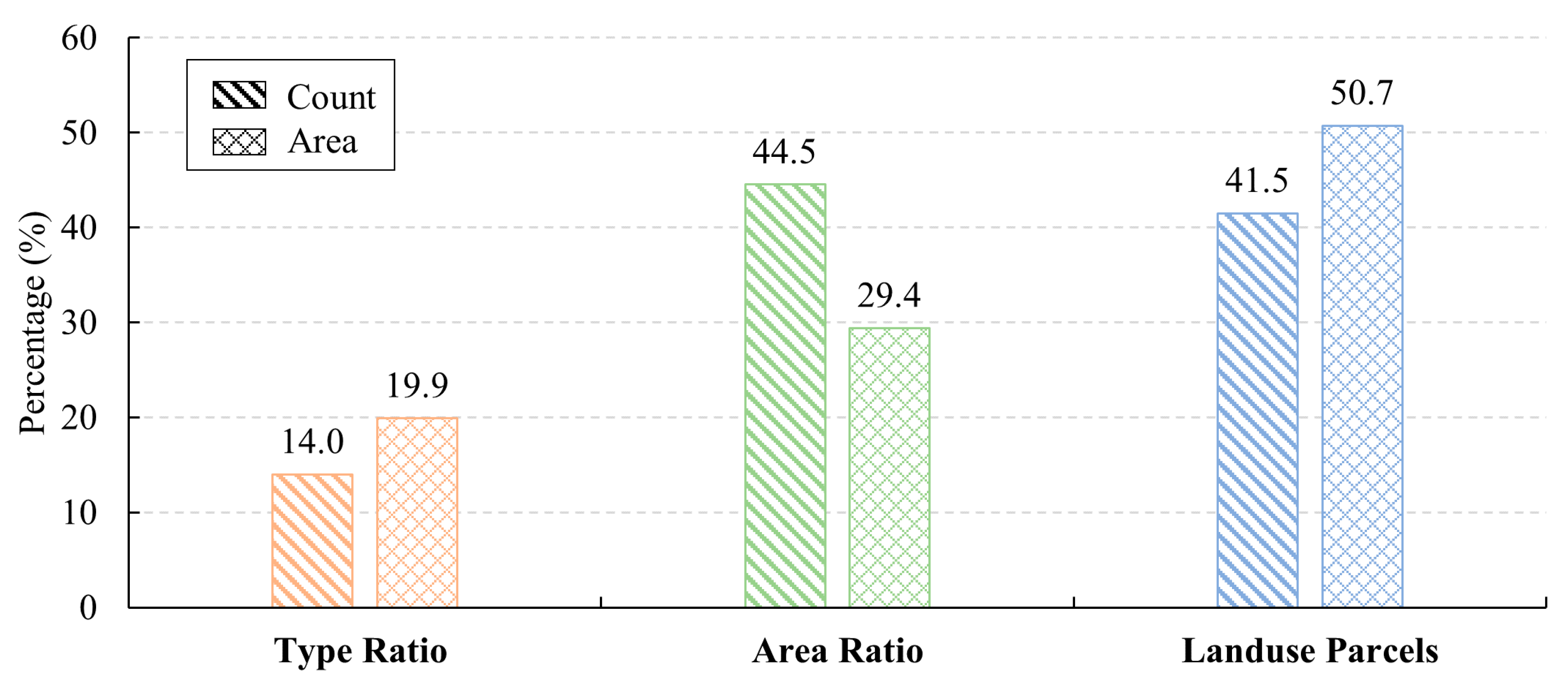
3.2.1. Type Ratio
3.2.2. Area Ratio
3.3. Accuracy Assessment
4. Results
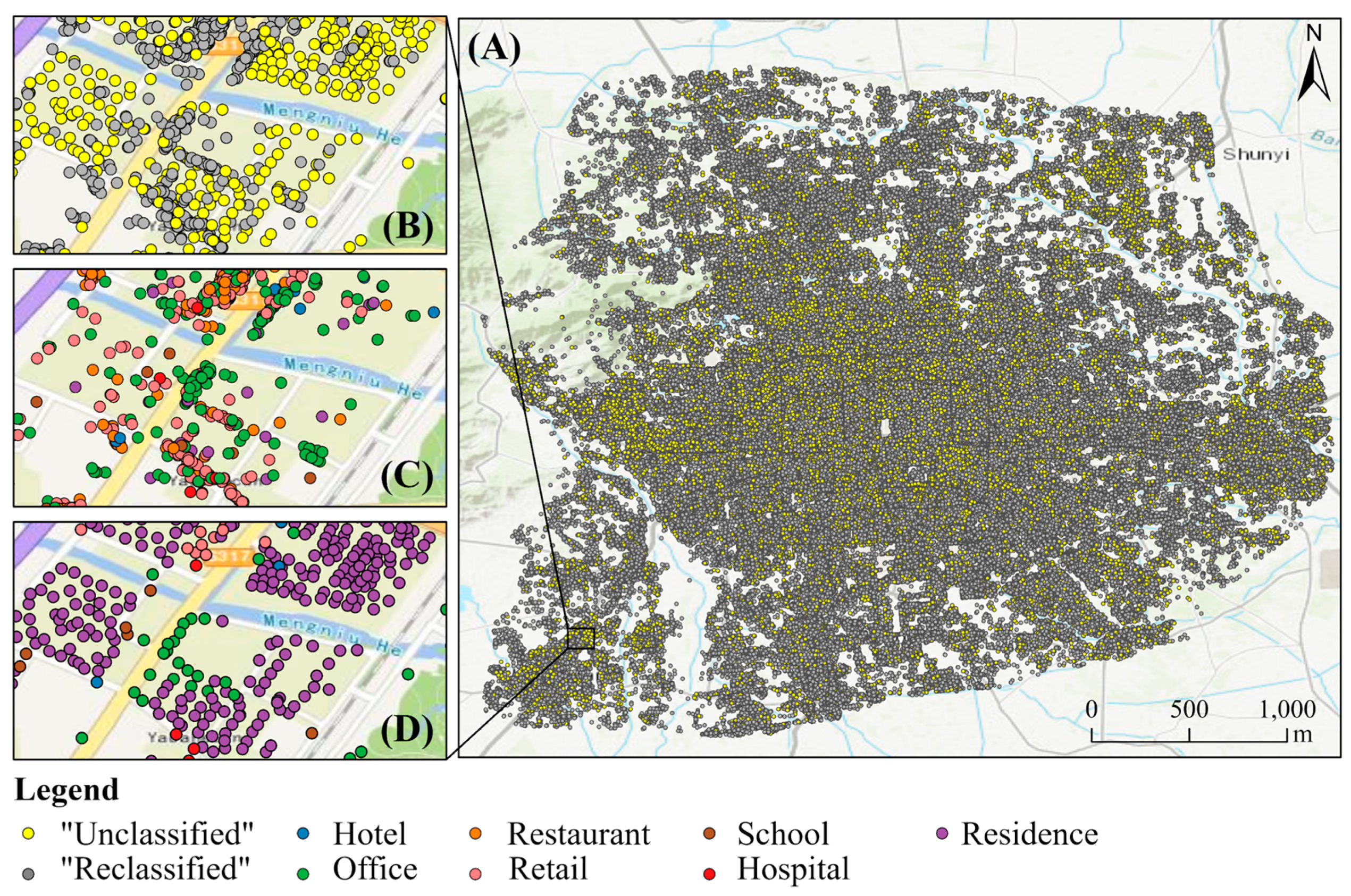
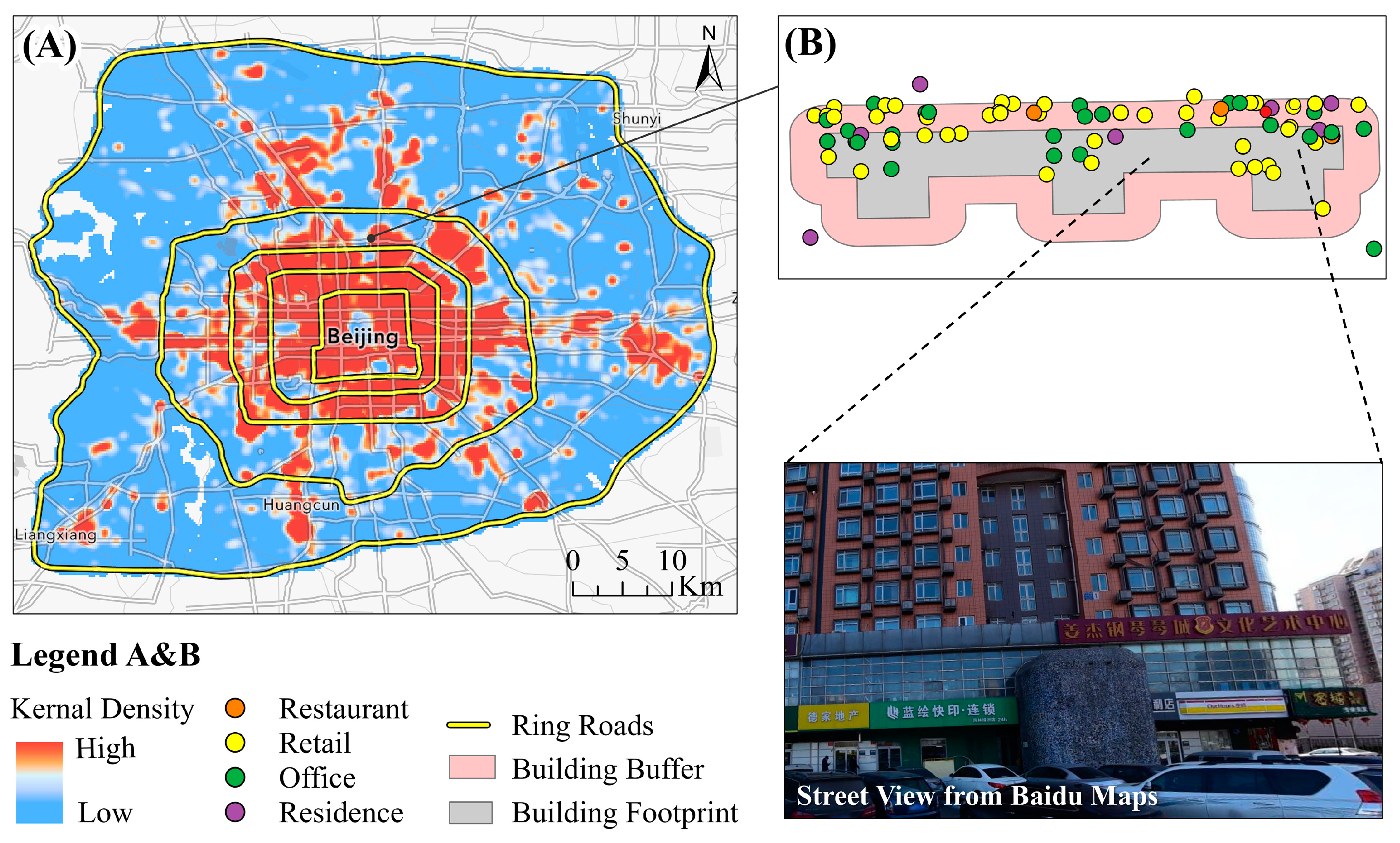
4.1. Spatial Pattern of Identified Building Types
4.2. Performance of the NLP-Based Approach
4.3. Accuracy Assessment of Identified Building Types
5. Discussion
5.1. Comparisons with Other Methods
5.2. Implications
5.3. Future Work
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lu, Z.; Im, J.; Rhee, J.; Hodgson, M. Building type classification using spatial and landscape attributes derived from LiDAR remote sensing data. Landsc. Urban. Plan. 2014, 130, 134–148. [Google Scholar] [CrossRef]
- Li, M.; Koks, E.; Taubenböck, H.; van Vliet, J. Continental-scale mapping and analysis of 3D building structure. Remote Sens. Environ. 2020, 245, 111859. [Google Scholar] [CrossRef]
- Li, W.; Zhou, Y.; Cetin, K.S.; Yu, S.; Wang, Y.; Liang, B. Developing a landscape of urban building energy use with improved spatiotemporal representations in a cool-humid climate. Build. Environ. 2018, 136, 107–117. [Google Scholar] [CrossRef]
- Vetter-Gindele, J.; Braun, A.; Warth, G.; Bui, T.T.Q.; Bachofer, F.; Eltrop, L. Assessment of household solid waste generation and composition by building type in Da Nang, Vietnam. Resources 2019, 8, 171. [Google Scholar] [CrossRef]
- Yeh, C.-H.; Loh, C.-H.; Tsai, K.-C. Overview of Taiwan earthquake loss estimation system. Nat. Hazards 2006, 37, 23–37. [Google Scholar] [CrossRef]
- Yao, Y.; Liu, X.; Li, X.; Zhang, J.; Liang, Z.; Mai, K.; Zhang, Y. Mapping fine-scale population distributions at the building level by integrating multisource geospatial big data. Int. J. Geogr. Inf. Sci. 2017, 31, 1220–1244. [Google Scholar] [CrossRef]
- Xie, J.; Zhou, J. Classification of urban building type from high spatial resolution remote sensing imagery using extended MRS and soft BP network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3515–3528. [Google Scholar] [CrossRef]
- Du, S.; Zhang, F.; Zhang, X. Semantic classification of urban buildings combining VHR image and GIS data: An improved random forest approach. ISPRS J. Photogramm. Remote Sens. 2015, 105, 107–119. [Google Scholar] [CrossRef]
- Wurm, M.; Taubenbock, H.; Roth, A.; Dech, S. Urban structuring using multisensoral remote sensing data: By the example of the German cities Cologne and Dresden. In Proceedings of the 2009 Joint Urban Remote Sensing Event, Shanghai, China, 20–22 May 2009; pp. 1–8. [Google Scholar]
- Sritarapipat, T.; Takeuchi, W. Building classification in Yangon City, Myanmar using Stereo GeoEye images, Landsat image and night-time light data. Remote Sens. Appl. Soc. Environ. 2017, 6, 46–51. [Google Scholar] [CrossRef]
- Chen, W.; Huang, H.; Dong, J.; Zhang, Y.; Tian, Y.; Yang, Z. Social functional mapping of urban green space using remote sensing and social sensing data. ISPRS J. Photogramm. Remote Sens. 2018, 146, 436–452. [Google Scholar] [CrossRef]
- Zhuo, L.; Shi, Q.; Zhang, C.; Li, Q.; Tao, H. Identifying building functions from the spatiotemporal population density and the interactions of people among buildings. ISPRS Int. J. Geo-Inf. 2019, 8, 247. [Google Scholar] [CrossRef]
- Niu, N.; Liu, X.; Jin, H.; Ye, X.; Liu, Y.; Li, X.; Chen, Y.; Li, S. Integrating multi-source big data to infer building functions. Int. J. Geogr. Inf. Sci. 2017, 31, 1871–1890. [Google Scholar] [CrossRef]
- Liu, X.; Niu, N.; Liu, X.; Jin, H.; Ou, J.; Jiao, L.; Liu, Y. Characterizing mixed-use buildings based on multi-source big data. Int. J. Geogr. Inf. Sci. 2018, 32, 738–756. [Google Scholar]
- Steiniger, S.; Lange, T.; Burghardt, D.; Weibel, R. An approach for the classification of urban building structures based on discriminant analysis techniques. Trans. GIS 2008, 12, 31–59. [Google Scholar] [CrossRef]
- Arunplod, C.; Nagai, M.; Honda, K.; Warnitchai, P. Classifying building occupancy using building laws and geospatial information: A case study in Bangkok. Int. J. Disaster Risk Reduct. 2017, 24, 419–427. [Google Scholar] [CrossRef]
- Chao, H.; Cao, Y.; Zhang, J.; Xia, F.; Zhou, Y.; Shan, H. Population Density-Based Hospital Recommendation with Mobile LBS Big Data. In Proceedings of the 2018 IEEE International Conference on Big Data and Smart Computing (BigComp), Shanghai, China, 15–17 January 2018; pp. 37–44. [Google Scholar]
- He, Y.; Zheng, Y.; Deng, J.; Pan, H. Design and implementation of a POI collection and management system based on public map service. In Proceedings of the 2016 Fourth International Conference on Ubiquitous Positioning, Indoor Navigation and Location Based Services (UPINLBS), Shanghai, China, 3–4 November 2016; pp. 197–200. [Google Scholar]
- Wang, C.; Li, Y.; Shi, X. Information Mining for Urban Building Energy Models (UBEMs) from Two Data Sources: OpenStreetMap and Baidu Map. Energy Buding. 2017, 157, 166–175. [Google Scholar]
- Liu, X.; Long, Y. Automated identification and characterization of parcels with OpenStreetMap and points of interest. Environ. Plan. B Plan. Des. 2016, 43, 341–360. [Google Scholar] [CrossRef]
- Ye, T.; Zhao, N.; Yang, X.; Ouyang, Z.; Liu, X.; Chen, Q.; Hu, K.; Yue, W.; Qi, J.; Li, Z. Improved population mapping for China using remotely sensed and points-of-interest data within a random forests model. Sci. Total Environ. 2019, 658, 936–946. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, F.; Hsieh, H.-P. U-air: When urban air quality inference meets big data. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 13–14 August 2013; pp. 1436–1444. [Google Scholar]
- Hu, T.; Yang, J.; Li, X.; Gong, P. Mapping urban land use by using landsat images and open social data. Remote Sens. 2016, 8, 151. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.; Huang, H.; Wu, W.; Du, X.; Wang, H. The combined use of remote sensing and social sensing data in fine-grained urban land use mapping: A case study in Beijing, China. Remote Sens. 2017, 9, 865. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, X.; Liu, Z.; Li, X. Understanding the spatial organization of urban functions based on co-location patterns mining: A comparative analysis for 25 Chinese cities. Cities 2020, 97, 102563. [Google Scholar] [CrossRef]
- Gao, S.; Janowicz, K.; Couclelis, H. Extracting urban functional regions from points of interest and human activities on location-based social networks. Trans. GIS 2017, 21, 446–467. [Google Scholar] [CrossRef]
- Deng, X.; Newsam, S. Quantitative comparison of open-source data for fine-grain mapping of land use. In Proceedings of the 3rd ACM SIGSPATIAL Workshop on Smart Cities and Urban Analytics, Redondo Beach, CA, USA, 7 November 2017; pp. 1–8. [Google Scholar]
- Vaz, E.; Arsanjani, J.J. Crowdsourced mapping of land use in urban dense environments: An assessment of Toronto. Can. Geogr. Géographe Can. 2015, 59, 246–255. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, Q.; Zhang, Y.; Du, X. Improving the accuracy of fine-grained population mapping using population-sensitive POIs. Remote Sens. 2019, 11, 2502. [Google Scholar] [CrossRef]
- Wang, Y.; Xie, X.; Liang, S.; Zhu, B.; Yao, Y.; Meng, S.; Lu, C. Quantifying the response of potential flooding risk to urban growth in Beijing. Sci. Total Environ. 2019, 705, 135868. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.; Wang, H.; Du, X.; Huang, H. Community scale livability evaluation integrating remote sensing, surface observation and geospatial big data. Int. J. Appl. Earth Obs. Geoinf. 2019, 80, 173–186. [Google Scholar] [CrossRef]
- Winkler, W.E. The State of Record Linkage and Current Research Problems. In Statistical Research Division, US Census Bureau; Citeseer: Tokyo, Japan, 1999. [Google Scholar]
- Cohen, W.W.; Ravikumar, P.; Fienberg, S.E. A Comparison of string distance Metrics for Name-Matching Tasks. In Proceedings of the IIWeb, Acapulco, Mexico, 9–10 August 2003; Volume 2003, pp. 73–78. [Google Scholar]
- Hecht, R.; Meinel, G.; Buchroithner, M. Automatic identification of building types based on topographic databases—a comparison of different data sources. Int. J. Cartogr. 2015, 1, 18–31. [Google Scholar] [CrossRef]
- Huo, T.; Ren, H.; Zhang, X.; Cai, W.; Feng, W.; Zhou, N.; Wang, X. China’s energy consumption in the building sector: A Statistical Yearbook-Energy Balance Sheet based splitting method. J. Clean. Prod. 2018, 185, 665–679. [Google Scholar] [CrossRef]
- Chen, S.; Li, N.; Guan, J.; Xie, Y.; Sun, F.; Ni, J. A statistical method to investigate national energy consumption in the residential building sector of China. Energy Build. 2008, 40, 654–665. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| POI Categories from Gaode Maps | Reclassified POI Category (Building Type) | ||
|---|---|---|---|
| Level I | Level II | Level III | |
| Auto Service | All | Retail | |
| Auto Dealers | All | Retail | |
| Auto Repair | All | Retail | |
| Motorcycle Service | All | Retail | |
| Sports and Recreation | All | Retail | |
| Daily Life Service | All | Retail | |
| Shopping | All | Retail | |
| Medical Service | Pharmacy | All | Retail |
| Veterinary Hospital | All | Retail | |
| Others | All | Hospital | |
| Food and Beverages | All | Restaurant | |
| Accommodation Service | All | Hotel | |
| Science/Culture and Education Service | School | All | School |
| Others | All | Office | |
| Tourist Attraction | All | Office | |
| Governmental Organization and Social Group | All | Office | |
| Commercial House | Industrial Park | All | Office |
| Building | Industrial Building | Office | |
| Business Office Building | Office | ||
| Others | Residence | ||
| Transportation Service | Airport Related | All | Office |
| Railway Station | All | Office | |
| Port and Marina | All | Office | |
| Coach Station | All | Office | |
| Border Crossing | All | Office | |
| Others | All | Unrelated | |
| Road Furniture | All | Unrelated | |
| Finance and Insurance Service | ATM | All | Unrelated |
| Others | All | Office | |
| Enterprises | All | Office | |
| Place Name and Address | Address Sign | Building Number | Unclassified |
| Others | Unrelated | ||
| Others | All | Unrelated | |
| Pass Facilities | Gate of buildings | All | Unclassified |
| Gate of Street House | All | Unclassified | |
| Virtual Gate | All | Unrelated | |
| Public Facility | All | Unrelated | |
| Incidents and Events | All | Unrelated | |
| Indoor facilities | All | Unrelated | |
| Code | Land Use Type | Building Type |
|---|---|---|
| 3192 | Residential districts | Residence |
| 3197 | Government, Industrial district, Company | Office |
| 3194 | Hospital | Hospital |
| 3195 | Primary/Secondary/High School, Kindergarten | School |
| 5640 | University | School |
| 3193 | Park | Office |
| 36126/36130 | Shopping mall | Retail |
| 3201 | Resort Hotel | Hotel |
| 3198 | Airport | Office |
| 4125/5644 | Parking lots | Unrelated |
| 31642/41124/41150/4128-4144/41472/6301 | Subway station | Unrelated |
| 3185/5636-5638 | Lake/waterway | Unrelated |
| 5645-5650/3177/3182 | Sport ground | Unrelated |
| 3174/5642/5643 | Greenspace | Unrelated |
| Hospital | Hotel | Office | Residence | Restaurant | Retail | School | Total | UA (%) | |
|---|---|---|---|---|---|---|---|---|---|
| Hospital | 20 | 0 | 0 | 0 | 0 | 0 | 0 | 20 | 100.00 |
| Hotel | 0 | 15 | 6 | 4 | 0 | 0 | 0 | 25 | 60.00 |
| Office | 1 | 1 | 70 | 19 | 0 | 1 | 3 | 95 | 73.68 |
| Residence | 0 | 0 | 2 | 266 | 0 | 1 | 1 | 270 | 98.52 |
| Restaurant | 0 | 1 | 0 | 6 | 12 | 1 | 0 | 20 | 60.00 |
| Retail | 1 | 0 | 4 | 2 | 0 | 33 | 0 | 40 | 82.50 |
| School | 0 | 0 | 0 | 1 | 0 | 0 | 29 | 30 | 96.67 |
| Total | 22 | 17 | 82 | 298 | 12 | 36 | 33 | 500 | |
| PA (%) | 90.91 | 88.24 | 85.37 | 89.26 | 100.00 | 91.67 | 87.88 |
| Hospital | Hotel | Office | Residence | Restaurant | Retail | School | Total | UA (%) | |
|---|---|---|---|---|---|---|---|---|---|
| Hospital | 16 | 0 | 1 | 2 | 0 | 1 | 0 | 20 | 80.00 |
| Hotel | 0 | 11 | 5 | 9 | 0 | 0 | 0 | 25 | 44.00 |
| Office | 0 | 0 | 114 | 38 | 1 | 9 | 3 | 165 | 69.09 |
| Residence | 0 | 0 | 2 | 145 | 0 | 3 | 0 | 150 | 96.67 |
| Restaurant | 0 | 0 | 4 | 8 | 23 | 0 | 0 | 35 | 65.71 |
| Retail | 0 | 0 | 7 | 12 | 0 | 41 | 0 | 60 | 68.33 |
| School | 0 | 0 | 1 | 3 | 0 | 0 | 41 | 45 | 91.11 |
| Total | 16 | 11 | 134 | 217 | 24 | 54 | 44 | 500 | |
| PA (%) | 100.00 | 100.00 | 85.07 | 66.82 | 95.83 | 75.93 | 93.18 |
| Case | Category | Study Area/The Number of Buildings | Data Source | Characteristics | Method | Building Types | Accuracy |
|---|---|---|---|---|---|---|---|
| [1] | RS-based 1 | Denver, USA/1510 buildings | LiDAR | Geometry, landscape | Supervised machine learning approaches (SVM, Random Forest, etc.) | Single-family houses, multiple-family houses, non-residential buildings | OA2 > 70%, Kappa8 > 0.5 |
| [10] | RS-based | Yangon, Myanmar/64.11 km2 | GeoEye/Landsat/NPP-VIIRS | Geometry, Spectrum | Unsupervised machine leaning (Hierarchy classification) | Residential, commercial, industrial buildings | OA = 76% Kappa = 0.58 |
| [7] | RS-based | A small area of Beijing, China | Quickbird/Worldview | Geometry, texture | Supervised machine learning (Back Propagation Neural Network Algorithm) | High-rise buildings, multi-story residential buildings, old-fashioned courtyard dwellings | OA = 91.5% Kappa = 0.892 |
| [8] | RS-based | A small area of Beijing, China/8831 buildings | Quickbird | Geometry, texture, spectrum | Supervised machine learning (Random Forest) | Low-story shantytowns, medium-story apartments, high-rising apartments, administrative buildings, commercial buildings, industrial buildings, auxiliary buildings | OA = 79.54% Kappa = 0.72 |
| [9] | RS-based | Cologne, Dresden, German | IKONOS, Airborne laser scanning data | Geometry | Unsupervised machine leaning (Fuzzy logic classification) | Non-residential/industrial, detached/semi-detached, terraced, building blocks and high-rise buildings | NA |
| [34] | Map-based | Dresden, Halle Krefeld, Stolpen, Saxony, German | Building footprint vector data, topographic raster maps | Geometry | Supervised machine learning approaches (SVM, Random Forest, etc.) | Single/two-family houses, multi-family houses, industrial/commercial, special purpose | OA is about 90% |
| [15] | Map-based | City of Zurich, Switzerland | Building footprints vector data from topographic map and MasterMap | Geometry | Supervised machine learning approaches (SVM, AdaBoost, etc.) | Industrial and commercial areas, inner city, dense buildings, disperse buildings, single building | OA = 75% Kappa = 0.66 |
| [12] | SS-based | Haizhu District, Guangzhou, China/20,928 buildings | Taxi GPS trajectory data/Tencent user density data | Spatiotemporal distribution characteristics | Unsupervised machine leaning (K-means clustering) | Public facilities, multistore Residential buildings, high-rise residential buildings, business and service buildings, urban village | OA = 85.66% Kappa = 0.8174 |
| [13] | SS-based | Tianhe District, Guangzhou, China 68,997 buildings | Taxi GPS trajectory data/Tencent user density data/POI database | Spatiotemporal distribution characteristics | Unsupervised machine leaning (DBSCAN clustering) | Residential buildings, offices, shopping centers, hotels, hospitals, schools | OA = 72.22% |
| [14] | SS-based | Tianhe District, Guangzhou, China/63,961 buildings | Taxi GPS trajectory data/Tencent user density data/POI database | Spatiotemporal distribution characteristics | Probabilistic model | Single function building, Multifunctional building (Recreation, office and residential building; Recreation and residential building, etc.) | OA = 85% |
| [16] | RS/SS-based | Bangkok, Thailand/2 km2 | ALOS/POI database | Spectrum, geometry, land use | GIS spatial analysis functions and logical statements (if–then–else) | Residential (single house, townhouse), Commercial (single, townhouse), Industrial (factory, warehouse), Theater, Shopping mall | OA > 75% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Zhou, Y.; Wu, Q.; Chen, G.; Huang, X.; Yu, B. Urban Building Type Mapping Using Geospatial Data: A Case Study of Beijing, China. Remote Sens. 2020, 12, 2805. https://doi.org/10.3390/rs12172805
Chen W, Zhou Y, Wu Q, Chen G, Huang X, Yu B. Urban Building Type Mapping Using Geospatial Data: A Case Study of Beijing, China. Remote Sensing. 2020; 12(17):2805. https://doi.org/10.3390/rs12172805
Chicago/Turabian StyleChen, Wei, Yuyu Zhou, Qiusheng Wu, Gang Chen, Xin Huang, and Bailang Yu. 2020. "Urban Building Type Mapping Using Geospatial Data: A Case Study of Beijing, China" Remote Sensing 12, no. 17: 2805. https://doi.org/10.3390/rs12172805
APA StyleChen, W., Zhou, Y., Wu, Q., Chen, G., Huang, X., & Yu, B. (2020). Urban Building Type Mapping Using Geospatial Data: A Case Study of Beijing, China. Remote Sensing, 12(17), 2805. https://doi.org/10.3390/rs12172805