A Ridgeline-Based Terrain Co-registration for Satellite LiDAR Point Clouds in Rough Areas



Abstract
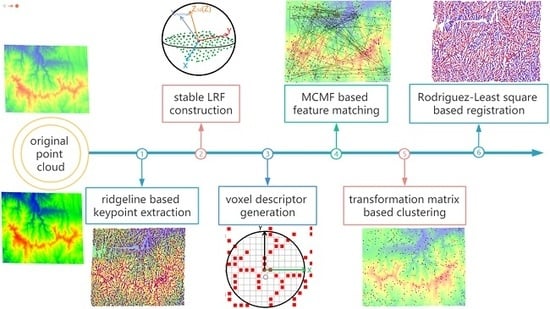
1. Introduction
1.1. Related Work
1.1.1. RANSAC and Its Variations
1.1.2. PCS and Its Variations
1.1.3. LS and Its Variations
1.2. Contribution
1.3. Overview
2. Datasets
3. Methodology
3.1. Ridgeline-Based Keypoint Extraction
3.2. Stable LRF Construction
3.3. Descriptor Generation
3.4. Max Flow Min Cost-Based Graph-Matching
3.5. Transformation Matrices-Based Clustering
3.5.1. Transformation Matrix Computation
3.5.2. Maximum Sample Set Chosen by Clustering
3.6. Rodriguez and LS-Based Registration
4. Criteria
4.1. Criteria for Keypoints Extraction
4.2. Criteria for LRF Construction
4.3. Criteria for Feature-Matching
4.4. Criteria for Registration
5. Results
5.1. Results of Keypoint Extraction
5.2. Results of LRF Construction
5.3. Results of Feature-Matching
5.4. Results of Registration
6. Discussion
6.1. Different Overlap
6.2. Different Topography
6.3. Different Noise
7. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input: Similarity Matrix Output: Maximum Flow With Minimum Cost |
|---|
| (1) initialize the capacity cost graph G = (V, E, c, w); initialize the maximum flow as 0; (2) construct weighted residual digraph; (3) search an augmented path p from vs to vt in the residual digraph. If it is found, return to step 4; otherwise, return to step 6. (4) search for a path with the minimum cost and maximum flow fij in augmented paths; (5) update the cost and capacity of related arcs in current residual digraph and return to step 3; (6) get a feasible maximum flow f = { f1, f2, f3,…, fk} with minimum cost, exit. |
| Input: Initial Correspondences with Their Transformation Matrices, i = 0 Output: Cluster with The Maximum Size |
|---|
| (1) if the current stack T is empty, select any unmarked matching pair as a seed and put the seed in the stack with a label i; (2) pop up the top pair of the stack and look for all unmarked pairs. If the differences between both translation and rotation are less than thresholds, put it into the stack with a label i; (3) repeat step (2) until the stack is empty; (1) i++; repeat steps (1)–(3) until all pairs are marked. |
| Input: Remained Correspondences Output: Optimal Transformation Matrix |
|---|
| (1) list the observation equation: (2) list the error equation: (3) calculate according to the principle of least squares: (4) calculate the rotation matrix R according to Equation (11); (5) calculate the translation of all points in the maximum similar set: |
References
- Zhou, R.; Jiang, W.; Jiang, S. A Novel Method for High-voltage Bundle Conductor Reconstruction from Airborne LiDAR Data. Remote Sens. 2018, 10, 2051. [Google Scholar] [CrossRef]
- López, F.J.; Lerones, P.M.; Llamas, J.; Gómez-García-Bermejo, J.; Zalama, E. A Framework for Using Point Cloud Data of Heritage Buildings Toward Geometry Modeling in A BIM Context: A Case Study on Santa Maria La Real De Mave Church. Int. J. Archit. Herit. 2017, 11, 965–986. [Google Scholar] [CrossRef]
- Cheng, Y.; Yang, C.; Lin, J. Application for Terrestrial LiDAR on Mudstone Erosion Caused by Typhoons. Remote Sens. 2019, 11, 2425. [Google Scholar] [CrossRef]
- Markus, T.; Neumann, T.; Martino, A.; Abdalati, W.; Brunt, K.; Csatho, B.; Farrell, S.; Fricker, H.; Gardner, A.; Harding, D.; et al. The Ice, Cloud, and land Elevation Satellite-2 (ICESat-2): Science requirements, concept, and implementation. Remote Sens. Environ. 2017, 190, 260–273. [Google Scholar] [CrossRef]
- Corbi, H.; Riquelme, A.; Megias-Banos, C.; Abellan, A. 3-D Morphological Change Analysis of a Beach with Seagrass Berm Using a Terrestrial Laser Scanner. Int. J. Geo-Inf. 2018, 7, 234. [Google Scholar] [CrossRef]
- Tao, M.E.N.; Zhao, S.H.E.N.; Rong, X.U. Development status and tendency of space target laser ranging technique. Laser Infrared 2018, 48, 1451–1458. [Google Scholar]
- Li, G.; Tang, X. Analysis and Validation of ZY-302 Satellite Laser Altimetry Data. Acta Geod. Cartogr. Sin. 2017, 46, 1939–1949. [Google Scholar] [CrossRef]
- Qi, W.; Dubayah, R.O. Combining Tandem-X InSAR and simulated GEDI lidar observations for forest structure mapping. Remote Sens. Environ. 2016, 187, 253–266. [Google Scholar] [CrossRef]
- Herzfeld, U.C.; Mcdonald, B.W.; Wallin, B.F.; Neumann, T.A.; Markus, T.; Brenner, A.; Field, C. Algorithm for Detection of Ground and Canopy Cover in Micropulse Photon-Counting Lidar Altimeter Data in Preparation for the ICESat-2 Mission. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2109–2125. [Google Scholar] [CrossRef]
- Glenn, N.F.; Neuenschwander, A.; Vierling, L.A.; Spaete, L.; Li, A.; Shinneman, D.J.; Pilliod, D.S.; Arkle, R.S.; Mcilroy, S.K. Remote Sensing of Environment Landsat 8 and ICESat-2: Performance and potential synergies for quantifying dryland ecosystem vegetation cover and biomass. Remote Sens. Environ. 2016, 185, 233–242. [Google Scholar] [CrossRef]
- Zhang, B.; Chen, K.; Zhou, Y.; Xie, M.; Zhang, H. ICESat laser point assisted bloch adjustment for mapping satellite stereo image. Acta Geod. Cartogr. Sin. 2018, 47, 359–369. [Google Scholar] [CrossRef]
- Abdelrahman, M.; Ali, A.; Elhabian, S.; Farag, A.A. Solving geometric co-registration problem of multi-spectral remote sensing imagery using SIFT-based features toward precise change detection. Lect. Notes Comput. Sci. 2011, 6939, 607–616. [Google Scholar]
- Han, Y.; Oh, J. Automated Geo/Co-Registration of Multi-Temporal Very-High-Resolution Imagery. Sensors 2018, 18, 1599. [Google Scholar] [CrossRef] [PubMed]
- Scheffler, D.; Hollstein, A.; Diedrich, H.; Segl, K.; Hostert, P. AROSICS: An Automated and Robust Open-Source Image Co-Registration Software for Multi-Sensor Satellite Data. Remote Sens. 2017, 9, 676. [Google Scholar] [CrossRef]
- Persad, R.A.; Armenakis, C. Automatic co-registration of 3D multi-sensor point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 130, 162–186. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Kleppe, A.L.; Tingelstad, L.; Egeland, O. Coarse Alignment for Model Fitting of Point Clouds Using a Curvature-Based Descriptor. IEEE Trans. Autom. Sci. Eng. 2019, 16, 811–824. [Google Scholar] [CrossRef]
- Xu, B.; Jiang, W.; Shan, J.; Zhang, J.; Li, L. Investigation on the Weighted RANSAC Approaches for Building Roof Plane Segmentation from LiDAR Point Clouds. Remote Sens. 2016, 8, 5. [Google Scholar] [CrossRef]
- Myatt, R.D.; Torr, S.P.H.; Nasuto, J.S.; Bishop, J.M.; Craddock, R. NAPSAC: High Noise, High Dimensional Robust Estimation. In Proceedings of the British Machine Vision Conference 2002, BMVC 2002, Cardiff, UK, 2–5 September 2002; pp. 458–467. [Google Scholar]
- Chum, O.; Matas, J. Matching with PROSAC—Progressive Sample Consensus. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 220–226. [Google Scholar]
- Raguram, R.; Frahm, J.M.; Pollefeys, M. A Comparative Analysis of RANSAC Techniques Leading to Adaptive Real-Time Random Sample Consensus. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 12–18 October 2008; pp. 500–513. [Google Scholar]
- Ni, K.; Jin, H.; Dellaert, F. GroupSAC: Efficient Consensus in the Presence of Groupings. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Quan, S.; Ma, J.; Hu, F.; Fang, B.; Ma, T. Local voxelized structure for 3D binary feature representation and robust registration of point clouds from low-cost sensors. Inf. Sci. 2018, 444, 153–171. [Google Scholar] [CrossRef]
- Aiger, D.; Mitra, N.J.; Cohen-Or, D. 4-points congruent sets for robust pairwise surface registration. ACM Trans. Graph. 2008, 27, 1–10. [Google Scholar] [CrossRef]
- Theiler, P.W.; Wegner, J.D.; Schindler, K. Markerless point cloud registration with keypoint-based 4-points congruent sets. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 1, 282–288. [Google Scholar] [CrossRef]
- Mellado, N.; Aiger, D.; Mitra, N.J. Super 4PCS Fast Global Pointcloud Registration via Smart Indexing. Comput. Graph. Forum 2014, 33, 205–215. [Google Scholar] [CrossRef]
- Mohamad, M.; Rappaport, D.; Greenspan, M. Generalized 4-Points Congruent Sets for 3D Registration. In Proceedings of the 2014 2nd International Conference on 3D Vision, Tokyo, Japan, 8–11 December 2014. [Google Scholar]
- Mohamad, M.; Ahmed, M.T.; Rappaport, D.; Greenspan, M. Super Generalized 4PCS for 3D Registration. In Proceedings of the 2015 International Conference on 3D Vision (3DV), Lyon, France, 19–22 October 2015. [Google Scholar]
- Ge, X. Automatic markerless registration of point clouds with semantic-keypoint-based 4-points congruent sets. ISPRS J. Photogramm. Remote Sens. 2017, 130, 344–357. [Google Scholar] [CrossRef]
- Raposo, C.; Barreto, J.P. Using 2 point+normal sets for fast registration of point clouds with small overlap. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Xu, Z.; Xu, E.; Zhang, Z.; Wu, L. Multiscale Sparse Features Embedded 4-Points Congruent Sets for Global Registration of TLS Point Clouds. IEEE Geosci. Remote Sens. Lett. 2018, 16, 286–290. [Google Scholar] [CrossRef]
- Huang, J.; Kwok, T.H.; Zhou, C. V4PCS: Volumetric 4PCS Algorithm for Global Registration. In Proceedings of the ASME 2017 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Cleveland, OH, USA, 6–9 August 2017. [Google Scholar]
- Xu, Y.; Boerner, R.; Yao, W.; Hoegner, L.; Stilla, U. Pairwise coarse registration of point clouds in urban scenes using voxel- based 4-planes congruent sets. ISPRS J. Photogramm. Remote Sens. 2019, 151, 106–123. [Google Scholar] [CrossRef]
- Gruen, A.; Akca, D. Least squares 3D surface and curve matching. ISPRS J. Photogramm. Remote Sens. 2005, 59, 151–174. [Google Scholar] [CrossRef]
- Chen, W.; Qing, Y.; Chen, Y. Application of constrained total least- squares to cloud point registration. J. Geod. Geodyn. 2008, 31, 137–141. [Google Scholar]
- Aydar, D.; Akca, M.; Altan, O.; Akyilmaz, O. Total least squares registration of 3D surfaces. In Proceedings of the ISPRS Joint International Geoinformation Conference, Antalya, Turkey, 28–30 October 2015; pp. 25–30. [Google Scholar]
- Ge, X.; Wunderlich, T. Surface-based matching of 3D point clouds with variable coordinates in source and target system. ISPRS J. Photogramm. Remote Sens. 2016, 111, 1–12. [Google Scholar] [CrossRef]
- Ahmed, S.M.; Das, N.R.; Chaudhury, K.N. Least-squares registration of point sets over SE(d) using closed-form. Comput. Vis. Image Underst. 2019, 183, 20–32. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Y.; Wang, B.; Ye, Q.; Cai, J. An Advanced Outlier Detected Total Least-Squares Algorithm for 3-D Point Clouds Registration. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4789–4798. [Google Scholar] [CrossRef]
- Xiong, H.; Li, X. A New Method to Extract Terrain Feature Line. Geomat. Inf. Sci. Wuhan Univ. 2015, 40, 498–502. [Google Scholar]
- Kong, Y.; Su, J.; Zhang, Y. A new method for extracting terrain feature lines by morphology. Geomat. Inf. Sci. Wuhan Univ. Inf. 2012, 15, 2585. [Google Scholar]
- Lam, L.; Lee, S.; Suen, C. Thinning methodology-a comprehensive survey. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 869–885. [Google Scholar] [CrossRef]
- Cheng, L.; Tong, L.; Wang, Y.; Li, M. Extraction of Urban Power Lines from Vehicle-Borne LiDAR Data. Remote Sens. 2014, 6, 3302–3320. [Google Scholar] [CrossRef]
- Dong, Z.; Yang, B.; Liu, Y.; Liang, F.; Li, B.; Zang, Y. A novel binary shape context for 3D local surface description. ISPRS J. Photogramm. Remote Sens. 2017, 130, 431–452. [Google Scholar] [CrossRef]
- Zhou, R.; Li, X.; Jiang, W. 3D Surface Matching by a Voxel-Based Buffer-Weighted Binary Descriptor. IEEE Access 2019, 7, 86635–86650. [Google Scholar] [CrossRef]
- Xu, Y.; Tuttas, S.; Hoegner, L.; Stilla, U. Reconstruction of scaffolds from a photogrammetric point cloud of construction sites using a novel 3D local feature descriptor. Autom. Constr. 2018, 85, 76–95. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, Q.; Xiao, Y.; Cao, Z. TOLDI: An effective and robust approach for 3D local shape description. Pattern Recognit. 2017, 65, 175–187. [Google Scholar] [CrossRef]
- Lemus, E.; Bribiesca, E.; Garduño, E. Representation of enclosing surfaces from simple voxelized objects by means of a chain code. Pattern Recognit. 2014, 47, 1721–1730. [Google Scholar] [CrossRef]
- Xiong, F.; Han, X. A 3D surface matching method using keypoint- based covariance matrix descriptors. IEEE Access 2017, 5, 14204–14220. [Google Scholar] [CrossRef]
- Ahuja, R.K.; Magnanti, T.L.; Orlin, J.B. Network Flows Theory Algorithms and Applications; Prentice-Hall: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Yang, J.; Xiao, Y.; Cao, Z.; Yang, W. Ranking 3D feature correspondences via consistency voting Ranking 3D feature correspondences via consistency voting. Pattern Recognit. Lett. 2018, 117, 1–8. [Google Scholar] [CrossRef]
- Zeng, W.; Tao, B. Non-Linear Adjustment Model of Three-Dimensional Coordinate Transformation. Geomat. Inf. Sci. Wuhan Univ. 2003, 28, 566–568. [Google Scholar]
- Yao, J.; Han, B.; Yang, Y. Applications of Lodrigues Matrix in 3D Coordinate Transformation. Geomat. Inf. Sci. Wuhan Univ. 2006, 31, 2004–2007. [Google Scholar] [CrossRef]
- Li, P.; Xing, S.; Jiang, T. Rodriguez 3D Point Cloud Registration Algorithm Based on Total Least Square. Geomat. Sci. Eng. 2017, 37, 67–74. [Google Scholar]
- Tombari, F.; Salti, S.; Stefano, L. Performance Evaluation of 3D Keypoint Detectors. Int. J. Comput. Vis. 2013, 102, 198–220. [Google Scholar] [CrossRef]
- Xu, Z.; Xu, E.; Wu, L.; Liu, S.; Mao, Y. Registration of Terrestrial Laser Scanning Surveys Using Terrain-Invariant Regions for Measuring Exploitative Volumes over Open-Pit Mines. Remote Sens. 2019, 11, 606. [Google Scholar] [CrossRef]











| Figure 1 | Dataset | Area | Vertical Resolution | Parallel Resolution | Points |
|---|---|---|---|---|---|
| (a) | SRTM 90 | 58,281 m * 57,505 m | 90 m | 90 m | 226,426 |
| (b) | ASTER 30 | 58,281 m * 57,505 m | 30 m | 30 m | 2,037,003 |
| (c) | ALOS 12 | 58,281 m * 57,505 m | 12 m | 12 m | 12,388,722 |
| (d) | Line 1 | 17,000 m * 60,000 m | 2 m | 120 m | 7,418,831 |
| Line 2 | 17,000 m * 60,000 m | 2 m | 120 m | 7,418,831 | |
| (e) | Line 3 | 17,000 m * 60,000 m | 2 m | 120 m | 7,445,621 |
| Line 4 | 17,000 m * 60,000 m | 2 m | 120 m | 7,445,621 | |
| (f) | IN-1 | 15,483 m * 24,341 m | 1 m | 1 m | 150,274,036 |
| IN-2 | 15,638 m * 25,353 m | 1 m | 1 m | 158,146,927 |
| Dataset | Original | Sampling | Ridgelines | Keypoints | Efficiency (s) |
|---|---|---|---|---|---|
| ALOS 12 | 12,388,722 | 122738 | 24,791 | 2430 | 2.138 |
| ASTER 30 | 2,037,003 | 122650 | 23,140 | 2291 | 0.901 |
| SRTM 90 | 226,426 | 122233 | 24,723 | 2533 | 0.651 |
| Data | 0 mr | 0.1 mr | 0.2 mr | 0.3 mr | 0.5 mr | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| rabs | rrel (%) | rabs | rrel (%) | rabs | rrel (%) | rabs | rrel (%) | rabs | rrel (%) | |
| ALOS 12 | 2430 | 100 | 2322 | 95.55 | 2314 | 93.87 | 2286 | 92.88 | 2156 | 87.18 |
| ASTER 30 | 2291 | 100 | 2178 | 86.05 | 2205 | 84.48 | 2041 | 78.31 | 1999 | 73.11 |
| SRTM 90 | 2533 | 100 | 1693 | 51.08 | 2068 | 43.76 | 2352 | 39.53 | 2507 | 37.14 |
| Dataset | Coordinate | Normal Vector | Proposed Method | ||||||
|---|---|---|---|---|---|---|---|---|---|
| X | Y | Z | X | Y | Z | X | Y | Z | |
| ALOS 0.1 mr | 2001 | 1997 | 2097 | 2019 | 1867 | 1915 | 2026 | 2034 | 2097 |
| ALOS 0.2 mr | 1925 | 1922 | 2049 | 2014 | 1874 | 1890 | 2013 | 2016 | 2049 |
| ALOS 0.3 mr | 1905 | 1898 | 2018 | 1982 | 1868 | 1897 | 1980 | 1985 | 2018 |
| ASTER 0.1 mr | 1726 | 1721 | 1873 | 1802 | 1568 | 1608 | 1807 | 1812 | 1873 |
| ASTER 0.2 mr | 1414 | 1405 | 1548 | 1516 | 1448 | 1479 | 1522 | 1531 | 1548 |
| ASTER 0.3 mr | 1350 | 1347 | 1479 | 1430 | 1227 | 1263 | 1422 | 1431 | 1479 |
| SRTM 0.1 mr | 528 | 526 | 601 | 577 | 539 | 565 | 584 | 592 | 605 |
| SRTM 0.2 mr | 169 | 165 | 212 | 200 | 183 | 191 | 200 | 204 | 212 |
| SRTM 0.3 mr | 113 | 111 | 156 | 153 | 136 | 141 | 148 | 154 | 156 |
| Dataset | Ks | Kt | KM Algorithm | MCMF Algorithm | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mp | Time (s) | Cp | Pr (%) | Re (%) | Mp | Time (s) | Cp | Pr (%) | Re (%) | |||
| ASTER & ALOS | 2291 | 2430 | 2430 | 5.890 | 647 | 26.6 | 37.7 | 937 | 0.088 | 528 | 56.4 | 30.8 |
| ASTER & SRTM | 2291 | 2533 | 2533 | 7.087 | 419 | 16.5 | 27.1 | 527 | 0.026 | 319 | 60.5 | 20.6 |
| SRTM & ALOS | 2533 | 2430 | 2533 | 3.632 | 557 | 22.0 | 34.9 | 589 | 0.039 | 433 | 73.5 | 27.1 |
| Data | The Proposed Method | BSC [44]+KM+RANSAC | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ① | ② | ③ | ④ | ⑤ | ⑥ | ① | ② | ③ | ④ | ⑤ | ⑥ | |
| Ar | 0 | 0 | 0 | 0.2 | 0 | 0 | 9.3 | 36.2 | 13.1 | 238.0 | 974.9 | 0 |
| AT | 47.1 | 18.3 | 33.1 | 9.9 | 0 | 22.2 | 165.1 | 295.9 | 164.2 | 2857.2 | 19,196.7 | 0 |
| Dsum | 66.1 | 80.7 | 66.8 | 56.0 | 1.4 | 15.3 | 87.0 | 234.7 | 126.6 | 511.6 | 556.3 | 1.3 |
| Dx | 51.9 | 67.4 | 39.5 | 6.1 | 0 | 18.1 | 117.3 | 87.9 | 129.5 | 292.9 | 387.8 | 0 |
| Dy | 59.6 | 75.1 | 62.4 | 3.0 | 0 | 14.7 | 79.2 | 192.6 | 120.4 | 478.4 | 517.9 | 0 |
| Dz | 20.3 | 22.9 | 17.0 | 54.9 | 0 | 1.5 | 24.1 | 107.6 | 29.7 | 104.6 | 118.3 | 0 |
| Tre | 8.55 | 7.19 | 8.56 | 8.40 | 12.0 | 2.83 | 602.4 | 469.0 | 490.1 | 628.1 | 626.3 | 183.2 |
| The Proposed Method | BSC [44]+KM+RANSAC | |||||||
|---|---|---|---|---|---|---|---|---|
| Line 5 & Line 6 | Line 7 & Line 8 | Line 9 & Line 10 | Line 11 & Line 12 | Line 5 & Line 6 | Line 7 & Line 8 | Line 9 & Line 10 | Line 11 & Line 12 | |
| Mp | 2377 | 1247 | 546 | 403 | 359 | 238 | 388 | 230 |
| Cp | 159 | 464 | 195 | 204 | 5 | 9 | 13 | 25 |
| Ar (°) | 0.14 | 0 | 0 | 0 | 944.2 | 842.6 | 357.6 | 338.6 |
| AT (m) | 52.1 | 0.4 | 3.0 | 6.1 | 34,956.4 | 15,269.6 | 10,918.4 | 1271.4 |
| Dsum (m) | 158.8 | 2.6 | 29.0 | 34.9 | 728.9 | 845.6 | 795.6 | 362.8 |
| Dx (m) | 142.2 | 2.2 | 62.8 | 61.5 | 429.6 | 508.8 | 462.7 | 361.6 |
| Dy (m) | 91.5 | 1.1 | 17.2 | 22.4 | 552.2 | 794.6 | 753.5 | 141.5 |
| Dz (m) | 114.3 | 0.7 | 15.2 | 15.3 | 398.2 | 169.0 | 243.6 | 307.3 |
| The Proposed Method | BSC [44]+KM+RANSAC | |||||||
|---|---|---|---|---|---|---|---|---|
| 0 mr | 0.1 mr | 0.2 mr | 0.3 mr | 0 mr | 0.1 mr | 0.2 mr | 0.3 mr | |
| Mp | 403 | 1371 | 1688 | 1763 | 230 | 247 | 247 | 242 |
| Cp | 204 | 192 | 156 | 112 | 25 | 11 | 11 | 7 |
| Ar (°) | 0 | 0 | 0 | 0 | 338.6 | 154.6 | 191.2 | 812.6 |
| AT (m) | 6.1 | 5.3 | 8.0 | 31.7 | 1271.4 | 3023.9 | 2988.9 | 12,249.5 |
| Dsum (m) | 34.9 | 69.3 | 93.1 | 122.8 | 362.8 | 567.2 | 207.3 | 603.7 |
| Dx (m) | 61.5 | 60.0 | 81.1 | 68.0 | 361.6 | 422.1 | 362.4 | 420.5 |
| Dy (m) | 22.4 | 64.4 | 86.9 | 117.6 | 141.5 | 556.4 | 362.5 | 539.3 |
| Dz (m) | 15.3 | 18.7 | 26.1 | 21.9 | 307.3 | 97.1 | 22.6 | 222.6 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, R.; Jiang, W. A Ridgeline-Based Terrain Co-registration for Satellite LiDAR Point Clouds in Rough Areas. Remote Sens. 2020, 12, 2163. https://doi.org/10.3390/rs12132163
Zhou R, Jiang W. A Ridgeline-Based Terrain Co-registration for Satellite LiDAR Point Clouds in Rough Areas. Remote Sensing. 2020; 12(13):2163. https://doi.org/10.3390/rs12132163
Chicago/Turabian StyleZhou, Ruqin, and Wanshou Jiang. 2020. "A Ridgeline-Based Terrain Co-registration for Satellite LiDAR Point Clouds in Rough Areas" Remote Sensing 12, no. 13: 2163. https://doi.org/10.3390/rs12132163
APA StyleZhou, R., & Jiang, W. (2020). A Ridgeline-Based Terrain Co-registration for Satellite LiDAR Point Clouds in Rough Areas. Remote Sensing, 12(13), 2163. https://doi.org/10.3390/rs12132163