Comparison of Object Detection and Patch-Based Classification Deep Learning Models on Mid- to Late-Season Weed Detection in UAV Imagery


 , , ,
, , ,
Abstract
1. Introduction
- Evaluate the performance of two object detection models with different detection performance and inference speed—Faster RCNN and the Single Shot Detector (SSD) models—in detecting mid- to late-season weeds from UAV imagery using precision, recall, f1 score, and mean IoU as the evaluation metrics for their detection performance and inference time as the metric for their speed;
- Compare the performance of object detection CNN models with the patch-based CNN model in terms of weed detection performance using mean IoU and inference time.
2. Materials and Methods
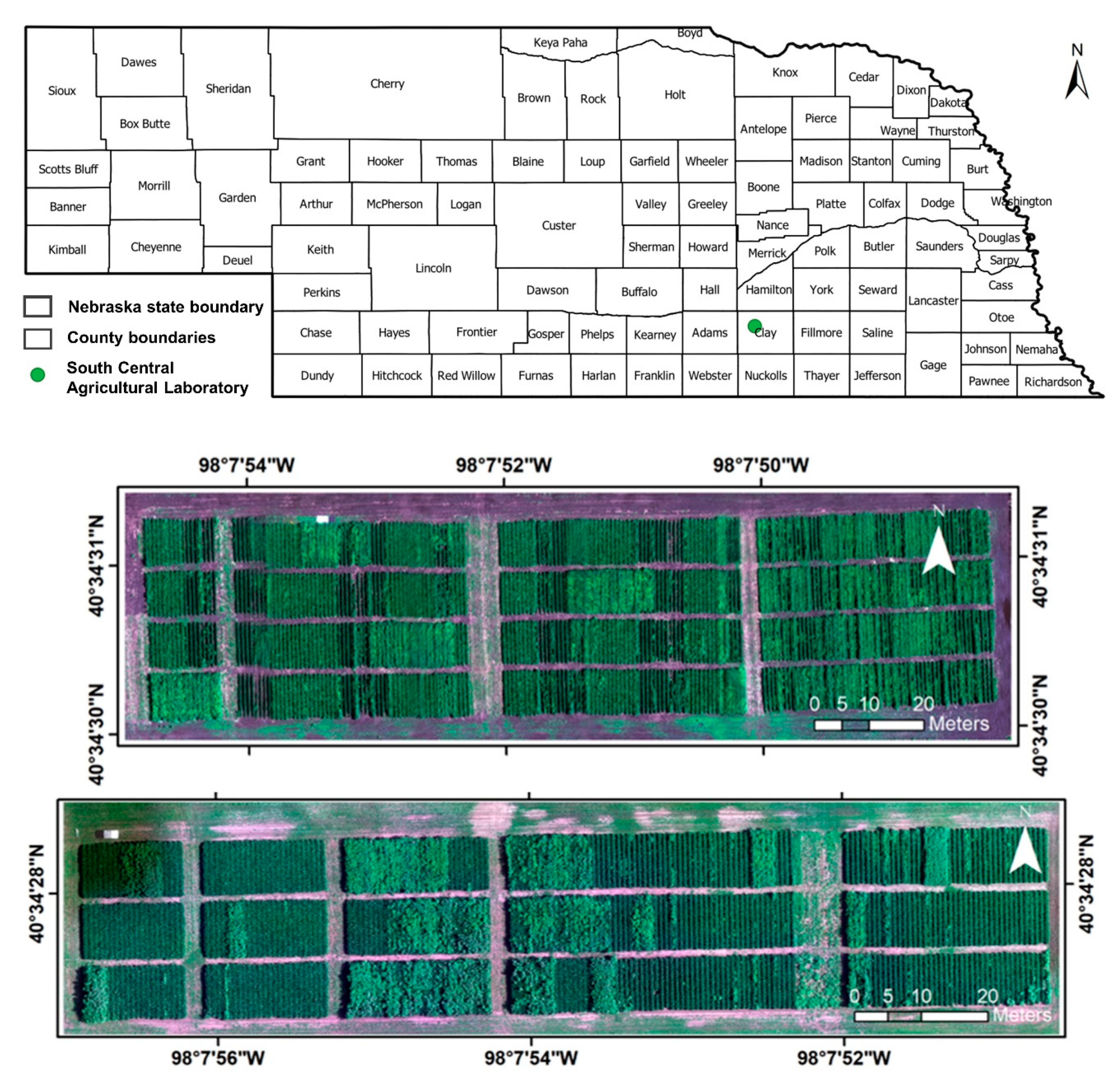
2.1. Study Site
2.2. UAV Data Collection
2.3. Data Annotation and Processing
2.4. Patch Based CNN
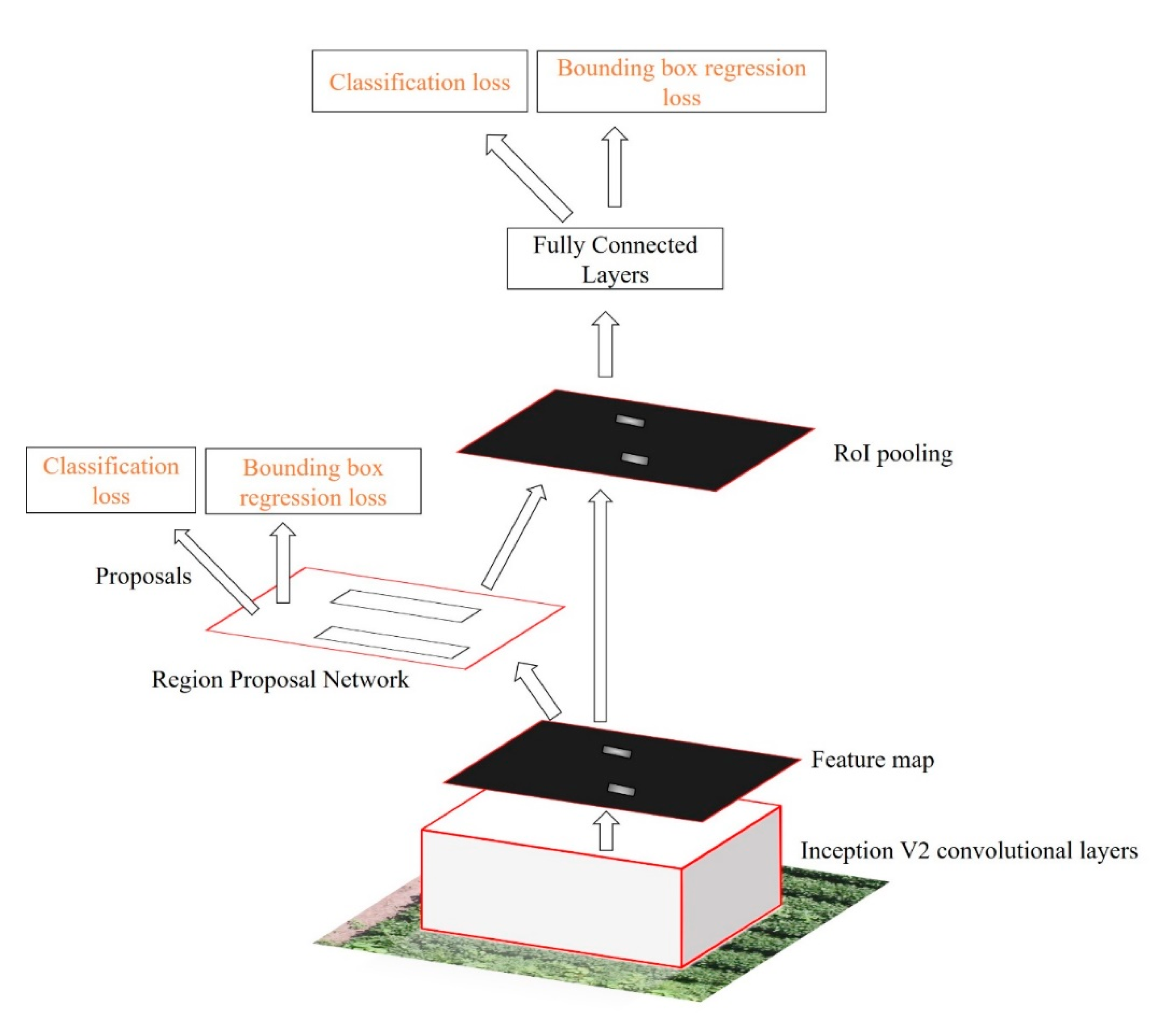
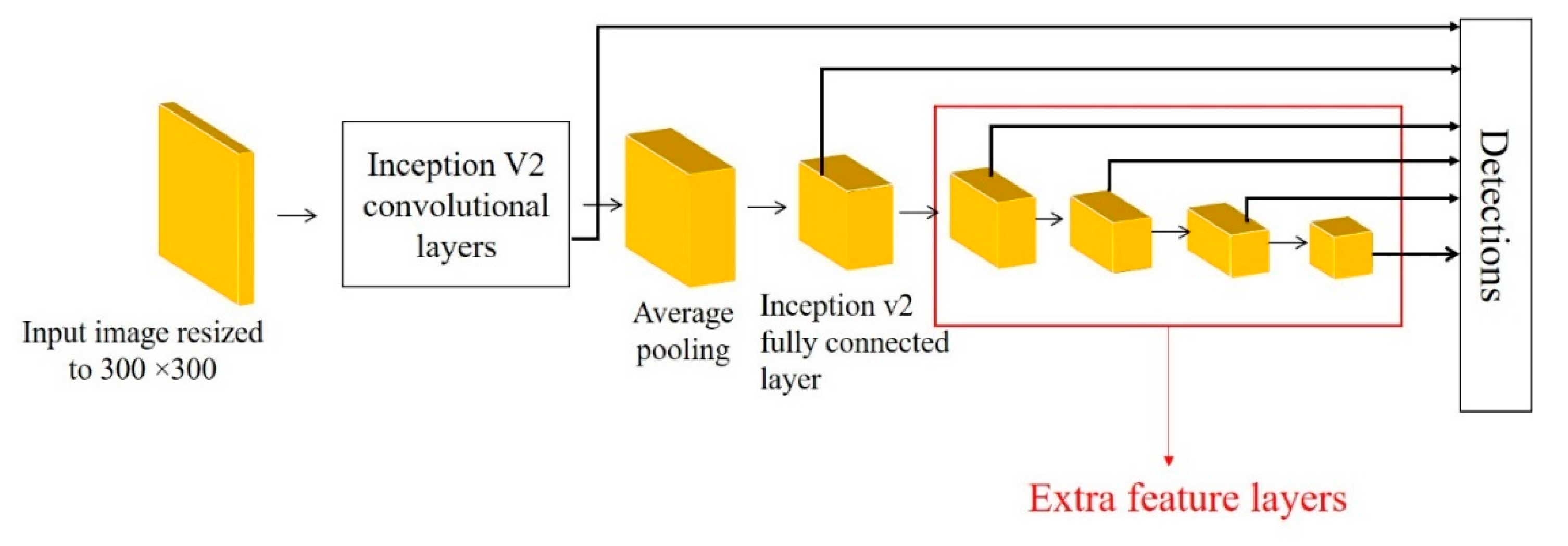
2.5. Object Detection Models
2.5.1. Faster RCNN
2.5.2. Hyperparameters of the Architecture
2.5.3. Single Shot Detector
2.5.4. Hyperparameters of the Architecture
2.6. Hardware and Software Used
2.7. Evaluation Metrics
3. Results and Discussion
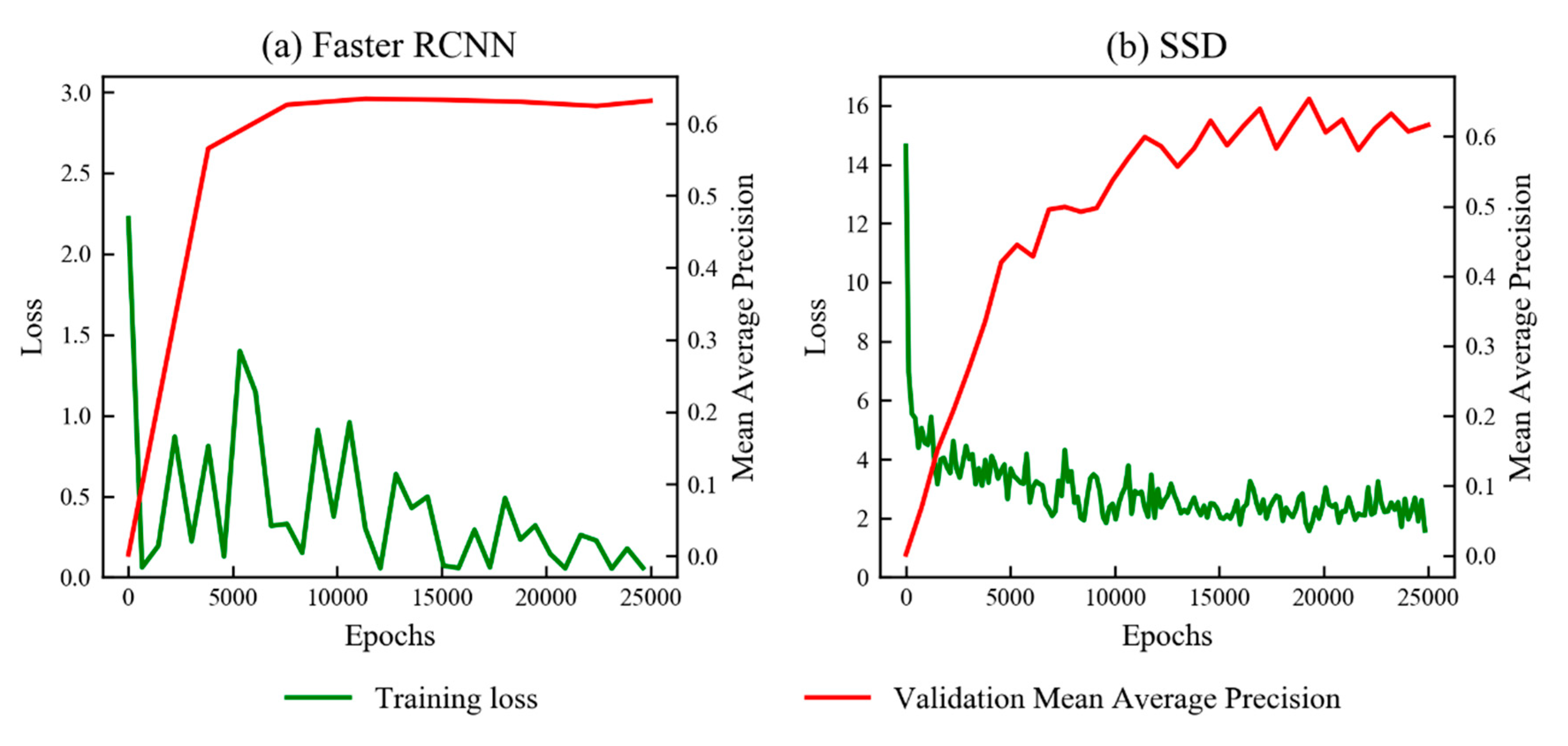
3.1. Training of Faster RCNN and SSD
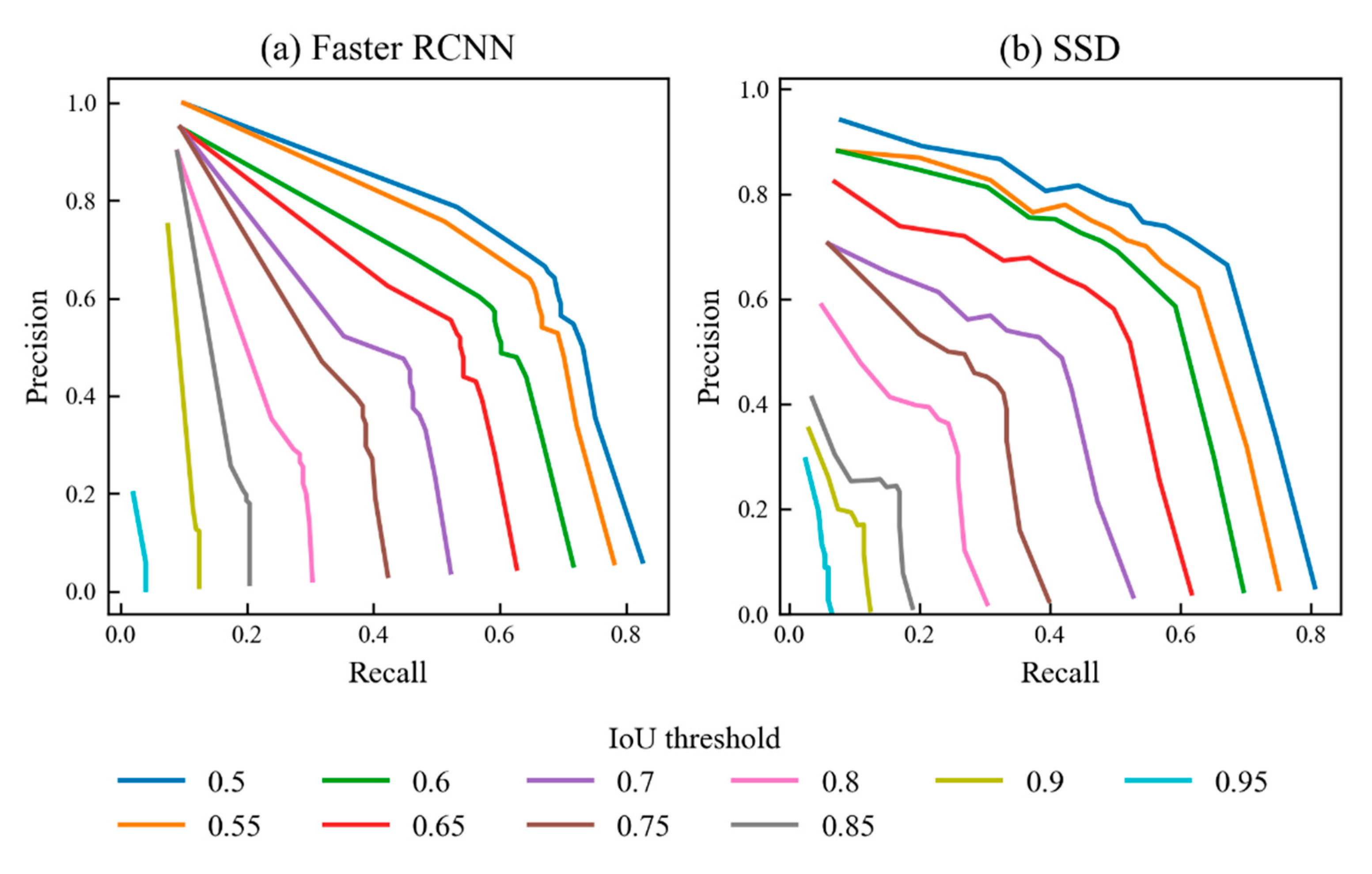
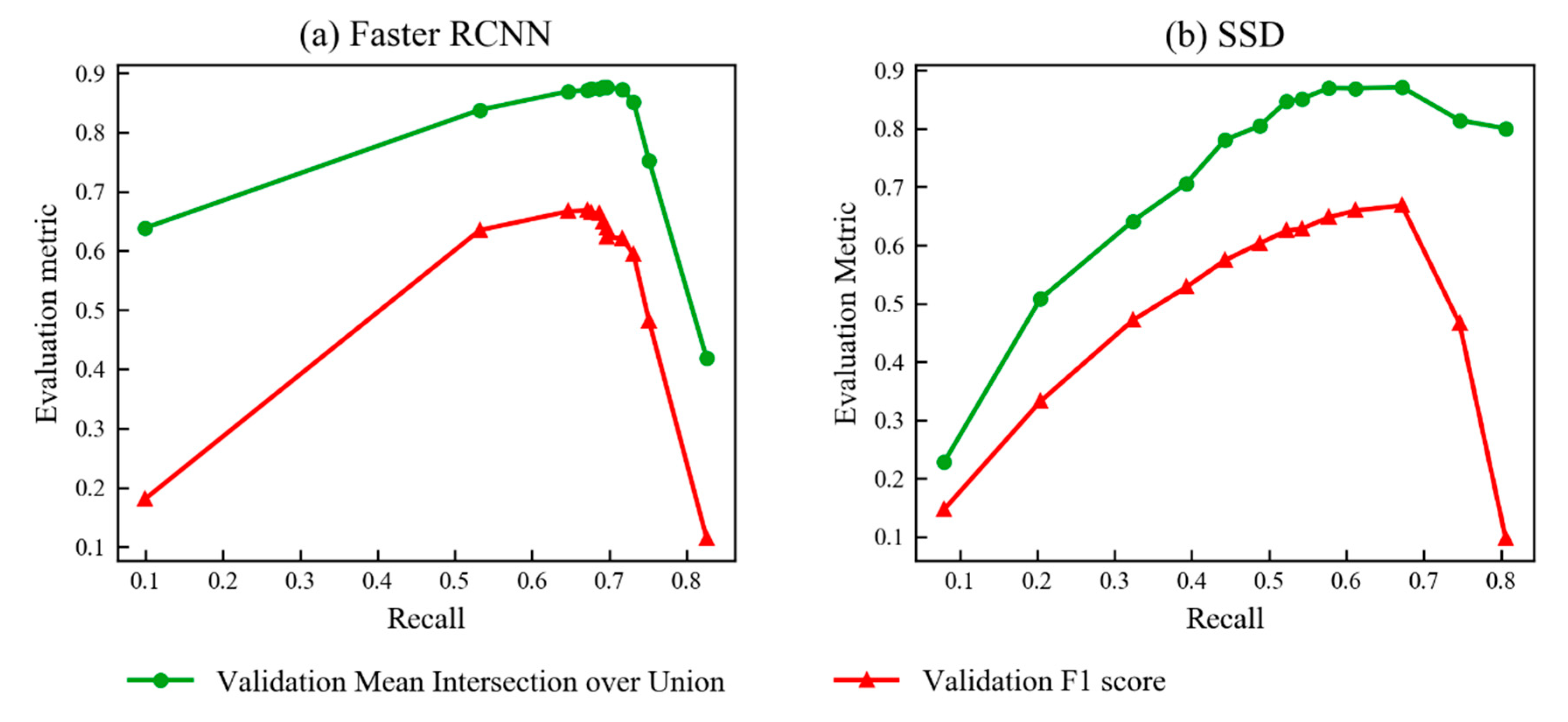
3.2. Optimal IoU and Confidence Thresholds for Faster RCNN and SSD
3.3. Comparison of Performance of Faster RCNN and SSD
3.4. Comparison of Performance of Faster RCNN and Patch-Based CNN
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dos Santos Ferreira, A.; Matte Freitas, D.; Gonçalves da Silva, G.; Pistori, H.; Theophilo Folhes, M. Weed detection in soybean crops using ConvNets. Comput. Electron. Agric. 2017, 143, 314–324. [Google Scholar] [CrossRef]
- Thorp, K.R.; Tian, L.F. A Review on Remote Sensing of Weeds in Agriculture. Precis. Agric. 2004, 5, 477–508. [Google Scholar] [CrossRef]
- Weis, M.; Gutjahr, C.; Rueda Ayala, V.; Gerhards, R.; Ritter, C.; Schölderle, F. Precision farming for weed management: Techniques. Gesunde Pflanz. 2008, 60, 171–181. [Google Scholar] [CrossRef]
- Christensen, S.; SØgaard, H.T.; Kudsk, P.; NØrremark, M.; Lund, I.; Nadimi, E.S.; JØrgensen, R. Site-specific weed control technologies. Weed Res. 2009. [Google Scholar] [CrossRef]
- Zhang, N.; Wang, M.; Wang, N. Precision agriculture—A worldwide overview. Comput. Electron. Agric. 2002, 36, 113–132. [Google Scholar] [CrossRef]
- O’Donovan, J.T.; De St. Remy, E.A.; O’Sullivan, P.A.; Dew, D.A.; Sharma, A.K. Influence of the Relative Time of Emergence of Wild Oat ( Avena fatua ) on Yield Loss of Barley ( Hordeum vulgare ) and Wheat ( Triticum aestivum). Weed Sci. 1985. [Google Scholar] [CrossRef]
- Swanton, C.J.; Mahoney, K.J.; Chandler, K.; Gulden, R.H. Integrated Weed Management: Knowledge-Based Weed Management Systems. Weed Sci. 2008. [Google Scholar] [CrossRef]
- JUDGE, C.A.; NEAL, J.C.; DERR, J.F. Response of Japanese Stiltgrass (Microstegium vimineum) to Application Timing, Rate, and Frequency of Postemergence Herbicides 1. Weed Technol. 2005. [Google Scholar] [CrossRef]
- Chauhan, B.S.; Singh, R.G.; Mahajan, G. Ecology and management of weeds under conservation agriculture: A review. Crop. Prot. 2012, 38, 57–65. [Google Scholar] [CrossRef]
- De Castro, A.I.; Torres-Sánchez, J.; Peña, J.M.; Jiménez-Brenes, F.M.; Csillik, O.; López-Granados, F. An automatic random forest-OBIA algorithm for early weed mapping between and within crop rows using UAV imagery. Remote Sens. 2018, 10, 285. [Google Scholar] [CrossRef]
- Fernández-Quintanilla, C.; Peña, J.M.; Andújar, D.; Dorado, J.; Ribeiro, A.; López-Granados, F. Is the current state of the art of weed monitoring suitable for site-specific weed management in arable crops? Weed Res. 2018, 58, 259–272. [Google Scholar] [CrossRef]
- López-Granados, F. Weed detection for site-specific weed management: Mapping and real-time approaches. Weed Res. 2011. [Google Scholar] [CrossRef]
- Barroso, J.; Fernàndez-Quintanilla, C.; Ruiz, D.; Hernaiz, P.; Rew, L.J. Spatial stability of Avena sterilis ssp. ludoviciana populations under annual applications of low rates of imazamethabenz. Weed Res. 2004. [Google Scholar] [CrossRef]
- Koger, C.H.; Shaw, D.R.; Watson, C.E.; Reddy, K.N. Detecting Late-Season Weed Infestations in Soybean (Glycine max) 1. Weed Technol. 2003. [Google Scholar] [CrossRef]
- De Castro, A.I.; Jurado-Expósito, M.; Peña-Barragán, J.M.; López-Granados, F. Airborne multi-spectral imagery for mapping cruciferous weeds in cereal and legume crops. Precis. Agric. 2012. [Google Scholar] [CrossRef]
- De Castro, A.I.; López-Granados, F.; Jurado-Expósito, M. Broad-scale cruciferous weed patch classification in winter wheat using QuickBird imagery for in-season site-specific control. Precis. Agric. 2013. [Google Scholar] [CrossRef]
- Castillejo-González, I.L.; López-Granados, F.; García-Ferrer, A.; Peña-Barragán, J.M.; Jurado-Expósito, M.; de la Orden, M.S.; González-Audicana, M. Object- and pixel-based analysis for mapping crops and their agro-environmental associated measures using QuickBird imagery. Comput. Electron. Agric. 2009. [Google Scholar] [CrossRef]
- Meyer, G.E.; Mehta, T.; Kocher, M.F.; Mortensen, D.A.; Samal, A. Textural imaging and discriminant analysis for distinguishing weeds for spot spraying. Trans. Am. Soc. Agric. Eng. 1998. [Google Scholar] [CrossRef]
- Burks, T.F.; Shearer, S.A.; Payne, F.A. Classification of weed species using color texture features and discriminant analysis. Trans. Am. Soc. Agric. Eng. 2000, 43, 411. [Google Scholar] [CrossRef]
- Wang, A.; Zhang, W.; Wei, X. A review on weed detection using ground-based machine vision and image processing techniques. Comput. Electron. Agric. 2019, 158, 226–240. [Google Scholar] [CrossRef]
- Sankaran, S.; Khot, L.R.; Espinoza, C.Z.; Jarolmasjed, S.; Sathuvalli, V.R.; Vandemark, G.J.; Miklas, P.N.; Carter, A.H.; Pumphrey, M.O.; Knowles, N.R.; et al. Low-altitude, high-resolution aerial imaging systems for row and field crop phenotyping: A review. Eur. J. Agron. 2015, 70, 112–123. [Google Scholar] [CrossRef]
- Rasmussen, J.; Nielsen, J.; Streibig, J.C.; Jensen, J.E.; Pedersen, K.S.; Olsen, S.I. Pre-harvest weed mapping of Cirsium arvense in wheat and barley with off-the-shelf UAVs. Precis. Agric. 2019. [Google Scholar] [CrossRef]
- Casa, R.; Pascucci, S.; Pignatti, S.; Palombo, A.; Nanni, U.; Harfouche, A.; Laura, L.; Di Rocco, M.; Fantozzi, P. UAV-based hyperspectral imaging for weed discrimination in maize. In Proceedings of the Precision Agriculture 2019—Papers Presented at the 12th European Conference on Precision Agriculture, ECPA 2019, Montpellier, France, 8–11 July 2019; Wageningen Academic Publishers: Wageningen, The Netherlands, 2019; pp. 365–371. [Google Scholar]
- Sánchez-Sastre, L.F.; Casterad, M.A.; Guillén, M.; Ruiz-Potosme, N.M.; Veiga, N.M.S.A.; da Navas-Gracia, L.M.; Martín-Ramos, P. UAV Detection of Sinapis arvensis Infestation in Alfalfa Plots Using Simple Vegetation Indices from Conventional Digital Cameras. AgriEngineering 2020, 2, 12. [Google Scholar] [CrossRef]
- Peña-Barragán, J.M.; López-Granados, F.; Jurado-Expósito, M.; García-Torres, L. Spectral discrimination of Ridolfia segetum and sunflower as affected by phenological stage. Weed Res. 2006. [Google Scholar] [CrossRef]
- Gray, C.J.; Shaw, D.R.; Gerard, P.D.; Bruce, L.M. Utility of Multispectral Imagery for Soybean and Weed Species Differentiation. Weed Technol. 2008. [Google Scholar] [CrossRef]
- Martin, M.P.; Barreto, L.; RiañO, D.; Fernandez-Quintanilla, C.; Vaughan, P. Assessing the potential of hyperspectral remote sensing for the discrimination of grassweeds in winter cereal crops. Int. J. Remote Sens. 2011. [Google Scholar] [CrossRef]
- De Castro, A.I.; Jurado-Expósito, M.; Gómez-Casero, M.T.; López-Granados, F. Applying neural networks to hyperspectral and multispectral field data for discrimination of cruciferous weeds in winter crops. Sci. World J. 2012. [Google Scholar] [CrossRef]
- Peña, J.M.; Torres-Sánchez, J.; de Castro, A.I.; Kelly, M.; López-Granados, F. Weed Mapping in Early-Season Maize Fields Using Object-Based Analysis of Unmanned Aerial Vehicle (UAV) Images. PLoS ONE 2013, 8, e77151. [Google Scholar] [CrossRef]
- Torres-Sánchez, J.; López-Granados, F.; De Castro, A.I.; Peña-Barragán, J.M. Configuration and Specifications of an Unmanned Aerial Vehicle (UAV) for Early Site Specific Weed Management. PLoS ONE 2013, 8, e58210. [Google Scholar] [CrossRef]
- Torres-Sánchez, J.; Peña, J.M.; de Castro, A.I.; López-Granados, F. Multi-temporal mapping of the vegetation fraction in early-season wheat fields using images from UAV. Comput. Electron. Agric. 2014. [Google Scholar] [CrossRef]
- Pérez-Ortiz, M.; Peña, J.M.; Gutiérrez, P.A.; Torres-Sánchez, J.; Hervás-Martínez, C.; López-Granados, F. A semi-supervised system for weed mapping in sunflower crops using unmanned aerial vehicles and a crop row detection method. Appl. Soft Comput. 2015, 37, 533–544. [Google Scholar] [CrossRef]
- Castaldi, F.; Pelosi, F.; Pascucci, S.; Casa, R. Assessing the potential of images from unmanned aerial vehicles (UAV) to support herbicide patch spraying in maize. Precis. Agric. 2017. [Google Scholar] [CrossRef]
- López-Granados, F.; Torres-Sánchez, J.; Serrano-Pérez, A.; de Castro, A.I.; Mesas-Carrascosa, F.-J.; Peña, J.-M. Early season weed mapping in sunflower using UAV technology: Variability of herbicide treatment maps against weed thresholds. Precis. Agric. 2016, 17, 183–199. [Google Scholar] [CrossRef]
- Liu, D.; Xia, F. Assessing object-based classification: Advantages and limitations Assessing object-based classification: Advantages and limitations. Remote Sens. Lett. 2010. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Steen, K.; Christiansen, P.; Karstoft, H.; Jørgensen, R.; Steen, K.A.; Christiansen, P.; Karstoft, H.; Jørgensen, R.N. Using Deep Learning to Challenge Safety Standard for Highly Autonomous Machines in Agriculture. J. Imaging 2016, 2, 6. [Google Scholar] [CrossRef]
- Song, X.; Zhang, G.; Liu, F.; Li, D.; Zhao, Y.; Yang, J. Modeling spatio-temporal distribution of soil moisture by deep learning-based cellular automata model. J. Arid Land 2016, 8, 734–748. [Google Scholar] [CrossRef]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using Deep Learning for Image-Based Plant Disease Detection. Front. Plant. Sci. 2016, 7, 1419. [Google Scholar] [CrossRef]
- Kuwata, K.; Shibasaki, R. Estimating crop yields with deep learning and remotely sensed data. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 858–861. [Google Scholar]
- Rahnemoonfar, M.; Sheppard, C.; Rahnemoonfar, M.; Sheppard, C. Deep Count: Fruit Counting Based on Deep Simulated Learning. Sensors 2017, 17, 905. [Google Scholar] [CrossRef]
- Andrea, C.-C.; Mauricio Daniel, B.B.; Jose Misael, J.B. Precise weed and maize classification through convolutional neuronal networks. In Proceedings of the 2017 IEEE Second Ecuador Technical Chapters Meeting (ETCM), Salinas, Ecuador, 16–20 October 2017; pp. 1–6. [Google Scholar]
- Dyrmann, M.; Mortensen, A.; Midtiby, H.; Jørgensen, R. Pixel-wise classification of weeds and crops in images by using a fully convolutional neural network. In Proceedings of the International Conference on Agricultural Engineering, Aarhus, Denmark, 26–29 June 2016; pp. 26–29. [Google Scholar]
- Milioto, A.; Lottes, P.; Stachniss, C. Real-Time Semantic Segmentation of Crop and Weed for Precision Agriculture Robots Leveraging Background Knowledge in CNNs. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2229–2235. [Google Scholar]
- Lottes, P.; Behley, J.; Milioto, A.; Stachniss, C. Fully Convolutional Networks With Sequential Information for Robust Crop and Weed Detection in Precision Farming. IEEE Robot. Autom. Lett. 2018, 3, 2870–2877. [Google Scholar] [CrossRef]
- Lottes, P.; Khanna, R.; Pfeifer, J.; Siegwart, R.; Stachniss, C. UAV-based crop and weed classification for smart farming. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3024–3031. [Google Scholar]
- Lottes, P.; Behley, J.; Chebrolu, N.; Milioto, A.; Stachniss, C. Robust joint stem detection and crop-weed classification using image sequences for plant-specific treatment in precision farming. J. Field Robot. 2020, 37, 20–34. [Google Scholar] [CrossRef]
- Sa, I.; Chen, Z.; Popovic, M.; Khanna, R.; Liebisch, F.; Nieto, J.; Siegwart, R. WeedNet: Dense Semantic Weed Classification Using Multispectral Images and MAV for Smart Farming. IEEE Robot. Autom. Lett. 2018, 3, 588–595. [Google Scholar] [CrossRef]
- Sa, I.; Popović, M.; Khanna, R.; Chen, Z.; Lottes, P.; Liebisch, F.; Nieto, J.; Stachniss, C.; Walter, A.; Siegwart, R.; et al. WeedMap: A Large-Scale Semantic Weed Mapping Framework Using Aerial Multispectral Imaging and Deep Neural Network for Precision Farming. Remote Sens. 2018, 10, 1423. [Google Scholar] [CrossRef]
- Bah, M.D.; Dericquebourg, E.; Hafiane, A.; Canals, R. Deep Learning Based Classification System for Identifying Weeds Using High-Resolution UAV Imagery. In Intelligent Computing. SAI 2018; Advances in Intelligent Systems and Computing: Cham, Switzerland, 2019; Volume 857, pp. 176–187. [Google Scholar]
- Huang, H.; Deng, J.; Lan, Y.; Yang, A.; Deng, X.; Zhang, L. A fully convolutional network for weed mapping of unmanned aerial vehicle (UAV) imagery. PLoS ONE 2018, 13, e0196302. [Google Scholar] [CrossRef]
- Yu, J.; Schumann, A.W.; Cao, Z.; Sharpe, S.M.; Boyd, N.S. Weed Detection in Perennial Ryegrass With Deep Learning Convolutional Neural Network. Front. Plant Sci. 2019, 10. [Google Scholar] [CrossRef] [PubMed]
- Tzutalin LabelImg. LabelImg 2015. Available online: https://github.com/tzutalin/labelImg (accessed on 30 June 2020).
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Torrey, L.; Shavlik, J. Transfer learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; IGI Global: Hershey, PA, USA, 2010; pp. 242–264. [Google Scholar]
- Karimi, Y.; Prasher, S.O.; McNairn, H.; Bonnell, R.B.; Dutilleul, P.; Goel, P.K. Classification accuracy of discriminant analysis, artificial neural networks, and decision trees for weed and nitrogen stress detection in corn. Trans. Am. Soc. Agric. Eng. 2005. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Chollet, F. Transfer Learning Using Pretrained ConvNets. Available online: https://www.tensorflow.org/alpha/tutorials/images/transfer_learning (accessed on 30 June 2020).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Computer Vision—ECCV 2014; Lecture Notes in Computer Science: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Murphy, K. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7310–7311. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 2016, pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 2016, pp. 770–778. [Google Scholar]
- Liu, S.; Deng, W. Very deep convolutional neural network based image classification using small training sample size. In Proceedings of the 3rd IAPR Asian Conference on Pattern Recognition, ACPR 2015, Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 730–734. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Lecture Notes in Computer Science: Cham, Switzerland, 2015. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Doersch, C.; Gupta, A.; Efros, A.A. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Brust, C.A.; Käding, C.; Denzler, J. Active learning for deep object detection. In Proceedings of the VISIGRAPP 2019—14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Prague, Czech, 25–27 February 2019; SciTePress: Setúbal, Portugal, 2019; Volume 5, pp. 181–190. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision | Recall | F1 Score | Mean IoU | Inference Time of 1152 × 1152 Image in Seconds |
|---|---|---|---|---|---|
| Faster RCNN | 0.65 | 0.68 | 0.66 | 0.85 | 0.23 |
| SSD | 0.66 | 0.68 | 0.67 | 0.84 | 0.21 |
| Model | Mean IoU | Inference Time in Seconds for Each Sub-Image (1152 × 1152) |
|---|---|---|
| Faster RCNN with 200 proposals | 0.85 | 0.21 |
| Patch based CNN sliced with overlap | 0.61 | 1.03 |
| Patch based CNN sliced without overlap | 0.6 | 0.22 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Veeranampalayam Sivakumar, A.N.; Li, J.; Scott, S.; Psota, E.; J. Jhala, A.; Luck, J.D.; Shi, Y. Comparison of Object Detection and Patch-Based Classification Deep Learning Models on Mid- to Late-Season Weed Detection in UAV Imagery. Remote Sens. 2020, 12, 2136. https://doi.org/10.3390/rs12132136
Veeranampalayam Sivakumar AN, Li J, Scott S, Psota E, J. Jhala A, Luck JD, Shi Y. Comparison of Object Detection and Patch-Based Classification Deep Learning Models on Mid- to Late-Season Weed Detection in UAV Imagery. Remote Sensing. 2020; 12(13):2136. https://doi.org/10.3390/rs12132136
Chicago/Turabian StyleVeeranampalayam Sivakumar, Arun Narenthiran, Jiating Li, Stephen Scott, Eric Psota, Amit J. Jhala, Joe D. Luck, and Yeyin Shi. 2020. "Comparison of Object Detection and Patch-Based Classification Deep Learning Models on Mid- to Late-Season Weed Detection in UAV Imagery" Remote Sensing 12, no. 13: 2136. https://doi.org/10.3390/rs12132136
APA StyleVeeranampalayam Sivakumar, A. N., Li, J., Scott, S., Psota, E., J. Jhala, A., Luck, J. D., & Shi, Y. (2020). Comparison of Object Detection and Patch-Based Classification Deep Learning Models on Mid- to Late-Season Weed Detection in UAV Imagery. Remote Sensing, 12(13), 2136. https://doi.org/10.3390/rs12132136