Automatic Annotation of Hyperspectral Images and Spectral Signal Classification of People and Vehicles in Areas of Dense Vegetation with Deep Learning

Abstract
1. Introduction
2. Materials and Methods
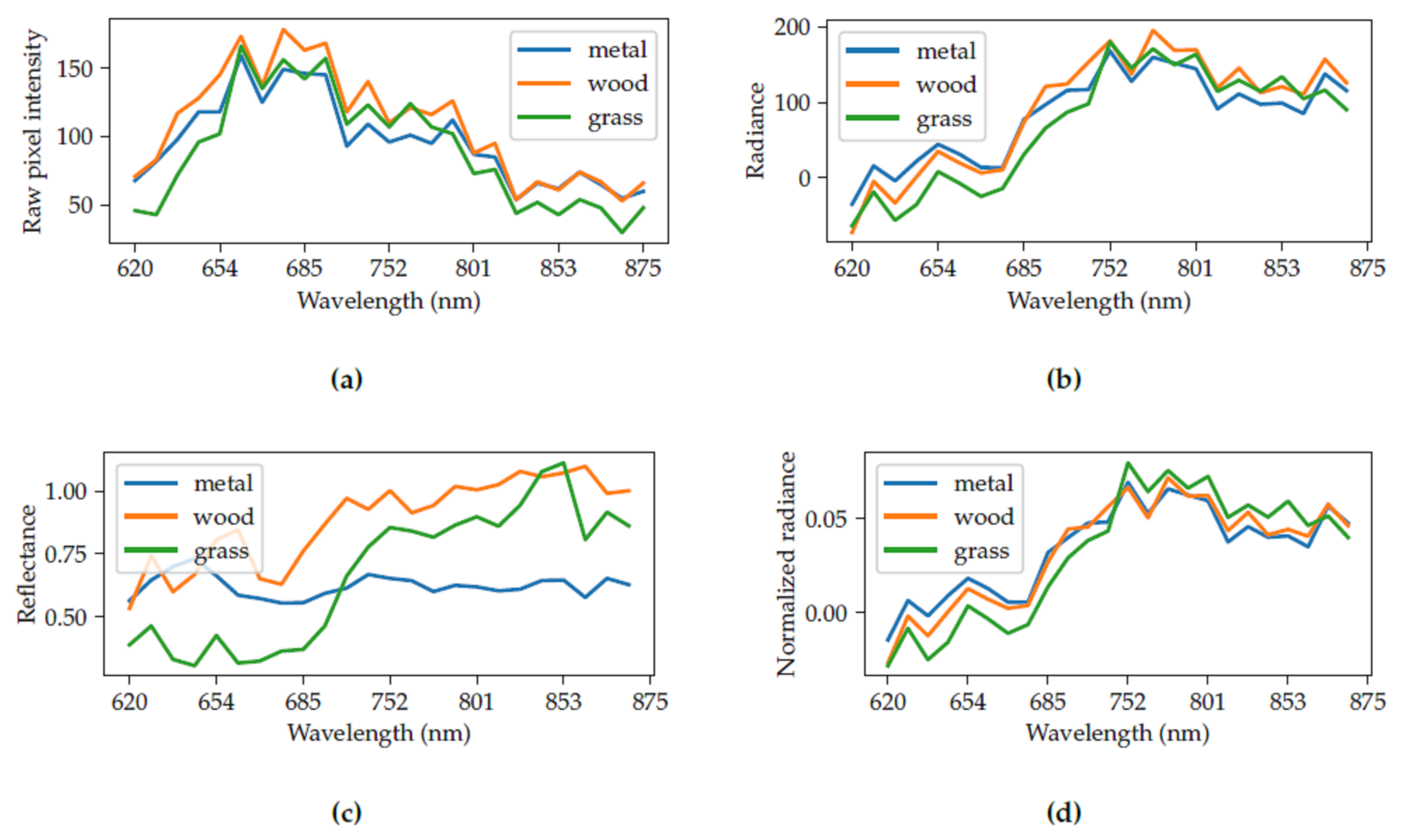
2.1. Radiometry
2.2. Existing Spectral Datasets
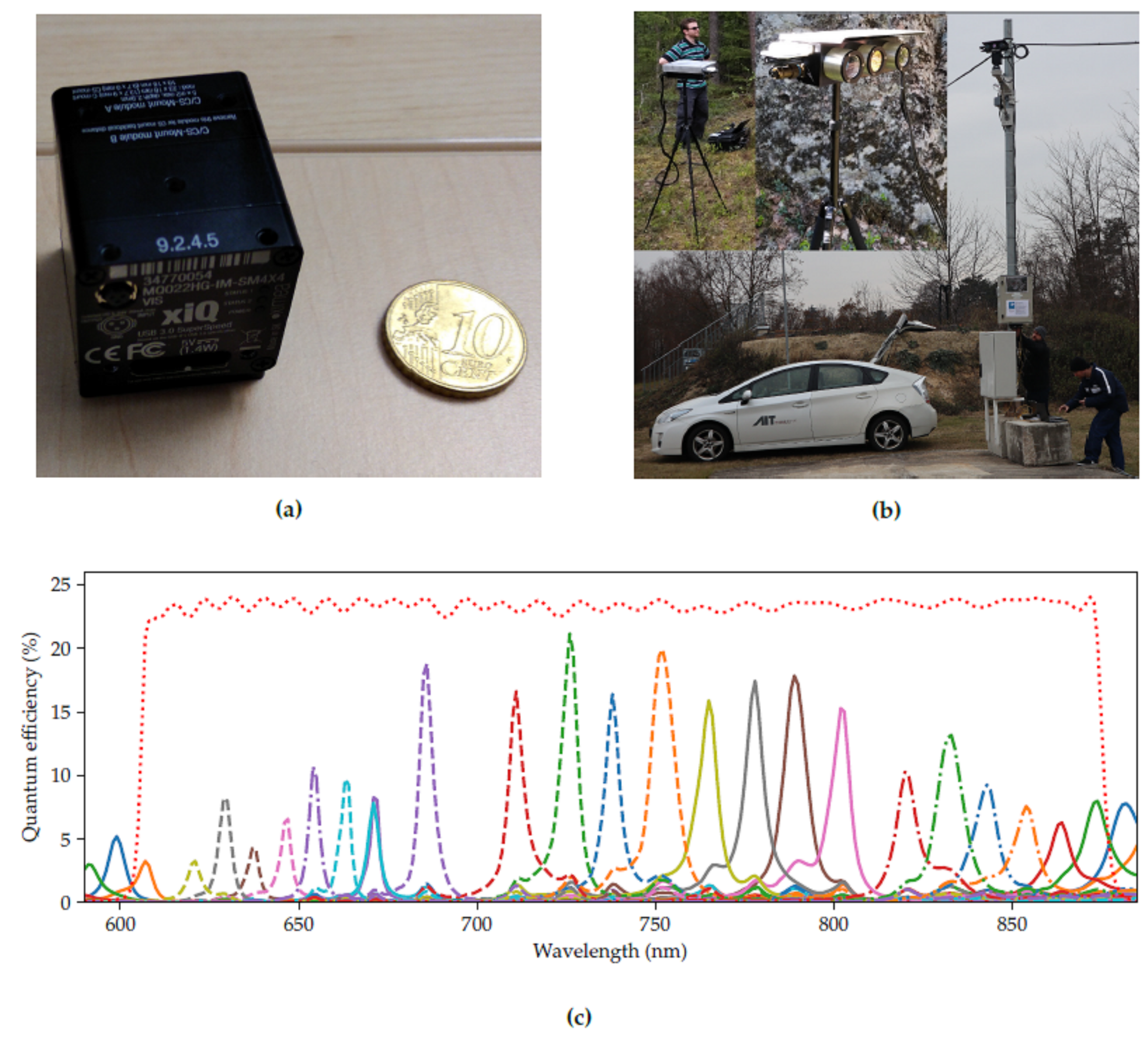
2.3. Compact Passive Hyperspectral Cameras
2.3.1. Hyperspectral Frame to Hyperspectral Cube Conversion
- x is the horizontal spatial coordinate,
- y is the vertical spatial coordinate,
- is the horizontal raw spectral coordinate in one mosaic pattern array,
- is the vertical raw spectral coordinate in one mosaic pattern array,
- is the corrected spectral coordinate.
2.3.2. Overlapping Spectral Radiances
2.3.3. Radiance to Reflectance Transformation
2.4. Data Acquisition
2.4.1. Camera System
2.4.2. Recording Scenarios
2.4.3. Vegetation
2.4.4. High Dynamic Range for Hyperspectral Images
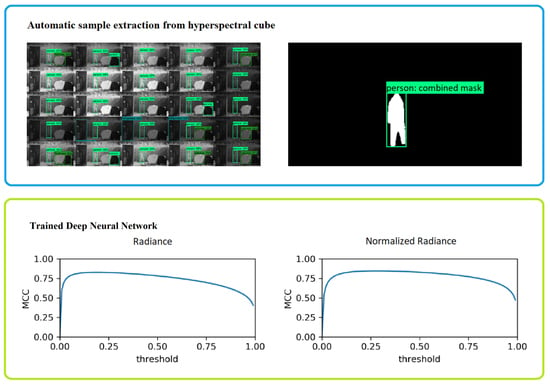
2.5. Automatic Annotation of Hyperspectral Frames
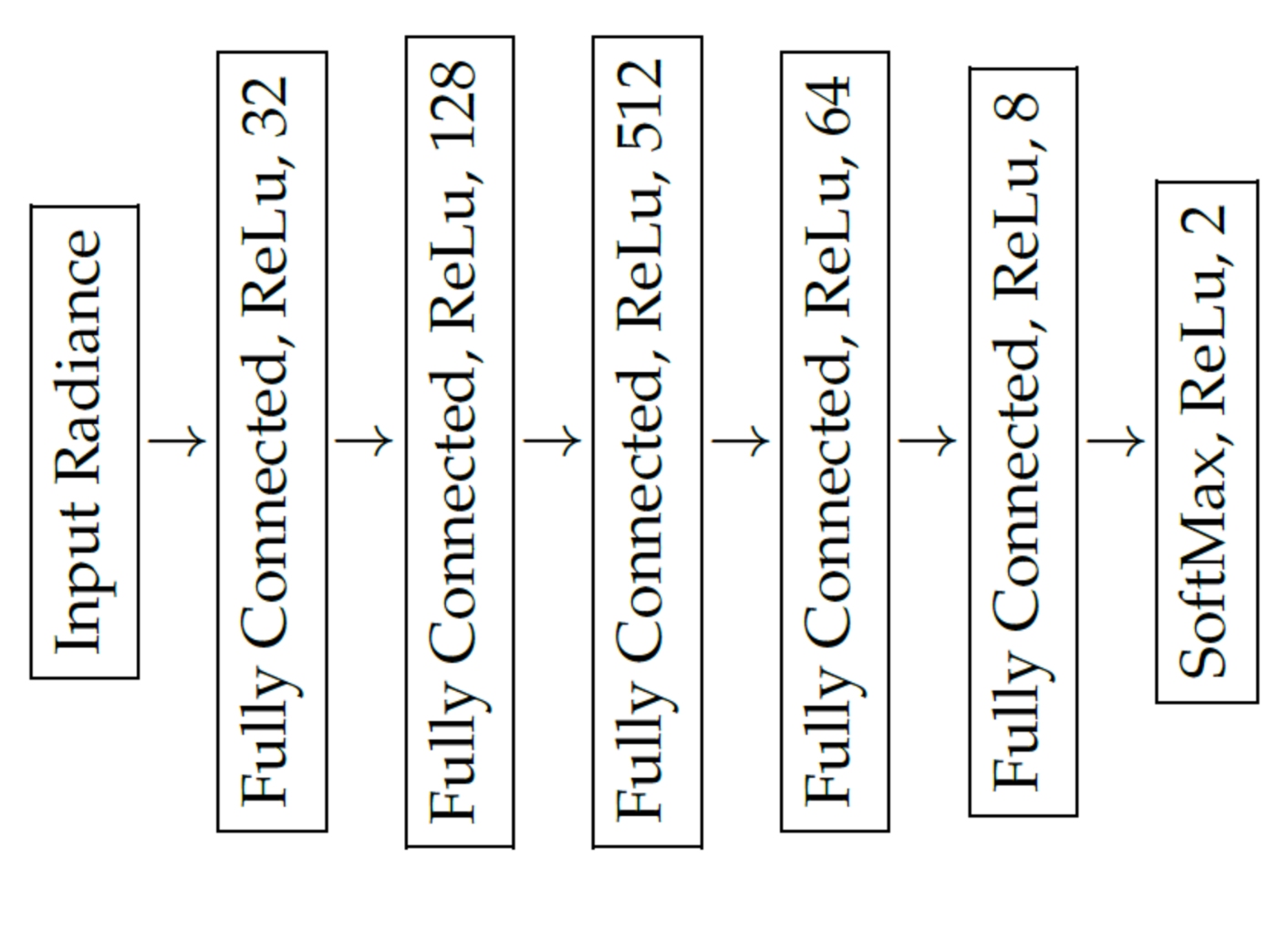
2.6. Spectral Signal Classification
| Algorithm 1: Automatic annotation of hyperspectral frames. |
 |
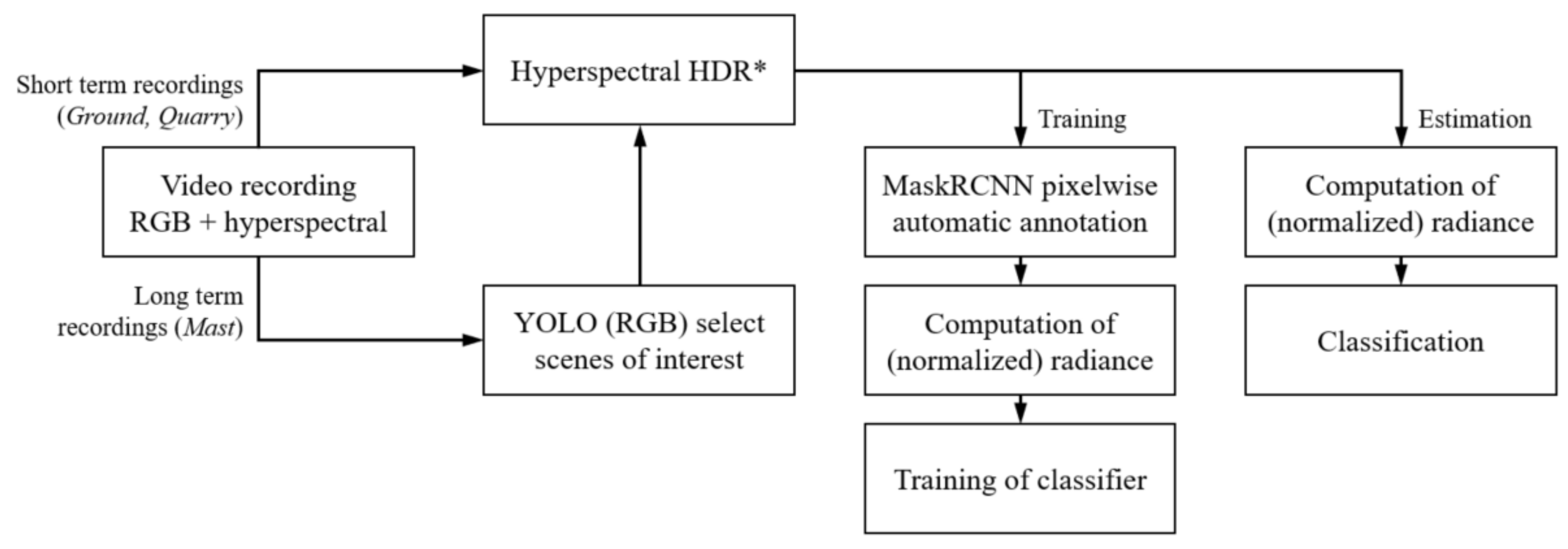
2.7. Implementation and Workflow
3. Results
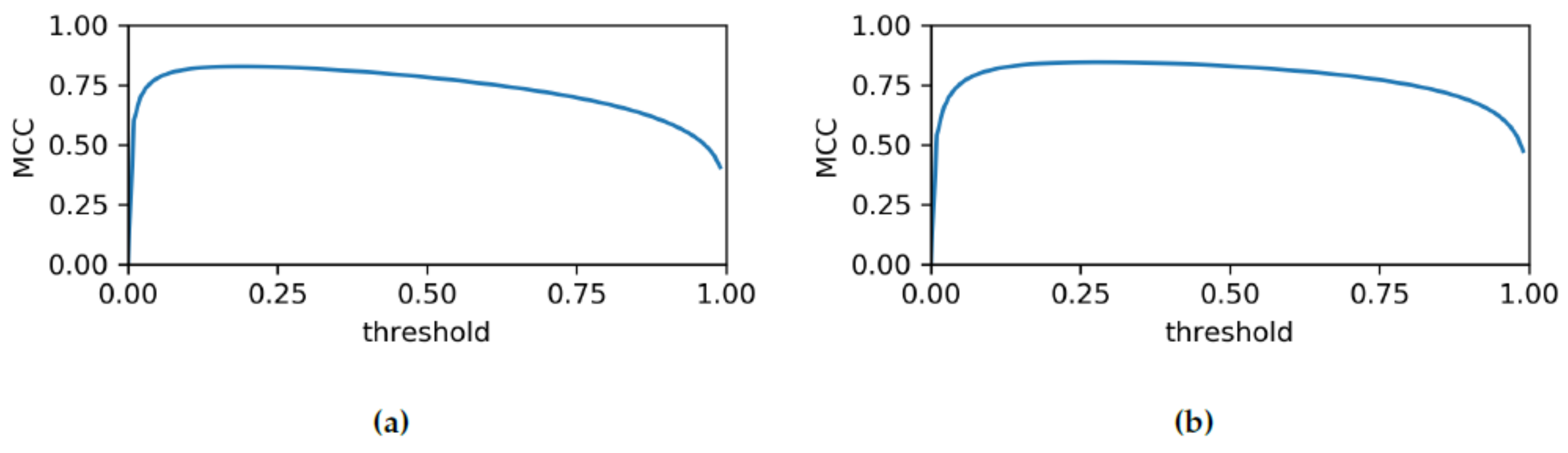
3.1. Quantitative Results
3.2. Visual Results
4. Discussion
5. Conclusions
Supplementary Materials
Supplementary File 1Author Contributions
Funding
 . The project AREAS is funded by the Austrian security research programme KIRAS of the Federal Ministry of Agriculture, Regions and Tourism.
. The project AREAS is funded by the Austrian security research programme KIRAS of the Federal Ministry of Agriculture, Regions and Tourism.Conflicts of Interest
References
- Adão, T.; Hruška, J.; Pádua, L.; Bessa, J.; Peres, E.; Morais, R.; Sousa, J.J. Hyperspectral imaging: A review on UAV-based sensors, data processing and applications for agriculture and forestry. Remote Sens. 2017, 9, 1110. [Google Scholar] [CrossRef]
- Kanning, M.; Kühling, I.; Trautz, D.; Jarmer, T. High-resolution UAV-based hyperspectral imagery for LAI and chlorophyll estimations from wheat for yield prediction. Remote Sens. 2018, 10, 2000. [Google Scholar] [CrossRef]
- Ishida, T.; Kurihara, J.; Viray, F.A.; Namuco, S.B.; Paringit, E.C.; Perez, G.J.; Takahashi, Y.; Marciano, J.J., Jr. A novel approach for vegetation classification using UAV-based hyperspectral imaging. Comput. Electron. Agric. 2018, 144, 80–85. [Google Scholar] [CrossRef]
- Aasen, H.; Burkart, A.; Bolten, A.; Bareth, G. Generating 3D hyperspectral information with lightweight UAV snapshot cameras for vegetation monitoring: From camera calibration to quality assurance. ISPRS J. Photogramm. Remote Sens. 2015, 108, 245–259. [Google Scholar] [CrossRef]
- Guo, M.; Li, J.; Sheng, C.; Xu, J.; Wu, L. A review of wetland remote sensing. Sensors 2017, 17, 777. [Google Scholar] [CrossRef] [PubMed]
- Cao, J.; Leng, W.; Liu, K.; Liu, L.; He, Z.; Zhu, Y. Object-based mangrove species classification using unmanned aerial vehicle hyperspectral images and digital surface models. Remote Sens. 2018, 10, 89. [Google Scholar] [CrossRef]
- Jung, A.; Vohland, M.; Thiele-Bruhn, S. Use of a portable camera for proximal soil sensing with hyperspectral image data. Remote Sens. 2015, 7, 11434–11448. [Google Scholar] [CrossRef]
- Gowen, A.; O’Donnell, C.; Cullen, P.; Downey, G.; Frias, J. Hyperspectral imaging—An emerging process analytical tool for food quality and safety control. Trends Food Sci. Technol. 2007, 18, 590–598. [Google Scholar] [CrossRef]
- Al-Sarayreh, M.; Reis, M.M.; Yan, W.Q.; Klette, R. Deep spectral-spatial features of snapshot hyperspectral images for red-meat classification. In Proceedings of the 2018 International Conference on Image and Vision Computing New Zealand (IVCNZ), Auckland, New Zealand, 19–21 November 2018; pp. 1–6. [Google Scholar]
- Bradley, D.; Thayer, S.; Stentz, A.; Rander, P. Vegetation Detection for Mobile Robot Navigation; Technical Report CMU-RI-TR-04-12; Robotics Institute, Carnegie Mellon University: Pittsburgh, PA, USA, 2004. [Google Scholar]
- Grönwall, C.; Hamoir, D.; Steinvall, O.; Larsson, H.; Amselem, E.; Lutzmann, P.; Repasi, E.; Göhler, B.; Barbé, S.; Vaudelin, O.; et al. Measurements and analysis of active/passive multispectral imaging. In Proceedings of the Electro-Optical Remote Sensing, Photonic Technologies, and Applications VII; and Military Applications in Hyperspectral Imaging and High Spatial Resolution Sensing, Dresden, Germany, 25–26 September 2013; p. 889705. [Google Scholar]
- Kandylakisa, Z.; Karantzalosa, K.; Doulamisa, A.; Karagiannidisb, L. Multimodal data fusion for effective surveillance of critical infrastructure. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 87–93. [Google Scholar] [CrossRef]
- Puttonen, E.; Hakala, T.; Nevalainen, O.; Kaasalainen, S.; Krooks, A.; Karjalainen, M.; Anttila, K. Artificial target detection with a hyperspectral LiDAR over 26-h measurement. Opt. Eng. 2015, 54, 013105. [Google Scholar] [CrossRef]
- Winkens, C.; Sattler, F.; Paulus, D. Hyperspectral Terrain Classification for Ground Vehicles. In Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (5: VISAPP), Porto, Portugal, 27 February–1 March 2017; pp. 417–424. [Google Scholar]
- Cavigelli, L.; Bernath, D.; Magno, M.; Benini, L. Computationally efficient target classification in multispectral image data with Deep Neural Networks. In Proceedings of the SPIE Target and Background Signatures II, Edinburgh, UK, 26–27 September 2016; Volume 9997, p. 99970L. [Google Scholar]
- Howell, J.R.; Menguc, M.P.; Siegel, R. Thermal Radiation Heat Transfer; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Meerdink, S.K.; Hook, S.J.; Roberts, D.A.; Abbott, E.A. The ECOSTRESS spectral library version 1.0. Remote Sens. Environ. 2019, 230, 111196. [Google Scholar] [CrossRef]
- Baldridge, A.M.; Hook, S.; Grove, C.; Rivera, G. The ASTER spectral library version 2.0. Remote Sens. Environ. 2009, 113, 711–715. [Google Scholar] [CrossRef]
- Geelen, B.; Tack, N.; Lambrechts, A. A compact snapshot multispectral imager with a monolithically integrated per-pixel filter mosaic. In Proceedings of the SPIE Advanced Fabrication Technologies for Micro/Nano Optics and Photonics VII, San Francisco, CA, USA, 3–5 February 2014; Volume 8974, p. 89740L. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE international Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45166.pdf (accessed on 29 June 2020).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Camera Type (MQ022HG-IM) | SM4X4-VIS | SM5X5-NIR | SM5X5-NIR |
|---|---|---|---|
| External Optical Filter | - | Short Pass | Long Pass |
| Wavelength (nm) | 465–630 | 600–875 | 675–975 |
| Pattern Size (pixels) | |||
| Spectral Resolution (bands) | 16 | 25 | 25 |
| Spatial Resolution (pixels/band) |
| Raw Pixel Values | Radiance | Reflectance |
|---|---|---|
| Light source | Light source | Material properties |
| Atmospheric absorption | Atmospheric absorption | |
| Camera characteristics | Material properties | |
| Material properties |
| Name | Runtime Days | Recorded Minutes | Comments |
|---|---|---|---|
| Ground | - | 10 | Manual annotation, single exposure |
| Quarry | - | 15 | Manual annotation, single exposure |
| Mast October | 21 | 350 | Auto annotation, multiple exposure |
| Mast November | 18 | 142 | Auto annotation, multiple exposure |
| Mast October Dataset—Positive Samples | |||||
| Radiance | Norm. Radiance | ||||
| Label | TP(%) | FN(%) | TP(%) | FN(%) | Count |
| car | 93.44 | 6.56 | 96.40 | 3.60 | 1,433,115 |
| person | 94.43 | 5.57 | 96.42 | 3.58 | 3,209,489 |
| truck | 91.72 | 8.28 | 94.63 | 5.37 | 1,555,581 |
| Mast November Dataset—Positive Samples | |||||
| Radiance | Norm. Radiance | ||||
| Label | TP(%) | FN(%) | TP(%) | FN(%) | Count |
| car | 79.74 | 20.26 | 86.64 | 13.36 | 8,407,865 |
| person | 93.12 | 6.88 | 95.49 | 4.51 | 641,724 |
| truck | 75.48 | 24.52 | 82.41 | 17.59 | 2,390,360 |
| Mast October Dataset—Negative Samples | |||||
| Radiance | Norm. Radiance | ||||
| Label | FP(%) | TN(%) | FP(%) | TN(%) | Count |
| tarmac | 1.31 | 98.69 | 3.05 | 96.95 | 1,258,540 |
| tree | 3.89 | 96.11 | 3.94 | 96.06 | 11,872 |
| vegetation | 4.11 | 95.89 | 4.66 | 95.34 | 1,204,848 |
| Quarry Dataset—Negative Samples | |||||
| Radiance | Norm. Radiance | ||||
| Label | FP(%) | TN(%) | FP(%) | TN(%) | Count |
| forest-density-low | 16.17 | 83.83 | 66.98 | 33.02 | 598,825 |
| forest-density-medium | 5.60 | 94.40 | 2.06 | 97.94 | 642,958 |
| ground-vegetation-medium | 0.05 | 99.95 | 0.17 | 99.83 | 2,066,311 |
| Ground Dataset—Negative Samples | |||||
| Radiance | Norm. Radiance | ||||
| Label | FP(%) | TN(%) | FP(%) | TN(%) | Count |
| forest-density-medium | 35.17 | 64.83 | 46.40 | 53.60 | 141,431 |
| ground-vegation-low | 8.35 | 91.65 | 20.09 | 79.91 | 97,074 |
| ground-vegetation-medium | 20.36 | 79.64 | 24.98 | 75.02 | 959,979 |
| Ground Dataset—Positive Samples | |||||
| Radiance | Norm. Radiance | ||||
| Label | TP(%) | FN(%) | TP(%) | FN(%) | Count |
| clothes-clothesid-11 | 56.77 | 43.23 | 47.95 | 52.05 | 11,148 |
| clothes-clothesid-16 | 4.44 | 95.56 | 3.24 | 96.76 | 4258 |
| clothes-clothesid-18 | 74.95 | 25.05 | 70.16 | 29.84 | 9054 |
| clothes-clothesid-20 | 99.39 | 0.61 | 99.93 | 0.07 | 12,142 |
| clothes-clothesid-24 | 29.86 | 70.14 | 26.44 | 73.56 | 7542 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papp, A.; Pegoraro, J.; Bauer, D.; Taupe, P.; Wiesmeyr, C.; Kriechbaum-Zabini, A. Automatic Annotation of Hyperspectral Images and Spectral Signal Classification of People and Vehicles in Areas of Dense Vegetation with Deep Learning. Remote Sens. 2020, 12, 2111. https://doi.org/10.3390/rs12132111
Papp A, Pegoraro J, Bauer D, Taupe P, Wiesmeyr C, Kriechbaum-Zabini A. Automatic Annotation of Hyperspectral Images and Spectral Signal Classification of People and Vehicles in Areas of Dense Vegetation with Deep Learning. Remote Sensing. 2020; 12(13):2111. https://doi.org/10.3390/rs12132111
Chicago/Turabian StylePapp, Adam, Julian Pegoraro, Daniel Bauer, Philip Taupe, Christoph Wiesmeyr, and Andreas Kriechbaum-Zabini. 2020. "Automatic Annotation of Hyperspectral Images and Spectral Signal Classification of People and Vehicles in Areas of Dense Vegetation with Deep Learning" Remote Sensing 12, no. 13: 2111. https://doi.org/10.3390/rs12132111
APA StylePapp, A., Pegoraro, J., Bauer, D., Taupe, P., Wiesmeyr, C., & Kriechbaum-Zabini, A. (2020). Automatic Annotation of Hyperspectral Images and Spectral Signal Classification of People and Vehicles in Areas of Dense Vegetation with Deep Learning. Remote Sensing, 12(13), 2111. https://doi.org/10.3390/rs12132111