Multi-View Features Joint Learning with Label and Local Distribution Consistency for Point Cloud Classification

 ,
,  , ,
, , 

Abstract
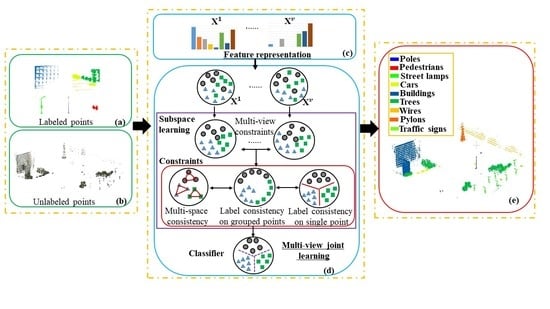
1. Introduction
2. Materials and Methods
2.1. Multi-View Point Cloud Feature Extraction
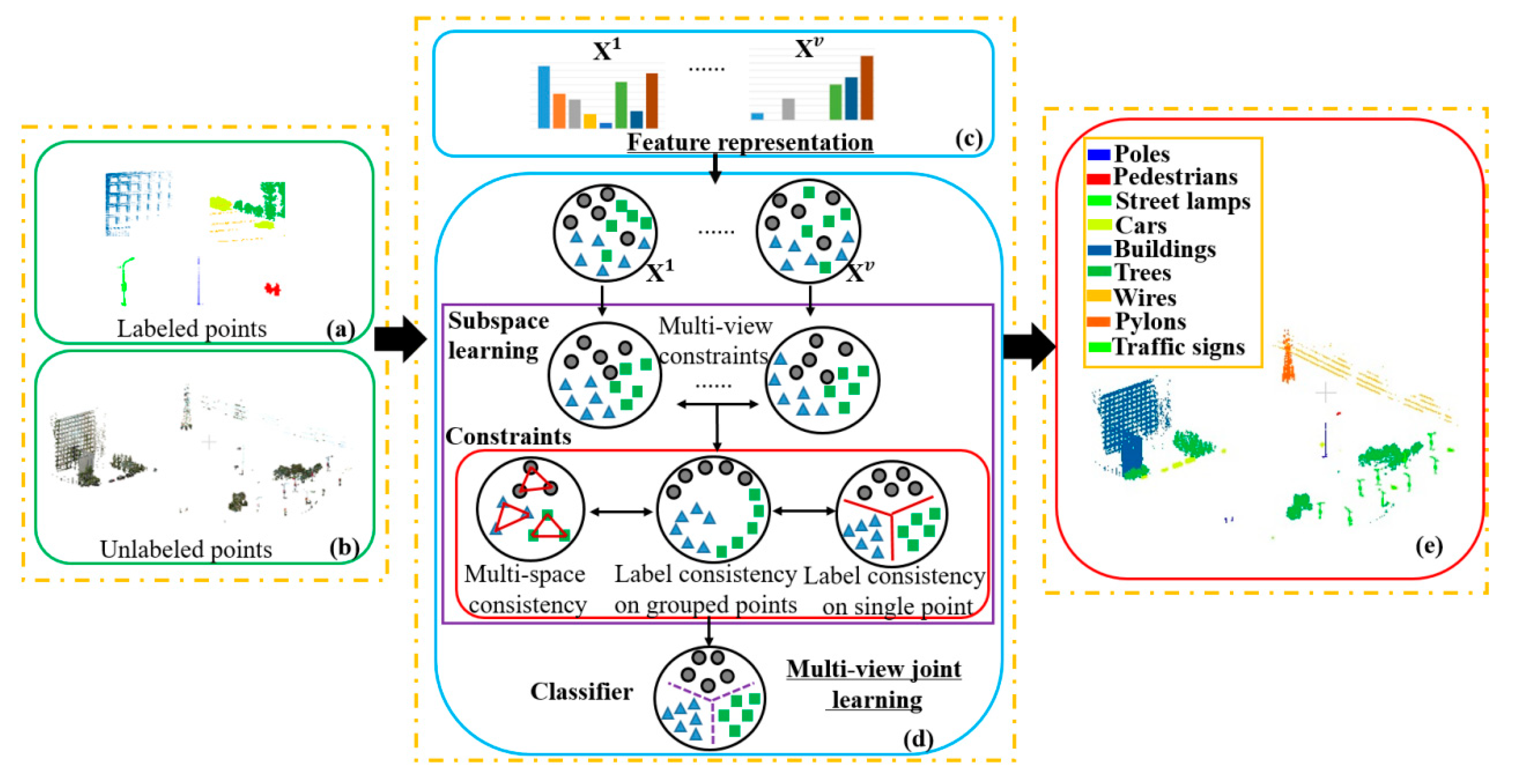
2.2. Multiple Views and Space Representation Consistency under Constraints of Label Consistency (MvsRCLC)
2.2.1. Reconstruction Independent Component Analysis (RICA) Subspace Learning
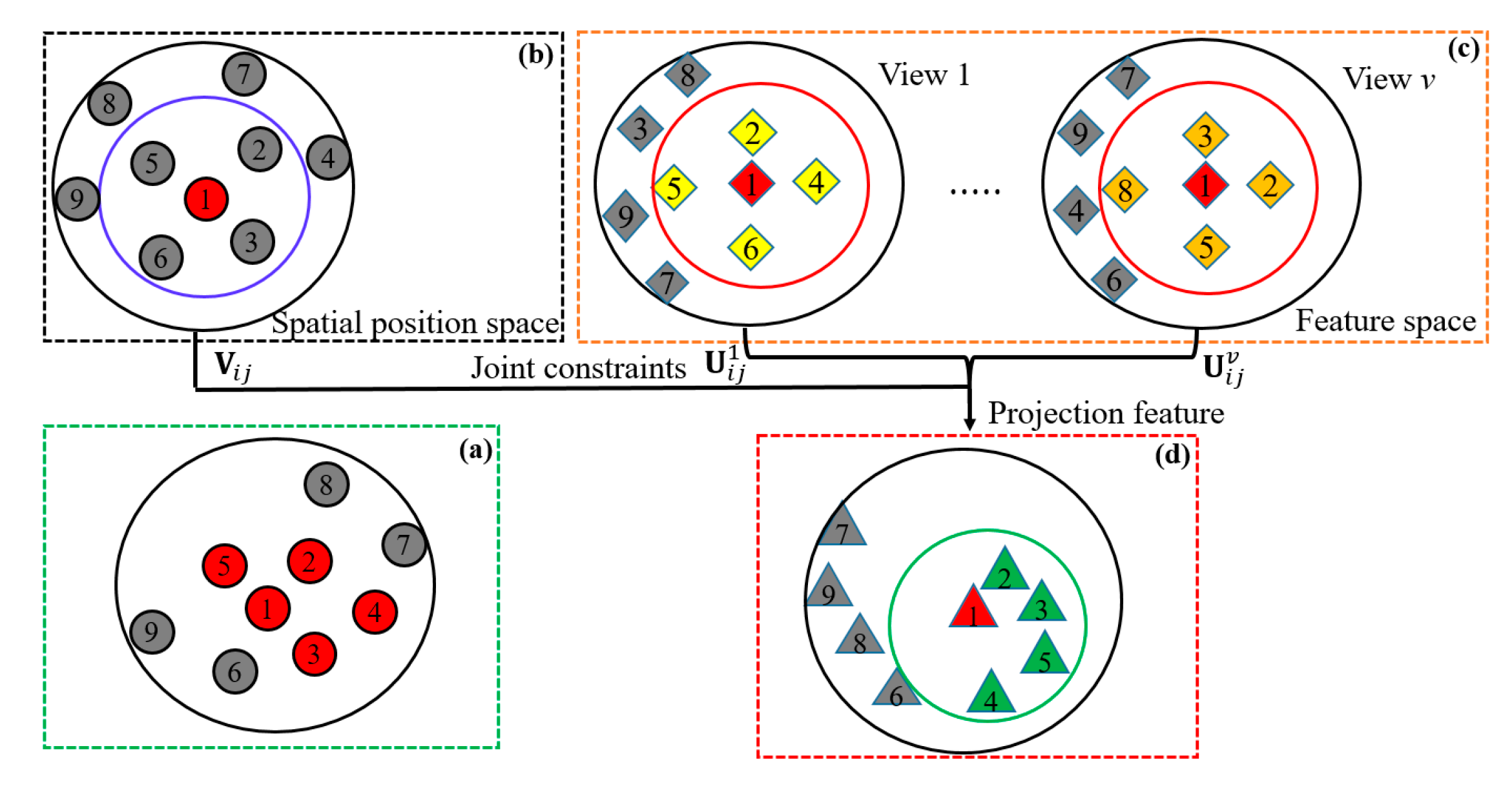
2.2.2. Multi-View Local Distribution Consistency Constraints
2.2.3. Label Consistency
2.2.4. Objective Function of MvsRCLC
2.3. Optimization Technique
2.3.1. Update of W
2.3.2. Update of G
2.3.3. Update of H
2.4. Point Cloud Labeling
| Algorithm 1: MvsRCLC optimization algorithm (The pseudocode of the multiple views and space representation consistency under constraints of label consistency (MvsRCLC) optimization algorithm.) |
| Input: multi-view feature matrix: }, ground truth label matrix of single point: F, ground truth label matrix of grouped points: G Parameters: α, β, γ, , convergence error: and the maximum number of iterations: T Initialization: , iter = 0 Calculating Laplacian matrix of spatial position while not converged do for each view while iter ≤ T do Update : Fixed , can be solved by the unconstrained optimization operator L-BFGS according to Equation (13). Update : Fixed , update according to Equation (15) Update : Fixed , update according to Equation (17) Update: iter = iter + 1 end end Convergence condition: ≤ If not converge, update: t = t + 1 end Output: projection matrix:}, linear classifier:}. |
3. Performance Evaluation
3.1. Experiment Data and Evaluation Metrics
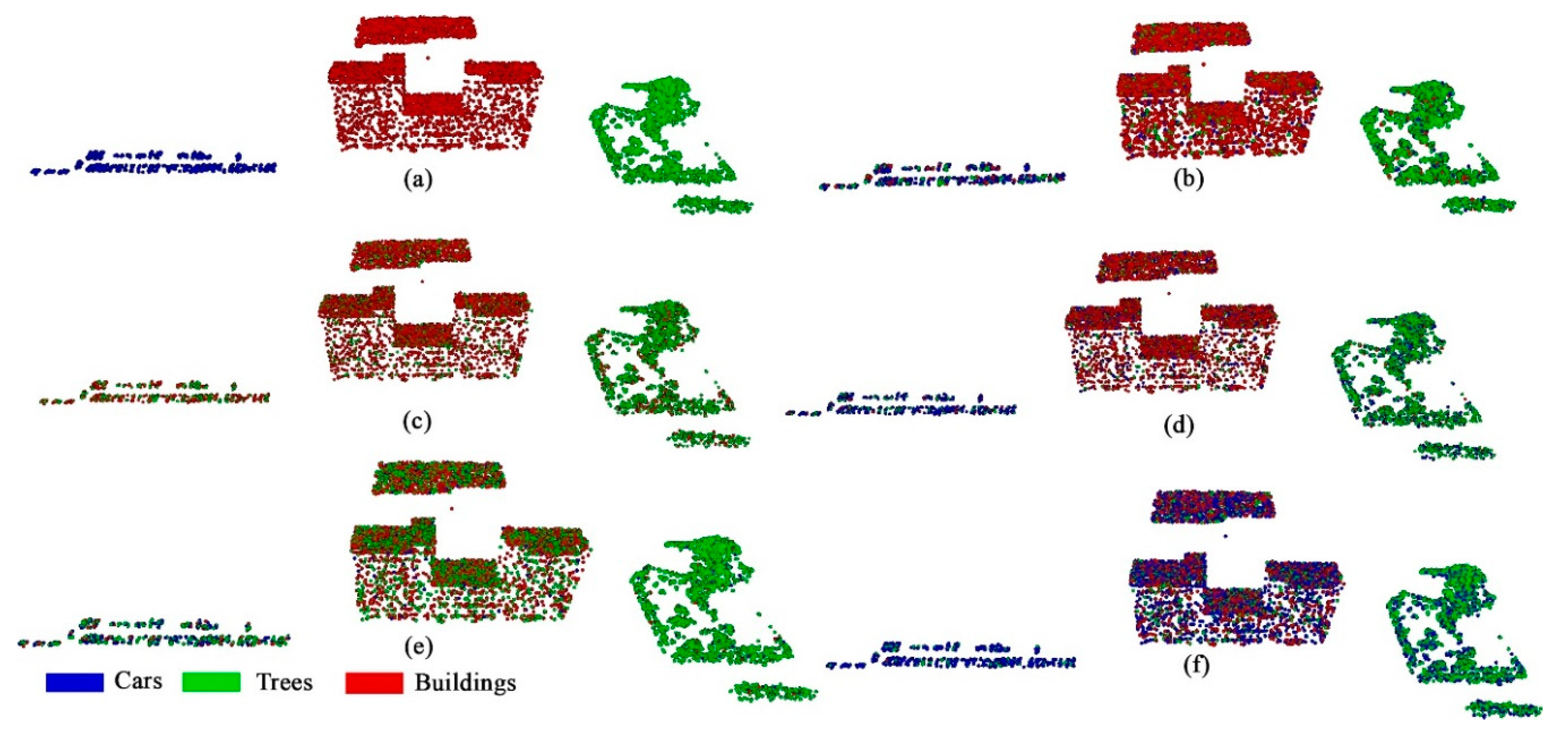
3.2. Experimental Results
3.2.1. The First Experimental Group
3.2.2. The Second Experimental Group
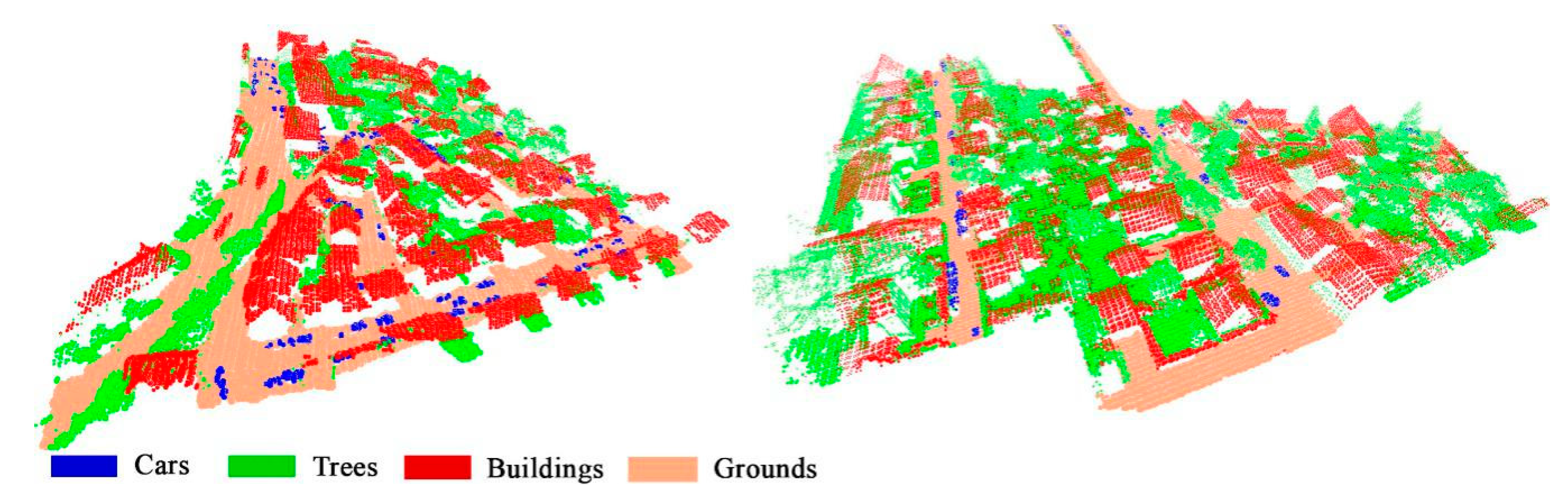
3.3. Effectiveness on ISPRS 3D Semantic Labeling Dataset
3.4. Effectiveness of Multiple Constraints
3.5. Parameters Analysis
3.6. Convergence Analysis
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, Z.; Zhang, L.; Tong, X. Discriminative-dictionary-learning-based multilevel point-cluster features for ALS point-cloud classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7309–7322. [Google Scholar] [CrossRef]
- Farabet, C.; Couprie, C.; Najman, L. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1915–1929. [Google Scholar] [CrossRef]
- Li, Y.; Tong, G.; Du, X. A single point-based multilevel features fusion and pyramid neighborhood optimization method for ALS point cloud classification. Appl. Sci. 2019, 9, 951. [Google Scholar] [CrossRef]
- Li, Y.; Tong, G.; Li, X. MVF-CNN: Fusion of multilevel features for large-scale point cloud classification. IEEE Access. 2019, 7, 46522–46537. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, L.; Fang, T. A multiscale and hierarchical feature extraction method for terrestrial laser scanning point cloud classification. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2409–2425. [Google Scholar] [CrossRef]
- Guo, B.; Huang, X.; Zhang, F. Classification of airborne laser scanning data using JointBoost. ISPRS J. Photogramm. Remote Sens. 2015, 100, 71–83. [Google Scholar] [CrossRef]
- Weinmann, M.; Jutzi, B.; Hinz, S. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- Chen, D.; Peethambaran, J.; Zhang, Z. A supervoxel-based vegetation classification via decomposition and modelling of full-waveform airborne laser scanning data. Int. J. Remote Sens. 2018, 39, 2937–2968. [Google Scholar] [CrossRef]
- Li, Y.; Chen, D.; Du, X. Higher-order conditional random fields-based 3D semantic labeling of airborne laser-scanning point clouds. Remote Sens. 2019, 11, 1248. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, B. Discriminative K-SVD for dictionary learning in face recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Jiang, Z.; Lin, Z.; Davis, L. Label consistent K-SVD: Learning a discriminative dictionary for recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2651–2664. [Google Scholar] [CrossRef] [PubMed]
- Mei, J.; Wang, Y.; Zhang, L. PSASL: Pixel-level and superpixel-level aware subspace learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4278–4293. [Google Scholar] [CrossRef]
- Le, Q.; Karpenko, A.; Ngiam, J. ICA with reconstruction cost for efficient overcomplete feature learning. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–14 December 2011. [Google Scholar]
- Martínez, A.; Kak, A. PCA versus LDA. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 228–233. [Google Scholar] [CrossRef]
- Nie, F.; Yuan, J.; Huang, H. Optimal mean robust principal component analysis. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Mei, J.; Zhang, L.; Wang, Y. Joint margin, cograph, and label constraints for semisupervised scene parsing from point clouds. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3800–3813. [Google Scholar] [CrossRef]
- Zhu, P.; Zhang, L.; Wang, Y. Projection learning with local and global consistency constraints for scene classification. ISPRS J. Photogramm. Remote Sens. 2018, 144, 202–216. [Google Scholar] [CrossRef]
- Fang, X.; Xu, Y.; Li, X. Learning a nonnegative sparse graph for linear regression. IEEE Trans. Image Process. 2015, 24, 2760–2771. [Google Scholar] [CrossRef]
- Johnson, A. A Representation for 3D Surface Matching. Ph.D. Thesis, Robotics Institute, Carnegie Mellon University, Pittsburgh, PA, USA, 1997. [Google Scholar]
- Rusu, R.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Rusu, R.; Bradski, G.; Thibaux, R. Fast 3D recognition and pose using the Viewpoint Feature Histogram. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010. [Google Scholar]
- Nie, F.; Li, J.; Li, X. Parameter-free auto-weighted multiple graph learning: A framework for multiview clustering and semi-supervised classification. In Proceedings of the International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Nie, F.; Cai, G.; Li, X. Multi-view clustering and semi-supervised classification with adaptive neighbours. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Nie, F.; Cai, G.; Li, J. Auto-weighted multi-view learning for image clustering and semi-supervised classification. IEEE Trans. Image Process. 2018, 27, 1501–1511. [Google Scholar] [CrossRef]
- Nie, F.; Tian, L.; Li, X. Multiview clustering via adaptively weighted procrustes. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018. [Google Scholar]
- Zhang, C.; Hu, Q.; Fu, H. Latent multi-view subspace clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, X.; Guo, X.; Lei, Z. Exclusivity-consistency regularized multi-view subspace clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Cao, X.; Zhang, C.; Fu, H. Diversity-induced multi-view subspace clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wang, Y.; Wu, L.; Lin, X. Multiview spectral clustering via structured low-rank matrix factorization. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 4833–4843. [Google Scholar] [CrossRef]
- Tang, C.; Zhu, X.; Liu, X. Learning joint affinity graph for multi-view subspace clustering. IEEE Trans. Multimedia 2019, 21, 1724–1736. [Google Scholar] [CrossRef]
- Griffiths, D.; Boehm, J. A Review on deep learning techniques for 3D sensed data classification. Remote Sens. 2019, 11, 1499. [Google Scholar] [CrossRef]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3D shape recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Boulch, A.; Guerry, J.; Le Saux, B.; Audebert, N. SnapNet: 3D point cloud semantic labeling with 2D deep segmentation networks. Comput. Graph. 2018, 71, 189–198. [Google Scholar] [CrossRef]
- Felix, J.; Martin, D.; Patrik, T.; Goutam, B.; Fahad, S.; Michael, F. Deep projective 3D semantic segmentation. In International Conference on Computer Analysis of Images and Patterns; Lecture Notes in Computer Science Series Volume 10424; Springer: Cham, Switzerland, 2017; pp. 95–107. [Google Scholar]
- Qin, N.; Hu, X.; Dai, H. Deep fusion of multi-view and multimodal representation of ALS point cloud for 3D terrain scene recognition. ISPRS J. Photogramm. Remote Sens. 2018, 143, 205–212. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Lecture Notes in Computer Science Series Volume 9351; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 2481–2495. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Malouf, R. A comparison of algorithms for maximum entropy parameter estimation. In Proceedings of the 6th Conference on Computational Natural Language Learning CoNLL 2002, Taipei, Taiwan, 31 August–1 September 2002. [Google Scholar]
- Zhang, Z.; Zhang, L.; Tong, X.; Mathiopoulos, P.; Guo, B.; Huang, X.; Wang, Z.; Wang, Y. A multilevel point-cluster-based discriminative feature for ALS point cloud classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3309–3321. [Google Scholar] [CrossRef]
- Huang, H.; Wang, L.; Jiang, B. Precision verification of 3D SLAM backpacked mobile mapping robot. Bull. Surv. Mapp. 2016, 12, 68–73. [Google Scholar]
- Tong, G.; Li, Y.; Zhang, W.; Chen, D.; Zhang, Z.; Yang, J.; Zhang, J. Point set multi-level aggregation feature extraction based on multi-scale max pooling and LDA for point cloud classification. Remote Sens. 2019, 11, 2846. [Google Scholar] [CrossRef]
- Chang, C.; Lin, C. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Sörgel, U. Contextual classification of lidar data and building object detection in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | ALS | MLS | TLS | ||
|---|---|---|---|---|---|
| Scenes | Scene1 | Scene2 | Scene3 | Scene4 | Scene5 |
| Trees | 68,802/213,990 | 39,743/73,207 | 65,295 | 516,960 | 214,151 |
| Buildings | 37,128/200,549 | 64,952/156,186 | 312,475 | 230,910 | 88,818 |
| Cars | 5380/7816 | 4584/7409 | 91,967 | 103,983 | 31,026 |
| Pedestrians | -- | -- | -- | 2780 | 51,163 |
| Wire poles | -- | -- | 9352 | 2286 | -- |
| Street lamps | -- | -- | -- | 32,713 | -- |
| Traffic signs | -- | -- | -- | 1556 | -- |
| Wires | -- | -- | -- | 3875 | -- |
| Pylons | -- | -- | -- | 5196 | -- |
| Total points | 111,310/422,355 | 109,279/236,802 | 479,089 | 900,200 | 385,158 |
| Scene1 | Methods | OA | mIoU | Kappa | F1-Score | mF1 |
|---|---|---|---|---|---|---|
| Multiple features | Our method | 77.49 | 45.04 | 57.15 | 81.65/10.93/75.31 | 55.96 |
| Adaboost | 62.04 | 36.25 | 39.56 | 81.53/4.99/54.42 | 46.98 | |
| LC-KSVD1 | 69.06 | 41.13 | 47.64 | 78.39/6.41/71.49 | 52.1 | |
| LC-KSVD2 | 68.95 | 41.06 | 47.54 | 78.82/6.23/71.17 | 51.98 | |
| DKSVD | 68.57 | 40.65 | 46.9 | 78.33/6.22/70.39 | 51.65 | |
| RICA-SVM | 72.94 | 43.78 | 52.85 | 82.18/8.17/72.87 | 54.41 | |
| Single feature | FC(our) | 77.2 | 44.62 | 56.58 | 81.39/10.25/74.92 | 55.52 |
| FSI(our) | 68.93 | 38.3 | 44.76 | 79.10/4.74/64.03 | 49.29 | |
| FC(SVM) | 73.51 | 43.39 | 52.95 | 82.22/7.87/71.98 | 54.02 | |
| FSI(SVM) | 72.05 | 43.21 | 51.69 | 80.97/6.72/73.56 | 53.75 |
| Scene2 | Methods | OA | mIoU | Kappa | F1-Score | mF1 |
|---|---|---|---|---|---|---|
| Multiple features | Our method | 84.84 | 50.66 | 67.37 | 79.48/8.90/89.75 | 59.38 |
| Adaboost | 69.32 | 35.95 | 42.65 | 81.53/4.99/54.42 | 46.61 | |
| LC-KSVD1 | 75.31 | 43.66 | 50.51 | 68.63/16.16/82.36 | 55.71 | |
| LC-KSVD2 | 61.92 | 34.45 | 34.7 | 61.53/12.26/68.79 | 47.53 | |
| DKSVD | 59.9 | 31.76 | 27.55 | 55.84/4.69/70.25 | 43.59 | |
| RICA-SVM | 78.56 | 42.15 | 51.04 | 66.44/3.61/85.62 | 51.89 | |
| Single feature | FC(our) | 84.44 | 49.02 | 66.95 | 79.31/0.00/89.68 | 56.33 |
| FSI(our) | 79.12 | 49.05 | 58.1 | 73.10/22.37/87.00 | 60.82 | |
| FC(SVM) | 80.83 | 43.02 | 53.68 | 68.49/0.00/87.02 | 51.83 | |
| FSI(SVM) | 82.56 | 45.99 | 60.53 | 74.52/0.00/88.00 | 53.71 |
| Scenes | Our Method | Adaboost | LC-KSVD1 | LC-KSVD2 | DKSVD | RICA-SVM |
|---|---|---|---|---|---|---|
| Scene1 | 1.03 | 32.85 | 127.15 | 125.82 | 201.55 | 2.33 |
| Scene2 | 0.79 | 17.79 | 29.01 | 57.06 | 85.66 | 1.35 |
| Scene3 | Method | OA | mIoU | Kappa | F1-Score | mF1 |
|---|---|---|---|---|---|---|
| Multiple features | Our method | 70.68 | 41.65 | 51.14 | 21.88/79.41/42.69/76.17 | 55.01 |
| Adaboost | 65.23 | 38.7 | 45.87 | 17.99/73.90/41.36/75.15 | 52.1 | |
| LC-KSVD1 | 69.56 | 42.26 | 50.67 | 20.56/78.40/43.54/79.04 | 55.39 | |
| LC-KSVD2 | 69.36 | 42.01 | 50.48 | 20.29/78.27/43.72/78.48 | 55.19 | |
| DKSVD | 62.2 | 35.86 | 39.86 | 15.00/73.60/34.22/72.14 | 48.74 | |
| RICA-SVM | 68.41 | 41.72 | 49.5 | 18.84/77.31/42.50/79.85 | 54.63 | |
| Single feature | FC(our) | 61.99 | 35.01 | 39.9 | 12.23/72.81/29.53/74.19 | 47.19 |
| FSI(our) | 69.71 | 41.05 | 49.94 | 21.59/78.76/42.48/75.15 | 54.49 | |
| FC(SVM) | 59.78 | 34.9 | 38.47 | 12.23/70.20/32.26/74.83 | 47.38 | |
| FSI(SVM) | 68.08 | 39.78 | 47.88 | 19.56/77.94/39.74/74.69 | 52.98 |
| Scene4 | Method | OA | mIoU | Kappa | F1-Score | mF1 |
|---|---|---|---|---|---|---|
| Multiple features | Our method | 80.93 | 30.92 | 68.62 | 12.71/81.55/91.67/40.95/6.96 /60.15/28.71/24.87/25.48 | 41.46 |
| Adaboost | 63.22 | 27.18 | 46.35 | 23.16/69.86/77.96/49.25/2.16 /44.60/60.92/12.57/3.90 | 38.27 | |
| LC-KSVD1 | 77.42 | 29.97 | 63.94 | 11.40/77.34/90.65/2.41/4.07 /55.49/39.90/7.74/17.15 | 40.68 | |
| LC-KSVD2 | 77.89 | 30.13 | 64.53 | 12.09/78.51/90.68/41.31/3.88 /55.84/39.64/26.58/18.79 | 40.81 | |
| DKSVD | 76.37 | 27.61 | 62.16 | 11.24/77.24/89.84/36.91/4.76 /52.58/32.87/22.36/9.59 | 37.49 | |
| RICA-SVM | 77.08 | 31.19 | 63.78 | 11.77/78.31/89.64/45.98/5.19 /56.20/55.17/18.70/16.19 | 41.91 | |
| Single feature | FC(our) | 63.23 | 17.74 | 44.78 | 2.35/67.37/81.94/5.29/2.12 /32.84/9.69/14.80/3.40 | 24.42 |
| FSI(our) | 77.1 | 27.88 | 63.4 | 9.79/80.31/88.91/39.52/5.51 /52.91/28.91/15.54/17.88 | 37.69 | |
| FC(SVM) | 59.61 | 20.38 | 42.12 | 2.55/68.57/77.75/13.52/1.57 /34.80/43.57/14.30/3.06 | 28.85 | |
| FSI(SVM) | 76.55 | 28.73 | 63.06 | 9.82/81.07/87.92/42.08/2.89 /54.28/34.85/15.86/20.89 | 38.85 |
| Scene5 | Method | OA | mIoU | Kappa | F1-Score | mF1 |
|---|---|---|---|---|---|---|
| Multiple features | Our method | 69.7 | 39.39 | 35.08 | 31.93/84.29/16.28/72.50 | 51.25 |
| Adaboost | 64.66 | 29.93 | 18.02 | 28.44/80.31/0.87/52.56 | 40.55 | |
| LC-KSVD1 | 67.03 | 37.55 | 32.04 | 32.49/80.75/22.98/66.76 | 50.74 | |
| LC-KSVD2 | 67.16 | 37.91 | 32.07 | 33.36/80.80/22.23/67.14 | 50.89 | |
| DKSVD | 54.84 | 27.31 | 20.37 | 19.20/72.57/18.75/47.72 | 39.56 | |
| RICA-SVM | 67.96 | 38.5 | 32.17 | 36.71/80.81/18.24/69.84 | 51.4 | |
| Single feature | FC(our) | 66 | 34.92 | 28.19 | 26.29/80.72/18.78/63.47 | 47.31 |
| FSI(our) | 51.35 | 25.18 | 20.74 | 24.55/70.32/21.52/33.95 | 37.59 | |
| FC(SVM) | 67.16 | 34.7 | 28.8 | 26.04/81.65/15.86/63.19 | 46.68 | |
| FSI(SVM) | 45.68 | 17.56 | 12.35 | 1.40/63.37/36.76/1.24 | 25.69 |
| Method | Building | Car | Tree | OA | mIoU | Kappa | mF1 |
|---|---|---|---|---|---|---|---|
| Our method | 83.3/76.5 /66.3/79.8 | 29.9/67.1 /26.1/41.4 | 91.6/83.1 /77.2/87.2 | 79.7 | 56.6 | 64.3 | 69.4 |
| AWP | 69.2/78.6 /58.2/73.6 | 0.0/0.0 /0.0/0.0 | 84.4/84.3 /70.0/82.3 | 75.9 | 42.7 | 53.3 | 52 |
| AMGL | 81.9/70.3 /60.9/75.7 | 23.0//77.3 /21.5/35.5 | 95.1/77.4 /74.4/85.3 | 74.9 | 52.3 | 58.4 | 65.5 |
| MLAN | 48.7/100.0/ /48.7/65.5 | 0.0/0.0 /0.0/0.0 | 100.0/59.9 /59.9/74.9 | 64.8 | 36.2 | 41.4 | 46.8 |
| NNSG | 73.3/64.3 /52.1/68.5 | 12.0/87.9 /11.8/21.1 | 99.2/34.2 /34.1/50.9 | 48.4 | 32.7 | 30.5 | 46.8 |
| SVM | 84.6/66.7 /59.5/74.6 | 24.7/72.4/ /22.6/36.8 | 91.9/83.2 /77.5/87.3 | 76. 7 | 53.2 | 60 | 66.3 |
| FC(our) | 84.7/74.2 /65.5/79.1 | 27.1/65.4 /23.7/38.3 | 90.8/82.8 /76.4/86.6 | 78.6 | 55.2 | 62.7 | 68 |
| FSI(our) | 77.2/64.8 /54.3/70.5 | 22.8/59.8 /19.7/33.0 | 88.0/80.1 /72.2/83.9 | 73.4 | 48.8 | 53.8 | 62.5 |
| FC(SVM) | 83.8/65.4 /58.0/73.5 | 22.1/67.5 /20.0/33.3 | 90.1/80.7 /74.1/85.1 | 74.5 | 50.7 | 56.5 | 64 |
| FSI(SVM) | 81.3/55.8 /49.5/66.2 | 21.0/52.3 /17.6/30.0 | 84.5/86.0 /74.3/85.2 | 73.1 | 47.1 | 52 | 60.5 |
| Method | Pole | Building | Car | Tree | OA | mIoU | Kappa | mF1 |
|---|---|---|---|---|---|---|---|---|
| Our method | 70.7/64.1 /50.7/67.3 | 62.1/70.1 /49.1/65.9 | 67.5/40.8 /34.1/50.9 | 68.3/92.9 /65.0/78.7 | 70 | 49.7 | 56 | 65.7 |
| AWP | 32.4/74.5 /29.2/45.2 | 0.0/0.0 /0.0/0.0 | 18.9/32.1 /13.5/23.8 | 0.0/0.0 /0.0/0.0 | 26.6 | 10.7 | 2.2 | 17.2 |
| AMGL | 31.1/22.4 /15.0/26.0 | 31.4/49.6 /23.8/38.5 | 31.0/16.9 /12.3/21.9 | 33.0/38.0 /21.5/35.3 | 31.7 | 18.1 | 9 | 30.4 |
| MLAN | 100.0/57.2 /57.2/72.8 | 69.2/57.8 /46.0/63.0 | 44.6/34.1 /24.0/38.7 | 60.3/100.0 /60.3/75.2 | 62.8 | 46.9 | 49.3 | 62.4 |
| NNSG | 53.7/49.1 /34.5/51.3 | 69.7/27.7 /24.8/39.6 | 74.1/13.0 /12.5/22.1 | 36.6/91.9 /35.4/52.4 | 45.5 | 26.8 | 27.3 | 41.4 |
| SVM | 63.0/66.0 /47.6/64.5 | 64.4/62.1 /46.2/63.2 | 61.1/46.7 /36.0/52.9 | 73.2/89.7 /67.6/80.6 | 66.1 | 49.3 | 54.8 | 65.3 |
| FC(our) | 54.5/59.1 /39.6/56.7 | 55.5/61.0 /41.0/58.1 | 56.3/30.8 /24.9/39.8 | 67.4/85.7 /60.6/75.5 | 65 | 47.8 | 53.3 | 64.1 |
| FSI(our) | 68.5/62.2 /48.4/65.2 | 60.6/68.7 /47.5/64.4 | 61.2/42.6 /33.5/50.2 | 68.4/86.4 /61.7/76.4 | 59.2 | 41.5 | 45.5 | 57.5 |
| FC(SVM) | 53.6/59.2 /39.2/56.3 | 57.3/55.9 /39.5/56.6 | 52.6/39.7 /29.2/45.3 | 69.8/81.3 /60.1/75.1 | 59 | 42 | 45.4 | 58.3 |
| FSI(SVM) | 66.4/60.6 /46.4/63.4 | 57.1/69.0 /45.5/62.5 | 56.3/36.0 /28.2/43.9 | 69.4/86.0 /62.3/76.8 | 62.9 | 45.6 | 50.5 | 61.7 |
| Metrics | Grounds | Cars | Buildings | Trees |
|---|---|---|---|---|
| Precision | 91.4 | 92.1 | 93.4 | 85 |
| Recall | 94.2 | 48.3 | 87.3 | 90.8 |
| F1-Score | 92.8 | 63.4 | 90.2 | 87.8 |
| OA | 89.5 | |||
| mIoU | 73.3 | |||
| Kappa | 84.4 | |||
| mF1 | 83.5 | |||
| Scene | Method | OA | mIoU | Kappa |
|---|---|---|---|---|
| Scene1 (ALS) | IC1 | 72.95 | 41.6 | 50.49 |
| IC2 | 74.46 | 43.32 | 53.42 | |
| IC3 | 72.42 | 43.06 | 51.82 | |
| Ours | 77.49 | 45.04 | 57.15 | |
| Scene 4 (MLS) | IC1 | 79.29 | 29.35 | 66.37 |
| IC2 | 80.68 | 30.86 | 68.3 | |
| IC3 | 79.39 | 31.38 | 67.05 | |
| Ours | 80.93 | 30.92 | 68.62 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tong, G.; Li, Y.; Chen, D.; Xia, S.; Peethambaran, J.; Wang, Y. Multi-View Features Joint Learning with Label and Local Distribution Consistency for Point Cloud Classification. Remote Sens. 2020, 12, 135. https://doi.org/10.3390/rs12010135
Tong G, Li Y, Chen D, Xia S, Peethambaran J, Wang Y. Multi-View Features Joint Learning with Label and Local Distribution Consistency for Point Cloud Classification. Remote Sensing. 2020; 12(1):135. https://doi.org/10.3390/rs12010135
Chicago/Turabian StyleTong, Guofeng, Yong Li, Dong Chen, Shaobo Xia, Jiju Peethambaran, and Yuebin Wang. 2020. "Multi-View Features Joint Learning with Label and Local Distribution Consistency for Point Cloud Classification" Remote Sensing 12, no. 1: 135. https://doi.org/10.3390/rs12010135
APA StyleTong, G., Li, Y., Chen, D., Xia, S., Peethambaran, J., & Wang, Y. (2020). Multi-View Features Joint Learning with Label and Local Distribution Consistency for Point Cloud Classification. Remote Sensing, 12(1), 135. https://doi.org/10.3390/rs12010135