Building Footprint Extraction from High-Resolution Images via Spatial Residual Inception Convolutional Neural Network

 ,
,  ,
, 

Abstract
1. Introduction
2. Proposed Method
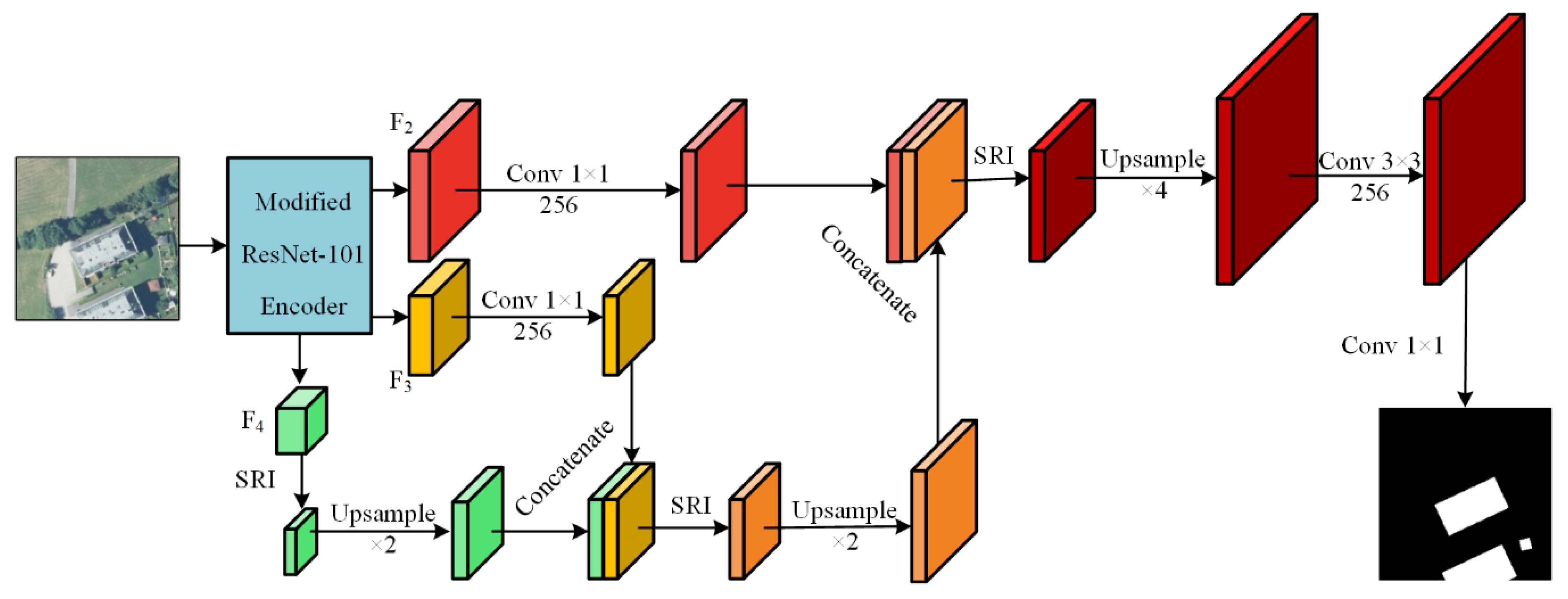
2.1. Model Overview
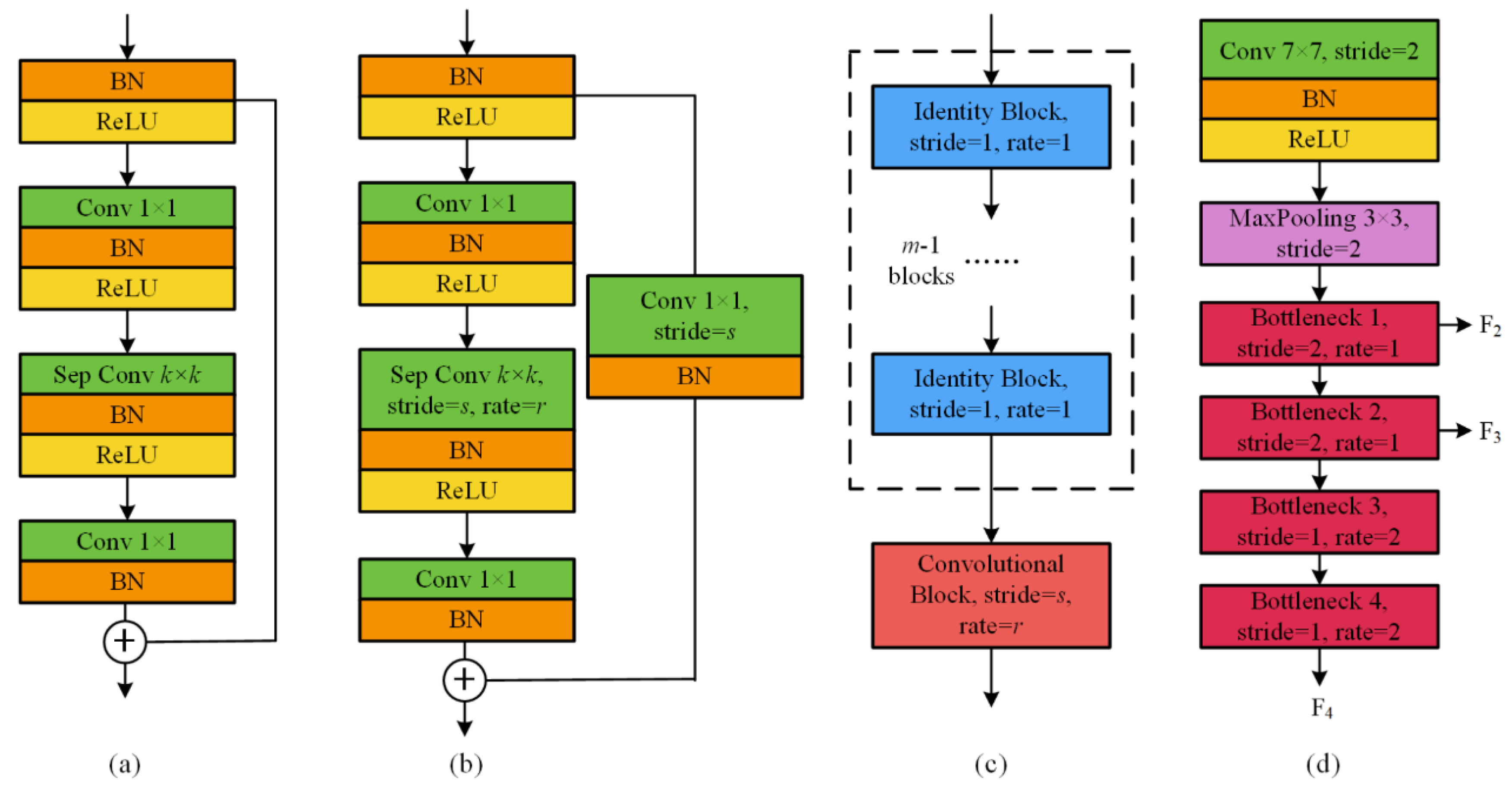
2.2. Modified ResNet-101 as Encoder
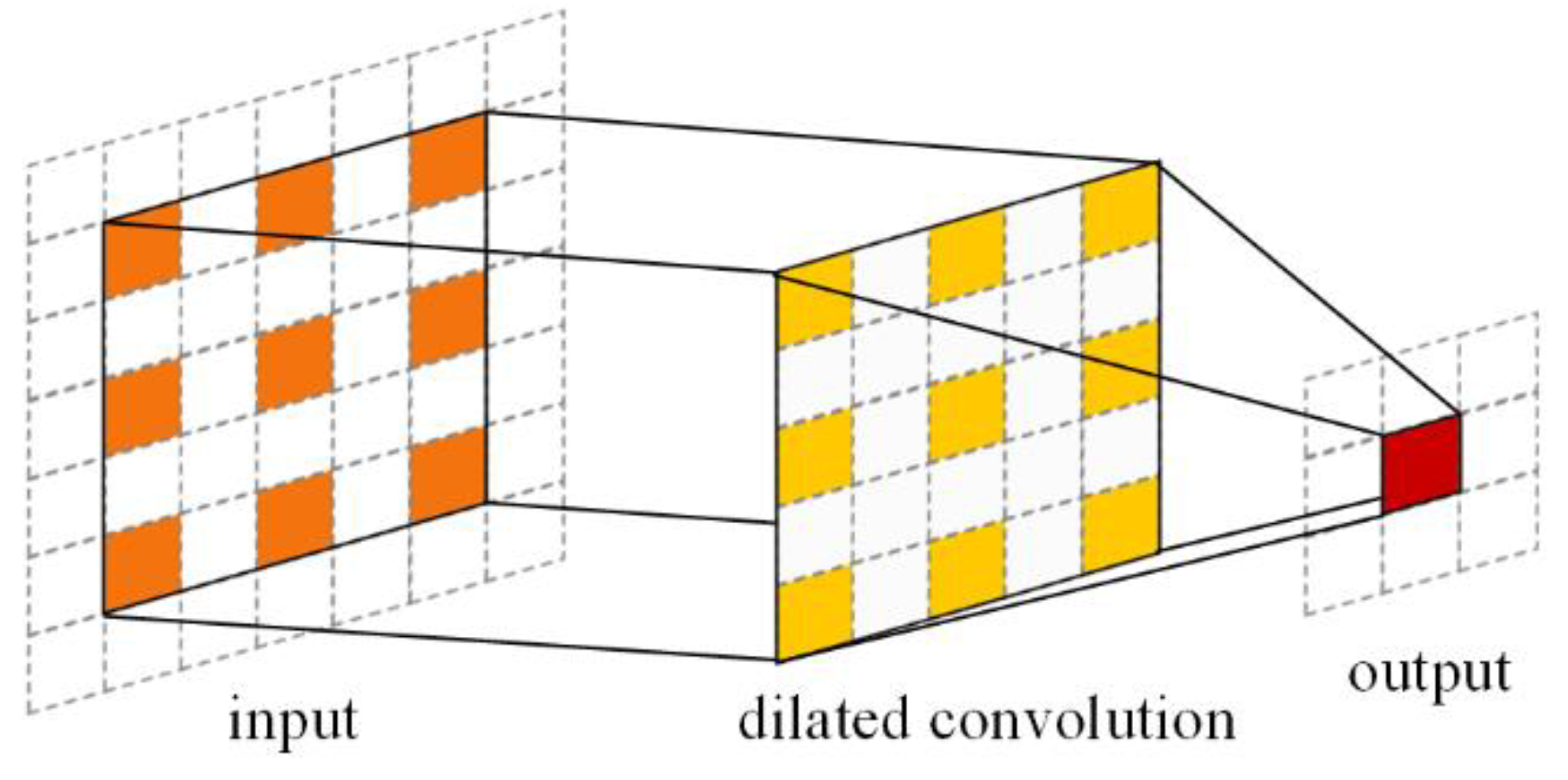
2.2.1. Dilated/Atrous Convolution
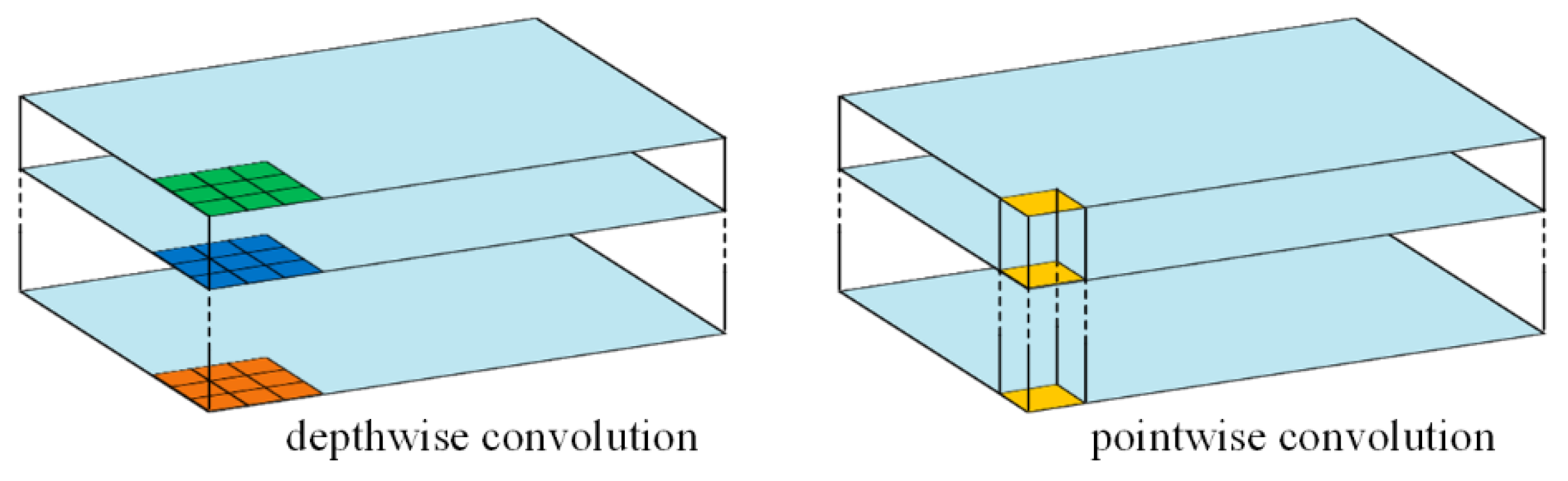
2.2.2. Depthwise Separable Convolution
2.2.3. Residual Block
2.2.4. Encoder Design
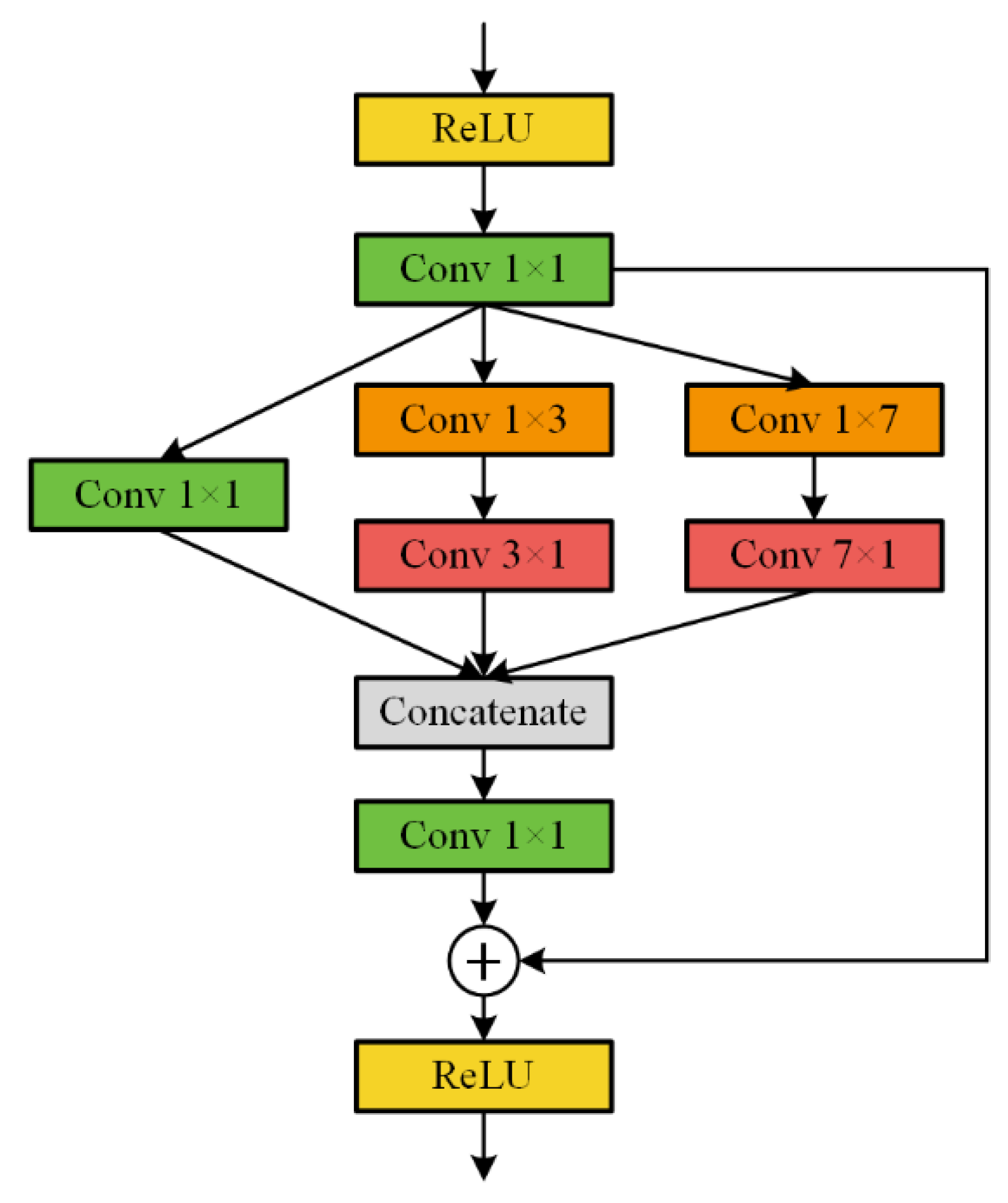
2.3. Decoder with SRI Module
2.4. Evaluation Metrics
3. Experiments and Evaluations
3.1. Datasets
3.2. Implementation Settings
3.3. Model Comparisons
3.4. Experimental Results
3.4.1. Comparison on the Inria Aerial Image Labeling Dataset
3.4.2. Comparison on the WHU Aerial Building Dataset
4. Discussion
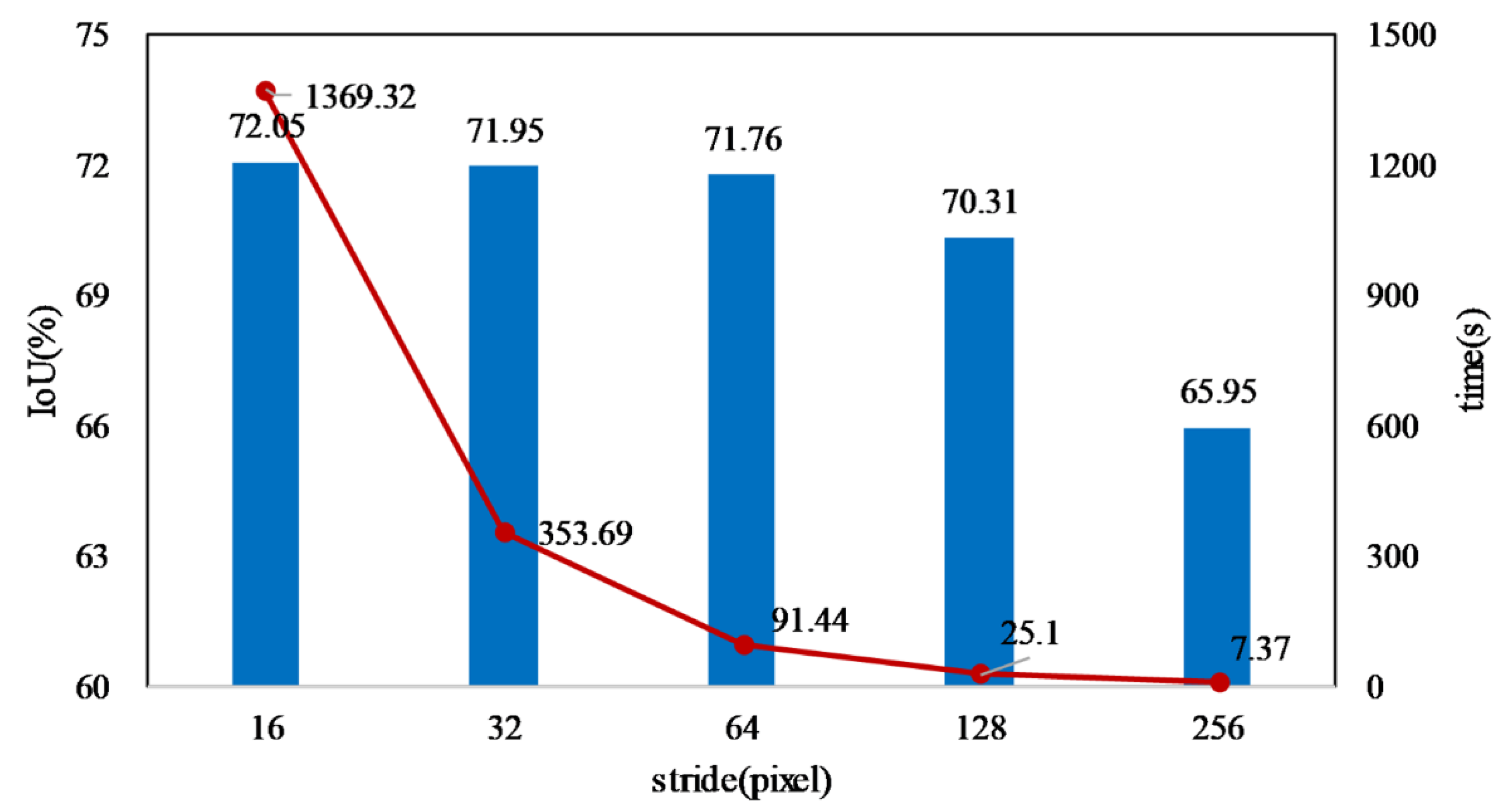
4.1. Influence of Stride on Large Image Prediction
4.2. Pretrained ResNet-101 on the University of California (UC) Merced Land Use Dataset
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Stephan, A.; Crawford, R.H.; de Myttenaere, K. Towards a comprehensive life cycle energy analysis framework for residential buildings. Energy Build. 2012, 55, 592–600. [Google Scholar] [CrossRef]
- Dobson, J.E.; Bright, E.A.; Coleman, P.R.; Durfee, R.C.; Worley, B.A. LandScan: A global population database for estimating populations at risk. Photogramm. Eng. Remote Sens. 2000, 66, 849–857. [Google Scholar]
- Liu, X.; Liang, X.; Li, X.; Xu, X.; Ou, J. A Future Land Use Simulation Model (FLUS) for simulating multiple land use scenarios by coupling human and natural effects. Landsc. Urban Plan. 2017, 168, 94–116. [Google Scholar] [CrossRef]
- Liu, X.; Hu, G.; Chen, Y.; Li, X. High-resolution Multi-temporal Mapping of Global Urban Land using Landsat Images Based on the Google Earth Engine Platform. Remote Sens. Environ. 2018, 209, 227–239. [Google Scholar] [CrossRef]
- Chen, Y.; Li, X.; Liu, X.; Ai, B. Modeling urban land-use dynamics in a fast developing city using the modified logistic cellular automaton with a patch-based simulation strategy. Int. J. Geogr. Inform. Sci. 2014, 28, 234–255. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, X.; Li, X. Road Detection from Remote Sensing Images by Generative Adversarial Networks. IEEE Access 2018, 6, 25486–25494. [Google Scholar] [CrossRef]
- Chen, X.; Shi, Q.; Yang, L.; Xu, J. ThriftyEdge: Resource-Efficient Edge Computing for Intelligent IoT Applications. IEEE Netw. 2018, 32, 61–65. [Google Scholar] [CrossRef]
- Shi, Q.; Zhang, L.; Du, B. A Spatial Coherence based Batch-mode Active learning method for remote sensing images Classification. IEEE Trans. Image Process. 2015, 24, 2037–2050. [Google Scholar] [PubMed]
- Gilani, S.; Awrangjeb, M.; Lu, G. An automatic building extraction and regularisation technique using lidar point cloud data and orthoimage. Remote Sens.-Basel 2016, 8, 258. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L.; Zhu, T. Building change detection from multitemporal high-resolution remotely sensed images based on a morphological building index. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 105–115. [Google Scholar] [CrossRef]
- Ok, A.O.; Senaras, C.; Yuksel, B.J.I.T.o.G.; Sensing, R. Automated detection of arbitrarily shaped buildings in complex environments from monocular VHR optical satellite imagery. IEEE Trans. Geosci. Remote Sens. 2013, 51, 1701–1717. [Google Scholar] [CrossRef]
- Xin, H.; Yuan, W.; Li, J.; Zhang, L. A New Building Extraction Postprocessing Framework for High-Spatial-Resolution Remote-Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 654–668. [Google Scholar]
- Belgiu, M.; Drǎguţ, L. Comparing supervised and unsupervised multiresolution segmentation approaches for extracting buildings from very high resolution imagery. ISPRS J. Photogramm. Remote Sens. 2014, 96, 67–75. [Google Scholar] [CrossRef] [PubMed]
- Chen, R.X.; Li, X.H.; Li, J. Object-Based Features for House Detection from RGB High-Resolution Images. Remote Sens.-Basel 2018, 10, 451. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep Learning Earth Observation Classification Using ImageNet Pretrained Networks. IEEE Geosci. Remote Sens. 2016, 13, 105–109. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, ND, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv, 2016; arXiv:1608.06993. [Google Scholar]
- Lu, X.Q.; Zheng, X.T.; Yuan, Y. Remote Sensing Scene Classification by Unsupervised Representation Learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5148–5157. [Google Scholar] [CrossRef]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. Building detection in very high resolution multispectral data with deep learning features. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 1873–1876. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv, 2018; arXiv:1802.02611. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Tran. Pattern anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv, 2015; arXiv:1511.07122. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv, 2014; arXiv:1412.7062. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv, 2017; arXiv:1706.05587. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials. arXiv, 2012; arXiv:1210.5644. [Google Scholar]
- Teichmann, M.T.T.; Cipolla, R. Convolutional CRFs for Semantic Segmentation. arXiv, 2018; arXiv:1805.04777. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene parsing through ade20k dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 633–641. [Google Scholar]
- Yu, B.; Yang, L.; Chen, F. Semantic Segmentation for High Spatial Resolution Remote Sensing Images Based on Convolution Neural Network and Pyramid Pooling Module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3252–3261. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens.-Basel 2018, 10, 144. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, X.; Zhao, X.; Xin, Q. Extracting building boundaries from high resolution optical images and LiDAR data by integrating the convolutional neural network and the active contour model. Remote Sens.-Basel 2018, 10, 1459. [Google Scholar] [CrossRef]
- Yuan, J. Learning building extraction in aerial scenes with convolutional networks. IEEE Trans. Pattern Anal. 2018, 40, 2793–2798. [Google Scholar] [CrossRef]
- Bischke, B.; Helber, P.; Folz, J.; Borth, D.; Dengel, A. Multi-Task Learning for Segmentation of Building Footprints with Deep Neural Networks. arXiv, 2017; arXiv:1709.05932. [Google Scholar]
- Liu, Y.C.; Fan, B.; Wang, L.F.; Bai, J.; Xiang, S.M.; Pan, C.H. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95. [Google Scholar] [CrossRef]
- Rakhlin, A.; Davydow, A.; Nikolenko, S. Land Cover Classification from Satellite Imagery With U-Net and Lovász-Softmax Loss. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 257–2574. [Google Scholar]
- Shrestha, S.; Vanneschi, L. Improved fully convolutional network with conditional random fields for building extraction. Remote Sens. Lett. 2018, 10, 1135. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Dalla Mura, M. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? the inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Ji, S.P.; Wei, S.Q.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction From an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. arXiv, 2016; arXiv:1603.05027. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv, 2015; arXiv:1502.03167. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters–Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv, 2015; arXiv:1512.00567. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Huang, X.; Zhang, L. Morphological building/shadow index for building extraction from high-resolution imagery over urban areas. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. Lett. 2012, 5, 161–172. [Google Scholar] [CrossRef]
- Zhang, Q.; Huang, X.; Zhang, G. A morphological building detection framework for high-resolution optical imagery over urban areas. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1388–1392. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Araucano Park, Chile, 11–18 December 2015. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; pp. 424–432. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. A scale robust convolutional neural network for automatic building extraction from aerial and satellite imagery. Int. J. Remote Sens. 2018, 1–15. [Google Scholar] [CrossRef]
- Yi, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the Sigspatial International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Residual Block Type | Depthwise Separable Convolution Index | Number of Filters | Kernel Size |
|---|---|---|---|
| Identity block | 1 | n | 1×1 |
| 2 | n | 5×5 | |
| 3 | n | 1×1 | |
| Convolutional block | 1 | n | 1×1 |
| 2 | n | 5×5 | |
| 3 | 4n | 1×1 | |
| shortcut | 4n | 1×1 |
| Precision | Recall | F1 | IoU | |
|---|---|---|---|---|
| MBI | 54.68 | 50.72 | 52.63 | 35.71 |
| SegNet | 79.63 | 75.35 | 77.43 | 63.17 |
| U-Net | 83.14 | 81.13 | 82.12 | 69.67 |
| RefineNet | 85.36 | 80.26 | 82.73 | 70.55 |
| Deeplab v3+ | 84.93 | 81.32 | 83.09 | 71.07 |
| SRI-Net α1 | 84.18 | 81.39 | 82.76 | 70.59 |
| SRI-Net α2 | 84.44 | 81.86 | 83.13 | 71.13 |
| SRI-Net | 85.77 | 81.46 | 83.56 | 71.76 |
| Precision | Recall | F1 | IoU | |
|---|---|---|---|---|
| MBI | 58.42 | 54.60 | 56.45 | 39.32 |
| SegNet | 92.11 | 89.93 | 91.01 | 85.56 |
| U-Net | 94.59 | 90.67 | 92.59 | 86.20 |
| RefineNet | 93.74 | 92.29 | 93.01 | 86.93 |
| Deeplab v3+ | 94.27 | 92.20 | 93.22 | 87.31 |
| SRI-Net α1 | 93.37 | 92.43 | 92.90 | 86.74 |
| SRI-Net α2 | 94.47 | 92.26 | 93.35 | 87.53 |
| SRI-Net | 95.21 | 93.28 | 94.23 | 89.09 |
| Dataset | Strategy | Precision | Recall | F1 | IoU |
|---|---|---|---|---|---|
| Inria Aerial Image Labeling Dataset | Direct training | 95.97 | 96.02 | 95.97 | 71.76 |
| Pre-training | 96.44 | 96.53 | 96.44 | 73.35 | |
| WHU Aerial Building Dataset | Direct training | 95.21 | 93.28 | 94.23 | 89.09 |
| Pre-training | 95.67 | 93.69 | 94.51 | 89.23 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building Footprint Extraction from High-Resolution Images via Spatial Residual Inception Convolutional Neural Network. Remote Sens. 2019, 11, 830. https://doi.org/10.3390/rs11070830
Liu P, Liu X, Liu M, Shi Q, Yang J, Xu X, Zhang Y. Building Footprint Extraction from High-Resolution Images via Spatial Residual Inception Convolutional Neural Network. Remote Sensing. 2019; 11(7):830. https://doi.org/10.3390/rs11070830
Chicago/Turabian StyleLiu, Penghua, Xiaoping Liu, Mengxi Liu, Qian Shi, Jinxing Yang, Xiaocong Xu, and Yuanying Zhang. 2019. "Building Footprint Extraction from High-Resolution Images via Spatial Residual Inception Convolutional Neural Network" Remote Sensing 11, no. 7: 830. https://doi.org/10.3390/rs11070830
APA StyleLiu, P., Liu, X., Liu, M., Shi, Q., Yang, J., Xu, X., & Zhang, Y. (2019). Building Footprint Extraction from High-Resolution Images via Spatial Residual Inception Convolutional Neural Network. Remote Sensing, 11(7), 830. https://doi.org/10.3390/rs11070830