NLOS Mitigation in Sparse Anchor Environments with the Misclosure Check Algorithm

 ,
,  , ,
, ,  , and
, and 
Abstract
1. Introduction
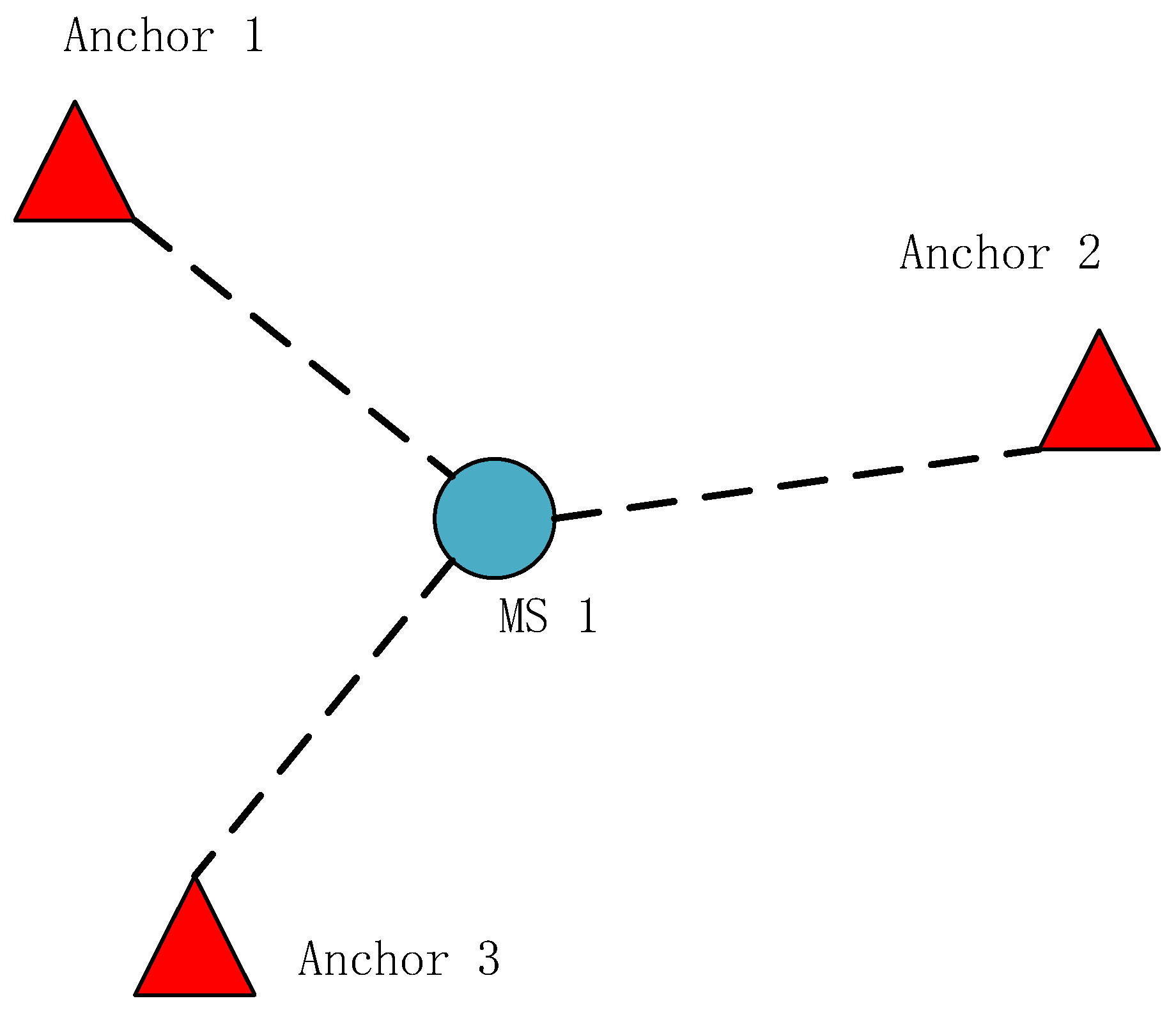
2. NLOS Mitigation with the Misclosure Check Algorithm
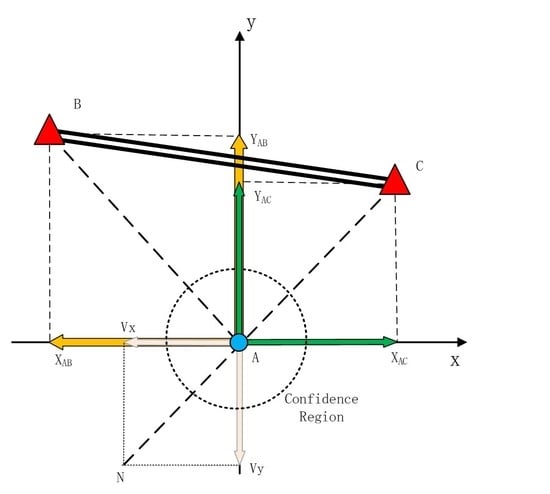
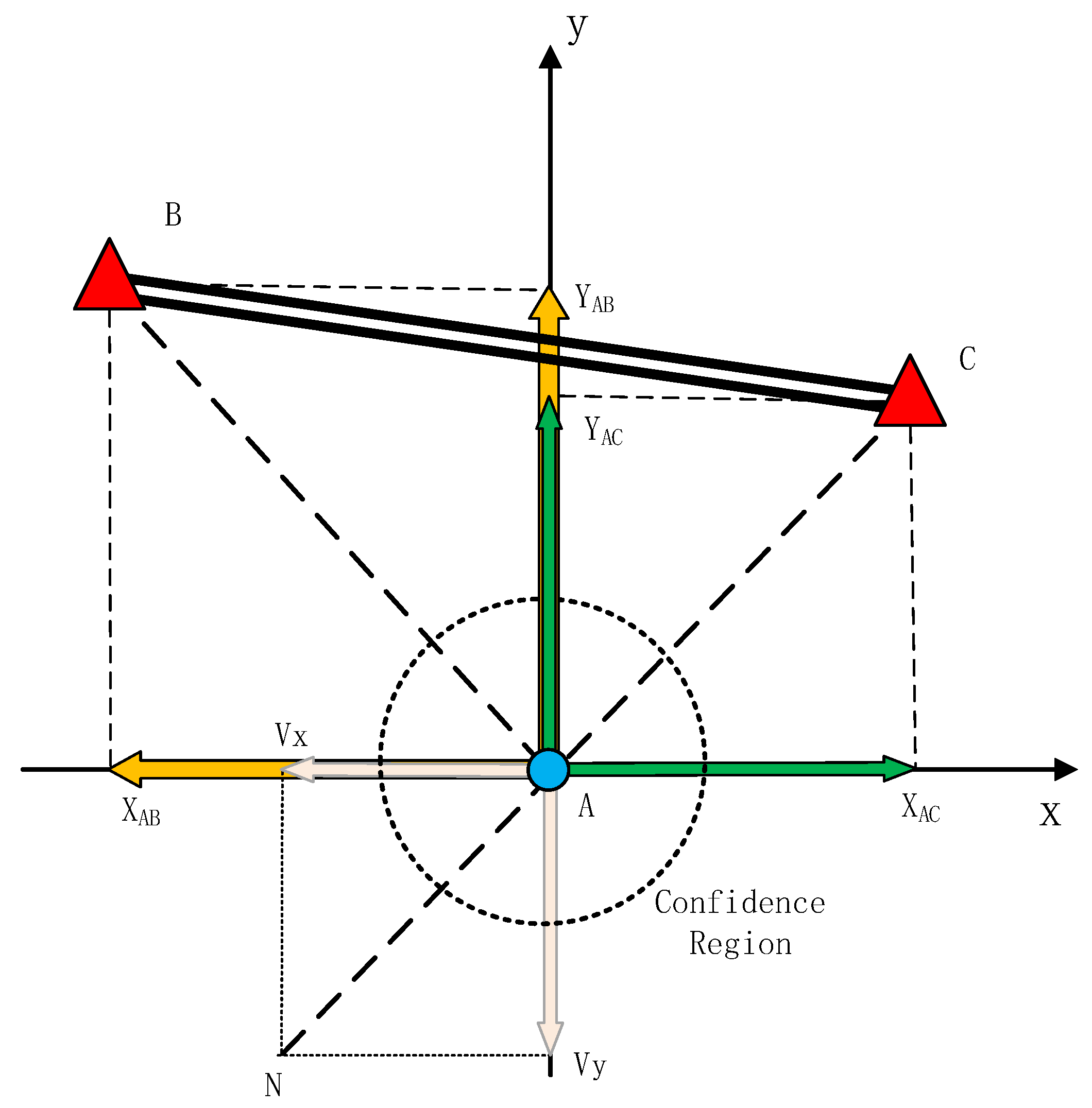
2.1. Enclosure Condition in Source Localization
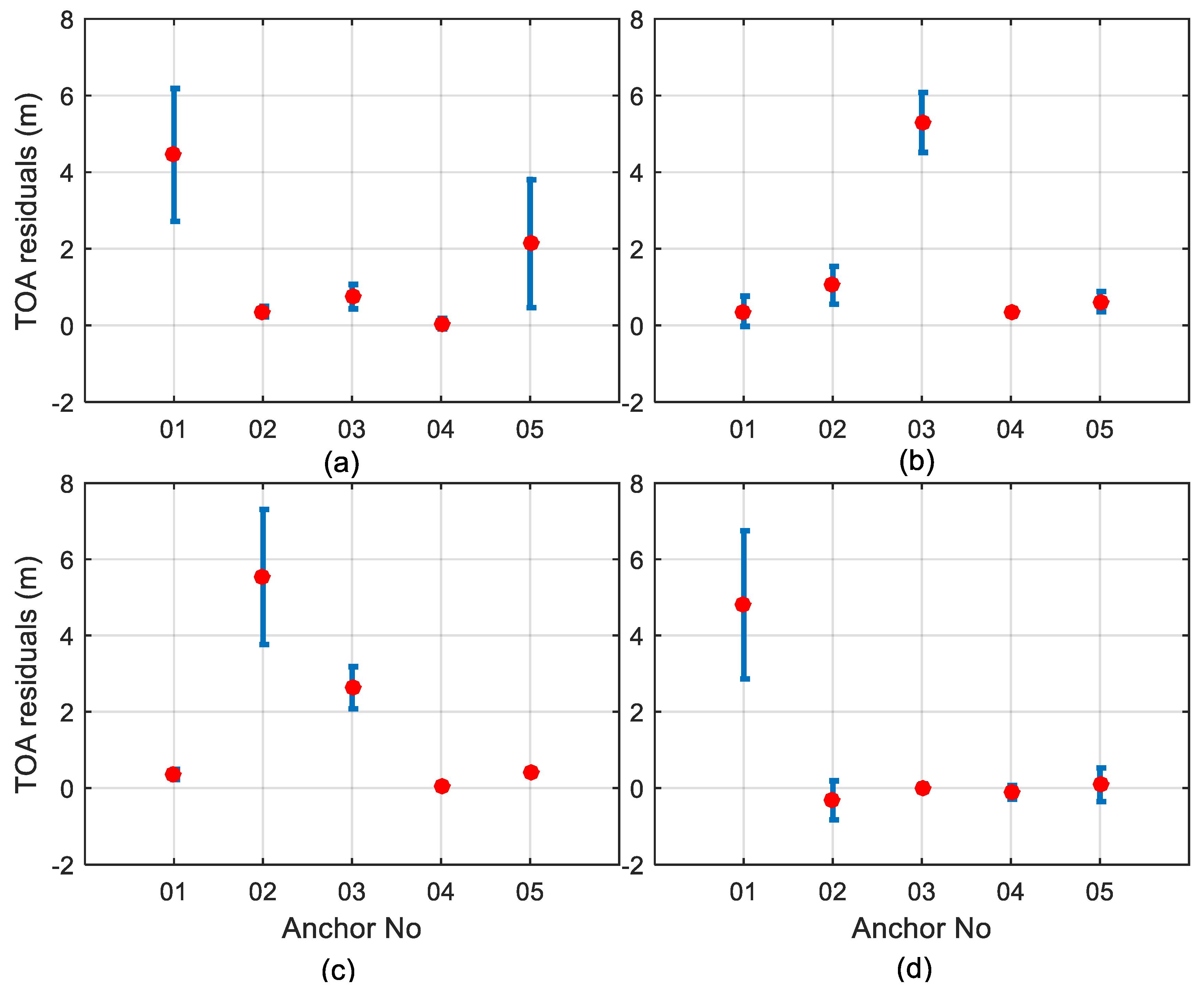
2.2. NLOS Discrimination Algorithm
| NLOS Discrimination Algorithm |
| For each misclosure test statistics in the dataset V If For j=1:2 If Remove from C End End End |
| End |
2.3. NLOS Mitigation Algorithm
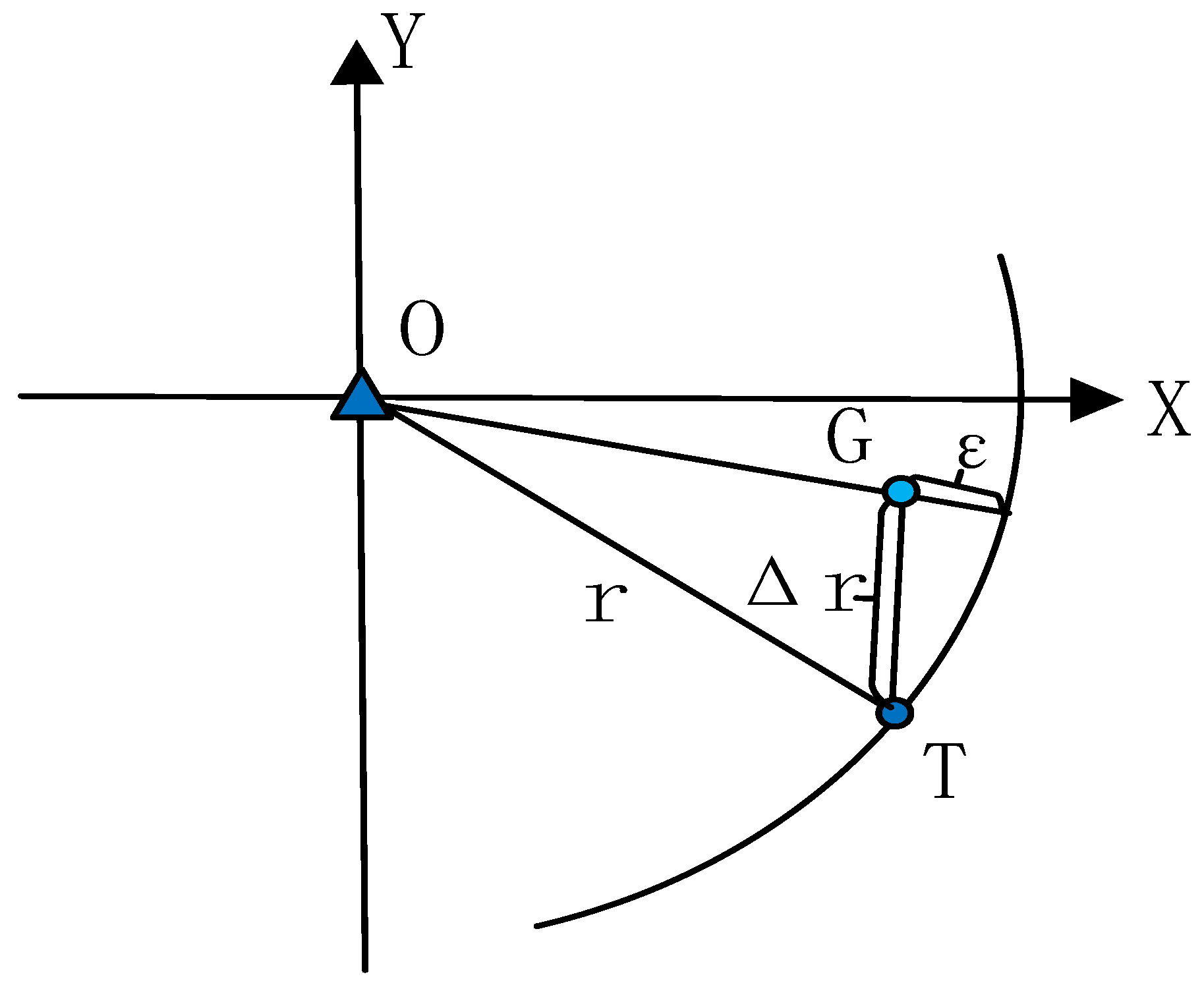
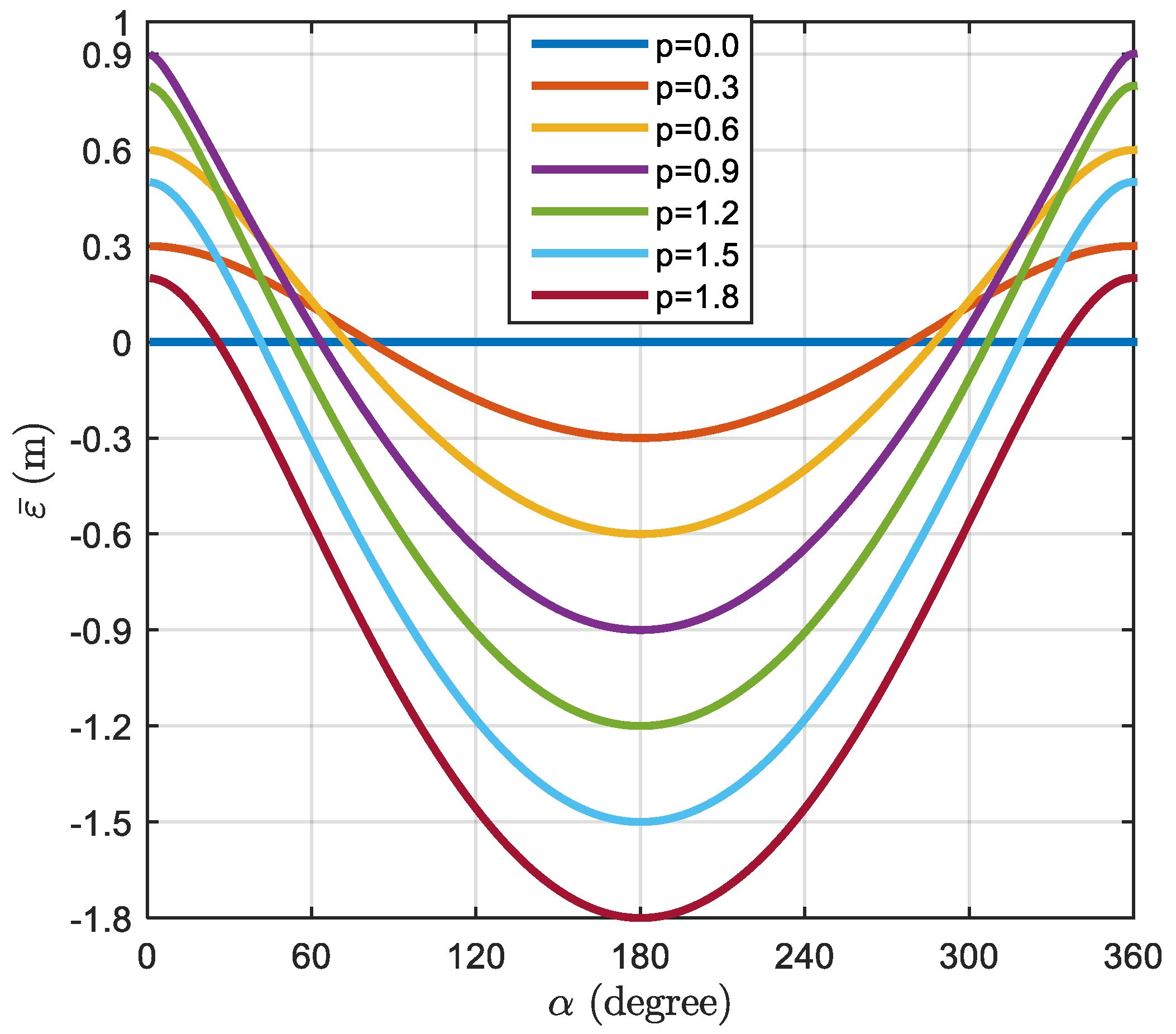
3. Misclosure Error Introduced by the Approximate Position
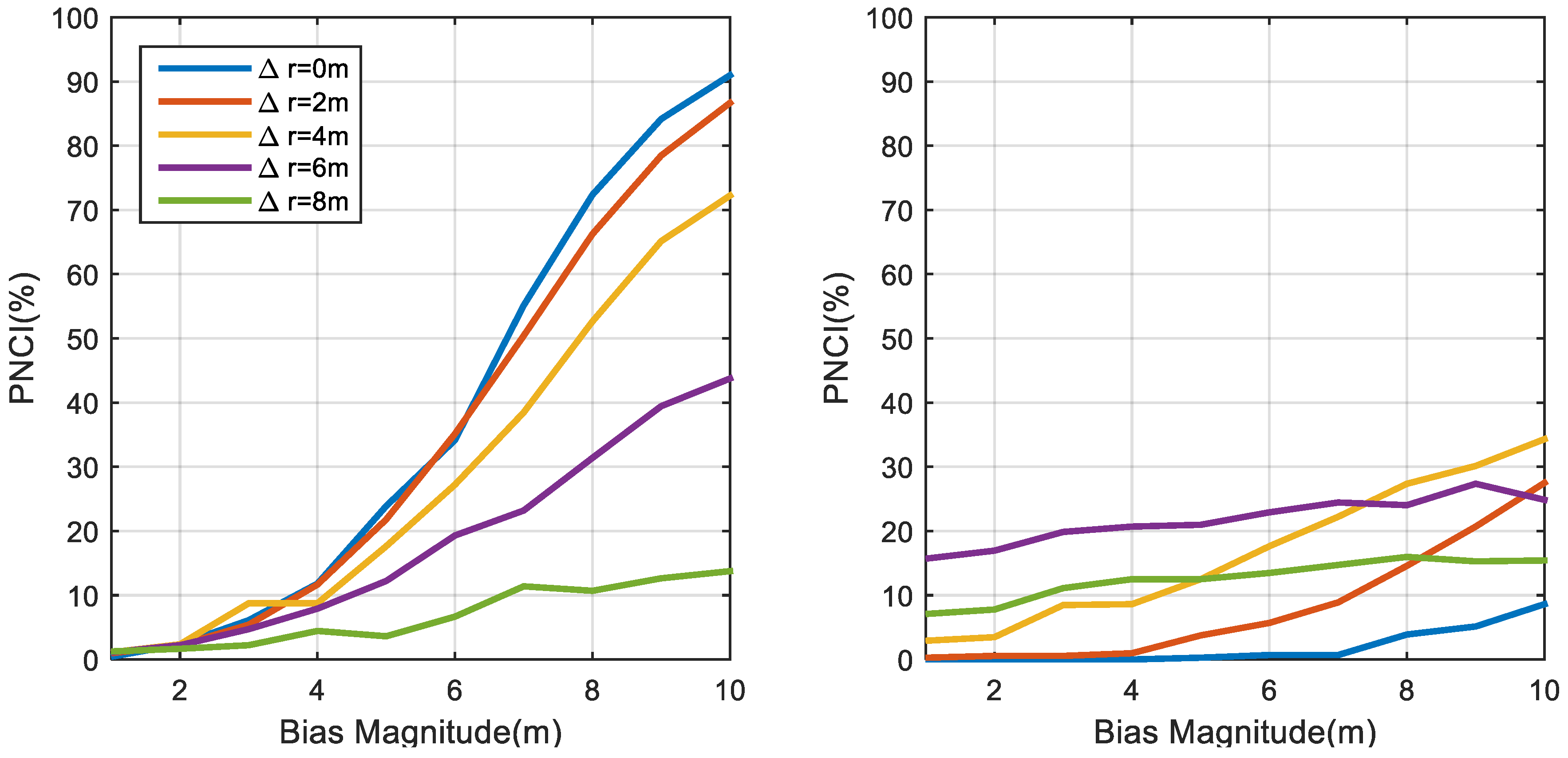
4. NLOS Identification Performance of the MC Algorithm
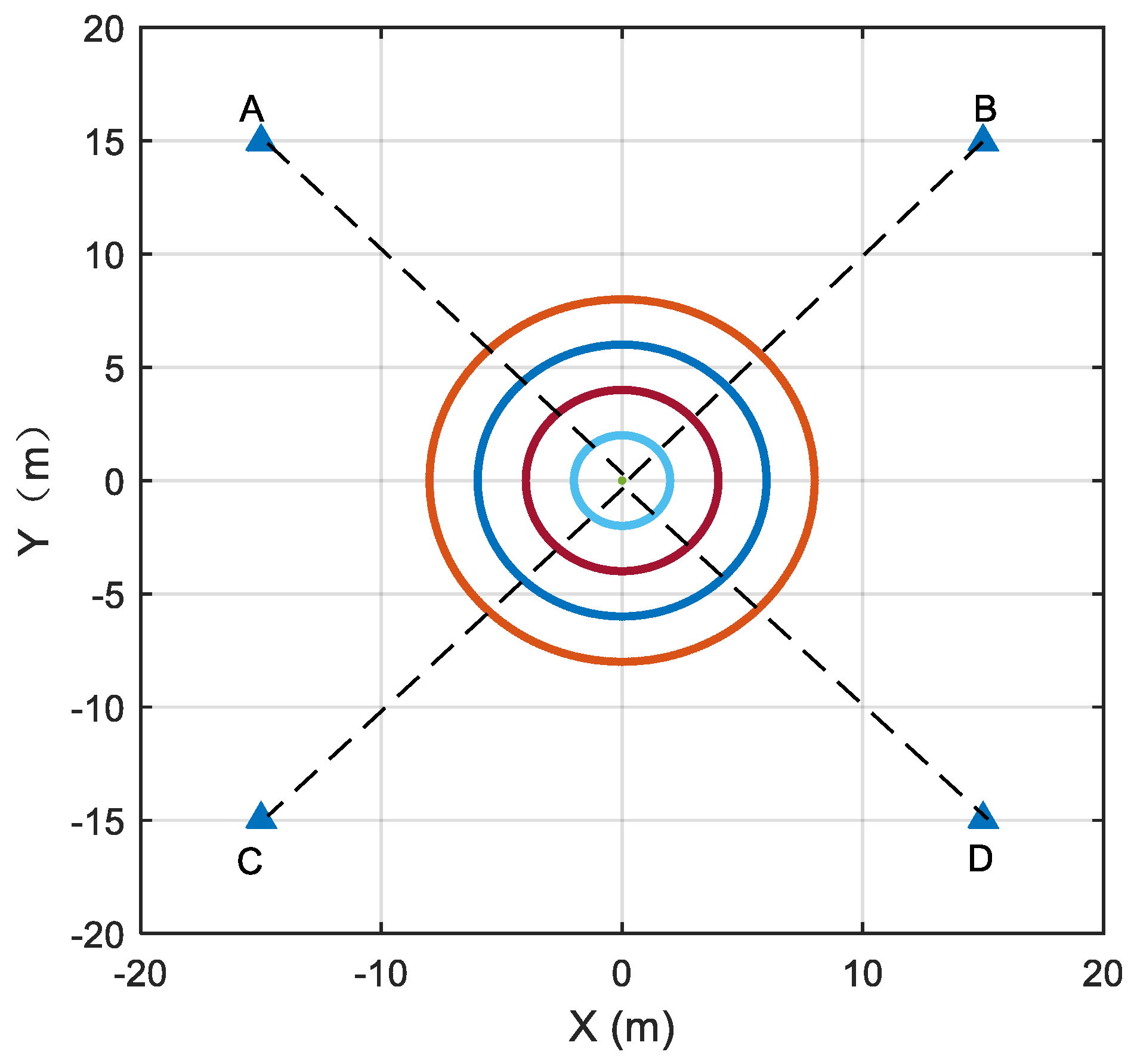
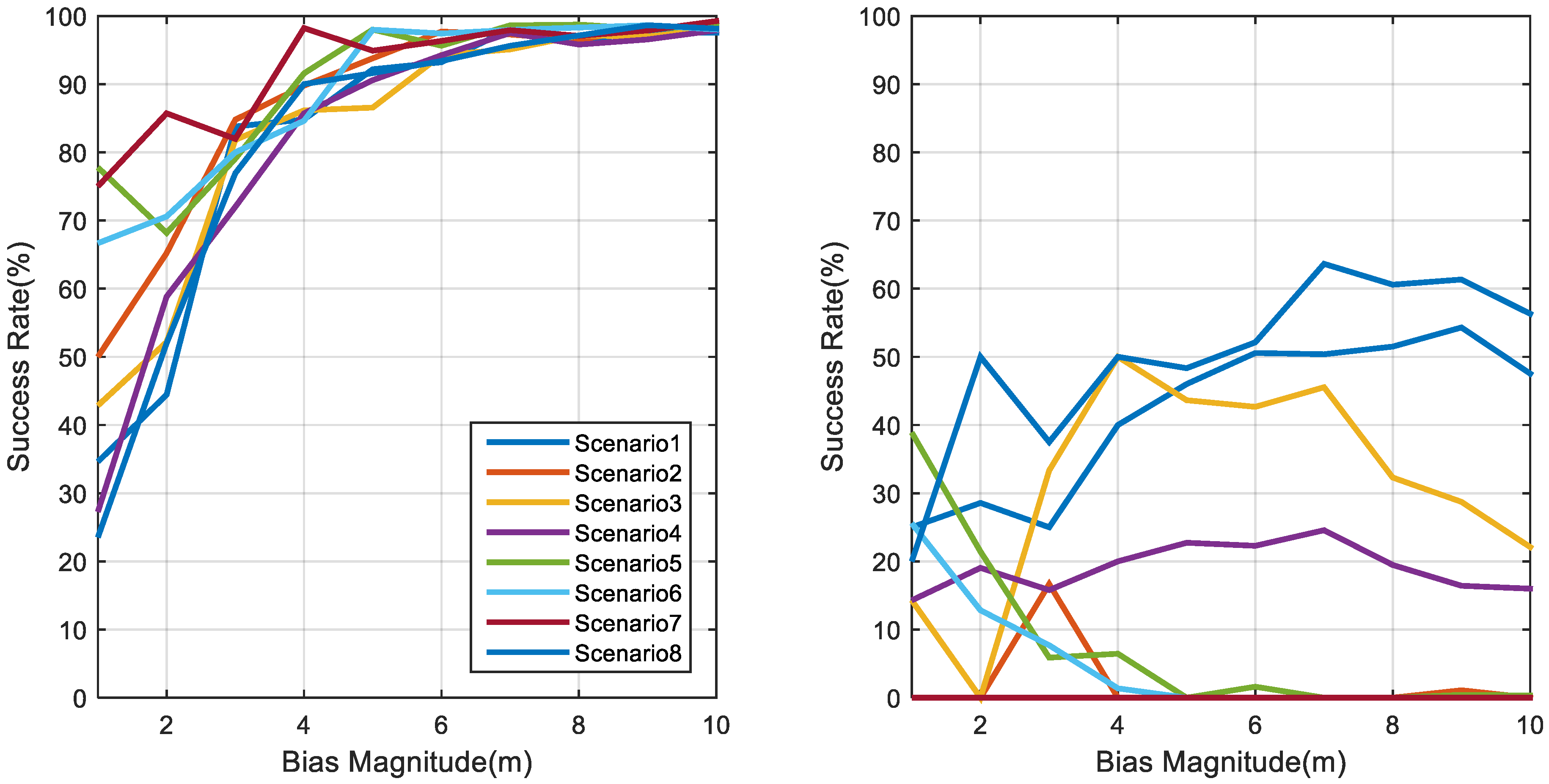
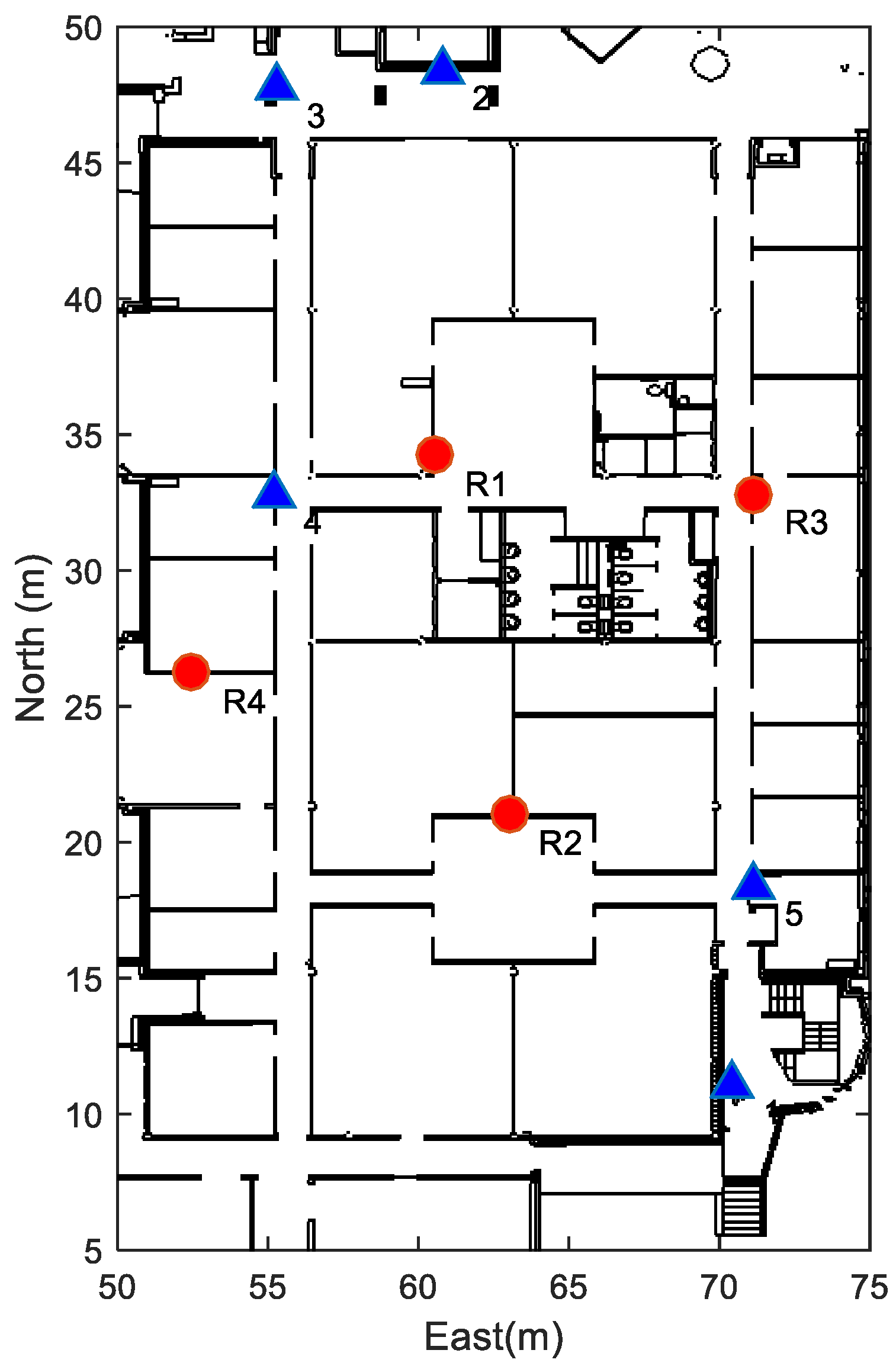
4.1. Simulation Setups
4.2. The Impact of the Approximation Position
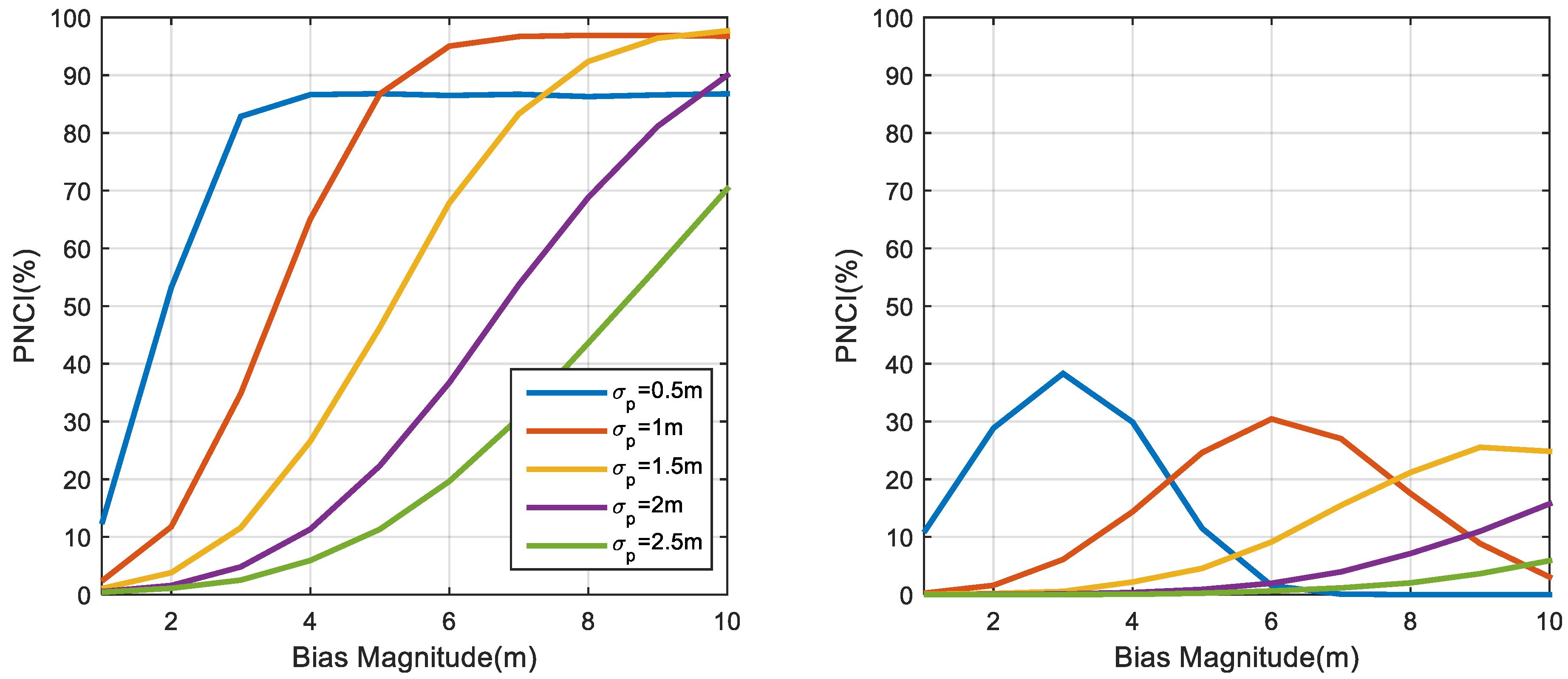
4.3. The Impact of the TOA Measurement Accuracy
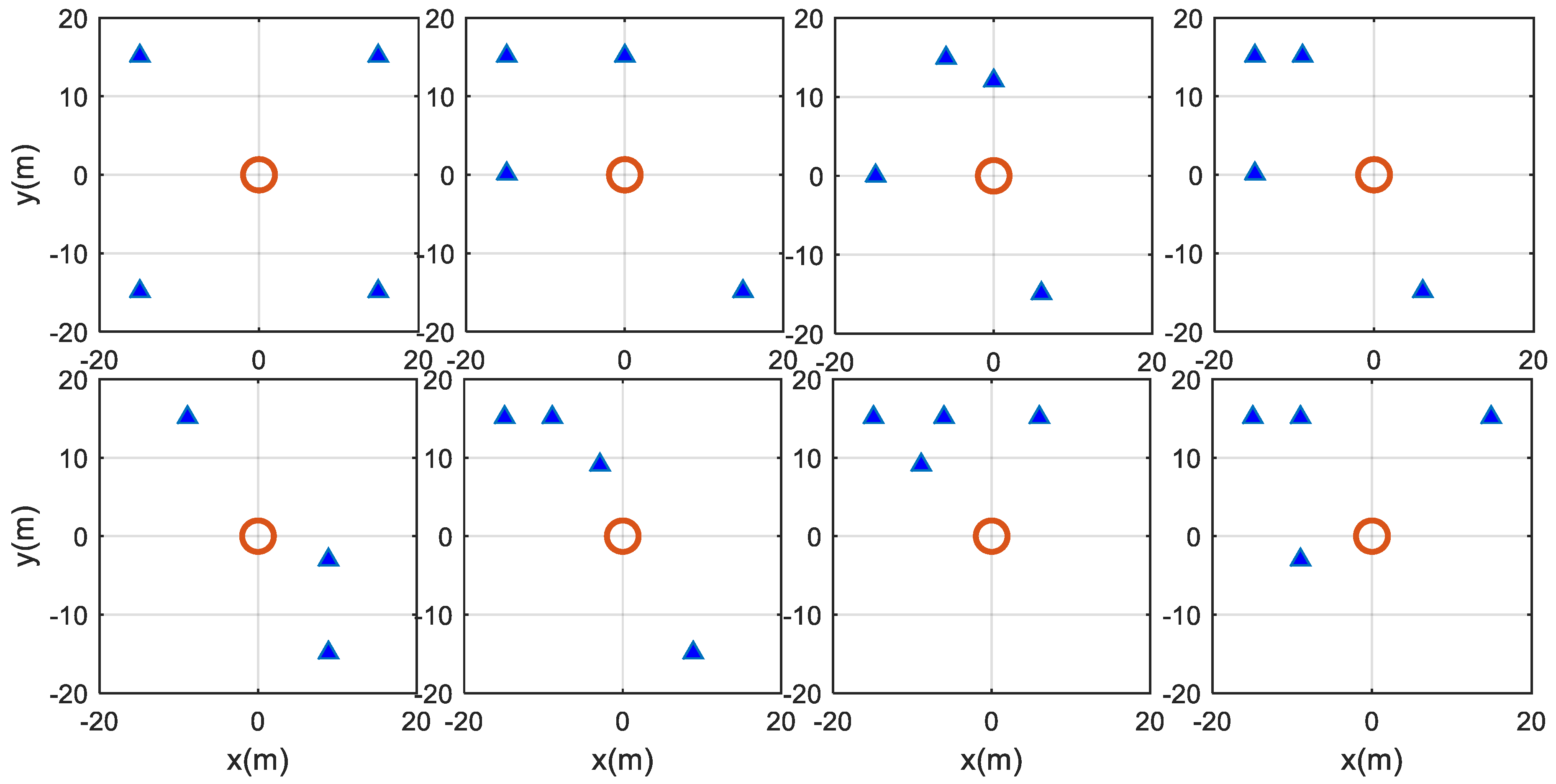
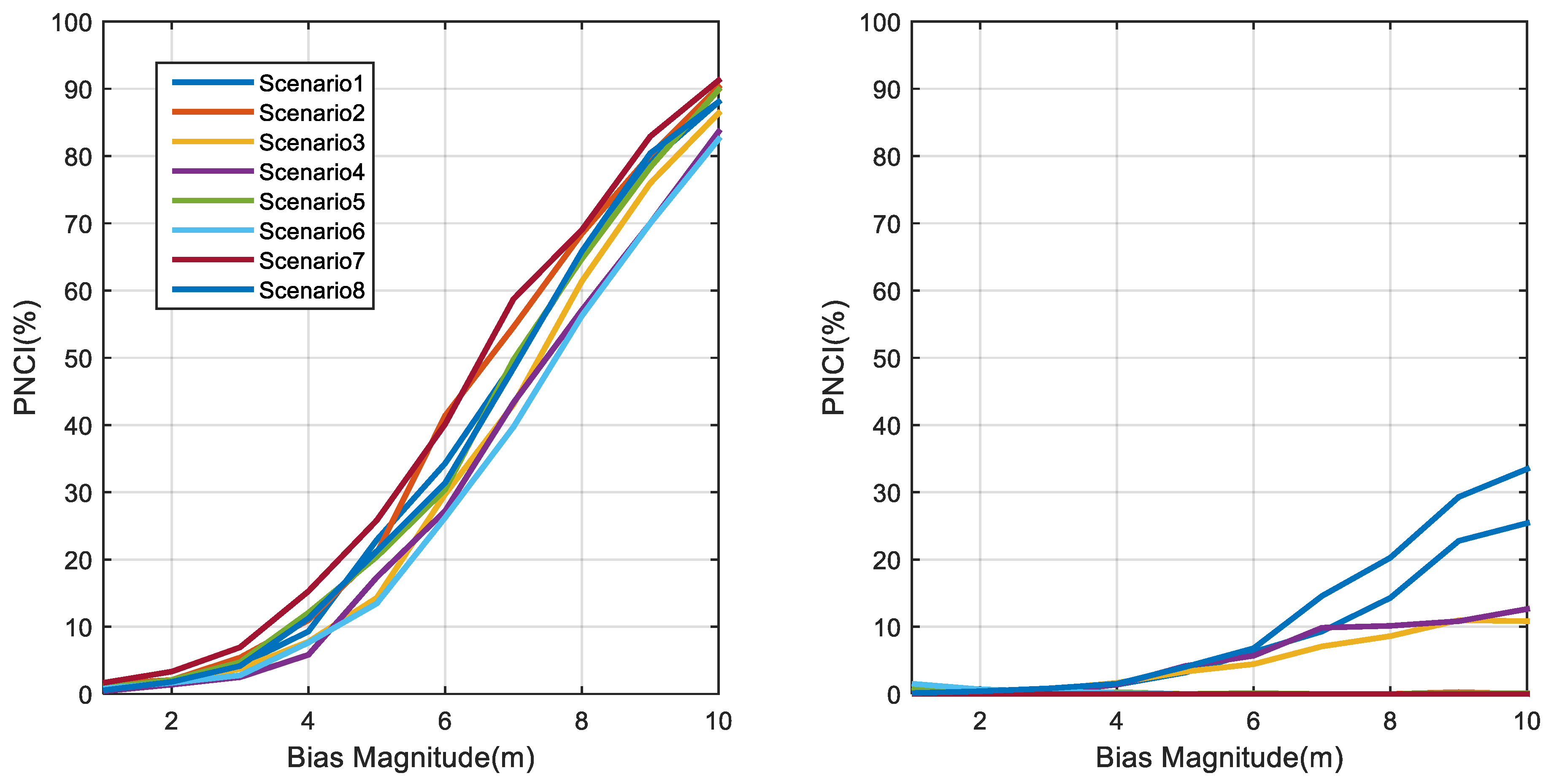
4.4. The Impact of Different Anchor Geometry
4.5. Multiple NLOS Scenario
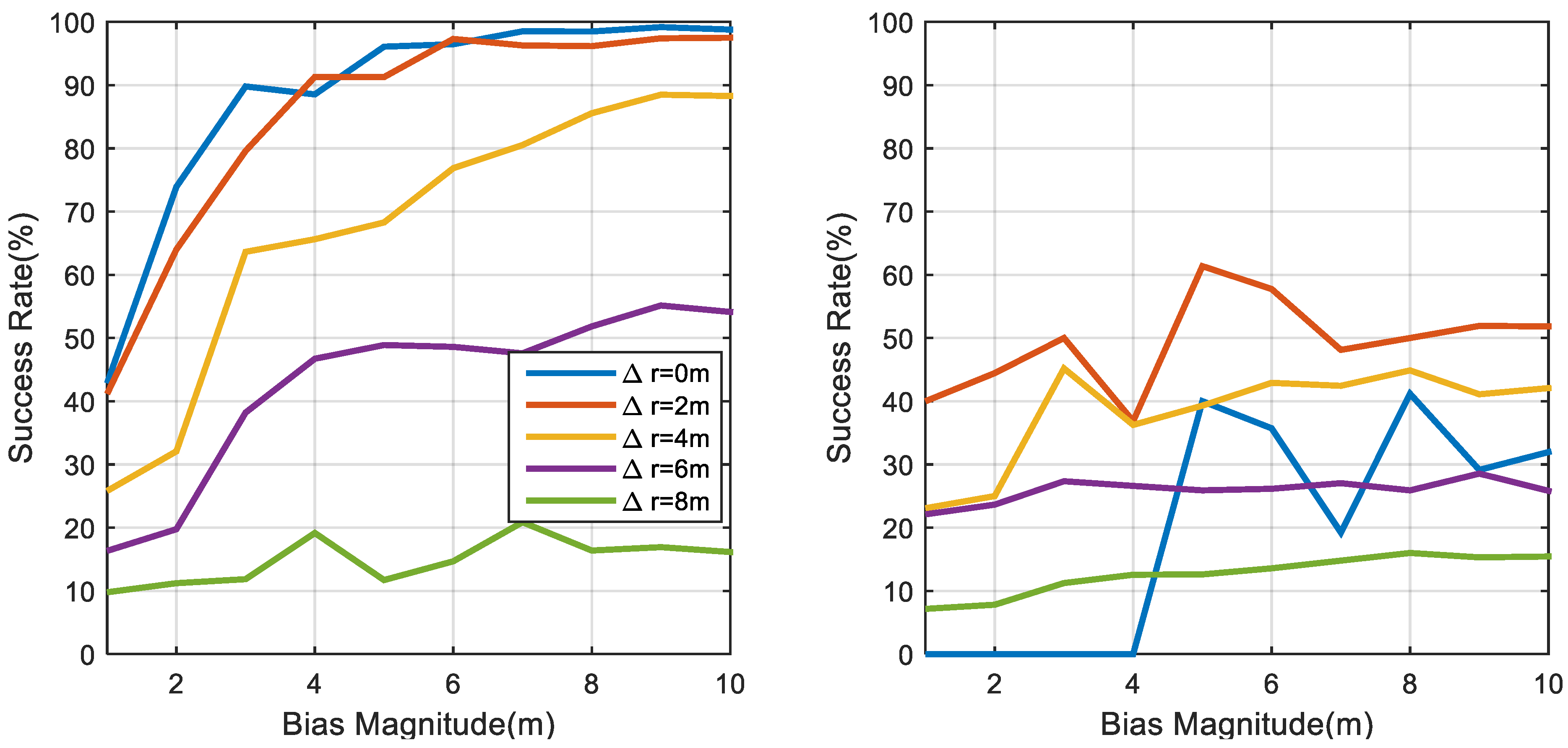
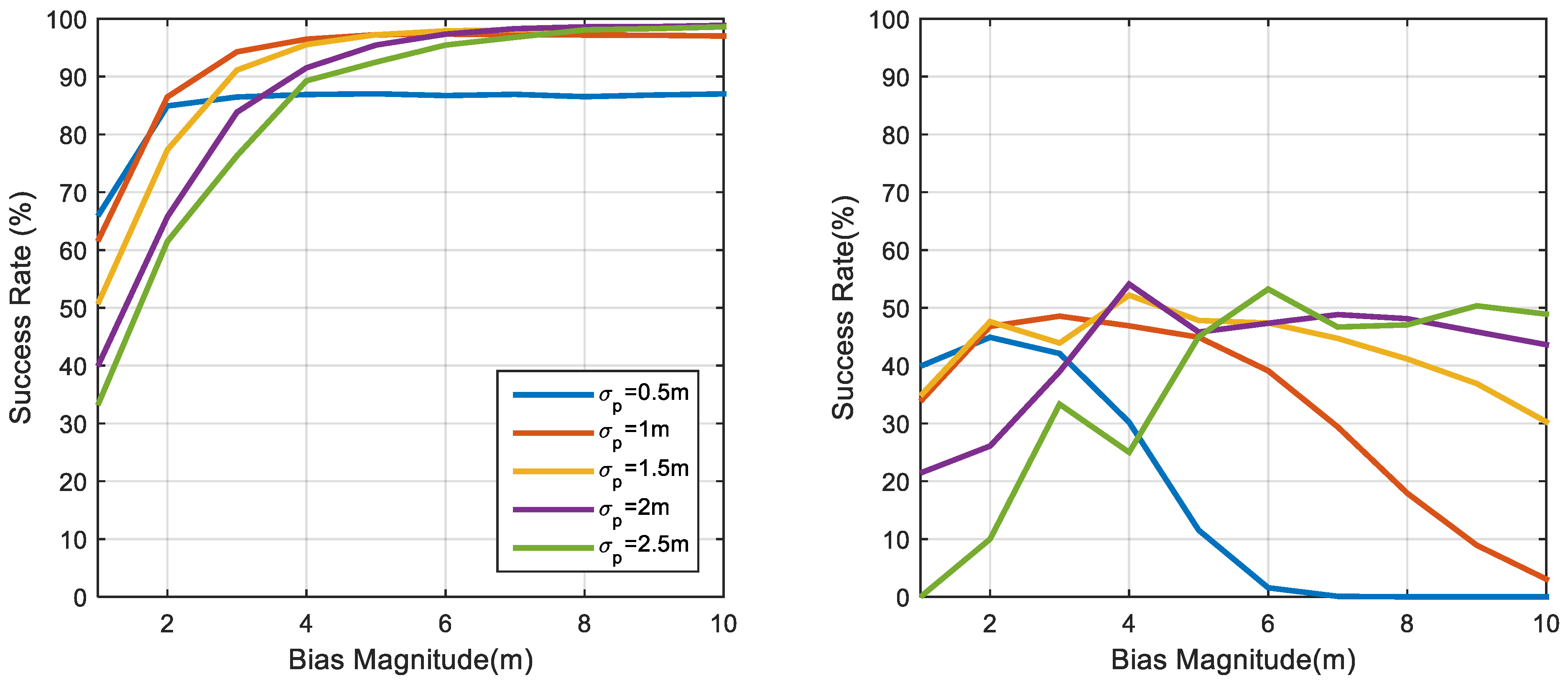
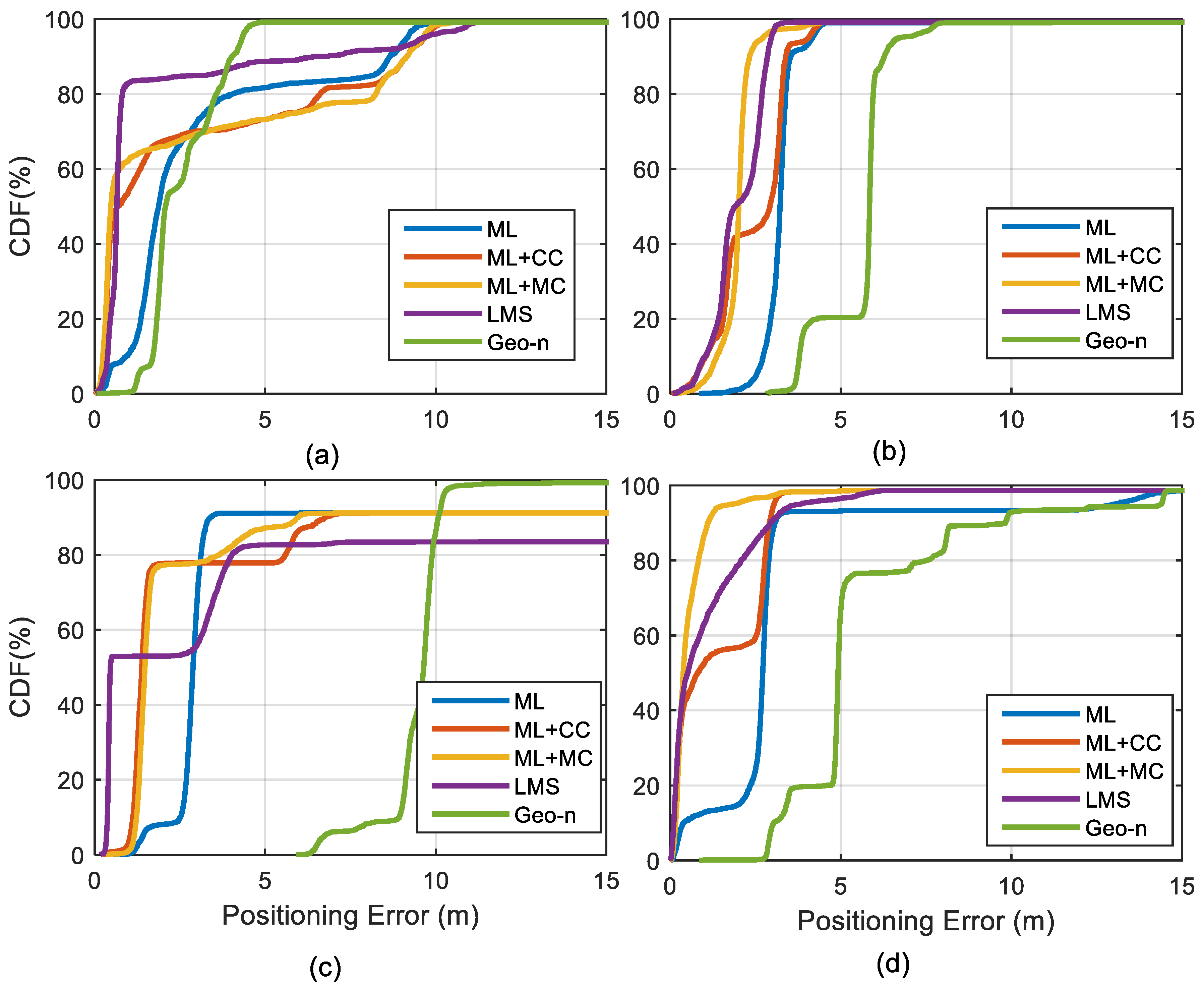
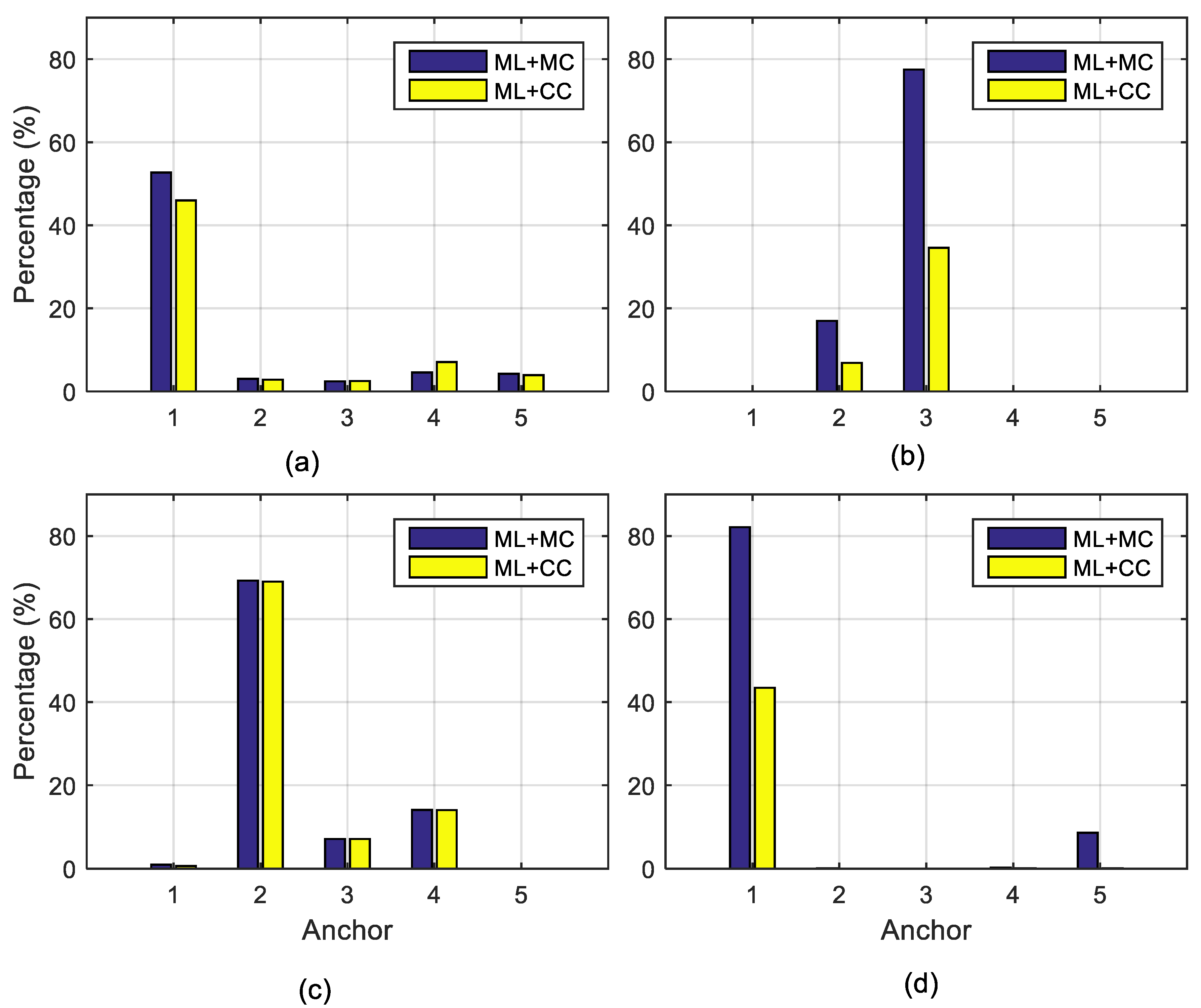
5. Positioning Precision Evaluation with the MC Algorithm
- (1)
- The maximum likelihood estimation denoted as ‘ML’.
- (2)
- The maximum likelihood estimation with consistency check denoted as ‘ML+CC’.
- (3)
- The maximum likelihood estimation with the misclosure check denoted as ‘ML+MC’.
- (4)
- The least median squares estimator.
- (5)
- The Geo-n algorithm.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mautz, R. Indoor Positioning Technologies; ETH Zurich: Zurich, Switzerland, 2012. [Google Scholar] [CrossRef]
- Khodjaev, J.; Park, Y.; Saeed Malik, A. Survey of NLOS identification and error mitigation problems in UWB-based positioning algorithms for dense environments. Ann. Telecommun. 2010, 65, 301–311. [Google Scholar] [CrossRef]
- Guvenc, I.; Chong, C.-C. A Survey on TOA Based Wireless Localization and NLOS Mitigation Techniques. IEEE Commun. Surv. Tutor. 2009, 11, 107–124. [Google Scholar] [CrossRef]
- Li, C.; Zhuang, W. Non-Line-of-Sight Error Mitigation in TDOA Mobile Location. In Proceedings of the IEEE Global Telecommunications Conference, San Antonio, TX, USA, 25–29 November 2001. [Google Scholar]
- Bao, L.; Ahmed, K.; Tsuji, H. Mobile Location Estimator with NLOS Mitigation Using Kalman Filtering. In Proceedings of the IEEE Wireless Communications and Networking, New Orleans, LA, USA, 16–20 March 2003; pp. 1969–1973. [Google Scholar]
- Chen, L.; Wu, L. Mobile Positioning in Mixed LOS/NLOS Conditions Using Modified EKF Banks and Data Fusion Method. IEICE Trans. Commun. 2009, 92-B, 1318–1325. [Google Scholar] [CrossRef]
- Chan, Y.-T.; Tsui, W.Y.; So, H.C.; Ching, P.C. Time-of-Arrival Based Localization under NLOS Conditions. IEEE Trans. Veh. Technol. 2006, 55, 17–24. [Google Scholar] [CrossRef]
- Petrus, P. Robust Huber Adaptive Filter. IEEE Trans. Signal Process. 1999, 47, 1129–1133. [Google Scholar] [CrossRef]
- Casas, R.; Marco, A.; Guerrero, J.J.; Falcó, J. Robust Estimator for Non-Line-of-Sight Error Mitigation in Indoor Localization. Eurasip J. Adv. Signal Process. 2006, 2006, 1–9. [Google Scholar] [CrossRef]
- Wang, W.; Wang, G. Robust Weighted Least Squares Method for TOA based Localization under Mixed LOS/NLOS Conditions. IEEE Commun. Lett. 2017, 21, 2226–2229. [Google Scholar] [CrossRef]
- Wang, L.; Chen, R.; Chen, L.; Shen, L.; Zhang, P.; Pan, Y.; Li, M. A Robust Filter for TOA Based Indoor Localization in Mixed LOS/NLOS Environment. In Proceedings of the 2018 Ubiquitous Positioning, Indoor Navigation and Location-Based Services (UPINLBS), Wuhan, China, 22–23 March 2018. [Google Scholar]
- Yan, L.; Lu, Y.; Zhang, Y. An Improved NLOS Identification and Mitigation Approach for Target Tracking in Wireless Sensor Networks. IEEE Access 2017, 5, 2798–2807. [Google Scholar] [CrossRef]
- Yang, L.; Wang, J.; Knight, N.L.; Shen, Y. Outlier separability analysis with a multiple alternative hypotheses test. J. Geod. 2013, 87, 591–604. [Google Scholar] [CrossRef]
- Hekimoglu, S. Finite Sample Breakdown Points of Outlier Detection Procedures. J. Surv. Eng. 1997, 123, 15–31. [Google Scholar] [CrossRef]
- Qiao, T.; Liu, H. Improved Least Median of Squares Localization for NLOS mitigation. IEEE Commun. Lett. 2014, 18, 1451–1454. [Google Scholar] [CrossRef]
- Rousseeuw, P.J.; Leroy, A.M. Robust Regression and Outlier Detection; John Wiley & Sons: Hoboken, NJ, USA, 1987. [Google Scholar]
- Rousseeuw, P.J. Least Median of Squares Regression. J. Am. Stat. Assoc. 1984, 79, 871–880. [Google Scholar] [CrossRef]
- Tomic, S.; Beki, M.; Dinis, R.; Montezuma, P. A Robust Bisection based Estimator for TOA based Target Localization in NLOS Environments. IEEE Commun. Lett. 2017, 21, 2488–2491. [Google Scholar] [CrossRef]
- Robles, J.J.; Pola, J.S.; Lehnert, R. Extended min-max algorithm for position estimation in Sensor Networks. In Proceedings of the 9th Workshop on Positioning, Navigation and Communication, Dresden, Germany, 15–16 March 2012. [Google Scholar]
- Luo, H.; Li, H.; Zhao, F.; Peng, J. An Iterative Clustering-Based Localization Algorithm for Wireless Sensor Networks. China Commun. 2011, 8, 58–64. [Google Scholar]
- Cota-Ruiz, J.; Rosiles, J.G.; Sifuentes, E.; Rivas-Perea, P. A low-complexity geometric bilateration method for localization in Wireless Sensor Networks and its comparison with Least-Squares methods. Sensors 2012, 12, 839–862. [Google Scholar] [CrossRef] [PubMed]
- Kuruoglu, G.S.; Erol, M.; Oktug, S. Localization in Wireless Sensor Networks with Range Measurement Errors. In Proceedings of the 2009 Fifth Advanced International Conference on Telecommunications, Venice, Italy, 24–28 May 2009; pp. 261–266. [Google Scholar]
- Will, H.; Hillebrandt, T.; Kyas, M. The Geo-n localization algorithm. In Proceedings of the 2012 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Sydney, Australia, 13–15 November 2012. [Google Scholar]
- Li, S.; Hedley, M.; Collings, I.B.; Humphrey, D. TDOA-Based Localization for Semi-Static Targets in NLOS Environments. IEEE Wirel. Commun. Lett. 2015, 4, 513–516. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, S. Adaptive AR Model Based Robust Mobile Location Estimation Approach in NLOS Environment. In Proceedings of the IEEE Vehicular Technology Conference, Milan, Italy, 17–19 May 2004; pp. 2682–2685. [Google Scholar]
- Wann, C.D.; Hsueh, C.S. NLOS mitigation with biased Kalman filters for range estimation in UWB systems. In Proceedings of the TENCON 2007—2007 IEEE Region 10 Conference, Taipei, Taiwan, 30 October–2 November 2007; pp. 1–4. [Google Scholar]
- Xiao, Z.; Wen, H.; Markham, A.; Trigoni, N.; Blunsom, P.; Frolik, J. Non-Line-of-Sight Identification and Mitigation Using Received Signal Strength. IEEE Trans. Wirel. Commun. 2015, 14, 1689–1702. [Google Scholar] [CrossRef]
- Li, S.; Hedley, M.; Collings, I.B.; Johnson, M. Accurate Tracking in NLOS Environments using Integrated IMU and Fixed Lag Smoother. In Proceedings of the 19th International Conference on Information Fusion Position, Heidelberg, Germany, 5–8 July 2016. [Google Scholar]
- Wymeersch, H.; Maranò, S.; Gifford, W.M.; Win, M.Z. A Machine Learning Approach to Ranging Error Mitigation for UWB Localization. IEEE Trans. Commun. 2012, 60, 1719–1728. [Google Scholar] [CrossRef]
- Khatab, Z.E.; Hajihoseini, A.; Gohorashi, S.A. A Fingerprint method for indoor localization using autoencoder based deep extreme learning machine. IEEE Sens. Lett. 2018, 2, 1–4. [Google Scholar] [CrossRef]
- Hsu, L.; Gu, Y.; Kamijo, S. NLOS Correction/Exclusion for GNSS Measurement Using RAIM and City Building Models. Sensors 2015, 15, 17329–17349. [Google Scholar] [CrossRef]
- Yan, Q.; Chen, J.; De Strycker, L. An Outlier Detection Method Based on Mahalanobis Distance for Source Localization. Sensors 2018, 18, 2186. [Google Scholar] [CrossRef] [PubMed]
- Huber, P.J.; Ronchetti, E.M. Robust Statistic; John Wiley & Sons: Hoboken, NJ, USA, 1981. [Google Scholar]
- Leick, A.; Rapoport, L.; Tatrnikov, D. GPS Satellite Surveying, 4th ed.; John Wiley & Sons Inc: Hoboken, NJ, USA, 2015. [Google Scholar]
- Foy, W.H. Position Location Solutions by Taylor Series Estimation. IEEE Trans. Aerosp. Electron. Syst. 1976, 2, 187–194. [Google Scholar] [CrossRef]
- Caffery, J.J. A New Approach to the Geometry of TOA Location. In Proceedings of the IEEE Vehicular Technology Conference, Boston, MA, USA, 24–28 September 2000; pp. 1943–1949. [Google Scholar]
- Chan, Y.-T.; Ho, C.K. A Simple and Efficient Estimator for Hyperbolic Location. IEEE Trans. Signal Process. 1994, 42, 1905–1915. [Google Scholar] [CrossRef]
- Bancroft, S. An algebraic solution of the GPS equations. IEEE Trans. Aerosp. Electron. Syst. 1985, 21, 56–59. [Google Scholar] [CrossRef]
- Beck, A.; Stoica, P.; Li, J. Exact and Approximate Solutions of Source Localization Problems. IEEE Trans. Signal Process. 2008, 56, 1770–1778. [Google Scholar] [CrossRef]
- Cheung, K.W.; So, H.C.; Ma, W.K.; Chan, Y.T. Least Squares Algorithms for Time-of-Arrival-Based Mobile Location. IEEE Trans. Signal Process. 2004, 52, 1121–1128. [Google Scholar] [CrossRef]
- Koch, K.-R. Parameter Estimation and Hypothesis Testing in Linear Models; Springer: Berlin, German, 1988. [Google Scholar]
- Wang, Y.; Huang, J.; Cheng, L.; Li, C.; Song, X. A Hierarchical Voting Based Mixed Filter Localization method for wireless sensor metwork in mixed LOS/NLOS Environment. Sensors 2018, 18, 2348. [Google Scholar] [CrossRef]
- Tsai, Y.-H.; Chang, F.-R.; Yang, W.-C. GPS fault detection and exclusion using moving average filters. IEEE Proc. Radar Sonar Navig. 2004, 151, 240–247. [Google Scholar] [CrossRef]
- Chang, X.; Guo, Y. Huber’s M-estimation in relative GPS positioning: Computational aspects. J. Geod. 2005, 79, 351–362. [Google Scholar] [CrossRef]
- Yang, Y.; Song, L.; Xu, T. Robust estimator for correlated observations based on bifactor equivalent weights. J. Geod. 2002, 76, 353–358. [Google Scholar] [CrossRef]
- Sathyan, T.; Humphrey, D.; Hedley, M. WASP: A System and Algorithms for Accurate Radio Localization Using Low-Cost Hardware. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2011, 41, 211–222. [Google Scholar] [CrossRef]
- Li, S.; Hedley, M.; Collings, I.B. New Efficient Indoor Cooperative Localization Algorithm with Empirical Ranging Error Model. IEEE J. Sel. Areas Commun. 2015, 33, 1407–1417. [Google Scholar] [CrossRef]
- Li, S.; Hedley, M.; Collings, I.B.; Humphrey, D. Indoor Positioning based on Ranging Offset Model and Learning. In Proceedings of the IEEE International Conference on Communications Workshops, Paris, France, 21–25 May 2017; pp. 1265–1270. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Misclosure Test Statistics | TOA1 | TOA2 |
|---|---|---|
| … | … | … |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Chen, R.; Shen, L.; Qiu, H.; Li, M.; Zhang, P.; Pan, Y. NLOS Mitigation in Sparse Anchor Environments with the Misclosure Check Algorithm. Remote Sens. 2019, 11, 773. https://doi.org/10.3390/rs11070773
Wang L, Chen R, Shen L, Qiu H, Li M, Zhang P, Pan Y. NLOS Mitigation in Sparse Anchor Environments with the Misclosure Check Algorithm. Remote Sensing. 2019; 11(7):773. https://doi.org/10.3390/rs11070773
Chicago/Turabian StyleWang, Lei, Ruizhi Chen, Lili Shen, Haiyang Qiu, Ming Li, Peng Zhang, and Yuanjin Pan. 2019. "NLOS Mitigation in Sparse Anchor Environments with the Misclosure Check Algorithm" Remote Sensing 11, no. 7: 773. https://doi.org/10.3390/rs11070773
APA StyleWang, L., Chen, R., Shen, L., Qiu, H., Li, M., Zhang, P., & Pan, Y. (2019). NLOS Mitigation in Sparse Anchor Environments with the Misclosure Check Algorithm. Remote Sensing, 11(7), 773. https://doi.org/10.3390/rs11070773