Description Generation for Remote Sensing Images Using Attribute Attention Mechanism



Abstract
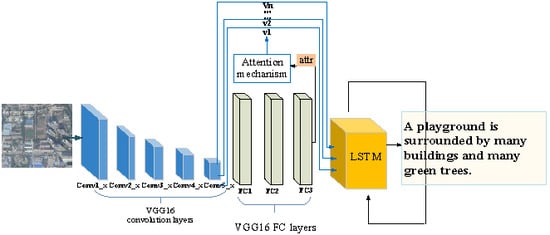
:
1. Introduction
2. Related Work
2.1. Progress on Natural Image Captioning
2.2. Progress on Remote Sensing Image Captioning
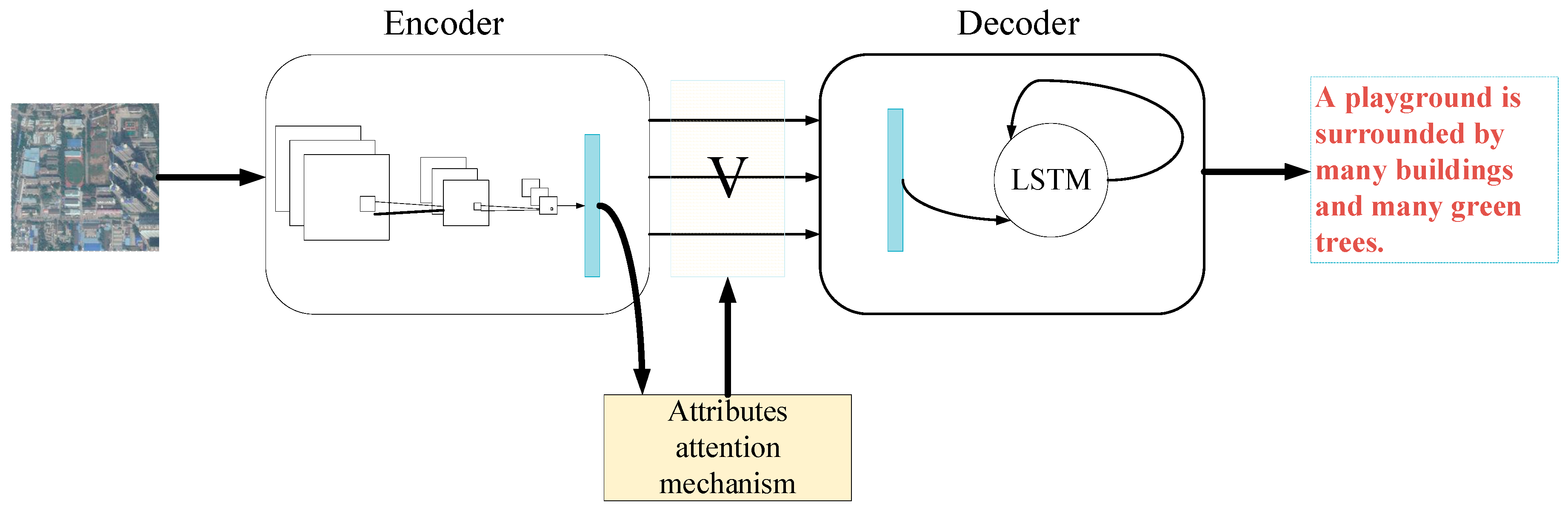
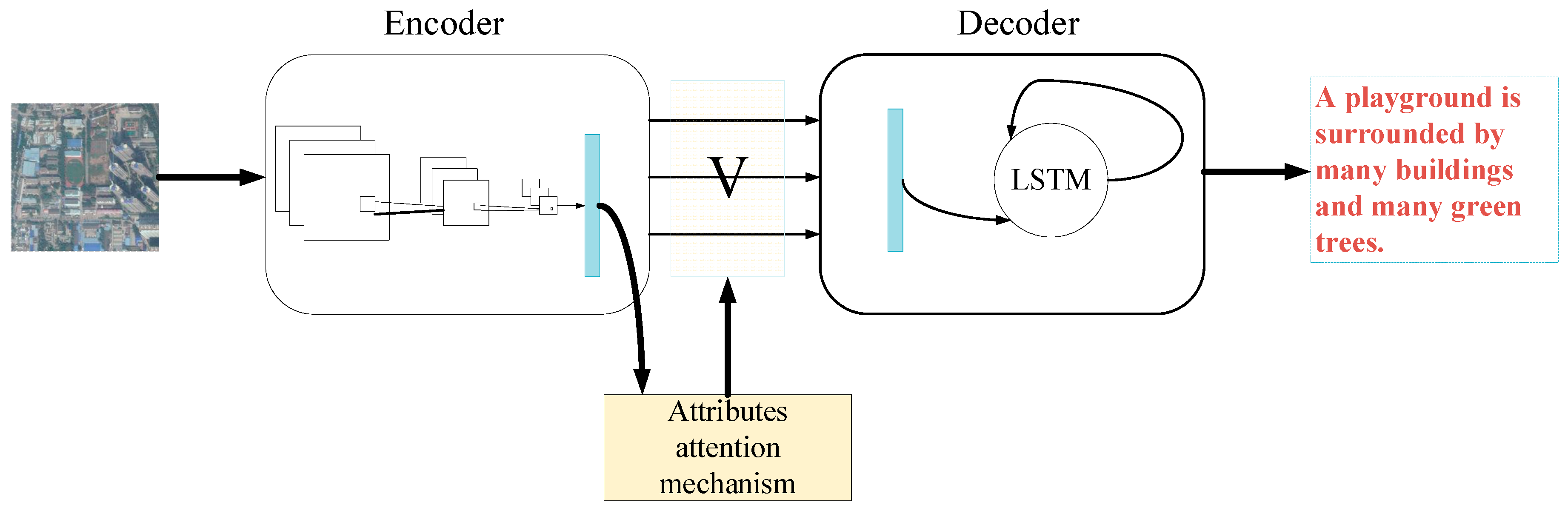
3. Remote Sensing Image Captioning with Feature Extraction and Attribute Attention
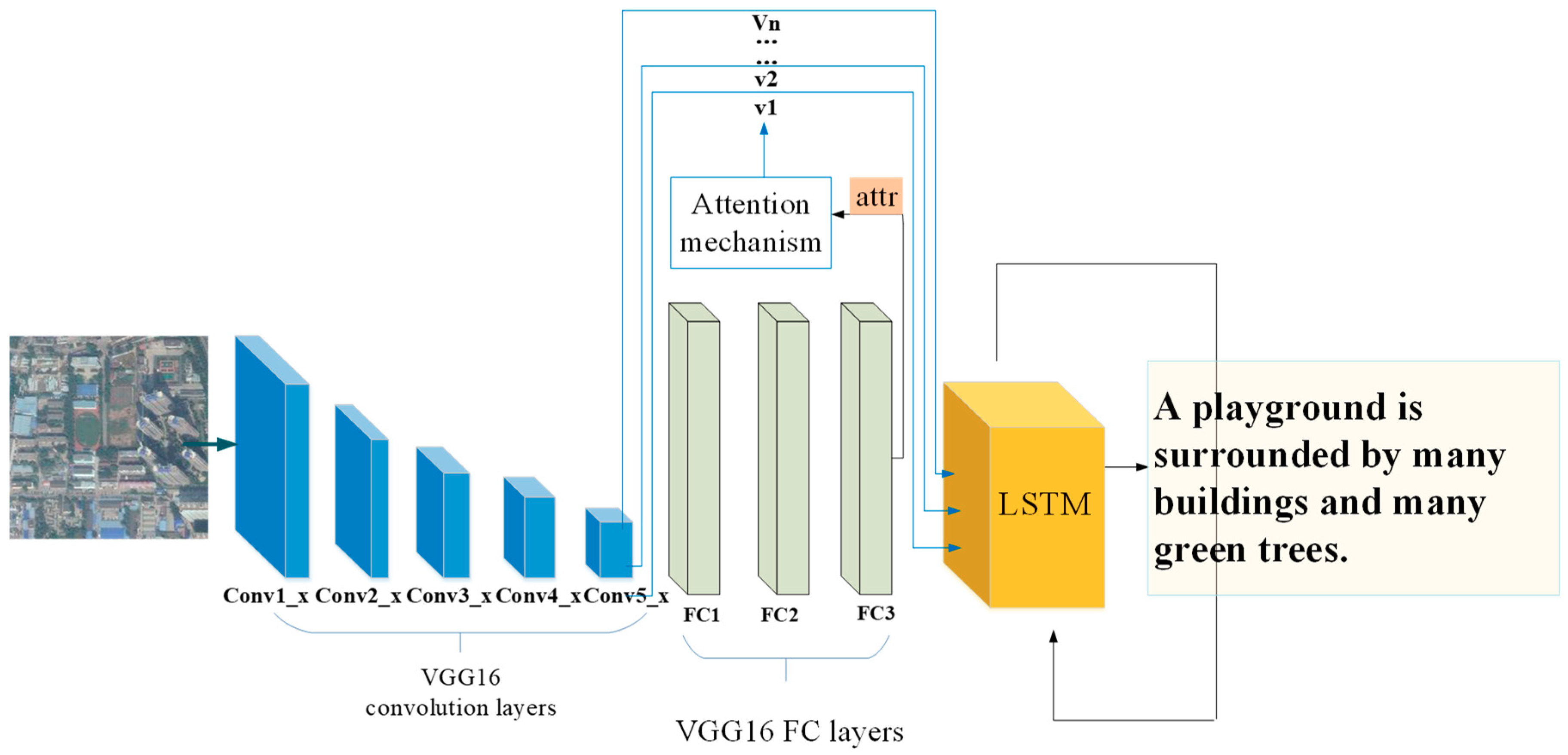
3.1. Feature Extraction
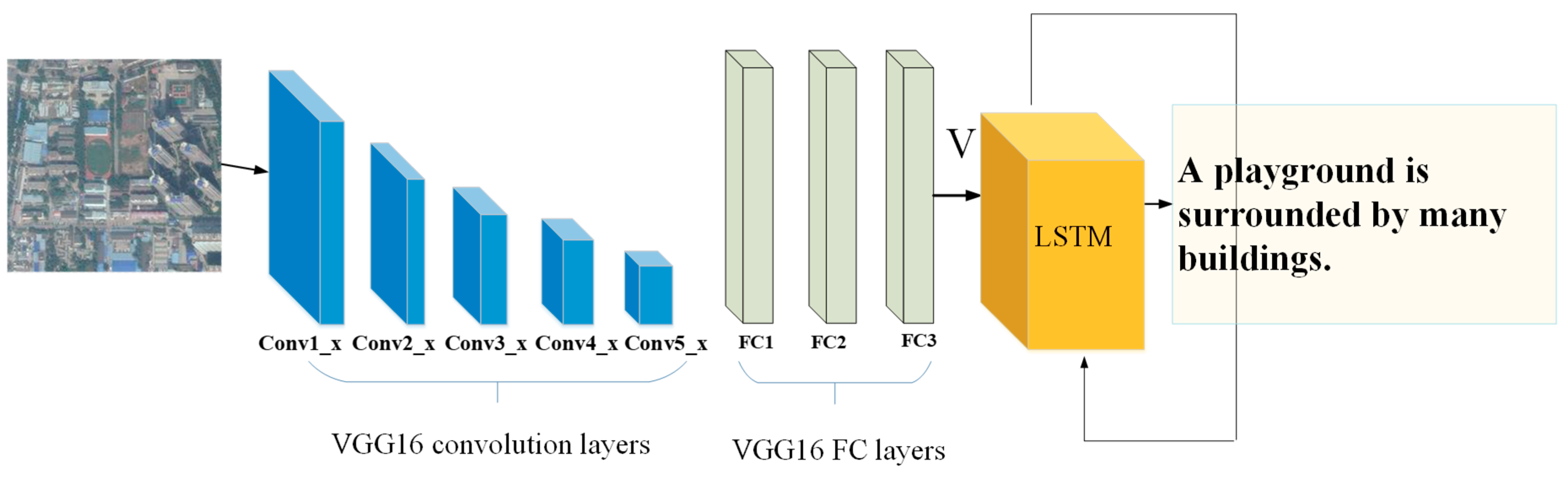
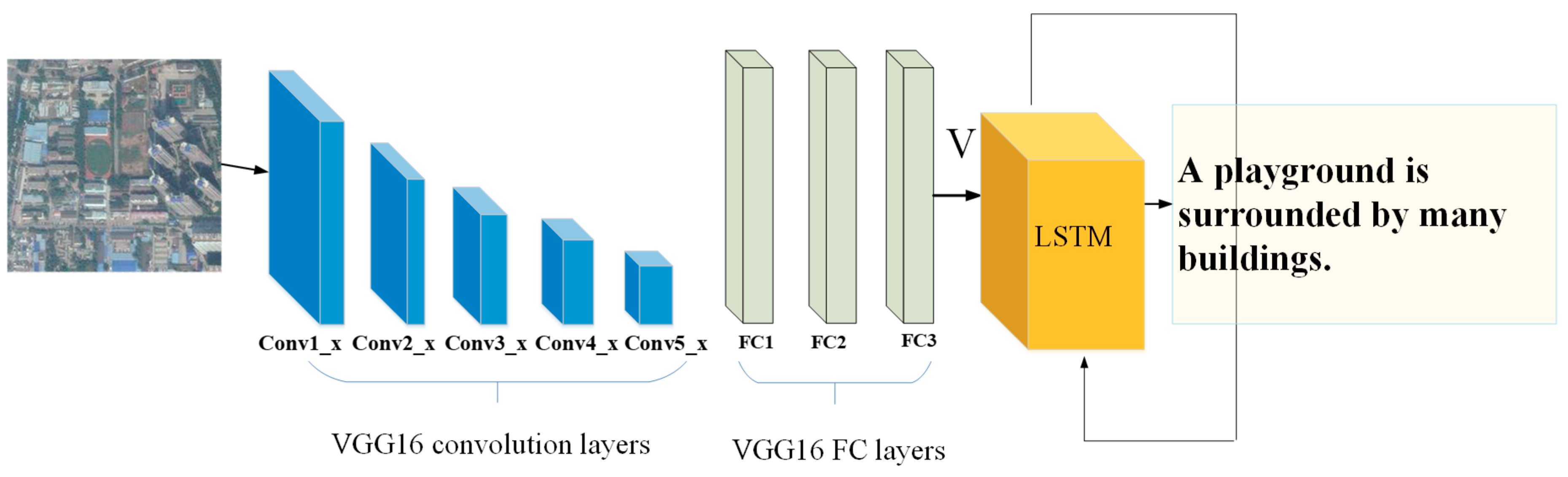
3.1.1. Image Feature Extraction
3.1.2. Sentence Feature Extraction
3.1.3. Overall Framework
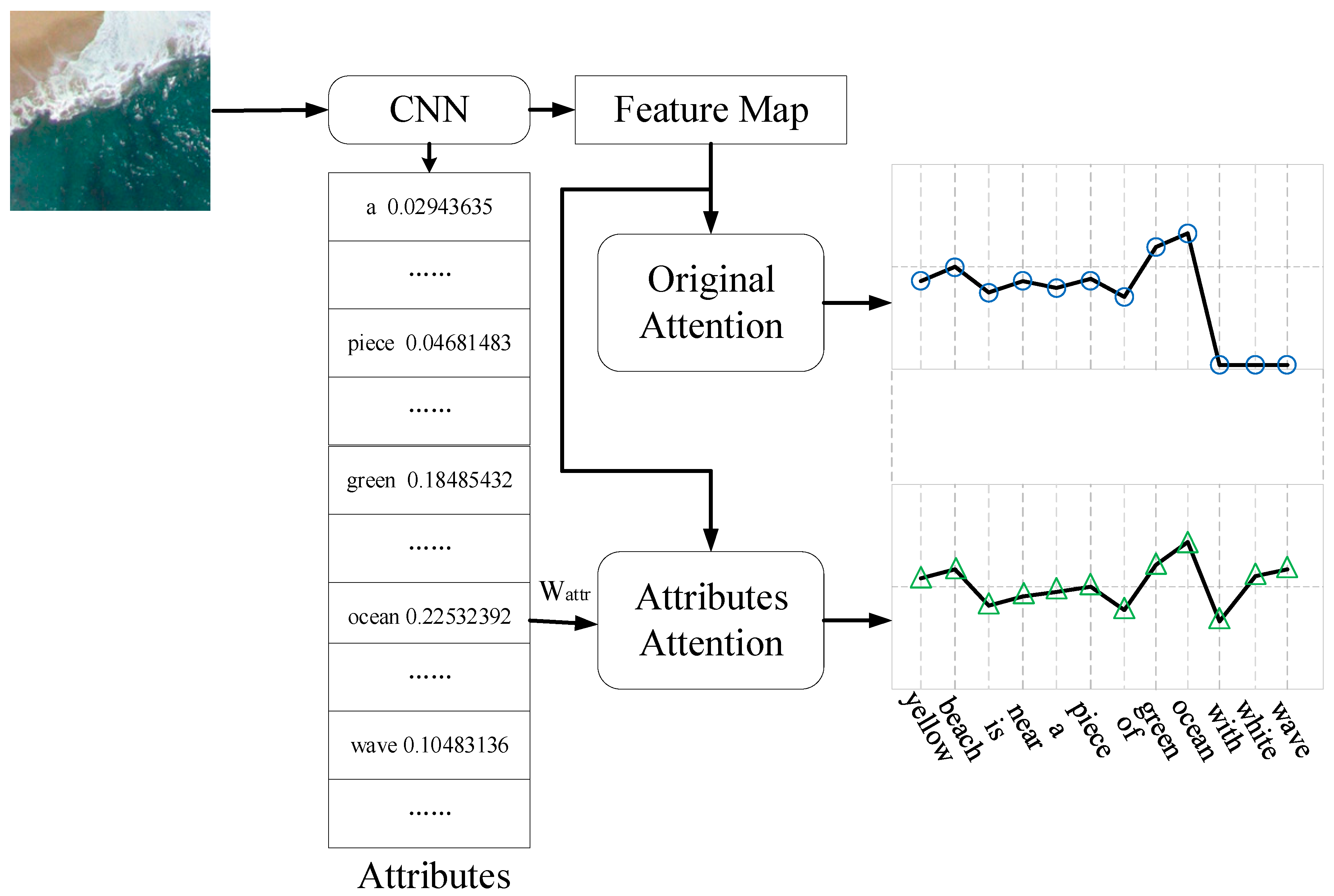
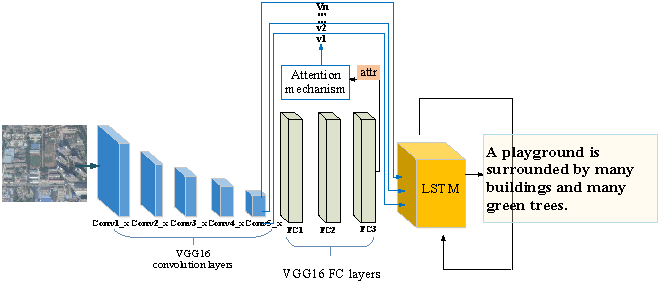
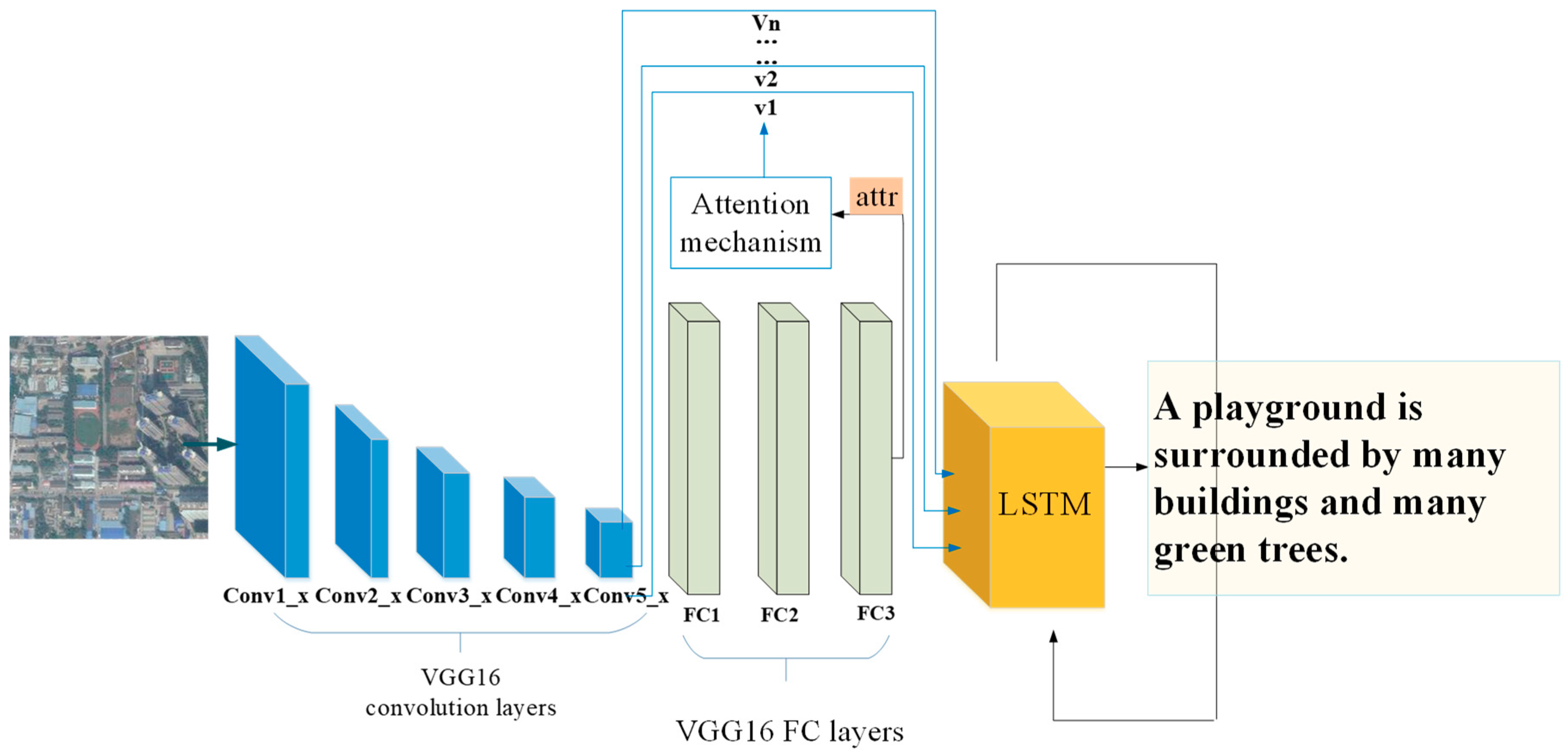
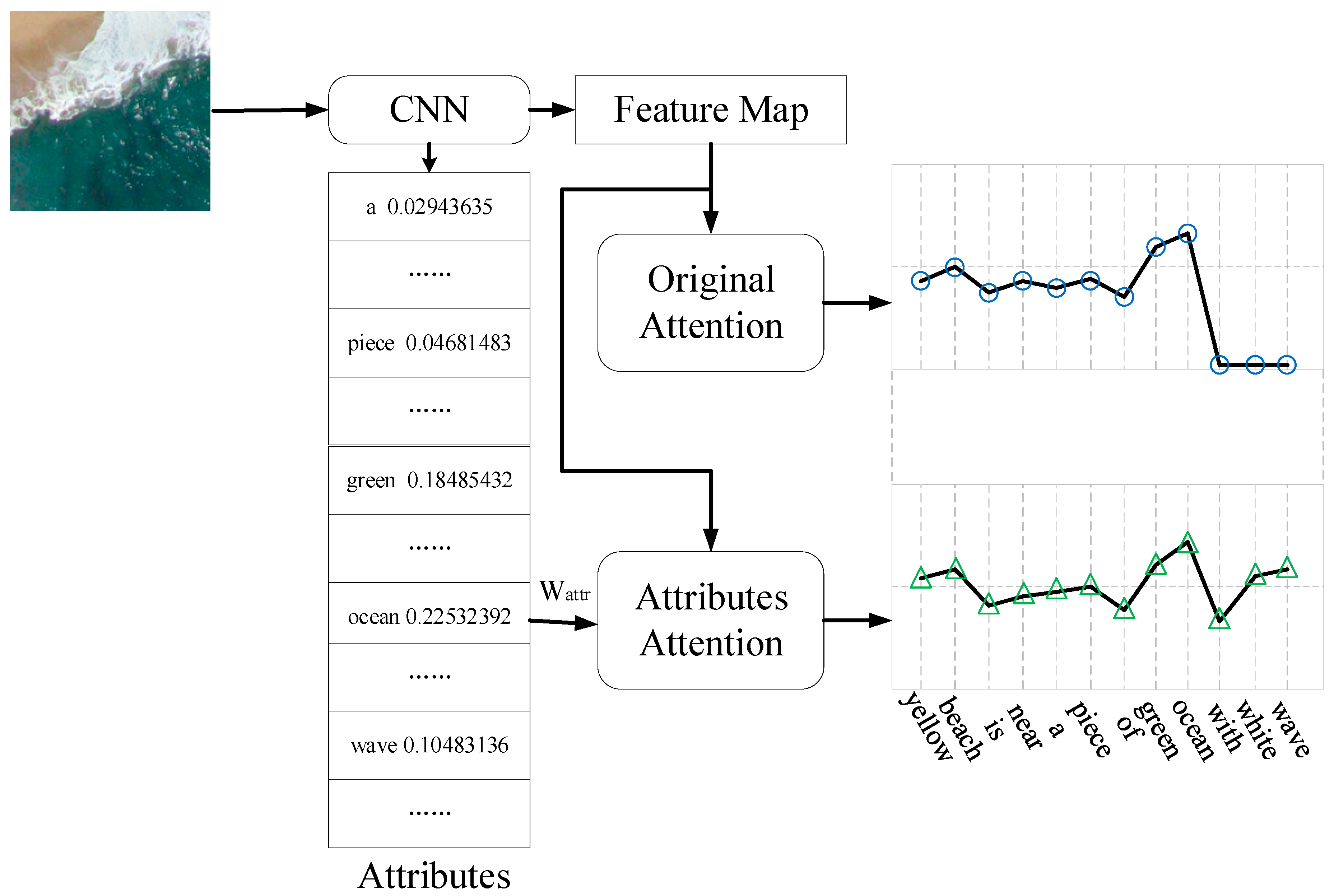
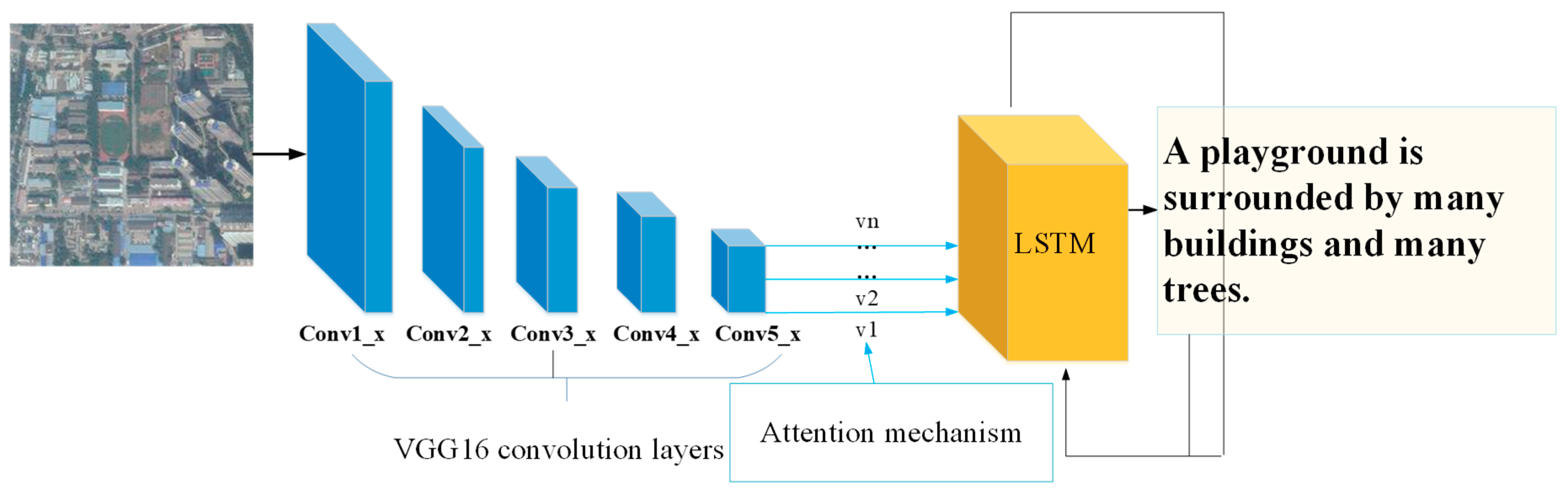
3.2. Attribute Attention Model
4. Experiments
4.1. Dataset
4.2. Metrics and Baselines
4.3. Results on Three Datasets
4.3.1. Results on Sydney Dataset
4.3.2. Results on UCM Dataset
4.3.3. Results on RSICD
4.4. Results Analysis
- The generated content is not in the image. There is no building in Figure 9g, but the word “buildings” is in its generated sentence. Due to the high frequency of some words appearing together in the training set, the proposed model may misclassify them. For example, a parking lot often appears in the same image with trees, so there are a large number of reference sentences in which both “parking lot” and “trees” appear at the same time. If an image contains a parking lot in the test set, the generated sentence tends to have "trees" whether or not there are trees in the image.
- Misrecognition. In Figure 9h, the scene is misrecognized as the commercial area while the ground truth is an industrial area as they are very similar. Both industrial and commercial areas in remote sensing images have the same characteristics of dense and crowded buildings. This is a challenge in the field of remote sensing image/scene classification, which is called the small interclass dissimilarity problem [44]. More work needs to be done to get over around this problem.
- Both above problems occurred. In Figure 9i, the key object is a center but it is recognized as a circle square. In addition, a square often appears with buildings around in the training set, which leads to “buildings” shown in the generated sentence.
4.5. Parameter Analysis
4.6. Computational Cost
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Toth, C.; Jóźków, G. A survey, journal of photogrammetry and remote sensing. Remote Sens. Platforms Sens. 2016, 115, 22–36. [Google Scholar]
- Rahaman, K.R.; Hassan, Q.K. Application of remote sensing to quantify local warming trends: A review. In Proceedings of the 5th International Conference on Informatics, Electronics and Vision (ICIEV), Dhaka, Bangladesh, 13–14 May 2016; pp. 256–261. [Google Scholar]
- Aroma, R.J.; Raimond, K. A review on availability of remote sensing data. In Proceedings of the IEEE Technological Innovation in ICT for Agriculture and Rural Development (TIAR), Chennai, India, 10–12 July 2015; pp. 150–155. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Lu, X.; Zheng, X.; Yuan, Y. Remote sensing scene classification by unsupervised representation learning. IEEE Trans. Geosci. Remote Sens. 2017, 99, 1–10. [Google Scholar] [CrossRef]
- Han, X.; Zhong, Y.; Zhang, L. An efficient and robust integrated geospatial object detection framework for high spatial resolution remote sensing imagery. Remote Sens. 2017, 9, 666. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Y. Airport detection and aircraft recognition based on two-layer saliency model in high spatial resolution remote-sensing images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2017, 10, 1511–1524. [Google Scholar] [CrossRef]
- Liu, T.T.; Li, P.X.; Zhang, L.P.; Chen, X. A remote sensing image retrieval model based on semantic mining. Geomatics Inf. Sci. Wuhan Univ. 2009, 34, 684–687. [Google Scholar]
- Zhu, Q.; Zhong, Y.; Zhang, L. Multi-feature probability topic scene classifier for high spatial resolution remote sensing imagery. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec, QC, Canada, 13–18 July 2014; pp. 2854–2857. [Google Scholar]
- Yang, J.; Jiang, Z.; Quan, Z. Remote sensing image semantic labeling based on conditional random field. Acta Aeronaut. Et Astronaut. Sin. 2015, 36, 3069–3081. [Google Scholar]
- Wang, J.; Zhou, H. Research on key technologies of remote sensing image data retrieval based on semantics. Comput. Digit. Eng. 2012, 40, 48–50. [Google Scholar]
- Chen, K.M.; Zhou, Z.X.; Guo, J.E.; Zhang, D.B.; Sun, X. Semantic scene understanding oriented high resolution remote sensing image change information analysis. In Proceedings of the Annual Conference on High Resolution Earth Observation, Beijing, China, 1 December 2013; pp. 1–12. [Google Scholar]
- Li, Y. Target Detection Method of High Resolution Remote Sensing Image Based on Semantic Model; Graduate University of Chinese Academy of Sciences: Beijing, China, 2012. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: Lessons learned from the mscoco image captioning challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 652–663. [Google Scholar] [CrossRef] [PubMed]
- Mao, J.; Xu, W.; Yang, Y.; Wang, J.; Huang, Z.; Yuille, A. Deep caption with multimodal recurrent neural networks (m-rnn). arXiv, 2014; arXiv:1412.6632. [Google Scholar]
- Chen, X.; Lawrence Zitnick, C. Mind’s eye: A recurrent visual representation for image captioning generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2422–2431. [Google Scholar]
- Karpathy, A.; Joulin, A.; Fei-Fei, L.F. Deep fragment embeddings for bidirectional image sentence mapping. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1889–1897. [Google Scholar]
- Qu, B.; Li, X.; Tao, D.; Lu, X. Deep semantic understanding of high resolution remote sensing image. In Proceedings of the 2016 International Conference on Computer, Information and Telecommunication Systems (CITS), Kunming, China, 6–8 July 2016; pp. 1–5. [Google Scholar]
- Shi, Z.; Zou, Z. Can a machine generate humanlike language descriptions for a remote sensing image? IEEE Trans. Geosci. Remote Sens. 2017, 55, 3623–3634. [Google Scholar] [CrossRef]
- Lu, X.; Wang, B.; Zheng, X.; Li, X. Exploring models and data for remote sensing image caption generation. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2183–2195. [Google Scholar] [CrossRef]
- Spratling, M.W.; Johnson, M.H. A feedback model of visual attention. J. Cogn. Neurosci. 2004, 16, 219–237. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image captioning generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3242–3250. [Google Scholar]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image captioning with semantic attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4651–4659. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Qiu, Z.; Mei, T. Boosting image captioning with attributes. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4904–4912. [Google Scholar]
- Wu, Q.; Shen, C.; Wang, P.; Dick, A.; van den Hengel, A. Image captioning and visual question answering based on attributes and external knowledge. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1367–1381. [Google Scholar] [CrossRef] [PubMed]
- Hossain, M.D.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A Comprehensive Survey of Deep Learning for Image Captioning. Available online: https://arxiv.org/pdf/1810.04020.pdf (accessed on 13 March 2019).
- Farhadi, A.; Hejrati, M.; Sadeghi, M.A.; Young, P.; Rashtchian, C.; Hockenmaier, J.; Forsyth, D. Every picture tells a story: Generating sentences from images. In Proceedings of the 11th European Conference on Computer Vision: Part IV, ECCV’10, Crete, Greece, 5–11 September 2010; pp. 15–29. [Google Scholar]
- Li, S.; Kulkarni, G.; Berg, T.L.; Berg, A.C.; Choi, Y. Composing simple image descriptions using web-scale n-grams. In Proceedings of the Fifteenth Conference on Computational Natural Language Learning, Portland, OR, USA, 23–24 June 2011; pp. 220–228. [Google Scholar]
- Kulkarni, G.; Premraj, V.; Dhar, S.; Li, S.; Choi, Y.; Berg, A.C.; Berg, T.L. Baby talk: Understanding and generating image descriptions. In Proceedings of the 24th CVPR, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1601–1608. [Google Scholar]
- Gong, Y.; Wang, L.; Hodosh, M.; Hockenmaier, J.; Lazebnik, S. Improving image-sentence embeddings using large weakly annotated photo collections. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 529–545. [Google Scholar]
- Sun, C.; Gan, C.; Nevatia, R. Automatic concept discovery from parallel text and visual corpora. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 2596–2604. [Google Scholar]
- Hodosh, M.; Young, P.; Hockenmaier, J. Framing image description as a ranking task: Data, models and evaluation metrics. J. Artif. Intell. Res. 2013, 47, 853–899. [Google Scholar] [CrossRef]
- Wu, Q.; Shen, C.; Liu, L.; Dick, A.; Van Den Hengel, A. What value do explicit high level concepts have in vision to language problems? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, America, 26 June–1 July 2016; pp. 203–212. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2175–2184. [Google Scholar] [CrossRef]
- Wang, B.; Lu, X.; Zheng, X.; Li, X. Semantic Descriptions of High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2019. [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv, 2014; arXiv:1409.0473. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 11 June 2005; pp. 65–72. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGH | CIDEr | |
|---|---|---|---|---|---|---|---|
| CSMLF [38] | 0.5998 | 0.4583 | 0.3869 | 0.3433 | 0.2475 | 0.5018 | 0.7555 |
| Multimodal [19] | 0.6966 | 0.6123 | 0.5431 | 0.5040 | 0.3588 | 0.6347 | 2.2022‘ |
| Attention [21] | 0.7905 | 0.7020 | 0.6232 | 0.5477 | 0.3925 | 0.7206 | 2.2013 |
| FC-Att+LSTM | 0.8076 | 0.7160 | 0.6276 | 0.5544 | 0.4099 | 0.7114 | 2.2033 |
| SM-Att+LSTM | 0.8143 | 0.7351 | 0.6586 | 0.5806 | 0.4111 | 0.7195 | 2.3021 |
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGH | CIDEr | |
|---|---|---|---|---|---|---|---|
| CSMLF [38] | 0.4361 | 0.2728 | 0.1855 | 0.1210 | 0.1320 | 0.3927 | 0.2227 |
| Multimodal [19] | 0.7087 | 0.5966 | 0.5521 | 0.4599 | 0.3426 | 0.6612 | 2.9254 |
| Attention [21] | 0.7993 | 0.7355 | 0.6790 | 0.6244 | 0.4174 | 0.7441 | 3.0038 |
| FC-Att+LSTM | 0.8135 | 0.7502 | 0.6849 | 0.6352 | 0.4173 | 0.7504 | 2.9958 |
| SM-Att+LSTM | 0.8154 | 0.7575 | 0.6936 | 0.6458 | 0.4240 | 0.7632 | 3.1864 |
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGH | CIDEr | |
|---|---|---|---|---|---|---|---|
| CSMLF [38] | 0.5759 | 0.3859 | 0.2832 | 0.2217 | 0.2128 | 0.4455 | 0.5297 |
| Multimodal [19] | 0.6378 | 0.4756 | 0.4004 | 0.3006 | 0.2905 | 0.5333 | 2.2536 |
| Attention [21] | 0.7336 | 0.6129 | 0.5190 | 0.4402 | 0.3549 | 0.6419 | 2.2486 |
| FC-Att+LSTM | 0.7459 | 0.6250 | 0.5338 | 0.4574 | 0.3395 | 0.6333 | 2.3664 |
| SM-Att+LSTM | 0.7571 | 0.6336 | 0.5385 | 0.4612 | 0.3513 | 0.6458 | 2.3563 |
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGH | CIDEr | |
|---|---|---|---|---|---|---|---|
| 256-FC | 0.74467 | 0.62012 | 0.52313 | 0.44390 | 0.34823 | 0.64175 | 2.35417 |
| 256-SM | 0.74189 | 0.62112 | 0.52809 | 0.45019 | 0.33937 | 0.63333 | 2.29751 |
| 512-FC | 0.74592 | 0.62498 | 0.53381 | 0.45740 | 0.33947 | 0.63325 | 2.36639 |
| 512-SM | 0.75711 | 0.63360 | 0.53850 | 0.46118 | 0.35134 | 0.64575 | 2.35632 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Wang, X.; Tang, X.; Zhou, H.; Li, C. Description Generation for Remote Sensing Images Using Attribute Attention Mechanism. Remote Sens. 2019, 11, 612. https://doi.org/10.3390/rs11060612
Zhang X, Wang X, Tang X, Zhou H, Li C. Description Generation for Remote Sensing Images Using Attribute Attention Mechanism. Remote Sensing. 2019; 11(6):612. https://doi.org/10.3390/rs11060612
Chicago/Turabian StyleZhang, Xiangrong, Xin Wang, Xu Tang, Huiyu Zhou, and Chen Li. 2019. "Description Generation for Remote Sensing Images Using Attribute Attention Mechanism" Remote Sensing 11, no. 6: 612. https://doi.org/10.3390/rs11060612
APA StyleZhang, X., Wang, X., Tang, X., Zhou, H., & Li, C. (2019). Description Generation for Remote Sensing Images Using Attribute Attention Mechanism. Remote Sensing, 11(6), 612. https://doi.org/10.3390/rs11060612