Abstract
Detailed vegetation maps are needed for wetland conservation and restoration as different vegetation communities have distinct water requirements. It is a continuous challenge to map the distribution of different wetland types on a regional scale, and a trade-off between the categorical details and availability of resources to ensure broad applications is often necessary for operational mapping. Here, we evaluated the capacity and performance of statistical learning in discriminating wetland types using Landsat time series and geomorphological variables computed from Light Detection and Ranging (LiDAR) and Shuttle Radar Topography Mission (SRTM) digital elevation model (DEM). Our study showed that there was a discrimination limit of statistical learning in wetland mapping. The approach was clearly inadequate in distinguishing certain wetland types. In semiarid Australia, our results suggested that the appropriate level for floodplain wetland mapping included four classes: tree-dominated woodlands, shrublands, vegetated swamps, and non-flood-dependent terrestrial communities. Our results also demonstrated that the geomorphological metrics significantly improved the accuracy of wetland classification. Furthermore, geomorphological metrics derived from the freely available coarser resolution SRTM DEM were as beneficial for wetland mapping as those extracted from finer scale commercially-based LiDAR DEM. The finding enables the widespread applications of our approach, as both data sources are freely available globally.
1. Introduction
Wetlands provide a range of key ecological services including maintaining regional and global biodiversity [1], controlling flooding and diffusive pollution [2], and sequestering carbon [3]. Increasing recognition of the ecological importance of wetlands has resulted in a growing interest in mapping their distribution [4,5], and a range of wetland maps was developed at the global [6,7], the continental and regional [8,9], and the catchment and local scales [10,11]. The methods by which wetlands have been identified or classified have varied, and the results have often been incompatible or inconsistent within and across spatial scales [6,12,13].
It is widely recognized that ecological services are closely associated with wetland types; for example, alluvial floodplain swamps are efficient at nitrogen processing [14], and isolated forest swamps have the capacity for carbon sequestration [15]. In addition to wetland delineation, which maps the distribution, size and shape of wetlands, regional or catchment scale wetland classification maps describing wetland types are, therefore, needed to monitor and evaluate the ecological function for adaptive management [16,17]. Vegetation formations are often the foundation for wetland classification because they are relatively persistent in the hydrologically dynamic wetland environment [18], and they integrate past and current hydrological conditions [19], soil moisture, and fertility [20]. Most wetland classification systems are essentially a description of wetland vegetation types [21].
Vegetation mapping is undertaken using a variety of methods depending on the requirements of the purpose. The most demanding level of vegetation mapping requires intensive field work, including taxonomical information, and the visual estimation of percentage cover for each species [5]. This approach is time-consuming, labour intensive, and costly; thus, it is only practical across relatively small areas [22]. It can be usefully supplemented by the manual interpretation of high-resolution aerial photographs (e.g., in Reference [23]); however, the costs associated with accessing repeat photography can limit opportunities for a time series analysis. The manual interpretation of aerial photographs also relies heavily on the knowledge of the photo interpreter on vegetation community identification [24]. While high spatial-resolution aerial photography is able to provide valuable spatial information and to delineate a target boundary, photographic analyses cannot be semiautomated to discriminate the target due to the coarse spectral-resolution [25].
Some recent vegetation mapping efforts have been focused on (semi-) automating digital analysis images acquired from satellite remote sensing platforms including Landsat (mainly TM and ETM+), SPOT, MODIS, NOAA-AVHRR, IKONOS, and QuickBird [5,26]. Among these efforts, image fusion and statistical learning have proven to be efficient tools in wetland vegetation mapping. The former is an algorithm to combine relevant information from two or more images (normally from different sources) into a single image [26,27,28]. The latter is a data mining technique used to discover knowledge from large amounts of data [29,30,31].
Topography and landscape position play key roles in wetland formation [32,33]. LiDAR data can provide detailed and accurate ground elevation information for identifying topographic features and, in some cases, for indicating the boundary of wetlands that would otherwise be undetected [32]. In wetland-rich areas such as floodplains where the complex nesting of features may cause mapping confusion and inaccuracy [33], geomorphological variable-derived fine-scale elevation data can be particularly helpful [34,35].
In this study, we used stochastic gradient boosting machines (GBM, a machine learning technique) to predict vegetation communities in the Barwon-Darling, a large semiarid floodplain wetland complex in Australia. Our overall goal in this study was to explore the capacity and performance of image fusion and statistical learning in discriminating wetland vegetation types and to demonstrate to wetland ecologists the accessibility of remote sensing for the monitoring and assessment of floodplain vegetation. We have two specific objectives:
- To investigate the discrimination limits of the predictive models through evaluating the performance of predictive models at three vegetation formation levels. Our approach involved building predictive models for three vegetation classification levels: at a broad functional group level (two classes: wetland vs. non-wetlands), an intermediate level (four classes) which further divides wetlands into vegetation structural groups, and a more detailed level involving vegetation floristics (dominant species—nine classes).
- To evaluate the predictive power of various predictor variables. In wetland ecosystems, vegetation distribution is strongly affected by the moisture gradient, which is often highly correlated with micro-topography [36,37]. The combined use of LiDAR-based geomorphological data and Landsat data may present an opportunity for refined vegetation mapping. Our study, therefore, assesses the individual and combined contributions of geomorphological variables to classification accuracy by building models with three combinations of predictor variables: full models with all Landsat and LiDAR DEM-based geomorphological variables; the geomorphological models with only LiDAR DEM-based geomorphological variables; and the Landsat models fitted with only Landsat variables.
2. Materials and Methods
2.1. Study Site
The study area covers more than 338,800 ha of floodplain in the Barwon-Darling River system located in the northwest New South Wales (NSW) (Figure 1). The area has a semiarid climate with low rainfall, hot summers, and cold winters. The average annual rainfall (1998–2016) is 306.2 mm. The mean maximum summer and mean minimum winter temperatures (1998–2016) are 37.2 °C and 4.2 °C, respectively [38].
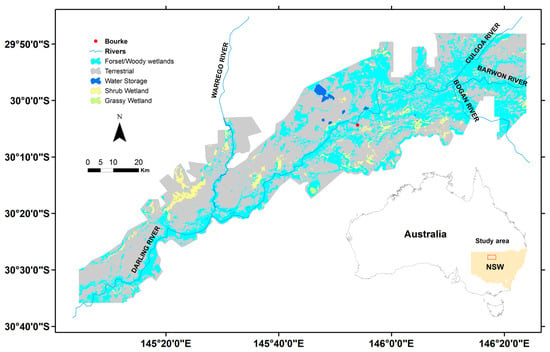
Figure 1.
The vegetation communities in the Barwon-Darling and Condamine-Balonne floodplain systems of New South Wales (NSW), Australia: The classes were based on community structure. The inset shows the location of the study site.
The floodplain consists of a wide range of floodplain forests and woodlands, including river red gum (RRG) (Eucalyptus camaldulensis), black box (E. largiflorens), coolabah (E. coolabah), and river cooba (Acacia stenophylla). There are also areas of wet meadows including species such as spikerush (Eleocharis spp.), nardoo (Marsilea spp.), and Marshwort (Nymphoides spp.) scattered across the lower depressions. The native vegetation communities can be broadly separated into flood-dependent and non-flood-dependent. Flood-dependent vegetation requires periodic inundation to regenerate and survive, whereas non-flood-dependent systems rely on local rainfall and generally sit at slightly elevated terrains off the floodplain. Flood-dependent vegetation includes the riparian forests of River Red Gum (Eucalyptus camaldulensis) that fringe the major rivers (including the Darling, Bokhara, and Culgoa) and the extensive floodplain woodlands dominated by Coolibah (E. coolabah) and Black Box (E. largiflorens). We include these flood-dependent forests and woodlands into our wetland functional grouping. Along the ephemeral channels and within low lying depressions, additional various wetland communities occur, including large semipermanent wetlands and inland lakes and smaller ephemeral wetlands dominated by Eleocharis spp., Marsilea spp., and Nymphoides spp. The shrublands dominated by Lignum (Duma florulenta) and Nitre Goosefoot (Chenopodium nitrariaceum) are commonly associated with minor channels and low-lying areas throughout the region.
2.2. Wetland Vegetation Map
We used vegetation maps produced by References [39,40,41]. The mapping process for these studies was guided by on-screen aerial photographic interpretation, the incorporation of existing map data, and an extensive program of field reconnaissance. The combined vegetation map has 26 PCTs (plant community types). Croplands and man-made features such as dams were excluded in this study. The PCT classification was developed by New South Wales Office of Environment and Heritage [42] to establish an unambiguous master community-level scheme for use in vegetation mapping programs, in BioMetric-based regulatory decisions, and as a standard typology for other planning and data gathering programs.
To test the discrimination power of statistical learning, we grouped the 26 PCTs into three hierarchical levels of vegetation classes for modelling (Table 1) and then compared the performance of the models at the three levels:

Table 1.
The types of the Barwon-Darling used in this study.
- (1)
- Level one contains the two broadest functional groups: flood-dependent (wetland) and non-flood-dependent terrestrial vegetation communities. PCTs were assessed as either flood-dependent (wetland) or terrestrial based on knowledge of the wetland plant indicator status of dominant plant species. The wetland indicator plant species list is from derived, descriptive information recorded in the NSW Flora Online [43].
- (2)
- Level two has three classes which divide the flood-dependent group (wetlands) into three broad structural groups: woodland, shrubland, and grassy/herbaceous wetlands. We grouped the PCTs into these structural groups based on the dominant life form of the tallest plant layer [44].
- (3)
- Level three comprises nine vegetation classes, formed by grouping PCTs per dominant species (floristics), and the conceptual understanding of the landscape position and water requirements of these communities described in the NSW Vegetation Information System Classification database [42].
Since we focused on wetland vegetation communities, the non-flood-dependent vegetation, including salt bush, mixed chenopod shrubland, and Belah Woodland, was not separated further. With the vegetation map, we extracted 57,005 stratified (in terms of vegetation types, Table 1) random points using the Create Random Points tool in ArcGIS (ArcGIS 10.4, ESRI, Redlands, CA, USA) for the vegetation community type modelling.
2.3. Inputs of GBM Classifier
2.3.1. Geomorphological Variables
A detailed topographic survey was conducted for the study area by Geoscience Australia in 2014 using airborne Light Detection and Ranging (LiDAR). A 1-m DEM (digital elevation model) with a vertical accuracy of 0.15 m was built from the LiDAR 3-D point cloud model [45]. To reduce the computation time, using bilinear interpolation, we resampled the 1-m DEM to a 5-m DEM following References [46], which found that a resolution of 5 m for LiDAR surface models best balances the classification performance and computational challenges posed by large land-area assessments. From the 5-m DEM, we derived a range of primary and secondary topographic metrics using the GradientMetrics tool (available from https://github.com/jeffreyevans/GradientMetrics) developed for ArcGIS. The primary variables include landform and COV, and the secondary variables include CTI:
- CTI: Compound Topographic Index, a steady state wetness index [47];
- Landform: surface curvature (concavity/convexity) index [48];
- COV: the coefficient of variation of elevation within a 100 m × 100 m window; and
- LDFG: local deviation from a 100 m × 100 m global window.
Since flow is a key driver for floodplain vegetation distribution [49], we computed the cost distance: the Euclidean distance (m) to streams and rivers weighted by elevation. These variables are related to landscape shape and position and are the main determinants of inundation [47,49]. We also computed the same geomorphological variables from the 1-arc second Hydrologically Enforced DEM (from Geoscience Australia: www.ga.gov.au/topographic-mapping/digital-elevation-data.html), referred to as the 30-m geomorphological variables. The actual elevation, which was highly associated with LDFG (Pearson’s r of −0.99), was not included in the modelling. The paired correlation coefficients (Pearson’s r) for the selected predictors are low (Pearson’s r less than 0.50).
2.3.2. Variables derived from Landsat TM and ETM+ Images
1. Inundation Counts
An inundation raster was developed using Landsat images spanning the period of 2000 to 2016. We selected images with lower percentages of cloud cover (cloud cover less than 25%) and with greater areas of inundation (i.e., we selected images from wetter periods) using a model built in ArcGIS. Each image was processed to a binary (water/non-water) raster using the water index developed by Reference [50]. The binary rasters were then summed to produce the inundation count raster.
2. Fractional Cover Polar Statistics
While a single Landsat image can be insufficient for discriminating vegetation types in wetland environments due to seasonal variations in condition [51], studies have shown that a multi-temporal analysis can achieve a relatively accurate classification [52,53]. A time series of the seasonal fractional cover developed from Landsat TM and ETM+ images are available from AusCover (http://www.auscover.org.au). The individual Landsat images were converted to standardised surface reflectance measurements [54] and then combined to produce seasonal composite images, providing four composite images per year. The fractional cover model is applied to the Landsat imagery to predict the fractions of bare ground, green vegetation and nongreen vegetation, and a model fitting error [55].
The time series (1987–2013) of seasonal fractional cover images were used to develop metrics that characterised the variation in green and nongreen vegetation. First, an individual fractional cover image, which encloses the proportion of green vegetation, nongreen vegetation, and bare soil within each pixel (55), was converted into a polar coordinate system, and the fraction of green and nongreen vegetation was expressed as the distance from the origin to the reference point and the polar angle (θ) between the projected line from the origin to the reference point and the positive horizontal axis (green vegetation) (Figure 2). Second, the time series pixel values of the distance, angle, and hop length (defined as the distance between two successive points in the polar space) were used to produce a range of statistics. We selected the following five after a primary assessment of the applicability using simple linear regression.
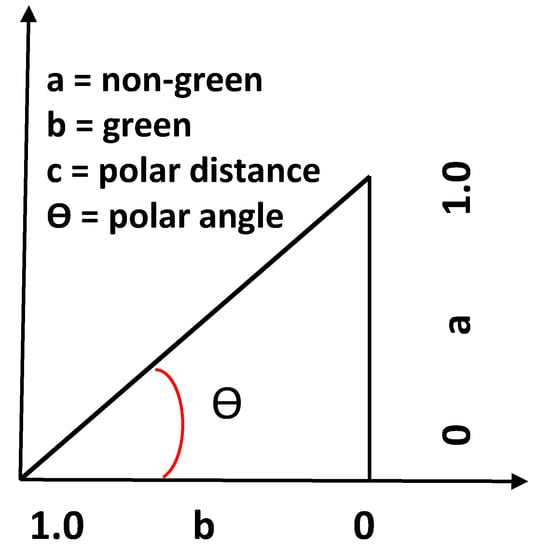
Figure 2.
The projection of fractional data into a polar coordinate system.
- The polar angle median (V1)
- The vector distance median (V2)
- The vector distance maximum (V3)
- The hop length median (V4)
- The skewness in the vector distance based on the statistical distribution of the distance values at a pixel (V5)
We checked the correlation between the predictor variables using the Pearson correlation coefficient. A highly correlated variable was excluded, and the correlations among the remaining predictors are low to moderate (paired Pearson’s |r| ranges from 0.04 between Landform and LDFG to 0.72 between V3 and V4).
2.4. Stochastic Gradient Boosting Machines
We used GBM methodology implemented in the R package “gbm” [56] to build the predictive models for the vegetation community. We built three sets of models, one for each level of wetland class (Table 1). In the GBM algorithm, regression trees are sequentially fitted to residuals to minimize the loss function, after which a new tree is added to the model. Many weak regression trees are combined (by restricting tree depth) in a successive fashion (i.e., boosting) to optimize the predictive performance [57,58]. To avoid overfitting, the contribution of each added tree to the previous iteration’s predicted value is reduced by the learning rate λ.
The dataset was split into training (25% or 14,259 samples) and testing (75% or 42,746 samples) subsets using stratified random sampling. We used a smaller portion of data for model training to restrain the computing time. Moreover, we deliberately used most samples as a testing dataset to examine the stability of the trained models. With the training dataset, a 5-fold repeated (5 times) cross-validation method was used for the model tuning.
GBM has four hyperparameters to optimize: number of trees, learning rate, tree complexity, and minimum number of observations. In searching for the best model, we fixed the minimum number of observations to be 10 and let the other three vary: tree depth could be 1, 3, 5, or 7; the learning rate could be 0.01, 0.03, …, or 0.1; and the number of trees could be 100, 150, …, or 500. The GBM models were fitted to all combinations of the three hyper-parameters, and the optimal model was selected on the basis of overall accuracy (OAA).
2.5. Accuracy Assessment and Model Comparison
We report four indicators to compare the performance of the models: OAA, balanced accuracy (BA), Kappa coefficient of agreement, and AUC (Area Under the Receiver Operating Characteristic curve, or ROC Curve). As the dataset is highly unbalanced (Table 1), BA, which is calculated as the mean of Sensitivity and Specificity and conceptually defined as the average accuracy obtained on all classes, might provide a better indicator of the model performance.
To assess the value of the Landsat variables (i.e., inundation prevalence value and polar statistics of fractional cover time series), three GBMs were fitted using the above procedures: M1 with all predictor variables; M2 fitted with only topographic variables; and M3 fitted with only Landsat variables. In addition, to evaluate the freely available 1-s SRTM (Shuttle Radar Topography Mission) DEM in vegetation community classification, we built predictive models with the 30-m geomorphological variables and Landsat variables (M4) and the 30-m geomorphological variables only (M5). All predictor variables were normalized before model fitting.
For each of the five models, the variable influence for the decision tree ensembles was computed based on the decision trees influences [59] using the method proposed by Reference [60]. To facilitate a comparison, we scaled the total influence to be 100 and calculated the relative importance of every variable.
The performance of the five models was evaluated in two ways. First, a permutation t-test implemented in the R package “perm” [61] was conducted for the final train model performance metrics (i.e., OAA and Kappa). Permutation tests are a class of widely applicable nonparametric tests. They use random shuffles of the data to get the correct distribution of a test statistic under a null hypothesis [62]. Second, we compared and ranked the performance of the five models using the testing sub-dataset. McNemar’s test [63], which is nonparametric and based on the model error matrices, was used to test the significance in the difference of model performance. The difference in accuracy for a pair of classifications is considered as being statistically significant at the 95% confidence level if the z-score is larger than 1.96 in the McNemar test. This test has previously been used to compare the accuracies of two or more classifications [64] and is known for its efficiency in comparing classification accuracies [65]. The difference was also tested using a paired permutation t-test based on 100 resamples of the final models for each of three performance criteria.
3. Results
3.1. Model Performance
3.1.1. Level 1 Models
The training model performance metrics for the Level 1 models are shown in Figure 3. The performances of Level 1 models M1 and M4 were superior to all other models. The model rank from highest to lowest values of Kappa and OAA was M1, M4, M3, M2, and M5 (Figure 3). The difference in accuracy between M1 and M4 was insignificant through a comparison of the box and whiskers in Figure 3. This was confirmed by the paired permutation t-tests on OOA between M1 and M4 (mean p = 0.822 with 99% confidence interval of 0.741 and 0.903 based on 999 Monte Carlo replications). The difference between all other pairs was significant (p ranges from 0.000 to 0.002). The model evaluation based on Kappa showed similar results.
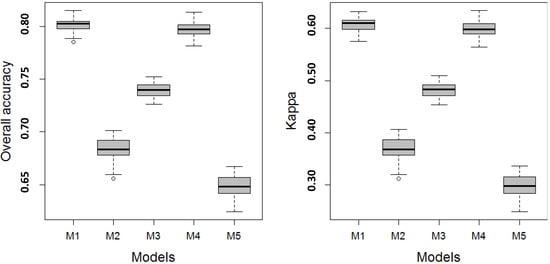
Figure 3.
The metrics shown as boxplots of overall accuracy (OAA) and Kappa for Level 1 vegetation classes were based on a resampling of the final model ensemble (n = 100). The boxplots convey the median (dark line), the lower (25%) and upper (75%) quartiles (boxes), and the minimum and maximum (whiskers). The outliers are indicated by circles.
The predictive power of the models was evaluated using the testing dataset, and they ranged from fair to substantial (Table 2). Model M1, which used both Landsat based variables and geomorphological metrics computed from the 5-m LiDAR DEM achieved the highest overall accuracy of 83.73%. Model M4, which used the 30-m geomorphological variables and Landsat variables ranked second (OAA 83.27%). There was no significant difference between these two models, and the accuracy was considered substantial based on Kappa [66]. Model M5, which used only the 30-m geomorphological predictors, had the worst performance with an overall accuracy of 70.72%. With AUC greater than 0.70, all five models but M5 were assessed as acceptable for conservation purposes [67].
Table 2.
The prediction accuracy of Level 1 models using the testing dataset, which is independent to the training dataset.
Using the overall correctly and erroneously predicted cases as a two-dimensional contingency table, we examined the difference in model performance using the nonparametric McNemar’s test. While Model M1 was slightly better than Model M4, the difference was not significant (McNemar’s chi-squared = 2.429, df = 1, p = 0.119). The other paired tests were all significant (p < 0.001).
3.1.2. Level 2 Models
The training model performance metrics for the Level 2 models are shown in Figure 4. Like the Level 1 models, the performances of Level 2 models M1 and M4 were superior to all other models. The model ranking from highest to lowest values of Kappa and OAA was M1, M4, M2, M3, and M5 (Figure 4). The difference in accuracy between M1 and M4 was insignificant by visually comparing the box and whiskers in Figure 3. The nonsignificant difference in model performance was confirmed by the paired permutation t-tests on OOA and Kappa between M1 and M4 (p = 0.336 and 0.246 for the OOA and Kappa comparisons, respectively). The difference between all other model pairs was significant (p < 0.01).
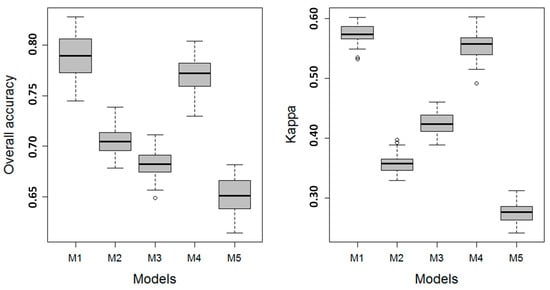
Figure 4.
The metrics shown as boxplots of overall accuracy (OAA) and Kappa for Level 2 vegetation classes were based on a resampling of the final model ensemble (n = 100). The boxplots convey the median (dark line), the lower (25%) and upper (75%) quartiles (boxes), and the minimum and maximum (whiskers). The outliers are indicated by circles.
The ranking of the models based on predictive power followed the same order as that suggested by the training metrics (Table 3). Model M1 achieved the highest overall accuracy of 79.57%, which was noticeably but not significantly different to the accuracy of Model M4 at 78.92% (Figure 3). Using the overall rightly and wrongly predicted cases, the paired McNemar’s test confirmed that there was no significant difference between M1 and M4 (McNemar’s chi-squared = 1.768, df = 1, p = 0.184), but the difference was significant for all other paired tests (p-values ranged from 0.000 to 0.007). Model M5, again, had the lowest overall accuracy at 64.00%.
Table 3.
The prediction accuracy of Level 2 models using the testing dataset, which is independent to the training dataset.
Based on Kappa coefficients, models M1 and M4 were considered substantial, M2 and M3 were moderate, and M5 was fair (Table 3). With AUC less than 0.70, Models M2, M3, and M5 were considered unacceptable for conservation purposes [67]. With balanced accuracies greater than or close to 80% for all classes, M1 and M4 achieved a satisfactory vegetation classification (Table 3).
For the best performing model, M1, we compared the discriminative power of the model for each of the vegetation classes using the paired McNemar’s test. While the model had a comparable predictive capacity for flood-dependent woody wetlands and non-flood-dependent terrestrial systems (McNemar’s chi-squared = 1.792, df = 1, p = 0.181), the discriminative power was significantly lower for grassy and shrub dominated wetlands (p < 0.001). For the least accurately classified flood-dependent shrub-dominated wetlands, the confusion was mainly due to a difficulty in separating them from terrestrial communities and flood-dependent woodlands (i.e., there was less confusion between grasslands and shrublands). For grassy wetlands, however, the misclassification was mainly due to the erroneous allocation of forest/woodland wetlands into the target classes.
In order to test the difference in discriminative power between Level and Level 2 paired models, we again used McNemar’s test. The results indicated that the models for level two classification had significantly lower discriminative power (p < 0.001) for each pair, except for M4, which had a comparable performance for both levels (McNemar’s chi-squared = 1.455, df = 1, p = 0.228).
3.1.3. Level 3 Models
The performance metrics for the Level 3 training models are shown in Figure 5. The performance ranking was M1, M4, M3, M2, and M5 (Figure 5). For M1 and M4, which the performances of were comparable for the Level 1 and Level 2 classes, the performances were significantly different for the Level 3 classes (permutation t-tests, p = 0.01 and 0.004 for Kappa coefficient and OAA, respectively). Nevertheless, the prediction performance of the two models was similar according to McNemar’s test using the total correctly and wrongly allocated cases as contingency table (McNemar’s chi-squared = 2.429, df = 1, p-value = 0.119). The permutation t-tests indicated the performance differences between the remaining models was significant for all paired comparisons.
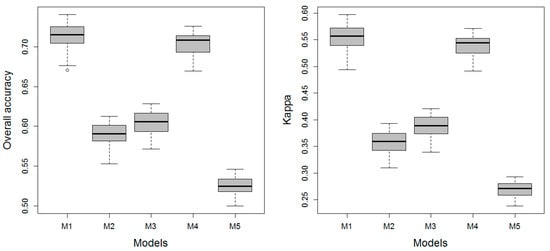
Figure 5.
The metrics shown as boxplots of overall accuracy (OAA) and Kappa for Level 3 vegetation classes were based on a resampling of the final model ensemble (n = 100). The boxplots convey the median (dark line), the lower (25%) and upper (75%) quartiles (boxes), and the minimum and maximum (whiskers). The outliers are indicated by circles.
The Kappa coefficients showed that M1 and M4 had a substantial predictive power, and the performance of M2 and M3 was moderate, whereas M5 was considered fair (Table 4). Both M1 and M4 were considered acceptable based on AUC [67] (Table 4). These performance assessments were the same as the results reported for the Level 2 models, indicating a limited debilitation of the model performance when increasing the number of classes from four to nine.
Table 4.
A summary of the Level 3 model prediction power, using testing dataset.
There are nine wetland types in the Level 3 classification. Although assessed as having a substantial discriminative capacity, the top two models (M1 and M4) achieved satisfactory results for only four of the seven classes based on the producer’s and user’s accuracy, namely River Red Gum forests, lignum dominated shrublands, inland floodplain swamps, and terrestrial class (Table 4). The models were particularly efficient for River Red Gum forests with over 75% user’s and producer’s accuracy (Table 4). However, the models were ineffective in distinguishing Black Box woodlands, Coolibah woodland, and Nitre Goosefoot-dominated shrublands from other classes. For Black Box woodlands, apart from being misclassified as non-flood-dependent uplands, the confusion within the same functional group was the largest source of error. Out of the 753 cases of Black Box woodland, 304 and 324 were classed as other woodlands by M1 and M4, respectively. For the two types of shrub-dominated wetlands, however, the confusion mainly came from forest/woodland (both Black Box woodlands and other forest/woodland types) and the terrestrial (non-wetland) class.
The paired McNemar’s tests indicated that the models for Level three classification had a significantly lower discriminative power than those for Level two (p < 0.001).
3.2. Relative Variable Influence
Although the relative importance of variables varied among models for different vegetation levels, the changes were marginal and the ranks of predictor importance generally remained consistent. In addition, the rank of variables in simpler models (i.e., with less predictors) largely stayed the same in the more complicated models. To illustrate, we determined the relative variable influence for the two more complicated models for Level 2 wetland vegetation classes (Figure 6). Generally, both topographic variables and multispectral indices computed from satellite imagery were important in a successful wetland vegetation classification (the relative contribution of topographic predictors was 55.34% and 47.45% for M1 and M4, respectively (Figure 6).
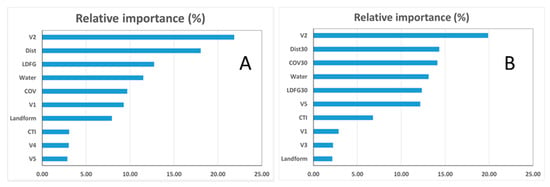
Figure 6.
The relative influence of variables in Model M1 (A) and Model M4 (B) for Level 2 wetland types: The importance scores are scaled so that the total is 100.
For both models, V2, a measure of the long-term mix of green and dead components within a grid, was the most important predictor for floodplain wetland classification (21.86% and 19.90 % for M1 and M4 respectively, Figure 5). The cost distance (calculated as the Euclidean distance to streams and rivers weighted by elevation), a hydro-geomorphic variable that quantifies the flood potential of a location, was the second most influential predictor. LDFG, the topographic metric describing the local deviation from global in elevation, ranked the third as an important predictor for M1 (a similar topographic variable, COV, the coefficient of variation in elevation within a 100 m × 100 m, was the third for M4). Other important predictors (in order of relative importance) included COV, V3, Landform, and V5. For M4, COV, the coefficient of variation in elevation within a 100 m × 100 m window, was the second important predictor. Other important predictors included the inundation counts (ranked 4th in both models), V1, CTI, and V5 (Figure 5).
4. Discussion
4.1. The Discriminative Limits of Predictive Models Using Landsat and DEM-Derived Predictors
We evaluated the final models using a much larger (5.56 times more) independent samples. The performance criteria (i.e., Kappa, OAA, BA, and AUC) calculated from the testing results were comparable to those of the training models, suggesting there was little concern of overfitting. The stable predictive performance was achieved as a result of the multiple 10-fold cross-validation model tuning process.
As our objective is to investigate the discriminative limit of statistical learning, the discussion was focused on the best models. Although the prediction of the models was considered as acceptable based on the performance metrics (i.e., Kappa and AUC, [66,67], the overall accuracy of our models was less than that reported in previous studies using a similar approach. For example, using a phenological metric extracted from long-term Landsat images [68] was able to discriminate a wetland forest from an upland forest with high accuracy (88.5%). However, the performance declined significantly when the number of vegetation types increased to 3 (82.2%). Similarly, Reference [53] mapped the land cover of Chile using the time series of Landsat images and SRTM DEM with an overall accuracy of 80%, 73%, and 59% for the Level 1 (10 classes), 2 (30 classes), and 3 (35 classes) classification schemes. There are a number of possible reasons for the relative underperformance of our study. First, the misclassification in the original vegetation map may increase the errors as the modelling performance is also dependent on the accuracy of reference data [69]. For models at all levels, the majority of the confusion came from the misallocation of non-wetland into the targeting classes. For example, out of the 11,718 non-wetland testing samples, the Level one model incorrectly classified 1551, 664, and 516 as flood dependent woodlands, flood-dependent shrublands, and semipermanent grassy wetlands, respectively. In the semiarid Barwon-Darling catchment, many wetlands, especially the riparian forests and grass-dominated wetlands, are small or narrow, formed in a variety of landforms (Figure 1). The hydrology in these wetlands is affected by small changes in elevation [70], complicating their identification. In many cases, the vegetation communities of the drier wetlands (such as lignum dominated swamps) are not dramatically different at wetland boundaries from the adjacent uplands, making wetland demarcation even more difficult. Second, a class imbalance can adversely impact the performance of a predictive model [71]. In our study, more than 50% of the data points were non-wetland resulting from the random stratified sampling as a large portion (>50%) of the floodplain was mapped as arid shrublands and semiarid woodlands, which was classified as terrestrial (Table 1). Although resampling methods (such as up-sampling or down-sampling) can quickly deal with the problem of unbalanced samples, they give more importance to the data in the majority class and neglect potentially important data in the minority class, thus limiting the effectiveness and repeatability of classification [72]. Class imbalance remains an issue in machine learning research [71].
As expected, the overall performance of models decreased with increasing wetland classes. The functional group level model (four classes, Table 1) was considered as substantial based on the Kappa coefficient (Kappa = 0.76 and 0.75 for training and testing, respectively) achieved an OAA of 79.57%. Although the performance of the Level 3 model (with Nine classes) was also high with an OAA of 76.57%, the discriminative powers for the individual classes varied and was considered as lower for black box woodlands, other woodlands, Nitre Goosefoot Shrublands, and other shrublands based on the user’s and producer’s accuracy (Table 4). The difficulty arises because of the similarity in the spectral reflectance properties of the vegetation communities with a comparable structure and physiognomy [5]. The temporal changes in the community composition could also contribute to the misclassification. Seed banks in a semiarid Australian floodplain are very persistent and capable to respond quickly to the unpredictable rainfall events [18,73]. During an over-three-decades-long study period, the vegetation community in some areas may undergo fundamental changes and transit from one PCT to another. For example, water couch (wetland species) can colonize chenopod shrublands (terrestrial community) rapidly and at a large spatial scale in wet conditions [74] and authors’ field observation]. Despite the decrease in OAA with the increase of wetland classes, the models at all levels were highly effective to distinguish terrestrial uplands, and the paired McNemar’s tests suggested that there was no significant difference in the performance of the models in terms of isolating the terrestrial vegetation from wetlands (balanced accuracy was 86.09%, 82.06%, and 81.77% for the Level 1, 2, and 3 models). Also, grass-dominated swamps were also discriminated adequately, and the prediction power did not decline significantly with increasing wetland classes. In addition, our approach had a high discriminative power in isolating the Riparian River Red Gum Forest from other types of wetlands (producer’s and user’s accuracies were 79.23% and 75.16%, respectively, Table 4), although they only occupied a small portion of the floodplain (1.61%, Table 1).
Hyperspectral remote sensing imagery (e.g., HyMap, CASI, and Hyperion) provide a promising tool to distinguish these underperformed wetland types [5,75]. For example, combining aerial photography, hyperspectral imagery, and LiDAR [26] produced a detailed vegetation map (11 classes) with an overall accuracy of 91.1% and Kappa value of 0.89 in a portion of the central Florida Everglades. However, substantial challenges to using the hyperspectral data, such as a high cost, a large data volume, and the complexity of image processing (therefore, long processing time and specialized software), have restricted their widespread application. For these reasons, hyperspectral data are not used operationally for wetland mapping other than for particularly difficult problems, such as the discrimination of vegetation species (e.g., types of mangroves, [76]).
4.2. The Importance of Integrating Geomorphological Variables in Floodplain Vegetation Mapping
As hydrological features, the distribution of wetlands (and the vegetation communities within them) is clearly in part controlled by topography and landscape position [77]. Consequently, a number of researchers investigated the value of topographic variables for wetland mapping (for examples, see References [78,79,80,81]). In agreement with these studies, our results showed that topographic metrics are indeed valuable for mapping wetland types at the three tested wetland class levels: the OAA increased 5.3%, 10.3%, and 9.0% by integrating LiDAR DEM-derived geomorphologic variables for the Level one, two, and three predictive models, respectively. Furthermore, these improvements were significant for both the training and testing results indicated by the nonparametric McNemar’s test. Nevertheless, the performance of the models using geomorphological variables alone was less satisfactory, and OAA (and other performance criteria) decreased for more detailed classification. It should be noted that LiDAR generates rich data about the structure of the vegetation community, such as canopy height, which have been successfully applied in wetland vegetation mapping (e.g., in Reference [82]). In this study, we only used the DEM, and did not explore the full potential of the LiDAR data.
As with the geomorphologic variables derived the more detailed LiDAR DEM, we found that geomorphologic variables computed from SRTM DEM were also useful for enhancing the models’ discrimination power. The OAA increased 4.86%, 9.62%, t and 8.41% for the Level one, two, and three models, respectively. More importantly, we found no significant difference in the overall accuracies of the models using the finer 5-m LiDAR DEM and those using the coarser 30-m SRTM DEM, albeit the collective contribution of topographic variables was much smaller for the coarser SRTM DEM. This may be due to the incomparable spatial resolution between the LiDAR DEM and the Landsat, which exerted a greater influence on the model performance. Nevertheless, References [79,83] also reported that the source of elevation data and the type of topographic derivatives used in wetland classification were not major factors. This is a significant finding considering the great coverage of the freely available SRTM DEM. For example, the 30-m SRTM DEM is available for all of Australia while only a fraction has LiDAR coverage (3.14%, [45]). However, the models using coarse geomorphological variables alone were evaluated as inadequate to distinguish wetland types at all levels based on Kappa statistics.
A variety of terrain variables have been used in wetland mapping. Although many studies have demonstrated the value of geomorphologic variables, there are some inconsistence in the assessment of the specific metrics. For example, References [79] found that the primary metric slope was important for differentiating palustrine wetlands from uplands in Yellowstone National Park, USA, and the secondary metric CTI was of comparatively little value. In contrast, CTI is the key variable for discriminating wetlands from uplands in Minnesota, USA [34]. Reference [80] found that both the primary (surface curvature) and secondary (CTI) metrics were similarly valuable for modelling wetland types. The inconsistency maybe be due to the scale of the study and the degree of landscape heterogeneity. Of the six derived geomorphological metrics, we found that LDFG, a primary metric quantifying the topographic position of the focus cell [84], was the most important one. LDFG is capable of distinguishing the subtle changes in complex landscapes [85] and, therefore, might be suitable for the floodplains, which are very flat and relatively fragmented resulting from flow regulation. Another variable, the elevation-weighted distance from stream, also had a considerable contribution to differentiating wetland types. On the other hand, we found that the commonly used secondary indices (i.e., CTI) had limited influence on the performance of the models, with a relative importance less than 5%. Additional researches should be carried out to explore the relative merit of these variables for mapping wetlands in geographic settings such as coastal regions.
5. Conclusions
A detailed vegetation map is needed for wetland conservation and restoration as different vegetation communities may have distinct requirements such as flow regimes. It is a continuous challenge to map the distribution of different wetland types on a regional scale, and a trade-off between categorical details and the availability of resources to ensure broad applications is often necessary for operational mapping. A number of studies have demonstrated the value of topographic variables [34,35,81] and multitemporal satellite images [52,53] in mapping wetland at site and regional scale. In this study, we have evaluated the capacity and performance of statistical learning in discriminating wetland types using a freely available Landsat time series and geomorphological variables computed from LiDAR and STRM DEM. Our study showed that there was a discrimination limit of statistical learning with the Landsat time series and geomorphological variables in wetland mapping. The approach was clearly inadequate in distinguishing certain wetland types, which are often located at the boundaries of drier wetlands. In semiarid Australia, our results suggested that the appropriate level for floodplain wetland mapping included four classes: tree-dominated forests and woodlands, shrublands, vegetated swamps, and non-flood-dependent terrestrial communities. Our results also demonstrated that the geomorphological metrics significantly improved the accuracy of wetland classification. Furthermore, geomorphological metrics derived from the freely available coarser resolution STRM DEM were as beneficial for wetland mapping as those extracted from the finer scale LiDAR DEM. The findings enable the widespread application of our approach as both data sources are freely available globally.
Author Contributions
Conceptualization, L.W. and M.P.; methodology, L.W., M.P., T.D.; software, L.W., G.H.; validation, L.W.; formal analysis, L.W., M.P.; investigation, M.P., G.H., T.D., J.L., M.H. and L.W.; writing—original draft preparation, M.P. and L.W.; writing—review and editing, M.P., G.H., T.D., J.L., M.H. and L.W.; visualization, L.W.; supervision, M.H.
Funding
The study was partially funded by NSW OEH Wetland Inventory: Pilot Study.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gibbs, J.P. Wetland loss and biodiversity conservation. Conserv. Biol. 2000, 14, 314–317. [Google Scholar] [CrossRef]
- Georgiou, S.; Turner, R.K. Valuing Ecosystem Services: The Case of Multi-Functional Wetlands; Routledge: New York, NY, USA, 2012. [Google Scholar]
- Mitch, W.J.; Gosselink, J.G. Wetlands, 4th ed.; Wiley & Sons: Hoboken, NJ, USA, October 2008. [Google Scholar]
- Rebela, L.M.; Finlayson, C.M.; Nagabhatla, N. Remote Sensing and GIS for wetland inventory, mapping and change analysis. J. Environ. Manag. 2009, 90, 2144–2153. [Google Scholar] [CrossRef] [PubMed]
- Adam, E.; Mutanga, O.; Rugege, D. Multispectral and hyperspectral remote sensing for identification and mapping of wetland vegetation: A review. Wetl. Ecol. Manag. 2010, 18, 281–296. [Google Scholar] [CrossRef]
- Lehner, B.; Doll, P. Development and validation of a global database of lakes, reservoirs and wetlands. J. Hydrol. 2004, 296, le22. [Google Scholar] [CrossRef]
- Jones, K.; Lanthier, Y.; van der Voet, P.; van Valkengoed, E.; Taylor, D.; Fernandez-Prieto, D. Monitoring and assessment of wetlands using Earth Observation: The GlobWetland project. J. Environ. Manag. 2009, 90, 2154–2169. [Google Scholar] [CrossRef] [PubMed]
- Johnston, R.M.; Barson, M.M. Remote sensing of Australian wetlands: An evaluation of Landsat TM data for inventory and classification. Mar. Freshw. Res. 1993, 44, 235–252. [Google Scholar] [CrossRef]
- Merot, P.; Squividant, H.; Aurousseau, P.; Hefting, M.; Burt, T.; Maitre, V.; Kruk, M.; Butturini, A.; Thenail, C.; Viaud, V. Testing a climato-topographic indiex for predicting wetlands distribution along a European climate gradient. Ecol. Model. 2003, 163, 51–71. [Google Scholar] [CrossRef]
- Curie, F.; Gaillard, S.; Ducharne, A.; Bendjoudi, H. Geomorphological methods to characterise wetlands at the scale of the Seine watershed. Sci. Total Environ. 2007, 375, 59–68. [Google Scholar] [CrossRef]
- MacAlister, C.; Mahaxay, M. Mapping wetlands in the Lower Mekong Basin for wetland resource and conservation management using Landsat ETM images and field survey data. J. Environ. Manag. 2009, 90, 2130–2137. [Google Scholar] [CrossRef]
- Finlayson, C.M.; Davidson, N.C.; Spiers, A.G.; Stevenson, N.J. Global wetland inventory–current status and future priorities. Mar. Freshw. Res. 1999, 50, 717–727. [Google Scholar] [CrossRef]
- Zedler, J.B.; Kercher, S. Wetland resources: Status, trends, ecosystem services, and restorability. Annu. Rev. Environ. Resour. 2005, 30, 39–74. [Google Scholar] [CrossRef]
- Brinson, M.M.; Bradshaw, H.D.; Kane, E.S. Nutrient assimilative capacity of an alluvial floodplain swamp. J. Appl. Ecol. 1984, 21, 1041–1057. [Google Scholar] [CrossRef]
- Bernal, B.; Mitsch, W.J. Comparing carbon sequestration in temperate freshwater wetland communities. Glob. Chang. Biol. 2012, 18, 1636–1647. [Google Scholar] [CrossRef]
- Maltby, E.; Barker, T. (Eds.) The Wetlands Handbook, 2 Volume Set; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Zedler, J.B. Progress in wetland restoration ecology. Trends Ecol. Evol. 2000, 15, 402–407. [Google Scholar] [CrossRef]
- Capon, S.J.; Brock, M.A. Flooding, soil seed bank dynamics and vegetation resilience of a hydrologically variable desert floodplain. Freshw. Biol. 2006, 51, 206–223. [Google Scholar] [CrossRef]
- Follner, K.; Henle, K. The performance of plants, molluscs, and carabid beetles as indicators of hydrological conditions in floodplain grasslands. Int. Rev. Hydrobiol. 2006, 91, 364–379. [Google Scholar] [CrossRef]
- Honsova, D.; Hejcman, M.; Klaudisova, M.; Pavlu, V.; Kocourkova, D.; Hakl, J. Species composition of an alluvial meadow after 40 years of applying nitrogen, phospohorus and potassium fertilizer. Preslia 2007, 79, 245–258. [Google Scholar]
- Junk, W.J.; Piedade, M.T.F.; Schöngart, J.; Cohn-Haft, M.; Adeney, J.M.; Wittmann, F.A. Classification of major naturally-occurring Amazonian lowland wetlands. Wetlands 2011, 31, 623–640. [Google Scholar] [CrossRef]
- Küchler, A.W. The classification of vegetation. In Vegetation Mapping; Springer: Dordrecht, The Netherlands, 1988; pp. 67–80. [Google Scholar]
- Ridgeway, G. Package ‘GBM’: Generalized Boosted Regression Models; R Package Version 2.1.3; Scientific Research: Wuhan, China, 2013. [Google Scholar]
- Schmidt, K.S.; Skidmore, A.K. Spectral discrimination of vegetation types in a coastal wetland. Remote Sens. Environ. 2003, 85, 92–108. [Google Scholar] [CrossRef]
- Shaw, G.A.; Burke, H.K. Spectral imaging for remote sensing. Linc. Lab. J. 2003, 14, 3–28. [Google Scholar]
- Zhang, C.; Selch, D.; Cooper, H. A Framework to Combine Three Remotely Sensed Data Sources for Vegetation Mapping in the Central Florida Everglades. Wetlands 2016, 36, 201–213. [Google Scholar] [CrossRef]
- Gómez-Chova, L.; Tuia, D.; Moser, G.; Camps-Valls, G. Multimodal classification of remote sensing images: A review and future directions. IEEE 2015, 103, 1560–1584. [Google Scholar] [CrossRef]
- Joshi, N.; Baumann, M.; Ehammer, A.; Fensholt, R.; Grogan, K.; Hostert, P.; Jepsen, M.R.; Kuemmerle, T.; Meyfroidt, P.; Mitchard, E.T.; et al. A Review of the Application of Optical and Radar Remote Sensing Data Fusion to Land Use Mapping and Monitoring. Remote Sens. 2016, 8, 70. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013; Volume 6. [Google Scholar]
- van Beijma, S.; Comber, A.; Lamb, A. Random forest classification of salt marsh vegetation habitats using quad-polarimetric airborne SAR, elevation and optical RS data. Remote Sens. Environ. 2014, 149, 118–129. [Google Scholar] [CrossRef]
- Szantoi, Z.; Escobedo, F.J.; Abd-Elrahman, A.; Pearlstine, L.; Dewitt, B.; Smith, S. Classifying spatially heterogeneous wetland communities using machine learning algorithms and spectral and textural features. Environ. Monit. Assess. 2015, 187, 1–15. [Google Scholar] [CrossRef]
- Lang, M.; McCarty, G.; Oesterling, R.; Yeo, I.Y. Topographic metrics for improved mapping of forested wetlands. Wetlands 2013, 33, 141–155. [Google Scholar] [CrossRef]
- Maxa, M.; Bolstad, P. Mapping northern wetlands with high resolution satellite images and LiDAR. Wetlands 2009, 29, 248. [Google Scholar] [CrossRef]
- Rampi, L.P.; Knight, J.F.; Pelletier, K.C. Wetland mapping in the upper midwest United States. Photogramm. Eng. Remote Sens. 2014, 80, 439–448. [Google Scholar] [CrossRef]
- Tang, Z.; Li, R.; Li, X.; Jiang, W.; Hirsh, A. Capturing LiDAR-Derived Hydrologic Spatial Parameters to Evaluate Playa Wetlands. J. Am. Water Resour. Assoc. 2014, 50, 234–245. [Google Scholar] [CrossRef]
- Fisk, M.C.; Schmidt, S.K.; Seastedt, T.R. Topographic patterns of above-and belowground production and nitrogen cycling in alpine tundra. Ecology 1998, 79, 2253–2266. [Google Scholar] [CrossRef]
- Zelnik, I.; Čarni, A. Distribution of plant communities, ecological strategy types and diversity along a moisture gradient. Community Ecology 2008, 9, 1–9. [Google Scholar] [CrossRef]
- Australian Bureau of Meteorology (BOM). Climate Statistics for Australian Locations. 2008. Available online: http://www.bom.gov.au/climate/averages/tables/cw_070282.shtml (accessed on 26 April 2017).
- Ecological Australia. Vegetation of the Barwon-Darling and Condamine-Balonne Floodplain Systems of New South. Wales: Mapping and Survey of Plant Community Types. Prepared for the Murray Darling Basin Authority; 2015. Available online: https://www.mdba.gov.au/sites/default/files/pubs/MDBA_vegetation_mapping_report_final.pdf (accessed on 12 December 2018).
- Schultz, N.; Gowans, S.; Westbrooke, M. Survey and Mapping of Darling Floodplain Vegetation between Tilpa and Brewarrina; Prepared by the NSW Government Office of Environment and Heritage by Centre for Environmental Management; Federation University Australia: Ballarat, Australia, 2014. [Google Scholar]
- Gowans, S.; Milne, R.; Westbrooke, M.; Palmer, G. Survey of Vegetation and Vegetation Condition of Toorale; Prepared for the NSW Government Office for Environment and Heritage by the Centre for Environmental Management; University of Ballarat: Ballarat, Victoria, Australia, 2012. [Google Scholar]
- OEH, New South Wales. Vegetation Information System: Classification. 2011. Available online: http://www.environment.nsw.gov.au/research/Visclassification.htm (accessed on 17 October 2016).
- PlantNET (The NSW Plant Information Network System). Royal Botanic Gardens and Domain Trust, Sydney. Available online: http://plantnet.rbgsyd.nsw.gov.au (accessed on 5 March 2017).
- Specht, R.L. Vegetation. In Australian Environment, 4th ed.; Leeper, G.W., Ed.; Melbourne University Press: Melbourne, Australia, 1970; pp. 44–67. [Google Scholar]
- Geoscience Australia. Digital Elevation Model (DEM) of Australia Derived from LiDAR 5 Metre Grid. 2016. Available online: http://www.ga.gov.au/metadata-gateway/metadata/record/gcat_89644 (accessed on 24 June 2016).
- Singh, K.K.; Vogler, J.B.; Shoemaker, D.A.; Meentemeyer, R.K. LiDAR-Landsat data fusion for large-area assessment of urban land cover: Balancing spatial resolution, data volume and mapping accuracy. ISPRS J. Photogramm. Remote Sens. 2012, 74, 110–121. [Google Scholar] [CrossRef]
- Moore, I.D.; Gessler, P.E.; Nielsen, G.A.E.; Peterson, G.A. Soil attribute prediction using terrain analysis. Soil Sci. Soc. Am. J. 1993, 57, 443–452. [Google Scholar] [CrossRef]
- McNab, W.H. A topographic index to quantify the effect of mesoscale landform on site productivity. Can. J. For. Res. 1993, 23, 1100–1107. [Google Scholar] [CrossRef]
- Martinez, J.M.; Le Toan, T. Mapping of flood dynamics and spatial distribution of vegetation in the Amazon floodplain using multitemporal SAR data. Remote Sens. Environ. 2007, 108, 209–223. [Google Scholar] [CrossRef]
- Fisher, A.; Flood, N.; Danaher, T. Comparing Landsat water index methods for automated water classification in eastern Australia. Remote Sens. Environ. 2016, 175, 167–182. [Google Scholar] [CrossRef]
- Harvey, K.R.; Hill, G.J.E. Vegetation mapping of a tropical freshwater swamp in the Northern Territory, Australia: A comparison of aerial photography, Landsat TM and SPOT satellite imagery. Int. J. Remote Sens. 2001, 22, 2911–2925. [Google Scholar] [CrossRef]
- Dronova, I.; Gong, P.; Wang, L.; Zhong, L. Mapping dynamic cover types in a large seasonally flooded wetland using extended principal component analysis and object-based classification. Remote Sens. Environ. 2015, 158, 193–206. [Google Scholar] [CrossRef]
- Zhao, Y.; Feng, D.; Yu, L.; Wang, X.; Chen, Y.; Bai, Y.; Hernández, H.J.; Galleguillos, M.; Estades, C.; Biging, G.S.; et al. Detailed dynamic land cover mapping of Chile: Accuracy improvement by integrating multi-temporal data. Remote Sens. Environ. 2016, 183, 170–185. [Google Scholar] [CrossRef]
- Flood, N.; Danaher, T.; Gill, T.; Gillingham, S. An operational scheme for deriving standardised surface reflectance from Landsat TM/ETM+ and SPOT HRG imagery for Eastern Australia. Remote Sens. 2013, 5, 83–109. [Google Scholar] [CrossRef]
- Flood, N. Seasonal composite Landsat TM/ETM+ images using the Medoid (a multi-dimensional median). Remote Sens. 2013, 5, 6481–6500. [Google Scholar] [CrossRef]
- Ridgeway, G. Generalized Boosted Models: A Guide to the Gbm Package. 2007. Available online: http://cran.open-source-solution.org/web/packages/gbm/vignettes/gbm.PDF (accessed on 22 November 2018).
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar]
- Breiman, L.; Freidman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth: Monterey, CA, USA, 1984. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Fay, M.P.; Shaw, P.A. Exact and Asymptotic Weighted Logrank Tests for Interval Censored Data: The interval R package. J. Stat. Softw. 2010, 36, 1–34. [Google Scholar] [CrossRef]
- Proschan, M.; Glimm, E.; Posch, M. Connections between permutation and t-tests: Relevance to adaptive methods. Stat. Med. 2014, 33, 4734–4742. [Google Scholar] [CrossRef]
- McNemar, Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika 1947, 12, 153–157. [Google Scholar] [CrossRef]
- Duro, D.C.; Franklin, S.E.; Dube, M.G. A comparison of pixel-based and object-based image analysis using selected machine learning algorithms for the classification of agricultural landscapes using SPOT-5 HRG imagery. Remote Sens. Environ. 2012, 118, 259–272. [Google Scholar] [CrossRef]
- Schmidt, T.; Schuster, C.; Kleinschmit, B.; Förster, M. Evaluating an Intra-Annual Time Series for Grassland Classification—How Many Acquisitions and What Seasonal Origin Are Optimal? IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 3428–3439. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef]
- Pearce, J.; Ferrier, S. Evaluating the predictive performance of habitat models developed using logistic regression. Ecol. Model. 2000, 133, 225–245. [Google Scholar] [CrossRef]
- Kayastha, N. Application on Lidar and Time Series Landsat Data for Mapping and Monitoring Wetlands. Ph.D. Dissertation, Virginia Polytechnic Institute, Blacksburg, VA, USA, 2014. [Google Scholar]
- Corcoran, J.M.; Knight, J.F.; Gallant, A.L. Influence of multi-source and multi-temporal remotely sensed and ancillary data on the accuracy of random forest classification of wetlands in Northern Minnesota. Remote Sens. 2013, 5, 3212–3238. [Google Scholar] [CrossRef]
- Wen, L.; Macdonald, R.; Morrison, T.; Hameed, T.; Saintilan, N.; Ling, J. From hydrodynamic to hydrological modelling: Investigating long-term hydrological regimes of key wetlands in the Macquarie Marshes, a semi-arid lowland floodplain in Australia. J. Hydrol. 2013, 500, 45–61. [Google Scholar] [CrossRef]
- Chawla, N.V.; Japkowicz, N.; Kotcz, A. Editorial: Special issue on learning from imbalanced data sets. SIGKDD Explor. 2004, 6, 1–6. [Google Scholar] [CrossRef]
- Provost, F. Machine learning from imbalanced data sets 101. In Proceedings of the AAAI’2000 Workshop on Imbalanced Data Sets, Austin, TX, USA, 30 July–1 August 2000; pp. 1–3. [Google Scholar]
- Sims, N.C.; Colloff, M.J. Remote sensing of vegetation responses to flooding of a semi-arid floodplain: Implications for monitoring ecological effects of environmental flows. Ecol. Ind. 2012, 18, 387–391. [Google Scholar] [CrossRef]
- Brock, P.M. The significance of the physical environment of the Macquarie Marshes. Aust. Geogr. 1998, 29, 71–90. [Google Scholar] [CrossRef]
- Hestir, E.L.; Brando, V.E.; Bresciani, M.; Giardino, C.; Matta, E.; Villa, P.; Dekker, A.G. Measuring freshwater aquatic ecosystems: The need for a hyperspectral global mapping satellite mission. Remote Sens. Environ. 2015, 167, 181–195. [Google Scholar] [CrossRef]
- Vaiphasa, C.; Ongsomwang, S.; Vaiphasa, T.; Skidmore, A. Tropical mangrove species discrimination using hyperspectral data: A laboratory study. Estuar. Coast. Shelf Sci. 2005, 65, 371–379. [Google Scholar] [CrossRef]
- Mertes, L.A.; Daniel, D.L.; Melack, J.M.; Nelson, B.; Martinelli, L.A.; Forsberg, B.R. Spatial patterns of hydrology, geomorphology, and vegetation on the floodplain of the Amazon River in Brazil from aremotesensing perspective. Geomorphology 1995, 13, 215–232. [Google Scholar] [CrossRef]
- Wright, C.; Gallant, A. Improved wetland remote sensing in Yellowstone National Park using classification trees to combine TM imagery and ancillary environmental data. Remote Sens. Environ. 2007, 107, 582–605. [Google Scholar] [CrossRef]
- Knight, J.F.; Tolcser, B.P.; Corcoran, J.M.; Rampi, L.P. The effects of data selection and thematic detail on the accuracy of high spatial resolution wetland classifications. Photogramm. Eng. Remote Sens. 2013, 79, 613–623. [Google Scholar] [CrossRef]
- Zlinszky, A.; Mücke, W.; Lehner, H.; Briese, C.; Pfeifer, N. Categorizing wetland vegetation by airborne laser scanning on Lake Balaton and Kis-Balaton, Hungary. Remote Sens. 2012, 4, 1617–1650. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Strager, M.P. Predicting palustrine wetland probability using random forest machine learning and digital elevation data-derived terrain variables. Photogramm. Eng. Remote Sens. 2016, 82, 437–447. [Google Scholar] [CrossRef]
- Wilson, J.P.; Gallant, J.C. Digital terrain analysis. Terrain Anal. Princ. Appl. 2000, 6, 1–27. [Google Scholar]
- Maxwell, A.E.; Warner, T.A. Is high spatial resolution DEM data necessary for mapping palustrine wetlands? Int. J. Remote Sens. 2019, 40, 118–137. [Google Scholar] [CrossRef]
- McGarigal, K.; Tagil, S.; Cushman, S. Surfacemetrics: An alternative to patchmetrics for the quantification of landscape structure. Landsc. Ecol. 2009, 24, 433–450. [Google Scholar] [CrossRef]
- Wen, L.; Powell, M.; Saintilan, N. Landscape position strongly affects the resistance and resilience to water deficit anomaly of floodplain vegetation community. Ecohydrology 2018, 11, e2027. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).