1. Introduction
Remote sensing (RS) researchers have created land cover maps from a variety of data sources, including panchromatic [
1], multispectral [
2], hyperspectral [
3], and synthetic aperture radar [
4], as well as from the fusion of two or more of these data sources [
5]. Using these different data sources, a variety of approaches have also been developed to produce land cover maps. According to the literature, approaches that rely on supervised classifiers often outperform approaches based on unsupervised classifiers [
6]. This is because the classes of interest may not present the clear spectral separability required by unsupervised classifiers [
6]. Maximum Likelihood (ML), Neural Networks (NN) and fuzzy classifiers are classical supervised classifiers. However, there are unsolved issues with these classifiers. ML assumes a Gaussian distribution, which may not always occur in complex remote sensed data [
7,
8]. NN classifiers have a large number of parameters (weights) which require a high number of training samples to optimize particularly when the dimensionality of input increases [
9]. Moreover, NN is a black-box approach that hides the underlying prediction process [
9]. Fuzzy classifiers require dealing with the issue of how to best present the output to the end user [
10]. Moreover, classical classifiers have difficulties with the complexity and size of the new datasets [
11]. Several works have compared classification methods over satellite images, and report Random Forest (RF) and Support Vector Machine (SVM) as top classifiers, in particular, when dealing with high-dimensional data [
12,
13]. Convolutional neural networks and other deep learning approaches require huge computational power and large amounts of ground truth data [
14].
With recent developments in technology, high and very high spatial resolution data are becoming more and more available with enhanced spectral and temporal resolutions. Therefore, the abundance of information in such images brings new technological challenges to the domain of data analysis and pushes the scientific community to develop more efficient classifiers. The main challenges that an efficient supervised classifier should address are [
15]: handling the Hughes phenomenon or curse of dimensionality that occurs when the number of features is much larger than the number of training samples [
16], dealing with noise in labeled and unlabeled data, and reducing the computational load of the classification [
17]. The Hughes phenomenon is a common problem for several remote sensing data such as hyperspectral images [
18] and time series of multispectral satellite images where [
6] spatial, spectral and temporal features are stacked on top of the original spectral channels for modeling additional information sources [
19]. Over the last two decades, the Hughes phenomenon has been tackled in different ways by the remote sensing community [
20,
21]. Among them, kernel-based methods have drawn increasing attention because of their capability to handle nonlinear high-dimensional data in a simple way [
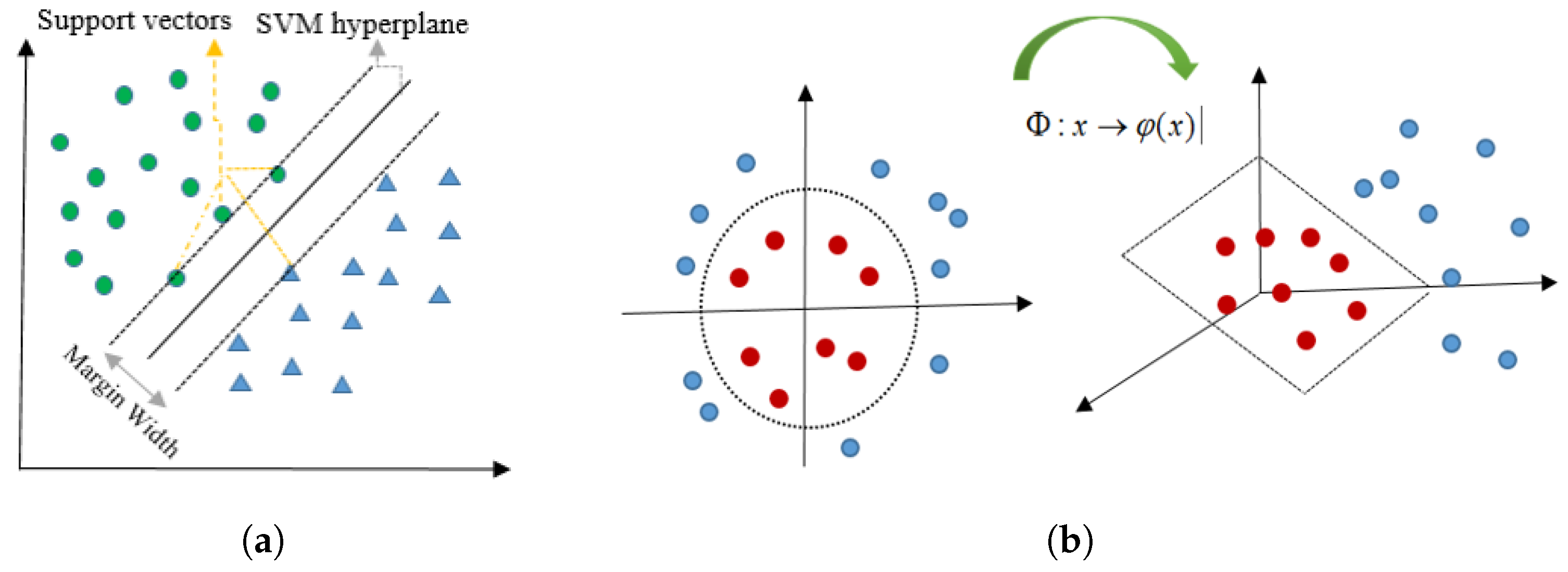
22]. By using a nonlinear mapping function, kernel-based methods map the input data into a Reproducing Kernel Hilbert Space (RKHS) where the data is linearly separable. There is no need to work explicitly with the mapping function because one can compute the nonlinear relations between data via a kernel function. The function kernel reproduces the similarity of the data in pairs in RKHS. In other words, kernel-based methods require computing a pairwise matrix of similarities between the samples. Thus, a matrix is obtained using the kernel function in the classification procedure [
23]. The kernel methods generally show good performance for high-dimensional problems.
SVM as a kernel-based non-parametric method [
24] has been successfully applied for land cover classification of mono-temporal [
25], multi-temporal [
26], multi-sensor [
27] and hyperspectral [
28] datasets. However, the main challenge of the SVM classifier is the selection of the kernel parameters. This selection is usually implemented through computationally intensive cross-validation processes. The most commonly nonlinear kernel function used for SVM is Radial Basis Function (RBF), which represents a Gaussian function. In SVM-RBF classifier, selecting the best values for kernel parameters is a challenging task since classification results are strongly influenced by them. The selection of RBF kernel parameters typically requires to define appropriate ranges for each of them and to find the best combination through a cross-validation process. Moreover, the performance of SVM-RBF decreases significantly when the number of features is much higher than the number of training samples. To address this issue, here we introduce and evaluate the use of a Random Forest Kernel (RFK) in an SVM classifier. The RFK can easily be derived from the results of an RF classification [
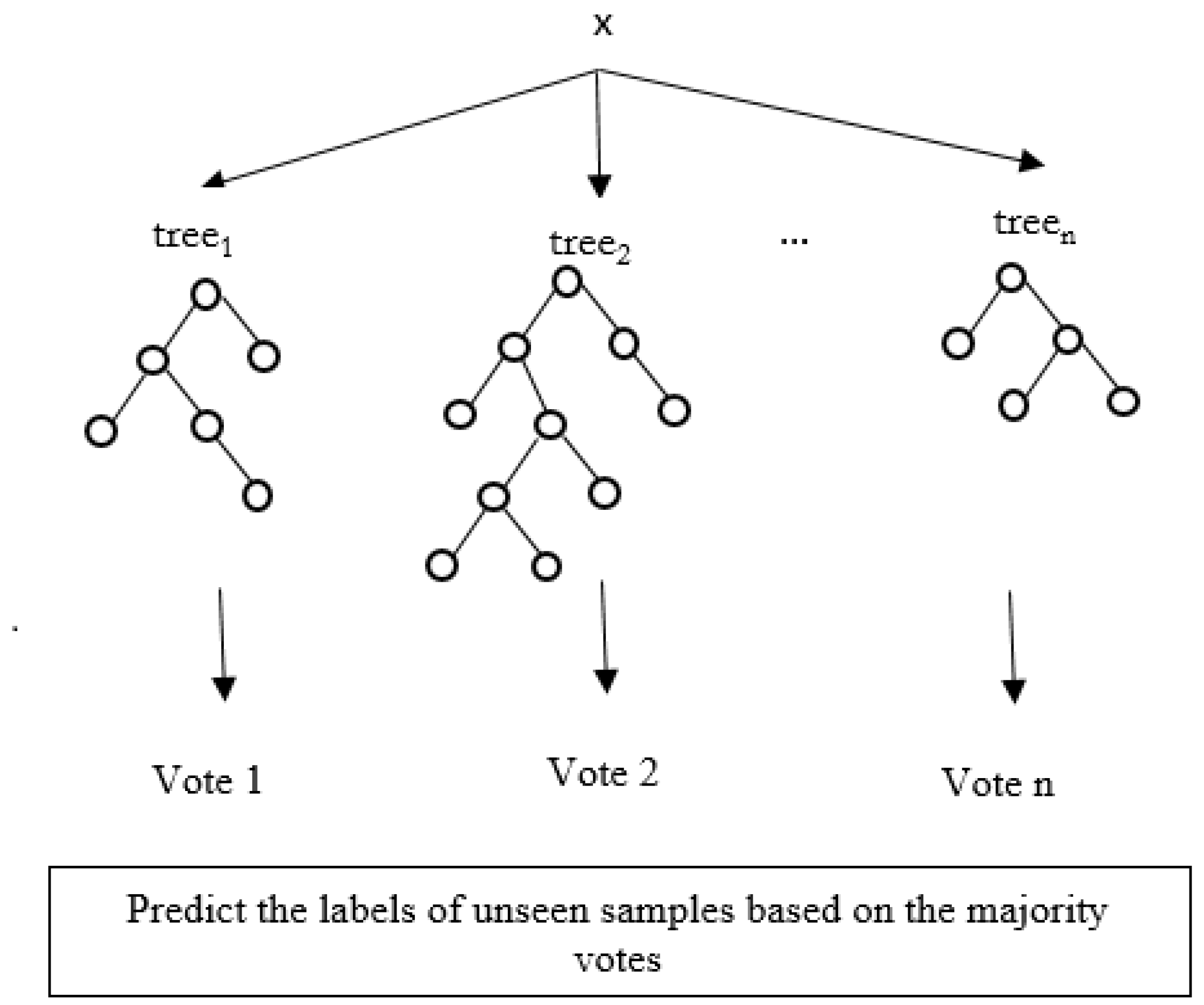
29]. RF is another well-known non-parametric classifier that can compete with the SVM in high-dimensional data classification. RF is an ensemble classifier that uses a set of weak learners (classification trees) to predict class labels [
30]. A number of studies review the use of RF classifier for mono-temporal [
31], multi-temporal [
32], multi-sensor [
33] and hyperspectral [
34] data classification. Compared to other machine learning algorithms, RF is known for being fast and less sensitive to a high number of features, a few numbers of training samples, overfitting, noise in training samples, and choice of parameters. These characteristics make RF an appropriate method to classify high-dimensional data. Moreover, the tree-based structure of the RF can be used to create partitions in the data and to generate an RFK that encodes similarities between samples based on the partitions [
35]. However, RF is difficult to visualize and interpret in detail, and it has been observed to overfit for some noisy datasets. Hence, the motivation of this work is to introduce the use of SVM-RFK as a way to combine the two most prominent classifiers used by the RS community and evaluating whether this combination can overcome the limitations of each single classifier while maintaining their strong points. Finally, it is worth mentioning that our evaluation is illustrated with a time series of very high spatial resolution data and with a hyperspectral image. Both datasets were acquired over agricultural lands. Hence, our study cases aim at mapping crop types.
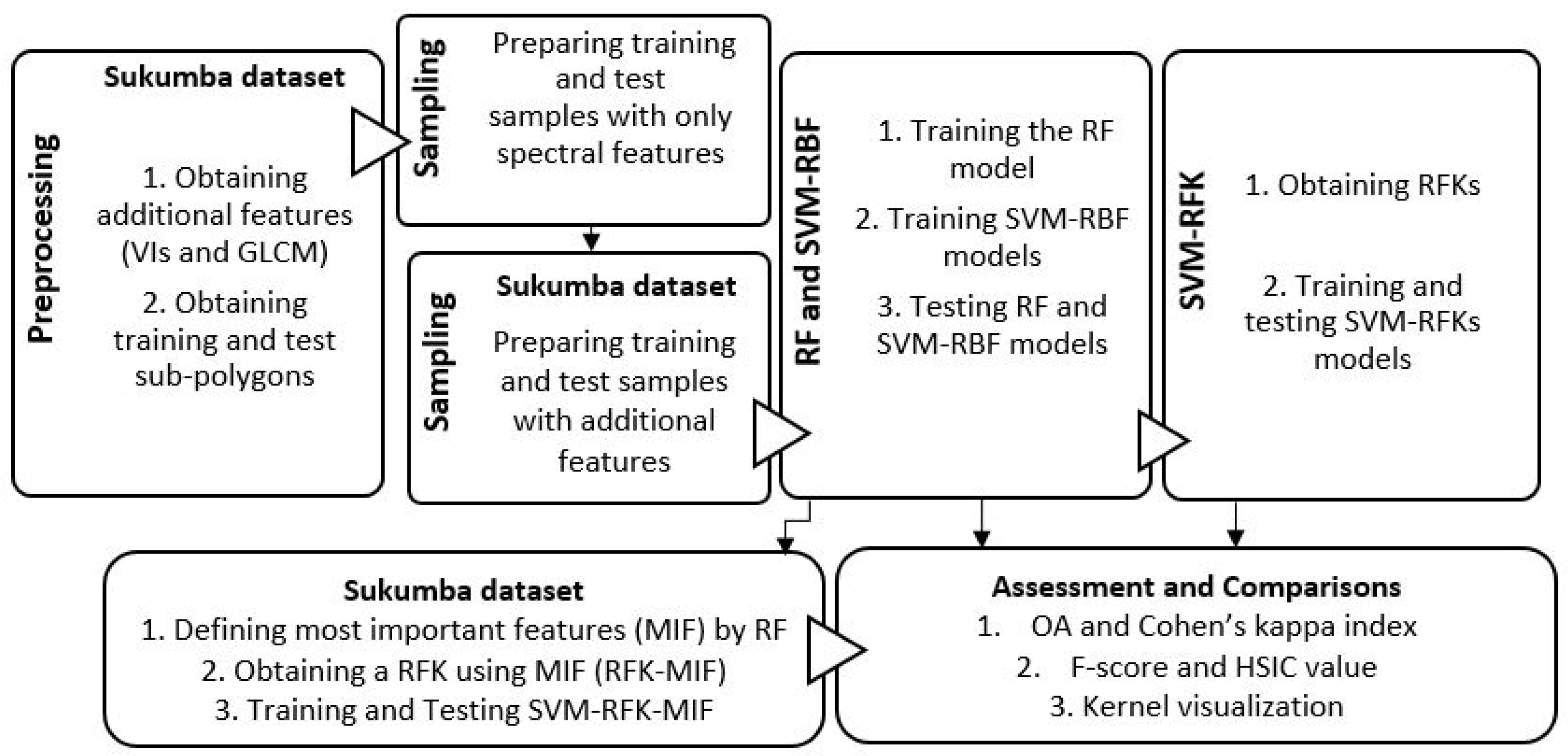
5. Results and Discussion
This section presents the classification results obtained with the proposed RF-based kernels and with the standard RF and SVM classifiers. All results were obtained by averaging the results of the 10 subsets used in each experiment. Results obtained with the default value of mtry are shown with RF and RFK, and those obtained with optimized mtry are shown by RF and RFK.
The OA and
index averages of ten subsets are shown in
Table 3 and
Figure 5. In both cases, Sukumba and Salinas, results show high accuracies for all the classifiers for spectral features. The computational times for each classifier are depicted in
Figure 6.
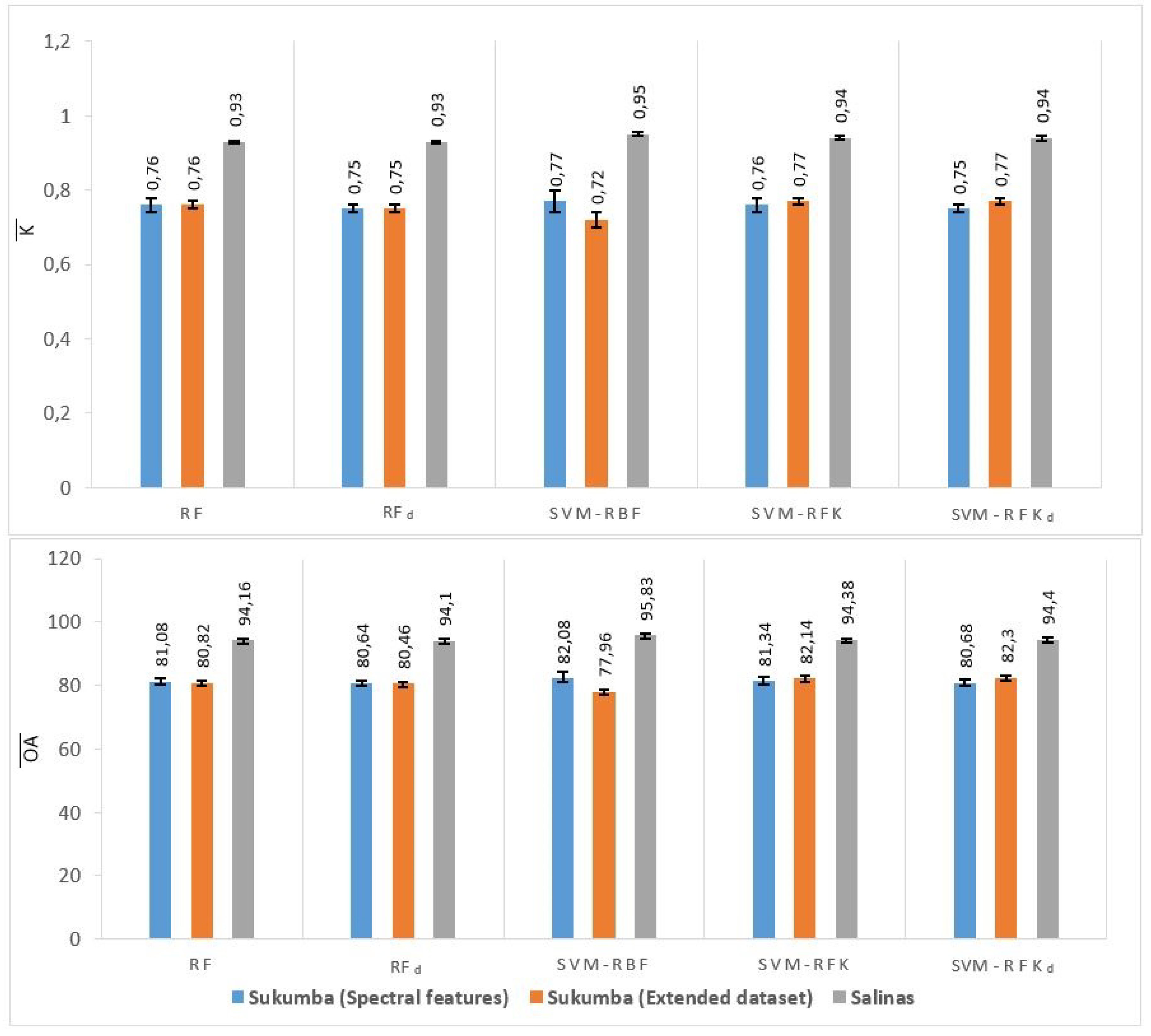
Table 3 and
Figure 5 show that the three classifiers compete closely in the experiments using only spectral features. Comparing SVM-RFK and RF, SVM-RFK improves the results compared to RF in terms of OA and
for all Sukumba and Salinas datasets. Focusing on only the spectral features, the RFK improvement is marginal. Optimizing the
mtry parameter also helps the RF and SVM-RFK to outperform marginally compared to the models with the default values of the
mtry. Although RF and RFK get better results by optimizing
mtry parameter, the higher optimization cost required allows us to avoid it (
Figure 6). This fact also make evident that optimizing the RF parameters is not crucial for obtaining an RFK.
Focusing on spectral features, the SVM-RBF yields slightly better results than SVM-RFK in terms OA and
, reaching a difference of
and
in OA for Salinas dataset and Sukumba datasets, respectively. However, considering the Standard Deviation (SD) of these OAs, the performances of the classifiers are virtually identical (
Table 3). Moreover,
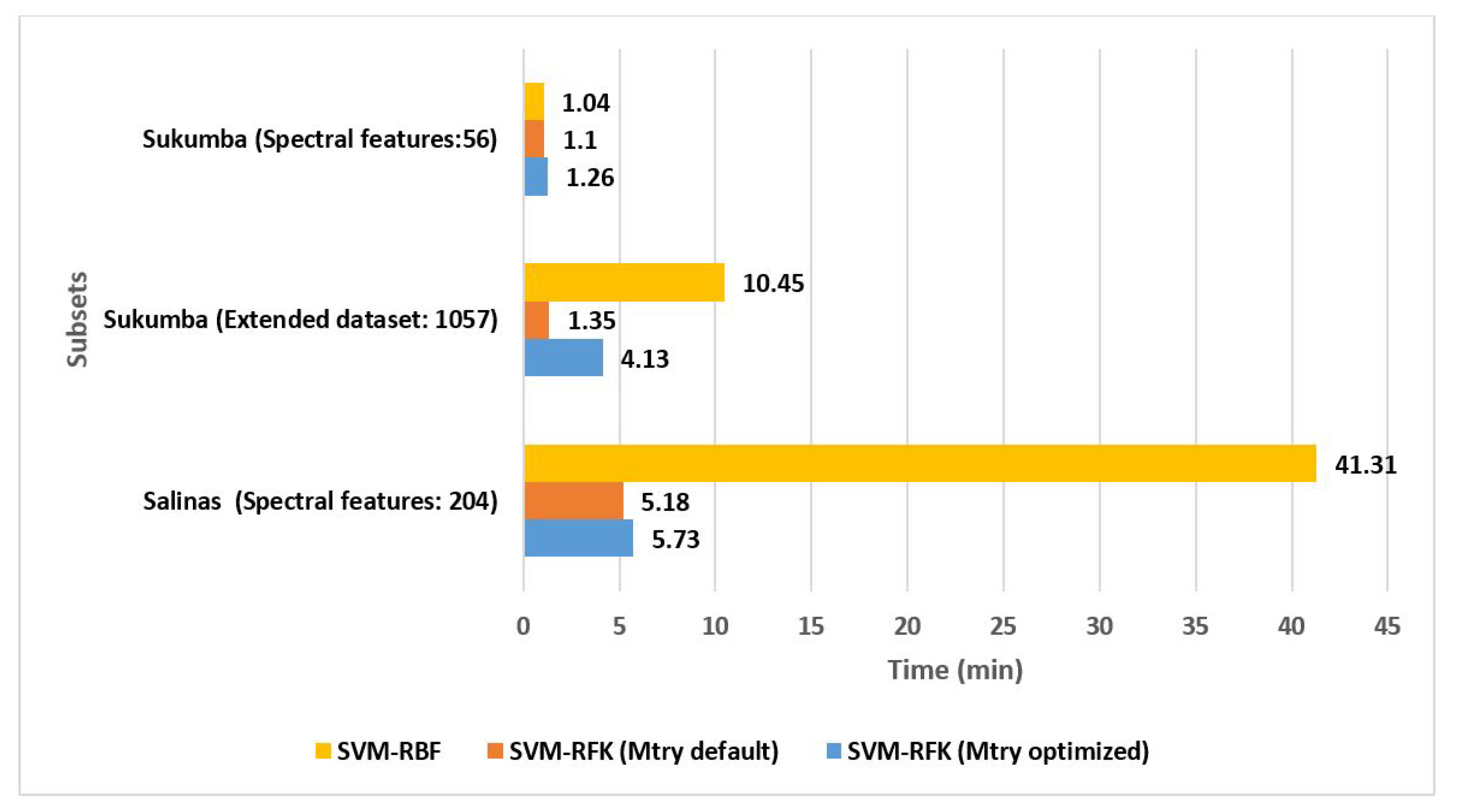
Figure 6 shows that the computational time for RFK is considerably lower than the RBF kernel for Salinas specifically without the
mtry optimization. For spectral features of Sukumba, RFK and RBF computational times are at about the same level.
A notable fact is that SVM-RFK results improve considerably by extending the Sukumba dataset from 56 to 1057 dimensions, whereas RF and SVM-RBF classifiers get less accuracy with the extended dataset. For the extended Sukumba dataset, SVM-RFK outperforms SVM-RBF and RF with a difference of
and
in OA, respectively. Furthermore, RFK gets similar results for both
mtry default and
mtry optimized, whereas the computational time is three times higher using optimized parameter (
Figure 6). Moreover, the time required to perform SVM-RFK
is also about seven times less than that of SVM-RBF (
Figure 6). This fact could be seen as the first evidence of the potential of RFKs to deal with data coming from the latest generation of Earth observation sensors, which are able to acquire and deliver high dimensional data at global scales.
More evidence for the advantages of the RFKs is presented in
Table 4 by exploiting the RF characteristics. This table shows that employing the RF to define the top 100 features (out of 1057 features) for Sukumba dataset, and obtaining the RFK based on a new RF model trained only with top 100 features improved the OA of the SVM-RFK by 2.66%.
Moreover, the HSIC measures presented in
Table 5 reveal the alignment of the kernels with an ideal kernel for the training datasets. The lower separability of the classes results in poorer alignment between input and the ideal kernel matrices, and that leads in a lower value of HSIC [
47]. Focusing on the spectral features, RFKs slightly outperform RBF for both Salinas and Sukumba datasets while both show almost equal alignment with an ideal kernel. The higher value of the HSIC measure for the RFKs compared to RBF is noticeable when the number of features is increased for the Sukumba dataset.
The analysis of the classifications results for each class is carried out by mean of the F-scores.
Table 6 and
Table 7 show the results of
for each classifier, spectral case and dataset. In Sukumba (
Table 6), the
has little variability, with standard deviations smaller or equal to 0.04. Furthermore, all classes have an
value larger than
(i.e., good balance between precision and recall). The classes Millet, Sorghum have the best
values, whereas the classes Maize and Peanut are harder to classify, irrespective of the chosen classifier. Focusing on the SVM-RBF and SVM-RFK classifiers, we see that the relative outperformance of SVM-RBF in terms of OA for spectral features (
Table 3 and
Figure 5) is mainly caused by the Maize and Millet classes, and this is while SVM-RFK and SVM-RBF show equal
values for classes Peanut and Sorghum, and SVM-RFK improves slightly the
value for the class Cotton compared to SVM-RBF. Moreover, SVM-RFK
competes closely with SVM-RFK and SVM-RBF while presenting slightly poorer
values.
Regarding Salinas, the show results above for all the classes except for Grapes untrained, and Vineyard untrained. For the latter two classes, the are respectively around and for the RF-based classifiers. However, SVM-RFK improves the values to for both these classes. In this dataset, the SD values have also little variability (same as the ones found in Sukumba), with standard deviations smaller or equal to 0.05. For Salinas dataset, SVM-RFK also competes closely with SVM-RFK and SVM-RBF while it presents slightly poorer values.
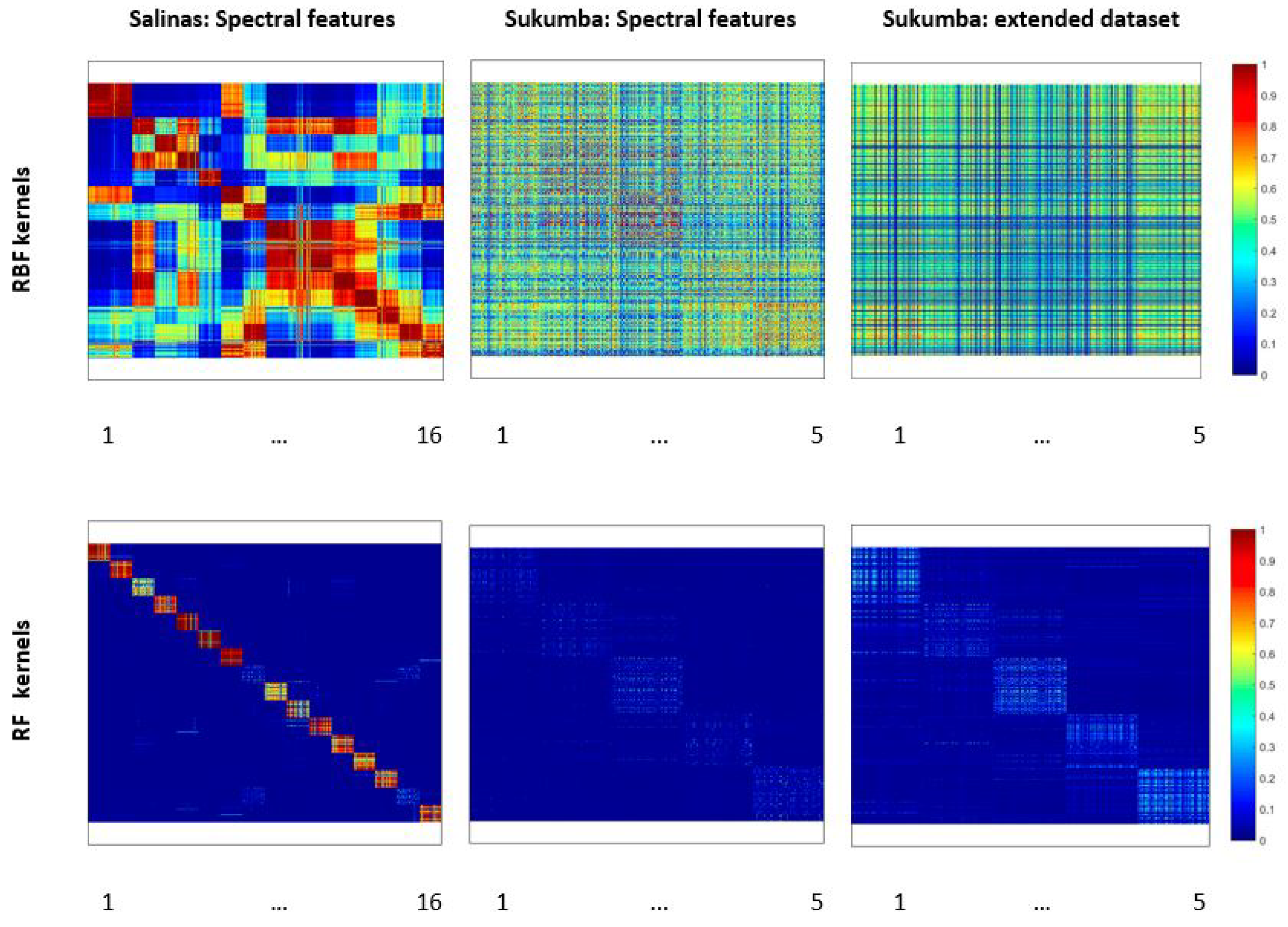
A deeper analysis of the SVM-based classifiers can be achieved by visualizing their kernels.
Figure 7 shows the pairwise similarity of training and test samples sorted by class. Here, we only visualize the RFK (with optimized
mtry) because of the similarity of the results to RFK
.
Focusing on the spectral features, this figure shows that the kernels obtained for Salinas are more “blocky” than those obtained for Sukumba. This makes it evident that a higher number of relevant features can improve the representation of the kernel. It also shows that the RFKs generated for Sukumba are less noisy than the RBF kernels. However, the similarity values of the RFKs are lower than those obtained for the RBF kernels. The visualization of the kernels confirms the higher
values found in the Salinas dataset. A detailed inspection of the RFKs obtained from this dataset shows low similarity values for classes 8 and 15, which correspond to Grapes untrained and Vineyard untrained. As stated before, these classes have the largest imbalance between precision and recall. Increasing the number of features to 1057 by extending the spectral features for Sukumba dataset represents a blockier kernel, by improving only the intraclass similarity values. However, the RBF kernel loses the class separability by increasing both intraclass and interclass similarity values by increasing the number of features for Sukumba dataset; this can be observed by RFK visualizations in
Figure 7 and f-score values in
Table 6. Focusing on the RFK, there are samples that their similarity values to other samples in their class are low for the RFK (Gaps inside the blocks), these samples could be outliers since RFK is based on the classes and the features while the RBF kernel is based on the Euclidean distances between the samples. Thus, removing outliers using RF can improve the representation of the RFK.
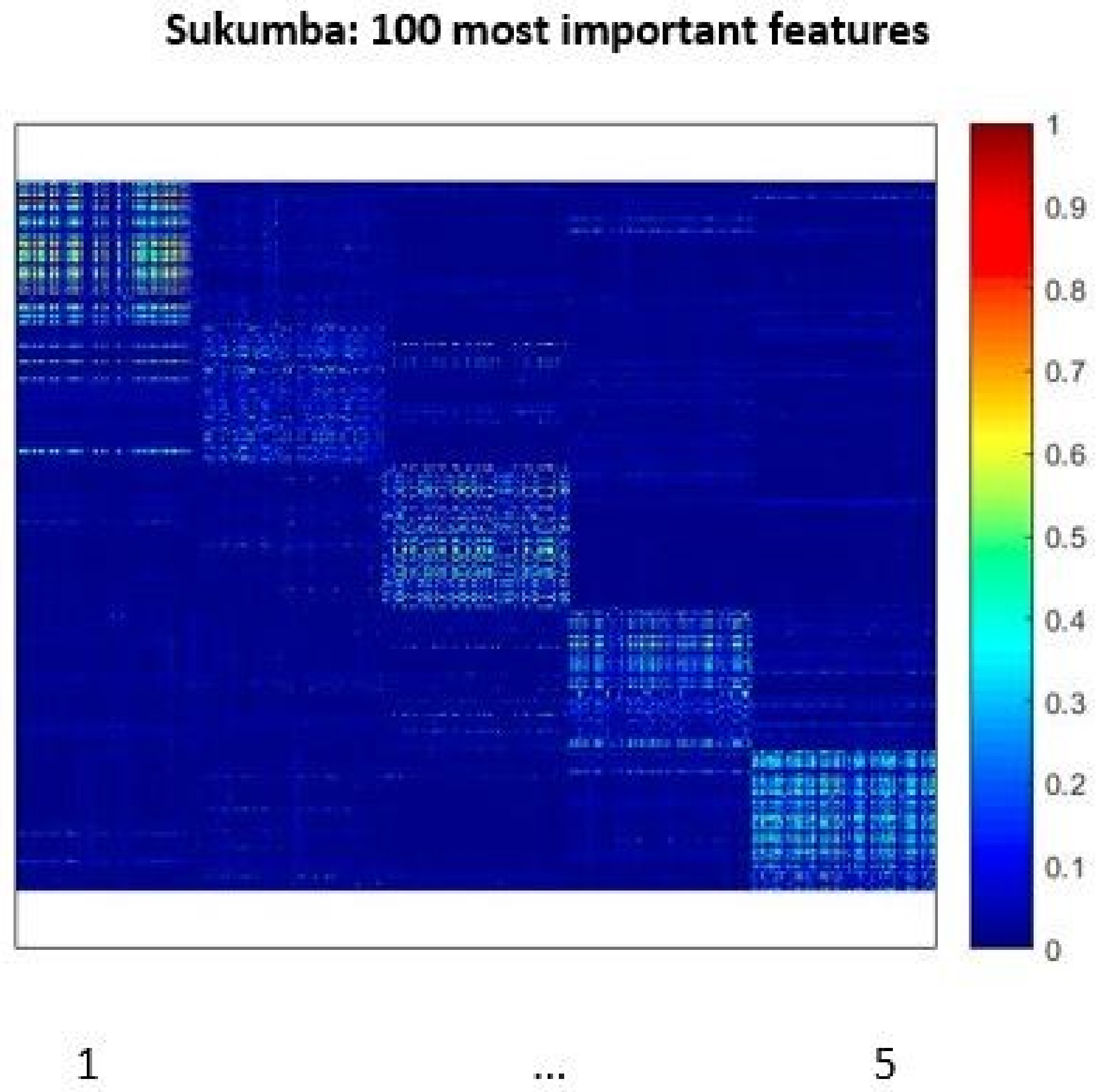
Figure 8 shows the kernel visualization of RFK based on the 100 most important features selected by RF. As it can be observed in this figure, the similarity between the samples in the same classes is increased in particular for the classes one and five compared to the kernel using all 1057 features.
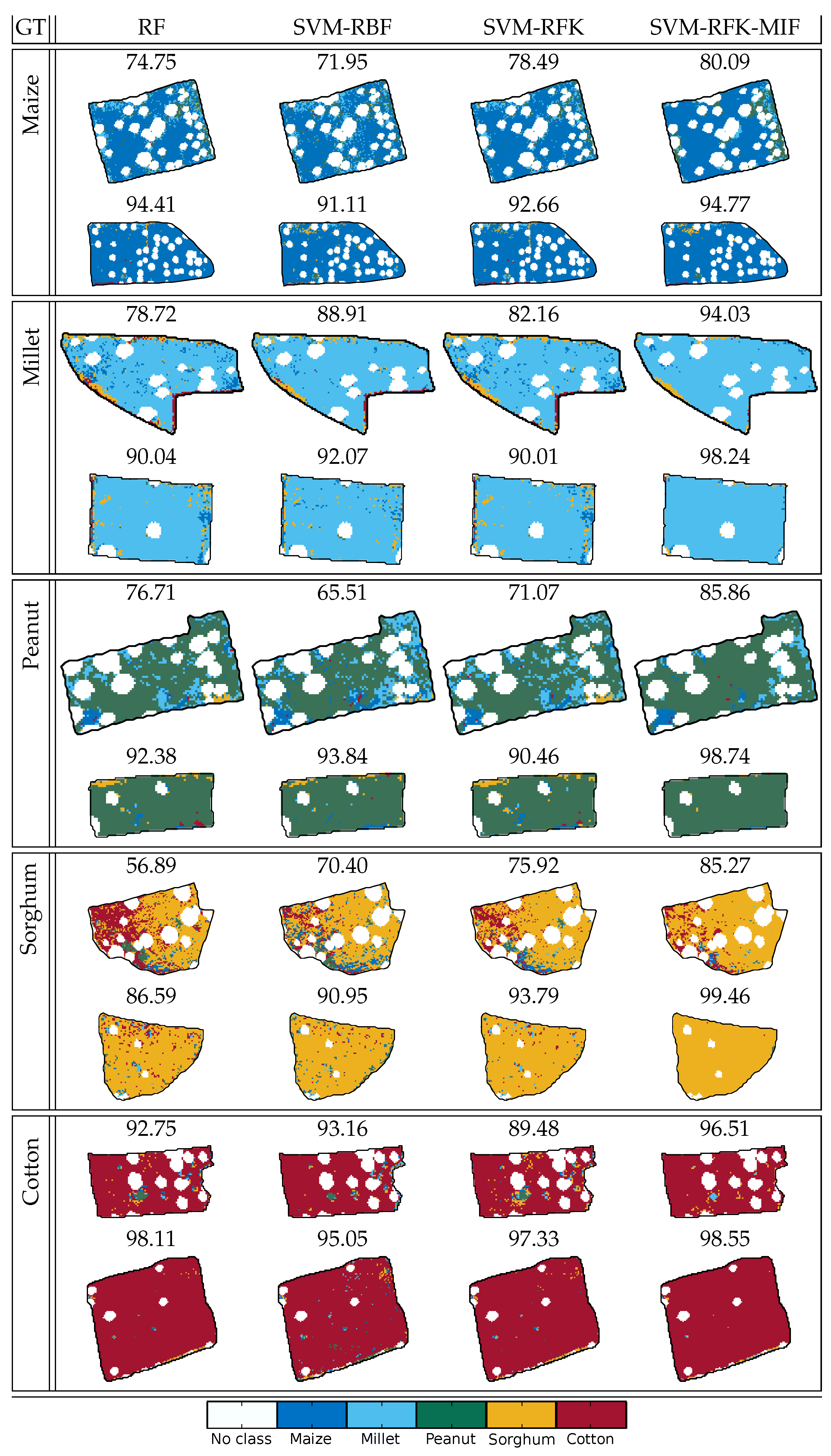
Finally, we present the classification maps obtained using the trained classifiers with spectral features. For Sukumba dataset, we also obtain the classification maps using SVM-RFK based on the top 100 features. For visibility reasons, we only present classified fields for Sukumba and classification maps for Salinas. In particular,
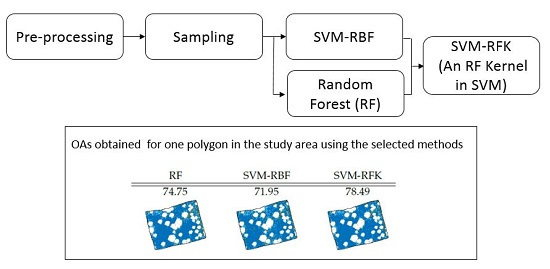
Figure 9 shows two fields for each of the classes considered in Sukumba. These fields were classified using the best training subset of the ten subsets, and the percentage of pixels correctly classified are included on the top of each field. In general, the SVM classifiers perform better than the RF classifiers. Focusing on the various kernels, the RFKs outperform the results of RBF for the majority of the polygons.
Moreover, we observe a great improvement in the OA for all polygons by using the SVM-RFK-MIF. This means that RF can be used intuitively to define an RFK based on only the top 100 features, and this kernel can improve the results significantly compared to RF, SVM-RBF, and SVM-RFK.
Classification maps for Salinas and their corresponding OAs are depicted in
Figure 10. In this dataset, all classifiers have difficulties with fields where Brocoli_2 (class 2) and Soil_Vineyard (class 9) are grown. Moreover, it is worth mentioning that the performance of three classifiers is at about the same level. However, the SVM-RFK classifier has a marginally higher OA than the RF classifier, and SVM-RBF slightly outperforms SVM-RFK. This can be explained by the relatively high number of training samples used to train the classifiers compared with the dimensionality of the Salinas image. However, the computational time of classification for SVM-RBF is higher compared to RF and SVM-RFK (
Figure 6).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}