1. Introduction
As remote sensing technology develops, remote sensing images can capture detailed features of an object due to improved resolution, which lays the foundation for remote sensing image interpretation. Aircraft recognition, one subfield of remote sensing image interpretation, has received considerable research attention because aircraft recognition in remote sensing images is of great significance in aerospace applications, intelligence information and so on.
In the early stage, aircraft recognition methods for remote sensing images rely mainly on handcrafted features, such as histograms of oriented gradients (HOG) [
1] and scale invariant feature transform (SIFT) [
2,
3]. Hsieh et al. [
4] introduces several preprocessing methods and uses four feature extraction methods to classify aircraft. Some methods are based on template matching methods [
5,
6], such as the combination of an artificial bee colony algorithm and edge potential function in [
5] and the coarse-to-fine thought proposed in [
6] utilizing the parametric shape model. These approaches play an important role in the performance improvement of aircraft recognition, and some are still being used today. However, due to the strong dependence on handcrafted features, these methods lack discriminative representation ability and perform poorly in terms of robustness and generalization.
In recent years, with the improvement of hardware performance, deep neural networks have experienced tremendous development and have been widely applied in various fields, such as classification [
7,
8], detection [
9,
10], and segmentation [
11,
12]. Specifically, deep neural network have made breakthroughs in aircraft recognition in remote sensing images. Diao et al. [
13] is the earliest attempt to introduce deep belief networks (DBNs) to address this problem. By combining aircraft detection and template matching, Ref. [
14] proposes a vanilla network. Zuo et al. [
15] use a convolutional neural network (CNN) for semantic segmentation and then feed the segmented aircraft mask into a classification algorithm based on template matching. Zhang et al. [
16] realize aircraft classification based on the features extracted from conditional generative adversarial networks. Compared with handcrafted-feature-based methods, neural-network-based models achieve substantial improvement in both generalization and robustness. Moreover, the feature representations of neural networks are more discriminative. However, in these methods, object features are extracted from the whole image, and it is difficult to distinguish the detailed differences between similar object classes.
Depending on the level of interclass variance, the classification problem can be divided into general object classification and fine-grained visual classification (FGVC). General object classification aims to classify different categories with large interclass variance, for example, distinguishing cats from dogs. Methods for general object classification treat entire images as a whole and do not concentrate on the part features of an object. Correspondingly, the categories to be distinguished by FGVC are subcategories of the same parent category, such as species of birds [
17,
18] and different types of cars [
19], which is achieved according to the small interclass variance. Some popular classification methods based on convolutional networks, such as ResNet [
20] and GoogLeNet [
21], achieve state-of-the-art performance in general object recognition. However, if these models are directly applied to the FGVC, their performance decreases because concentrating on only the whole object features is not sufficient for subcategory classification. Inspired by this limitation, FGVC extracts features from discriminative parts [
22,
23,
24,
25,
26,
27,
28,
29] for subcategory classification. From this perspective, aircraft recognition in remote sensing images can be regarded as an FGVC problem. In this task, each aircraft belongs to the same parent class and must be classified by aircraft type. To the best of our knowledge, the aforementioned aircraft recognition methods in remote sensing images all treat this task as a general object classification problem. In this paper, we introduce the ideas of FGVC into aircraft recognition in remote sensing images and attempt to make use of the features from discriminative object parts.
FGVC is a challenging classification problem because of the small interclass variance and large intraclass variance. Small interclass variance means that all subcategories are quite similar in appearance, behavior, and so on. On the other hand, large intraclass variance means that objects from the same subcategory show relatively obvious differences in color, action and posture. In addition, for aircraft recognition in remote sensing images, the complex background and characteristics of different satellites cause additional difficulties. For example, the shadow, shape, and color of an object may be influenced by the solar radiation angle, the radar radiation angle, and the surrounding environment.
Methods for FGVC can be divided into strong supervision and weak supervision methods, both of which require image-level class annotation. For strongly supervised FGVC methods, discriminative object parts must also be annotated manually. The initial studies use strongly supervised methods. Huang et al. [
22] directly detect the discriminative parts in a supervised manner and stacks part features for further classification. Wei et al. [
23] translate part annotations into segmentation annotations and achieves state-of-art result for birds [
17] with the segmentation method. Although the strongly supervised methods achieve satisfactory performance, the annotation is very difficult because it is hard to decide where the discriminative object parts are, and part annotation is time consuming. These disadvantages make it unrealistic to apply strongly supervised FGVC methods to new fine-grained visual classification tasks.
Weakly supervised FGVC methods do not require manual discriminative part annotation. These methods solve two main problems. One is discriminative part localization, which aims to locate important parts automatically. Xiao et al. [
24] use selective search to generate abundant image parts and learn to acquire important parts with a discriminator. The other is discriminative feature representation, which aims to extract the effective features in the discriminative parts. Zhang et al. [
25] use a Fisher vector to map features from the CNN output to a new space, which makes the classifier easier to train and achieves high accuracy. Lin et al. [
26] fuse the image features and position features for further classification. Some recent studies report that discriminative part localization and discriminative feature representation can influence each other [
27]. Subsequently, Ref. [
28], in which a class activation mapping (CAM) method is proposed, proves that a CNN network is capable of addressing the interaction between discriminative part localization and discriminative feature representation. CAM utilizes a class activation map of a trained CNN to locate objects. Some methods [
29,
30,
31] use CAM as an intermediate step to locate discriminative parts for FGVC and segmentation; however, one drawback of CAM is that it uses only the class activation map of the single predicted type. If the predication result is wrong, the class activation map of CAM will be inaccurate. For some specific hard problems such as FGVC, the prediction of CNN is not sufficiently reliable. Thus, CAM will add incorrect information to the subsequent steps when the prediction is wrong.
In this paper, we propose a fine-grained aircraft recognition method for remote sensing images based on multiple class activation mapping (MultiCAM). To the best of our knowledge, the aforementioned aircraft recognition methods [
13,
14,
15,
16] for remote sensing images all treat this task as a general object classification problem, but our method attempts to use FGVC to address the aircraft recognition problem. The overall architecture consists of two subnetworks, i.e., the target net and the object net. First, the target net extracts features from the original whole image. By fusing multiple class activation maps based on the target net, MultiCAM is able to locate discriminative object parts in the original image. Second, a mask filter strategy is proposed to eliminate the interference of background areas. Then, the object net extracts features from the combinations of discriminative object parts. Finally, we fuse the features from the target net and the object net via a selective connected feature fusion approach and obtain the final classification result. Furthermore, our method uses only image-level annotation and works in a weakly supervised manner. The main contributions are as follows:
We propose the MultiCAM method for discriminative object parts localization. MultiCAM overcomes the problem of the class activation map of a single predicted type in CAM.
To reduce the interference from the background in remote sensing images, a mask filter strategy is proposed. This strategy retains the discriminative regions to the greatest extent and preserves the object scale information.
To make use of features from both the original whole image and the discriminative parts, we propose a selective connected feature fusion approach.
Experimental results are provided to verify that our method achieves good performance in fine-grained aircraft recognition.
The rest of this paper is organized as follows.
Section 2 introduces our method in detail. In
Section 3, our dataset is described, and the proposed algorithm is experimentally tested to demonstrate its effectiveness. In
Section 4, we discuss the issues of our network according to the experimental results. Finally, conclusions are drawn in
Section 5.
2. Materials and Methods
A convolutional neural network is generally utilized to extract object features from whole images, and a subsequent classifier is built based on fully connected layers, support vector machine, or another machine learning method. As an evaluation criterion, the loss function computes the loss between the ground truth and the predicted category. The trained network cannot be obtained until the loss function converges. For each image, we can extract the feature map in each layer via forward propagation of the trained network. The feature map in the lower layer represents marginal information, while the feature map in the higher layer contains more semantic information. From the semantic information, we can obtain the activated region in the feature map corresponding to the region in the original image, which inspires us to extract discriminative object parts from the semantic information.
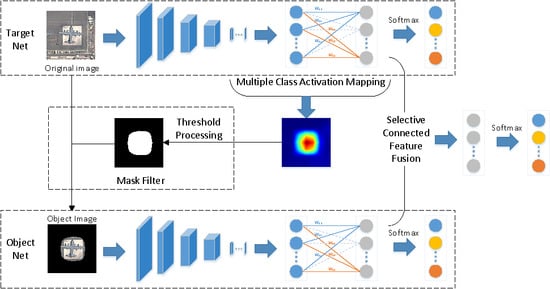
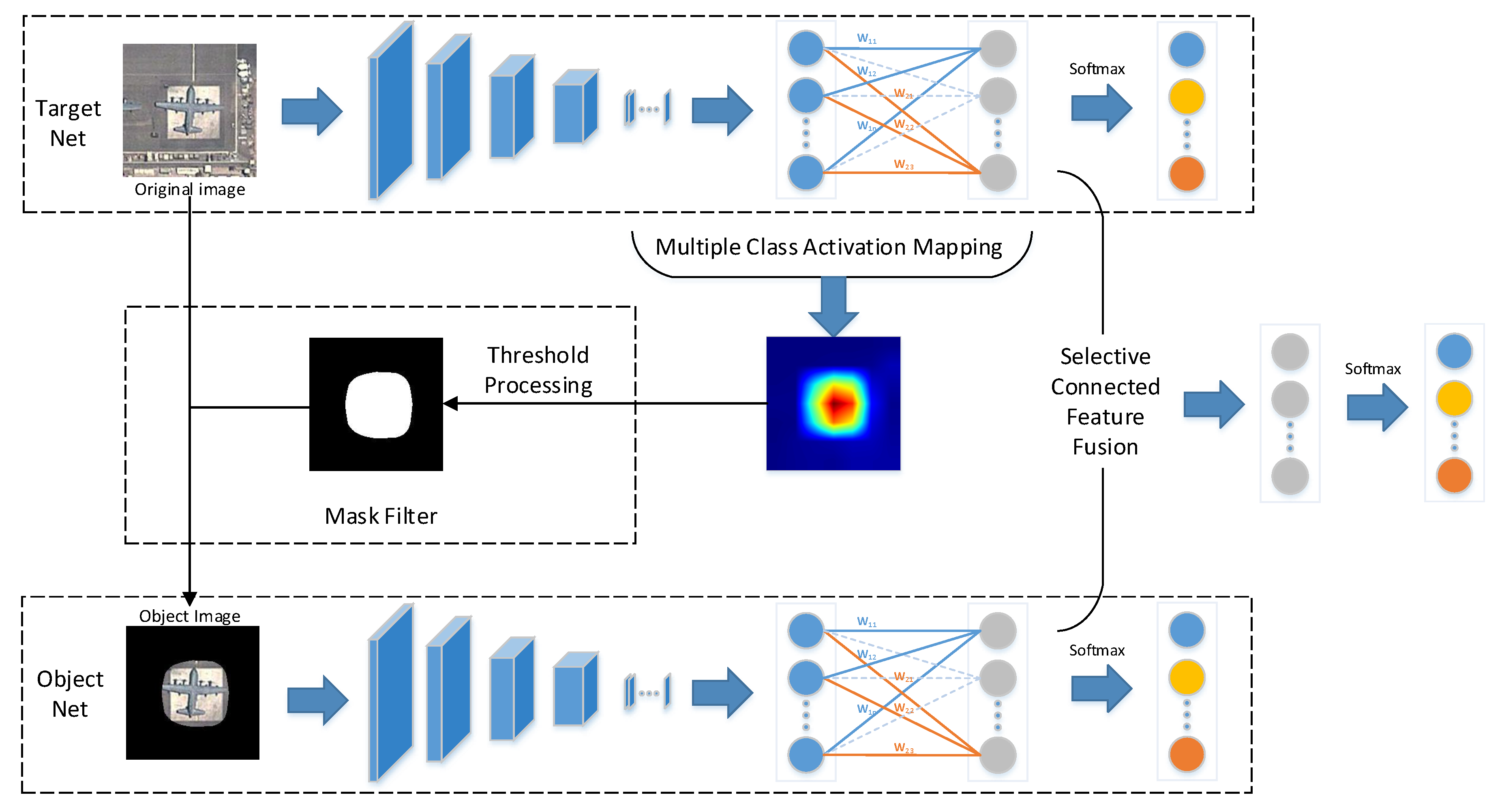
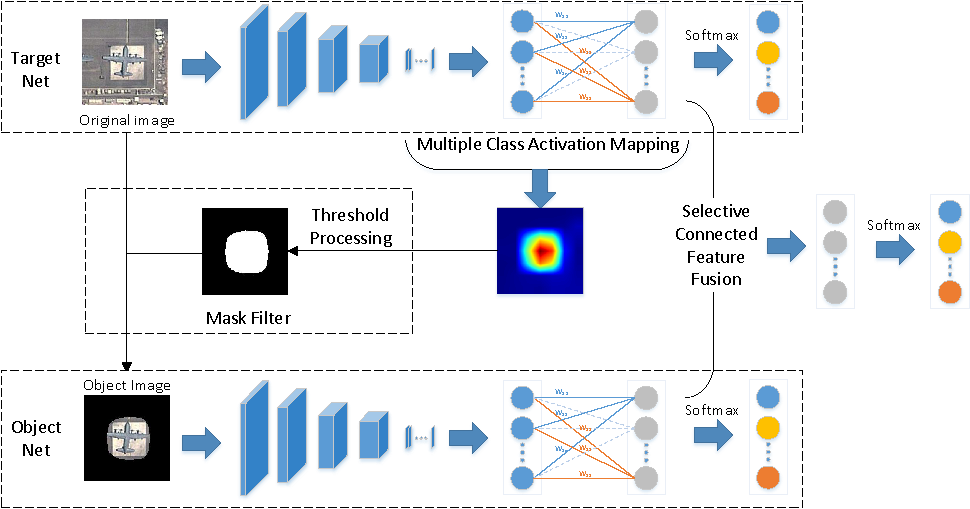
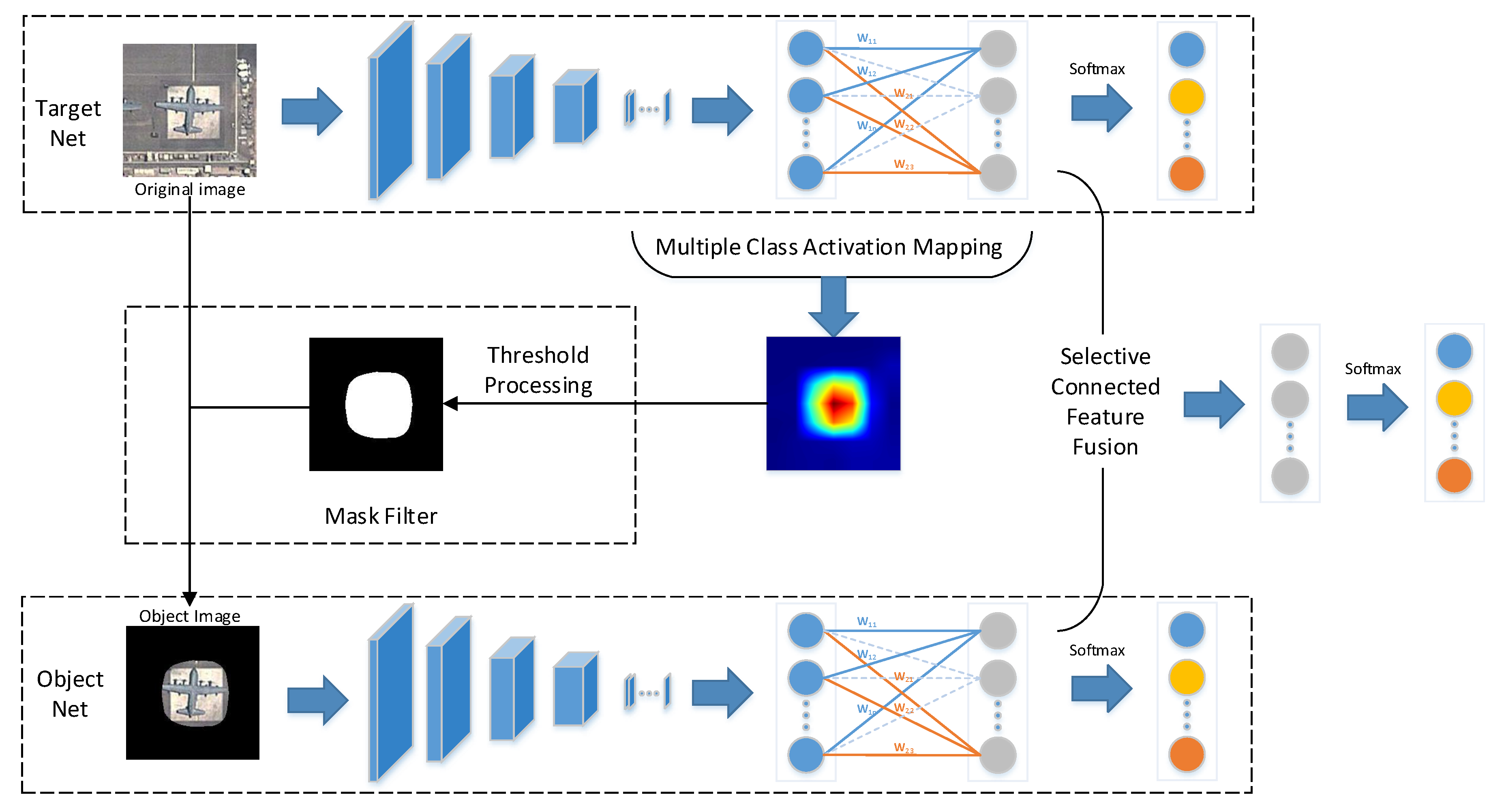
The overall network, which consists of two subnetworks, i.e., the target net and the object net, is illustrated in
Figure 1. First, the target net is used to extract features from the original image. Second, with the help of MultiCAM, the discriminative object parts are located, and the object saliency map is obtained. Third, based on the object saliency map, the object image is generated by applying a mask filter to the original image, which restores the object and filters the background. Then, the object image is fed into the object net to realize feature extraction and concentrate on the object. Finally, selective connected feature fusion is applied to classify the images by fusing the features from the two subnetworks. The key parts of the proposed network are addressed in detail in the following sections.
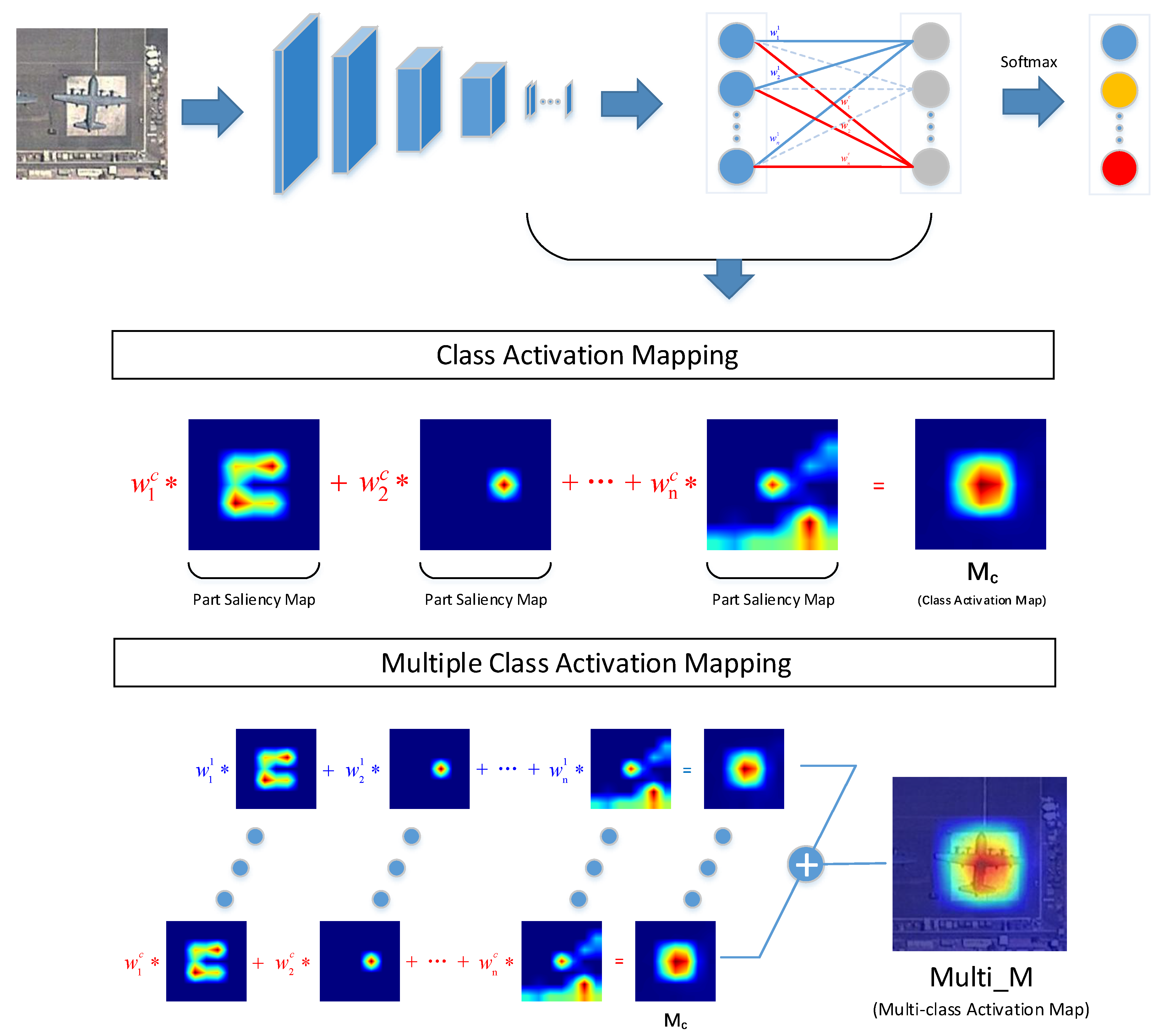
2.1. Multiple Class Activation Mapping
Similar to the popular CNN, the proposed network uses global average pooling in the final pooling layer and contains a subsequent fully connected softmax layer in the two subnetworks. For each image I, the last convolutional feature map
f of each image can be acquired by the CNN:
where
F denotes a series of operations in the CNN, including convolution, pooling and activation. In addition, the kth channel of the feature map is denoted by
, and
represents the value in spatial location
.
According to [
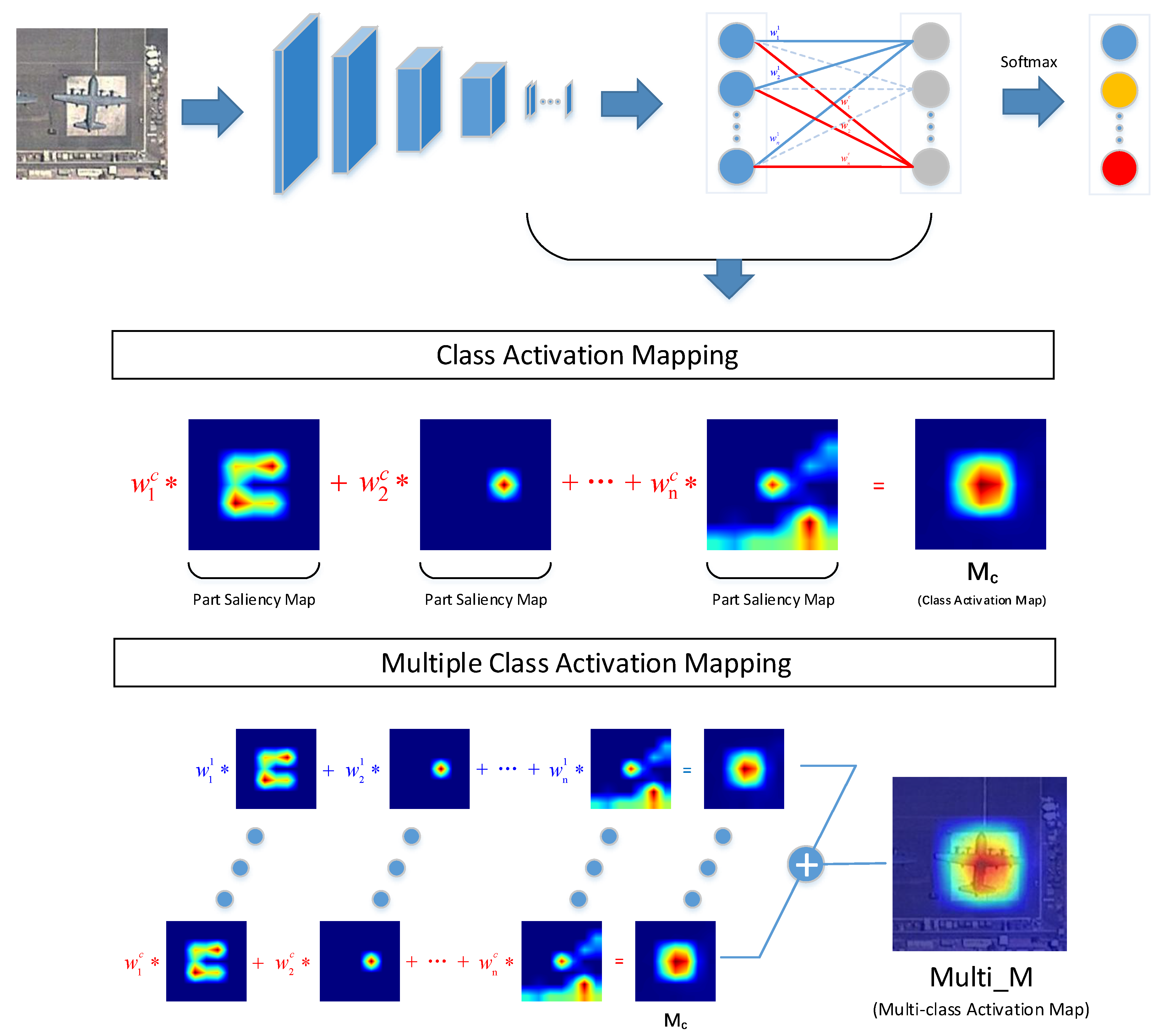
28], the proposed CAM acquires the class activation map and determines the object region by a recognitive task, as shown in
Figure 2. Theoretically, based on the ground truth, CAM extracts the class activation map, which is the sum of each channel of the weighted feature map. The true class activation map can activate class-specific discriminative regions, as shown in
Figure 2. In consideration of practical application, CAM replaces the ground truth with the prediction category result to obtain the class activation map. The function representation of CAM is:
where
is the class activation map of class
c and
represents the kth weight of the softmax layer of class
c. Furthermore, we define
as the part saliency map, as illustrated in
Figure 2, because different part saliency maps activate different object regions, which also represent different object parts.
consists of a series of part saliency maps with different weights indicating the significance degree. The larger the weight the part saliency map obtains, the more discriminative the object part is. CAM utilizes the composed features of discriminative object parts to achieve further localization and classification tasks.
Zhou et al. [
28] and Peng et al. [
29] use the prediction category result to obtain the class activation map. The prediction category result contains only one category and ignores other categories, which has a disadvantage. An incorrect prediction category will lead to an inaccurate class activation map. Specially, for some difficult problems, such as FGVC, the network accuracy is generally not very high, and the prediction result is not sufficiently reliable. When we use CAM for object localization, the incorrect information may be included and lead to property reduction in the object net, thereby deteriorating the performance of the whole network.
To overcome the disadvantages caused by CAM using single type prediction, we propose the MultiCAM method, as shown in
Figure 2, which utilizes the predictions results of all categories to acquire the multiclass activation map. The multiclass activation map is obtained by adding the elements in the same position
in each class activation map, which can be expressed as:
where
is the multiclass activation map and
indicates the importance of each pixel in the original image.
is introduced in Equation (
2). Note that bilinear upsampling is applied to ensure that the multiclass activation map is the same size as the input image. The complete procedure of MultiCAM is shown in Algorithm 1. As shown in
Figure 2, each class activation map consists of a series of part saliency maps, but the same part saliency map in different categories has different weights, which represent the discrimination of the part saliency map in different categories. After combining these discriminative object parts of each category to obtain each class activation map, we accumulate each class activation map to obtain the multiclass activation map. MultiCAM fuses all class activation maps to acquire their combined features. Because there is no distinction between categories, MultiCAM eliminates the influence of a single prediction class. Whether the prediction category result is correct or not, the multiclass activation map will always cover the true class activation map to the greatest extent, which objectively enlarges the saliency region in the multiclass activation map. However, this influence is limited as all categories have small interclass variance in FGVC.
| Algorithm 1: The procedure of MultiCAM. |
![Remotesensing 11 00544 i001]() |
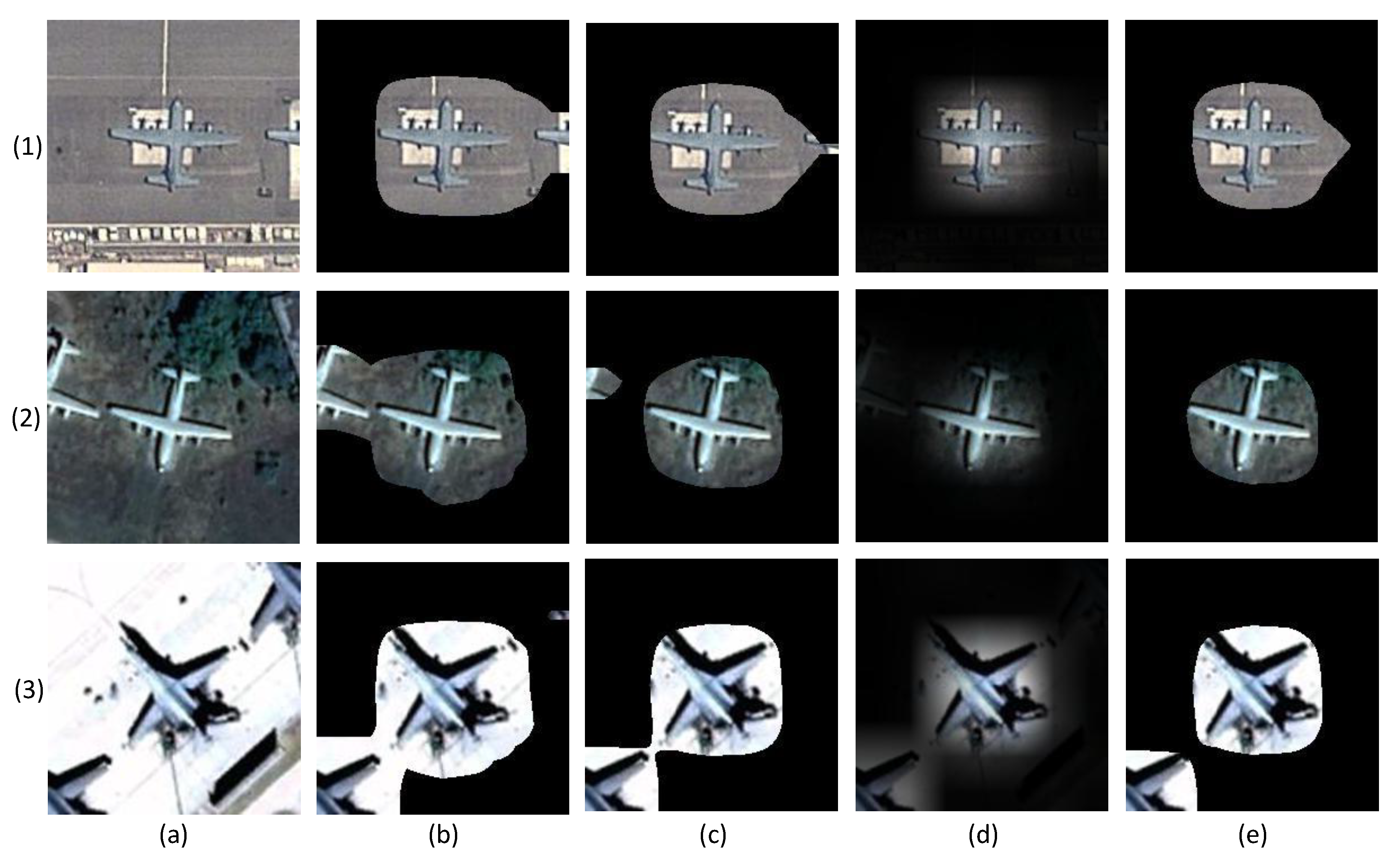
2.2. Mask Filter
In [
28,
29], the input image of the object net is generated by cropping the original image according to the bounding box and resizing the cropped image to a uniform size. Nevertheless, as the bounding box of each object is different, the resizing operation inevitably changes the object scale and increases the difficulty of classification. To solve this problem, we utilize the mask filter (MF) to eliminate the background interference according to the multiclass activation map and generate the object image containing the original scale information.
The multiclass activation map indicates the significance of each pixel in the original image instead of the explicit object saliency region. Therefore, in the first step of the mask filter, the object saliency region is determined according to the following threshold processing:
where
denotes the pixel value of the mask at position
. Then, the object saliency region, a set of pixels
, is obtained. Although MultiCAM eliminates the effect of wrong information generated by incorrect single prediction category results, it inevitably enlarges the object saliency region compared with CAM. To address this trade-off problem, the threshold should be adaptive instead of a fixed value applied to all images because different images have different pixel value distributions. Considering that the pixel importance in the multiclass activation map increases as the corresponding pixel value increases, the threshold of the mask filter is determined according to the maximum pixel value of the multiclass activation map:
where
is the maximizing operation. The changeable threshold used in [
28,
29] effectively filters noise and retains the main part of the object. In addition, we attempt to apply the following methods to generate the mask:
where
is the averaging operation and
is the ReLU operation. An analysis and object classification performance comparison among Equations (
5)–(
7) will be presented in the following experimental section.
Subsequently, on the basis of the original image
, the object image
is obtained with mask
indicating the object saliency region:
In this way, background interference can be suppressed to some extent, and the object’s original scale information can be preserved. The complete MF procedure is shown in Algorithm 2.
| Algorithm 2: The MF procedure. |
![Remotesensing 11 00544 i002]() |
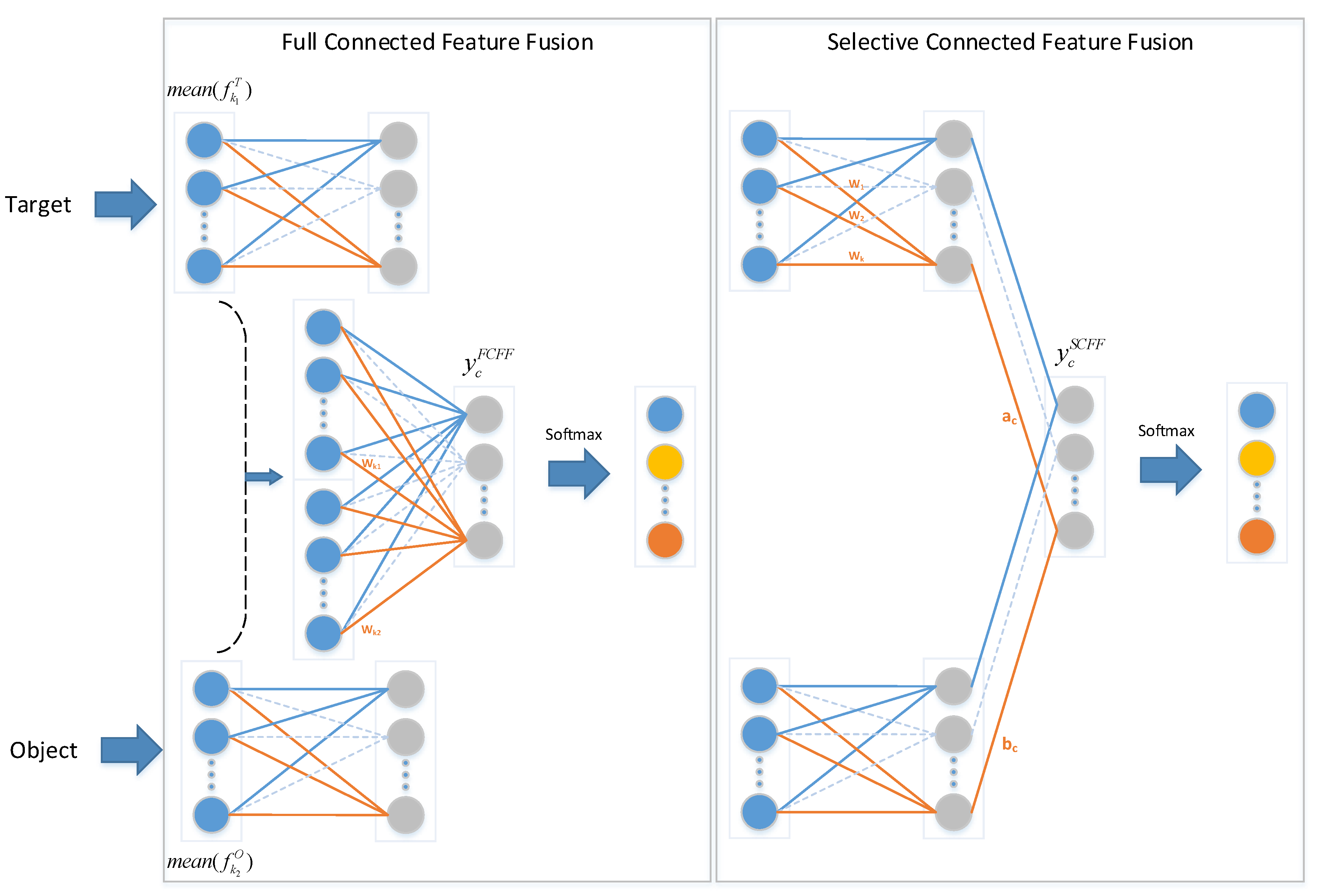
2.3. Selective Connected Feature Fusion
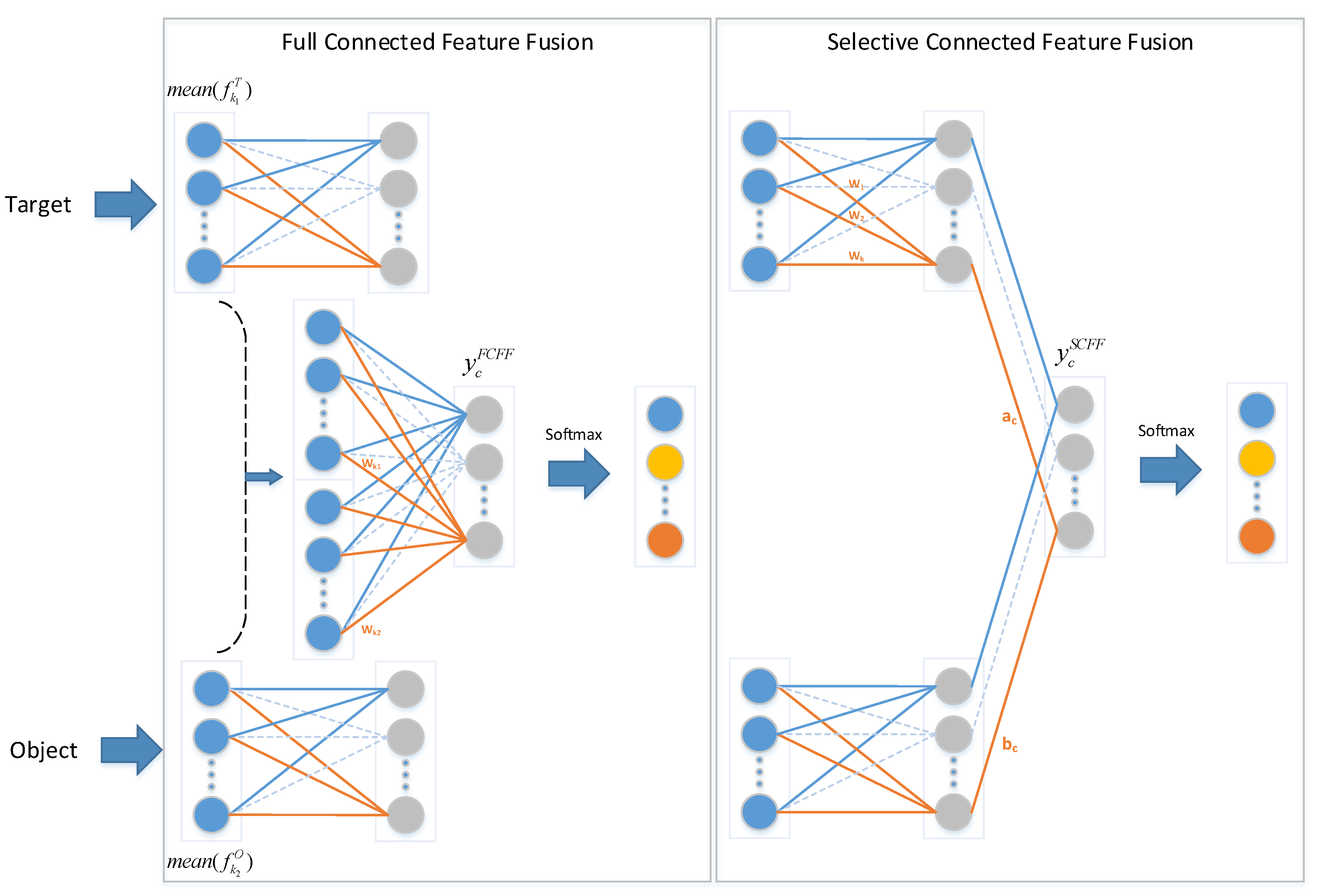
The proposed network contains two subnets with different functions. The target net focuses on the original images, while the object net concentrates on object images. Considering that the two subnets extract different image features, two fusion methods are implemented to improve the image feature extraction, as illustrated in
Figure 3. One method, called full connected feature fusion (FCFF), combines the features from two networks from the final global average pooling layer and subsequently implements a fully connected softmax layer, which is also used in other approaches [
22,
27]. Before the softmax layer in FCFF, the forward function is expressed as:
where
is the value of class c before the softmax layer.
and
are the feature maps of class
c in the last convolutional layer of the target net and the object net, respectively.
and
, depicted in blue circles, as shown in
Figure 3, are the results of global average pooling.
and
are the weights obtained by training the fully connected softmax layer.
The other method, called selective connected feature fusion (SCFF), conducts feature fusion of the two networks before the softmax layer and implements a local connected softmax layer at the end. Before the softmax layer in SCFF, the forward function is as follows:
where
is the value of class
c before the softmax layer.
and
, depicted by gray circles in
Figure 3, are the values of class
c before the softmax layer in the target net and the object net, respectively.
and
are the trained weights of the local connected softmax layer.
The two methods concentrate on different perspective. FCFF views the features from the two networks identically and learns the significance of different features for classification. By contrast, SCFF regards each network as a whole and learns the weights of different categories in the two networks. However, the two feature fusion approaches are theoretically equivalent. Taking the target net as an example, for each class c, we can obtain:
where
is obtained from the fully connected layer in the target net. Although the expressions on both sides of Equation (
11) are equivalent, the corresponding numbers of parameters are different. After global average pooling, the number of parameters in FCFF is
, while SCFF requires
parameters. However, in the fitting process, we train only the weights in Equations (
9) and (
10) and leave the parameters in the other layers unchanged. According to Equation (
9), the number of parameters needed to be trained in FCFF is
, while the number is
in the SCFF method based on Equation (
10). Therefore, the computational complexity of the feature fusion of SCFF is far less than that of FCFF. In addition, SCFF utilizes features from two networks before the softmax layer. If the target net and the object net achieve optimal performance together, which means that the extracted features from the two networks have sufficient representation ability, SCFF can achieve greater performance improvement. A comparison of the two feature fusion methods will be presented in the experiment section.
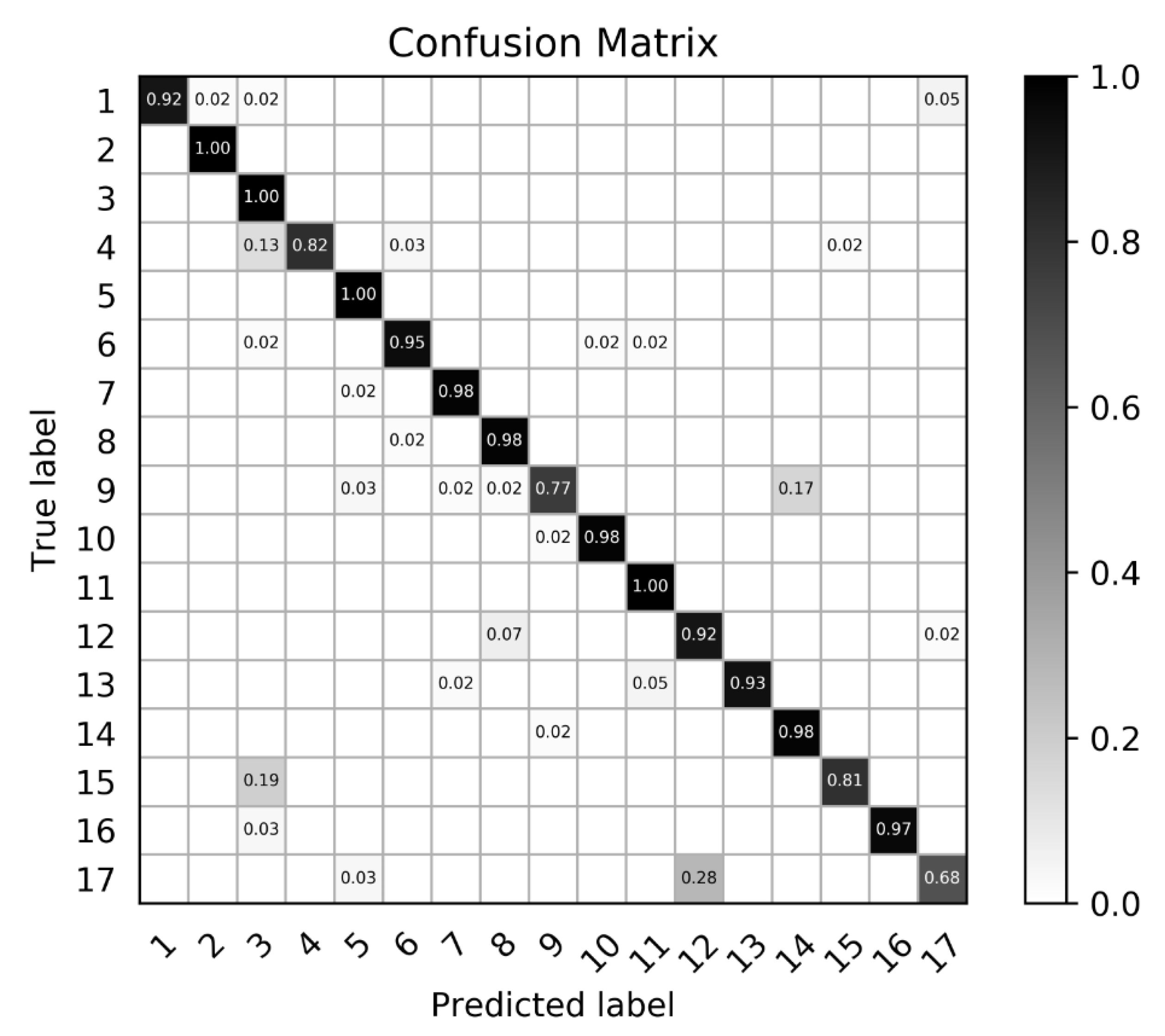
4. Discussion
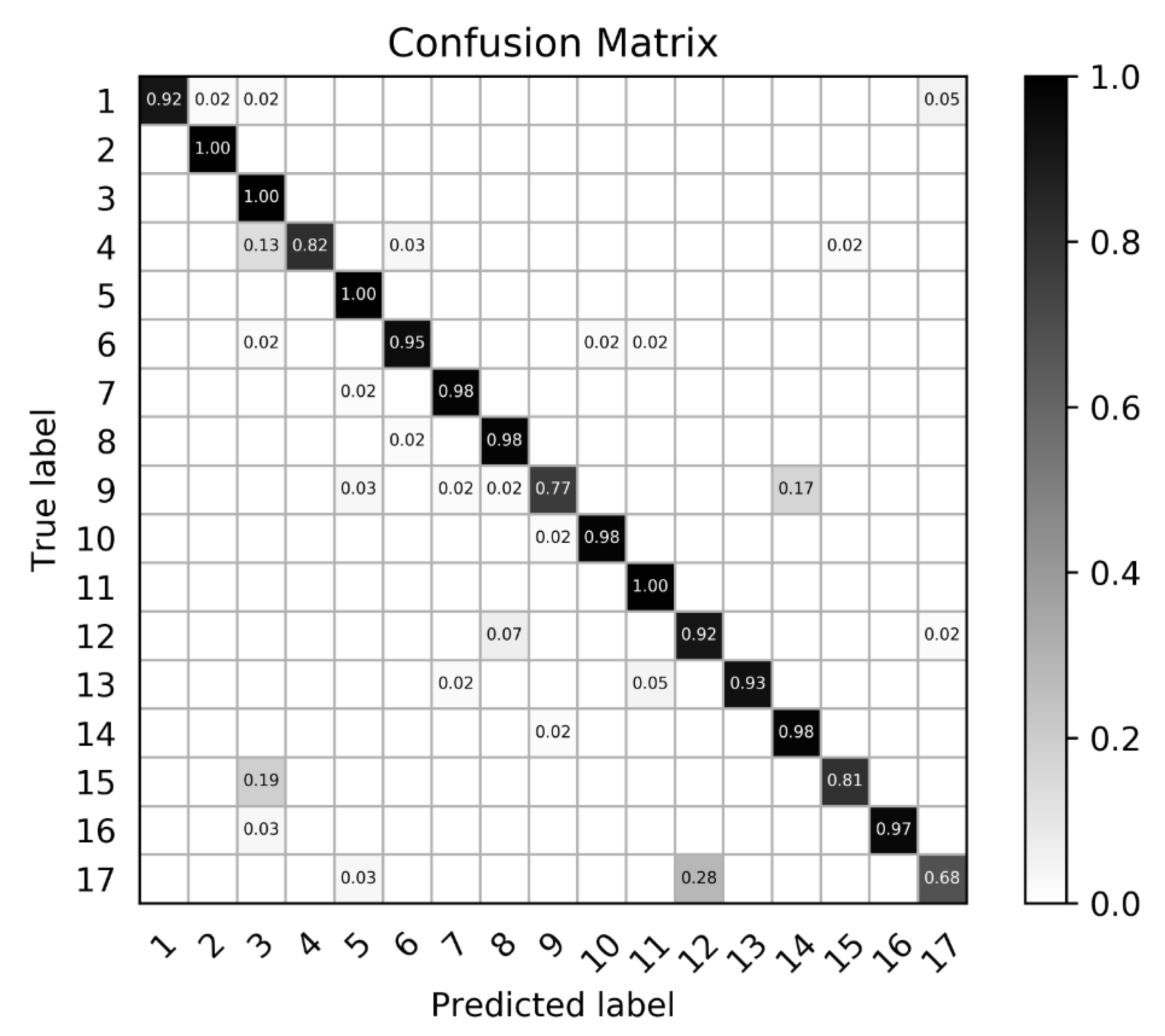
According to the experimental results and analysis in
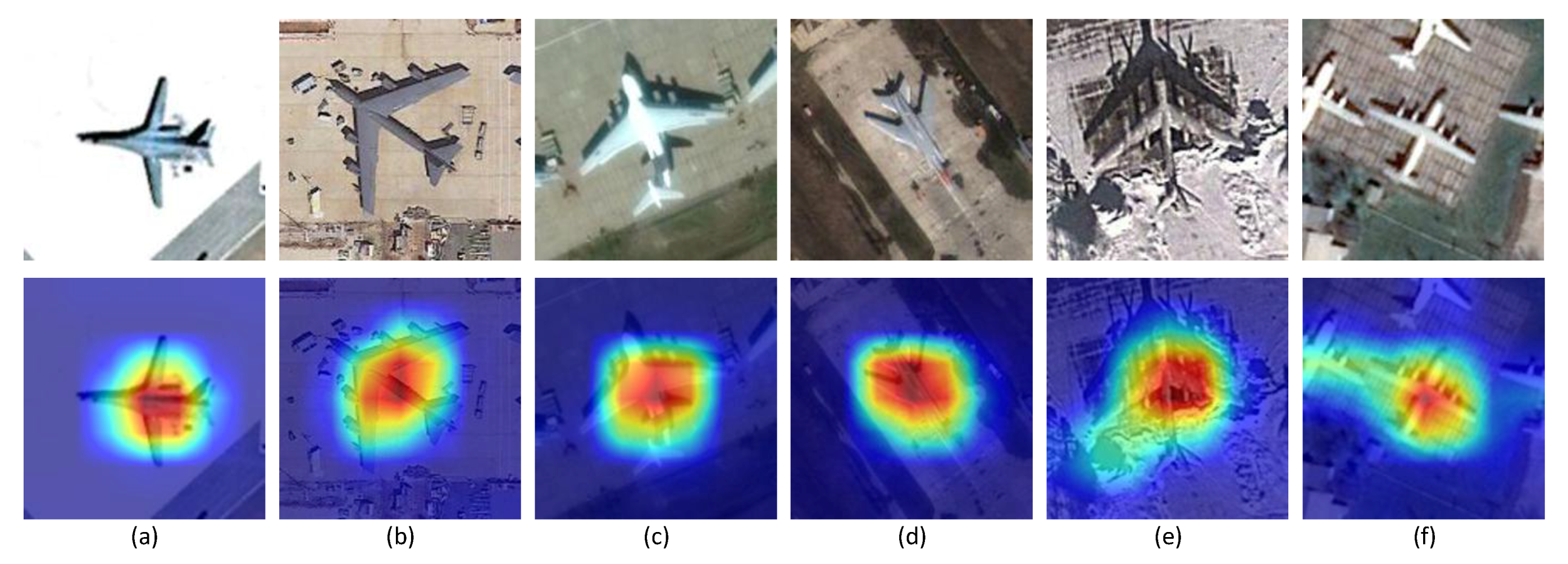
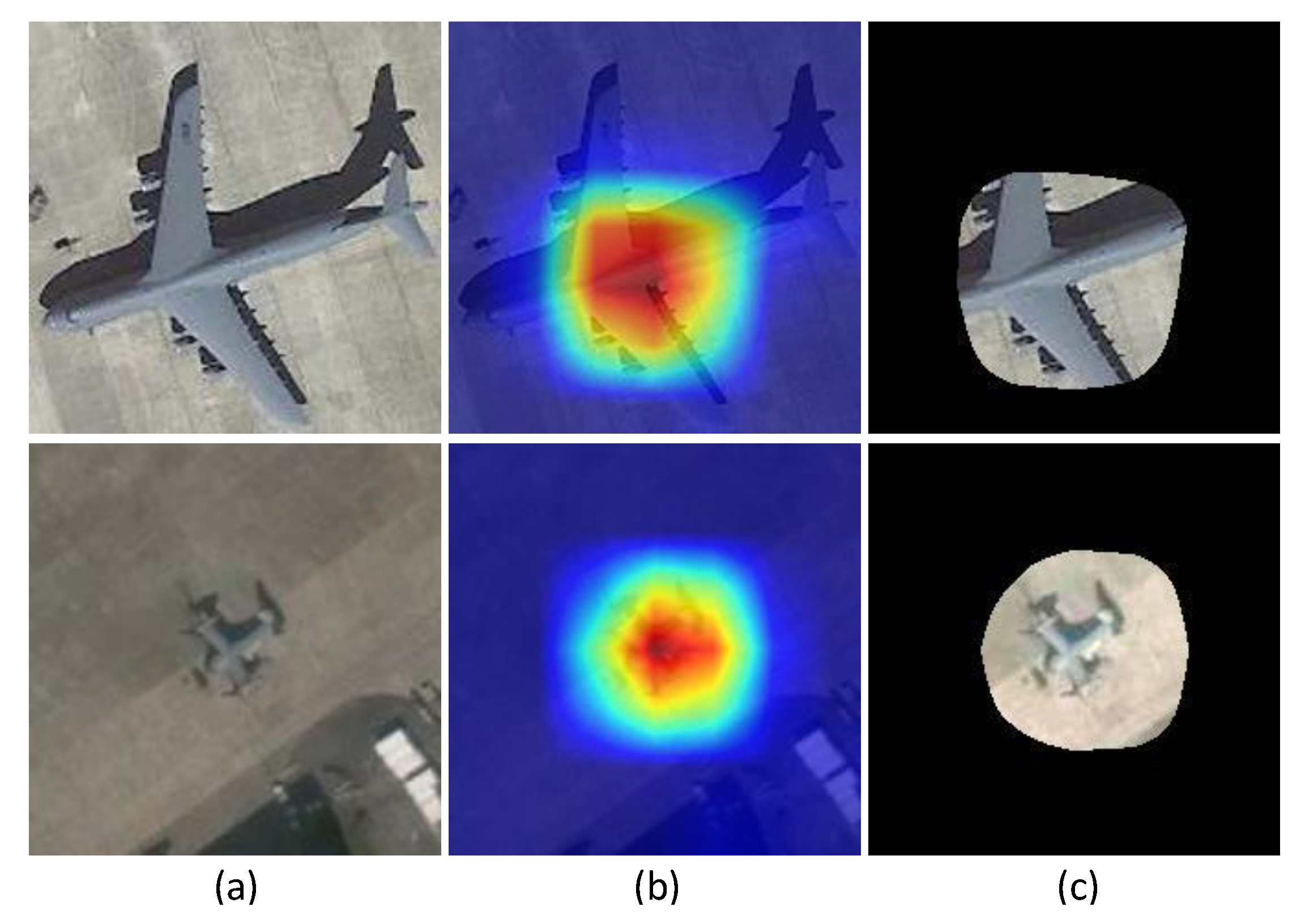
Section 3.2, the proposed algorithm performs better than the other methods. However, there remains some unsatisfactory examples in the results, as illustrated in
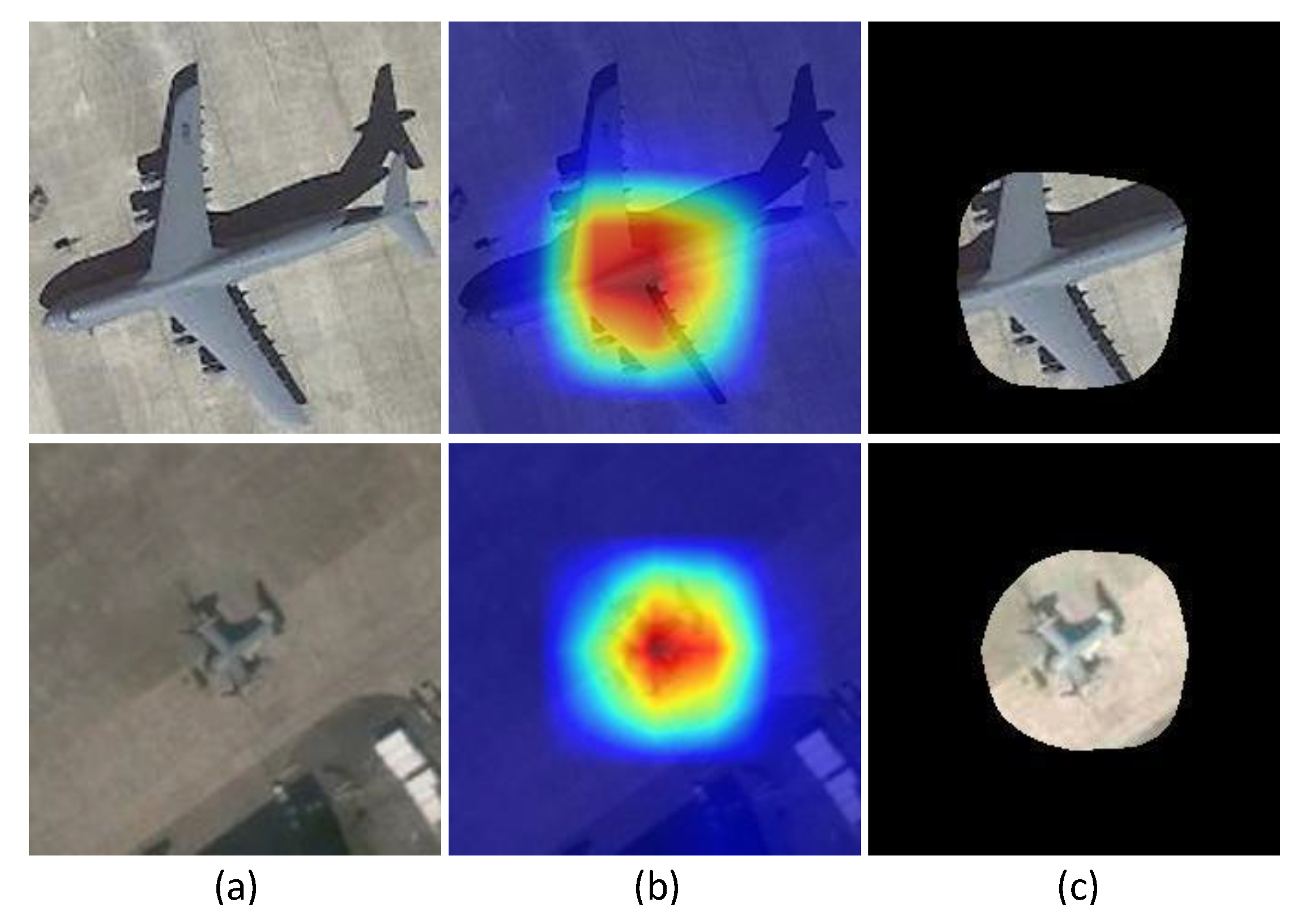
Figure 9. For a large aircraft in the slice, the object saliency region is rather small, which leads to the omission of the aircraft head, aircraft tail and wingtips in the object image. For a small aircraft, the object saliency region is much larger, resulting in more background interference.
Two explanations are provided for the above phenomenon. One is that the object saliency region is influenced by the respective field. Generally, the size of the effective receptive field in a CNN is smaller than that of the theoretical receptive field [
39], which may be suitable for certain object sizes. However, for a large aircraft, the object saliency region may be too small to cover the intact aircraft, and the object saliency region will have substantial redundant space for a small aircraft. The other reason is that the mapping from the original image to the feature map is rather complex after multiple convolution, pooling and the ReLU function in CNN. It is not suitable to upsample the multiclass activation map to the original size via simple bilinear interpolation. The roughly built saliency region represents a coarse saliency region rather than a fine saliency region [
40]. The causes of the unsatisfactory examples will be investigated in our future work.
Although sufficient remote sensing images are acquired every day, the interpretation of large numbers of airplanes remains difficult due to the lack of aircraft information. Furthermore, the number of aircraft of different types has an unbalanced distribution. Only a minority of aircraft types have sufficient samples that meet the dataset requirement, while the majority of aircraft types have limited samples. In the future, when accumulating the aircraft samples, we will investigate the aircraft type classification in remote sensing images based on limited samples. Additionally, we will explore the utilization of the part saliency map to improve the aircraft recognition performance.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}