Validation of Copernicus Sentinel-2 Cloud Masks Obtained from MAJA, Sen2Cor, and FMask Processors Using Reference Cloud Masks Generated with a Supervised Active Learning Procedure


Abstract
1. Introduction
2. Validation Results for Operational Processors and Discussion
3. Cloud and Cloud Shadow Detection Methods
- a threshold in the visible range, preferably after a basic atmospheric correction, as surface reflectance is low, while cloud reflectance is higher.
- spectral tests to check that the cloud is white in the visible and near infra-red range.
- a threshold on the reflectance in the 1.38-m band, when it is available (for instance on Landsat-8 and Sentinel-2). This spectral band is centered on a deep water vapor absorption band that absorbs all light in that wavelength passing through the lower layers of the atmosphere ([21]). As a result, only objects on the upper layers can be observed. These objects are usually clouds, but some mountains in a dry atmosphere can also be observed [22].
- thresholds on the Normalized Difference Snow Index (NDSI) to tell snow from clouds, because snow has a much lower reflectance in the short wave infra-red ([23]).
- Cloud edges are usually fuzzy, and some parts could be undetected.
- Clouds also scatter light to their neighborhood, and this adjacency effect is very complicated to correct as it is very dependent on cloud altitude and thickness, which are not well known.
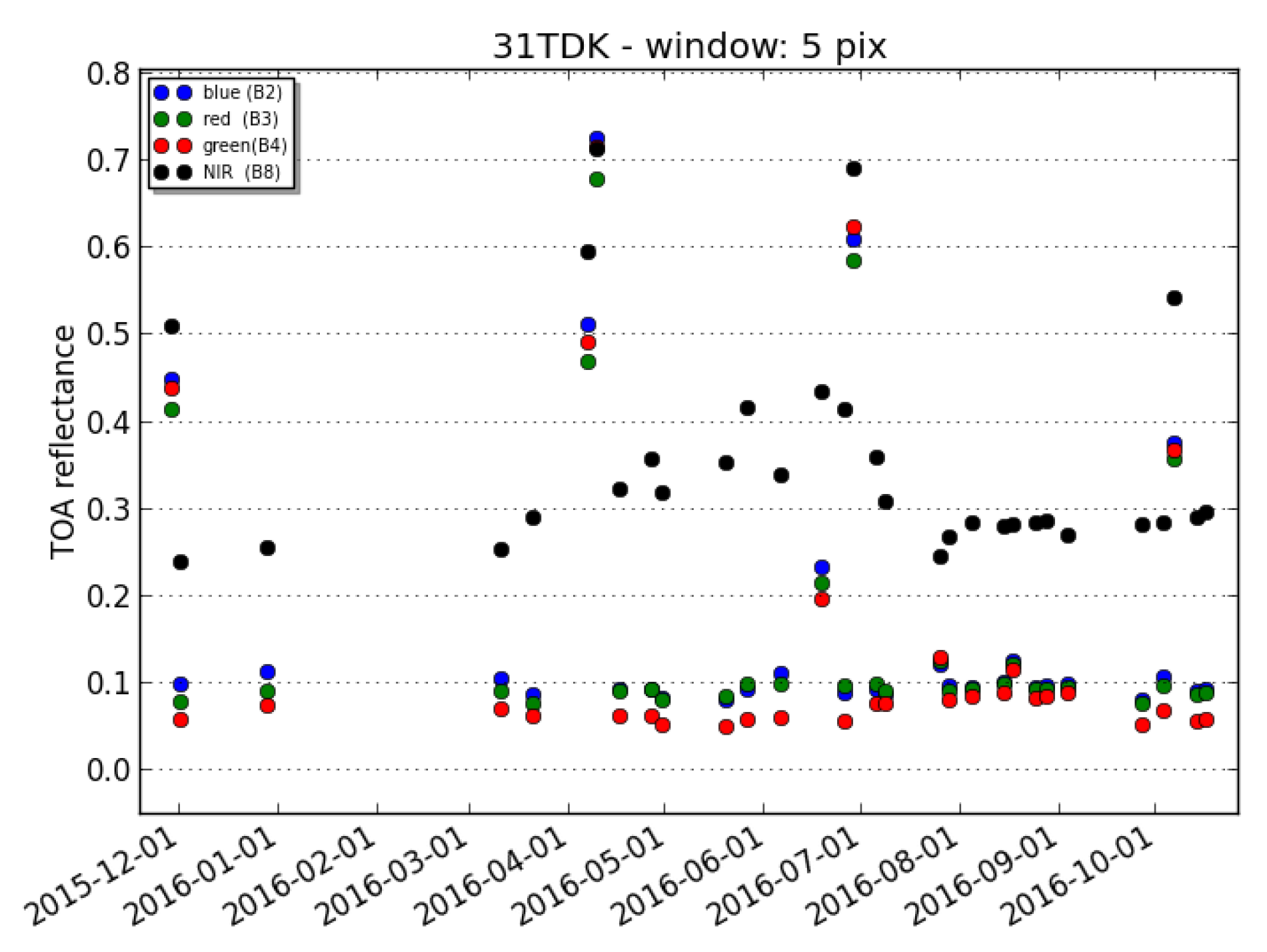
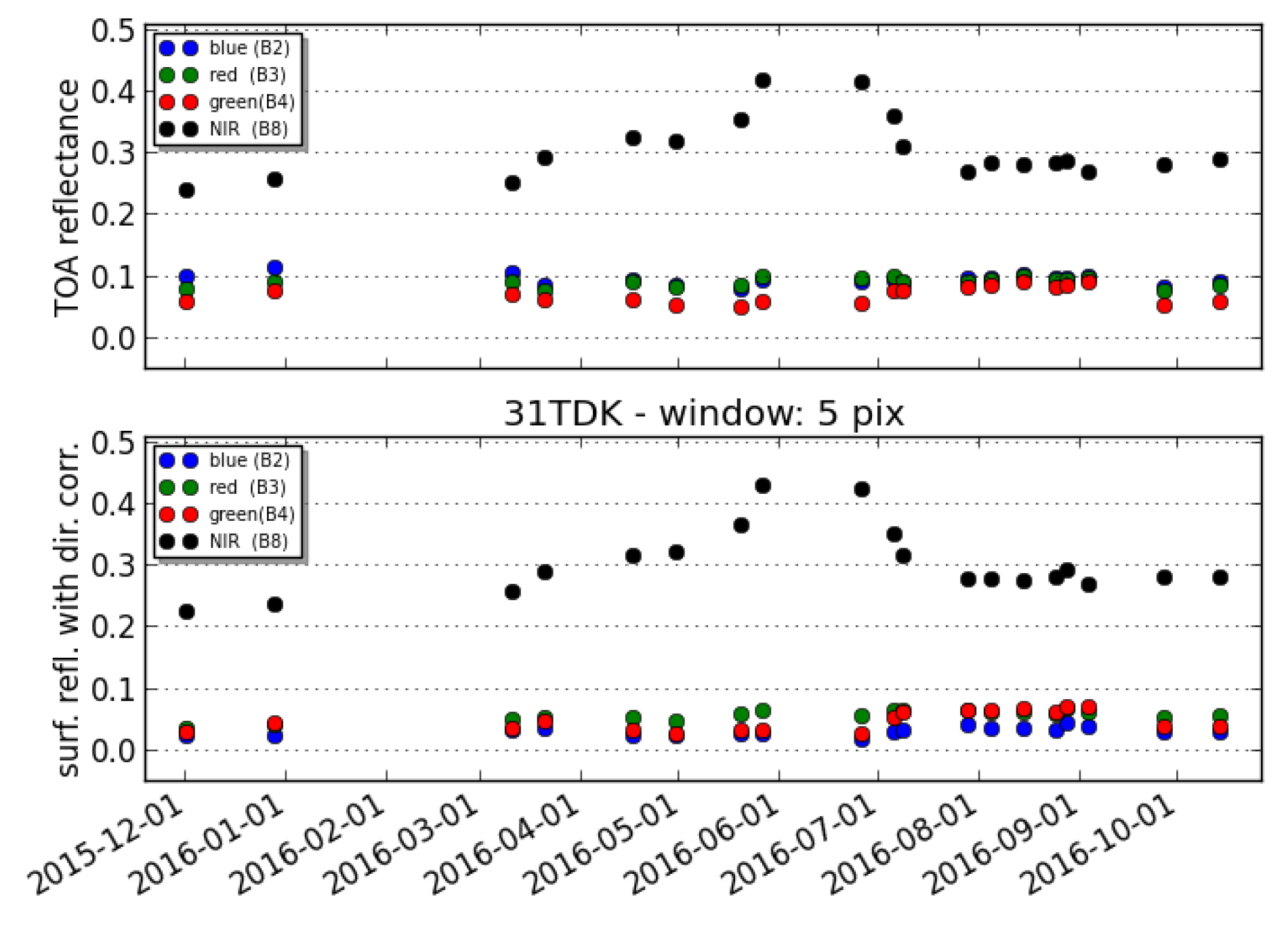
- Sentinel-2 spectral bands observe the Earth with viewing angles that can differ by about one degree. A parallax of 14km is observed on the ground, which is corrected by the geometric processing of L1C. However, this processing takes only the terrain altitude into account and not of the cloud altitude, resulting in uncorrected parallax errors, which can reach 200m for the bands that have the largest separation (B2 and B8a). Moreover, the acquisition of these two bands is also separated by two seconds, and wind speeds of 10–20 m/s are not uncommon in the atmosphere, adding a few tens of meters to the possible displacement. The parallax effect occurs mostly along the direction of the satellite motion and slightly in the perpendicular direction because of the time difference between acquisitions.
3.1. MAJA Cloud and Cloud Shadow Detection
- mono-temporal test
- multi-temporal test
- high cloud
- geometric cloud shadows
- radiometric cloud shadow
- cloud or shadow detected by any of the above tests
- cloud detected by any of the above cloud detection tests
3.2. Sen2Cor Cloud Detection Method
- senescent vegetation (using the near infra-red/green ratio),
- soils (using the short wave infra-red/blue ratio),
- bright rocks or sands (using the near-infra-red/sand ratio).
3.3. FMask Cloud Detection Method
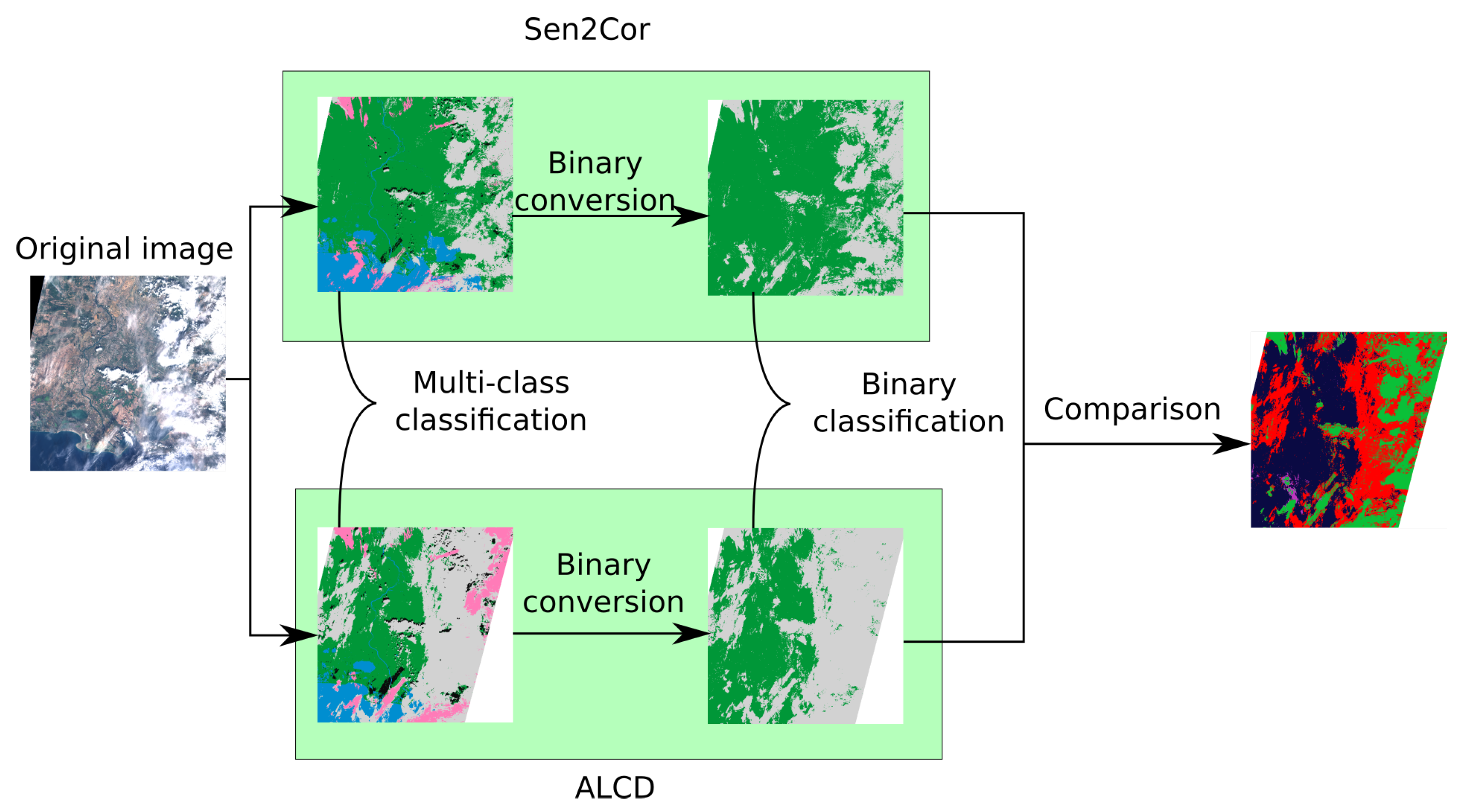
4. Method to Create Reference Cloud Masks
4.1. How to Recognize a Cloud
4.2. Active Learning Cloud Detection Method
- Compute the image features to provide to the classifier.
- While the classification is not satisfactory:
- Select of a set of samples for the 6 classes. After the first iteration, select these samples where the image classification is wrong or where the classification confidence is low.
- Train a random forest [29] model with the samples.
- Perform the classification with the model obtained at Step 2.
- end while.
4.2.1. Feature Selection
- Twelve bands from the image to classify. Among the 13 available bands, the B8A band was discarded, as its information is redundant with respect to that of B8.
- The Digital Elevation Model (DEM). Its purpose is two-fold: First, it aims at improving the distinction between snow and clouds, in high altitude areas. Snow is generally present above a given altitude, and the threshold altitude is often more or less uniform on the scene. The combination of information coming from the reflectances and the DEM can help the classifier distinguish between those two classes. It can also partially avoid the false-positive detection of cirrus with Band 10 (1.38 m) over mountains.
- The multi-temporal difference between bands of the image to classify and a clear image. For this, we used a cloud-free date (referred to as the “clear date”) acquired less than a month apart from the date we wanted to classify. We provided the difference of these images to the classifier, for all bands except Band 10, as it does not allow observing the surface except at a high altitude. Band 8A was also discarded, for the reason exposed above. Thus, 11 multi-temporal features were computed, from all the other bands.
- MAJA also uses a multi-temporal method. In MAJA, the scenes are processed in chronological order using cloud-free pixels acquired before the date to classify. To obtain results that are independent of those of MAJA, the cloud-free reference image used for ALCD was selected after the date to classify. Moreover, the clear date has to be close to the one to be classified, to allow considering that the landscape did not change. Therefore, we constrained the ALCD reference date to be less than 30 days after the date to classify.
- A side effect of requiring a cloud-free image within a month, but posterior to the date to classify, is that our method cannot produce a reference cloud mask for any Sentinel-2 image. Anyway, there is no need to be exhaustive in the generation of cloud mask validation images. However, the need to find an almost cloud-free image as a reference for the ALCD method prevents us from working on sites that are almost always cloudy, such as regions of Congo or French Guyana for instance. As the multi-temporal features of MAJA would not be very efficient for such regions, this can introduce a small bias in favor of MAJA in our analysis. Still, we included three cloudy sites in our analysis (Alta Floresta, Orleans, Munich) to try to minimize this bias. Finally, the necessity to find a cloud-free reference image has an advantage: it is an objective criterion for the selection of the images to use as reference cloud masks, which avoids a subjective bias for the selection of the images to be processed.
4.2.2. Sample Selection
4.2.3. Machine Learning
4.2.4. Classification and Confidence Evaluation
4.3. Validation of ALCD Masks
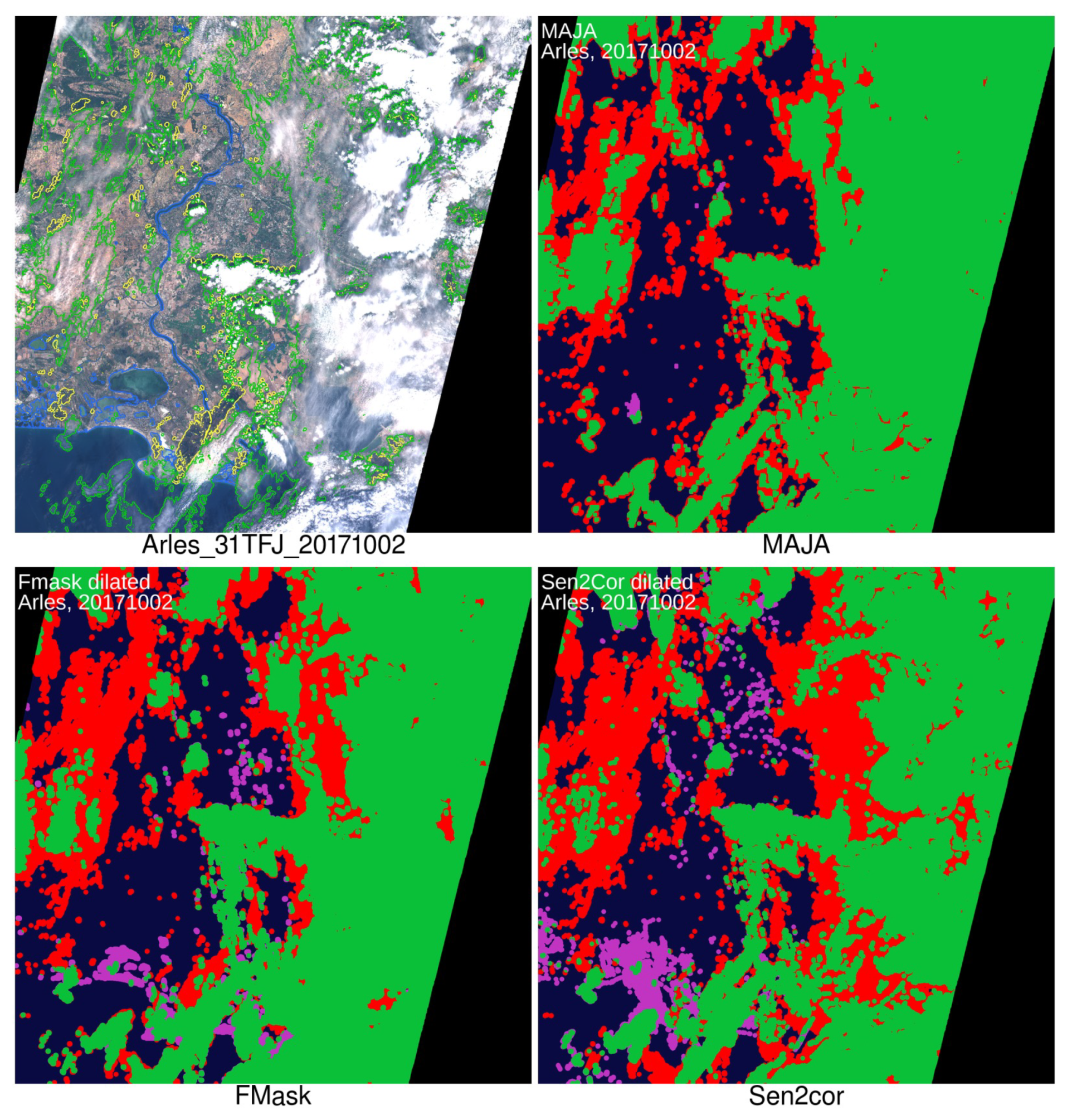
4.3.1. Visual Evaluation
4.3.2. Cross-Validation
- TP, the number of True Positive pixels, for which both the classified pixel and the reference sample were invalid,
- TN, the number of True Negative pixels, for which both the classified pixel and the reference sample were valid,
- FN, the number of False Negative pixels, for which the classified pixel was valid and the reference sample was invalid,
- FP, the number of False Positive pixels, for which the classified pixel was invalid and the reference sample was valid
4.3.3. Comparison with an Existing Dataset
4.3.4. Conclusions on ALCD Validation
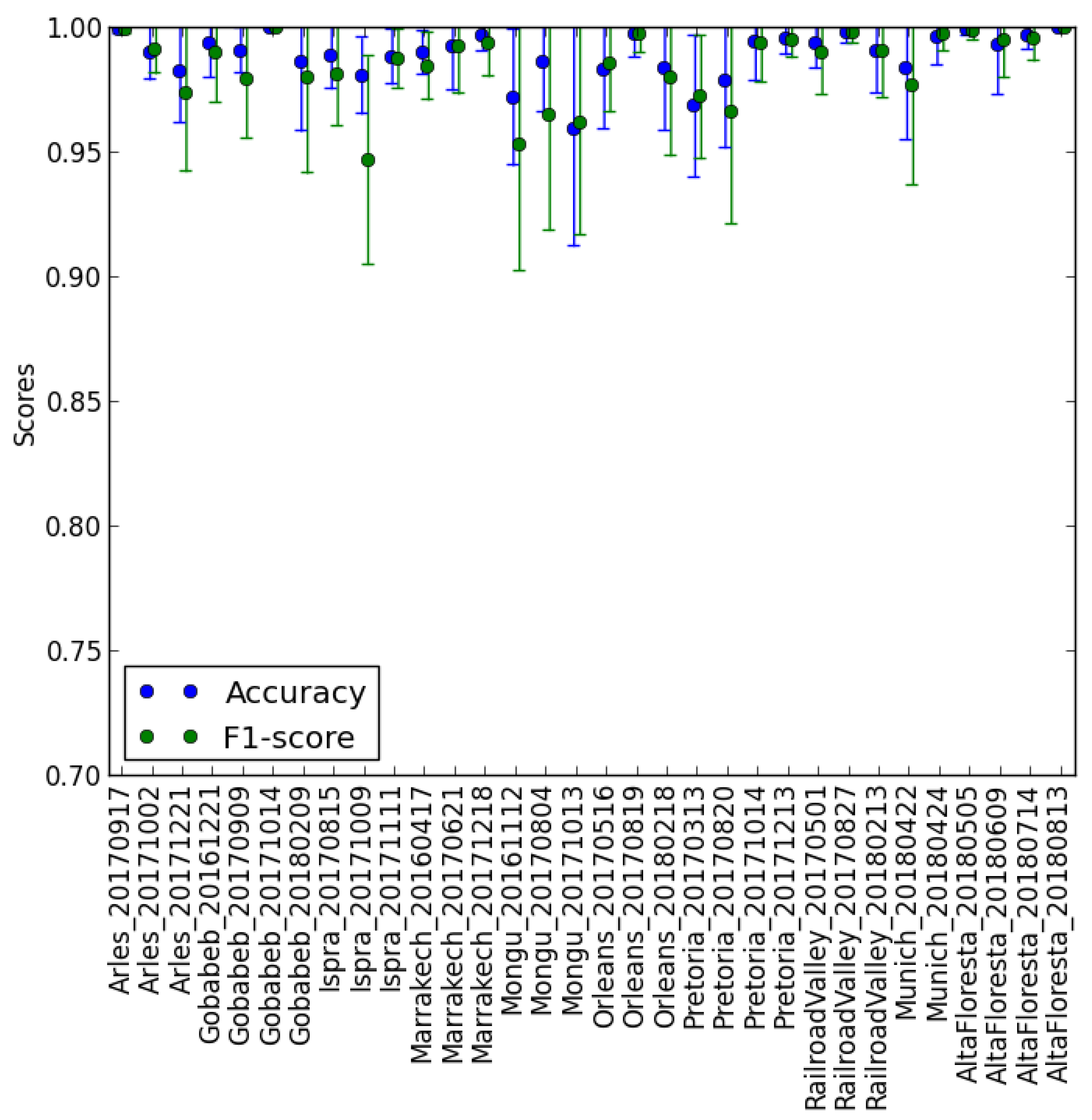
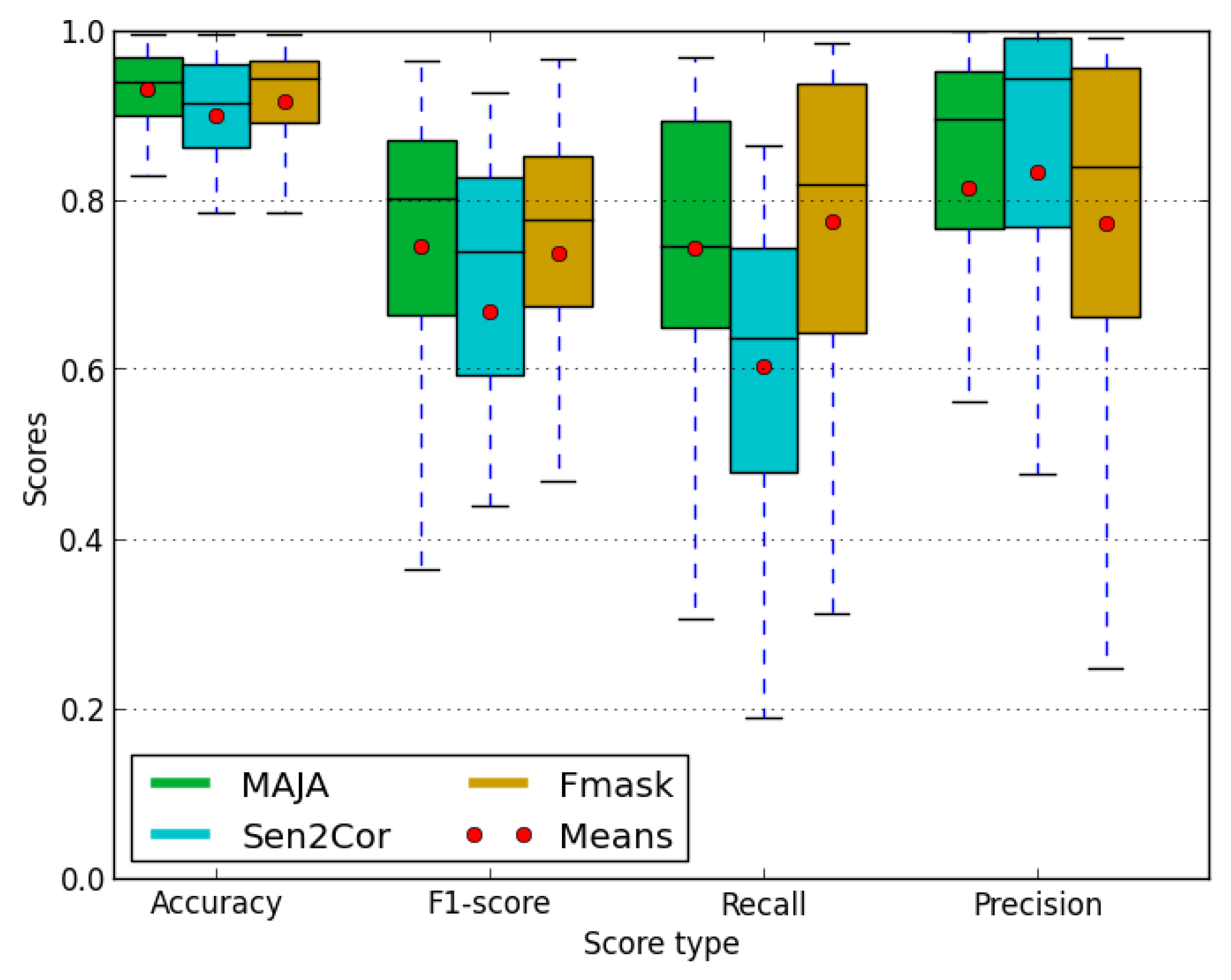
5. Validation Results for Operational Processors and Discussion
- comparison of non-dilated cloud masks, which means we had to erode the MAJA cloud mask, as the dilation was built-in within MAJA;
- comparison of dilated cloud masks, for which we dilated ALCD, FMask, and Sen2Cor using the same kernel as the one used by MAJA; in this comparison, of course, we used the MAJA cloud mask with its built-in dilation.
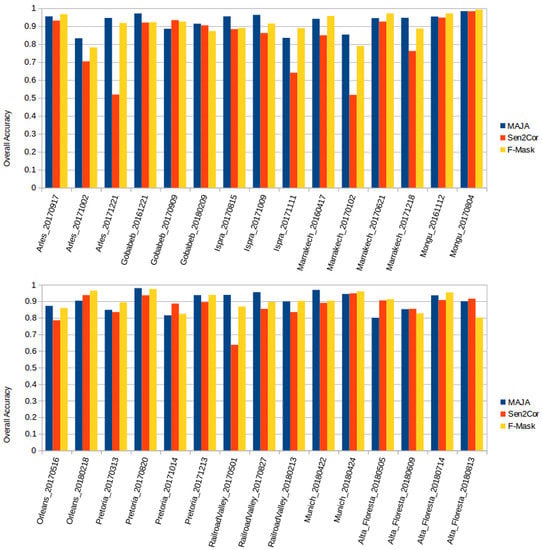
5.1. Comparison of the Results for Non-Dilated Cloud Masks
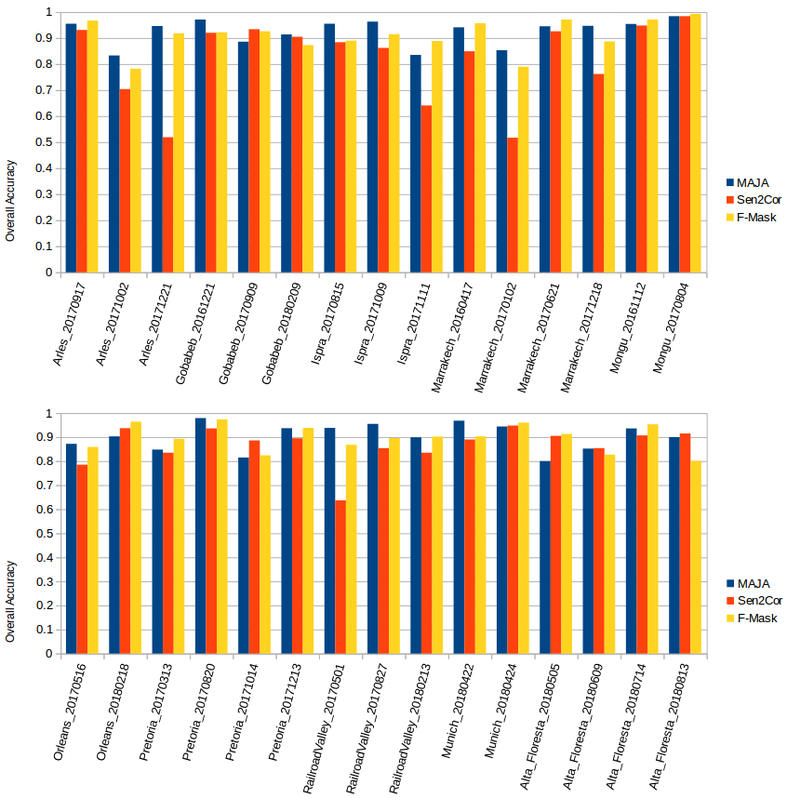
5.2. Comparison of Results for Dilated Cloud Masks
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Woodcock, C.E.; Allen, R.; Anderson, M.; Belward, A.; Bindschadler, R.; Cohen, W.; Gao, F.; Goward, S.N.; Helder, D.; Helmer, E.; et al. Free Access to LANDSAT Imagery. Science 2008, 320, 1011. [Google Scholar] [CrossRef] [PubMed]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- CEOS Analysis Ready Data. Available online: http://ceos.org/ard/ (accessed on 19 February 2019).
- Hagolle, O.; Huc, M.; Pascual, D.V.; Dedieu, G. A multi-temporal method for cloud detection, applied to FORMOSAT-2, VENμS, LANDSAT and SENTINEL-2 images. Remote Sens. Environ. 2010, 114, 1747–1755. [Google Scholar] [CrossRef]
- Le Hegarat-Mascle, S.; Andre, C. Use of Markov Random Fields for automatic cloud/shadow detection on high resolution optical images. ISPRS J. Photogramm. Remote Sens. 2009, 64, 351–366. [Google Scholar] [CrossRef]
- Irish, R.R. LANDSAT 7 automatic cloud cover assessment. In SPIE Proceedings Series; SPIE: Bellingham, WA, USA, 2000; Volume 4049, pp. 348–355. [Google Scholar]
- Roy, D.P.; Wulder, M.A.; Loveland, T.R.; Woodcock, C.E.; Allen, R.G.; Anderson, M.C.; Helder, D.; Irons, J.R.; Johnson, D.M.; Kennedy, R.; et al. LANDSAT-8: Science and product vision for terrestrial global change research. Remote Sens. Environ. 2014, 145, 154–172. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Arias, M.; Tardy, B.; Morin, D.; Rodes, I. Operational High Resolution Land Cover Map Production at the Country Scale Using Satellite Image Time Series. Remote Sens. 2017, 9, 95. [Google Scholar] [CrossRef]
- Muller-Wilm, U. Sentinel-2 MSI—Level 2A Products Algorithm Theoretical Basis Document; ESA Report 2012, ref S2PAD-ATBD-0001 Issue 2.0; European Space Agency: Paris, France, 2012. [Google Scholar]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the FMask algorithm: Cloud, cloud shadow, and snow detection for LANDSATs 4–7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Hagolle, O.; Huc, M.; Villa Pascual, D.; Dedieu, G. A Multi-Temporal and Multi-Spectral Method to Estimate Aerosol Optical Thickness over Land, for the Atmospheric Correction of FormoSat-2, LANDSAT, VENμS and Sentinel-2 Images. Remote Sens. 2015, 7, 2668–2691. [Google Scholar] [CrossRef]
- Richter, R. Correction of satellite imagery over mountainous terrain. Appl. Opt. 1998, 37, 4004–4015. [Google Scholar] [CrossRef]
- Hughes, M.J.; Hayes, D.J. Automated Detection of Cloud and Cloud Shadow in Single-Date LANDSAT Imagery Using Neural Networks and Spatial Post-Processing. Remote Sens. 2014, 6, 4907–4926. [Google Scholar] [CrossRef]
- Zhan, Y.; Wang, J.; Shi, J.; Cheng, G.; Yao, L.; Sun, W. Distinguishing Cloud and Snow in Satellite Images via Deep Convolutional Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1785–1789. [Google Scholar] [CrossRef]
- Foga, S.; Scaramuzza, P.L.; Guo, S.; Zhu, Z.; Dilley, R.D.; Beckmann, T.; Schmidt, G.L.; Dwyer, J.L.; Joseph Hughes, M.; Laue, B. Cloud detection algorithm comparison and validation for operational LANDSAT data products. Remote Sens. Environ. 2017, 194, 379–390. [Google Scholar] [CrossRef]
- Hollstein, A.; Segl, K.; Guanter, L.; Brell, M.; Enesco, M. Ready-to-Use Methods for the Detection of Clouds, Cirrus, Snow, Shadow, Water and Clear Sky Pixels in Sentinel-2 MSI Images. Remote Sens. 2016, 8, 666. [Google Scholar] [CrossRef]
- Iannone, R.Q.; Niro, F.; Goryl, P.; Dransfeld, S.; Hoersch, B.; Stelzer, K.; Kirches, G.; Paperin, M.; Brockmann, C.; Gómez-Chova, L.; et al. Proba-V cloud detection Round Robin: Validation results and recommendations. In Proceedings of the 2017 9th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Brugge, Belgium, 27–29 June 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Wulder, M.A.; Masek, J.G.; Cohen, W.B.; Loveland, T.R.; Woodcock, C.E. Opening the archive: How free data has enabled the science and monitoring promise of LANDSAT. Remote Sens. Environ. 2012, 122, 2–10. [Google Scholar] [CrossRef]
- Ackerman, S.A.; Strabala, K.I.; Menzel, W.P.; Frey, R.A.; Moeller, C.C.; Gumley, L.E. Discriminating clear sky from clouds with MODIS. J. Geophys. Res. 1998, 103, 32141–32157. [Google Scholar] [CrossRef]
- Breon, F.M.; Colzy, S. Cloud detection from the spaceborne POLDER instrument and validation against surface synoptic observations. J. Appl. Meteorol. 1999, 38, 777–785. [Google Scholar] [CrossRef]
- Gao, B.C.; Goetz, A.F.H.; Wiscombe, W.J. Cirrus cloud detection from airborne imaging spectrometer data using the 1.38 mum water vapor band. Geophys. Res. Lett. 1993, 20, 301–304. [Google Scholar] [CrossRef]
- Ben-Dor, E. A precaution regarding cirrus cloud detection from airborne imaging spectrometer data using the 1.38 μm water vapor band. Remote Sens. Environ. 1994, 50, 346–350. [Google Scholar] [CrossRef]
- Dozier, J. Spectral signature of alpine snow cover from the LANDSAT Thematic Mapper. Remote Sens. Environ. 1989, 28, 9–22. [Google Scholar] [CrossRef]
- Lyapustin, A.; Wang, Y.; Frey, R. An automatic cloud mask algorithm based on time series of MODIS measurements. J. Geophys. Res. 2008, 113, D16207. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in LANDSAT imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Frantz, D.; Haß, E.; Uhl, A.; Stoffels, J.; Hill, J. Improvement of the FMask algorithm for Sentinel-2 images: Separating clouds from bright surfaces based on parallax effects. Remote Sens. Environ. 2018, 215, 471–481. [Google Scholar] [CrossRef]
- Lewis, D.D.; Gale, W.A. A Sequential Algorithm for Training Text Classifiers. In Proceedings of the 17th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’94), Dublin, Ireland, 3–6 July 1994; pp. 3–12. [Google Scholar]
- Tuia, D.; Ratle, F.; Pacifici, F.; Kanevski, M.F.; Emery, W.J. Active learning methods for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2218. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Rouse, J., Jr.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation Systems in the Great Plains with ERTS. In Proceedings of the Third ERTS Symposium, Washington, DC, USA, 10–14 December 1973; Volume 45, pp. 309–317. [Google Scholar]
- Gao, B.c. NDWI—A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- QGIS Development Team. QGIS Geographic Information System. Available online: http://qgis.osgeo.org (accessed on 19 February 2019).
- Gascon, F.; Bouzinac, C.; Thepaut, O.; Jung, M.; Francesconi, B.; Louis, J.; Lonjou, V.; Lafrance, B.; Massera, S.; Gaudel-Vacaresse, A.; et al. Copernicus Sentinel-2A Calibration and Products Validation Status. Remote Sens. 2017, 9, 584. [Google Scholar] [CrossRef]
- Orfeo ToolBox: Open Source Processing of Remote Sensing Images|Open Geospatial Data, Software and Standards|Full Text. Available online: https://opengeospatialdata.springeropen.com/articles/10.1186/s40965-017-0031-6 (accessed on 19 February 2019).
- Pelletier, C.; Valero, S.; Inglada, J.; Champion, N.; Dedieu, G. Assessing the robustness of Random Forests to map land cover with high resolution satellite image time series over large areas. Remote Sens. Environ. 2016, 187, 156–168. [Google Scholar] [CrossRef]
- Kohavi, R. A Study of Cross-validation and Bootstrap for Accuracy Estimation and Model Selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence IJCAI’95, Montreal, QC, Canada, 20–25 August 1995; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1995; Volume 2, pp. 1137–1143. [Google Scholar]
- Baetens, L.; Hagolle, O. Sentinel-2 Reference Cloud Masks Generated by an Active Learning Method. Type: Dataset. Available online: https://zenodo.org/record/1460961 (accessed on 19 February 2019). [CrossRef]
- Baetens, L. Active Learning Cloud Detection Tool. Type: Source Code. Available online: https://github.com/CNES/ALCD (accessed on 19 February 2019).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Location | Tile | Date | Scene Content |
|---|---|---|---|
| Alta Floresta(Brazil) | 21LWK | 05 May 2018 | Scattered small cumulus |
| Alta Floresta (Brazil) | 21LWK | 09 June 2018 | Thin cirrus |
| Alta Floresta (Brazil) | 21LWK | 14 July 2018 | Mid=altitude small clouds |
| Alta Floresta (Brazil) | 21LWK | 14 August 2018 | Thin cirrus |
| Arles (France) | 31TFJ | 17 September 2017 | Large cloud cover |
| Arles (France) | 31TFJ | 02 October 2017 | Thick and thin clouds |
| Arles (France) | 31TFJ | 21 December 2017 | Mid-altitude thick clouds and snow |
| Gobabeb (Namibia) | 33KWP | 21 December 2016 | Thick clouds above desert |
| Gobabeb (Namibia) | 33KWP | 09 September 2017 | Small and low clouds |
| Gobabeb (Namibia) | 33KWP | 09 February 2018 | High and thin clouds |
| Ispra (Italy) | 32TMR | 15 August 2017 | Clouds over mountains with snow |
| Ispra (Italy) | 32TMR | 09 October 2017 | Clouds over mountains with snow and bright soil |
| Ispra (Italy) | 32TMR | 11 November 2017 | Clouds over mountains and mist |
| Marrakech (Morocco) | 29RPQ | 17 April 2016 | Scattered cumulus and thin cirrus |
| Marrakech (Morocco) | 29RPQ | 02 January 2017 | Clear image with with snow and two thin cirrus |
| Marrakech (Morocco) | 29RPQ | 21 June 2017 | Scattered cumulus and some cirrus |
| Marrakech (Morocco) | 29RPQ | 18 December 2017 | Scattered cumulus and snow |
| Mongu (Zambia) | 34LGJ | 12 November 2016 | Large thick cloud cover and some cirrus |
| Mongu (Zambia) | 34LGJ | 04 April 2017 | Clear image and a few mid-altitude clouds |
| Mongu (Zambia) | 34LGJ | 13 October 2017 | Large thin cirrus cover |
| Munich (Germany) | 32UPU | 22 April 2018 | Mostly cloud-free with a few small clouds |
| Munich (Germany) | 32UPU | 24 April 2018 | Large cloud cover with cumulus and cirrus |
| Orleans (France) | 31UDP | 16 May 2017 | Thick and thin cirrus clouds |
| Orleans (France) | 31UDP | 19 Aougust 2017 | Large mid-altitude cloud cover |
| Orleans (France) | 31UDP | 18 Feburary 2018 | Stratus |
| Pretoria (South Africa) | 35JPM | 13 March 2017 | Diverse cloud types |
| Pretoria (South Africa) | 35JPM | 20 August 2017 | Scattered small clouds |
| Pretoria (South Africa) | 35JPM | 14 October 2017 | Large thin cirrus cover |
| Pretoria (South Africa) | 35JPM | 13 December 2017 | Altostratus and scattered small clouds |
| Railroad Valley(USA) | 11SPC | 01 May 2017 | Small cumulus over bright soil |
| Railroad Valley (USA) | 11SPC | 27 August 2017 | Large cumulus over bright soil |
| Railroad Valley (USA) | 11SPC | 13 February 2018 | Large stratus and some cumulus |
| Band Name | Sentinel-2 Spectral Band | Wavelength (nm) |
|---|---|---|
| Blue | B1 | 445 |
| Green | B3 | 560 |
| Red | B4 | 670 |
| NIR | B8a | 865 |
| Cirrus | B10 | 1380 |
| SWIR | B11 | 1650 |
| Tile | Date | Clear Date | Nb. of Pixels in the Polygons | % of Correctly Classified Pixels | |
|---|---|---|---|---|---|
| with the Original Dataset | with the Modified Dataset | ||||
| 29RPQ | 17 Nov. 2016 | 27 Apr. 2016 | 19,371 | 99.8% | 99.8% |
| 32TMR | 23 Mar. 2016 | 26 Mar. 2016 | 11,558 | 99.9% | 99.9% |
| 32TNR | 08 Nov. 2016 | 29 Oct. 2016 | 8547 | 99.2% | 99.2% |
| 33UUU | 17 Aug. 2016 | 27 Aug. 2016 | 3372 | 98.0% | 98.0% |
| 35VLJ | 31 Aug. 2016 | 13 Sep. 2016 | 5996 | 93.5% | 99.7% |
| 37PGQ | 06 Dec. 2015 | 16 Nov. 2015 | 15,691 | 96.0% | 100.0% |
| 49JGL | 26 Jan. 2016 | 05 Feb. 2016 | 5961 | 100.0% | 100.0% |
| Mean | 98.3% | 99.7% | |||
| Label | Classification | Binary Classification |
|---|---|---|
| 0 | no data | no data |
| 1 | saturated or defective | no data |
| 2 | dark area pixels | valid |
| 3 | cloud shadows | invalid |
| 4 | vegetation | valid |
| 5 | bare soils | valid |
| 6 | water | valid |
| 7 | unclassified | valid |
| 8 | cloud medium probability | invalid |
| 9 | cloud high probability | invalid |
| 10 | thin cirrus | invalid |
| 11 | snow | valid |
| Label | Classification | Binary Classification |
|---|---|---|
| 255 | null value | no data |
| 0 | clear land | valid |
| 1 | water | valid |
| 2 | cloud shadow | invalid |
| 3 | snow | valid |
| 4 | cloud | invalid |
| Label | Classification | Binary Classification |
|---|---|---|
| 0 | null value | no data |
| 2 | low clouds | invalid |
| 3 | high clouds | invalid |
| 4 | cloud shadows | invalid |
| 5 | land | valid |
| 6 | water | valid |
| 7 | snow | valid |
| Location | Tile | Date | MAJA | Sen2Cor | FMask | |||
|---|---|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | |||
| Alta Floresta | 21LWK | 20180505 | 0.936 | 0.444 | 0.954 | 0.635 | 0.954 | 0.775 |
| Alta Floresta | 21LWK | 20180609 | 0.884 | 0.856 | 0.855 | 0.810 | 0.819 | 0.760 |
| Alta Floresta | 21LWK | 20180714 | 0.971 | 0.600 | 0.959 | 0.152 | 0.974 | 0.633 |
| Alta Floresta | 21LWK | 20180813 | 0.900 | 0.849 | 0.892 | 0.833 | 0.788 | 0.614 |
| Arles | 31TFJ | 20170917 | 0.932 | 0.952 | 0.866 | 0.895 | 0.943 | 0.959 |
| Arles | 31TFJ | 20171002 | 0.864 | 0.867 | 0.638 | 0.546 | 0.785 | 0.776 |
| Arles | 31TFJ | 20171221 | 0.952 | 0.802 | 0.918 | 0.618 | 0.951 | 0.802 |
| Gobabeb | 33KWP | 20161221 | 0.952 | 0.885 | 0.917 | 0.736 | 0.944 | 0.843 |
| Gobabeb | 33KWP | 20170909 | 0.831 | 0.364 | 0.980 | 0.781 | 0.962 | 0.606 |
| Gobabeb | 33KWP | 20180209 | 0.946 | 0.710 | 0.930 | 0.569 | 0.919 | 0.473 |
| Ispra | 32TMR | 20170815 | 0.966 | 0.694 | 0.973 | 0.738 | 0.963 | 0.730 |
| Ispra | 32TMR | 20171009 | 0.979 | 0.593 | 0.973 | 0.438 | 0.960 | 0.468 |
| Ispra | 32TMR | 20171111 | 0.893 | 0.824 | 0.859 | 0.751 | 0.917 | 0.861 |
| Marrakech | 29RPQ | 20160417 | 0.925 | 0.737 | 0.913 | 0.621 | 0.944 | 0.812 |
| Marrakech | 29RPQ | 20170102 | 0.951 | 0.049 | 0.908 | 0.026 | 0.884 | 0.018 |
| Marrakech | 29RPQ | 20170621 | 0.972 | 0.786 | 0.959 | 0.639 | 0.979 | 0.859 |
| Marrakech | 29RPQ | 20171218 | 0.937 | 0.817 | 0.879 | 0.518 | 0.891 | 0.702 |
| Mongu | 34LGJ | 20161112 | 0.969 | 0.964 | 0.940 | 0.927 | 0.969 | 0.966 |
| Mongu | 34LGJ | 20170804 | 0.995 | 0.764 | 0.995 | 0.769 | 0.996 | 0.822 |
| Mongu | 34LGJ | 20171013 | 0.857 | 0.840 | 0.896 | 0.892 | 0.763 | 0.702 |
| Munich | 32UPU | 20180422 | 0.978 | 0.632 | 0.982 | 0.670 | 0.980 | 0.695 |
| Munich | 32UPU | 20180424 | 0.916 | 0.944 | 0.851 | 0.890 | 0.888 | 0.923 |
| Orleans | 31UDP | 20170516 | 0.853 | 0.874 | 0.710 | 0.699 | 0.820 | 0.838 |
| Orleans | 31UDP | 20180218 | 0.938 | 0.959 | 0.785 | 0.841 | 0.944 | 0.963 |
| Pretoria | 35JPM | 20170313 | 0.922 | 0.778 | 0.917 | 0.753 | 0.925 | 0.832 |
| Pretoria | 35JPM | 20170820 | 0.995 | 0.583 | 0.994 | 0.504 | 0.993 | 0.652 |
| Pretoria | 35JPM | 20171014 | 0.828 | 0.732 | 0.904 | 0.866 | 0.829 | 0.736 |
| Pretoria | 35JPM | 20171213 | 0.964 | 0.828 | 0.970 | 0.857 | 0.971 | 0.882 |
| Railroad Valley | 11SPC | 20170501 | 0.976 | 0.549 | 0.858 | 0.090 | 0.905 | 0.371 |
| Railroad Valley | 11SPC | 20170827 | 0.959 | 0.923 | 0.894 | 0.805 | 0.902 | 0.841 |
| Railroad Valley | 11SPC | 20180213 | 0.899 | 0.916 | 0.801 | 0.820 | 0.895 | 0.912 |
| Location | Tile | Date | MAJA | Sen2Cor | FMask | |||
|---|---|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | |||
| Alta Floresta | 21LWK | 20180505 | 0.799 | 0.615 | 0.905 | 0.853 | 0.913 | 0.885 |
| Alta Floresta | 21LWK | 20180609 | 0.840 | 0.842 | 0.854 | 0.859 | 0.827 | 0.831 |
| Alta Floresta | 21LWK | 20180714 | 0.936 | 0.641 | 0.907 | 0.409 | 0.953 | 0.759 |
| Alta Floresta | 21LWK | 20180813 | 0.880 | 0.845 | 0.915 | 0.894 | 0.801 | 0.712 |
| Arles | 31TFJ | 20170917 | 0.954 | 0.971 | 0.931 | 0.957 | 0.967 | 0.979 |
| Arles | 31TFJ | 20171002 | 0.830 | 0.866 | 0.704 | 0.759 | 0.782 | 0.828 |
| Arles | 31TFJ | 20171221 | 0.946 | 0.867 | 0.519 | 0.459 | 0.918 | 0.835 |
| Gobabeb | 33KWP | 20161221 | 0.971 | 0.953 | 0.920 | 0.856 | 0.922 | 0.860 |
| Gobabeb | 33KWP | 20170909 | 0.886 | 0.785 | 0.934 | 0.856 | 0.926 | 0.828 |
| Gobabeb | 33KWP | 20180209 | 0.914 | 0.733 | 0.905 | 0.699 | 0.873 | 0.551 |
| Ispra | 32TMR | 20170815 | 0.954 | 0.789 | 0.884 | 0.658 | 0.890 | 0.659 |
| Ispra | 32TMR | 20171009 | 0.962 | 0.731 | 0.862 | 0.489 | 0.915 | 0.588 |
| Ispra | 32TMR | 20171111 | 0.837 | 0.814 | 0.641 | 0.699 | 0.889 | 0.867 |
| Marrakech | 29RPQ | 20160417 | 0.941 | 0.869 | 0.849 | 0.724 | 0.957 | 0.914 |
| Marrakech | 29RPQ | 20170102 | 0.863 | 0.037 | 0.517 | 0.015 | 0.790 | 0.020 |
| Marrakech | 29RPQ | 20170621 | 0.944 | 0.769 | 0.926 | 0.724 | 0.971 | 0.898 |
| Marrakech | 29RPQ | 20171218 | 0.947 | 0.900 | 0.762 | 0.634 | 0.887 | 0.810 |
| Mongu | 34LGJ | 20161112 | 0.954 | 0.953 | 0.948 | 0.947 | 0.971 | 0.972 |
| Mongu | 34LGJ | 20170804 | 0.984 | 0.659 | 0.984 | 0.708 | 0.993 | 0.854 |
| Mongu | 34LGJ | 20171013 | 0.782 | 0.800 | 0.897 | 0.916 | 0.734 | 0.747 |
| Munich | 32UPU | 20180422 | 0.967 | 0.796 | 0.890 | 0.597 | 0.903 | 0.627 |
| Munich | 32UPU | 20180424 | 0.941 | 0.967 | 0.948 | 0.971 | 0.960 | 0.978 |
| Orleans | 31UDP | 20170516 | 0.866 | 0.903 | 0.785 | 0.836 | 0.859 | 0.898 |
| Orleans | 31UDP | 20180218 | 0.902 | 0.942 | 0.937 | 0.965 | 0.964 | 0.980 |
| Pretoria | 35JPM | 20170313 | 0.845 | 0.748 | 0.835 | 0.768 | 0.893 | 0.865 |
| Pretoria | 35JPM | 20170820 | 0.979 | 0.671 | 0.936 | 0.483 | 0.974 | 0.729 |
| Pretoria | 35JPM | 20171014 | 0.804 | 0.728 | 0.886 | 0.866 | 0.824 | 0.775 |
| Pretoria | 35JPM | 20171213 | 0.936 | 0.813 | 0.895 | 0.735 | 0.938 | 0.857 |
| Railroad Valley | 11SPC | 20170501 | 0.938 | 0.608 | 0.637 | 0.279 | 0.868 | 0.584 |
| Railroad Valley | 11SPC | 20170827 | 0.955 | 0.936 | 0.854 | 0.823 | 0.896 | 0.873 |
| Railroad Valley | 11SPC | 20180213 | 0.899 | 0.927 | 0.835 | 0.888 | 0.902 | 0.932 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baetens, L.; Desjardins, C.; Hagolle, O. Validation of Copernicus Sentinel-2 Cloud Masks Obtained from MAJA, Sen2Cor, and FMask Processors Using Reference Cloud Masks Generated with a Supervised Active Learning Procedure. Remote Sens. 2019, 11, 433. https://doi.org/10.3390/rs11040433
Baetens L, Desjardins C, Hagolle O. Validation of Copernicus Sentinel-2 Cloud Masks Obtained from MAJA, Sen2Cor, and FMask Processors Using Reference Cloud Masks Generated with a Supervised Active Learning Procedure. Remote Sensing. 2019; 11(4):433. https://doi.org/10.3390/rs11040433
Chicago/Turabian StyleBaetens, Louis, Camille Desjardins, and Olivier Hagolle. 2019. "Validation of Copernicus Sentinel-2 Cloud Masks Obtained from MAJA, Sen2Cor, and FMask Processors Using Reference Cloud Masks Generated with a Supervised Active Learning Procedure" Remote Sensing 11, no. 4: 433. https://doi.org/10.3390/rs11040433
APA StyleBaetens, L., Desjardins, C., & Hagolle, O. (2019). Validation of Copernicus Sentinel-2 Cloud Masks Obtained from MAJA, Sen2Cor, and FMask Processors Using Reference Cloud Masks Generated with a Supervised Active Learning Procedure. Remote Sensing, 11(4), 433. https://doi.org/10.3390/rs11040433