1. Introduction
In remote sensing, hyperspectral sensors [
1,
2] capture hundreds of contiguous bands with a higher spectral resolution (e.g., 0.01 μm). Using hyperspectral data, it is possible to reduce classes’ overlaps, and enhance the capability to differentiate subtle spectral differences. In recent years, the hyperspectral image classification has been applied to many applications [
3]. Typical techniques applied to hyperspectral image classification include many traditional pattern recognition methods [
4], kernel based methods [
5], and recently developed deep learning approaches, such as the transfer learning [
6] and the active learning [
7], etc. Data fusion involves the combination of information from different sources, either with differing textual or rich-media representations. Due to its capability of reducing redundancy and uncertainty for decision-making, research has been carried out to apply data fusion to remote sensing. For example, a fusion framework based on multi-scale transform and sparse representation is proposed in Liu et al. [
8] for image fusion. A review on different pixel-level fusion schemes is given in Li et al. [
9]. A decision level fusion is proposed in Waske et al. [
10], in which two Support Vector Machines (SVMs) are individually applied to two data sources and their outputs are combined to reach a final decision. In Yang et al. [
11], a fusion strategy is investigated to integrate the results from a supervised classifier and an unsupervised classifier. The final decision is obtained by a weighted majority voting rule. In Makarau et al. [
12], factor graphs are used to combine the output of multiple sensors. Similarly in Mahmoudi et al. [
13], a context-sensitive object recognition method is used to combine multi-view remotely sensed images by exploiting the scene contextual information. In Chunsen et al. [
14], a probabilistic weighted fusion framework is proposed to classify spectral-spatial features from the hyperspectral data. In Polikar et al. [
15], a review on various decision fusion approaches is provided, and more fusion methods on remote sensing can be found in Luo et al. [
16], Stavrakoudis et al. [
17], and Wu et al. [
18].
Extended from our early research on acoustic signals fusion [
19] and hyperspectral image classification [
20,
21], in this research we focus on decision fusion approaches from a broader choice of fusion collections. Decision level fusion can be viewed as a procedure of choosing one hypothesis from multiple hypotheses given multiple sources. Generally speaking, decision level fusion is used to improve decision accuracy as well as reduce communication burden. Here, for the purpose of better scene classification accuracy, we adopt the decision level fusion to obtain a new decision from one
single hyperspectral data source. One particular reason for such a choice is that in the decision level fusion the fused information may or
may not come from the identical sensors. In the first manner, the decision fusion can combine the outputs of each classifier to make an overall decision. On the contrary, the data-level and the feature-level fusion usually integrate multiple data source or multiple feature sets. Thus, information fusion can be implemented, either by combining different
sensors’ output (like the traditional fusion), or by integrating different knowledge extractions (such as “experts’ different views”). The latter fusion scheme actually compensates the deficiency inherited from a
single view or a
single knowledge description. Thus, on a typical hyperspectral data-cube that is apparently acquired from a single hyperspectral sensor, we are still able to explore many effective decision fusion strategies. By this idea, we recover new opportunities to further improve the classification performance, especially for the high-dimensional remotely sensed data such as the hyperspectral imagery that is rich in feature representation and interpretation.
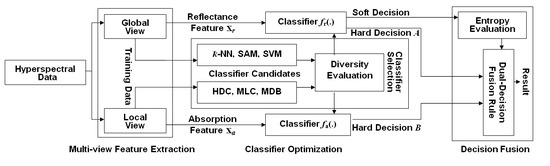
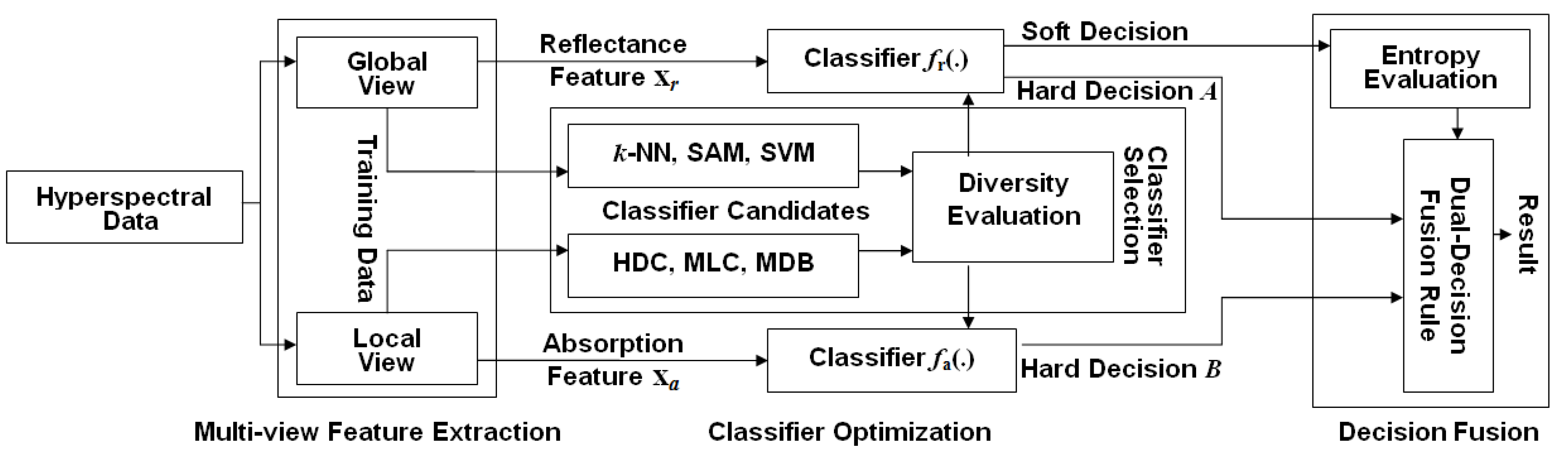
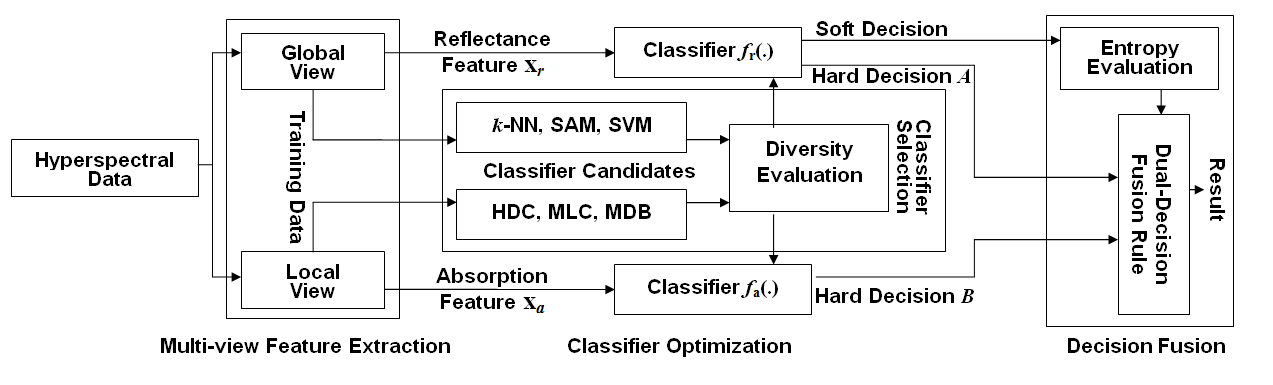
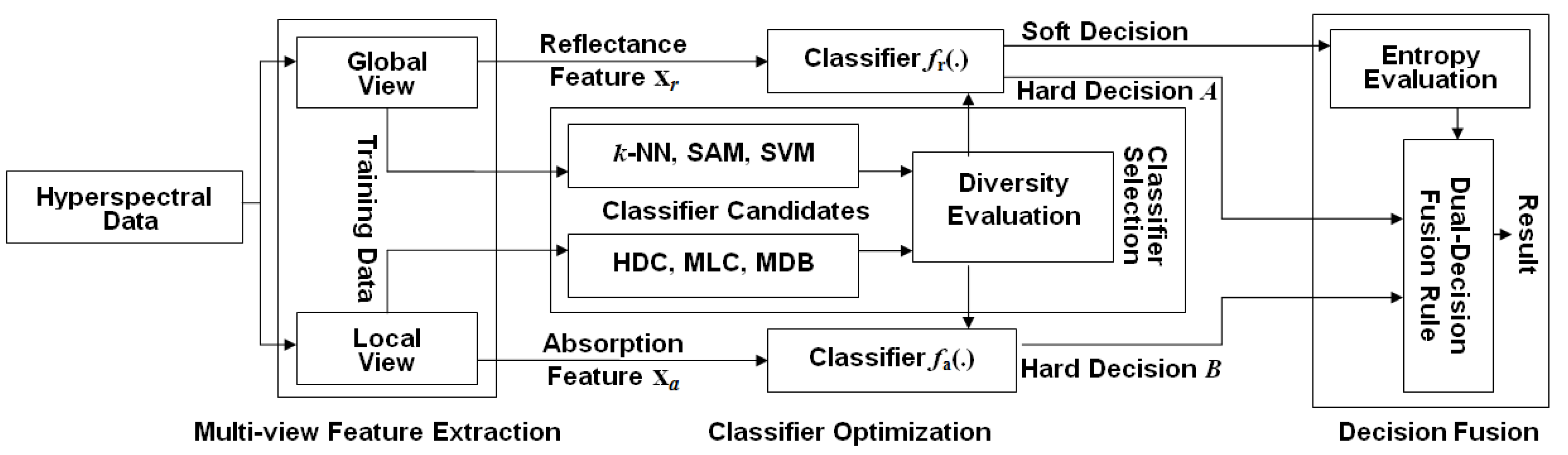
Following the aforementioned motivation, we propose a novel decision level fusion framework for hyperspectral image classification. In the first step, we extract the spectra from every pixel, and use them as holistic features. These features characterize the lighting interaction between the materials and the incident sun light. In the second step, we define a series of valleys in a spectral reflectance curve, and use them as local features. These features describe the spectral absorptions caused by the materials. The set of absorption features is formed by marking an absorption vector with a positive one at the position where absorption happens over the corresponding wavelength or band. Therefore, the absorption feature vector records the bands where the incident light is absorbed by the material’s components (e.g., the material’s atoms or molecules) contained in the pixel. This gives us a valuable local-view regarding the material’s ingredients as well as its identity. Based on this assumption, we propose a decision level fusion framework to exploit the two groups of or two views of features for hyperspectral image classification.
By considering the nature of the local features and the holistic features, two groups of classifiers are firstly chosen as the candidates to classify them. The first group of classifiers, used for the reflectance features, consists of the nearest neighbor classifier (
k-NN), the spectral angle mapping (SAM) and the support vector machine (SVM). The second group of classifiers, used for the absorption features, consists of the minimum Hamming distance (MHD) classifier and the diagnostic bands classifier (DBC). Among them, the diagnostic bands classifier (DBC) is a new algorithm that we proposed in this research to classify the absorption features, which will be discussed in
Section 4.3. Next, a pairwise diversity between every reflectance-feature classifiers and every absorption-feature classifiers is evaluated, and the two classifiers with the greatest diversity are selected as the individually favored algorithms to classify the reflectance and absorption features. Finally, by using an information entropy rule, which is mediated by the entropy from the classification outputs of the reflectance features, a dual-decision fusion method is developed to exploit the results from each of the individually favored classifiers.
Comparing to the traditional fusion methods in remotely sensed image classification, the proposed approach looks at the hyperspectral data from different views and integrates multiple views of features accordingly. The idea is different from those of conventional multi-source/multi-sensor data fusion methods, which emphasize the problem of how to supplement information from different sensors. However, the proposed approach and the traditional sensor fusion or classifiers combination share the same fusion principle. The difference is that the proposed fusion framework is developed to exploit the capabilities of different model assumptions. On the contrary, the conventional sensor fusion is considered to correct the incompleteness by different observations.
The rest of the paper is organized as follows. By a detailed discussion of absorption features, we present the hyperspectral feature extraction by multiple views in
Section 3. Then, an entropy-mediated fusion scheme is presented in
Section 4, as well as a discussion on classifier selection. In
Section 5, we carried out several experiments to evaluate the performance of the proposed method. Finally, in Conclusions, we summarize the research and propose several future works.
2. Hyperspectral Data Sets
In this paper, three datasets are researched. The first one is AVIRIS 92AV3C hyperspectral data, which is acquired by an AVIRIS sensor over the test site of Indian Pine in northwestern Indiana, USA [
22]. The sensor provides 224 bands of data, covering a wavelength range from 400 nm to 2500 nm. Four of the 224 bands contain only zeros, so they are usually discarded and the remaining 220 bands are formed as the 92AV3C dataset. The scene of the AVIRIS 92AV3C is 145 × 145 pixels, and a reference map is provided to indicate partial ground truth. Both the dataset and the reference map can be downloaded from Website [
23]. The AVIRIS 92AV3C dataset is mainly used to demonstrate the problem of hyperspectral image analysis for land use survey. Thus, the pixels are labeled as belonging to one of 16 classes of vegetation, including ‘Alfalfa’, ‘Corn’, ‘Corn(mintill)’, ‘Corn(notill)’, ‘Grass/trees’, ‘Grass/pasture(mowed)’, ‘Grass(pasture)’, ‘Hay(windrowed)’, ‘Oats’, ‘Soybean(clean)’, ‘Soybean(notill)’, ‘Soybean(mintill)’, ‘Wheat’, ‘Woods’, ‘Buildings/Grass/Trees/Drives’, and ‘Stone Steel Towers’. In our research, pixels of the all 16 classes of vegetation are used in the simulation.
The second dataset is Salinas scene, which is also collected by the 224-band AVIRIS sensor over Salinas Valley, California. This dataset is characterized by the higher spatial resolution (3.7-meter pixels comparing to 92AV3C’s 20-meter pixels). The area covered comprises 512 lines by 217 samples. As the same as the 92AV3C scene, the 20 water absorption bands are discarded. The pixels of the Salinas scene are labeled as belonging to one of 16 classes, including ‘Brocoli_green_weeds (type1)’, ‘Brocoli_green_weeds (type2)’, ‘Fallow’, ‘Fallow (rough plow)’, ‘Fallow (smooth)’, ‘Stubble’, ‘Celery’, ‘Grapes (untrained)’, ‘Soil_vineyard (develop)’, ‘Corn (senesced green weeds)’, ‘Lettuce romaine (4wk)’, ‘Lettuce romaine (5wk)’, ‘Lettuce romaine (6wk)’, ‘Lettuce romaine (7wk)’, ‘Vineyard (untrained)’, and ‘Vineyard (vertical trellis)’. In our research, pixels of the all 16 classes are used in the simulation.
The third dataset is used to analyze non-vegetation materials, which is recorded by an ASD (a Visible, NIR and SWIR spectrometers) field spectrometer (see website [
24]) with a spectrum range from 350 nm to 2500 nm and with wavelength step 1 nm. The data was compared to a white reference board and was normalized before processing. In this dataset, we focus more on mineral and man-made materials, including ‘aluminum’, ‘polyester film’, ‘titanium’, ‘silicon dioxide’, etc.
3. Hyperspectral Features Extraction via Multiple Views
To classify hyperspectral images effectively, the first priority is to define appropriate features. On the one hand, features should be extracted to characterize the intrinsic distinctness among materials. On the other hand, it is desired that these features are robust to various interferences, such as the atmospheric noise or neighboring pixels’ interference. One example of the hyperspectral features is the complete spectra [
5,
25]. Other conventional hyperspectral features are the spectral bands [
20], the transformed features [
22,
26], etc. Considering the characteristics of the hyperspectral curves, it is also useful to apply new transforms with the capability of local description, such as Wavelet Transforms [
27] and Shapelet Transform [
28].
In this paper, rather than pursuing the competence of each single set of features like a lot of previous research did, we are using the idea of the multi-view learning [
29,
30,
31]. In image retrieval research, the multi-view learning emphasizes the capability of exploiting different feature sets based on a
single image. In more detail, the multi-view learning uses multiple functions to describe different views of the
same input data and optimizes all the functions jointly by exploiting the redundancy or complementary content among different views. This is a particularly useful idea for our hyperspectral image classification for it gives us the opportunity to improve the learning performance without inputting other sensors’ data. Therefore, under the umbrella of information fusion, we can combine the information that naturally corresponds to various views of the same hyperspectral data-cube. This makes it possible to improve learning performance further.
Based on the multi-view’s idea, we consider the hyperspectral feature extraction from two distinct views, namely the view of reflectance and the view of absorption. The corresponding two feature sets, which we called the reflectance spectra and the absorption features, respectively, which are discussed as follows.
3.1. Features from Reflectance View
In mass spectrometry, a material reflects incident light, and the intensity of the reflectance is related to the specific chemistry or the molecular structure regarding the material. When the reflectance was recorded for different wavelengths of the incident light, the output of the spectrometry will come out as a special curve, which we may call as the reflectance spectra. These spectra are electromagnetic reflectance of the material to the incident light, so they can be described as a function against the different wavelengths or bands. Since materials may be classified or categorized by their constituent atoms or molecules, the spectra can be considered as a special “spectral-signature”. Thus, by analyzing spectra captured by hyperspectral sensors, we get an effective way to classify different materials.
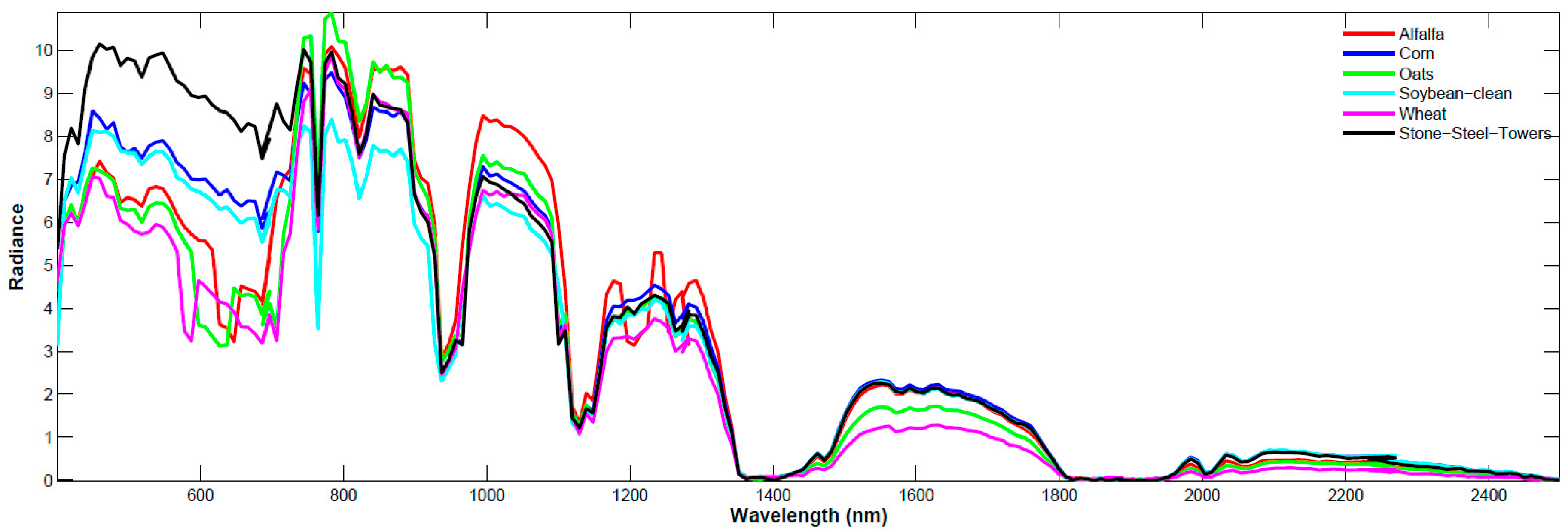
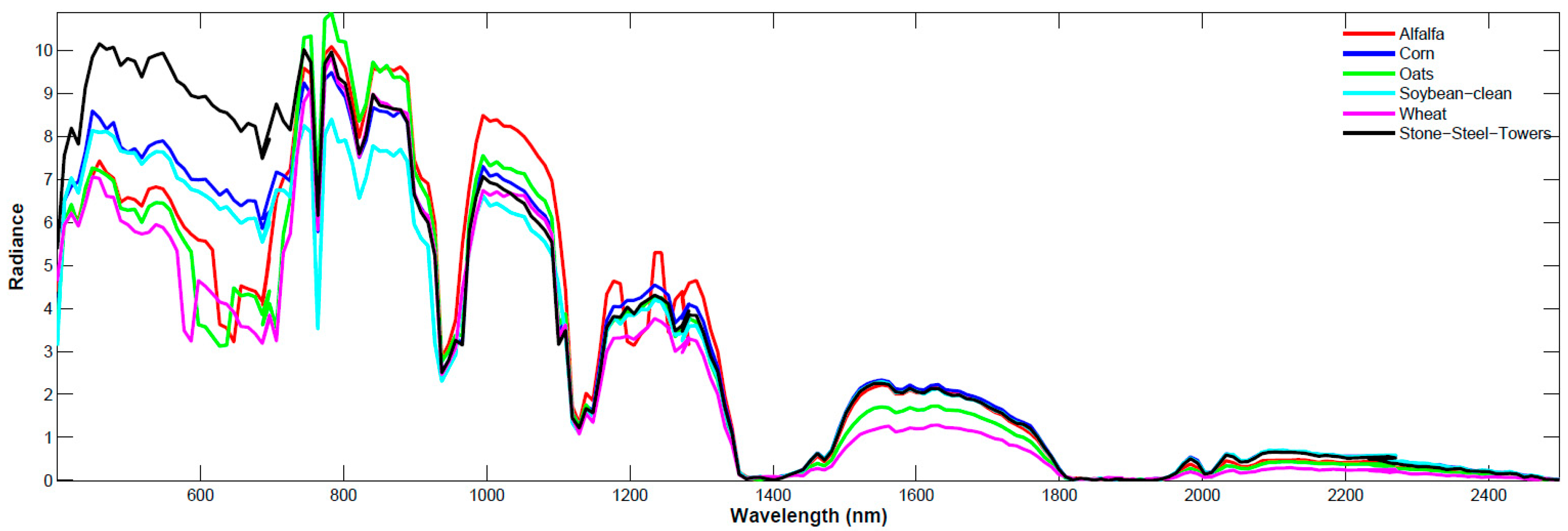
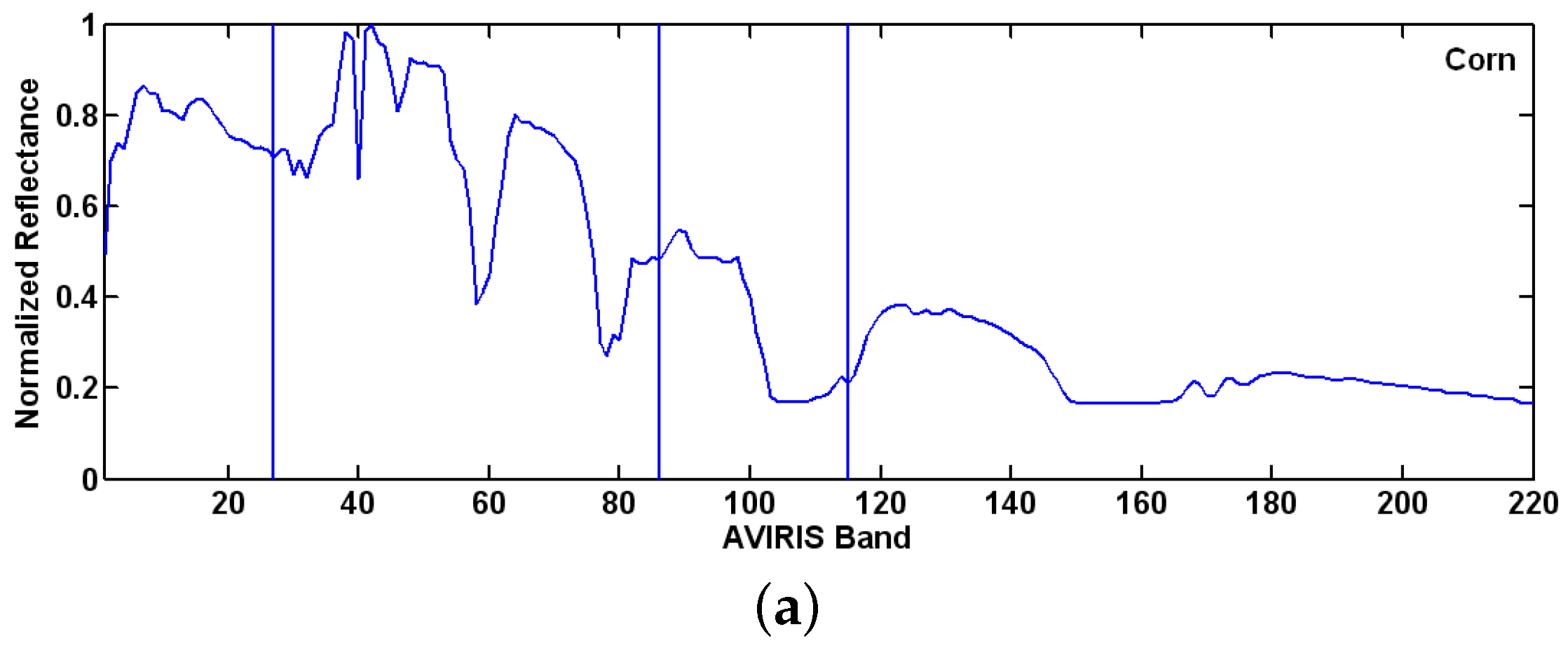
Figure 1 shows the reflectance spectra of four classes of vegetation and one man-made object extracted from the AVIRIS 92AV3C dataset. The
x-axis shows wavelengths (nm), and the
y-axis shows the radiance value measured at different wavelengths. From
Figure 1, it is seen that a different substance indeed can be differentiated by their spectra, and the spectra can be used as the features to classify the objects.
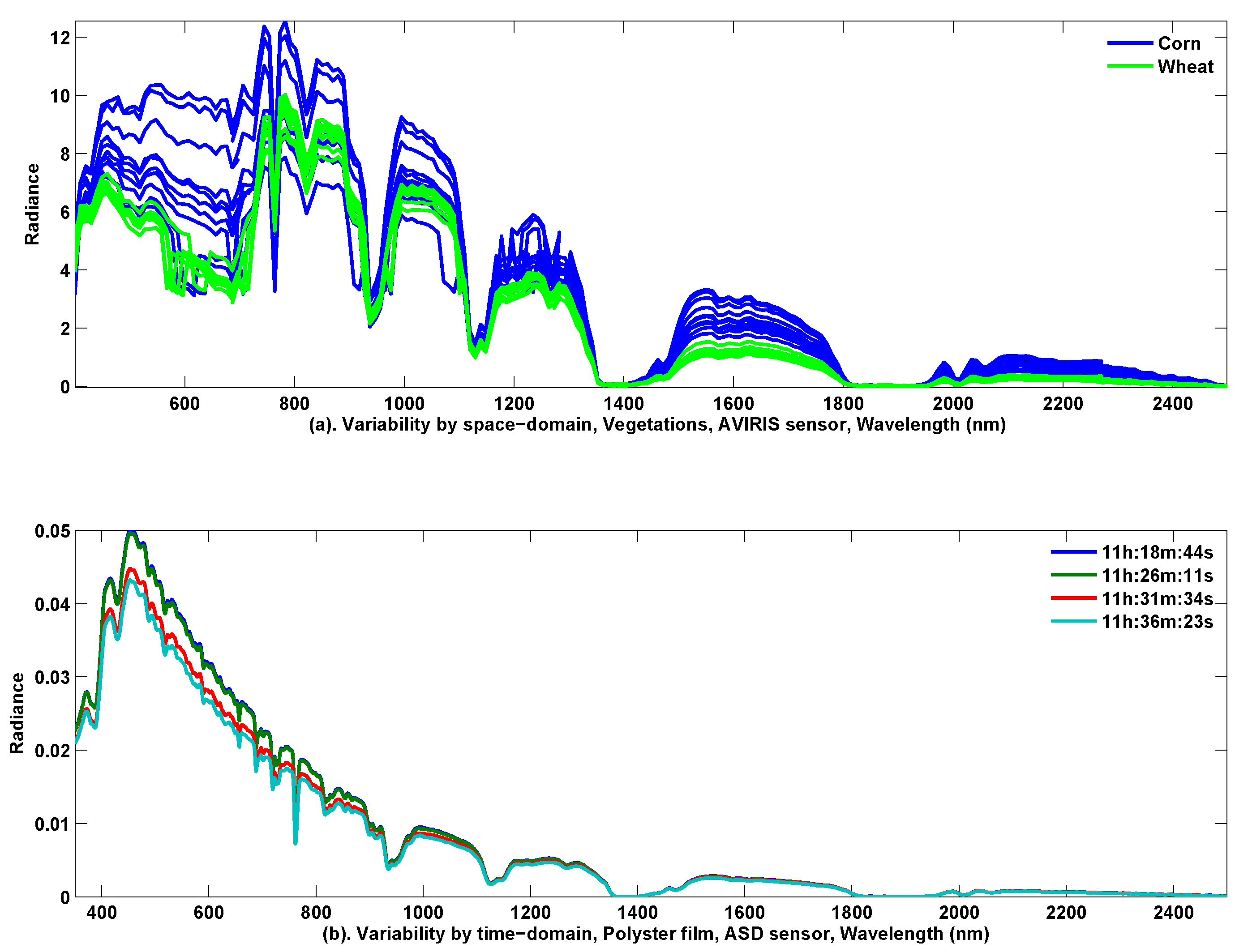
Using the reflectance as the features to separate materials is straightforward. However, we may encounter one major obstacle in classification, i.e., the variability of the spectral curves, which may take place both in the spatial-domain and the time-domain.
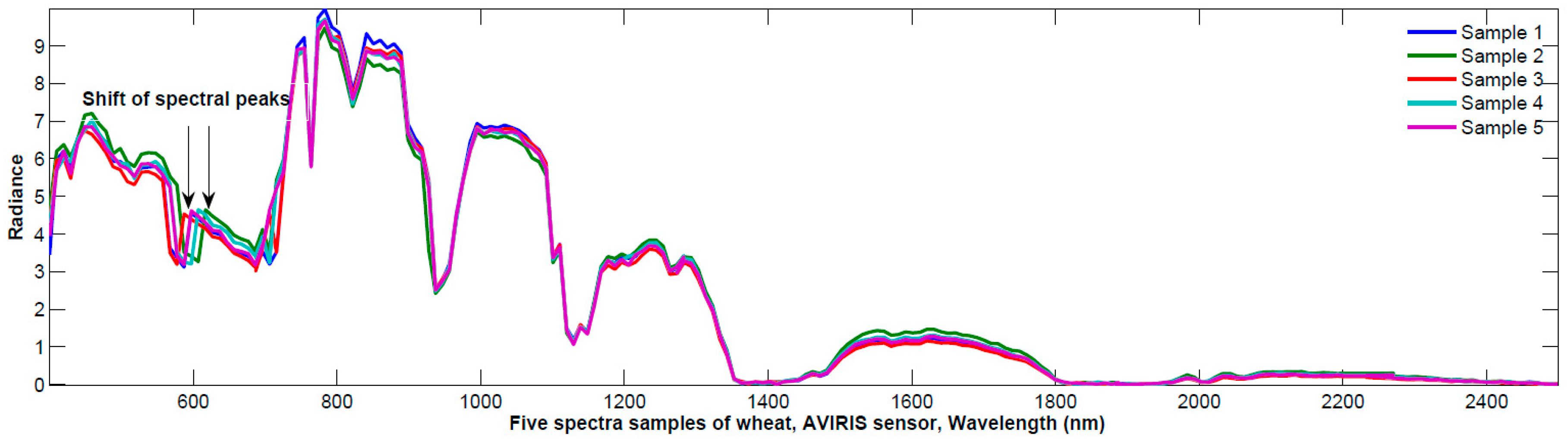
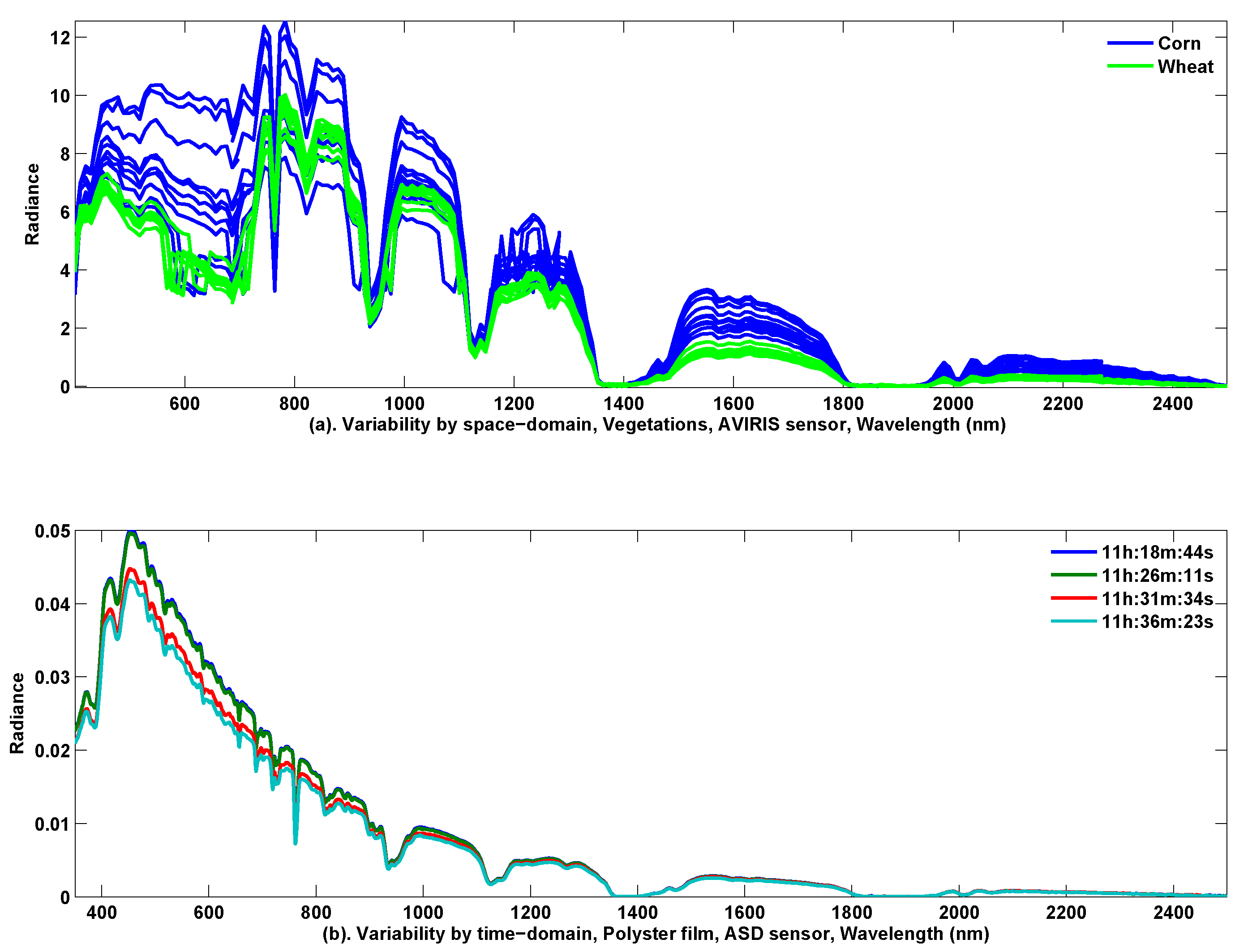
Figure 2a depicts 10 samples’ spectral reflectance for ‘corn’ and ‘wheat’. These pixels are extracted from the aforementioned AVIRIS 92AV3C hyperspectral imagery. The 10 samples are distributed randomly at different locations in the surveyed yard. Considering the spatial resolution of 50 m and the scenery dimensionality of 145 × 145 pixels, the maximal distance between any two samples is less than
meters. From
Figure 2a, we clearly see the reflectance’s variability caused by the different sampling-locations, i.e., the spatial-domain variability.
Figure 2b illustrates three samples of spectral reflectance of polyester film, acquired by an ASD field spectrometer at 5–8 minute intervals. From
Figure 2b, we also find substantial variability, which demonstrates that the severe variation may be made at different times of sampling, i.e., the time-domain variability.
Apparently, both types of the variability can bring out severe overlaps between classes, and this will worsen the separability of the features. Considering that the separability measures the probability of correct classification, we may expect that classification performance will be hampered by only relying on the spectra features. To alleviate this problem, some methods have been considered, such as band selection that avoids those less informative bands in the first place, or customized classifiers that reduce the interference from the overlapped bands. In this paper, we cope with this problem by the multi-view’s idea, i.e., to investigate the hyperspectral feature extraction from an additional absorption-view.
3.2. View of Absorption
Absorptions can be seen as dips or ‘valleys’ that appear on the reflectance spectra. These absorptions happen when the energy of the incident light was consumed by the material’s components, such as its atoms or molecules. In [
32], it is argued that the absorptions are associated with the material’s constituents, surface roughness, etc. Thus, we can use absorptions as an alternative feature of imaging spectroscopy for materials’ identification [
33].
In our research, we extract the absorption features as follows. First, each of the hyperspectral curves is normalized to the range of [0,1]. Then, based on the normalized spectra, we use a peak detection method to find all absorption valleys. Next, to correct wrong absorption valleys, two criteria are set up: (1) the absorption valley should show, at least, a certain level of intensity, i.e., the depth of the absorption should be larger than a threshold (it can be decided by empirical observations); and (2) the absorption features should appear on more than half of the training spectra. By these two criteria, the incorrect valleys can be removed and only the absorptions that do matter to the mass identification have been retained. Finally, the absorption features are encoded as a binary vector or a bit array.
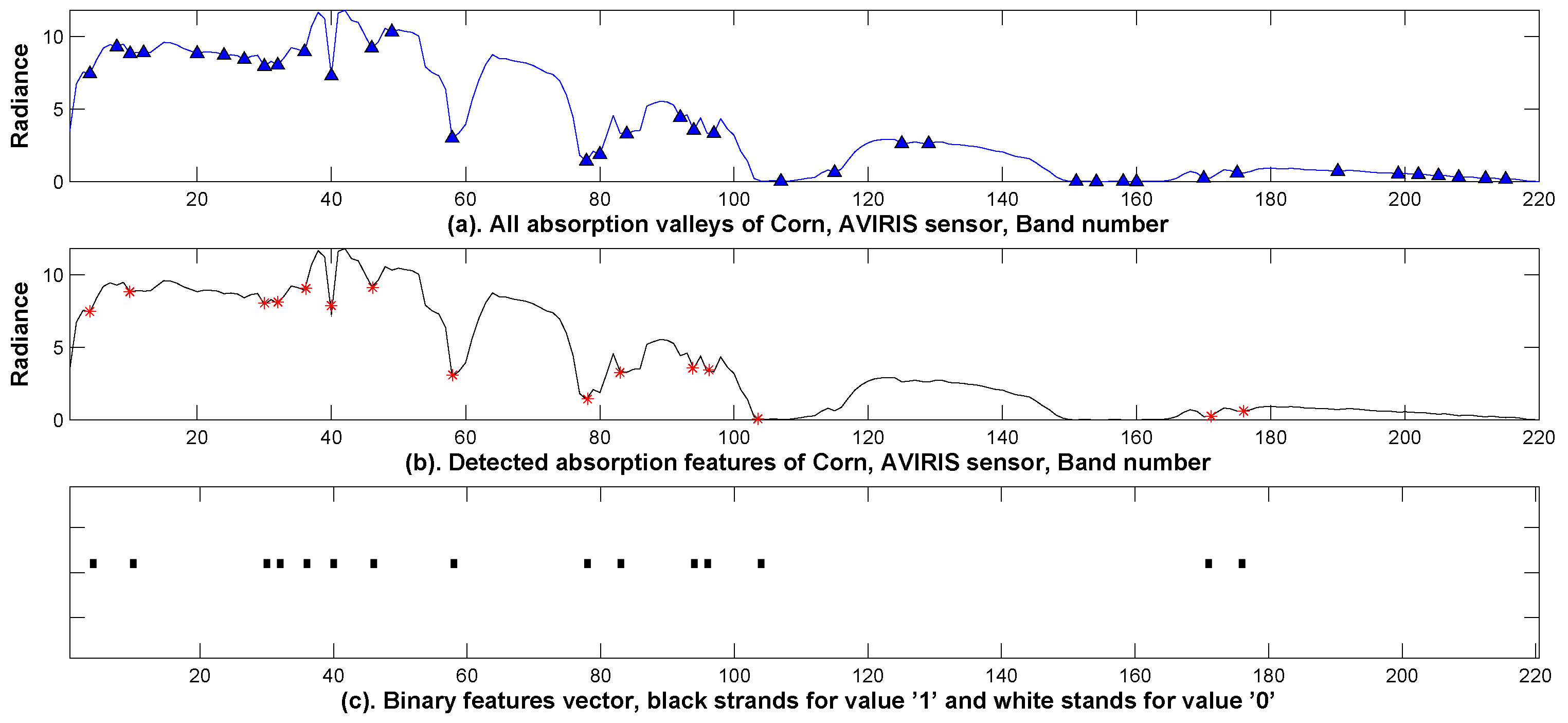
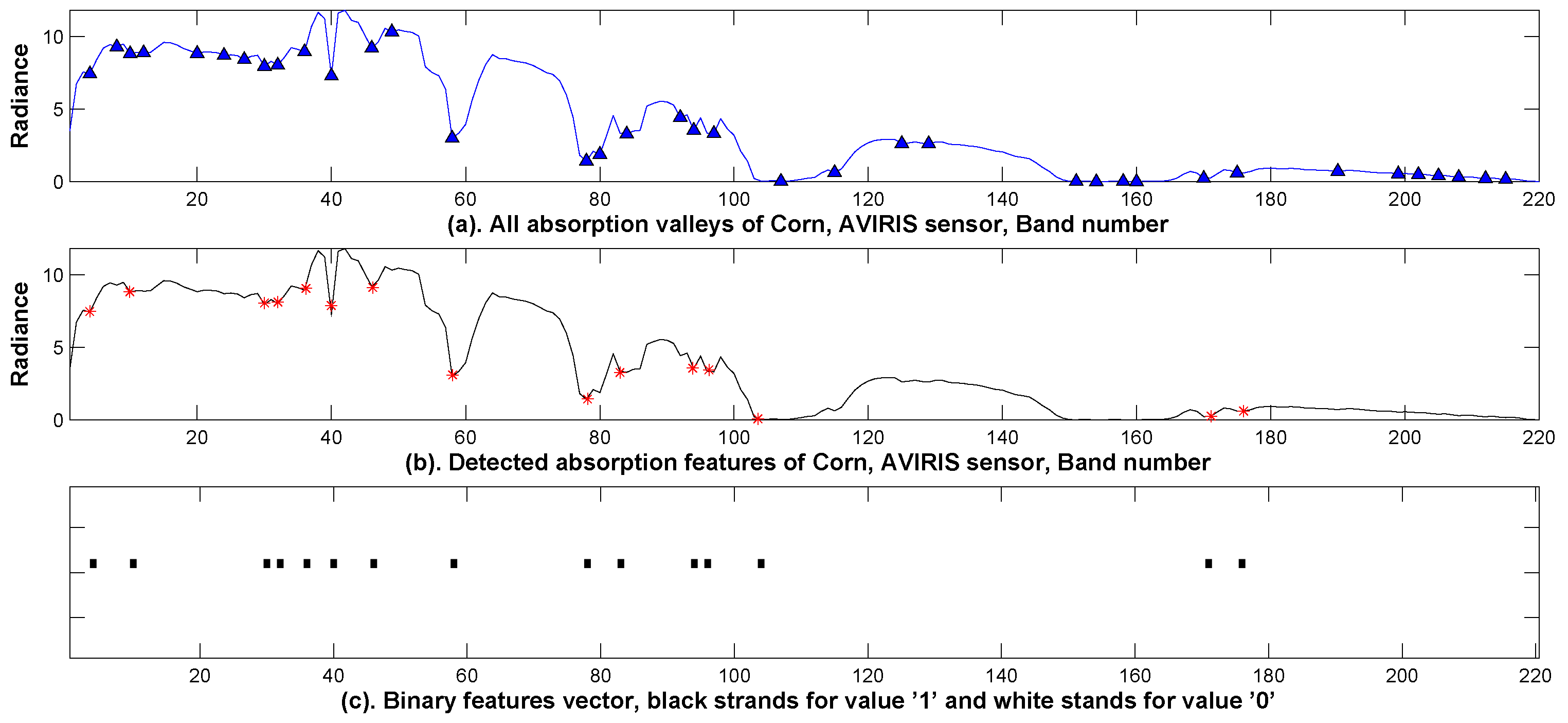
Figure 3 shows a spectral curve extracted from a pixel in the AVIRIS AV923C dataset. All detected absorption valleys are shown in
Figure 3a, and the selected absorption features, filtered by the aforementioned two criteria, are labeled as in
Figure 3b. The corresponding binary vector is illustrated as in
Figure 3c, where the dark blocks (represented by values ‘1’) are interpreted as the presence of absorption and the white blocks (represented by value ‘0’) are interpreted as the absence of absorption. It is seen that the binary vector in
Figure 3c can be considered as a mapping from the spectral curve in
Figure 3a by the absorption detection algorithm in
Figure 3b to values in a binary set
.
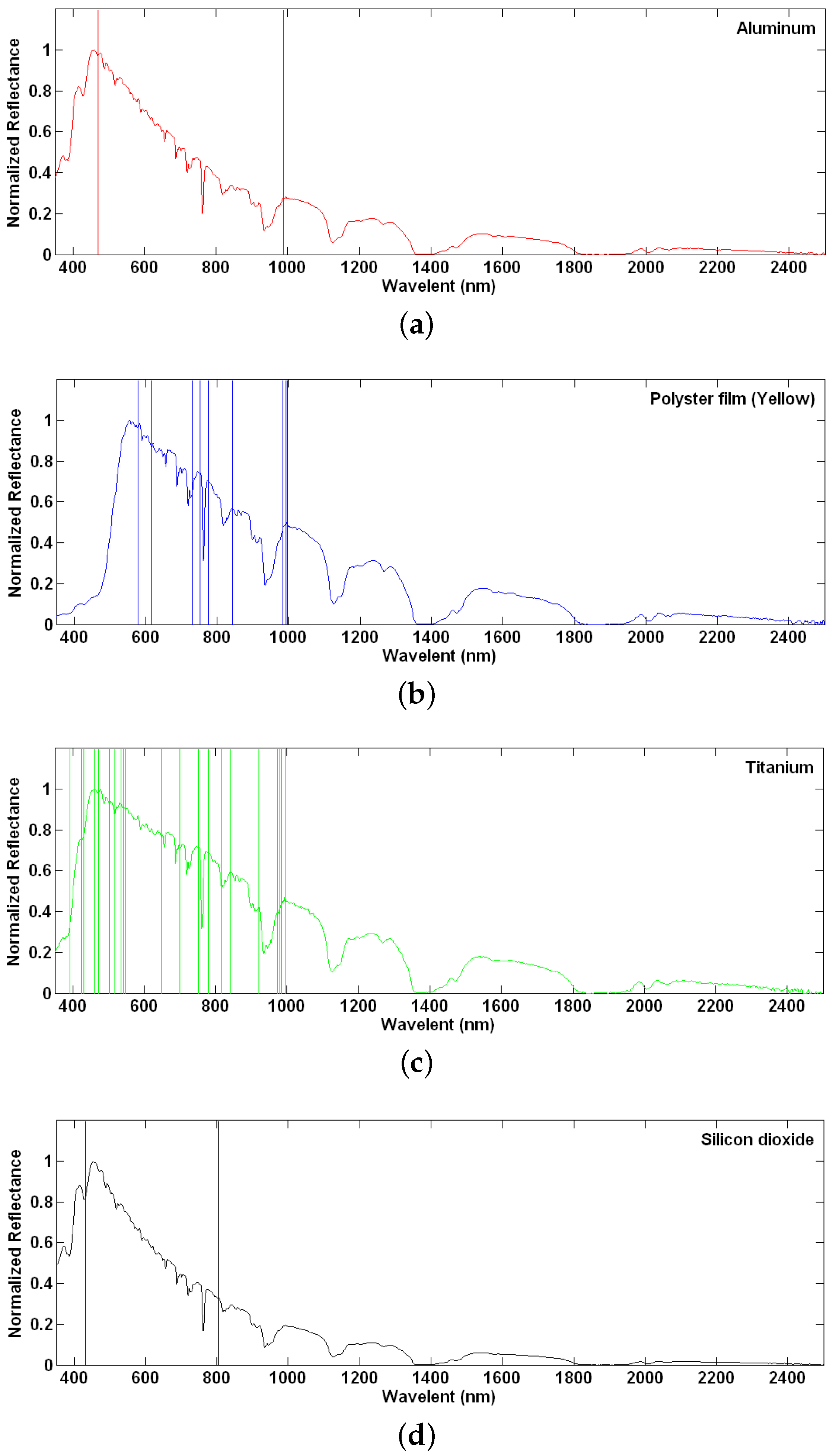
To demonstrate the using of the absorption features for mass identification, we illustrate in
Figure 4 the absorption features of four types of mineral materials, including ‘aluminum’, ‘yellow polyester film’, ‘titanium’ and ‘silicon dioxide’ ( (
Figure 4a–d), respectively, which were recorded by the ASD field spectrometer.
In
Figure 4, to discover unique features for mass identification, the absorption valleys of one type of material are compared against other three types of materials. Only the different absorptions are retained as the material’s exclusive features, which can distinguish this material from the other three.
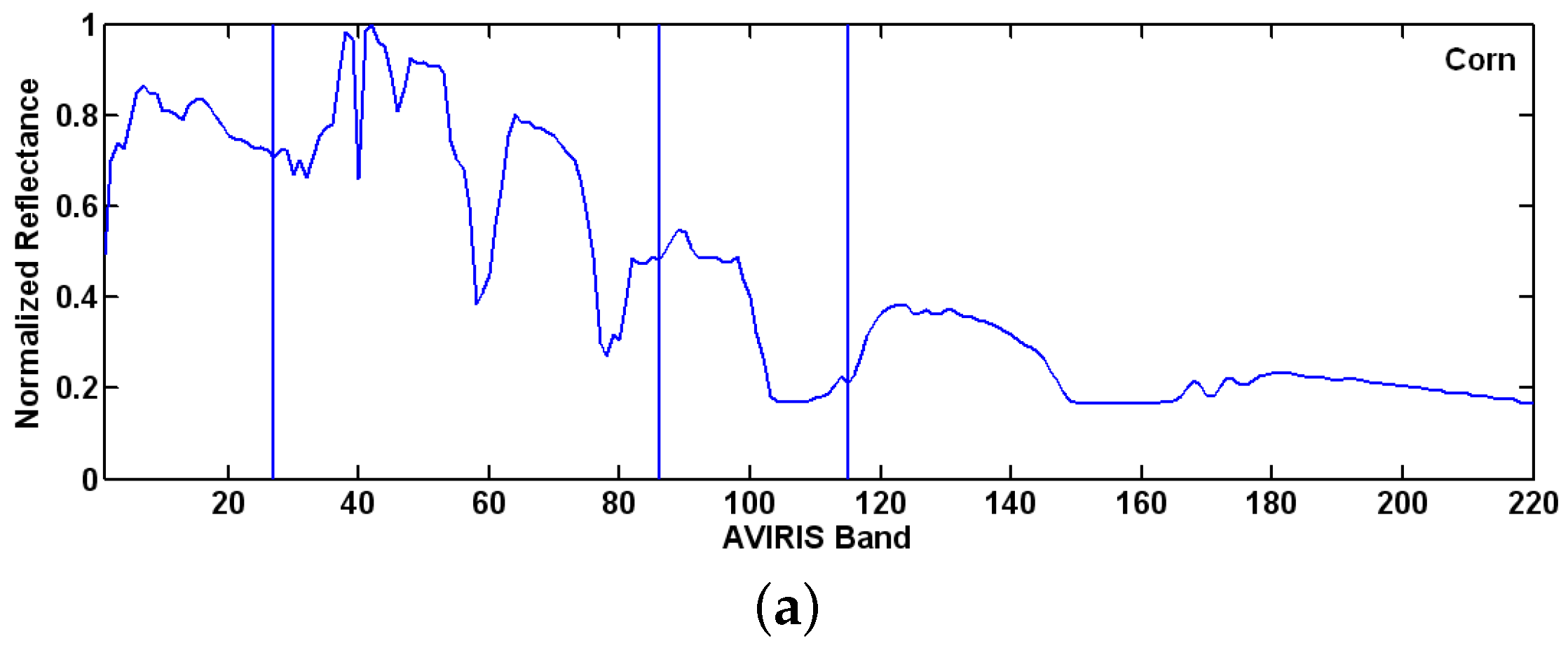
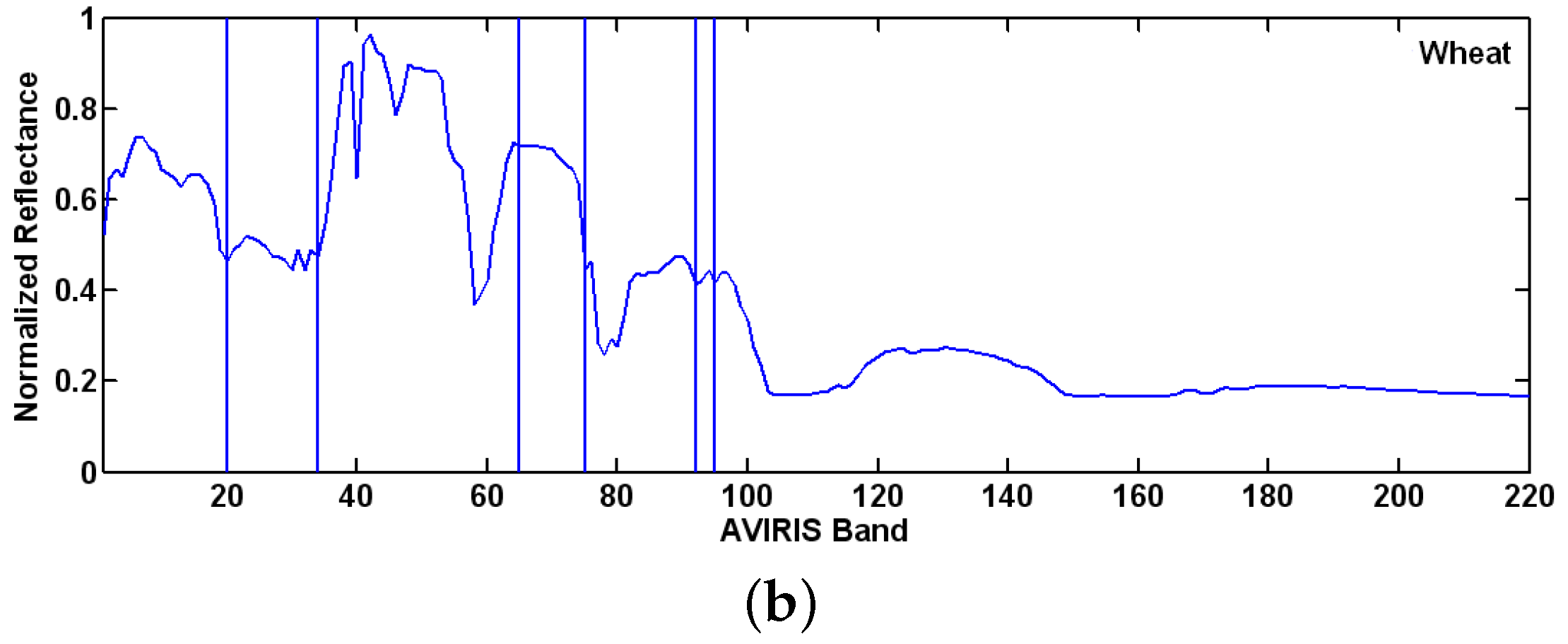
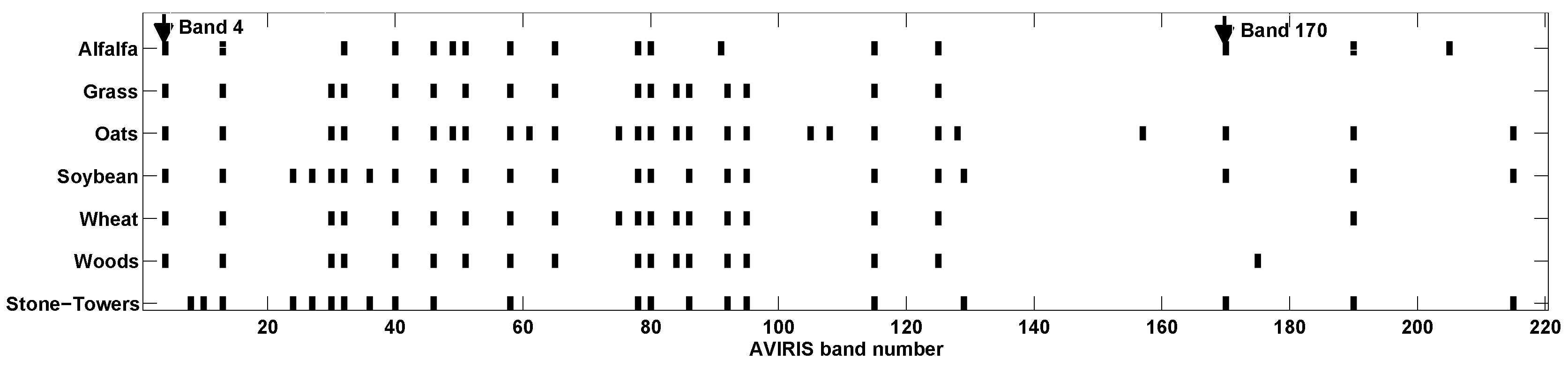
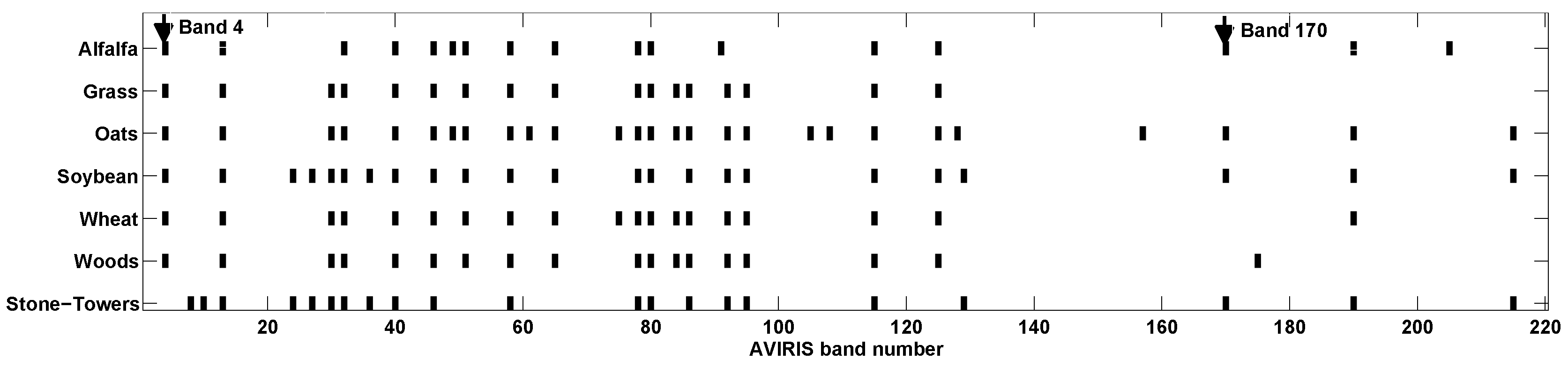
Figure 4a–d show the distinct absorption features as vertical lines for each of the four materials. Another example is given in
Figure 5, where the remotely sensed AVIRIS 92AV3C data are used. Two types of vegetation, including corn (
Figure 5a) and wheat (
Figure 5b), are studied. It is seen that no matter whether the four mineral materials are acquired by the field spectrometer ASD or the two types of vegetation are acquired by remotely sensed AVIRIS sensor, they indeed can be identified simply by checking their unique absorption features.
However, only using the absorption features in classification would encounter two major problems. First, much information embedded in the hyperspectral data has not been used efficiently, which may curb the hyperspectral data’s effectiveness. For example, to classify the four types of materials in
Figure 4, there is not a single absorption feature that can be found in the spectrum range from 1000 nm–2500 nm (i.e., the shortwave infrared region). However, it is well known that the shortwave bands indeed contain rich information for classification. For example, the four classes of materials can be differentiated apparently by observing their amplitudes’ difference. Therefore, simply using the absorption features in hyperspectral image classification may lose valuable information. Second, when more materials are involved in identification, the absorption valleys detected in one type of material have to be compared with more absorption valleys detected from other types of materials. With the increase of the number of absorption valleys, the likelihood of finding a unique absorption-feature goes down significantly. This may lead to failures of this approach. For example, in the case of AVIRIS 92AV3C dataset, it is found that no unique absorption features can be detected to identify any of the vegetation from the remaining 13 classes of vegetation.
3.3. Multi-View Feature Representation
Aiming at hyperspectral image classification, we have discussed two sets of features, namely the reflectance spectra and the absorption features. Through observing the hyperspectral data from two different sensors, i.e., the airborne AVIRIS sensor and the field ASD sensor, it is found that both of the features have a certain capability to identify materials, but also with considerable limitations or weakness. We believe that classification using only one feature set may lose useful information. For example, each feature set is extracted based on a model, and every feature extraction models have their intrinsic limitations due to model assumptions. On the other hand, by considering the diversity of different views, classification based on multiple distinct feature sets may provide great potential to improve classification accuracy, though these feature sets may be extracted based on a single sensor’s input.
For hyperspectral data, because each of the spectra is actually a reflectance curve against different wavelengths, we may consider the features that are based on the
whole spectra or its various transformations (e.g., Principal Component Analysis) as a feature-set from the
global view. On the contrary, the feature-set based on absorption is extracted by observing the dips or ‘valleys’ that are located around certain
narrow wavelengths or bands. Thus, we may consider the absorptions as a feature-set as from the
local views. Because the spectra feature-set is based on the reflectance values and the ‘valley’ feature-set is based on absorption intensity to the incident light, the spectra feature-set and the absorption feature-set are complementary in nature [
34]. Moreover, these two feature-sets describe the data from the global view and the local view, respectively, and therefore increase their complementary capability further. Thus, combining these two feature-sets through information fusion may improve classification accuracy, which we will discuss in the next section.
5. Results
Experiments have been carried out to assess the classification performance of the proposed fusion method on two hyperspectral datasets, i.e., the AVIRIS 92AV3C and Salinas, respectively. To implement the proposed fusion method, first we select the best pair of the classifiers
and
(see
Figure 6). Using the aforementioned diversity measurements, we assess the complementary potentials of each pair of the candidate classifiers. Results are shown in
Table 2.
From
Table 2, it is seen that, in all three of the diversity standards, the classifiers combination of SVM and DBC achieved the largest diversity. Thus, we use the classifier SVM as
to classify the reflectance feature
, and the classifier DBC as
to classify the reflectance feature
.
In our algorithm, the threshold
is used to trigger the fusion processing and it is chosen by examining the training data. In more detail, we first use a random variable
Y to represent the output of the classifier
, and use two conditions
and
to represent correct decisions and incorrect decisions, respectively. Then, we calculate the histograms of
and
from the training examples. Next, by normalizing the above conditional probability distributions, we estimate two conditional probability distributions, i.e.,
and
.
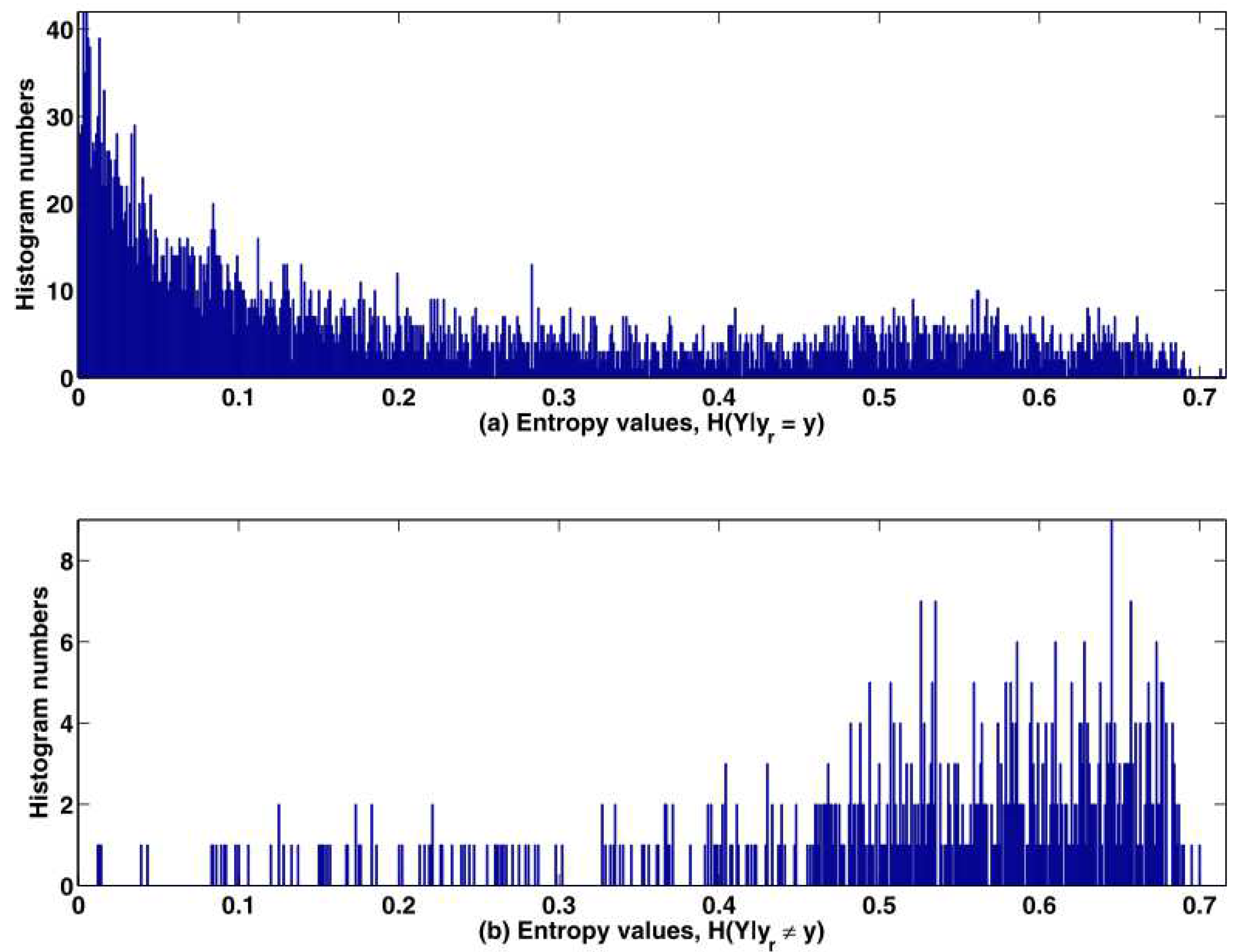
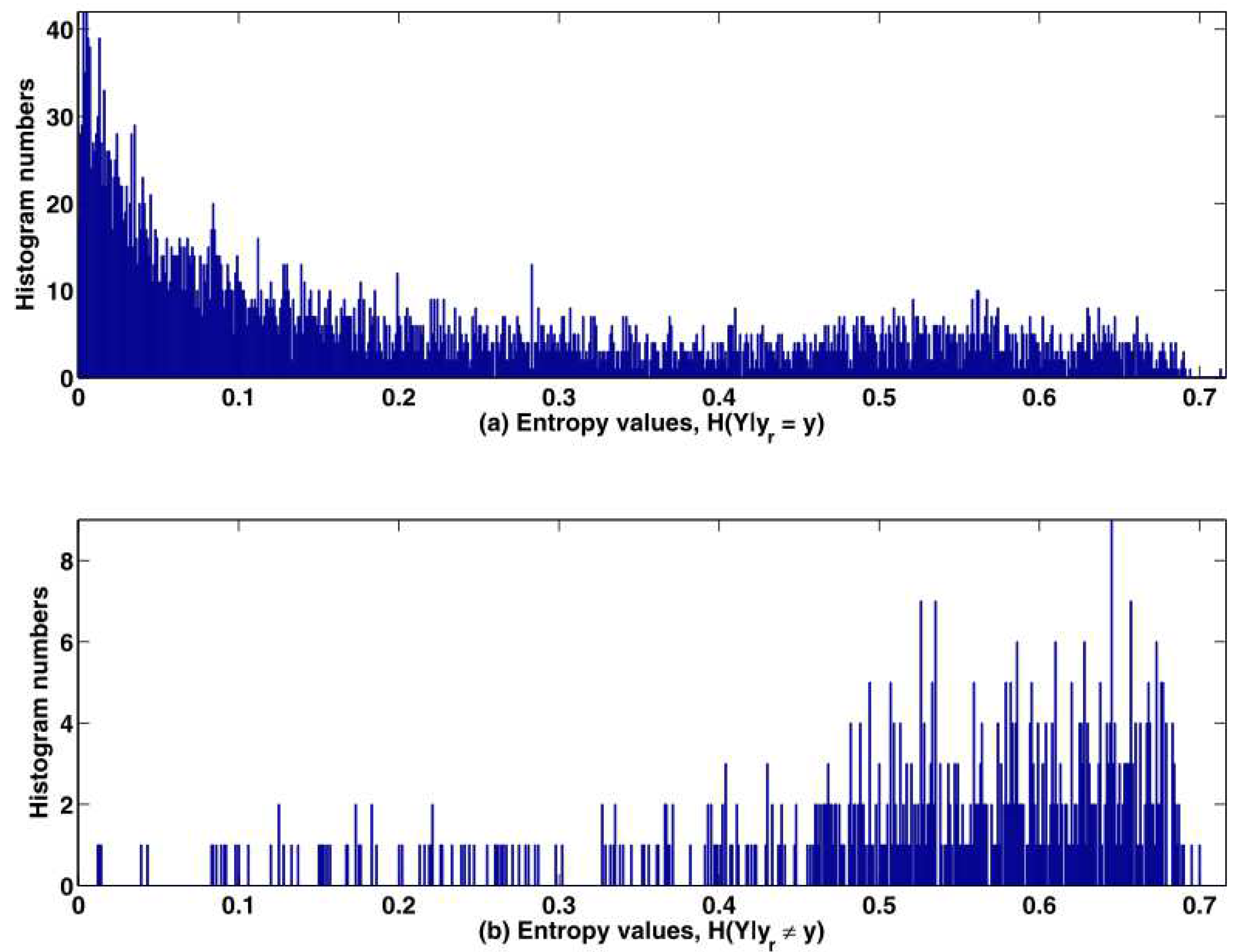
Figure 9 shows the estimated distributions of entropies of
and
. Based on
Figure 9, we choose the value of the threshold
, at which that the probability of the misclassification is just above the probability of the correct classification, i.e., the solution of the following inequality:
By searching the two conditional probability distributions
and
as in Equation (
21), we found that to the AVIRIS dataset the best value of the threshold
should be set as 0.625, where the number of the incorrect classification (313) is just above the number of the correct classification (307).
To assess the performance of the proposed method, we design three sets of experiments. In the first experiment, we compare the proposed fusion method with three classical hyperspectral classification methods, i.e., the SVM [
5] and the SAM [
39], and the
k-NN method, respectively. Moreover, a recently developed method, i.e., the transfer learning (TL) based Convolutional Neural Network [
46] is also used to assess the performance of the proposed method against the state-of-the-art approaches [
6,
7]. For the TL method, the network we used is a Convolutional Neural Network (CNN) VGGNet-VD16 (see website [
47]), which is already trained by a visual dataset ImageNet. The specific transfer strategy is adopted from [
46].
For accuracy assessment, we randomly chose 10% pixels from each class as the training dataset, and the remaining 90% pixels from each class are chosen as the test set. Based on the training dataset, a validation dataset is further formed by dividing the training samples evenly. All parameters associated with each of the involved classifiers are obtained by a two-fold cross validation using only the training samples:
Particularly, for the SVM classifier, the kernel function used is a heterogeneous polynomial. The polynomial order d and the penalty parameter C are optimized by the aforementioned twofold validation procedure using only training data. The searching ranges for the parameters d and C are [1,10] and [, ], respectively. As for this AVIRIS training set, we found that the best values of the polynomial order and the penalty parameter C are 4 and 1500, respectively, which are then applied to the following testing stage.
The classification results are shown in
Table 3, where the best results are in bold. By comparing the individual classification accuracies in
Table 3, it is seen that the proposed method achieved the best results at 13 classes among all 16 classes. As for the overall accuracy, the proposed method is also outperformed other competitive methods (89.92% versus 83.8% of the TL method, 81.50% of the SVM-based method, 67.34% of the SAM method, and 67.63% of the
k-NN). The Cohen’s kappa coefficient measures statistic agreement for categorical items, so we also calculated the kappa coefficient for each methods. It is found that the kappa coefficient of the proposed method is 0.88, which is significantly higher than the TL method (0.81), the SVM-based method (0.79), the SAM method (0.63), and the
k-NN method (0.63).
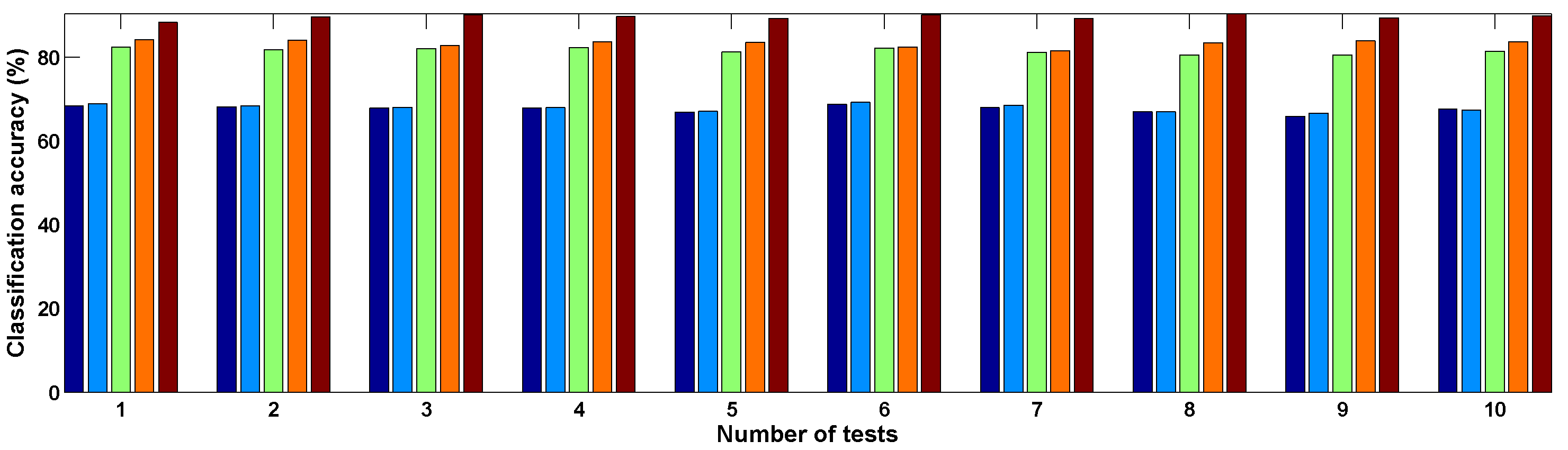
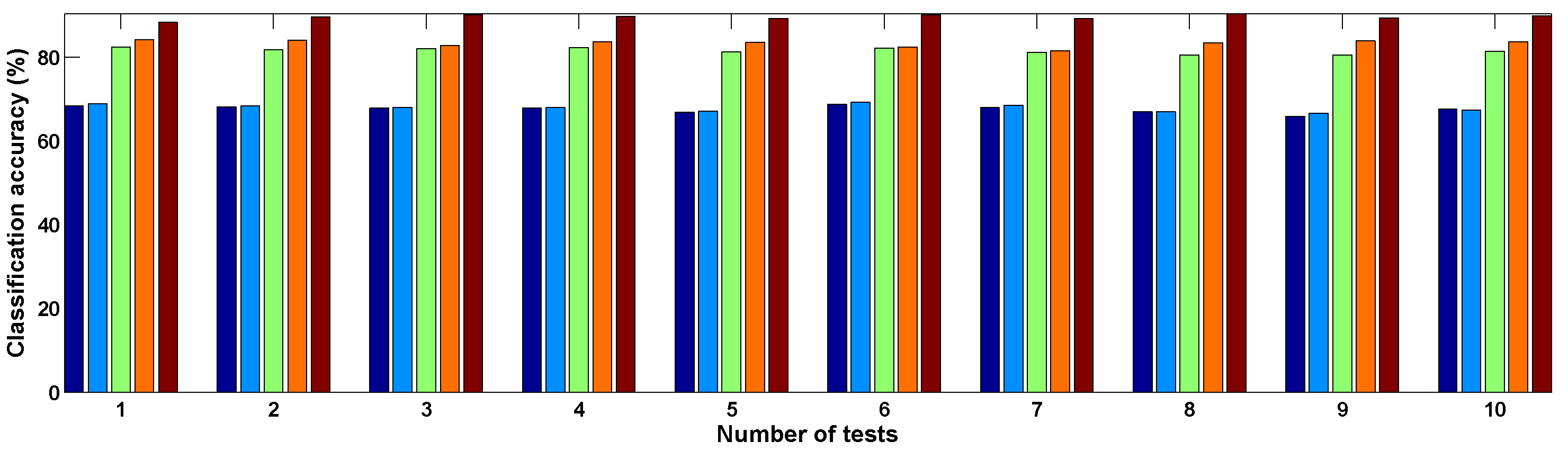
In the above experiment, the training samples are randomly selected. To avoid sampling bias, we repeat the testing ten times and
Figure 10 shows the classification results. It is seen that the proposed approach outperformed the SVM, the SAM, the
k-NN and methods in all of the 10 tests. Based on the ten times of random sampling, the average numbers for the above ten tests’ results and the error in the random samplings are summarized in
Table 4. By comparing the overall classification accuracy and the Kappa coefficient, the proposed method is found to be better than other methods.
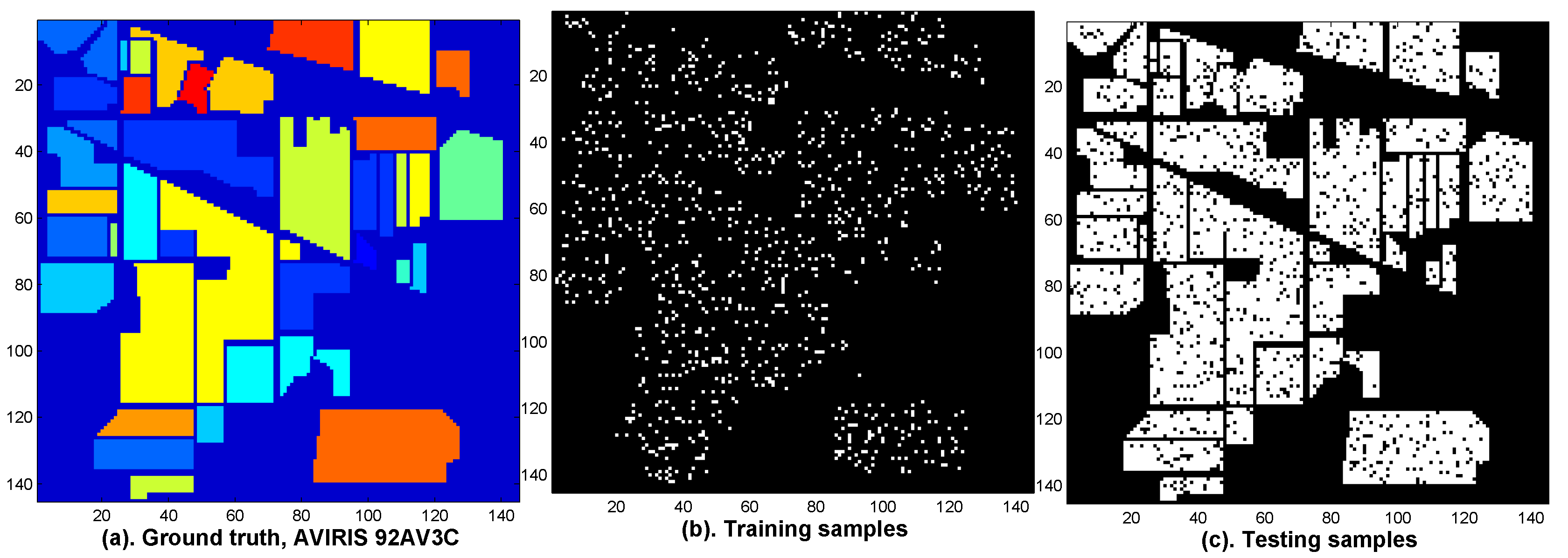
We further compare the classification results of various methods by visual classification maps.
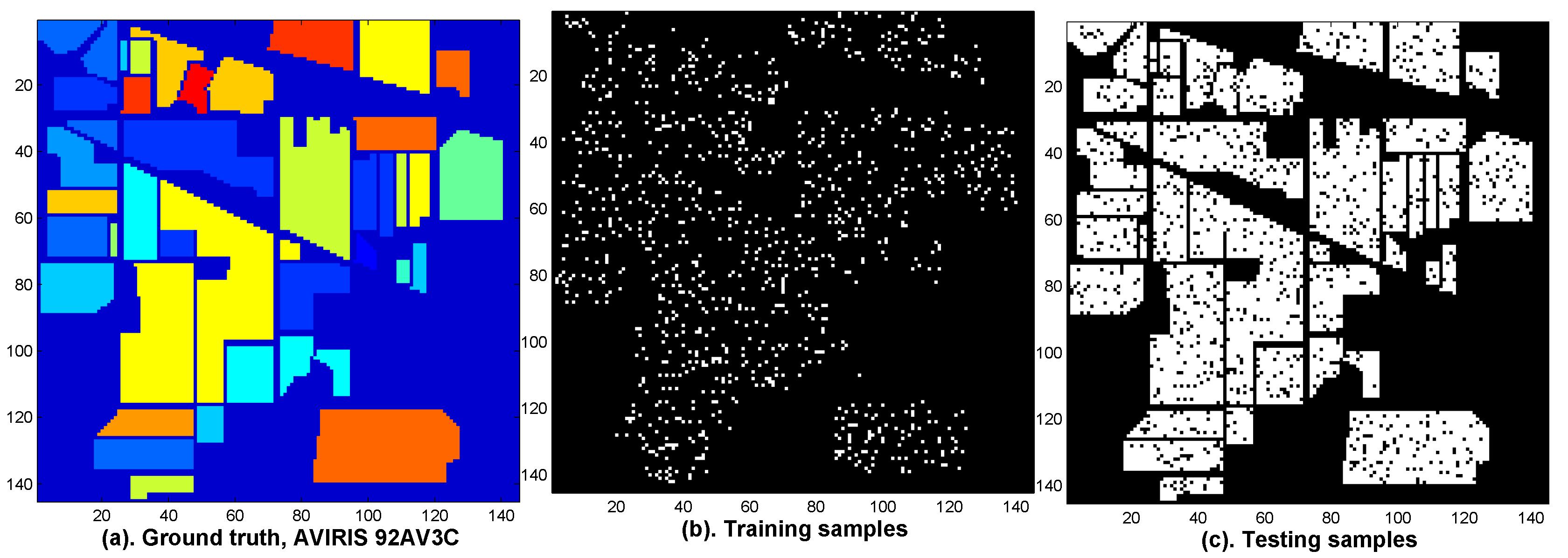
Figure 11 illustrates the ground truth of the AVIRIS 92AV3C (
Figure 11a), the distribution maps of the training samples (
Figure 11b) and the testing samples (
Figure 11c).
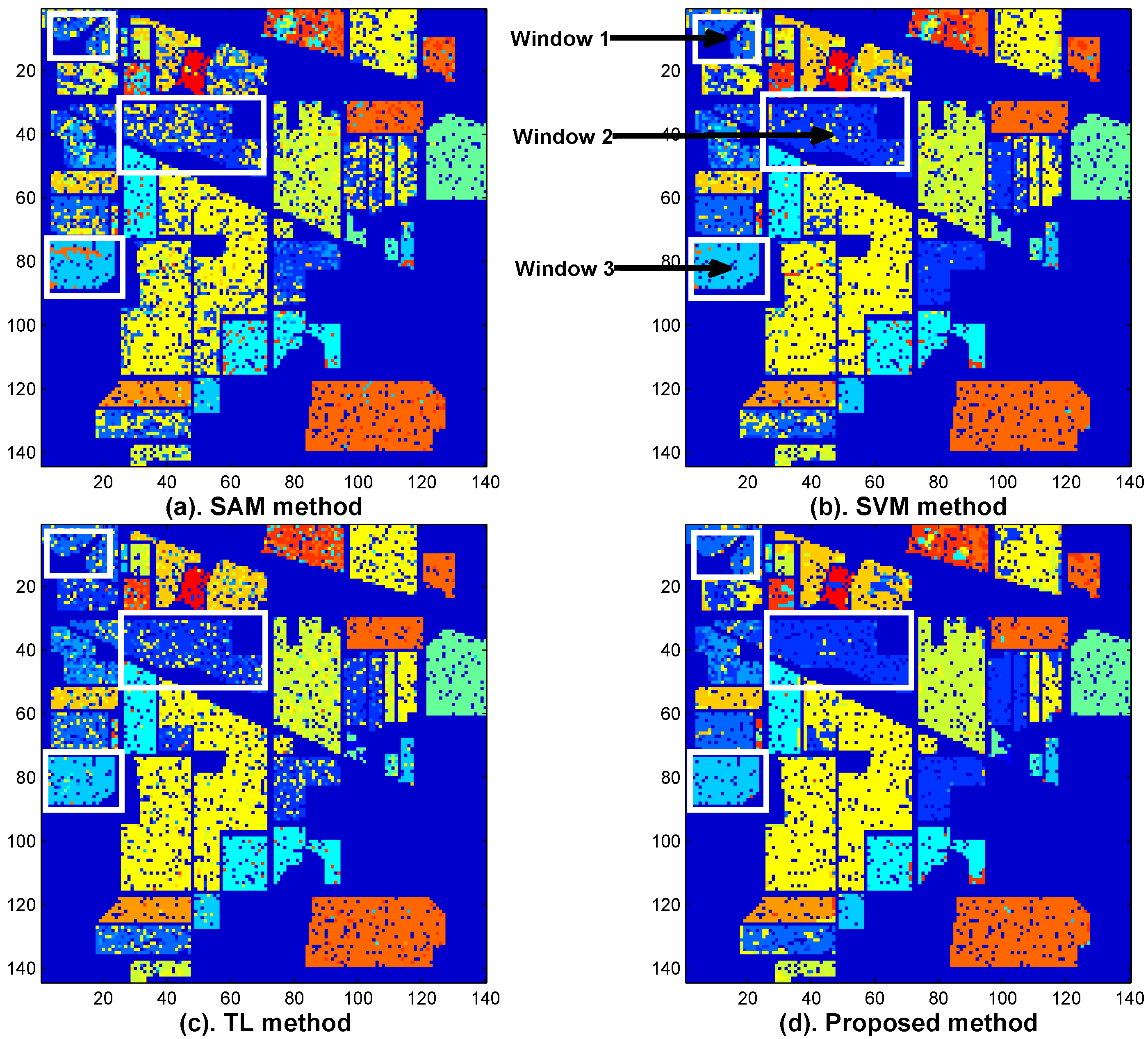
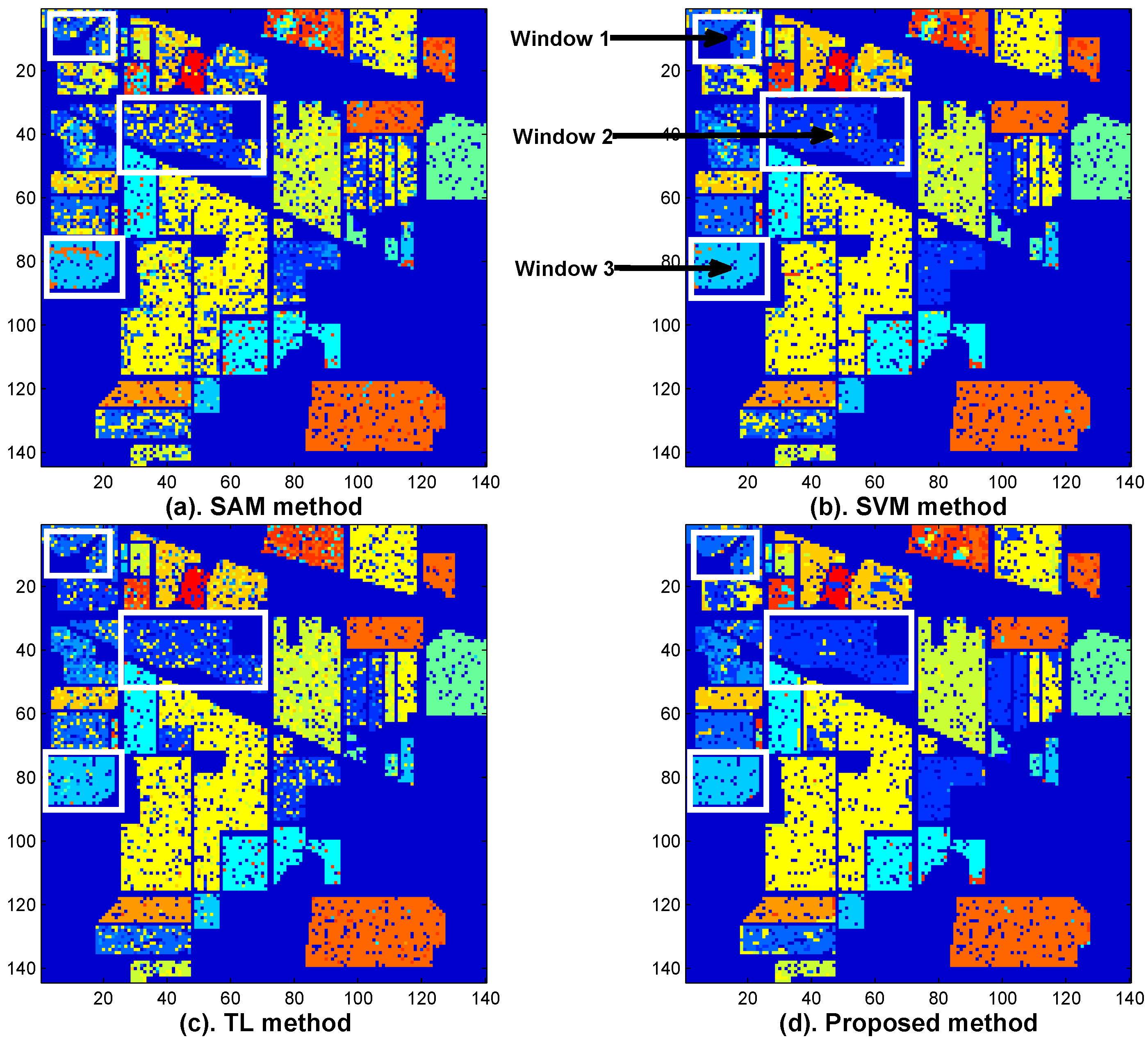
Figure 12 shows the classification maps of the SAM method (
Figure 12a), the SVM method (
Figure 12b), the TL method (
Figure 12c), and the proposed method (
Figure 12d). We use three white boxes as the observing windows to see if improvement of classification accuracy can be made by the proposed method. By comparing the white windows at
Figure 12 with
Figure 11, it is seen that the proposed method indeed corrects some classification errors which are made by the other methods (see the white boxes in
Figure 12).
In the second experiment, we compare the proposed method with other popular fusion methods. To be consistent with the experiment settings of [
33], we choose seven classes of vegetation from AVIRIS 92AV3C for classification test, including ‘Corn (notill)’, ‘Corn (mintill)’, ‘Grass&trees’, ‘Soybean (notill)’, ‘Soybean (mintill)’, ‘Soybean (clean)’ and ‘Woods’. The sampling percentages are the same as those in [
33], i.e., about 5% of samples are used for training and the remaining 95% of samples are used for evaluation. Two popular fusion methods, namely the Production-rule fusion method [
15] and the SAM+ABS (Absorption Based Scheme) fusion method [
33] are compared with proposed method. The results are shown in
Table 5. It is seen that the overall accuracy of the proposed method is relatively higher than the state-of-the-art fusion approach, i.e., the SAM+ABS fusion [
33], and is significantly higher than the classical Production-rule fusion.
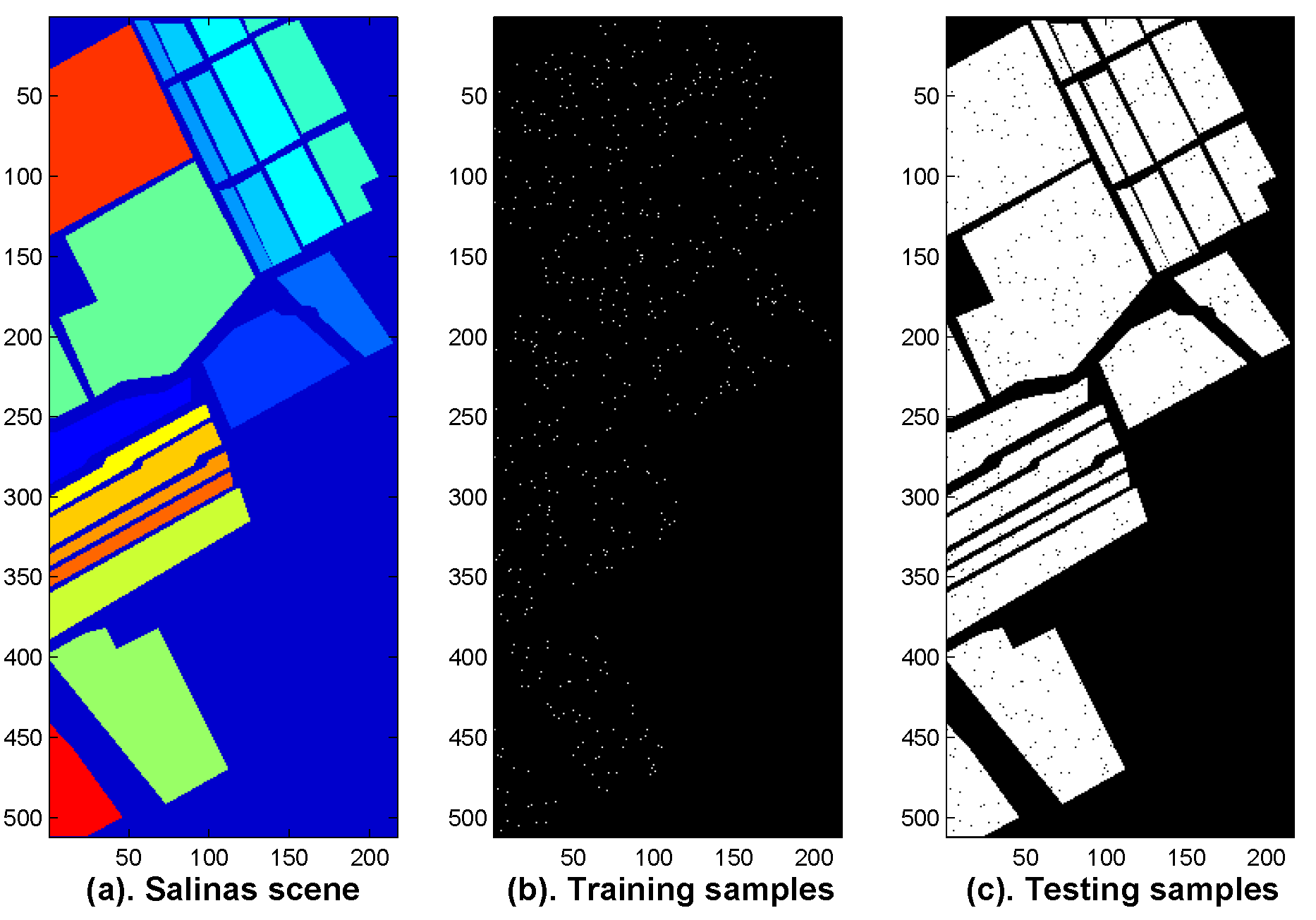
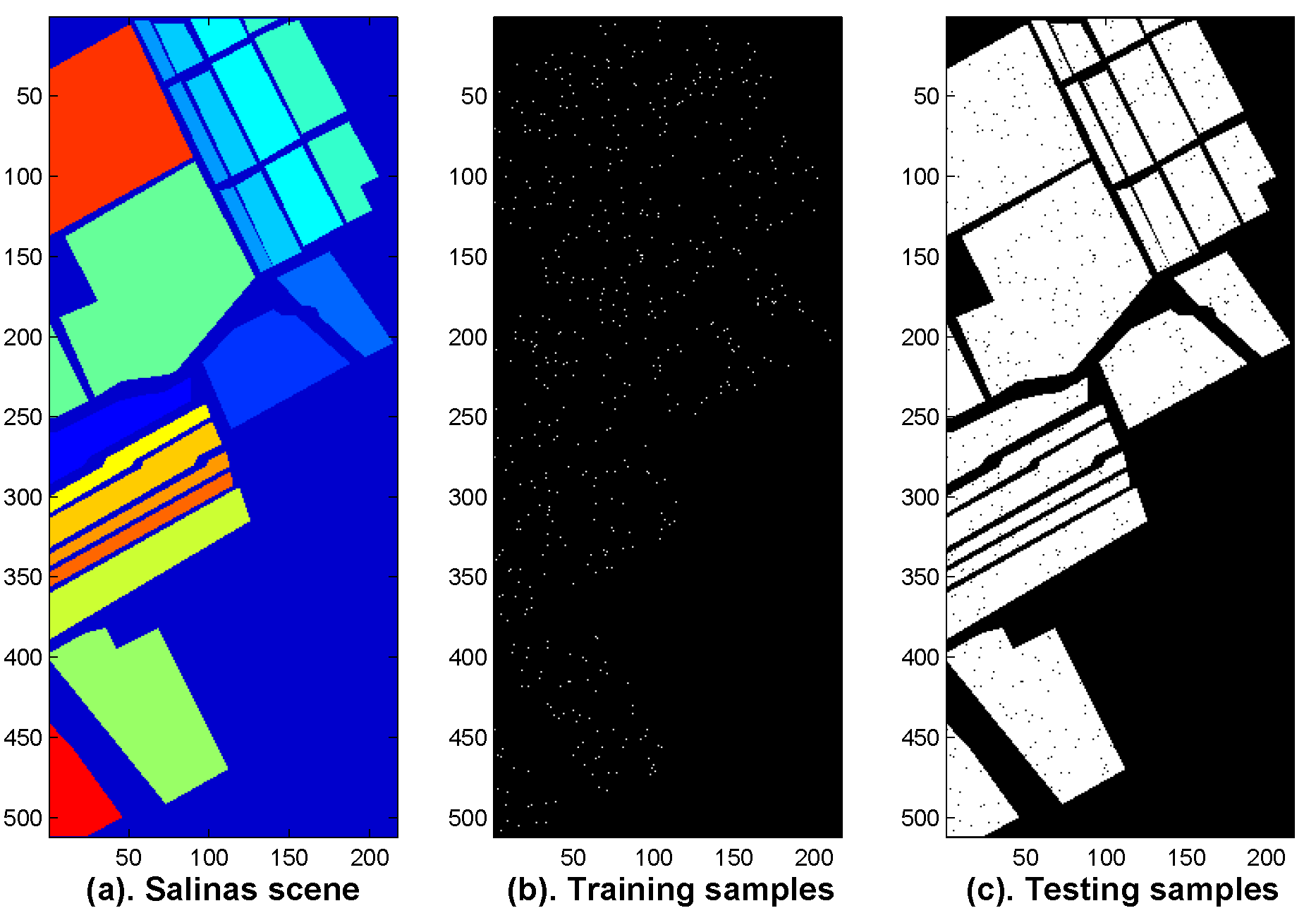
To further evaluate the proposed fusion strategy, the third experiment is carried out on the Salinas hyperspectral dataset. The data was collected over Salinas Valley, CA, USA by the same AVIRIS sensor. The scene is 512 lines by 217 samples, and covers 16 classes materials, including vegetables, bare soils, and vineyard fields (see
Figure 13a). In the experiment, about 1% of samples (see
Figure 13b) were used as the training samples and the remaining 99% samples were used as the testing set (see
Figure 13c). Individual classification accuracies are listed in
Table 6. It is seen that the proposed method outperforms its competitors in nine classes out of all 16 classes. As for the overall accuracies, the proposed method is better than other methods (92.48% versus 88.72%, 89.47%, 84.43%, 83.81%). The comparison of the Kappa coefficient also shows that the proposed method is superior to the benchmarked approaches (0.92% versus 0.87%, 0.88%, 0.83%, 0.82%).
Visual comparison of classification results are shown in
Figure 13 and
Figure 14.
Figure 13 illustrates the ground truth of the Salinas scene (
Figure 13a), the distribution maps of the training samples (
Figure 13b) and the testing samples (
Figure 13c).
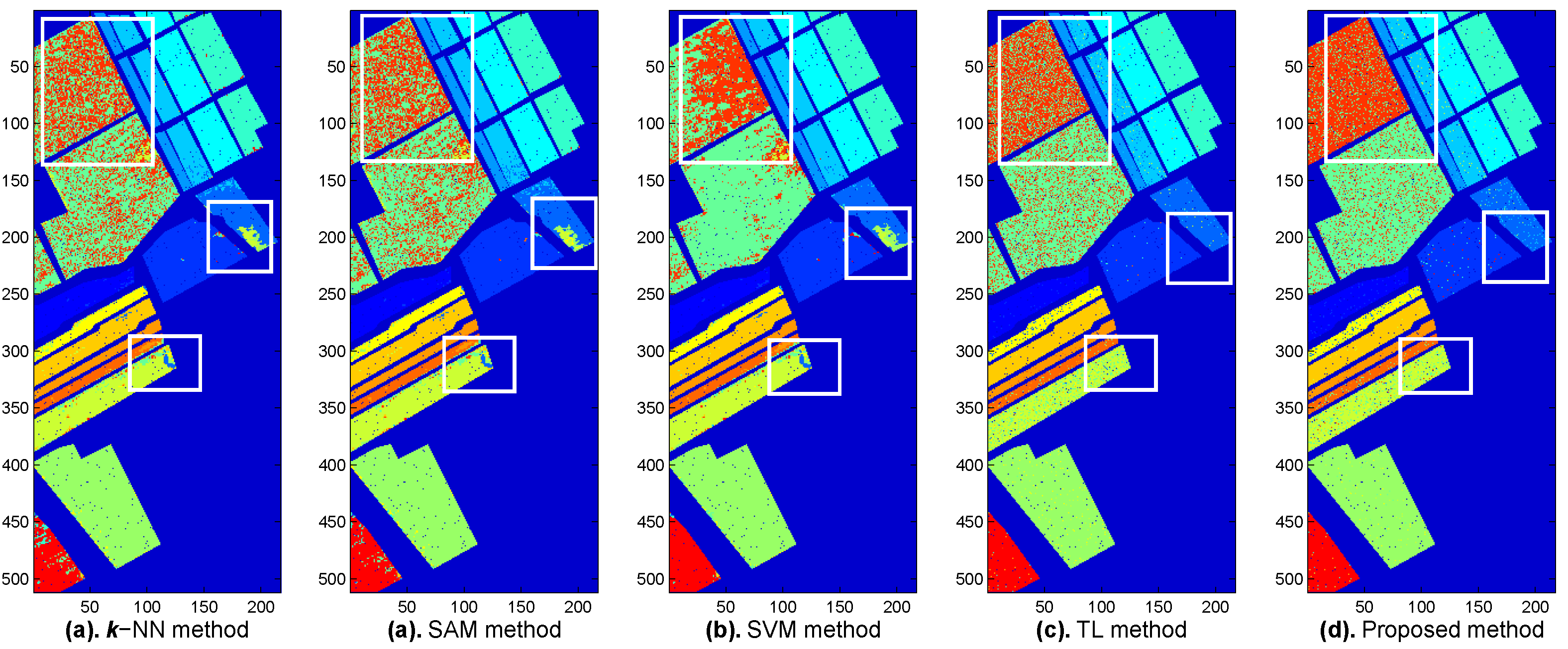
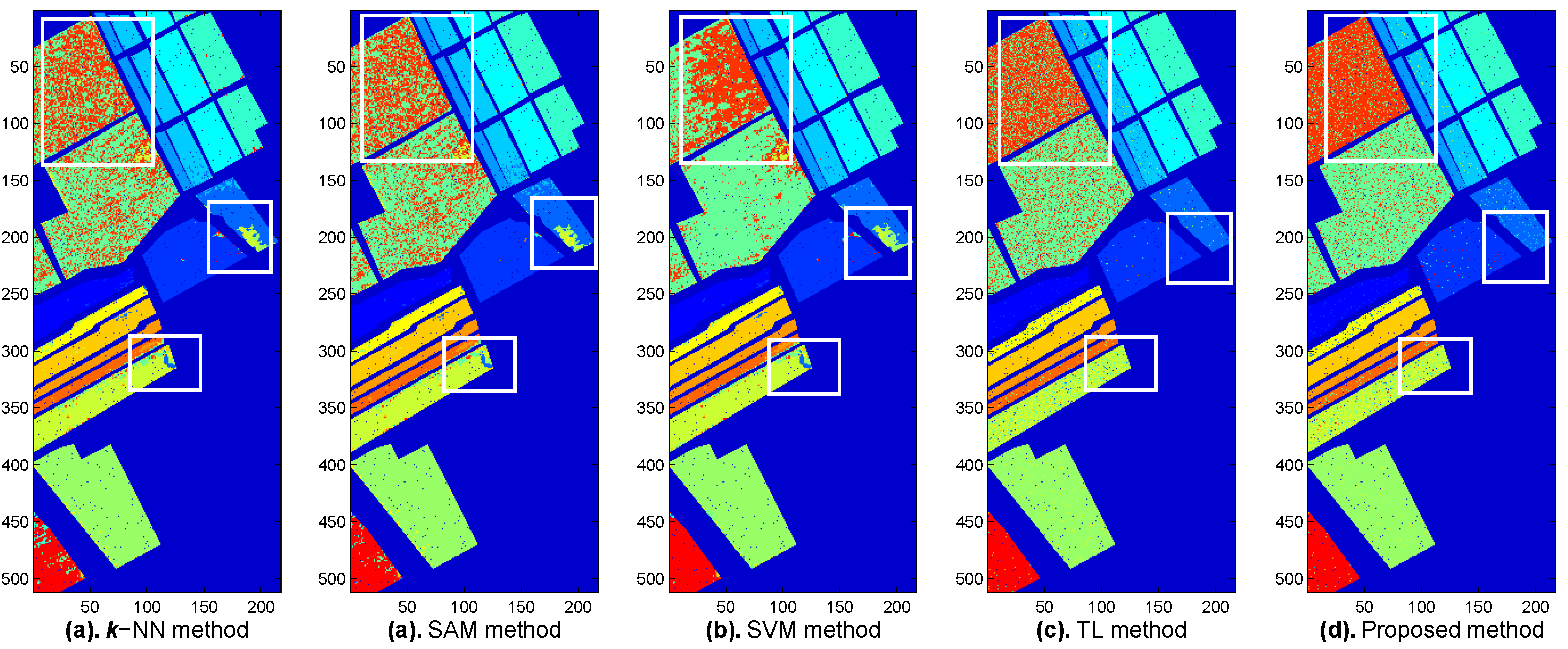
Figure 14 shows the classification results of the
k-NN method (
Figure 14a), the SAM method (
Figure 14b), the SVM method (
Figure 14c), the TL method (
Figure 14d), and the proposed method (
Figure 14e). Three white windows are labeled at each of the classification maps (see
Figure 14a,b), from which we can look at whether the misclassified pixels can be corrected by the proposed method. By observing each white window at
Figure 14 and comparing with
Figure 13, it is seen that the proposed method had a better classification accuracy and can correct some classification errors made by other methods.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}