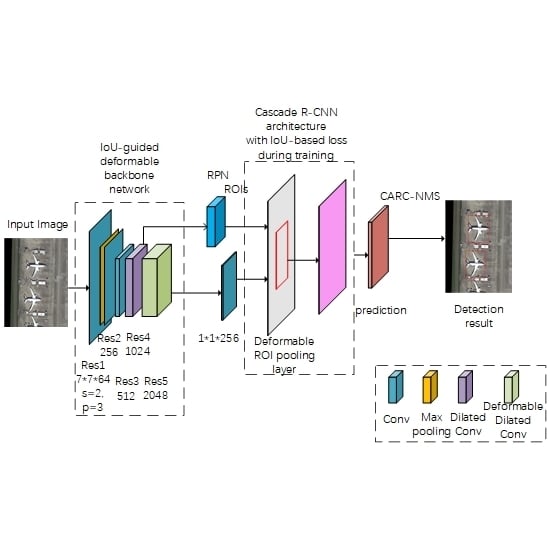
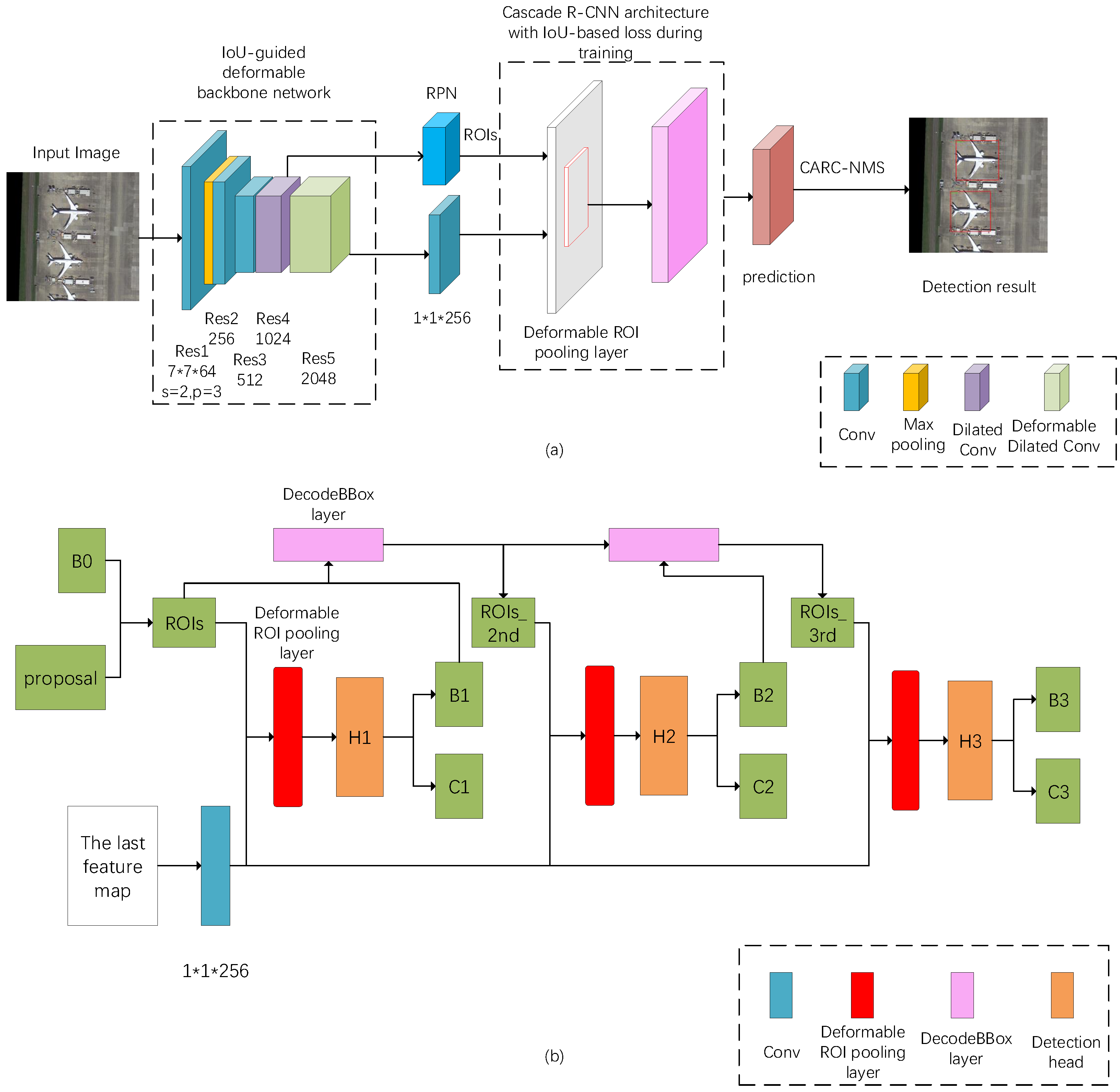
In this section, we first show different roles of IoU in the network and the effectiveness of our method with comprehensive ablation experiments. Then, we show that our approach achieves state-of-the-art results on DOTA benchmarks with the final optimal model. Our method outperforms all the published methods evaluated on the HBB prediction task benchmark. Visualization of the objects detected by IoU-Adaptive Deformable R-CNN in the DOTA dataset is shown in
Figure 5. From
Figure 5, IoU-Adaptive Deformable R-CNN shows satisfactory detection results in recognizing adjacent or overlapping objects such as ships, harbors, storage tanks, and ball courts. In particular, the AP values of small objects like ships, small vehicles and large vehicles increase more than other objects, which illustrate the favorable performance of our methods for small object detection.
4.1. Ablation Experiments
A couple of ablation experiments have been run to analyze the different roles of IoU in the network and the effectiveness of our method on the DOTA validation set. We use AP to evaluate the detection performance of different methods. All detectors are reimplemented with MXNet, on the same codebase released by MSRA [
18] for comparison.
The impact of dilated convolutions: It can be seen from
Table 3 that the baseline network Deformable Faster R-CNN performs poorly on small object detection when compared with the work of Azimi et al. [
23], which get the best detection results in all published methods. In order to better detect a large number of small objects in the dataset, we use the dilated convolutions in the 4th and 5th network stages of the original backbone network. On the one hand, increasing the feature map makes the object features, especially the small object features more expressive. On the other hand, compared with the previous network, increasing the anchor density enables small objects to obtain matching anchors with larger IoUs. At the same time, there are more positive ROIs corresponding to small objects participating in the training of the network. As shown in the
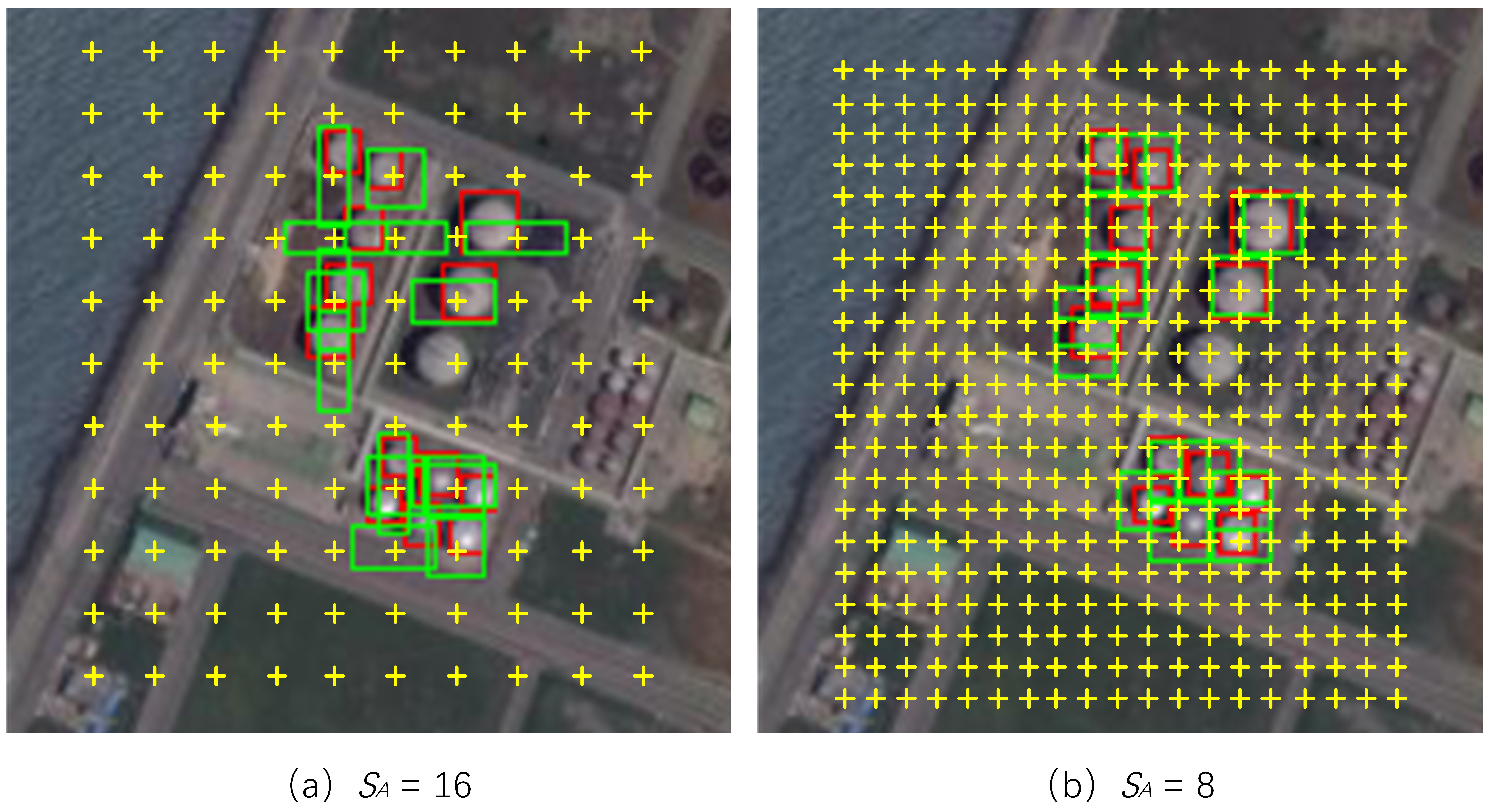
Figure 6, we draw the GT boxes of small objects with red rectangles, and the anchors or positive ROIs corresponding to the small object with green rectangles. The number in the first column images is the average IoU of anchors corresponding to the small objects. It can be seen that when we use suitable number of dilated convolutions, the anchors and positive ROIs involved in network training are more reasonable.
By using dilated convolutions, we can obtain more reasonable anchors corresponding to small objects to participate in the training of the RPN network. In addition, as shown in
Figure 6, we can get more positive ROIs corresponding to small objects to participate in the training of the detection head, and a higher recall rate can be obtained during the inference. As shown in
Table 3, the detection performance of some categories, especially those with many small objects (such as ship, storage-tank) has been significantly improved. Meanwhile, the detection performance of some categories has been declined, may be due to the fact that the network generates more anchors and introduces more FPs.
The impact of reducing IoU threshold of the detectors: The quality of a detector is defined by Cai et al. [
15]. Since a bounding box usually includes an object and some amount of background, it is difficult to determine a detection is positive or negative. We usually make judgment by using the IoU overlap between detection BB and the GT box. If the IoU is above a predefined threshold
u, the patch is considered an example of the foreground. Thus, the class label of a hypothesis
x is a function of
u,
where
is the class label of the GT object
g and the IoU threshold defines the quality of the detector.
As shown in the last column of
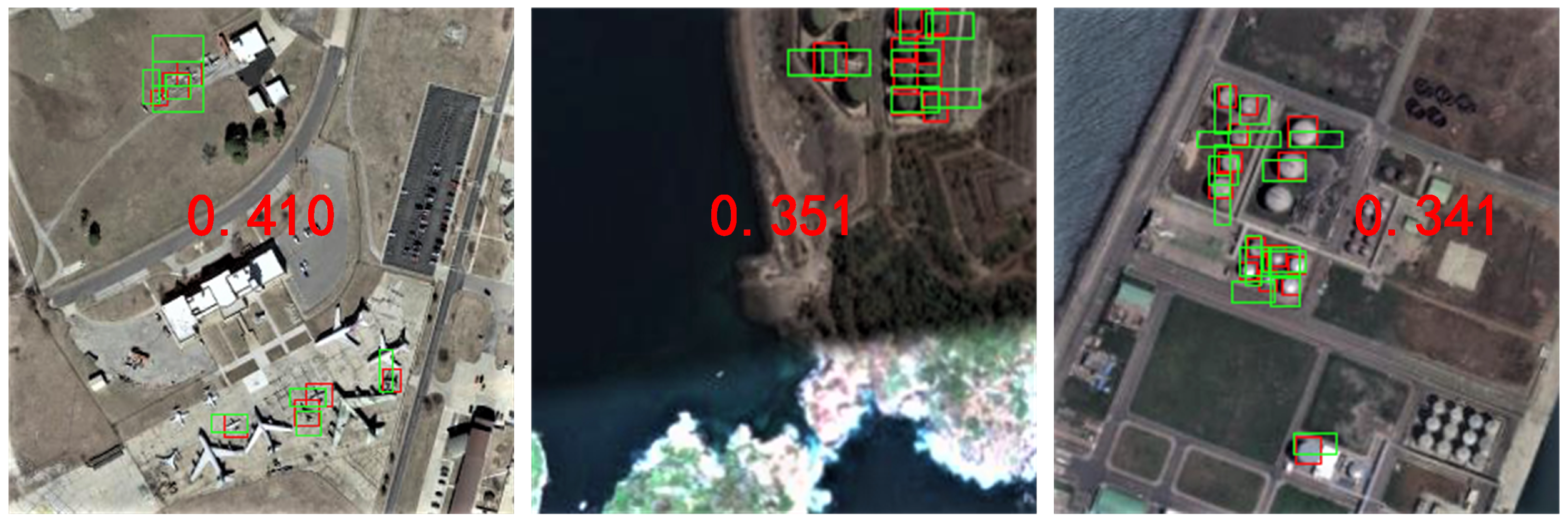
Figure 6, there are many small objects that are ignored and do not participate in the training of the network. Even if the density of the anchor is increased by using more dilated convolutions, there are still small objects lacking the corresponding positive ROIs. Therefore, we appropriately reduce the IoU threshold of the detector so that more small objects can participate in the training of the network. As shown in
Figure 7, when the detector’s IoU threshold is changed from 0.5 to 0.4, more small objects participate in the training of the network. With the participation of these ROIs, which have small IoU values during training, the regression branch can make the proposal with a lower IoU regress to the position of the GT box more efficiently. The detection performance is listed in
Table 4, for most categories, the detection performance is improved when the detector’s IoU threshold is lowered.
The impact of Cascade R-CNN architecture: Although the use of dilated convolutions and lowering the IoU threshold of the detector can effectively improve the ability of the network to handle small object detection problems, it may reduce the detection performance of other objects due to the reasons indicated in
Section 2.1.
As compensation, we use the Cascaded R-CNN architecture to improve the overall detection performance. Additional cascading of two detection heads of the same structure with increasing IoU thresholds based on the original detection head structure, we get more accurate detection results, and the detection results can get closer to the corresponding GT boxes through multiple regression. In addition, more True Positive results can be obtained when used the Cascaded R-CNN architecture. It is helpful to improve the overall detection performance as shown in
Table 5.
The impact of the IoU-based Weighted Loss: To the best of our knowledge, we are the first to propose that the loss function can be weighted by the IoU value of the ROI during training to improve the detection performance. In order to analyze the different effects on classification branch and regression branch when we introduce the influence of the IoU weighting function, we designed three different loss functions based on the basic framework to introduce the impact of the IoU value on the network learning. Results in
Table 6 show that all three weighted loss functions improve the detection accuracy. There is no significant difference in the final detection performance when we used three different loss functions for training. In the following experiments, we use the IoU weighted loss function that affects both the classification branch and the regression branch by default.
To analyze the impact of using different weighting method on detection performance, we also use other weight calculation formulas. For example, we change the weight of the classification loss as
when a positive ROI has an IoU larger than 0.5, which remove the problem of weight jump changes existing in Equation (
7), but there is no significant difference in the final detection performance (the mAP is 70.41 when use Equation (
7) while the mAP is 70.47 when we use the new weight calculation formula). Furthermore, we change the weight of the regression loss as
or
during training when a positive ROI has an IoU larger than the IoU threshold of the detector. As the weight value increases, the detection performance has a small increase as shown in
Table 7. A more reasonable weight calculation method will be studied in our future work.
The impact of the Class Aspect Ratio Constrained NMS (CARC-NMS): As shown in
Table 8, we list the mean, standard deviation, and corresponding constraint factors of the distribution of different classes of samples
which are calculated according to the annotations of the training set. When evaluated on the test set, our final detection framework used CARC-NMS instead of NMS can lead to an additional increase of 0.8% for the mean average precision metric (from 71.93% to 72.72%), and an average 0.8% performance gain can be get when we evaluated on the validation set.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}