1. Introduction
The emergence of HRRSI poses new challenges and requirements for the interpretation and recognition of remote sensing images. Geographic object detection on HRRSI is an important issue for interpreting geospatial information, analyzing the relationship between the geospatial objects and the automatic modeling of outdoor scenes [
1,
2].
During the past decades, many methods were studied for object detection of HRRSI. In general, these methods can be mainly divided into four categories [
3]: Template matching-based object detection [
4,
5,
6], Knowledge-based object detection [
7,
8,
9], Object-based object detection [
10,
11,
12], and Machine learning-based object detection [
13,
14,
15]. The similarity measure is utilized to find the best matches of templates generated manually or from the labeled instances in the template matching-based object detection. However, these methods are sensitive to shape and perspective changes. Therefore, it is difficult to design a universal template with limited prior information or parameters of the geometric shapes. Knowledge-based object detection methods represent the geometric and context information such as shape, geometry, spatial relationship and other features for object extraction in the form of rules to determine the objects satisfying the rules. But some objects may be missing if the detection rules are strict. At the same time, false positives may exist. Object-based object detection methods consist of image segmentation followed by object classification. The scale in the segmentation is a parameter that is difficult to control which may heavily influence the classification accuracy. Moreover, the features need to be designed manually for classification. Machine learning-based object detection methods mainly involve feature extraction, dimension reduction, classification and other processes [
16]. The advanced semantic features extracted by deep learning methods have shown great success in object detection [
17]. Therefore, the CNN-based object detection algorithms are studied in this paper.
At present, the methods based on CNN for object detection in the natural images are mainly divided into two categories according to the detection process: one is one-stage methods such as Single Shot Multi-Box Detector (SSD) [
18], You Only Look Once (YOLO) [
19] and its improved versions YOLOv2 [
20], YOLOv3 [
21]. The other is two-stage object detection methods involving region proposal and classification, like Regions with CNN features (RCNN) [
22], Fast Region-based CNN (Fast RCNN) [
23] and Faster Region-based CNN (Faster RCNN) [
24]. The two-stage object detection methods usually perform better than the one-stage methods while the one-stage methods are usually faster in detection. The Faster RCNN framework can provide satisfactory performance with relatively less computational cost among all above-mentioned approaches. Therefore, the Faster RCNN framework is studied in this paper.
The Faster RCNN framework was proved to perform well in the object detection of HRRSI in recent years [
25,
26,
27]. However, because of different spatial resolutions, spatial distributions and scales between natural images and HRRSI, the following limitations may exist in the Faster RCNN.
Compared with objects in the natural images, the spatial distribution of geographic objects is more complex and diverse and the scale of geographic objects varies more significantly. As shown in
Figure 1, objects in HRRSI have a large scale range because of different spatial resolutions, shooting angles and the size of objects. It is difficult to detect well geographic objects of different scales simultaneously, such as playground and vehicles. The fixed anchor size provided for the Faster RCNN may be inappropriate for the scales of different objects, which may lead to the missing detections.
In Faster RCNN framework, the quality of bounding boxes of the region proposal network used in the classification process may affect the detection results. Non-Maximum Suppression (NMS) method [
24], [
28] may directly delete the bounding boxes with high overlap, leading to the missing detection of dense objects. The bounding boxes containing different objects may increase diversity of samples during the training process and removing the bounding boxes containing no objects may reduce the negative influence of the background information on the testing process. Therefore, it is necessary to choose the effective boxes from the predicted boxes for the classification stage.
The quality of samples and the proportion of the number of positive samples to that of negative samples will affect the results in the CNN classifier. Compared with the one-stage detection algorithm, the Faster RCNN algorithm can adjust the ratio of the number of positive samples to that of negative samples but it still cannot control the ratio of the number of hard samples to that of easy samples during the training process. The difficult samples play a more important role in the classifier than the easy samples in terms of the classification accuracy.
In order to detect objects with different scales, some methods have been proposed [
29,
30]. The Multi-Scale CNN [
31] proposed a multi-scale object proposal network that uses feature maps at different layers to generate the multi-scale anchor boxes and improve the detection accuracy. However, the shallow layer with less semantic information may generate some negative bounding boxes and the anchors that are also required to initialize the network influence the object detection performance. The recurrent detection with activated semantics (RDAS) [
32] incorporates semantic information with bounding boxes segmentation of the ground truth into low-level features to improve the recall ratio of small scale objects and geometrically variant objects. The role of the activated semantics in RDAS on the objects with large scales is also limited. The above-mentioned multi-scale object detection methods use fixed anchor size, which is inappropriate for multi-scale objects. In order to solve this problem, this paper adds a class-specific anchor block to learn the suitable anchor size for each category according to the Intersection-over-Union (IOU) [
33] method from true bounding boxes. The class-specific anchors can provide more appropriate initial values to generate the predicted bounding boxes covering the scales of all categories and improve the recall ratio. However, the class-specific anchors may provide less context information than the fixed anchors especially for small objects, which may decrease the classification precision. That is because the bounding boxes generated by the proposed class-specific anchors are usually comparable to the size of true bounding boxes but with less context information, which does not benefit the classification process [
34]. Therefore, we propose to incorporate the context information into the original high-level feature to increase the feature dimension and improve the discriminative ability of the classifier for higher precision in the object detection.
In order to reduce the redundant boxes, NMS is a common method to delete the predicted boxes containing the same objects on the basis of IOU of the boxes with the highest score belonging to the foreground. However, the spatial distribution of geographic objects is randomly positional and directional. If the density of objects is high, some overlap usually exists between the predicted bounding boxes. The NMS method may directly filter out the bounding boxes containing different objects, leading to some undetected objects. In this paper, a soft filter is proposed by using the weights related to IOU to decrease the score of the highly overlapped predicted boxes and deleting the boxes with low scores in the iterative process. The soft filter can increase the diversity of the samples to improve the classifier and avoid missing or false detection to some extent in the testing procedure.
The hard samples can help to improve the classifier in distinguishing the similar bounding boxes. Online Hard negative Example Mining (OHEM) [
35] is a method sorting the loss of the samples to select the difficult samples and improve the discriminative ability of a trained model. However, training the network with only the hard samples is unsuitable for all conditions since not all samples are hard samples. In training process of classification, the number of the samples to train the classification network is usually limited and the difficulty of the samples is hard to control. In order to improve the influence of hard samples on the classifier, the focal loss [
36] is introduced to our method by giving easy samples lower weights and relatively improving the role of hard samples in the loss function.
The major contributions of this paper are four-fold:
Unlike the fixed anchors set manually and empirically in the traditional methods, we design a class-specific anchor block to learn suitable anchors for objects in each category with different scales and shapes to improve the recall ratio.
Considering the limited label information of the class-specific anchor size especially for small objects, we expand the original feature with the context information to increase the discriminative ability of feature for classification.
The soft filter method is proposed to select effective boxes by retaining the boxes including different objects and deleting the background boxes for the classification stage. The soft filter method can improve the diversity of samples for classification and avoid some missing or false detection of the objects.
We introduce the focal loss to replace the traditional cross entropy loss. In the focal loss, the samples are weighted to reduce the influence of easy samples on the objective function and improve the ability of the classifier to distinguish the difficult samples.
The rest of this paper is organized as follows. The class-specific anchor based and context-guided object detection method with CNN is presented in
Section 2, which mainly consists of a class-specific anchor based region proposal network and a discriminative feature with context information classification network. The dataset description along with implementation details are outlined in
Section 3.
Section 4 presents the object detection results of the proposed method and the state-of-the-arts.
Section 5 analyzes the proposed method from the aspect of recall and precision along with sensitivity analysis.
Section 6 concludes the paper with potential future directions.
2. Methodology
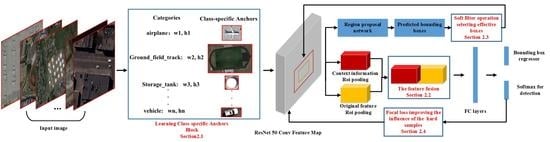
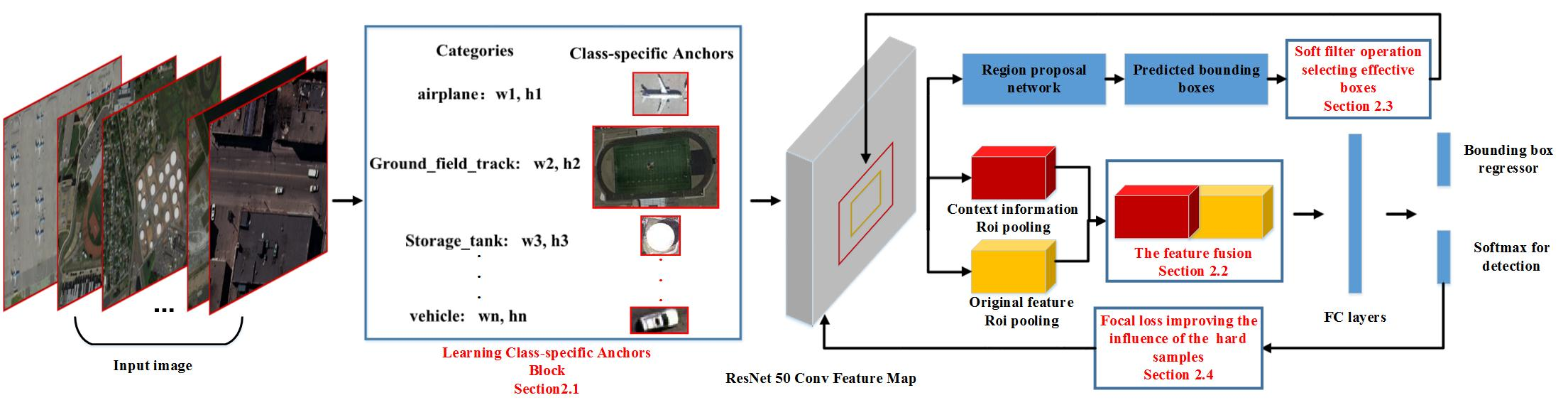
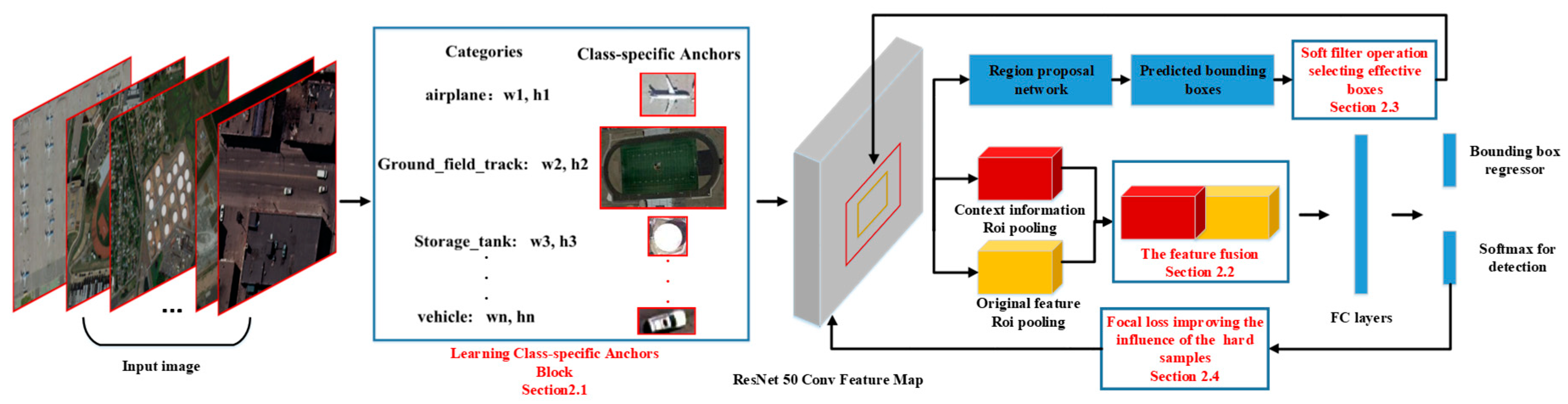
This paper proposes a class-specific anchor based and context-guided multi-class object detection method with convolutional neural network (CACMOD CNN) for HRRSI by making several improvements on the Faster RCNN framework. The proposed method consists of a class-specific anchor object proposal network and a discriminative feature with context information classification network.
Figure 2 shows the architecture of CACMOD CNN. The procedures of the CACMOD CNN can be illustrated as follows.
In the RPN, in order to improve the ability to detect objects of different scales, we design a block to learn the class-specific anchors to make the generated bounding boxes cover the scales of different geographic objects. After training the RPN, numerous predicted bounding boxes are generated by the class-specific anchors. In order to improve the quality of the bounding boxes in the classification stage, a soft filter is proposed to retain the bounding boxes containing different objects and remove the predicted boxes containing no objects. The class-specific anchor block and soft filter can provide more effective bounding boxes for the classification stage.
In the classification stage, considering the limited label information provided by class-specific anchors of small objects in the feature map, the context information is merged with the original feature to improve the discriminative ability of features in recognizing the objects. However, it is still difficult for the classifier to distinguish hard samples. Therefore, the focal loss is introduced to increase the role of the difficult samples in the loss function.
2.1. Learn the Class-Specific Anchors Automatically
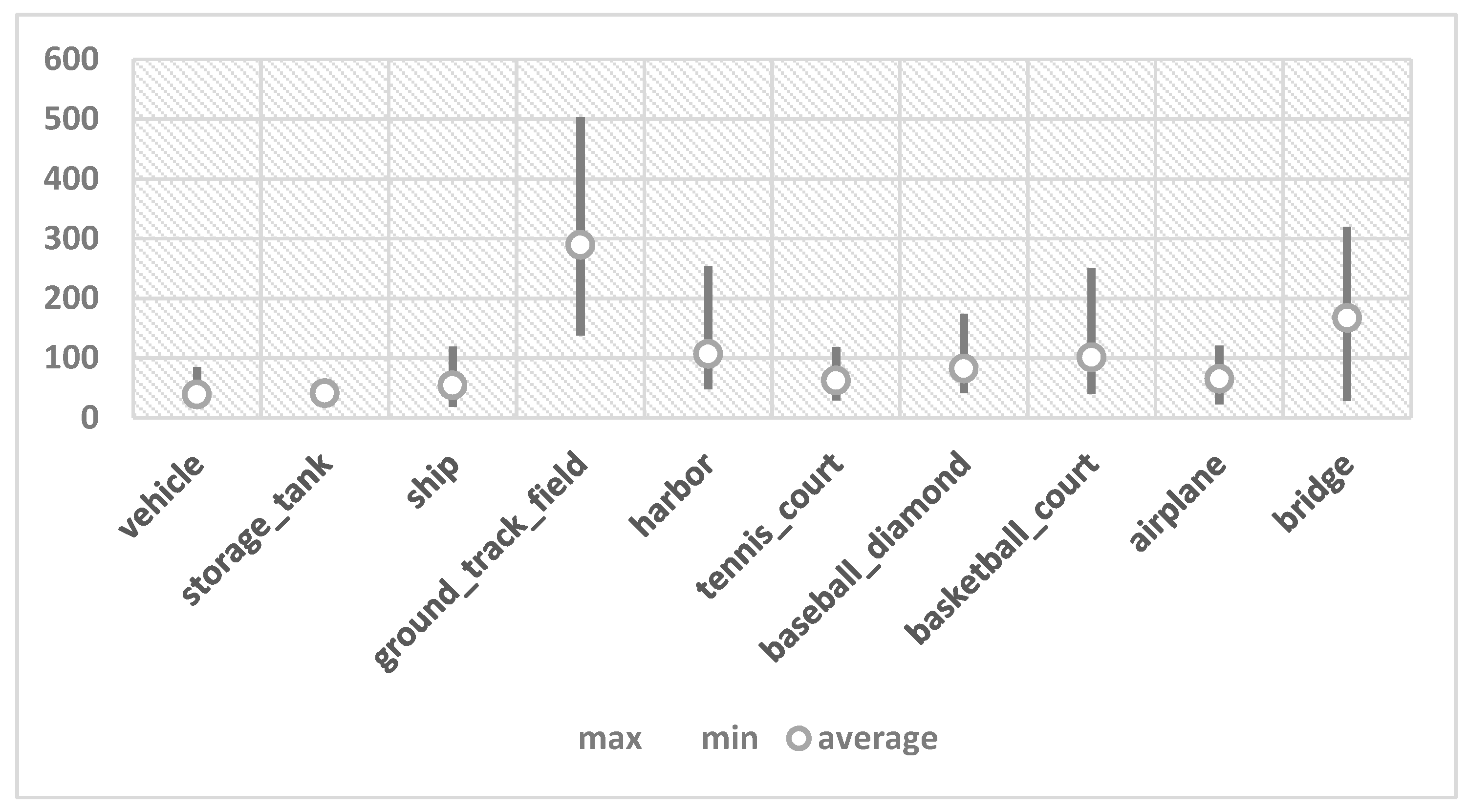
For the two-stage object detection method, the anchor size to generate candidate boxes is important for the region proposal stage. The anchor sizes which can cover as many true bounding boxes as possible are beneficial to detect multi-scale objects. Faster RCNN uses the anchors with a fixed size to detect objects of different scales in natural images. The anchors in the Faster RCNN usually have the length-width ratios of 1:1, 1:2, 2:1 and scales of 128, 256, 512. Since the distance between the shooting position and the objects is usually close, the fixed anchors in Faster RCNN may deliver good object detection performance in the natural images. However, these parameters are inappropriate for HRRSI with a large coverage area and multiple types of geographic objects. There exist significant changes in the scale and orientation for geographic objects due to different sizes of geographic objects, shooting angles and flight heights. Take the NWPUVHR-10 benchmark dataset as an example, we make statistics of the average width and length of the class-specific objects to explain why the parameters in the Faster RCNN are inappropriate for geographic objects.
In
Table 1, we found that the average width and length of the geographic objects range between 40 and 282. The scales of some categories are not included in the anchor size of Faster RCNN, such as vehicle, storage tank and ship. Similarly, the length-width ratios of 1:1, 1:2, 2:1 are also unsuitable for geographic objects with different shapes. Although the RPN can learn to adjust the boxes appropriately, the unsuitable anchor size may lead to missing detection since the predicted bounding boxes cannot cover all geographic objects.
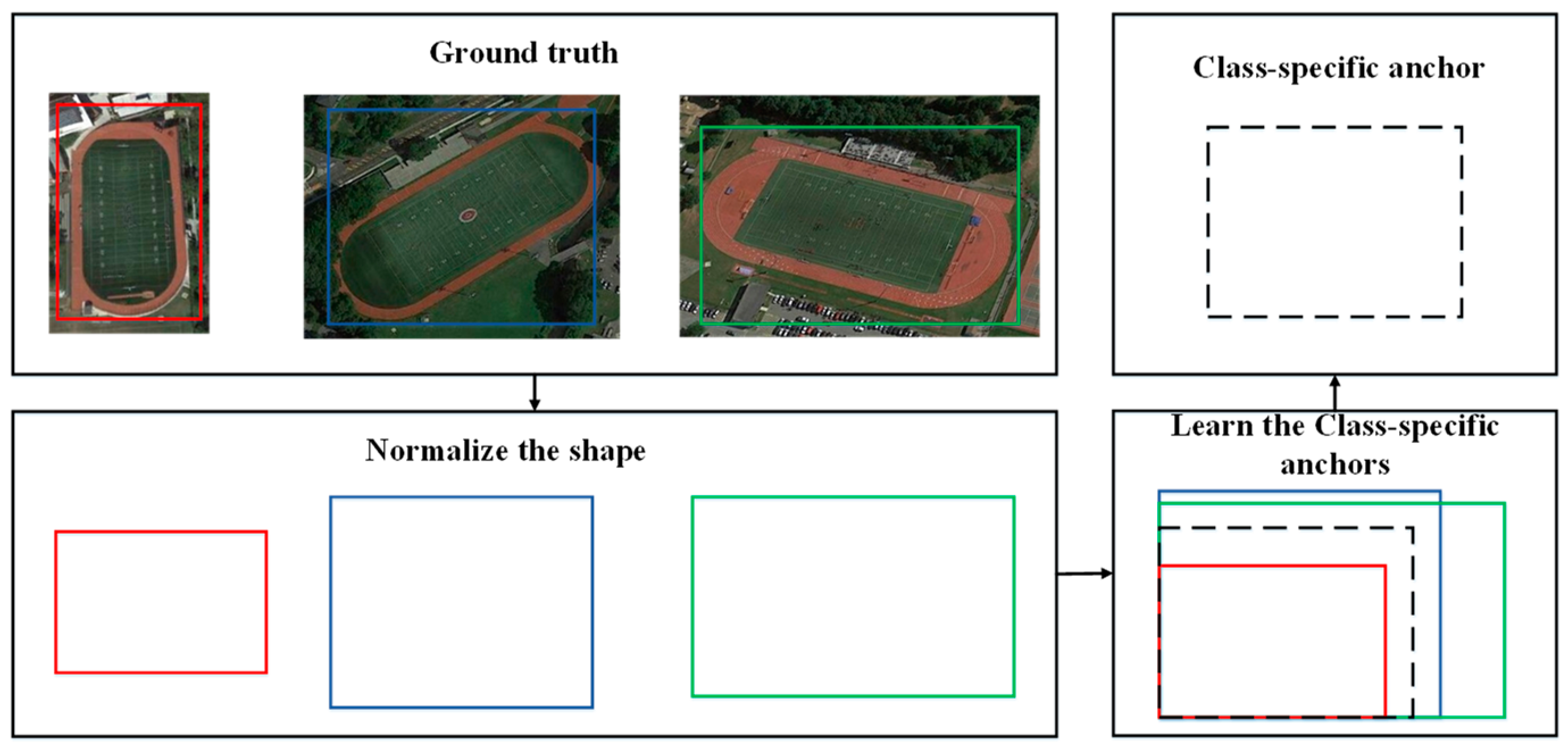
The scale and shape of the geographic objects from different categories vary greatly in the HRRSI because of the different object sizes, while those in the same category caused by different flight heights and shooting angles change relatively little. Therefore, we propose the class-specific anchor block to learn the anchor of the most suitable scale for each category from the training dataset in the specific category and generate the bounding boxes covering the scales of all the categories.
In training process of the RPN, the bounding boxes are annotated as positive ones or negative ones according to the IOU between the anchor and the true bounding boxes in Equation (1). If the IOU is over the upper threshold
, the anchor is labeled as a positive sample.
A larger IOU between anchor and true bounding box is more helpful to the RPN and generates the bounding boxes with the sizes comparable with the true bounding box. Therefore, the function relevant to IOU is selected as the distance loss for calculating class-specific anchors in Equation (2).
Considering the intra-class diversity of shapes and orientations, the IOU between the anchor and bounding box of each object needs to be large. Therefore, the class-specific anchor is automatically calculated from all training samples by minimizing the loss function shown in Equation (3), and n is the number of the bounding boxes of each category.
Considering the random orientations of geographic objects and making the shape of class-specific anchors more suitable for true bounding boxes, we fixed the width as the short side of the true bounding boxes and the height as the long side to calculate the optimum class-specific anchor shapes for each category in the
Figure 3. The detailed procedure of the class-specific anchor based region proposal network is shown in
Algorithm 1.
| Algorithm 1. The procedure of the class-specific anchor based region proposal network |
| Input: The training dataset of truth bounding boxes for the current class, ; |
| indicates the bounding boxes for class i; |
| the width of the truth bounding boxes, ; |
| the height of the truth bounding boxes, ; |
| the number of the current classes, N |
| the upper threshold of IOU, ; |
| Output: The class-specific anchor set, ; |
| the width of class-specific anchor i, ; |
| the height of the class-specific anchor i, . |
| 1: Normalize the shape of the training set as shown in Figure 3 |
| 2: Randomly initialize the and for the i-th class-specific anchor. |
| 3: While no convergence of loss |
| 4: For t = 1, …, T do |
| 5: calculate the loss function
according to the Equation(3); |
| 6: if |
| 7: update |
| 8: return |
| 9: Considering the orientation of the objects, respectively calculate the IOU between with the size or and truth bounding box by Equation (1). |
| 10: The class-specific anchor shape with a larger IOU is selected as the positive samples to train RPN.
|
2.2. Merge the Context Information to Improve the Feature Representation
The CNN architecture has shown great success in object detection [
37], [
38] because more discriminative features can be extracted by the CNN architectures such as AlexNet [
39], VGGNet [
40], CaffeNet [
41], GoogLeNet [
42] and ResNet [
43] for HRRSI. ResNet performs better than other methods in the classification by increasing the depth of network to generate the feature with more semantic information. In this paper, ResNet50 is used to extract features in both the region proposal and the classification stage.
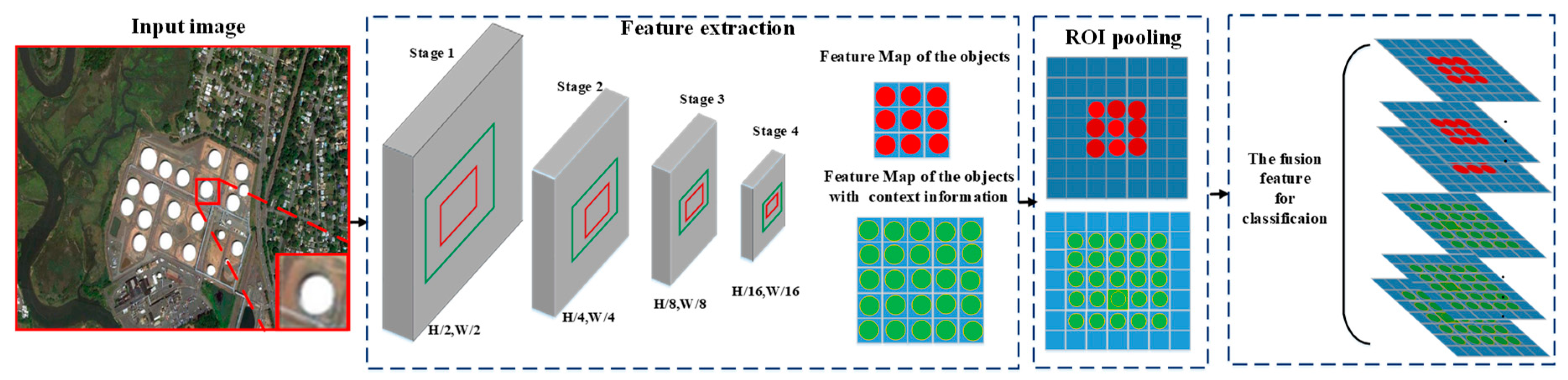
Figure 4 depicts the structure of the ResNet50 network.
As shown in
Figure 5, the size of feature map in Resnet50 is decreased due to the pooling layer in each stage. After four stages, the ratio of the size of original image to that of the final feature map is 16 to 1. The predicted bounding boxes have different sizes, so feature maps for different bounding boxes have different sizes. In order to ensure that the feature of each box is with the same dimension in classification, ROI-pooling is adopted to normalize different bounding boxes with the same size. The size of feature maps after ROI-pooling is usually set to 7 × 7 pixels empirically, meaning that the most suitable size of original images is 112 × 112 pixels. As shown in
Table 1, we can find that the shape of small objects such as vehicles and storage tanks is only about 40 × 40 pixels, which is much smaller than 112 × 112 pixels. Although the ROI-pooling can resize the feature map with 7 × 7 by up-sampling or down-sampling, the small feature map may decrease the accuracy in object detection due to a less discriminative ability of features to express the label information. Therefore, it is fundamental to increase the discriminative ability of features for higher classification accuracy.
The bounding boxes generated by class-specific anchors have a comparable size to the true bounding boxes but with limited label information. That is because that the size of the bounding boxes generated by class-specific anchors for small objects is limited in providing enough label information for classification. The context information around the objects could provide the useful background information to increase the label information in a bounding box. Therefore, this paper proposed to concatenate the context information with the original feature to expand the feature dimension. We doubled the size of the predicted box with the center in the predicted box to incorporate the context information. As shown in
Figure 5, the features of objects and context information are normalized with ROI-pooling respectively. The final feature for classification is obtained by concatenating the normalized context feature and the normalized original feature. The feature fusion process extends the dimension of the effective features and improves the discriminative ability of the features, especially for the small objects.
2.3. Soft Filter Effective Predicted Boxes to the Classification
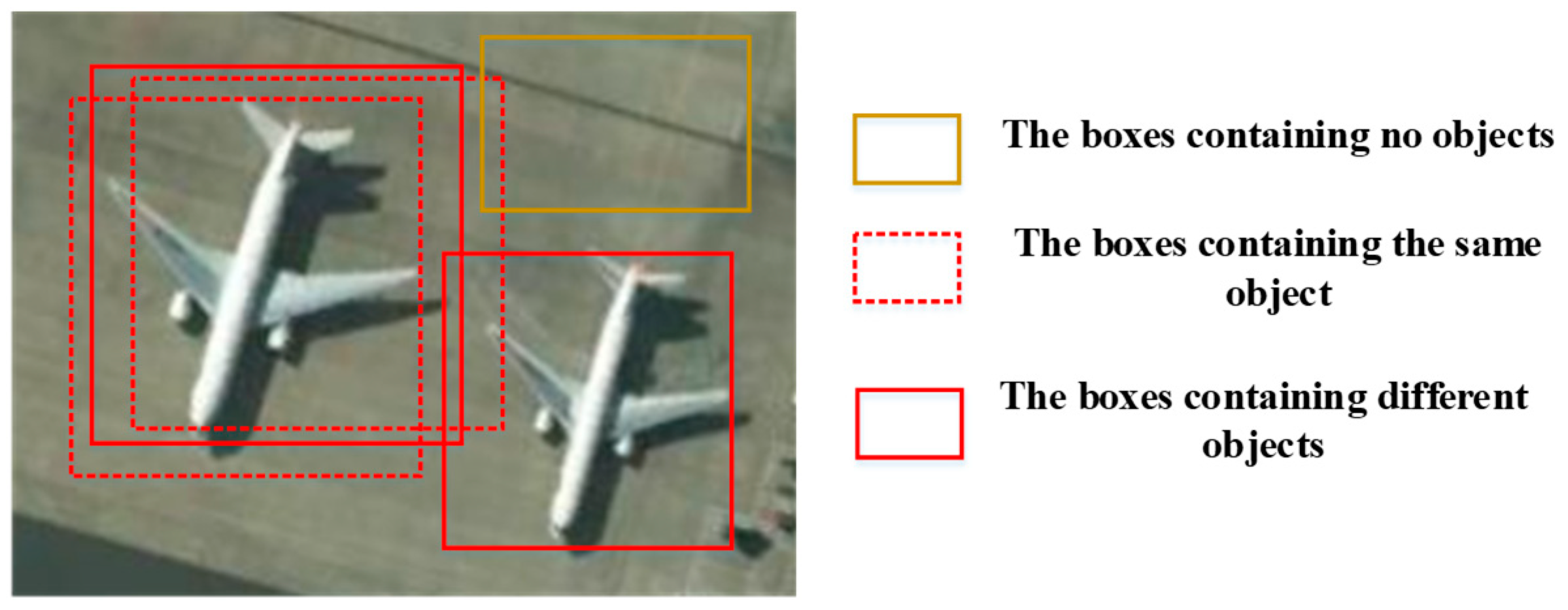
After the region proposal stage, we can obtain many predicted boxes from the feature maps. As shown in
Figure 6, the predicted boxes could be divided into two types, the red boxes containing the objects and the yellow boxes containing no objects. The boxes containing objects may include several overlapped boxes with the same object shown with red dotted lines. In training stage of classification, the trained samples in the classification stage are randomly selected according to the IOU between the predicted boxes and true bounding boxes. The boxes containing different objects may have a positive effect on the training. The boxes containing the same objects may decrease the diversity of samples due to the limited trained samples and the boxes containing no objects provide no label information. In the testing stage of classification, if all predicted boxes are tested, the computational cost may be large. The boxes containing no object sometimes may be confused with the object category because of the similar spectral information. Therefore, the redundant predicted bounding boxes containing the same objects and no objects may decrease the classification accuracy in the object detection. It is necessary to select the effective boxes for the classification stage.
The NMS algorithm is the most common method to remove redundant boxes based on the score and the IOU with the highest score in the testing stage of classification. If the IOU between the candidate bounding box and that with the highest score is above the defined threshold, the corresponding box is eliminated. If we directly use the NMS method to filter the predicted boxes, two obvious limits exist in the training and testing processes of classification:
1. Geographic objects are with a random arrangement of orientation and spatial distribution. When the objects are densely distributed, the random direction will cause a large overlap between predicted boxes containing different objects. In the testing process, improper IOU threshold in NMS will directly eliminate the boxes containing different objects, leading to missing detection.
2. In the training process, deleting the bounding boxes containing different objects directly by NMS may reduce the diversity of the samples in the classification, affecting the discriminative ability of the classification model.
Considering the above limitations, we proposed the soft filter algorithm to select the effective predicted boxes in the testing and training process of the classification. The soft filter algorithm reduces the score of the predicted box overlapped with those having the highest score according to their IOU ratio in the Equation (4), and removes the predicted boxes whose foreground scores are below a certain threshold during the iterative process.
Soft filter is an effective method retaining the boxes containing different objects. The process is elaborated on as
Algorithm 2:
| Algorithm 2. The procedure of a soft filter to select effective bounding boxes |
| Input: The predicted bounding box set, ; the score set, ; represents the possibility of the boxes belonging to the foreground; the overlapped threshold, ; the background threshold, ; The number of B, N. |
| Output: the effective bounding box set, ; |
| 1: Find the box with the highest score from the predicted box set ; |
| 2: Calculate the IOU between other boxes and the ; |
| 3:Update the score set S according to Equation(4); |
| 4: For t = 1, … N do |
| 5: If the score : |
| 6: The box will be removed from set B since they may belong to background boxes; |
| 7: Update set B, set S. |
| 8: Repeat Step 1-7 until all the boxes are repeated. |
2.4. Focal Loss to Improve the Influence of Hard Samples on the Classifier
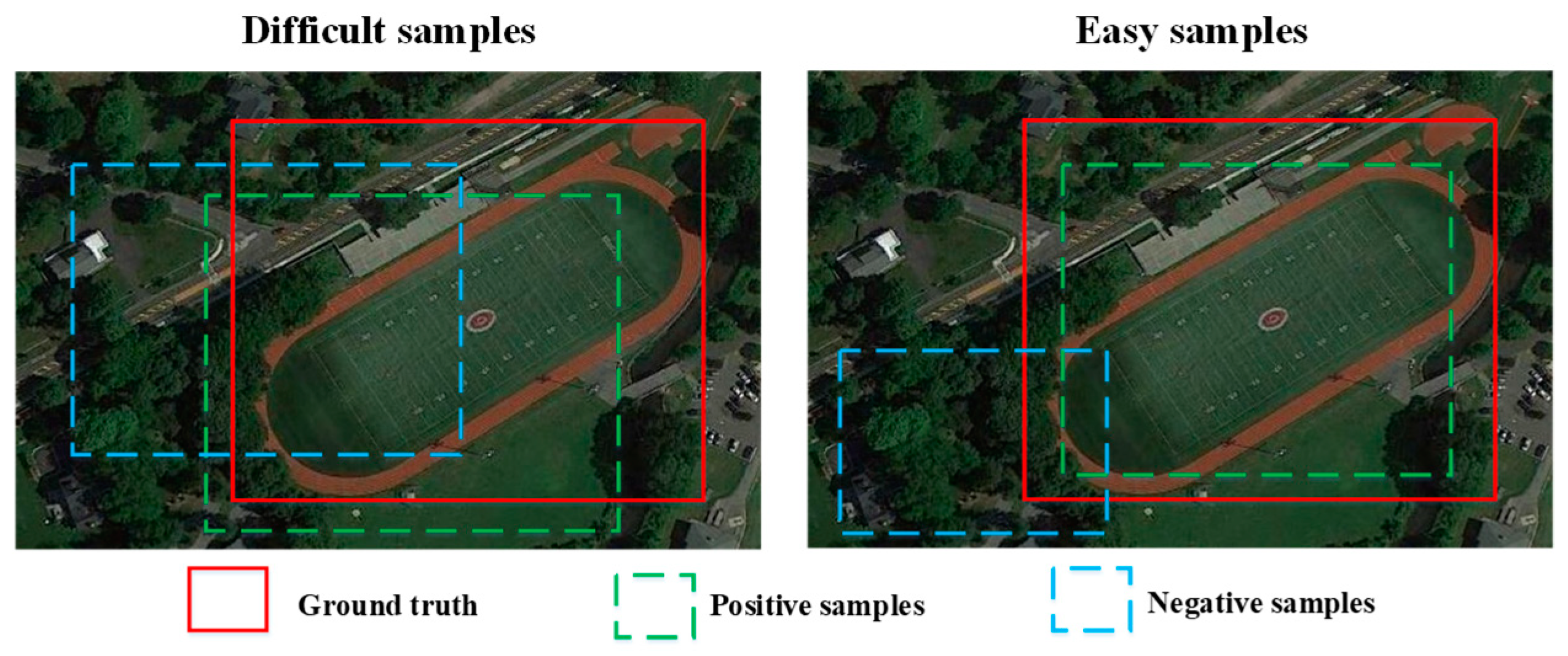
The quality of the samples plays a fundamental role in training a convolutional neural network. In the training process, Faster RCNN divides the predicted boxes into positive and negative samples by setting a threshold over the IOU between the predicted boxes and true boxes. If the IOU is above the upper threshold, the predicted box is considered to be a positive sample, and vice versa. As shown in
Figure 7, there are two types of samples used for training according to the difficulty in classification: easy samples and difficult samples. In the training process, the difficult samples can increase the value of the loss functions in classification and thus improve the ability of the classifier to distinguish similar objects.
Our proposed framework is a two-stage algorithm. We can set the same number for the positive samples and negative samples to improve the classification accuracy, but we cannot keep the balance between the number of difficult and easy samples. Therefore, this paper replaces the existing cross entropy loss with the focal loss in the classification to decrease the role of the easy samples in the loss function and increase the discriminative ability of the classifier.
The loss function for object detection consisting of region proposal network and classification network is defined as Equation (5):
Here, is an adjustable equilibrium weight, setting to 1 in this paper. and are classification and region proposal loss respectively. When the anchor is a positive sample, , Otherwise, .
The focal loss function of the CACMOD CNN in the classification stage is defined in Equation (6):
where
is the probability that
i-th bounding box belongs to the predicted category, and
is the weight controlling the role of easy samples, empirically setting to 2 in this paper. The value
of the easy sample is usually large, the weight
will reduce the contribution of the easy sample to the loss.
Equation (7) defines the loss function of the bounding box regression in the CACMOD CNN:
Here, represents the parameterized coordinates of the candidate bounding box, and represents the coordinates of the true bounding box.
4. Results
Figure 8 shows the detection results of 10 categories in the NWPU VHR-10 dataset. The proposed method can correctly identify most targets for all categories. The small objects such as the storage tanks and vehicles can be detected with few missing objects, as shown in
Figure 8d,e. The context feature and the class-specific anchors can improve both the precision and recall ratio for the small objects due to having more discriminative features and more appropriate scales for the classification and detection of these categories. The method is also effective for the objects with a dense spatial distribution such as tennis courts and harbors as shown in
Figure 8b,f. The soft filter in the proposed method can increase the possibility of detecting overlapped bounding boxes before the classification stage in the
Figure 8h.
Figure 9 shows a comparison between the object detection results of the proposed CACMOD CNN and Faster R-CNN in categories such as airplanes, harbors, vehicles. The CACMOD CNN performs better in those categories, while Faster R-CNN is with some missing targets and false alarms. The size in specific-class anchors is more suitable than that in Faster RCNN especially for the small objects since they can provide the initial anchors covering the scales of all the categories. Therefore, the proposed method can detect the vehicles successfully. As shown in
Figure 9a,c, undetected vehicles and confusion exist between the background and the objects in Faster RCNN. The features in Faster RCNN for classification may be indiscriminative because the bounding box of small objects may provide little context information for distinguishing different categories. The detection results in
Figure 9d,f show that the CACMOD CNN can effectively increase the discriminative ability of the features extracted from bounding boxes by expanding the original features with context information and improving the classifier to distinguish the hard samples. As shown in
Figure 9e, our method can also successfully detect the dense objects such as harbors whose shape may change to some extent. In contrast, some missing objects may exist in the results shown in
Figure 9b.
As shown in
Figure 10, the CACMOD CNN delivers good detection results in categories whose objects are highly overlapped. The soft filter can decrease the possibility of missing detection of dense objects and improve the recall ratio by retaining effective bounding boxes. The proposed class-specific anchor can reduce the effect of intra-class and inter-class scale difference caused by different flight heights, shooting angles and sizes of objects.
The AP values of each category and mAP of the CACMOD CNN and existing object detection methods are presented in
Table 2. The highest AP value of each category is shown in boldface. As can be seen in
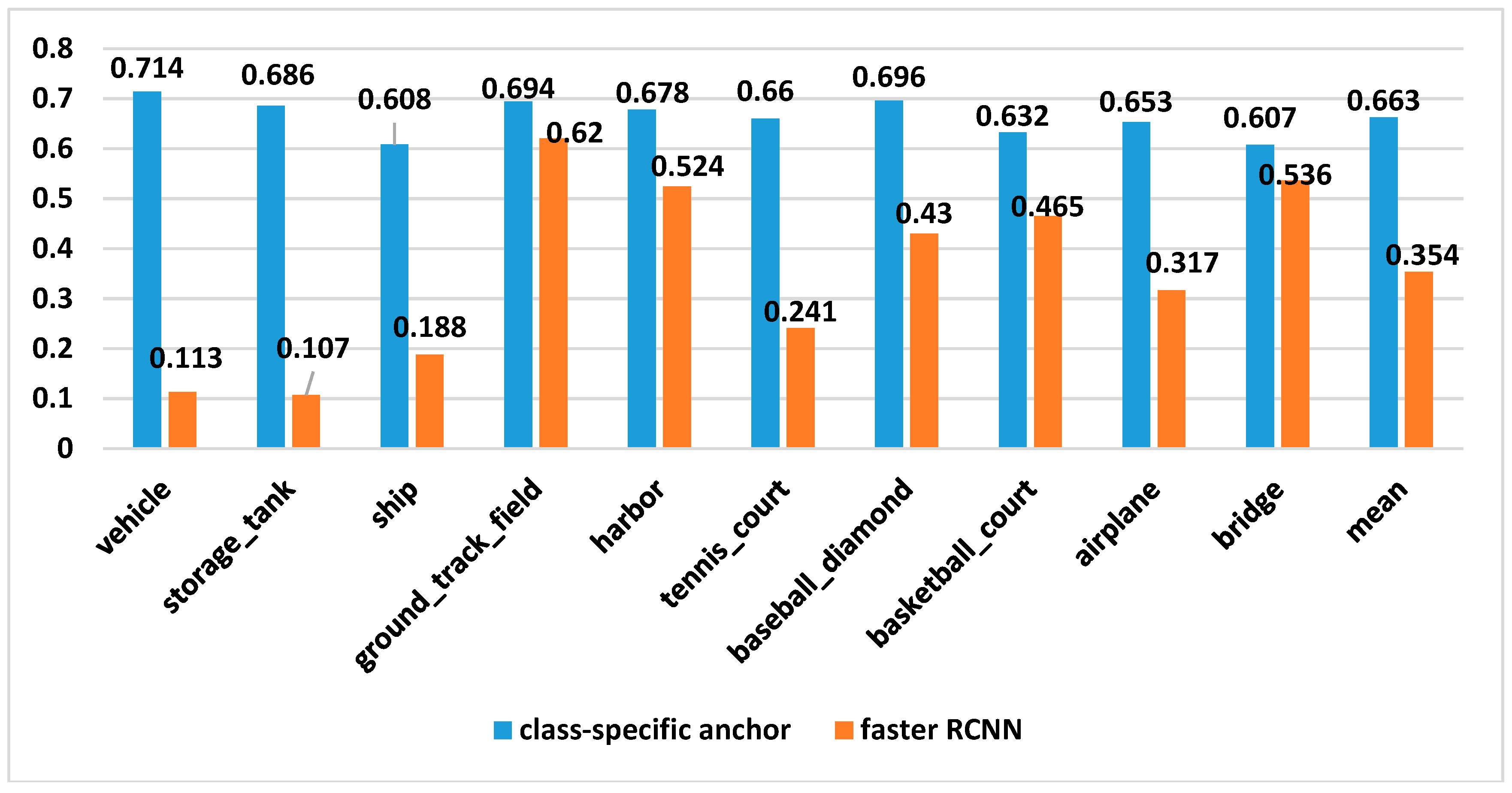
Table 2, the proposed CACMOD CNN outperforms other object detection methods with a mAP of 90.4%. The CACMOD CNN making improvements on the Faster RCNN outperforms the Faster RCNN in all categories except the ground track field with a mAP of 6.9%. Compared with other methods, the CACMOD CNN performs better in bridges, tennis-courts and harbors since these categories belong to the objects with variable shapes, and their objects are overlapped due to the random orientations of geographic targets. The class-specific anchor can adapt to objects of different shapes and random orientations and increase the recall ratio. Moreover, merging context information can help to increase the discriminative ability of features and the precision ratio. The soft filter can decrease the possibility of miss detection of dense objects and improve the recall ratio by retaining effective bounding boxes. RDAS512 with Segmentation Branch and the multi-scale CNN are aimed at multi-scale object detection. RDAS512 with Segmentation Branch method delivers better performance in small objects including vehicles and storage tanks since it incorporates semantic information with bounding boxes segmentation of the ground truth into low-level features to improve the recall ratio of small scale objects. The multi-scale CNN performs better in ground track fields, ships and baseball diamonds since it adds multi-scale anchor boxes to multi-scale feature maps and a larger number of object proposals could improve the recall rate of the detection. The CACMOD CNN makes improvements to the adaptive ability of anchors and discriminative ability of features, which may lead to a comparable mAP to the above-mentioned methods. The proposed CACMOD CNN framework delivers a higher mAP at the expense of more detection time compared with other methods because the soft filter may spend a longer time retaining effective bounding boxes.
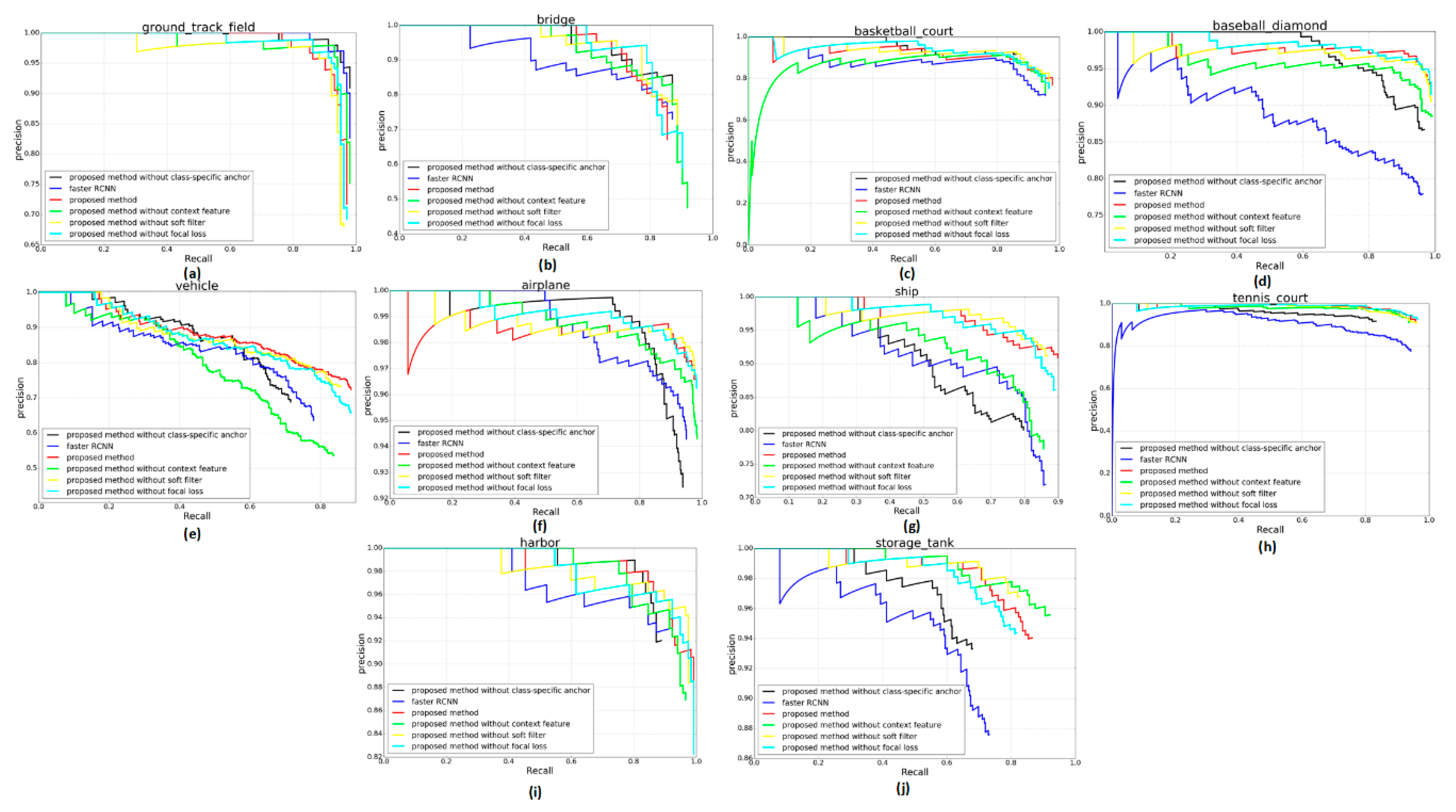
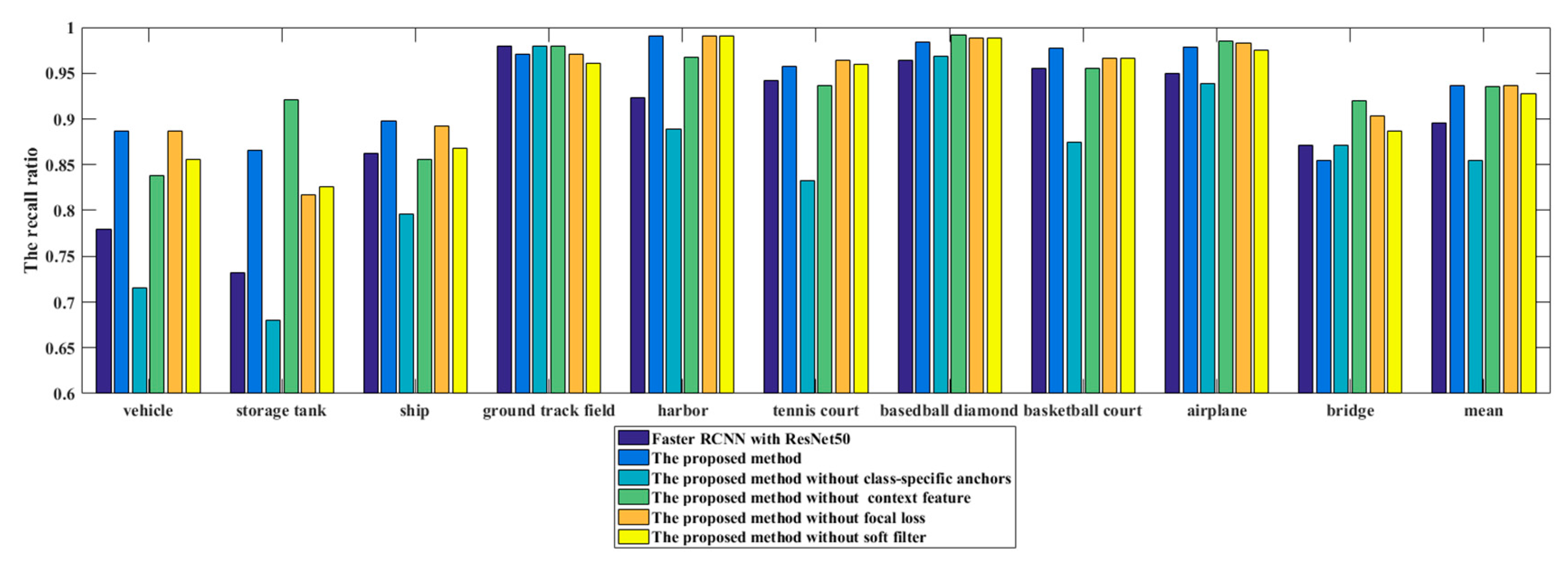
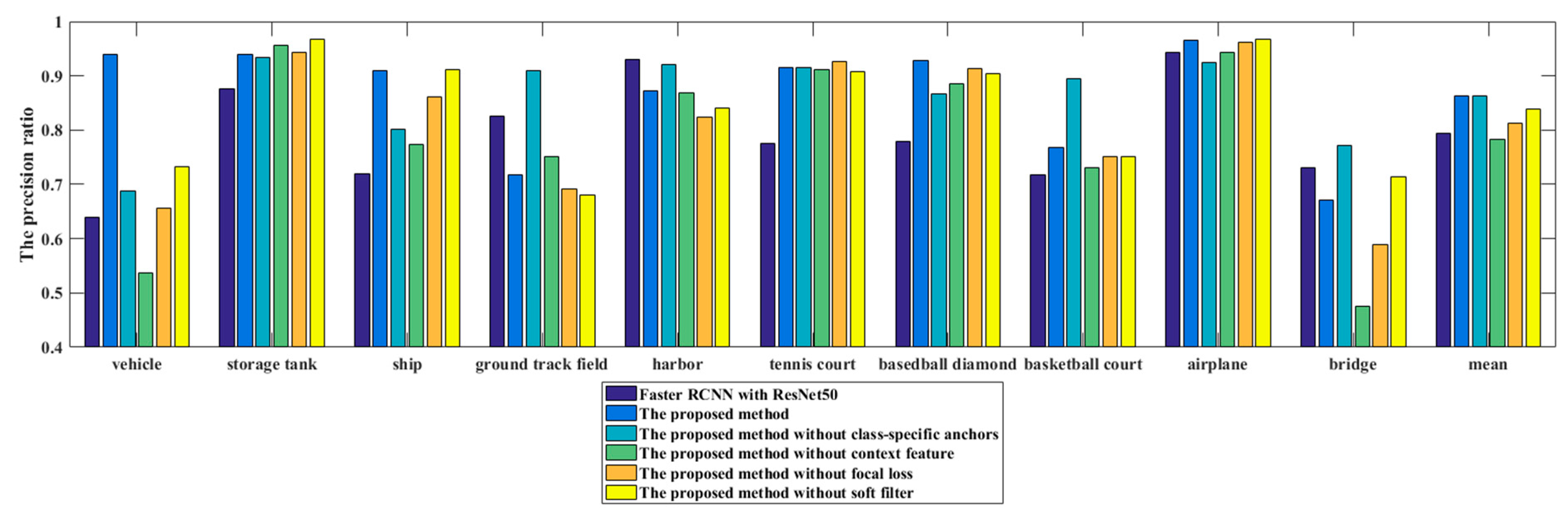
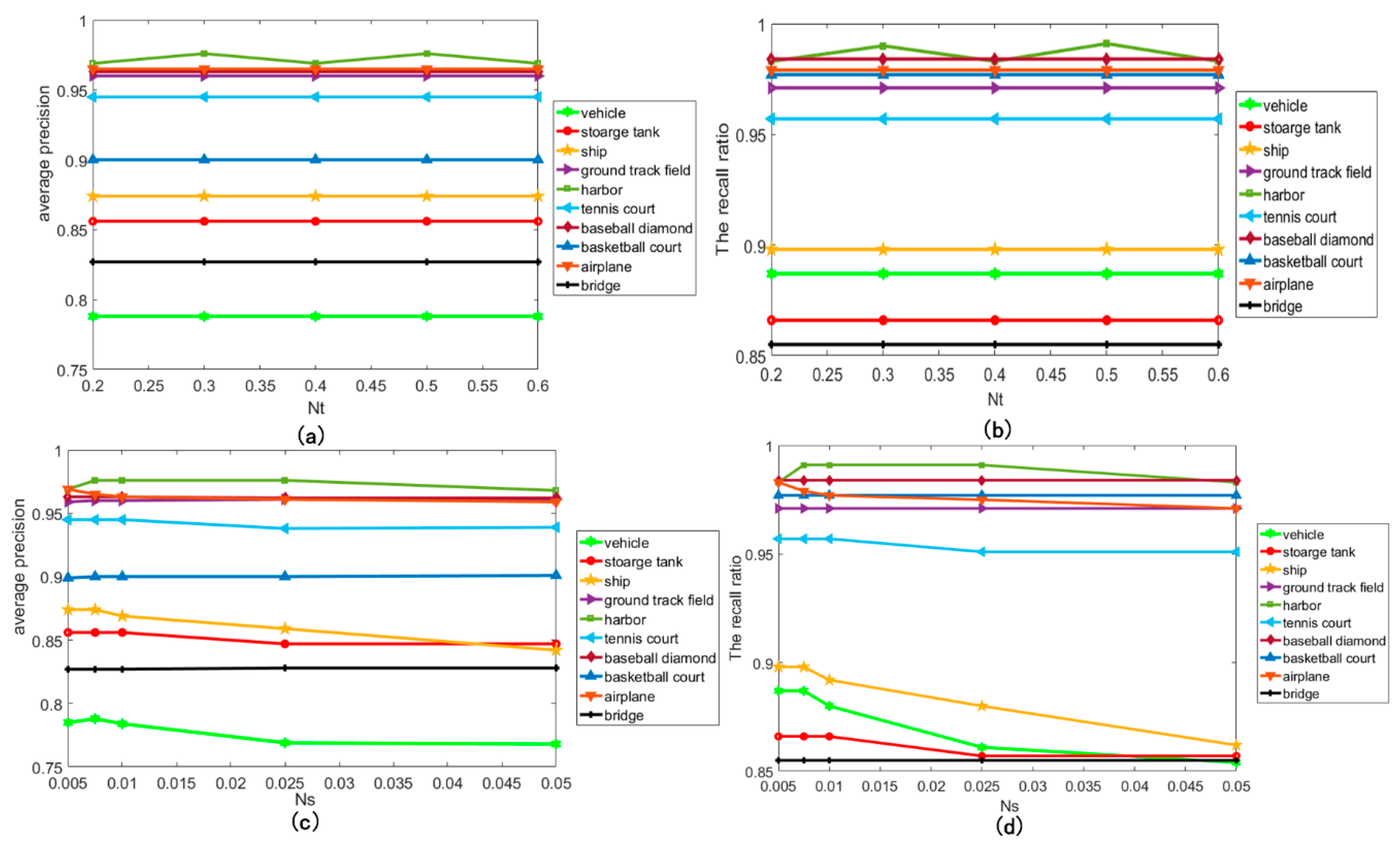
To analyze the contribution of each step to the proposed algorithm in this paper, we conducted an ablation study, where ResNet50 is used for extracting convolutional features for all methods. The APs and mAPs of the ablation study are shown in
Table 3 and
Figure 11 shows the PRCs of the proposed method as well as five ablation studies. If the PRC is further from the x-axis, the performance is better. As shown in
Table 3, each step in the proposed method all improved the mAP. The highest value of each category is shown in boldface. Among them, the class-specific anchor contributes most to the CACMOD CNN and the focal loss contributes the least. The class-specific anchor can increase the recall ratio of most categories, especially for vehicle, storage tank, ship, harbor and tennis court. That is because anchor boxes whose scales are more appropriate for most objects can be produced by the detector. The AP values of the proposed method except the ground track field are largely improved. The AP values of ground track field slightly are lower than those of Faster RCNN by 2.8% respectively. That is because the proposed class-specific anchor size of ground track field is around 280 and objects of ground track field have large size changes. The proposed method delivers a slightly poorer performance in detecting several objects with a size much larger or smaller than the class-specific anchor size. The Faster RCNN with a fixed anchor size of 128, 256 and 512 can better adapt to a ground track being filed. The CACMOD CNN without context feature is with the highest AP in airplanes and storage tanks among all other methods, since the airplanes and storage tanks may be objects with unique shape information that is easy to be distinguished. The context features have a larger positive influence on the vehicle, ship, and basketball court than on the airplane and storage tank. Focal loss and a soft filter can improve the mAP in almost all categories by selecting hard samples and effective bounding boxes.
6. Conclusions
In this paper, a CACMOD CNN for multi-class geospatial object detection in HRRSI is proposed. We proposed a class-specific anchor block to initialize the region proposal network, providing the suitable predicted boxes for each category. We also merged this feature with the background feature to provide more context information for improving the discriminative ability of classification. In order to further increase the precision ratio of the object detection, a soft filter to select effective boxes is proposed for the classification stage and focal loss to improve the role of hard samples in the loss function is adopted in the proposed method. According to the experimental results, the following conclusions can be drawn:
(1) Unlike the fixed anchors in the traditional methods, the proposed class-specific anchors can better adapt to the large scale variation of multi-class objects in the HRRSI and effectively improve the recall ratio of categories that have small objects or limited shape changes, such as vehicles, storage tanks, ships, harbors, tennis courts and so on.
(2) The context information plays an important role in increasing the precision ratio of the categories that may be confused with background information especially for vehicles, ships and bridges.
(3) The soft filter can better detect overlapped dense objects such as harbors and tennis courts compared with NMS. The soft filter also improves the precision of classes which be confused with other objects including vehicles, ground track fields, harbors, baseball diamonds and basketball courts.
(4) Focal loss is helpful for the precision ratio of almost all categories including vehicle, ship, ground track field, harbor, baseball diamond, basketball court and bridge.
(5) The proposed method outperforms some state-of-the-art methods of multi-class geographic object detection with a mAP of 90.4% on the NWPU VHR-10 dataset.
However, the proposed method does not perform well on the geographic objects with shape changes that occur more often than normal. The features and anchors will be designed to detect the objects with more frequent shape changes than normal for improving object detection accuracy in future work.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}