Pre-Constrained Machine Learning Method for Multi-Year Mapping of Three Major Crops in a Large Irrigation District




Abstract

1. Introduction
2. Data
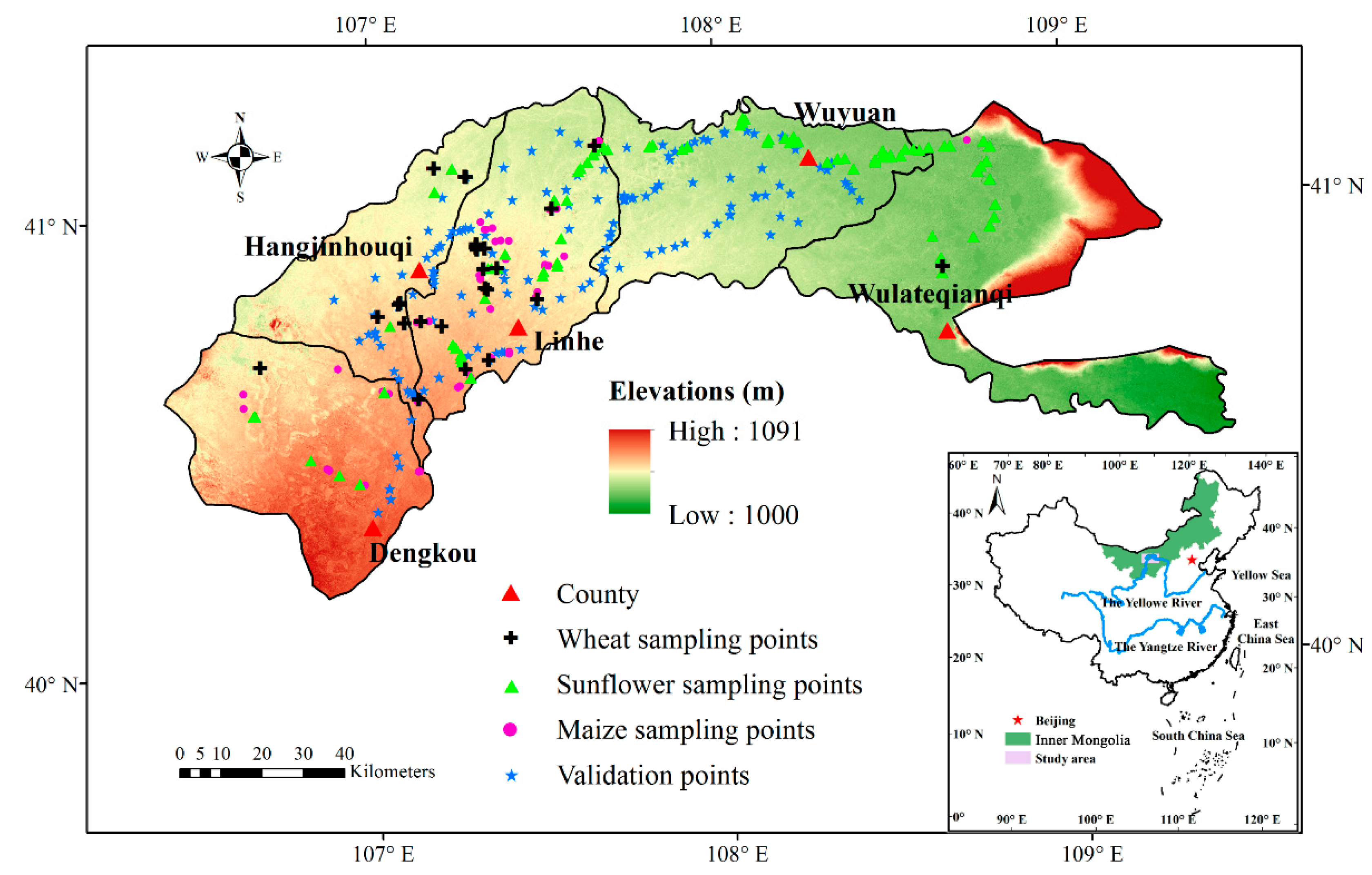
2.1. StudyArea
2.2. Satellite Images
2.3. Reference Data
3. Classification Method
3.1. Feature Extraction
3.2. Pre-Constrained Classification Method
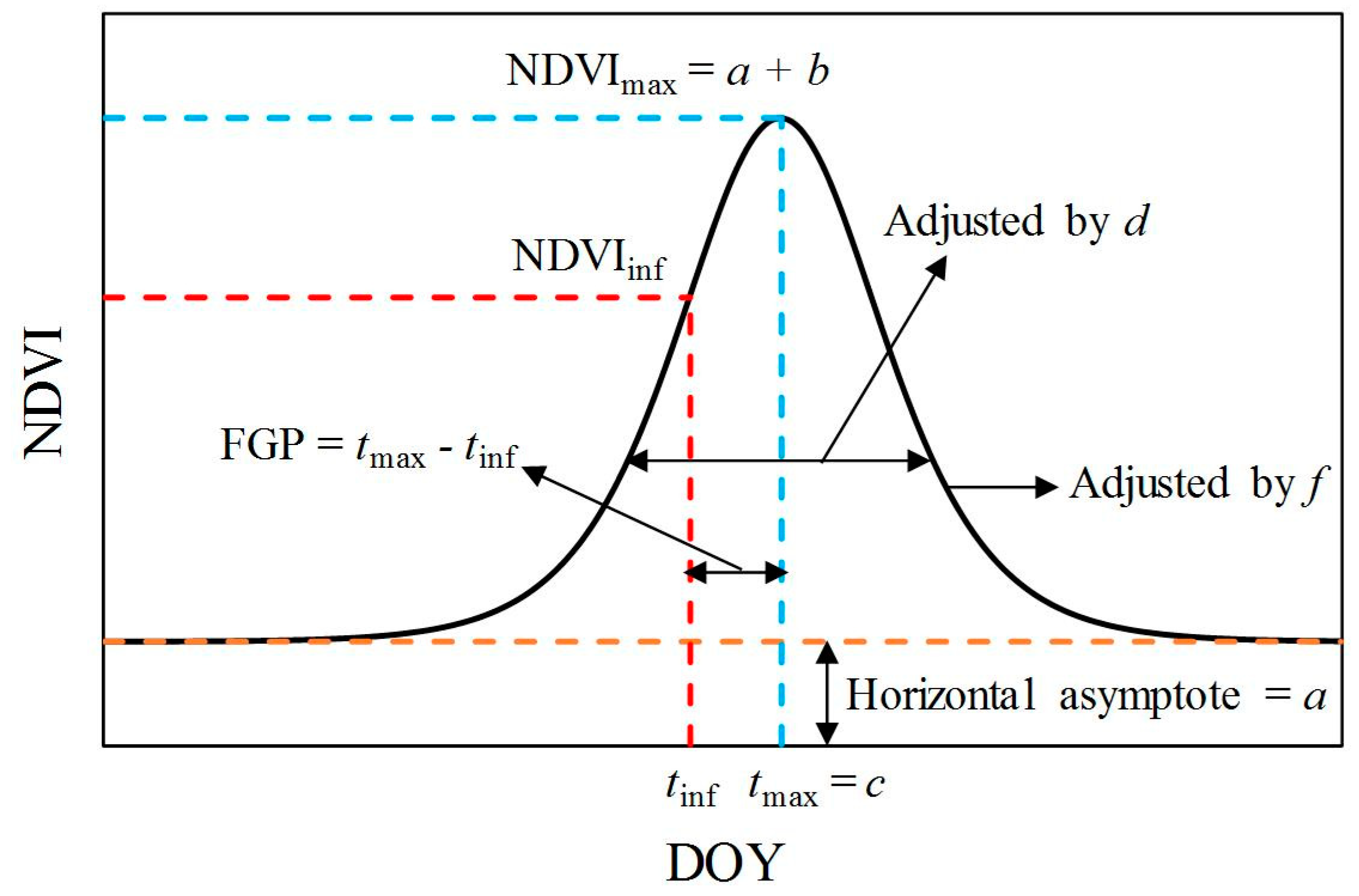
3.2.1. Phenology-Vegetation Indexes Classifier
3.2.2. Support Vector Machines and Random Forests
3.3. Assessment of Classifier Performance
4. Results
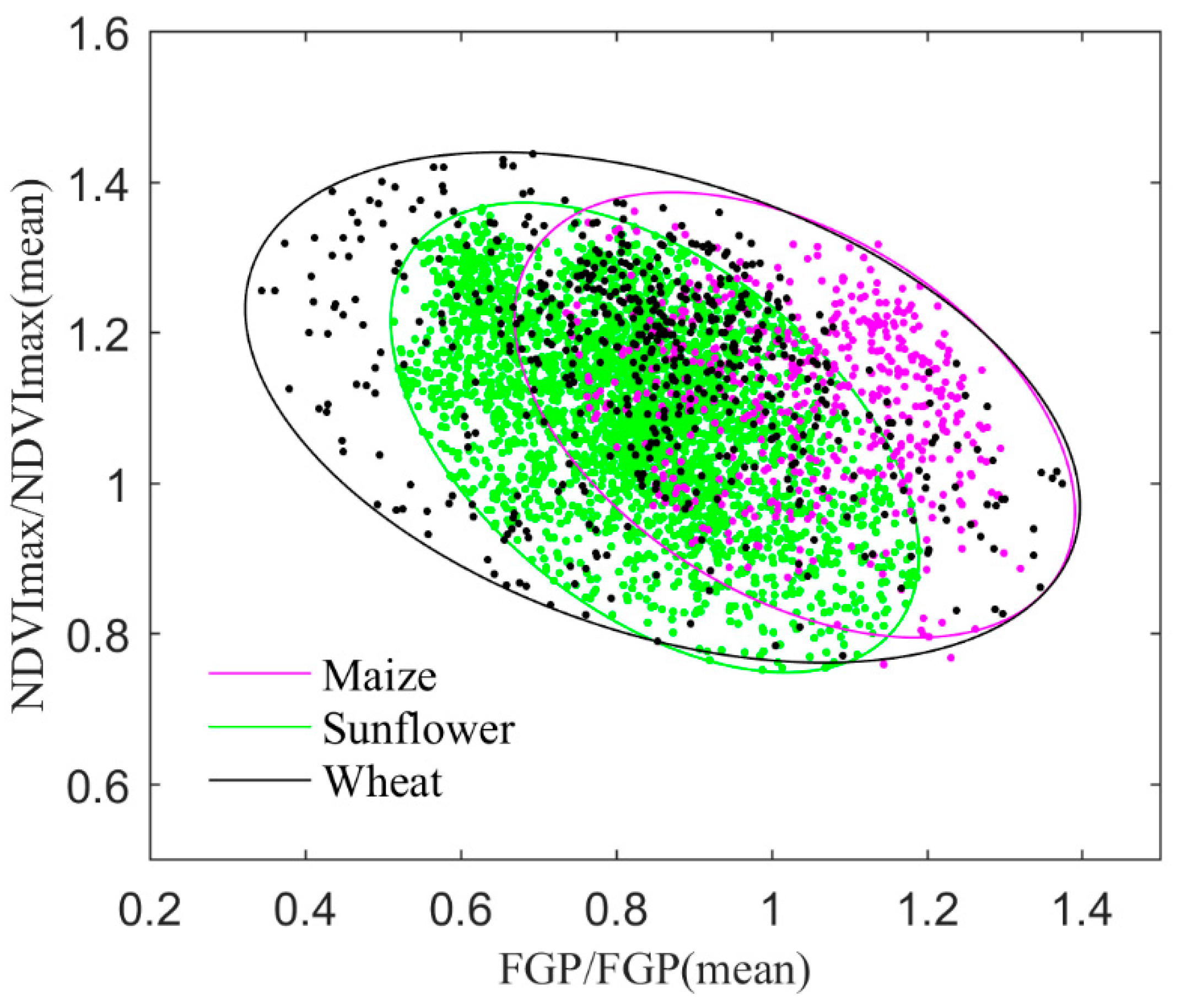
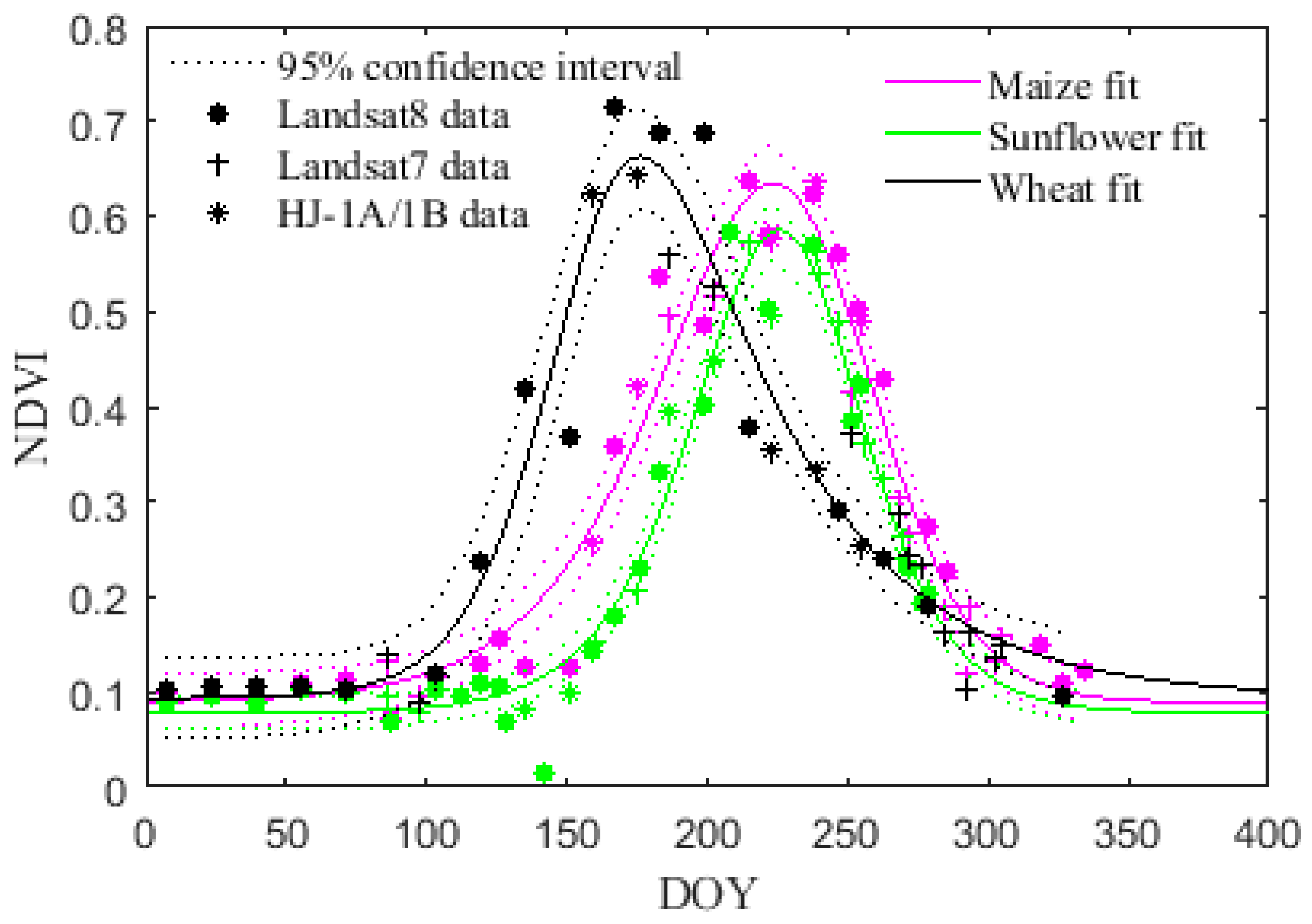
4.1. Evaluation of Asymmetric Logistic Curve and Fused Spectral Features
4.2. Training and Testing Results of Classifiers
4.3. Assessment of the Classifier Performance Using Independent Datasets
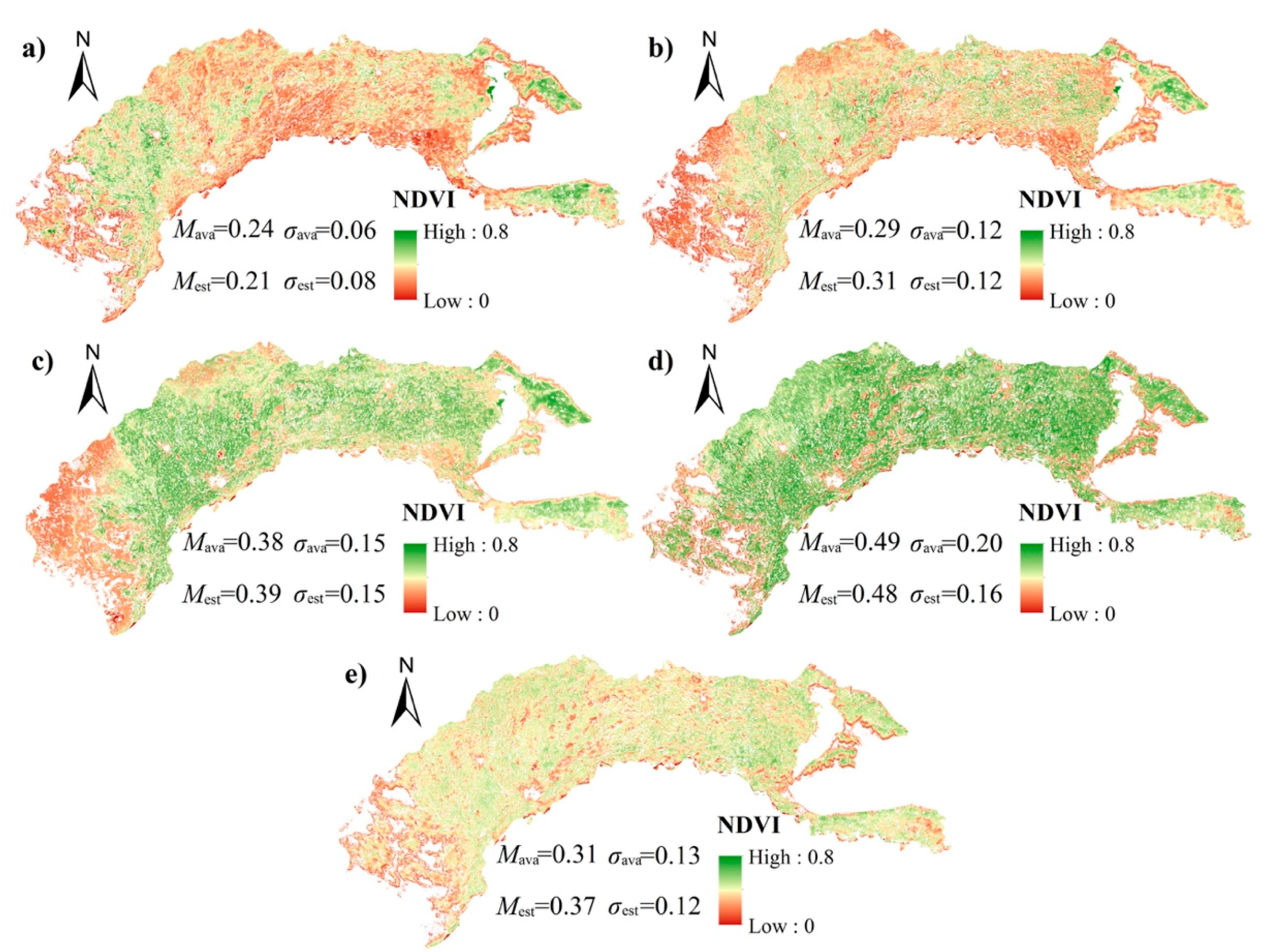
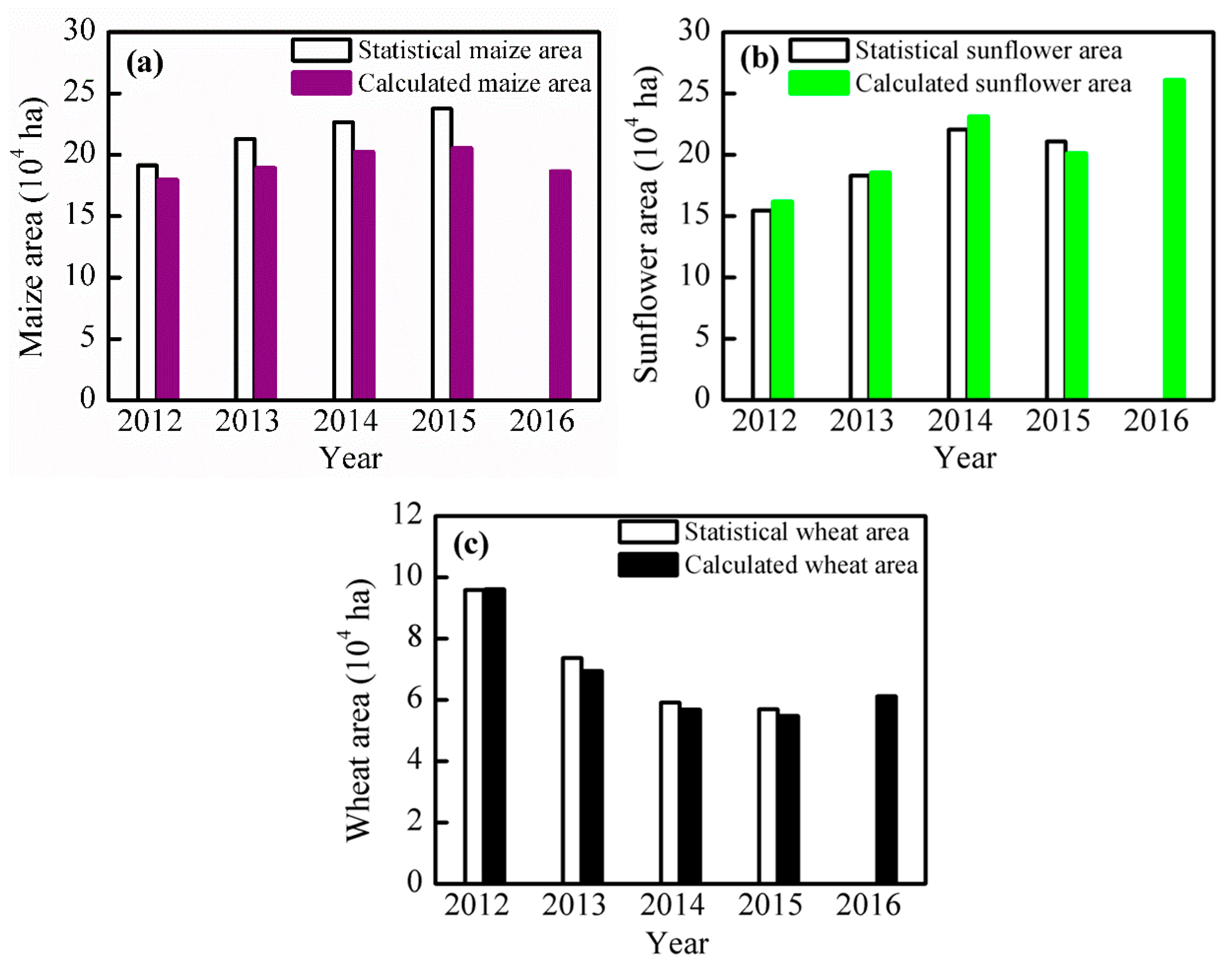
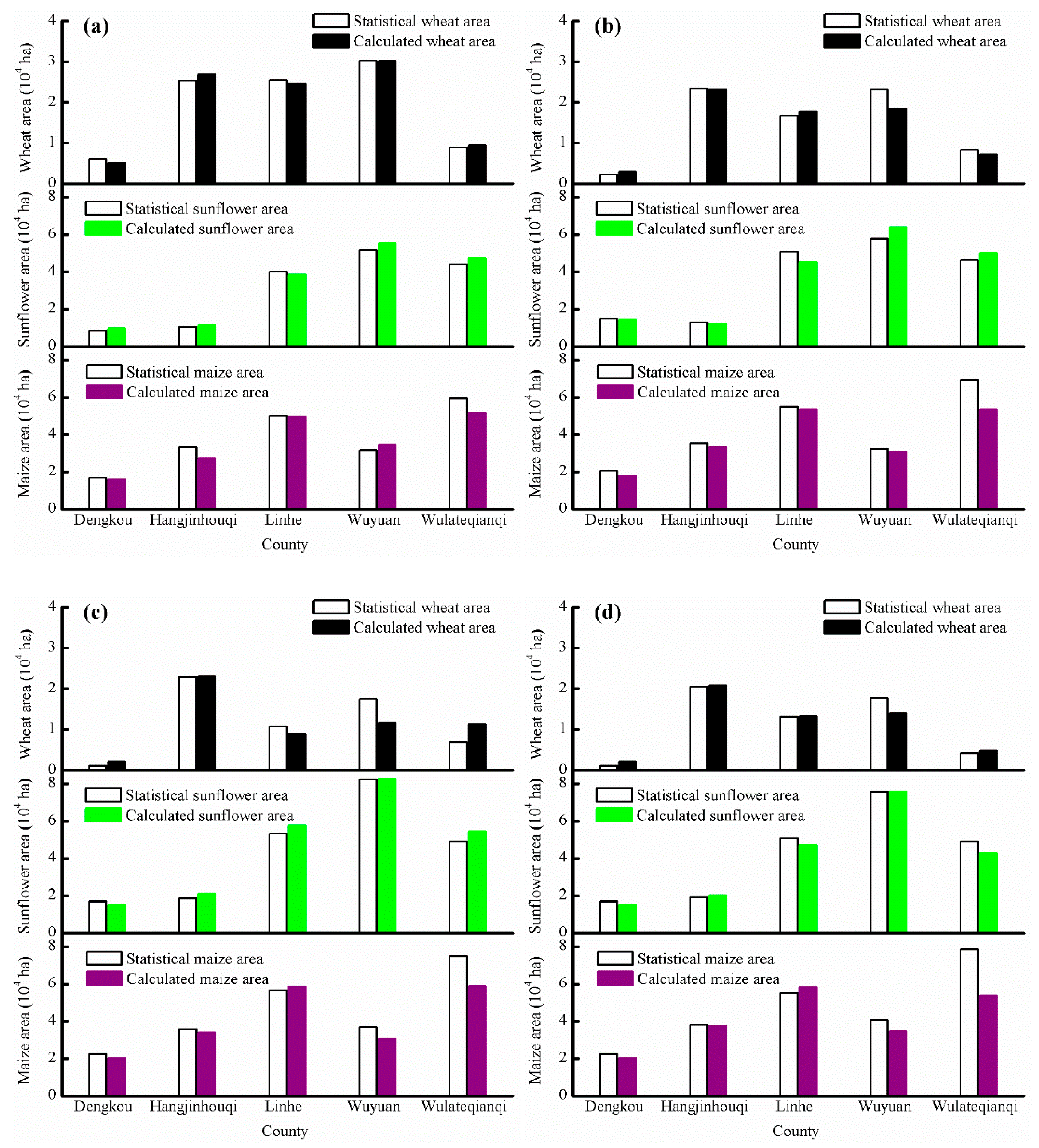
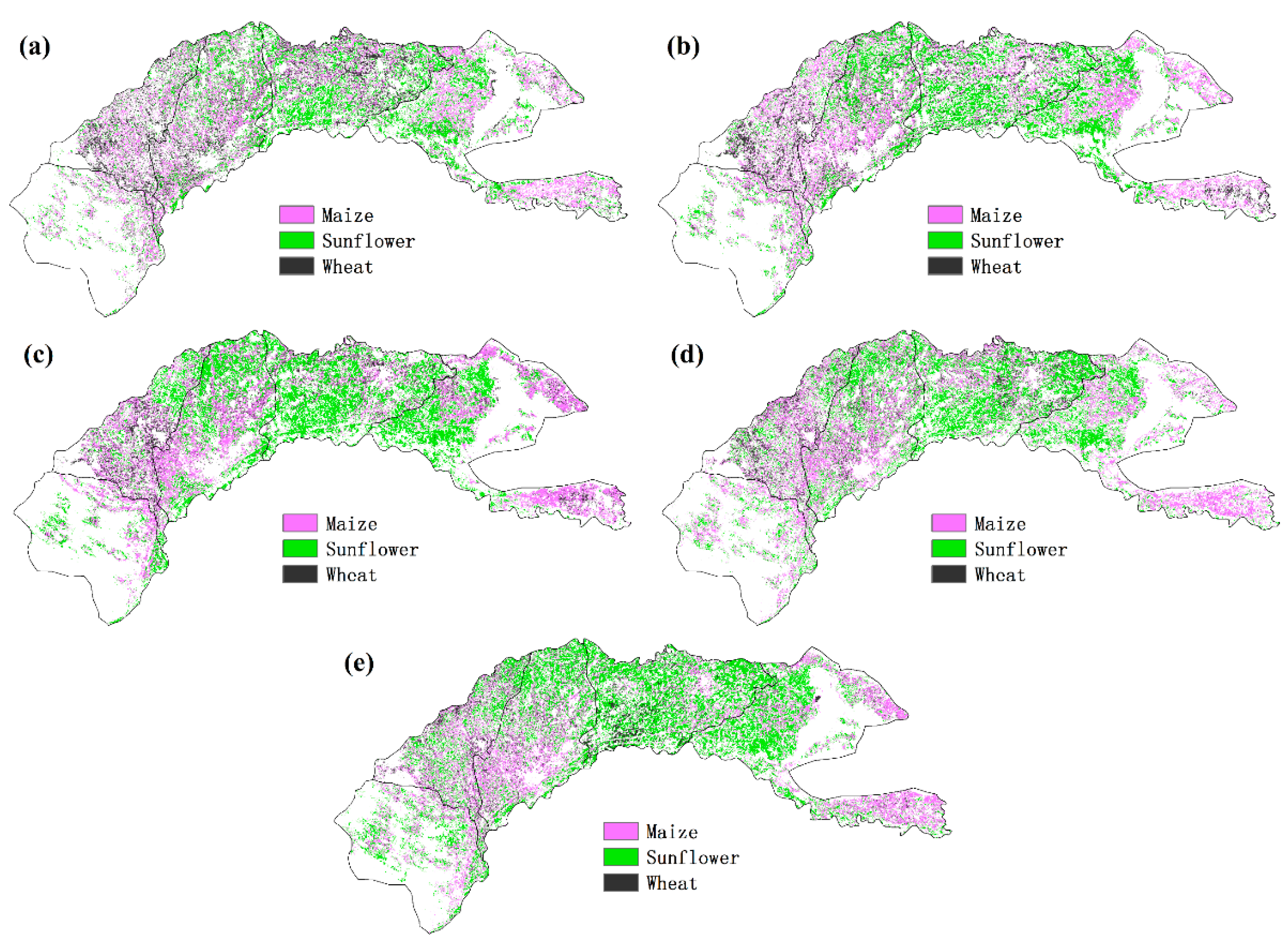
4.4. Spatial and Temporal Distribution of Major Crops in the Study Region
5. Discussion
5.1. Performance of the Classifier in Crop Classification
5.2. Characteristics of the Crop Planting Distribution
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Inglada, J.; Arias, M.; Tardy, B.; Hagolle, O.; Valero, S.; Morin, D.; Dedieu, G.; Sepulcre, G.; Bontemps, S.; Defourny, P.; et al. Assessment of an operational system for crop type map production using high temporal and spatial resolution satellite optical imagery. Remote Sens. 2015, 7, 12356–12379. [Google Scholar] [CrossRef]
- Hassan-Esfahani, L.; Torres-Rua, A.; McKee, M. Assessment of optimal irrigation water allocation for pressurized irrigation system using water balance approach, learning machines, and remotely sensed data. Agric. Water Manag. 2015, 153, 42–50. [Google Scholar] [CrossRef]
- Jiang, Y.; Xu, X.; Huang, Q.Z.; Huo, Z.L.; Huang, G.H. Assessment of irrigation performance and water productivity in irrigated areas of the middle Heihe River basin using a distributed agro-hydrological model. Agric. Water Manag. 2015, 147, 67–81. [Google Scholar] [CrossRef]
- Ren, D.Y.; Xu, X.; Hao, Y.Y.; Huang, G.H. Modeling and assessing field irrigation water use in a canal system of Hetao, upper Yellow River basin: Application to maize, sunflower and watermelon. J. Hydrol. 2016, 532, 122–139. [Google Scholar] [CrossRef]
- Pelletier, C.; Valero, S.; Inglada, J.; Champion, N.; Dedieu, G. Assessing the robustness of Random Forests to map land cover with high resolution satellite image time series over large areas. Remote Sens. Environ. 2016, 187, 156–168. [Google Scholar] [CrossRef]
- Szuster, B.W.; Chen, Q.; Borger, M. A comparison of classification techniques to support land cover and land use analysis in tropical coastal zones. Appl. Geogr. 2011, 31, 525–532. [Google Scholar] [CrossRef]
- Esch, T.; Metz, A.; Marconcini, M.; Keil, M. Combined use of multi-seasonal high and medium resolution satellite imagery for parcel-related mapping of cropland and grassland. Int. J. Appl. Earth Obs. 2014, 28, 230–237. [Google Scholar] [CrossRef]
- Senf, C.; Leitao, P.J.; Pflugmacher, D.; van der Linden, S.; Hostert, P. Mapping land cover in complex Mediterranean landscapes using Landsat: Improved classification accuracies from integrating multi-seasonal and synthetic imagery. Remote Sens. Environ. 2015, 156, 527–536. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L.; Kastens, J.H. Analysis of time-series MODIS 250 m vegetation index data for crop classification in the US Central Great Plains. Remote Sens. Environ. 2007, 108, 290–310. [Google Scholar] [CrossRef]
- Fritz, S.; Massart, M.; Savin, I.; Gallego, J.; Rembold, F. The use of MODIS data to derive acreage estimations for larger fields: A case study in the south-western Rostov region of Russia. Int. J. Appl. Earth Obs. 2008, 10, 453–466. [Google Scholar] [CrossRef]
- Long, J.A.; Lawrence, R.L.; Greenwood, M.C.; Marshall, L.; Miller, P.R. Object-oriented crop classification using multitemporal ETM plus SLC-off imagery and random forest. Gisci. Remote Sens. 2013, 50, 418–436. [Google Scholar] [CrossRef]
- Debats, S.R.; Luo, D.; Estes, L.D.; Fuchs, T.J.; Caylor, K.K. A generalized computer vision approach to mapping crop fields in heterogeneous agricultural landscapes. Remote Sens. Environ. 2016, 179, 210–221. [Google Scholar] [CrossRef]
- Yu, B.; Shang, S.H. Multi-year mapping of maize and sunflower in Hetao irrigation district of China with high spatial and temporal resolution vegetation index series. Remote Sens. 2017, 9, 855. [Google Scholar] [CrossRef]
- Gao, F.; Anderson, M.C.; Zhang, X.Y.; Yang, Z.W.; Alfieri, J.G.; Kustas, W.P.; Mueller, R.; Johnson, D.M.; Prueger, J.H. Toward mapping crop progress at field scales through fusion of Landsat and MODIS imagery. Remote Sens. Environ. 2017, 188, 9–25. [Google Scholar] [CrossRef]
- Lv, Z.Y.; Zhang, P.L.; Benediktsson, J.A.; Shi, W.Z. Morphological profiles based on differently shaped structuring elements for classification of images with very high spatial resolution. IEEE J. Sel. Topics Appl. Earth Obs. Remote Sens. 2014, 7, 4644–4652. [Google Scholar] [CrossRef]
- Khatami, R.; Mountrakis, G.; Stehman, S.V. A meta-analysis of remote sensing research on supervised pixel-based land-cover image classification processes: General guidelines for practitioners and future research. Remote Sens. Environ. 2016, 177, 89–100. [Google Scholar] [CrossRef]
- Atkinson, P.M.; Tatnall, A.R.L. Neural networks in remote sensing—Introduction. Int. J. Remote Sens. 1997, 18, 699–709. [Google Scholar] [CrossRef]
- Low, F.; Conrad, C.; Michel, U. Decision fusion and non-parametric classifiers for land use mapping using multi-temporal RapidEye data. Isprs. J. Photogramm. 2015, 108, 191–204. [Google Scholar] [CrossRef]
- Vapnik, V.N. An overview of statistical learning theory. IEEE T. Neural Networ. 1999, 10, 988–999. [Google Scholar] [CrossRef]
- Zheng, B.J.; Myint, S.W.; Thenkabail, P.S.; Aggarwal, R.M. A support vector machine to identify irrigated crop types using time-series Landsat NDVI data. Int. J. Appl. Earth Obs. 2015, 34, 103–112. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Zhong, L.H.; Gong, P.; Biging, G.S. Efficient corn and soybean mapping with temporal extendability: A multi-year experiment using Landsat imagery. Remote Sens. Environ. 2014, 140, 1–13. [Google Scholar] [CrossRef]
- Martinez-Casasnovas, J.A.; Martin-Montero, A.; Casterad, M.A. Mapping multi-year cropping patterns in small irrigation districts from time-series analysis of Landsat TM images. Eur. J. Agron. 2005, 23, 159–169. [Google Scholar] [CrossRef]
- Zhong, L.H.; Hawkins, T.; Biging, G.; Gong, P. A phenology-based approach to map crop types in the San Joaquin Valley, California. Int. J. Remote Sens. 2011, 32, 7777–7804. [Google Scholar] [CrossRef]
- Walker, J.J.; de Beurs, K.M.; Wynne, R.H. Dryland vegetation phenology across an elevation gradient in Arizona, USA, investigated with fused MODIS and Landsat data. Remote Sens. Environ. 2014, 144, 85–97. [Google Scholar] [CrossRef]
- Jiang, L.; Shang, S.H.; Yang, Y.T.; Guan, H.D. Mapping interannual variability of maize cover in a large irrigation district using a vegetation index—Phenological index classifier. Comput. Electron. Agr. 2016, 123, 351–361. [Google Scholar] [CrossRef]
- Wang, Q. Technical system design and construction of China’s HJ-1 satellites. Int. J. Digit. Earth 2012, 5, 202–216. [Google Scholar] [CrossRef]
- Masek, J.G.; Vermote, E.F.; Saleous, N.E.; Wolfe, R.; Hall, F.G.; Huemmrich, K.F.; Gao, F.; Kutler, J.; Lim, T.K. A Landsat surface reflectance dataset for North America, 1990–2000. IEEE Geosci. Remote Sens. Lett. 2006, 3, 68–72. [Google Scholar] [CrossRef]
- Hagolle, O.; Huc, M.; Pascual, D.V.; Dedieu, G. A multi-temporal method for cloud detection, applied to FORMOSAT-2, VEN mu S, LANDSAT and SENTINEL-2 images. Remote Sens. Environ. 2010, 114, 1747–1755. [Google Scholar] [CrossRef]
- Defries, R.S.; Townshend, J.R.G. NDVI-derived land cover classifications at a global scale. Int. J. Remote Sens. 1994, 15, 3567–3586. [Google Scholar] [CrossRef]
- Wang, Q.; Tenhunen, J.; Dinh, N.Q.; Reichstein, M.; Vesala, T.; Keronen, P. Similarities in ground- and satellite-based NDVI time series and their relationship to physiological activity of a Scots pine forest in Finland. Remote Sens. Environ. 2004, 93, 225–237. [Google Scholar] [CrossRef]
- Liu, C.; Shang, J.; Vachon, P.W.; Mcnairn, H. Multiyear crop monitoring using polarimetric radarsat-2 data. IEEE Trans. Geosci. Remote. 2013, 51, 2227–2240. [Google Scholar] [CrossRef]
- Valero, S.; Morin, D.; Inglada, J.; Sepulcre, G.; Arias, M.; Hagolle, O.; Dedieu, G.; Bontemps, S.; Defourny, P.; Koetz, B. Production of a dynamic cropland mask by processing remote sensing image series at high temporal and spatial resolutions. Remote Sens. 2016, 8, 55. [Google Scholar] [CrossRef]
- Royo, C.; Aparicio, N.; Blanco, R.; Villegas, D. Leaf and green area development of durum wheat genotypes grown under Mediterranean conditions. Eur. J. Agron. 2004, 20, 419–430. [Google Scholar] [CrossRef]
- Rogan, J.; Franklin, J.; Roberts, D.A. A comparison of methods for monitoring multitemporal vegetation change using thematic mapper imagery. Remote Sens. Environ. 2002, 80, 143–156. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. Isprs J. Photogramm. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Edwards, M.; Richardson, A.J. Impact of climate change on marine pelagic phenology and trophic mismatch. Nature 2004, 430, 881–884. [Google Scholar] [CrossRef] [PubMed]
- Ganguly, S.; Friedl, M.A.; Tan, B.; Zhang, X.Y.; Verma, M. Land surface phenology from MODIS: Characterization of the Collection 5 global land cover dynamics product. Remote Sens. Environ. 2010, 114, 1805–1816. [Google Scholar] [CrossRef]
- Fernandez-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we need hundreds of classifiers to solve real world classification problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Ben-Hur, A.; Weston, J. A User’s guide to support vector machines. Methods Mol. Biol. 2010, 609, 223–239. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classification of remotely sensed data. Remote Sens. Environ. 1998, 37, 270–279. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Presutti, M.E.; Franklin, S.E.; Moskal, L.M.; Dickson, E.E. Supervised classification of multisource satellite image spectral and texture data for agricultural crop mapping in buenos aires province, argentina. Can. J. Remote Sens. 2001, 27, 6. [Google Scholar] [CrossRef]
- Arvor, D.; Jonathan, M.; Meirelles, M.S.P.; Dubreuil, V.; Durieux, L. Classification of modis EVI time series for crop mapping in the state of mato grosso, brazil. Int. J. Remote Sens. 2011, 32, 7847–7871. [Google Scholar] [CrossRef]
- Lanjeri, S.; Segarra, D.; Joaquín, M. Interannual vineyard crop variability in the Castilla-La Mancha region during the period 1991–1996 with Landsat Thematic Mapper images. Int. J. Remote Sens. 2004, 25, 2441–2457. [Google Scholar] [CrossRef]
- De Wit, A.J.W.; Clevers, J.G.P.W. Efficiency and accuracy of per-field classification for operational crop mapping. Int. J. Remote Sens. 2004, 25, 4091–4112. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L. Large-area crop mapping using time-series MODIS 250 m NDVI data: An assessment for the U.S. Central Great Plains. Remote Sens. Environ. 2008, 112, 1096–1116. [Google Scholar] [CrossRef]
- Deng, Y.; Wang, Y.; Ma, T. Isotope and minor element geochemistry of high arsenic groundwater from Hangjinhouqi, the Hetao Plain, Inner Mongolia. Appl. Geochem. 2009, 24, 587–599. [Google Scholar] [CrossRef]
- Huang, Q.; Xu, X.; Lv, L.; Ren, D.; Ke, J.; Xiong, Y.; Huo, Z.; Huang, G. Soil salinity distribution based on remote sensing and its effect on crop growth in hetao irrigation district. Trans. Chin. Soc. Agric. Mach. 2018, 34, 102–109. (In Chinese) [Google Scholar]
- Guo, S.; Ruan, B.; Chen, H.; Guan, X.; Wang, S.; Xu, N.; Li, Y. Characterizing the spatiotemporal evolution of soil salinization in Hetao Irrigation District (China) using a remote sensing approach. Int. J. Remote Sens. 2018, 1–21. [Google Scholar] [CrossRef]
- Bai, L.L.; Cai, J.B.; Liu, Y.; Cai, X.L.; Chen, H.; Zhang, B.Z. Temporal and spatial variation of crop planting structure and its correlation analysis with groundwater in large irrigation area. Trans. Chin. Soc. Agric. Mach. 2016, 9, 202–211. (In Chinese) [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Landsat-8 | Landsat-7 | HJ-1A/1B | ||
|---|---|---|---|---|---|
| Path 129, Row 31/32 | Path 128, Row 32 | Path 129, Row 31/32 | Path 128, Row 32 | ||
| 2012 | 10 (84–292 DOY) | 10 (93–317 DOY) | 28 (103–298 DOY) | ||
| 2013 | 10 (110–334 DOY) | 10 (103–343DOY) | 36 (101–300 DOY) | ||
| 2014 | 18 | 12 (74–362DOY) | 1 (185 DOY) | 3 (162–226 DOY) | 25 (103–295 DOY) |
| 2015 | 17 | 17 | 3 (181–245 DOY) | 15 (110–293 DOY) | |
| 2016 | 18 | 11 (100–320DOY) | 5 (159–255 DOY) | 15 (86–305 DOY) | |
| Features | Parameters |
|---|---|
| Temporal features | Parameters including a, b, c (tmax), d, f, tinf, NDVImax, NDVIinf, FGP, MSE |
| Spectral features | NDVI of 165, 185, 195, 225, and 245 DOY |
| Spectral bands (Green and shortwave infrared bands) | Spectral bands of 165 and 245 DOY |
| Classifier | Maize | Sunflower | Wheat | ||||
|---|---|---|---|---|---|---|---|
| Training | Testing | Training | Testing | Training | Testing | ||
| P-VI | Input features | FGP, NDVImax | |||||
| Dataset | 613 | 3482 | 628 | ||||
| SVM | Input features | b, d, NDVI at 165/225 DOY | b, d, NDVI at 165/225 DOY | c, e, NDVI at 165/225 DOY | |||
| Dataset (Crop + others) | 300 + 700 | 313 + 721 | 1000 + 1000 | 2497 + 2205 | 300 + 600 | 328 + 700 | |
| Average accuracy | 92.5% | 92.4% | 93.5% | 92.5% | 98.3% | 97.8% | |
| RF | Input features | a, b, c (tmax), d, f, NDVIinf, FGP, MSE, NDVI at 165, 185, 195, 225, and 245 DOY, Green and shortwave infrared bands at 165 and 245 DOY | |||||
| Dataset | 300 | 313 | 600 | 2897 | 300 | 328 | |
| Average accuracy | 94.8% | 95.6% | 95.8% | 97.0% | 96.3% | 96.4% | |
| Overall accuracy | Training: 95.7% | Testing: 96.8% | |||||
| Identified Class | Actual Class | ||||
|---|---|---|---|---|---|
| Maize | Sunflower | Others | Total | Correct | |
| Maize | 71 | 9 | 1 | 81 | 87.7% |
| Sunflower | 8 | 108 | 3 | 119 | 90.8% |
| Others | 2 | 5 | 25 | 32 | 78.1% |
| Total | 81 | 122 | 29 | 232 | OA = 87.9% κ = 0.796 |
| Crop Categories | 2012 | 2013 | 2014 | 2015 |
|---|---|---|---|---|
| Maize | −24.3 | 15.8 | −25.5 | −0.9 |
| Sunflower | 8.15 | 104.3 | 9.0 | 61.0 |
| Wheat | 13.1 | −17.8 | 1.5 | 47.4 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, Y.; Shang, S.; Rahman, K.U. Pre-Constrained Machine Learning Method for Multi-Year Mapping of Three Major Crops in a Large Irrigation District. Remote Sens. 2019, 11, 242. https://doi.org/10.3390/rs11030242
Wen Y, Shang S, Rahman KU. Pre-Constrained Machine Learning Method for Multi-Year Mapping of Three Major Crops in a Large Irrigation District. Remote Sensing. 2019; 11(3):242. https://doi.org/10.3390/rs11030242
Chicago/Turabian StyleWen, Yeqiang, Songhao Shang, and Khalil Ur Rahman. 2019. "Pre-Constrained Machine Learning Method for Multi-Year Mapping of Three Major Crops in a Large Irrigation District" Remote Sensing 11, no. 3: 242. https://doi.org/10.3390/rs11030242
APA StyleWen, Y., Shang, S., & Rahman, K. U. (2019). Pre-Constrained Machine Learning Method for Multi-Year Mapping of Three Major Crops in a Large Irrigation District. Remote Sensing, 11(3), 242. https://doi.org/10.3390/rs11030242