1. Introduction
Remote sensing images with simultaneous high spatial and high temporal resolution play a critical role in land surface dynamics research [
1], such as crop and forest monitoring [
2,
3], and land-use and land-cover changes detection [
4]. These applications require dense time-series data to capture ground changes and also finespatialresolution surface details, such as textures and structures of ground objects, to perform accurate classification and identification or some advanced quantitative calculation. Even though advances of sensor technology in recent years have greatly prompted the precision of satellite observation, due to some inevitable technical and budget limitations, there is always a tradeoff among spatial, temporal, and spectral resolutions for Earth observation data [
5,
6]. Fortunately, this problem that it is not easy to directly acquire high spatiotemporal resolution images from existing satellite observation systems can be partly alleviated by some data post-processing processes [
7,
8,
9]. Among them, spatiotemporal remote sensing image fusion is a class of techniques used to synthesize dense-time images with high spatial resolution from at least two different data sources [
1,
5,
10]. In most cases, one is the coarsespatialresolution image with high temporal but low spatial resolution (HTLS), while the other is the finespatialresolution image with low temporal but high spatial resolution (LTHS). A typical example is to fuse Landsat and Moderate Resolution Image Spectroradiometer (MODIS) images to derive high spatial resolution images in a dense time sequence. The spatial resolution of Landsat for most spectral bands is 30 m and its temporal resolution is around 16 days [
11]. MODIS images, in contrast, are acquired daily but only with a coarse spatial resolution ranging from 250 to 1000 m for different bands [
12]. By fusing these two data sources, composite images can gain the spatial resolution of Landsat and the temporal resolution of MODIS within a certain error tolerance.
Generally speaking, the existing algorithms for spatiotemporal data fusion can be classified into four categories: (1) transformationbased; (2) reconstructionbased; (3) Bayesian-based; and (4) learning-based models [
5,
10,
13]. Transformationbased models use some advanced mathematical transformations, such as wavelet transformation, to integrate multi-source information in a transformed space [
5]. This type of method not only can be applied in spatiotemporal fusion [
14] but also is widely employed in the fusion of panchromatic and multispectral images (referred to as pansharpening) [
15]. Reconstructionbased methods are the most prosperous branch according to the statistics [
5]. Generally, there are two major subbranches of reconstructionbased methods: weightfunctionbased and unmixingbased [
5]. The weightfunctionbased methods evaluate LTHS images as well as the corresponding HTLS images through a local moving window with some hand-crafted weighting functions, such as the Spatial and Temporal Adaptive Reflectance Fusion Model (STARFM) [
7] and the Spatial and Temporal Adaptive Algorithm for Mapping Reflectance Change (STAARCH) [
16]. The unmixing-based methods estimate the selected end-member fractions of HTLS image pixels to reconstruct the corresponding LTHS image with spectral unmixing theory, such as the flexible spatiotemporal data fusion (FSDAF) method [
17] and the spatial attraction model [
18]. Bayesian-based models utilize Bayesian statistical inference to perform prediction with multiple reference images, such as the unified fusion method proposed by [
19] and the Bayesian fusion approach proposed by [
20]. The biggest advantage of Bayesian-based models is that they can handle the uncertainty of input images and produce the most probable predictions naturally [
10]. At present, some of these models have been applied in practical applications, such as crop monitoring, forest phenology analysis, and daily evapotranspiration evaluation, and achieved desirable results [
2,
3,
21]. However, theoretically speaking, a conventional model with hand-crafted fusion rules, even though elaborately designed with enormous complexity, cannot handle all situations well considering spatial heterogeneity of ground surfaces and uneven quality of acquired data. As a result, the conventional fusion algorithm may be performed well in some areas for some data, but cannot always maintain high accuracy.
Today, the learning-based model has become a new research hotspot with comparatively higher accuracy and robustness. In general, learning-based fusion models do not or seldom need to manually design fusion rules and can automatically learn essential features from massive archived data and generate dense-time images with fine spatial resolution. Current learning-based methods mostly employ sparse representation and deep learning techniques to establish their domain-specific models [
13,
22,
23]. The theoretical assumption of sparserepresentationbased methods is the HTLS and LTHS image pair acquired on the same day share the same sparse codes. By jointly learning two dictionaries corresponding to HTLS and LTHS image patches in advance, the LTHS images for prediction can be reconstructed with the learned dictionaries as well as sparse encoding algorithms [
22,
24]. The deep learning approach simulates the way in which human neurons work and tries to establish a complex, nonlinear relation mapping between input(s) and output(s) with several hidden layers, potentially containing massive amounts of learnable parameters [
25,
26]. There are various building blocks to construct a deep learning network for a specific task, among which convolutional neural network (CNN) turns to be an effective and efficient architecture for image feature extraction and recognition problems [
25]. As the study goes on, CNN-based models are gradually applied in data fusion domain, and relevant research is being undertaken [
13,
23,
27,
28,
29].
There have been many studies, so far, concentrating on remote sensing image fusion with deep convolutional networks. Some research applied CNN models to pansharpening fusion for panchromatic and multispectral images [
29,
30]; some introduced CNNs to multispectral and hyperspectral image fusion [
31]; some utilized CNNs to blend optical and microwave remote sensing images to improve optical image quality [
32]. However, the exploration of the deep learning approach for spatiotemporal data fusion is still limited and preliminary. [
23] proposed a hybrid approach for spatiotemporal image fusion named STFDCNN. First, a nonlinear mapping between HTLS and resampled low-spatial-resolution LTHS is learned with a CNN (NLMCNN), then a second super-resolution CNN (SRCNN) is established between the low-spatial-resolution LTHS and original LTHS. For best results, the output of the first CNN on prediction date is not directly fed into the SRCNN model, but is tweaked with a high-pass modulation. [
13] proposed a CNN-based, one-stop method termed Deep Convolutional SpatioTemporal Fusion Network (DCSTFN) to perform MODIS-Landsat image fusion. The inputs are one pair of LTHS and HTLS images for reference and another HTLS for prediction. Information is merged in the form of extracted feature maps, then the merged features are reconstructed to the predicted image. [
33] proposed a residual fusion network termed StfNet by learning pixel differences between reference and prediction dates. The fusion process of StfNet is performed at raw pixel level instead of feature level, therefore, the StfNet model can preserve abundant texture details.
These aforementioned work initially introduces CNN approach to spatiotemporal data fusion domain for remote sensing images and improves fusion accuracy considerably compared with conventional methods. Still, there are some shortcomings of existing CNN-based fusion models. First, predicted images from CNN models are not as sharp and clear as actual observations for feature-level fusion. This is partly because a convolutional network minimizes its losses to make predictions as close to ground truths as possible, therefore, errors are balanced among each pixel to reach a global optimum. Moreover, practices indicate that the de-factor loss function—
loss (i.e., mean squared error (MSE)) for image reconstruction renders it much likely to yield blurry images [
34]. Second, it is crucial to select appropriate LTHS reference images in spatiotemporal fusion, from which all the detailed high-frequency information comes, thus, predictions are necessarily affected by their references causing fusion results to resemble the references to some degree. It could be much worse when there are significant ground changes during the reference and prediction period. These problems should be resolved or mitigated so that image quality of prediction can be further improved.
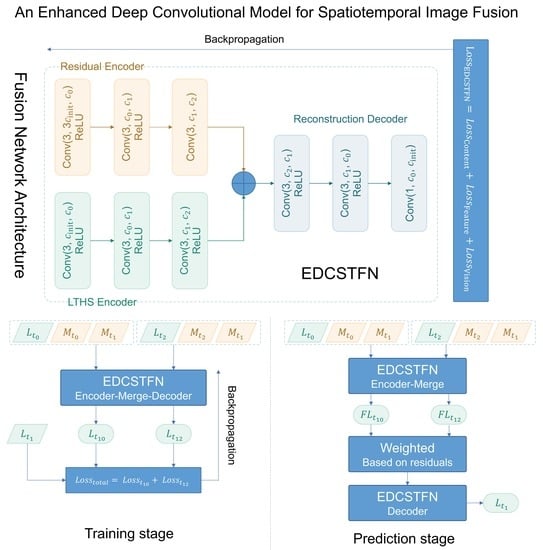
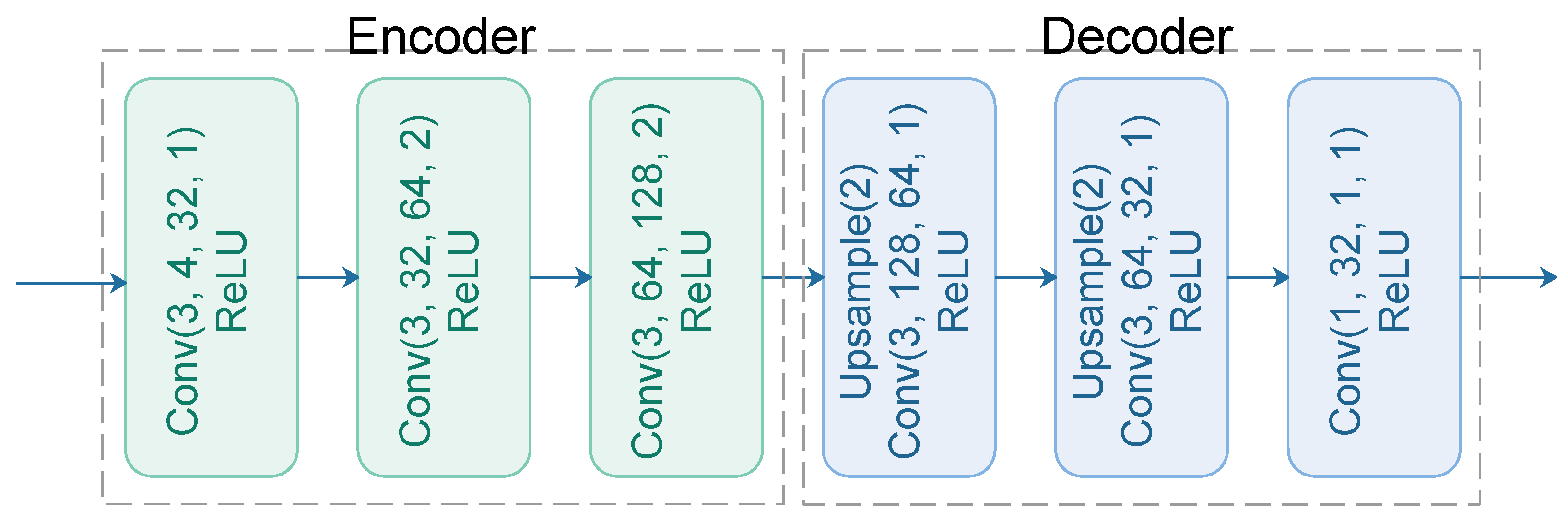
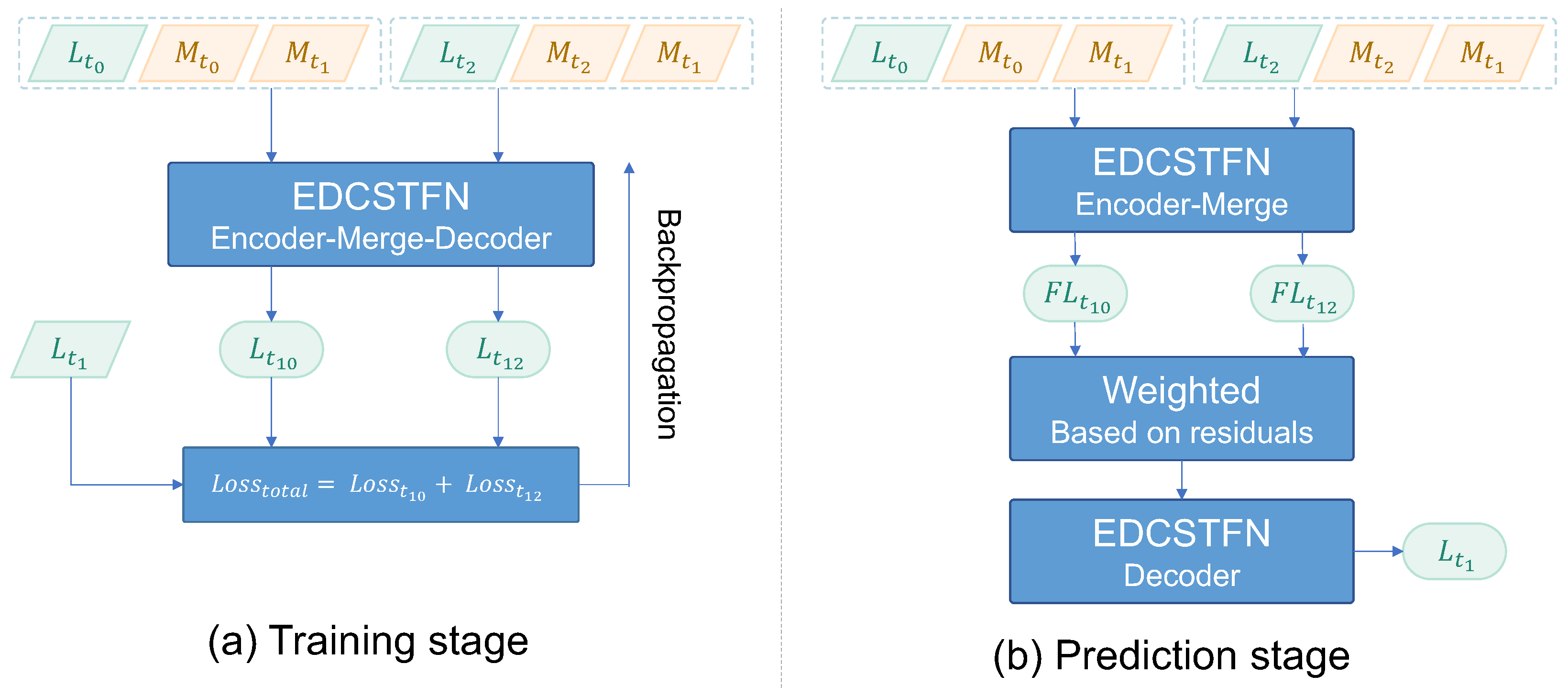
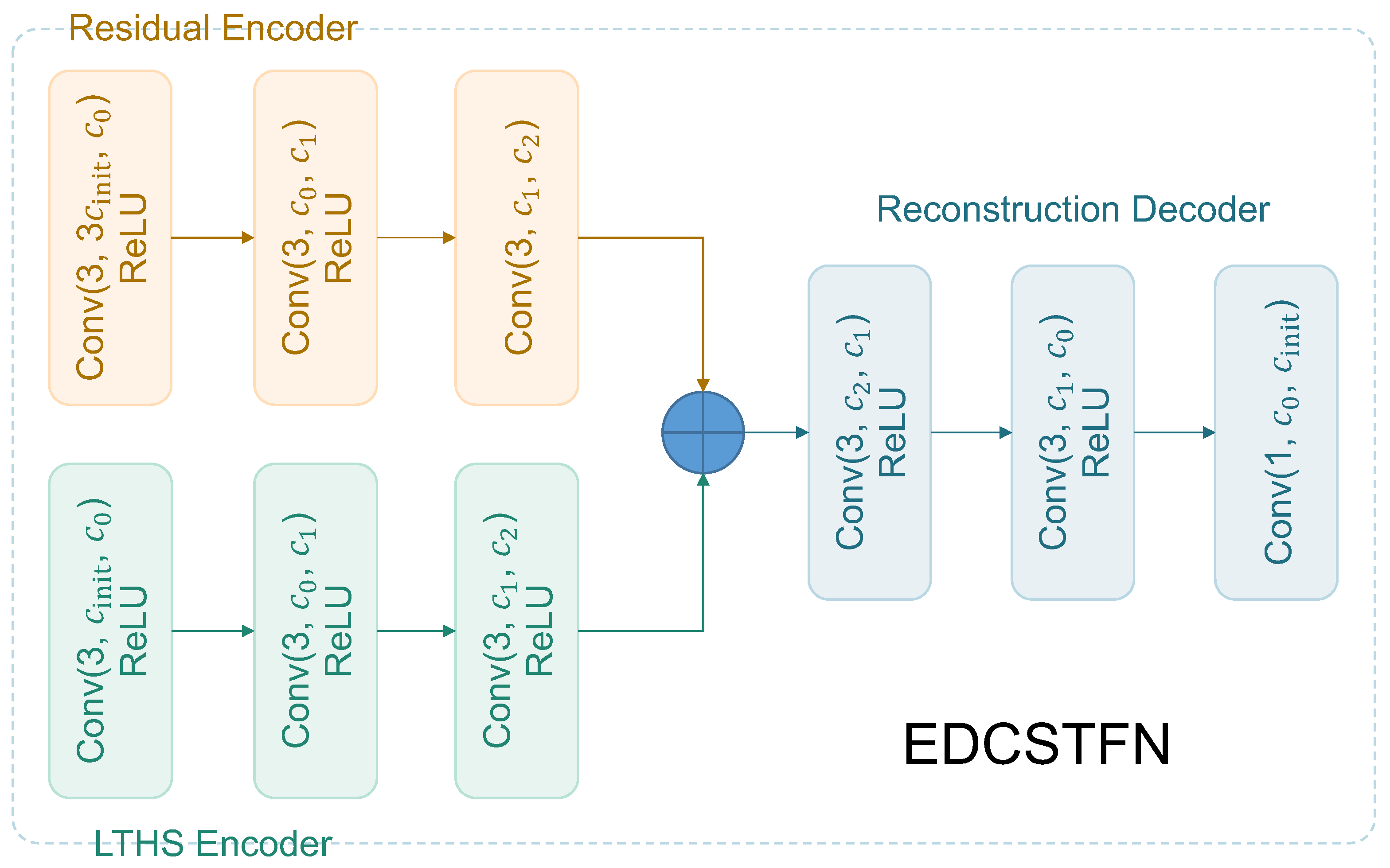
This paper continues previous work on CNN-based spatiotemporal fusion model to further explore possibilities to improve the DCSTFN model. By redesigning network architecture, an enhanced deep convolutional spatiotemporal fusion network (EDCSTFN) was developed to alleviate the aforementioned problems. The EDCSTFN model needs at least one pair of MODIS-Landsat images as fusion references, and spectral information of prediction is derived based on spectrum changes between the reference and prediction dates. The novelty of the EDCSTFN model is that differences between reference and prediction dates are completely learned from actual data, not like the DCSTFN model in which the relation between inputs and output is established on a hypothetical equation. Second, high-frequency information is preserved as much as possible by using a new compound loss function, which combines the accuracy and vision loss to generate sharp and clear images. Third, two pairs of references, usually from the time before and after the prediction date, are supported to make predictions less reliant on a single reference and thus to improve the accuracy and robustness of the model. In the experiments, by taking MODIS and Landsat 8 Operational Land Imager (OLI) data fusion as an example, a series of comparative evaluations were performed. The results demonstrate that not only fusion accuracy is improved, and also the predicted result gains more clarity and sharpness, significantly improving fusion image quality.
The rest of this paper is organized as follows. The former DCSTFN model is briefly recalled and the new EDCSTFN model is introduced in
Section 2.
Section 3 dives into the details of the experiments, and the corresponding results and discussion are presented in
Section 4. Conclusion and future work are summarized in
Section 5.
4. Results and Discussion
4.1. Evaluation Indices
Currently, there is no internationally-accepted standard that can uniquely determine the quality of fused images [
44]. Different fusion metrics have their limitations and can only reveal some parts of the fused image quality [
45], thus, several metrics are selected for the evaluation in this experiment, including the root mean square error (RMSE), structural similarity index (SSIM), spectral angle mapper (SAM) [
46], and relative dimensionless global error (ERGAS) [
47]. The RMSE, formulated as Equation (
11), measures the distance between ground truth and prediction. A small RMSE shows high accuracy.
In Equation (
11) and following equations,
M denotes the number of spectral bands;
N denotes the total number of pixels of the image;
and
denote the
ith observed value and predicted value. The SSIM, formulated as Equation (
7), is a visual indicator to measure the similarity between two images, and a higher value shows higher similarity. The SAM, formulated as Equation (
12), evaluates spectral distortion by spectral angle and a small SAM indicates a better result.
The ERGAS, formulated as Equation (
13), comprehensively evaluates fusion results based on prediction errors, and a smaller ERGAS indicates a better result. The
h and
l in Equation (
13) denote the spatial resolution of LTHS and HTLS images;
stands for the RMSE of the
ith band.
4.2. Experimental Results
4.2.1. The Guangdong Region
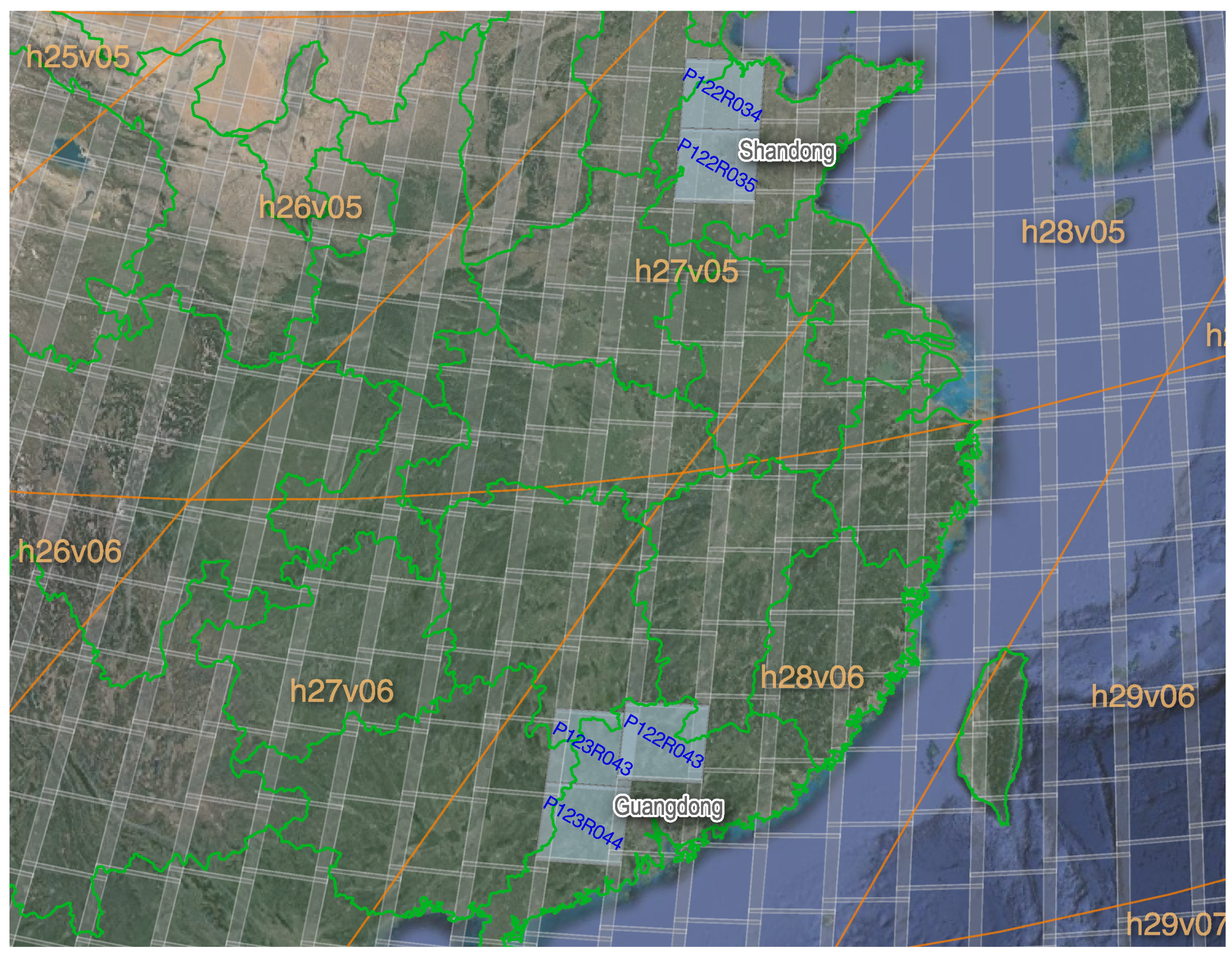
Guangdong was selected to test the improvement for image sharpness because of its heterogenous ground features, especially for the rapidly-developed city areas. Meanwhile, the impact of input image bands for the EDCSTFN model was also explored with this dataset. For these purposes, the STARFM, FSDAF, DCSTFN, EDCSTFN with single-band inputs (EDCSTFN-S), and EDCSTFN with multi-band inputs (EDCSTFN-M) were comparatively tested.
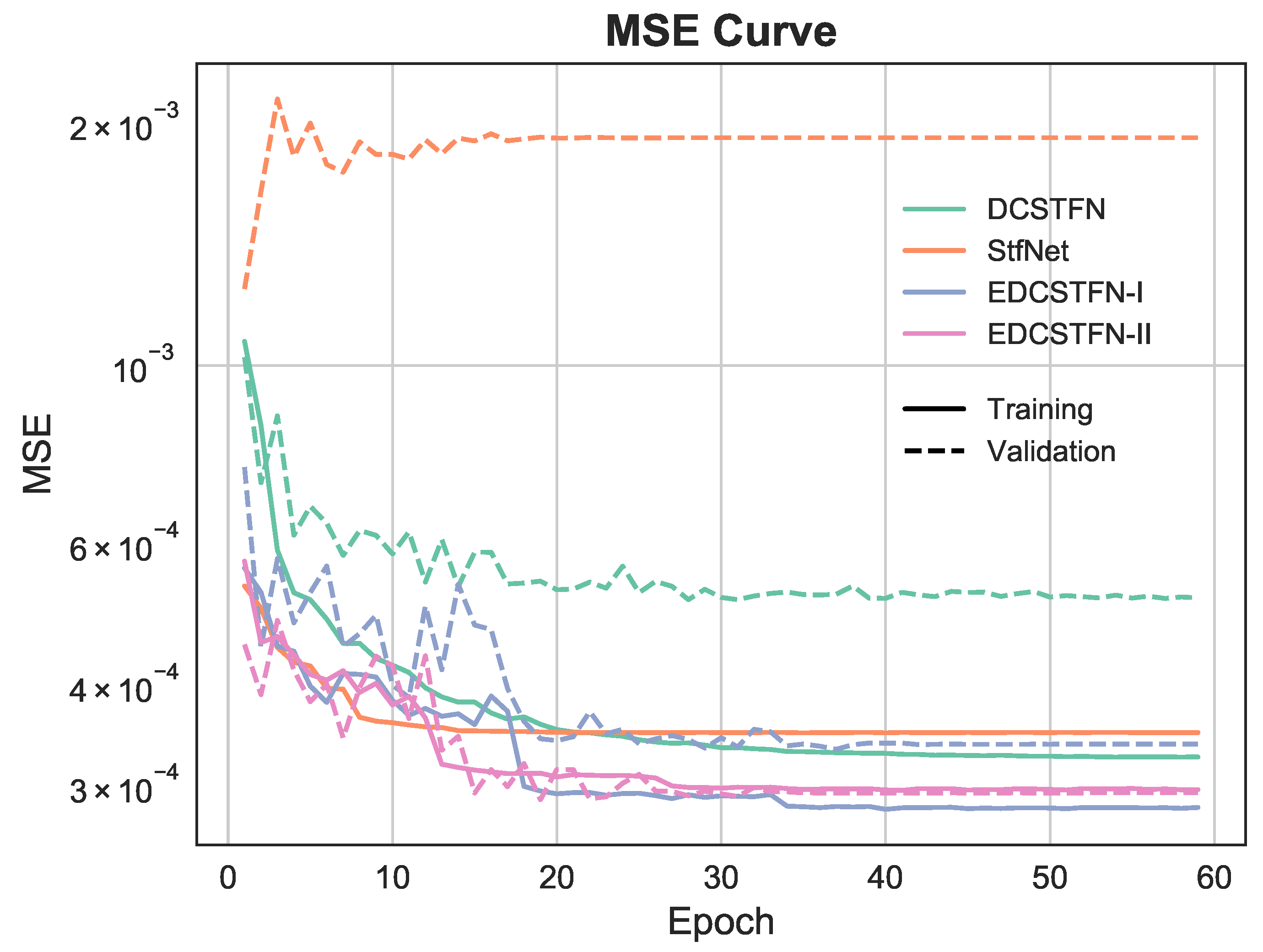
Figure 6 gives the learning curve showing the MSE losses over epochs for the deeplearningbased fusion models in Guangdong test area. The errors are summarized over all image patches with the moving window for the training and validation datasets. For the model trained with a single spectrum band, the errors are averaged among all the bands. The solid line and dashed line indicate error curves for the training and validation datasets respectively. From
Figure 6, it can be seen that the models are converged after 40 epochs around. The EDCSTFN model outperforms DCSTFN and the EDCSTFN-M shows slight superiority over EDCSTFN-S.
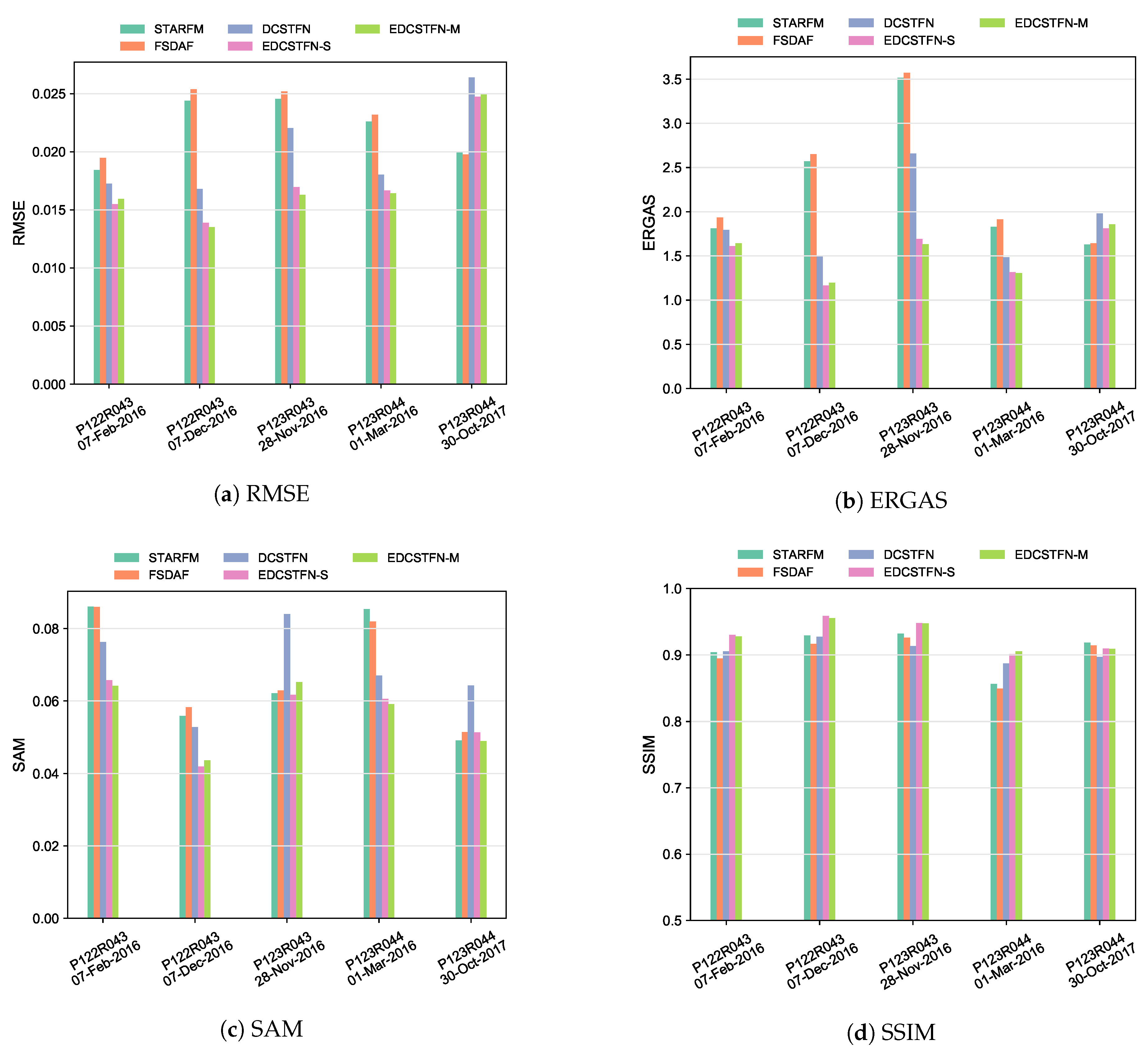
Figure 7 presents the quantitative metrics on the five validation data groups. The metrics are calculated across the entire image for each group. Generally, the EDCSTFN model can generate much better results than the DCSTFN model whether from the perspective of statistic errors or vision index. Second, the EDCSTFN predictions for most of the tests have higher accuracy than conventional methods, except for the last one (the group on 30 October 2017 in P123R044 tile) with a tiny lag difference. Third, there is little difference between the quantitative metrics of EDCSTFN-S and EDCSTFN-M, which means the input spectral bands have some influence on fusion results, but not significantly. Last, the EDCSTFN prediction results remain comparatively stable than other methods, showing strong robustness.
Table 1 lists the averaged quantitative metrics of Guangdong areas on the whole validation dataset. The columns of EDCSTFN models are in bold. Every quantitative index shows the EDCSTFN model outperforms other methods, which demonstrates the proposed model does improve the fusion accuracy.
Figure 8 illustrates part of the results on December 7th, 2016 in the P122R043 region. The first column exhibits the standard true color composite images for the ground truth, predictions of STARFM, FSDAF, DCSTFN, EDCSTFN-S, and EDCSTFN-M. The second column gives the bias between fusion results and ground truth corresponding to the first column. The values are stretched between 0.0 and 0.1 to highlight the differences. The third column shows the zoomed-in details of the red rectangles marked in the first column. The last column is the calculated normalized difference vegetation index (NDVI), a commonly-used vegetation indicator in remote sensing, corresponding to the third column. First, the second row demonstrates that prediction errors from conventional methods are much more significant than deeplearningbased models. Second, the third column shows the EDCSTFN model sharpens miscellaneous ground features compared with the DCSTFN model, nearly as clear as the observed ground truth. This also implies the comprehensive compound loss function works quite well for image fusion tasks. Third, distinct white flakes are scattering in the results of STARFM and FSDAF, showing they failed to predict ground features in heterogeneous city areas. Fourth, the results of EDCSTFN-S and EDCSTFN-M do have some differences visually, but not significantly. Theoretically, four individual networks are trained for the EDCSTFN-S corresponding to the four spectral bands, and each network is specially optimized catering for the characteristics of each unique band, while the EDCSTFN-M is a one-size-fit-all network where all the bands are treated equally and some common features may be highlighted in this case. Training an EDCSTFN-S model for production is much more time-consuming than EDCSTFN-M does, and the accuracy improvement is not obvious, so multiple-band images can be safely used for training in normal cases. Last, the calculated NDVIs from CNN-based models are more close to the actual observation visually.
Figure 9 exhibits part of the results on 30 October 2017 in the P123R044 region, where the predictions of conventional methods produced fewer errors than the DCSTFN model. The arrangement of the subfigures is the same as above. It can be seen there are some distinguishable small abnormal blue patterns in the results of STARMF and FSDAF from the first column. Overall, the prediction of EDCSTFN-M resembles ground truth best visually. From the third column, there are noticeable abnormal patterns produced by STARMF and FSDAF marked with yellow rectangles, while the EDCSTFN model yield quite reliable results for heterogeneous city areas. From the last NDVI results, still, the EDCSTFN model represents the most accurate results compared with others. In brief, although the conventional methods produce smaller errors averagely in this data group, there are some obvious mistakes in the fusion results, which means the conventional model is not so robust as the EDCSTFN model. Moreover, the outlines of the city are much more clear with the EDCSTFN model seen from the third column, which means the EDCSTFN model significantly improves image sharpness compared with the DCSTFN model.
4.2.2. The Shandong Region
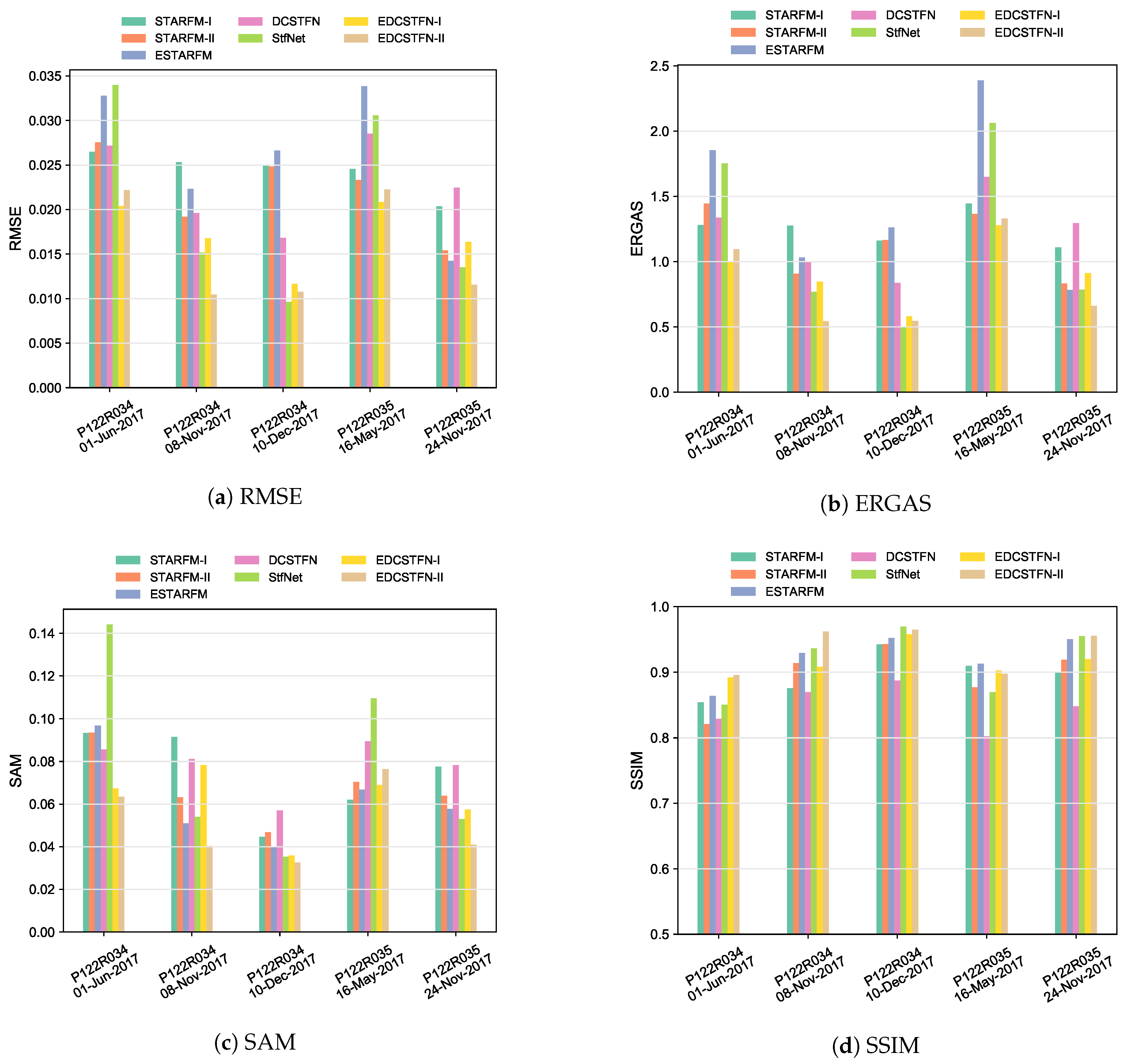
The climate of Shandong is not humid as Guangdong’s, thus more Landsat data with little or without cloud coverage are available. For this reason, the enhanced data strategy was tested here and comparisons between DCSTFN and other models that need two reference images were performed in this area. Five models, including seven cases: STARFM with one reference (STARFM-I), STARFM with two references (STARFM-II), ESTARFM, DCSTFN, StfNet, EDCSTFN with one reference (EDCSTFN-I) and EDCSTFN with two references (EDCSTFN-II), were tested here.
Figure 10 gives the learning curve of the deeplearningbased fusion models in the Shandong test area. Clearly, the average errors of StfNet over validation patches are significantly larger than the EDCSTFN model. The prediction accuracy of EDCSTFN-II is pretty higher than EDCSTFN-I, showing the improvement with the two-reference-enhanced strategy.
Figure 11 shows the quantitative metrics on the five validation data groups. Generally, EDCSTFN-II outperforms other models. For one thing, the EDCSTFN model shows significant high-score metrics than others; for another, the prediction of EDCSTFN remains stable for all the data groups. The classical ESTARFM and recently-proposed StfNet fluctuate heavily for different data groups, showing they are not so robust as EDCSTFN. With respect to the effect of reference data pairs on prediction, in most cases, the two-reference strategy can contribute to the improvement of model accuracy both for the STARFM and the EDCSTFN, but this is not always the case. It may relate to the reference image quality as well as significant ground changes.
Table 2 lists the averaged quantitative metrics of Shandong areas on the whole validation dataset. The columns of EDCSTFN models are in bold. Every quantitative index shows the EDCSTFN-II model outperforms other methods, which further demonstrates the enhanced data strategy can truly boost the fusion accuracy.
Figure 12 demonstrates part of the fusion results on 24 November 2017 in P122R035 region. The first column exhibits the overview of the whole scene. The second column shows the zoomed-in details of the red rectangles marked in the first column. The third column gives the bias between fusion results and ground truth corresponding to the second column. The fourth column presents the zoomed-in details of the yellow rectangles in the second column. The last column is the calculated NDVI corresponding to the fourth column. Generally, the EDCSTFN and StfNet show the best results from the overview. The third column shows the EDCSTFN-II produces minimum errors. The fourth column shows that the result of DCSTFN lacks clarity and sharpness, while the other models can preserve more texture details. From the NDVI view of the last column, the EDCSTFN-II predictions are the closest to the ground truth. Overall, EDCSTFN-II produces better results than others.
Figure 13 illustrates part of the fusion results on 10 December 2017 in P122R034 region. The arrangement of the subfigures is the same as
Figure 12. Obviously, the conventional methods fail to make the right prediction on the bottom left areas of the images in the first column. From the third and fourth columns, it clearly demonstrates the results of EDCSTFN-II matches the ground truth best for areas covering fields and villages and predict the changes in crops with considerable accuracy. Besides, the image tone of DCSTFN and StfNet is strikingly different from the ground truth seen from the fourth column. In conclusion, the EDCSTFN model outperforms other models from statistical metrics and visual observation in Shandong province. The two-reference-enhanced strategy can reduce fusion errors on a large scale.
4.3. Discussion
First, the experiments performed in Guangdong province reveal that by the new architecture and the comprehensive compound loss function, the EDCSTFN model can sharpen predicted images and remedy the defects of DCSTFN model. Also the prediction accuracy is significantly improved compared with DCSTFN model, which renders quantitative analysis in remote sensing applications more reliable. The input image bands also have a certain impact on prediction, but it is not that obvious, so training a fusion network using multiple-band images is doable in practice with less time consumption.
Second, the experiments of Shandong province prove that the EDCSTFN model outperforms other spatiotemporal fusion models. By applying the enhanced data strategy in the experiments, it can be seen that additional reference data do gain performance improvement in most cases, but the accuracy is also strongly influenced by the data quality. If one of the references is not in good quality, the result is even worse than prediction with one reference. In practice, it may be not always easy to collect source data with high quality for some areas. Our model supports both one and two data references no matter in training or prediction and allows limited existence of clouds and missing data, which shows the EDCSTFN model is quite flexible and has a fair fault-tolerant capacity.
Third, three deeplearningbased fusion models are compared and the EDCSTFN model achieves state-of-the-art results. Not only is the prediction accuracy improved considerably, but also the image sharpness and clarity is highly enhanced compared with the DCSTFN model. Moreover, the EDCSTFN model shows more robustness when handling poor-quality data compared with the StfNet. This is because the EDCSTFN model performs the fusion in abstract feature space, while StfNet does the fusion in the raw pixel space. If there are a small number of noisy pixels or missing values, the EDCSTFN decoder have partial ability to denoise prediction images and try to restore clean pixels. If the fusion process directly performed on pixels, then input noises definitely will be transmitted to prediction results.
Despite the aforementioned improvements, there are still some inadequacies in our work. First, daily MODIS data should be further used for model validation. Second, the prediction accuracy for areas with significant ground changes during the reference and prediction needs to be tested in future work. Once sufficient qualified data are collected and reasonable comparative cases can be designed to perform advanced analysis.
In general, the research on spatiotemporal image fusion with a deep learning approach is still limited. This paper compares the basic ideas of the existing models to provide a reference for further study. First, the STFDCNN model is based on superresolution approach to gradually upsample HTLS images. The advantage of superresolutionbased models is that they can preserve the correctness of spectral information maximally. However, because of lacking the injection of high-frequency information with super-resolution, the output images turn to be somewhat blurry. Second, the StfNet model performs fusion in raw pixel level by learning pixel differences between reference and prediction. The advantage of this approach is that all the texture information can be preserved. However, since this type of method directly merges information with pixel values, input data in poor quality is unacceptable. If there are two reference data available, this limitation can be abated partially. But still, how to automatically select good-quality pixels from the two candidates becomes a problem. Third, the DCSTFN and EDCSTFN models perform fusion in a high-level abstract feature space level. This type of method turns to be less sensitive to input data quality than the second approach. Because information merges in a high-level feature space, the network can take full advantage of CNNs and be trained to automatically fix small input data errors.
In the end, this paper summarizes some practical tricks when designing and implementing a spatiotemporal fusion network: (1) input data quality is the most important factor for a fusion network. When collected data are not in good quality, it is recommended to use two references to eliminate prediction errors. (2) Too-deep networks may easily lead to overfitting, and networks with too deeper layers are not doable in the current situation. (3) Normalization, such as batch normalization [
48] or instance normalization [
49], do no good for the aforementioned fusion networks, because the normalization will destroy the original data distribution and thus it will reduce the fusion accuracy. (4) The input data of models would better include high-frequency information, otherwise the output image turns to be less sharp. (5) The fusion process is recommended to be performed in high-level feature space instead of raw pixel space to provide much more robustness. (6) Transposed convolution should be avoided for up-sampling, because the transposed convolution in image reconstruction easily leads to the “checkerboard artifacts” [
40]. (7) The
loss function can easily lead to a blurry output, but it is more sensitive for outliers. So it is of much importance to design a comprehensive loss function for remote sensing image reconstruction tasks. Above are some empirical rules provided for a reference when designing a new spatiotemporal fusion network.
5. Conclusions and Prospects
This paper is devoted to improving prediction accuracy and result image quality using deep learning techniques for spatiotemporal remote sensing image fusion. The contribution of this paper is twofold. First, an improved spatiotemporal fusion network is proposed. With this brand-new architecture, compound loss function and enhanced data strategy, not only does the predicted image gain more sharpness and clarity, but also the prediction accuracy is highly boosted. A series of experiments in two different areas demonstrate the superiority of our EDCSTFN model. Second, the advantages and disadvantages of existing fusion methods are discussed, and a succinct guideline is presented to offer some practical tricks when designing a workable spatiotemporal fusion network.
In spatiotemporal image fusion, much of detailed information needs to be inferred from coarsespatialresolution images as well as extra auxiliary data, especially for the MODIS-Landsat image fusion with the upsampling factor of sixteen. It cannot be denied that there must be a limit regarding prediction accuracy for this ill-posed problem and further improvement may not be easy. Generative adversarial networks (GANs), a class of generative models in deep learning domain, [
36,
50], present a promising prospect in solving the spatiotemporal fusion problem because they specialize in generating information with higher reliability and fidelity. As a matter of fact, GANs have been applied to image super-resolution with an upsampling factor of four and outperformed other models generating photorealistic images with more details [
36,
51]. In addition, the prediction accuracy of each pixel for a certain model varies extensively, so the reliability of the fusion result should be concerned. By interacting Bayesian networks into deep learning technologies, it would be possible to solve this uncertainty problem. Currently, limited researches are using Bayesian CNN for computer vision [
52], which could be explored to apply in spatiotemporal image fusion.
Except for concentrating on fusion model accuracy, on the other hand, more efforts should be focused on the usability and robustness of fusion models. First, the transplantability of the model needs to be explored. In our experiment, different models are trained for different areas, which means each area owns its unique model with different parameters. If a model is trained for one place and used in another place, currently the accuracy is unknown. The idea of transfer learning [
53] could be borrowed to study the transplantability of CNN-based spatiotemporal fusion models. Second, input image quality has a significant impact on the predicted results. A good model should lessen the impact of input data quality. For example, a model needs to handle the situation automatically where there are fairly notable changes during the reference and predation period. The model should have a high tolerance for inputs with limited clouds or missing data because this is a common situation in practical applications. Third, reference images are usually needed for most spatiotemporal data fusion models, and it is often not easy to collect appropriate data pairs in practice. Hence, it is quite necessary to develop models that can map HTLS images to LTHS images without references in the prediction phase and the key question is how to fabricate enough ground details without losing accuracy for this type of model. Last but not least, the existing spatiotemporal fusion networks all adopt a supervised learning approach, while the acquired appropriate training dataset in some study areas is not easy. Hence, it will be beneficial to devise some training schemes for unsupervised learning. All of these questions need further exploration.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}