Sparse Unmixing for Hyperspectral Image with Nonlocal Low-Rank Prior




Abstract
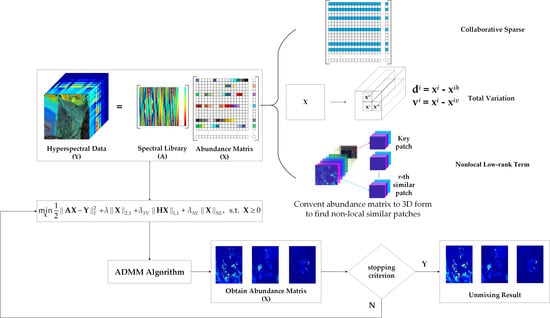
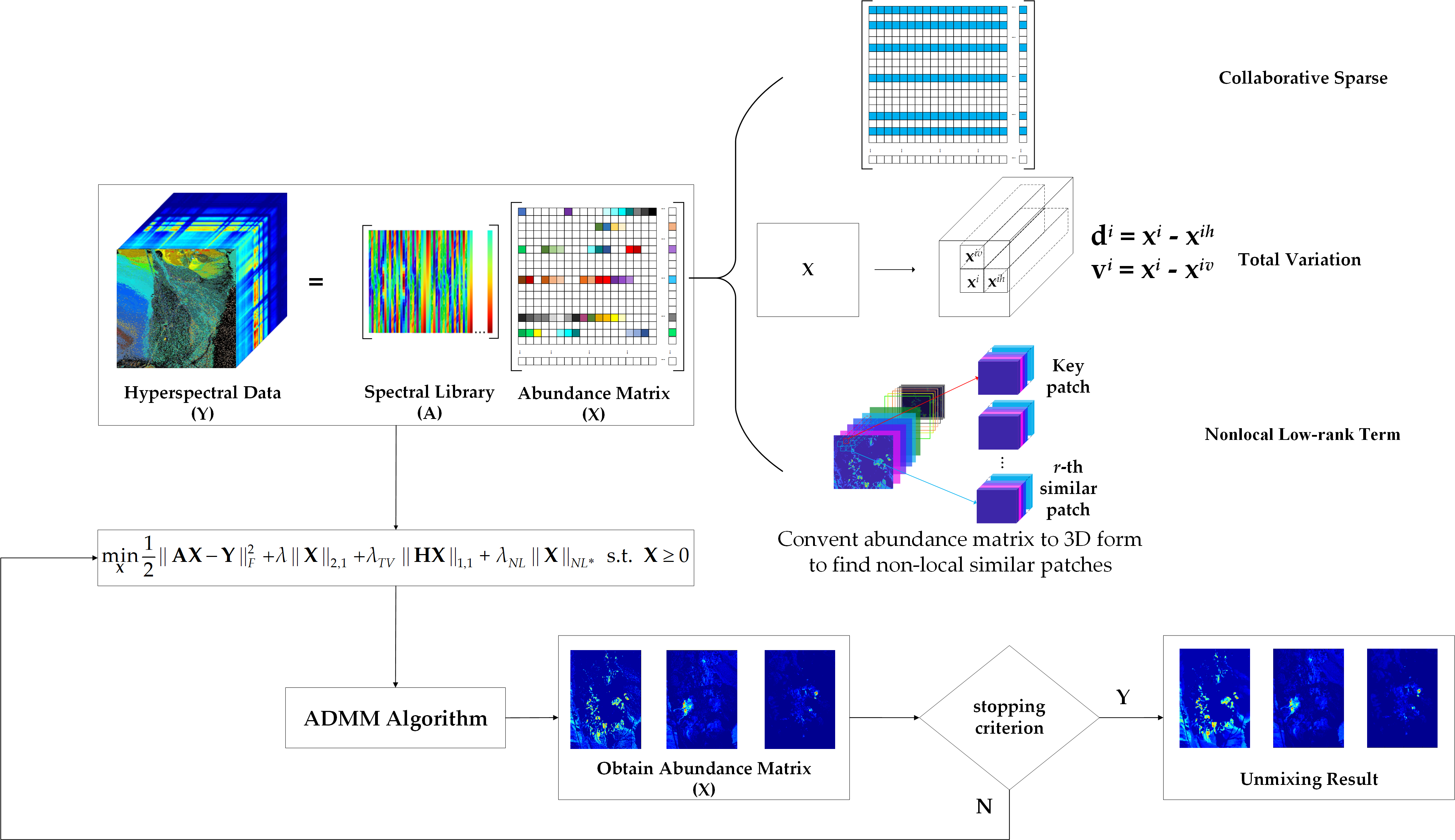
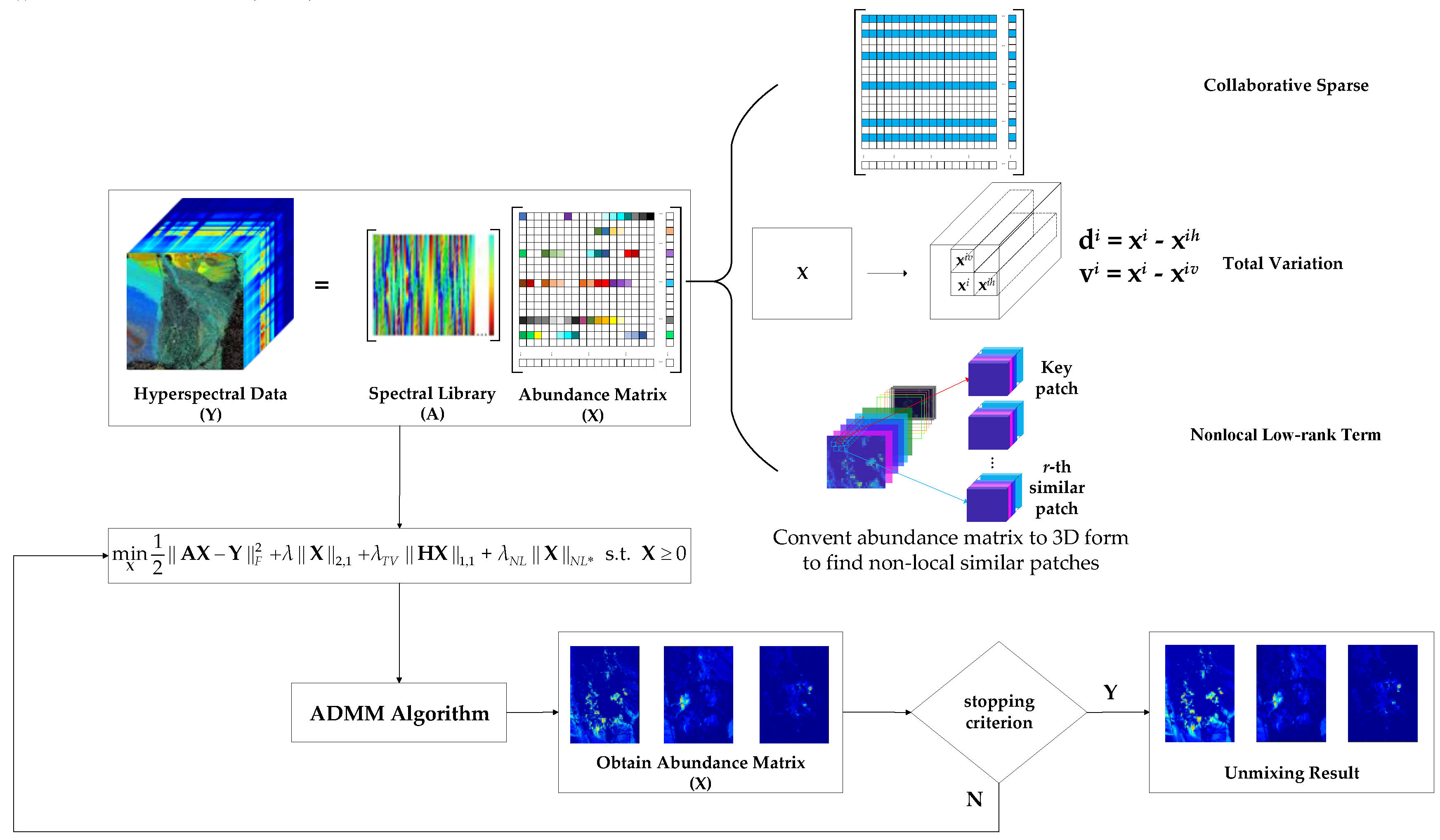
1. Introduction
- (1)
- The non-local low-rank regularization can help to preserve the details of the image better than the state-of-the-art algorithms. In addition, the proposed algorithm utilizes both spectral and spatial information simultaneously to obtain better unmixing results.
- (2)
- In order to improve unmixing performance, a large spectral library is used as an endmember matrix instead of extracting endmembers from the hyperspectral image directly.
- (3)
- The optimization problem of the proposed algorithm with all convex terms is solved by the alternating direction multiplier method (ADMM).
- (4)
- Extensive experiments on both simulated and real data sets validate the superiority of the proposed method in unmixing hyperspectral images.
2. Related Works
2.1. Linear Spectral Unmixing
2.2. Sparse Unmixing
3. Proposed Algorithm
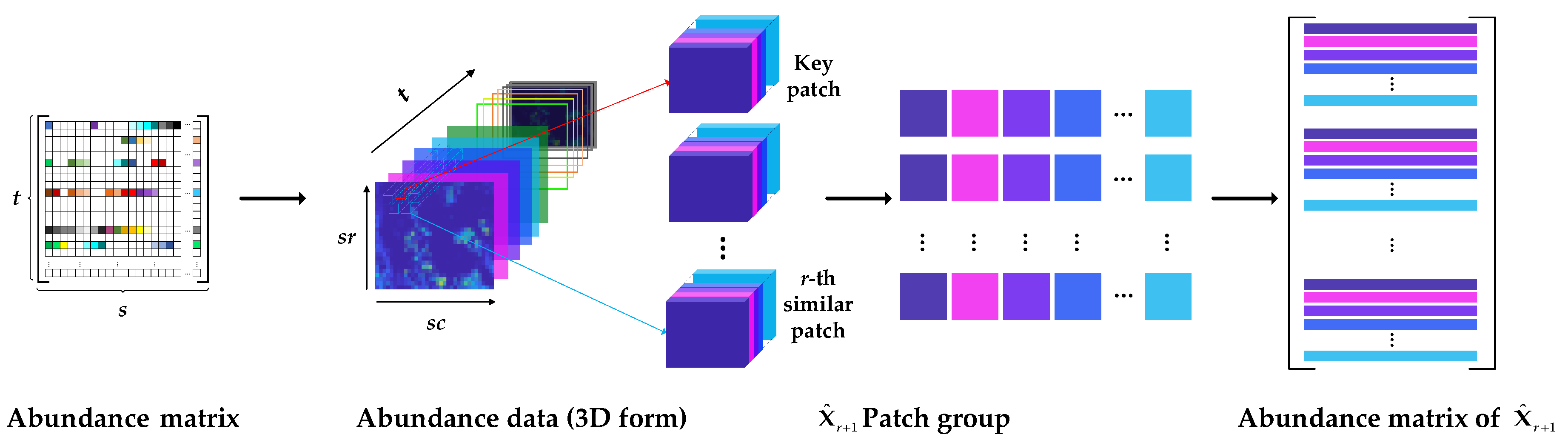
3.1. Nonlocal Self-Similarity
3.2. Nonlocal Low-Rank Regularization
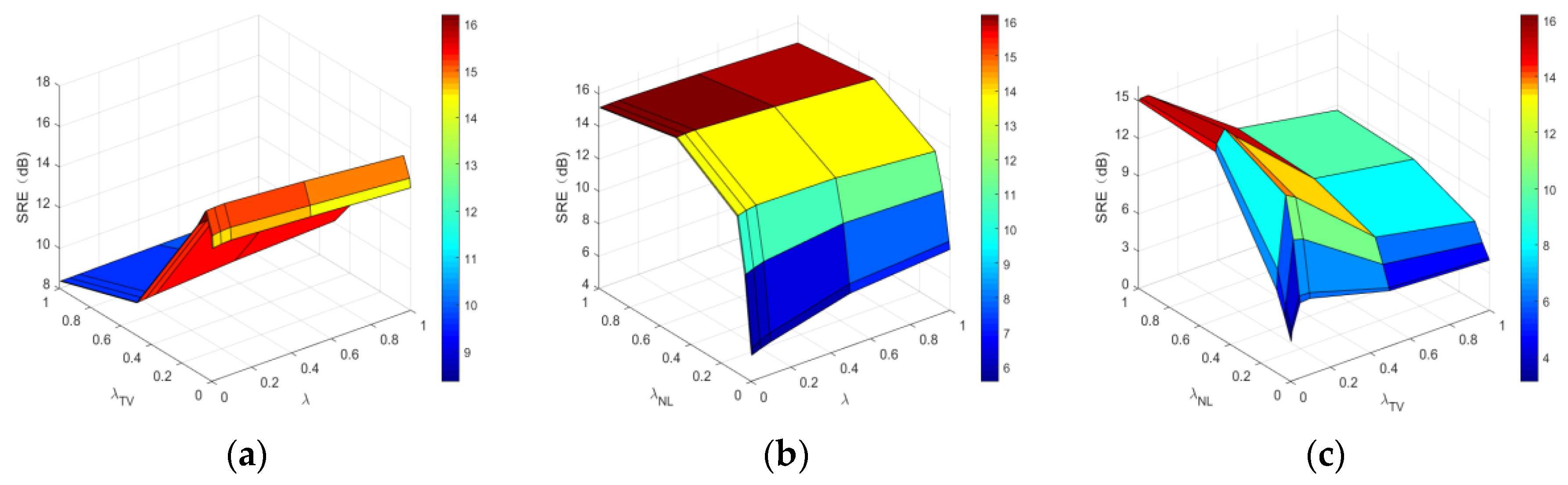
3.3. Proposed Model and Optimization
| Algorithm 1: Pseudocode of the NLLRSU algorithm. |
|
3.4. Computational Complexity
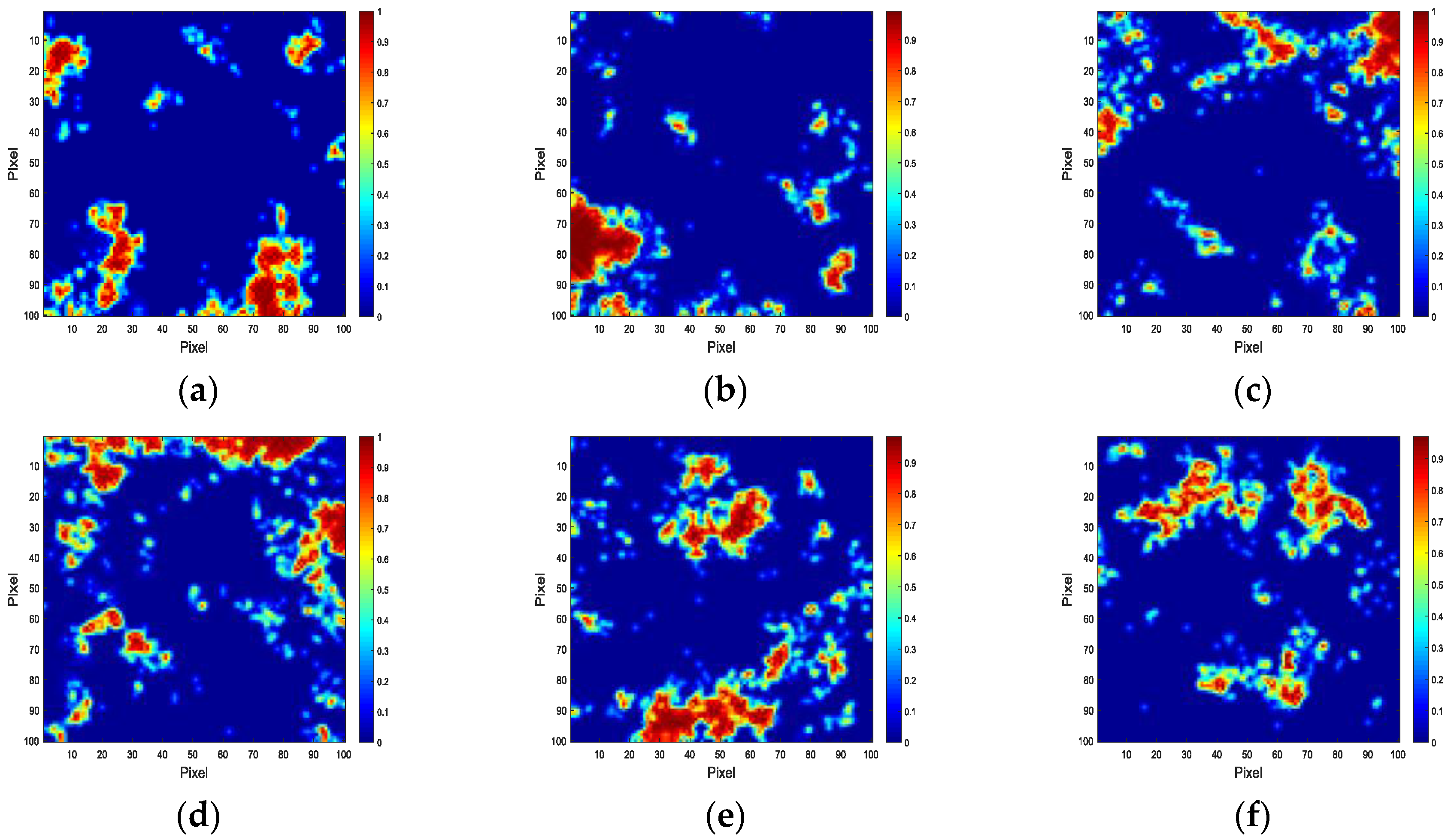
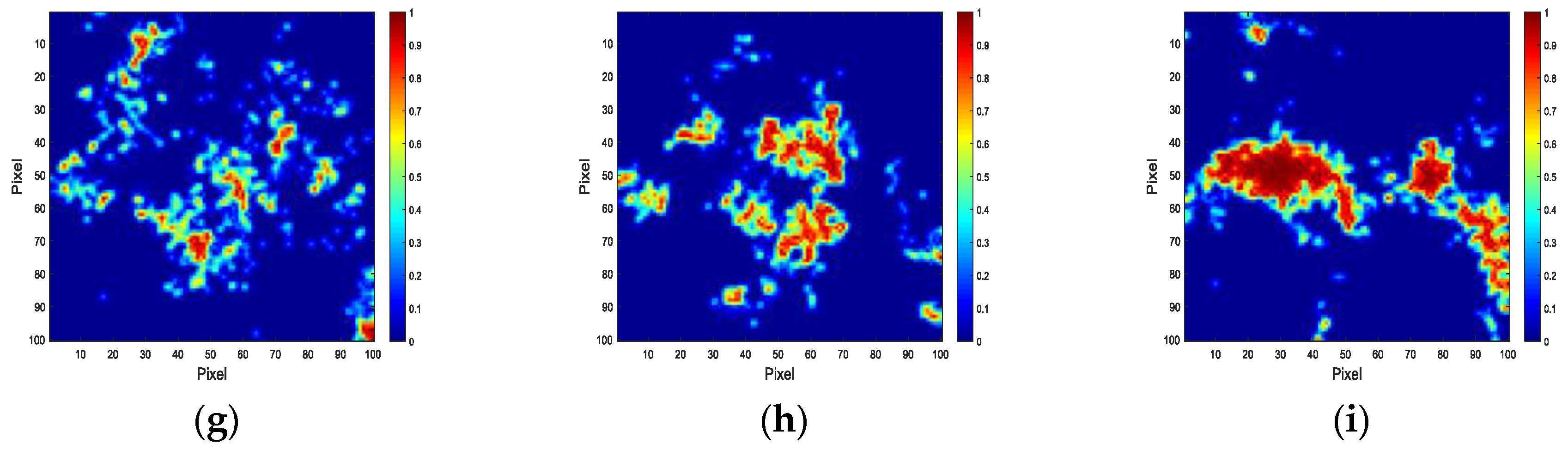
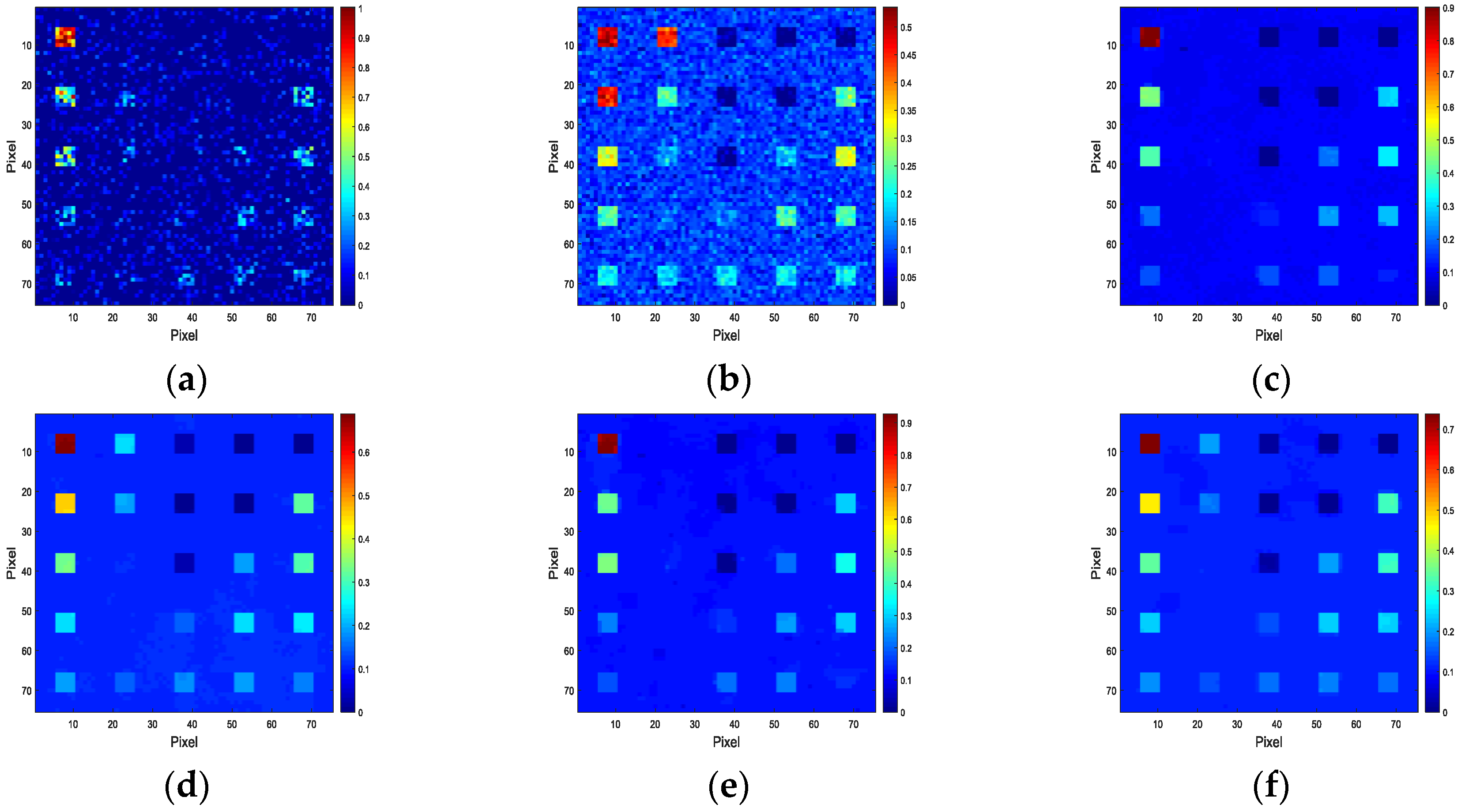
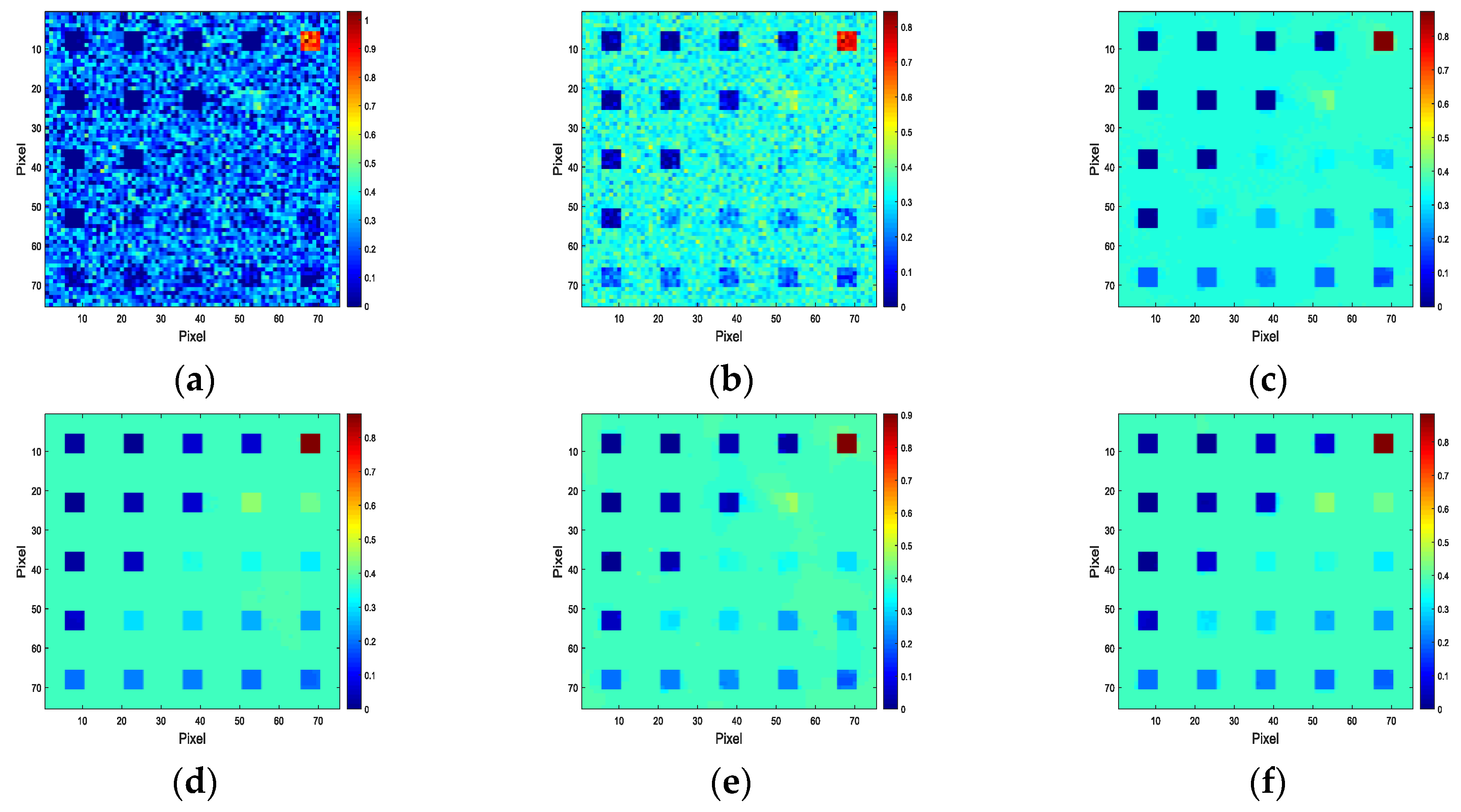
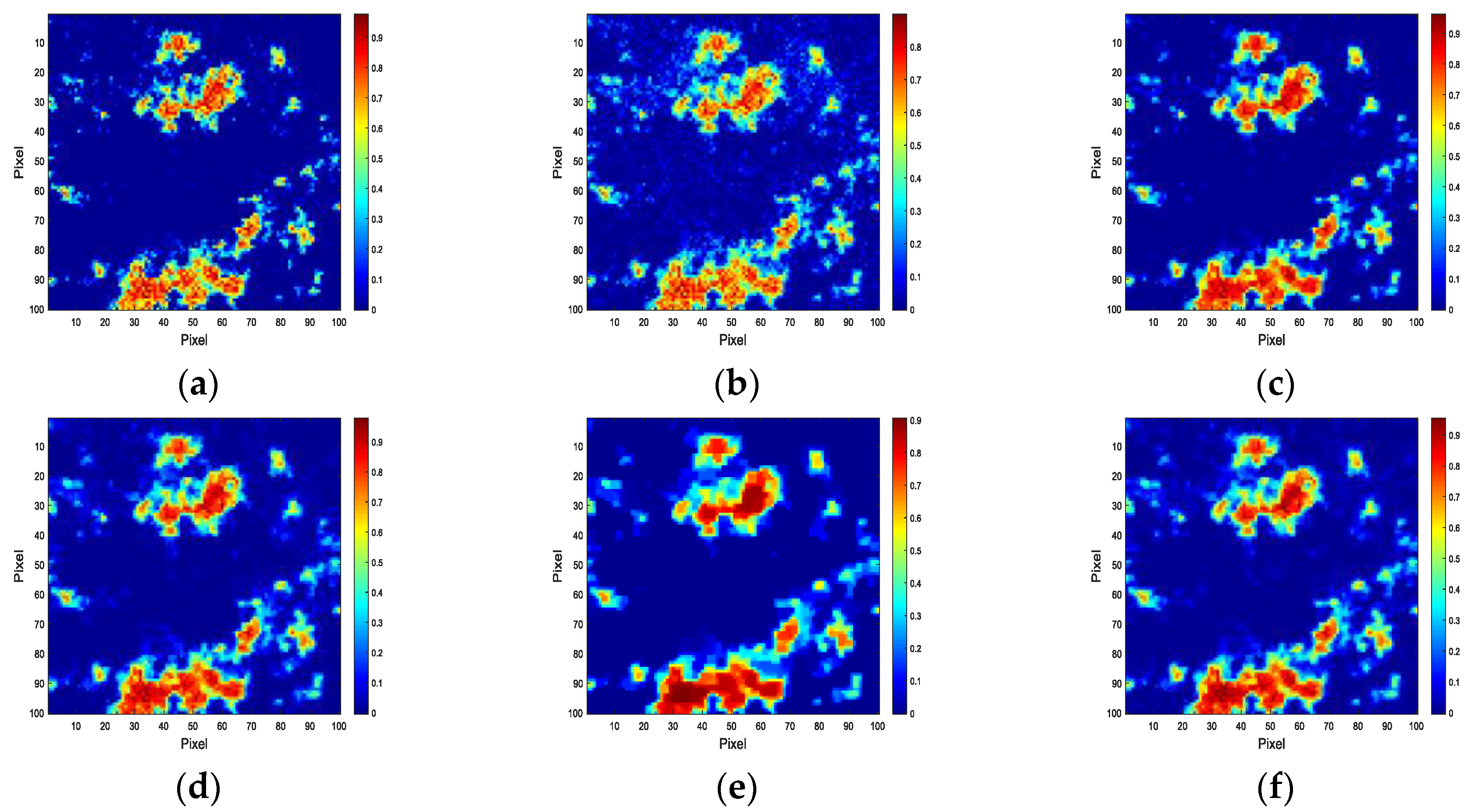
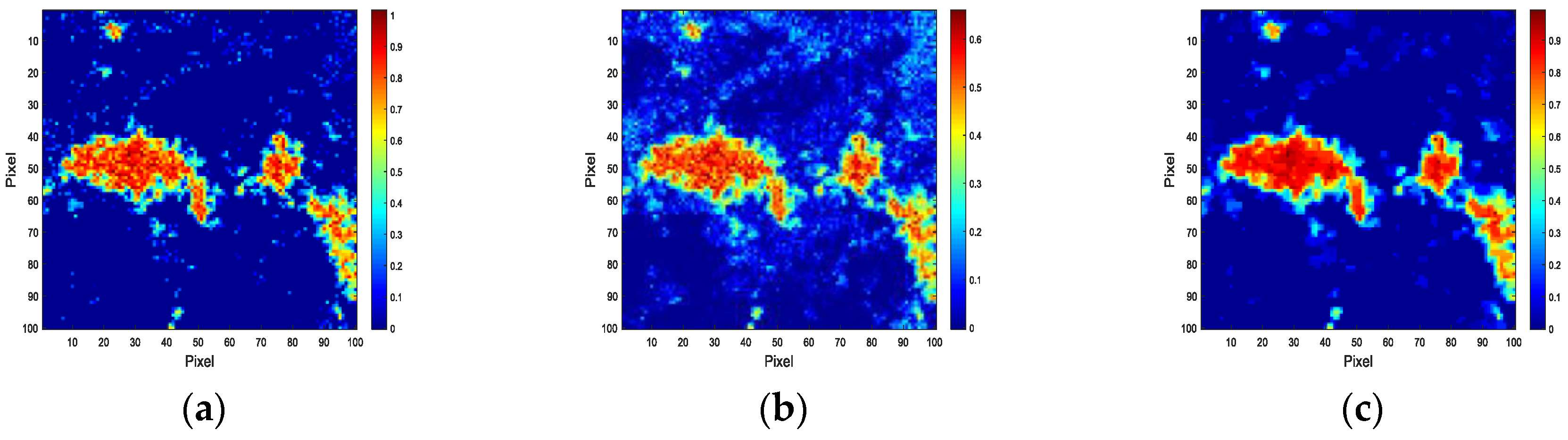
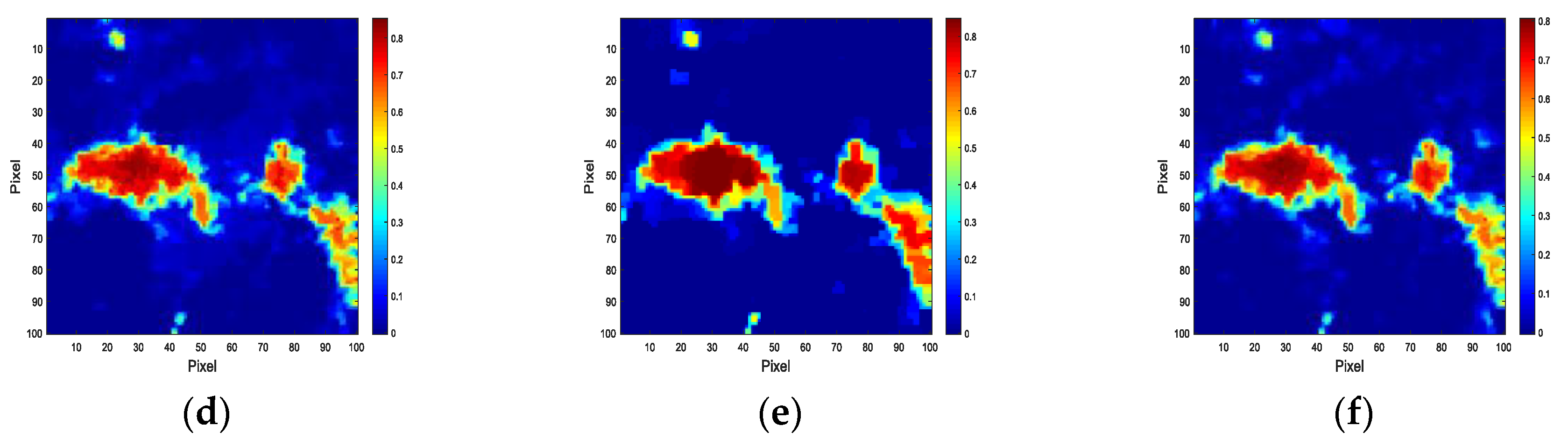
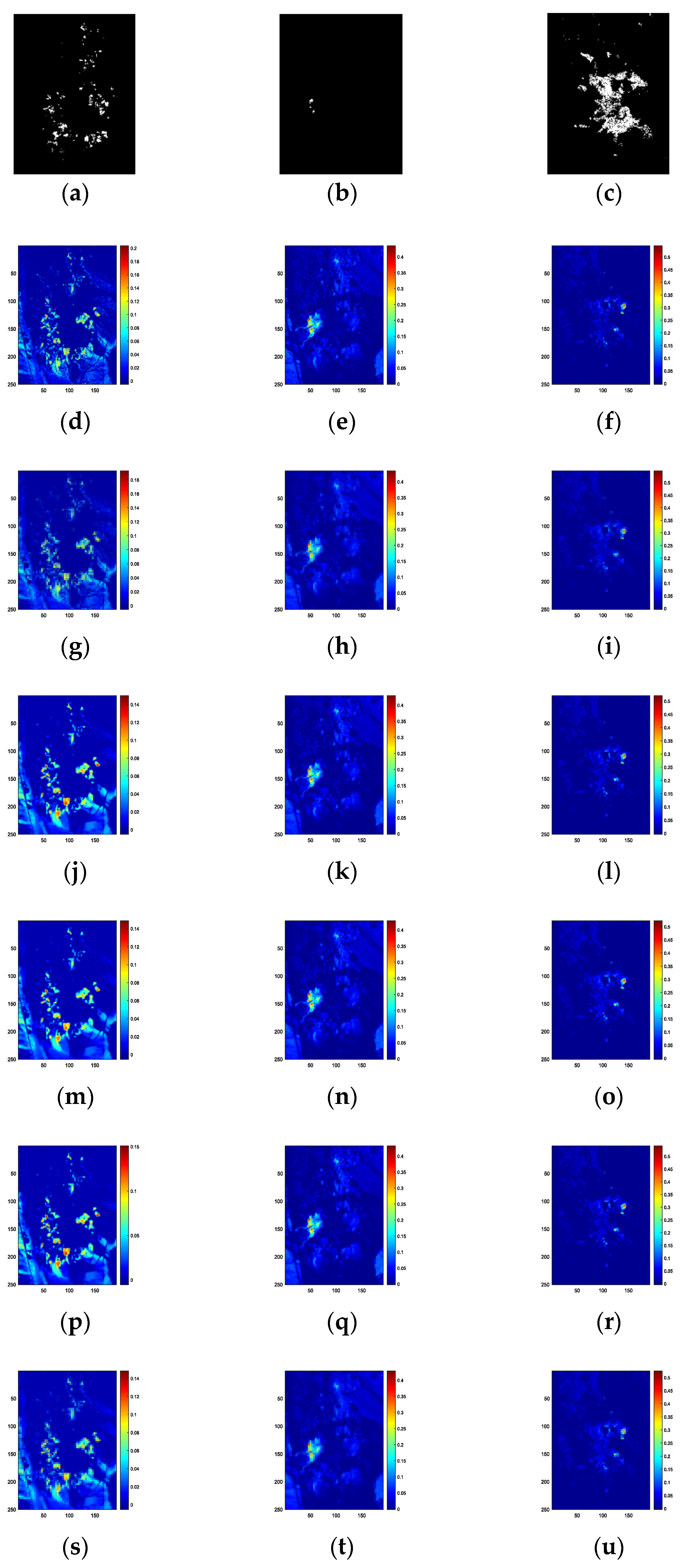
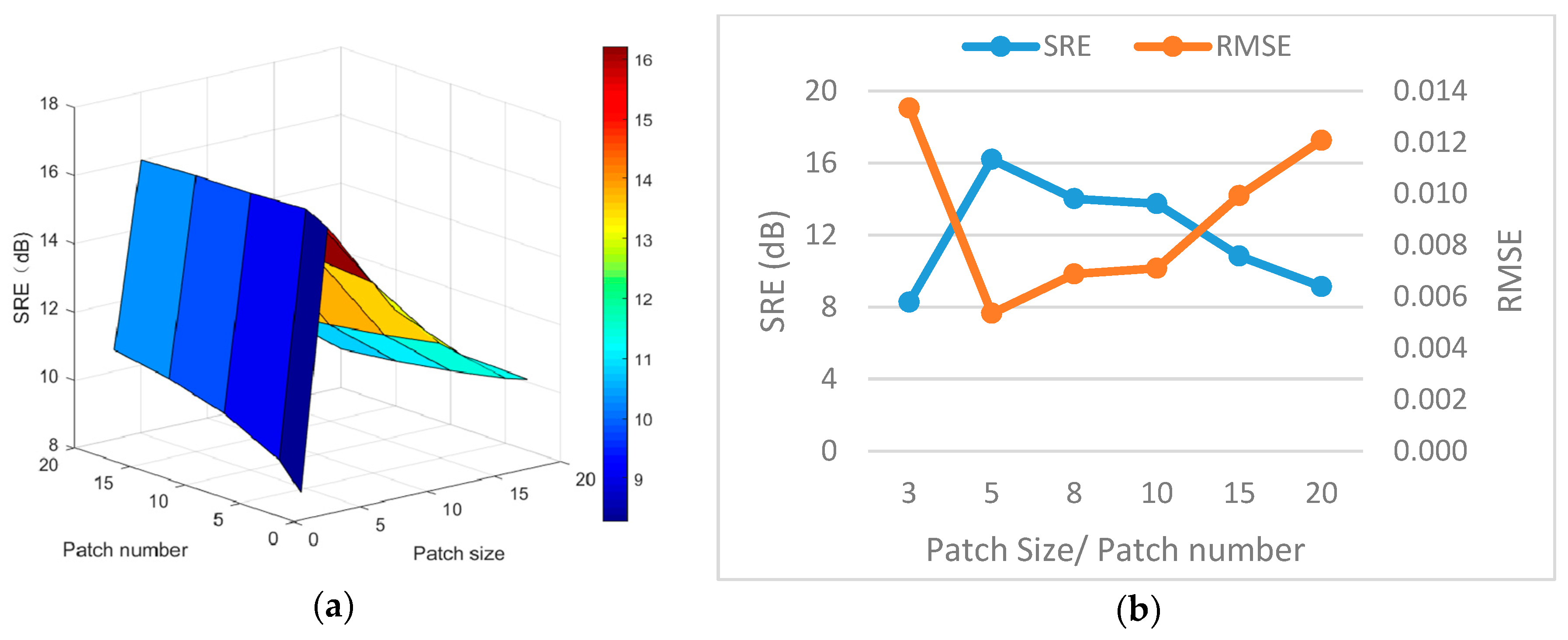
4. Experiment and Analysis
4.1. Experiments with Simulated Data
4.2. Experiments with Real Data
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bioucas-Dias, J.M.; Plaza, A.; Dobigeon, N.; Parente, M.; Du, Q.; Gader, P.; Chanussot, J. Hyperspectral unmixing overview: Geometrical, statistical, and sparse regression-based approaches. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef]
- Mwaniki, M.W.; Matthias, M.S.; Schellmann, G. Application of remote sensing technologies to map the structural geology of central region of kenya. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1855–1867. [Google Scholar] [CrossRef]
- Yang, S.; Shi, Z. Hyperspectral image target detection improvement based on total variation. IEEE. Trans. Image Process. 2016, 25, 2249–2258. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Liu, J.; Yu, H. An automatic sparse pruning endmember extraction algorithm with a combined minimum volume and deviation constraint. Remote Sens. 2018, 10, 32. [Google Scholar] [CrossRef]
- Jiao, C.; Chen, C.; McGarvey, R.G.; Bohlman, S.; Jiao, L.; Zare, A. Multiple instance hybrid estimator for hyperspectral target characterization and sub-pixel target detection. ISPRS-J. Photogramm. Remote Sens. 2018, 146, 235–250. [Google Scholar] [CrossRef]
- Wang, X.; Zhong, Y.; Xu, Y.; Zhang, L.; Xu, Y. Saliency-based endmember detection for hyperspectral imagery. IEEE. Trans. Geosci. Remote Sens. 2018, 56, 3667–3680. [Google Scholar] [CrossRef]
- Xu, X.; Shi, Z.; Pan, B. A supervised abundance estimation method for hyperspectral unmixing. Remote Sens. Lett. 2018, 9, 383–392. [Google Scholar] [CrossRef]
- Bashir, S.; Carter, E.M. Robust mixture of linear regression models. Commun. Stat. Theory Methods 2012, 41, 3371–3388. [Google Scholar] [CrossRef]
- Shi, C.; Wang, L. Linear spatial spectral mixture model. IEEE. Trans. Geosci. Remote Sens. 2016, 54, 3599–3611. [Google Scholar] [CrossRef]
- Ahmed, A.M.; Duran, O.; Zweiri, Y.; Smith, M. Hybrid spectral unmixing: Using artificial neural networks for linear/non-linear switching. Remote Sens. 2017, 9, 22. [Google Scholar] [CrossRef]
- Li, C.; Liu, Y.; Cheng, J.; Song, R.; Peng, H.; Chen, Q.; Chen, X. Hyperspectral unmixing with bandwise generalized bilinear model. Remote Sens. 2018, 10, 19. [Google Scholar] [CrossRef]
- Marinoni, A.; Plaza, A.; Gamba, P. Harmonic mixture modeling for efficient nonlinear hyperspectral unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4247–4256. [Google Scholar] [CrossRef]
- Nascimento, J.M.P.; Dias, J.M.B. Vertex component analysis: A fast algorithm to unmix hyperspectral data. IEEE. Trans. Geosci. Remote Sens. 2005, 43, 898–910. [Google Scholar] [CrossRef]
- Guo, J.; Li, Y.; Liu, K.; Lei, J.; Wang, K. Fast FPGA implementation for computing the pixel purity index of hyperspectral images. J. Circuits Syst. Comput. 2018, 27, 10. [Google Scholar] [CrossRef]
- Wu, C.; Chen, H.; Chang, C. Real-time N-finder processing algorithms for hyperspectral imagery. J. Real-Time Image Process. 2012, 7, 105–129. [Google Scholar] [CrossRef][Green Version]
- Zhang, S.; Agathos, A.; Li, J. Robust minimum volume simplex analysis for hyperspectral unmixing. IEEE. Trans. Geosci. Remote Sens. 2017, 55, 6431–6439. [Google Scholar] [CrossRef]
- Geng, X.; Ji, L.; Yang, W.; Ling, C. The multiplicative update rule for an extension of the iterative constrained endmembers algorithm. Int. J. Remote Sens. 2017, 38, 7457–7467. [Google Scholar] [CrossRef]
- Zhou, G.X.; Xie, S.L.; Yang, Z.Y.; Yang, J.M.; He, Z.S. Minimum-volume-constrained nonnegative matrix factorization: Enhanced sbility of learning parts. IEEE. Trans. Neural Netw. 2011, 22, 1626–1637. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A.; Liu, L. Robust collaborative nonnegative matrix factorization for hyperspectral unmixing. IEEE. Trans. Geosci. Remote Sens. 2016, 54, 6076–6090. [Google Scholar] [CrossRef]
- Li, X.; Jia, X.; Wang, L.; Zhao, K. Reduction of spectral unmixing uncertainty using minimum-class-variance support vector machines. IEEE. Geosci. Remote Sens. Lett. 2016, 13, 1335–1339. [Google Scholar] [CrossRef]
- Chen, Y.; Xiong, J.; Xu, W.; Zuo, J. A novel online incremental and decremental learning algorithm based on variable support vector machine. Cluster Comput. 2019, 22, 7435–7445. [Google Scholar] [CrossRef]
- Chen, Y.; Xu, W.; Zuo, J.; Yang, K. The fire recognition algorithm using dynamic feature fusion and IV-SVM classifier. Clust. Comput. 2019, 22, 7665–7675. [Google Scholar] [CrossRef]
- Tu, Y.; Lin, Y.; Wang, J.; Kim, J.U. Semi-supervised learning with generative adversarial networks on digital signal modulation classification. Comput. Mater. Contin. 2018, 55, 243–254. [Google Scholar]
- Meng, R.; Rice, S.; Wang, J.; Sun, X. A fusion steganographic algorithm based on faster R-CNN. Comput. Mater. Contin. 2018, 55, 1–16. [Google Scholar]
- Long, M.; Zeng, Y. Detecting iris liveness with batch normalized convolutional neural network. Comput. Mater. Contin. 2019, 58, 493–504. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.C.; Han, J.W. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE. Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Zhang, J.; Jin, X.; Sun, J.; Wang, J.; Sangaiah, A.K. Spatial and semantic convolutional features for robust visual object tracking. Multimed. Tools Appl. 2018, 1, 1–21. [Google Scholar] [CrossRef]
- Zeng, D.; Dai, Y.; Li, F.; Wang, J.; Kumar, A. Aspect based sentiment analysis by a linguistically regularized CNN with gated mechanism. J. Intell. Fuzzy Syst. 2019, 36, 3971–3980. [Google Scholar] [CrossRef]
- Licciardi, G.A.; Frate, F.D. Pixel unmixing in hyperspectral data by means of neural networks. IEEE. Trans. Geosci. Remote Sens. 2011, 49, 4163–4172. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE. Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Iordache, M.D.; Bioucas-Dias, J.M.; Plaza, A. Sparse unmixing of hyperspectral data. IEEE. Trans. Geosci. Remote Sens. 2011, 49, 2014–2039. [Google Scholar] [CrossRef]
- Chen, X.H.; Chen, J.; Jia, X.P.; Somers, B.; Wu, J.; Coppin, P. A quantitative analysis of virtual endmembers’ increased impact on the collinearity effect in spectral unmixing. IEEE. Trans. Geosci. Remote Sens. 2011, 49, 2945–2956. [Google Scholar] [CrossRef]
- Song, Y.; Yang, G.; Xie, H.; Zhang, D.; Sun, X. Residual domain dictionary learning for compressed sensing video recovery. Multimed. Tools Appl. 2017, 76, 10083–10096. [Google Scholar] [CrossRef]
- He, S.L.Z.; Tang, Y.; Liao, Z.; Wang, J.; Kim, H.J. Parameters compressing in deep learning. Comput. Mater. Contin. 2019, 1–16. [Google Scholar]
- Clark, R.N.; Swayze, G.A.; Wise, R.A.; Livo, K.E.; Hoefen, T.M.; Kokaly, R.F.; Sutley, S.J. USGS Digital Spectral Library Splib06a; U.S. Geological Survey: Reston, VA, USA, 2007; p. 231.
- Yuan, J.; Zhang, Y.; Gao, F. An overview on linear hyperspectral unmixing. J. Infrared Millim. Waves 2018, 37, 553–571. [Google Scholar]
- Eckstein, J.; Bertsekas, D.P. On the Douglas-Rachford splitting method and the proximal point algorithm for maximal monotone operators. Math. Program. 1992, 55, 293–318. [Google Scholar] [CrossRef]
- Iordache, M.D.; Bioucas-Dias, J.M.; Plaza, A. Collaborative sparse regression for hyperspectral unmixing. IEEE. Trans. Geosci. Remote Sens. 2014, 52, 341–354. [Google Scholar] [CrossRef]
- Tang, W.; Shi, Z.; Wu, Y.; Zhang, C. Sparse unmixing of hyperspectral data using spectral a priori information. IEEE. Trans. Geosci. Remote Sens. 2015, 53, 770–783. [Google Scholar] [CrossRef]
- Zhang, S.Q.; Li, J.; Liu, K.; Deng, C.Z.; Liu, L.; Plaza, A. Hyperspectral unmixing based on local collaborative sparse regression. IEEE. Geosci. Remote Sens. Lett. 2016, 13, 631–635. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Iordache, M.D.; Bioucas-Dias, J.M.; Plaza, A. Total variation spatial regularization for sparse hyperspectral unmixing. IEEE. Trans. Geosci. Remote Sens. 2012, 50, 4484–4502. [Google Scholar] [CrossRef]
- Sun, L.; Ge, W.; Chen, Y.; Zhang, J.; Jeon, B. Hyperspectral unmixing employing l(1)–l(2) sparsity and total variation regularization. Int. J. Remote Sens. 2018, 39, 6037–6060. [Google Scholar] [CrossRef]
- Qu, Q.; Nasrabadi, N.M.; Tran, T.D. Abundance estimation for bilinear mixture models via joint sparse and low-rank representation. IEEE. Trans. Geosci. Remote Sens. 2014, 52, 4404–4423. [Google Scholar]
- Zhang, H.; He, W.; Zhang, L.; Shen, H.; Yuan, Q. Hyperspectral image restoration using low-rank matrix recovery. IEEE. Trans. Geosci. Remote Sens. 2014, 52, 4729–4743. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.; Zhang, L.; Shen, H. Total-variation-regularized low-rank matrix factorization for hyperspectral image restoration. IEEE. Trans. Geosci. Remote Sens. 2016, 54, 176–188. [Google Scholar] [CrossRef]
- Zhao, Y.Q.; Yang, J.X. Hyperspectral image denoising via sparse representation and low-rank constraint. IEEE. Trans. Geosci. Remote Sens. 2015, 53, 296–308. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.; Zhong, S. Hyper-Laplacian regularized unidirectional low-rank tensor recovery for multispectral image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5901–5909. [Google Scholar]
- Sun, L.; Ma, C.; Chen, Y.; Shim, H.J.; Wu, Z.; Jeon, B. Adjacent superpixel-based multiscale spatial-spectral kernel for hyperspectral classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 12, 1905–1919. [Google Scholar] [CrossRef]
- Sun, L.; Ma, C.; Chen, Y.; Zheng, Y.; Shim, H.J.; Wu, Z.; Jeon, B. Low rank component Induced spatial-spectral kernel method for hyperspectral image classification. IEEE Trans. Circuits Syst. Video Technol. 2019, 26, 613–626. [Google Scholar] [CrossRef]
- Chen, Y.; Xia, R.; Wang, Z.; Zhang, J.; Yang, K.; Cao, Z. The visual saliency detection algorithm research based on hierarchical principle component analysis method. Multimed. Tools Appl. 2019, 75, 16943–16958. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, Y.; Chan, J.; Kong, S. Coupled sparse denoising and unmixing with low-rank constraint for hyperspectral image. IEEE. Trans. Geosci. Remote Sens. 2016, 54, 1818–1833. [Google Scholar] [CrossRef]
- Giampouras, P.V.; Themelis, K.E.; Rontogiannis, A.A.; Koutroumbas, K.D. Simultaneously sparse and low-rank abundance matrix estimation for hyperspectral image unmixing. IEEE. Trans. Geosci. Remote Sens. 2016, 54, 4775–4789. [Google Scholar] [CrossRef]
- Mei, X.; Ma, Y.; Li, C.; Fan, F.; Huang, J.; Ma, J. Robust GBM hyperspectral image unmixing with superpixel segmentation based low rank and sparse representation. Neurocomputing 2018, 275, 2783–2797. [Google Scholar] [CrossRef]
- Rizkinia, M.; Okuda, M. Joint local abundance sparse unmixing for hyperspectral images. Remote Sens. 2017, 9, 22. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE. Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Bioucas-Dias, J.M. A variable splitting augmented Lagrangian approach to linear spectral unmixing. In Proceedings of the First Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing, Grenoble, France, 26–28 August 2009; pp. 1–4. [Google Scholar]
- Zhang, X.R.; Li, C.; Zhang, J.Y.; Chen, Q.M.; Feng, J.; Jiao, L.C.; Zhou, H.Y. Hyperspectral unmixing via low-rank representation with space consistency constraint and spectral library pruning. Remote Sens. 2018, 10, 21. [Google Scholar] [CrossRef]
- Lou, Y.; Yin, P.; He, Q.; Xin, J. Computing sparse representation in a highly coherent dictionary based on difference of l1 and l2. J. Sci. Comput. 2015, 64, 178–196. [Google Scholar] [CrossRef]
- Sun, L.; Wu, Z.; Liu, J.; Xiao, L.; Wei, Z. Supervised spectral-spatial hyperspectral image classification with weighted markov random fields. IEEE. Trans. Geosci. Remote Sens. 2015, 53, 1490–1503. [Google Scholar] [CrossRef]
- Bruckstein, A.M.; Elad, M.; Zibulevsky, M. On the uniqueness of nonnegative sparse solutions to underdetermined systems of equations. IEEE. Trans. Inf. Theory 2008, 54, 4813–4820. [Google Scholar] [CrossRef]
- Wright, S.J.; Nowak, R.D.; Figueiredo, M.A.T. Sparse reconstruction by separable approximation. IEEE. Trans. Signal Process. 2009, 57, 2479–2493. [Google Scholar] [CrossRef]
- Vinchurkar, P.P.; Rathkanthiwar, S.V.; Kakde, S.M. HDL Implementation of DFT Architectures Using Winograd Fast Fourier Transform Algorithm. In Proceedings of the Fifth International Conference on Communication Systems and Network Technologies (CSNT), Gwalior, India, 4–6 April 2015; pp. 397–401. [Google Scholar]
- Combettes, P.L.; Wajs, V.R. Signal recovery by proximal forward-backward splitting. Multiscale Model. Simul. 2005, 4, 1168–1200. [Google Scholar] [CrossRef]
- USGS Digital Spectral Library 06. Available online: https://speclab.cr.usgs.gov/spectral.lib06 (accessed on 8 June 2016).
- Altmann, Y.; Pereyra, M.; Bioucas-Dias, J.M. Collaborative sparse regression using spatially correlated supports-application to hyperspectral unmixing. IEEE. Trans. Image Process. 2015, 24, 12. [Google Scholar] [CrossRef] [PubMed]
- Guerra, R.; Santos, L.; Lopez, S.; Sarmiento, R. A new fast algorithm for linearly unmixing hyperspectral images. IEEE. Trans. Geosci. Remote Sens. 2015, 53, 6752–6765. [Google Scholar] [CrossRef]
- Datasets & Ground Truths. Available online: http://www.escience.cn/people/feiyunZHU/Dataset_GT.html (accessed on 8 November 2019).
- Zhu, F.Y.; Wang, Y.; Fan, B.; Xiang, S.M.; Meng, G.F.; Pan, C.H. Spectral unmixing via data-guided sparsity. IEEE Trans. Image Process. 2014, 23, 5412–5427. [Google Scholar] [CrossRef] [PubMed]
- Zhu, F.Y.; Wang, Y.; Xiang, S.M.; Fan, B.; Pan, C.H. Structured sparse method for hyperspectral unmixing. ISPRS-J. Photogramm. Remote Sens. 2014, 88, 101–118. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhao, M.; Hu, C.; He, L.; Bai, H.; Wang, J. A parallel FP-growth algorithm on World Ocean Atlas data with multi-core CPU. J. Supercomput. 2019, 75, 732–745. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | DS1 | DS2 | |||||
|---|---|---|---|---|---|---|---|
| SNR | 10dB | 15dB | 20dB | 10dB | 15dB | 20dB | |
| SUnSAL [31] | |||||||
| CLSUnSAL [38] | |||||||
| SUnSAL-TV [42] | |||||||
| J-LASU [55] | |||||||
| L1-L2 SUnSAL-TV [43] | |||||||
| NLLRSU | |||||||
| Data | SNR | SUnSAL [31] | CLSUnSAL [38] | SUnSAL-TV [42] | J-LASU [55] | L1-L2 SUnSAL-TV [43] | NLLRSU |
|---|---|---|---|---|---|---|---|
| DS1 | 10dB | 0.2017 | 1.6544 | 3.9803 | 10.6039 | 4.1424 | 11.5466 |
| 15dB | 0.9448 | 4.4945 | 6.4204 | 13.4001 | 6.0267 | 13.9307 | |
| 20dB | 2.4218 | 6.0518 | 7.1069 | 15.3860 | 7.0245 | 16.2008 | |
| DS2 | 10dB | 1.2568 | 1.0144 | 3.6093 | 3.5925 | 3.6494 | 3.9300 |
| 15dB | 1.9727 | 2.3747 | 4.5860 | 4.8039 | 4.8445 | 5.1034 | |
| 20dB | 4.1627 | 3.3961 | 5.5352 | 6.3062 | 6.2078 | 6.7188 |
| Data | SNR | SUnSAL [31] | CLSUnSAL [38] | SUnSAL-TV [42] | J-LASU [55] | L1-L2 SUnSAL-TV [43] | NLLRSU |
|---|---|---|---|---|---|---|---|
| DS1 | 10dB | 0.0338 | 0.0286 | 0.0218 | 0.0102 | 0.0214 | 0.0091 |
| 15dB | 0.0310 | 0.0206 | 0.0165 | 0.0074 | 0.0173 | 0.0069 | |
| 20dB | 0.0261 | 0.0172 | 0.0152 | 0.0059 | 0.0154 | 0.0054 | |
| DS2 | 10dB | 0.0426 | 0.0438 | 0.0325 | 0.0325 | 0.0323 | 0.0313 |
| 15dB | 0.0392 | 0.0374 | 0.0290 | 0.0283 | 0.0282 | 0.0273 | |
| 20dB | 0.0305 | 0.0333 | 0.0260 | 0.0238 | 0.0241 | 0.0227 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Y.; Wu, F.; Shim, H.J.; Sun, L. Sparse Unmixing for Hyperspectral Image with Nonlocal Low-Rank Prior. Remote Sens. 2019, 11, 2897. https://doi.org/10.3390/rs11242897
Zheng Y, Wu F, Shim HJ, Sun L. Sparse Unmixing for Hyperspectral Image with Nonlocal Low-Rank Prior. Remote Sensing. 2019; 11(24):2897. https://doi.org/10.3390/rs11242897
Chicago/Turabian StyleZheng, Yuhui, Feiyang Wu, Hiuk Jae Shim, and Le Sun. 2019. "Sparse Unmixing for Hyperspectral Image with Nonlocal Low-Rank Prior" Remote Sensing 11, no. 24: 2897. https://doi.org/10.3390/rs11242897
APA StyleZheng, Y., Wu, F., Shim, H. J., & Sun, L. (2019). Sparse Unmixing for Hyperspectral Image with Nonlocal Low-Rank Prior. Remote Sensing, 11(24), 2897. https://doi.org/10.3390/rs11242897