1. Introduction
Hyperspectral sensors collect the energy in electromagnetic spectrum with many contiguous narrow spectral channels. A detailed distribution of reflectance or radiance can be captured in each pixel. Obviously, each physical material has its own characteristic reflectance or radiance signature with rich spectral information. Therefore, hyperspectral remote sensors have a superior distinguishing ability, particularly for visually similar materials. This distinctive characteristics create lots of applications in computer vision and remote sensing fields, e.g., military target detection, resource management and medical diagnosis, etc. However, there has a trade-off between spatial resolution and high spectral resolution. Due to the narrow slicing of the spectrum, a very limited fraction of the overall radiant energy can reach the sensor. To achieve an acceptable signal-to-noise ratio, a feasible scheme is to increase the pixel spatial size. However, because of fundamental physical limits in practice, it is difficult to improve the sensor capability. Consequently, compared with conventional RGB or multispectral cameras, the obtained hyperspectral image (HSI) is always with a relative low spatial resolution, which limits their practical applications. In recent years, HSI super-resolution (SR) has attracted more and more attention in the remote sensing community.
HSI SR is a promising signal post-processing technique aiming at acquiring a high resolution (HR) image from its low resolution (LR) version to overcome the inherent resolution limitations [
1]. Generally, we can roughly divide this technique into two categories, according to the availability of an HR auxiliary image, e.g., the single HSI super-resolution or pan sharpening methods with the HR panchromatic image. For example, the popular single HSI super-resolution methods are bilinear [
2] and bicubic interpolation [
3] based on interpolation, and [
4,
5] based on regularization. Pansharpening methods can be roughly divided into five categories: component substitution (CS) [
6,
7,
8], which may cause spectral distortion; multiresolution analysis (MRA) [
9,
10,
11,
12], which can keep spectral consistency at the cost of much computation and great complexity of parameter setting; bayesian methods [
13,
14,
15] and matrix factorization [
16], which can achieve prior spatial and spectral performance at a very high computational cost; and hybrid methods [
17,
18,
19], which are combinations of different algorithms.
In situations without prior high resolution images, hyperspectral single image super-resolution (HSISR) is a challenging task. Although several deep learning-based HSISR algorithms have been proposed, they cannot effectively utilize sufficient spatial–spectral features while ignoring the influence from non-local regions. Non-local operation computes the response at a position as a weighted sum of the features at all positions. Therefore, non-local operations can capture long-range dependencies [
20]. Different from the existing approaches, we argue that the separation and gradual fusion strategy can provide a novel method to deal with the HSISR problem, that is, extracting the deep spatial–spectral information separately and fusing them later in an incremental way [
21]. In this way, we avoid the difficulty of spatial–spectral information jointly learning and further provide a unified framework on HSISR and hyperspectral pansharpening to conduct these two related tasks together. While, at present, few of works in the literature promote a unified framework to solve the pan-sharpening and HSISR problem simultaneously. Therefore, it is urgent and progressive to promote a uniform and flexible resolution enhancement framework to address the HSISR and hypespectral pansharpening simultaneously.
Additionally, considering that only employing local micro-scale spatial information cannot extract spatial features fully, the global spatial characteristics also need to be considered. Attention mechanism as an effective tool for global context information has not yet been utilized in the HSI resolution enhancement problem widely. Thus, for learning macro-scale spatial characteristics, attention mechanism is added to our novel network.
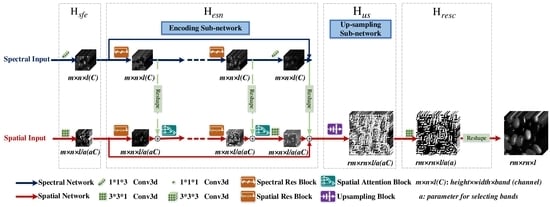
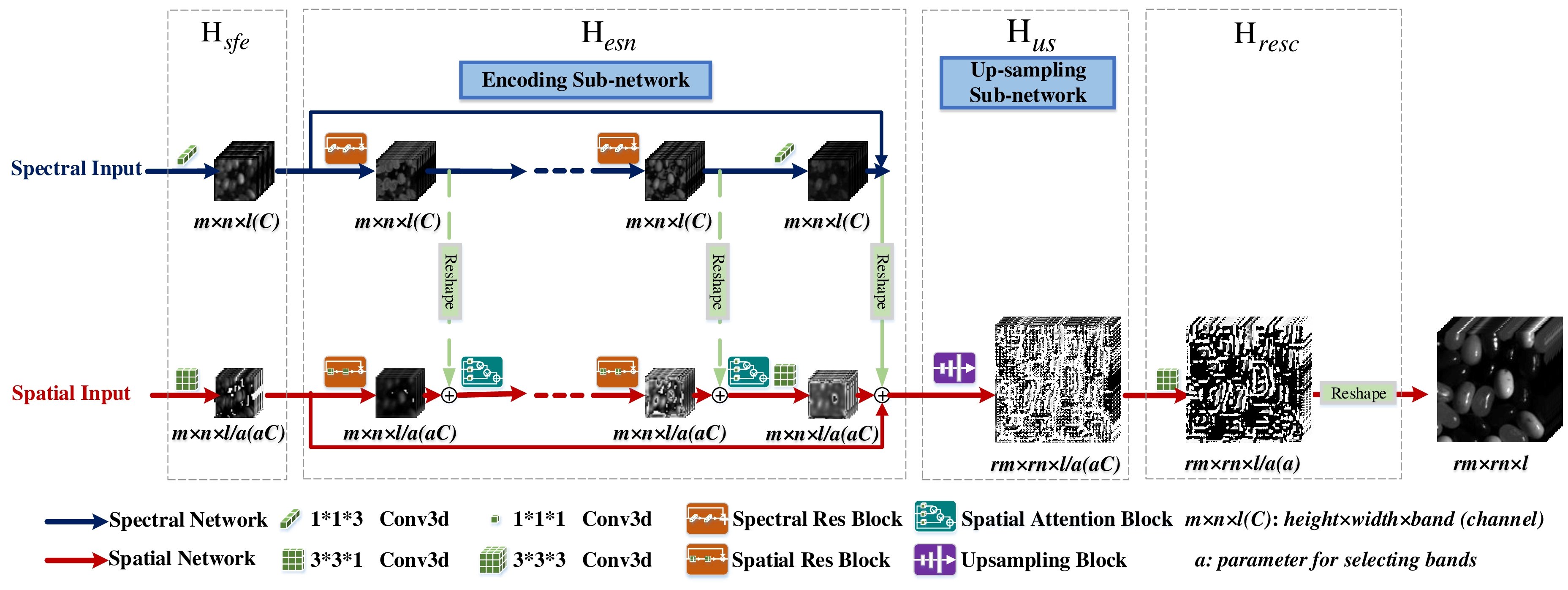
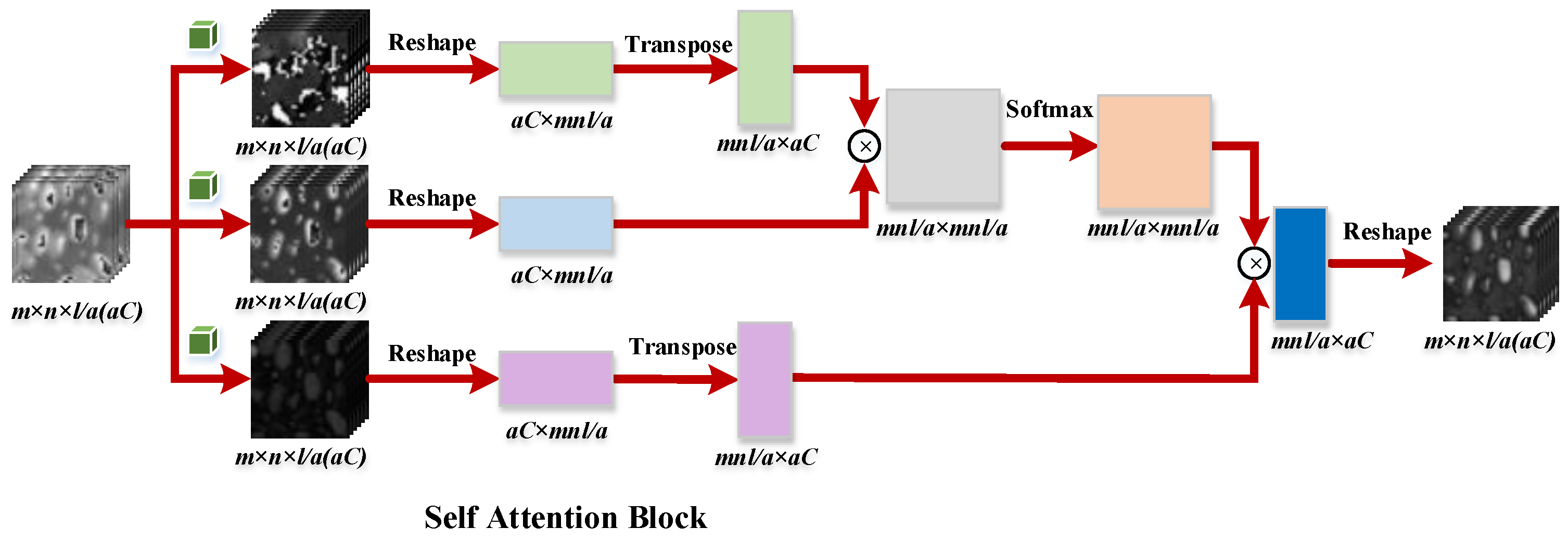
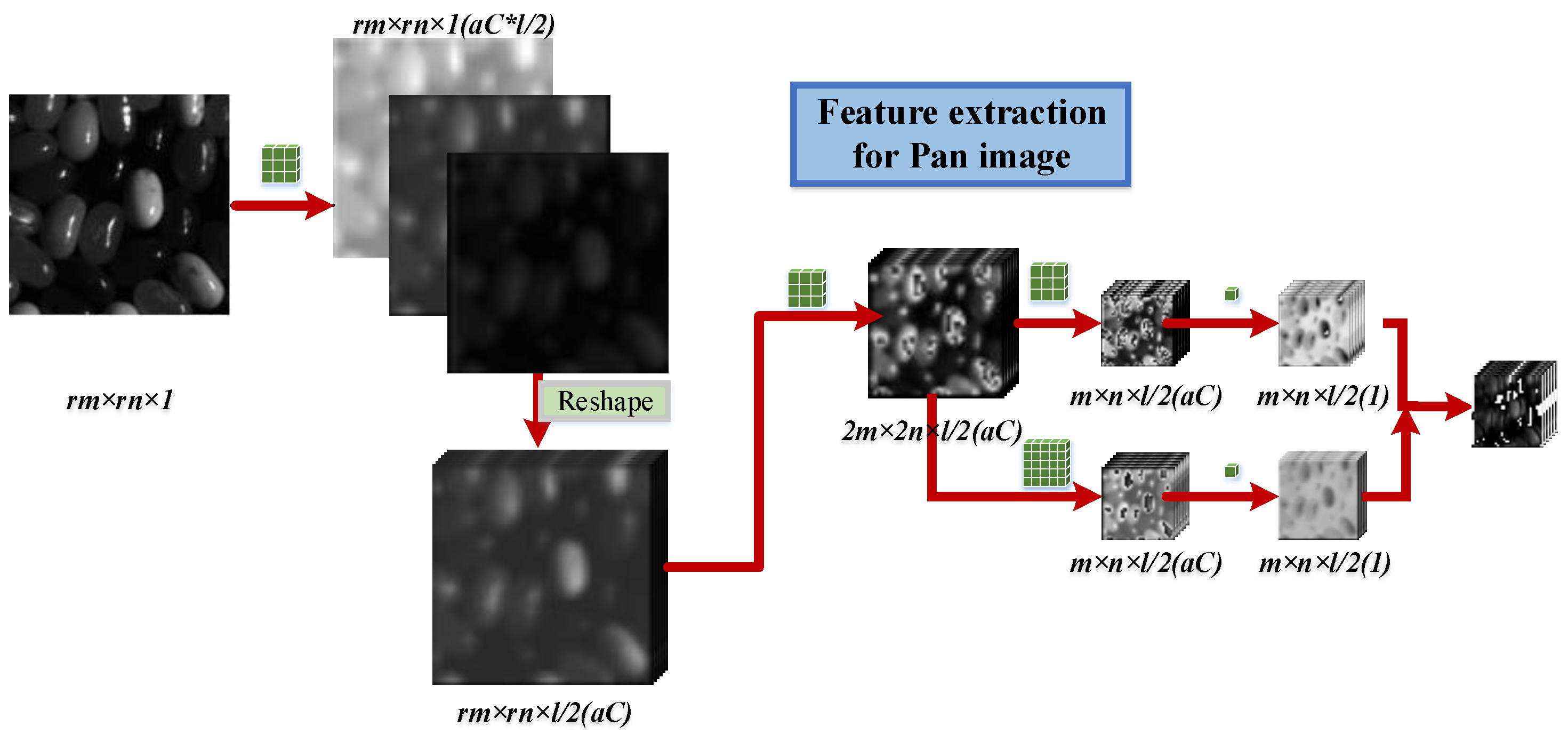
Therefore, in this paper, a novel 1D–2D attentional convolutional neural network (CNN) is proposed in this paper, which provides a elegant solution for HSISR. In addition, we explore the potential of this proposed network in hyperspectral pansharpening task with the modification of the network inputs. Firstly, 1D stream spectral and 2D stream spatial residual neural networks with parallel layout are established respectively. Secondly, self attention mechanism based on spatial features for employing non local information is promoted and embedded in our 2D stream spatial residual network directly, and is beneficial to enhance the spatial representation. At last, the norm loss and spectral loss functions are imposed to guide the network training. Compared with the typical 3D convolution, our network is much more effective; it needs less parameters but can achieve superior performance for the HSI resolution enhancement problem.
In conclusion, the main contributions of this paper can be summarized as below.
A novel 1D–2D attentional CNN is proposed for HSISR. Compared with the typical 3D CNN, our architecture is very elegant and efficient to encode spatial–spectral information for HSI 3D cube, which is also totally end-to-end trainable structure. More important, the ability to resolve hyperspectral pansharpening is also developed based on the uniform network.
To take full consideration of the spatial information, a self attention mechanism is exploited in spatial network, which can efficiently employ the global spatial feature through learning non-local spatial information.
Extensive experiments on the widely used benchmarks demonstrate that the proposed method could out perform other SOTA methods in both the HSISR and pan-sharpening problem.
2. Related Works
Generally speaking, current HSISR methods mainly includes two branches: hyperspectral single-image SR (HSISR) and fusion with other auxiliary high spatial resolution images. As for image fusion based methods, the additional higher spatial resolution images such as panchromatic image and multispectral image are needed as prior to assist SR. Especially, hyperspectral pansharpening as a typical case of fusion based method has attracted lots of attention in the hyperspectral spatial resolution enhancement literature. A taxonomy of hyperspectral pansharpening methods can be referenced in the literature. They can be roughly divided into five categories: component substitution (CS), multiresoltuion analysis (MRA), bayesian methods, matrix factorization based methods, and hybrid methods. The CS and MRA algorithms are relatively traditional hyperspectral pansharpening algorithms. The CS algorithms often project the HS image into a new domain to separate the spectral and spatial information, then utilize the PAN image to replace the spatial component.However, these algorithms cause spectral distortion. The typical CS methods include the principal component analysis (PCA) algorithm [
6], the intensity-hue-saturation (IHS) algorithm [
7], and the Gram–Schmidt (GS) algorithm [
8], etc. However, these algorithms cause spectral distortion. The typical MRA methods are smoothing filter-based intensity modulation (SFIM) [
9], MTF-generalized Laplacian pyramid (MTF-GLP) [
10], MTF-GLP with high pass modulation (MGH) [
11], “a-trous” wavelet transform (ATWT) [
12], etc. Although the MRA algorithm can keep spectral consistency, they cost much in computation and have great complexity of parameter setting. The nonnegative matrix factorization (NMF) can also be employed for hyperspectral pansharpening, and the typical matrix factorization based approaches are coupled nonnegative matrix factorization (CNMF) [
22], nonnegative sparse coding (NNSC) [
16], etc. Bayesian approaches transform the hyperspectral pansharpening problem into a distinct probabilistic framework and regularize it through an appropriate prior distribution, which include Bayesian sparsity promoted gaussian prior (Bayesian sparse) [
13], Bayesian hysure [
14], Bayesian naive gaussian prior (Bayesian naive) [
15], etc. Both the Bayesian and the matrix factorization methods can achieve prior spatial and spectral performance at a very high computational cost. Hybrid methods are combinations of different algorithms, such as guided filter PCA (GFPCA) [
17]. Therefore, hybrid methods take advantages of algorithms in different algorithms. In addition, several variants and several variants with PCA [
18,
19] are exploited widely in hyperspectral pansharpening.
The HSISR does not need any other prior or auxiliary information. Traditionally, the SR problem can be partially solved by filtering based methods, such as bilinear [
2] and bicubic interpolation [
3], etc. However, these filtering based methods often lead to edge blur and spectral distortions due to without considering the inherent image characteristic. Then, the regularization based methods is proposed to employ the image statistical distribution as prior, and regularize the solution space using prior assumptions. For instance, Paterl proposed an algorithm employing the discrete wavelet transform through using a sparsity-based regularization framework [
4] and Wang et al. proposed an algorithm based on TV-regularization and low-rank tensor [
5]. Sub-pixel mapping [
23,
24] and self-similarity based [
25] algorithms are also utilized for dealing with this problem. Although these algorithms can perform well, they ignore significant characteristic of HSI, such as the correlation among spectral bands. To consider both spatial and spectral information, Li et al. presented an efficient algorithm through combining the sparsity and the nonlocal self-similarity in both the spatial and spectral domains [
23]. However, due to complex details in HSIs, these algorithms with shallow heuristic models may cause spectral distortion. These algorithms can be used to enhance the spatial resolution of the spatial resolution of HSI in a band-by-band manner [
5], which ignores the correlation of the band.
Deep neural networks, especially CNNs, have already demonstrated great success in computer vision [
26,
27,
28,
29,
30]. Inspired by successful applications in RGB image processing, deep learning is also widely utilized in HSI [
31,
32]. CNNs have been frequently employed in hyperspectral classification for better classification accuracy [
33,
34,
35]. Chen et al. [
36] proved that a 3D CNN can extract distinguished spatial–spectral features for the HSI classification problem. Recently, transfer learning [
37,
38] has been employed to solve the task of hyperspectral super-resolution and pansharpening. However, the spectral distortions may not be solved well by transferring directly from the network used in RGB image super-resolution methods to hyperspectral image super-resolution [
39]. Mei et al. [
40] proposed a 3D CNN architecture to encode spatial and spectral information jointly. Although 3D CNN is effective, this typical structure is far from an optimal choice. Wang et al. [
41] proposed a deep residual convolution network for SR, however, the learning process is after the up-sampling process, which costs too much in computation. Lei et al. [
42] promoted learning multi-level representation using a local-global combined network. Though it is effective, it contains too many parameters to be tuned through extensive training examples. To increase the generalization capacity, Li et al. [
43] presented a grouped deep recursive residual network, called GDRRN. Jia et. al [
44] combined a spatial network and a spectral network serially to take full use of spatial and spectral information. To address the spectral disorder caused by 2D convolution, Zheng et al. [
45] proposed a separable-spectral and inception network (SSIN) to enhance the resolution in a coarse-to-fine manner.
From the above-mentioned brief introduction, it can be seen that the existing HSI SR algorithms still focus on 3D convolution fashion, which is difficult to train. Very recently, there have been many mixed 2D-3D convolution based methods proposed in the RGB video analysis literature [
21,
46]. The hypotheses of these works is that the decomposition of 3D CNN could achieve better performance due to the redundancy between frames. A similar phenomenon occurs in the HSI field, in that spectral bands are highly redundant. Furthermore, the hyperspectral SR problem can be divided into a spatial part and a spectral part. It can be concluded that the hyperspectral SR problem concentrates on the spatial resolution enhancement and the spectral fidelity. Therefore, decomposition of 3D convolution into 1D–2D convolution can provide an efficient idea, through which the HSI SR problem can be solved via a two-stream network based on 1D and 2D convolution respectively. e.g., 1D convolution can extract the efficient spectral features, while 2D convolution can capture the spatial information without using full spectral bands.
4. Experiments Setting
In this section, we conduct a series of experiments on four typical hyperspectral sets to evaluate the performance of our proposed network. As the performance of deep learning-based algorithms is better than the traditional algorithm, three state-of-the-art deep learning methods with public codes are selected as the baseline for comparison purposes in hyperspectral SISR: LapSRN [
50], 3DFCNN [
40] and GDRRN [
43]. Three classic hyperspectral pansharpening algorithms are also selected for comparison, such as the GFPCA [
17], the CNMF [
22], and the Hysure [
14].
4.1. Evaluation Criteria
To comprehensively evaluate the performance of the proposed methods, several classical evaluation metrics are utilized: mean peak signal-to noise ratio (MPSNR), mean structural similarity index (MSSIM), mean root mean square error (MRMSE), spectral angle mapper (SAM), the cross correlation (CC), and the erreur relative global adimensionnelle de synthese (ERGAS).
The MPSNR and MRMSE can estimate the similarity between the generated image and the ground truth image through the mean squared error. The MSSIM emphasizes the structural consistency with the ground truth image. The SAM is utilized to evaluate the spectral reconstruction quality of each spectrum at pixel-levels, which calculates the average angle between spectral vectors of the generated HSI and the ground truth one. The CC reflects the geometric distortion, and the ERGAS is a global indicator of the fused image quality [
51]. The ideal values of the MPSNR, MSSIM and CC are 1. As for the SAM, RMSE, and ERGAS, the optimal values are 0.
Given a reconstruction image
and a ground truth image
S, these four evaluation metrics are defined as:
where
is the maximum intensity in the
k-th band,
and
are the mean values of
and
respectively,
and
are the variance of
and
respectively,
is the covariance between
and
,
and
are two constants used to improve stability,
is the number of pixels,
denotes the dot product of two spectra
and
,
represents
norm operation, and
d denotes the ratio between the pixel size of the PAN image and the HSI.
In these evaluation metrics, the larger the MPSNR, MSSIM, and CC, the more similar the reconstructed HSI and the ground truth one. Meanwhile, the smaller the SAM, MRMSE, and ERGAS, the more similar the reconstructed and the ground truth ones.
4.2. Datasets and Parameter Setting
Pavia University and Pavia Center are two hyperspectral scenes acquired via the ROSIS sensor, which covers 115 spectral bands from 0.43 to 0.86 m, which are employed in our experiments for hyperspetral SISR comparison. The geometric resolution is 1.3 m. The University of Pavia image has 610 × 340 pixels, each having 103 bands after bad-band and noisy band removal. The Pavia Center scene contains 1096 × 1096 pixels, 102 spectral bands left after bad-band removal. In the Pavia center scene, only 1096 × 715 valid pixels are utilized after discarding the samples with no information in this experiment. For each dataset, a 144 × 144 sub-region is selected to evaluate the performance of our proposed 1D–2D attentional CNN, another 144 × 144 sub-region is selected for verication, while the remaining are used for training.
The CAVE dataset and Harvard dataset are two publicly available hyperspectral datasets for hyperspectral pansharpening comparison. The CAVE dataset includes 32 HSIs of real-world materials and objects captured in the laboratory environment. All the HSIs in the CAVE dataset have 31 spectral bands ranging from 400 nm to 700 nm at 10 nm spectral resolution, and each band has a spatial dimension of pixels. The Harvard dataset comprises 50 HSIs of indoor and outdoor scenes such as offices, streetscapes, and parks under daylight illumination. Each HSI has a spatial resolution of with 31 spectral bands covering the spectrum range from 420 nm to 720 nm at steps of 10 nm. For CAVE dataset, we select the first 16 images as the training dataset, four images as the validation dataset, and the remaining 12 images are utilized as the testing dataset. For the Harvard dataset, we employ 26 HSIs for training, six HSIs for verification and the remaining 18 for testing. The simulated PAN images with the same spatial size as the original HSIs are generated by averaging the spectral bands of the visible range of the original HSIs.
The proposed 1D–2D attentional framework is implemented on the deep learning framework named Pytorch. Training was performed on an NVIDIA GTX1080Ti GPU. The parameters of the network were optimized using Adam modification and the initial learning rate is set to . We try the learning rate set . The experimental results show that when the initial learning rate is 0.001, we get the best results compared to other learning rates.
5. Experimental Results and Discussions
In this section, we evaluate our proposed algorithm from the quantitative and qualitative analysis on both HSISR and hyperspectral pansharpening results. For adaptive different SR tasks, a is set to 2 in our experiments. It is worth noting that all the algorithms are under same condition of the experimental setting, which indicates that both the comparison algorithms and the proposed algorithm are well-trained through employing same training samples. Furthermore, through the aforementioned introduction of data sets, the test data is not included in the training data.
5.1. Discussion on the Proposed Framework: Ablation Study
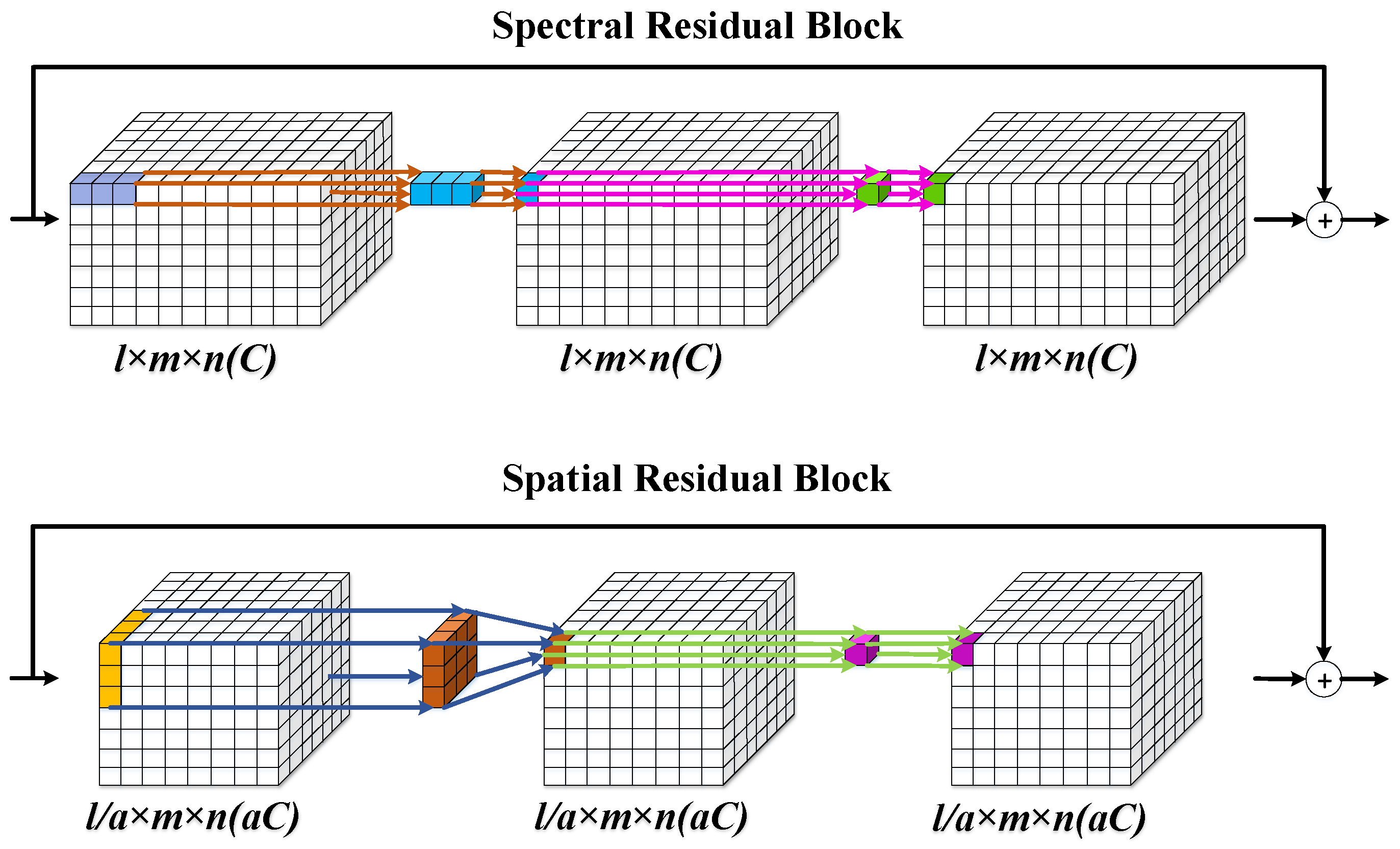
In this section, we first evaluate the efficiency of our proposed architecture taking the Pavia Center dataset as a example. Our proposed approach contains two parallel architectures: 2D stream spatial residual CNN and 1D stream spectral residual CNN. Traditionally, 3D convolutional kernels are utilized for extracting and encoding the spatial–spectral information simultaneously with heavy parameters tuning. Here we use a 1D () and a 2D () convolutions for learning spatial–spectral features respectively but with similar or even better results. To demonstrate our effectiveness of 1D–2D convolutional kernels, we conduct a set of experiments on the Pavia Center dataset. Spa denotes only a 2D stream spatial network in our proposed algorithm is employed for evaluation. Spe denotes that only a 1D stream spectral network is utilized. The 3D conv indicates using a 3D convolutional kernel to extract spatial–spectral information simultaneously but with the same number of layers as our proposed algorithm. The spe-spa denotes our proposed algorithm without using spatial attention. The number of channels utilized are depicted following the algorithms’ name. For instance, the numbers of channels in the Spe-spa network are set to (32,32), which means the channels of the spatial network are set to 32 (with full bands). Meanwhile, the channels of the spectral network are set to 32. For evaluation our proposed parallel framework, the channels are set to 32 for all the compared methods.
From
Table 3, we can see that when using only the spatial or spectral network, the four criteria cannot reach satisfying values simultaneously. For instance, the MRMSE and MPSNR obtained via the spectral network is smaller than with the Spe-spa network, which indicates that the spatial information cannot be well extracted and encoded. The SAM achieved only by the spatial network is larger than other networks, as the inadequate spectral information is learned while suppressing the spectral fidelity. Furthermore, our proposed algorithm offers the best resolution enhancement result compared to the Spe-spa network implying that our spatial attention mechanism can take a positive role in the resolution enhancement problem. In addition, we tabulate the kernels, channels, and strides used in comparison experiments. The total number of parameters utilized in each network are also listed in each network learning. From
Table 4, it can be concluded that the design of parallel architecture does reduce the number of parameters and has a low computational complexity.
Our 1D–2D attentional convolutional neural network employs a separation strategy to extract the spatial–spectral information and then fuse them gradually. Specifically, a a 1D convolution path is used for spectral feature encoding, and a 2D convolution path is used for the spatial features. In fact, the spectral bands of HSI are highly redundant, so, we do not need to utilize full bands of HSIs. Dimensionality reduction is an effective preprocessing step to discard the redundant information [
52,
53,
54]. Therefore, instead of using full bands we select part of the bands for spatial enhancement through the
a parameter. Furthermore, the emphasis of the spatial network is to extract and enhance the spatial features. The less bands we select, the more filters are used, and the network can learn more sufficient and deeper spatial information. Additionally, this method can ensure that the shape of the spectral path is the same as the spatial path after the reshape operation, and can integrate the information of the two branches through hierarchical side connections. We evaluate our proposed network through
a factors such as 1, 2, 4, and 8. From
Figure 5, we can see that with the increasing number of
a, the performance of our proposed algorithm based on the Pavia Center dataset increases first and then decreases. When
a is equal to 4, the SR results have the best performance. Specifically, when
a is equal to 1, all bands are utilized and the spectral bands of HSI are highly redundant. If
a is equal to 2 or 4, then half of the bands or a 1/4 of the bands are utilized, but more channels are employed for deeper extraction. All of them can achieve better results. If
a is equal to 8, then 1/8 of the bands are utilized. There is a greater possibility that information loss is severe, resulting in a poor performance result. This is because when
a is too small, the spectral information is redundant and when
a is too large, the information loss is serious. Then, the performance decreases. Therefore, there exists a trade-off between redundant information and information loss. Experiments show that when
a is equal to 4, the SR results has the best performance on Pavia Center dataset.
In this section, we evaluate our proposed algorithm from the quantitative and qualitative analysis on both HSISR and hyperspectral pansharpening results. For adaptive different SR tasks, a is set to 2 in our experiments.
5.1.1. Results of Hyperspectral SISR and Analysis
We evaluate our proposed network through different up-sampling factors such as 2, 4, and 8.
Table 5 and
Table 6 tabulate the quantitative results under different up-sampling factors. Their corresponding visual results are depicted in
Figure 6 and
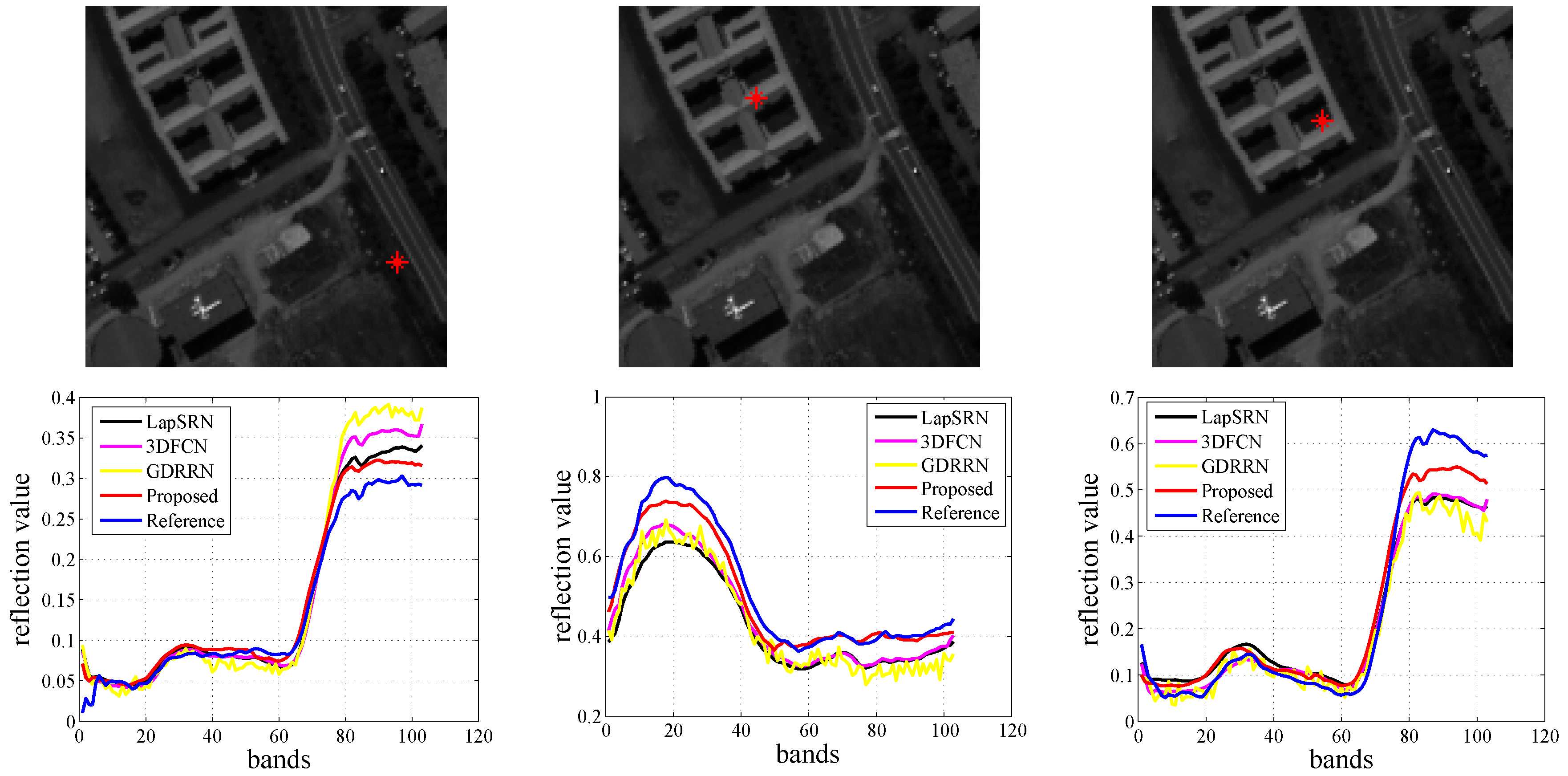
Figure 7. The Pavia University dataset is displayed in band 49. The Pavia Center dataset is displayed in band 13.
Our proposed method outperforms other comparison algorithms with different up-sampling factors. Despite the difficulty of HSISR at a large up-sampling factor, our 8x model still performed well. For the results achieved from the Pavia University dataset, it is observed that: (1) The proposed method significantly outperforms with the highest MPSNR, MSSIM, and lowest MRMSE and SAM values for all the cases; (2) Compared with the GDRRN, the improvements of our methods are 2.1276 dB and 0.0672 in terms of MPSNR and MSSIM, meanwhile the decreases are 1.7729 and 1.4089 in terms of MRMSE and SAM through averaging the values under different up-sampling factor; (3) The proposed method achieves the best spatial reconstruction compared to other SR methods irrelevant to the up-sampling factor. It can also be clearly seen from
Figure 6 that the image reconstructed by the proposed method has finer texture details than the other comparison methods, especially, when under 8x up-sampling factor, the texture and edge information of the region in the red rectangle is clearer than the other methods; (4) The proposed method achieves the best spectral fidelity with the lowest SAM in all the cases.
Figure 8 further demonstrates the spectrum after hyperspectral resolution enhancement. It is implied that the spectra reconstructed by the proposed algorithm is the closest to its ground-truth than those achieved by comparison methods.
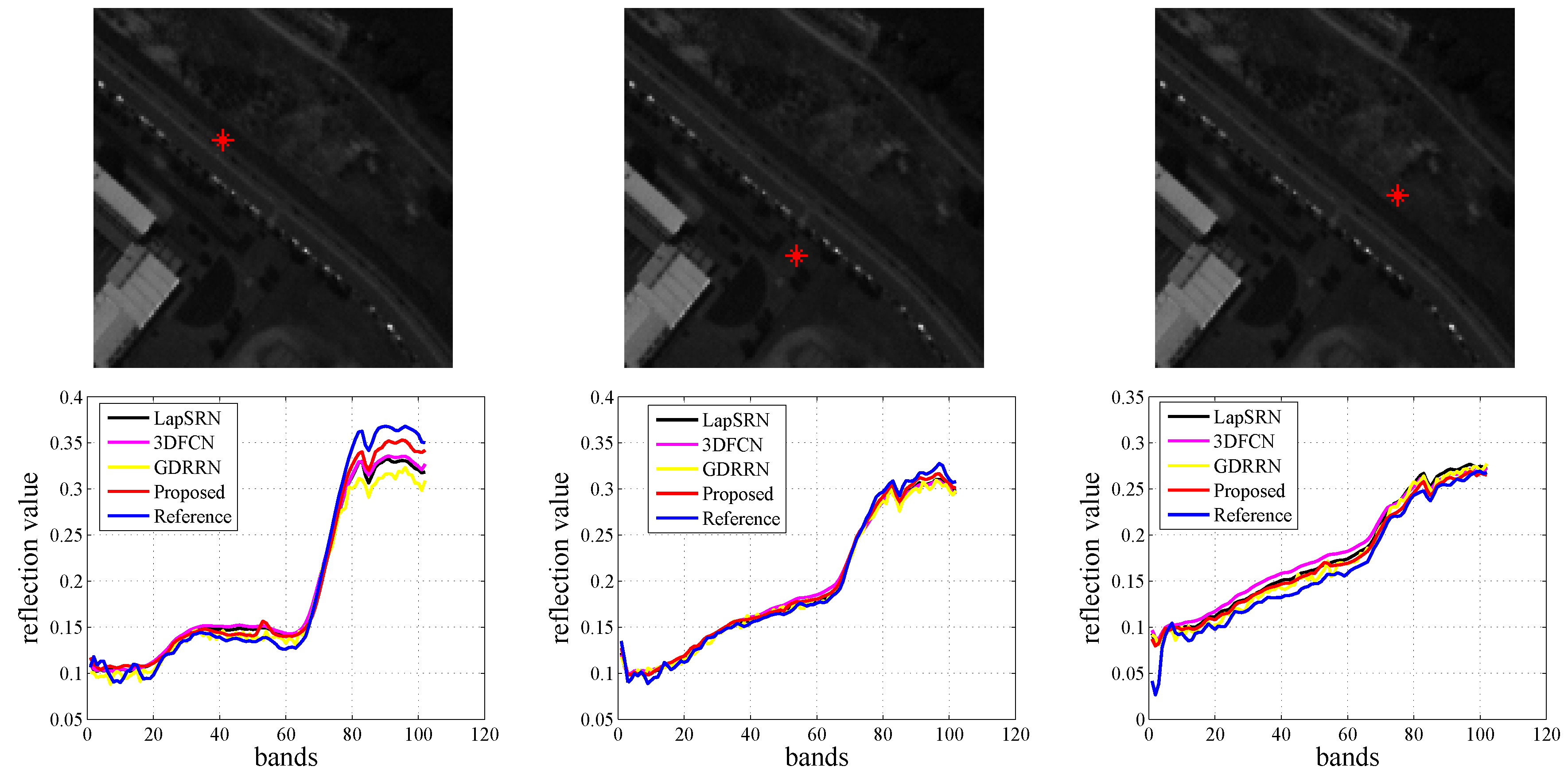
From the results obtained from the Pavia Center dataset in
Figure 7 and
Table 6, we can see that, compared with other methods, our proposed method still has superior SR results. For instance, compared with the GDRRN, MPSNR increased by an average of 2.2042, MSSIM improved by 0.0457, MRMSE decreased by 1.4783, and SAM dropped by 0.9212. Furthermore,
Figure 9 depicts the spectral accuracy achieved via different HSISR methods, and it indicates that our proposed method can reconstruct more similar spectra than other methods. Therefore, the results on the Pavia Center dataset have similar phenomena as the results on the Pavia University dataset.
From the results presented above, the values of MPSNR, MSSIM, MRMSE and SAM metrics achieved by our proposed algorithm are preferable than other methods implying that the proposed algorithm can learn and enhance the spatial features more reasonable with consistency of the structure features when considering non-local spatial information through the spatial attention mechanism. Furthermore, the spectral fidelity of algorithm is kept most accurate due to the fact that a separate spectral residual network is used specifically for maintaining spectral information. Therefore, it can be concluded that the proposed algorithm outperforms on these two datasets acquired by the ROSIS sensor.
5.1.2. Results of Hyperspectral Pansharpening and Analysis
We also evaluate our proposed network in hyperspectral pansharpening when the up-sampling factor is set as 4.
Table 7 tabulates the quantitative results of different hyperspectral pansharpening methods based on the Cave dataset. It can be seen that our proposed method achieved the best performance in terms of ERGAS, CC, MRMSE, and SAM. Both SAM and ERGAS are far smaller than the other comparison algorithms. Compared with the GFPCA algorithm, CC increased by 0.0161, ERGAS decreased by 2.1487, MRMSE reduced by 0.0099, and SAM dropped by 1.443. Indicating that the proposed resolution enhancement algorithm can not only extract better spatial information but also better refrains the spectral distortion.
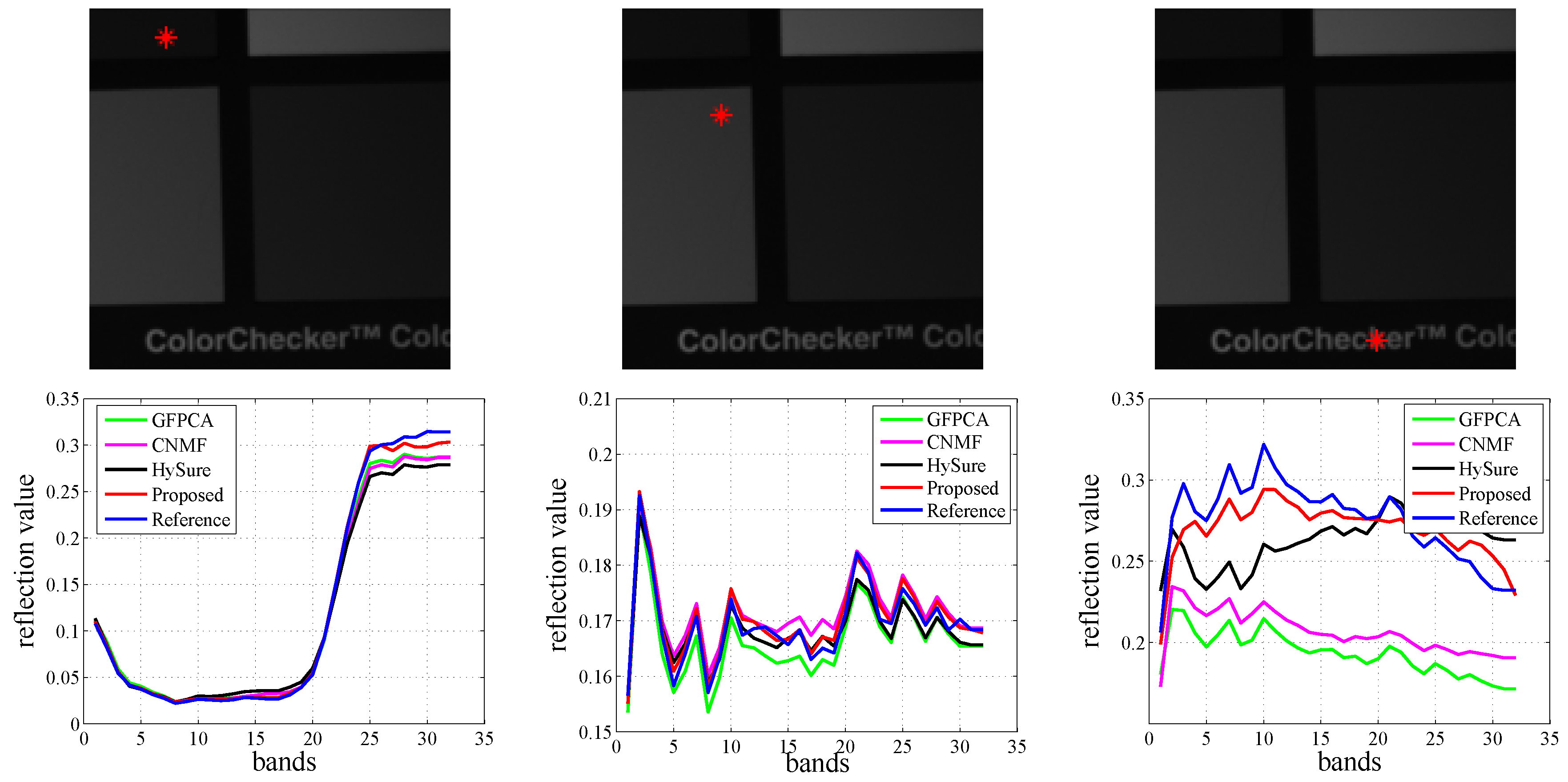
Figure 10 and
Figure 11 demonstrate the visual results and spectrum of the super-resolved HSI respectively, from which we can acknowledge that the texture and edge features obtained by our proposed algorithm are the clearest and most accurate. The CAVE dataset is displayed in band 28, and the Harvard dataset is displayed in band 18.
In addition, we design a set of experiments on the Harvard dataset.
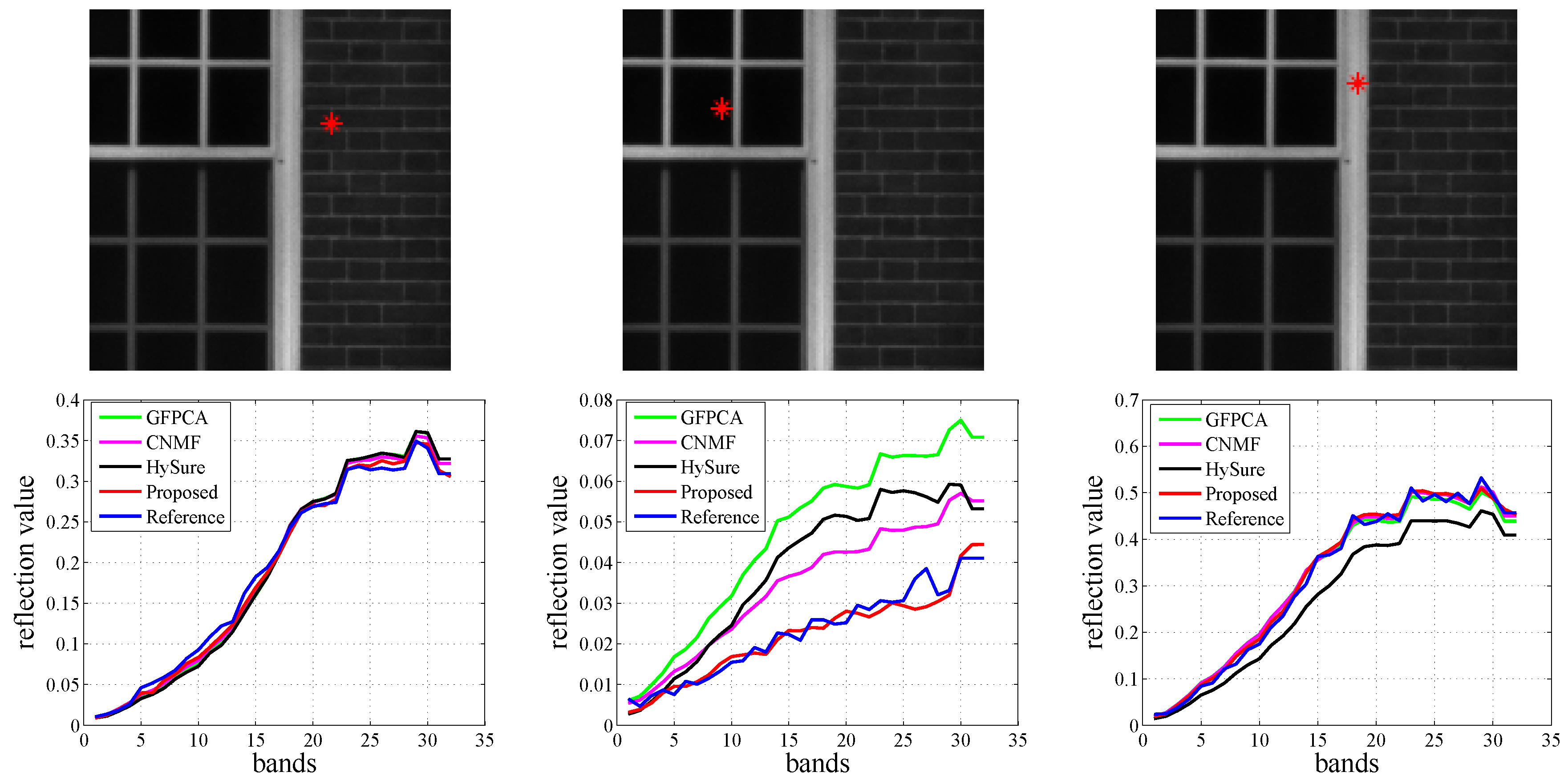
Table 8 tabulates the quantitative results of different hyperspectral pansharpening methods based on the Harvard dataset. Furthermore, our proposed algorithm has the best fusion performance compared to the other comparison algorithms. In specific, the ERGAS obtained via our method is the smallest, which means that our 1D–2D attentional CNN can obtain the best fusion performance. Also, the displays from
Figure 12 and
Figure 13 further demonstrate the superiority and advantage of our proposed algorithm for spatial resolution enhancement and spectral reconstruction.
Based on HSISR and hyperspectral pansharpening, our model can provide a performance superior to other state-of-the-art methods.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}