Point Set Multi-Level Aggregation Feature Extraction Based on Multi-Scale Max Pooling and LDA for Point Cloud Classification

 ,
,  ,
,  ,
,
Abstract
:
1. Introduction
2. Multi-Level Point Sets Construction
2.1. Large-Scale Point Set Construction Based on Point Cloud Density
2.2. Adaptive Small-Scale Point Sets Construction Based on K-Means
| Algorithm 1: K-Means-Based Adaptive Small-Scale Point Sets Construction Algorithm. |
| Input: The coarse point sets obtained by DBSCAN V = {V1,…,VN } (N is the number of point sets) |
| Parameters: The number of cluster centers K, The maximum point threshold in point set: maximum number of iterations Titer. |
| forI = 1:N |
| 1: An unlabeled point set Vi is selected, and K points are selected as the initial centroid , c = 1,2,…,K. (Make sure the distance between centroids is not too close). |
| 2:While stop condition not met do |
| 2.1: For the input point set, calculate the Euclidean distance of each point from the centroid . Discriminate the category of each point according to the following equation, and obtain the point cloud clusters of each category . |
| 2.2: Update the centroid of each category: , is the points number of the c-th point cloud cluster. |
| 2.3: The stop condition: , or Titer. |
| end |
| 3: forc = 1:K in |
| 3.1: if |
| , v is the v-th output over-segmented point set. |
| V = v+1. |
| 3.2: else |
| , s is the s-th point set with more than T points. |
| = +1 |
| end |
| end |
| 4: Repeat step 2 and step 3 until the point cloud clusters . |
| end |
| Output: Over-segmented point sets: = { }. |
2.3. Multi-Level Point Sets Generation
3. Multi-Level Point Set Features Extraction
3.1. Multi-Scale Single Point Features Extraction
3.2. LLC-Based Dictionary Learning and Sparse Coding for Single Point Features
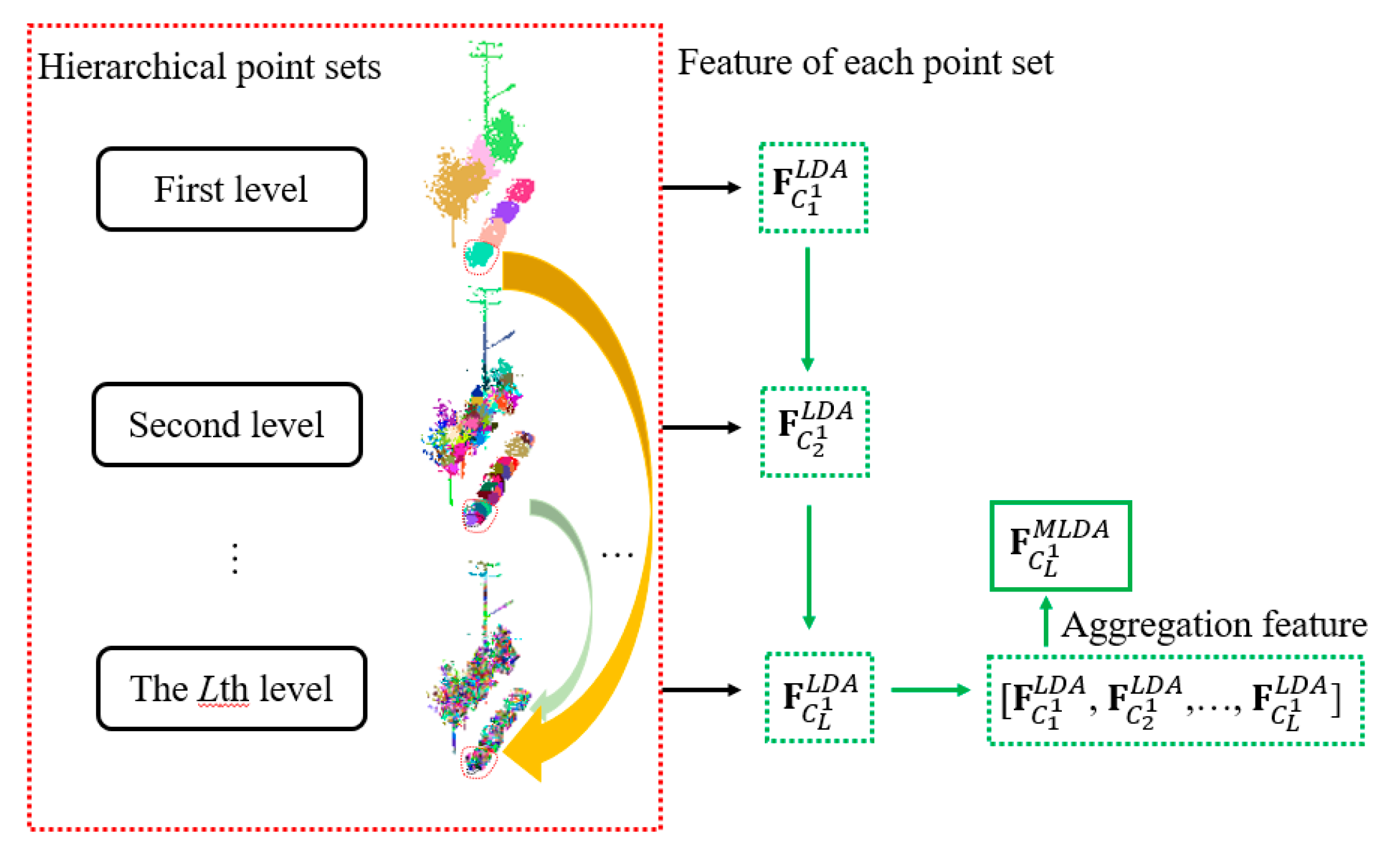
3.3. Multi-Level Point Set Features Construction
3.3.1. Point Set Features Extraction Based on LDA (LLC-LDA)
3.3.2. Point Set Features Extraction Based on Multi-Scale Max Pooling (LLC-MP)
4. Point Cloud Classification Based on Fusion of Multi-Level Point Set Features
5. Experimental Results and Analysis
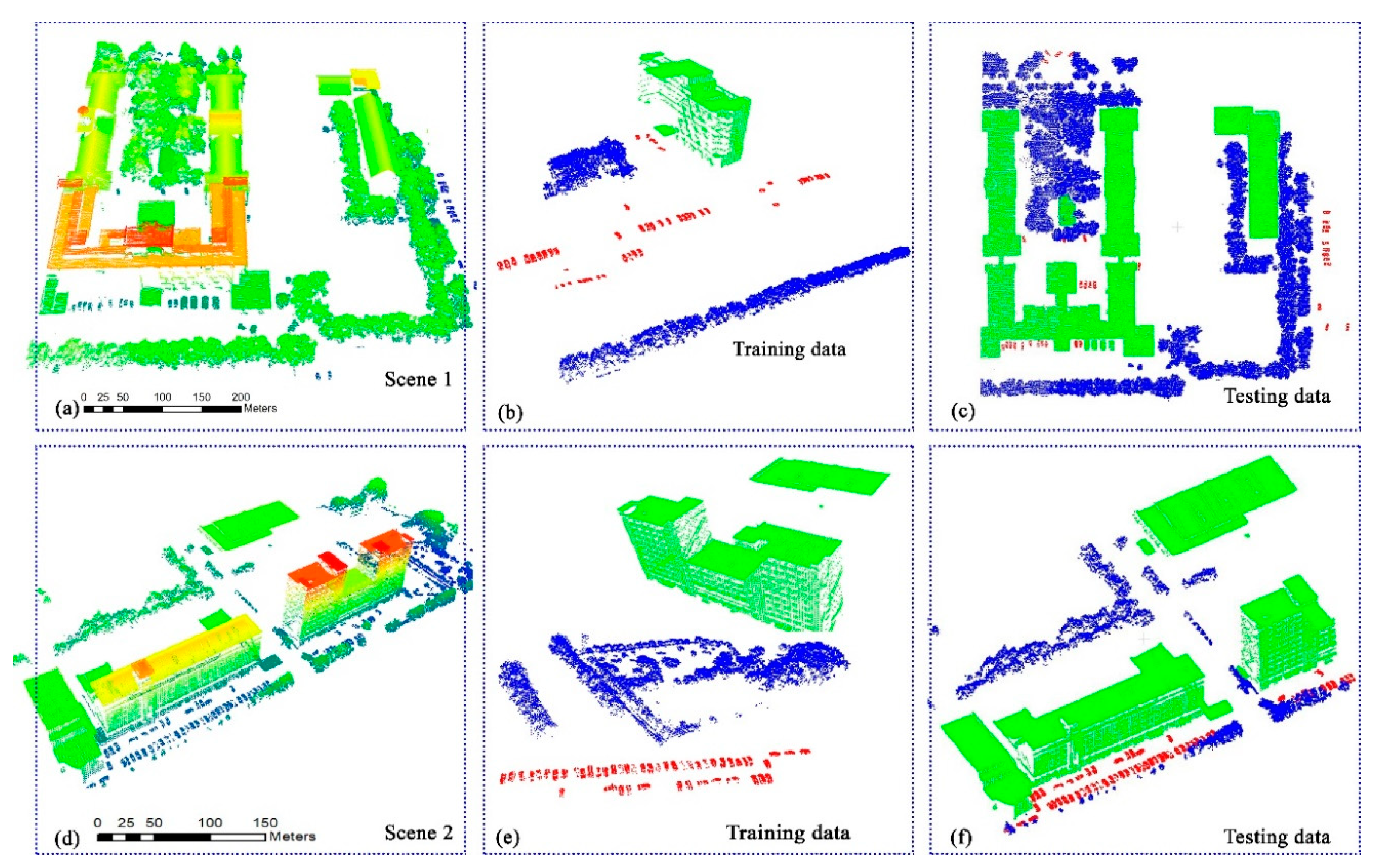
5.1. Experiment Data
5.2. Comparisons
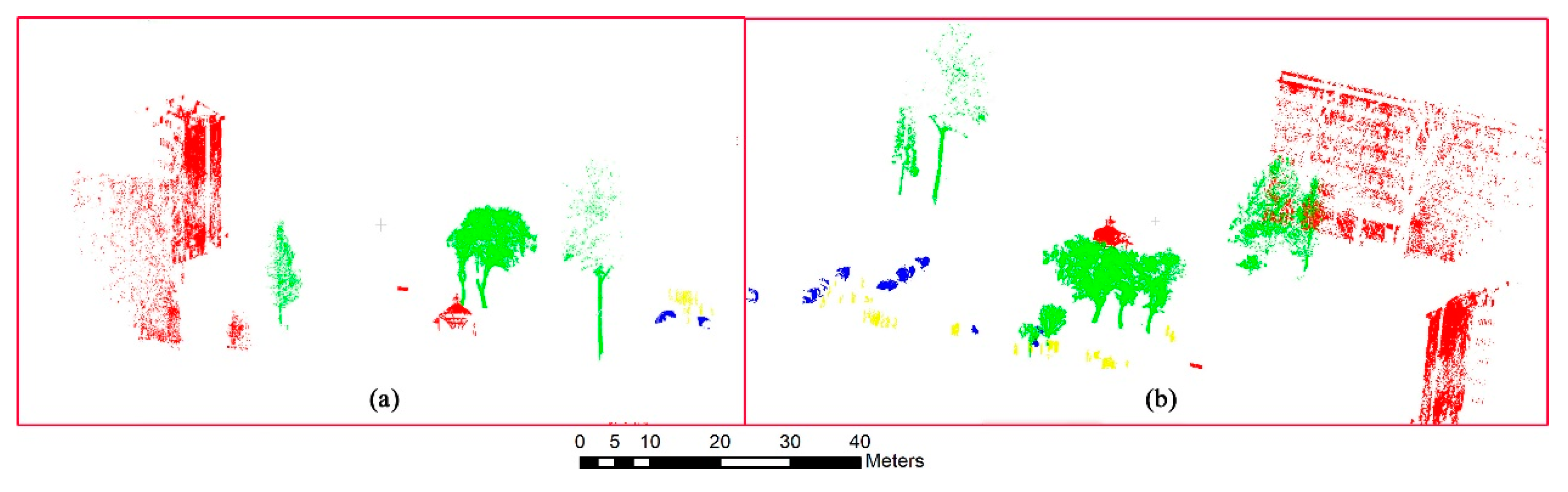
5.2.1. ALS Point Clouds
5.2.2. MLS and TLS Point Clouds
5.3. Parameters Sensitivity Analysis
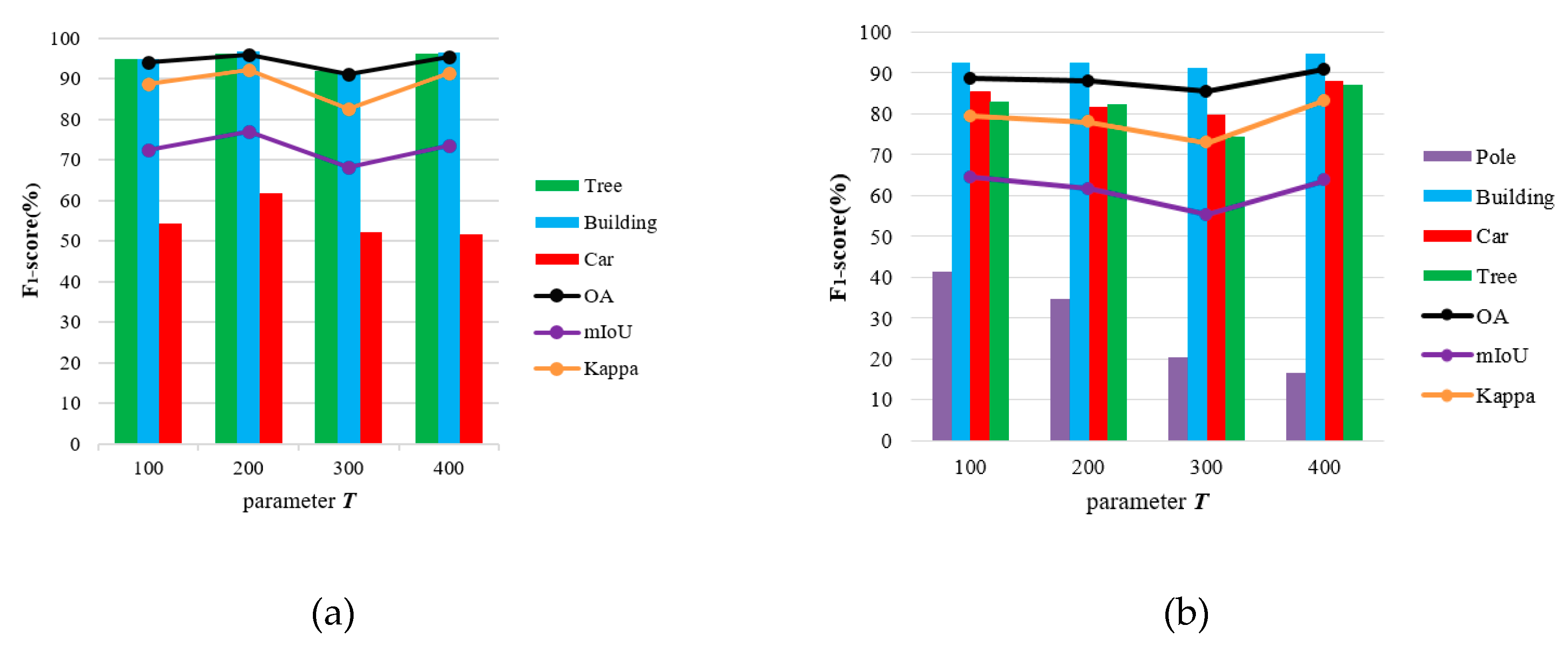
5.3.1. Sensitivity Analysis of Parameter T
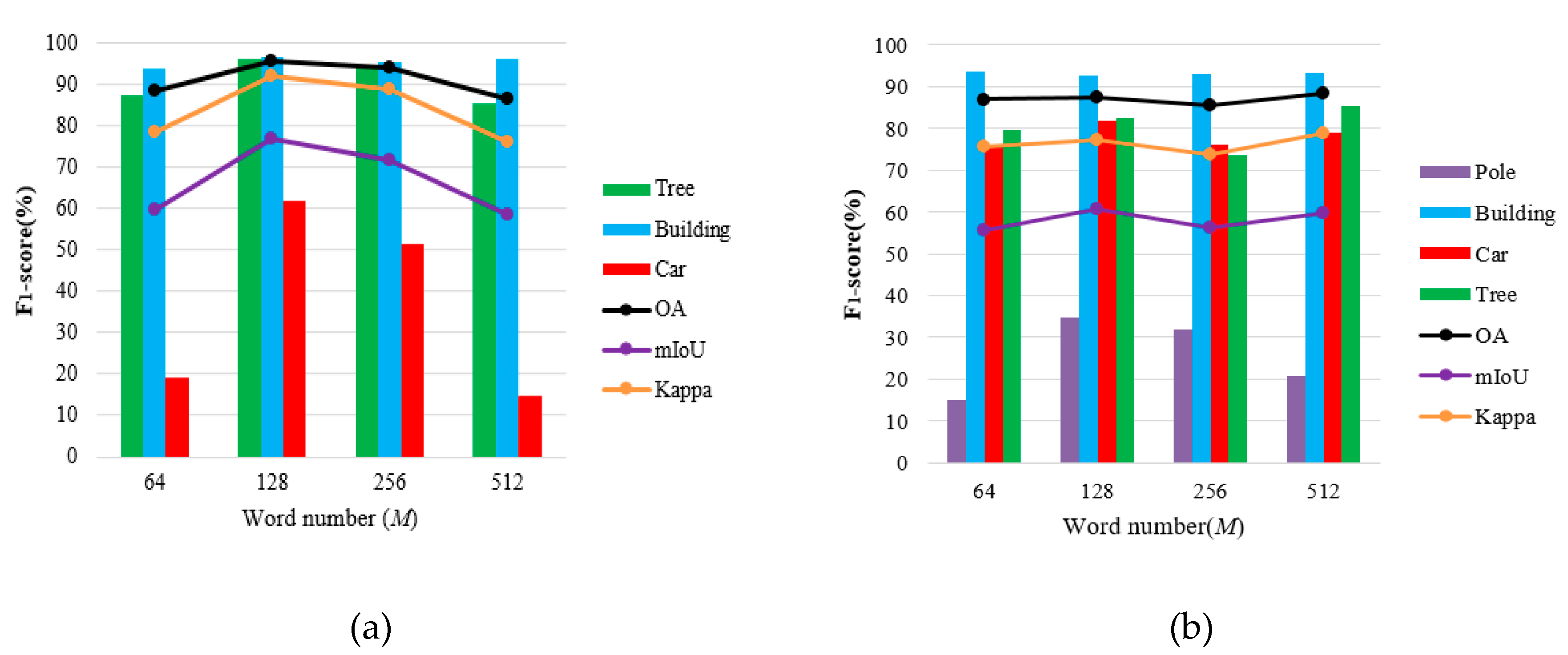
5.3.2. Sensitivity Analysis of Parameters on Dictionary Learning and Sparse Representation
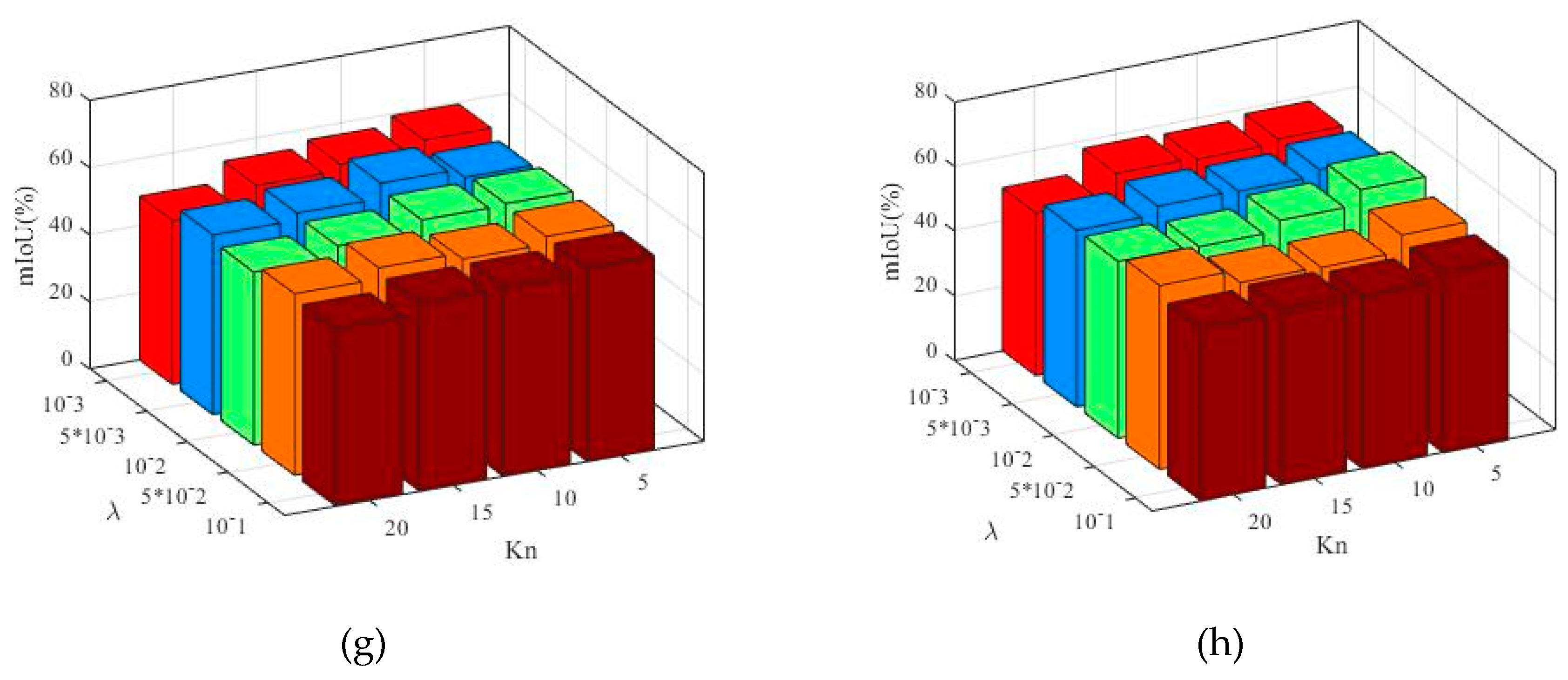
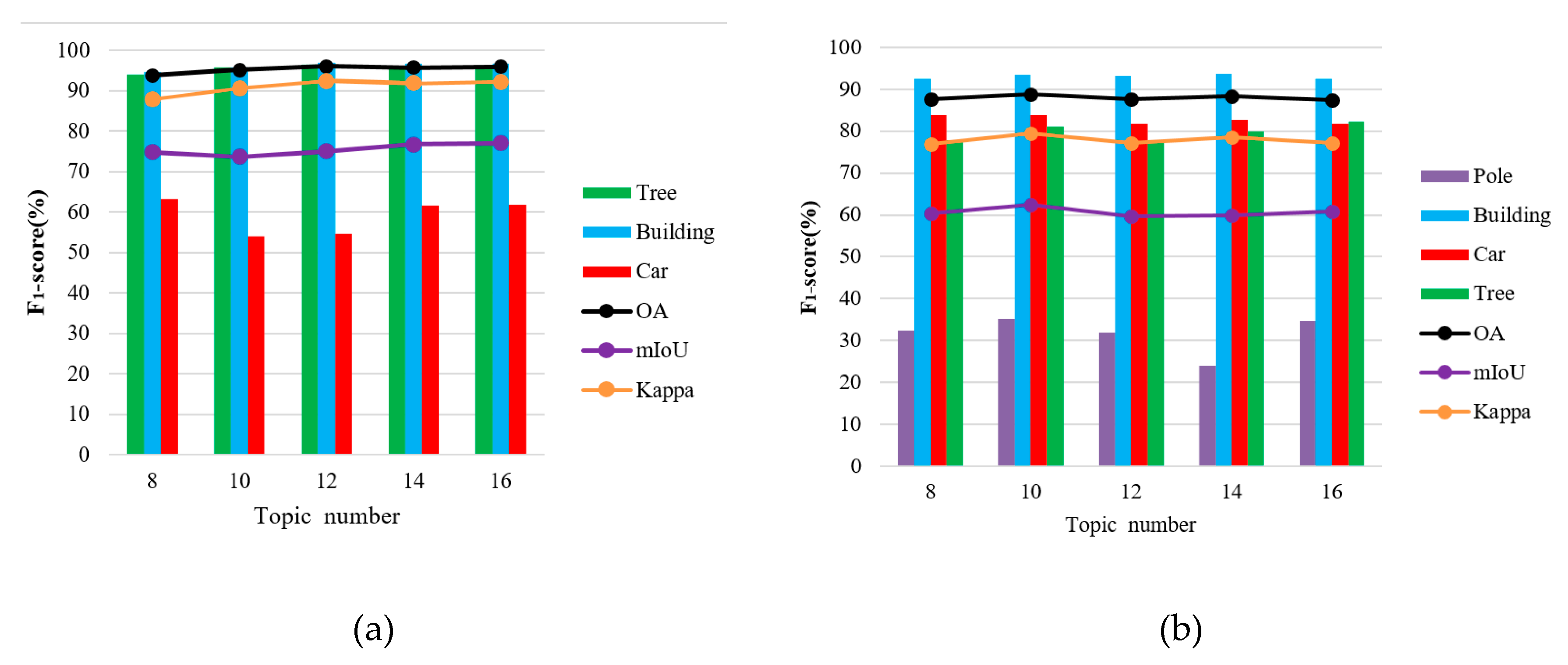
5.3.3. Sensitivity Analysis of Latent Topics Number
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Landrieu, L.; Simonovsky, M. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yang, B.; Dong, Z.; Liu, Y.; Liang, F.; Wang, Y. Computing multiple aggregation levels and contextual features for road facilities recognition using mobile laser scanning data. ISPRS J. Photogramm. Sens. 2017, 126, 180–194. [Google Scholar] [CrossRef]
- Bircher, A.; Alexis, K.; Burri, M.; Oettershagen, P.; Omari, S.; Mantel, T.; Siegwart, R. Structural inspection path planning via iterative viewpoint resampling with application to aerial robotics. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015. [Google Scholar]
- Gonzalez-Aguilera, D.; Crespo-Matellan, E.; Hernandez-Lopez, D.; Rodriguez-Gonzalvez, P. Automated urban analysis based on LiDAR-derived building models. IEEE Trans. Geosci. Remote Sens. 2013, 51, 1844–1851. [Google Scholar] [CrossRef]
- Li, Y.; Tong, G.; Du, X.; Yang, X.; Zhang, J.; Yang, L. A single point-based multilevel features fusion and pyramid neighborhood optimization method for ALS point cloud classification. Appl. Sci. 2019, 9, 951. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, L.; Fang, T.; Mathiopoulos, P.; Tong, X.; Qu, H.; Xiao, Z.; Li, F.; Chen, D. A multiscale and hierarchical feature extraction method for terrestrial laser scanning point cloud classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2409–2425. [Google Scholar] [CrossRef]
- Ni, H.; Lin, X.; Zhang, J. Classification of ALS point cloud with improved point cloud segmentation and random forests. Remote Sens. 2017, 9, 288. [Google Scholar] [CrossRef]
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- Mei, J.; Zhang, L.; Wang, Y.; Zhu, Z.; Ding, H. Joint margin, cograph, and label constraints for semisupervised scene parsing from point clouds. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3800–3813. [Google Scholar] [CrossRef]
- Johnson, A. Spin-Images: A Representation for 3D Surface Matching. Ph.D. Thesis, Robotics Institute, Carnegie Mellon University, Pittsburgh, PA, USA, 1997. [Google Scholar]
- Lin, C.; Chen, J.; Su, P.; Chen, C. Eigen-feature analysis of weighted covariance matrices for LiDAR point cloud classification. ISPRS J. Photogramm. Remote Sens. 2014, 94, 70–79. [Google Scholar] [CrossRef]
- Rusu, R.; Bradski, G.; Thibaux, R.; Hsu, J. Fast 3D recognition and pose using the viewpoint feature histogram. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010. [Google Scholar]
- Aldoma, A.; Vincze, M.; Blodow, N.; Gossow, D.; Gedikli, S.; Rusu, R.; Bradski, G. CAD-model recognition and 6DOF pose estimation using 3D cues. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Mei, J.; Wang, Y.; Zhang, L.; Zhang, B.; Liu, S.; Zhu, P.; Ren, Y. PSASL: Pixel-level and superpixel-level aware subspace learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4278–4293. [Google Scholar] [CrossRef]
- Wang, Y.; Mei, J.; Zhang, L.; Zhang, B.; Li, A.; Zheng, Y.; Zhu, P. Self-supervised low-rank representation (SSLRR) for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5658–5672. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, L.; Tong, X.; Mathiopoulos, P.; Guo, B.; Huang, X.; Wang, Z.; Wang, Y. A multilevel point-cluster-based discriminative feature for ALS point cloud classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3309–3321. [Google Scholar] [CrossRef]
- Qi, C.; Su, H.; Mo, K.; Guibas, L. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, Z.; Liu, Y.; Chen, D.; Zhang, L.; Zhong, R.; Xu, Z.; Han, Y. Progress in research of feature representation of laser scanning point cloud. Geogr. Geo-Inf. Sci. 2018, 34, 33–39. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, L.; Mathiopoulos, P.; Liu, F.; Zhang, L.; Li, S.; Liu, H. A hierarchical methodology for urban facade parsing from TLS point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 123, 75–93. [Google Scholar] [CrossRef]
- Babahajiani, P.; Fan, L.; Kämäräinen, J.; Gabbouj, M. Urban 3D segmentation and modelling from street view images and LiDAR point clouds. Mach. Vis. Appl. 2017, 28, 679–694. [Google Scholar] [CrossRef]
- Lodha, S.; Fitzpatrick, D.; Helmbold, D. Aerial LiDAR data classification using AdaBoost. In Proceedings of the Sixth International Conference on 3-D Digital Imaging and Modeling (3DIM 2007), Montreal, QC, Canada, 21–23 August 2007. [Google Scholar]
- Zhang, J.; Lin, X.; Ning, X. SVM-based classification of segmented airborne LiDAR point clouds in urban areas. Remote Sens. 2013, 5, 3749–3775. [Google Scholar] [CrossRef]
- Li, Y.; Chen, D.; Du, X.; Xia, S.; Wang, Y.; Xu, S.; Yang, Q. Higher-order conditional random fields-based 3D semantic labeling of airborne laser-scanning point clouds. Remote Sens. 2019, 11, 1248. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; Le Cam, L.M., Neyman, J., Eds.; University of California Press: Berkeley/Los Angeles, CA, USA, 1967; Volume I Theory of Statistics. [Google Scholar]
- Wu, Y.; Li, F.; Liu, F.; Cheng, L.; Guo, L. Point cloud segmentation using Euclidean cluster extraction algorithm with the Smoothness. Meas. Control. Technol. 2016, 35, 36–38. [Google Scholar]
- Feng, C.; Taguchi, Y.; Kamat, V. Fast plane extraction in organized point clouds using agglomerative hierarchical clustering. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014. [Google Scholar]
- Ester, M.; Kriegel, H.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the KDD'96 Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Liu, P.; Zhou, D.; Wu, N. VDBSCAN: Varied density based spatial clustering of applications with noise. In Proceedings of the International Conference on Service Systems and Service Management, Chengdu, China, 9–11 June 2007. [Google Scholar]
- Li, M.; Sun, C. Refinement of LiDAR point clouds using a super voxel based approach. ISPRS J. Photogramm. Remote Sens. 2018, 143, 213–221. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Fischler, M.; Bolles, R. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM. 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Awadallah, M.; Abbott, L.; Ghannam, S. Segmentation of sparse noisy point clouds using active contour models. In Proceedings of the IEEE International Conference on Image Processing, Paris, France, 27–30 October 2014. [Google Scholar]
- Xu, Z.; Zhang, Z.; Zhong, R.; Dong, C.; Sun, T.; Deng, X.; Li, Z.; Qin, C. Content-sensitive multilevel point cluster construction for ALS point cloud classification. Remote Sens. 2019, 11, 342. [Google Scholar] [CrossRef]
- Li, Y.; Tong, G.; Li, X.; Zhang, L.; Peng, H. MVF-CNN: Fusion of multilevel features for large-scale point cloud classification. IEEE Access 2019, 7, 46522–46537. [Google Scholar] [CrossRef]
- Qi, C.; Yi, L.; Su, H.; Guibas, L. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Jeong, J.; Lee, I. Classification of LiDAR data for generating a high-precision roadway map. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 251–254. [Google Scholar] [CrossRef]
- Wang, J.; Yang, J.; Yu, K.; Lv, F.; Huang, T.; Gong, Y. Locality-constrained linear coding for image classification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Guo, B.; Huang, X.; Zhang, F.; Sohn, G. Classification of airborne laser scanning data using JointBoost. ISPRS J. Photogramm. Remote Sens. 2015, 100, 71–83. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, L.; Tong, X.; Guo, B.; Zhang, L.; Xing, X. Discriminative-dictionary-learning-based multilevel point-cluster features for ALS point-cloud classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7309–7322. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, L.; Tan, Y.; Zhang, L.; Liu, F.; Zhong, R. Joint discriminative dictionary and classifier learning for ALS point cloud classification. IEEE Trans. Geosci. Remote Sens. 2017, 56, 524–538. [Google Scholar] [CrossRef]
- Blei, D.; Ng, A.; Jordan, M. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Chang, C.; Lin, C. LIBSVM: A library for support vector machines. ACM Trans. Intell. Sys. Technol. (TIST) 2011, 2, 27. [Google Scholar] [CrossRef]
- Huang, H.; Wang, L.; Jiang, B.; Luo, D. Precision verification of 3D SLAM backpacked mobile mapping robot. Bull. Surv. Mapp. 2016, 12, 68–73. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, B. Discriminative K-SVD for dictionary learning in face recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Jiang, Z.; Lin, Z.; Davis, L. Label consistent K-SVD: Learning a discriminative dictionary for recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2651–2664. [Google Scholar] [CrossRef]
- Yang, J.; Yu, K.; Gong, Y.; Huang, T. Linear spatial pyramid matching using sparse coding for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | ALS | MLS | TLS |
|---|---|---|---|
| Scenes | Scene1/Scene2 | Scene3 | Scene4 |
| Scanners | Leica ALS50 system | Backpacked mobile mapping robot (Omni SLAMTM) [43] | RIEGL MS-Z620 |
| Range | A mean flying height of 500 m above ground and a 45° field of view | 0–100 m / field of view: 360° × 360° | 2–2000 m/ Horizontal and vertical angle spacing 0.57° |
| Accuracy/Precision | 150 mm/80 mm | 50 mm/30 mm | 10 mm/5 mm |
| Characteristic | The average strip overlap was 30%. Buildings with different roof shapes, e.g., flat and gable roofs, are surrounded by trees and cars. There are buildings with different heights, dense complex trees, and cars on the roads. The classes are unbalanced. | Buildings have varied densities, shapes, and sizes. Other pole-like objects (trees and poles) and cars are connected and mixed together. There are certain degree of noise and outliers scattered in this point clouds. Less affected by the distance changing. The classes are unbalanced. | The density of the point cloud varies according to the distance from the objects to the scanner. Trees are different shapes and densities. Many objects in this scene are incomplete, and many noise points distributes in this scene. The classes are unbalanced. |
| Point density | approximately 20–30 points/m2 | approximately 100–180 points/m2 | approximately 50–250 points/m2 |
| Area | ~(237.7 m × 58.1 m)/ ~ (334.6 m ×0.5 m) | ~ (151.7 m × 178.3 m) | ~ (107.1 m × 79.9 m) |
| Scene type | Residential/Urban, Tianjin | Downtown, Shenyang | Campus, Beijing |
| Training set Points | Test set Points | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Tree | Building | Car | Pole | Pedestrian | Tree | Building | Car | Pole | Pedestrian | |
| Scene1 | 68,802 | 37,128 | 5380 | 0 | 0 | 213,990 | 200,549 | 7816 | 0 | 0 |
| Scene2 | 39,743 | 64,952 | 4,584 | 0 | 0 | 73,207 | 156,186 | 7409 | 0 | 0 |
| Scene3 | 35,078 | 140,164 | 15,936 | 5641 | 0 | 49,359 | 172,311 | 56,889 | 3711 | 0 |
| Scene4 | 125,610 | 45,341 | 1722 | 0 | 3087 | 178,391 | 13,906 | 48,759 | 0 | 16,381 |
| Method | Point Set Construction | Point Cloud Features | Dictionary and Features Expression | Classifier |
|---|---|---|---|---|
| Our method | Multi-level clustering | FSI + Fcov | LLC, Point set features fusion of LLC-LDA and LLC-MP | SVM |
| LLC-LDA-SVM | Multi-level clustering | FSI + Fcov | LLC, Point set features of LLC-LDA | SVM |
| LLC-MP-SVM | Multi-level clustering | FSI + Fcov | LLC, Point set features of LLC-MP | SVM |
| DKSVD [44] | Single point | FSI + Fcov | DKSVD, Dictionary-based sparse representation | Linear classifier |
| LCKSVD1 [45] | Single point | FSI + Fcov | LCKSVD1, Sparse representation based on saliency dictionary | Linear classifier |
| LCKSVD2 [45] | Single point | FSI + Fcov | LCKSVD2, Sparse representation based on saliency dictionary | Linear classifier |
| MSF-SVM [42] | Single point | FSI + Fcov | No dictionary, single point features | SVM |
| ECF-SVM [5] | Single point | Fz + Fcov | No dictionary, single point features | SVM |
| JointBoost [38] | Single point | Geometry, strength, and statistical features | No dictionary, single point features | JointBoost |
| AdaBoost [16] | Single point | FSI + Fcov | No dictionary, single point features | AdaBoost |
| BoW-LDA [6] | Graph cut and linear transformation | FSI +Fcov | K-means, Point set features of LDA | AdaBoost |
| DD-SCLDA [39] | Graph cut and exponential transformation | FSI + Fcov | LCKSVD, Point set features of DD-SCLDA | AdaBoost |
| SC-LDA-MP [16,46] | Multi-level clustering | FSI + Fcov | SC, Point set features fusion of SC-LDA and SC-MP (SC-LDA-MP) | SVM |
| PointNet [17] | Point cloud block | Point features based on deep learning | No dictionary, multi-layer perceptron (MLP) | Softmax |
| Scene1 | Tree | Building | Car | OA | mIoU | Kappa | F1-score | mF1 |
| Our method | 96.6/97.7 | 98.6/96.0 | 47.9/87.0 | 96.7 | 77.9 | 93.6 | 97.2/97.3/61.8 | 85.4 |
| LLC-LDA-SVM | 97.6/86.7 | 89.0/98.6 | 24.6/18.0 | 92.8 | 65.8 | 86.3 | 91.8/93.6/20.8 | 73.1 |
| LLC-MP-SVM | 98.3/85.7 | 88.2/98.6 | 37.9/39.5 | 87.3 | 59.2 | 75.6 | 91.6/93.1/38.7 | 69.5 |
| DKSVD | 85.4/71.3 | 76.4/88.1 | 1.6/1.6 | 79.2 | 44.6 | 59.0 | 77.7/81.8/1.6 | 53.7 |
| LCKSVD1 | 84.3/59.2 | 71.1/86.7 | 2.6/10.1 | 72.8 | 39.8 | 47.6 | 69.6/78.1/4.1 | 50.6 |
| LCKSVD2 | 88.2/70.7 | 77.0/90.3 | 3.0/4.4 | 80.2 | 45.9 | 60.9 | 78.5/83.1/3.6 | 55.1 |
| MSF-SVM | 91.0/82.3 | 84.0/93.1 | 0.0/0.0 | 87.0 | 51.8 | 74.2 | 86.4/88.3/0.0 | 58.2 |
| ECF-SVM | 99.2/84.9 | 86.8/99.3 | 99.9/42.7 | 91.9 | − | − | 91.5/92.7/59.8 | 81.3 |
| JointBoost | 89.7/98.1 | 97.9/89.1 | 65.2/46.6 | 92.9 | − | − | 93.7/93.3/54.4 | 80.5 |
| AdaBoost | 85.7/92.9 | 92.0/83.8 | 56.9/54.7 | 87.9 | − | − | 89.2/87.7/55.8 | 77.6 |
| BOW-LDA | 94.8/93.8 | 93.5/92.3 | 41.2/66.7 | 92.6 | − | − | 94.3/92.9/50.9 | 79.4 |
| DD-SCLDA | 93.1/96.0 | 95.2/92.6 | 73.3/62.2 | 93.7 | − | − | 94.5/93.9/67.3 | 85.2 |
| SC-LDA-MP | 98.3/93.7 | 93.8/98.5 | 55.6/37.3 | 95.6 | 71.2 | 91.3 | 95.4/95.7/43.4 | 78.9 |
| PointNet | 65.1/93.7 | 95.6/19.5 | 93.4/8.2 | 65.3 | − | − | 76.8/32.4/15.1 | 41.4 |
| Scene2 | Tree | Building | Car | OA | mIoU | Kappa | F1-score | mF1 |
| Our method | 93.4/92.7 | 99.2/97.5 | 52.4/73.9 | 95.3 | 76.0 | 90.1 | 93.1/98.4/61.3 | 84.3 |
| LLC-LDA-SVM | 93.9/90.6 | 97.7/97.3 | 48.9/68.8 | 94.3 | 73.6 | 88.1 | 92.2/97.5/57.2 | 82.3 |
| LLC-MP-SVM | 76.2/93.2 | 99.1/88.3 | 49.4/53.0 | 88.7 | 64.7 | 77.2 | 83.8/93.4/51.2 | 76.1 |
| DKSVD | 66.0/79.5 | 88.2/83.2 | 4.4/0.8 | 79.4 | 44.0 | 56.7 | 72.1/85.6/1.4 | 53.0 |
| LCKSVD1 | 47.1/79.6 | 87.1/54.3 | 5.0/10.2 | 60.7 | 31.9 | 30.6 | 59.2/66.9/6.7 | 44.3 |
| LCKSVD2 | 67.7/76.3 | 88.2/83.5 | 9.7/8.4 | 78.8 | 45.2 | 56.0 | 71.7/85.8/9.0 | 55.5 |
| MSF-SVM | 77.1/81.5 | 88.7/90.6 | 0.0/0.0 | 84.9 | 49.0 | 66.9 | 79.3/89.6/0.0 | 56.3 |
| ECF-SVM | 83.2/92.9 | 98.5/92.8 | 62.6/65.7 | 92.0 | − | − | 87.8/95.6/64.1 | 82.5 |
| JointBoost | 86.8/91.2 | 96.8/95.5 | 44.1/34.8 | 92.2 | − | − | 88.9/96.1/38.9 | 74.6 |
| AdaBoost | 73.9/91.2 | 93.6/88.2 | 29.5/25.4 | 87.2 | − | − | 81.6/90.8/27.3 | 66.6 |
| BOW-LDA | 90.3/93.9 | 97.6/96.5 | 49.4/42.0 | 94.1 | − | − | 92.1/97.0/45.4 | 78.2 |
| DD-SCLDA | − | − | − | − | − | − | − | − |
| SC-LDA-MP | 90.8/94.4 | 98.0/97.6 | 66.4/46.4 | 95.0 | 73.2 | 89.3 | 92.6/97.8/54.6 | 81.7 |
| PointNet | 78.2/91.4 | 90.4/20.1 | 87.1/12.3 | 41.3 | − | − | 84.3/32.9/21.6 | 46.3 |
| Scene3 | Pole | Building | Car | Tree | OA | mIoU | Kappa | F1-score | mF1 |
| Our method | 33.1/36.4 | 90.6/94.6 | 77.0/87.4 | 96.4/71.8 | 87.5 | 60.8 | 77.2 | 34.7/92.6/81.9/82.3 | 72.3 |
| LLC-LDA-SVM | 47.7/17.5 | 92.8/55.9 | 34.1/85.0 | 90.5/86.0 | 66.5 | 44.8 | 49.3 | 25.6/69.8/48.8/88.2 | 58.1 |
| LLC-MP-SVM | 24.2/36.4 | 87.1/93.4 | 77.7/81.2 | 96.8/68.9 | 85.6 | 58.1 | 73.3 | 29.1/90.1/79.4/80.5 | 69.8 |
| DKSVD | 1.4/0.8 | 70.3/86.7 | 31.0/4.5 | 58.7/62.7 | 66.4 | 27.9 | 31.8 | 1.0/77.6/7.9/60.6 | 36.8 |
| LCKSVD1 | 3.0/6.0 | 74.6/65.3 | 24.6/13.5 | 42.0/71.4 | 56.7 | 25.3 | 26.3 | 4.0/69.6/17.4/5.9 | 36.0 |
| LCKSVD2 | 5.0/9.6 | 71.2/82.1 | 29.3/4.0 | 50.6/62.0 | 63.5 | 26.8 | 29.2 | 6.6/76.3/7.0/55.7 | 36.4 |
| MSF-SVM | 0.0/0.0 | 72.9/95.7 | 0.0/0.0 | 78.7/77.5 | 74.1 | 33.7 | 44.8 | 0.0/82.8/0.0/78.1 | 42.7 |
| Scene4 | Pedestrian | Building | Car | Tree | OA | mIoU | Kappa | F1-score | mF1 |
| Our method | 72.6/23.7 | 76.4/100.0 | 100.0/7.7 | 77.3/99.7 | 77.5 | 45.8 | 39.6 | 35.7/87.1/14.3/86.6 | 55.9 |
| LLC-LDA-SVM | 90.5/14.7 | 23.9/99.8 | 71.3/5.7 | 75.2/81.3 | 63.7 | 27.0 | 22.0 | 25.3/78.1/10.6/38.6 | 38.1 |
| LLC-MP-SVM | 86.0/28.9 | 58.9/40.4 | 98.2/13.1 | 75.2/99.4 | 75.4 | 36.8 | 31.1 | 43.3/85.6/23.1/47.9 | 50.0 |
| DKSVD | 8.7/1.3 | 23.9/77.4 | 24.3/1.2 | 74.9/87.2 | 64.9 | 23.0 | 18.3 | 2.3/80.6/2.3/36.5 | 30.4 |
| LCKSVD1 | 10.5/3.8 | 18.2/28.0 | 35.0/6.6 | 73.5/91.0 | 66.1 | 22.4 | 13.6 | 5.6/81.3/11.1/22.1 | 30.0 |
| LCKSVD2 | 12.0/1.7 | 23.6/51.4 | 33.5/0.9 | 74.5/93.4 | 67.8 | 23.1 | 17.5 | 3.0/82.9/1.8/32.3 | 30.0 |
| MSF-SVM | 0.0/0.0 | 35.1/89.4 | 0.0/0.0 | 75.7/94.2 | 70.1 | 26.5 | 24.2 | 0.0/83.9/0.0/50.4 | 33.6 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tong, G.; Li, Y.; Zhang, W.; Chen, D.; Zhang, Z.; Yang, J.; Zhang, J. Point Set Multi-Level Aggregation Feature Extraction Based on Multi-Scale Max Pooling and LDA for Point Cloud Classification. Remote Sens. 2019, 11, 2846. https://doi.org/10.3390/rs11232846
Tong G, Li Y, Zhang W, Chen D, Zhang Z, Yang J, Zhang J. Point Set Multi-Level Aggregation Feature Extraction Based on Multi-Scale Max Pooling and LDA for Point Cloud Classification. Remote Sensing. 2019; 11(23):2846. https://doi.org/10.3390/rs11232846
Chicago/Turabian StyleTong, Guofeng, Yong Li, Weilong Zhang, Dong Chen, Zhenxin Zhang, Jingchao Yang, and Jianjun Zhang. 2019. "Point Set Multi-Level Aggregation Feature Extraction Based on Multi-Scale Max Pooling and LDA for Point Cloud Classification" Remote Sensing 11, no. 23: 2846. https://doi.org/10.3390/rs11232846
APA StyleTong, G., Li, Y., Zhang, W., Chen, D., Zhang, Z., Yang, J., & Zhang, J. (2019). Point Set Multi-Level Aggregation Feature Extraction Based on Multi-Scale Max Pooling and LDA for Point Cloud Classification. Remote Sensing, 11(23), 2846. https://doi.org/10.3390/rs11232846