Matching RGB and Infrared Remote Sensing Images with Densely-Connected Convolutional Neural Networks


Abstract
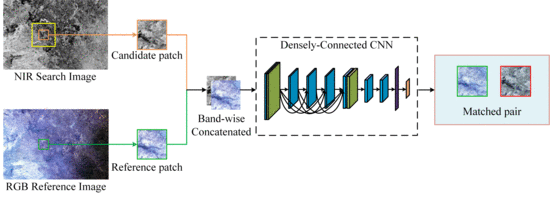
1. Introduction
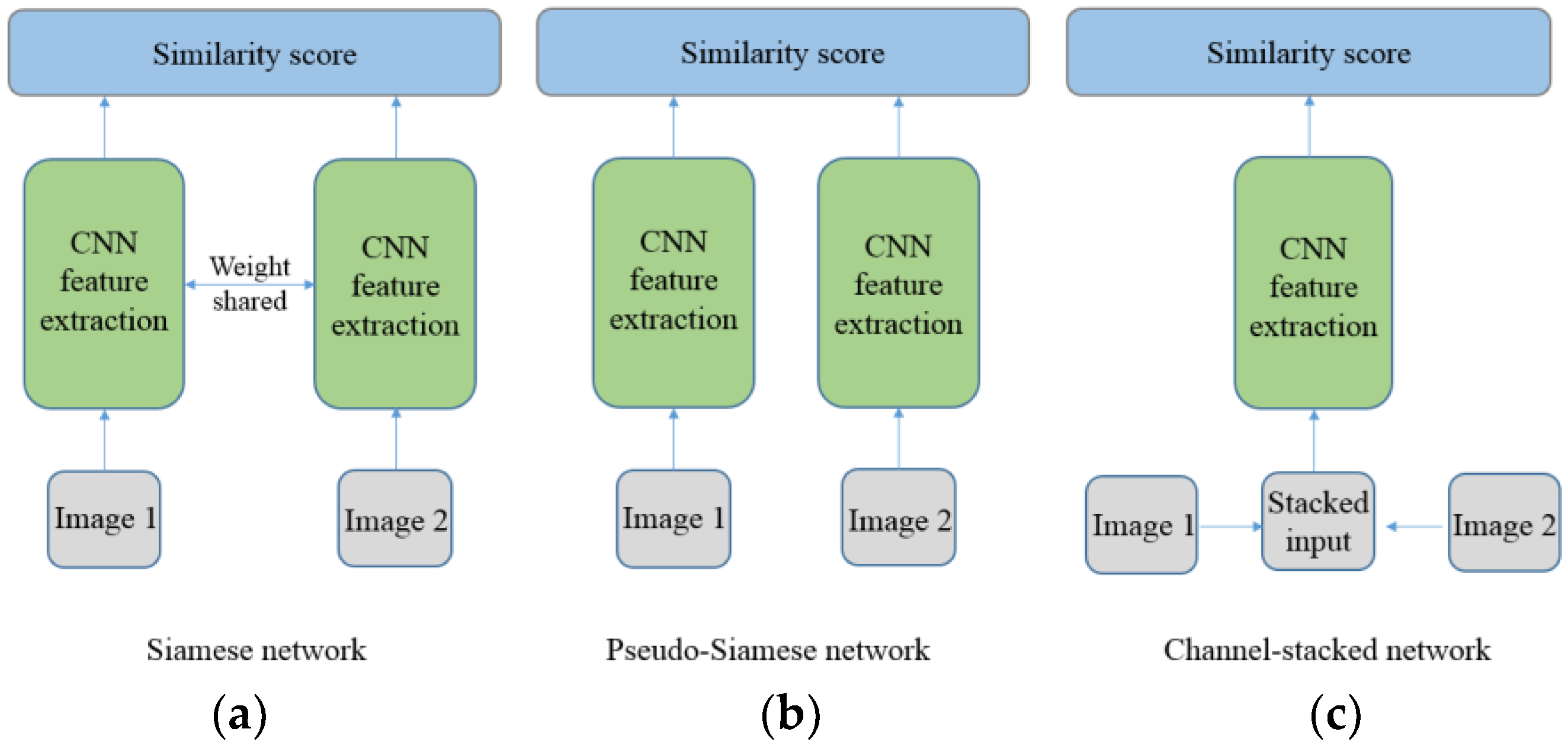
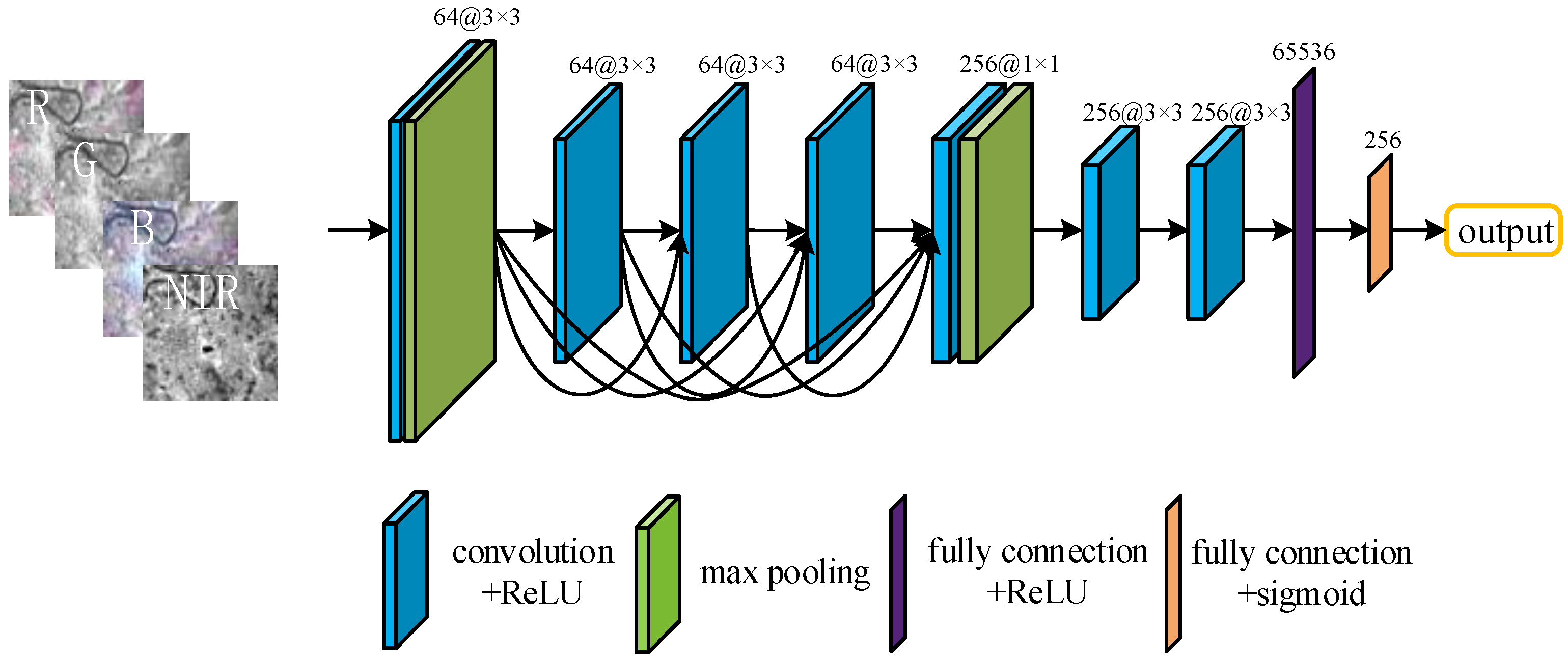
2. Methods
2.1. Network
2.2. Augmented Loss Function
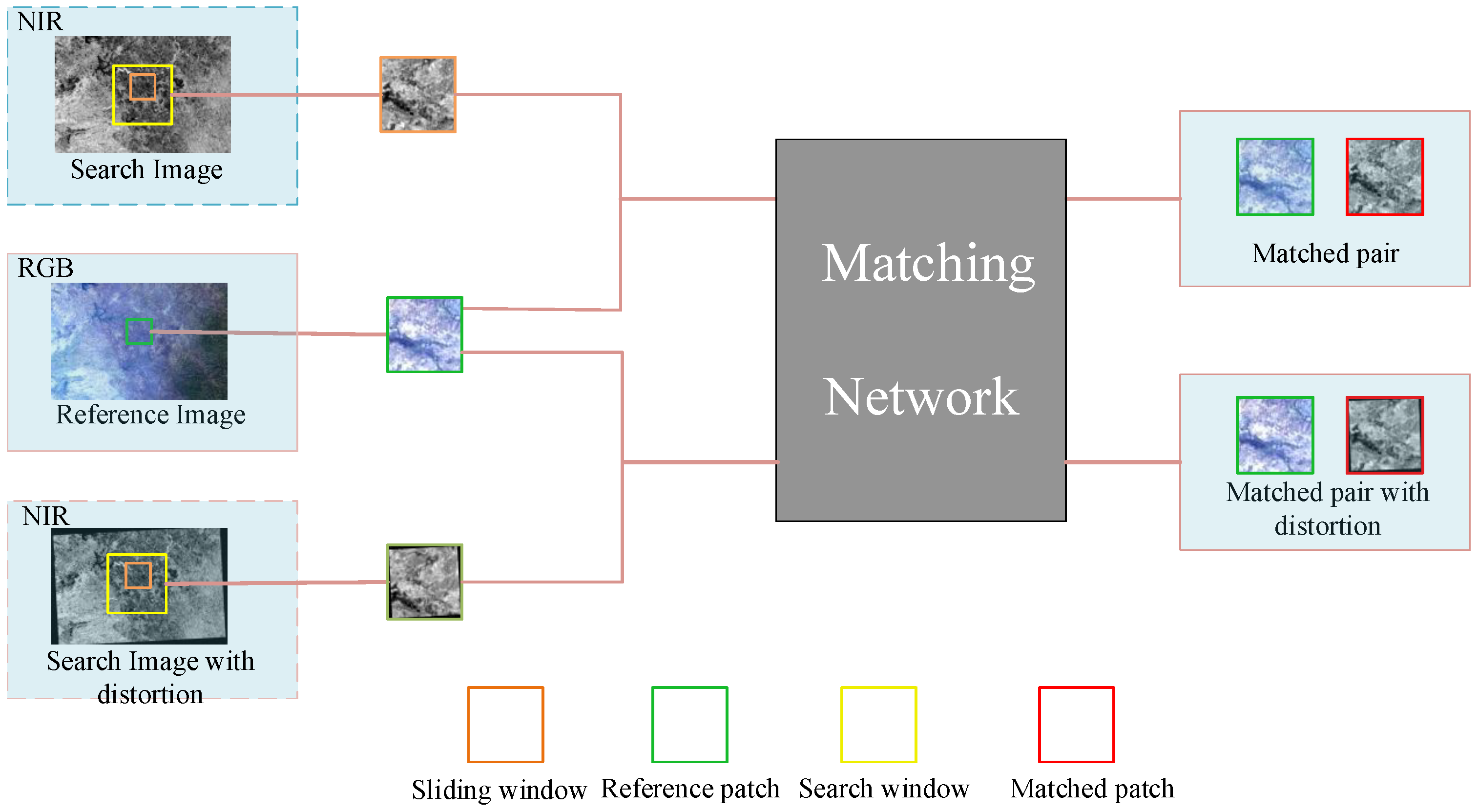
2.3. Template Matching
3. Experiments and Results
3.1. Data and Experimental Design
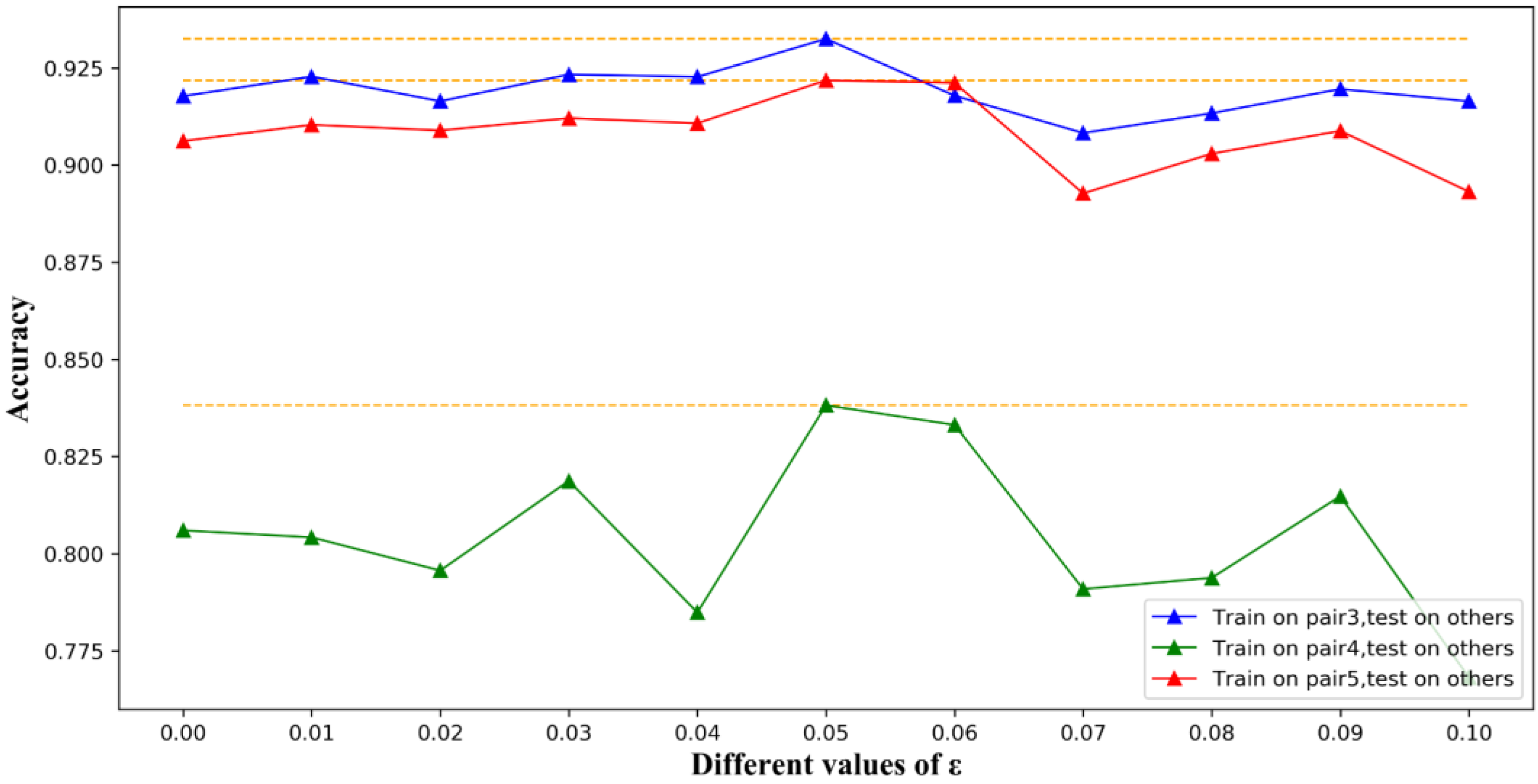
3.2. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Barbara, Z.J.; Flusser, J. Image registration methods: A survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar]
- Kern, J.P.; Pattichis, M.S. Robust multispectral image registration using mutual-information models. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1494–1505. [Google Scholar] [CrossRef]
- Amankwah, A. Image registration by automatic subimage selection and maximization of combined mutual information and spatial information. IEEE Geosci. Remote Sens. Sym. 2013, 4, 4379–4382. [Google Scholar]
- Bleyer, M.; Rhemann, C.; Rother, C. PatchMatch stereo-stereo matching with slanted support windows. In Proceedings of the 2011 British Machine Vision Conference (BMVC), Dundee, UK, 29 August–2 September 2011; Volume 10. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Morel, J.M.; Yu, G.S. ASIFT: A new framework for fully affine invariant image comparison. Siam J. Imaging Sci. 2009, 2, 438–469. [Google Scholar] [CrossRef]
- Sedaghat, A.; Mohammadi, N. Uniform competency-based local feature extraction for remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 135, 142–157. [Google Scholar] [CrossRef]
- Ma, W.P.; Wen, Z.L.; Wu, Y.; Jiao, L.C.; Gong, M.G.; Zheng, Y.F.; Liu, L. Remote sensing image registration with modified SIFT and enhanced feature matching. IEEE Geosci. Remote Sens. Lett. 2017, 14, 3–7. [Google Scholar] [CrossRef]
- Ye, Y.X.; Shan, J.; Bruzzone, L.; Shen, L. Robust registration of multimodal remote sensing images based on structural similarity. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2941–2958. [Google Scholar] [CrossRef]
- Li, J.Y.; Hu, Q.W.; Ai, M.Y. RIFT: Multi-modal image matching based on radiation-invariant feature transform. arXiv 2018, arXiv:1804.09493. [Google Scholar]
- Liu, X.Z.; Ai, Y.F.; Zhang, J.L.; Wang, Z.P. A novel affine and contrast invariant descriptor for infrared and visible image registration. Remote Sens. 2018, 10, 658. [Google Scholar] [CrossRef]
- Dong, Y.Y.; Jiao, W.L.; Long, T.F.; He, G.J.; Gong, C.J. An extension of phase correlation-based image registration to estimate similarity transform using multiple polar fourier transform. Remote Sens. 2018, 10, 1719. [Google Scholar] [CrossRef]
- Yan, L.; Wang, Z.Q.; Liu, Y.; Ye, Z.Y. Generic and automatic markov random field-based registration for multimodal remote sensing image using grayscale and gradient information. Remote Sens. 2018, 10, 1228. [Google Scholar] [CrossRef]
- Ma, Q.; Du, X.; Wang, J.H.; Ma, Y.; Ma, J.Y. Robust feature matching via Gaussian field criterion for remote sensing image registration. J. Real Time Image Process. 2018, 15, 523–536. [Google Scholar] [CrossRef]
- Yong, S.K.; Lee, J.H.; Ra, J.B. Multi-sensor image registration based on intensity and edge orientation information. Pattern Recogn. 2008, 41, 3356–3365. [Google Scholar]
- Gong, M.; Zhao, S.; Jiao, L.; Tian, D.; Shuang, W. A novel coarse-to-fine scheme for automatic image registration based on SIFT and mutual information. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4328–4338. [Google Scholar] [CrossRef]
- Zhao, C.Y.; Goshtasby, A.A. Registration of multitemporal aerial optical images using line features. ISPRS J. Photogramm. Remote Sens. 2016, 117, 149–160. [Google Scholar] [CrossRef]
- Arandjelović, O.; Pham, D.S.; Venkatesh, S. Efficient and accurate set-based registration of time-separated aerial images. Pattern Recogn. 2015, 48, 3466–3476. [Google Scholar] [CrossRef]
- Long, T.F.; Jiao, W.L.; He, G.J.; Wang, W. Automatic line segment registration using Gaussian mixture model and expectation-maximization algorithm. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1688–1699. [Google Scholar] [CrossRef]
- Wang, X.; Xu, Q. Multi-sensor optical remote sensing image registration based on Line-Point Invariant. In Proceedings of the 2016 Geoscience Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 2364–2367. [Google Scholar]
- Sui, H.G.; Xu, C.; Liu, J.Y. Automatic optical-to-SAR image registration by iterative line extraction and voronoi integrated spectral point matching. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6058–6072. [Google Scholar] [CrossRef]
- Guo, Q.; He, M.; Li, A. High-resolution remote-sensing image registration based on angle matching of edge point features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2881–2895. [Google Scholar] [CrossRef]
- Zbontar, J.; LeCun, Y. Computing the stereo matching cost with a convolutional neural network. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1592–1599. [Google Scholar]
- Suarez, P.L.; Sappa, A.D.; Vintimilla, B.X. Cross-Spectral image patch similarity using convolutional neural network. In Proceedings of the 2017 IEEE International Workshop of Electronics, Control, Measurement, Signals and Their Application to Mechatronics (ECMSM), San Sebastian, Spain, 24–26 May 2017. [Google Scholar]
- Jahrer, M.; Grabner, M.; Bischof, H. Learned local descriptors for recognition and matching. In Proceedings of the Compute Vision Winter Workshop (CVWW), Moravske Toplice, Slovenija, 4–6 February 2008. [Google Scholar]
- He, H.Q.; Chen, M.; Chen, T.; Li, D.J. Matching of remote sensing images with complex background variations via Siamese convolutional neural network. Remote Sens. 2018, 10, 355. [Google Scholar] [CrossRef]
- Han, X.F.; Leung, T.; Jia, Y.Q.; Sukthankar, R.; Berg, A.C. MatchNet: Unifying feature and metric learning for patch-based matching. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3279–3286. [Google Scholar]
- He, H.Q.; Chen, M.; Chen, T.; Li, D.J.; Cheng, P.G. Learning to match multitemporal optical satellite images using multi-support-patches Siamese networks. Remote Sens. Lett. 2019, 10, 516–525. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Liu, W.; Xuelun, S.; Cheng, W.; Zhihong, Z.; Chenglu, W.; Jonathan, L. H-Net: Neural network for cross-domain image patch matching. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; pp. 856–863. [Google Scholar]
- Aguilera, C.A.; Aguilera, F.J.; Sappa, A.D.; Aguilera, C.; Toledo, R. Learning cross-spectral similarity measures with deep convolutional neural networks. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 267–275. [Google Scholar]
- Saxena, S.; Verbeek, J. Heterogeneous face recognition with CNNs. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 483–491. [Google Scholar]
- Alba, P.-M.; Casas, J.R.; Javier, R.-H. Correspondence matching in unorganized 3D point clouds using Convolutional Neural Networks. Image Vis. Comput. 2019, 83, 51–60. [Google Scholar]
- Perol, T.; Gharbi, M.; Denolle, M. Convolutional neural network for earthquake detection and location. Sci. Adv. 2018, 4, e1700578. [Google Scholar] [CrossRef]
- En, S.; Lechervy, A.; Jurie, F. TS-NET: Combing modality specific and common features for multimodal patch matching. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3024–3028. [Google Scholar]
- Baruch, E.B.; Keller, Y. Multimodal matching using a Hybrid Convolutional Neural Network. arXiv 2018, arXiv:1810.12941. [Google Scholar]
- Hoffer, E.; Ailon, N. Deep metric learning using triplet network. In Similarity-Based Pattern Recognition, Simbad 2015; Feragen, A., Pelillo, M., Loog, M., Eds.; Springer: Cham, Switzerland, 2015; Volume 9370, pp. 84–92. [Google Scholar]
- Aguilera, C.A.; Sappa, A.D.; Aguilera, C.; Toledo, R. Cross-spectral local descriptors via quadruplet network. Sensors 2017, 17, 873. [Google Scholar] [CrossRef]
- Jure, Z.; Yann, L. Stereo matching by training a convolutional neural network to compare image patches. Comput. Sci. 2015, 17, 2. [Google Scholar]
- Wang, S.; Quan, D.; Liang, X.F.; Ning, M.D.; Guo, Y.H.; Jiao, L.C. A deep learning framework for remote sensing image registration. ISPRS J. Potogramm. 2018, 145, 148–164. [Google Scholar] [CrossRef]
- He, T.; Zhang, Z.; Zhang, H. Bag of tricks for image classification with convolutional neural networks. arXiv 2018, arXiv:1812.01187. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. J. Mach. Learn Res. 2010, 9, 249–256. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Han, Z.; Weiping, N.; Weidong, Y.; Deliang, X. Registration of multimodal remote sensing image based on deep fully convolutional neural network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3028–3042. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Gool, L.V. SURF: Speeded up robust features. In Proceedings of the 9th European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006. [Google Scholar]
- Gioi, R.G.V.; Jakubowicz, J.; Morel, J.-M. LSD: A fast line segment detector with a false detection control. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 722–732. [Google Scholar] [CrossRef] [PubMed]
- Brown, M.; Susstrunk, S. Multi-spectral sift for scene category recognition. In Proceedings of the 24th Conference on Compute Vision and Pattern Recognition (CVPR), Providence, RI, USA, 20–25 June 2011; pp. 177–184. [Google Scholar]
- Yi, B.; Yu, P.; He, G.Z.; Chen, J. A fast matching algorithm with feature points based on NCC. In Proceedings of the 2013 International Academic Workshop on Social Science (IAW-SC), Changsha, China, 18–20 October 2013; Shao, X., Ed.; Volume 50, pp. 955–958. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Pair | Date | Number of Samples Training/Validation/Test | Patch Size | Usage |
|---|---|---|---|---|
| Pair 1 | 27 April 2017 | 496/124/228 | 64 × 64 | Training and testing |
| Pair 2 | 16 May 2018 | 496/124/228 | 64 × 64 | Training and testing |
| Pair 3 | 23 December 2017 | -/-/228 | 64 × 64 | Testing |
| Pair 4 | 13 March 2018 | -/-/228 | 64 × 64 | Testing |
| Pair 5 | 4 November 2017 | -/-/228 | 64 × 64 | Testing |
| Image Pair | SFcNet [44] | Pseudo-Siamese Network | 2-ch Network [31] | Our Method (Wo/Aug-Loss) | Our Method |
|---|---|---|---|---|---|
| Pair 1 | 79.87% | 77.10% | 92.97% | 93.87% | 97.00% |
| Pair 2 | 73.76% | 79.51% | 76.74% | 91.17% | 91.65% |
| Pair 3 | 55.18% | 81.56% | 80.28% | 90.91% | 91.46% |
| Pair 4 | 76.75% | 79.21% | 88.10% | 89.26% | 94.88% |
| Pair 5 | 75.33% | 89.74% | 93.13% | 96.32% | 99.37% |
| AMR | 72.18% | 81.42% | 86.24% | 92.31% | 94.87% |
| Runtime (ms) | 2.29 | 2.33 | 0.94 | 1.15 | 1.15 |
| Image Pair | 2-ch Network [31] | Our Method (Wo/Aug-Loss) | Our Method | |||
|---|---|---|---|---|---|---|
| 1 Pixel | 2 Pixels | 1 Pixel | 2 Pixels | 1 Pixel | 2 Pixels | |
| Pair 1 | 55.70% | 72.81% | 70.18% | 86.40% | 74.12% | 86.40% |
| Pair 2 | 72.37% | 94.30% | 82.89% | 96.49% | 79.82% | 93.86% |
| Pair 3 | 78.95% | 100.00% | 82.46% | 99.56% | 86.40% | 100.00% |
| Pair 4 | 78.07% | 97.81% | 84.21% | 97.81% | 90.35% | 99.56% |
| Pair 5 | 67.11% | 87.28% | 80.26% | 97.81% | 92.11% | 99.12% |
| AMR | 70.44% | 90.44% | 80.00% | 95.61% | 84.56% | 95.79% |
| RMSE | 0.836 | 0.994 | 0.804 | 0.932 | 0.771 | 0.872 |
| Image Pair | 2-ch Network [31] | Our Method (Wo/Aug-Loss) | Our Method | |||
|---|---|---|---|---|---|---|
| 1 Pixel | 2 Pixels | 1 Pixel | 2 Pixels | 1 Pixel | 2 Pixels | |
| Pair 2 | 65.79% | 85.09% | 73.25% | 86.84% | 81.14% | 92.11% |
| Pair 1 | 36.40% | 53.51% | 52.63% | 67.11% | 53.51% | 73.25% |
| Pair 3 | 73.25% | 98.25% | 85.53% | 100.00% | 83.33% | 100.00% |
| Pair 4 | 71.49% | 92.11% | 85.09% | 98.68% | 89.91% | 99.56% |
| Pair 5 | 57.02% | 72.81% | 77.63% | 96.49% | 78.07% | 91.23% |
| AMR | 60.79% | 80.35% | 74.83% | 89.82% | 77.19% | 91.23% |
| RMSE | 0.828 | 1.005 | 0.815 | 0.943 | 0.816 | 0.934 |
| Method | Key Points RGB/NIR | 1 pixel | 2 pixels | ||
|---|---|---|---|---|---|
| MPN | RMSE | MPN | RMSE | ||
| Small distortion | |||||
| SIFT [5] | 12,814/17,216 | 28 | 0.802 | 29 | 0.823 |
| SURF [45] | 1755/4123 | 13 | 0.734 | 17 | 0.939 |
| Affine-SIFT [6] | 93,096/26,3174 | 480 | 0.789 | 616 | 0.962 |
| PSO-SIFT [8] | 6928/9448 | 225 | 0.730 | 261 | 0.858 |
| RIFT [10] | 2499/2498 | 238 | 0.775 | 319 | 0.978 |
| LSD [46] | 90/120 | 0 | / | 0 | / |
| Feature-based CNN [40] | 7948/12,008 | 0 | / | 0 | / |
| Our method | 7948/- | 6751 | 0.640 | 7399 | 0.743 |
| Large distortion | |||||
| SIFT [5] | 12,814/15,609 | 28 | 0.732 | 3 | 0.823 |
| SURF [45] | 1755/4033 | 16 | 0.750 | 19 | 0.889 |
| Affine-SIFT [6] | 93,096/253,781 | 431 | 0.778 | 584 | 0.985 |
| PSO-SIFT [8] | 6928/8569 | 243 | 0.748 | 255 | 0.920 |
| RIFT [10] | 2499/2498 | 214 | 0.791 | 302 | 1.013 |
| LSD [46] | 90/135 | 0 | - | 0 | - |
| Feature-based CNN [40] | 7922/11,474 | 0 | - | 0 | - |
| Our method | 7922/- | 6226 | 0.672 | 6973 | 0.774 |
| Image Pair | Date RGB/NIR | Sample Number | Patch Size | Description |
|---|---|---|---|---|
| Pair 6 | 27 April 2017 13 March 2018 | 228 | 64 × 64 | Only for test, distortion added |
| Pair 7 | 27 April 2017 23 December 2017 | 228 | 64 × 64 | Only for test, distortion added |
| Image Pair | 2-ch Network [31] | Our Method (Wo/Aug-Loss) | Our Method | |||
|---|---|---|---|---|---|---|
| 1 pixel | 2 pixels | 1 pixel | 2 pixels | 1 pixel | 2 pixels | |
| Pair 6 | 25.00% | 39.91% | 39.91% | 51.75% | 42.54% | 55.26% |
| Pair 7 | 28.95% | 42.98% | 31.58% | 45.18% | 32.02% | 46.05% |
| AMR | 26.98% | 41.45% | 35.75% | 48.47% | 37.28% | 50.66% |
| RMSE | 0.862 | 1.087 | 0.849 | 1.029 | 0.815 | 1.01 |
| Network | Country | Field | Forest | Indoor | Mountain | Building | Street | Urban | Water | Mean |
|---|---|---|---|---|---|---|---|---|---|---|
| 2-ch network | 98.63% | 92.55% | 97.20% | 90.73% | 92.95% | 94.62% | 95.70% | 96.07% | 93.67% | 94.68% |
| Our (wo/aug-loss) | 99.10% | 92.96% | 97.67% | 93.16% | 92.85% | 94.73% | 95.83% | 97.62% | 92.87% | 95.20% |
| Our method | 98.96% | 93.32% | 98.00% | 93.13% | 92.93% | 94.55% | 96.14% | 97.46% | 92.89% | 95.26% |
| Image Pair | NCC | SSIM | ||
|---|---|---|---|---|
| 1 pixel | 2 pixels | 1 pixel | 2 pixels | |
| Pair 1 | 0.44% | 1.32% | 12.72% | 13.16% |
| Pair 7 | 0.88% | 0.88% | 1.32% | 1.32% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, R.; Yu, D.; Ji, S.; Lu, M. Matching RGB and Infrared Remote Sensing Images with Densely-Connected Convolutional Neural Networks. Remote Sens. 2019, 11, 2836. https://doi.org/10.3390/rs11232836
Zhu R, Yu D, Ji S, Lu M. Matching RGB and Infrared Remote Sensing Images with Densely-Connected Convolutional Neural Networks. Remote Sensing. 2019; 11(23):2836. https://doi.org/10.3390/rs11232836
Chicago/Turabian StyleZhu, Ruojin, Dawen Yu, Shunping Ji, and Meng Lu. 2019. "Matching RGB and Infrared Remote Sensing Images with Densely-Connected Convolutional Neural Networks" Remote Sensing 11, no. 23: 2836. https://doi.org/10.3390/rs11232836
APA StyleZhu, R., Yu, D., Ji, S., & Lu, M. (2019). Matching RGB and Infrared Remote Sensing Images with Densely-Connected Convolutional Neural Networks. Remote Sensing, 11(23), 2836. https://doi.org/10.3390/rs11232836