Enhanced Feature Extraction for Ship Detection from Multi-Resolution and Multi-Scene Synthetic Aperture Radar (SAR) Images





Abstract
1. Introduction
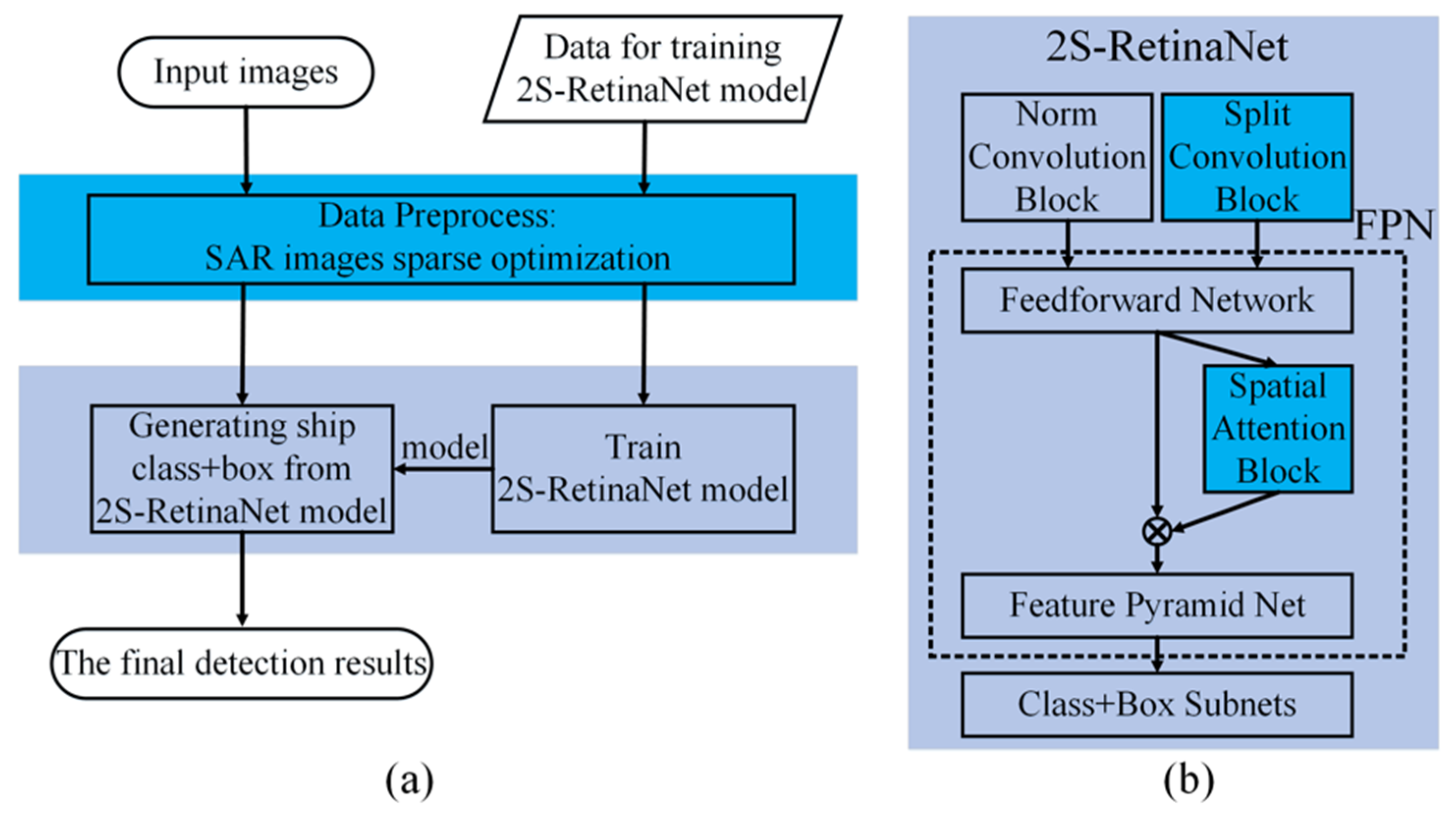
2. Materials and Methods
2.1. Data Preprocess: SAR Image Sparse Optimization
2.2. Background on RetinaNet
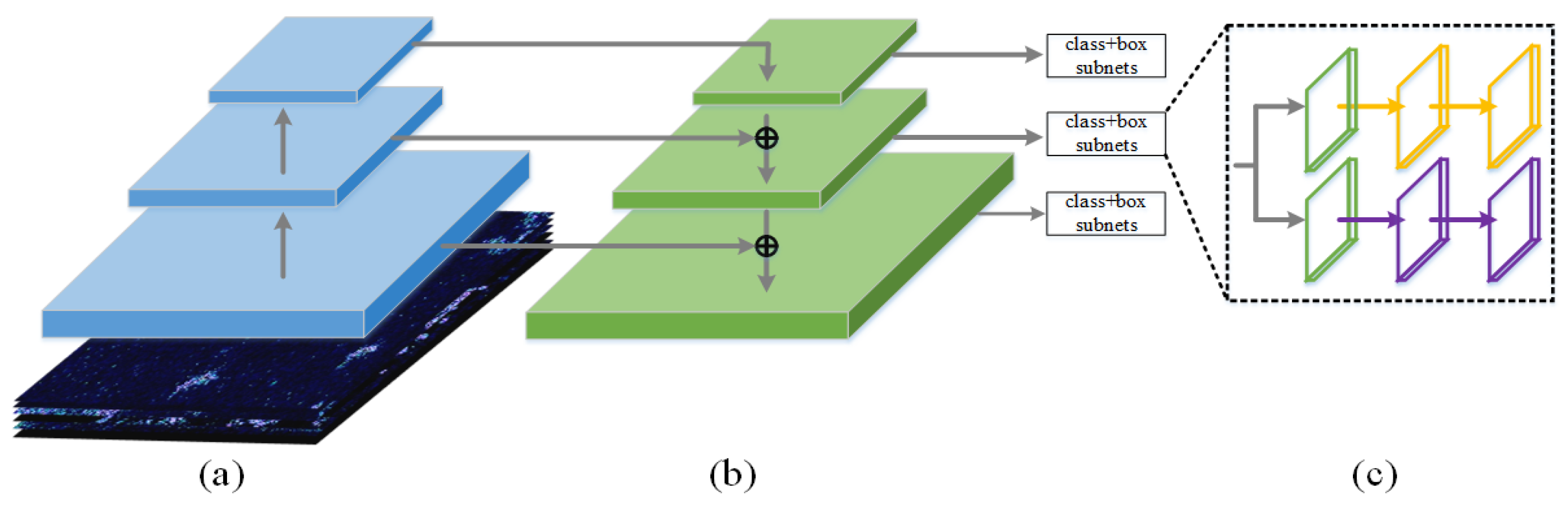
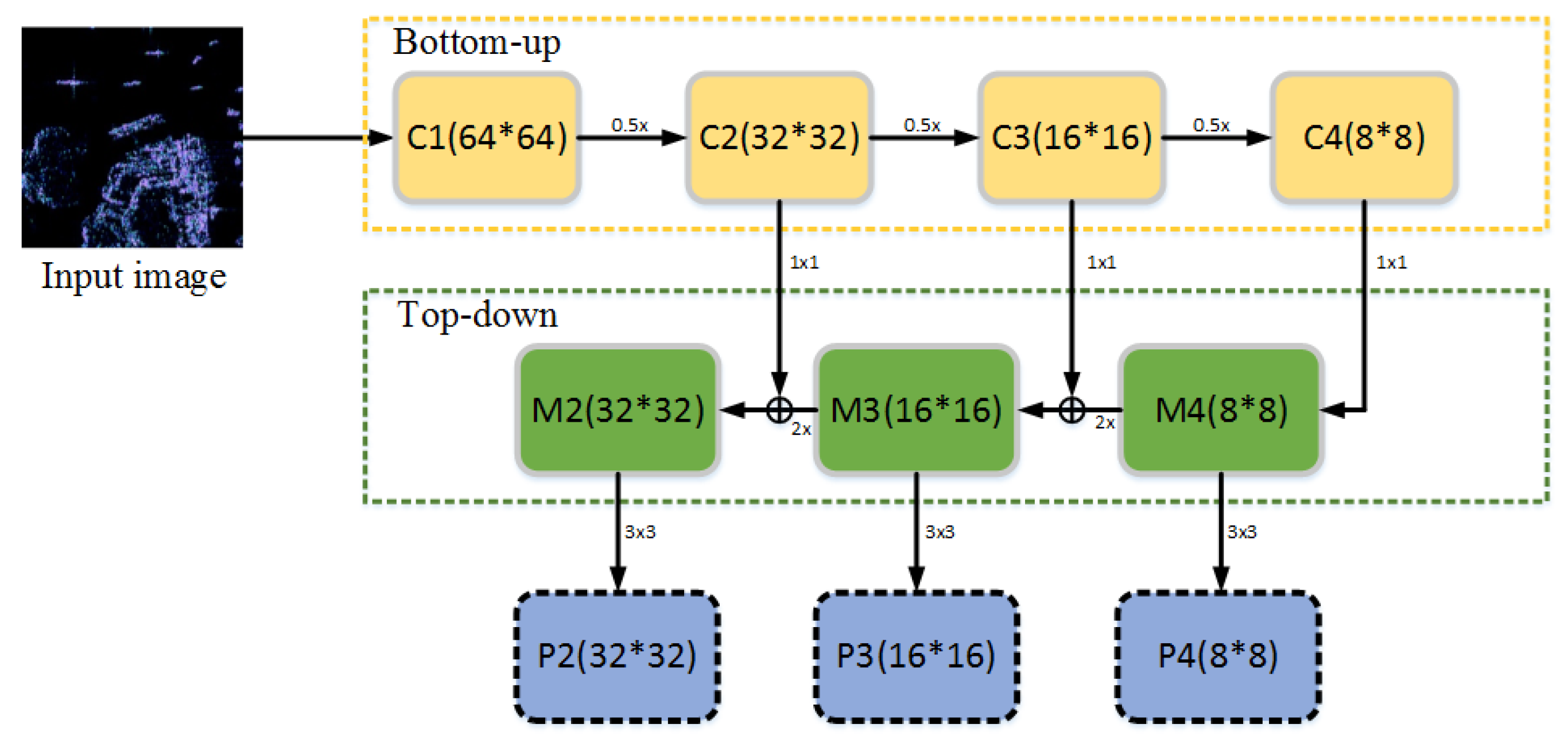
2.2.1. FPN (Feature Pyramid Network)
2.2.2. Focal Loss
2.3. The Improvements on RetinaNet
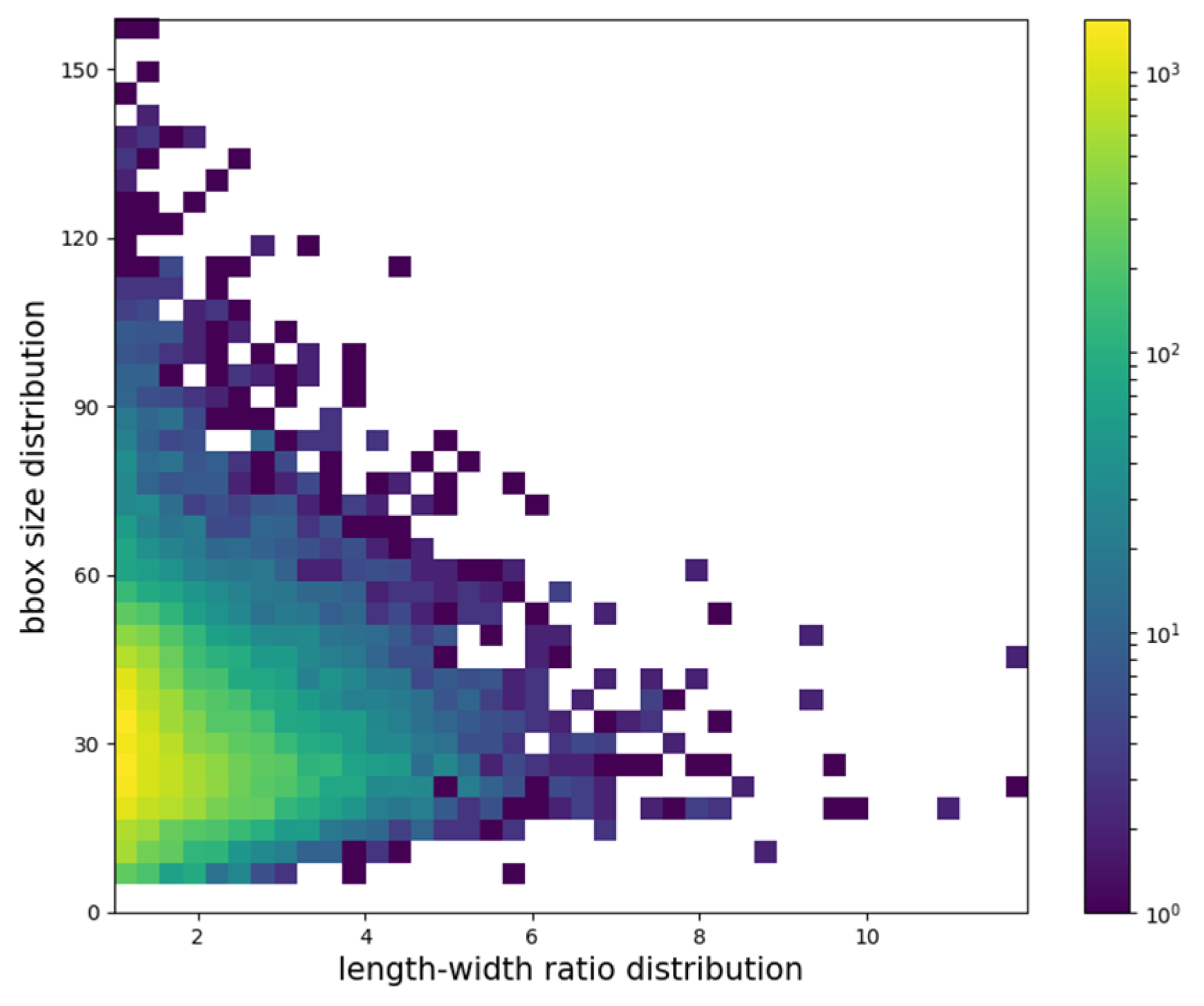
2.3.1. Multi-Scale Anchor Design
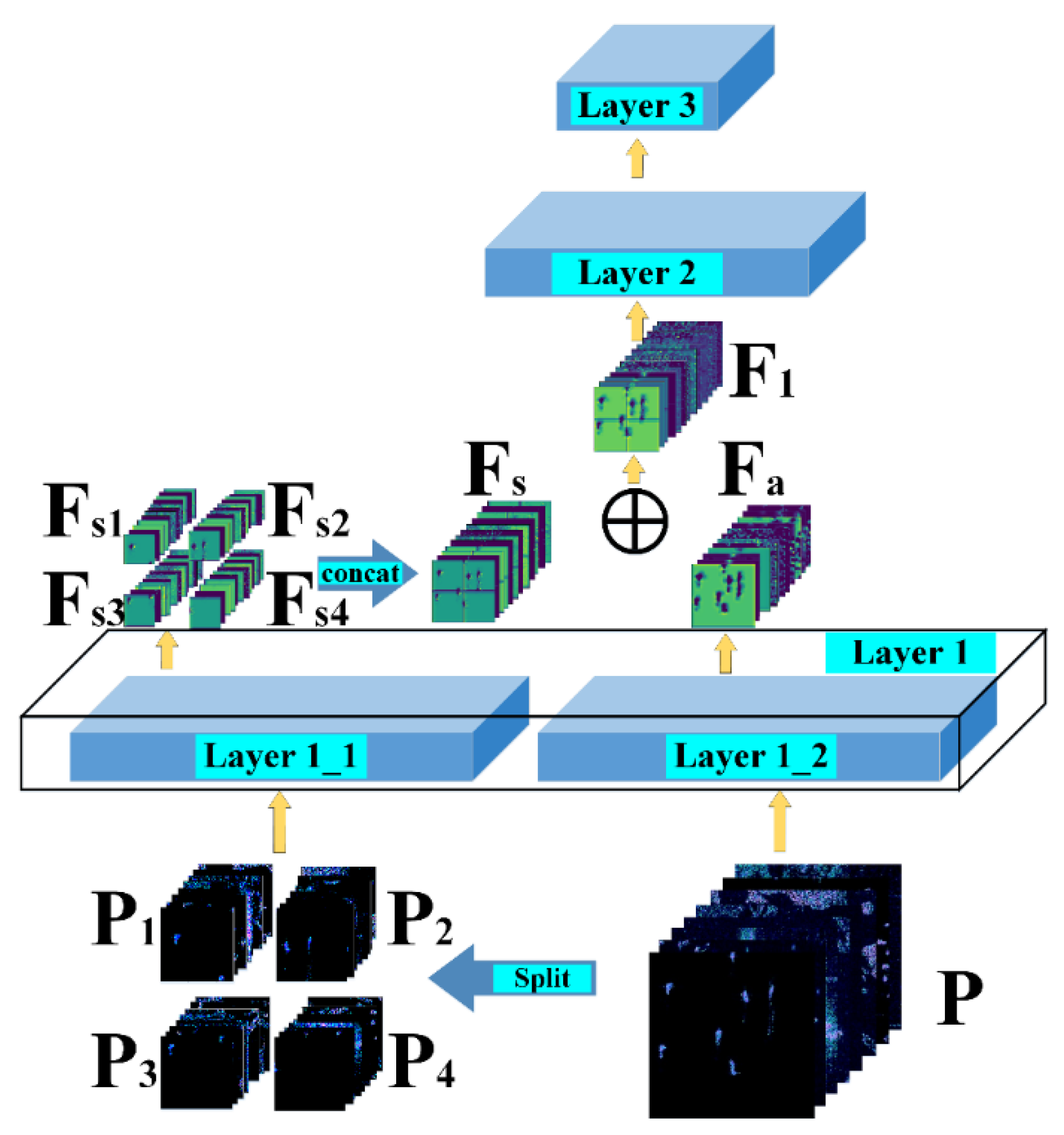
2.3.2. Split Convolution Block (SCB)
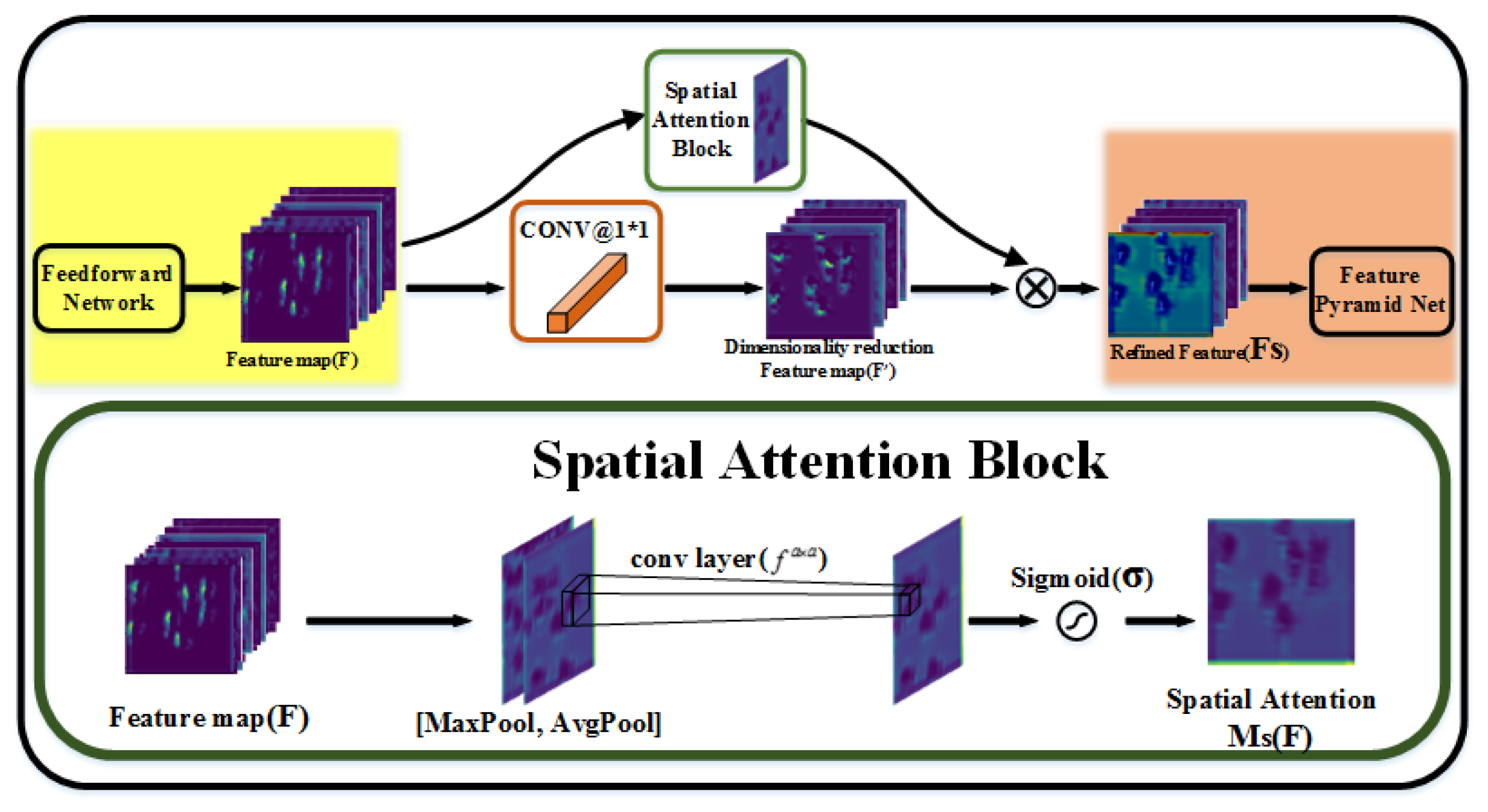
2.3.3. Spatial Attention Block (SAB)
3. Results and Discussions
3.1. Configuration
3.1.1. Dataset Description
3.1.2. Evaluation Metrics
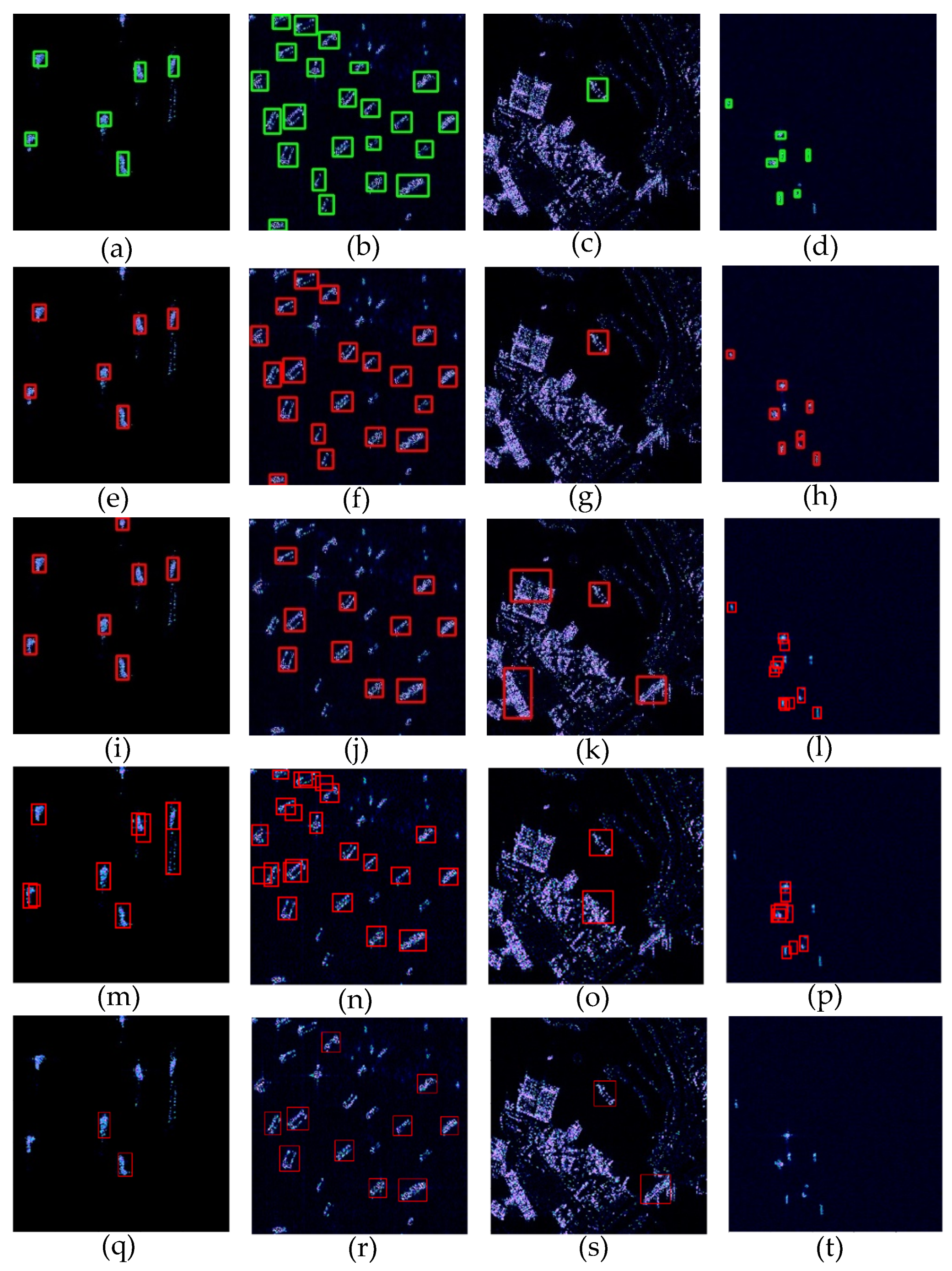
3.2. Experiment Results
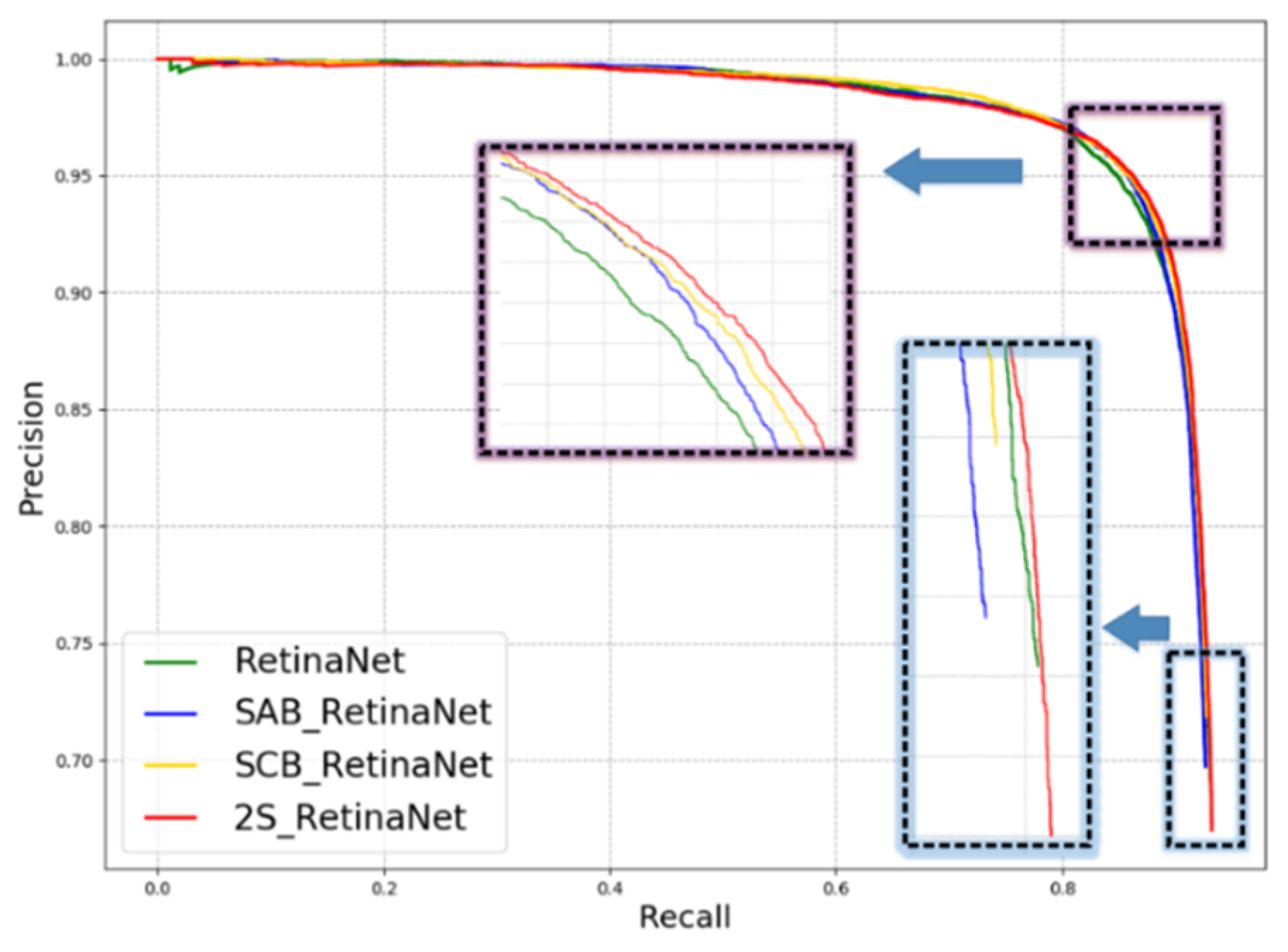
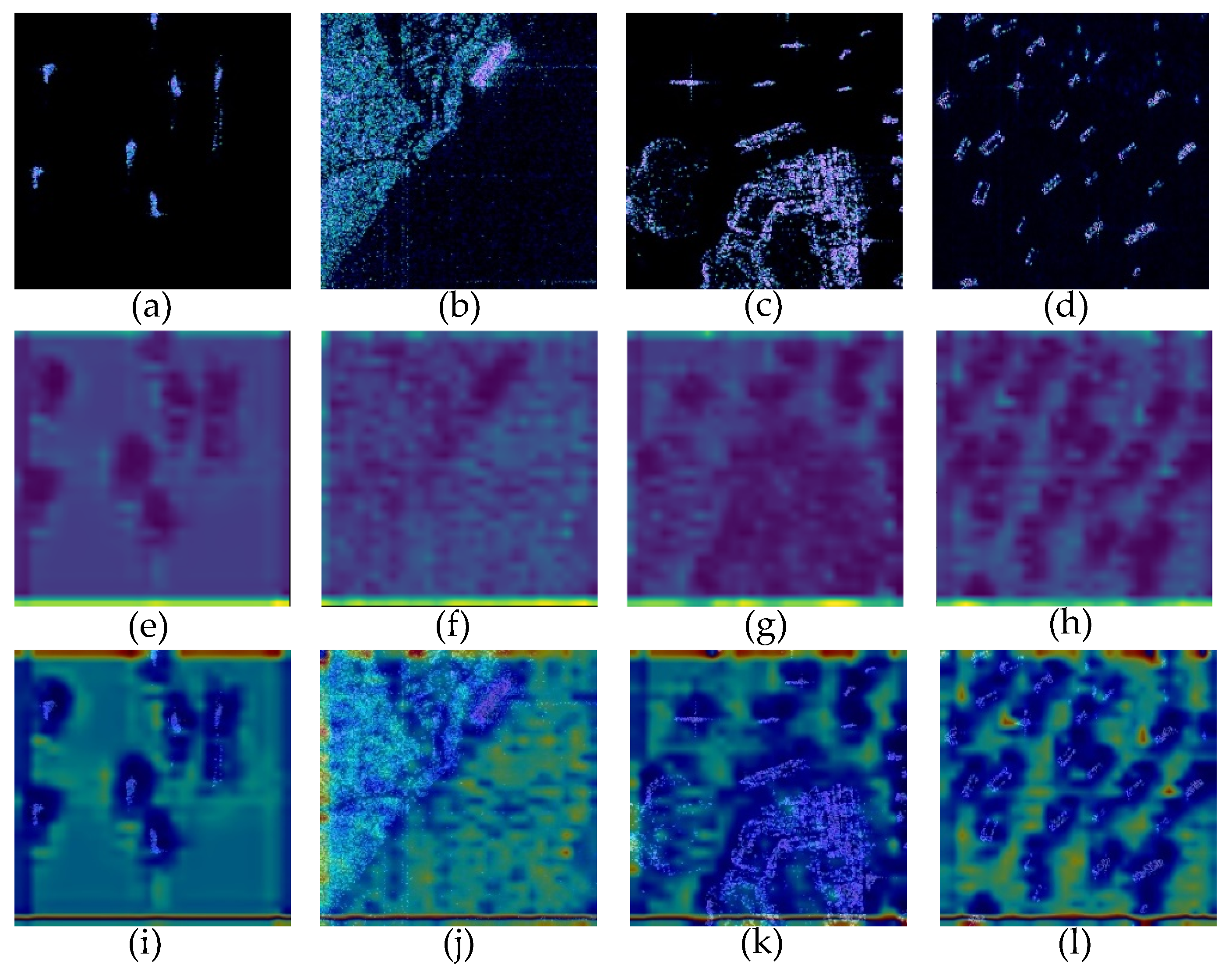
3.3. Discussion
3.3.1. Split Convolution Block (SCB)
3.3.2. Spatial Attention Block (SAB)
3.4. Comparison Experiments with Other Methods
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, C. Synthetic Aperture Radar Principle, System Analysis and Application; Science Press: Beijing, China, 1989; pp. 163–178. [Google Scholar]
- Gao, F.; Ma, F.; Zhang, Y.; Wang, J.; Sun, J.; Yang, E. Biologically Inspired Progressive Enhancement Target Detection from Heavy Cluttered SAR Images. Cogn. Comput. 2016, 8, 955–966. [Google Scholar] [CrossRef]
- Gao, F.; Ma, F.; Wang, J.; Sun, J.; Zhou, H. Visual Saliency Modeling for River Detection in High-resolution SAR Imagery. IEEE Access 2017, 6, 1000–1014. [Google Scholar] [CrossRef]
- Yue, Z.; Gao, F.; Xiong, Q.; Wang, J.; Huang, T.; Yang, E. A Novel Semi-Supervised Convolutional Neural Network Method for Synthetic Aperture Radar Image Recognition. Cogn. Comput. 2019, 1–12. [Google Scholar] [CrossRef]
- Gao, F.; Huang, T.; Sun, J.; Wang, J.; Hussain, A.; Yang, E. A New Algorithm for SAR Image Target Recognition Based on an Improved Deep Convolutional Neural Network. Cogn. Comput. 2018, 1–16. [Google Scholar] [CrossRef]
- Xing, X.; Chen, Z.; Zou, H.; Zhou, S. A fast algorithm based on two-stage CFAR for detecting ships in SAR images. In Proceedings of the 2nd Asian-Pacific Conference on Synthetic Aperture Radar, Xian, China, 26–30 October 2009; pp. 506–509. [Google Scholar]
- Smith, M.E.; Varshney, P.K. Vi-cfar: A novel cfar algorithm based on data variability. In Proceedings of the IEEE National Radar Conference, Syracuse, NY, USA, 13–15 May 1997; pp. 263–268. [Google Scholar]
- Gao, G.; Liu, L.; Zhao, L.; Shi, G.; Kuang, G. An adaptive and fast cfar algorithm based on automatic censoring for target detection in high-resolution sar images. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1685–1697. [Google Scholar] [CrossRef]
- Farrouki, A.; Barkat, M. Automatic censoring cfar detector based on ordered data variability for nonhomogeneous environments. IEE Proc. Radar Sonar Navig. 2005, 152, 43–51. [Google Scholar] [CrossRef]
- Pastina, D.; Fico, F.; Lombardo, P. Detection of ship targets in COSMO-SkyMed SAR images. In Proceedings of the Radar Conference (RADAR), Kansas City, MO, USA, 23–27 May 2011; pp. 928–933. [Google Scholar]
- Ngiam, J.; Coates, A.; Lahiri, A.; Prochnow, B.; Le, Q.V.; Ng, A.Y. On optimization methods for deep learning. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 265–272. [Google Scholar]
- Le, Q.V.; Zou, W.Y.; Yeung, S.Y.; Ng, A.Y. Learning Hierarchical Spatio-Temporal Features for Action Recognition with Independent Subspace Analysis. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 20–25 June 2011. [Google Scholar]
- Messina, M.; Greco, M.; Fabbrini, L.; Pinelli, G. Modified Otsu’s algorithm: A new computationally efficient ship detection algorithm for SAR images. In Proceedings of the Tyrrhenian Workshop on Advances in Radar and Remote Sensing (TyWRRS), Naples, Italy, 12–14 September 2012; pp. 262–266. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H. Combining a single shot multibox detector with transfer learning for ship detection using sentinel-1 sar images. Remote Sens. Lett. 2018, 9, 780–788. [Google Scholar] [CrossRef]
- Huang, X.; Yang, W.; Zhang, H.; Xia, G.-S. Automatic ship detection in sar images using multi-scale heterogeneities and an a contrario decision. Remote Sens. 2015, 7, 7695–7711. [Google Scholar] [CrossRef]
- El-Darymli, K.; McGuire, P.; Power, D.; Moloney, C.R. Target detection in synthetic aperture radar imagery: A state-of-the-art survey. J. Appl. Remote Sens. 2013, 7, 7–35. [Google Scholar]
- Crisp, D.J. The State-of-the-Art in Ship Detection in Synthetic Aperture Radar Imagery. Available online: https://www.researchgate.net/publication/27253731_The_state-of-the-art_in_ship_detection_in_Synthetic_Aperture_Radar_imagery (accessed on 13 September 2019).
- Migliaccio, M.; Nunziata, F.; Montuori, A.; Paes, R.L. Single-look complex COSMO-SkyMed SAR data to observe metallic targets at sea. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2012, 5, 893–901. [Google Scholar] [CrossRef]
- Wang, J.; Sun, L. Study on ship target detection and recognition in SAR imagery. In Proceedings of the 1st International Conference on Information Science and Engineering (ICISE), Nanjing, China, 26–28 December 2009; pp. 1456–1459. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. Automatic Ship Detection Based on RetinaNet Using Multi-Resolution Gaofen-3 Imagery. Remote. Sens. 2019, 11, 531. [Google Scholar] [CrossRef]
- Chang, Y.L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.Y.; Lee, W.H. Ship Detection Based on YOLOv2 for SAR Imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef]
- Hu, Y.; Shan, Z.; Gao, F. Ship Detection Based on Faster-RCNN and Multiresolution SAR. Radio Eng. 2018, 48, 96–100. [Google Scholar]
- Zhao, J.; Zhang, Z.; Yu, W.; Truong, T.K. A cascade coupled convolutional neural network guided visual attention method for ship detection from SAR images. IEEE Access 2018, 6, 50693–50708. [Google Scholar] [CrossRef]
- Jiao, J.; Zhang, Y.; Sun, H.; Yang, X.; Gao, X.; Hong, W.; Sun, X. A densely connected end-to-end neural network for multiscale and multiscene SAR ship detection. IEEE Access 2018, 6, 20881–20892. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Sun, X.; Yan, M.; Guo, Z.; Fu, K. Position detection and direction prediction for arbitrary-oriented ships via multitask rotation region convolutional neural network. IEEE Access 2018, 6, 50839–50849. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–13 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–13 June 2015; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the 31th Conference on Artificial Intelligence(AAAI), San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Doerry, A.W.; Bishop, E.; Miller, J.; Horndt, V.; Small, D. Designing interpolation kernels for SAR data resampling. Radar Sens. Technol. XVI 2012. [Google Scholar] [CrossRef]
- Zang, T.; Long, T. Polynomial Fitting Used in Spaceborne SAR Interpolation Processing and its Error Analysis. Mod. Radar 2004, 26, 43–45. [Google Scholar]
- Bi, H.; Zhang, B.; Wang, Z.; Hong, W. Lq regularisation-based synthetic aperture radar image feature enhancement via iterative thresholding algorithm. Electron. Lett. 2016, 52, 1336–1338. [Google Scholar] [CrossRef]
- Çetin, M.; Karl, W.C. Feature-enhanced synthetic aperture radar image formation based on nonquadratic regularization. IEEE Trans. Image Process. 2001, 10, 623–631. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhang, Q. System Design and Key Technologies of the GF-3 Satellite. Acta Geodaetica et Cartographica Sinica 2017, 46, 269–277. [Google Scholar]
- European Space Agency. Sentinel-1 User Handbook; European Space Agency: Paris, France, 2013. [Google Scholar]
- Daubechies, I.; Defrise, M.; De Mol, C. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Commun. Pure Appl. Math. 2004, 57, 1413–1457. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 10–16 October 2016; pp. 630–645. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–13 June 2015; pp. 3431–3440. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processsing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Navon, D. Forest before trees: The precedence of global features in visual perception. Cogn. Psychol. 1977, 9, 353–383. [Google Scholar] [CrossRef]
- Shihui, H. The global precedence in visual information processing. J. Chin. Psychol. 2000, 32, 337–347. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Gao, F.; Shi, W.; Wang, J.; Hussain, A.; Zhou, H. A Semi-Supervised Synthetic Aperture Radar (SAR) Image Recognition Algorithm Based on an Attention Mechanism and Bias-Variance Decomposition. IEEE Access 2019, 7, 108617–108632. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wie, S. A SAR Dataset of Ship Detection for Deep Learning under Complex Backgrounds. Remote Sens. 2019, 11, 765. [Google Scholar] [CrossRef]
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Object retrieval with large vocabularies and fast spatial matching. In Proceedings of the IEEE Computer Vision and Pattern Recognition; 2007; pp. 1–8. [Google Scholar]
- Sasaki, Y. The truth of the F-measure. Teach. Tutor. Mater. 2007, 1, 1–5. [Google Scholar]
- Flach, P.; Kull, M. Precision-recall-gain curves: PR analysis done right. In Proceedings of the Advances in Neural Information Processsing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 838–846. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processsing Systems (NIPS), Lake Tahoe, CA, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 10–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Imaging Mode | Resolution Rg. × Az.(m) | Swath (km) | Incident Angle (°) | Polarization | Number of Images |
|---|---|---|---|---|---|---|
| GF-3 | UFS | 3 × 3 | 30 | 20~50 | Single | 12 |
| GF-3 | FS1 | 5 × 5 | 50 | 19~50 | Dual | 10 |
| GF-3 | QPSΙ | 8 × 8 | 30 | 20~41 | Full | 5 |
| GF-3 | FSΙ | 10 × 10 | 100 | 19~50 | Dual | 15 |
| GF-3 | QPSΙΙ | 25 × 25 | 40 | 20~38 | Full | 5 |
| Sentinel-1 | SM | 1.7 × 4.3 to 3.6 × 4.9 | 80 | 20~45 | Dual | 49 |
| Sentinel-1 | IW | 20 × 22 | 250 | 29~46 | Dual | 10 |
| Methods | Precision | Recall | F1 Score | mAP | Average Time (ms) Per Image |
|---|---|---|---|---|---|
| RetinaNet | 0.9214 | 0.8663 | 0.8901 | 91.59% | 42.88 |
| SAB-RetinaNet | 0.9301 | 0.8730 | 0.9007 | 91.69% | 43.23 |
| SCB-RetinaNet | 0.9256 | 0.8875 | 0.9061 | 92.07% | 50.98 |
| 2S-RetinaNet | 0.9370 | 0.8877 | 0.9117 | 92.59% | 52.50 |
| Model | 2S-RetinaNet | SSD | YOLOv3 | Faster R-CNN |
|---|---|---|---|---|
| mAP | 92.59% | 82.96% | 83.49% | 88.34% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, F.; Shi, W.; Wang, J.; Yang, E.; Zhou, H. Enhanced Feature Extraction for Ship Detection from Multi-Resolution and Multi-Scene Synthetic Aperture Radar (SAR) Images. Remote Sens. 2019, 11, 2694. https://doi.org/10.3390/rs11222694
Gao F, Shi W, Wang J, Yang E, Zhou H. Enhanced Feature Extraction for Ship Detection from Multi-Resolution and Multi-Scene Synthetic Aperture Radar (SAR) Images. Remote Sensing. 2019; 11(22):2694. https://doi.org/10.3390/rs11222694
Chicago/Turabian StyleGao, Fei, Wei Shi, Jun Wang, Erfu Yang, and Huiyu Zhou. 2019. "Enhanced Feature Extraction for Ship Detection from Multi-Resolution and Multi-Scene Synthetic Aperture Radar (SAR) Images" Remote Sensing 11, no. 22: 2694. https://doi.org/10.3390/rs11222694
APA StyleGao, F., Shi, W., Wang, J., Yang, E., & Zhou, H. (2019). Enhanced Feature Extraction for Ship Detection from Multi-Resolution and Multi-Scene Synthetic Aperture Radar (SAR) Images. Remote Sensing, 11(22), 2694. https://doi.org/10.3390/rs11222694