High-Quality Cloud Masking of Landsat 8 Imagery Using Convolutional Neural Networks

Abstract

1. Introduction
2. Materials and Methods
2.1. Training and Evaluation Data
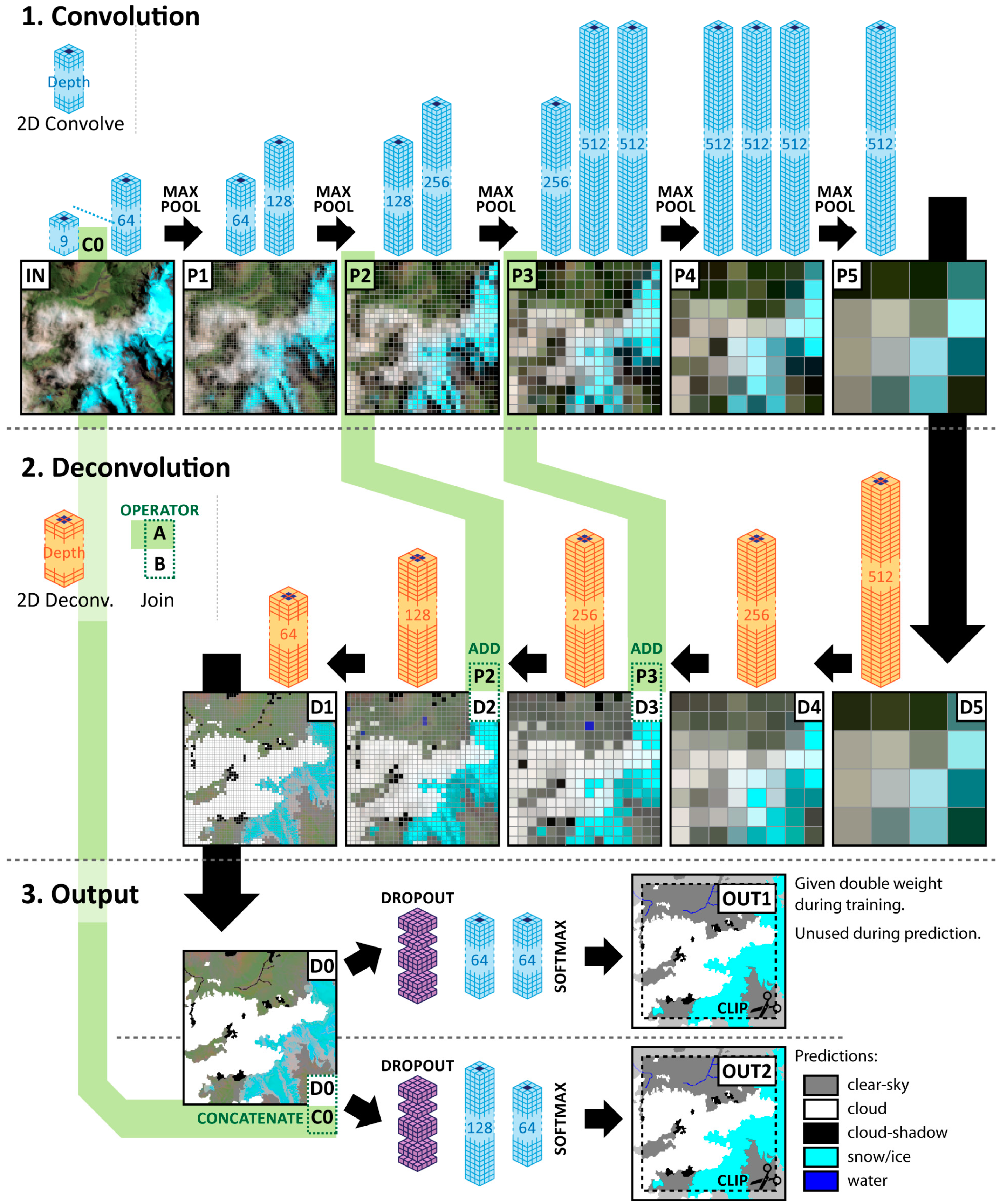
2.2. Neural Network Architechture
2.3. Processing
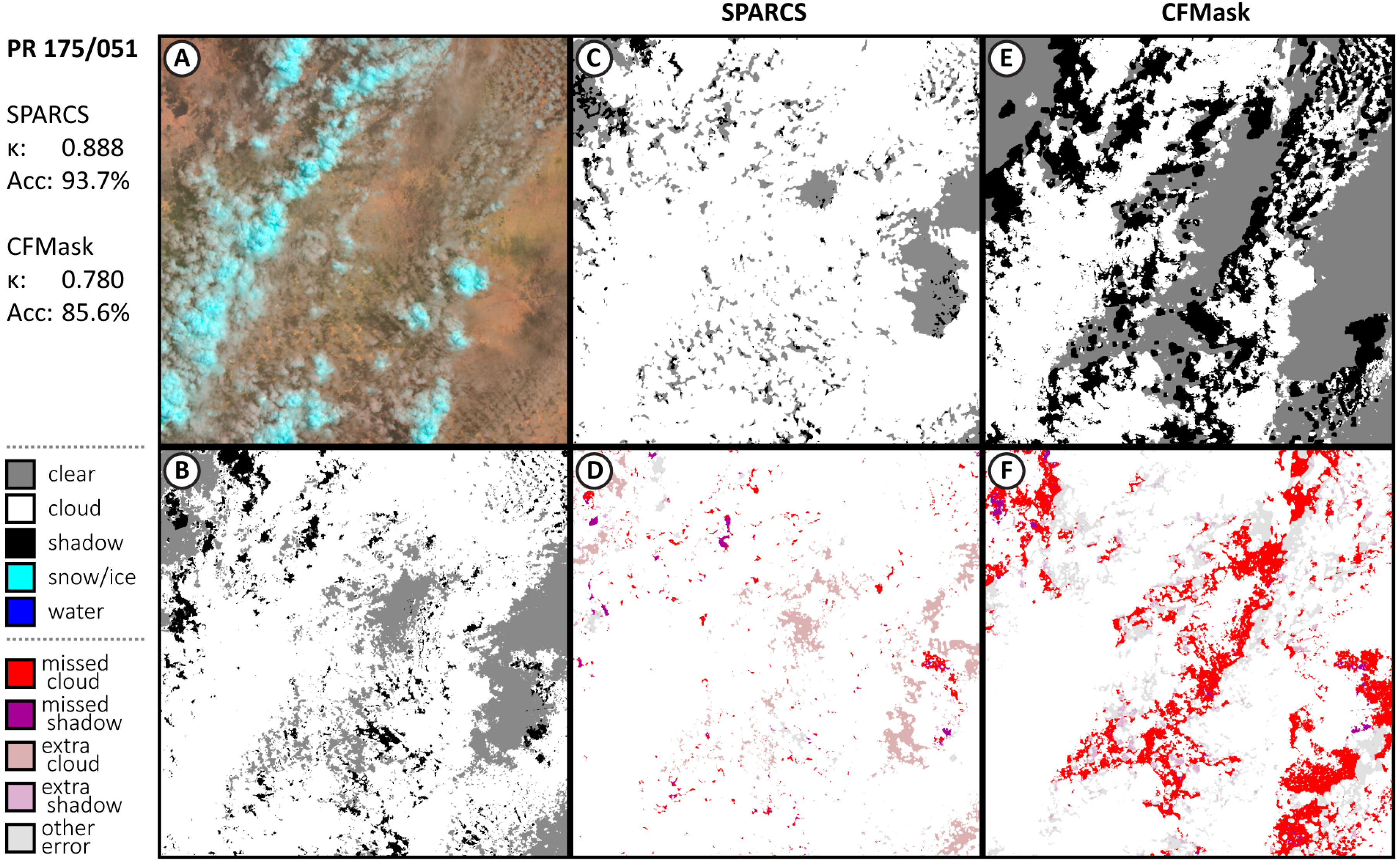
2.4. Evaluation
3. Results
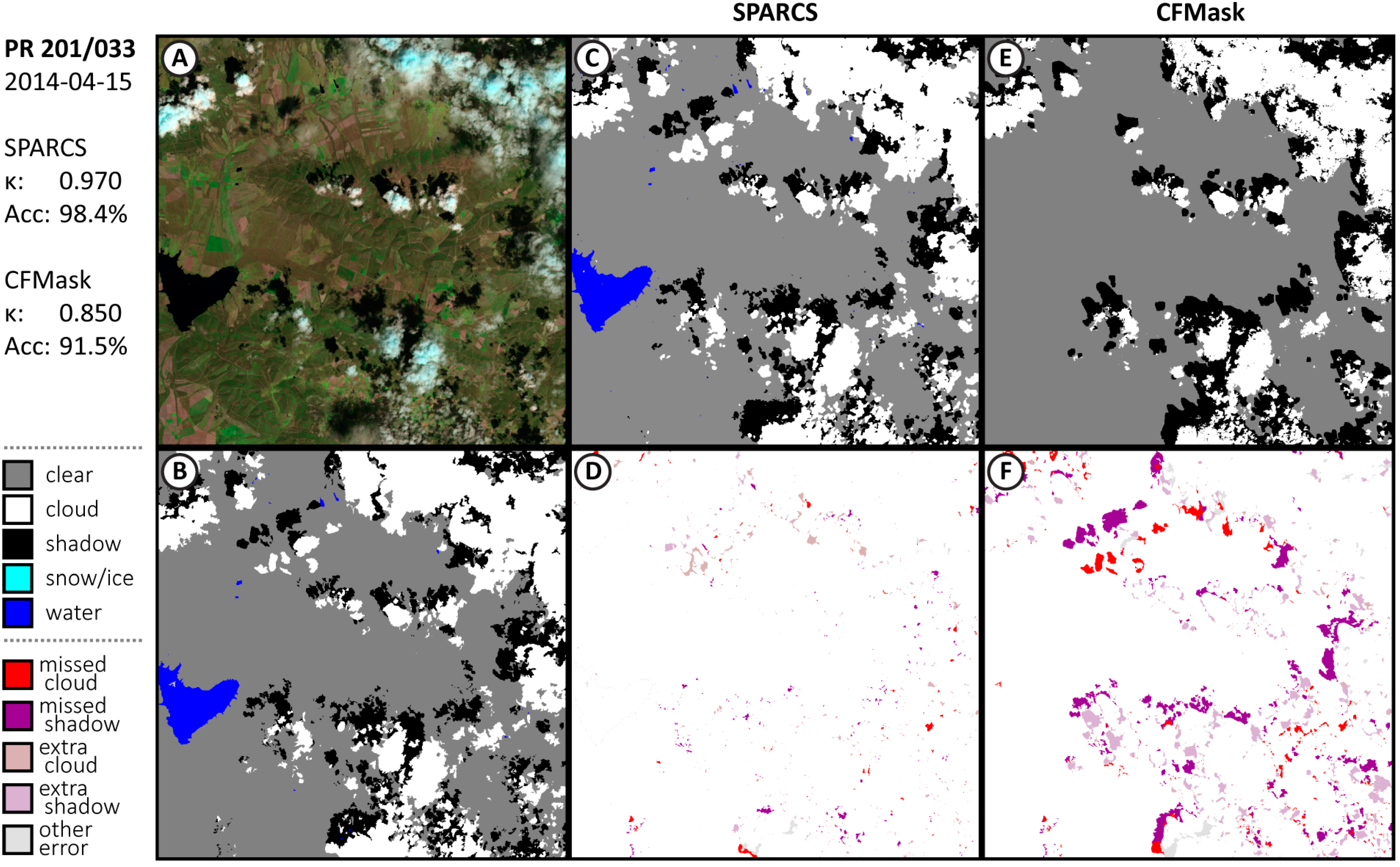
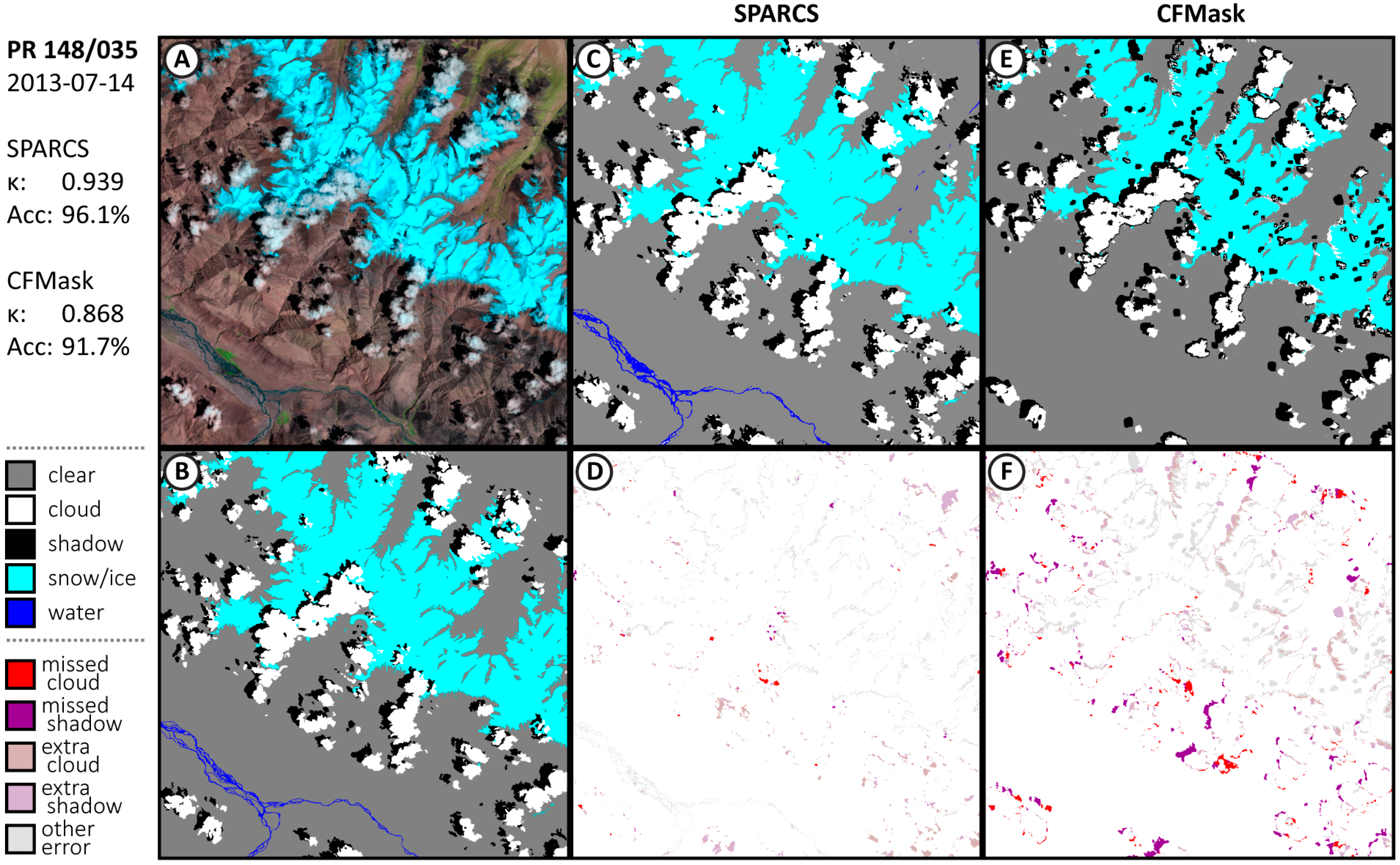
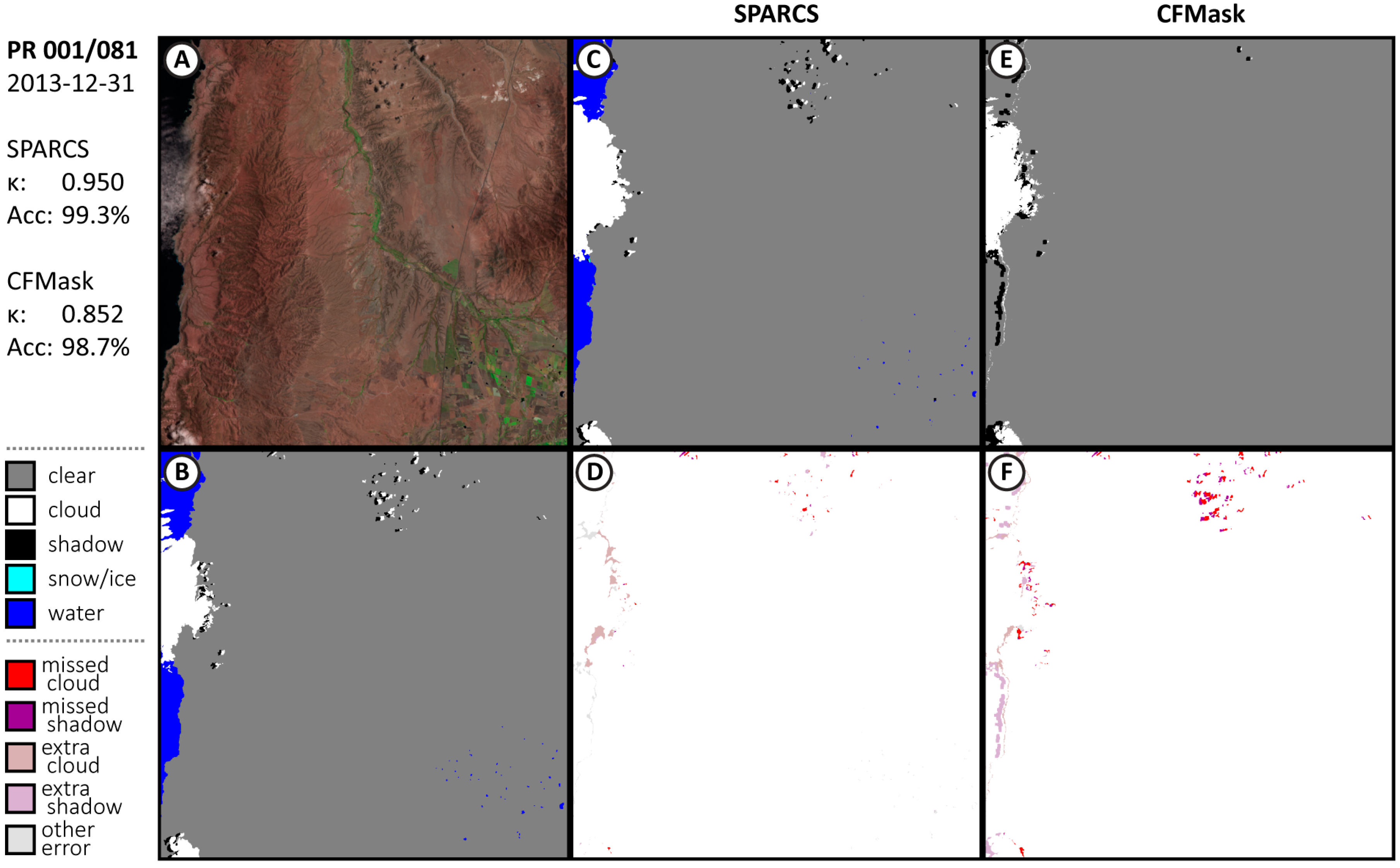
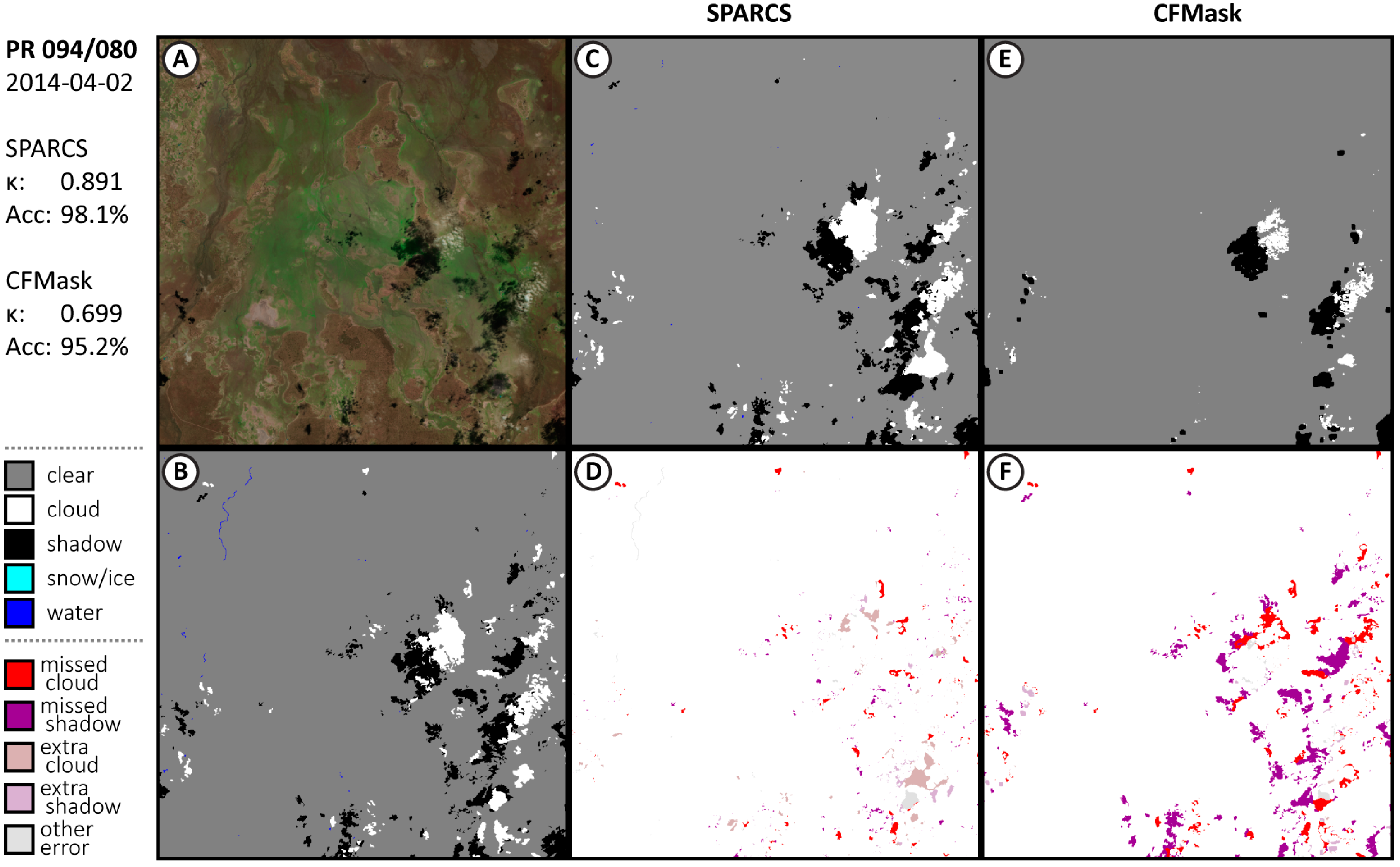
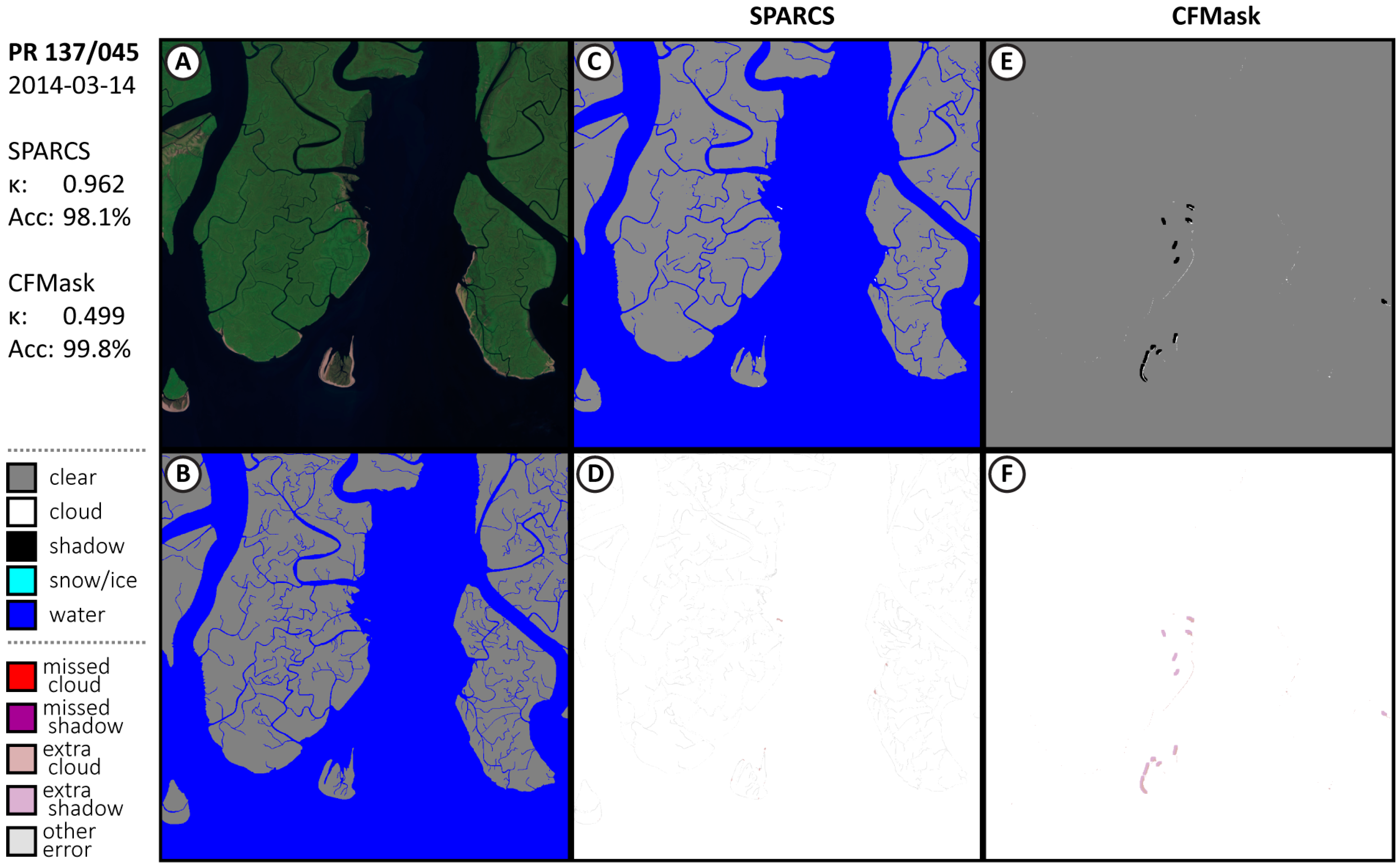
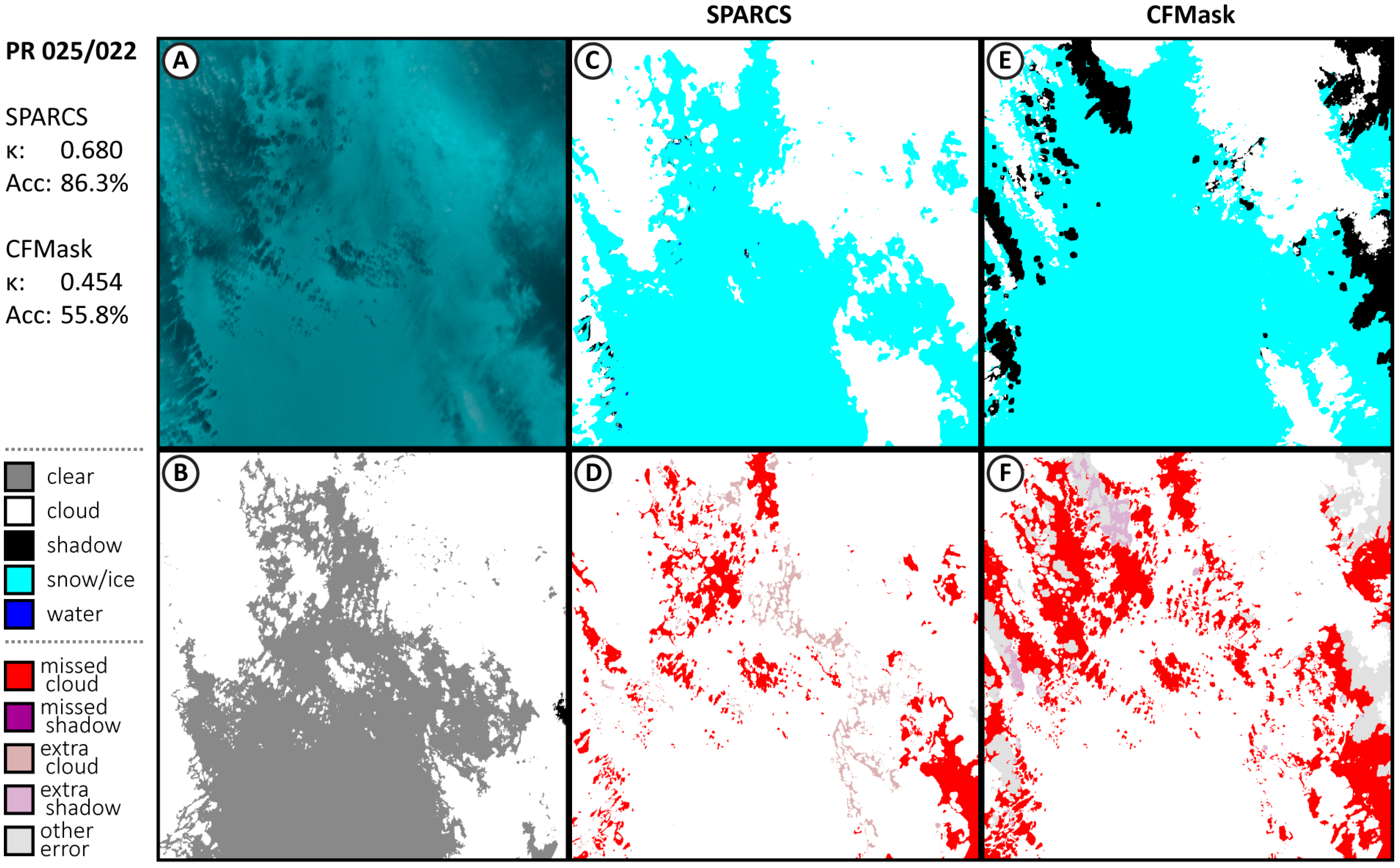
3.1. Performance of CNN SPARCS
3.2. Human Interpreter Consistency
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
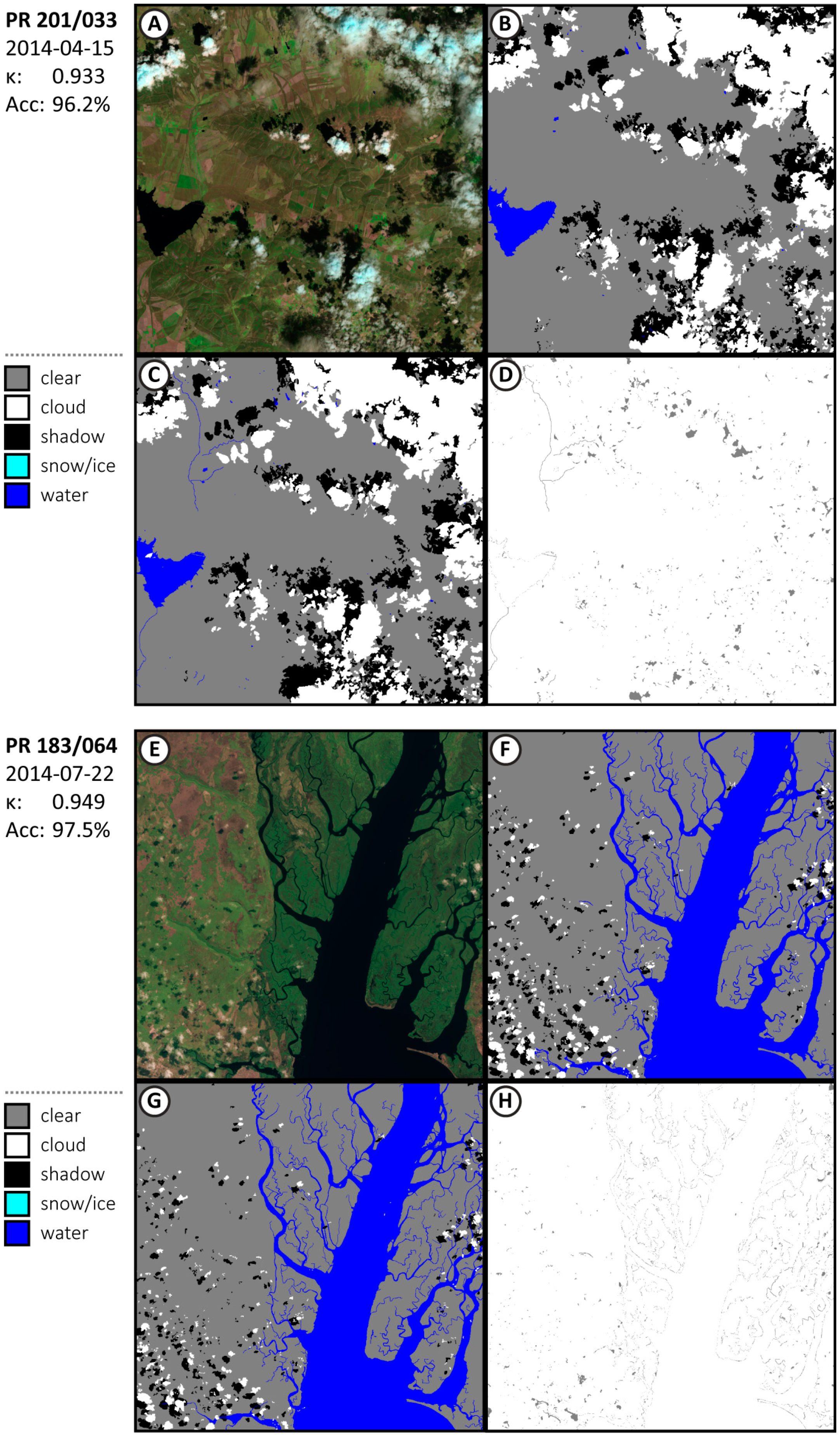
Appendix A.1. Additional Results from Validation Subscenes






Appendix A.2. Comparison with Biome Dataset

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| With 2-px Buffer | Without 2-px Buffer | |||||||
|---|---|---|---|---|---|---|---|---|
| SPARCS | CFMask | SPARCS | CFMask | |||||
| Scene Identifier | Kappa | Acc. | Kappa | Acc. | Kappa | Acc. | Kappa | Acc. |
| LC80010732013109LGN00 | 0.813 | 94.2% | 0.712 | 88.3% | 0.763 | 92.1% | 0.680 | 86.3% |
| LC80070662014234LGN00 | 0.949 | 99.0% | 0.928 | 98.5% | 0.880 | 97.6% | 0.868 | 97.2% |
| LC80160502014041LGN00 | 0.970 | 98.2% | 0.905 | 94.0% | 0.848 | 89.7% | 0.773 | 83.9% |
| LC80200462014005LGN00 | 0.966 | 98.8% | 0.879 | 95.6% | 0.847 | 93.7% | 0.751 | 89.4% |
| LC80250022014232LGN00 | 0.680 | 86.3% | 0.454 | 55.8% | 0.633 | 82.7% | 0.425 | 51.4% |
| LC80290372013257LGN00 | 0.915 | 95.7% | 0.866 | 92.9% | 0.838 | 91.1% | 0.792 | 88.3% |
| LC80750172013163LGN00 | 0.523 | 99.9% | 0.499 | 98.8% | 0.523 | 99.9% | 0.499 | 98.8% |
| LC80980712014024LGN00 | 0.856 | 90.9% | 0.813 | 87.7% | 0.715 | 79.0% | 0.690 | 76.9% |
| LC81010142014189LGN00 | 0.827 | 91.5% | 0.773 | 88.6% | 0.696 | 84.4% | 0.642 | 81.4% |
| LC81020802014100LGN00 | 0.767 | 89.6% | 0.803 | 91.3% | 0.590 | 81.0% | 0.633 | 82.9% |
| LC81130632014241LGN00 | 0.893 | 97.9% | 0.858 | 97.0% | 0.779 | 94.3% | 0.755 | 93.5% |
| LC81310182013108LGN01 | 0.706 | 98.3% | 0.779 | 98.8% | 0.667 | 97.9% | 0.724 | 98.3% |
| LC81490432014141LGN00 | 0.930 | 100.0% | 0.897 | 100.0% | 0.882 | 99.9% | 0.841 | 99.9% |
| LC81620582014104LGN00 | 0.849 | 98.8% | 0.772 | 97.8% | 0.764 | 97.7% | 0.712 | 96.8% |
| LC81640502013179LGN01 | 0.805 | 95.3% | 0.863 | 97.1% | 0.728 | 92.6% | 0.786 | 95.1% |
| LC81750512013208LGN00 | 0.888 | 93.7% | 0.780 | 85.6% | 0.780 | 86.2% | 0.696 | 77.8% |
| LC81750622013304LGN00 | 0.883 | 95.9% | 0.807 | 93.2% | 0.744 | 90.1% | 0.716 | 89.3% |
| LC81770262013254LGN00 | 0.896 | 98.5% | 0.823 | 97.1% | 0.812 | 96.9% | 0.745 | 95.1% |
| LC81820302014180LGN00 | 0.907 | 99.8% | 0.900 | 99.8% | 0.828 | 99.7% | 0.826 | 99.7% |
| LC81910182013240LGN00 | 0.635 | 99.5% | 0.581 | 99.1% | 0.601 | 99.3% | 0.566 | 98.9% |
| LC81930452013126LGN01 | 0.833 | 92.1% | 0.828 | 90.7% | 0.754 | 87.2% | 0.777 | 86.9% |
| LC82020522013141LGN01 | 0.785 | 94.0% | 0.587 | 75.4% | 0.731 | 92.0% | 0.552 | 71.3% |
| LC82150712013152LGN00 | 0.924 | 95.8% | 0.760 | 84.2% | 0.843 | 90.5% | 0.686 | 77.7% |
| LC82290572014141LGN00 | 0.811 | 88.4% | 0.765 | 85.0% | 0.681 | 78.4% | 0.639 | 75.1% |
| All Scenes | 0.906 | 95.4% | 0.833 | 91.3% | 0.838 | 91.4% | 0.771 | 87.2% |




References
- Wulder, M.A.; Masek, J.G.; Cohen, W.B.; Loveland, T.R.; Woodcock, C.E. Opening the archive: How free data has enabled the science and monitoring promise of Landsat. Remote Sens. Environ. 2012, 122, 2–10. [Google Scholar] [CrossRef]
- Wulder, M.A.; Loveland, T.R.; Roy, D.P.; Crawford, C.J.; Masek, J.G.; Woodcock, C.E.; Allen, R.G.; Anderson, M.C.; Belward, A.S.; Cohen, W.B.; et al. Current status of Landsat program, science, and applications. Remote Sens. Environ. 2019, 225, 127–147. [Google Scholar] [CrossRef]
- Ju, J.; Roy, D.P. The availability of cloud-free Landsat ETM+ data over the conterminous United States and globally. Remote Sens. Environ. 2008, 112, 1196–1211. [Google Scholar] [CrossRef]
- Kennedy, R.E.; Yang, Z.; Braaten, J.; Copass, C.; Antonova, N.; Jordan, C.; Nelson, P. Attribution of disturbance change agent from Landsat time-series in support of habitat monitoring in the Puget Sound region, USA. Remote Sens. Environ. 2015, 166, 271–285. [Google Scholar] [CrossRef]
- Cohen, W.; Healey, S.; Yang, Z.; Stehman, S.; Brewer, C.; Brooks, E.; Gorelick, N.; Huang, C.; Hughes, M.; Kennedy, R. How similar are forest disturbance maps derived from different Landsat time series algorithms? Forests 2017, 8, 98. [Google Scholar] [CrossRef]
- Healey, S.P.; Cohen, W.B.; Yang, Z.; Brewer, C.K.; Brooks, E.B.; Gorelick, N.; Hernandez, A.J.; Huang, C.; Hughes, M.J.; Kennedy, R.E. Mapping forest change using stacked generalization: An ensemble approach. Remote Sens. Environ. 2018, 204, 717–728. [Google Scholar] [CrossRef]
- Hollingsworth, B.V.; Chen, L.; Reichenbach, S.E.; Irish, R.R. Automated cloud cover assessment for Landsat TM images. Proc. SPIE 1996, 2819, 170–179. [Google Scholar]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Hughes, M.; Hayes, D. Automated detection of cloud and cloud shadow in single-date Landsat imagery using neural networks and spatial post-processing. Remote Sens. 2014, 6, 4907–4926. [Google Scholar] [CrossRef]
- Foga, S.; Scaramuzza, P.L.; Guo, S.; Zhu, Z.; Dilley, R.D., Jr.; Beckmann, T.; Schmidt, G.L.; Dwyer, J.L.; Hughes, M.J.; Laue, B. Cloud detection algorithm comparison and validation for operational Landsat data products. Remote Sens. Environ. 2017, 194, 379–390. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [PubMed]
- Wei, Y.; Xia, W.; Huang, J.; Ni, B.; Dong, J.; Zhao, Y.; Yan, S. Cnn: Single-label to multi-label. arXiv 2014, arXiv:1406.5726. [Google Scholar]
- Shi, M.; Xie, F.; Zi, Y.; Yin, J. Cloud detection of remote sensing images by deep learning. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 701–704. [Google Scholar]
- Xie, F.; Shi, M.; Shi, Z.; Yin, J.; Zhao, D. Multilevel cloud detection in remote sensing images based on deep learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3631–3640. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Mateo-García, G.; Gómez-Chova, L.; Camps-Valls, G. Convolutional neural networks for multispectral image cloud masking. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 2255–2258. [Google Scholar]
- Zhan, Y.; Wang, J.; Shi, J.; Cheng, G.; Yao, L.; Sun, W. Distinguishing cloud and snow in satellite images via deep convolutional network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1785–1789. [Google Scholar] [CrossRef]
- Drönner, J.; Korfhage, N.; Egli, S.; Mühling, M.; Thies, B.; Bendix, J.; Freisleben, B.; Seeger, B. Fast Cloud Segmentation Using Convolutional Neural Networks. Remote Sens. 2018, 10, 1782. [Google Scholar] [CrossRef]
- Liu, C.-C.; Zhang, Y.-C.; Chen, P.-Y.; Lai, C.-C.; Chen, Y.-H.; Cheng, J.-H.; Ko, M.-H. Clouds Classification from Sentinel-2 Imagery with Deep Residual Learning and Semantic Image Segmentation. Remote Sens. 2019, 11, 119. [Google Scholar] [CrossRef]
- Wieland, M.; Li, Y.; Martinis, S. Multi-sensor cloud and cloud shadow segmentation with a convolutional neural network. Remote Sens. Environ. 2019, 230, 111203. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Cheng, Q.; Liu, Y.; You, S.; He, Z. Deep learning based cloud detection for medium and high resolution remote sensing images of different sensors. ISPRS J. Photogramm. Remote Sens. 2019, 150, 197–212. [Google Scholar] [CrossRef]
- Shao, Z.; Pan, Y.; Diao, C.; Cai, J. Cloud Detection in Remote Sensing Images Based on Multiscale Features-Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4062–4076. [Google Scholar] [CrossRef]
- Yang, J.; Guo, J.; Yue, H.; Liu, Z.; Hu, H.; Li, K. CDnet: CNN-Based Cloud Detection for Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6195–6211. [Google Scholar] [CrossRef]
- Chai, D.; Newsam, S.; Zhang, H.K.; Qiu, Y.; Huang, J. Cloud and cloud shadow detection in Landsat imagery based on deep convolutional neural networks. Remote Sens. Environ. 2019, 225, 307–316. [Google Scholar] [CrossRef]
- Jeppesen, J.H.; Jacobsen, R.H.; Inceoglu, F.; Toftegaard, T.S. A cloud detection algorithm for satellite imagery based on deep learning. Remote Sens. Environ. 2019, 229, 247–259. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2010), San Francisco, CA, USA, 13–18 June 2010; p. 7. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), Toronto, ON, Canada, 24–28 June 2017; pp. 1–12. [Google Scholar]
- Olson, D.M.; Dinerstein, E. The Global 200: Priority ecoregions for global conservation. Ann. Mo. Bot. Gard. 2002, 89, 199–224. [Google Scholar] [CrossRef]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 648–656. [Google Scholar]
- USGS; EROS; NASA. Landsat 8 (L8) Data User’s Handbook Version 4. 2019. Available online: https://prd-wret.s3-us-west-2.amazonaws.com/assets/palladium/production/atoms/files/LSDS-1574_L8_Data_Users_Handbook_v4.pdf (accessed on 25 April 2019).
- Data Input Pipeline Performance. Available online: https://www.tensorflow.org/guide/performance/datasets (accessed on 21 August 2019).
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]





| Clear-Sky | Cloud | Shadow | Snow/Ice | Water | Recall | |
|---|---|---|---|---|---|---|
| Clear-Sky | 5,185,970 | 27,372 | 18,209 | 35,057 | 15,755 | 98.2% |
| Cloud | 37,807 | 1,004,243 | 3399 | 2052 | 1563 | 95.7% |
| Shadow | 26,711 | 5993 | 494,661 | 1541 | 10,199 | 91.8% |
| Snow/Ice | 14,509 | 1837 | 1973 | 407,209 | 212 | 95.6% |
| Water | 20,419 | 2057 | 3154 | 4229 | 673,863 | 95.8% |
| Accuracy | 98.1% | 96.4% | 94.9% | 90.5% | 96.0% | 97.1% |
| CFMask | Clear-Sky | Cloud | Shadow | Snow/Ice | Recall |
|---|---|---|---|---|---|
| Clear-Sky | 5,874,317 | 218,065 | 204,209 | 19,264 | 93.0% |
| Cloud | 27,099 | 793,830 | 693 | 114,182 | 84.8% |
| Shadow | 85,715 | 18,543 | 313,738 | 31,022 | 69.9% |
| Snow/Ice | 195 | 365 | 1143 | 285,620 | 99.4% |
| Accuracy | 98.1% | 77.0% | 60.4% | 63.5% | 90.9% |
| Clear-Sky | Cloud | Shadow | Snow/Ice | Water | ||
|---|---|---|---|---|---|---|
| Clear-Sky | 2,573,774 | 22,919 | 19,882 | 9655 | 8456 | 97.7% |
| Cloud | 22,506 | 605,888 | 2289 | 36,063 | 2943 | 90.5% |
| Shadow | 675 | 7 | 240,210 | 4 | 417 | 99.5% |
| Snow/Ice | 5583 | 911 | 47 | 124,801 | 3 | 95.0% |
| Water | 30,341 | 107 | 501 | 1783 | 290,235 | 89.9% |
| 97.8% | 96.2% | 91.4% | 72.4% | 96.1% | 95.9% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hughes, M.J.; Kennedy, R. High-Quality Cloud Masking of Landsat 8 Imagery Using Convolutional Neural Networks. Remote Sens. 2019, 11, 2591. https://doi.org/10.3390/rs11212591
Hughes MJ, Kennedy R. High-Quality Cloud Masking of Landsat 8 Imagery Using Convolutional Neural Networks. Remote Sensing. 2019; 11(21):2591. https://doi.org/10.3390/rs11212591
Chicago/Turabian StyleHughes, M. Joseph, and Robert Kennedy. 2019. "High-Quality Cloud Masking of Landsat 8 Imagery Using Convolutional Neural Networks" Remote Sensing 11, no. 21: 2591. https://doi.org/10.3390/rs11212591
APA StyleHughes, M. J., & Kennedy, R. (2019). High-Quality Cloud Masking of Landsat 8 Imagery Using Convolutional Neural Networks. Remote Sensing, 11(21), 2591. https://doi.org/10.3390/rs11212591