1. Introduction
A hyperspectral image is a data cube that simultaneously conveys rich spatial information and spectral information [
1,
2]. It can collect a wide range of electromagnetic spectrum nearly from visible to long-wavelength infrared. These spectra are represented by hundreds of continuous bands that can meticulously describe the characteristics of different materials to recognize their subtle differences [
3]. Therefore, owing to this good discriminative property of hyperspectral image, it has been widely used in many remote sensing research fields [
4,
5], such as image denoising [
6,
7], hyperspectral unmixing [
8,
9], band selection [
10,
11], target detection [
12,
13], and image classification [
14,
15]. They all have important practical applications in geological exploration, urban remote sensing and planning management, environment and disaster monitoring, precision agriculture, archaeology, etc.
Due to its property of knowing nothing about the hyperspectral image scene, anomaly detection, as one special research problem of target detection, has attracted lots of attention in remote sensing field [
16]. It aims at detecting the abnormal pixel whose spectrum has significant deviation from that of the given reference background. As it does not need any prior knowledge of both the target and the background, anomaly detection fits well with requirements of practical application because there is usually not a lot of information for unknown geographic scene. Consequently, it can be successfully used in a lot of practical applications [
17,
18,
19,
20], such as intelligent defense, food safety, medicine and health, forest fire protection, etc. Hyperspectral anomaly detection has played a crucial role in both military and civilian areas.
Over the past decades, a large number of anomaly detection methods for hyperspectral images have been proposed [
21,
22,
23,
24,
25]. They can be roughly divided into two categories, i.e., distribution hypothesis-based methods and geometric model-based methods, which will be introduced in detail as follows. For the first category, the well-known Reed-Xiaoli (RX) [
26] method is the most typical algorithm. It assumes that the background obeys the multivariate normal distribution. Therefore, Mahalanobis distance is adopted to compute the difference between one abnormal pixel and its surrounding background. Although RX is the most traditional method regarded as the benchmark, it still suffers from some important problems causing unsatisfactory detection performance when analyzing real-world images [
27]. The small sample size is a tough problem of RX, which generates a badly conditioned matrix computation resulting in unstable results. In addition, unavoidable contamination of some potential abnormal targets embedding in the background will reduce the detection performance as well. Nevertheless, the intrinsic problem is the simple Gaussian distribution cannot accurately model the real hyperspectral image because of complex characteristics of the covered materials.
Many methods have been proposed aiming at improving the performance of RX through making some revisions to RX from different views. Instead of computing the covariance matrix using the reference background delineated by a local sliding window for local RX (LRX), the global RX (GRX) can directly use the whole image as background to evaluate its statistics. The regularized-RX (RRX) [
28] method takes use of a scaled identity matrix to well adjust the property of estimated covariance matrix in order to address the effect of small sample size. There are also many methods that improve the performance through purifying background. For example, the random-selection-based anomaly detector (RSAD) [
29] designs a sample random selection process to iteratively pick out some representative background pixels. Through carrying out this selection process for sufficient times, a better and purer background set can be obtained. The traditional blocked adaptive computationally efficient outlier nominator (BACON) [
30] is also a robust method to the effects of anomalies. It starts from a basic subset that is affine equivariant and then continuously updates the basic set to construct the final basic subset to realize anomalies’ recognition. The kernel technique-based methods intend to improve the discrimination between background spectra and target information by mapping the original hyperspectral image into a feature space with high dimension. For example, kernel-RX (KRX) [
31], a nonlinear version of RX, maps the linear non-Gaussian distribution data into nonlinear Gaussian that proves to be more accurate for anomaly detection. To improve the accuracy of background description, the cluster-based anomaly detector (CBAD) [
32] is proposed, which adopts a clustering technique to segment the whole image into different clusters and, further, makes the hypothesis about each cluster obeying multivariate normal distribution. However, although these methods show their ability to improve the performance of RX, the intrinsic assumption still limits its performance.
As for the second category, geometric model-based methods commonly consider that there exist some representative spectra or dictionary bases to well characterize the background information. As one of the most important data representation types, sparse representation has been successfully applied in hyperspectral anomaly detection [
33,
34,
35,
36,
37,
38,
39]. According to this philosophy, many methods have emerged in recent years. Yuan et al. [
39] propose a local sparsity divergence method which simultaneously takes use of spectral and spatial divergence to analyze anomalies from the local reference background defined by a sliding window. Li et al. [
36] propose constructing a collaborative representation-based detector (CRD), assuming that the background pixel can be approximately linearly represented by its surroundings, which is also a sparse representation-based detector (SRD). It further adopts a similarity matrix to regularize the collaborative representation in order to suppress the effects of anomalies. To obtain a more accurate description of background, a background joint sparse representation model [
37] is designed to pick out the most active dictionary bases with the good ability to represent background. Taking sparse coefficient matrix having capabilities to reflect the atom usage frequency into consideration, a sparsity score estimation framework [
40] is proposed to compute abnormal degree through combining the coefficient vector and atom usage probability. Ling et al. [
41] propose a constrained sparse representation model which introduces both the sum-to-one and non-negativity constraints to satisfy physical meaning and simultaneously remove the constraint on the upper bound of sparsity level to avoid parameter setting. Taking advantage of the low rank property of background, Zhang et al. present a low-rank and sparse matrix decomposition-based Mahalanobis distance method (LSMAD) [
38]. They impose the low-rank constraint on the background and the sparse constraint on anomalies in order to better decompose the background information from original hyperspectral images. Besides, there are also some manifold learning based methods which explore the data structure to detect anomalies. Olson et al. [
42] construct a hyperspectral anomaly detection model in which the manifold learning technique is used to learn the background information. Yuan et al. [
27] design a graph pixel selection process through combining the manifold learning technique and graph theory. The locally linear embedding (LLE) is used to discover the data structure that can contributes to the representation of anomalies.
In addition, some deep learning technique-based methods have been proposed in recent years. Using the advantages of deep learning architecture in data feature mining, researchers have explored its specific implementation in hyperspectral anomaly detection. There are two main ways: one is to fully learn the abstract representation of high-dimensional data from the perspective of unsupervised learning; the other is to use some label information or target information to guide the understanding of data characteristics from the perspective of supervised learning. Bati et al. propose an anomaly detection method based on autoencoder [
43]. Through the coding–decoding process, background data can be decoded with a small reconstruction error, whereas the anomaly will have the larger reconstruction error. Zhao et al. use the stacked denoising autoencoders [
44] to automatically learn the nonlinear deep features of hyperspectral images and achieve better detection results. Ma et al. design a detector based on a deep confidence network in which an adaptive weighting strategy is proposed to reduce the effect of local anomalies [
45]. As for the supervised learning, it mainly uses external labeled hyperspectral images to guide the detection of anomalies in unknown scenes. Li et al. construct a transferred deep convolutional neural network to detect anomalies in the hyperspectral image [
46]. Using the reference data with real labels, pixel pairs are generated to train the multi-layer CNN. For the pixel under test, its corresponding pixel pairs are obtained through computing the difference spectral vectors between it and all its surrounding pixels. Through statistically analyzing the similarity scores computed by the network, the final detection result can be obtained.
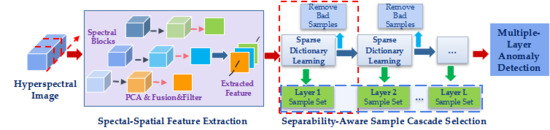
This work aims at addressing some challenges in the field of hyperspectral anomaly detection from the view of using traditional machine learning method. Although sparse representation based methods have proven its effectiveness in hyperspectral anomaly detection from the recently published literature [
47], there are still some important problems that can have effects on the performance of anomaly detection. As we all know, real hyperspectral images commonly cover a vast geographical scene containing various materials with different spectral properties. Therefore, when directly exploring the background information using all the image pixels, an accurate background representation is hard to be learned because of the complex spectral interactions and inter-/intra-difference of different samples. Consequently, the detection performance will be reduced. Besides, potential anomalies embedding in the image scene can affect the background representation resulting in deterioration of performance as well. To address these problems, this paper proposes a novel hyperspectral anomaly detection based on separability-aware sample cascade, which tries to improve the description ability of background from the view of complex samples selection. Considering different pixels have different separable degrees from others, we can effectively divide them into different sample sets reflecting various material characteristics according to their separability. As a result, more accurate and complete background representation can be effectively obtained corresponding to each sample set belonging to different separation grades. Even though for the samples that are hard to be separated, the specially learned background information can also ensure the good ability to represent them. In our method, we gradually sift out all the samples layer-by-layer through the cascade structure in which sparse representation is used, to compute the separability of each sample. At the same time, we also remove potential anomalies from each layer in order to avoid feeding them into the next layer, which can ensure the good ability of background representation to resist the effects of anomalies. In addition, as spatial information is also important to recognize anomalies, we adopt a spectral–spatial feature extraction strategy to enhance the expressive ability. Note that our detection framework is applicable to different anomaly detectors, and the sparse representation is replaceable in this work. Main contributions of the proposed method can be summarized as follows.
- (1)
Through identifying separability of hyperspectral pixels, a novel separability-aware sample cascade method is proposed to deeply and comprehensively explore the background characteristics. According to their separable degrees, it can effectively sift out all the pixel samples layer-by-layer, so that the learned background representation is more accurate and discriminative to express complex real hyperspectral image scenes.
- (2)
Benefiting from automatically removing all the pixels with relatively lower separability in each cascade layer, it can directly avoid feeding the potential anomalies into the subsequent layers. Consequently, the proposed method can not only prepare purer data samples for sample selection of each layer, but also further ensure that the background characteristics have the good ability to restrain the effects of anomalies.
- (3)
Taking both spectral and spatial information into consideration, a good spectral–spatial feature extraction strategy is used in this work. Through effectively combining the rich spectral properties naturally contained in the hyperspectral data and the structure properties obtained by using edge-preserving filter operation, we can extract features with higher expressive ability to characterize the deviation between target and background.
The rest parts of this paper are organized as follows. In
Section 2, the proposed method is elaborated. In
Section 3, experiments carried on five real hyperspectral images are introduced in detail. Finally, our work is summarized in
Section 4.
2. Our Method
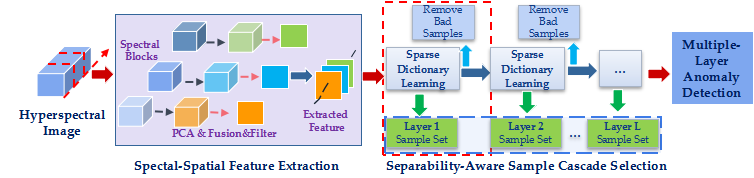
In this paper, we propose a novel anomaly detection method through constructing a separability-aware sample cascade model. As hyperspectral image pixels have complex spectral interactions and inter-/intra-difference, directly analyzing these samples as a whole to estimate background characteristics will result in unsatisfactory and inaccurate background evaluation. Consequently, anomaly detection will be further deeply affected. More precisely, when the analyzed pixels contain various kinds of materials or complicated interactions, precise background information presentation is really hard to be obtained. In fact, different pixels can be separated from others with different separability. If samples can be sifted out according to their different difficulties of separability, different background representation can be specifically obtained to make aware of samples with different deviations. In other words, for each kind of sample separated, from easily to difficultly separated, we can learn more accurate information to express samples’ characteristics. Our method contains three main procedures: (1) spectral–spatial feature extraction, (2) separability-aware sample cascade selection, and (3) multilayer anomaly detection.
First, we apply a new spectral–spatial feature extraction technique to take discriminative spectra and structure property into account at the same time. The traditional PCA and edge-preserving filtering are used in this operator, which can not only effectively remove redundant information, but also obtain useful spatial structure information to enhance expressive ability of each pixel sample. Secondly, we construct separability-aware sample cascade selection framework. Sparse representation is used to compute separability of each sample. According to their separable degrees, the relatively easily separated samples are sifted out and the bad samples with extremely low separability are simultaneously removed to delete their interference. Then the rest samples are fed into the next cascade layer to perform the same sample selection. Through passing all the samples layer-by-layer, we can obtain different sample sets with different separability-aware degrees from each cascade layer. Last, a multilayer anomaly detection strategy is presented to comprehensively take advantage of different separability-aware abilities of each layer in order to improve the detection performance. The proposed method will be elaborated in the following sections.
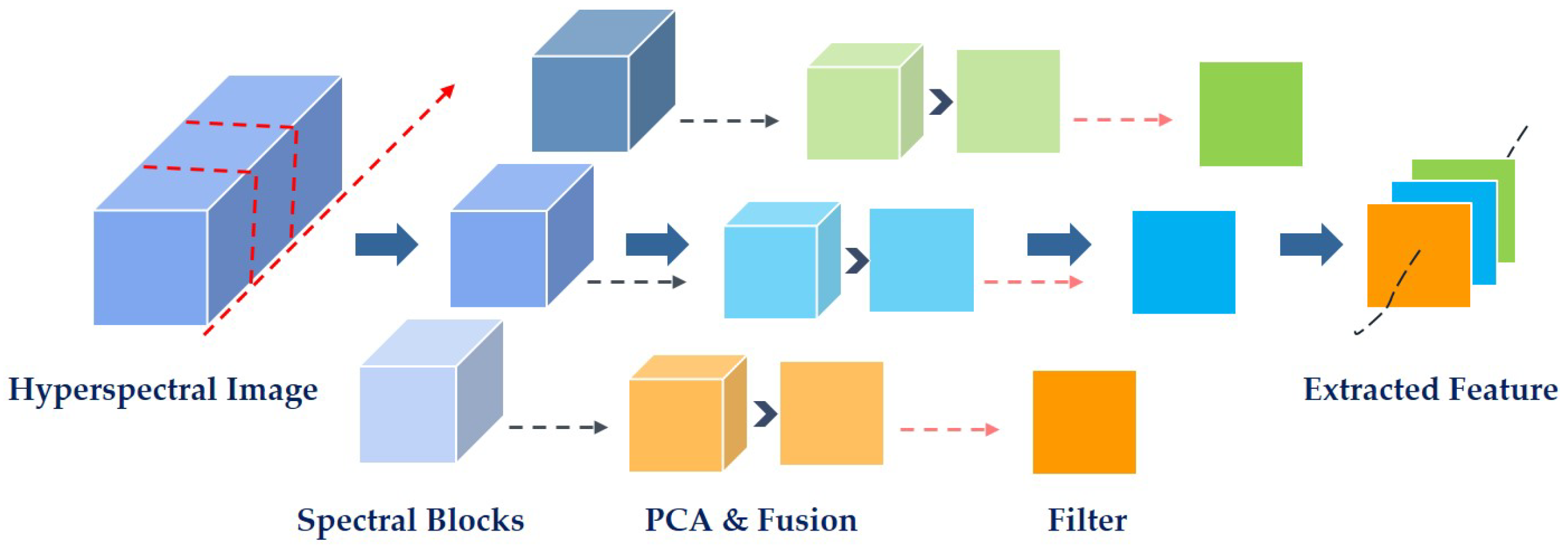
2.1. Spectral-Spatial Feature Extraction
This part will introduce a new and simple spectral–spatial feature extraction technique.
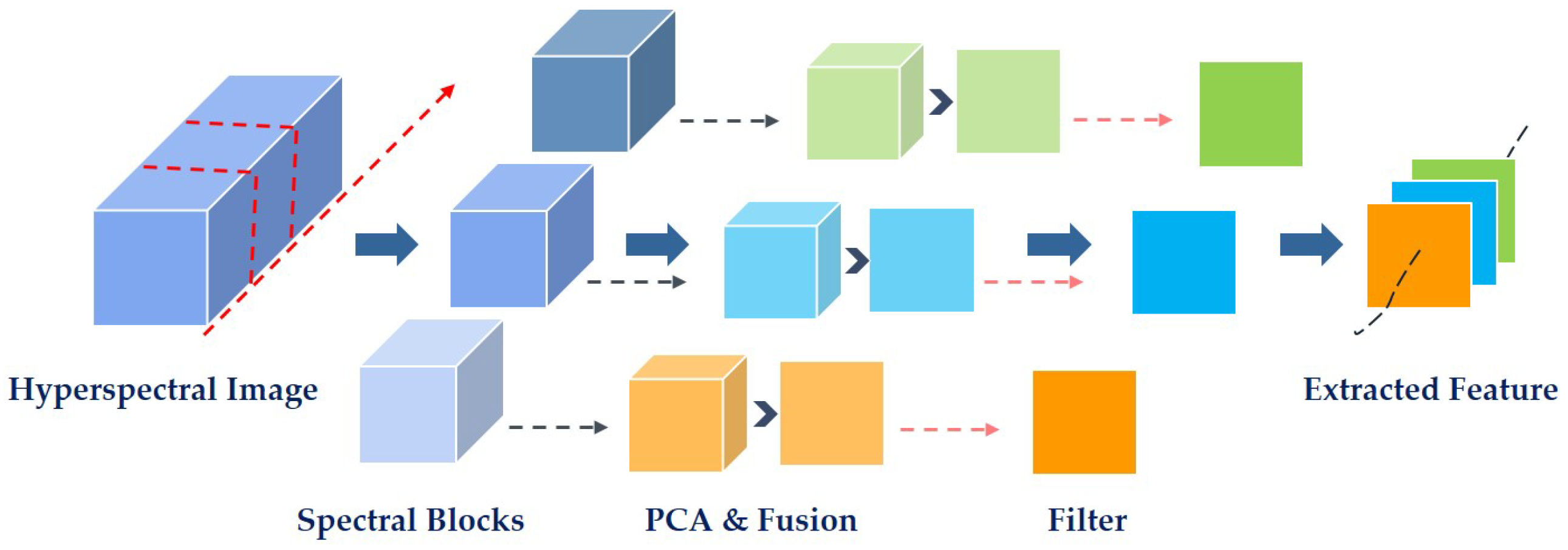
Figure 1 shows the flow chart of our feature extraction strategy. Through using this technique, the extracted feature can not only deliver rich spectral information, but also contain spatial structure information, which will have the stronger expressive ability to represent each data sample. At the same time, its low dimensional characteristic ensures the good performance in efficiency as well. Note that our used spectral–spatial feature extraction technique is inspired by that in [
48], whose good performance has been demonstrated. Instead of directly using the technique proposed in [
48], we embed the principal component analysis (PCA) strategy in it in order to eliminate the effects of some low signal–noise rate bands or unless bands.
As shown in
Figure 1, we first divide the original hyperspectral cube into small blocks along the spectral dimension. Then for each block, PCA is used to explore the main pattern in data and remove noise as well. In order to take full use of different virtues of all the principal components, band fusion operation is carried out to completely combine all these principal bands together for further dimension reduction and information enhancement. After that, the edge-preserving filtering is carried out on each fused band to well preserve the spatial information. Finally, concatenating each fused band corresponding to each block together, a small new data cube with lower feature dimension is generated which delivers both the spectral and spatial information.
As our used spectral–spatial feature extraction technique is similar to the work [
48]; therefore, we will briefly introduce it here following the flow chart shown in
Figure 1. For a hyperspectral image cube
,
H means the image height,
W denotes the image width, and
B is the number of spectral bands. Therefore, a single band image can be denoted as
. When we divide
into
K blocks along the spectral dimension, each block can be regarded as a set built with some adjacent band images. The index set of image bands contained in each blocks can be defined as follows,
where
is the index set for
block, the
function means that
is rounded down to get the integer value, and
is a set of positive integers. Therefore, each image block set
can be further obtained.
Then, the PCA technique is carried out and
m principal components are remained for each block. The fusion operation is further implemented on
m principal components by using the traditional averaging strategy. Therefore, we can totally obtain
K fused bands and the
element can be denoted as
. Then, according to the authors of [
48,
49], we carry out the edge-preserving filtering on each fused band. Therefore, our finally obtained small cube
can be described as follows,
where
denotes the
filtered band in the obtained cube data
H. We adopt the same filter function
, which is the transform domain recursive filter defined in [
48]. Here,
denotes the space standard deviation which mainly controls the blurring degree, and
corresponds to the range, which mainly determines edge preservation. These two parameters can affect the effectiveness of the filter together.
2.2. Separability-Aware Sample Cascade Selection
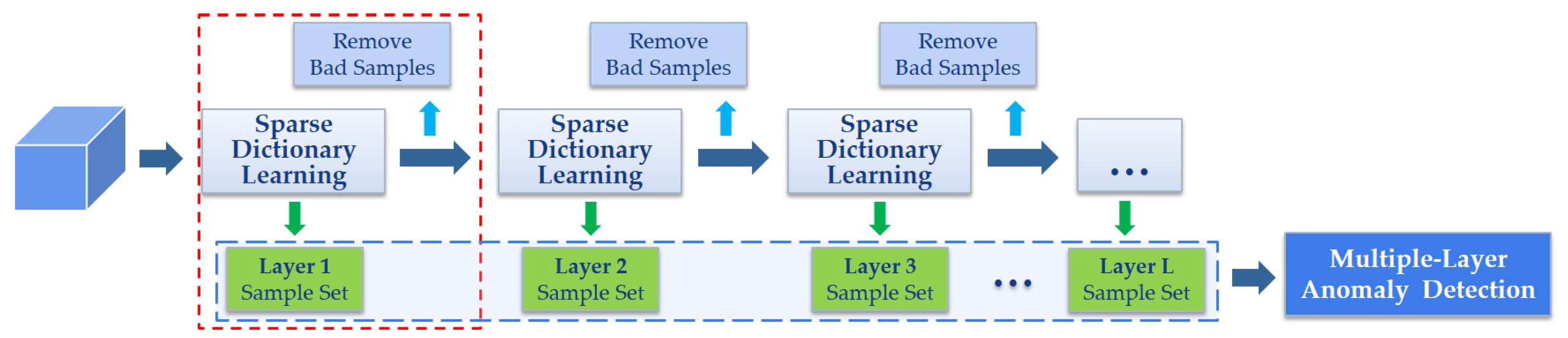
This part will introduce the separability-aware sample cascade selection process in detail. As sparse representation is commonly used in anomaly detection for its decent performance, our method is designed based on this representation model as well. However, due to the complex interference of various kinds of materials, accurate background representation will be affected. Therefore, we aim to address this problem through constructing a sample cascade selection on the basis of separability-aware idea. As per our proposed framework shown in
Figure 2, different samples aware of different separable degrees can be effectively sifted out from the whole data set through the proposed sample cascade selection process. Meanwhile, we remove some potential targets as bad samples. Consequently, we can not only collect different sample sets with better representation ability specific to different background characteristics but also benefit from restraining the effects of some potential abnormal samples. The technical details will be introduced below.
For the small cube data
obtained by the above mentioned spectral–spatial feature extraction strategy, we reshape it into a 2D representation matrix
, in which each row is generated by transforming each filtered band of
into a vector, respectively. Here,
is the total number of the cube data, and each column of
,
denotes a pixel sample with
K dimensions. Therefore, the traditional sparse representation model [
50] can be formulated as
where
is the sparse representation dictionary containing
M bases,
is the sparse coefficient matrix, and
is the regularization parameter. In this work, the dictionary learning technique proposed by Mairal et al. [
51] is used to compute matrix
. As for
, when
is fixed, it turns to be the typical Lasso problem which can be easily solved. Therefore, the sparse reconstruction error
for each sample can be computed as follows,
Therefore, reconstruction error vector for N input samples can be expressed as . For simplicity, we directly regard the recovery value as the separability degree of each sample. The lower the reconstruction error is, the easier the sample is to be separated from others.
Then, we sift out the samples according to their separable degrees. First, the samples with relatively lower recovery errors will be picked out to build the separability-aware sample set for the current selection process. Second, the samples with relatively higher recovery errors which can be regarded as potential anomaly targets will be removed in order to reduce their effects on the next sample selection. The rest samples will be fed into the next layer to conduct the same selection process. By this way, we construct multiple layers connected in a cascade way to gradually separate all the pixels samples layer-by-layer according to different separability-aware degrees.
For better understanding, new mathematical symbols are introduced. As described above, the small cube data
is fed into the first layer to be sifted out. Consequently, it can be denoted as
, where
. The corresponding
can be expressed as
. Assuming that the input samples of the
layer is
, where
is the total number of samples in current layer and
L is the number of cascade layers in total; therefore, using Equations (
4) and (
5), we can learn the sparse dictionary, solve the coefficient matrix, and compute the reconstruction error vector
. Note that the matrix representation of the input samples can be simply regarded as a set whose elements correspond to the column vectors
in this work.
Then, we can sift out the separability-aware sample set
for the
layer which can be written as
where
is the separable threshold. Instead of fixing it at a constant, we use the value corresponding to the
percentile of all the elements of current recovery error vector
. Different
will determine different
.
The removed sample set can be built as
where
is the removed threshold, which can be computed by the same way as
through setting the
percentile value. Therefore, we can finally obtain the rest samples which will be fed into the
layer as its input data
by Equation (
8).
Removing the potential interference information is beneficial for learning background representation, because sample set
can be purified resulting in the following sample selection more accurate and robust. We will not terminate the same sample selection process until the stop condition is satisfied. In this work, we define the stop condition as
The function is used to count the number of elements in a set. Therefore, this condition means that for a layer when the number of its input samples is less than a given constant C, the whole separability-aware sample cascade selection process will be stopped. At this time, if the last layer is the layer, there are totally L separability-aware sample sets . Algorithm 1 summarizes the whole proposed selection process.
| Algorithm 1 Separability-Aware Sample Cascade Selection |
| Input: Cube data sample set , regularized parameter , separable percentile , removed percentile , and constant C. |
| Output: All separability-aware sample sets . |
- 1:
Initialize , , . - 2:
repeat - 3:
Calculate the reconstruction errors by solving Equations ( 4) and ( 5). - 4:
Calculate the separability-aware sample set . - 5:
Calculate the removed sample set . - 6:
Calculate the input sample set for next layer . - 7:
until.
|
2.3. Multiple-Layer Anomaly Detection
After finishing the separability-aware sample cascade selection process, totally
L sample sets are generated from different layers. These sets have different separable degrees from each other. In other words, each sample set can characterize one specific property of the image scene. They can represent different discriminative abilities to perceive each sample’s deviation from the image scene. Therefore, we further present a multilayer anomaly detection strategy. Through comprehensively taking advantage of the different discriminative abilities of all these generated sample sets, the better detection performance can be achieved.
Figure 2 also shows the multilayer anomaly detection strategy. Specifically, we feed each separability-aware sample set
as the dictionary into the traditional sparse representation model described by Equation (
4), so the corresponding sparse matrix can be solved. Here, we denote each coefficient matrix as
. Consequently, the joint detection results through fusing different decisions of all the layers can be computed as follows,
where
is the
sample of the input cube data,
is its corresponding sparse coefficient vector which is the
column vector of matrix
, and
is its final anomaly detection probability. Owing to the good virtue of multilayer anomaly detection strategy, we believe the proposed method has the better ability to detect various targets. No matter whether the target under test has higher separable degree or lower degree from the image scene, we can effectively recognize it by using the different discriminative abilities of different layers.
4. Conclusions
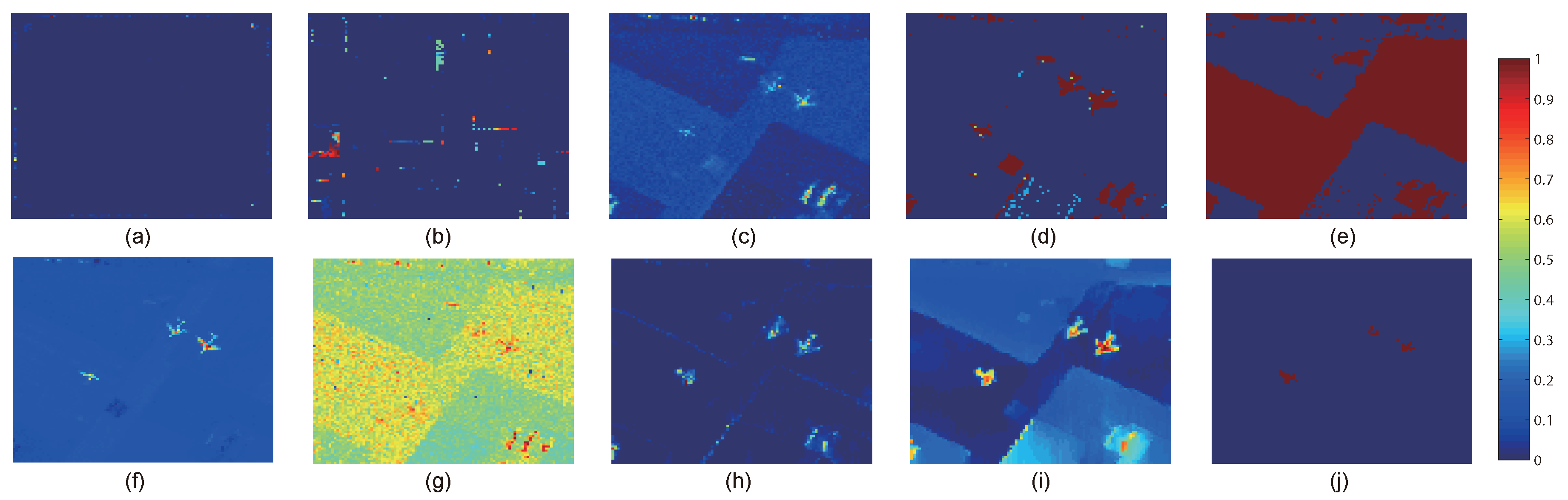
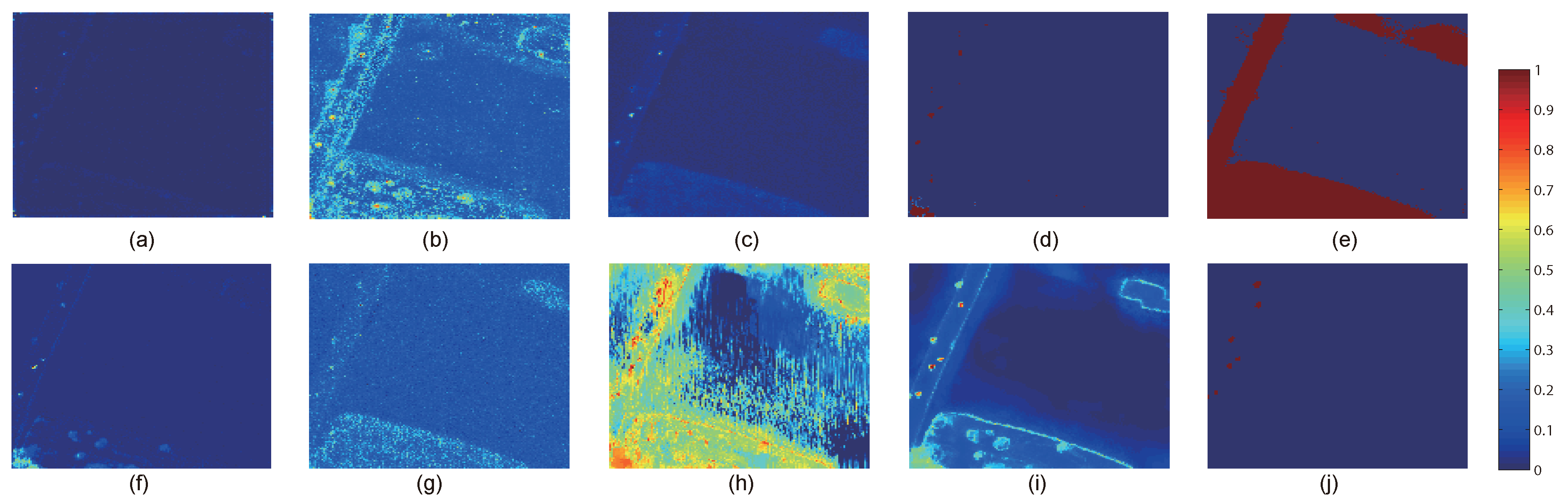
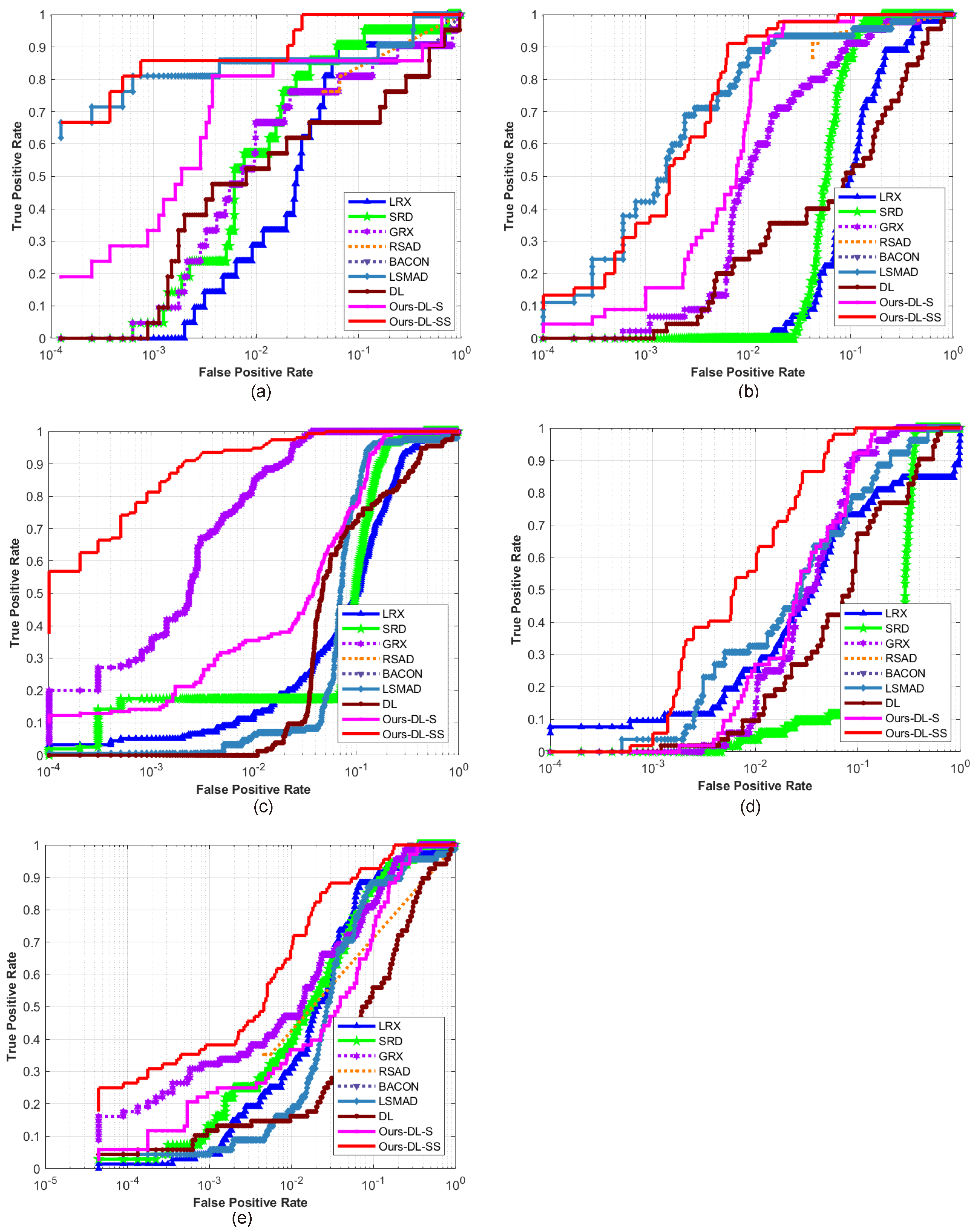
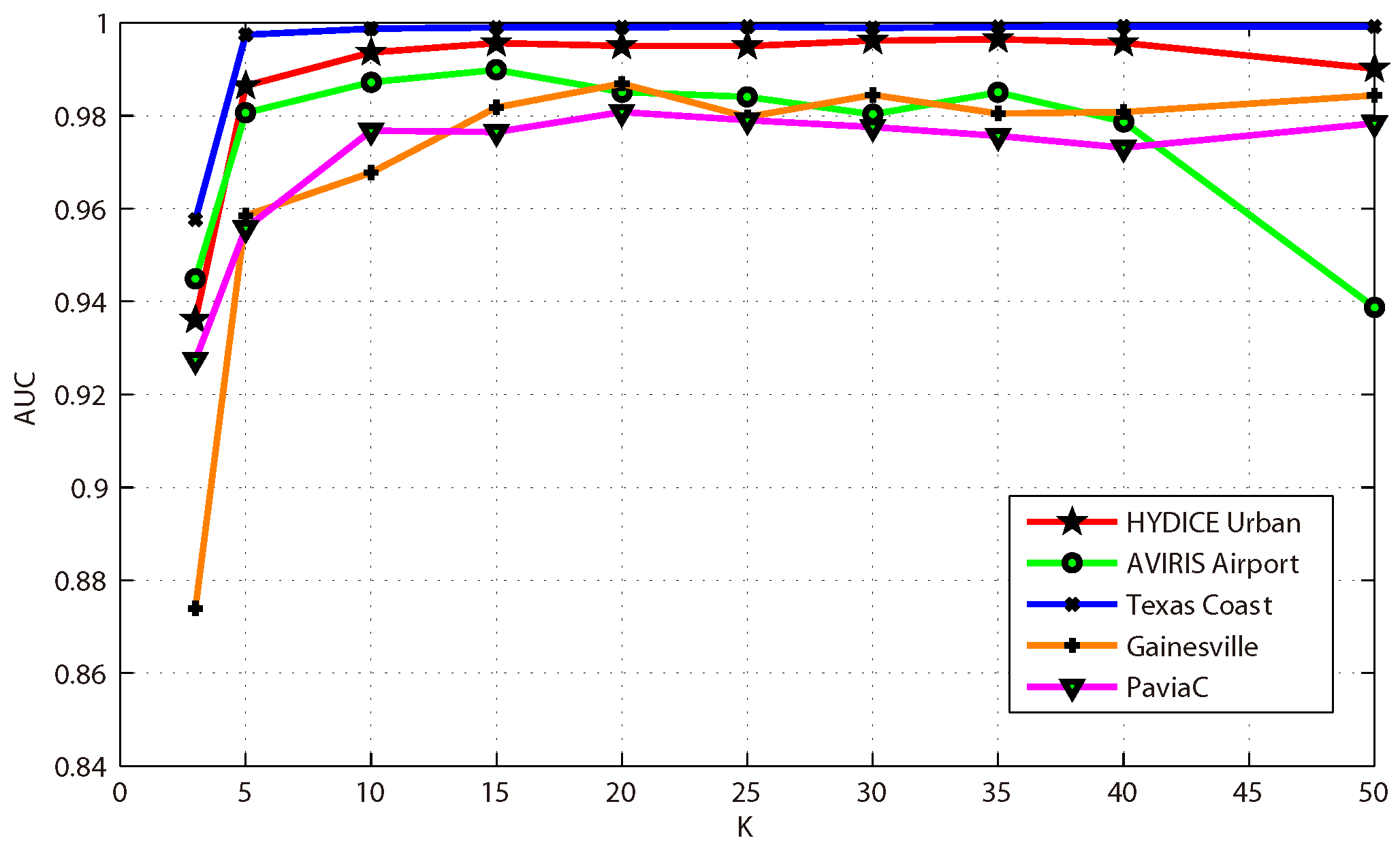
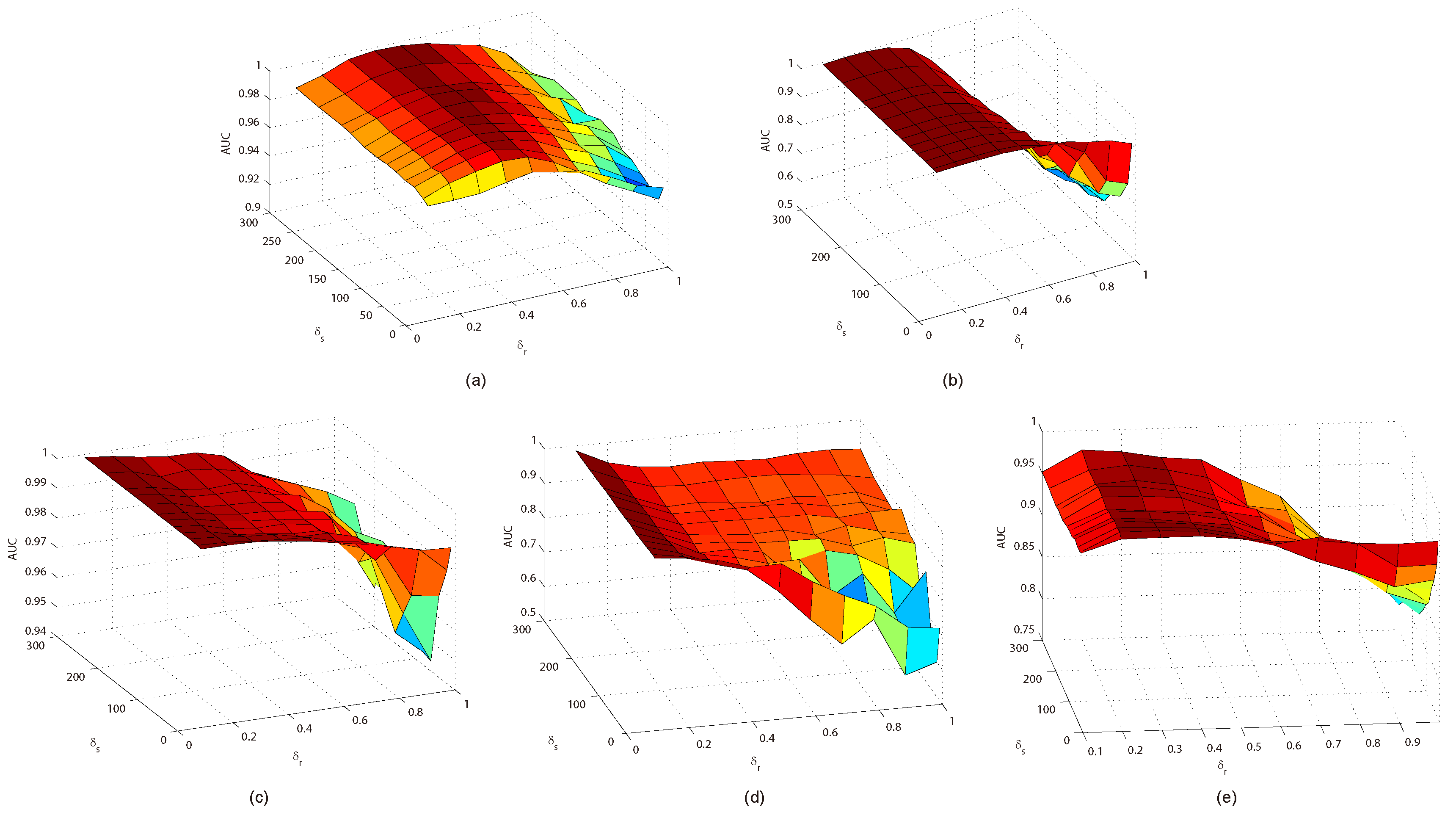
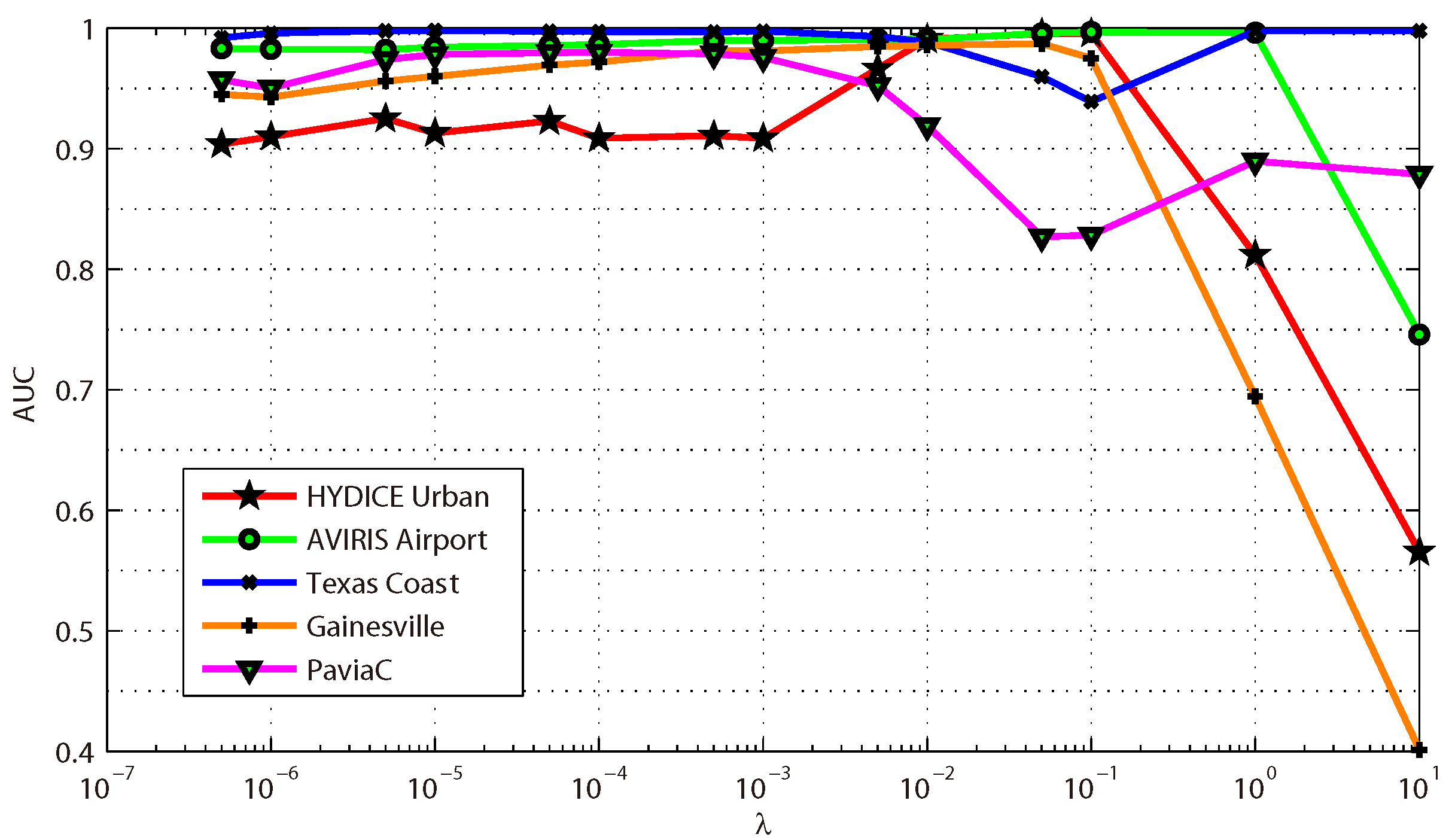
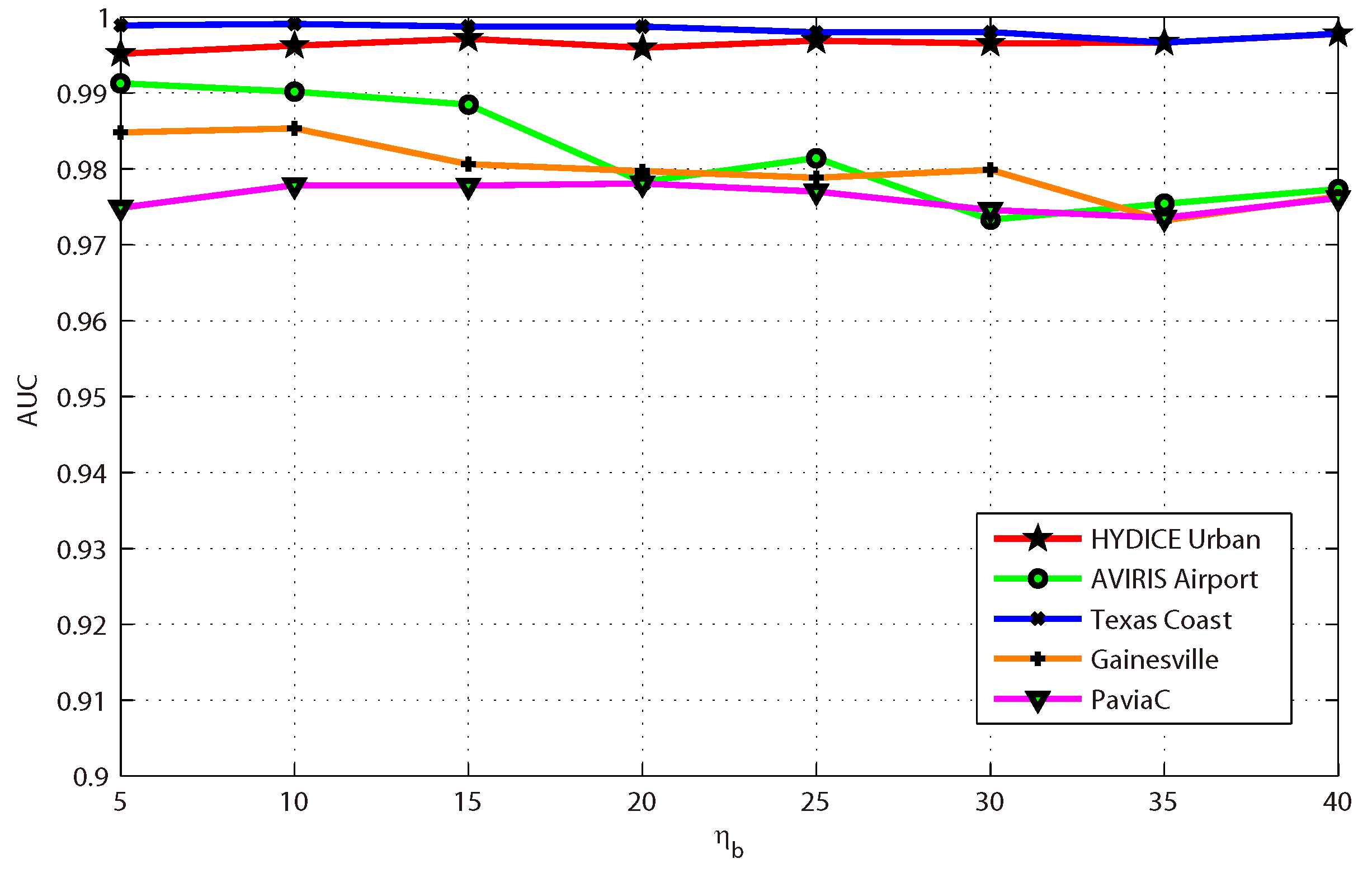
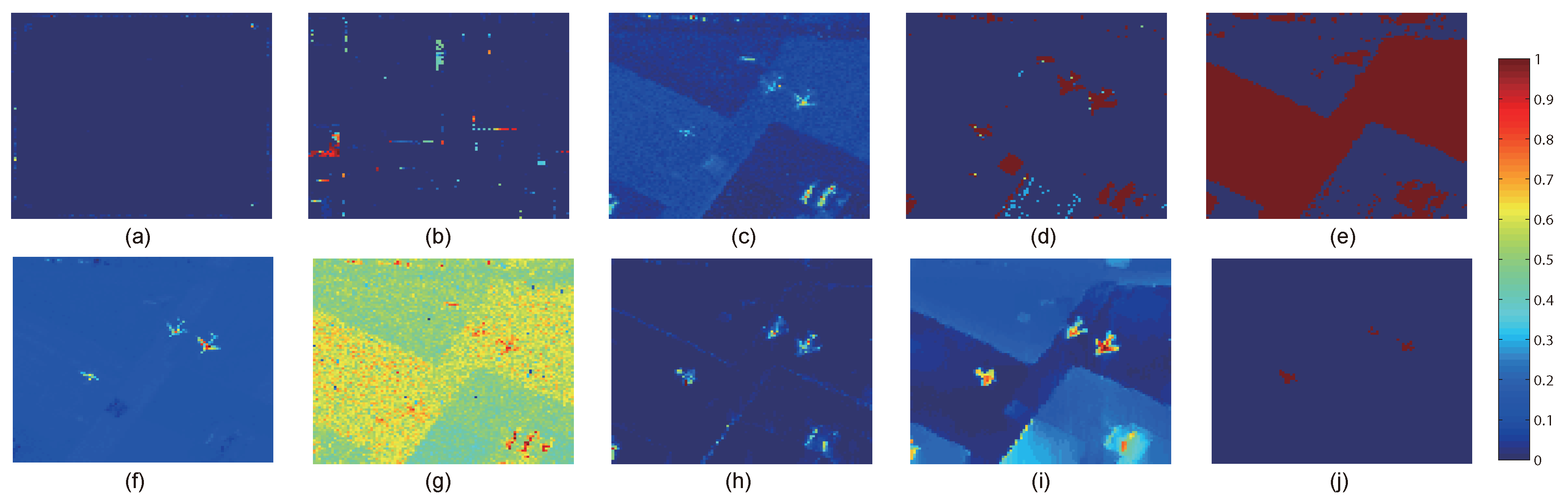
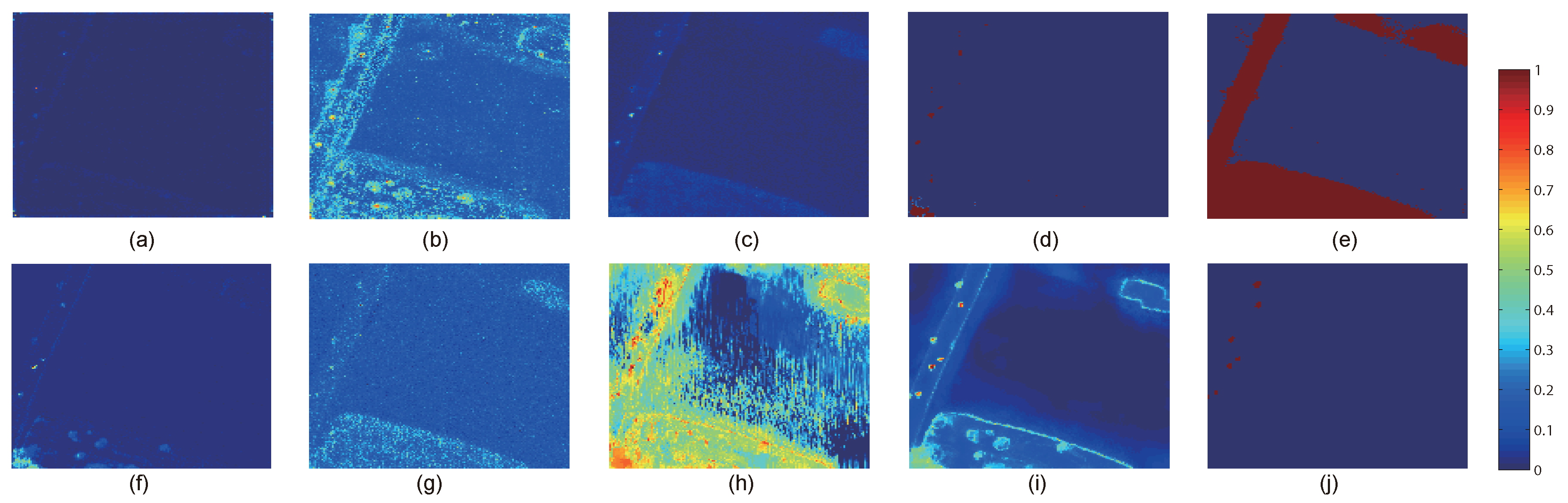
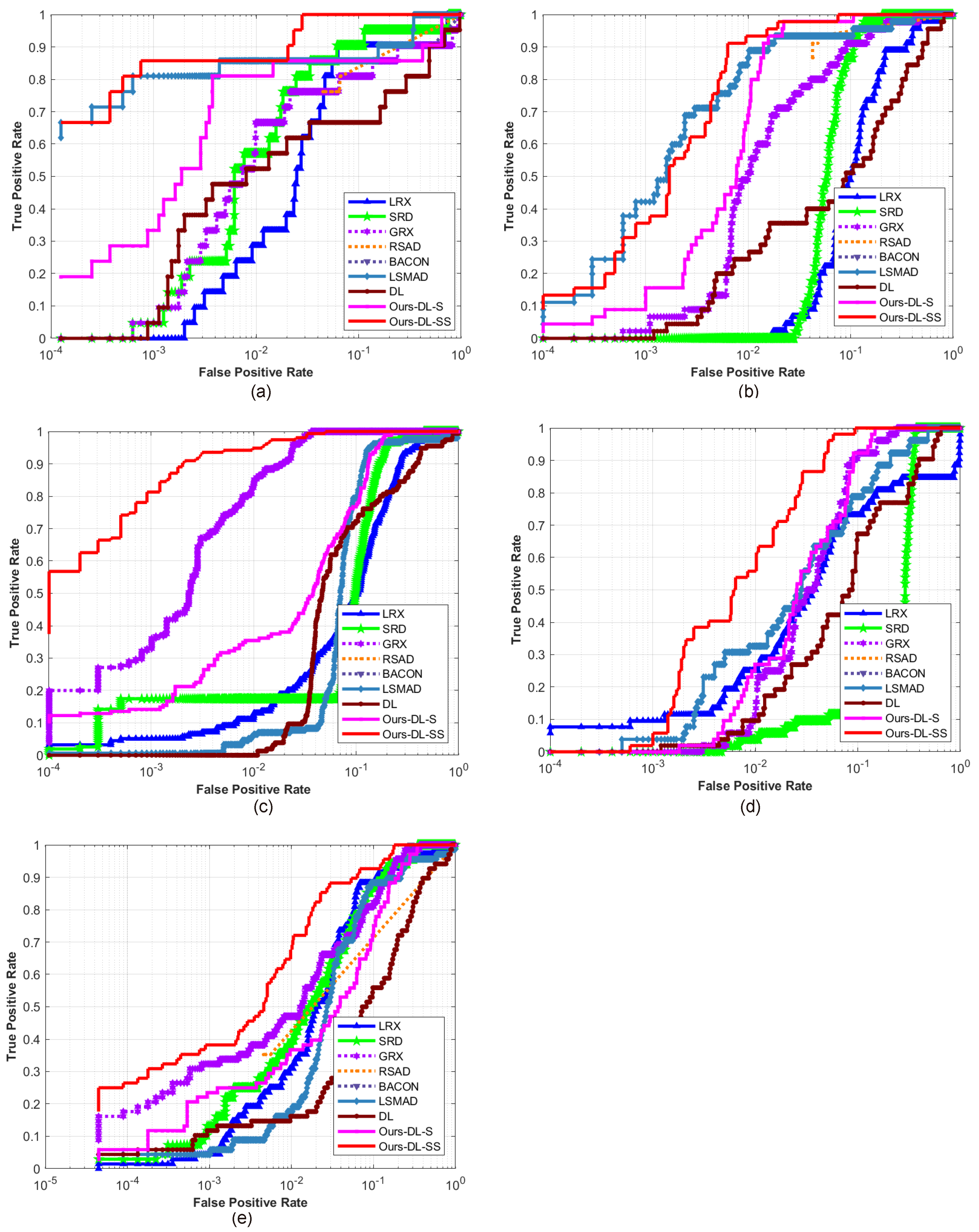
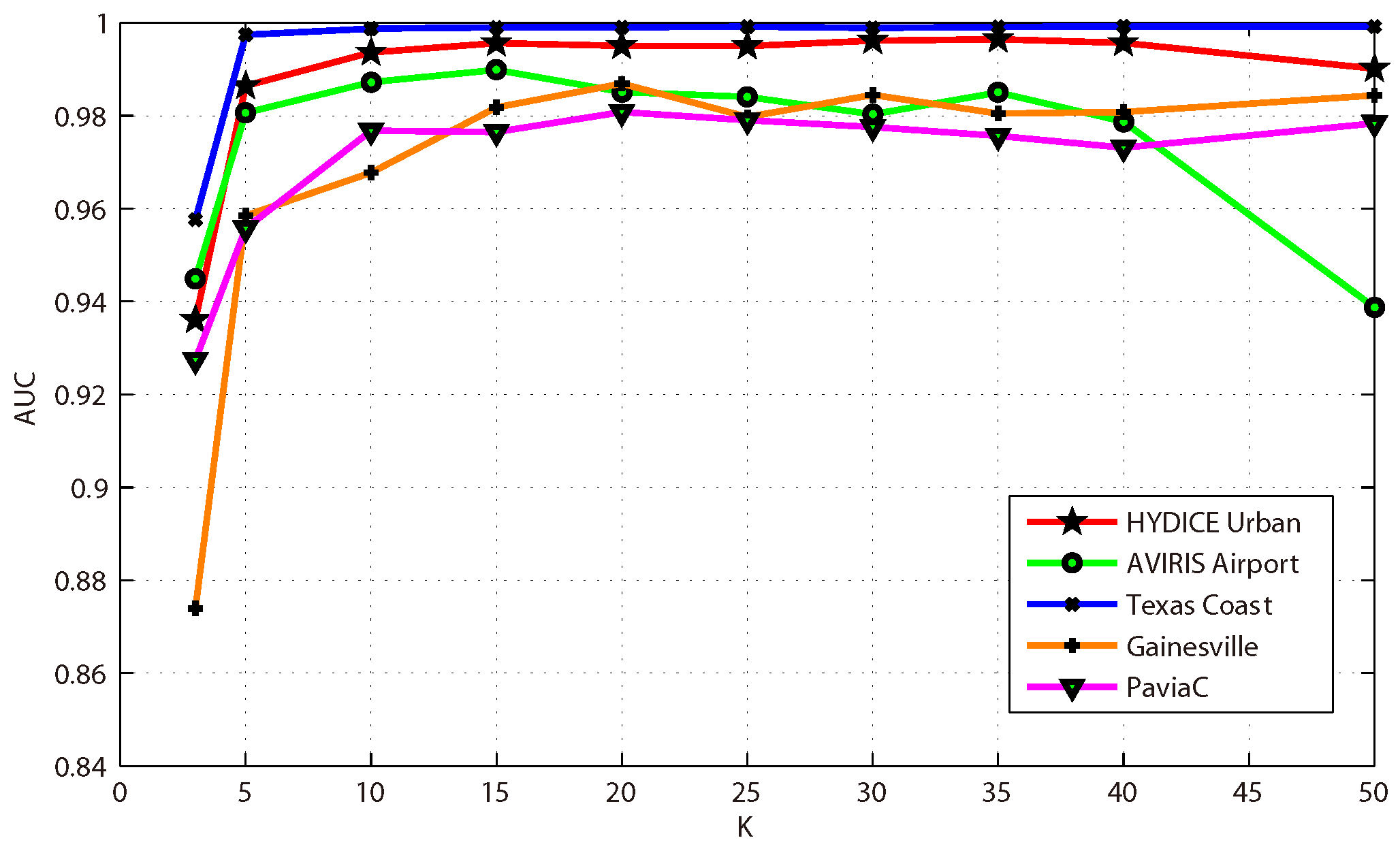
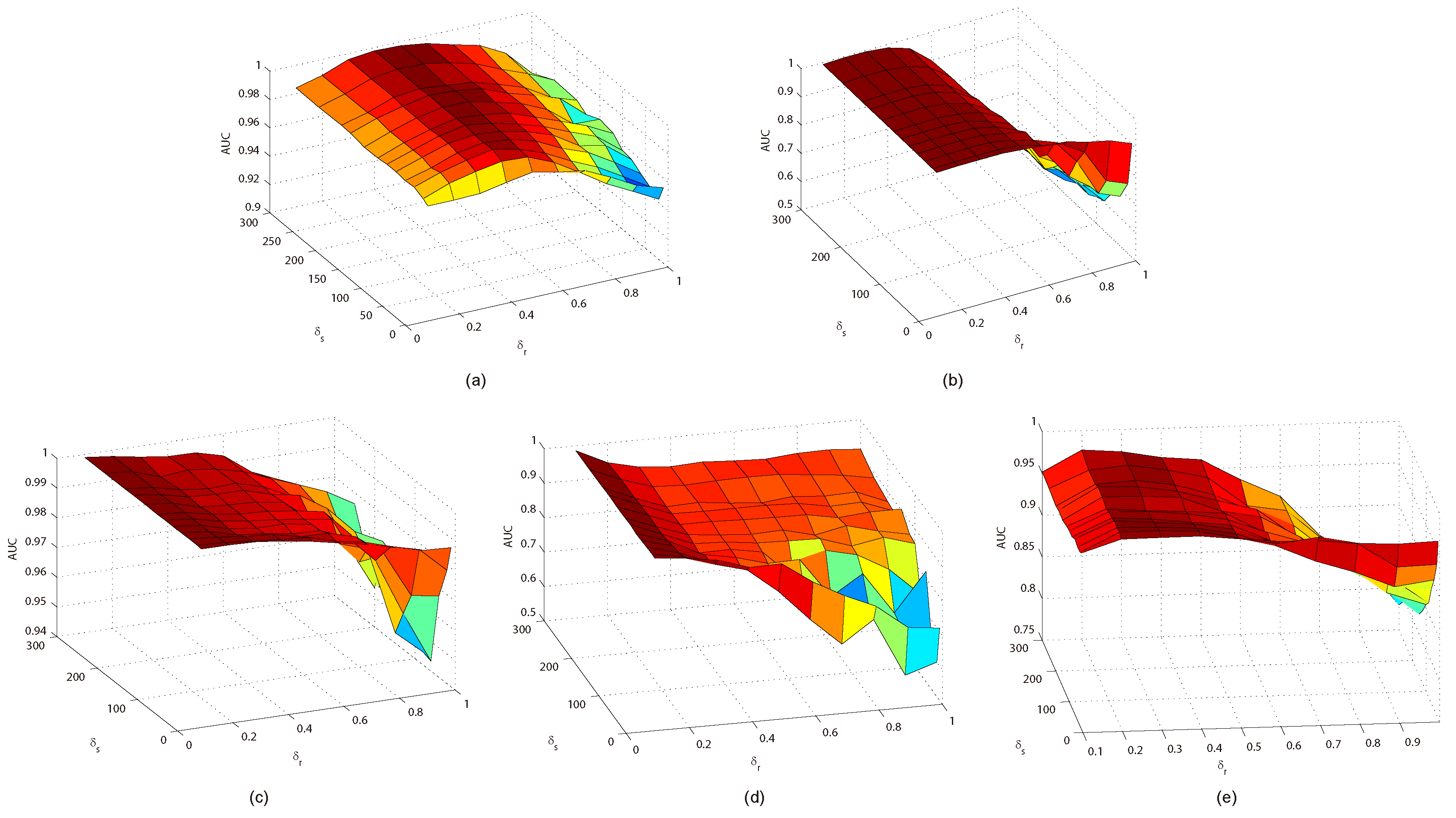
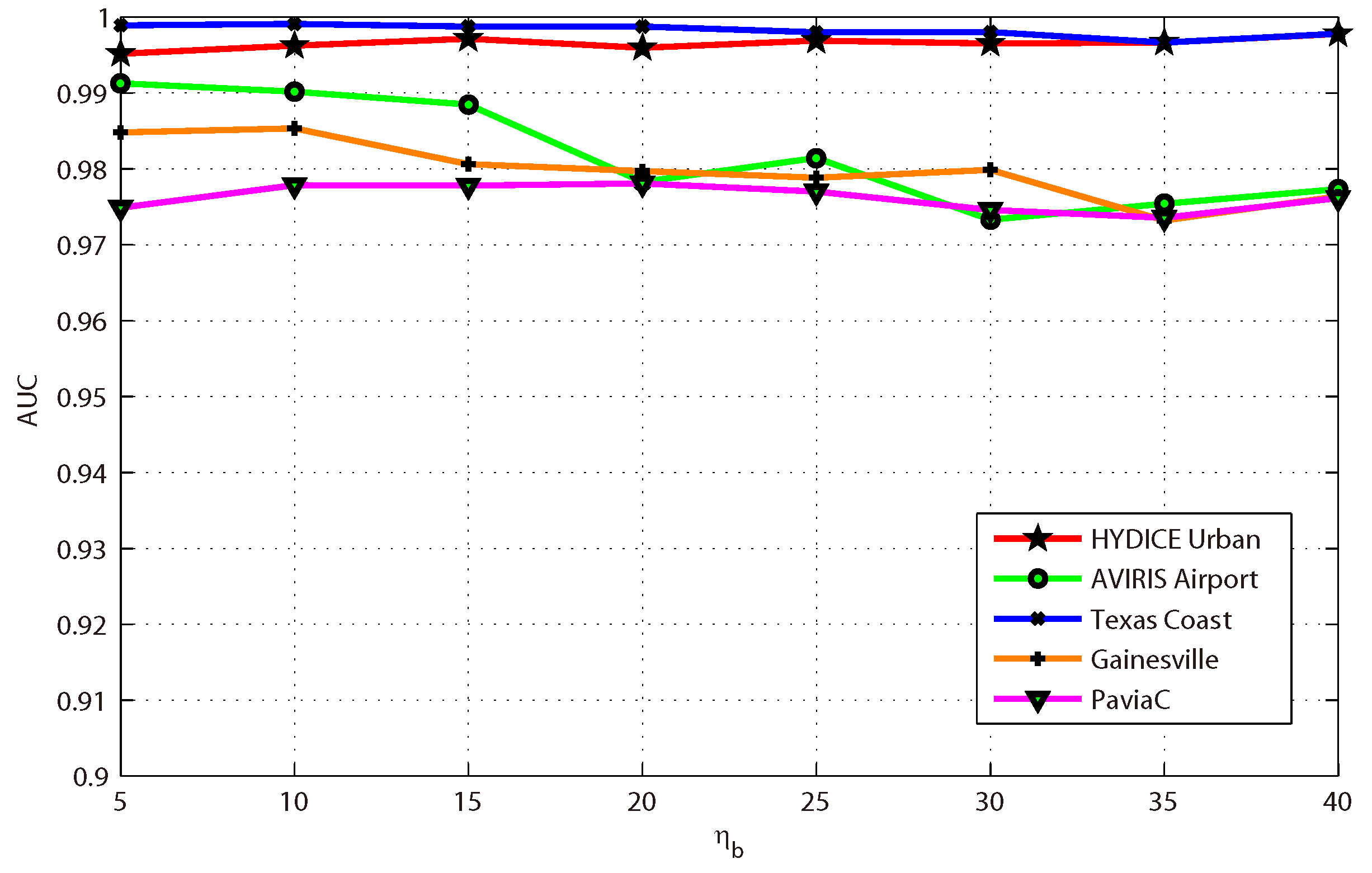
This paper presents an effective anomaly detection method for hyperspectral images through designing a separability-aware sample cascade model. It aims at addressing the unsatisfactory detection performance caused by the inaccurate scene information representation because of complex spectral interactions and inter-/intra-difference of different samples. Through sifting out all the hyperspectral pixel samples according to their different separable degrees, more accurate and complete background information can be explored specific to different separated sample sets with various material characteristics. The proposed method mainly consists of three important procedures including spectral–spatial feature extraction, separability-aware sample cascade selection, and multilayer anomaly detection. Taking use of spectral–spatial feature extraction, both spectral information and spatial structure information can be obtained which can enhance the expressive ability to recognize targets. Then, we construct the separability-aware sample cascade selection framework, which can divide samples into different sets layer-by-layer and simultaneously removes the potential abnormal targets at each selection step. Consequently, our learned background representation can not only have good distinctiveness to recognize different anomalies from real images scenes, but also benefits from the good ability to restrain effects of potential anomalies. Finally, we simply adopt the multilayer anomaly detection strategy in order to comprehensively take different good characteristics of all the separability-aware layers into consideration. In the experiments, our proposed method is compared with seven state-of-the-art detectors on five different real-world hyperspectral images to fairly and convincingly evaluate its performance. Extensive experimental results demonstrate the effectiveness of our method. It has achieved superior performance to all these representative competitors. Specifically, compared with LRX, SRD, GRX, RSAD, BACON, LSMAD, and DL, our method has obvious performance improvement of about , , , , , , and , respectively, in accordance with their average AUC values of all the hyperspectral images. Besides, through deeply analyzing and discussing the sufficient parameter setting experiment, our method also has good robustness to different parameters. On the whole, the proposed method has good performance to detect different abnormal targets from various hyperspectral scenes covering different materials, which outperforms all the employed state-of-the-art competitors.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}